
Abstract
Visual short-term memory (VSTM) refers to our ability in remembering visual information for a limited amount of time. In the VSTM literature, mixed findings have been reported regarding whether items are encoded individually or globally in the context of other items. This study adopted a color change detection task and manipulated color and spatial relations of the items on display to test whether inter-item relational information and processing can facilitate change detection performance. Results showed that only when a post-cue was presented to reduce decision load (Experiments 1 and 3), both color and spatial relations facilitated color change detection. However, when there was no post-cue to lessen the decision load, preserving spatial relations at test impaired color change detection (Experiment 2). Furthermore, spatial and color relational processing interactively affected color change detection. Benefit of the spatial relations was observed only when color grouping cues can aid change detection, and the utilization of color relations was optimized when spatial relations were preserved to cue the retrieval of color relations. Our results support the hierarchical representation hypothesis, which assumes that both individual items and item relations are encoded and maintained in VSTM. The amount of cognitive resources for retrieving different levels of representations is highly constrained by the decision load.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
When one views a brief display of multiple items, are the items encoded individually or are they encoded globally with inter-item relations? This question has to do with the fundamental nature of visual short-term memory (VSTM), the temporary storage buffer that stores visual information for retrieval and manipulation, and is an essential element to our visual awareness. Ever since Phillips began a series of experiments on VSTM (Phillips 1974), studies investigating the nature of VSTM have flourished in the past four decades, mostly focusing on three different but interrelated aspects of VSTM: 1) capacity, 2) precision, and 3) contents and organization (for a comprehensive review covering all these areas, please see Luck, 2008). Of these different aspects, contents and organization are the most fundamental of all, because the way information is encoded and organized in VSTM has a direct impact on its capacity and precision. For example, whether items are encoded individually (Woodman, Vogel, & Luck, 2012) or globally with item relations (Brady & Alvarez, 2011; Brady, Konkle, & Alvarez, 2011; Brady & Tenenbaum, 2013; Clevenger & Hummel, 2014; Jiang, Olson, & Chun, 2000) may ultimately decide how many items can be stored (capacity) and how detailed their representations can be (precision).
The literature does not have a coherent account regarding the contents and organization of VSTM yet. We outline two hypotheses that have each gained empirical support. First, the independent encoding hypothesis specifies that each individual item is encoded and stored independent of each other (Woodman et al., 2012). This idea can be viewed as an extension of the slot-based model (Luck & Vogel, 1997) that specifies a fixed number of slots (3-4 objects) in VSTM (Cowan, Chen, & Rouder, 2004). Based on the idea of object-based VSTM (Walker & Davies, 2003; Xu, 2002), this hypothesis states that the basic units of VSTM are objects rather than features. Thus, each object, regardless of the number of its features, is encoded as a whole yet separate from other object representations. Although not explicitly stated, this also is the underlying assumption across different estimating functions for VSTM capacity (Cowan, 2001; Cowan et al., 2004; Pashler, 1988). Consequently, the independent encoding hypothesis predicts that the encoding and storage of one particular item will not be influenced by the same processes for other items (e.g., Woodman et al., 2012).
The relational encoding hypothesis, in contrast, suggests that item relations are encoded along with each item (e.g., Alvarez, 2011) and can influence the representations of those items. This view implies that VSTM is organized by item relations, either featurally (Quinlan & Cohen, 2012) or spatially (Jiang et al., 2000). Notably, Quinlan and Cohen (2012) found a color-sharing effect in VSTM such that detection of an in-group color change (i.e., a change occurs in a square that can be grouped by color with surrounding items) was better than that of an out-group color change (i.e., a change occurs in a square that has a unique color and thus cannot be grouped), presumably because items of similar colors are stored and retrieved as one chunk. Similarly, Brady and colleagues also have reported that participants tend to encode higher-order (ensemble) statistics, such as mean stimulus size (Brady & Alvarez, 2011) or color grouping information to facilitate memory performance, even in simplistic displays, such as those used in a typical change detection paradigm (Brady & Tenenbaum, 2013). These findings somewhat contradict the slot-based account, which would predict no difference in detection performance between an in-group and out-group color change. Studies also have found that similarity between items’ colors can enhance VSTM representation (Lin & Luck, 2008; Sanocki & Sulman, 2009, 2011). Thus, in the context of detecting color changes, task-relevant relational information, such as color grouping, seems to be robust in facilitating VSTM.
Further support comes from Jiang et al. (2000), who manipulated the spatial configuration between the pre- and post-change displays and found that performance of detecting a color change was better when spatial configuration of colored squares remained the same between the two displays (the whole-display condition) than when all items were removed except for the critical probe in the post-change display (the single-probe condition). This whole-display superiority was observed despite the fact that spatial information was less relevant in a color change detection task, and therefore suggests that the contents of VSTM are organized by spatial relations between individual items. More recent studies by Hollingworth (2007) using object stimuli manipulated absolute and relative positional changes between the pre- and post-change displays and found that performance of detecting an object change was primarily affected by changes in relative object locations, implying that individual objects are encoded and stored in VSTM by their relative spatial relations.
Although the whole-display superiority provides strong support for the relational encoding hypothesis, it is important to note that not all studies have been able to reproduce the same effect. For example, in a series of systematic investigations of change detection along different featural dimensions, Wheeler and Treisman (2002) paired a color change detection task with either a single-probe or a whole-display condition. Interestingly, they found that when the task was difficult enough (set size = 6), participants performed worse when they viewed the whole display in comparison to the single probe (Wheeler & Treisman, 2002, Fig. 6b and d), a result that contradicts the prediction of relational encoding hypothesis. The reversal of the whole-display superiority (also called single-probe advantage) also was reported by Yeh, Yang, and Chiu (2005) and Kondo and Saiki (2012). Based on these inconsistent findings regarding the effect of whole-display superiority, it is apparent that the literature to date does not have a consensus on whether task-irrelevant relational information (spatial relations) is facilitative, not facilitative, or not effective. Consequently, the specifics to the independent encoding hypothesis and the relational encoding hypothesis remain unclear.
To account for the seemingly contradictory findings above, we propose that the independent encoding hypothesis and the relational encoding hypotheses need not be mutually exclusive and can possibly be reconciled with a hybrid account, the hierarchical representation hypothesis. Specifically, people may encode and store multiple levels of representations in VSTM, both featural and relational (e.g., representations of individual items, representations of relations between items, and the abstract representation of a display scene, such as gist and schema). Therefore, with relational information encoded in VSTM, the key to explain the varying results from previous studies now becomes what is actually retrieved and used to aid decision. As we have mentioned before, even when spatial relation information is not necessary in performing a color change detection task, it has been shown to aid detection of color changes (Jiang et al., 2000), suggesting that relational information may be encoded and retrieved regardless of task relevancy. Thus, to approach this issue from another angle, in this study we tested another possibility that may further constrain the hierarchical representation hypothesis: decision load. That is, the amount of cognitive resources for retrieving different levels of representations is highly constrained by the level of load, whether at the retrieval, comparison, or decision stage. The importance of load can be understood by comparing studies that either did or did not observe the whole-display superiority. Notably, the critical difference between the Jiang et al. (2000) study and others (e.g., Kondo & Saiki, 2012; Wheeler & Treisman, 2002; Yeh et al., 2005) is that the former study presented a post-cue in the post-change display while others did not. It is plausible that the post-cue had significantly reduced the amount of load by narrowing down the number of retrieval and comparison to one item. On the other hand, without a post-cue, participants had to compare between the pre- and post-change displays by each item, thus increasing overall load. If each comparison produces a certain amount of decision noise, then pooling all comparison results for a single decision should produce n (set-size) times the decision noise [see John Palmer and colleagues’ studies (Palmer, 1990, 1995; Palmer, Ames, & Lindsey, 1993; Palmer & Jonides, 1988)]. In this view, under low load, there is enough resource to retrieve and use relational information for decision making. In contrast, high load spares less resources, hence that relational information cannot aid change detection performance. Consequently, as load increases, task-irrelevant relational information cannot be retrieved to aid change detection.
To test this idea, in the present study we manipulated the presence of a post-cue (load), color grouping (color relations), and probe condition (spatial configuration) to investigate whether different levels of relational information processing in VSTM are affected by levels of load. We predict that only under low load will task-irrelevant spatial relations aid color change detection and we expect to observe the whole-display superiority. By contrast, under high load, we predict to observe a reversal of whole-display superiority. We also expect to observe the color-sharing effect that has been reported by many (e.g., Quinlan & Cohen, 2012) in the whole-display condition, regardless of load.
Experiment 1
In the first experiment, a simultaneous post-cue was presented in the post-change display to reduce the load in change detection. Under low load, we expected to replicate Jiang et al.’s (2000) findings of the whole-display superiority: a better detection performance in a whole-display condition than in a single-probe condition. In addition, we manipulated color grouping and tested the color-sharing effect reported by Quinlan and Cohen (2012). We expected to observe a better detection performance for an in-group color change than an out-group color change.
Method
Participants
Twenty-one students from National Cheng Kung University volunteered to participate in this experiment. Each participant received NTD 100 or a bonus course credit in an introductory psychology course for his or her participation. All were age 18 to 29 years with normal or corrected-to-normal vision. All participants signed a written, informed consent prior to the experiment.
Equipment
A PC with a 2.40-GHz Intel Pentium IV processor-controlled stimulus displays and recorded responses. The experiment was run with E-Prime 1.1 (Schneider, Eschman, & Zuccolotto, 2002). The visual events were presented on a 19-inch color monitor with a vertical refresh rate of 75 Hz. The viewing distance was 60 cm.
Design and Stimuli
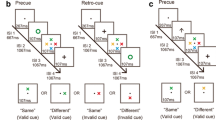
Each trial was constructed by a pre-change display and a post-change display. There was either a color change or no color change between the two displays. A post-cue (an outline box, Fig. 1) was presented to cue a critical probe. Participants had to judge whether the cued item changed its color or not.

An illustration of the experimental procedure in Experiment 1. The bottom left panel is an example of the whole-display condition and the bottom right panel is an example of the single-probe condition.
The pre-change display was composed of eight colored squares, which were randomly presented at a 10 × 10 invisible grid (9.6° in width × 9.3° in height). Each square was 0.76° in width and 0.73° in height and their colors were black (x = 0.319, y = 0.302, luminance = 0.02 cd∕m 2), blue (x = 0.149, y = 0.078, luminance = 0.200 cd∕m 2), red (x = 0.621, y = 0.334, luminance = 0.400 cd∕m 2), green (x = 0.295, y = 0.606, luminance = 0.980 cd∕m 2), yellow (x = 0.430, y = 0.496, luminance = 1.340 cd∕m 2), magenta (x = 0.279, y = 0.151, luminance = 0.550 cd∕m 2), cyan (x = 0.203, y = 0.277, luminance = 1.190 cd∕m 2), or white (x = 0.282, y = 0.284, luminance = 1.520 cd∕m 2). All the colored squares were presented on a gray background (x = 0.294, y = 0.217, luminance = 0.090 cd∕m 2). The CIE coordinate was measured by RPS 380 portable spectroradiometer from International Light Inc.
Color grouping was manipulated. Three of the eight colored squares were of the same color, and the rest were of different colors such that for every trial the memory display always contained exactly six colors. A color change may occur either at a square that was grouped by color (in-group change) or at a square that had a unique color in the test display (out-group change). The locations of the squares were random; therefore squares of the same color may or may not be located around each other. The color-sharing effect was tested by comparing the detection performance of the in-group change condition with that of the out-group change condition.Footnote 1
In addition, there were two types of probe conditions. In a whole-display condition (Fig. 1, bottom left panel), the items not cued by the box maintained their previous colors and locations in the post-change display. In a single-probe condition (Fig. 1, bottom right panel), only the critical probe was presented in the post-change display. Information of spatial relations was thus absent in the post-change display.
Participants first practiced 12 trials, and then they performed the formal test trials. There were a total of 160 test trials. Half of the test trials were change trials, and the others were no-change trials. In the change trials, all the combinations of change condition (in-group change vs. out-group change) and the probe condition (whole-display vs. single-probe) were equally probable and randomly presented in each block.
Procedure
The experiment was tested individually. Each trial began with a fixation cross for 507 ms (Fig. 1). A pre-change display was presented for 400 ms. Following a retention interval of 907 ms, a post-change display was presented until the participants made a response. If a change was detected, they had to press “z”; otherwise, they had to press “m.” Accuracy instead of speed was emphasized in this experiment.
Results and Discussion
Table 1 presents the mean detection performance.Footnote 2 Fig. 2 presents the results of mean detection sensitivity (d’) as a function of change condition and probe condition, and they were analyzed with a 2 (change condition) × 2 (probe condition) repeated-measures analysis of variance (ANOVA). Results showed that the main effect of change condition was significant [F(1, 20) = 31.84, p < 0.005, η 2 p = 0.61], indicating that detecting an in-group change was more accurate than detecting an out-group change with higher detection sensitivity. The main effect of probe condition also was significant [F(1, 20) = 5.71, p < 0.05, η 2 p = 0.22], indicating a better detection performance in the whole-display condition than in a single-probe condition. The interaction effect was marginally significant [F(1, 20) = 4.11, p = 0.053, η 2 p = 0.17]. Post-hoc analysis showed that whole-display superiority was only observed in the in-group change condition [F(1, 40) = 9.67, p < 0.005, η 2 p = 0.20], whereas in the out-group change condition, there were no significant differences between the detection performance between the whole-display and single-probe conditions (p > 0.05). On the other hand, the color-sharing effect was observed both in the single-probe condition [F(1, 40) = 4.90, p < 0.05, η 2 p = 0.11] and in the whole-display condition [F(1, 40) = 27.59, p < 0.005, η 2 p = 0.41]. The color-sharing effect was much larger in the latter condition.

Mean detection sensitivity (d’) as a function of the change condition and probe condition in Experiment 1. Error bar represents the standard error.
In summary, when a post-cue was presented in the post-change display to reduce the load in retrieval, comparison, and decision, whole display benefited change detection performance when a change occurred at an in-group color location. However, neither benefit nor cost was observed for the whole display compared to the single probe when a change occurred at an out-group color location. These results suggest that the benefit from the task-irrelevant spatial relations for color change detection was predetermined by color grouping.
On the other hand, the color-sharing effect was observed in both the whole-display and single-probe conditions, suggesting that task-relevant color relations consistently facilitated color change detection performance no matter when spatial relational information was maintained or not. More interestingly, this effect was larger in the whole-display condition than in the single-probe condition, which suggests that spatial relations played a role in retrieving color relational information for detecting a color change.
According to these findings, we suggest that both spatial and color relational information are maintained in VSTM, and these two types of relational information can interactively influence color change detection performance. These findings are consistent with the Gestalt principles of perceptual organization, where similarity (color relations) and proximity (spatial relations) are two of the most important Gestalt principles to organize a visual event (e.g., Ben-Av & Sagi, 1995). Also, these findings are consistent with the current view that relational processing guides visual attention and eye movements (Becker, 2010; Becker, Folk, & Remington, 2013), and consequently affects the contents encoded and stored in VSTM (Becker, 2013). Participants would encode and retain both color relations and spatial relations simultaneously to form a coherent percept. For example, the three squares of the same color can be taken as a perceptual unit. As a result, participants would not maintain eight color squares individually in memory; their strategy would be to encode and retain three color squares of the same color as a perceptual unit against the other five squares of different colors. The spatial relations of the eight units would be encoded to form a hierarchical, spatial representation for color change detection. With the hierarchical, spatial representation held in memory, the beneficial effect of the spatial relational information would be observed only when color grouping information can aid change detection. On the other hand, the beneficial effect of the color relational information would be optimized when spatial configuration holds across the pre- and post-change displays for retrieving color relations.
Experiment 2
In the second experiment, the post-cue was removed such that correct change detection required the participants to compare the pre- and post-change displays by each item. Under this manipulation, load in memory retrieval, comparison, and decision increases drastically and spares very little cognitive resources for the retrieval of other information, and thus we expect that task-irrelevant spatial relations cannot aid color change detection in this case. Presenting all the items in the post-change display can even result in a reversal of whole-display superiority due to the increasing load in memory retrieval, comparison, and decision. Lastly, we expect that task-relevant color relations should consistently aid color change detection, resulting in a color-sharing effect.
Method
Participants
Twenty-one students from National Cheng Kung University volunteered to participate in this experiment. Each participant received NTD 100 or a bonus course credit in an introductory psychology course for his or her participation. All were age 18 to 29 years with normal or corrected-to-normal vision. All participants signed a written informed consent prior to the experiment.
Stimuli, design, and procedure
The stimuli, design, and procedure were the same as Experiment 1 except that there was no post-cue to indicate the location of the critical probe. Unlike Experiment 1, in the whole-display condition participants had to compare the pre- and post-change displays by each item.
Results and Discussion
Table 2 presents the mean detection performance. Figure 3 presents the results of mean d’ as a function of change condition and probe condition, and they were analyzed with a two-way repeated-measures ANOVA. Results showed that the main effect of change condition was significant [F(1, 20) = 9.67, p < 0.01, η 2 p = 0.33], indicating that detecting an in-group change was more accurate than detecting an out-group change with higher detection sensitivity. The main effect of probe condition also was significant [F(1, 20) = 28.83, p < 0.001, η 2 p = 0.60], indicating a better detection performance in the single-probe condition than in the whole-display condition, a reversal of whole-display superiority. The interaction effect was significant [F(1, 20) = 7.43, p < 0.05, η 2 p = 0.27]. Post-hoc analysis showed that a reversal of the whole-display superiority was both observed in the in-group change condition [F(1, 40) = 4.24, p < 0.05, η 2 p = 0.10] and out-group change condition [F(1, 40) = 33.45, p < 0.001, η 2 p = 0.46]. The effect was much larger in the latter context. On the other hand, the color-sharing effect was observed in the whole-display condition [F(1, 40) = 17.10, p < 0.001, η 2 p = 0.30], whereas this effect was eliminated in the single-probe condition (p = 0.62).

Mean detection sensitivity (d’) as a function of the change condition and probe condition in Experiment 2. Error bar represents the standard error.
In summary, when post-cues were removed from the post-change display such that participants had to compare the pre- and post-change displays by each item, we observed a reversal of the whole-display superiority. These results are consistent with previous findings (e.g., Kondo & Saiki, 2012; Wheeler & Treisman, 2002; Yeh et al., 2005): under high load where participants did not have enough cognitive resources to retrieve spatial relations, task-irrelevant spatial relations cannot aid color change detection performance. That is, presenting all the items in the post-change display deteriorated color change detection performance.
Unlike Experiment 1, the color-sharing effect was only observed in the whole-display condition, and this effect was eliminated in the single-probe condition. Consistent with Experiment 1, the observation of the color-sharing effect in the whole-display condition suggest that color relations facilitated color change detection performance especially when spatial relations remained intact on display to aid the retrieval of color relations. The absence of the color-sharing effect in the single-probe condition may be due to the context effect. Specifically, all of the experimental conditions were intermixed and randomly presented in a block. With the absence of the post-cues, whole-display conditions required the participants to retrieve all the items from memory and make item-by-item comparisons for a change decision. This response strategy would result in a decreased level of cognitive resources for retrieving color relations, such that the color-sharing effect was reduced or even eliminated when spatial relations were not available to aid the retrieval of color relations. To verify this possibility, we compared the magnitude of the color-sharing effect across the two experiments, and we found the presence of a post-cue did not interact with the probe condition (p = 0.22). There was a general decrement in the magnitude in Experiment 2 compared to Experiment 1 (whole-display: 0.69 in Experiment 1 vs. 0.58 in Experiment 2; single-probe: 0.29 in Experiment 1 vs. 0.07 in Experiment 2).
Experiment 3
As we have mentioned in Experiment 1, one potential setback of its design was that participants could learn that each trial always contained three same-colored squares and five different-colored squares. With this information, at least in the whole-display condition, one could strategically count the number of same-colored squares in the test display, where two same-colored squares means a definite change and three same-colored squares means a 50:50 chance either way (no change or out-group change). To account for this potential setback, in this experiment we modified the test display in the whole-display condition such that only the probe item was colored (correct or incorrect), and the other seven squares were gray. With this manipulation, the whole-display condition in the present experiment became slightly more similar to the single probe condition (e.g., color is not preserved except for the probe item) but still different because it retained all the spatial-relation context information at test display. Therefore, if the color-sharing effect and the effect of whole-display superiority from Experiment 1 were due to a counting strategy, the two effects would not be observed in the present setup. In contrast, the presence of a color-sharing effect and whole-display superiority would validate our observation from Experiment 1.
Method
Participants
Fifteen students from National Cheng Kung University volunteered to participate in this experiment. Each participant received NTD 100 or a bonus course credit in an introductory psychology course for his or her participation. All were age 18 to 30 years with normal or corrected-to-normal vision. All participants signed a written informed consent prior to the experiment.
Stimuli, design, and procedure
The stimuli, design, and procedure were the same as Experiment 1 except for the test display in the whole-display condition. In the whole-display condition, all the squares except for the probe item were replaced by gray squares at test (Fig. 4). This manipulation prevents the participants from using a counting strategy to detect a color change while preserving the spatial configuration of all the items.

An illustration of the experimental procedure in Experiment 3. The bottom left panel is an example of the whole-display condition (color is not preserved except for the probe item) and the bottom right panel is an example of the single-probe condition.
Results and Discussion
Table 3 presents the mean detection performance.Footnote 3 Fig. 5 presents the results of mean d’ as a function of change condition and probe condition, and they were analyzed with a two-way repeated-measures ANOVA. Results showed that the main effect of change condition was significant [F(1, 14) = 4.56, p < 0.05, η 2 p = 0.25], indicating that detecting an in-group change was more accurate than detecting an out-group change with higher detection sensitivity. The main effect of probe condition was not significant (p > 0.1). The interaction effect was significant [F(1, 14) = 6.63, p < 0.05, η 2 p = 0.32]. Post-hoc analysis showed that the whole-display superiority was only observed in the in-group change condition [F(1, 28) = 6.71, p < 0.01, η 2 p = 0.19], whereas this effect was eliminated in the out-group condition (p = 0.30). On the other hand, the color-sharing effect was only observed in the whole-display condition [F(1, 28) = 10.65, p < 0.01, η 2 p = 0.28], whereas this effect was eliminated in the single-probe condition (p = 0.59).

Mean detection sensitivity (d’) as a function of the change condition and probe condition in Experiment 3. Error bar represents the standard error.
In this experiment, we observed the effect of whole-display superiority only in the in-group but not the out-group color change condition. This is the same observation as Experiment 1 despite the fact that no color information was given in the test displays. However, note that the overall d’ was lower in Experiment 3 than that in Experiment 1, thus suggesting that the preservation of the color frame can still aid the retrieval of color information to certain extent. In addition, we observed the color-sharing effect only in the whole-display but not the single-probe condition, which is the same as our Experiment 2 results. Therefore, under low decision load (e.g., cue available), relational processing of context information, such as the spatial configuration of the squares could still facilitate change detection. This is consistent with the results from both Experiments 1 and 2.
General Discussion
In this study, we manipulated the presence of a post-cue, color grouping, and probe condition to investigate how load modulates the utilization of the task-relevant (color relations) and task-irrelevant (spatial relations) relational information in color change detection. Our results showed that under low load (Experiments 1 and 3), we replicated Jiang, et al.’s (2000) findings of whole-display superiority when a change occurred at an in-group color location; that is, better change detection performance in the whole-display condition than in the single-probe condition. This beneficial effect was not observed at out-group color locations. In contrast, under high load (Experiment 2), we observed a reversal of whole-display superiority (single-probe advantage), regardless of the change condition. In addition, the color-sharing effect was consistently observed in all experiments except for the single-probe condition in Experiments 2 and 3. Also, the color-sharing effect was larger in the whole-display condition than in the single-probe condition. Finally, the addition of Experiment 3 ruled out the possibility of the use of counting strategy in Experiment 1. Although it is not possible to create a similar version for Experiment 2 (whole-display test array cannot be displayed without cue and all items grayed-out), we think the results from Experiment 3 also validates our observations from Experiment 2, because, if a counting strategy was used in Experiment 2, then whole-display performance should exceed single-probe performance, but we observed the opposite.
Role of retrieval, comparison, and decision in change detection
Previous studies have mostly utilized a change detection task to investigate the capacity, precision, and contents and organization of VSTM. In a typical change detection task, participants first view a pre-change display composed of multiple items, followed by a blank interval and a post-change display. Participants have to detect whether there is any change between the two displays. Successful change detection requires the participants to encode the pre- and post-change items, retrieve the pre-change items from memory representation, and compare them with the post-change representations. Finally, participants also have to make a correct decision, based on their internal comparison outputs. Hit rate and false alarm rate of this paradigm have been cleverly used to infer how many items can be stored in one’s VSTM (Cowan, 2001; Pashler, 1988) and how precise they are (Bays, Catalao, & Husain, 2009; Ma, Husain, & Bays, 2014; Zhang & Luck, 2008). Importantly, comparing change detection performance across different conditions also may provide insights to the content and organization of VSTM (Christophel, Hebart, & Haynes, 2012; Jiang et al., 2000; Orhan & Jacobs, 2013), as well as one’s comparison and decision processes (Hollingworth, 2003; Hyun, Woodman, Vogel, Hollingworth, & Luck, 2009; Mitroff, Simons, & Levin, 2004; Yang, 2011; Yang, Chang, & Wu, 2013; Yang, Hsu, Huang, & Yeh, 2011).
Failure at each processing stage can result in Change Blindness (CB), i.e., failure to detect a change (Simons, 2000; Simons & Rensink, 2005). However, it is now clear that CB does not necessarily reflect the absence of a detailed pre-change representation (Hollingworth, 2006). In many studies, researchers demonstrated that even when participants were unable to detect a change, both explicit measures (i.e., recognition memory task) (Mitroff et al., 2004; Yeh & Yang, 2008) and implicit measures (i.e., perceptual identification task) (Silverman & Mack, 2006; Yeh & Yang, 2009) revealed that the pre-change representation was preserved in memory. This evidence suggests that CB can occur because of retrieval and comparison failure (Hollingworth, 2003; Mitroff et al., 2004; Yang & Yeh, 2009) or decision difficulty (Wilken & Ma, 2004; Yeh & Yang, 2008; Zelinsky, 2003).
Based on previous findings that relational processing can enhance VSTM (Alvarez, 2011; Brady & Alvarez, 2011; Brady & Tenenbaum, 2013; Clevenger & Hummel, 2014; Hollingworth, 2007; Jiang et al., 2000; Lin & Luck, 2008; Quinlan & Cohen, 2012; Sanocki & Sulman, 2009, 2011), the current study further tested the effects of load in memory retrieval, comparison, and decision and task relevancy on different levels of relational processing. It is worthwhile to note that whether relational processing can facilitate change detection performance is largely dependent on 1) the amount of cognitive resources for retrieving such relational information to aid decision, and 2) whether this relational information is task-relevant.
Organizations of VSTM: Independent, Relational, or Hierarchical?
Our results do not support the independent encoding hypothesis (Cowan, 2001; Cowan et al., 2004; Luck & Vogel, 1997; Pashler, 1988; Woodman et al., 2012). According to this hypothesis, items are assumed to be encoded and stored independent of each other, and thus this hypothesis predicts that color change detection performance would not be affected by any manipulation of the relational information. The observations of the color-sharing effect from all experiments and the whole-display superiority (see Experiments 1 and 3) go against this prediction. In addition, our results do not fully support the relational encoding hypothesis either (Alvarez, 2011; Hollingworth, 2007; Jiang et al., 2000; Lin & Luck, 2008; Quinlan & Cohen, 2012; Sanocki & Sulman, 2009, 2011). According to this hypothesis, relational information as well as item information is assumed to be encoded and stored in VSTM, and this hypothesis would predict that both spatial and color relations can facilitate change detection performance regardless of the task relevancy. However, our results show that spatial relations facilitated color change detection performance only when a post-cue was presented; preserving spatial relations would deteriorate color change detection performance when no post-cue was presented to indicate the critical probe for decision making. The observation of the reversal of whole-display superiority, or single-probe advantage, goes against the relational encoding prediction.
Our results are better explained with the hierarchical representation hypothesis. This hypothesis suggests that both item information and relational information are encoded and stored in VSTM (Brady & Alvarez, 2011; Brady & Tenenbaum, 2013; Clevenger & Hummel, 2014). The benefit from relational processing on change detection is determined by both task relevancy and load at memory retrieval, comparison, and decision stages. Relational information would facilitate change detection regardless of the load when it is task-relevant. On the contrary, task-irrelevant relational information would aid change detection only when participants have enough cognitive resources to utilize the relational information for memory retrieval, comparison, and decision; otherwise, task-irrelevant relational information would interfere with change detection. Our results support the argument, and more interestingly, we found that spatial and color relational processing interactively affected color change detection. Specifically, benefit of the spatial relations was observed only when color grouping cues can aid change detection, and the utilization of color relations was optimized when spatial relations were preserved in the post-change display and served cues for retrieving color relations. These results imply that color relations are coded in a spatial structure, and the basic perceptual unit of the spatial representation is multiple items grouped by color, rather than individual items. From this perspective, Jiang et al.’s (2000) first report of whole-display superiority indeed fits the two criterions we have tested above: low load (i.e., post-cue) and color grouping. Notably, in the present study we have adopted their design so that each particular color can repeat up to three times in a display, and it is clear that color grouping occurs automatically in such context, ours and theirs, given that enough cognitive resources are available. Therefore, the findings from Jiang et al. (2000) can be reconciled with others’ findings when color grouping and load are taken into account. As such, to our knowledge the present findings are the first to demonstrate systematically how different levels of relational processing would interact on VSTM representations and can readily resolve some of the inconsistent reports that have been previously raised in the literature regarding the whole-display superiority.
Future directions
In this study, we tested the effects of color and spatial relational processing on color change detection, and we suggested that task-relevant relational processing can consistently facilitate change detection regardless of load, whereas task-irrelevant relational processing can aid change detection only when load is low for retrieving relational information for decision making. These findings open a new door to a number of possibilities that need to be tested in the future. First, color grouping is a very salient grouping cue to organize a perceptual event. It remains unclear whether the current results can be generalized to the other contexts when less salient features, e.g., shape, are used as cues for perceptual grouping. If the saliency of the grouping cues and load can interactively influence the utilization of relational information, we would expect that only under low load would less salient and task-relevant relational information aid change detection, whereas under high load, this beneficial effect would be eliminated.
Second, in many change detection studies (Treisman & Zhang, 2006; Wheeler & Treisman, 2002; Yeh et al., 2005), it has been found that location is a special feature, which induces a different behavioral pattern than the other features. Processing surface features (e.g., color, shape) is automatically bound to a spatial position (Treisman & Zhang, 2006). Location processing is of unlimited capacity and is completed in a parallel fashion at the pre-attentive stage (Treisman & Gelade, 1980). Accordingly, we may speculate that the irrelevant spatial relation can aid color change detection because of its unique role in perception and memory. As such, our ongoing study is designed to test the effect of task relevancy on relational processing in VSTM when both task-relevant and task-irrelevant relational information are of different featural relations.
Finally, we are curious about how relational processing affects binding change detection. Detecting a binding change requires participants to focus their attention to integrate two features at a spatial location; by contrast, detecting a feature change does not require the participants’ focal attention. To understand how relational processing affects binding change, detection can further researchers’ understandings of the organization of feature bindings in VSTM.
Notes
With this design, one concern is that participants could develop an implicit strategy where they only pay attention to the number of same-color squares in the test display (we thank one anonymous reviewer for pointing this out). In this scenario, two same-color squares (originally three) in the test display would signal an in-group change, whereas three same-color squares would indicate either an out-group change or no change, thereby creating better performance for the in-group condition.
Note that the in-group and out-group conditions shared the same total false alarm rate because both conditions were intermixed within a block.
Note that the false-alarm rates in the whole-display conditions were higher than those in Experiments 1 and 2. It is perhaps because the current setup (color is not preserved except for the probe item) made the participants biased toward responding change.
References
Alvarez, G. A. (2011). Representing multiple objects as an ensemble enhances visual cognition. Trends in Cognitive Sciences, 15(3), 122–131.
Bays, P. M., Catalao, R. F. G., & Husain, M. (2009). The precision of visual working memory is set by allocation of a shared resource. Journal of Vision, 9(10), 1–11.
Becker, S. I. (2010). The role of target–distractor relationships in guiding attention and the eyes in visual search. Journal of Experimental Psychology: General, 139(2), 247–265.
Becker, S. I. (2013). Simply shapely: Relative, not absolute shapes are primed in pop-out search. Attention, Perception, & Psychophysics, 75(5), 845-861.
Becker, S. I., Folk, C. L., & Remington, R. W. (2013). Attentional Capture Does Not Depend on Feature Similarity, but on Target-Nontarget Relations. Psychological Science.
Ben-Av, M. B., & Sagi, D. (1995). Perceptual grouping by similarity and proximity: Experimental results can be predicted by intensity autocorrelations. Vision Research, 35(6), 853–866.
Brady, T. F., & Alvarez, G. A. (2011). Hierarchical encoding in visual working memory: Ensemble statistics bias memory for individual items. Psychological Science, 22(3), 384–392.
Brady, T. F., Konkle, T., & Alvarez, G. A. (2011). A review of visual memory capacity: Beyond individual items and toward structured representations. Journal of Vision, 11(5), 1–34.
Brady, T. F., & Tenenbaum, J. B. (2013). A probabilistic model of visual working memory: Incorporating higher order regularities into working memory capacity estimates. Psychological Review, 120(1), 85–109.
Christophel, T. B., Hebart, M. N., & Haynes, J.-D. (2012). Decoding the contents of visual short-term memory from human visual and parietal cortex. The Journal of Neuroscience, 32(38), 12983–12989.
Clevenger, P., & Hummel, J. (2014). Working memory for relations among objects. Attention, Perception, & Psychophysics, 76(7), 1933–1953.
Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and Brain Sciences, 24(1), 87–185.
Cowan, N., Chen, Z., & Rouder, J. N. (2004). Constant capacity in an immediate serial-recall task: A logical sequel to Miller (1956). Psychological Science, 15(9), 634–640.
Hollingworth, A. (2003). Failures of retrieval and comparison constrain change detection in natural scenes. Journal of Experimental Psychology: Human Perception and Performance, 29(2), 388–403.
Hollingworth, A. (2006). Visual memory for natural scenes: Evidence from change detection and visual search. Visual Cognition, 14(4–8), 781–807.
Hollingworth, A. (2007). Object-position binding in visual memory for natural scenes and object arrays. Journal of Experimental Psychology: Human Perception and Performance, 33(1), 31–47.
Hyun, J.-s., Woodman, G. F., Vogel, E. K., Hollingworth, A., & Luck, S. J. (2009). The comparison of visual working memory representations with perceptual inputs. Journal of Experimental Psychology: Human Perception and Performance, 35(4), 1140–1160.
Jiang, Y., Olson, I. R., & Chun, M. M. (2000). Organization of visual short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26(3), 683–702.
Kondo, A., & Saiki, J. (2012). Feature-specific encoding flexibility in visual working memory. PLoS ONE, 7(12), e50962.
Lin, P.-H., & Luck, S. (2008). The influence of similarity on visual working memory representations. Visual Cognition, 17(3), 356–372.
Luck, S. J. (2008). Visual short-term memory. In S. J. Luck & A. Hollingworth (Eds.), Visual memory (pp. 43–86). New York: Oxford University Press.
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390(6657), 279–281.
Ma, W. J., Husain, M., & Bays, P. M. (2014). Changing concepts of working memory. Nat Neurosci, 17(3), 347–356.
Mitroff, S. R., Simons, D. J., & Levin, D. T. (2004). Nothing compares 2 views: Change blindness can occur despite preserved access to the changed information. Perception & Psychophysics, 66(8), 1268–1281.
Orhan, A. E., & Jacobs, R. A. (2013). A probabilistic clustering theory of the organization of visual short-term memory. Psychological Review, 120(2), 297–328.
Palmer, J. (1990). Attentional limits on the perception and memory of visual information. Journal of Experimental Psychology: Human Perception and Performance, 16(2), 332–350.
Palmer, J. (1995). Attention in visual search: Distinguishing four causes of a set-size effect. Current Directions in Psychological Science, 4(4), 118–123.
Palmer, J., Ames, C. T., & Lindsey, D. T. (1993). Measuring the effect of attention on simple visual search. Journal of Experimental Psychology: Human Perception and Performance, 19(1), 108–130.
Palmer, J., & Jonides, J. (1988). Automatic memory search and the effects of information load and irrelevant information. Journal of Experimental Psychology: Learning, Memory, and Cognition, 14(1), 136–144.
Pashler, H. (1988). Familiarity and visual change detection. Perception & Psychophysics, 44(4), 369–378.
Phillips, W. (1974). On the distinction between sensory storage and short-term visual memory. Perception & Psychophysics, 16(2), 283–290.
Quinlan, P. T., & Cohen, D. J. (2012). Grouping and binding in visual short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition.
Sanocki, T., & Sulman, N. (2009). Color harmony increases the capacity of visual short term memory. Journal of Vision, 9(8), 322.
Sanocki, T., & Sulman, N. (2011). Color relations increase the capacity of visual short-term memory. Perception, 40(6), 635–648.
Schneider, W., Eschman, A., & Zuccolotto, A. (2002). E-Prime: User's Guide: Psychology Software Inc.
Silverman, M. E., & Mack, A. (2006). Change blindness and priming: When it does and does not occur. Consciousness and Cognition, 15(2), 409–422.
Simons, D. J. (2000). Current approaches to change blindness. Visual Cognition, 7(1–3), 1–15.
Simons, D. J., & Rensink, R. A. (2005). Change blindness: Past, present, and future. Trends in Cognitive Sciences, 9(1), 16–20.
Treisman, A., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12(1), 97–136.
Treisman, A., & Zhang, W. (2006). Location and binding in visual working memory. Memory & Cognition, 34(8), 1704–1719.
Walker, P., & Davies, S. J. (2003). Perceptual completion and object-based representations in short-term visual memory. Memory & Cognition, 31(5), 746–760.
Wheeler, M. E., & Treisman, A. M. (2002). Binding in short-term visual memory. Journal of Experimental Psychology: General, 131(1), 48–64.
Wilken, P., & Ma, W. J. (2004). A detection theory account of change detection. Journal of Vision, 4(12), 1120–1135.
Woodman, G. F., Vogel, E. K., & Luck, S. J. (2012). Flexibility in visual working memory: Accurate change detection in the face of irrelevant variations in position. Visual Cognition, 20(1), 1–28.
Xu, Y. (2002). Limitations of object-based feature encoding in visual short-term memory. Journal of Experimental Psychology: Human Perception and Performance, 28(2), 458–468.
Yang, C.-T. (2011). Relative saliency in change signals affects perceptual comparison and decision processes in change detection. Journal of Experimental Psychology: Human Perception & Performance, 37(6), 1708–1728.
Yang, C.-T., Chang, T.-Y., & Wu, C.-J. (2013). Relative change probability affects the decision process of detecting multiple feature changes. Journal of Experimental Psychology: Human Perception & Performance, 39(5), 1365–1385.
Yang, C.-T., Hsu, Y.-F., Huang, H.-Y., & Yeh, Y.-Y. (2011). Relative salience affects the process of detecting changes in orientation and luminance. Acta Psychologica, 138(3), 377–389.
Yang, C.-T., & Yeh, Y.-Y. (2009). Memory error in recognizing a pre-change object. Psychological Research, 73, 75–88.
Yeh, Y.-Y., & Yang, C.-T. (2008). Object memory and change detection: Dissociation as a function of visual and conceptual similarity. Acta Psychologica, 127(1), 114–128.
Yeh, Y.-Y., & Yang, C.-T. (2009). Is a pre-change object representation weakened under correct detection of a change? Consciousness and Cognition, 18, 91–102.
Yeh, Y.-Y., Yang, C.-T., & Chiu, Y.-C. (2005). Binding or prioritization: The role of selective attention in visual short-term memory. Visual Cognition, 12(5), 759–799.
Zelinsky, G. J. (2003). Detecting changes between real-world objects using spatiochromatic filters. Psychonomic Bulletin & Review, 10(3), 533–555.
Zhang, W., & Luck, S. J. (2008). Discrete fixed-resolution representations in visual working memory. Nature, 453(7192), 233–235.
Acknowledgments
This work was supported by grants from the Ministry of Science and Technology, Taiwan (MOST 100-2410-H-006-028-MY2 and MOST 102-2628-H-006 -001 -MY3), and NCKU 2014 top-notch project proposal to C.-T. Yang. Philip Tseng was supported by MOST 101-2811-H-008-014. Parts of the results were presented at the 50th Annual Meeting of Taiwanese Psychological Association, Taichung, Taiwan.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yang, CT., Tseng, P. & Wu, YJ. Effect of Decision Load on Whole-Display Superiority in Change Detection. Atten Percept Psychophys 77, 749–758 (2015). https://doi.org/10.3758/s13414-015-0834-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-015-0834-4