
Abstract
The data contained within the electronic health record (EHR) is “big” from the standpoint of volume, velocity, and variety. These circumstances and the pervasive trend towards EHR adoption have sparked interest in applying big data predictive analytic techniques to EHR data. Acute kidney injury (AKI) is a condition well suited to prediction and risk forecasting; not only does the consensus definition for AKI allow temporal anchoring of events, but no treatments exist once AKI develops, underscoring the importance of early identification and prevention. The Acute Dialysis Quality Initiative (ADQI) convened a group of key opinion leaders and stakeholders to consider how best to approach AKI research and care in the “Big Data” era. This manuscript addresses the core elements of AKI risk prediction and outlines potential pathways and processes. We describe AKI prediction targets, feature selection, model development, and data display.
Abrégé
Les données figurant dans les dossiers médicaux électroniques (DMÉ) sont considérables, tant au point de vue du volume que du débit ou de la variété. Ces trois caractéristiques et la tendance générale à adopter les DMÉ ont soulevé un intérêt pour appliquer les techniques d’analyse prédictive des mégadonnées aux données contenues dans les dossiers médicaux électroniques. L’insuffisance rénale aiguë (IRA) est une maladie qui convient parfaitement à une méthode de prévision et de prévention des risques: non seulement la définition acceptée de cette affection permet-elle un ancrage temporel des événements ; mais il n’existe aucun traitement une fois que la maladie est déclarée, ce qui montre l’importance d’une détection précoce. L’Acute Dialysis Quality Initiative (ADQI) a convoqué un groupe de travail constitué de leaders d’opinion et autres intervenants du milieu pour se pencher sur la meilleure façon d’approcher la recherche et les soins offerts aux patients atteints d’IRA en cette ère de mégadonnées. Le présent article traite des éléments centraux de la prévention des risques et en expose les procédures potentielles. Nous y décrivons les cibles de prévention de l’IRA, la sélection des paramètres, l’élaboration des modèles et l’affichage des données.
Similar content being viewed by others

Background
The term “big data” has traditionally been used to describe extraordinarily large and complex datasets. For many medical practitioners, this concept was initially epitomized by genomics – the colossal amount of discrete data generated by high throughput sequencing techniques required analytic methods ranging far beyond standard statistical approaches [1]. However, “omics” are now ubiquitous and “big data” has become vernacular in medicine [2, 3]. Clinical researchers are beginning to employ innovative, high-content analytic techniques capable of integrating and exploring the exceedingly large and diverse datasets contained within the electronic health record (EHR).
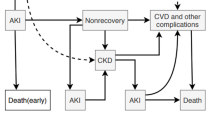
EHR data, which are generated through the routine provision of clinical care, are “big” from the standpoint of volume (number of discrete data points available), velocity (rate at which new data accumulates), and variety (myriad of data elements available for interrogation) [3, 4]. These aspects, along with its singular clinical relevance, make EHR data ideal for disease prediction and risk forecasting. In particular, acute kidney injury (AKI) is a syndrome which lends itself well to predictive modeling and early risk stratification (Fig. 1). The presence of a standard, consensus definition allows accurate and efficient AKI diagnosis [5]; temporal anchoring of the AKI event creates a distinct pre-disease dataset to which high-content, high-throughput predictive techniques can be applied (Fig. 1). Additionally, although AKI has been associated with poor short and long term outcomes in both adults and children, no treatments exist to mitigate or cure AKI once it has developed [6–13]. The ability to predict AKI in hospitalized patients would provide the opportunity to modify care pathways and implement interventions. This, in turn, could prevent AKI events, thereby reducing mortality, shortening length of stay, averting the development of chronic kidney disease, and potentially creating novel quality of care indicators [13, 14]. In this manuscript, we present evidence informed, consensus driven statements regarding the concepts of primary relevance when considering the capacity of EHR data to be used in AKI prediction applications.

Signal Identification for AKI Development and Progression. Current consensus AKI definitions allow AKI events to be precisely anchored from a temporal standpoint, clearly defining a pre-disease state. As the patient progresses from “No AKI” to “AKI,” the pattern of data generated within the EHR changes, creating an “AKI signal” which can be identified through advanced analytic techniques. This signal can be translated into a prediction model which is capable of identifying patients at high risk for AKI development. Reproduced with permission from ADQI
Methods
This consensus meeting following the established ADQI process, as previously described [15]. The broad objective of ADQI is to provide expert-based statements and interpretation of current knowledge for use by clinicians according to professional judgment and identify evidence care gaps to establish research priorities. The 15th ADQI Consensus Conference Chairs convened a diverse panel representing relevant disciplines from five countries from North America and Europe around the theme of “Acute Kidney Injury in the Era of Big Data” for a 2-day consensus conference in Banff, Canada on September 6–8, 2015. During the pre-conference phase of the meeting, each work group performed a comprehensive literature search to summarize areas where broad consensus exists, categorize knowledge gaps, and identify future priorities for research. Specifically for the AKI prediction workgroup, the literature search was conducted using the terms “acute kidney injury prediction”, “acute renal failure prediction”, and “AKI prediction” in MEDLINE using PUBMED as the search engine. This search yielded a total of 679 articles for review. Studies were limited to articles published in 2010–2015 to reflect more recent harmonized AKI definitions. Studies were included if they discussed a prediction model and did not isolate the analysis to identification of independent risk factors. Studies were excluded if the focus of the prediction model was novel biomarkers due to practical issues in using these markers in current clinical practice. Thirty-four articles were selected in the initial review. Upon reviewing the articles, there was a consensus amongst work group members to include seven additional articles published prior to 2010; these articles used earlier consensus definitions for AKI, laid the groundwork for the subsequently developed models, and were archetype models when published [16–22]. Four core questions/concepts were crafted for presentation to the entire ADQI consensus group during the conference (Table 1). During the conference our work group developed consensus positions, and plenary sessions involving all ADQI contributors were used to present, debate, and refine these positions. Following the conference this summary report was generated, revised, and approved by all members of the work group.
Results
Question 1: Across the spectrum of AKI, which event or events should be targeted for prediction?
Prior to developing a model, it is important to carefully choose the target for prediction. From the outset, the consensus group believed it was imperative that, for the purposes of prediction, AKI be diagnosed and identified according to the generally accepted consensus definition and classification scheme, the KDIGO criteria [5]. This is the most current consensus definition, it harmonizes the previously proposed AKI criteria (RIFLE, pRIFLE, and AKIN), and is applicable to both adults and children [5, 23–25]. In order to build the strongest and most useful predictive model, we would recommend forecasting AKI events with a horizon of 48–72 h. While it would be advantageous to identify AKI events as early as possible, lengthening the event horizon reduces the accuracy of the model; we believe the suggested horizon gives practitioners adequate time to modify practice, optimize hemodynamics, and mitigate potential injury without sacrificing predictive power. The group additionally believed that rather than targeting all AKI, it would be initially advantageous to predict “moderate/severe” AKI as defined as KDIGO stage 2 or 3. While this recommendation is based on evidence-informed opinion, there are rational justifications for making it. First, this is consistent with the initial ADQI consensus statement which described the RIFLE criteria; operationally, Stage 1 KDIGO-defined AKI correlates with RIFLE stage “Risk” [24]. Treating KDIGO-defined Stage 1 AKI as “AKI risk,” allows it to become a subsequent predictor for moderate/severe AKI. Second, AKI predictors or risk factors have traditionally been more strongly associated with higher severity AKI [26, 27]. The greater strength of association will likely result in more powerful predictive modeling by reducing confounding; the development of robust models is of paramount importance for these initial big data attempts at predictive AKI analytics. Finally, while “mild” Stage 1 AKI has been associated with poorer outcomes, the association with these outcomes is significantly stronger for Stages 2/3 [6, 11, 27–31]. This ability to strongly link AKI with outcomes has an additional benefit as it will allow the models to predict not only AKI, but AKI-related outcomes as well. In one potential scenario proposed by the workgroup, a model would provide predictive AKI risk up until the occurrence of AKI then, at the inflection point of AKI development, it would provide a one-time predictive risk for patient-centered, clinically important outcomes. The workgroup acknowledges that if only Stage 2 and 3 AKI are targeted for prediction, early simulative subanalysis should be performed to evaluate the suitability of this approach.
Consensus Statement
For the purpose of developing AKI prediction models using the data contained within the EHR, the prototype should predict risk both for developing KDIGO-defined Stage 2/3 AKI as well as patient-centered and clinically important AKI-related outcomes.
Question 2: For the purposes of predictive modelling, what paradigm should be used for variable identification and selection?
Prior to applying “big data” analytics to AKI prediction, the consensus group believed it was important to appraise the AKI prediction models which had been developed to date. Based upon our predictive goals outlined in the prior section, model variables of particular interest would be causally and/or temporally associated both with the development of AKI and with AKI-related outcomes.
A number of investigators have approached AKI prediction using standard multivariable regression methodology [17–22, 32, 33]. Models have been developed for a variety of patient populations with a particular emphasis on cardiac surgery patients [34, 35]; notably, less work has been performed in general critical care populations despite the fact that they are also at high risk for AKI [36–38]. Even less established are prediction models in non-critically ill patients. However, given the ultimate goal of preventing AKI, we also need to consider predictive modeling in these populations in order to identify high-risk patients as early as possible [39, 40]. A fairly comprehensive list of studies and variables are shown in Table 2. Variables from patient-specific models are often constrained to the clinical care specific to that population; for example, models for cardiac surgery patients include cardiopulmonary bypass time and number of bypass grafts. However, a number of variables commonly appear across many of the existing models (i.e., age, baseline renal function, medications, diabetes, hypertension, etc.); these variables may be better suited for a generalized model. Most models had modest predictive success with area under the receiver operating curves (AUC) approximating 0.75; a few models reached AUCs as high as 0.9, although the sample sizes were smaller and there was a pre-selection of high-risk patients [41–44]. Regardless of their ultimate utility in defining predictive variables, these models give us a minimum AUC threshold to target for successful model development.
As stated, ideal variables would be associated with both the development of AKI and patient centered, clinically important outcomes following AKI. Notably, many of the same risk factors described in Table 2 as predicting AKI occurrence have also been shown to predict AKI-associated mortality [36, 45–51]. In addition to these factors, positive fluid balance has been associated with increased mortality in both pediatric and adult patients with AKI [52–56]. Receipt of renal replacement therapy (RRT) is another outcome worth forecasting after AKI has occurred. Although most of the published clinical scores predicting receipt of RRT have focused on post-cardiac surgery patients, they have identified many of the same predictors for AKI occurrence in broader populations [17, 19, 32, 34]. AKI is known to be associated with the development of CKD and ESRD, therefore, prediction of these long-term outcomes among AKI survivors should also be targeted; archetype variables associated with these outcomes are shown in Table 2 [8, 57–68].
While the group believed it was imperative that previously identified AKI predictors be reviewed, to truly harness the power of the EHR a de novo approach which considers the entirety of the dataset is required (Fig. 2). There are a number of potential data-mining, machine learning approaches to this sort of feature selection which could be used alone or in combination (Table 3). One method, neural networks, employ non-linear models that feed a set of predictors (inputs) into a hidden layer of units which then use a non-linear transformation to send a value to an output; the prediction is a summation of all the values coming from the hidden layer [69]. This non-linear technique is sometimes described as a “black box” method since it’s difficult to determine the form of the final predictive model. However, this is of little concern in feature selection, as identifying the group of the most influential variables is of interest. A second potential method is that of random forests which is an extension of the binary split classification tree approach [70, 71]. Multiple trees are created by allowing a random number of the predictor variables to be considered at each split of each tree. This results in trees that cover a larger solution space, potentially increasing accuracy. Another set of methods is cluster analysis, a group of unsupervised learning techniques. Observations are grouped according to their similarities in a multidimensional space, based on a distance measure [72]. The resultant clusters can then be further explored to see which ones have a very high or a very low incidence of the outcome measure. A similar method is a technique known as self-organizing maps, in which unsupervised neural networks map a highly dimensional space onto a two-dimensional map [73, 74]. Principal components analysis and support vector machines are two similar feature selection methods which could be employed in this space [75, 76]. Although this is not a comprehensive list of the methods that might be considered, these are excellent exemplar techniques which can be used to identifying novel features and transform known risk factors.

Development of AKI Prediction Algorithm. The first step in the development of an AKI prediction model is feature selection. This process would evaluate known risk factors identified from the literature and would use machine learning techniques to identify novel risk factors from amongst the EHR dataset. All appropriate features would be considered for inclusion in the actual prediction model which would weight individual variables to create a generalizable model. This model would be validated using a different (or subset of existing) dataset. Once validated, the model could then be integrated directly into the EHR to allow real time AKI alerting. Reproduced with permission from ADQI
In summary, the suggested approach highlights our belief that accurate prediction of AKI takes precedence over finding putative variables, though the suggested approaches do not preclude discovery of new risk factors for AKI. Additionally, while it is useful to review previously established variables associated with AKI from existing studies, application of high content, machine learning techniques to the complete EHR dataset will be the driving force behind variable selection. The ability to dynamically identify and integrate variables from amongst innumerable patient-level data elements represents a marked departure from classically developed model building approaches.
Consensus Statement
Variables included in prototype AKI prediction models should be identified using a hybrid approach; risk factors which are well established in the literature should be considered along with novel risk factors identified via machine learning techniques. Application of these unsupervised approaches should take precedence as it allows feature selection to be dynamic, thereby generating the strongest prediction from existing data elements.
Question 3: What is the optimal approach for model building and EHR integration?
Once the aforementioned hybrid variable selection process was complete, previously identified risk factors and potential predictors discovered via big data techniques could be considered for inclusion in a model. Inclusion criteria could include:
-
1.
Evidence over multiple studies that the risk factor was a powerful predictor of AKI
-
2.
Identification by machine learning techniques to be predictive of AKI and outcomes
-
3.
Available discretely within the EHR to allow easy integration
-
4.
Reliably/accurately recorded within the EHR
Variables need not necessarily be universal. For example, pediatric or ICU specific variables could be considered; the model could be dynamic with certain features active/inactive in certain locations/populations. Additionally, it is possible that effect modification of the variables could vary between patients or populations; the presence or absence of certain variables might change the weighting of the residual variables.
While we advocate for a big data approach to identify novel predictive features, initially we would recommend that the predictive model itself be built through more standard statistical modelling. This is primarily due to the inherent limitations of current EHR architecture. EHRs are built to optimize patient level data review and display; they are not necessarily organized to optimize cohort level analysis [77]. This makes implementation of a resource-intense machine learning algorithm into the EHR itself technically and operationally problematic. Therefore, once the variables were identified by literature search and machine learning methodology, it is likely that a logistic regression model, discriminant analysis, or decision tree algorithm would be employed to predict the development of AKI [71, 78, 79]. Data could accumulate on a “rolling window” concept and a prediction could be generated at a pre-specified interval (hourly, every two hours, every shift); alternatively, the model could generate a score in real time as each new data value is received. One conceptual approach would allow this model to generate a risk score ranging from 0 to 100; low scores would be indicative of minimal AKI risk and high scores would be indicative of significant AKI risk. Scoring on a continuous scale would allow both low and high thresholds to be set. In many ways, the ability to identify patients at negligible AKI risk could be as valuable as identifying patients at great AKI risk. An algorithm such as this could be active up until the time the patient develops AKI. At that inflection point, a final, one-time score could be generated which would be reflective of the patients AKI-related outcome risk, thereby allowing practitioners to identify patients at great risk for poorer outcomes.
It is important to note that while the EHR has operational and structural limitations to the application of big data techniques, alternatives should be available in the future. For example, many clinical data warehouse (CDW) solutions have become available for analytic purposes [80–83]. These CDWs represent “shadow” EHRs in which data has been manipulated, linked, and stored in a fashion conducive to high-content, high-throughput analytics [82, 83]. Once such CDWs become as ubiquitous as EHRs, big data approaches could be applied directly to the CDW environment. However, to truly exploit the full capacity of the EHR and EHR data, a more progressive approach is necessary. The EHR has transcended its original purpose; although it is currently a care monitoring and delivery tool, it has the potential to revolutionize clinical care paradigms. To achieve this, data architecture must become as important as data entry and analytics must be prioritized. The creation of a true “learning EHR” could be the key to higher quality, lower cost care delivered with greater efficacy and efficiency.
Consensus Statement
While machine learning techniques should be used to identify novel AKI risk factors, prototype AKI prediction models should be built using more standard statistical weighing techniques to allow effective EHR integration. However, analytics should attain higher priority and the operational limitations of the EHR should be addressed. Consequently, subsequent predictive iterations should progress towards full EHR-integration of high content analytic techniques.
Question 4: What is the optimal output of an archetype predictive model?
After the rigorous steps undertaken to select variables and develop a predictive model, we propose that any prototypes be directly integrated into the EHR for automated real time usage. The increasingly widespread use of EHRs across hospitals has substantially increased the amount of data available to providers [84]. However, while EHRs purportedly improve patient outcomes, studies that have validated these benefits are lacking [85–87]. Several potential EHR-related barriers to improving outcomes have been identified and include information overload, ineffective data display, and poor implementation processes [88–90] Therefore, it is imperative that an AKI prediction model not only harness the power of the EHR data set, but also that it effectively conform to the strengths and limitations of EHR processes. Ideally, AKI risk prediction tools should directly extract relevant data predictors in real-time, deliver a relevant “renal risk score,” and provide feedback to practitioners regarding potential actionable items. One potential a concept would be to create a “renal dashboard” (Fig. 3a and b).

a and b Renal Dashboard. Once the risk prediction model is developed and validated, it is important to determine how to deliver the information to providers. One possible output might be a “Renal Dashboard” (a). The display would visually display the time trend of AKI as well as a numeric value (with confidence intervals) for the current risk. For any patients who develop AKI, information about outcome risk would be provided; in this example, the outcomes of interest are need for RRT, mortality, development of ESRD, and likelihood of renal recovery. The dashboard could be dynamic, allowing providers to drill into the risk score. In the patient level display (b), information would be available about how the risk had trended over the past 24 h as well as what factors were affecting the current risk score most significantly. In this example, AKI risk information is provided in a visually stimulating manner with a dynamic component capable of driving care modification. Reproduced with permission from ADQI
The main objective of the renal dashboard would be to provide feedback on the absolute risk of developing moderate to severe AKI within the next 48–72 h as well as to present information about the clinical features contributing to these risks. The electronic dashboard format could be tailored for a particular provider, service, or unit. Each patient could have a risk score (in percentage) with an accompanying confidence interval (Fig. 3a); a confidence interval component would give practitioners an idea of how certain the AKI risk was at any given time. In addition to absolute risk scores, the dashboard could be configured to display time trends in risk scores which might give a better sense of evolving AKI risk. Time trends should be displayed in a visually stimulating fashion (i.e., sparklines) to demonstrate the dynamic nature of real-time AKI-risk. A fully optimized dashboard might allow providers to “drill into” the risk score (Fig. 3b), revealing a magnified view as well as more detailed data on the most recent predictors that contributed to a significant increase in risk score. The identification of specific vital sign indicators, laboratory parameters, medication administration data, or other clinical factors that contributed directly to a rise in AKI risk will help guide providers toward implementing risk reduction actions.
A secondary objective of the dashboard might be to provide updated feedback on the risk of adverse outcomes associated with AKI once it actually develops. Early iterations of this sort of prototype may be limited to one-time scores for AKI-related outcomes. However, at the inflection of AKI development, separate risk scores for mortaltiy, receipt of RRT, CKD, and renal recovery could be provided. As an example, the ability to predict receipt of RRT may help providers plan for appropriate patient disposition (i.e., transfer to ICU for CRRT) and timely procedures (i.e., placement of dialysis catheter). Prediction of long-term renal and cardiovascular outcomes could be especially useful at the time of discharge, facilitating appropriate referrals, vascular access planning, and long-term care goal discussions.
We anticipate that a renal dashboard such as this could be displayed either directly within the system or independently from the EHR platform. Although information would be directly fed to the prediction model from up-to-date EHR data, each healthcare system, service, or unit may tailor the physical setting of the dashboard display to fit their workflows. For example, in an ICU setting where incidence of AKI may be as high as 40 %, the renal dashboard may be displayed on computerized workstations on wheels so that providers can incorporate the real-time information and feedback provided by the renal dashboard into their multi-disciplinary rounds [31]. For other services and locations where incidence of AKI is much lower - for example, the labor and delivery unit - the renal dashboard may serve in a more adjunctive role, to be monitored by a specialized “renal response” team (akin to traditional “rapid response” teams).
The consensus group acknowledges that numerous such dashboards could be created for similar medical conditions to assist with risk stratification. The approach described in this manuscript is designed to underscore the utility of a dashboard scheme. We realize that developing multiple dashboards for individualized diseases is unlikely to be efficient or effective in the long run. Operationally, a superior approach would be to seamlessly integrate a renal dashboard component into existing dashboard which is used to evaluate a range of quality and performance indicators.
Consensus Statement
The output from predictive models should be delivered to practitioners in a fashion that is cognizant of EHR limitations and strengths, minimizes workflow inefficiency, and maximizes utility.
Conclusion
The EHR dataset is a massive collection of clinically relevant data elements generated through the routine provision of patient care. Its size and complexity lend themselves to “big data” techniques; these in turn offer the potential to use the entire EHR dataset to predict AKI and AKI related outcomes. Variable selection should employ high-content, unsupervised analytic techniques. Developing predictive models should focus on EHR integration and optimize the output for clinical utility.
Abbreviations
- AKI:
-
acute kidney injury
- KDIGO:
-
Kidney Disease: Improving Global Outcomes
- RIFLE:
-
Risk, Injury, Failure, Loss, ESRD
- AKIN:
-
Acute kidney injury network
- ADQI:
-
Acute Dialysis Quality Initiative
- EHR:
-
Electronic health record
References
Schadt EE, Linderman MD, Sorenson J, Lee L, Nolan GP. Computational solutions to large-scale data management and analysis. Nature reviews Genetics. 2010;11(9):647–57. doi:10.1038/nrg2857.
Berger B, Peng J, Singh M. Computational solutions for omics data. Nature reviews Genetics. 2013;14(5):333–46. doi:10.1038/nrg3433.
Baro E, Degoul S, Beuscart R, Chazard E. Toward a Literature-Driven Definition of Big Data in Healthcare. BioMed research international. 2015;2015:639021. doi:10.1155/2015/639021.
Wang W, Krishnan E. Big data and clinicians: a review on the state of the science. JMIR medical informatics. 2014;2(1):e1. doi:10.2196/medinform.2913.
Kidney Disease. Improving Global Outcomes (KDIGO) Acute Kidney Injury Work Group. KDIGO Clinical Practice Guideline for Acute Kidney Injury. Kidney international. 2012;2:1–138.
Sutherland SM, Byrnes JJ, Kothari M, Longhurst CA, Dutta S, Garcia P, et al. AKI in hospitalized children: comparing the pRIFLE, AKIN, and KDIGO definitions. Clin J Am Soc Nephrol. 2015;10(4):554–61. doi:10.2215/cjn.01900214.
Sutherland SM, Ji J, Sheikhi FH, Widen E, Tian L, Alexander SR, et al. AKI in hospitalized children: epidemiology and clinical associations in a national cohort. Clin J Am Soc Nephrol. 2013;8(10):1661–9. doi:10.2215/CJN.00270113.
Mammen C, Al Abbas A, Skippen P, Nadel H, Levine D, Collet JP, et al. Long-term risk of CKD in children surviving episodes of acute kidney injury in the intensive care unit: a prospective cohort study. Am J Kidney Dis. 2012;59(4):523–30. doi:10.1053/j.ajkd.2011.10.048.
Askenazi DJ, Feig DI, Graham NM, Hui-Stickle S, Goldstein SL. 3–5 year longitudinal follow-up of pediatric patients after acute renal failure. Kidney Int. 2006;69(1):184–9. doi:10.1038/sj.ki.5000032.
Alkandari O, Eddington KA, Hyder A, Gauvin F, Ducruet T, Gottesman R, et al. Acute kidney injury is an independent risk factor for pediatric intensive care unit mortality, longer length of stay and prolonged mechanical ventilation in critically ill children: a two-center retrospective cohort study. Crit Care. 2011;15(3):R146. doi:10.1186/cc10269.
Chertow GM, Burdick E, Honour M, Bonventre JV, Bates DW. Acute kidney injury, mortality, length of stay, and costs in hospitalized patients. Journal of the American Society of Nephrology : JASN. 2005;16(11):3365–70. doi:10.1681/asn.2004090740.
Chawla LS, Eggers PW, Star RA, Kimmel PL. Acute kidney injury and chronic kidney disease as interconnected syndromes. N Engl J Med. 2014;371(1):58–66. doi:10.1056/NEJMra1214243.
Khwaja A. KDIGO Clinical Practice Guidelines for Acute Kidney Injury. Nephron Clin Pract. 2012;120(4):179–84. doi:10.1159/000339789.
Ftouh S, Lewington A. Prevention, detection and management of acute kidney injury: concise guideline. Clinical medicine (London, England). 2014;14(1):61–5. doi:10.7861/clinmedicine.14-1-61.
Kellum JA, Bellomo R, Ronco C. Acute Dialysis Quality Initiative (ADQI): methodology. The International journal of artificial organs. 2008;31(2):90–3.
Mehta RH, Grab JD, O'Brien SM, Bridges CR, Gammie JS, Haan CK, et al. Bedside tool for predicting the risk of postoperative dialysis in patients undergoing cardiac surgery. Circulation. 2006;114(21):2208–16. doi:10.1161/circulationaha.106.635573.
Thakar CV, Arrigain S, Worley S, Yared JP, Paganini EP. A clinical score to predict acute renal failure after cardiac surgery. Journal of the American Society of Nephrology : JASN. 2005;16(1):162–8. doi:10.1681/asn.2004040331.
Palomba H, de Castro I, Neto AL, Lage S, Yu L. Acute kidney injury prediction following elective cardiac surgery: AKICS Score. Kidney Int. 2007;72(5):624–31. doi:10.1038/sj.ki.5002419.
Wijeysundera DN, Karkouti K, Dupuis JY, Rao V, Chan CT, Granton JT, et al. Derivation and validation of a simplified predictive index for renal replacement therapy after cardiac surgery. Jama. 2007;297(16):1801–9. doi:10.1001/jama.297.16.1801.
Brown JR, Cochran RP, Leavitt BJ, Dacey LJ, Ross CS, MacKenzie TA, et al. Multivariable prediction of renal insufficiency developing after cardiac surgery. Circulation. 2007;116(11 Suppl):I139–43. doi:10.1161/circulationaha.106.677070.
Aronson S, Fontes ML, Miao Y, Mangano DT. Risk index for perioperative renal dysfunction/failure: critical dependence on pulse pressure hypertension. Circulation. 2007;115(6):733–42. doi:10.1161/circulationaha.106.623538.
Mehran R, Aymong ED, Nikolsky E, Lasic Z, Iakovou I, Fahy M, et al. A simple risk score for prediction of contrast-induced nephropathy after percutaneous coronary intervention: development and initial validation. Journal of the American College of Cardiology. 2004;44(7):1393–9. doi:10.1016/j.jacc.2004.06.068.
Mehta RL, Kellum JA, Shah SV, Molitoris BA, Ronco C, Warnock DG, et al. Acute Kidney Injury Network: report of an initiative to improve outcomes in acute kidney injury. Crit Care. 2007;11(2):R31. doi:10.1186/cc5713.
Bellomo R, Ronco C, Kellum JA, Mehta RL, Palevsky P. Acute Dialysis Quality Initiative w. Acute renal failure - definition, outcome measures, animal models, fluid therapy and information technology needs: the Second International Consensus Conference of the Acute Dialysis Quality Initiative (ADQI) Group. Crit Care. 2004;8(4):R204–12. doi:10.1186/cc2872.
Akcan-Arikan A, Zappitelli M, Loftis LL, Washburn KK, Jefferson LS, Goldstein SL. Modified RIFLE criteria in critically ill children with acute kidney injury. Kidney Int. 2007;71(10):1028–35. doi:10.1038/sj.ki.5002231.
Kristovic D, Horvatic I, Husedzinovic I, Sutlic Z, Rudez I, Baric D, et al. Cardiac surgery-associated acute kidney injury: risk factors analysis and comparison of prediction models. Interactive cardiovascular and thoracic surgery. 2015;21(3):366–73. doi:10.1093/icvts/ivv162.
Leedahl DD, Frazee EN, Schramm GE, Dierkhising RA, Bergstralh EJ, Chawla LS, et al. Derivation of urine output thresholds that identify a very high risk of AKI in patients with septic shock. Clin J Am Soc Nephrol. 2014;9(7):1168–74. doi:10.2215/cjn.09360913.
Zeng X, McMahon GM, Brunelli SM, Bates DW, Waikar SS. Incidence, outcomes, and comparisons across definitions of AKI in hospitalized individuals. Clin J Am Soc Nephrol. 2014;9(1):12–20. doi:10.2215/CJN.02730313.
Basu RK, Zappitelli M, Brunner L, Wang Y, Wong HR, Chawla LS, et al. Derivation and validation of the renal angina index to improve the prediction of acute kidney injury in critically ill children. Kidney Int. 2014;85(3):659–67. doi:10.1038/ki.2013.349.
Kandler K, Jensen ME, Nilsson JC, Moller CH, Steinbruchel DA. Acute kidney injury is independently associated with higher mortality after cardiac surgery. Journal of cardiothoracic and vascular anesthesia. 2014;28(6):1448–52. doi:10.1053/j.jvca.2014.04.019.
Hoste EA, Bagshaw SM, Bellomo R, Cely CM, Colman R, Cruz DN, et al. Epidemiology of acute kidney injury in critically ill patients: the multinational AKI-EPI study. Intensive Care Med. 2015;41(8):1411–23. doi:10.1007/s00134-015-3934-7.
Mehta RH, Grab JD, O'Brien SM, Bridges CR, Gammie JS, Haan CK, et al. Bedside tool for predicting the risk of postoperative dialysis in patients undergoing cardiac surgery. Circulation. 2006;114(21):2208–16. doi:10.1161/CIRCULATIONAHA.106.635573.
Fortescue EB, Bates DW, Chertow GM. Predicting acute renal failure after coronary bypass surgery: cross-validation of two risk-stratification algorithms. Kidney Int. 2000;57(6):2594–602. doi:10.1046/j.1523-1755.2000.00119.x.
Englberger L, Suri RM, Li Z, Dearani JA, Park SJ, Sundt TM, et al. Validation of clinical scores predicting severe acute kidney injury after cardiac surgery. Am J Kidney Dis. 2010;56(4):623–31. doi:10.1053/j.ajkd.2010.04.017.
Kiers HD, van den Boogaard M, Schoenmakers MC, van der Hoeven JG, van Swieten HA, Heemskerk S, et al. Comparison and clinical suitability of eight prediction models for cardiac surgery-related acute kidney injury. Nephrol Dial Transplant. 2013;28(2):345–51. doi:10.1093/ndt/gfs518.
Uchino S, Kellum J, Bellomo R, Doig G, Morimatsu H, Morgera S, et al. Acute renal failure in critically ill patients: a multinational, multicenter study. Jama. 2005;294(7):813–8. doi:10.1001/jama.294.7.813..
Chawla LS, Davison DL, Brasha-Mitchell E, Koyner JL, Arthur JM, Shaw AD, et al. Development and standardization of a furosemide stress test to predict the severity of acute kidney injury. Crit Care. 2013;17(5):R207. doi:10.1186/cc13015.
Kane-Gill SL, Sileanu FE, Murugan R, Trietley GS, Handler SM, Kellum JA. Risk factors for acute kidney injury in older adults with critical illness: a retrospective cohort study. Am J Kidney Dis. 2015;65(6):860–9. doi:10.1053/j.ajkd.2014.10.018.
Forni LG, Dawes T, Sinclair H, Cheek E, Bewick V, Dennis M, et al. Identifying the patient at risk of acute kidney injury: a predictive scoring system for the development of acute kidney injury in acute medical patients. Nephron Clin Pract. 2013;123(3–4):143–50. doi:10.1159/000351509.
Soto K, Papoila AL, Coelho S, Bennett M, Ma Q, Rodrigues B, et al. Plasma NGAL for the diagnosis of AKI in patients admitted from the emergency department setting. Clin J Am Soc Nephrol. 2013;8(12):2053–63. doi:10.2215/CJN.12181212.
Medha S. A, Pandey RM, Sawhney C, Upadhayay AD, Albert V. Incidence, clinical predictors and outcome of acute renal failure among North Indian trauma patients. J Emerg Trauma Shock. 2013;6(1):21–8. doi:10.4103/0974-2700.106321.
Meersch M, Schmidt C, Van Aken H, Martens S, Rossaint J, Singbartl K, et al. Urinary TIMP-2 and IGFBP7 as early biomarkers of acute kidney injury and renal recovery following cardiac surgery. PLoS One. 2014;9(3), e93460. doi:10.1371/journal.pone.0093460.
Kim JM, Jo YY, Na SW, Kim SI, Choi YS, Kim NO, et al. The predictors for continuous renal replacement therapy in liver transplant recipients. Transplant Proc. 2014;46(1):184–91. doi:10.1016/j.transproceed.2013.07.075.
Demirjian S, Schold JD, Navia J, Mastracci TM, Paganini EP, Yared JP, et al. Predictive models for acute kidney injury following cardiac surgery. Am J Kidney Dis. 2012;59(3):382–9. doi:10.1053/j.ajkd.2011.10.046.
Demirjian S, Chertow GM, Zhang JH, O'Connor TZ, Vitale J, Paganini EP, et al. Model to predict mortality in critically ill adults with acute kidney injury. Clin J Am Soc Nephrol. 2011;6(9):2114–20. doi:10.2215/CJN.02900311.
Chertow GM, Soroko SH, Paganini EP, Cho KC, Himmelfarb J, Ikizler TA, et al. Mortality after acute renal failure: models for prognostic stratification and risk adjustment. Kidney Int. 2006;70(6):1120–6. doi:10.1038/sj.ki.5001579.
Mehta RL, Pascual MT, Gruta CG, Zhuang S, Chertow GM. Refining predictive models in critically ill patients with acute renal failure. Journal of the American Society of Nephrology : JASN. 2002;13(5):1350–7.
Lins RL, Elseviers M, Daelemans R, Zachée P, Gheuens E, Lens S, et al. Prognostic value of a new scoring system for hospital mortality in acute renal failure. Clin Nephrol. 2000;53(1):10–7.
Lins RL, Elseviers MM, Daelemans R, Arnouts P, Billiouw JM, Couttenye M, et al. Re-evaluation and modification of the Stuivenberg Hospital Acute Renal Failure (SHARF) scoring system for the prognosis of acute renal failure: an independent multicentre, prospective study. Nephrol Dial Transplant. 2004;19(9):2282–8. doi:10.1093/ndt/gfh364.
Chang JW, Jeng MJ, Yang LY, Chen TJ, Chiang SC, Soong WJ, et al. The epidemiology and prognostic factors of mortality in critically ill children with acute kidney injury in Taiwan. Kidney Int. 2015;87(3):632–9. doi:10.1038/ki.2014.299.
Poukkanen M, Vaara ST, Reinikainen M, Selander T, Nisula S, Karlsson S, et al. Predicting one-year mortality of critically ill patients with early acute kidney injury: data from the prospective multicenter FINNAKI study. Crit Care. 2015;19:125. doi:10.1186/s13054-015-0848-2.
Foland JA, Fortenberry JD, Warshaw BL, Pettignano R, Merritt RK, Heard ML, et al. Fluid overload before continuous hemofiltration and survival in critically ill children: a retrospective analysis. Crit Care Med. 2004;32(8):1771–6.
Sutherland SM, Zappitelli M, Alexander SR, Chua AN, Brophy PD, Bunchman TE, et al. Fluid overload and mortality in children receiving continuous renal replacement therapy: the prospective pediatric continuous renal replacement therapy registry. Am J Kidney Dis. 2010;55(2):316–25. doi:10.1053/j.ajkd.2009.10.048.
Grams ME, Estrella MM, Coresh J, Brower RG, Liu KD. National Heart Ln, and Blood Institute Acute Respiratory Distress Syndrome Network. Fluid balance, diuretic use, and mortality in acute kidney injury. Clin J Am Soc Nephrol. 2011;6(5):966–73. doi:10.2215/CJN.08781010.
Bouchard J, Soroko SB, Chertow GM, Himmelfarb J, Ikizler TA, Paganini EP, et al. Fluid accumulation, survival and recovery of kidney function in critically ill patients with acute kidney injury. Kidney Int. 2009;76(4):422–7. doi:10.1038/ki.2009.159.
Payen D, de Pont AC, Sakr Y, Spies C, Reinhart K, Vincent JL, et al. A positive fluid balance is associated with a worse outcome in patients with acute renal failure. Crit Care. 2008;12(3):R74. doi:10.1186/cc6916.
Lo L, Go A, Chertow G, McCulloch C, Fan D, Ordoñez J, et al. Dialysis-requiring acute renal failure increases the risk of progressive chronic kidney disease. Kidney Int. 2009;76(8):893–9. doi:10.1038/ki.2009.289.
Amdur RL, Chawla LS, Amodeo S, Kimmel PL, Palant CE. Outcomes following diagnosis of acute renal failure in U.S. veterans: focus on acute tubular necrosis. Kidney Int. 2009;76(10):1089–97. doi:10.1038/ki.2009.332.
Coca SG, Singanamala S, Parikh CR. Chronic kidney disease after acute kidney injury: a systematic review and meta-analysis. Kidney Int. 2012;81(5):442–8. doi:10.1038/ki.2011.379.
Bucaloiu ID, Kirchner HL, Norfolk ER, Hartle JE, Perkins RM. Increased risk of death and de novo chronic kidney disease following reversible acute kidney injury. Kidney Int. 2012;81(5):477–85. doi:10.1038/ki.2011.405.
Ishani A, Nelson D, Clothier B, Schult T, Nugent S, Greer N, et al. The magnitude of acute serum creatinine increase after cardiac surgery and the risk of chronic kidney disease, progression of kidney disease, and death. Arch Intern Med. 2011;171(3):226–33. doi:10.1001/archinternmed.2010.514.
Ishani A, Xue J, Himmelfarb J, Eggers P, Kimmel P, Molitoris B, et al. Acute kidney injury increases risk of ESRD among elderly. Journal of the American Society of Nephrology : JASN. 2009;20(1):223–8. doi:10.1681/ASN.2007080837.
Wald R, Quinn R, Luo J, Li P, Scales D, Mamdani M, et al. Chronic dialysis and death among survivors of acute kidney injury requiring dialysis. Jama. 2009;302(11):1179–85. doi:10.1001/jama.2009.1322.
Hsu CY, Chertow GM, McCulloch CE, Fan D, Ordoñez JD, Go AS. Nonrecovery of kidney function and death after acute on chronic renal failure. Clin J Am Soc Nephrol. 2009;4(5):891–8. doi:10.2215/CJN.05571008.
Chawla LS, Amdur RL, Amodeo S, Kimmel PL, Palant CE. The severity of acute kidney injury predicts progression to chronic kidney disease. Kidney Int. 2011;79(12):1361–9. doi:10.1038/ki.2011.42.
Cerdá J, Liu KD, Cruz DN, Jaber BL, Koyner JL, Heung M, et al. Promoting Kidney Function Recovery in Patients with AKI Requiring RRT. Clin J Am Soc Nephrol. 2015;10(10):1859–67. doi:10.2215/CJN.01170215.
Heung M, Chawla LS. Predicting progression to chronic kidney disease after recovery from acute kidney injury. Curr Opin Nephrol Hypertens. 2012;21(6):628–34. doi:10.1097/MNH.0b013e3283588f24.
Hickson LJ, Chaudhary S, Williams AW, Dillon JJ, Norby SM, Gregoire JR, et al. Predictors of Outpatient Kidney Function Recovery Among Patients Who Initiate Hemodialysis in the Hospital. Am J Kidney Dis. 2014;65(4):592–602. doi:10.1053/j.ajkd.2014.10.015.
Widrow B, Lehr M. Perceptron, Madaline, and back propagation. Proceedings of IEEE. 1990;78(9):1415–42.
Brieman L. Random Forests. Machine Learning. 2001;45(1):5–32.
Breiman L, Friedman JH, Olshen RA, Stone CJ. Classification and Regression Trees. Monterey, CA: Wadsworth & Brooks; 1984.
Bailey K. Typologies and Taxonomies: An Introduction to Classification Techniques. Thousand Oaks, CA: Sage University Paper. Sage Publications; 1994.
Kohonen T. Self-organized formation of topologically correct feature maps. Biol Cybern. 1982;43(1):59–69. doi:10.1007/BF00337288.
Kramer A, Lee D, Axelrod R. Use of a Kohonen Neural Network to Characterize Respiratory Patients for Medical Intervention. In: Malmgren H, Borga M, Niklasson L, editors. Artificial Neural Networks in Medicine and Biology. Perspectives in Neural Computing. London: Springer; 2000. p. 192–6.
Abdi H, Williams LJ. Principal component analysis. Wiley Interdisciplinary Reviews: Computational Statistics. 2010;2(4):433–59. doi:10.1002/wics.101.
Drucker H, Chris, Kaufman B, Smola A, Vapnik V (eds). Support vector regression machines. Advances in Neural Information Processing Systems 9; 1997.
Hoffman M, Williams M. Electronic medical records and personalized medicine. Hum Genet. 2011;130(1):33–9. doi:10.1007/s00439-011-0992-y.
Hosmer DW, Lemeshow S. Applied logistic regression. Statistics in Medicine, vol 7. New York: Wiley; 1989.
Fisher RA. The use of multiple measurements in taxonomic problems. Annals of Eugenics. 1936;7(2):179–88. doi:10.1111/j.1469-1809.1936.tb02137.x.
Frankovich J, Longhurst CA, Sutherland SM. Evidence-Based Medicine in the EMR Era. New England Journal of Medicine. 2011;365(19):1758–9. doi:10.1056/NEJMp1108726.
Odgers DJ, Dumontier M. Mining Electronic Health Records using Linked Data. AMIA Summits on Translational Science Proceedings. 2015;2015:217–21.
Lowe HJ, Ferris TA, Hernandez PM, Weber SC. STRIDE – An Integrated Standards-Based Translational Research Informatics Platform. AMIA Annual Symposium Proceedings. 2009;2009:391–5.
Murphy SN, Mendis ME, Berkowitz DA, Kohane I, Chueh HC. Integration of Clinical and Genetic Data in the i2b2 Architecture. AMIA Annual Symposium Proceedings. 2006;2006:1040.
Jha AK, DesRoches CM, Campbell EG, Donelan K, Rao SR, Ferris TG, et al. Use of electronic health records in U.S. hospitals. N Engl J Med. 2009;360(16):1628–38. doi:10.1056/NEJMsa0900592.
Han YY, Carcillo JA, Venkataraman ST, Clark RS, Watson RS, Nguyen TC, et al. Unexpected increased mortality after implementation of a commercially sold computerized physician order entry system. Pediatrics. 2005;116(6):1506–12. doi:10.1542/peds.2005-1287.
Chaudhry B, Wang J, Wu S, Maglione M, Mojica W, Roth E, et al. Systematic review: impact of health information technology on quality, efficiency, and costs of medical care. Ann Intern Med. 2006;144(10):742–52.
Ash JS, Berg M, Coiera E. Some unintended consequences of information technology in health care: the nature of patient care information system-related errors. J Am Med Inform Assoc. 2004;11(2):104–12. doi:10.1197/jamia.M1471.
Hemp P. Death by information overload. Harv Bus Rev. 2009;87(9):82–9. 121.
Pickering BW, Dong Y, Ahmed A, Giri J, Kilickaya O, Gupta A, et al. The implementation of clinician designed, human-centered electronic medical record viewer in the intensive care unit: a pilot step-wedge cluster randomized trial. Int J Med Inform. 2015;84(5):299–307. doi:10.1016/j.ijmedinf.2015.01.017.
Sittig DF, Ash JS, Zhang J, Osheroff JA, Shabot MM. Lessons from "Unexpected increased mortality after implementation of a commercially sold computerized physician order entry system". Pediatrics. 2006;118(2):797–801. doi:10.1542/peds.2005-3132.
Aronson S, Fontes ML, Miao Y, Mangano DT. Group IotMSoPIR, Foundation IRaE. Risk index for perioperative renal dysfunction/failure: critical dependence on pulse pressure hypertension. Circulation. 2007;115(6):733–42. doi:10.1161/CIRCULATIONAHA.106.623538.
Brown JR, Cochran RP, Leavitt BJ, Dacey LJ, Ross CS, MacKenzie TA, et al. Multivariable prediction of renal insufficiency developing after cardiac surgery. Circulation. 2007;116(11 Suppl):I139–43. doi:10.1161/CIRCULATIONAHA.106.677070.
Koyner JL, Davison DL, Brasha-Mitchell E, Chalikonda DM, Arthur JM, Shaw AD, et al. Furosemide Stress Test and Biomarkers for the Prediction of AKI Severity. Journal of the American Society of Nephrology : JASN. 2015;26(8):2023–31. doi:10.1681/ASN.2014060535.
Chong E, Shen L, Poh KK, Tan HC. Risk scoring system for prediction of contrast-induced nephropathy in patients with pre-existing renal impairment undergoing percutaneous coronary intervention. Singapore Med J. 2012;53(3):164–9.
Cruz DN, Ferrer-Nadal A, Piccinni P, Goldstein SL, Chawla LS, Alessandri E, et al. Utilization of small changes in serum creatinine with clinical risk factors to assess the risk of AKI in critically lll adults. Clin J Am Soc Nephrol. 2014;9(4):663–72. doi:10.2215/CJN.05190513.
Gao YM, Li D, Cheng H, Chen YP. Derivation and validation of a risk score for contrast-induced nephropathy after cardiac catheterization in Chinese patients. Clin Exp Nephrol. 2014;18(6):892–8. doi:10.1007/s10157-014-0942-9.
Grimm JC, Lui C, Kilic A, Valero V, Sciortino CM, Whitman GJ, et al. A risk score to predict acute renal failure in adult patients after lung transplantation. Ann Thorac Surg. 2015;99(1):251–7. doi:10.1016/j.athoracsur.2014.07.073.
Gurm HS, Seth M, Kooiman J, Share D. A novel tool for reliable and accurate prediction of renal complications in patients undergoing percutaneous coronary intervention. Journal of the American College of Cardiology. 2013;61(22):2242–8. doi:10.1016/j.jacc.2013.03.026.
Ho J, Reslerova M, Gali B, Nickerson PW, Rush DN, Sood MM, et al. Serum creatinine measurement immediately after cardiac surgery and prediction of acute kidney injury. Am J Kidney Dis. 2012;59(2):196–201. doi:10.1053/j.ajkd.2011.08.023.
Hong SH, Park CO, Park CS. Prediction of newly developed acute renal failure using serum phosphorus concentrations after living-donor liver transplantation. J Int Med Res. 2012;40(6):2199–212.
Kim MY, Jang HR, Huh W, Kim YG, Kim DJ, Lee YT, et al. Incidence, risk factors, and prediction of acute kidney injury after off-pump coronary artery bypass grafting. Ren Fail. 2011;33(3):316–22. doi:10.3109/0886022X.2011.560406.
Kim WH, Lee SM, Choi JW, Kim EH, Lee JH, Jung JW, et al. Simplified clinical risk score to predict acute kidney injury after aortic surgery. Journal of cardiothoracic and vascular anesthesia. 2013;27(6):1158–66. doi:10.1053/j.jvca.2013.04.007.
Legrand M, Pirracchio R, Rosa A, Petersen ML, Van der Laan M, Fabiani JN, et al. Incidence, risk factors and prediction of post-operative acute kidney injury following cardiac surgery for active infective endocarditis: an observational study. Crit Care. 2013;17(5):R220. doi:10.1186/cc13041.
McMahon GM, Zeng X, Waikar SS. A risk prediction score for kidney failure or mortality in rhabdomyolysis. JAMA Intern Med. 2013;173(19):1821–8. doi:10.1001/jamainternmed.2013.9774.
Ng SY, Sanagou M, Wolfe R, Cochrane A, Smith JA, Reid CM. Prediction of acute kidney injury within 30 days of cardiac surgery. J Thorac Cardiovasc Surg. 2014;147(6):1875–83. doi:10.1016/j.jtcvs.2013.06.049.
Park MH, Shim HS, Kim WH, Kim HJ, Kim DJ, Lee SH, et al. Clinical Risk Scoring Models for Prediction of Acute Kidney Injury after Living Donor Liver Transplantation: A Retrospective Observational Study. PLoS One. 2015;10(8):e0136230. doi:10.1371/journal.pone.0136230.
Rahmanian PB, Kwiecien G, Langebartels G, Madershahian N, Wittwer T, Wahlers T. Logistic risk model predicting postoperative renal failure requiring dialysis in cardiac surgery patients. Eur J Cardiothorac Surg. 2011;40(3):701–7. doi:10.1016/j.ejcts.2010.12.051.
Rodríguez E, Soler MJ, Rap O, Barrios C, Orfila MA, Pascual J. Risk factors for acute kidney injury in severe rhabdomyolysis. PLoS One. 2013;8(12):e82992. doi:10.1371/journal.pone.0082992.
Romano TG, Schmidtbauer I, Silva FM, Pompilio CE, D'Albuquerque LA, Macedo E. Role of MELD score and serum creatinine as prognostic tools for the development of acute kidney injury after liver transplantation. PLoS One. 2013;8(5):e64089. doi:10.1371/journal.pone.0064089.
Schneider DF, Dobrowolsky A, Shakir IA, Sinacore JM, Mosier MJ, Gamelli RL. Predicting acute kidney injury among burn patients in the 21st century: a classification and regression tree analysis. J Burn Care Res. 2012;33(2):242–51. doi:10.1097/BCR.0b013e318239cc24.
Simonini M, Lanzani C, Bignami E, Casamassima N, Frati E, Meroni R, et al. A new clinical multivariable model that predicts postoperative acute kidney injury: impact of endogenous ouabain. Nephrol Dial Transplant. 2014;29(9):1696–701. doi:10.1093/ndt/gfu200.
Slankamenac K, Beck-Schimmer B, Breitenstein S, Puhan MA, Clavien PA. Novel prediction score including pre- and intraoperative parameters best predicts acute kidney injury after liver surgery. World J Surg. 2013;37(11):2618–28. doi:10.1007/s00268-013-2159-6.
Tsai TT, Patel UD, Chang TI, Kennedy KF, Masoudi FA, Matheny ME, et al. Validated contemporary risk model of acute kidney injury in patients undergoing percutaneous coronary interventions: insights from the National Cardiovascular Data Registry Cath-PCI Registry. J Am Heart Assoc. 2014;3(6):e001380. doi:10.1161/JAHA.114.001380.
Wang M, Wang J, Wang T, Li J, Hui L, Ha X. Thrombocytopenia as a predictor of severe acute kidney injury in patients with Hantaan virus infections. PLoS One. 2013;8(1):e53236. doi:10.1371/journal.pone.0053236.
Wang YN, Cheng H, Yue T, Chen YP. Derivation and validation of a prediction score for acute kidney injury in patients hospitalized with acute heart failure in a Chinese cohort. Nephrology (Carlton). 2013;18(7):489–96. doi:10.1111/nep.12092.
Wong B, St Onge J, Korkola S, Prasad B. Validating a scoring tool to predict acute kidney injury (AKI) following cardiac surgery. Can J Kidney Health Dis. 2015;2:3. doi:10.1186/s40697-015-0037-x.
Xu X, Ling Q, Wei Q, Wu J, Gao F, He ZL, et al. An effective model for predicting acute kidney injury after liver transplantation. Hepatobiliary Pancreat Dis Int. 2010;9(3):259–63.
ADQI 15 Consensus Meeting Contributors
Sean M. Bagshaw, Division of Critical Care Medicine, Faculty of Medicine and Dentistry, University of Alberta, Edmonton, AB, Canada; Rajit Basu, Division of Critical Care and the Center for Acute Care Nephrology, Department of Pediatrics, Cincinnati Children’s Hospital Medical Center, Cincinnati, OH, USA; Azra Bihorac, Division of Critical Care Medicine, Department of Anesthesiology, University of Florida, Gainesville, FL, USA; Lakhmir S. Chawla, Departments of Medicine and Critical Care, George Washington University Medical Center, Washington, DC, USA; Michael Darmon, Department of Intensive Care Medicine, Saint-Etienne University Hospital, Saint-Priest-En-Jarez, France; R.T. Noel Gibney, Division of Critical Care Medicine, Faculty of Medicine and Dentistry, University of Alberta, Edmonton, AB, Canada; Stuart L. Goldstein, Department of Pediatrics, Division of Nephrology &Hypertension, Cincinnati Children’s Hospital Medical Center, Cincinnati, OH, USA; Charles E. Hobson, Department of Health Services Research, Management and Policy, University of Florida, Gainesville, FL, USA; Eric Hoste, Department of Intensive Care Medicine, Ghent University Hospital, Ghent University, Ghent, Belgium, and Research Foundation – Flanders, Brussels, Belgium; Darren Hudson, Division of Critical Care Medicine, Faculty of Medicine and Dentistry, University of Alberta, Edmonton, AB, Canada; Raymond K. Hsu, Department of Medicine, Division of Nephrology, University of California San Francisco, San Francisco, CA, USA; Sandra L. Kane-Gill, Departments of Pharmacy, Critical Care Medicine and Clinical Translational Sciences, University of Pittsburgh, Pittsburgh, PA, USA; Kianoush Kashani, Divisions of Nephrology and Hypertension, Division of Pulmonary and Critical Care Medicine, Department of Medicine, Mayo Clinic, Rochester, MN, USA; John A. Kellum, Center for Critical Care Nephrology, Department of Critical Care Medicine, University of Pittsburgh, Pittsburgh, PA, USA; Andrew A. Kramer, Prescient Healthcare Consulting, LLC, Charlottesville, VA, USA; Matthew T. James, Departments of Medicine and Community Health Sciences, Cumming School of Medicine, University of Calgary, Calgary, Canada; Ravindra Mehta, Department of Medicine, UCSD, San Diego, CA, USA; Sumit Mohan, Department of Medicine, Division of Nephrology, College of Physicians & Surgeons and Department of Epidemiology Mailman School of Public Health, Columbia University, New York, NY, USA; Hude Quan, Department of Community Health Sciences, Cumming School of Medicine, University of Calgary, Calgary, Canada; Claudio Ronco, Department of Nephrology, Dialysis and Transplantation, International Renal Research Institute of Vicenza, San Bortolo Hospital, Vicenza, Italy; Andrew Shaw, Department of Anesthesia, Division of Cardiothoracic Anesthesiology, Vanderbilt University Medical Center, Nashville, TN, USA; Nicholas Selby, Division of Health Sciences and Graduate Entry Medicine, School of Medicine, University of Nottingham, UK; Edward Siew, Department of Medicine, Division of Nephrology, Vanderbilt University Medical Center, Nashville, TN, USA; Scott M. Sutherland, Department of Pediatrics, Division of Nephrology, Stanford University, Stanford, CA, USA; F. Perry Wilson, Section of Nephrology, Program of Applied Translational Research, Yale University School of Medicine, New Haven, CT, USA; Hannah Wunsch, Department of Critical Care Medicine, Sunnybrook Health Sciences Center and Sunnybrook Research Institute; Department of Anesthesia and Interdepartmental Division of Critical Care, University of Toronto, Toronto, Canada
Continuing medical education
The 15th ADQI Consensus Conference held in Banff, Canada on September 6–8th, 2015 was CME accredited Continuing Medical Education and Professional Development, University of Calgary, Calgary, Canada.
Financial support
Funding for the 15th ADQI Consensus Conference was provided by unrestricted educational support from: Division of Critical Care Medicine, Faculty of Medicine and Dentistry, and the Faculty of Medicine and Dentistry, University of Alberta (Edmonton, AB, Canada); Center for Acute Care Nephrology, Cincinnati Children's Hospital Medical Center (Cincinnati, OH, USA); Astute Medical (San Diego, CA, USA); Baxter Healthcare Corp (Chicago, IL, USA); Fresenius Medical Care Canada (Richmond Hill, ON, Canada); iMDsoft Inc (Tel Aviv, Israel); La Jolla Pharmaceutical (San Diego, CA, USA); NxStage Medical (Lawrence, MA, USA); Premier Inc (Charlotte, NC, USA); Philips (Andover, MA, USA); Spectral Medical (Toronto, ON, Canada).
Author information
Authors and Affiliations
Consortia
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests
Authors’ contributions
SS, LC, SK, RH, and AK performed the initial comprehensive literature search, formulated the key questions and concepts, presented their findings to the 15th ADQI Consensus Group and drafted the initial manuscript. SG, JK, CR, and SB guided and chaired the pre-, intra-, and post-conference sessions, critiqued and oversaw the conference debate and refinement process, and revised the final manuscript. The 15th ADQI group participated in the conference, debate, and refinement process which led to the final core concepts and manuscript output. All authors read, revised, and approved the final manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Sutherland, S.M., Chawla, L.S., Kane-Gill, S.L. et al. Utilizing electronic health records to predict acute kidney injury risk and outcomes: workgroup statements from the 15th ADQI Consensus Conference. Can J Kidney Health Dis 3, 11 (2016). https://doi.org/10.1186/s40697-016-0099-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40697-016-0099-4