
Abstract
Under natural viewing conditions, a large amount of information reaches our senses, and the visual system uses attention and perceptual grouping to reduce the complexity of stimuli in order to make real-time perception possible. Prior studies have shown that attention and perceptual grouping operate in synergy; exogenous attention is deployed not only to the cued item, but also to the entire group. Here, we investigated how attention and perceptual grouping operate during the formation and dissolution of groups. Our results showed that reaction times are higher in the presence of perceptual groups than they are for ungrouped stimuli. On the other hand, attentional benefits of perceptual grouping were observed during both the formation and the dissolution of groups. The dynamics were similar during group formation and dissolution, showing a gradual effect that takes approximately half a second to reach its maximum level. In the case of group dissolution, the attentional benefits persisted for about a quarter of a second after dissolution of the group. Taken together, our results reveal the dynamics of how attention and grouping work in synergy during the transient period when groups form or dissolve.
Similar content being viewed by others

Under natural viewing conditions, a large amount of information reaches our senses, and the brain uses visual processes to reduce the complexity of the stimuli, in order to operate in real time. One of the complexity reduction processes is attention, which can prioritize and/or filter select parts of the stimuli for further processing. Another process of complexity reduction is perceptual grouping, which consists of clustering together stimuli according to certain regularities that generally indicate a common origin (Wagemans et al., 2012; Wertheimer, 1923/1938). Instead of processing every pixel in an image as an independent input, perceptual grouping allows the processing of millions of pixels united into wholes (e.g., a face). Given that both attention and perceptual grouping play major roles in stimulus complexity reduction, it is important to understand how they work together to make real-time perception possible.
Visual attention has two modes of orienting (e.g., Cheal & Lyon, 1991; Egeth & Yantis, 1997; Jonides, 1981; Müller & Rabbitt, 1989; Nakayama & Mackeben, 1989; Posner, 1980; Posner & Cohen, 1984; Weichselgartner & Sperling, 1987): Endogenous attention is under voluntary control and can be allocated flexibly to stimuli on the basis of the task demands. Hence, stimulus complexity reduction by endogenous attention takes place on a voluntary and task-dependent fashion. For example, when searching for a red object, endogenous attention can be deployed to enhance the processing of red stimuli while suppressing the rest of the stimuli. On the other hand, exogenous attention is involuntary and constitutes a reflexive response to the stimulus itself. Because it lacks the flexibility inherent to endogenous attention, a question arises as to which aspects of a stimulus exogenous attention becomes allocated to. Several studies have reported that, similar to endogenous attention, exogenous attention can be allocated to retinotopic and spatiotopic locations as well as to “objects” (e.g., Boi, Vergeer, Ogmen, & Herzog, 2011; Brown, Breitmeyer, Leighty, & Denney, 2006; Egly, Driver, & Rafal, 1994; Egly, Rafal, Driver, & Starreveld, 1994; Iani, Nicoletti, Rubichi, & Umiltà, 2001; Lamy & Egeth, 2002; Lamy & Tsal, 2000; Moore, Yantis, & Vaughan, 1998; Reppa, Schmidt, & Leek, 2012; Theeuwes, Mathôt, & Grainger, 2013; Vecera & Farah, 1994). However, what defines an “object” remains an ill-posed problem (e.g., Humphreys & Riddoch, 2003; Kasai, Moriya, & Hirano, 2011; Marr, 1982; Pinna, 2014; Scholl, 2001). Contour closure is often used as an important property of objects, and explanations of how attention spreads from the location of the cue to the entire object may be based on a process that is limited by the closed contours of the object (e.g., Carey & Xu, 2001; Scholl & Leslie, 1999). However, “object”-based attentional benefits have been reported for stimuli with open contours (e.g., Avrahami, 1999; Marino & Scholl, 2005; Marrara & Moore, 2003), for Gestalt groups without contours (Marrara & Moore, 2003), and for spatiotemporal Gestalt grouping relations (Boi et al., 2011; Gonen, Hallal, & Ogmen, 2014). These findings suggest an important role for perceptual grouping in the allocation of exogenous attention: It directs exogenous attention to simpler and behaviorally meaningful wholes, rather than allowing it to spread indiscriminately over a complex stimulus. Recent studies have also shown a more nuanced concept of “object,” from a perceptual to a semantic object (Li & Logan, 2008;Yuan & Fu, 2014), or to a higher level of object (Zhao, Cosman, Vatterott, Gupta, & Vecera, 2014). Li and Logan showed that forming a compound word is much more efficient in terms of attentional shift, when compared to forming a nonword (Li & Logan, 2008). Yuan and Fu demonstrated that relation-based knowledge could also link objects to form perceptual-based groups, similar to how Gestalt principles operate (Yuan & Fu, 2014). Zhao and colleagues studied objects’ representation strengths by comparing top-down to bottom-up objects, and they found that attention would be allocated to the higher-strength object (Zhao et al., 2014).
In our previous study, in which we investigated the joint operation of exogenous attention and perceptual grouping (Gonen et al., 2014), we used the grouping principle of “common fate” to form distinct groups of moving disks and showed that when a cue was presented within one of the disks, it facilitated responses not only for the cued moving disk, but also for other disks that shared the same direction of motion as the cued disk (Gonen et al., 2014). In other words, exogenous attention was allocated to the entire perceptual group formed by the principle of common fate. The common-fate principle is known to affect perceptual organization and, hence, attentional allocation using perceptual objects (Kahneman & Henik, 1981; Tipper, Brehaut, & Driver, 1990; Watson & Kramer, 1999). Kahneman and Henik argued that preattentive processes are responsible for early perceptual units or perceptual objects. After the preattentive processes, by the allocation of attention, the process of analyzing all properties of the perceptual object is done (Kahneman & Henik, 1981). Tipper, Brehaut, and Driver found that distractors moving with the same speed as the targets created more inhibitory performance than did static distractors, because of the common-fate principle (Tipper et al., 1990). Watson and Kramer, in their “wrench-shaped object” study, demonstrated that the perceptual groups or objects don’t have to be single-regioned, as long as all the regions inside the perceptual group (or object) are task-relevant (Watson & Kramer, 1999).
In Gonen et al. (2014), a stable perceptual group was already established at the time the cue appeared. In a natural environment, groups can be dynamically formed and dissolved. For example, a herd of animals may initiate a coordinated movement pattern; as an animal in camouflage starts to move, the movements of different body parts can dynamically form a perceptual group; similarly, when the herd disperses or the animal stops, the dynamic perceptual group dissolves. In many survival situations, it is important to detect and allocate attention to such dynamic groups as soon as possible. Similarly, as a dynamic group dissolves, it is important to be able to maintain the identity of the group as long as possible. The goal of the present study was to investigate how exogenous attention is allocated during the formation and during the dissolution of perceptual groups.
Experiment 1: Exogenous attention during group formation
The goal of the first experiment was to investigate the allocation of exogenous attention during the formation of perceptual groups.
Method
Protocol and subjects
All experiments reported in this study were conducted in accordance with the federal regulations, 45 CFR 46, the ethical principles established by the Belmont Report, and the principles expressed in the Declaration of Helsinki, according to a protocol approved by the University of Houston Committee for the Protection of Human Subjects. Twelve University of Houston students participated in each experiment. All of the subjects had either normal or corrected-to-normal vision. With the exception of the first author, who also served as a subject, all subjects were naive to the purpose of the experiments. Subjects’ participation was voluntary and they gave their written informed consent according to a protocol approved by the University of Houston Committee for the Protection of Human Subjects.
Apparatus
The stimuli were presented on a 20-in. NANAO FlexScan color monitor in a dark room. The resolution of the display was 656 × 492 pixels with a 100 Hz frame rate. A video card (Visual Stimulus Generator; VSG 2/3) manufactured by Cambridge Research Systems was used for stimulus generation. A head-and-chin-rest was fixed at a distance of 1 m from the display monitor. The screen size was approximately 23° × 17.5°, and one pixel corresponded to 1.7 arcmin. A joystick interfaced with the VSG board was used to measure reaction times.
Stimulus and procedure
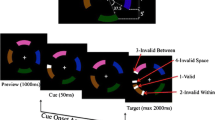
Figure 1 shows a schematic depiction of the stimulus. The stimulus consisted of six disks, each of which had a diameter of 0.8° of visual angle. The fixation point was a white plus sign (+) placed in the center of the monitor. Each disk moved along a linear trajectory with a speed of 5°/s. When the paths of different disks crossed, they continued their independent linear trajectories by passing across each other. The initial positions of the disks were selected to lie inside a virtual circle centered on the fixation point and of diameter 5°, so that the disks would never reach the edge of the screen. The CIE 1931 XYZ space was used. The initial color of all the disks was blue, with a luminance of 4 cd/m2 (CIE XYZ coordinates: 0.3044, 0.6541, 4). The background was black. The cue and the target appeared on top of one disk and had smaller diameters (0.6° visual angle) than the disks. Their CIE color coordinates were 0.2044, 0.48085, corresponding to white with a luminance value of 20 cd/m2. The task of the subject, while fixing his or her eyes on the fixation cross, was to press a joystick button as soon as the target appeared. At the beginning of each trial, six disks, with six randomly chosen starting positions (inside the aforementioned virtual circle), started to move along linear trajectories, with each direction of motion selected randomly. Prior to grouping, each disk moved in a randomly selected direction of motion, with the constraint that the disks were 20° apart from each other, in order for them not to form a prior perceptual group. At the start of the grouping, half of the disks moved in a common, randomly selected direction, whereas the other half moved in another common, randomly selected direction. The two directions of motion were selected randomly with the constraint that they were at least 30° apart from each other, in order to have a salient difference between the two groups. After the initial preview period of 500 ms, the cue appeared in one of the randomly selected disks and traveled along with this disk for 100 ms, and disappeared at the end of the 100 ms. A target was presented in one of the disks 100 ms after the disappearance of the cue. The target also traveled with the disk. Catch trials were included, in which no target appeared and the subjects had to abstain from pressing the joystick button. Any incorrect responses on catch trials were indicated to the subject by audio feedback. The maximum duration of the target was set to 1,000 ms, during which the subject had to press the joystick button.

The sequences of events (a) when grouping started 100 ms after the cue onset (i.e., the cue onset asynchrony with respect to grouping [COAG] = 100 ms), and (b) when grouping started 500 ms before the onset of the cue, COAG = −500 ms. Each trial started with a preview of 500 ms. Following the preview, the exogenous cue was presented for 100 ms. The cue onset asynchrony with respect to the target (COAT) was set to 200 ms—that is, the target was presented 200 ms after the onset of the cue. The target stayed on for 1,000 ms or until the subject’s response. The thick, vertical arrows indicate the initiation of grouping. As is shown in the last frame, there were four different target options: The target could appear in the cued disk (valid), or in a noncued disk that moved in the same direction as the cued disk (invalid-within), or in a noncued disk that moved in a different direction than the cued disk (invalid-between), or at the spatial location where the cue had appeared initially (invalid-space)
The experiment had a total of 16 different values of the independent variable, which was the start of grouping with respect to the onset of the exogenous cue (cue onset asynchrony with respect to grouping, COA G ). Figure 2 shows the relationship between the cue onset asynchrony with respect to the target (COA T ), which was fixed at 200 ms, to obtain a strong exogenous attention effect (Klein, 2000), and the COAG for each of the 16 values of COAG. Each open box in this figure represents a different case in terms of COAG. In the first case, the COAG was set to −500 ms (the earliest moment possible); thus, grouping started from the very beginning. This case was identical to the experiments in Gonen et al. (2014). The motion trajectories during the entire trial consisted of two linear, randomly chosen trajectories. The case in which the COAG was 0 refers to the situation in which grouping and the onset of the cue happened at the same time. In the case in which the COAG was 1,200, there was no grouping, since 1,200 ms corresponded to the end of the target presentation. As is shown in Fig. 2, the values for COAG were −500, −400, −300, −200, −150, −100, −50, 0, 50, 100, 150, 200, 250, 350, 450, and 1,200. A “valid” target appeared in the same disk as the cue. An “invalid-within” target appeared in a disk that belonged to the same perceptual group as the cued disk (i.e., a disk that moved along the same motion direction as the cued disk). An “invalid-between” target appeared in a disk that did not belong to the same group as the cued disk (i.e., a disk that moved in a different direction of motion than the cued disk). Another target option was “invalid-space,” in which the target did not appear in any disk, but its appearance was in the original retinotopic/spatiotopic location of the cue. This target option was valid from a space-based point of view. In order to remove any distance-based effect between the invalid-within and invalid-between conditions, the average distance (calculated over all trials) between the cue and the invalid-within condition was set equal to the average distance between the cue and the invalid-between condition. The cue’s average eccentricity was kept balanced by making this average eccentricity equal across blocks. The average eccentricity was 3.5°. To keep the eccentricity of the target the same between the invalid-between and invalid-within conditions, the average distance between the invalid-within target and the fixation point was set equal to the average distance between the invalid-between target and the fixation. The presentation of all target options was randomized within each block. Each block had 48 trials for each target option (catch trials were also considered as one of the five target options), yielding 240 trials per block. Four sessions per subject yielded 960 trials, with an additional 300 training trials.

A simplified overview of the relationship between the cue onset asynchrony with respect to grouping (COAG) and the cue onset asynchrony with respect to the target (COAT) for the 16 values of COAG. Each open box depicts the onsets of the cue and the target. COAT was fixed at 200 ms, to obtain a strong exogenous-attention effect (Klein, 2000). The 16 COAG values are represented in the timeline. When COAG = 0, the onset of grouping occurred at the same time as the onset of the cue
Results and discussion
Reaction times (RTs) less than 150 ms and greater than 1,000 ms were excluded from all analyses. These exclusions constituted 1.8 % of all data. Accuracy in catch trials was higher than 95 % for all subjects. The RT data were analyzed by one-way repeated measures analyses of variance (ANOVAs). Figure 3 shows the raw data for each target type. In general, the RTs ranged from 240 to 290 ms, in accordance with the RTs found in simple detection tasks (Abrams & Law, 2000; Gonen et al., 2014; Jordan & Tipper, 1999; List & Robertson, 2007; Marino & Scholl, 2005; Posner, 1980; Ro & Rafal, 1999). The effect of COAG was significant [F(1, 15) = 8.611, p < .001, η p 2 = .365], and in general, large COAG values yielded faster RTs. One exception was the invalid-space case at COAG = 0 ms, which yielded a relatively high RT. When COAG = 0 ms, the cue appeared at the same time that the disks changed their direction of motion to initiate the two groups. Since a change in the direction of motion is a very salient event itself, the occurrence of this salient event at the time of the appearance of the cue may have reduced the effectiveness of the cue, hence leading to an increased RT. However, it is not clear why this would happen only in the invalid-space case and not in the others. A possible explanation is that the change of motion direction may have guided attention toward the disks and away from the original spatial location of the cue. If this speculation were true, one would then expect all three target options, with the exception of invalid space, to still benefit from attentional resources. For many COAG values, invalid space generated the fastest RTs, indicating the presence of space-based attention; however, space-based attention did not produce the fastest RTs consistently for all COAGs.

Mean reaction times for all target options in Experiment 1 (formation of groups), as a function of the cue onset asynchrony with respect to grouping (COAG)
In order to examine object-based attentional facilitation, we show in Fig. 4 the mean RT difference between invalid-within and invalid-between conditions. As can be seen from Fig. 4, when grouping happens early enough (i.e., when the COAG values are negative enough; e.g., −500, −400, and −300 ms), the RT difference is negative, indicating a clear attentional facilitation. The overall effect of COAG on the RT difference was significant [F(1, 15) = 3.675, p < .01, η p 2 = .962]. In order to determine which RT differences (invalid-within – invalid-between) were significantly different from zero, we ran a t test for all of the data points in Fig. 4. The Bonferroni-corrected confidence interval was adjusted from .05 to .003125. All RT differences for negative COAG values from −500 to −50 ms were significantly different from zero [for COAG = −500, t(11) = 3.956, p = .002, d = 0.605; for COAG = −400, t(11) = 3.314, p = .003, d = 0.216; for COAG = −300, t(11) = 2.114, p = .0029, d = 0.197; for COAG = −200, t(11) = 2.427, p = .002, d = 0.321; for COAG = −150, t(11) = 4.432, p = .0013, d = 0.754; for COAG = −50, t(11) = 3.221, p = .0031, d = 0.124]. The most negative value of COAG corresponds to the case in which grouping starts from the beginning, as in our previous study (Gonen et al., 2014). In both studies, we found a strong attentional facilitation for the entire group. We also observed here that the attentional facilitation became weaker when the timing of the initiation of the group became closer to the timing of the cue.

Mean reaction time differences (± standard errors) for invalid-within – invalid-between trials in Experiment 1 (formation of groups). The negative differences indicate attentional facilitation of grouping. For group formation, the largest effect is present when COAG is −500 ms. As the grouping time approaches (i.e., as the COAG increases toward) the cue presentation, the effect decreases
Hence, in terms of the formation of groups, the results indicated that the effect of grouping was gradual and built up within the interval of 500 ms examined in this experiment. In addition to grouping-based comparisons of attentional effects, we also compared the RTs of the valid target option to the invalid-within option, to assess space-based attentional effects. We found a significant space-based attentional effect [F(1, 15) = 14.972, p = .002, η p 2 = .5].
In the data in Fig. 4, there is no apparent saturation in the benefits of attentional effects, since the RT differences seem to follow a linear decrease as COAG becomes more and more negative. In order to investigate whether there is a critical duration of group formation after which the attentional effect becomes saturated, we collected additional data, in which we had COAG values of −600 and −700 for 12 subjects (all University of Houston graduate students, age average 28 years, min age 26, max age 31; only four of the subjects were new). The trials consisted of only the invalid-within and the invalid-between trials, presented in random order. Each block had 120 trials for each target option, including 24 catch trials (20 %). Four sessions per subject yielded 1,440 trials, with an additional 300 training trials. The results are plotted in Fig. 5. For comparison, the COAG = −500 ms data point from Fig. 4 is also included (circle). Paired t tests between the RT differences at COAG = −700 and −600 ms resulted in a nonsignificant effect [t(11) = 2.1745, p = .1934, d = 1.71]. Considering the data point from Fig. 4 also, one can see that the effect saturated beyond COAG = −500 ms.

Mean reaction time differences (± standard errors) for invalid-within – invalid-between trials when COAG was −600 and −700 ms. For comparison, the data point from COAG = −500 ms in Fig. 4 is shown with the red circle
Taken together, the results of these experiments show that the effectiveness with which exogenous attention allocates resources to perceptual groups depends on the temporal history of group formation. It is a relatively slow process, building up within a few hundred milliseconds and leveling to a steady state in half a second.
Experiment 2: Exogenous attention during group dissolution
The goal of the second experiment was to determine the allocation of exogenous attention during the dissolution of perceptual groups. As in Experiment 1, we used the common-fate principle and varied the relative timing between the appearance of the cue and the dissolution of perceptual groups. Similar to Experiment 1, we separated objects into two distinct groups by their directions of motion. Each COAG value represented a different delay as compared to the onset of the exogenous cue, but this time representing the dissolution of the already-established perceptual group.
Method
The methods were same as in Experiment 1 with the following exception. The 16 different COAG values represented the onset time of the cue with respect to the onset of the dissolution of the group. For instance, if the COAG was −300 ms, with the start of the preview (see Fig. 1), the disks would start their motion already distinguished into two groups, and after 200 ms (300 ms prior to the exogenous cue), the two groups would dissolve, resulting in six disks having six different random (linear) trajectories.
Results and discussion
RTs less than 150 ms and greater than 1,000 ms were excluded from all analyses, constituting 1.4 % of all data. The accuracy in catch trials was higher than 96 %. The RT data were analyzed with one-way repeated measures ANOVAs. Figure 6 shows the raw data for each target type. The effect of COAG was significant [F(1, 15) = 34.079, p < .001, η p 2 = .694]. RTs started in the 280-ms to 300-ms range, close to the ones observed in Experiment 1, but became gradually slower as the COAG increases. The invalid-space condition tended to produce the fastest RTs, especially for negative values of COAG, indicating the presence of space-based exogenous attention.

Mean reaction times for all of the target options in Experiment 2 (dissolution of groups), as a function of the cue onset asynchrony with respect to grouping (COAG)
Figure 7 shows the mean RT differences between the invalid-within and invalid-between conditions. The effect of COAG on RT differences was significant [F(1, 15) = 18.642, p < .005, η p 2 = .209], and negative RT difference values indicated clear attentional facilitation. To determine which RT differences (invalid-within – invalid-between) were significantly different from zero, we ran a t test for all data points in Fig. 7. The Bonferroni-corrected confidence interval was adjusted from .05 to .003125. For the COAG values equal to 1,200, 450, 350, 250, 150, 100, 50, 0, −50, and −100 ms, the RT differences were significantly different from zero [for COAG = 1,200, t(11) = 3.475, p = .001, d = 0.051; for COAG = 450, t(11) = 3.124, p = .001, d = 0.017; for COAG = 350, t(11) = 2.994, p = .0021, d = 0.265; for COAG = 250, t(11) = 4.616, p = .003, d = 0.62; for COAG = 150, t(11) = 3.921, p = .0021, d = 0.654; for COAG = 100, t(11) = 4.541, p = .003, d = 1.23; for COAG = 50, t(11) = 2.113, p = .001, d = 0.852; for COAG = 0, t(11) = 0.741, p = .003, d = 0.795; for COAG = −50, t(11) = 4.328, p < .001, d = 0.991; for COAG = −100, t(11) = 2.634, p = .001, d = 1.14]. Note that here COAG represents the time at which grouping dissolved with respect to the onset of the cue. Negative and positive COAG values indicate that the grouping dissolved before and after, respectively, the presentation of the cue. As expected, attentional benefits of grouping occurred strongly for positive values of COAG and decayed as COAG became negative. The attentional benefits for negative values of COAG show that the attentional benefits of grouping persisted for some time after the dissolution of the groups. As in Experiment 1, in order to see the effect of space-based attention, we compared the RTs of the valid target option and the invalid-within option. Overall, the COAG effect on space-based attention was significant [F(1, 15) = 12.944, p = .003, η p 2 = .463].

Mean reaction time differences (± standard errors) for invalid-within – invalid-between trials in Experiment 2 (dissolution of groups), as a function of COAG. The negative differences indicate attentional facilitation of grouping
General discussion
Stimuli impinging on the retina are very complex, and the real-time processing of vision necessitates the reduction of this complexity. Attention and perceptual grouping are two processes involved in complexity reduction. There have been extensive investigations into how each of these processes in isolation can reduce stimulus complexity. Starting with the rejection of the atomistic view, Gestalt theory introduced a variety of perceptual-grouping principles that lead to more holistic, simplified, and behaviorally relevant representations of the environment (for reviews, see Koffka, 1935; Wagemans et al., 2012). Research on attention has identified “space-based” as well as “object-based” processes (Egeth & Yantis, 1997; Egly, Driver, & Rafal, 1994). However, as we discussed in the introduction, the concept of an “object” remains ill-defined. One possible perspective is to consider “objects” as outcomes of the perceptual-grouping process, a view that provides a natural connection between the two processes of complexity reduction—namely, attention and perceptual grouping. In fact, in a previous study it has been shown that attentional resources are allocated to entire groups, highlighting the synergy between these two processes (Gonen et al., 2014). Gonen et al. examined the case in which perceptual groups were already established and, hence, were in a steady state. In a natural environment, perceptual groups spontaneously form and dissolve, as in the case of an animal in camouflage starting or stopping movement against a camouflaging background. When the animal moves, the grouping of its parts on the basis of common motion reveals the animal as a whole. When the animal stops, the common motion information vanishes, and the animal vanishes into the camouflage. In this study, our goal was to bring the investigation into a more ecological setting by addressing how exogenous attention is allocated during the formation and dissolution of perceptual groups.
We observed attentional benefits of perceptual grouping during both the formation and the dissolution of groups. Figure 8 shows the mean RT differences from both experiments. Because COAG was defined with respect to the beginning and the end of grouping in Experiments 1 and 2, respectively, we flipped the results of Experiment 2 with respect to the y-axis in order to compare them directly with the results of Experiment 1. Since we do not know the relative latency between the time the cue is processed in the brain and the dynamics of grouping processes (Öğmen, Patel, Bedell, & Camuz, 2004; Purushothaman, Patel, Bedell, & Ogmen, 1998), we cannot reach conclusions about the brain timing of attention and grouping. We can, nevertheless, compare the group formation and dissolution data directly, since they were based on identical stimulus parameters. As can be seen in Fig. 8, the time courses of the attentional benefits of grouping are remarkably similar in the cases of group formation and dissolution, operating within a half-second time frame. We can also observe an important difference for the COAG values between 0 and +500 ms: Whereas, during group formation, the RT difference reaches zero at COAG = 0 and thereafter, a persistent effect was observed during group dissolution within this interval. This effect is akin to other persistence effects, such as visible persistence. In terms of the raw RTs (Figs. 3 and 6), we observed an increase in RTs when grouping was present as compared to when it was not. Hence, overall, grouped stimuli tend to slow down absolute reaction times, while giving an attentional advantage to all elements of the group.

The data from Figs. 4 and 7 are plotted together, to compare the time courses of attentional facilitation by grouping during the formation and the dissolution of groups. The dissolution data are flipped around the y-axis, to take into account the fact that COAG represented asynchrony with respect to the beginning and the end of the groups in Experiments 1 and 2, respectively. To reduce clutter, the group formation and dissolution data are presented only with –SEM and + SEM, respectively
Taken together, our results reveal the dynamics of how attention and grouping work in synergy during the transient period when groups form or dissolve.
References
Abrams, R. A., & Law, M. B. (2000). Object-based visual attention with endogenous orienting. Perception & Psychophysics, 62, 818–833. doi:10.3758/BF03206925
Avrahami, J. (1999). Object of attention, objects of perception. Perception & Psychophysics, 61, 1604–1612. doi:10.3758/BF03213121
Boi, M., Vergeer, M., Ogmen, H., & Herzog, M. H. (2011). Nonretinotopic exogenous attention. Current Biology, 21, 1732–1737. doi:10.1016/j.cub.2011.08.059
Brown, J. M., Breitmeyer, B. G., Leighty, K. A., & Denney, H. I. (2006). The path of visual attention. Acta Psychologica, 121, 199–209. doi:10.1016/j.actpsy.2004.10.020
Carey, S., & Xu, F. (2001). Infant knowledge of objects: Beyond object files and object tracking. Cognition, 80, 179–213. doi:10.1016/S0010-0277(00)00154-2
Cheal, M., & Lyon, D. R. (1991). Central and peripheral precuing of forced-choice discrimination. Quarterly Journal of Experimental Psychology, 43A, 859–880. doi:10.1080/14640749108400960
Egeth, H. E., & Yantis, S. (1997). Visual attention: Control, representation, and time course. Annual Review of Psychology, 48, 269–297. doi:10.1146/annurev.psych.48.1.269
Egly, R., Driver, J., & Rafal, R. D. (1994). Shifting visual attention between objects and locations: Evidence from normal and parietal lesion participants. Journal of Experimental Psychology: General, 123, 161–177. doi:10.1037/0096-3445.123.2.161
Egly, R., Rafal, R., Driver, J., & Starreveld, Y. (1994). Covert orienting in the split-brain reveals hemispheric specialization for object-based attention. Psychological Science, 5, 380–383. doi:10.1111/j.1467-9280.1994.tb00289.x
Gonen, F. F., Hallal, H., & Ogmen, H. (2014). Facilitation by exogenous attention for static and dynamic gestalt groups. Attention, Perception & Psychophysics, 76, 1709–1720. doi:10.3758/s13414-014-0679-2
Humphreys, G. W., & Riddoch, M. J. (2003). From what to where: Neuropsychological evidence for implicit interactions between object- and space-based attention. Psychological Science, 14, 487–492. doi:10.1111/1467-9280.02457
Iani, C., Nicoletti, R., Rubichi, S., & Umiltà, C. (2001). Shifting attention between objects. Cognitive Brain Research, 11, 157–164. doi:10.1016/S0926-6410(00)00076-8
Jonides, J. (1981). Voluntary vs. automatic control over the mind’s eye’s movement. In J. Long & A. Baddeley (Eds.), Attention and performance IX (pp. 187–203). Hillsdale, NJ: Erlbaum.
Jordan, H., & Tipper, S. P. (1999). Spread of inhibition across an object’s surface. British Journal of Psychology, 90, 495–507.
Kahneman, D., & Henik, A. (1981). Perceptual organization and attention. In M. Kubovy & J. R. Pomerantz (Eds.), Perceptual organization (pp. 181–211). Hillsdale, NJ: Erlbaum.
Kasai, T., Moriya, H., & Hirano, S. (2011). Are objects the same as groups? ERP correlates of spatial attentional guidance by irrelevant feature similarity. Brain Research, 1399, 49–58. doi:10.1016/j.brainres.2011.05.016
Klein, R. M. (2000). Inhibition of return. Trends in Cognitive Sciences, 4, 138–147. doi:10.1016/S1364-6613(00)01452-2
Koffka, K. (1935). Principles of gestalt psychology. London, UK: Routledge & Kegan Paul.
Lamy, D., & Egeth, H. (2002). Object-based selection: The role of attentional shifts. Perception & Psychophysics, 64, 52–66. doi:10.3758/BF03194557
Lamy, D., & Tsal, Y. (2000). Object features, object locations, and object files: Which does selective attention activate and when? Journal of Experimental Psychology: Human Perception and Performance, 26, 1387–1400. doi:10.1037/0096-1523.26.4.1387
Li, X., & Logan, G. D. (2008). Object-based attention in Chinese readers of Chinese words: Beyond Gestalt principles. Psychonomic Bulletin & Review, 15, 945–949. doi:10.3758/PBR.15.5.945
List, A., & Robertson, L. C. (2007). Inhibition of return and object-based attentional selection. Journal of Experimental Psychology: Human Perception and Performance, 33, 1322–1334. doi:10.1037/0096-1523.33.6.1322
Marino, A. C., & Scholl, B. J. (2005). The role of closure in defining the “objects” of object-based attention. Perception & Psychophysics, 67, 1140–1149. doi:10.3758/BF03193547
Marr, D. (1982). Vision: A computational investigation into the human representation and processing of visual information. San Francisco, CA: Freeman.
Marrara, M. T., & Moore, C. M. (2003). Object-based selection in the two-rectangles method is not an artifact of the three-sided directional cue. Perception & Psychophysics, 65, 1103–1109. doi:10.3758/BF03194837
Moore, C. M., Yantis, S., & Vaughan, B. (1998). Object-based visual selection: Evidence from perceptual completion. Psychological Science, 9, 104–110. doi:10.1111/1467-9280.00019
Müller, H. J., & Rabbitt, P. M. (1989). Reflexive and voluntary orienting of visual attention: Time course of activation and resistance to interruption. Journal of Experimental Psychology: Human Perception and Performance, 15, 315–330. doi:10.1037/0096-1523.15.2.315
Nakayama, K., & Mackeben, M. (1989). Sustained and transient components of focal visual attention. Vision Research, 11, 1631–1647.
Öğmen, H., Patel, S. S., Bedell, H. E., & Camuz, K. (2004). Differential latencies and the dynamics of the position computation process for moving targets, assessed with the flash-lag effect. Vision Research, 44, 2109–2128. doi:10.1016/j.visres.2004.04.003
Pinna, B. (2014). What is a perceptual object? Beyond the Gestalt theory of perceptual organization. In A. Geremek, M. W. Greenlee, & S. Magnussen (Eds.), Perception beyond gestalt: Progress in vision research (pp. 48–66). London, UK: Psychology Press.
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. In H. Bouma & D. G. Bouwhuis (Eds.), Attention and performance X: Control of language processes (pp. 531–556). Hillsdale, NJ: Erlbaum.
Posner, M. I. (1980). Orienting of attention. Quarterly Journal of Experimental Psychology, 32, 3–25. doi:10.1080/00335558008248231
Purushothaman, G., Patel, S. S., Bedell, H. E., & Ogmen, H. (1998). Moving ahead through differential visual latency. Nature, 396, 424.
Reppa, I., Schmidt, W. C., & Leek, E. C. (2012). Successes and failures in producing attentional object-based cueing effects. Attention, Perception & Psychophysics, 74, 43–69. doi:10.3758/s13414-11-0211-x
Ro, T., & Rafal, R. D. (1999). Components of reflexive visual orienting to moving objects. Perception & Psychophysics, 61, 826–836.
Scholl, B. J. (2001). Objects and attention: The state of the art. Cognition, 80, 1–46. doi:10.1016/S0010-0277(00)00152-9
Scholl, B. J., & Leslie, A. M. (1999). Explaining the infant’s object concept: Beyond the perception/cognition dichotomy. In E. Lepore & Z. Pylyshyn (Eds.), What is cognitive science? (pp. 26–73). Oxford, UK: Blackwell.
Theeuwes, J., Mathôt, S., & Grainger, J. (2013). Exogenous object- centered attention. Attention, Perception & Psychophysics, 75, 812–818. doi:10.3758/s13414-013-0459-4
Tipper, S. P., Brehaut, J. C., & Driver, J. (1990). Selection of moving and static objects for the control of spatially directed action. Journal of Experimental Psychology: Human Perception and Performance, 16, 492–504. doi:10.1037/0096-1523.16.3.492
Vecera, S. P., & Farah, M. J. (1994). Does visual attention select objects or locations? Journal of Experimental Psychology: General, 123, 146–160. doi:10.1037/0096-3445.123.2.146
Wagemans, J., Elder, J. H., Kubovy, M., Palmer, S. E., Peterson, M. A., Singh, M., & von der Heydt, R. (2012). A century of Gestalt psychology in visual perception: I. Perceptual grouping and figure–ground organization. Psychological Bulletin, 138, 1172–1217. doi:10.1037/a0029333
Watson, S. E., & Kramer, A. F. (1999). Object-based visual selective attention and perceptual organization. Perception & Psychophysics, 61, 31–49. doi:10.3758/BF03211947
Weichselgartner, E., & Sperling, G. (1987). Dynamics of automatic and controlled visual attention. Science, 238, 778–780. doi:10.1126/science.3672124
Wertheimer, M. (1938). Laws of organization in perceptual forms. In W. D. Ellis (Ed.), A source book of Gestalt psychology (pp. 71–88). New York, NY: Humanities Press (Original work published 1923).
Yuan, J., & Fu, S. (2014). Attention can operate on semantic objects defined by individual Chinese characters. Visual Cognition, 22, 770–788. doi:10.1080/13506285.2014.916772
Zhao, L., Cosman, J. D., Vatterott, D. B., Gupta, P., & Vecera, S. P. (2014). Visual statistical learning can drive object-based attentional selection. Attention, Perception & Psychophysics, 76, 2240. doi:10.3758/s13414-014-0708-1
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Gonen, F.F., Ogmen, H. Exogenous attention during perceptual group formation and dissolution. Atten Percept Psychophys 79, 593–602 (2017). https://doi.org/10.3758/s13414-016-1235-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-016-1235-z