
Abstract
Background
Understanding the intricacies of wildfire impact across diverse geographical landscapes necessitates a nuanced comprehension of fire dynamics and areas of vulnerability, particularly in regions prone to high wildfire risks. Machine learning (ML) stands as a formidable ally in addressing the complexities associated with predicting and mapping these risks, offering advanced analytical capabilities. Nevertheless, the reliability of such ML approaches is heavily contingent on the integrity of data and the robustness of training protocols. The scientific community has raised concerns about the transparency and interpretability of ML models in the context of wildfire management, recognizing the need for these models to be both accurate and understandable. The often-opaque nature of complex ML algorithms can obscure the rationale behind their outputs, making it imperative to prioritize clarity and interpretability to ensure that model predictions are not only precise but also actionable. Furthermore, a thorough evaluation of model performance must account for multiple critical factors to ensure the utility and dependability of the results in practical wildfire suppression and management strategies.
Results
This study unveils a sophisticated spatial deep learning framework grounded in TabNet technology, tailored specifically for delineating areas susceptible to wildfires. To elucidate the predictive interplay between the model’s outputs and the contributing variables across a spectrum of inputs, we embark on an exhaustive analysis using SHapley Additive exPlanations (SHAP). This approach affords a granular understanding of how individual features sway the model’s predictions. Furthermore, the robustness of the predictive model is rigorously validated through 5-fold cross-validation techniques, ensuring the dependability of the findings. The research meticulously investigates the spatial heterogeneity of wildfire susceptibility within the designated study locale, unearthing pivotal insights into the nuanced fabric of fire risk that is distinctly local in nature.
Conclusion
Utilizing SHapley Additive exPlanations (SHAP) visualizations, this research meticulously identifies key variables, quantifies their importance, and demystifies the decision-making mechanics of the model. Critical factors, including temperature, elevation, the Normalized Difference Vegetation Index (NDVI), aspect, and wind speed, are discerned to have significant sway over the predictions of wildfire susceptibility. The findings of this study accentuate the criticality of transparency in modeling, which facilitates a deeper understanding of wildfire risk factors. By shedding light on the significant predictors within the models, this work enhances our ability to interpret complex predictive models and drives forward the field of wildfire risk management, ultimately contributing to the development of more effective prevention and mitigation strategies.
Resumen
Antecedentes
El entender las complejidades de los impactos de los incendios de vegetación a través de los diversos paisajes geográficos, requieren de una detallada comprensión de la dinámica del fuego y de las áreas de vulnerabilidad, particularmente en regiones propensas y con alto riesgo de incendios. El aprendizaje automático (Machine Learning o ML, en idioma inglés), aparece como un formidable aliado para abordar las complejidades asociadas con la predicción y el mapeo de esos riesgos. Sin embargo, la confiabilidad de estos enfoques usando esta técnica de aprendizaje automático (ML) es altamente dependiente de la integridad de los datos y de la robustez de los protocolos de entrenamiento. La comunidad científica ha sembrado dudas sobre la transparencia e interpretación de los modelos de ML en el contexto del manejo del fuego, reconociendo la necesidad de que esos modelos sean a su vez precisos y entendibles. La frecuentemente opaca naturaleza de los complejos algoritmos del ML, pueden oscurecer la racionalidad que debe haber por detrás de los resultados, haciéndose imperativo el priorizar la claridad e interpretación para asegurar que los modelos de predicción no sólo sean precisos sino también procesables. Adicionalmente, una completa evaluación de la performance del modelo en cuanto a los múltiples factores críticos debe tenerse en cuenta para asegurar la utilidad y dependencia de los resultados en estrategias de prácticas de supresión y manejo del fuego.
Resultados
Este estudio devela un marco espacialmente sofisticado de aprendizaje profundo (deeep learnig) basado en tecnología de TabNet, diseñado específicamente para delinear áreas susceptibles a incendios de vegetación. Para dilucidar las interacciones predictivas entre los resultados del modelo y las variables contributivas a través de un espectro de entradas, nos embarcamos en un análisis exhaustivo usando SHapley Additive exPlanations (SHAP). Esta aproximación aborda un entendimiento granular sobre cómo las características individuales influencian las predicciones del modelo. Además, la robustez del modelo predictivo fue rigurosamente validado 5 veces a través de técnicas de validación cruzadas, asegurando la dependencia de los resultados. EL trabajo investigó meticulosamente la variabilidad espacial de la susceptibilidad dentro del estudio local, desenterrando ideas fundamentales sobre riesgo de incendios que implican matices distintivos de naturaleza local.
Conclusiones
Utilizando visualizaciones del SHapley Additive exPlanations (SHAP), esta investigación identificó meticulosamente variables clave, cuantificó su importancia y desmitificó la mecánica de toma de decisiones del modelo. Los factores críticos, incluyendo temperatura, elevación, el NDVI (Índice Normalizado de Diferencias de Vegetación), aspecto, y velocidad del viento, fueron descifrados para que tengan una influencia significativa en la predicción de la susceptibilidad a los incendios. Los resultados de este estudio acentúan la crítica a la transparencia de los modelos, lo que facilita un entendimiento más profundo de los factores críticos del riesgo de incendios. Mediante el esclarecimiento de los predictores significativos del modelo, este trabajo aumenta nuestra habilidad para interpretar modelos predictivos complejos, e impulsa hacia adelante el campo del manejo del riesgo de incendios, contribuyendo en última instancia al desarrollo de estrategias de prevención y mitigación más efectivas.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Introduction
Annually, fires result in significant destruction to vast expanses of rangelands and forests worldwide (Zhongming et al. 2020). Natural forest fires can occur in forested areas as a result of various factors, such as dry litter friction, the accumulation of litter, lightning strikes, insufficient rainfall, the impacts of global warming, deforestation, the presence of hot winds, shifts in climate patterns, and suboptimal land management (Ganteaume et al. 2013). Throughout the passage of time, there has been a discernible escalation in the occurrence rate of wildfires, resulting in an estimated yearly global forest devastation of roughly 37 million hectares (Ajin et al. 2015). Besides the significant impacts on physical infrastructure and human welfare, wildfires have resulted in substantial ecological devastation (Sayad et al. 2019). In order to minimize the negative impact of fires, it is imperative to employ various tactics, as outlined by Jaiswal et al. (2002). These strategies encompass the identification of regions that are more prone to wildfires, the implementation of proactive measures, and the adoption of fire safety protocols. It is crucial to identify the elements that contribute to the occurrence of fires, including human activities, topographical features, climatic conditions, and fuel qualities, in order to determine places that are prone to fires (Vasilakos et al. 2009). Therefore, it is imperative to establish a direct association between these characteristics and the likelihood of wildfires (Naderpour et al. 2021). The establishment of a thorough fire inventory is imperative in order to maintain accurate records of past fire occurrences. Subsequently, a comparative examination of these sites, in conjunction with the layers representing factors influencing fire vulnerability, is essential for the identification and understanding of their interconnectedness (Smith and Lyon 2000). The modeling and mapping of wildfire susceptibility involve the utilization of a comprehensive system of wildfire parameters. These parameters encompass various scales and factors, including climate variables such as rainfall, temperature, wind speed, and humidity, as well as topographical characteristics like elevation, slope, and aspect. Furthermore, the inclusion of landcover and vegetation elements as predictive variables is also taken into consideration in this approach (Iban and Sekertekin 2022). Numerous studies (Abdollahi and Pradhan 2023) have been conducted by researchers worldwide to address the challenge of mapping wildfire susceptibility. In order to forecast and simulate spatial patterns of wildfire probability in various geographical areas, a wide range of spatial modeling methodologies has been devised, each utilizing unique sets of predictive factors (Talukdar et al. n.d.). A number of research projects have incorporated the utilization of remote sensing data and geographic information systems (GIS) data in conjunction with multi-criteria decision analysis (MCDA) methodologies to assess and determine the susceptibility of wildfires. The study (Nami et al. 2018) employed the evidentiary belief function (EBF) approach to assess wildfire vulnerability in the Hyrcanian ecoregion located in northern Iran. Their study incorporated a dataset consisting of 1162 wildfire occurrences and 14 predictive variables. The findings highlight the efficacy of the Geographic Information System (GIS)-based Empirical Bayesian Framework (EBF) model in forecasting the likelihood of wildfires, as evidenced by an area under the curve (AUC) value of 84.14%. The study (Full article: Comparison of the fuzzy AHP method, the spatial correlation method, and the Dong model to predict the fire high-risk areas in Hyrcanian forests of Iran 2023) conducted a study to assess the importance of several elements contributing to wildfires and to identify areas at high risk of wildfires in Mazandaran Province, Iran. To achieve this, the researchers utilized a knowledge-based analytical hierarchical process (AHP) in combination with fuzzy sets. The results of their study showcased the effectiveness of the fuzzy Analytic Hierarchy Process (AHP) technique in accurately identifying regions inside Iran’s Hyrcanian forests that are at a heightened danger of fire.
Extensive research has been conducted on the spatial distribution of natural disasters, such as wildfires, through the utilization of diverse machine learning (ML) models for prediction purposes. The aforementioned models incorporate many methodologies, including random forest (RF) (Multi-temporal analysis of forest fire probability using socio-economic and environmental variables 2023), logistic regression (Kuter et al. 2011), neural networks (NNs) (Big data integration shows Australian bush-fire frequency is increasing significantly 2023), and support vector machine (SVM). The effectiveness of machine learning (ML) algorithms in this particular domain relies on the presence of sufficient training data, and many ML techniques possess unique strengths and limitations (A Google Earth Engine approach for wildfire susceptibility prediction fusion with remote sensing data of different spatial resolutions 2023). Machine learning (ML) models have exhibited their capacity to proficiently address non-linearities in spatial simulation, modeling, and mapping, particularly in the domain of mapping sensitivity to natural disasters, as highlighted by reference (Eskandari et al. 2021). Moreover, the integration of machine learning (ML) algorithms with geographic information system (GIS) methodologies offers several advantages over conventional techniques such as multi-criteria decision analysis (MCDA). These advantages often encompass enhanced wildfire forecast accuracy and expedited data processing capabilities (Jaafari et al. 2019). The study (Comparisons of diverse machine learning approaches for wildfire susceptibility mapping 2023) conducted a thorough investigation on wildfire susceptibility, employing a range of statistical and machine learning (ML) models such as neural networks (NN), random forest (RF), SVM, least angle regression, radial basis function, and logistic regression. The study’s accuracy assessment indicated that the Random Forest (RF) model demonstrated the best level of accuracy in predicting wildfires, achieving an area under the curve (AUC) of 88%. This was followed by the Support Vector Machine (SVM) model, which achieved a 79% AUC. In their study, Kim et al. (2019) utilized two machine learning models, specifically Random Forest (RF) and maximal entropy, to detect and determine the forest fire locations in South Korea.The study conducted by Forest fire susceptibility prediction based on machine learning models with resampling algorithms on remote sensing data (2023) demonstrated a significant correlation between wildfire risks and human-related variables, with the greatest likelihood of wildfires occurring in close proximity to inhabited regions. Kalantar et al. (2020) utilized three ML techniques containing multivariate adaptive regression splines, support vector machine (SVM), and boosted regression tree, in their endeavor to map wildfire susceptibility. The aforementioned models were constructed utilizing a set of 14 pivotal indications that have influence on wildfires. In the realm of remote sensing, there has been a growing interest in the utilization of advanced machine learning methods, specifically deep learning models (DLs), for the purpose of wildfire susceptibility predictions (Naderpour et al. 2021). In their study, (Bjånes et al. 2021) utilized an ensemble methodology that integrated two deep learning (DL) models with the purpose of mapping wildfire susceptibility identification in two regions of Chile. In order to enable the generation of a dataset that is utilized for training the models, satellite data comprising 15 elements that influence fires within the study area was obtained. The findings of this study indicate that the proposed model demonstrated a high level of accuracy, as evidenced by a notable area under the curve (AUC) score of 95.3% in the projected susceptibility maps. The assessment of wildfire susceptibility and risk in the Northern Beaches region of Sydney, Australia was the focus of a recent study undertaken by Naderpour et al. (2021). The researchers utilized a deep learning (DL) model for this purpose. The model was provided with 36 essential key variables that impact the danger of forest fires. The variables were systematically mapped from several perspectives, including physical, social, human-induced, climate-related, morphology-based, and topographical elements. The conclusive findings highlighted an exceptional accuracy of the created model in evaluating the vulnerability of forests to fire. The detailed explanation of critical analysis for contemporary state-of-the-art approaches is illustrated in Table 1.
Critical analysis of contemporary wildfire susceptibility models
The utilization of machine learning models in practical wildfire control scenarios presents a notable challenge in terms of trust, explainability, and transparency. Based on an extensive analysis of the current state-of-the-art literature, we have identified the limitations as outlined below:
-
The clarity and comprehensibility of machine learning methods utilized in wildfire control have been identified as areas of concern by researchers (Abdollahi and Pradhan 2023; A method to evaluate task-specific importance of spatio-temporal units based on explainable artificial intelligence 2023; Maddy et al. 2021).
-
The complexity of these models is sometimes characterized as “black boxes” because to their utilization of considerable training data (Abdollahi et al. 2022; A method to evaluate task-specific importance of spatio-temporal units based on explainable artificial intelligence 2023; Maddy et al. 2021).
-
Machine learning is the preferred approach for wildfire evaluation among scholars and policymakers. However, it is crucial to underline the importance of generating model outputs that are clear and easily comprehensible (Abdollahi et al. 2022; A method to evaluate task-specific importance of spatio-temporal units based on explainable artificial intelligence 2023; Maddy et al. 2021).
-
To the best of our knowledge, non of the existing studies investigates the conncetion among the model and features across different input parameters in the area of wildfire susceptibility.
-
We contend that during the assessment of the applied machine learning model’s performance, several crucial factors require due consideration to attain exceptional accuracy, an aspect that has often been overlooked.
Explainable artificial intelligence (XAI) focuses on opacity by developing AI systems that possess enhanced transparency and interpretability (Barredo Arrieta et al. 2020; Cilli et al. 2022). XAI accomplishes this objective by the utilization of either less intricate algorithms or by rendering the internal mechanisms of intricate models comprehensible (Barredo Arrieta et al. 2020; Cilli et al. 2022). XAI technologies facilitate users in gaining a comprehensive understanding of the decision-making process of AI models, hence augmenting transparency in a broader sense (Barredo Arrieta et al. 2020; Cilli et al. 2022).
Motivation
The primary contribution of this research consists in its utilization of an interpretable TabNet-based deep learning methodology to delineate wildfire vulnerability. The objective of this study is to provide a comprehensive analysis of the topographic, meteorological, and landcover elements that impact the prediction model. This analysis will determine the significance of each parameter, examine the interrelationships between these features, and provide a reason for the specific decisions made in the model. The objective of this study is to elucidate the mechanisms underlying the generation of precise outcomes in wildfire forecasting for the Gippsland area in Victoria, Australia, through the utilization of a deep learning approach.
Contribution
The present study constitutes a groundbreaking endeavor within the existing body of literature, as it brings an innovative methodology that has not been previously investigated. This marks the inaugural implementation of the proposed concept. As a result, this research initiative also aims to offer insights on model outputs by utilizing various SHAP plots.
To recapitulate, the prime contributions of the proposed study are listed below:
-
i)
The formulation of a TabNet-based spatial deep learning (DL) framework for the purpose of mapping wildfire susceptibility.
-
ii)
The investigation of the relation among the employed machine learning model and input parameters, accomplished by conducting an analysis of individual forecasts utilizing Shapley outputs.
-
iii)
The utilization of cross-validation as a means to improve the accuracy of evaluating model performance.
-
iv)
The examination of spatial variations in model results concerning wildfire susceptibility predictions for the study area.
Australia is confronted with a major wildfire danger on a yearly basis. In light of the increasing frequency of these fires, it becomes imperative to prioritize the improvement of the nation’s forest fire risk management plan. Therefore, the establishment of a resilient and dependable framework, such as an interpretable machine learning model, arises as a pivotal undertaking. This model has the potential to enhance decision-making by providing a comprehensive comprehension of model outputs. It can also aid in identifying crucial elements that have substantial influence on the model. Resultantly, it can enable more efficient management and reduction of fire hazards.
The paper is organized as follows: TabNet-based proposed wildfire susceptibility model section presents the details of the proposed TabNet prediction model. Prediction outcomes section discusses the prediction module, including details and results. Performance analysis of Shapely explainable model section is dedicated to the results of the SHAP (SHapley Additive exPlanations) analysis. Discussion section presents discussion of the outcomes and finally, Conclusion section provides the conclusion of the paper.
TabNet-based proposed wildfire susceptibility model
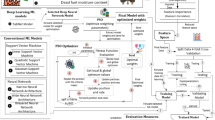
In this study, a thorough technique has been developed for the generation of a map for wildfire susceptibility (Fig. 1). The framework comprises following stages:
-
Identification of contributing elements: At the outset, we undertook the identification and evaluation of 11 pivotal features pertaining to wildfire susceptibility analysis.
-
Development of a deep learning model: In this study, a TabNet-based deep learning (DL) approach was employed to create a model. The selected parameters were utilized as inputs for the model. The model was subjected to a process of training and testing, utilizing both the contributing components and a dataset comprising historical wildfire data.
-
We also apply the explainable AI that is harnessed to interpret the outcomes of the applied TabNet classification model. This approach enabled the assessment of the specific influence of each input component on the classification, so guaranteeing the clarity and understandability of the study.
-
To enhance the robustness and dependability of the findings, we employed a five-fold cross-validation technique.
-
The model’s findings were utilized to generate a spatial representation of wildfire vulnerability within the study area.
-
The standard classification evaluation measures encompassing precision, recall, F-measure, accuracy, and receiver operating characteristic (ROC) analysis to illustrate the results.

Proposed wildfire susceptibility prediction deep learning using TabNet and its interpretation using Explainable AI
Data set
The Gippsland region in Australia, exhibits a wide range of landforms, encompassing the entirety of southeastern Victoria. Spanning an expansive area of 41,556 km2, it extends from a longitude of 147.46°E to a latitude of −37.58°S. The region under consideration exhibits a wide array of geographical features, including but not limited to bushlands, lakes, farmlands, mountains, and coastal beaches. Gippsland has a documented record of recurrent wildfires throughout its history, rendering it as one of the regions in the country that is highly susceptible to bushfires. Significantly, throughout the 2019–2020 Australian bushfire season, also known as the “Black Summer”, extensive wildfires caused substantial devastation across several regions of Australia. The Gippsland region has been experiencing prolonged drought conditions for a duration exceeding 3 years prior to the fire season during 2019–2020. The fires in East Gippsland that occurred during this time period led to the unfortunate demise of four individuals, the devastation of numerous residences, and the displacement of over one thousand inhabitants. Figure 2 depicts the geographical position of the research region within, Australia, so offering a spatial framework for the study. In order to generate the map of wildfire inventory and accurately identify the geographic coordinates of wildfires, we employed data derived from the moderate resolution image spectroradiometer (MODIS). More specifically, we utilized the MCD64A1 dataset, as well as the MOD14/MYD14 fire and thermal anomalies datasets. Furthermore, we have included historical records spanning from the year 2019 to 2020, which are accessible via the provided hyperlink.Footnote 1 The topic of discussion pertains to the historical occurrences of fires, specifically focusing on wildfires and prescribed burns. Wildfire initiation in Australia is subject to seasonal fluctuations, with the highest probability of occurrence observed during the summer and spring periods, encompassing the months from October to May. Significantly, during the month of November in 2019, all states of Australia had a highly significant forest fire occurrence, which stands out as one of the most catastrophic events in recent recollection. This event was predominantly propelled by exceptionally adverse weather circumstances. The training dataset utilized in this experiment comprised of labeled samples obtained from a total of 521 wildfire locations. The samples were assigned two distinct sets of inventory values, namely 0 and 1. A numerical value of 1 denoted the occurrence of a fire event at a particular geographical point, while a value of 0 indicated the nonexistence of a fire event. The labeled information was utilized to train the susceptibility model, which aims to forecast wildfire susceptibility.

The study area, situated in Gippsland, within the state of Victoria, Australia
Potential features
The magnitude and intensity of wildfires can be influenced by certain elements, commonly known as contributing parameters (Eskandari and Khoshnevis 2020). The present study has centered its attention on 11 notable features that have been classified into three distinct groups: climatic, topography, and landcover/vegetation aspects, specifically pertaining to the year 2020. The criteria in question have been meticulously chosen in order to evaluate their link with the prediction of wildfire vulnerability within the designated study area.
-
1.
The influence of topographical elements on climatic conditions, such as rainfall and temperature distribution, is of utmost importance. Three crucial topographic factors, namely aspect, slope, and elevation, have been integrated into our study. These variables were derived from a digital elevation model (DEM) obtained from the Shuttle Radar Topography Mission (SRTM) dataset. These topographic factors play a pivotal role in understanding and predicting wildfire susceptibility in the region, as highlighted by A Google Earth Engine approach for wildfire susceptibility prediction fusion with remote sensing data of different spatial resolutions (2023).
-
2.
According to Ljubomir et al. (2019) fire incidence is significantly influenced by landcover and vegetation characteristics. We assessed various parameters, including vegetation indices like GNDVI, NDMI, and NDVI, derived from Sentinel-2 data with a 20-m spatial resolution, known for its effectiveness in gauging plant health and moisture content (Dandois et al. 2013). Landcover information was obtained from the ESRI 2020 global land cover dataset, generated from Sentinel-2 data and comprising ten distinct land cover classes. To ensure consistency, we resampled the landcover dataset to match the spatial resolution of the Sentinel-2 vegetation indices. These landcover and vegetation-related attributes play a vital role in our analysis of wildfire risk in the study area.
-
3.
Meteorological factors, including wind speed, rainfall, temperature, and humidity, play a vital role in wildfire vulnerability. Wind can both spread fires and dry out vegetation, increasing ignition risk, especially in dry and windy conditions. We sourced wind speed data from the Wind Global Atlas and meteorological data from Australian climate datasets, aligning them with Sentinel-2 vegetation indices for consistency. These factors are key in our wildfire susceptibility assessment.
Data preprocessing
In the context of our wildfire susceptibility investigation, we employed data preparation methodologies to enhance the data quality. Initially, the min-max normalization technique was employed to standardize the feature values, hence ensuring consistency throughout the dataset. In addition, the K-nearest neighbors (KNN) method was utilized to perform data imputation, effectively handling missing values by considering the proximity of neighboring data points. The implementation of these preprocessing processes has potential significance in enhancing the dependability and resilience of our wildfire prediction model.
TabNet Model Architecture
In this study, we employ a TabNet-based DNN classification model to identify wildfire susceptibility employing the data set mentioned above. Deep neural networks (DNNs), characterized by their several hidden layers, have demonstrated exceptional performance in tasks involving images, text, and audio. Deep neural networks (DNNs) offer an effective approach to encode tabular data through end-to-end training, reducing the need for extensive feature engineering, especially with large datasets.
TabNet decoder (Fig. 3)

The structural layout of TabNet encoder module architecture (Qayyum et al. 2023)
Feature selection
The mask module is used for the feature selection at each decision step. with the Attentive converter that provides a precise execution function. Figure 4 shows the feature selection process that uses attentive transformer at the selected step. This is done with the help of mask employing learning process. The numerical number supplied to each element in Fig. 4 signifies the sequential organization of tensor flow. This value holds significance in terms of its interpretation.
-
(1)
The tensor generated by the Feature transformer in the preceding judgment phase is subsequently transmitted to the split module.
-
(2)
The split module divides the tensor to obtain a[k − 1].
-
(3)
a[k − 1] undergoes the hi layer, combining features for higher dimensionality and abstraction.
-
(4)
The output of the hi layer is multiplied by the prior scale p[k − 1] obtained from previous steps, which represents the extent to which features are utilized. More prior-step usage reduces current-step weight.
-
(5)
M[i] is computed using (Martins and Astudillo 2016) as shown in Eq. (1):
$$M\left[k\right]=sparsemax\left\{P\left[k-1\right]*{h}_{k}\left(a-1\right)\right\}$$(1)

The structural layout of the TabNet attentive transformer layer (Qayyum et al. 2023)
The equation ensures that the sum of the product of S[k] and j[l] for l ranging from 1 to L is equal to 1, where L indicates the dimension of the feature. The sparsemax algorithm allocates weight distributions to individual features, denoted as l, in each sample, denoted as b. This allocation guarantees that the sum of weights for all features in each sample is equal to 1, hence facilitating instance-wise feature selection (Yoon et al. 2018). TabNet employs a sparse regularization term in order to regulate the level of sparsity in the features.
Feature sparsity in selection benefits accuracy when many dataset features are redundant.
-
(6)
S[k] updates p[k] with Eq. (3).
$$P\left[k\right]= \prod\nolimits_{l=1}^{k}(r-S\left[j\right])$$(3)
When β equals 1, it signifies that each feature is exclusively assigned to a single decision step.
-
(7)
The process of selecting features for the current decision step in S[i] is accomplished by multiplying them with feature elements.
-
(8)
The aforementioned features are subsequently inputted into the feature transformer, which enables the generation of a new decision step loop.
Feature processing
The filtered features are then further processed using the mask in the Feature transformer layer for extra manipulation. The mentioned qualities are divided into two separate components: one component acts as the output for the current phase, while the other component acts as the input for the next step, as depicted in Eq. (4).
Figure 5 shows the batch normalization (BN) layer, the gated linear unit (GLU) layer, and the fully connected (FC) layer, which are three main elements of the feature transformer layer.

Feature transformer structure module in TabNet architecture (Qayyum et al. 2023)
Decoder architecture
The decoder uses the code shown in Fig. 6, but it does not use the fully connected (FC) layer. The decoder uses a feature transformer layer to turn the representation vector into a feature. This feature is made through several steps. All the main parts of TabNet are used to determine wildfire risk.

The structural layout of TabNet decoder module architecture (Qayyum et al. 2023)
PSO-enabled learning to optimization
The proposed study also encompasses a learning-to-optimization approach that uses particle swarm optimization (PSO) optimizers to refine the TabNet model’s weights in order to enhance its accuracy. Initially, training data was used to create a precise predictive model. The weights are optimized using PSO optimizer, improving the performance of wildfire susceptibility prediction. Random weights were generated in the first epoch and optimized using the PSO algorithm. The optimal weights from PSO are then used in subsequent training epochs. We assessed the effectiveness of the PSO using unseen data examples and evaluated the overall performance.
SHAP interpretable model
In 2021, Chen introduced a method called SHAP, based on game theory, to evaluate how well prediction systems work. SHAP uses a straightforward method to explain the model's output. It does this by showing the model's output as a sum of its input variables. SHAP's strong theory background makes it very useful in supervised learning situations. It clarifies specific forecasts by giving Shapley values to elements that satisfy certain conditions (Mangalathu et al. 2020)
-
1.
It's important that the explanation method matches the main model's results for accurate local-level results.
-
2.
The explanation technique should effectively handle missing features by ignoring any inputs that are not in the main model.
-
3.
It is vital to keep the importance of each variable constant, even when changing how much the model depends on that variable, no matter how important other variables are.
Therefore, SHAP has the ability to accurately describe both global and local phenomena. The proposed methodology in this study utilizes essential background information from the dataset to develop an interpretable approach that considers the proximity to the specific event (Ribeiro et al. 2016). The SHAP framework incorporates explanation techniques, namely LIME (‘Why should I trust you?’ 2023) and DeepLIFT (Shrikumar et al. 2017), into the realm of additive feature attribution methods. In the basic methodology, referred to as g(y), the input variables y = (y1, y2, y3, …, yp), where p represents the quantity of input parameters, are utilized. The explanation technique \({\text{h}}\left({{\text{y}}}^\prime\right)\) can be obtained by simplifying the input \({{\text{y}}}^\prime\) according to the following procedure:
We have S as the input parameter quantity, and ϕ0 as the constant value. Various methods exist for estimating SHAP values, encompassing Deep SHAP, kernel SHAP, and Tree SHAP, as discussed by Lundberg and Lee (2017). Kernel SHAP employs Shapley values and linear LIME (‘Why should I trust you?’ 2023) for localized interpretation. We chose Kernel SHAP for this study due to its superior precision and efficiency compared to alternative sampling-based methods (Abdollahi et al. 2022).
Data split
The usual way to build machine learning model is to apply a certain settings training dataset and then using it to make predictions/classifications to determine wildfire suspectibility. However, using small or inadequate training and test datasets can lead to wrong and unreliable results (A machine learning-based approach for wildfire susceptibility mapping 2023).
To make sure we accurately assess how well a model works, it's good to use a hold-out dataset along with cross-validation (CV) methods. CV helps reduce bias in the dataset and prevents overfitting or underfitting when optimizing machine learning algorithms. We used this method to prepare the dataset for training and evaluating our deep learning (DL) models. According to a source, AUC (area under curve) values help measure model performance. 0.50-0.60 means the model failed, 0.60-0.70 is mediocre, 0.70-0.80 is medium, 0.80-0.90 is good, and 0.90-1.00 is exceptional. For our wildfire dataset, named 'f', we split it into five parts ('f1' to 'f5') using random partitioning. Our approach involved five rounds of testing, each time using a different part for validation and the rest for training. This meant training the model on 80% of the data and testing it on the remaining 20% each time. Figure 7 shows how we applied this five-fold cross-validation on the wildfire dataset.

Five-fold cross-validation (CV) technique to improve model prediction performance
Model evaluation
To check how reliable our wildfire risk model is, we used four well-known measures: the receiver operating characteristic (ROC), recall, precision, F1 score, and accuracy. We applied a five-fold cross-validation method to ensure a consistent evaluation of the model. We assessed the model by comparing the validation parts of our data with the results from our method. This included using ROC curves, a popular way to measure accuracy. ROC curves show the balance between the false positive rate (FPR) and the true positive rate (TPR), with FPR on the X-axis and TPR on the Y-axis. We calculated the area under the curve (AUC) using Eq. 6.
As stated in (Schneider and Gil Pontius 2001), the parameters m, nk, and mk are defined as follows: m represents the total number of pixels, nk denotes the percentage of pixels that are successfully predicted, and mk signifies the percentage of pixels that are mistakenly forecasted. AUC values in proximity to 0 indicate that the forecast is arbitrary, while AUC values approaching 1 indicate a high level of accuracy in the context of a wildfire susceptibility map.
Prediction outcomes
As mentioned earlier, a five-fold cross-validation (CV) approach was employed to comprehensively evaluate the effectiveness of the deep learning (DL) model employed for wildfire susceptibility mapping. Figure 8 demonstrates the quantitative outcomes of the proposed model, including precision, recall, accuracy, and F1 score, over all folds. The findings encompass both the average values for the training and validation sets. Furthermore, ROC curves have been created using a five-fold cross-validation approach for the test dataset. These curves are visually depicted in Fig. 9. These evaluations offer a comprehensive review of the model’s performance and its capacity to accurately predict wildfire vulnerability.

Results of precision, recall, F-measure, and accuracy metrics achieved across various folds in both the training and validation datasets

The ROC curve generated on test data set as a result of five-fold cross-validation
The findings indicate that the technique described in this study exhibited remarkable performance, as seen by an average accuracy above 94% across many metrics on the training dataset and 89% on the validation dataset across all folds utilized. Furthermore, the model successfully attained a mean AUC (Area Under the Curve) of 91% for the test dataset, which is a noteworthy achievement. Moreover, the wildfire susceptibility map for the designated study area was developed utilizing the proposed TabNet-based methodology, hence highlighting the practical applicability of this strategy.
The wildfire susceptibility prediction was classified into three distinct categories, namely low, moderate, and high. This categorization was accomplished using the natural break algorithm, a well-established technique that aims to efficiently group comparable values together (Febrianto et al. 2016). The results of this classification are presented in Fig. 10a. Significantly, as compared to other climate variables, the region’s diminished levels of precipitation and temperature played a role in increasing its susceptibility to the initiation of wildfires. The aforementioned susceptibility is exacerbated by the extensive prevalence of arboreal and shrub vegetation, particularly in geographical areas such as East Gippsland. According to the classification in Fig. 10a, communities such as Wellington East Gippsland were categorized as areas with a high susceptibility to wildfires. The classification presented in this study corresponds to the results obtained from the burned area map, which relies on historical fire data. The map reveals that a significant portion of the burned areas, including both wildfires and prescribed burns, are concentrated in the Wellington and East Gippsland regions, as shown in Fig. 10b. The repeated findings underscore the precision and credibility of the wildfire susceptibility forecast. Table 2 presents an overview of the level of wildfire susceptibility prediction for every class. Approximately 47% of the research area is comprised of places that can be categorized as low susceptibility. On the contrary, it can be observed that over 10.5% of the geographical area in question is situated within zones characterized by low susceptibility. Approximately 16% of the research region is characterized as a high susceptibility zone.

a Susceptibility map generated employing proposed Tab-Net model. b Real burnt area in the region
In conclusion, the adoption of a resilient and dependable framework, as demonstrated by the use of XAI models and the examination of diverse SHAP plots in this study, presents notable benefits to individuals responsible for making decisions. The utilization of this approach improves comprehension of model outputs, discerns influential aspects in wildfire prediction, and facilitates the formulation of more knowledgeable and efficient methods for managing wildfire risk. Explainable artificial intelligence (XAI) offers a potentially effective strategy for mitigating the constraints associated with conventional opaque AI models. However, it is important to acknowledge that XAI also poses its own set of issues. The task of striking a delicate equilibrium between precision and interpretability during the design of explainable artificial intelligence (XAI) models might provide a multifaceted challenge. Certain explainable artificial intelligence (XAI) models might make a compromise between achieving high accuracy and ensuring interpretability. Additionally, the efficacy of explainable artificial intelligence (XAI) models is contingent upon the presence of high-caliber data, as insufficient or subpar data can diminish both the accuracy and interpretability of these models.
Performance analysis of Shapely explainable model
This section presents SHAP interpretations, commonly visualized using partial dependence plots, bar plots for feature significance (Barredo Arrieta et al. 2020), and SHAP dependence graphs. These visualizations help illustrate how specific features impact model predictions. SHAP dependence graphs offer a precise representation of feature interdependencies, making them a valuable alternative to partial dependence plots. They visually convey the model’s reliance on specific features by displaying how changes in these features affect model outputs. We deepen our understanding of interrelationships in wildfire prediction by employing SHAP values, as shown in Fig. 11. Figure 8a explores the relationship between rainfall and NDMI, while Fig. 8b investigates the relation between NDVI and GNDVI. These visualizations depict SHAP values associated with each variable using colors as indicators, with the X and Y-axes representing variable magnitudes. The depiction of the impact of rainfall is observed through the variable range of Normalized Difference Moisture Index (NDMI) spanning from 0.2 to 1.0. Similarly, the influence of Normalized Difference Vegetation Index (NDVI) is displayed by modifications in Green Normalized Difference Vegetation Index (GNDVI) ranging from 0.0 to 1.0. Figure 8a clearly demonstrates that when rainfall measurements fall below 150 mm, the accompanying SHAP values for rainfall exhibit values below 0.2. In situations characterized by reduced rainfall and a low Normalized Difference Moisture Index (NDMI), the SHAP values demonstrate a significant decline, hence enhancing the potential for wildfire prediction.

SHAP dependence plots illustrating the impact of a NDMI and rainfall, and b GNDVI and NDVI on wildfire susceptibility prediction within the proposed methodology
Figure 12a shows a decision map displaying the key features influencing the wildfire score predictions of our model. Model components are listed on the Y-axis by importance, while the X-axis represents the model’s output values. Each observation’s prediction is represented by a line, connecting at the expected value for that observation. Moving from the bottom to the top of the graph, SHAP values for each parameter progressively combine with the model’s base value. This cumulative representation effectively illustrates each factor’s impact on the prediction outcome. Factors shifting the plot to the right positively correlate with higher wildfire scores, while leftward shifts indicate a negative effect. Figure 12b employs a bar graph to provide a concise representation of the complete dataset, facilitating the computation of the mean absolute value of SHAP values for each individual feature. The X-axis represents the magnitude of logarithmic odds differences. Due to the continuous nature of all features, they are vertically arranged based on rank, showcasing their combined impact on classification. Features with lower ranks contribute less to predictions, while those with higher ranks exert more influence. Both the decision plot and bar graph offer a comprehensive overview of predictive contributions. These visualizations reveal that temperature, elevation, NDVI, aspect, and windspeed are the key factors significantly influencing wildfire predictions. These parameters play a critical role in the model’s predictions and greatly affect wildfire vulnerability assessments.

An overview of global prediction contributions displayed through a a decision plot and b a bar graph
A summary plot, illustrated in Fig. 13, integrates feature significance with their respective impacts. Each data point in the plot corresponds to a Shapley value associated with a feature-sample combination. The Y-axis represents features, and the X-axis represents Shapley values, with colors indicating attribute values from low to high. Positive values are on the X-axis, with red indicating higher values. This summary plot provides a comprehensive view of the impact of various features on the wildfire prediction model.

A SHAP summary visualization of the proposed model specifying impact of each feature on model output
The graph shown in Fig. 14 presented depicts the relationship between different environmental and geographical factors and the output values of the model. A range of model output values is observed on the x-axis. The y-axis enumerates various factors, including slope, temperature, NDMI, elevation, windspeed, humidity, landcover, NDVI, GNDVI, aspect, and rainfall. Every parameter is associated with a specific point or line on the graph, which represents the corresponding value or values of the model output. As an illustration, both the parameters “temperature” and “elevation” yield a model output value of roughly 1044.71. In the interim, the metrics denoted as “windspeed” and “humidity” exhibit a value in proximity to 2. The graph facilitates comprehension of the influence of each of these parameters on the model’s output when incorporated into the model, so offering valuable insights into the importance of each parameter within the study’s framework.

A correlation between environmental and geographical parameters and their respective model output values
Discussion
The deep learning model demonstrated a notable level of accuracy in its ability to map wildfire susceptibility, as seen by the significantly high average accuracy scores observed on both the training and validation datasets. The model’s mean AUC on the test dataset provided strong support for these findings, highlighting its predictive accuracy. The classification of wildfire susceptibility into three distinct categories has provided insight into the relationship between climate variables, such as precipitation and temperature, as well as the existence of specific vegetation types. This categorization has shed light on the regional wildfire dangers, particularly in regions like East Gippsland. The observed correlation between this classification and historical burn patterns serves to strengthen the overall validity of the model. Furthermore, the research highlights the significant contribution of explainable artificial intelligence (XAI) in improving decision-making procedures pertaining to the management of wildfires. The utilization of SHAP analysis, in conjunction with informative visual representations such as decision maps and bar graphs, serves the purpose of not only elucidating the predictive behavior of the model but also outlining the primary elements that contribute to the vulnerability of wildfires. Despite the potential benefits of explainable artificial intelligence (XAI), it presents some challenges that must be addressed for its effective implementation. One such challenge is the inherent trade-off between accuracy and interpretability, which requires careful consideration. Additionally, the reliance on high-quality data is a crucial factor that needs to be taken into account for the ongoing advancement and practical use of XAI in the context of predicting natural disasters.
Conclusion
Assessing wildfire risks in susceptible areas is a critical component of land emergency management, crucial for mitigating natural disasters and supporting the efforts of firefighters in responding to and recovering from such events. These risks not only endanger property but also human lives. This paper has presented a created framework for assessing wildfire vulnerability in the Gippsland region of Victoria, Australia. The system utilizes an explainable machine learning model to harness its capabilities. The proposed technique incorporates a range of contributing components that are classified into meteorological, topographical, and land cover/vegetation aspects. The primary objective is to explore the relationships between these factors and their predictions of wildfire susceptibility. To achieve this, we employ the SHAP (SHapley Additive exPlanations) model, which helps assess the significance of features and interpret the results generated by the wildfire susceptibility prediction model. By assigning SHAP values to individual features that impact the model’s predictions, we successfully identify the most influential components within the prediction process. Our study underscores the substantial impact of factors such as temperature, elevation, normalized difference vegetation index (NDVI), aspect, and windspeed on the accuracy of wildfire susceptibility predictions. These insights were derived from a thorough analysis and interpretation of the model’s results using various SHAP plots.
Availability of data and materials
The data that support the findings of this study are available from the corresponding author upon request.
Change history
12 August 2024
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1186/s42408-024-00313-8
References
A Google Earth Engine approach for wildfire susceptibility prediction fusion with remote sensing data of different spatial resolutions. Remote Sensing. https://www.mdpi.com/2072-4292/14/3/672. Accessed 14 Sept 2023.
A machine learning-based approach for wildfire susceptibility mapping. The Case Study of the Liguria Region in Italy. Geosciences. https://www.mdpi.com/2076-3263/10/3/105. Accessed 14 Sept 2023.
A method to evaluate task-specific importance of spatio-temporal units based on explainable artificial intelligence. International Journal of Geographical Information Science 35(10). https://www.tandfonline.com/doi/abs/10.1080/13658816.2020.1805116. Accessed 14 Sept 2023.
Abdollahi, A., and B. Pradhan. 2023. Explainable artificial intelligence (XAI) for interpreting the contributing factors feed into the wildfire susceptibility prediction model. Science of the Total Environment 879: 163004. https://doi.org/10.1016/j.scitotenv.2023.163004.
Abdollahi, A., Y. Liu, B. Pradhan, A. Huete, A. Dikshit, and N. Nguyen Tran. 2022. Short-time-series grassland mapping using Sentinel-2 imagery and deep learning-based architecture. The Egyptian Journal of Remote Sensing and Space Science 25 (3): 673–685. https://doi.org/10.1016/j.ejrs.2022.06.002.
Ajin, R., A.-M. Ciobotaru, P. Vinod, and M.K. Jacob. 2015. Forest and wildland fire risk assessment using geospatial techniques: A case study of Nemmara forest division, Kerala, India. Journal of Wetlands Biodiversity 5: 29–37.
BarredoArrieta, A., et al. 2020. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion 58: 82–115. https://doi.org/10.1016/j.inffus.2019.12.012.
Big data integration shows Australian bush-fire frequency is increasing significantly. Royal Society Open Science. https://royalsocietypublishing.org/doi/full/10.1098/rsos.150241. Accessed 14 Sept 2023.
Bjånes, A., R. De La Fuente, and P. Mena. 2021. A deep learning ensemble model for wildfire susceptibility mapping. Ecological Informatics 65: 101397. https://doi.org/10.1016/j.ecoinf.2021.101397.
Cilli, R., et al. 2022. Explainable artificial intelligence (XAI) detects wildfire occurrence in the Mediterranean countries of Southern Europe. Scientific Reports 12 (1): 1. https://doi.org/10.1038/s41598-022-20347-9.
Comparisons of diverse machine learning approaches for wildfire susceptibility mapping. Symmetry. https://www.mdpi.com/2073-8994/12/4/604. Accessed 14 Sept 2023.
Dandois, J.P., and E.C. Ellis. 2013. High spatial resolution three-dimensional mapping of vegetation spectral dynamics using computer vision. Remote Sensing of Environment 136: 259–276.
Eskandari, S., and M. Khoshnevis. 2020. Evaluating and mapping the fire risk in the forests and rangelands of Sirachal using fuzzy analytic hierarchy process and GIS. Forest Research and Development 6 (2): 219–245. https://doi.org/10.30466/jfrd.2020.120862.
Eskandari, S., H.R. Pourghasemi, and J.P. Tiefenbacher. 2021. Fire-susceptibility mapping in the natural areas of Iran using new and ensemble data-mining models. Environmental Science and Pollution Research 28 (34): 47395–47406. https://doi.org/10.1007/s11356-021-13881-y.
Febrianto, H., A. Fariza, and J.A. Nur Hasim. 2016. Urban flood risk mapping using analytic hierarchy process and natural break classification (Case study: Surabaya, East Java, Indonesia). In 2016 International Conference on Knowledge Creation and Intelligent Computing (KCIC), 148–154. https://doi.org/10.1109/KCIC.2016.7883639.
Forest fire susceptibility prediction based on machine learning models with resampling algorithms on remote sensing data. Remote Sensing. https://www.mdpi.com/2072-4292/12/22/3682. Accessed 14 Sept 2023.
Full article: Comparison of the fuzzy AHP method, the spatial correlation method, and the Dong model to predict the fire high-risk areas in Hyrcanian forests of Iran. https://www.tandfonline.com/doi/full/10.1080/19475705.2017.1289249. Accessed 14 Sept 2023.
Ganteaume, A., A. Camia, M. Jappiot, J. San-Miguel-Ayanz, M. Long-Fournel, and C. Lampin. 2013. A review of the main driving factors of forest fire ignition over Europe. Environmental Management 51 (3): 651–662. https://doi.org/10.1007/s00267-012-9961-z.
Iban, M.C., and A. Sekertekin. 2022. Machine learning based wildfire susceptibility mapping using remotely sensed fire data and GIS: A case study of Adana and Mersin provinces, Turkey. Ecological Informatics 69: 101647. https://doi.org/10.1016/j.ecoinf.2022.101647.
Jaafari, A., E.K. Zenner, M. Panahi, and H. Shahabi. 2019. Hybrid artificial intelligence models based on a neuro-fuzzy system and metaheuristic optimization algorithms for spatial prediction of wildfire probability. Agricultural and Forest Meteorology 266–267: 198–207. https://doi.org/10.1016/j.agrformet.2018.12.015.
Jaiswal, R.K., S. Mukherjee, K.D. Raju, and R. Saxena. 2002. Forest fire risk zone mapping from satellite imagery and GIS. International Journal of Applied Earth Observation and Geoinformation 4 (1): 1–10. https://doi.org/10.1016/S0303-2434(02)00006-5.
Kalantar, B., N. Ueda, M.O. Idrees, S. Janizadeh, K. Ahmadi, and F. Shabani. 2020. Forest fire susceptibility prediction based on machine learning models with resampling algorithms on remote sensing data. Remote Sens 12: 3682.
Kim, S.J., C.-H. Lim, G.S. Kim, J. Lee, T. Geiger, O. Rahmati, et al. 2019. Multi-temporal analysis of forest fire probability using socio-economic and environmental variables. Remote Sens 11: 86.
Kuter, N., F. Yenilmez, and S. Kuter. 2011. Forest fire risk mapping by kernel density estimation. Croatian Journal of Forest Engineering: Journal for Theory and Application of Forestry Engineering 32 (2): 599–610.
Ljubomir, G., D. Pamučar, S. Drobnjak, and H.R. Pourghasemi. 2019. 15 - Modeling the spatial variability of forest fire susceptibility using geographical information systems and the analytical hierarchy process. In Spatial modeling in GIS and R for earth and environmental sciences, ed. H.R. Pourghasemi and C. Gokceoglu, 337–369. Elsevier. https://doi.org/10.1016/B978-0-12-815226-3.00015-6.
Lundberg, S.M., and S.-I. Lee. 2017. A unified approach to interpreting model predictions. In Advances in neural information processing systems. Curran Associates, Inc. Available: https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html. Accessed 14 Sept 2023.
Lyon, L.J., J.K. Brown, M.H. Huff, and J.K. Smith. 2000. Wildland fire in ecosystems: Effects of fire on fauna, 1–7. Ogden: U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station.
Maddy, E.S., and S.A. Boukabara. 2021. MIIDAPS-AI: An explainable machine-learning algorithm for infrared and microwave remote sensing and data assimilation preprocessing - application to LEO and GEO sensors. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 14: 8566–8576. https://doi.org/10.1109/JSTARS.2021.3104389.
Mangalathu, S., S.-H. Hwang, and J.-S. Jeon. 2020. Failure mode and effects analysis of RC members based on machine-learning-based SHapley Additive exPlanations (SHAP) approach. Engineering Structures 219: 110927. https://doi.org/10.1016/j.engstruct.2020.110927.
Martins A., and R. Astudillo. 2016. From softmax to sparsemax: A sparse model of attention and multi-label classification. In Proceedings of the 33rd international conference on machine learning, PMLR, 1614–1623. Available: https://proceedings.mlr.press/v48/martins16.html. Accessed 14 Sept 2023.
Multi-temporal analysis of forest fire probability using socio-economic and environmental variables. Remote Sensing. https://www.mdpi.com/2072-4292/11/1/86. Accessed 14 Sept 2023.
Naderpour, M., H.M. Rizeei, and F. Ramezani. 2021. Forest fire risk prediction: A spatial deep neural network-based framework. Remote Sensing 13 (13): 13. https://doi.org/10.3390/rs13132513.
Nami, M.H., A. Jaafari, M. Fallah, and S. Nabiuni. 2018. Spatial prediction of wildfire probability in the Hyrcanian ecoregion using evidential belief function model and GIS. International Journal of Environmental Science and Technology 15 (2): 373–384. https://doi.org/10.1007/s13762-017-1371-6.
Qayyum, F., M. Ali Khan, D.-H. Kim, H. Ko, and G.-A. Ryu. 2023. Explainable AI for Material Property Prediction Based on Energy Cloud: A Shapley-Driven Approach. Materials 16 (23): 7322.
Ribeiro, M.T., S. Singh, and C. Guestrin. 2016. Why should i trust you? Explaining the predictions of any classifier. In Proceedings of the 22nd ACMSIGKDD International Conference on Knowledge Discovery and Data Mining, 1135–1144.
Sayad, Y.O., H. Mousannif, and H. Al Moatassime. 2019. Predictive modeling of wildfires: A new dataset and machine learning approach. Fire Safety Journal 104: 130–146. https://doi.org/10.1016/j.firesaf.2019.01.006.
Schneider, L.C., and R. Gil Pontius. 2001. Modeling land-use change in the Ipswich watershed, Massachusetts, USA. Agriculture, Ecosystems & Environment 85 (1): 83–94. https://doi.org/10.1016/S0167-8809(01)00189-X.
Shrikumar, A., P. Greenside, and A. Kundaje. 2017. Learning important features through propagating activation differences. International Conference on Machine Learning. PMLR 3145–3153.
Shahfahad, Swapan Talukdar, Tanmoy Das, Mohd Waseem Naikoo, Mohd Rihan, and Atiqur Rahman. 2022. Forest fire susceptibility mapping by integrating remote sensing and machine learning algorithms. Advances in Remote Sensing for Forest Monitoring, 179–195. https://doi.org/10.1002/9781119788157.ch9.
Vasilakos, C., K. Kalabokidis, J. Hatzopoulos, and I. Matsinos. 2009. Identifying wildland fire ignition factors through sensitivity analysis of a neural network. Natural Hazards 50 (1): 125–143. https://doi.org/10.1007/s11069-008-9326-3.
‘Why should I trust you?’. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. https://dl.acm.org/doi/abs/10.1145/2939672.2939778. Accessed 14 Sept 2023.
Yoon, J., J. Jordon, and M. van der Schaar. 2018. INVASE: Instance-wise variable selection using neural networks. In Presented at the international conference on learning representations. Available: https://openreview.net/forum?id=BJg_roAcK7. Accessed 14 Sept 2023.
Zhongming, Z., L. Linong, Y. Xiaona, Z. Wangqiang, and L. Wei. 2020. The state of the world’s forests: Forests, biodiversity and people. Rome: FAO.
Acknowledgements
This work was supported by the University of Huddersfield. Faiza Qayyum and Harun Jamil contributed to this work equally.
Funding
No funding is used for this research.
Author information
Authors and Affiliations
Contributions
Contributions to this manuscript were made by all authors. All authors have read and approved the final manuscript. F.Q.: conceptualization, methodology, formal analysis, and drafting of the manuscript. H.J. and T.A.: conceptualization, methodology, formal analysis, funding, and revision of the manuscript. M.H.: conceptualization, methodology, formal analysis, and revision of the manuscript. F.Q., H.J., T.A., M.H.,: methodology and revision of the manuscript. All authors read and approved the final manuscript.
Authors’ information
Faiza Qayyum received the M.S. degree in computer science from the Capital University of Science and Technology (CUST), Islamabad, Pakistan, in 2017. She is currently pursuing the Ph.D. degree in computer engineering with Jeju National University (JNU), South Korea. Her research interests include machine learning, data mining, smart grid optimization, web mining, and information retrieval. She has been associated with academia, since the last 4 years, where she has been involved in preparing RD proposals and projects at national and international levels.
Harun Jamil received his B.Sc. degree in electronic engineering from the Capital University of Science and Technology, Islamabad, Pakistan, and the M.S.E.E. degree in electrical engineering from Air University, Islamabad, in 2019. He is currently pursuing a Ph.D. degree with the Department of Electronic Engineering, Jeju National University, Jeju-Si, South Korea. His research interests include indoor localization, data fusion techniques, nanogrids, energy optimization, and prediction.
Tariq Alsboui is a lecturer in Computing within the School of Computing and Engineering at the University of Huddersfield. He received his BSc in Internet Computing from Manchester Metropolitan University, UK in 2010, and his Ph.D. in Computer Science from the University of Huddersfield, UK in 2021. Tariq is a Fellow of the Higher Education Academy (FHEA). Tariq has authored several peer-reviewed International Journals and Conference papers. Tariq is a reviewer of high-impact-factor journals such as IEEE Access and IEEE Internet of Things Journal. His research interests are in the Internet of Things (IoT), distributed intelligence in IoT, distributed ledger technology, multi-agent systems, and wireless sensor networks.
Dr. Mohammad Hijjawi is an associate professor in computer science department in faculty of information technology at Applied Science private University (ASU). He received his PhD from Manchester Metropolitan University at UK in 2011. Dr. Mohammad has previous computing-based training in several domains. Also, he was an IT training manager for specialized training center in the ASU beside his work as an ASU Cisco academy manager and an authorized Cisco-based courses. Currently, Dr. Mohammad act as the faculty of information technology dean at ASU from Sep. 2015 beside his responsibilities according to the ASU’s committees.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1186/s42408-024-00313-8
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Qayyum, F., Jamil, H., Alsboui, T. et al. RETRACTED ARTICLE: Wildfire risk exploration: leveraging SHAP and TabNet for precise factor analysis. fire ecol 20, 10 (2024). https://doi.org/10.1186/s42408-023-00236-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s42408-023-00236-w