
Abstract
Laser-powder bed fusion (L-PBF) is a popular additive manufacturing (AM) process with rich data sets coming from both in situ and ex situ sources. Data derived from multiple measurement modalities in an AM process capture unique features but often have different encoding methods; the challenge of data registration is not directly intuitive. In this work, we address the challenge of data registration between multiple modalities. Large data spaces must be organized in a machine-compatible method to maximize scientific output. FAIR (findable, accessible, interoperable, and reusable) principles are required to overcome challenges associated with data at various scales. FAIRified data enables a standardized format allowing for opportunities to generate automated extraction methods and scalability. We establish a framework that captures and integrates data from a L-PBF study such as radiography and high-speed camera video, linking these data sets cohesively allowing for future exploration.
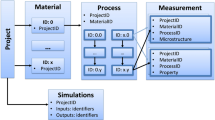
Graphical abstract

Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
As new characterization techniques are developed and these processes increase complexity, the amount of data generated also increases. Performing analysis using larger data sources, or big data, is known as the fourth paradigm of scientific research [1]. This new paradigm of data-driven research includes but not limited to machine learning, statistical analysis, data mining, and modeling [1]. To take advantage of big data and maximize time and resource efficiency, an automated framework is necessary which outlines the workflow of materials science data from collection to modeling.
Developments in advanced computational methods, instrumentation, and data storage capabilities have enabled new approaches in many fields like engineering, medicine, physical and social sciences [2]. The data generated with newer methods are increasing in cost and volume of data can easily reach terabytes or even petabytes in scale. Traditional research methodologies and processes may not be sufficient in sustainable data management, which can lead to research waste and one-time utility of expensive data sets. In order to meet these evolving challenges, data-centric approaches, like FAIR principles, are needed.
FAIR principles, a framework for data governance, aim to make data findable, accessible, interoperable, and reusable (FAIR) [3]. Additionally, integration of data sets from a diverse range of fields can uncover new insights, but the processes or mechanisms in which to integrate disparate data sets are not intuitive. The FAIR initiative is a joint effort launched in 2016 by a group of scientists and industries proposing to revolutionize the way organizations manage, store, process, and exchange data [3]. By defining a set of recommendations and technical guidance for each FAIR principle, the FAIR initiative promotes an efficiency and transparency in data management systems.
Substantial work has been reported in the literature toward adoption of FAIRification for scientific study [4,5,6,7]. However, the interpretations and application of FAIR principles in most cases have been incomplete and irregular. When multiple domains are integrated, it is unclear on how the FAIR practices are applied across disciplines needed for material characterization. These characterization techniques, for example, can span from mechanical testing, chemical composition, and metallography, which requires domain expertise for each technique. Global initiatives, such as NOMAD [8], that aim to improve data governance such as developing FAIR are increasing in practice and diversity in disciplines; some of these curated efforts are expanding into material science [9] and benefits fields that require multiple disparate disciplines. Since AM is an interdisciplinary field, development of FAIRified data streams allows for easy data registration such as combining in situ measurements and ex situ characterization.
Laser-powder bed fusion (L-PBF), selective laser sintering (SLS), direct metal laser sintering (DMLS), and selective laser melting (SLM) are popular techniques for additive manufacturing of metal parts. In addition, there has been work on developing ontologies for L-PBF and other advanced manufacturing methods [10, 11]. L-PBF AM process is often costly and with data generated from various measurement modalities. Typical systems are equipped with multiple measuring modalities to understand the manufacturing behavior throughout every step of the part generation. These measurement tools are coupled with the machine providing in situ, or real-time, information during part generation and then ex situ characterization for assessing finished parts. In situ measurements commonly found in L-PBF are pyrometry [12] and high-speed camera videos that monitor [13] the melt pool and metal powder fusion behavior, while ex situ radiography characterizes the overall print porosity, completeness, and dimensions [14, 15]. However, each modality contains specific data formats and interpreting the information requires specific domain knowledge. Often these result in discussions between data practitioners and domain experts downstream, which is research waste.
While having a lot of data is key toward understanding the manufacturing process, it is not intuitive how disparate modalities can be registered together. Depending on the resolution and diversity of data collected, the resulting data set can become increasingly complex and massive. Currently, exploring workflows and frameworks to address this big data challenge are seldom investigated. Applying FAIR principles is an increasingly popular tool for easier interoperability and reusability of data sets and provides human- and machine-readable formatting. Frameworks utilizing FAIR principles will benefit additive manufacturing by allowing the full leveraging of AI and machine learning in large scale [16, 17].
In this study, we propose a framework for the FAIRification of L-PBF with in situ and ex situ characterization techniques. We obtained a rich data set from an L-PBF study containing both data and metadata from high-speed camera videos, pyrometer measurements, and radiography images. We highlight the need and importance of a comprehensive study protocol that follows a systematic and well-structured data registration and keeping adherence to FAIR principles [18]. FAIR principles were incorporated in our automated pipeline framework to both curate and format the data and metadata. While the scope of our work is limited toward L-PBF systems, our generalized framework is applicable across multiple systems.
Analytical framework
There is a need for standardizing research and fostering a culture of good practices when uncovering insights from big data science using a well-established study protocol, as shown in Fig. 1 [7, 19].

Study protocol pipeline for scientific investigations and process to develop the extraction process of translating features found in data into a combined study that can be further refined. The first step is to exhaust the historical data of a topic in a systematic review that feeds into the Data Engineering Model used to inform the software and statistics approaches needed to refine and analyze data so that it may constitute a true FAIRified study. This process allows for more robust data analysis tin order to allow for the community of material science to become more reliable
We focus on the application of a systematic review to establish the features of divergent data sources, then forming data models that find the relations between these data sources in order to achieve the final step of integration and FAIRification.
Systematic review
Systematic review in a study protocol includes domain expert guidance within a topical study. The concept of a study protocol is well-implemented in medical studies [20] with established guidelines such as systematic reviews and meta-analyses [21]. These guidelines for reporting systematic medical studies include full disclosure of goals, methods, and findings [22, 23]. More recently, new guidelines address the implementation of machine learning (ML) [24]. Protocols aid in organizing a research plan by communicating the critical questions to be addressed, tailoring a data collection plan, explaining how the data will be processed and then modeled in a comprehensive framework [22], Also, protocols communicate a well-defined research focus, especially where the problem being addressed is largely unstructured [25].
In AM, the first step involves querying in situ techniques from historical printing campaigns and related open-data repositories. These studies show what tools are available, what output is typical among measurement modalities, and what were common errors and hazards when using the technique. With historical errors identified for a measurement method, a data collection plan can be drafted. A data collection plan details what each device is able to record about the print along with the manner of output. Next, a data processing plan is required to determine how the researcher is going to approach extracting data and its insights. This allows for a comparison of the scientific record of similar experiments to the current output for comparing studies. Most importantly, having structured and transparent frameworks grants the ability for other researchers to properly reproduce and replicate past works [20, 26]. Poorly structured studies become prone to questionable validity, biased outcomes, and research that is unused [27]. Therefore, there is equal emphasis on the scientific findings and the workflow process that leads to those findings.
Data integration
After developing an initial framework from the systematic review, common methods can be compared. Each method measurement has a feature that some relationship to outlined part. The part has an exact coordinate related to original build schematic to position along a part. As shown in Fig. 2a, we focus on L-PBF use of in situ pyrometry measurements and high-speed camera video along with ex situ radiography. Both in situ methods have common coordinates based on the temporal relationship of occurring simultaneously as the part printed. For the registration of radiographic objects, the unique part of our build was identified first based on the length of active pyrometry signal to the presence of sample, as shown in Fig. 2b.

Generalized schematic of a AM L-PBF part from initial schematic transferred to a printer tool. As the print occurs, the building recipe has monitors that output a raw data format shown in (a). This is supplemented by a print assessment such as examining the length and completeness of the print or presence of known problematic features. Data registration is the joining of two data sets together based on a common set of variables between the two data sets, shown in (b)
Radiography is multiple X-ray projections from an X-ray generator such as a synchrotron. Synchrotrons have a variety of “recipes" that alters exposure depending on the materials composition or desire resolution of features. Automated image stitching is used to generate a single image from multiple high-resolution images, resulting in multiple partIDs on the same file. Post-processing is required for correcting raw outputs. Our radiography images were prepossessed to enhance contrast and reduce director noise. For better findability and interoperability, the image was separated into the unique partID to align all files based on the partID.
Based on historic image analysis methods, we can extract numeric descriptions about images spatiotemporal related to the desired Build plan. As a result, we achieve a compact and traceable process that takes raw output from a machine into an informative representation. As shown in Fig. 2b, we have the resulting width length of the final part that is spatially related to the pyrometry measurement position which is temporally related to the melt pool dimensions at the time.
Data analytics automation
Integrating multimodal data requires a user-defined and standardized framework where the integration process is monitored and follows data standards that enable it to be Findable, Accessible, Interoperable, and Reusable. The FAIR framework proposed herein facilitates the integration of data from in situ and ex situ methods in a L-PBF experiment by defining a schema where consistent naming convention and uniquely persistent identifiers are used to link subdomains. Figure 3 illustrates the steps involved in the fairification process.

FAIR implementation. User starts a new domain using the FAIRmaterials package to create the respective OWL and JSON-LD templates. To FAIRify their data, users input a .csv with metadata terms mapped to PMDCo, and .json and .owl files are returned
The first step of the proposed methodology is the schema mapping, consisting of a schematic representation of features and variables relevant to the domain. A comprehensive list of information related to the sample (partID), instrument (tool), recipe (measurement metadata), and results is stored. The terms in the schema are mapped to PMD Core Ontology (PMDCo [28]) terms in a spreadsheet template available in the package. PMDCo is a mid-level materials science ontology compliant with BFO [29], a top Level Ontology (TLO).
After assigning and mapping the domain terms to PMDCo, the Fairmaterials package [30] is used to generate the JavaScript Object Notation for Linked Data JSON-LD templates and fairified .json files, in addition to the domain-specific ontologies(.owl files).
The integration of domains (i.e., radiography and high-speed camera images) takes place by linking the subdomains by unique persistent identifiers that follow the orcid-userdefinedid-harsh structure. The first part of the IDs corresponds to the orcid of the user. userdefinedid is a convention adopted by the domain expert and harsh allows users to monitor file integrity. A unique ID associated with the operator’s orcid and process identifier ID is assigned to the printed part, in a similar process to the sample, tool, and recipe. The metadata of the part is stored in the orcid-part-harsh.json file that contains printing parameters metadata. The part is linked to the ex situ and in situ methods by chaining the part ID name to the tool/recipe/results metadata. A result from a part that was subjected to radiography and is output in the .tif format would be orcid-idresults-idrecipe-idtool-idpart-hash.tif and the meta data orcid-idresults-idrecipe-idtool-idpart-hash.json, as illustrated in Fig. 4.

Linking L-PBF with radiography and high-speed camera metadata. The printed part receives an id that is shared with the characterization methods and used to link to the tool, recipe, and results. This convention allows one to locate the instrument, metadata, and material used to produce a part as well as parameters related to the characterizations tool, recipe, and results details
Using this naming convention, the user can determine the tool, recipe, and material used. The partID must have a entry which links to each .json file. However, each recipe and tool id does not have an id part, the id part .json provides the linking node that may be filled by the interchanged tool and/or recipe version that is called by the partID. The JSON-LD provides the framework which each schematic links together.
A partID in L-PBF is the simple, unique, object designed from a computer model such as a .STL or parameter setup file.txt or .pxp from Fig. 2a. While the data amount of each point cumbersome, the object-relationship parting is not as data heavy. The .STL is a file that is related to the build object with each point sharing the relationship blueprint is related to object. Any change in the .STL requires new orcid-idtool-idrecipe.json. The object can be linked by a unique identification of the drafter sample with time of submitting to the tool. The unique object with the assigned [orcid] has starting properties such as assigned material, .STL for the sample, date, and time it was submitted to printing recorded in orcid-idmaterial-hash.
Tools are given a setup condition such as the operation range it is able to function under, the maximum and minimum operational allowance, the type of attachments present, and environment of operation. Recipes give instructions to the tool that inform how the printed process will occur under what parameters, what attachment used, what tool is being used, and other printer-user modified conditions applied recorded in orcid-idtool-idrecipe-idpart-hash. The resulting combined object of each set should have a standard output type output. This naming convention enables the user to not only easily locate the material, tool, and the recipe employed to produce a part, but also contributes to the generation of more efficient and reliable scripts and code automation.
Conclusion
The approach proposed herein allows the development of domain-specific schemas and JSON-LD templates which provides a baseline representation for a proper and efficient data management system. Furthermore, by having a proactive approach in design and a direction for instrumentation verification and a reproducible process on how and why the data are processed in a particular manner. With the series of the sample being recorded to the operator by the unique identifier of orcid along with the instrument process, the standard processing method, and the final result as it has been transformed allows for traceability. The framework proposed in this work consists on initially creating domain schema that are translated into a JSON-LD templates in a subsequent step containing the part, tool, recipe, and results specific information. This template can be used by individuals who makes the part using their orcid along with a part identification to ensure cross-sample identification with other experiments. Along with that, the tool being used also have the same connective information with the recipe as well as the results, that can be easily linked to the recipe, tool, and associated sample based on the file names. This results in four distinct JSON-LD templates that, using the FAIRmaterials package, converts csv-stored metadata into JSON-LD, providing machine readability and accessibility. The same concept is applied when linking different methods, where the part information stored in JSON-LD can be easily accessed and mapped to the characterization techniques (if applied). The framework proposed enables the development of a systematic, standard, and well-defined naming convention that allows FAIRified metadata JSON-LD to be easily findable and linked to other sources, which represents major advances toward efficiency and optimization of data analysis and modeling.
Data availability
Data sharing is not applicable to this article as no new data were created or analyzed in this study. This work was performed, in part, under the auspices of U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344, LLNL-JRNL-857803.
References
T. Hey, S. Tansley, K. Tolle, The fourth paradigm: data-intensive scientific discovery. Microsoft Corporation, Redmond Washington (2009). https://www.microsoft.com/en-us/research/publication/fourth-paradigm-data-intensive-scientific-discovery/, ISBN 9780982544204
R.M. Chang, R.J. Kauffman, Y. Kwon, Understanding the paradigm shift to computational social science in the presence of big data. Decis. Supp. Syst. 63, 67–80 (2014). https://doi.org/10.1016/j.dss.2013.08.008
M.D. Wilkinson, M. Dumontier, I.J. Aalbersberg,G. Appleton, M. Axton, A. Baak, N. Blomberg, J.-W. Boiten, L.B. da Silva Santos, P.E. Bourne,J. Bouwman, A.J. Brookes, T. Clark, M. Crosas, I. Dillo, O. Dumon, S. Edmunds, C.T. Evelo,R. Finkers, A. Gonzalez-Beltran, A.J.G. Gray, P. Groth, C. Goble, J.S. Grethe, J. Heringa, P.A.C. ’tHoen, R. Hooft, T. Kuhn, R. Kok, J. Kok, S.J. Lusher, M.E. Martone, A. Mons, A.L. Packer,B. Persson, P. Rocca-Serra, M. Roos, R. van Schaik, S.-A. Sansone, E. Schultes, T. Sengstag, T. Slater,G. Strawn, M.A. Swertz, M. Thompson, J. van der Lei, E. van Mulligen, J. Velterop,A. Waagmeester, P. Wittenburg, K. Wolstencroft, J. Zhao, B. Mons, The FAIR Guiding Principlesfor scientific data management and stewardship. Scientific Data 3(1), 1–9 (2016). https://doi.org/10.1038/sdata.2016.18. Accessed 29 Dec 2021
P. Rocca-Serra, W. Gu, V. Ioannidis, T. Abbassi-Daloii, S. Capella-Gutierrez, I. Chandramouliswaran, A. Splendiani, T. Burdett, R.T. Giessmann, D. Henderson, D. Batista, I. Emam, Y. Gadiya, L. Giovanni, E. Willighagen, C. Evelo, A.J.G. Gray, P. Gribbon, N. Juty, D. Welter, K. Quast, P. Peeters, T. Plasterer, C. Wood, E. van der Horst, D. Reilly, H. van Vlijmen, S. Scollen, A. Lister, M. Thurston, R. Granell, S.-A. Sansone, The FAIR cookbook-the essential resource for and by FAIR doers. Sci. Data 10(1), 292 (2023). https://doi.org/10.1038/s41597-023-02166-3
D. Welter, N. Juty, P. Rocca-Serra, F. Xu, D. Henderson, W. Gu, J. Strubel, R.T. Giessmann, I. Emam, Y. Gadiya, T. Abbassi-Daloii, E. Alharbi, A.J.G. Gray, M. Courtot, P. Gribbon, V. Ioannidis, D.S. Reilly, N. Lynch, J.-W. Boiten, V. Satagopam, C. Goble, S.-A. Sansone, T. Burdett, FAIR in action-a flexible framework to guide FAIRification. Sci. Data 10(1), 291 (2023). https://doi.org/10.1038/s41597-023-02167-2
L.M. Ghiringhelli, C. Baldauf, T. Bereau, S. Brockhauser, C. Carbogno, J. Chamanara, S. Cozzini, S. Curtarolo, C. Draxl, S. Dwaraknath, Á. Fekete, J. Kermode, C.T. Koch, M. Kühbach, A.N. Ladines, P. Lambrix, M.-O. Himmer, S.V. Levchenko, M. Oliveira, A. Michalchuk, R.E. Miller, B. Onat, P. Pavone, G. Pizzi, B. Regler, G.-M. Rignanese, J. Schaarschmidt, M. Scheidgen, A. Schneidewind, T. Sheveleva, C. Su, D. Usvyat, O. Valsson, C. Wöll, M. Scheffler, Shared metadata for data-centric materials science. Sci. Data 10(1), 626 (2023). https://doi.org/10.1038/s41597-023-02501-8
A. Nihar, R. Chawla, T. Ciardi, L.S. Bruckman, Y. Wu, R.H. French, Towards usability and reproducibility in distributed and high performance computing environment for big data research with CRADLE, 1
The NOMAD Laboratory: Claudia Draxl: stepping stones towards the fourth paradigm of materials science (2021)
L. Brinson, L. Bartolo, B. Blaiszik, D. Elbert, I. Foster, A. Strachan, P. Voorhees, Community action on fair data will fuel a revolution in materials research. MRS Bull. 49, 12–16 (2023). https://doi.org/10.1557/s43577-023-00498-4
B.-M. Roh, S.R.T. Kumara, H. Yang, T.W. Simpson, P. Witherell, A.T. Jones, Y. Lu, Ontology network-based in-situ sensor selection for quality management in metal additive manufacturing. J. Comput. Inform. Sci. Eng. 22(060905) (2022) https://doi.org/10.1115/1.4055853 . Accessed 24 April 2024
M. Huschka, M. Dlugosch, V. Friedmann, E.G. Trelles, K. Hoschke, U.E. Klotz, S. Patil, J. Preußner, C. Schweizer, D. Tiberto, The “alutrace” use case: harnessing lightweight design potentials via the materials data space®. In: TRUSTS-Trusted Secure Data Sharing Space Workshop: Data Spaces & Semantic Interoperability, Vienna Austria (2022)
J.-B. Forien, N.P. Calta, P.J. DePond, G.M. Guss, T.T. Roehling, M.J. Matthews, Detecting keyhole pore defects and monitoring process signatures during laser powder bed fusion: a correlation between in situ pyrometry and ex situ X-ray radiography 35, 101336 https://doi.org/10.1016/j.addma.2020.101336 . Accessed 24 April 2023
Q. Fang, Z. Tan, H. Li, S. Shen, S. Liu, C. Song, X. Zhou, Y. Yang, S. Wen, In-situ capture of melt pool signature in selective laser melting using u-net-based convolutional neural network 68, 347–355 https://doi.org/10.1016/j.jmapro.2021.05.052 . Accessed 28 April 2023
R. Cunningham, S.P. Narra, C. Montgomery, J. Beuth, A.D. Rollett, Synchrotron-based x-ray microtomography characterization of the effect of processing variables on porosity formation in laser power-bed additive manufacturing of ti-6al-4v 69(3), 479–484 https://doi.org/10.1007/s11837-016-2234-1 . Accessed 24 April 2023
A. Gaikwad, B. Giera, G.M. Guss, J.-B. Forien, M.J. Matthews, P. Rao, Heterogeneous sensing and scientific machine learning for quality assurance in laser powder bed fusion-a single-track study 36, 101659 https://doi.org/10.1016/j.addma.2020.101659 . Accessed 31 Jan 2024
A.Y.-T. Wang, R.J. Murdock, S.K. Kauwe, A.O. Oliynyk, A. Gurlo, J. Brgoch, K.A. Persson, T.D. Sparks, Machine learning for materials scientists: an introductory guide toward best practices. Chem. Mater. 32(12), 4954–4965 (2020). https://doi.org/10.1021/acs.chemmater.0c01907
A.E.A. Allen, A. Tkatchenko, Machine learning of material properties: predictive and interpretable multilinear models. Sci. Adv. 8(18), 7185 (2022). https://doi.org/10.1126/sciadv.abm7185
W.C. Oltjen, Y. Fan, J. Liu, L. Huang, X. Yu, M. Li, H. Seigneur, X. Xiao, K.O. Davis, L.S. Bruckman, Y. Wu, R.H. French, Fairification, quality assessment, and missingness pattern discovery for spatiotemporal photovoltaic data. In: 2022 IEEE 49th Photovoltaics Specialists Conference (PVSC), 0796–0801 (2022). https://doi.org/10.1109/PVSC48317.2022.9938523
Mingjian Lu, Liangyi Huang, Will Oltjen, Xuanji Yu, Arafath Nihar, Tommy Ciardi, Erika Barcelos, Pawan Tripathi, Abhishek Daundkar, Deepa Bhuvanagiri, Hope Omodolor, Hein Htet Aung, Kristen Hernandez, Mirra Rasmussen, Raymond Wieser, Sameera Nalin Venkat, Tian Wang, Weiqi Yue, Yangxin Fan, Rounak Chawla, Leean Jo, Zelin Li, Jiqi Liu, Justin Glynn, Kehley Coleman, Jeffery Yarus, Kristopher Davis, Laura Bruckman, Yinghui Wu, Roger French: Fairmaterials: Generate Json-Ld Format Files Based on FAIRification Standard (2023)
P. Steel, S. Beugelsdijk, H. Aguinis, The anatomy of an award-winning meta-analysis: recommendations for authors, reviewers, and readers of meta-analytic reviews. J. Int. Bus. Studies 52(1), 23–44 (2021). https://doi.org/10.1057/s41267-020-00385-z
S.G. Julian Higgins, Cochrane Handbook for Systematic Reviews of Interventions. Wiley
L. Shamseer, D. Moher, M. Clarke, D. Ghersi, A. Liberati, M. Petticrew, P. Shekelle, L.A. Stewart, Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015: elaboration and explanation. BMJ 349, 7647 (2015). https://doi.org/10.1136/bmj.g7647
J. Braithwaite, L. Testa, G. Lamprell, J. Herkes, K. Ludlow, E. McPherson, M. Campbell, J. Holt, Built to last? The sustainability of health system improvements, interventions and change strategies: a study protocol for a systematic review. BMJ Open 349, 7647 (2015). https://doi.org/10.1136/bmj.g7647
I.J. Marshall, B.C. Wallace, Toward systematic review automation: a practical guide to using machine learning tools in research synthesis. Syst. Rev. 8(1), 163 (2019). https://doi.org/10.1186/s13643-019-1074-9
H. Maimbo, G. Pervan, Designing a case study protocol for application in IS Research. Nature Machine Intelligence, 13 (2021)
K. Broman, M. Cetinkaya-Rundel, A. Nussbaum, C. Paciorek, R. Peng, D. Turek, H. Wickham, Recommendations to funding agencies for supporting reproducible research. Americal Statistical Association 2 (2017)
I. Chalmers, P. Glasziou, Avoidable waste in the production and reporting of research evidence. Lancet 374(9683), 86–89 (2009). https://doi.org/10.1016/S0140-6736(09)60329-9
B. Bayerlein, M. Schilling, H. Birkholz, M. Jung, J. Waitelonis, L. Mädler, H. Sack, Pmd core ontology: achieving semantic interoperability in materials science. Mater. Des. (2024) https://doi.org/10.1016/j.matdes.2023.112603
R. Arp, B. Smith, A.D. Spear, Building ontologies with basic formal ontology (2015). https://doi.org/10.7551/mitpress/9780262527811.001.0001. ISBN I9780262329583
W. Oltjen aut, R. cre, French, L. Huang, FAIRmaterials: make materials data FAIR (2021). https://CRAN.R-project.org/package=FAIRmaterials Accessed 22 Nov 2022
Funding
This material is based upon research conducted at the Materials Data Science for Stockpile Stewardship Center of Excellence (MDS3-COE), and supported by the Department of Energy’s National Nuclear Security Administration under Award Number(s) DE-NA0004104.
Author information
Authors and Affiliations
Contributions
The authors confirm contribution to the paper as follows: study conception, design, data collection: B.Giera, L.Bruckman, J.Jimenez, and R.French; analysis and interpretation of results: K.Hernandez, and E.Barcelos. A.Nihar; organizing meeting and drafting: P.Tripathi; and draft manuscript preparation: K.Hernandez, E.Barcelos, and L.Bruckman. All authors reviewed the results and approved the final version of the manuscript. This work made use of the High Performance Computing Resource in the Core Facility for Advanced Research Computing at Case Western Reserve University.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical Approval
The views expressed herein do not necessarily represent the views of the U. S. Department of Energy or the United States Government.
Additional information
Publisher's Note
Springer nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hernandez, K.J., Barcelos, E.I., Jimenez, J.C. et al. A data integration framework of additive manufacturing based on FAIR principles. MRS Advances 9, 844–851 (2024). https://doi.org/10.1557/s43580-024-00874-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1557/s43580-024-00874-5