
Abstract
Recently, assistive explanations for difficulties in the health check area have been made viable thanks in considerable portion to technologies like deep learning and machine learning. Using auditory analysis and medical imaging, they also increase the predictive accuracy for prompt and early disease detection. Medical professionals are thankful for such technological support since it helps them manage further patients because of the shortage of skilled human resources. In addition to serious illnesses like lung cancer and respiratory diseases, the plurality of breathing difficulties is gradually rising and endangering society. Because early prediction and immediate treatment are crucial for respiratory disorders, chest X-rays and respiratory sound audio are proving to be quite helpful together. Compared to related review studies on lung disease classification/detection using deep learning algorithms, only two review studies based on signal analysis for lung disease diagnosis have been conducted in 2011 and 2018. This work provides a review of lung disease recognition with acoustic signal analysis with deep learning networks. We anticipate that physicians and researchers working with sound-signal-based machine learning will find this material beneficial.
Similar content being viewed by others

Introduction
Diagnostics in contemporary medicine are more frequently based on visual or auditory data. Medical knowledge can be obtained in a variety of ways, but to a specialist, it is typically presented as visuals or sounds. It takes time and skill to properly detect health issues based on this information, yet 45% of member states of the World Health Organization (WHO) report having less than 1 doctor per 1000 people, which is the WHO ratio recommendation, according to WHO figures [44]. Given these dismal numbers, the fact that diagnosing entails studying each patient individually over a non-compressible period, and the fact that medical professionals are already overworked, their working conditions are not ideal, and mistakes can be made. The majority of frequent adventitious lung noises heard above the usual signals are crackles, wheezes, and squawks, and their presence typically suggests a pulmonary condition [23, 133, 142]. The traditional techniques of lung illness diagnosis were detected using an Artificial Intelligent (AI-based) method [27] or a Spirometry examination [75], both of which required photos as input to identify the disorders. Going to a hospital to get first analysis by x-ray or chest scan in the event of some Lung suffering condition, such as an asthma attack or heart attack, is time-consuming, expensive, and sometimes life-threatening. Furthermore, the model training over a large number of x-ray images with high-quality HD is required for autonomous an AI-based system of image-based recognition, which is challenging to get each time. A less and simpler resource-intensive system that is able to aid checkup practitioners in making an initial diagnosis is required instead.
This is why it’s important to find new shortcuts for doctors. Automatic and trustworthy tools can assist in diagnosing more patients or they can assist professionals in making fewer errors as a result of work overload. These new tools could come from computer science. For many years, advances in computer science have been steadily enhancing the capacity to autonomously analyze media data in real timing. Diagnosis service techniques should contain the ability to diagnose acoustic or/and visible data. By suggesting quicker and more precise techniques for diagnosis, computer technologies could help nursing personnel or medical experts [28]. The patient could receive adaptable instruments for medical monitoring from it.
Every respiratory examination includes audio auscultation, during which a medical professional uses a variety of instruments (including a sonogram and a stethoscope) to listen to noises coming from the patient’s body. This demonstrates how crucial sound analysis is for identifying lung diseases. Deep learning and machine learning are two new types of techniques that significantly advance the field of audio-based diagnosis [156]. Although less researched, several works analyze respiratory noises [181]. A 2011 review [62] emphasizes that previous studies can identify signs like wheezes or crackles. As earlier declared, the performance of classification and sound detection has significantly increased with the advent of deep and machine learning [42, 43], and research about lung sound analysis has benefited from this development [65, 110, 150]. Lung sound analysis may be converted into a classification problem [29] with the help of identified markers, which is a problem class that machine learning excels at resolving. This seems like a reasonable strategy, although this kind of analysis tends to concentrate more on the characteristics of the sound recording than on the patient level.
The rapid advancement of technology has resulted in a large rise in the volume of measured data, which often renders conventional analysis impractical due to the time required and the high level of medical competence required. Many researchers have offered different AI strategies to automate the categorization of respiratory sound signals to solve this issue. Incorporating machine learning (ML) techniques like Hidden Markov Models (HMM) and Support Vector Machine (SVM) [142], Long Short-Term Memory (LSTM), Residual Networks (ResNet), and Convolutional Neural Networks (CNNs), networks, and Recursive Neural Networks (RNN) are examples of Deep Learning (DL) networks [75]. Deep learning networks are commonly applied as LSTM, Restricted Boltzmann Machines (RBMs), CNN, and Sparse Auto-encoders [152]. In order to extract the relevant features, CNN employs numerous layers of element collections to interrelate the inputs. CNN is used in image recognition, NLP, and recommender systems. Probability distribution within the data collection is learned using RBM. All of these networks train via back-propagation. Gradient descent is used in back-propagation to reduce errors by changing the weights according to the partial error derivative relating to every weight.
The rest of this work is organized as follows: the next subsections provide an overview of breathing sound signals and a list of contributions of this work. “Motivations and problem definition” Section presents a definition of existing problems in the field of lung sound categorization. “Existing Solutions” Section discusses the existing solutions, while “Elaboration Studies” Section discusses the proposed solutions. “Conclusions” Section is represented by the elaboration, which demonstrates algorithms, methods, system components, datasets, and hybrid analysis. Finally, in Sect. 6, the study’s conclusions are presented.
An overview of breathing sound
Human’s breathing cycle has two distinct phases: inspiration and expiration. Air must be inhaled into the lungs in order to be inspired. The diaphragm drops and its muscles contract during inspiration. As a result, the chest hollow’s volume increases. The hollow in the chest loses air pressure. Outside the body, oxygenated air at high pressure enters the lungs swiftly. The oxygenated air in the lungs travels to the alveoli. The blood vessel network surrounds the slender alveoli walls, which are themselves. Expiration is the process of releasing air from the lungs. The diaphragm rises during expiration as a result of the diaphragm muscles relaxing. As a result, the chest hollow's capacity declines. As a result, carbon dioxide is expelled from the body. Figure 1 provides a demonstration of this procedure.

Diaphragm muscles during inhalation and exhalation
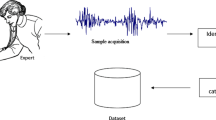
An example of an experimental setup to acquire respiratory audio waveforms is illustrated in Fig. 2, where an individual 4-channel audio sensor from four distinct places on the posterior chest of normal and 65 asthmatic individuals was used [72]. The pulmonologist recommended locations that give 66 fewer interfering with heart sounds throughout the lung sound recording procedure.

An experimental setup for collecting lung sounds from the back of the chest
Many studies have been conducted feature extraction and selection approaches for computerized lung sound examination and categorization. While conducting feature extraction from a lung sound, entropy-based features, chroma features, wavelet coefficients, Cepstral Coefficients (MFCC), Mel-Frequency and spectrograms are some of the most typically picked features. The deep learning framework employed by the majority of existing work can be generally divided into three stages. The first is respiratory sound preprocessing using audio filtering and noise-lessening methods. The second phase is feature extraction, which is accomplished by the use of signal processing methods such as spectrum analysis [41, 56, 69, 104], Cepstrum analysis [6, 19, 148], wavelet transformations [114, 137, 155], and statistics [113]. The third stage is classification, and the most often used classifiers have been K-nearest Neighbors [34, 63, 116, 127, 158], Support Vector Machines [20, 42, 43, 49, 131, 138], Gaussian Mixture models [105, 107], and ANN [35, 42, 43]. The workflow representation from preprocessing to classification can be shown in Fig. 3.

Workflow from preprocessing to classification
Contributions
This review will investigate the algorithms, advances, and diseases applications of sound-based diagnostic techniques of the lung and respiratory systems. Therefore, the characteristics and contributions of this work are as follows:
-
1.
This investigation can help researchers interested in sound-based disease analysis to realize the development trends and characteristics of using such prediction techniques and make sure that they will consciously choose the most suitable algorithms in their research process.
-
2.
The primary trends in prospective medical diagnosis and trends of integrating digital processing are analyzed, revealing that audio-based disease algorithms with deep learning have a shining future.
-
3.
The review searches for the existing problems of lung disease diagnosis with deep learning, such as few samples in the used dataset, poor quality of data, unbalanced data, and poor interpretability, to offer the available appropriate solutions.
-
4.
It presents different forms of comparison tables summarizing recent audio-based deep-learning algorithms in disease classification.
-
5.
Only two review studies based on signal analysis for lung disease diagnosis have been conducted in 2011 and 2018. Therefore, readers will comprehend the methods selection criteria of lung sound handling with large datasets via this paper.
Motivations and problem definition
Deep learning might be the most significant development in computer science in recent years. Almost all scientific disciplines have been impacted. The world’s leading IT companies and economies are striving to advance deep learning. In a number of sectors, deep learning has already surpassed human performance. This includes diagnosis of obstructive lung disease pattern recognition [38], signal classifiers for cough sound analysis [83], image processing for breast cancer [8], etc. Yann LeCun, Geoffrey Hinton, and Yoshua Bengio, three pioneers of DL, obtained the Award Turing, commonly recognized as the “Nobel Prize” of computers, on 27 of March 2019 [163]. Even if substantial advancements have been made, deep learning still has room for growth. With an additional accurate identification of situations like cancers [15], and the detection of a new medication [11], DL architectures have the prospective to boost human lives. For instance, the authors of the study [9] claimed that DL architectures were able to identify at a similar rank as 21 board-certified dermatologists once learning 2032 illnesses from 129,450 photos. In grading prostate cancer, Google AI could outperform the typical accuracy of USA general pathologists board-certified by 70% to 61% [71].
Only two review studies based on signal analysis for lung disease diagnosis have been conducted on 2011 and 2018. The various deep learning network architectural types, deep learning algorithms for sound-based lung disease diagnosis, their drawbacks, optimization techniques, and the most recent applications and implementations are all included in this review. This review’s objective is to offer a comprehensive overview of scattered knowledge in a single article while covering the large field of deep learning. By assembling the writings of eminent authors from the depth and breadth of deep learning, it delivers innovative work. Other related review publications (see Table 1) concentrate on particular implementations and topics without covering the entirety of the sound/audio-based lung diagnosis.
Existing solutions
The two main approaches used to diagnose the respiratory system are computer-based procedures and clinical methods. Three types of clinical assessment techniques exist classic general examination techniques, history-based techniques, and histopathological image-based techniques. In contrast, there are four main categories into which computer-based diagnosis techniques can be divided: wavelet, image analysis, image processing, and CNN research. Since this technology automatically identifies crucial components without the need for human intervention, we highlight CNN-based audio processing as an exciting area. In this work, we discuss the existing studies in terms of the following problems:
-
1. Dataset Selection: It is essential to obtain and maintain a noise-free database because the entire model is based on it. Preprocessing of the training data must be done correctly.
-
2. Deep learning algorithms choice: Understanding the purpose of the study is important. The best algorithms can be tested to see which ones deliver outcomes that are most similar to the desired outcome.
-
3. Feature extraction strategies: It is a crucial task in the creation of effective models. When high model accuracy is necessary, as well as optimal feature selection, which helps create redundant data during each cycle of data analysis, it is successful.
Dataset selection
The quality, confidence, and other features of the dataset are essential to measuring the accuracy of training and evaluation of models and architectures that perform on the classification of lung sounds. Several common respiratory/lung sound datasets are listed in Table 2.
Deep learning algorithms for lung sound
Deep Learning CNN (DLCNN) is being used to diagnose obstructive lung illnesses, which is a fascinating development. DLCNN algorithms function by identifying patterns in diagnostic test data that are possible utilization to forecast clinical outcomes or identify obstructive phenotypes. The objective of this work is to present the most recent developments and to speculate on DLCNN’s future potential in the diagnosis of obstructive lung disorders. DLCNN has been effectively employed in automated pulmonary function test interpretation for obstructive lung disease differential diagnosis [53, 54], where all sound data were examined to meet segmented into 5 s segments and 4 kHz sampling frequency. The architecture of the deep learning network contains two steps; bidirectional LSTM units and CNNs. Then, a number of processing steps were implemented to assure less noisy and smoother signals. This includes z-score normalization, displacement artifact removal, and wavelet smoothing. The proposed algorithm classified patients according to the different categories of lung diseases with the greatest precision of 98.85% and average accuracy of 99.62%. For obstructive pattern detection in computed tomography and associated acoustic data, deep learning algorithms such as neural networks using convolutions are state-of-the-art [39]. DLCNN has been applied in small-scale research to improve diagnostic procedures such as telemedicine, lung sound analysis, breath analysis, and, forced oscillation tests with promising results.
Deposits in the respiratory system limit airways and induce blood oxygen deficit, resulting in erratic breathing noises. Obtaining these respiratory sounds from test subjects, extracting audio features, and categorizing them will aid in the detection of sputum or other infections. These sickness stages can be accurately classified using deep learning convolution neural network methods. Several studies reviewed DLCNN such as [51], where its goal was to find the best CNN architecture for classifying lung carcinoma based on accuracy and training time calculations. Backpropagation is the best feed-forward neural network (FFNN) method, with an accuracy of 97.5 percent and training time of 12 s, and kernel extreme learning machine (KELM) is the best feedback neural network (FBNN) method, with an accuracy of 97.5 percent and an 18 min 04 s training time.
The majority of studies in the literature used numerous classifiers to see which one produced the greatest accuracy results that are regarded as a main performance metric of study. DLCNN methods such as VGG (VGG-B3, VGG-B1, VGG-V2, VGG-V1, and VGG-D1), Res-Net, LeNet, Inception-Net, and AlexNet, were applied to spectrum data for categorization functions, and the results were analyzed and compared with one another to improve categorization of aberrant respiratory sounds.
The distribution of publications by classification and feature extraction techniques is shown graphically in Fig. 4, where the majority of studies used CNNs for classification and MFCC for feature extraction. Along with other feature-based techniques that have been sparingly employed with machine learning and ensemble techniques, MFCC was routinely utilized with RNNs, ensemble learning, and machine learning. The main deep learning algorithms for sound-based classification employed in this study are mentioned in Table 3.

Graphical representation for the number of publications of crossing feature extraction methods with the categorisation in terms of circles of varying diameters
Feature extraction strategies
Data preprocessing begins with importing the re-sampling, cropping them, and sound files. Because recordings are made by different research teams using different recording equipment, sampling rates vary (4000 Hz, 44100 Hz, and 10000 Hz). All recordings may be re-sampled to a single sampling rate, such as 44100 Hz, and every sound is typically 3–10 s extended by zero-padding shorter segments and cropping larger ones. The respiratory sound data are divided into distinct breaths during preprocessing by detecting the lack of sound between breaths. Lung sounds captured from different participants will have varying loudness levels. As a result, before processing, the signals were adjusted such that they were roughly the same loudness regardless of the subject. Most of the methods from literature normalize a signal before being divided into frequency sub-bands using the discrete wavelet transform (DWT). To depict the allocation of wavelet coefficients, a set of numerical characteristics was collected from the sub-bands. A CNN-based scheme was implemented to classify the lung sound signal into one category: squawk, crackle, wheeze, normal, rhonchus, or stridor. The schematic block diagram of the signal preprocessing stage is described in Fig. 5.

A method for extracting and detecting characters based on lung sounds was described in the paper [149]. The wavelet de-noised approach removes noise from the collected lung sounds before employing wavelet decomposition to recover the wavelet features parameters of the denoised lung sound signals. Because the characteristic vectors of lung sounds have multi-dimensional following wavelet reconstruction and decomposition, a novel technique for converting them into reconstructed signal energy was developed. They also used linear discriminate analysis (LDA) to decrease the length of feature vectors for assessment in order to create a more efficient recognition technique. Finally, they employed a BP neural network to differentiate lung sounds, with 82.5 percent and 92.5 percent recognition accuracy, respectively, using relatively high-dimensional characteristic vectors as input and low-dimensional vectors as output. The study evaluated lung sound data using the Wavelet Packet Transform (WPT) and classification with an artificial neural network [93, 94]. Lung sound waves were separated into statistical parameters and frequency sub-bands using the WPT were derived from the sub-bands to describe the distribution of wavelet coefficients. The classification of lung sounds as normal, wheezing, or crackling is done using an ANN. This classifier was programmed by a microcontroller to construct a portable and automated device for studying and diagnosing respiratory function. In the study [93, 94], a method for distinguishing between two types of lung sounds was provided. The proposed technique was founded on an examination of wavelet packet decomposition (WPD). Data on normal abnormal and normal lung sounds were collected from a variety of patients. Each signal was split into two sections: expiration and inspiration. They used their multi-dimension WPD factors to create compressed and significant energy characteristic vectors, which they then fed into a CNN to recognize lung sound features. Widespread investigational results demonstrate that this characteristic extraction approach has high identification efficiency; nonetheless, it is not yet ready for clinical use. A common procedure to processing the lung sound can be listed as follows:
-
1.
As input, a Lung sound recording folder is used. Lung sounds are a combination of lung sounds and noise (signal interference).
-
2.
As a signal, sounds are able to be played and written.
-
3.
The Lung sounds are then examined by the scheme, saved in the data, and divided into an array of type bytes.
-
4.
The data array is transformed into a double-sized array.
-
5.
Repeatedly decomposing array data according to the chosen degree of disintegration creates two ranges, every half the duration of the data range. The initial array is known as a low-pass filter, while the second span is known as a high-pass filter.
-
6.
Apply the wavelet transform to the coefficients in each array.
-
7.
In the data array, both arrays are reconstructed, with a low-pass filter at the beginning and a high-pass filter at the ending time.
-
8.
The data array is processed via a threshold, creating respiratory sound signal noise and two arrays.
-
9.
Repeat restoration as many times as the stage of restoration set to each array.
-
10.
In the data array, reverse the order of the preceding half high pass filter and half low pass filter, discontinuous high pass filter low pass filter for every array.
-
11.
Re-perform each array's wavelet transform parameters.
-
12.
Data Array is then transformed from a double-sized array to a byte-sized array. The acoustic format and folder names that have been specified are functional to the information.
-
13.
A signal [data] of a breathing sound set is restructured to a breathing sound folder, and a data noise array is restructured to a noise beam.
Wavelet is relation of functions \({\varphi }_{a,b}t\) resulting from a foundation wavelet \(\varphi \left(t\right)\), called the “mother wavelet”, by translation and dilation [117] as described in Eq. (1):
Wavelet examination is essentially scaling and shifting a restricted shape of energy called the “mother wavelet” \(\mathrm{\varphi }\left(\mathrm{t}\right)\) of the preferred indication. So, the disconnected wavelet change is able written as follows:
The signal-to-noise ratio (\(SNR\)) is a dimensionless relation of the power of a signal to the associated power noise during recording, this can be expressed by [16]:
where \({A}_{noise}\) denotes root mean square (RMS) of noise amplitude, \({\mathrm{A}}_{\mathrm{signal}}\) represents the root mean square (RMS) of signal amplitude, \({P}_{noise}\) denotes the mean of noise power, and the \({P}_{\mathrm{signal}}\) denotes the mean of signal power.
The studies [93, 147] decomposition after evaluating the distribution characteristics of time–frequency respiratory sounds. The optimum wavelet packet foundation for feature extraction was chosen after the space partitioning of wavelet packets. They can perform quick random multi-scale WPT and get every high-dimension wavelet parameters matrix based on the best basis. The time-domain equal-value relationship between coefficients wavelet and signal energy was then established. The energy was used as an eigenvalue, and vectors of characteristics from a classification artificial neural network (ANN) were used as forms. This drastically reduces the number of ANN input vectors. Extensive experimental results reveal that the proposed feature extraction approach outperforms other approaches in terms of recognition performance. The time-domain equal-value relationship between wavelet coefficients and signal energy was then established. The energy was used as an eigenvalue, and feature vectors from a classification artificial neural network (ANN) were used as forms. The number of ANN input vectors is considerably reduced as a result. Extensive experimental findings show that in terms of recognition performance, the suggested feature extraction technique surpasses alternative approaches.
To provide a clear insight on features extractions of lung sound, we downloaded free samples of lung sounds from the [68] database [68] Challenge | ICBHI Challenge, n.d.) and performed both wavelet analysis and short-time Fourier transform (STFT) as a two different algorithms. The original waveforms are shown in Fig. 6a for Wheeze, Crackle, Wheeze + Crackle, and normal sound. For Wheeze signals, the prevalence of the spectrum power falls within the (100–1000) Hz frequency range, with a particular transient of shorter than 100 ms. Crackle signals have an oscillatory signature with (350–650) Hz frequency range and it lasts more than 20 ms. Figure 6b shows the STFT spectrogram for every respiratory segment. The wheeze and crackle signals are likewise supplied in the same records of the [68] database. Since the combined signals are frequently asymmetric and erratic, it can be challenging to isolate and identify the essential component from the STFT spectrums. In order to increase the accuracy of deep learning model, the study [101] additionally used the wavelet packet analysis. The wavelet generated spectrogram is shown Fig. 6c.

(a) Original sound signal. (b) STFT spectrogram (c) wavelet generated spectrogram of lung sounds. From respiratory sound database [68] Challenge | ICBHI Challenge, n.d.)
Mel Frequency Cepstral Coefficient (MFCC) was employed as sound clip characteristics. Speech recognition systems frequently employ MFCCs. They have also been extensively employed in prior employment on the recognition of unexpected respiratory sound signals because they give an indication of the time domain short-term power spectrum of the sounds. Because multiple adventitious sounds might appear in the same tape at different periods and have varied durations, both frequency and time content are significant in distinguishing between them. As a result, MFCC is useful for recording a signal’s transform in frequency components during the time. Frequencies are allocated to the MEL scale that are nonlinear frequencies with equal distance in the human auditory system. Before further processing, MFCC generates a two-dimensional vector feature (frequency and time) that is compressed into an array of one-dimensional scale. The MFCC computation technique is depicted in Fig. 7.

MFCC computation technique
Elaboration studies
The studies [37, 38, 61] provided a survey of cutting-edge deep-learning-based respiratory nodule analysis and screening algorithms, with an emphasis on their presentation and medical applications. The study [61] compared the network performance, limitations, and potential trends of lung nodule investigation. The review [37] evaluated why molecular and cellular processes are of relevance. DLCNN has been used in different diagnostic procedures such as lung sound analysis, forced oscillation test, telemedicine, and breath analysis, with encouraging outcomes in small-scale investigations, according to [38].
In the same context, the papers [26, 48, 85, 91, 95, 136, 163] reviewed cancer diagnosis of the lung using medical picture analysis. Lung cancer is the foremost source of mortality globally, with “1.76 million related deaths recorded in 2018,” according to [26]. In addition, “Lung highest incidence rate of cancer death in both men and women, accounting for over a quarter of all cancer fatalities globally.” [48].
There are many published journal papers that review and proposed original methods to assess lung disease using deep learning CNN as an artificial intelligence technique. For highlighting the importance of these publications, this review briefly provides a table that lists the analyzed sample, the CNN algorithm type, tested data (sound or image samples), and their significant findings as seen in Table 4.
The table shows a classification of some published articles and their achievements. The studies [1, 25, 74, 87] created a problem-based architecture that saves image data for identifying integration in a Chest Pediatric X-ray database. They designed a three-step pre-processing strategy to improve model generalization. An occlusion test is used to display model outputs and identify the observed relevant area in order to check the reliability of numerical findings. To test the universality of the proposed model, a different dataset is employed as additional validation. In real-world practice, the provided models can be used as computer-aided diagnosis tools. They thoroughly analyzed the datasets and prior studies based on them, concluding that the results could be misleading if certain precautions are not followed.
Conclusions
This work provided a review of lung disease recognition with acoustic signal analysis with deep learning networks. Compared to related review studies on lung disease classification/detection using deep learning algorithms, only two review studies based on signal analysis for lung disease diagnosis have been conducted in 2011 and 2018. Deep Learning Convolutional Neural Networks (DLCNN) are being used to diagnose obstructive lung illnesses, which is a fascinating development. DLCNN algorithms function by identifying patterns in diagnostic test data that can be applied to forecast and identify obstructive phenotypes or clinical outcomes. DLCNN will require consensus examination, data analysis, and interpretation techniques as it matures as medical technology. To enable big clinical trials and, ultimately, minimize ordinary clinical use, such tools are required to compare, understand, and reproduce study findings from and among diverse research organizations. It is necessary to make recommendations on how DLCNN data might be used to generate diagnoses and influence clinical decision-making and therapeutic planning. This review looks at how deep learning can be used in medical diagnosis. A thorough assessment of several scientific publications in the field of deep neural network applications in medicine was conducted. More than 200 research publications were discovered, with 77 of them being presented in greater detail as a result of various selection techniques. Overall, the use of a DLCNN in the detection of obstructive lung disorders has yielded promising results. Large-scale investigations, on the other hand, are still needed to validate present findings and increase their acceptance by the medical community. We anticipate that physicians and researchers working with DLCNN, as well as industrial producers of this technology, will find this material beneficial.
Availability of data and materials
Not applicable because it's a review paper.
References
Abbas Q. Lung-deep: a computerized tool for detection of lung nodule patterns using deep learning algorithms detection of lung nodules patterns. Int J Adv Comput Sci Appl. 2017. https://doi.org/10.1456/ijacsa.2017.081015.
Abumalloh RA, Nilashi M, Yousoof Ismail M, Alhargan A, Alghamdi A, Alzahrani AO, Saraireh L, Osman R, Asadi S. Medical image processing and COVID-19: a literature review and bibliometric analysis. J Infect Public Health. 2022. https://doi.org/10.1016/j.jiph.2021.11.013.
Acharya J, Basu A. Deep neural network for respiratory sound classification in wearable devices enabled by patient specific model tuning. IEEE Trans Biomed Circuits Syst. 2020. https://doi.org/10.1109/TBCAS.2020.2981172.
Adhi Pramono RX, Imtiaz SA, Rodriguez-Villegas E. Evaluation of features for classification of wheezes and normal respiratory sounds. PLoS ONE. 2019. https://doi.org/10.1371/journal.pone.0213659.
Aggarwal P, Mishra NK, Fatimah B, Singh P, Gupta A, Joshi SD. COVID-19 image classification using deep learning: advances, challenges and opportunities. Comput Biol Med. 2022. https://doi.org/10.1016/j.compbiomed.2022.105350.
Ajibola Alim S, Khair Alang Rashid N. Some commonly used speech feature extraction algorithms. Algorithms Appl. 2018. https://doi.org/10.5772/intechopen.80419.
Alahmari SS, Altazi B, Hwang J, Hawkins S, Salem T. A comprehensive review of deep learning-based methods for COVID-19 detection using chest X-ray images. IEEE Access. 2022. https://doi.org/10.1109/ACCESS.2022.3208138.
Albalawi U, Manimurugan S, Varatharajan R. Classification of breast cancer mammogram images using convolution neural network. Concurr Comput Practice Exp. 2022. https://doi.org/10.1002/cpe.5803.
Albawi S, Arif MH, Waleed J. Skin cancer classification dermatologist-level based on deep learning model. Acta Sci Technol. 2023. https://doi.org/10.4025/actascitechnol.v45i1.61531.
Alghamdi HS, Amoudi G, Elhag S, Saeedi K, Nasser J. Deep learning approaches for detecting COVID-19 from chest X-ray images: a survey. IEEE Access. 2021. https://doi.org/10.1109/ACCESS.2021.3054484.
Ali Z, Huang Y, Ullah I, Feng J, Deng C, Thierry N, Khan A, Jan AU, Shen X, Rui W, Qi G. Deep learning for medication recommendation: a systematic survey. Data Intell. 2023. https://doi.org/10.1162/dint_a_00197.
Altan D, Kutlu Y. (2020). RespiratoryDatabase@TR (COPD Severity Analysis). https://doi.org/10.1763/P9Z4H98S6J.1
Altan Gökhan, Kutlu Y, Garbi Y, Pekmezci AÖ, Nural S. Multimedia respiratory database (RespiratoryDatabase@TR): auscultation sounds and chest X-rays. Nat Eng Sci. 2017. https://doi.org/10.2897/nesciences.349282.
Altan G, Kutlu Y, Pekmezci AÖ, Nural S. Deep learning with 3D-second order difference plot on respiratory sounds. Biomed Signal Process Control. 2018. https://doi.org/10.1016/j.bspc.2018.05.014.
Anari S, Tataei Sarshar N, Mahjoori N, Dorosti S, Rezaie A. Review of deep learning approaches for thyroid cancer diagnosis. Math Probl Eng. 2022. https://doi.org/10.1155/2022/5052435.
Asatani N, Kamiya T, Mabu S, Kido S. Classification of respiratory sounds by generated image and improved CRNN. Int Conf Control Autom Syst. 2021. https://doi.org/10.2391/ICCAS52745.2021.9649906.
Aslani S, Jacob J. Utilisation of deep learning for COVID-19 diagnosis. Clin Radiol. 2023. https://doi.org/10.1016/j.crad.2022.11.006.
Aykanat M, Kılıç Ö, Kurt B, Saryal S. Classification of lung sounds using convolutional neural networks. Eurasip J Image Video Process. 2017. https://doi.org/10.1186/s13640-017-0213-2.
Ayvaz U, Gürüler H, Khan F, Ahmed N, Whangbo T, Bobomirzaevich AA. Automatic speaker recognition using mel-frequency cepstral coefficients through machine learning. Comput Mater Contin. 2022. https://doi.org/10.3260/cmc.2022.023278.
Azmy MM. Classification of lung sounds based on linear prediction cepstral coefficients and support vector machine. IEEE Jordan Conf Appl Electr Eng Comput Technol AEECT. 2015. https://doi.org/10.1109/AEECT.2015.7360527.
Baghel N, Nangia V, Dutta MK. ALSD-Net: Automatic lung sounds diagnosis network from pulmonary signals. Neural Comput Appl. 2021. https://doi.org/10.1007/s00521-021-06302-1.
Bahoura M. Pattern recognition methods applied to respiratory sounds classification into normal and wheeze classes. Comput Biol Med. 2009. https://doi.org/10.1016/j.compbiomed.2009.06.011.
Bardou D, Zhang K, Ahmad SM. Lung sounds classification using convolutional neural networks. Artif Intell Med. 2018. https://doi.org/10.1016/j.artmed.2018.04.008.
Basu V, Rana S. Respiratory diseases recognition through respiratory sound with the help of deep neural network. CINE. 2020. https://doi.org/10.1109/CINE48825.2020.234388.
Behzadi-khormouji H, Rostami H, Salehi S, Derakhshande-Rishehri T, Masoumi M, Salemi S, Keshavarz A, Gholamrezanezhad A, Assadi M, Batouli A. Deep learning, reusable and problem-based architectures for detection of consolidation on chest X-ray images. Comput Methods Programs Biomed. 2020. https://doi.org/10.1016/j.cmpb.2019.105162.
Binczyk F, Prazuch W, Bozek P, Polanska J. Radiomics and artificial intelligence in lung cancer screening. Transl Lung Cancer Res. 2021. https://doi.org/10.2103/tlcr-20-708.
Borrelli P, Ly J, Kaboteh R, Ulén J, Enqvist O, Trägårdh E, Edenbrandt L. AI-based detection of lung lesions in [18F]FDG PET-CT from lung cancer patients. EJNMMI Phys. 2021. https://doi.org/10.1186/s40658-021-00376-5.
Camara J, Neto A, Pires IM, Villasana MV, Zdravevski E, Cunha A. Literature review on artificial intelligence methods for glaucoma screening, segmentation, and classification. J Imag. 2022. https://doi.org/10.3390/jimaging8020019.
Chaiyot K, Plermkamon S, Radpukdee T. Effect of audio pre-processing technique for neural network on lung sound classification. IOP Conf Ser Mater Sci Eng. 2021. https://doi.org/10.1088/1757-899x/1137/1/012053.
Chamberlain D, Kodgule R, Ganelin D, Miglani V, Fletcher RR. Application of semi-supervised deep learning to lung sound analysis. Proc Ann Int Conf IEEE Eng Med Biol Soc EMBS. 2016. https://doi.org/10.1109/EMBC.2016.7590823.
Chambres G, Hanna P, Desainte-Catherine M. Automatic detection of patient with respiratory diseases using lung sound analysis. Proc Int Workshop Content-Based Multimed Index. 2018. https://doi.org/10.1109/CBMI.2018.8516489.
Chanane H, Bahoura M. Convolutional neural network-based model for lung sounds classification. Midwest Symp Circuit Syst. 2021. https://doi.org/10.1109/MWSCAS47672.2021.9531887.
Chawla J, Walia NK. Artificial intelligence based techniques in respiratory healthcare services: a review. ICAN. 2022. https://doi.org/10.1109/ICAN56228.2022.10007236.
Chen CH, Huang WT, Tan TH, Chang CC, Chang YJ. Using K-nearest neighbor classification to diagnose abnormal lung sounds. Sensors. 2015. https://doi.org/10.3390/s150613132.
Chen H, Yuan X, Pei Z, Li M, Li J. Triple-classification of respiratory sounds using optimized s-transform and deep residual networks. IEEE Access. 2019. https://doi.org/10.1109/ACCESS.2019.2903859.
Cong L, Feng W, Yao Z, Zhou X, Xiao W. Deep learning model as a new trend in computer-aided diagnosis of tumor pathology for lung cancer. J Cancer. 2020. https://doi.org/10.7150/jca.43268.
Cook GJR, Goh V. What can artificial intelligence teach us about the molecular mechanisms underlying disease? Eur J Nuclear Med Mol Imag. 2019. https://doi.org/10.1007/s00259-019-04370-z.
Das N, Topalovic M, Janssens W. Artificial intelligence in diagnosis of obstructive lung disease: current status and future potential. Curr Opin Pulm Med. 2018. https://doi.org/10.1097/MCP.0000000000000459.
Das N, Topalovic M, Janssens W. Artificial intelligence in diagnosis of obstructive lung disease. Curr Opin Pulm Med. 2018. https://doi.org/10.1097/mcp.0000000000000459.
Davis N, Suresh K. Environmental sound classification using deep convolutional neural networks and data augmentation. RAICS. 2019. https://doi.org/10.1109/RAICS.2018.8635051.
De Benito-Gorron D, Ramos D, Toledano DT. A multi-resolution CRNN-based approach for semi-supervised sound event detection in DCASE 2020 challenge. IEEE Access. 2021. https://doi.org/10.1109/ACCESS.2021.3088949.
Demir F, Ismael AM, Sengur A. Classification of lung sounds with cnn model using parallel pooling structure. IEEE Access. 2020. https://doi.org/10.1109/ACCESS.2020.3000111.
Demir F, Sengur A, Bajaj V. Convolutional neural networks based efficient approach for classification of lung diseases. Health Inf Sci Syst. 2020. https://doi.org/10.1007/s13755-019-0091-3.
Density of physicians (per 1000 population). (n.d.). Retrieved. https://www.who.int/data/gho/indicator-metadata-registry/imr-details/3107 2023
Diffallah Z, Ykhlef H, Bouarfa H, Ykhlef F. Impact of mixup hyperparameter tunning on deep learning-based systems for acoustic scene classification. ICRAMI. 2021. https://doi.org/10.1109/ICRAMI52622.2021.9585948.
Emmanouilidou D, McCollum ED, Park DE, Elhilali M. Computerized lung sound screening for pediatric auscultation in noisy field environments. IEEE Trans Biomed Eng. 2018. https://doi.org/10.1109/TBME.2017.2717280.
Esmaeilpour M, Cardinal P, Lameiras Koerich A. Unsupervised feature learning for environmental sound classification using weighted cycle-consistent generative adversarial network. Appl Soft Comput J. 2020. https://doi.org/10.1016/j.asoc.2019.105912.
Espinoza JL, Dong LT. Artificial intelligence tools for refining lung cancer screening. J Clin Med. 2020. https://doi.org/10.3390/jcm9123860.
Falah AH, Jondri J. Lung sounds classification using stacked autoencoder and support vector machine. ICoICT. 2019. https://doi.org/10.1109/ICoICT.2019.8835278.
Farhat H, Sakr GE, Kilany R. Deep learning applications in pulmonary medical imaging: recent updates and insights on COVID-19. Mach Vis Appl. 2020. https://doi.org/10.1007/s00138-020-01101-5.
Foeady AZ, Riqmawatin SR, Novitasari DCR. Lung cancer classification based on CT scan image by applying FCM segmentation and neural network technique. Telkomnika (Telecommun Comput Electron Control). 2021. https://doi.org/10.1292/TELKOMNIKA.v19i4.18874.
Forte GC, Altmayer S, Silva RF, Stefani MT, Libermann LL, Cavion CC, Youssef A, Forghani R, King J, Mohamed TL, Andrade RGF, Hochhegger B. Deep learning algorithms for diagnosis of lung cancer: a systematic review and meta-analysis. Cancers. 2022. https://doi.org/10.3390/cancers14163856.
Fraiwan L, Hassanin O, Fraiwan M, Khassawneh B, Ibnian AM, Alkhodari M. Automatic identification of respiratory diseases from stethoscopic lung sound signals using ensemble classifiers. Biocybernetics Biomed Eng. 2021. https://doi.org/10.1016/j.bbe.2020.11.003.
Fraiwan M, Fraiwan L, Alkhodari M, Hassanin O. Recognition of pulmonary diseases from lung sounds using convolutional neural networks and long short-term memory. J Ambient Intell Humaniz Comput. 2021. https://doi.org/10.1007/s12652-021-03184-y.
Gairola S, Tom F, Kwatra N, Jain M. RespireNet: a deep neural network for accurately detecting abnormal lung sounds in limited data setting. Proc Ann Int Conf IEEE Eng Med Biol Soc EMBS. 2021. https://doi.org/10.1109/EMBC46164.2021.9630091.
Gerhard D. Audio signal classification : history and current techniques. Saskatchewan Canada: Department of Computer Science University of Regina Regina; 2003.
Ghaderzadeh M, Asadi F. Deep learning in the detection and diagnosis of COVID-19 using radiology modalities: a systematic review. J Healthcare Eng. 2021. https://doi.org/10.1155/2021/6677314.
Ghrabli S, Elgendi M, Menon C. Challenges and opportunities of deep learning for cough-based COVID-19 diagnosis: a scoping review. Diagnostics. 2022. https://doi.org/10.3390/diagnostics12092142.
Gómez AFR, Orjuela-Cañón AD. Multilabel and multiclass approaches comparison for respiratory sounds classification. Commun Comput Inf Sci. 2022. https://doi.org/10.1007/978-3-030-91308-3_4.
Greco A, Petkov N, Saggese A, Vento M. AReN: a deep learning approach for sound event recognition using a brain inspired representation. IEEE Trans Inf Forensics Secur. 2020. https://doi.org/10.1109/TIFS.2020.2994740.
Gu D, Liu G, Xue Z. On the performance of lung nodule detection, segmentation and classification. Comput Med Imag Graph. 2021. https://doi.org/10.1016/j.compmedimag.2021.101886.
Gurung A, Scrafford CG, Tielsch JM, Levine OS, Checkley W. Computerized lung sound analysis as diagnostic aid for the detection of abnormal lung sounds: a systematic review and meta-analysis. Respir Med. 2011. https://doi.org/10.1016/j.rmed.2011.05.007.
Haider NS, Singh BK, Periyasamy R, Behera AK. Respiratory sound based classification of chronic obstructive pulmonary disease: a risk stratification approach in machine learning paradigm. J Med Syst. 2019. https://doi.org/10.1007/s10916-019-1388-0.
Hassan H, Ren Z, Zhou C, Khan MA, Pan Y, Zhao J, Huang B. Supervised and weakly supervised deep learning models for COVID-19 CT diagnosis: a systematic review. Comput Methods Progr Biomed. 2022. https://doi.org/10.1016/j.cmpb.2022.106731.
Hsu FS, Huang SR, Huang CW, Cheng YR, Chen CC, Hsiao J, Chen CW, Lai F. A progressively expanded database for automated lung sound analysis: an update. Appl Sci. 2022. https://doi.org/10.3390/app12157623.
Hsu FS, Huang SR, Huang CW, Huang CJ, Cheng YR, Chen CC, Hsiao J, Chen CW, Chen LC, Lai YC, Hsu BF, Lin NJ, Tsai WL, Wu YL, Tseng TL, Tseng CT, Chen YT, Lai F. Benchmarking of eight recurrent neural network variants for breath phase and adventitious sound detection on a selfdeveloped open-access lung sound database-HF_Lung_V1. PLoS ONE. 2021. https://doi.org/10.1371/journal.pone.0254134.
Huang S, Yang J, Fong S, Zhao Q. Artificial intelligence in the diagnosis of covid-19: challenges and perspectives. Int J Biol Sci. 2021. https://doi.org/10.7150/ijbs.58855.
ICBHI 2017 Challenge | ICBHI Challenge. (n.d.). Retrieved. https://bhichallenge.med.auth.gr/ICBHI_2017_Challenge 2022
Içer S, Gengeç Ş. Classification and analysis of non-stationary characteristics of crackle and rhonchus lung adventitious sounds. Digit Signal Proc A Rev J. 2014. https://doi.org/10.1016/j.dsp.2014.02.001.
Imoto K. Acoustic scene classification using multichannel observation with partially missing channels. Eur Signal Process Conf. 2021. https://doi.org/10.2391/EUSIPCO54536.2021.9616170.
Improved Grading of Prostate Cancer Using Deep Learning – Google AI Blog. (n.d.). Retrieved. https://ai.googleblog.com/2018/11/improved-grading-of-prostate-cancer.html 2023
Islam MA, Bandyopadhyaya I, Bhattacharyya P, Saha G. Multichannel lung sound analysis for asthma detection. Comput Methods Programs Biomed. 2018. https://doi.org/10.1016/j.cmpb.2018.03.002.
Jakovljević N, Lončar-Turukalo T. Hidden Markov model based respiratory sound classification. IFMBE Proc. 2018. https://doi.org/10.1007/978-981-10-7419-6_7.
Jang S, Song H, Shin YJ, Kim J, Kim J, Lee KW, Lee SS, Lee W, Lee S, Lee KH. Deep learning–based automatic detection algorithm for reducing overlooked lung cancers on chest radiographs. Radiology. 2020. https://doi.org/10.1148/radiol.2020200165.
Jeong O, Ryu SY, Park YK. The value of preoperative lung spirometry test for predicting the operative risk in patients undergoing gastric cancer surgery. J Korean Surg Soc. 2013. https://doi.org/10.4174/jkss.2013.84.1.18.
Jeong Y, Kim J, Kim D, Kim J, Lee K. Methods for improving deep learning-based cardiac auscultation accuracy: data augmentation and data generalization. Appl Sci. 2021. https://doi.org/10.3390/app11104544.
Kadyan V, Bawa P, Hasija T. In domain training data augmentation on noise robust Punjabi children speech recognition. J Ambient Intell Humaniz Comput. 2022. https://doi.org/10.1007/s12652-021-03468-3.
Karthik R, Menaka R, Hariharan M, Kathiresan GS. AI for COVID-19 detection from radiographs incisive analysis of state of the art techniques key challenges and future directions. IRBM. 2022. https://doi.org/10.1016/j.irbm.2021.07.002.
Kaur J, Kaur P. Outbreak COVID-19 in medical image processing using deep learning: a state-of-the-art review. Arch Comput Methods Eng. 2022. https://doi.org/10.1007/s11831-021-09667-7.
Kochetov K, Putin E, Balashov M, Filchenkov A, Shalyto A. Noise masking recurrent neural network for respiratory sound classification. Lect Notes Comput Sci. 2018. https://doi.org/10.1007/978-3-030-01424-7_21.
Koike T, Qian K, Schuller BW, Yamamoto Y. Transferring cross-corpus knowledge: an investigation on data augmentation for heart sound classification. Proc Ann Int Conf IEEE Eng Med Biol Soc EMBS. 2021. https://doi.org/10.1109/EMBC46164.2021.9629714.
Kulkarni S, Sonare PS. Deep learning approaches for detection of COVID 19 from CT image: a review. Indian J Artif Intell Neural Network. 2022. https://doi.org/10.5410/ijainn.c1050.042322.
Kumar A, Abhishek K, Ghalib MR, Nerurkar P, Shah K, Chandane M, Bhirud S, Patel D, Busnel Y. Towards cough sound analysis using the internet of things and deep learning for pulmonary disease prediction. Trans Emerging Telecommun Technol. 2022. https://doi.org/10.1002/ett.4184.
Lakhani S, Jhamb R. Classification of lung sounds and disease prediction using dense CNN network. Int J Eng Adv Technol. 2021. https://doi.org/10.3594/ijeat.a3207.1011121.
Lee H, Chen YPP. Image based computer aided diagnosis system for cancer detection. Expert Syst Appl. 2015. https://doi.org/10.1016/j.eswa.2015.02.005.
Lee H, Lee J. Neural network prediction of sound quality via domain knowledge-based data augmentation and Bayesian approach with small data sets. Mech Syst Signal Process. 2021. https://doi.org/10.1016/j.ymssp.2021.107713.
Lee JH, Sun HY, Park S, Kim H, Hwang EJ, Goo JM, Park CM. Performance of a deep learning algorithm compared with radiologic interpretation for lung cancer detection on chest radiographs in a health screening population. Radiology. 2020. https://doi.org/10.1148/radiol.2020201240.
Lella KK, PJA A. Automatic COVID-19 disease diagnosis using 1D convolutional neural network and augmentation with human respiratory sound based on parameters: cough, breath, and voice. AIMS Public Health. 2021. https://doi.org/10.3934/publichealth.2021019.
Li Z, Zhang J, Tan T, Teng X, Sun X, Zhao H, Liu L, Xiao Y, Lee B, Li Y, Zhang Q, Sun S, Zheng Y, Yan J, Li N, Hong Y, Ko J, Jung H, Liu Y, Litjens G. Deep learning methods for lung cancer segmentation in whole-slide histopathology images—the ACDC@LungHP challenge. IEEE J Biomed Health Inform. 2021. https://doi.org/10.1109/JBHI.2020.3039741.
Liu B, Chi W, Li X, Li P, Liang W, Liu H, Wang W, He J. Evolving the pulmonary nodules diagnosis from classical approaches to deep learning-aided decision support: three decades’ development course and future prospect. J Cancer Res Clin Oncol. 2020. https://doi.org/10.1007/s00432-019-03098-5.
Liu R, Cai S, Zhang K, Hu N. Detection of adventitious respiratory sounds based on convolutional neural network. ICIIBMS. 2019. https://doi.org/10.1109/ICIIBMS46890.2019.8991459.
Liu T, Siegel E, Shen D. Deep learning and medical image analysis for COVID-19 diagnosis and prediction. Ann Rev Biomed Eng. 2022. https://doi.org/10.1146/annurev-bioeng-110220-012203.
Liu Y, Zhang CM, Zhao YH, Dong L. Feature extraction and classification of lung sounds based on wavelet packet multiscale analysis. Chin J Comput. 2006;29(5):769.
Liu Y, Zhang C, Peng Y. Neural classification of lung sounds using wavelet packet coefficients energy. Lect Notes Comput Sci. 2006. https://doi.org/10.1007/11801603_31.
Liu Z, Yao C, Yu H, Wu T. Deep reinforcement learning with its application for lung cancer detection in medical internet of things. Futur Gener Comput Syst. 2019. https://doi.org/10.1016/j.future.2019.02.068.
Lu R, Duan Z, Zhang C. Metric learning based data augmentation for environmental sound classification. IEEE Workshop Appl Signal Proc Audio Acoust. 2017. https://doi.org/10.1109/WASPAA.2017.8169983.
Luthfi M, Goto S, Ytshi O. Analysis on the usage of topic model with background knowledge inside discussion activity in industrial engineering context. SmartIoT. 2020. https://doi.org/10.1109/SmartIoT49966.2020.00012.
Ma J, Song Y, Tian X, Hua Y, Zhang R, Wu J. Survey on deep learning for pulmonary medical imaging. Front Med. 2020. https://doi.org/10.1007/s11684-019-0726-4.
Ma X, Shao Y, Ma Y, Zhang WQ. Deep semantic encoder-decoder network for acoustic scene classification with multiple devices. In: 2020 asia-pacific signal and information processing association annual summit and conference (APSIPA ASC). IEEE; 2020. p. 365–370.
Ma Y, Xu X, Li Y. LungRN+NL: an improved adventitious lung sound classification using non-local block resnet neural network with mixup data augmentation. INTERSPEECH. 2020. https://doi.org/10.2143/Interspeech.2020-2487.
Ma Y, Xu X, Yu Q, Zhang Y, Li Y, Zhao J, Wang G. Lungbrn: a smart digital stethoscope for detecting respiratory disease using bi-resnet deep learning algorithm. BioCAS. 2019. https://doi.org/10.1109/BIOCAS.2019.8919021.
Madhu A, Kumaraswamy S. Data augmentation using generative adversarial network for environmental sound classification. Eur Signal Proc Conf. 2019. https://doi.org/10.2391/EUSIPCO.2019.8902819.
Mareeswari V, Vijayan R, Sathiyamoorthy E, Ephzibah EP. A narrative review of medical image processing by deep learning models: origin to COVID-19. Int J Ad Technol Eng Explor. 2022. https://doi.org/10.1910/IJATEE.2021.874887.
Maria A, Jeyaseelan AS. Development of optimal feature selection and deep learning toward hungry stomach detection using audio signals. J Control Autom Electr Syst. 2021. https://doi.org/10.1007/s40313-021-00727-8.
Maruf SO, Azhar MU, Khawaja SG, Akram MU. Crackle separation and classification from normal respiratory sounds using gaussian mixture model. ICIIS. 2016. https://doi.org/10.1109/ICIINFS.2015.7399022.
Mary Shyni H, Chitra E. A comparative study of X-ray and CT images in COVID-19 detection using image processing and deep learning techniques. Comput Methods Progr Biomed Update. 2022. https://doi.org/10.1016/j.cmpbup.2022.100054.
Mayorga P, Ibarra D, Zeljkovic V, Druzgalski C. Quartiles and mel frequency cepstral coefficients vectors in hidden markov-gaussian mixture models classification of merged heart sounds and lung sounds signals. HPCS. 2015. https://doi.org/10.1109/HPCSim.2015.7237053.
Mijwil MM, Aggarwal K, Doshi R, Hiran KK, Sundaravadivazhagan B. Deep learning techniques for COVID-19 detection based on chest X-ray and CT-scan images: a short review and future perspective. Asian J Appl Sci. 2022. https://doi.org/10.2420/ajas.v10i3.6998.
Minami K, Lu H, Kim H, Mabu S, Hirano Y, Kido S. Automatic classification of large-scale respiratory sound dataset based on convolutional neural network. Int Conf Control Autom Syst. 2019. https://doi.org/10.2391/ICCAS47443.2019.8971689.
Miyamoto M, Yoshihara S, Shioya H, Tadaki H, Imamura T, Enseki M, Koike H, Furuya H, Mochizuki H. Lung sound analysis in infants with risk factors for asthma development. Health Sci Rep. 2021. https://doi.org/10.1002/hsr2.379.
Mu W, Yin B, Huang X, Xu J, Du Z. Environmental sound classification using temporal-frequency attention based convolutional neural network. Sci Rep. 2021. https://doi.org/10.1038/s41598-021-01045-4.
Mushtaq Z, Su SF, Tran QV. Spectral images based environmental sound classification using CNN with meaningful data augmentation. Appl Acoust. 2021. https://doi.org/10.1016/j.apacoust.2020.107581.
Naqvi SZH, Arooj M, Aziz S, Khan MU, Choudhary MA, Ul Hassan MN. Spectral analysis of lungs sounds for classification of asthma and pneumonia wheezing. ICECCE. 2020. https://doi.org/10.1109/ICECCE49384.2020.9179417.
Naqvi SZH, Choudhry MA. An automated system for classification of chronic obstructive pulmonary disease and pneumonia patients using lung sound analysis. Sensors. 2020. https://doi.org/10.3390/s20226512.
Nayak J, Naik B, Dinesh P, Vakula K, Dash PB, Pelusi D. Significance of deep learning for Covid-19: state-of-the-art review. Res Biomed Eng. 2022. https://doi.org/10.1007/s42600-021-00135-6.
Neili Z, Fezari M, Redjati A. ELM and K-nn machine learning in classification of breath sounds signals. Int J Electr Comput Eng. 2020. https://doi.org/10.1159/ijece.v10i4.pp3528-3536.
Nguyen T, Pernkopf F. Crackle detection in lung sounds using transfer learning and multi-input convolutional neural networks. EMBS. 2021. https://doi.org/10.1109/EMBC46164.2021.9630577.
Nguyen T, Pernkopf F. Lung sound classification using co-tuning and stochastic normalization. IEEE Trans Biomed Eng. 2022. https://doi.org/10.1109/TBME.2022.3156293.
Niu J, Cai M, Shi Y, Ren S, Xu W, Gao W, Luo Z, Reinhardt JM. A novel method for automatic identification of breathing state. Sci Rep. 2019. https://doi.org/10.1038/s41598-018-36454-5.
Novotný O, Plchot O, Glembek O, Černocký J, “Honza”, & Burget, L. Analysis of DNN speech signal enhancement for robust speaker recognition. Comput Speech Lang. 2019. https://doi.org/10.1016/j.csl.2019.06.004.
Nugroho K, Noersasongko E, Purwanto M, Setiadi DRIM. Enhanced indonesian ethnic speaker recognition using data augmentation deep neural network. J King Saud University Comput Infor Sci. 2022. https://doi.org/10.1016/j.jksuci.2021.04.002.
Oweis RJ, Abdulhay EW, Khayal A, Awad A. An alternative respiratory sounds classification system utilizing artificial neural networks. Biomed J. 2015. https://doi.org/10.4103/2319-4170.137773.
Owens D. R.A.L.E Lung Sounds 3.0. J Hosp Palliat Nurs. 2003. https://doi.org/10.1097/00129191-200307000-00011.
Ozer I, Ozer Z, Findik O. Lanczos kernel based spectrogram image features for sound classification. Procedia Comput Sci. 2017. https://doi.org/10.1016/j.procs.2017.06.020.
Padovese B, Frazao F, Kirsebom OS, Matwin S. Data augmentation for the classification of North Atlantic right whales upcalls. J Acoust Soc Am. 2021. https://doi.org/10.1121/10.0004258.
Painuli D, Bhardwaj S, Köse U. Recent advancement in cancer diagnosis using machine learning and deep learning techniques: a comprehensive review. Comput Biol Med. 2022. https://doi.org/10.1016/j.compbiomed.2022.105580.
Palaniappan R, Sundaraj K, Sundaraj S. A comparative study of the svm and k-nn machine learning algorithms for the diagnosis of respiratory pathologies using pulmonary acoustic signals. BMC Bioinformatics. 2014. https://doi.org/10.1186/1471-2105-15-223.
Pervaiz A, Hussain F, Israr H, Tahir MA, Raja FR, Baloch NK, Ishmanov F, Zikria YB. Incorporating noise robustness in speech command recognition by noise augmentation of training data. Sensors. 2020. https://doi.org/10.3390/s20082326.
Petmezas G, Cheimariotis GA, Stefanopoulos L, Rocha B, Paiva RP, Katsaggelos AK, Maglaveras N. Automated lung sound classification using a hybrid CNN-LSTM network and focal loss function. Sensors. 2022. https://doi.org/10.3390/s22031232.
Pham L, Phan H, Palaniappan R, Mertins A, McLoughlin I. CNN-MoE based framework for classification of respiratory anomalies and lung disease detection. IEEE J Biomed Health Inform. 2021. https://doi.org/10.1109/JBHI.2021.3064237.
Phani Sudershan C, Narayana Rao SVN. Classification of crackle sounds using support vector machine. Mater Today Proc. 2020. https://doi.org/10.1016/j.matpr.2020.10.463.
Rahmani AM, Azhir E, Naserbakht M, Mohammadi M, Aldalwie AHM, Majeed MK, Taher Karim SH, Hosseinzadeh M. Automatic COVID-19 detection mechanisms and approaches from medical images: a systematic review. Multimed Tools Appl. 2022. https://doi.org/10.1007/s11042-022-12952-7.
Rajkumar S, Sathesh K, Goyal NK. Neural network-based design and evaluation of performance metrics using adaptive line enhancer with adaptive algorithms for auscultation analysis. Neural Comput Appl. 2020. https://doi.org/10.1007/s00521-020-04864-0.
Respiratory Sound Database | Kaggle. (n.d.). Retrieved. https://www.kaggle.com/datasets/vbookshelf/respiratory-sound-database 2022
Respiratory Sounds Classification | CS 7651 - Machine Learning (Team 7). (n.d.). Retrieved. https://fereshtehshah.github.io/Respiratory_Disorders/ 2022
Riquelme D, Akhloufi M. Deep learning for lung cancer nodules detection and classification in CT scans. AI. 2020. https://doi.org/10.3390/ai1010003.
Rizal A, Hidayat R, Nugroho HA. Comparison of discrete wavelet transform and wavelet packet decomposition for the lung sound classification. Far East J Electr Commun. 2017. https://doi.org/10.1765/EC017051065.
Rizal A, Priharti W, Rahmawati D, Mukhtar H. Classification of pulmonary crackle and normal lung sound using spectrogram and support vector machine. J Biomimetics Biomater Biomed Eng. 2022. https://doi.org/10.4028/p-tf63b7.
Romero Gómez AF, Orjuela-Cañón AD. Respiratory sounds classification employing a multi-label approach. ColCACI. 2021. https://doi.org/10.1109/ColCACI52978.2021.9469042.
Salamon J, Bello JP. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process Lett. 2017. https://doi.org/10.1109/LSP.2017.2657381.
Saraiva AA, Santos DBS, Francisco AA, Moura Sousa JV, Fonseca Ferreira NM, Soares S, Valente A. Classification of respiratory sounds with convolutional neural network. BIOSTEC. 2020. https://doi.org/10.5220/0008965101380144.
Sathesh K, Rajkumar S, Goyal NK. Least mean square (LMS) based neural design and metric evaluation for auscultation signal separation. Biomed Signal Process Control. 2020. https://doi.org/10.1016/j.bspc.2019.101784.
Sen I, Saraclar M, Kahya YP. A comparison of svm and gmm-based classifier configurations for diagnostic classification of pulmonary sounds. IEEE Trans Biomed Eng. 2015. https://doi.org/10.1109/TBME.2015.2403616.
Serbes G, Ulukaya S, Kahya YP. An automated lung sound preprocessing and classification system based onspectral analysis methods. IFMBE Proc. 2018. https://doi.org/10.1007/978-981-10-7419-6_8.
Serrurier A, Neuschaefer-Rube C, Röhrig R. Past and trends in cough sound acquisition automatic detection and automatic classification: a comparative review. Sensors. 2022. https://doi.org/10.3390/s22082896.
Shahnawazuddin S, Adiga N, Kathania HK, Sai BT. Creating speaker independent ASR system through prosody modification based data augmentation. Pattern Recogn Lett. 2020. https://doi.org/10.1016/j.patrec.2019.12.019.
Shaish H, Ahmed FS, Lederer D, D’Souza B, Armenta P, Salvatore M, Saqi A, Huang S, Jambawalikar S, Mutasa S. Deep learning of computed tomography virtual wedge resection for prediction of histologic usual interstitial pneumonitis. Ann Am Thorac Soc. 2021. https://doi.org/10.1513/AnnalsATS.202001-068OC.
Sharma G, Umapathy K, Krishnan S. Trends in audio signal feature extraction methods. Appl Acoust. 2020. https://doi.org/10.1016/j.apacoust.2019.107020.
Shi Y, Li Y, Cai M, Zhang XD. A lung sound category recognition method based on wavelet decomposition and BP neural network. Int J Biol Sci. 2019. https://doi.org/10.7150/ijbs.29863.
Shimoda T, Obase Y, Nagasaka Y, Nakano H, Kishikawa R, Iwanaga T. Lung sound analysis can be an index of the control of bronchial asthma. Allergol Int. 2017. https://doi.org/10.1016/j.alit.2016.05.002.
Shorten C, Khoshgoftaar TM, Furht B. Deep learning applications for COVID-19. J Big Data. 2021. https://doi.org/10.1186/s40537-020-00392-9.
Shrestha A, Mahmood A. Review of deep learning algorithms and architectures. In IEEE Access. 2019. https://doi.org/10.1109/ACCESS.2019.2912200.
Singh C, Imam T, Wibowo S, Grandhi S. A deep learning approach for sentiment analysis of COVID-19 reviews. Appl Sci. 2022. https://doi.org/10.3390/app12083709.
Soomro TA, Zheng L, Afifi AJ, Ali A, Yin M, Gao J. Artificial intelligence (AI) for medical imaging to combat coronavirus disease (COVID-19): a detailed review with direction for future research. Artif Intell Rev. 2022. https://doi.org/10.1007/s10462-021-09985-z.
Sreejyothi S, Renjini A, Raj V, Swapna MNS, Sankararaman SI. Unwrapping the phase portrait features of adventitious crackle for auscultation and classification: a machine learning approach. J Biol Phys. 2021. https://doi.org/10.1007/s10867-021-09567-8.
Srivastava A, Jain S, Miranda R, Patil S, Pandya S, Kotecha K. Deep learning based respiratory sound analysis for detection of chronic obstructive pulmonary disease. PeerJ Comput Sci. 2021. https://doi.org/10.7717/PEERJ-CS.369.
Sugiura T, Kobayashi A, Utsuro T, Nishizaki H. Audio synthesis-based data augmentation considering audio event class. GCCE. 2021. https://doi.org/10.1109/GCCE53005.2021.9621828.
Taspinar YS, Koklu M, Altin M. Identification of the english accent spoken in different countries by the k-nearest neighbor method. Int J Intell Syst Appl Eng. 2020. https://doi.org/10.1820/ijisae.2020466312.
The R.A.L.E. Repository. (n.d.). Retrieved June 24, 2022, from http://www.rale.ca/
Tobón DP, Hossain MS, Muhammad G, Bilbao J, Saddik AE. Deep learning in multimedia healthcare applications: a review. Multimedia Syst. 2022. https://doi.org/10.1007/s00530-022-00948-0.
Tran VT, Tsai WH. Stethoscope-sensed speech and breath-sounds for person identification with sparse training data. IEEE Sens J. 2020. https://doi.org/10.1109/JSEN.2019.2945364.
Trusculescu AA, Manolescu D, Tudorache E, Oancea C. Deep learning in interstitial lung disease—how long until daily practice. In European Radiology. 2020. https://doi.org/10.1007/s00330-020-06986-4.
Turing Award 2018: Nobel Prize of computing given to ‘godfathers of AI’ - The Verge. (n.d.). Retrieved. https://www.theverge.com/2019/3/27/18280665/ai-godfathers-turing-award-2018-yoshua-bengio-geoffrey-hinton-yann-lecun 2023
Vineth Ligi S, Kundu SS, Kumar R, Narayanamoorthi R, Lai KW, Dhanalakshmi S. Radiological analysis of COVID-19 using computational intelligence: a broad gauge study. J Healthcare Eng. 2022. https://doi.org/10.1155/2022/5998042.
Vryzas N, Kotsakis R, Liatsou A, Dimoulas C, Kalliris G. Speech emotion recognition for performance interaction. AES J Audio Eng Soc. 2018. https://doi.org/10.1774/jaes.2018.0036.
Wang S, Yang DM, Rong R, Zhan X, Fujimoto J, Liu H, Minna J, Wistuba II, Xie Y, Xiao G. Artificial intelligence in lung cancer pathology image analysis. Cancers. 2019. https://doi.org/10.3390/cancers11111673.
Wang S, Yang Y, Wu Z, Qian Y, Yu K. Data augmentation using deep generative models for embedding based speaker recognition. IEEE/ACM Trans Audio Speech Lang Proc. 2020. https://doi.org/10.1109/TASLP.2020.3016498.
Wang Y, Hargreaves CA. A review study of the deep learning techniques used for the classification of chest radiological images for COVID-19 diagnosis. Int J Inf Manag Data Insights. 2022. https://doi.org/10.1016/j.jjimei.2022.100100.
Wu G, Jochems A, Refaee T, Ibrahim A, Yan C, Sanduleanu S, Woodruff HC, Lambin P. Structural and functional radiomics for lung cancer. Eur J Nuclear Med Mol Imag. 2021. https://doi.org/10.1007/s00259-021-05242-1.
Wyatt S, Elliott D, Aravamudan A, Otero CE, Otero LD, Anagnostopoulos GC, Smith AO, Peter AM, Jones W, Leung S, Lam E. Environmental sound classification with tiny transformers in noisy edge environments. WF-IoT. 2021. https://doi.org/10.1109/WF-IoT51360.2021.9596007.
Xu L, Cheng J, Liu J, Kuang H, Wu F, Wang J. ARSC-Net: adventitious respiratory sound classification network using parallel paths with channel-spatial attention. BIBM. 2021. https://doi.org/10.1109/BIBM52615.2021.9669787.
Yang Z, Liu S, Song M, Parada-Cabaleiro E, Schuller BW. Adventitious respiratory classification using attentive residual neural networks. INTERSPEECH. 2020. https://doi.org/10.2143/Interspeech.2020-2790.
Yella N, Rajan B. Data augmentation using GAN for sound based COVID 19 diagnosis. IDAACS. 2021. https://doi.org/10.1109/IDAACS53288.2021.9660990.
Ykhlef H, Ykhlef F, Chiboub S. Experimental design and analysis of sound event detection systems: case studies. ISPA. 2019. https://doi.org/10.1109/ISPA48434.2019.8966798.
Zhang Z, Han J, Qian K, Janott C, Guo Y, Schuller B. Snore-GANs: improving automatic snore sound classification with synthesized data. IEEE J Biomed Health Inform. 2020. https://doi.org/10.1109/JBHI.2019.2907286.
Zhao L, Lediju Bell MA. A review of deep learning applications in lung ultrasound imaging of COVID-19 patients. BME Front. 2022. https://doi.org/10.3413/2022/9780173.
Zhao X, Shao Y, Mai J, Yin A, Xu S. Respiratory sound classification based on BiGRU-attention network with XGBoost. BIBM. 2020. https://doi.org/10.1109/BIBM49941.2020.9313506.
Zhao Y, Togneri R, Sreeram V. Replay anti-spoofing countermeasure based on data augmentation with post selection. Comput Speech Lang. 2020. https://doi.org/10.1016/j.csl.2020.101115.
Zheng Q, Zhao P, Li Y, Wang H, Yang Y. Spectrum interference-based two-level data augmentation method in deep learning for automatic modulation classification. Neural Comput Appl. 2021. https://doi.org/10.1007/s00521-020-05514-1.
Zheng X, Zhang C, Chen P, Zhao K, Jiang H, Jiang Z, Pan H, Wang Z, Jia W. A CRNN system for sound event detection based on gastrointestinal sound dataset collected by wearable auscultation devices. IEEE Access. 2020. https://doi.org/10.1109/ACCESS.2020.3020099.
Zulfiqar R, Majeed F, Irfan R, Rauf HT, Benkhelifa E, Belkacem AN. Abnormal respiratory sounds classification using deep CNN through artificial noise addition. Front Med. 2021. https://doi.org/10.3389/fmed.2021.714811.
Acknowledgements
This work was supported by the University of Putra Malaysia through a project under the title “A high efficient RLC inductive transmission coupling to monitor in-stent restenosis coronary artery,” under Geran Inisiatif Putra Siswazah (GP-IPS) Grant No. 9712900.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
A, N and A contributed to the design and implementation of the research, to the analysis of the results, and to the writing of the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Competing interests
The authors declare that they have no competing interests in relation to this research, whether financial, personal, authorship or otherwise, that could affect the research and its results presented in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sfayyih, A.H., Sulaiman, N. & Sabry, A.H. A review on lung disease recognition by acoustic signal analysis with deep learning networks. J Big Data 10, 101 (2023). https://doi.org/10.1186/s40537-023-00762-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40537-023-00762-z