
Abstract
Three recent studies reported retinotopic (eye-centered) and object-centered attentional facilitation following exogenous cuing in dynamic displays. The present study replicates this finding and shows, under the very same experimental conditions, inhibition of return (IOR) in both retinotopic and object-centered reference frames. Unlike in previous findings, we show that when a single object is present in the display, IOR is bound to both retinotopic and object-centered locations, defined as a specific location within the boundaries of a single object.
Similar content being viewed by others

It is generally agreed that attention can be flexibly deployed in a top-down, endogenous manner to locations of interest to the observer or may be captured in a bottom-up, exogenous way by salient events in the environment independently of observers’ intentions (for reviews, see Theeuwes, 2010; Theeuwes, Mathôt, & Grainger, 2013). One such event that is known to grab our attention in an exogenous way is the sudden appearance of an object, such as an abrupt onset (Theeuwes, 1991, 1994, 2010). Some recent studies showed that even when observers are explicitly searching for a color singleton, an irrelevant abrupt onset may grab attention (Schreij, Owens, & Theeuwes, 2008) or the eyes (Schreij, Los, Theeuwes, Enns, & Olivers, 2014). Mulckhuyse, Talsma, and Theeuwes (2007) showed that an abrupt onset may even capture attention when observers do not consciously perceive it. Together, these and other studies demonstrate that exogenous attention operates automatically and independently of an observer’s goals or conscious awareness.
Typically, studies investigating endogenous and exogenous attentional selection use a cuing procedure in which a cue provides information about the location of an upcoming target. If the cue (e.g., a centrally presented arrow) indicates with a high probability the location of the upcoming target, one speaks of endogenous attention, since observers use this information in a top-down way to improve performance (Posner, 1980). However, if the cue has no predictive value regarding the location of the target, then one speaks of exogenous attention, since there is no incentive to endogenously direct attention to that location. For example, in Posner and Cohen (1984), there were two peripheral placeholders, one of which was briefly brightened, thus serving as an exogenous cue. The typical result is that observers are faster in responding to a target when it appears at the cued, relative to the uncued, location, illustrating that an uninformative cue captures attention in an exogenous way.
Even though it was initially assumed that an abrupt onset only attracts attention to the exact location where the abrupt onset was presented (the eye-centered, retinotopic location; Posner & Cohen, 1984), three recent studies cast doubt on this notion. For example, in Boi, Vergeer, Ogmen, and Herzog (2011), participants viewed displays containing three gray squares. An exogenous cue (an abrupt onset) was presented at a particular location in the central square. Following the cue, all squares moved laterally in tandem as a group (i.e., the so-called Ternus–Pikler display). Then participants searched for a target that could appear at the retinotopically cued location (i.e., the originally cued location on the display), the object-centered cued location (i.e., the location that matched the cued location within the square), or an invalid location (i.e., any other location). Boi et al. demonstrated attentional facilitation not only at retinotopic, but also at object-centered locations and concluded that exogenous cuing can occur in a coordinate system that moves with the perceptual grouping relations present in the display. Even though Boi et al. argued that their findings were about exogenous cuing, this claim is not necessarily convincing, since, in their study, the cue was predictive of the target location in four out of five experiments. In other words, this study was largely about endogenous cuing instead of exogenous cuing.
Lin (2013) improved on the design of Boi et al. (2011) and used a moving frame configuration with two frames in succession, which formed either an apparent translational motion (i.e., a configuration that slid from left to right or vice versa) or mirror reflection (i.e., a configuration that “flipped” around the central vertical axis). The abrupt onset cue presented in the first frame had no predictive value. Crucially, observers were faster in finding the target when it happened to appear at the same relative location as the cue location, for both the translation and mirror reflection conditions.
In our own study (Theeuwes et al., 2013), we took a different approach and instead of using a variant of the Ternus–Pikler display, we presented a nonpredictive abrupt onset cue at one of the arms of a smoothly rotating cross (see Fig. 1 for an example). We showed equally strong retinotopic (eye-centered) and object-centered cuing effects and argued that exogenous attention operates in both retinotopic and object-centered reference frames.

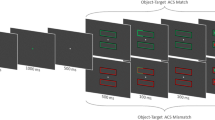
Experimental paradigm. a The target (Gabor patch) was presented immediately after the rotation (short SOA) or after an interval of 1,008 ms (long SOA). Opposing arms of the cross had an outline of the same color (equiluminant pink or green). b Critical conditions given a cue presented in the right arm, indicated by the dotted circle, and a counterclockwise rotation, indicated by the arrow
In sum, these three recent studies suggest that exogenous attention can operate in object-centered coordinates and is not, as previously assumed (e.g., Posner & Cohen, 1984), necessarily tied to the eye-centered (retinotopic) position. This conclusion is important since it suggests a flexibility in exogenous orienting that was previously assumed to exist only for endogenous, top-down attention. However, there is one crucial caveat in all these studies that would preclude such a conclusion. Although an abrupt onset was used to exogenously capture attention in all studies, some authors have argued that attentional capture by an abrupt onset always has an endogenous component as well, because observers have a default attentional set to look for dynamic changes (e.g., Gibson & Kelsey, 1998). As was argued by Burnham (2007), it is difficult to demonstrate pure exogenous orienting, because observers always use some perceptual feature as a signal for the target’s appearance. To establish pure exogenous attention, we need converging evidence that the attentional effects observed in these types of experiments are, in fact, exogenous and not driven by some endogenous attentional mechanism.
In the present study, we determined whether attentional facilitation such as we observed in our previous study (Theeuwes et al., 2013) would be followed by inhibition of return (IOR; Posner & Cohen, 1984). In general, in exogenous cuing, at the cued location, there are response time (RT) benefits at short cue–target intervals and RT costs at the longer cue–target intervals. The latter effect is known as IOR (see Klein, 2000, for a review). Crucial for the present study is the notion that IOR will only be found for exogenous orienting (Godijn & Theeuwes, 2004; Theeuwes & Chen, 2005; Theeuwes & Godijn, 2002). Indeed, Klein claimed that IOR is the hallmark of exogenous orienting. Typically, IOR does not follow a shift of attention that is under top-down control (Posner & Cohen, 1984; Pratt, Kingstone, & Khoe, 1997). In other words, finding initial facilitation followed by IOR can only be the result of a shift of exogenous attention. For example, Schreij et al. (2008; Schreij, Theeuwes, & Olivers, 2010) showed that when observers were set to look for a red object, a red cue preceding the search display captured attention, consistent with the notion of contingent capture (Folk et al., 1992). However, there was no sign of IOR at the location of the red cue, suggesting that this contingent capture may not have been exogenous, as was previously assumed. Crucially, in that very same experiment, abrupt onsets resulted in IOR regardless of the attentional set, indicating that this capture was purely exogenous (see also Pratt, Sekuler, and McAuliffe, 2001, for a similar result).
In the present experiment, we employed a variation of the task that we used in Experiment 2 of Theeuwes et al. (2013). The display consisted of a single object—that is, a cross with rotating arms (see Fig. 1). An abrupt onset was presented at one of its arms, and then the cross rotated 90°. A target was presented at the location that matched the cue retinotopically (the retinotopic location), the location that matched the cue in object-centered coordinates (object-centered location), or one of two control locations. The interval between the presentation of the target and the cue was either short (125 ms), as in our previous study, or long (1,134 ms). For the short delay, we expected to replicate our finding of attentional facilitation at both the retinotopic and the object-centered location. The question was what would happen at the long delay. If both retinotopic and object-centered cuing orienting are truly exogenous, we would expect to find IOR at both the retinotopic and object-centered locations. If only orienting toward the retinotopic location is truly exogenous, we would expect to find IOR at this location, but not at the object-centered location.
Previous studies that have examined the frame of reference of IOR have given mixed results. Tipper and colleagues (Tipper, Driver, & Weaver, 1991; Tipper, Jordan, & Weaver, 1999; Tipper, Weaver, Jerreat, & Burak, 1994) studied object-based IOR in displays in which three different objects were simultaneously present. For example, Tipper et al. (1999) showed participants three separate squares in a display, one of which was flashed. After the flash, the squares started moving. Tipper et al. (1999) found IOR both for a target that appeared at the square that moved to a new position and for a target presented at the original retinotopic location (now occupied by another square). These data suggest that when three separate objects are present in the display, IOR resides at both the retinotopic (eye-centered or environmental) and the object-centered locations. Crucially, however, when Tipper et al. (1999) connected these very same squares by line segments, encouraging the percept of a single object, there was IOR only at the object-centered location, but not at the retinotopic (eye-centered or environmental) location. If anything, there appeared to be some facilitation at this location.
Gibson and Egeth (1994) also used a single object in their display but came to a very different conclusion. They showed that IOR was associated with the location within the object (object-centered location), as well as the location cued in the environment (retinotopic location). In Gibson and Egeth, the object that was cued was a two-dimensional outline drawing of a brick shape. After cuing one of the corners of the brick, the brick would rotate in depth, and a target was presented in a location of the brick. The target could appear at the very same retinotopic location as the cue (eye- centered) or at a particular location on the brick (object-centered representation). Relative to a cue condition that held no relation to the location of the target, there was IOR at both the object-centered and eye-centered locations, a result that appears to be inconsistent with the results of the single-object condition of Tipper et al. (1999).
Even though these studies used very different paradigms, the question of whether IOR occurs at both retinotopic and object-centered locations within a single object is still wide open. The question has great theoretical importance, since it is generally believed that IOR functions as a “foraging facilitator” preventing observers from visiting the same locations over and over again (Klein, 1988). Because the object-centered location is relevant for search and action, the inhibition should be tied solely to this location, and not necessarily to the retinotopic location (for similar reasoning, see Mathôt & Theeuwes, 2010; Tipper et al., 1999). On the other hand, consistent with the findings of Posner and Cohen (1984), one could argue that exogenous attention and IOR should be more strongly tied to the retinotopic (eye-centered) representation and not, or very little, to object-based representations (see Reppa, Schmidt, & Leek, 2012, for a review).
Method
Participants
Forty-six observers participated for money or course credit. Participants were recruited from the student population of the VU University Amsterdam, and the experiment was conducted with approval of the local ethics committee of the VU University Amsterdam.
Apparatus
Experiments were run in a dimly lit cubicle. Stimuli were presented using OpenSesame (Mathôt, Schreij, & Theeuwes, 2012)/PsychoPy (Peirce, 2007) on a 19-in. CRT monitor (1,024 × 768 pixels; 120 Hz).
Stimuli, design, and procedure
Participant data, analyses scripts, and the experimental script can found at https://github.com/smathot/materials_for_P0008.6.
The paradigm was similar to that of Experiment 2 in Theeuwes et al. (2013), and a detailed description of the stimuli and procedure can be found there.
Participants fixated the center of a cross-shaped stimulus. An onset cue was briefly (58 ms) presented at the end of one arm (Fig. 1a). Next, the cross rotated by 90° in a rapid smooth movement that lasted for 75 ms. After the rotation, one target and three distractors were briefly presented (50 ms; one stimulus in each arm of the cross). The onset cue did not predict the location of the target. On short stimulus onset asynchrony (SOA) trials, the target was presented immediately after the rotation, resulting in a cue–target interval of 125 ms. On long-SOA trials, the rotation was followed by a 1,008-ms delay, resulting in a cue–target interval of 1,134 ms. The participant’s task was to indicate the orientation of the target, which was a leftward- or rightward-tilted Gabor patch, as quickly and accurately as possible by pressing a key on the keyboard.
We manipulated the location of the target relative to the cue (Fig. 1b). In the object-centered valid condition, the target appeared at the same location as the cue within the object (but a different location on the screen); in the object-centered Invalid condition, the target appeared at the location opposite from the cue within the object; in the retinotopic valid condition, the target appeared at the same location as the cue on the screen (but a different location within the object); and in the retinotopic invalid condition, the target appeared at the location opposite from the cued location on the screen.
Cue validity (valid/invalid) and reference frame (object centered/retinotopic) were varied within blocks. SOA (short/ long) was varied between blocks, and block order was counterbalanced between participants. Rotation direction (clockwise/counterclockwise) was fully randomized. The experiment consisted of 320 trials across 10 blocks and was preceded by 32 practice trials (of the short-SOA type).
Results
Participants with a mean RT that deviated more than 2 SDs from the grand mean were excluded (2 participants). For the remaining participants, the full data set was analyzed (44 participants; 15,488 trials).
Linear mixed-effects analysis
We used linear mixed-effects (LME) modeling for the main analyses as a more powerful alternative to the traditional repeated measures analysis of variance (ANOVA). First, we determined the preferred statistical model—that is, the model that could account for our data in the most parsimonious way. For all models, we used participant as a random effect and inverse RT (1/RT) as a dependent measure, including only correct trials. (Inverse RT is more robust to outliers than is untransformed RT [cf. Ratcliff, 1993)], and we used inversion as an alternative for outlier removal.) The complex model included all three experimental conditions as fixed effects (cue validity, SOA, reference frame, and all interaction terms). We also constructed three simple models, each of which omitted one condition as a fixed effect. We compared these simple models against the complex model to test whether the added complexity of the complex model was justified, given the additional variance explained (cf. Baayen, Davidson, & Bates, 2008). In other words, we tested whether any of the experimental conditions were redundant in explaining the observed data.
The results of the model comparison are clear: Dropping reference frame as a fixed effect is justified, χ 2(4) = 1.914, p = .752, but dropping cue validity, χ 2(4) = 78.093, p < .001, or SOA, χ 2(4) = 11.876, p = .018, is not. In other words, the preferred statistical model takes into account cue validity and SOA, but, strikingly, not whether cue validity was defined in a retinotopic or object-centered frame of reference.
The preferred model revealed the expected effects: an effect of cue validity, t = 2.74, p = .006, reflecting that facilitation at the short SOA was slightly stronger than IOR at the long SOA; an effect of SOA, t = 3.43, p < .001, reflecting that RTs were highest for the short SOA; and an SOA × cue validity interaction, t = 3.32, p < .001, reflecting that there was facilitation at the short SOA and IOR at the long SOA. (The fact that reference frame was excluded from the preferred model effectively means that it did not have a main effect on RT or interact with any of the other factors.) The p-values and 95 % confidence intervals (in Fig. 2a) were estimated using Markov chain Monte Carlo simulation (cf. Baayen et al., 2008).

Main results. a Response time (RT) as a function of cue validity (x-axis), condition (different lines), and cue–target SOA (different subplots). The typical pattern of a positive cue validity effect at the short SOA and a negative cue validity effect (inhibition of return) at the long SOA was observed. Strikingly, this pattern did not depend on whether cue validity was defined in a retinotopic or object-centered frame of reference. Dotted and dashed lines correspond to the retinotopic and object-centered frames of reference, respectively. Solid lines correspond to the preferred statistical model, which does not differentiate between the two frames of reference, illustrating that there is little to no difference in object-centered and retinotopic cuing. In line with the analysis, data points correspond to the inverse of the grand mean inverse RT on correct trials. b Error rate as a function of cue validity (x-axis), condition (different lines), and cue–target SOA (different subplots). Data points correspond to the grand mean error rate. Error bars correspond to 95 % confidence intervals for the cue validity effect (see the main text for details)
Applying the same model to the error rates revealed only a marginally significant SOA × cue validity interaction, t = 1.75, p = .080, and qualitatively mirrored the RT results (Fig. 2b).
Between-subjects correlations
The results described above suggest that object-centered and retinotopic attention are linked and that there is little behavioral difference between them. If this is indeed the case, one would expect attentional cuing in both reference frames to be strongly correlated. To test this, we determined the cuing effect separately for each participant, SOA, and reference frame. As for the main analysis, we used an inverse transformation to increase robustness to outliers (cf. Ratcliff, 1993), and the individual data points therefore corresponded to the inverse of the participant’s mean inverse RT on correct trials. Indeed, there was a strong correlation between the retinotopic and object-centered cuing effect at the short SOA, r = .475, p = .001. At the long SOA, this correlation was in the same direction, but weaker and not reliable, r = .159, p = .302.
Discussion
In this study, we replicated our previous findings (Theeuwes et al., 2013) showing attentional facilitation for both the retinotopic and object-centered reference frames. Crucially, we also showed IOR for both reference frames, suggesting that IOR is simultaneously present at retinotopic and object-centered locations. Since we obtained the classic signature for exogenous attention—that is, biphasic pattern of facilitation followed by inhibition—for both these locations, it is reasonable to argue that the earlier reported retinotopic and object-centered attentional facilitation effects are the result of true exogenous orienting. Our results are consistent with earlier findings suggesting that exogenous attention orienting does not need to be only retinotopically organized (Boi et al., 2011; Lin, 2013; Theeuwes et al., 2013). These earlier studies only showed facilitation, whereas the present study also shows IOR at both object-centered and retinotopic locations.
The present findings are inconsistent with those in Tipper et al. (1999), who showed both forms of IOR when there were separate squares present in the display but only object-centered IOR when these squares were connected by line segments. In their paper, Tipper et al. (1999) argued that when one single object is present in the display, IOR resides only in object-centered representations. In the present study, we also employed a single-object condition and provide compelling evidence for both retinotopic and object-centered IOR. Even though inconsistent with those of Tipper et al. (1999), our findings are similar to those of Gibson and Egeth (1994), who showed both types of IOR after cuing the corners of a rotating brick shape. It is hard to reconcile why Tipper et al. (1999) did not find retinotopic IOR, while the present data and those of Gibson and Egeth do find this. There are numerous differences in the experimental procedures; yet the most prominent difference between studies is the difference in the objectlike appearance of the single object in the display. While Tipper et al. (1999) used , as a single object, three squares (each having a different color) connected by thin lines, Gibson and Egeth and ourselves employed objects that were much objectlike in terms of Gestalt grouping: a rotating cross in our study (Fig. 1) and a rotating brick in the study by Gibson and Egeth. Because of a stronger object representation, it is possible that the retinotopic location remains tagged with inhibition. If one assumes that IOR functions as a “foraging facilitator” not only for search, but also for action, it may not be surprising for that for “real-like” objects that are graspable, both viewer- and object-centered representations remain intact. Indeed, in order to enable grasping of an object, parts of these objects that are graspable need to be attended and inhibited to allow adequate interactions with these objects. The role of automatic attentional allocation for graspable versus nongraspable objects has been well-documented in the literature (e.g., Handy, Grafton, Shroff, Ketay, & Gazzaniga, 2003; Humphreys & Riddoch, 2001)
The present data also reveal that there is very little difference between retinotopic and object-centered facilitation and inhibition. In a subsequent analysis, we examined the correlation between retinotopic cuing and object-centered cuing for both facilitation and inhibition (see Fig. 3). Given the high correlation between retinotopic and object-centered cuing at the short SOA, it is clear that at an individual subject level, these two mechanisms are strikingly similar. This is surprising, since it is generally assumed that the underlying brain mechanisms are different. For example, fMRI studies revealed that the intraparietal sulcus and frontal areas are more involved in object-centered attention, while the superior parietal lobule is involved in spatial attention (Yantis & Serences, 2003; see also Ungerleider & Mishkin, 1982). Our results suggest that although object-centered and retinotopic attention may rely on partly different brain areas, they are part of the same neural pathway. If you direct your attention to a (retinotopic) location in space, you will automatically direct attention to any object that is present at that location, and vice versa. Therefore, although object-centered attention relies on higher-level cortical areas (Yantis & Serences, 2003) and takes some time to emerge (Boon, Theeuwes, & Belopolsky, 2014), it is fully automatic and exogenous. We did not observe a reliable correlation between retinotopic and object-centered IOR. Possibly, this is due to the fact that IOR is less robust than attentional facilitation, and, despite having a large number of participants, we may not have had sufficient statistical power to observe any correlation between object-centered and retinotopic IOR.

There is a strong correlation between retinotopic and object-centered cuing at the short SOA (a), but not, or not reliably, at the long SOA (b). The cuing effect is plotted such that positive values reflect facilitation on validly cued, relative to invalidly cued, trials
In summary, three recent studies (Boi et al., 2011; Lin, 2013; Theeuwes et al., 2013) showed that exogenous cuing in dynamic displays results in retinotopic and object-centered attentional facilitation. The present study replicates these findings and shows, under the very same experimental conditions, the occurrence of IOR within both retinotopic and object-centered coordinate systems. Unlike previous claims (Tipper et al., 1999), we show that with a single object in the display, IOR is bound to both the object-centered and retinotopic locations within the object, basically identical to the way attentional facilitation is bound to these locations within an object.
References
Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language, 59(4), 390–412.
Boi, M., Vergeer, M., Ogmen, H., & Herzog, M. H. (2011). Nonretinotopic exogenous attention. Current Biology, 21(20), 1732–1737.
Boon, P., Theeuwes, J., & Belopolsky, A. (2014). Updating visual-spatial working memory during object movement. Vision Research, 94, 51–57.
Burnham, B. R. (2007). Displaywide visual features associated with a search display ’ s appearance can mediate attentional capture. Psychonomic Bulletin & Review, 14(3), 392–422.
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology: Human Perception & Performance, 18, 1030–1044.
Gibson, B. S., & Egeth, H. (1994). Inhibition of return to object-based and environment-based locations. Perception & Psychophysics, 55, 323–339.
Gibson, B. S., & Kelsey, E. M. (1998). Stimulus-driven attentional capture is contingent on attentional set for displaywide visual features. Journal of Experimental Psychology: Human Perception & Performance, 24, 699–706.
Godijn, R., & Theeuwes, J. (2004). The relationship between inhibition of return and saccade trajectory deviations. Journal of Experimental Psychology: Human Perception and Performance, 30, 538–554.
Handy, T. C., Grafton, S. T., Shroff, V. N. M., Ketay, S., & Gazzaniga, M. S. (2003). Graspable objects grasp attention when the potential for action is recognized. Nature Neuroscience, 6, 421–427.
Humphreys, G. W., & Riddoch, M. J. (2001). Detection by action: neuropsychological evidence for action-defined templates in search. Nature Neuroscience, 4, 84–88.
Klein, R. M. (1988). Inhibitory tagging system facilitates visual search. Nature, 334, 430–431.
Klein, R. M. (2000). Inhibition of return. Trends in Cognitive Sciences, 4, 138–147.
Lin, Z. (2013). Object-centered representations support flexible exogenous visual attention across translation and reflection. Cognition, 129(2), 221–231.
Mathôt, S., & Theeuwes, J. (2010). Gradual Remapping Results in Early Retinotopic and late Spatiotopic Inhibition of Return. Psychological Science, 21, 1793–1798.
Mathôt, S., Schreij, D., & Theeuwes, J. (2012). OpenSesame: An Open-source, Graphical Experiment Builder for the Social Sciences. Behavior Research Methods, 44(2), 314–324.
Mulckhuyse, M., Talsma, D., & Theeuwes, J. (2007). Grabbing attention without knowing: Automatic capture of attention by subliminal spatial cues. Visual Cognition, 15, 779–788.
Peirce, J. W. (2007). PsychoPy: Psychophysics software in Python. Journal of Neuroscience Methods, 162(1–2), 8–13. doi:10.1016/j.jneumeth.2006.11.017
Posner, M. I. (1980). Orienting of attention. Quarterly Journal of Experimental Psychology, 32, 3–26.
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. In H. Bouma & D. G. Bouwhuis (Eds.), Attention and performance X: Control of language processes (pp. 531–556). Hillsdale: Erlbaum.
Pratt, J., Kingstone, A., & Khoe, W. (1997). Inhibition of return in location- and identity-based choice decision tasks. Perception & Psychophysics, 59, 964–971.
Pratt, J., Sekuler, A. B., & McAuliffe, J. (2001). The role of attentional set on attentional cueing and inhibition of return. Visual Cognition, 8, 33–46.
Ratcliff, R. (1993). Methods of dealing with reaction time outliers. Psychological Bulletin, 114, 510–532.
Reppa, I., Schmidt, W. C., & Leek, E. C. (2012). Successes and failures in producing attentional object-based cueing effects. Attention, Perception, & Psychophysics, 74, 43–69.
Schreij, D., Owens, C., & Theeuwes, J. (2008). Abrupt onsets capture attention independent of top-down control settings. Perception & Psychophysics, 70(2), 208–218.
Schreij, D., Theeuwes, J., & Olivers, C. N. L. (2010). Irrelevant onsets cause inhibition of return regardless of attentional set. Attention, Perception & Psychophysics, 72, 1725–1729.
Schreij, D., Los, S.A., Theeuwes, J., Enns, J.T., & Olivers, C.N.L. (2014). The interaction between stimulus-driven and goal driven orienting as revealed by eye movements. Journal of Experimental Psychology: Human Perception and Performance, 40, 378–390.
Theeuwes, J. (1991). Exogenous and endogenous control of attention: The effect of visual onsets and offsets. Perception & Psychophysics, 49, 83–90.
Theeuwes, J. (1994). Stimulus-driven capture and attentional set: Selective search for color and visual abrupt onsets. Journal of Experimental Psychology: Human Perception & Performance, 20, 799–806.
Theeuwes, J. (2010). Top-down and bottom-up control of visual selection. Acta Psychologica, 123, 77–99.
Theeuwes, J., & Chen, C. Y. D. (2005). Attentional capture and inhibition (of return): the effect on perceptual sensitivity. Perception & Psychophysics, 67, 1305–1312.
Theeuwes, J., & Godijn, R. (2002). Irrelevant singletons capture attention: evidence from inhibition of return. Perception & Psychophysics, 64, 764–770.
Theeuwes, J., Mathôt, S., & Grainger, J. (2013). Exogenous object-centered attention. Attention, Perception & Psychophysics, 75, 812–818.
Tipper, S. P., Driver, J., & Weaver, B. (1991). Object-centered inhibition of return of visual attention. Quarterly Journal of Experimental Psychology, 43A, 289–298.
Tipper, S. P., Weaver, B., Jerreat, L. M., & Burak, A. L. (1994). Object based and environment-based inhibition of return of visual attention. Journal of Experimental Psychology: Human Perception and Performance, 20, 478–499.
Tipper, S. P., Jordan, H., & Weaver, B. (1999). Scene-based and object-centered inhibition of return: evidence for dual orienting mechanisms. Perception & Psychophysics, 61(1), 50–60.
Ungerleider, L. G., & Mishkin, M. (1982). Two cortical visual systems. In D. J. Ingle, M. A. Goodale, & R. J. W. Mansfield (Eds.), Analysis of visual behavior (pp. 549–586). Cambridge: MIT Press.
Yantis, S., & Serences, J. (2003). Neural mechanisms of space-based and object based attentional control. Current Opinion in Neurobiology, 13, 187–193.
Acknowledgments
We would like to thanks Bryan Burnham, Brad Gibson, and an anonymous reviewer for their very helpful comments to an earlier version of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Theeuwes, J., Mathôt, S. & Grainger, J. Object-centered orienting and IOR. Atten Percept Psychophys 76, 2249–2255 (2014). https://doi.org/10.3758/s13414-014-0718-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-014-0718-z