
Abstract
The effectiveness and longevity of IoT infrastructures heavily depend on the limitations posed by communication, multi-hop data transfers, and the inherent difficulties of wireless links. In dealing with these challenges, routing, and data transmission procedures are critical. Among the fundamental concerns are the attainment of energy efficiency and an ideal distribution of loads among sensing devices, given the restricted energy resources at the disposal of IoT devices. To meet these challenges, the present research suggests a novel hybrid energy-aware IoT routing approach that mixes the Particle Swarm Optimization (PSO) algorithm and fuzzy clustering. The approach begins with a fuzzy clustering algorithm to initially group sensor nodes by their geographical location and assign them to clusters determined by a certain probability. The proposed method includes a fitness function considering energy consumption and distance factors. This feature guides the optimization process and aims to balance energy efficiency and data transmission distance. The hierarchical topology uses the advanced PSO algorithm to identify the cluster head nodes. The MATLAB simulator shows that our method outperforms previous approaches. Various metrics have demonstrated significant improvements over DEEC and LEACH. The method reduces energy consumption by 52% and 16%, improves throughput by 112% and 10%, increases packet delivery rates by 83% and 15%, and extends the network lifespan by 48% and 27%, respectively, compared to DEEC and LEACH approaches.
Similar content being viewed by others


Introduction
The Internet of Things (IoT) is undergoing phenomenal expansion because of its ability to interconnect various physical devices, leading to the generation of substantial data volumes. This growth is projected to continue in the future [1]. The IoT encompasses the integration of connectedness and individual objects. It leverages widespread access to information and the cooperative creation of services, ultimately resulting in enhanced effectiveness and productivity for individuals in both professional and recreational pursuits [2].
Context
IoT integration offers a variety of benefits, including increased revenue and business volume [3]. The installation of sensors has resulted in a significant increase in sensor data, whether in the context of smart cities or healthcare settings for disease surveillance [4]. Moreover, sophisticated technologies such as smart switches, routers, and gateways carry out calculations and facilitate cognitive capacities [5]. Consequently, this has facilitated the advancement of IoT applications across numerous domains, transforming cities into smart cities and conventional healthcare into innovative healthcare [6]. These applications rely on connections and data produced by IoT devices to enhance services, provide new features, and increase efficiency [7].
Wireless sensor networks (WSNs) serve as the fundamental technology for facilitating the gathering and transmission of data from several sensors in a given environment as a component of IoT applications [8, 9]. This data is used to support decision-making, optimize processes, and increase system efficiency [10]. Health monitoring and natural disaster applications are examples of WSN-enabled IoT applications [11]. In IoT applications based on WSNs, a wide range of sensor nodes monitor the surroundings. Gateways, called base stations or sinks, allow sensor nodes to connect to the Internet or other external networks [12]. Data captured by sensor nodes is sent to a sink for analysis. Traditionally, sensor nodes are supplied with limited-capacity batteries. Therefore, sensor nodes in these networks must conserve energy to increase their lifetime [13]. Communication between sensor nodes and sinks can be performed via single-hop or multi-hop schemes. Since the single-hop method requires substantial energy to transport data over long distances, the multi-hop method provides better performance in terms of energy consumption. Moreover, the transceiver consumes the most power in a sensor node [14, 15].
Problem definition
Utilizing clustering approaches has been demonstrated to be beneficial in developing sustainable routing solutions that take into account energy limits [16]. This technique classifies nodes into distinct groupings known as clusters. Appointed cluster heads (CHs) are in charge of managing clusters. These CHs collect participant data and transmit it to the sink [17, 18]. Clustering reduces the amount of transmission bandwidth used, promotes scalability, and resolves routing problems among sensors, as depicted in Fig. 1. Cluster heads (CHs) additionally filter and consolidate extraneous material from the gathered information, therefore decreasing the quantity of data packets transmitted to the central node. A network with n nodes that lacks clustering generates m packets per round, whereas a cluster-based network generates much fewer packets. More packets result in longer delays and higher energy consumption [19]. Network energy consumption also changes when the packet count being delivered to the sink rises since all nodes have the same destination [20]. The sink is unique in that it gathers all packets routed to it from the network, which reduces the longevity of the network. An energy-efficient routing protocol can balance traffic among nodes in the network [21]. This modification prevents potential failure by spreading out the data collection process equally among all nodes. This will increase the longevity of the network by reducing the burden on the central node, thus enhancing network connectivity and reliability [22].

Clustering in a multi-hop WSN
Motivation and contribution
As a non-deterministic polynomial-time-hard (NP-hard) problem, developing an effective routing scheme for IoT networks integrated with WSNs is challenging. Researchers have recently tackled this issue by offering evolutionary and metaheuristic algorithms as potential solutions. The present study introduces a new method for selecting CH nodes termed ECPF. This method combines Particle Swarm Optimization (PSO) with fuzzy clustering. Before network functioning, the nodes are partitioned into several clusters of fuzzy subsets. This allows for concurrent operations between the subclusters, hence decreasing the computing workload and time inside each subgroup. We employ PSO and fuzzy clustering techniques to enhance the effectiveness of network routing. PSO and fuzzy clustering are selected for their distinct characteristics in tackling challenges related to the IoT. In the case of traditional clustering approaches, nodes are arranged into rigid clusters unsuitable for establishing accurate clustering, especially in scenarios involving dynamic and heterogeneous IoT networks. Rather than being strictly clustered, nodes are clustered with fuzzy clustering based on their membership to clusters, which varies from 0 to 1. The fuzzy clustering approach is more appropriate for the IoT environment where the nodes' competition and cooperation are constantly changing due to dynamic mechanisms, and node density and energy levels fluctuate.
The fuzzy clustering method is based on the energy of nodes and helps in a more balanced distribution of energy consumption of the network, which can extend the longevity of the network. One of the advantages of fuzzy clustering is its ability to handle internal uncertainties and varying distributions of nodes and their energy levels. PSO is suitable for optimizing solution evaluation in multi-dimensional and complex spaces. When integrated into the protocol, PSO can optimize the selection of the CH nodes dynamically by evaluating the current network status, which can ensure more efficient data transmission and energy usage. IoT devices often have limited energy, processing power, and bandwidth, requiring efficient and lightweight algorithms. The ability to scale as the number of devices increases is critical for IoT applications. Fuzzy clustering and PSO provide scalable solutions that can manage large, distributed networks without significant computational effort. This study contributes to the following areas:
-
Explanation of the two common routing approaches, path-based transmission, and cluster-based transmission, highlighting their respective advantages in different network scenarios;
-
Recognition of the challenges posed by the development of efficient routing protocols and the adoption of evolutionary and metaheuristic algorithms to address these challenges;
-
Introduction of a novel CH selection method, called ECPF, which combines the PSO algorithm with fuzzy clustering to initialize CH nodes;
-
Description of the advantages of ECPF, such as parallel operations among subclusters, reduced computation size and time, and improved efficiency of the routing protocol.
The rest of the paper is arranged as follows. Section 2 outlines IoT routing challenges and reviews related works. Section 3 presents the proposed routing protocol. Section 4 reports and discusses simulations and experiments. The paper concludes with a summary and possible research avenues in Sect. 5.
Backgrounds
This section discusses the routing issues in IoT networks and recent studies conducted to address these challenges. Table 1 provides a concise overview of recent efforts.
IoT routing challenges
Routing in IoT networks encounters a number of distinct challenges due to the extensive size, diversity, limited resources, constantly changing topology, and varying demands of the applications. IoT networks may contain thousands of devices that need efficient communication. Conventional routing strategies cannot handle such vast networks because of their computational complexity and overhead [23]. Scalable routing algorithms are essential for managing the growing number of IoT devices and maintaining efficient data delivery. IoT devices possess diverse functionalities, employ multiple communication technologies, function within certain power constraints, and establish connections to networks through different methods. Routing algorithms must possess adaptability to effectively handle a variety of devices and make optimal routing decisions, considering the varied capabilities of devices and network conditions. Adaptive routing protocols, cross-layer optimization, and context-aware routing can be utilized to address the problem of heterogeneity effectively.
Routing in IoT systems is a major challenge due to limited resources. On the whole, these devices lack adequate processing power, memory, energy, and bandwidth. In order to run resource-constrained devices effectively so that the network lifespan can be extended, routing algorithms should reduce resource consumption, especially minimize energy consumption [24]. Energy-efficient routing, sleep scheduling, and data aggregation are highly and frequently used methodologies to resolve resource limitations. Furthermore, IoT networks are difficult to manage due to their dynamic nature, as the IoT devices are often moving and changing their network topologies. In particular, for IoT systems with mobility, changes occur in the network topology through environmental factors or node failure, leading to changes in the long lives of the links or paths. This kind of happens in a dynamic fashion and these frequent changes would degrade the network’s stability [25]. It is very important that the routing algorithms should be robust in such dynamic environments and should be able to adapt quickly to the network to provide a constant connection for delivering data. There are several techniques used such as reactive routing, distributed coordination, and efficient route discovery mechanisms. In addition, IoT applications have diverse demands, and some applications may have different levels of data freshness, reliability, delay constraints, and the need for security. As such, routing algorithms should be able to handle these application-specific demands and optimize routing decisions accordingly. Moreover, QoS-aware routing, priority-based routing, and secure routing mechanisms are used to satisfy different IoT applications [26].
Related work
Mohseni, et al. [27] introduced CEDAR, a cluster-based routing protocol that combines fuzzy logic and the Capuchin search algorithm. This strategy effectively reduces energy consumption by clustering nodes in the network. Each CH serves as a router for its member nodes, and the proposed hybrid algorithm provides flexibility in responding to network circumstances, ensuring efficient packet routing. The experimental results demonstrate that CEDAR outperforms other comparable approaches concerning energy consumption, latency, and network longevity. Subramanian, et al. [28] combined Crow Search Optimization (CSO) and Grey Wolf Optimization (GWO) algorithms for optimal CH selection. The algorithm primarily focuses on minimizing delay, reducing node distance, and stabilizing energy consumption. CSO works with the GWO algorithm to achieve a harmonious equilibrium between exploration and exploitation processes while mitigating premature convergence. The proposed algorithm is tested in simulation experiments, and its performance is compared to existing CH selection algorithms, including ABC, GWO, and Firefly Optimization (FFO) algorithms. The results indicate that the suggested method successfully reduces energy use, enhances the network's lifespan, and creates a balanced distribution of operational and non-operational sensor nodes.
Yarinezhad and Sabaei [29] have proposed a novel clustering method to balance traffic loads in IoT-based WSNs. This clustering approach employs a 1.2-approximated algorithm to efficiently allocate the workload among the CHs. An energy-efficient routing protocol is also presented to transmit data from each CH to the respective destinations. This method strategically segments the area to distribute the communication load in areas closer to the destination. Statistical simulations demonstrate that the proposed clustering algorithm outperforms similar ones, making it suitable for large-scale networks and improving overall efficiency and performance. Raslan, et al. [30] have introduced an innovative algorithm called the Improved Sunflower Optimization Algorithm (ISFO) for selecting the optimal CHs. The SFO algorithm combined with Lévy flights prevents the algorithm from becoming trapped in local minima by achieving a balance between diversification and intensification. The ISFO algorithm is compared to other Swarm Intelligence (SI) algorithms, and the results substantiate its superior performance. The ISFO algorithm achieves reduced energy consumption in comparison to the other algorithms, leading to an extended network lifetime. Additionally, the ISFO algorithm sustains a higher number of active nodes, thereby reinforcing its supremacy concerning energy efficiency and network longevity.
Sankar, et al. [31] introduced a new algorithm called the Ncaledonian Crow Learning Algorithm (NCCLA) for identifying optimal CHs in the cluster formation process. The algorithm utilizes Euclidean distance to create clusters within the network and then applies the NCCLA algorithm to determine the most optimal CH for each cluster. The proposed algorithm was implemented and simulated using MATLAB R2019a. The simulation outcomes indicated that NCCLA performed superior to the other algorithms concerning network longevity and packet delivery efficiency. Vazhuthi, et al. [32] proposed a novel method to optimize the Quality of Service (QoS) in IoT-enabled WSNs by introducing fault management and energy-efficient inter-cluster routing schemes. The system employs a hybrid Adaptive Neuro-Fuzzy Inference System (ANFIS) to identify the most efficient route between clusters and the sink node. Additionally, a tuned supervision-based fault detection approach is employed to detect and diagnose various types of faults in the network. As per the findings, the suggested approach leads to notably lower energy consumption compared to other inter-cluster routing algorithms, highlighting its effectiveness in improving energy efficiency in IoT-enabled WSNs.
Sankar, et al. [33] proposed a novel optimization algorithm called the Sandpiper Optimization Algorithm (SOA) for selecting CHs. The SOA algorithm is utilized to optimize the selection of CHs among the network nodes. Additionally, the cluster formation process is performed using the Euclidean distance metric. To assess the efficiency of SOA, its performance is evaluated against other algorithms, including GWO, PSO, and ABC. The results indicate that SOA prolongs the network lifetime and boosts throughput compared to different algorithms.
Singh, et al. [34] combined the genetic algorithm with a greedy strategy-based mutation operation to optimize routing in heterogeneous WSNs. The protocol optimizes network performance and prolongs its functional duration in technologically advanced cities. The suggested algorithm incorporates a weighted fitness function that takes into account three key parameters: distance, energy, and node density. Moreover, a three-tier approach is adopted to enhance the network’s longevity, and an energy-efficient deployment approach is employed to distribute the sensor nodes effectively. Comparative analysis reveals that the proposed algorithm outperforms other optimization approaches such as optimized GA with multiple sinks (OptiGAS-StMS), GA-based optimized clustering (GAOC), multiple sinks (MS) based GAOC, and optimized GA with single sink (OptiGAS-StSS). The proposed protocol promotes an energy-conserving pattern for intelligent cities, boosting IoT-enabled WSNs’ performance and longevity.
Srinivasulu, et al. [35] developed the QoS-aware Energy Efficient Multipath Routing (QEMR) protocol, which utilizes a hybrid optimization method. The methodology starts by enhancing clustering through a modified Teaching-Learning-Based Optimization (MTLO) technique, then proceeds to choose cluster heads using the Nonlinear Regression-based Pigeon Optimization (NR-PO) approach. The Deep Kronecker Neural Network (DKNN) is utilized to ascertain the most efficient routing paths. The efficacy of the proposed QEMR protocol is assessed using the NS-3 simulation tool, taking into account variables like as node density, node velocity, and network congestion. The performance of the QEMR system is evaluated by comparing the simulation results with those of existing techniques.
Methods
This section introduces ECPF, a routing protocol based on the PSO algorithm, and fuzzy clustering to enhance the performance of the IoT network. ECPF demonstrates superior efficiency in throughput, packet delivery rate, energy usage, and network longevity. The subsections delve into the intricacies of ECPF: defining the problem, elucidating the network model, detailing the optimization models employed for evaluation, and providing a comprehensive overview of the proposed routing protocol. Fuzzy clustering is applied to cluster the sensor nodes initially based on their geographical location and energy level. At the same time, such a method enables the boundaries to be flexible because each node is given a membership degree for multiple clusters. The fuzzy clustering algorithm computes the probability value for each node, indicating the probability of becoming a CH. The fuzzy clustering algorithm generated membership value determines the CH selection. The membership value reveals the likelihood of being a CH which means a higher value for the members whose chances to be selected as a CH increases. The probability activity ensures that the nodes in better circumstances (e.g., in more favorable locations and having higher energy levels) are more likely to be selected as CHs.
Problem statement
Clustering is essential for controlling the topology of IoT-based networks, particularly in activating specific nodes such as CHs. These CH nodes comprise the backbone network, allowing other member nodes to enter hibernate mode to conserve energy. By periodically selecting CH nodes, energy consumption in the network can be balanced, thereby prolonging the network's lifespan. Each instance of selecting CH nodes and reconstructing the network is referred to as a round. In the considered scenario, sensor nodes are heterogeneous, limited in energy resources, distributed randomly, and stationary. All nodes have the same initial energy levels. In this system, the primary objective is to capture sensed data and transmit it to the BS for data processing while conserving node energy and maximizing their lifetimes. The direct transmission of sensor data to the BS is not efficient since nodes placed farther away from the BS experience faster energy drainage compared to nodes in close proximity. To address this issue, multi-hop communication with data aggregation is an effective solution. By aggregating correlated data through multiple hops, the problem can be resolved. A system is established within the proposed routing protocol where all nodes are systematically arranged into distinct clusters. The clustering process involves organizing related items into logical sets, serving several essential purposes such as streamlining communication, conserving energy, enhancing scalability, and achieving load balancing.
Network model
The study focuses on a wireless network-based IoT system with an infinitely supplied BS connected to the network. The network model, illustrated in Fig. 2, consists of randomly distributed n nodes in an M × M network area. While all nodes and the BS are stationary, their transmission power can be changed based on distance. Sensor nodes collect data in each round and send it to the BS. The sensor nodes are assembled into clusters to streamline data transmission and reduce network traffic. Each cluster is led by a CH, which is responsible for collecting data from the sensor nodes within the cluster and forwarding it to the BS for processing and decision-making. The CH nodes perform data aggregation to minimize network traffic.

Network model
A key innovation of the proposed network model lies in its routing protocol, which pursues several objectives, including increased packet delivery rate, minimization of energy consumption, and extension of network lifetime. By minimizing the number of messages exchanged between nodes and optimizing data aggregation at CHs, the protocol effectively enhances the packet delivery ratio and saves energy, thereby extending the operational life of the network. Furthermore, the proposed protocol eliminates data duplication and compresses the entire data set into a single package, further improving network efficiency and resource utilization. This approach represents a significant departure from traditional routing protocols, which often ignore the importance of data aggregation and energy-efficient communication strategies.
Energy consumption model
The energy consumption model used in this study is based on the Euclidean distance between network components. Data transmission between sensor nodes is only possible if their Euclidean distance is within a certain range (ri). To ensure a successful transmission, simultaneous data transmission from nodes within the interference range of the receiving node j is prevented. The choice of the energy consumption model depends on the Euclidean distance between the nodes. The free space model is applied if the distance between the nodes is less than a predefined threshold value (D0). On the other hand, if the distance exceeds this threshold, the multipath fading channel model is used. By considering these models, the energy consumption model determines the energy required for transmitting a certain number of bits (l) over the network. The energy consumption for data transmission (Etr) can be defined as follows:
In Eq. 1, various factors contributing to energy consumption during data transmission are taken into account. Eelec represents the energy consumed by the electronic circuitry of the sensor node, including signal processing, modulation, and other electronic operations. εfs denotes the energy inefficiency due to the amplifier in a free space channel, where the energy consumption increases with the distance between the nodes. εemp represents the energy inefficiency in a multipath fading channel, where reflections and interference lead to additional energy consumption. The energy consumption for receiving l-bit data (Ere) is also considered and is defined as:
Fuzzy clustering
We use a method of initialization based on a fuzzy clustering model to create clusters in the network. This approach takes into account the proximity of nodes since clustering is more common when nodes are near together because transmission requires less power. The fuzzy clustering approach is used to partition the sensor nodes into a number of fuzzy initial subgroups prior to the communication process. All nodes in the network have a given probability of belonging to these initial subgroups. Each node is randomly assigned to a subset at the beginning of each round. Each subset then performs concurrent operations to choose CHs and communicate with the BS. The size and time needed for computation are decreased by this parallel procedure. Unlike traditional deterministic clustering, which divides the basic set into disjoint subsets containing related items, our suggested technique considers the intricacy of actual clusters in real-world contexts. Real clusters often exhibit vague boundaries, and the membership of objects in these clusters is somewhat uncertain. Therefore, the concept of fuzzy clusters has been introduced. In our approach, a fuzzy clustering model is utilized for initialization, considering the fuzzy nature of the clusters.
Fuzzy clustering is a technique used to partition a set of n objects, denoted as F = f1, f2, ..., fn, into m fuzzy clusters, represented by h1, h2, ..., hm. The clustering process is described by an \(n\times m\) matrix, denoted as \(R=[{\omega }_{ij}](1\le i\le n,1\le j\le m)\), \({\omega }_{ij}\) where stands for the degree to which the ith item belongs to the jth cluster. To ensure the validity of the fuzzy clustering matrix R, the following conditions must be satisfied:
-
For each object fi and cluster hj, the value of \({\omega }_{ij}\) must be within the range of \(0\le {\omega }_{ij}\le 1\), indicating the degree of membership or belongingness of the object to the cluster.
-
For each object fi, the sum of \({\omega }_{ij}\) over all clusters j, denoted as \({\sum }_{j=1}^{m}{\omega }_{ij}\), should be equal to 1. This condition ensures that each object fully belongs to the clusters and accounts for the complete membership degree.
-
For each cluster hj, the sum of \({\omega }_{ij}\) over all objects i, denoted as \({\sum }_{j=1}^{n}{\omega }_{ij}\), should be greater than 0 and less than n. This condition ensures that each cluster contains at least one object and that no object fully belongs to all clusters.
-
The center of cluster hj (1 ≤ j ≤ m) is denoted as hj.
-
The distance between object fi and cluster center hj is represented by dist(fi, hj), which reflects the degree of belongingness of object fi to cluster hj. A smaller distance between object xi and cluster center hj indicates a higher likelihood of object xi belonging to cluster hj. The degree of belongingness is quantified by using the expression \(\frac{1}{{\text{dist}({f}_{i},{h}_{j})}^{2}}\), which is then normalized to obtain the value of \({\omega }_{ij}\). This normalization ensures that the conditions of the matrix R = [\({\omega }_{ij}\)] are satisfied, as depicted in Eq. 3.
$${\omega }_{ij}=\frac{\frac{1}{{dist({f}_{i},{h}_{j})}^{2}}}{{\sum }_{l=1}^{m}\frac{1}{{dist({f}_{i},{h}_{j})}^{2}}}$$(3)
Using fuzzy clustering, items can simultaneously belong to many groups. In this method, the expectation maximization technique is used to compute fuzzy clustering and produce m different groups. Algorithm 1 provides a thorough initialization approach based on fuzzy clustering.

Algorithm 1 Cluster initialization using the fuzzy clustering algorithm
In fuzzy clustering, it is important to determine the optimal number of clusters as it impacts the level of detail in the clustering and the balance between compressibility and accuracy. The sum of squared error (SSE) is a commonly used metric to assess the quality of clustering. The SSE for each cluster is calculated using Eq. 4, where \(p(p\ge 0)\) is a factor that assigns priority weights to the degree of belongingness \({\omega }_{ij}\). The total SSE for fuzzy clustering with k clusters can be used to indicate data fit, as defined in Eq. 5.
Objective function
In this paper, the focus is on topology control in order to minimize total energy consumption, which is primarily attributed to communication between nodes. Previous research has highlighted the impact of node distance on energy consumption. In this paper, the total network energy consumption during a round of data cycle is represented by Eq. 6.
where m refers to the number of CHs, \({E}_{CH}^{i}\) denotes the energy consumption of ith CH during a round, and \({E}_{\text{mem}}^{ij}\) is the energy consumption for a member node in ith cluster during a round. The maximum distance from CHs to the BS is denoted as dist1 and is calculated as the maximum value among the distances between each CH and the BS. Mathematically, it is represented by Eq. 7.
The maximum average distance from a member node to its CH node is denoted as dist2. This value represents the maximum average distance among all the clusters in the network. Mathematically, it is calculated using Eq. 8.
where CMij represents the jth member node in ith cluster, \(d({CM}_{ij},{CH}_{i})\) represents the distance between the member node and its corresponding CH. In order to consider the three factors (maximum average distance, maximum distance from CH nodes to the BS, and total energy consumption) in an integrated manner, a normalization function is applied to transform the data into a comparable level. The normalization function used in this paper is defined in Eq. 9.
To synthesize the indicators, the objective function is defined as Eq. 10.
Where Esum, dist1, and dist2 represent the normalized values of the total energy consumption, maximum average distance, and maximum distance from CHs to the BS, respectively. α, β, and γ are positive factors that determine the priority weighting of the three indicators, with α + β + γ = 1.
PSO algorithm for CH selection
The objective of topology control is to select a set of m CHs from a pool of candidates in order to minimize the objective function, which can be formulated as an optimization problem. Traditional algorithms have limitations when dealing with the increasing scale and complexity of IoT systems. On the other hand, PSO is an exceptionally efficient approach for resolving certain types of optimization issues. The PSO algorithm is a very efficient computer method that is inspired by studies on artificial life, specifically the collective behavior observed in bird flocks and fish schools. It integrates the principles of evolutionary algorithms and population-based algorithms.
In the PSO algorithm, a swarm comprises a specific number of particles, each representing a potential solution for the problem at hand. These particles navigate through the search space, adjusting their velocities based on their own experiences and the collective knowledge of the entire population. PSO does not rely on weights or volumes for particles, making it a simple yet powerful algorithm. Particles explore the search space and converge toward optimal solutions by dynamically adjusting their velocities. Combining individual and collective learning enables PSO to efficiently search for optimal solutions in complex optimization problems, including selecting CH nodes in topology control for IoT systems. The PSO parameters in this study were carefully selected to ensure effective convergence and optimization performance. PSO parameters were as follows:
-
Number of particles (S): the number of particles in the swarm is set to a value of S. This parameter determines the population size and affects the exploration-exploitation trade-off. A larger S may lead to better exploration but increased computational complexity.
-
Maximum iterations (T): the maximum number of iterations T controls the termination criterion for the PSO algorithm. It was set to ensure sufficient convergence in our experiments while avoiding unnecessary computational overhead.
-
Inertia weight (ω): the inertia weight ω was employed to control the retention rate of the particle's velocity. A suitable ω value was chosen to balance exploration and exploitation throughout the optimization process.
-
Cognitive coefficient (c1) and social coefficient (c2): these coefficients contribute to the knowledge factor and social factor, respectively. Appropriate values are set for c1 and c2 to influence particle behavior in terms of individual and collective learning.
-
Velocity constraints: to prevent particles from moving too fast, velocity constraints are imposed, limiting the maximum velocity (vmax) of each dimension in the particle's vector.
-
Random numbers: random numbers r1 and r2, generated between 0 and 1, were used to maintain population diversity and influence particle updates.
The PSO algorithm consists of placing an n-particle swarm in a D-dimensional space. Each particle i has a position vector \({X}_{i}=({x}_{i1},{x}_{i2},\dots ,{x}_{id})\) and a velocity vector \({V}_{i}=({v}_{i1},{v}_{i2},\dots ,{v}_{id})\). Additionally, each particle keeps track of the best position it has ever found, denoted \({P}_{i}=({p}_{i1},{p}_{i2},\dots ,{p}_{id})\). The best position experienced by the entire swarm is recorded as \({P}_{g}=({p}_{g1},{p}_{g2},\dots ,{p}_{gd})\). The quality of a particle’s position is evaluated using a fitness function. The concept of inertia weight is incorporated into PSO with inertia weight. The velocity and position updates for each particle are calculated using Eqs. 11 and 12.
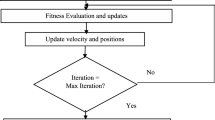
In these equations, i ranges from 1 to m, d ranges from 1 to D, where D represents the number of dimensions in the search space. The inertia weight ω controls the retention rate for the particle's velocity. The iteration time is denoted as t. The random numbers r1 and r2 are generated between 0 and 1 to maintain population diversity. The acceleration coefficients c1 and c2 represent the contribution of the knowledge and social factors, respectively. In this study, the PSO algorithm with inertia weight is utilized for the selection of CH nodes. To solve the clustering problem using PSO, the number of CHs Tj is determined for each initial cluster. Initially, S particles are initialized, where each particle is represented as a \(2\times {T}_{j}\) dimensional vector \({X}_{i}=({X}_{{i1}_{1}},{X}_{{i1}_{2}},{X}_{{i2}_{1}},{X}_{{i2}_{2}},\dots ,{X}_{{iT}_{{j}_{1}}},{X}_{{iT}_{{j}_{2}}})\), where \({X}_{{ik}_{1}}\) and \({X}_{{ik}_{2}}\) represent the coordinates of kth CH. The velocity of each dimension in the particle's vector is constrained by the maximum velocity vmax. The proposed process is presented as Algorithm 2, which combines fuzzy clustering and PSO, to achieve the selection of CH nodes.

Algorithm 2 The pseudocode of CH selection
The proposed method employs a combination of fuzzy clustering and the PSO algorithm for the efficient selection of CHs in IoT networks. Initially, the optimal number of clusters is determined using the elbow method, and fuzzy clustering is applied to assign nodes to clusters based on proximity. Subsequently, particles are initialized for each cluster to explore the search space and determine potential CH locations. Through iterative optimization, particles adjust their positions and velocities based on local and global best solutions, converging towards optimal CH selections. The PSO algorithm dynamically adjusts particle behavior, balancing exploration and exploitation to efficiently search for optimal solutions. By integrating fuzzy clustering and PSO, the proposed method optimizes CH selection, enhancing network performance and energy efficiency in IoT deployments.
Results and discussion
This section covers the experimental setup and performance evaluation of ECPF. The performance is analyzed using various metrics to assess the effectiveness of ECPF. The following performance measures are considered:
-
Throughput: Throughput indicates the volume of data successfully transferred in a given period of time. The data transfer rate in Mbps can be calculated using Eq. 13. Higher throughput values indicate better network performance regarding data transfer capacity.
-
Total packets sent: This metric measures the number of packets successfully transmitted in the network. It reflects the overall data delivery capability of the system. The calculation is determined by Eq. 14, which defines the ratio between the successfully transmitted packets to the BS and the total number of packets transmitted.
-
Average energy consumption: this metric calculates the mean energy consumption of nodes within the network. Lower average energy consumption signifies better energy efficiency and a longer network lifetime. This parameter is calculated by Eq. 1.
-
Alive nodes: this metric measures the number of active and operational nodes throughout the network lifespan. A higher number of alive nodes shows better network stability and resilience. This estimation is calculated using Eq. 15, where CMij represents the total matrix coverage, Li denotes the life of the sink node, and Nm represents the total number of nodes in the network.
$$N={\text{Min}}_{ij}(\frac{{\sum }_{i=1}{CM}_{ij}\times {L}_{i}}{{N}_{m}})$$(15)
MATLAB simulator was utilized to implement and validate ECPF. The simulation region was configured with a distribution area measuring 500 × 500. The initial energy of nodes is equally distributed throughout the range of 0.3 J to 1 J. Each data packet transmitted in the simulation had a length of 4000 bits. Also, the energy model employed in the analysis utilized a threshold value of 200, and the energy cost for data aggregation was set at 5nJ/bit. The simulation included 300 nodes randomly distributed within the specified area. To model the energy consumption of the nodes during data transmission, the first-order radio model was utilized, with parameters set as follows: Eelec = 50nJ/bit, Efs = 10pJ/bit/m2, and Emp = 0.001310pJ/bit/m4. These parameters determined the energy consumption of the nodes during data transmission. To assess the performance of the proposed method, a comparison was made with traditional approaches, such as LEACH (Low-Energy Adaptive Clustering Hierarchy) and DEEC (Distributed Energy-Efficient Clustering). These approaches are well-known in WSNs and are widely used to improve energy efficiency. Table 2 presents the average improvement percentage of ECPF over DEEC and LEACH.
Throughput assessment
Figures 3 and 4 compare ECPF, LEACH, and DEEC in terms of throughput under different conditions. The BS is positioned at the center of the field in the first scenario. This means that the BS is positioned relatively close to all the sensor nodes in the network. The second scenario involves distantly setting the BS at a distance. This means that the distance between the BS and the sensor nodes is significantly greater compared to the first scenario. The evaluation reveals that the proposed method achieves higher throughput than LEACH and DEEC. The superior throughput of the proposed method can be attributed to several factors. Firstly, LEACH and DEEC suffer from faster energy depletion in their sensor nodes compared to the proposed method. This higher energy consumption in LEACH and DEEC is primarily a result of their inappropriate selection of CHs.

Throughput comparison for the first and second scenarios

Throughput vs. number of nodes
In contrast, the proposed method adopts an energy-efficient CH selection process, ensuring that CHs with sufficient energy levels are chosen. This selection process helps to conserve energy and prolong the network’s lifetime. The proposed method uses the PSO algorithm to incorporate optimal route generation. This ensures that data packets are transmitted along the most efficient paths toward the BS. The proposed method minimizes energy consumption and maximizes data transmission by selecting optimal routes. Higher throughput is achieved in the proposed method because of the combination of optimal route selection and energy-efficient clustering, resulting in the transmission of more data bits than existing algorithms. The effective transmission of data packets to the BS contributes to the superiority of the proposed method in terms of throughput.
Packet delivery rate assessment
Two separate scenarios with varying node counts were considered when evaluating the total packets sent to the BS. The performance of three algorithms, namely ECPF, DEEC, and LEACH, was compared, and the results are depicted in Figs. 5 and 6. In both scenarios, the proposed method demonstrated superior performance over LEACH and DEEC concerning the number of received packets at the BS. This achievement can be attributed to the efficient fitness functions utilized in ECPF. The fitness functions employed in the ECPF are specifically designed to conserve node energy, ultimately optimizing node survival rates. This, in turn, results in more data packets being delivered to the BS. Additionally, the fitness function selectively chooses nodes with sufficient energy to transmit data packets to the BS. By doing so, ECPF ensures that packet drops are minimized during transmission, resulting in more data packets reaching the BS.

Packet delivery ratio comparison for the first and second scenarios

Packet delivery ratio vs. number of nodes
Energy consumption assessment
Figures 7, 8, 9 and 10 compare the energy consumption of the suggested technique to that of DEEC and LEACH. Figures 7 and 8 illustrate the mean energy use when the BS is positioned at the coordinates (100, 100) and at a distance from the sensing region (100, 250), respectively. Figures 9 and 10 show the mean energy use for networks consisting of 100 and 150 nodes, respectively. Based on the data presented, it can be inferred that the suggested technique outperforms the DEEC and LEACH algorithms in terms of energy efficiency. The higher energy consumption of LEACH is attributed to the use of single-hop data transfer and the random selection of cluster heads. Conversely, DEEC spends a greater amount of energy since it does not take into account the distance while selecting CH. The enhanced energy efficiency of the suggested technique may be ascribed to two essential elements. Initially, a meticulous procedure is conducted to pick the most suitable CH from the group of nodes, guaranteeing a balanced energy distribution among the CHs. This mitigates the irregular energy usage found in LEACH as a result of random CH selection. Furthermore, the suggested technique aims to provide an ideal route from the CHs to the BS, with the objective of decreasing the transmission distance. By decreasing the transmission distance, the energy consumption of nodes is efficiently decreased since energy consumption is in direct relation to the distance between nodes.

Energy consumption comparison for the first scenario

Energy consumption comparison for the second scenario

Energy consumption comparison for 100 nodes

Energy consumption comparison for 150 nodes
Network lifetime assessment
The efficacy of the suggested approach is assessed by measuring the number of active nodes across various situations and varying node quantities. A comparative analysis is conducted against established algorithms like LEACH and DEEC. Figure 11 demonstrates that the suggested strategy outperforms LEACH and DEEC as measured by the number of active nodes in the first scenario. In the second case, shown in Fig. 12, the proposed technique demonstrates enhanced performance in active nodes compared to LEACH and DEEC. This suggests that the suggested technique may increase the longevity of the nodes over a larger number of rounds as a result of its efficient cluster management and optimum routing methods in the WSN. The cluster maintenance step in the suggested technique guarantees the absence of non-functioning nodes in the network for a substantial number of rounds. The selection of CHs is determined by identifying nodes within the group of sensor nodes that possess greater residual energy. This selection criterion ensures the sustainability of a larger number of active nodes over an extended period of time. The suggested technique endures 8561 rounds in the first situation, while LEACH and DEEC endure 1395 and 1396 rounds, respectively.

Network lifetime comparison for the first scenario

Network lifetime comparison for the second scenario
The suggested technique surpasses LEACH and DEEC in terms of the number of active nodes in both scenarios. The constraints of LEACH, such as single-hop data transfer resulting in increased energy usage and reduced number of active nodes, may be identified as the cause. Within the DEEC algorithm, the process of selecting cluster heads based only on residual energy levels may not guarantee equitable energy use across nodes, leading to a reduced number of active nodes. The examination of active nodes reveals that the suggested approach attains enhanced efficiency in comparison to LEACH and DEEC. The equitable distribution of energy consumption among the sensor nodes in the suggested approach plays a crucial part in reaching more active nodes. Efficient energy consumption and the survival of a greater number of nodes are facilitated by determining the shortest route between source nodes and the BS.
As the number of IoT devices expands rapidly, the importance of scalable protocols is increasingly recognized. To address scalability issues, ECPF takes a hierarchical clustering approach that divides network management tasks across multiple levels of the hierarchy. However, further research is needed to evaluate scalability in large-scale deployments. IoT devices are resource-limited in terms of energy, processing resources, and storage. Therefore, ECPF should be assessed to consider these resource-constrained settings with regard to resource requirements such as storage, computational complexity, and memory usage. ECPF must optimize energy consumption and reduce communication overhead on resource-constrained IoT devices.
The IoT environments are dynamic and heterogeneous, and fluctuations in node density, energy levels, and communication patterns are common. There are adaptive mechanisms within ECPF to dynamically adapt to the changing network conditions, such as fuzzy clustering and PSO-based optimization. To adapt to changing environments while operating at an optimum level, ECPF can closely examine the network parameters and dynamically adjust the clustering and routing decision-making process. In actual IoT deployments, there will be node failures due to hardware problems, environmental factors, lack of power, etc. ECPF uses a number of fault-tolerant mechanisms to deal with the issue of node failure. For example, redundant routing paths and dynamic CH re-election schemes are in place in the case of node failure. When there is a failure of the CH node, an elected new CH will be performed by neighboring nodes through distributed means to ensure that the data transmission and network operation remains intact.
Conclusions
In the field of IoT design, sensor nodes effectively collect environmental data and transmit it to a central BS. However, such objects often have limited resources, particularly in terms of power supply. The energy consumption of these sensing devices needs to be managed effectively to extend the lifespan of the network. To address this challenge, the paper proposed a hybrid energy-aware routing method called ECPF. ECPF combines two techniques: the PSO algorithm and fuzzy clustering. The initial clustering of nodes is accomplished by fuzzy clustering, which groups them based on a variety of characteristics. Conversely, the enhanced PSO algorithm is utilized to pick CHs. The enhanced PSO algorithm incorporates a fitness function that takes into account three crucial factors: optimal energy use, the distances between CH and BS, and the distances between cluster members and their respective CH nodes. By optimizing these factors, the algorithm selects efficient CHs. ECPF significantly improves performance metrics, including throughput, packet delivery rate, network lifetime, and energy consumption. These enhancements indicate that ECPF effectively manages energy consumption and extends the overall longevity of the IoT network.
Our research has made considerable developments in energy consumption and network performance measures. This opens up new possibilities for further exploration in the realm of IoT design and energy-efficient routing. Firstly, it is required to thoroughly analyze the capability of the ECPF technique to adapt to dynamic network settings. This involves exploring adaptive methods that can dynamically modify clustering and routing techniques in response to variations in network topology and environmental conditions. Furthermore, the ECPF framework can enhance its autonomy and decision-making capabilities by incorporating machine learning methods like reinforcement learning. This enhancement would result in more efficient resource allocation and routing choices. Also, expanding the evaluation methodology to encompass real-life applications and other IoT situations would provide significant perspectives on the feasibility of the suggested strategy in different fields. By considering these possible future directions, progress in energy-efficient and scalable routing for IoT networks may be driven, ultimately enhancing the sustainability and longevity of IoT infrastructures.
Availability of data and materials
Not applicable.
Abbreviations
- ANFIS:
-
Adaptive neuro-fuzzy inference system
- CH:
-
Cluster head
- CSO:
-
Crow search optimization
- FFO:
-
Firefly optimization
- GWO:
-
Grey Wolf Optimization
- ISFO:
-
Improved sunflower optimization algorithm
- IoT:
-
Internet of Things
- NCCLA:
-
Ncaledonian Crow Learning Algorithm
- NP-hard:
-
Non-deterministic polynomial-time hard
- PSO:
-
Particle swarm optimization
- QoS:
-
Quality of service
- SOA:
-
Sandpiper optimization algorithm
- SSE:
-
Sum of squared error
- SI:
-
Swarm intelligence
- WSN:
-
Wireless sensor network
References
Pourghebleh B, Navimipour NJ (2017) Data aggregation mechanisms in the Internet of things: A systematic review of the literature and recommendations for future research. Journal of Network and Computer Applications 97:23–34
Kamalov F, Pourghebleh B, Gheisari M, Liu Y, Moussa S (2023) Internet of medical things privacy and security: challenges, solutions, and future trends from a new perspective. Sustainability 15(4):3317
Muneeswari G, Varun SS, Hegde R, Priya SS, Shermila PJ, Prasanth A (2023) Self-diagnosis platform via IOT-based privacy preserving medical data. Measurement: Sensors 25:100636
Pourghebleh B, Hayyolalam V (2020) A comprehensive and systematic review of the load balancing mechanisms in the Internet of Things. Cluster Computing 23(2):641–661. https://doi.org/10.1007/s10586-019-02950-0
Aruchamy P, Gnanaselvi S, Sowndarya D, Naveenkumar P (2023) An artificial intelligence approach for energy-aware intrusion detection and secure routing in internet of things-enabled wireless sensor networks. Concurrency and Computation: Practice and Experience 35(23):e7818
Pourghebleh B, Hekmati N, Davoudnia Z, Sadeghi M (2024) A roadmap towards energy‐efficient data fusion methods in the Internet of Things. Concurrency and Computation: Practice and Experience 34(15):e6959
Hasan MK et al (2022) A review on security threats, vulnerabilities, and counter measures of 5G enabled Internet-of-Medical-Things. IET Communications 16(5):421–432
Prasanth A, Jayachitra S (2020) A novel multi-objective optimization strategy for enhancing quality of service in IoT-enabled WSN applications. Peer-to-Peer Networking and Applications 13(6):1905–1920
J. Zandi, A. N. Afooshteh, and M. Ghassemian (2018) Implementation and analysis of a novel low power and portable energy measurement tool for wireless sensor nodes, in Electrical Engineering (ICEE), Iranian Conference on, IEEE, 1517-1522, https://doi.org/10.1109/ICEE.2018.8472439
Tewari P, Tripathi S (2023) An energy efficient routing scheme in internet of things enabled WSN: neuro-fuzzy approach. The Journal of Supercomputing 79(10):1–25
Santosh Kumar R, Prakash LNC, Suryanarayana G (2023) Drones enable IoT applications for smart cities. Drone Technology: Future Trends and Practical Applications. pp 207–241 (Chapter 9)
Ahmadi K, Esmaili M, Khorsandi S (2023) A P2P file sharing market based on blockchain and ipfs with dispute resolution mechanism, in 2023 IEEE International Conference on Artificial Intelligence, Blockchain, and Internet of Things (AIBThings) IEEE pp 1-5
Ghamry WK, Shukry S (2024) Multi-objective intelligent clustering routing schema for internet of things enabled wireless sensor networks using deep reinforcement learning, Cluster Computing pp 1-21
Xu M, Zu Y, Zhou J, Liu Y, Li C (2024) Energy-Efficient Secure QoS Routing Algorithm Based on Elite Niche Clone Evolutionary Computing for WSN. IEEE Internet of Things Journal. https://doi.org/10.1109/JIOT.2023.3342091
Larijani A, Dehghani F (2023) A computationally efficient method for increasing confidentiality in smart electricity networks. Electronics 13(1):170. https://doi.org/10.3390/electronics13010170
Larijani A, Dehghani F (2023) An efficient optimization approach for designing machine models based on combined algorithm. FinTech 3(1):40–54. https://doi.org/10.3390/fintech3010003
Maratha P, Gupta K (2023) Linear optimization and fuzzy-based clustering for WSNs assisted internet of things. Multimedia Tools and Applications 82(4):5161–5185
Omidi A, Mohammadshahi A, Gianchandani N, King R, Leijser L, Souza R (2024) Unsupervised domain adaptation of MRI skull-stripping trained on adult data to newborns, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision pp 7718-7727
Lu Y, Miao Z, Sahraeian P, Balasundaram B (2023) On atomic cliques in temporal graphs. Optimization Letters 17(4):813–828
Choupanzadeh R, Zadehgol A (2023) A deep neural network modeling methodology for efficient EMC assessment of shielding enclosures using MECA-generated RCS training data. IEEE Transactions on Electromagnetic Compatibility. https://doi.org/10.1109/TEMC.2023.3316916
Dutta A, Masrourisaadat N, Doan TT (2022) Convergence rates of decentralized gradient dynamics over cluster networks: multiple-time-scale Lyapunov approach, in 2022 IEEE 61st Conference on Decision and Control (CDC), IEEE pp 6497-6502
Sheena BG, Snehalatha N (2023) Multi-objective metaheuristic optimization-based clustering with network slicing technique for Internet of Things-enabled wireless sensor networks in 5G systems. Transactions on Emerging Telecommunications Technologies 34(8):e4626
Wasay Mudasser A, Ahmed Abdul Gafoor SA (2023) Secure Internet of Things based hybrid optimization techniques for optimal centroid routing protocol in wireless sensor network. Concurrency and Computation: Practice and Experience 23;35(6):1
Rabhi S, Abbes T, Zarai F (2023) IoT routing attacks detection using machine learning algorithms. Wireless Personal Communications 128(3):1839–1857
Reddy CS, Chouhan D, Udayaprasad P, Srinidhi N, Dilipkumar S (2022) Geographic routing scheme for resource and communication efficiency in the IoT ecosystem using swarm-intelligence based BFO algorithm. Journal of Information Technology Management 14(1):41–64
Sivakumar S, Vivekanandan P (2020) Efficient fault-tolerant routing in IoT wireless sensor networks based on path graph flow modeling with Marchenko-Pastur distribution (EFT-PMD). Wireless networks 26:4543–4555
Mohseni M, Amirghafouri F, Pourghebleh B (2023) CEDAR: A cluster-based energy-aware data aggregation routing protocol in the internet of things using capuchin search algorithm and fuzzy logic. Peer-to-Peer Networking and Applications 16(1):189–209
Subramanian P, Sahayaraj JM, Senthilkumar S, Alex DS (2020) A hybrid grey wolf and crow search optimization algorithm-based optimal cluster head selection scheme for wireless sensor networks. Wireless Personal Communications 113:905–925
Yarinezhad R, Sabaei M (2021) An optimal cluster-based routing algorithm for lifetime maximization of Internet of Things. Journal of Parallel and Distributed Computing 156:7–24
Raslan AF, Ali AF, Darwish A, El-Sherbiny H (2021) An improved sunflower optimization algorithm for cluster head selection in the internet of things. IEEE Access 9:156171–156186
Sankar S, Ramasubbareddy S, Luhach AK, Alnumay W. S., Chatterjee P (2022) NCCLA: new caledonian crow learning algorithm based cluster head selection for Internet of Things in smart cities. J Ambient Int Human Comput. 13(10):4651–4661
Vazhuthi PPI, Prasanth A, Manikandan S, Sowndarya KD (2023) A hybrid ANFIS reptile optimization algorithm for energy-efficient inter-cluster routing in internet of things-enabled wireless sensor networks. Peer-to-Peer Networking and Applications 16(2):1049–1068
Sankar S, Ramasubbareddy S, Dhanaraj RK, Balusamy B, Gupta P, Ibrahim W, Verma R (2023) Cluster head selection for the internet of things using a sandpiper optimization algorithm (SOA). Journal of Sensors 2023(1):3507600
Singh S, Garg D, Malik A (2023) A novel cluster head selection algorithm based IoT enabled heterogeneous WSNs distributed architecture for smart city, Microprocessors and Microsystems 101;104892
Srinivasulu M, Shivamurthy G, Venkataramana B (2023) Quality of service aware energy efficient multipath routing protocol for internet of things using hybrid optimization algorithm. Multimedia Tools and Applications 82(17):26829–26858
Acknowledgements
Not applicable.
Funding
No funding.
Author information
Authors and Affiliations
Contributions
CL contributed to writing—original draft preparation, and conceptualization. The author read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Lei, C. An energy-aware cluster-based routing in the Internet of things using particle swarm optimization algorithm and fuzzy clustering. J. Eng. Appl. Sci. 71, 135 (2024). https://doi.org/10.1186/s44147-024-00464-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s44147-024-00464-0