
Abstract
Background
Patients presenting with chest pain represent a large proportion of attendances to emergency departments. In these patients clinicians often consider the diagnosis of acute myocardial infarction (AMI), the timely recognition and treatment of which is clinically important. Clinical prediction models (CPMs) have been used to enhance early diagnosis of AMI. The Troponin-only Manchester Acute Coronary Syndromes (T-MACS) decision aid is currently in clinical use across Greater Manchester. CPMs have been shown to deteriorate over time through calibration drift. We aim to assess potential calibration drift with T-MACS and compare methods for updating the model.
Methods
We will use routinely collected electronic data from patients who were treated using TMACS at two large NHS hospitals. This is estimated to include approximately 14,000 patient episodes spanning June 2016 to October 2020. The primary outcome of acute myocardial infarction will be sourced from NHS Digital’s admitted patient care dataset. We will assess the calibration drift of the existing model and the benefit of updating the CPM by model recalibration, model extension and dynamic updating. These models will be validated by bootstrapping and one step ahead prequential testing. We will evaluate predictive performance using calibrations plots and c-statistics. We will also examine the reclassification of predicted probability with the updated TMACS model.
Discussion
CPMs are widely used in modern medicine, but are vulnerable to deteriorating calibration over time. Ongoing refinement using routinely collected electronic data will inevitably be more efficient than deriving and validating new models. In this analysis we will seek to exemplify methods for updating CPMs to protect the initial investment of time and effort. If successful, the updating methods could be used to continually refine the algorithm used within TMACS, maintaining or even improving predictive performance over time.
Trial registration
ISRCTN number: ISRCTN41008456
Similar content being viewed by others


Background
Chest pain accounts for approximately 6% of all Emergency Department (ED) attendances [1]. Despite recent advances in diagnostic technology and changes to national guidelines [2, 3], it remains the most common reason for emergency hospital admission in England and Wales [1]. These patients are frequently admitted to undergo diagnostic evaluation for suspected acute coronary syndrome (ACS). Improved diagnostic pathways could allow those without an ACS diagnosis (over 100,000 patients per year in England and Wales) to be discharged from the ED without an unnecessary hospital admission. Equally it is integral that we try to capture as many ACS diagnoses as we can, since a missed ACS infers twice the mortality of a detected ACS [4].
The Troponin-only Manchester Acute Coronary Syndromes (T-MACS) decision aid can be used to rapidly rule in, rule out and risk stratify patients with suspected ACS [5]. T-MACS was derived by logistic regression, using details of a patient's symptoms with electrocardiographic (ECG) findings and cardiac troponin (cTn) concentrations, measured on arrival at ED, to calculate the probability that a patient has ACS. T-MACS classified patients with <2% probability of ACS as being 'very low risk', in this population this strategy identified 40% of patients as eligible for safe, immediate discharge from the ED [5].
T-MACS has been externally validated in 1,459 patients from three prospective studies in the United Kingdom [5], 1,244 patients from Australasia [6], and multi-centre prospective trials from the United Kingdom [7], Thailand [8] and Norway [9], each of which demonstrated acceptable predictive performance. A pilot randomized controlled trial of a precursor version of the algorithm showed that its use led to significantly more safe discharges from the ED within 4 hours of arrival than standard care [10]. The data from UK studies (which did not rely on the use of surrogate variables) consistently show that over 40% of patients are categorised as very low risk and can have ACS ‘ruled out’ with one blood test. It has been shown to safely reduce unnecessary hospital admissions, outperforming the algorithms currently advocated in NICE guidelines [2, 11].
Countering calibration drift
However, the performance (calibration and discrimination) of many clinical prediction models, such as T-MACS, is likely to decline with time [12, 13]. For example, this has been demonstrated previously with the EuroScore model that predicts short-term mortality after cardiac surgery [14]. Therefore, the same phenomenon is likely to occur with the T-MACS algorithm as patient demographics change and diagnostic technology evolves. Indeed, the very fact that T-MACS is implemented in practice can lead to it losing diagnostic performance, since the implementation of the model changes the predictor-outcome associations and the case-mix, meaning that the performance of the model degrades over time [15, 16].
In part, the above issues with “calibration drift” can be attributed to the fact the algorithm itself is static, having been derived in one sample over a fixed time-period. It is unlikely to be the optimal algorithm for early diagnosis in various locations with diverse populations, due to the population and, possibly, intervention heterogeneity. This has been attempted previously with the EuroScore, which was shown to demonstrate calibration drift due to changing demographics [14]. Siregar et al investigated the merits of various methods through which to update such models [17]. They found many had a similar improvement on the clinical prediction models (regression co-efficient updating and dynamic updating).
Model updating and dynamic approaches to clinical prediction models
Statistical methods have previously been proposed to overcome issues such as calibration drift, by allowing prediction models to be re-derived and validated to maintain their predictive performance through time [18]. Such cycles of learning allow the models to account for demographic shifts and changes in diagnostic technology. This has several advantages over continuously re-developing the model de novo, as model updating utilises existing evidence (current versions of the model) and can potentially be delivered in almost real-time. Specifically, several different methods for updating clinical prediction models have been suggested [12, 18]; including regression coefficient updating, meta-model updating and dynamic updating. Regression coefficient updating only modifies individual coefficients within the model from a singular further analysis. Bayesian dynamic updating allows for continuous updating and derivation, once the method has been evaluated it can theoretically continuously re-derive with new data [19, 20]. Siregar et al’s analysis of dynamic updating suggested that a Bayesian approach may yield greater improvements in accuracy, when the sample is small [17]. Strobl et al [21] demonstrated that in updating prostate cancer risk assessment tools, there were also multiple methods that yielded similar improvement, with the exception of Random Forest regression (a machine learning form of dynamic updating) which was substantially worse than others.
In summary, T-MACS requires protection against calibration drift, and as such we aim to utilise prediction model updating methods to recalibrate it through time.
Here, we describe the protocol for the study that will deliver these objectives, in full accordance with the Transparent Reporting of the Predictive accuracy of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD) guidelines [22].
Methods
Study arm design and study setting
This will be a multi-centre retrospective cohort study. The study will use data collected from emergency departments at Manchester Royal Infirmary (MRI), Royal Blackburn Teaching Hospital (RBTH) and Burnley General Teaching Hospital (BGTH). MRI is a major trauma centre with 1,721 beds and an emergency department attendance of 104,449 in 2020, RBTH has 700 inpatient beds with an emergency department attendance of 104,009 in 2020 and BGTH has 219 beds and its urgent care centre has an annual attendance of 44,519. Each of these hospitals has implemented TMACS to guide the care of patients with suspected ACS.
Study population
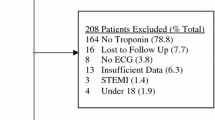
We will include patients who presented to the emergency department with chest pain and were assessed using the TMACS pathway since implementation at MRI, RBTH and BGTH. This is estimated to include approximately 14,000 patient episodes from June 2016 to October 2020.
Sample Size
We utilised the sample size calculation described by Riley et al [23] and also the rule of 10 primary outcome cases by variable used in similar logistic regression analyses. TMACS includes seven variables. As it is also planned to incorporate time, geographical location and the outcome of two alternative clinical prediction models (adding 8 variables), it is anticipated that the analysis will require a minimum of 170 cases in the training/optimization set. The prevalence of the primary outcome is 6.9% in the first 1,033 patients treated with TMACS. Based on that prevalence, a minimum of 2,464 patients would be required. This sample size was larger than that calculated by Riley et al, so we opted to be conservative and use the higher initial calculation [23].
Data Collection
This cohort will include patients who received routine care guided by TMACS, and whose data have been saved using bespoke interfaces deployed at Manchester Royal Infirmary (MRI), Royal Blackburn Teaching Hospital (RBTH) and Burnley General Teaching Hospital (BGTH). These tools are used in clinical practice and prospectively capture the data inputted by clinicians. This will be collated with data from local hospital servers to include: serial troponin assay results, and local diagnostic codes. This data will be cross-referenced with NHS Digital’s Hospital Episode Statistics (HES) database to include any diagnosis or intervention that occurs within 30 days of the index presentation. We will also link with the civil registry database for mortality outcomes.
Data Validation
Assuring the quality of the data is vital for the integrity of this study, particularly as we are collating multiple databases across multiple organisations. We will use the principles laid out by Weiskopf et al to assure the quality of the data [24] (see Table 1).
Outcome Variables
The primary outcome will be acute myocardial infarction (AMI) within 30 days. Patients will be considered to have a diagnosis of AMI if they have either a coded clinical diagnosis of AMI locally or held centrally with NHS Digital. Only primary ICD-10 codes will be used for the outcome, however a sensitivity analysis will be conducted where a code at any position is used. The relevant ICD-10 codes are: I21, I22, or I23 [25].. A secondary composite outcome of major adverse cardiovascular events within 30 days will also be measured including acute myocardial infarction, death (as per civil registry) and revascularisation. ICD-10 outcomes include I21, I22, I23, I46, R96, R99, K40-50, K63, and K75
The use of coded diagnoses is essential for the process to be automated in future. However, the effect of accepting these definitions must be carefully considered due to concerns over the limitations of the coding databases both centrally and locally. This will be explored by conducting data validation and the effect of the differing outcomes will be examined in sensitivity analyses. We will blind the adjudicators to the TMACS inputs and prediction.
In data validation we will examine the local coded diagnoses of any patients who had at least one cardiac concentration above the 99th percentile upper reference limit for the assay and an absolute change of at least half the 99th percentile on serial sampling (for samples drawn 3-6 hours apart). We will not examine patients with two (adequately timed) troponin concentrations within the normal range as they cannot fulfil the diagnosis of AMI. We will adjudicate outcomes by a central committee. AMI will be defined in accordance with the universal definition of myocardial infarction, which requires a rise and/or fall of cardiac troponin with at least one concentration above the 99th percentile upper reference limit of the assay. In addition, patients must have at least one of: symptoms compatible with myocardial ischaemia, ECG changes compatible with ischaemia, imaging evidence of new loss of viable myocardium or identification of intracoronary thrombus at coronary angiography. In the GM-TMACS project, initial implementation of TMACS will require all patients to have two cardiac troponin tests drawn 3 hours apart. Thus, all patients included in the analyses presented here will have an acceptable reference standard for the diagnosis of AMI according to national and international guidelines [2, 26]. Diagnoses will be adjudicated by two independent investigators with reference to all relevant clinical investigations. Disagreements will be resolved by consulting with a third independent investigator.
Analysis
The methodology optimising predictive performance for updating the TMACS algorithm will be identified from four candidate types. Predictive performance will be assessed by calibration plots, Brier scores, discrimination will be assessed with the c-statistic compared with DeLong’s method [27]. We will examine continuation of the current model (status quo), model recalibration, model revision, and Bayesian dynamic modelling [13, 18]. TMACS currently returns a probability of ACS, which is then used to classify patients into a categorical risk group (Eq 1 ). We will examine the re-classification of patients from the original TMACS algorithm and the dynamic modelling approach [28]. We will calculate the observed risk of the reclassified cases.
Equation [1] - The TMACS clinical prediction model. l = log-odds of the primary outcome acute myocardial infarction, xe = presence of ECG ischaemia, xa = crescendo angina, xr = paint radiating to the right arm, xv= pain associated with vomiting, xs = sweating observed, xh= hypotension, and xt = is high sensitivity troponin T result on arrival.
Status Quo
The current iteration of the TMACS algorithm will be validated with the existing co-efficient and intercept (from the derivation study). This will serve as a baseline for comparison, and we will use it to assess for evidence of change of discrimination and calibration over time (Eq 2).
Equation 2: The current iteration of the TMACS algorithm, where Zsq - the linear prediction of the current model, αTMACS - intercept and βi, TMACS previously derived regression coefficients.
Model recalibration
In this method we will recalibrate the TMACS algorithm with the entire dataset and apply an overall weight to the original algorithm and derive a new intercept, this is described in Eq. 3 [29]. This has been included as it is the simplest and has been used previously to updated CPMs [30].
Equation 3: Zmr - model updated by recalibration, \( \hat{\alpha} \) is the re-estimated intercept, \( \hat{\beta_o} \)the new overall calibration slope, and Zsq – is the linear prediction of the TMACS model.
Model extension
Additional variables will be considered for incorporation from other clinical prediction models that have been used for the same purpose (Eq. 4). These include predictors from the HEART score and Thrombolysis in Myocardial Infarction (TIMI) risk score [29, 30]. We will re-derive the algorithm with these covariates to investigate any improvement in diagnostic characteristics [18, 29]..
Equation 4: Ze - model updated by extension, βi are the original coefficients for the original covariables, s is the new covariates and \( {\hat{\beta}}_i \) their new coefficients.
Bayesian dynamic updating
Dynamic updating allows the original model’s intercepts and co-efficients to be updated after each patient episode, stabilising calibration and improving performance [12, 20]. This will be deployed incorporating guidance from our patient and public representatives. The representatives stated that if such a method were used then they felt that it initially ought to require human oversight. As such the initial updating will not be after each recorded patient episode instead it will be every three months for the first year to simulate a probationary period with quarterly meetings. After this period we will update the model after every patient episode. This is achieved through recursive estimation using the prediction equation
Where β is a dimensional vector of regression coefficients, Yt − 1 is a set of past outcomes, t is a given time and \( {R}_t=\raisebox{1ex}{${\hat{\sum}}_{t-1}$}\!\left/ \!\raisebox{-1ex}{${\lambda}_t$}\right. \). λt is known as the forgetting factor, which down-weights past observations by inflating the variance, and will be chosen in order to enable the sample size to continue to meet the specifications laid out by Riley et al [23].
When this is then taken into a Bayesian framework, the posterior is proportional to the product of the probability distribution at time t and t-1, giving
Validation
Model recalibration and model revision methods will be internally validated by using a bootstrap validation of 1000 samples. The dynamic updating methodologies will be internally validated with one-step a head prequential testing [13].
Ethics and dissemination:
This study has received ethical approval from a research ethics committee and the confidentiality advisory group (references 19/WA/0311, and 19/CAG/0209).
The study is registered on the ISRCTN number: ISRCTN41008456
First, we aim to publish our findings in peer reviewed journals. The primary target audience for the clinical study will be emergency medicine physicians, acute medicine physicians, cardiologists, clinical biochemists, public health professionals and industry leaders in acute diagnostics.
Further we will aim to present our findings at international and national conferences with relevant target audiences (e.g. European Society for Emergency Medicine Annual Congress, European Society of Cardiology Annual Conference, Royal College of Emergency Medicine Annual Scientific Conference). In addition, we will develop a public engagement strategy in conjunction with Public Programmes and our patient groups, in order that the local population have the opportunity to learn about our work and to engage with future work.
Discussion
We aim to recalibrate TMACS protecting the research investment of time and money, but potentially also improving it’s clinically efficacy. However, this method could be applied to any clinical prediction model, a plethora of which are deployed within emergency medicine. These range from the Well’s score for deep vein thrombosis to the Ottawa ankle score for fractures [31, 32]. These were all derived and then externally validated, but subsequently their upkeep stopped.
The recent focus of research has been the development and deployment of new clinical prediction models. Here we present a method that follows the paradigm shift in the focus of modelling research. The scientific community must adapt to an overly saturated environment of clinical prediction models [33, 34], part of the answer is assessing what already exists and seeking to protect and improve it . Not only is this an efficiency but it also recalibrates the community of clinical modelers to follow one of the central thesis of science, to build on the work of others [35].
Availability of data and materials
Due to data governance restrictions from the confidentiality advisory group and NHS Digital the sharing of data is not possible. However, requests to collaborate are welcome.
References
Publication, Part of Hospital Admitted Patient Care Activity, 2016-17 - NHS Digital. 2017. [Internet]. [cited 2017 Dec 11]. Available from: https://digital.nhs.uk/catalogue/PUB30098
Chest pain of recent onset: assessment and diagnosis | Guidance and guidelines | NICE. National Institute for Health and Care Excellence., 2010. CG95. Recent-Onset Chest Pain of Suspected Cardiac Origin: Assessment and Diagnosis. [Internet]. [cited 2017 Dec 11]. Available from: https://www.nice.org.uk/guidance/cg95
DG15, N.D.G., Myocardial infarction (acute): Early rule out using high-sensitivity troponin tests (Elecsys Troponin Thigh-sensitive, ARCHITECT STAT High Sensitive Troponin-I and AccuTnI+ 3 assays). 2014. National Institute forHealth and Care Excellence. https://www.nice.org.uk/guidance/dg15. [Accessed 13 Feb 2015].
Pope JH, Aufderheide TP, Ruthazer R, Woolard RH, Feldman JA, Beshansky JR, et al. Missed diagnoses of acute cardiac ischemia in the emergency department. N Engl J Med. 2000;342(16):1163–70. https://doi.org/10.1056/NEJM200004203421603.
Body R, Carlton E, Sperrin M, Lewis PS, Burrows G, Carley S, et al. Troponin-only Manchester Acute Coronary Syndromes (T-MACS) decision aid: single biomarker re-derivation and external validation in three cohorts. Emerg Med J. 2016. https://doi.org/10.1136/emermed-2016-205983.
Greenslade JH, Nayer R, Parsonage W, Doig S, Young J, Pickering JW, et al. Validating the Manchester Acute Coronary Syndromes (MACS) and Troponin-only Manchester Acute Coronary Syndromes (T-MACS) rules for the prediction of acute myocardial infarction in patients presenting to the emergency department with chest pain. Emerg Med J. 2017 Aug;34(8):517–23. https://doi.org/10.1136/emermed-2016-206366.
Body R, Morris N, Reynard C, Collinson PO. Comparison of four decision aids for the early diagnosis of acute coronary syndromes in the emergency department. Emerg Med J. 2020;37(1):8–13. https://doi.org/10.1136/emermed-2019-208898.
Ruangsomboon O, Thirawattanasoot N, Chakorn T, Limsuwat C, Monsomboon A, Praphruetkit N, et al. The utility of the 1-hour high-sensitivity cardiac troponin T algorithm compared with and combined with five early rule-out scores in high-acuity chest pain emergency patients. Int J Cardiol. 2020;322:23–8. https://doi.org/10.1016/j.ijcard.2020.08.099.
Steiro O-T, Tjora HL, Langørgen J, Bjørneklett R, Nygård OK, Skadberg Ø, et al. Clinical risk scores identify more patients at risk for cardiovascular events within 30 days as compared to standard ACS risk criteria: the WESTCOR study. Eur Heart J Acute Cardiovasc Care. 2020;10(3):287–301. https://doi.org/10.1093/ehjacc/zuaa016.
Body R, Boachie C, McConnachie A, Carley S, Van Den Berg P, Lecky FE. Feasibility of the Manchester Acute Coronary Syndromes (MACS) decision rule to safely reduce unnecessary hospital admissions: a pilot randomised controlled trial. Emerg Med J. 2017;34(9):586–92. https://doi.org/10.1136/emermed-2016-206148.
Carlton EW, Pickering JW, Greenslade J, Cullen L, Than M, Kendall J, et al. Assessment of the 2016 National Institute for Health and Care Excellence high-sensitivity troponin rule-out strategy. Heart. 2017;heartjnl-2017-311983.
Jenkins DA, Sperrin M, Martin GP, Peek N. Dynamic models to predict health outcomes: current status and methodological challenges. Diagnostic and Prognostic Research. 2018;2(1):1–9. https://doi.org/10.1186/s41512-018-0045-2.
Jenkins DA, Martin GP, Sperrin M, Riley RD, Debray TP, Collins GS, et al. Continual updating and monitoring of clinical prediction models: time for dynamic prediction systems? Diagnostic and Prognostic Research. 2021;5(1):1–7. https://doi.org/10.1186/s41512-020-00090-3.
Hickey GL, Grant SW, Murphy GJ, Bhabra M, Pagano D, McAllister K, et al. Dynamic trends in cardiac surgery: why the logistic EuroSCORE is no longer suitable for contemporary cardiac surgery and implications for future risk models. Eur J Cardiothorac Surg. 2013;43(6):1146–52. https://doi.org/10.1093/ejcts/ezs584.
Sperrin M, Jenkins D, Martin GP, Peek N. Explicit causal reasoning is needed to prevent prognostic models being victims of their own success. J Am Med Inform Assoc. 2019;26(12):1675–6. https://doi.org/10.1093/jamia/ocz197.
Lenert MC, Matheny ME, Walsh CG. Prognostic models will be victims of their own success, unless…. J Am Med Inform Assoc. 2019;26(12):1645–50.
Siregar S, Nieboer D, Vergouwe Y, Versteegh MIM, Noyez L, Vonk ABA, et al. Improved Prediction by Dynamic Modeling. Circ Cardiovasc Qual Outcomes. 2016;9(2):171–81. https://doi.org/10.1161/CIRCOUTCOMES.114.001645.
Su T-L, Jaki T, Hickey GL, Buchan I, Sperrin M. A review of statistical updating methods for clinical prediction models. Stat Methods Med Res. 2018;27(1):185–97. https://doi.org/10.1177/0962280215626466.
Raftery AE, Kárný M, Ettler P. Online prediction under model uncertainty via dynamic model averaging: Application to a cold rolling mill. Technometrics. 2010;52(1):52–66. https://doi.org/10.1198/TECH.2009.08104.
McCormick TH, Raftery AE, Madigan D, Burd RS. Dynamic logistic regression and dynamic model averaging for binary classification. Biometrics. 2012;68(1):23–30. https://doi.org/10.1111/j.1541-0420.2011.01645.x.
Strobl AN, Vickers AJ, Calster BV, Steyerberg E, Leach RJ, Thompson IM, et al. Improving patient prostate cancer risk assessment: Moving from static, globally-applied to dynamic, practice-specific risk calculators. J Biomed Inform. 2015;56:87–93. https://doi.org/10.1016/j.jbi.2015.05.001.
Moons KG, Altman DG, Reitsma JB, Ioannidis JP, Macaskill P, Steyerberg EW, et al. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): explanation and elaboration. Ann Intern Med. 2015;162(1):W1–73. https://doi.org/10.7326/M14-0698.
Riley RD, Snell KI, Ensor J, Burke DL, Harrell FE Jr, Moons KG, et al. Minimum sample size for developing a multivariable prediction model: PART II-binary and time-to-event outcomes. Stat Med. 2019;38(7):1276–96. https://doi.org/10.1002/sim.7992.
Weiskopf NG, Weng C. Methods and dimensions of electronic health record data quality assessment: enabling reuse for clinical research. J Am Med Inform Assoc. 2013;20(1):144–51. https://doi.org/10.1136/amiajnl-2011-000681.
Thygesen K, Alpert JS, Jaffe AS, Chaitman BR, Bax JJ, Morrow DA, et al. Fourth universal definition of myocardial infarction (2018). J Am Coll Cardiol. 2018;72(18):2231–64. https://doi.org/10.1016/j.jacc.2018.08.1038.
Roffi M, Patrono C, Collet J-P, Mueller C, Valgimigli M, Andreotti F, et al. 2015 ESC Guidelines for the management of acute coronary syndromes in patients presenting without persistent ST-segment elevation: Task Force for the Management of Acute Coronary Syndromes in Patients Presenting without Persistent ST-Segment Elevation of the European Society of Cardiology (ESC). Eur Heart J. 2016;37(3):267–315. https://doi.org/10.1093/eurheartj/ehv320.
DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. 1988;44(3):837–45. https://doi.org/10.2307/2531595.
Hippisley-Cox J, Coupland C, Brindle P. Development and validation of QRISK3 risk prediction algorithms to estimate future risk of cardiovascular disease: prospective cohort study. BMJ. 2017;357:j2099.
Steyerberg EW, Borsboom GJ, van Houwelingen HC, Eijkemans MJ, Habbema JDF. Validation and updating of predictive logistic regression models: a study on sample size and shrinkage. Stat Med. 2004;23(16):2567–86. https://doi.org/10.1002/sim.1844.
Sim J, Teece L, Dennis MS, Roffe C, SO□S Study Team. Validation and recalibration of two multivariable prognostic models for survival and independence in acute stroke. PLoS One. 2016;11(5):e0153527.
Stiell IG, Greenberg GH, McKnight RD, Nair RC, McDowell I, Worthington JR. A study to develop clinical decision rules for the use of radiography in acute ankle injuries. Ann Emerg Med. 1992;21(4):384–90. https://doi.org/10.1016/S0196-0644(05)82656-3.
Wells PS, Anderson DR, Rodger M, Ginsberg JS, Kearon C, Gent M, et al. Derivation of a simple clinical model to categorize patients probability of pulmonary embolism: increasing the models utility with the SimpliRED D-dimer. Thromb Haemost. 2000;83(03):416–20. https://doi.org/10.1055/s-0037-1613830.
Hemingway H, Riley RD, Altman DG. Ten steps towards improving prognosis research. BMJ. 2009;339(dec30 1):b4184. https://doi.org/10.1136/bmj.b4184.
Van Calster B, Wynants L, Riley RD, van Smeden M, Collins GS. Methodology over metrics: Current scientific standards are a disservice to patients and society. J Clin Epidemiol. 2021. https://doi.org/10.1016/j.jclinepi.2021.05.018.
Newton, I., 2019. Isaac Newton letter to Robert Hooke, 1675. HSP Discover. https://discover.hsp.org/Record/dc-9792/.
Acknowledgements
NA
Funding
Dr Charles Reynard has received funding from the National Institute for Health Research, the Royal College of Emergency medicine project grant and Manchester University NHS Foundation Trust grant.
The views expressed are those of the authors and not necessarily those of the NIHR or the Department of Health and Social Care
Professor Anthony Heagerty has received funding from the British Heart Foundation and the Ancestry and biological Informative Markers for stratification of Hypertension consortium.
Author information
Authors and Affiliations
Contributions
Concept: CR, RB, GM, EK. Design: CR, RB, GM, EK, DJ, AH, BM, AJ, RG, RB. Manuscript writing: CR, RB, GM, EK, DJ, AH, BM, AJ, RG, RB
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study has received ethical approval from a research ethics committee and the confidentiality advisory group (references 19/WA/0311, and 19/CAG/0209).
Consent for publication
As this is a retrospective study consent for publication was not possible
Competing interests
Professor Richard Body has consulted for Siemens, Roche, Beckman, Singulex, LumiraDx and Abbott
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Reynard, C., Martin, G.P., Kontopantelis, E. et al. Advanced cardiovascular risk prediction in the emergency department: updating a clinical prediction model – a large database study protocol. Diagn Progn Res 5, 16 (2021). https://doi.org/10.1186/s41512-021-00105-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s41512-021-00105-7