
Abstract
Background
Acute kidney injury (AKI) is one of the preventable complications of percutaneous coronary intervention (PCI). This study aimed to develop machine learning (ML) models to predict AKI after PCI in patients with acute coronary syndrome (ACS).
Methods
This study was conducted at Tehran Heart Center from 2015 to 2020. Several variables were used to design five ML models: Naïve Bayes (NB), Logistic Regression (LR), CatBoost (CB), Multi-layer Perception (MLP), and Random Forest (RF). Feature importance was evaluated with the RF model, CB model, and LR coefficients while SHAP beeswarm plots based on the CB model were also used for deriving the importance of variables in the population using pre-procedural variables and all variables. Sensitivity, specificity, and the area under the receiver operating characteristics curve (ROC-AUC) were used as the evaluation measures.
Results
A total of 4592 patients were included, and 646 (14.1%) experienced AKI. The train data consisted of 3672 and the test data included 920 cases. The patient population had a mean age of 65.6 ± 11.2 years and 73.1% male predominance. Notably, left ventricular ejection fraction (LVEF) and fasting plasma glucose (FPG) had the highest feature importance when training the RF model on only pre-procedural features. SHAP plots for all features demonstrated LVEF and age as the top features. With pre-procedural variables only, CB had the highest AUC for the prediction of AKI (AUC 0.755, 95% CI 0.713 to 0.797), while RF had the highest sensitivity (75.9%) and MLP had the highest specificity (64.35%). However, when considering pre-procedural, procedural, and post-procedural features, RF outperformed other models (AUC: 0.775). In this analysis, CB achieved the highest sensitivity (82.95%) and NB had the highest specificity (82.93%).
Conclusion
Our analyses showed that ML models can predict AKI with acceptable performance. This has potential clinical utility for assessing the individualized risk of AKI in ACS patients undergoing PCI. Additionally, the identified features in the models may aid in mitigating these risk factors.
Graphical Abstract

Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Introduction
Coronary artery disease, particularly acute coronary syndrome (ACS), is responsible for approximately one-third of all deaths in adults over 35. Nowadays percutaneous coronary intervention (PCI) is the most widely used treatment for ACS. Acute kidney injury (AKI) is a serious non-cardiovascular complication in patients with ACS, and nearly 12.8% of the patients develop AKI as a major post-PCI complication with a 20.2% attributed mortality rate during or after hospitalization [1, 2]. A growing body of evidence indicates that AKI is significantly associated with an increased risk of long-term morbidities such as repeated coronary revascularization, myocardial infarction, and stroke [3, 4].
To prevent contrast induced-AKI (CI-AKI), physicians can implement preventive measures such as regulating contrast volume and osmolarity, pre-procedural statin intake, and pre- and post-procedural hydration [1, 5]. Identifying PCI-related patient risks allows physicians to tailor strategies based on each individual’s risk profile, leading to fewer complications and improved clinical outcomes after a PCI procedure [1, 6]. Prediction models, such as the NCDR-AKI risk model, have been developed to assess the risk of CI-AKI prior to performing PCI with a c-statistics of 0.71 [7]. Traditional statistical models may not include all possible interactions when there are numerous candidate variables, resulting in a decrease in the model’s accuracy when these interactions are ignored [1, 8]. Machine Learning (ML)-based models do not depend on assumptions about the variables involved or their relationship with the outcome. Instead, they capture complex relationships in a data-driven manner, including nonlinearity and interactions that may be difficult to identify otherwise. These models have been used for the prediction of outcomes in cardiovascular medicine [9,10,11].
This study aims to evaluate novel ML-based models to more accurately predict the risk of PCI-induced AKI in ACS patients and subsequently reduce the risk of long-term complications. The efficacy of ML-based models will be compared with traditional stepwise selection models, and the study will investigate whether machine learning-based models can sufficiently reduce the variables needed for disease prognosis prediction.
Methods
Study design
We retrospectively reviewed all patients with ACS [ST-elevation myocardial infarction (STEMI), non-STEMI, and unstable angina (UA)] who underwent PCI at Tehran Heart Center between 2015 and 2020. The ethics committee of Tehran Heart Center approved this study (IR.TUMS.MEDICINE.REC.1402.178). The informed consent was waived due to the retrospective design of this study.
Variable’s definition and outcome
Pre-procedural variables used were: gender, age, left ventricular ejection fraction (LVEF), atrial fibrillation (AF), fasting plasma glucose (FPG), triglycerides (TG), total cholesterol (TC), low-density lipoprotein cholesterol (LDL-C), high-density lipoprotein cholesterol (HDL-C), drug history (lipid-lowering, anti-diabetes, anti-hypertension, anti-arrhythmia, and anti-thrombotic), hematocrit, body mass index (BMI), estimated glomerular filtration rate (eGFR), creatinine (Cr), type of diabetes management, past medical histories (cardiac, renal, previous PCI, previous CABG), and CAD risk factors.
Procedural variables were: non-ST elevation myocardial infarction (NSTEMI) in coronary angiography (CAG), acute MI in CAG, treated vessel, procedure result, stenosis, stent diameter, stent length, stent inflation pressure, post-procedural complications (arrhythmia, cardiopulmonary resuscitation (CPR), aborted cardiac arrest, and procedure-induced shock).
AKI, the primary outcome in this study, was defined based on the acute kidney injury necrosis (AKIN) as an absolute increase of ≥ 0.3 mg/dL or a relative increase of ≥ 50% in serum creatinine after the procedure [12].
Data cleaning
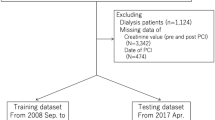
At first, patients with missing data for follow-up were removed and missing data for other features were handled through imputation with median values for numerical features and mode for categorical ones. Notably, features with more than 40% missing data were removed from the models. Then, the patients with end-stage renal disease (ESRD) (eGFR < 15 mL/min) were excluded. Moreover, we excluded individuals with implausible creatinine values (Cr < 0.3 mg/dL or Cr > 4.0 mg/dL). Label encoder (from the scikit-learn library) was used to change categorical variables into numerical variables.
Train/test split and feature selection
We randomly assigned each patient to the train (80%) or test (20%) dataset using stratified splitting. Five-fold cross-validation was used in this study for feature selection and hyperparameter tuning. To find the most important variables among the vast number of procedural and post-procedural features, and to reduce the complexity of our models, we first trained an RF model on these features from our training dataset as our feature selector. We selected the top 15 features based on the feature importance given by this model. This cutoff was defined as we wanted to use features, sum of which contributed to 80% of the total feature importance. The selected features are used as our procedural features to train the main models in this study. Moreover, SHapley Additive ExPlanations (SHAP), as a game-based feature analysis technique [13], based on the CatBoost model were used to generate beeswarm plots for feature importance.
We feature-engineered a few variables to provide the models with more context and useable features. As there were multiple creatinine measurements before the PCI procedure, we added creatinine standard deviation, creatinine mean, and creatinine change (defined as the difference between the last creatinine before PCI and the first creatinine levels), in addition to the last creatinine measurement before PCI for each patient.
Moreover, as there were multiple binary features for each patient encoding various past medical conditions, risk factors, and drug history, we defined the new features to reduce the complexity of our models. This was based on the fact that in most cases there was not a high number of cases positive for each feature and by merging them, the models could take advantage of variables with a higher proportion of positive cases. The following features were used: (i) cardiac risk factors which are defined as the number of all cardiac risk factors each patient had (family history, hyperlipidemia, diabetes, and hypertension); (ii) cardiac past medical history (PMH), which is defined as the number of cardiac conditions (STEMI, NSTEMI, CHF, PMH valvular heart disease, peripheral vascular disease, and CPR), renal PMH (renal failure, and dialysis); (iii) other PMH (SA, UA, chronic lung disease); (iv) anti-arrhythmic, which is defined as the number of all anti-arrhythmic medications the patient has been using (Digoxin and Amiodarone); (v) anti-thrombotic and platelet (Aspirin, Clopidogrel, and Warfarin); (vi) anti-hypertension (angiotensin receptor blockers, beta-blockers, calcium channel blockers, and diuretics); and (vii) diabetes medications (metformin, glibenclamide, acarbose, and insulin).
Model development
We used five models to predict AKI in patients who underwent PCI: Naïve Bayes (NB), logistic regression (LR), CatBoost (CB), multilayer perception (MLP), and Random Forest (RF). Each model was trained and evaluated using five-fold cross-validation. Test data remained unseen during model development.
Model evaluation
Models were evaluated using three metrics: area under the receiver operating characteristics curve (AUC), sensitivity, and specificity. The AUC is independent of the threshold and measures the discriminative ability of models by plotting the true positive rate against the false positive rate. Different AUC scores could be categorized as follows: (1) outstanding (AUC ≥ 0.9), (2) excellent (0.8 ≤ AUC < 0.9), (3) acceptable or fair (0.7 ≤ AUC < 0.8), (4) poor (0.6 ≤ AUC < 0.7), and no discrimination (AUC < 0.6). Finally, to make the RF model explainable and assess the effect of each variable on overall predictive ability, we used an explainable AI method on positive and negative individual cases separately, to gain more insight into the effect of each feature on the final probability predicted by the RF model [14].
Statistical analysis
Mean ± standard deviation or proportion (percentage) was used for reporting baseline characteristics of patients who developed and did not develop AKI in each of the test and train cohorts. Regarding AUCs, we calculated the 95% confidence interval (CI) of AUCs using a 1000-time bootstrap in the test cohort. We developed the models and performed all the analyses using Python (version 3.8). LR, RF, MLP, and NB models were trained using the scikit-learn (1.0.2) library [15] and CB using the CatBoost library (version 1.2) Python library.
Results
Patient characteristics
A total of 4592 patients were identified among which 646 (14.1%) had developed AKI after undergoing PCI. The train data consisted of 3672 (80%) patients (517 had AKI), and the test data included 920 cases (20%), among which 129 had AKI. Mean age of the total population was 65.6 ± 11.2 years (69.2 ± 11.6 in the AKI group and 65 ± 11.2 in the non-AKI group) and males contributed to 73.1% of the overall cohort. Moreover, with a mean BMI of 28.1 ± 4.4 kg/m2, 57.7% had hypertension, 44.9% were diabetic, and 39.1% were smokers. Recorded data showed that 82.3% of patients with AKI and 63.1% of those without had acute MI (STEMI or NSTEMI). Details of all baseline characteristics and angiography data for the test and train cohort are shown in Table 1.
Feature importance
Feature importance plots based on LR coefficients, RF model, and CB model for the prediction of AKI after PCI are shown using pre-procedural features in Fig. 1 and using all features in Fig. 2. The beeswarm plots for SHAP values based on the CB model are also illustrated in Fig. 3.

Feature importance for models using pre-procedural features only. A Logistic Regression Coefficients; B Random Forest Feature Importance; C CatBoost Feature Importance. LVEF left ventricular ejection fraction, FPG fasting plasma glucose, CPR cardiopulmonary resuscitation, PCI percutaneous coronary intervention, BMI body mass index, TC total cholesterol, LDL-C low-density lipoprotein cholesterol, PMH past medical history, UA unstable angina, MI myocardial infarction, TG triglyceride, HDL-C low-density lipoprotein cholesterol, CAD coronary artery disease, CABG coronary artery bypass grafting

Feature importance for models using pre-procedural, procedural, and post-procedural features. A Logistic Regression Coefficients; B Random Forest Feature Importance; C CatBoost Feature Importance. LVEF left ventricular ejection fraction, FPG fasting plasma glucose, CPR cardiopulmonary resuscitation, PCI percutaneous coronary intervention, BMI body mass index, TC total cholesterol, LDL-C low-density lipoprotein cholesterol, PMH past medical history, UA unstable angina, MI myocardial infarction, TG triglyceride, HDL-C low-density lipoprotein cholesterol, CAD coronary artery disease, CABG coronary artery bypass grafting

ROC-AUC Curves for the five ML models. A Using pre-procedure features only; B using pre-procedure and procedural features
Pre-procedural features
Figure 1 shows feature ranks based on LR coefficients in addition to the RF and CB models using pre-procedure features only. As illustrated in Fig. 1A, LVEF had the highest negative correlation with AKI occurrence post-PCI, while age had the highest positive association with the outcome. RF model also ranked LVEF as the top feature, followed by FPG and the last creatinine before PCI (Fig. 1B). Finally, the CB model represented LVEF and FPG as the highest predictors of AKI post-PCI (Fig. 1C). Also, as shown in Fig. 3A as a SHAP beeswarm plot, LVEF ranked the highest classifier among the pre-procedural features.
Pre-procedural, procedural, and post-procedural features
LR model showed that LVEF was the main predictor of AKI with an inverse relationship between AKI and LVEF. However, age and acute MI in coronary angiography were the top positively correlated features, as depicted in Fig. 2A. Investigating the feature importance of the RF model, LVEF was the main predictor while aborted cardiac arrest in PCI, and CPR in PCI were the second and third top predictors (Fig. 2B). Last creatinine before PCI, FPG, mean creatinine, and eGFR were the next predictors. Figure 2C shows that LVEF, age, and BMI were the top three features, considering the CB model. Similarly, the SHAP beeswarm plot shown in Fig. 3B reports LVEF and age as the main discriminatory variables among all features.
Model’s evaluation
In this study five models were assessed for the prediction of AKI after PCI, the evaluation was once done using pre-procedural features only and once with pre-procedural, procedural, and post-procedural features, details are described in Table 2. In pre-procedural features-only analysis, the CB model outperformed the other models with an AUC of 0.755 (95% CI 0.713–0.797). RF and LR models had the same AUC of 0.74 (95% CI 0.694–0.783 and 0.689–0.785, respectively), followed by the MLP model with an AUC of 0.732 (95% CI 0.687–0.778) (Fig. 4A). In terms of sensitivity and specificity, RF and MLP recorded the highest, with 75.97% and 64.35% sensitivity and specificity, respectively. When procedural and post-procedural features were added to training features, the RF model performed the best in terms of AUC (0.775, 95% CI 0.730–0.818), slightly higher than the CB model (AUC 0.774, 95% CI 0.728–0.816). LR and NB models had AUCs of 0.770 (95% CI 0.725–0.811) and 0.763 (95% CI 0.715–0.804), respectively (Fig. 4B). A sensitivity of 82.95% in the CB model and a specificity of 82.93% in the NB model were the highest sensitivity and specificity among the models. With regard to making the final RF model explainable, as shown in Fig. 5, the effect of each feature in terms of raw probability is observed for one positive (5A) and one negative case (5B). The occurrence of the post-procedure arrest and CPR was effective in assigning a high probability for the positive cases by the RF model and the normal FPG of the patient was effective in reducing the overall probability. In negative cases, LDL-C and creatinine change had the highest negative impact while acute MI, NSTEMI/UA, and LVEF had the highest positive impact.

SHAP beeswarm plot for feature importance based on the CatBoost model. A Using pre-procedure features only; B using pre-procedure and procedural features

Effects of each variable on the RF model using pre-procedure, procedural, and post-procedural features for (A) one positive case (with AKI), B one negative case (without AKI). LVEF left ventricular ejection fraction, FPG fasting plasma glucose, CPR cardiopulmonary resuscitation, PCI percutaneous coronary intervention, BMI body mass index, TC total cholesterol, LDL-C low-density lipoprotein cholesterol, PMH past medical history, UA unstable angina, MI myocardial infarction
Discussion
In this registry-based study, we employed ML algorithms to predict the AKI incidence in ACS patients who underwent PCI. Our results indicated a novel step toward predicting AKI occurrence following PCI with the aid of ML, as all five ML models (RF, LR, CB, MLP, and NB) were able to enhance the prediction of AKI using both pre-procedural features only and all features combined data, with all models exhibiting an acceptable predictive capability (AUC value > 0.7), based on AUC interpretation [16]. While the CB model was the best when running the models with pre-procedural features only (AUC = 0.755), the RF model demonstrated the best performance using all features combined data (AUC = 0.775). The study also found that the RF model outperformed in terms of sensitivity (75.97%) and MLP had the highest specificity (64.35%) in the pre-procedural features analysis. Once procedural features were added, the CB model became the best model in terms of sensitivity (82.95%), while the NB model exhibited the highest specificity (82.93%).
As AKI is a preventable complication after PCI, a precise risk prediction system is needed which can improve clinical decision-making and management strategies such as sufficient hydration and contrast volume reduction in high-risk patients [7, 17]. The traditional models for the prediction of the risk of AKI after PCI have provided a notable enhancement in decision support and quality of care; however, they have several limitations and drawbacks, leading to underestimating the risk of AKI in a small proportion of patients, while overestimating it in others [18, 19]. For instance, relying on subjective assumptions for choosing the candidate variables, which are often transformed into categorical variables due to the convenience of calculating the risk scores [6]. Moreover, the single-center or single-country nature of these studies may lead to limited application in other clinical settings and highlight the need for localized models designed for other regions. Another limitation was the lack of control for renal protective medications and the lack of implementing procedural features in some [7]. Even though helpful, the conventional models are not sufficiently precise for Individual personalized evaluation and shared decision-making models in the modern medicine [1, 20]. Therefore, looking for more competent alternatives to traditional risk estimation models seems indispensable. Through this purpose, ML models are being developed rapidly regarding risk stratification of AKI for further safety considerations before, during, and after PCI. The computational discipline of ML-based methods allows the algorithm formulation into models capable of recognizing complex patterns or interactions when utilizing extensive data [8, 21]. By incorporating ML into the model development process, there is the potential to enhance the accuracy of the AKI risk stratification [6, 22]. In addition, the utilization of all available variables in ML modeling along with a permutation test for variable selection could contribute to promoting the performance of the ML modeling. Accordingly, ML models demonstrated superior performance compared to conventional models in terms of predictive performance and risk stratification of AKI for patients with PCI [6].
Also, a recent study conducted by Kuno et al. attempted to compare the conventional logistic regression prediction model with that of an ML model concerning the calculation of the risk of AKI after PCI. They used the light gradient boosting model (GBM) ML algorithm, along with Lasso and SHAP methods for variable selection. Their results indicated that the ML model provided comparable risk quantification accuracy using fewer variables than the logistic regression model [8]. Our study had several similarities and differences with this study. One of the key differences was that in contrast with Kuno et al. study, we designed our ML models both with and without operative variables which might be helpful in clinical settings when operative features can also be utilized. The predictive ability of our models was comparable with those of this study in terms of AUC. In this study, the LR model had an AUC of 0.755 in the test dataset, while in ours, LR achieved an AUC of 0.74 and 0.77 in the model with pre-procedure features and the model with all features, respectively. One of the other differences was that this study used a different feature selection method, first using Lasso through LR and then subsequently with SHAP based on GBM, however, we implemented the RF feature selector while demonstrating feature importance with LR coefficients, RF model, and CB model, in addition to SHAP beeswarm plots.
In line with our results, the cohort study of Sun et al. suggested that ML algorithms, particularly the RF model, can promote the accuracy of contrast-induced AKI risk stratification following acute myocardial infarction. They identified that the RF machine learning algorithm achieved the highest sensitivity of 71.9%, an accuracy of 73.5%, and an AUC of 0.82, which notably outperformed LR models [1]. In agreement with previous studies, our results revealed that the RF model has the best predictive ability. The RF model, constructed using an ensemble of multiple decision trees, can overcome the issue of overfitting in ML analysis, by aggregating decisions across a vast number of randomly generated trees [23, 24]. One key advantage of the RF model is its ability to reduce the number of variables, thereby simplifying the final model which could be explained more easily and reducing the risk of overfitting it on noisy features. Furthermore, highly correlated features do not cause multi-collinearity issues for RF models. Hence, due to the RF model being an inherent ensemble model (ensemble of lots of decision trees) and knowing that it is more robust to inter-correlated features, we can expect better performance in most cases where RF is used, however, it’s not a universal rule [25, 26].
However, in contrast to the finding of the present study, Niimi et al. demonstrated that the XGBoost ML model can significantly improve the discrimination value for predicting the risk of AKI following PCI (C-statistics of 0.84, P < 0.001) [27]. XGBoost was one of the ideal candidates to be trained in our study as well; however, since XGBoost needs a large dataset such as the one in Niimi et al. study, acceptable performance could not be obtained using preliminary analyses in our study. In contrast, we used the CatBoost model, similar to XGBoost but with a lower chance of overfitting on smaller datasets. In our study, this model had the highest performance when using pre-procedural features, showing its strength in the prediction of AKI.
In a more recent publication, the support vector machine (SVM) model showed the most outstanding AUC of 0.784 in terms of identifying the risk of contrast-induced nephropathy in elective PCI patients. The SVM model also outperformed logistic regression models [28]. Therefore, although currently available evidence suggests the potential efficacy of ML models for AKI risk prediction after PCI, selecting the optimal model has remained controversial. Additionally, it has been shown that in datasets with imbalanced data, such as ours, RF could outperform support vector machine (SVM) and XGBoost [29]. SVM is also a time-consuming algorithm that takes plenty of time to train the models. On the other hand, the K-nearest neighbor (KNN) is not able to show the differences in the predictive ability of features. Hence, these models are not routinely used by the newer studies and have been replaced by methods such as RF.
In this study, we report the feature importance of the RF model, the CB model, and the coefficients of the LR model, both with and without procedural findings. Although selecting the suitable features based on the RF model might lead to eventually the overall better performance of the RF model, it should be noted that RF feature selection has been shown to perform better than the two other classifiers (Boruta and Recursive Feature Elimination) [26]. In performing feature engineering, we combined some of the variables such as risk factors and creatinine levels to produce new variables. Mean and SD of creatinine levels measured at different time points before PCI might add some complexity to the models. We created this variable to use more of the data available for patients. Clinicians can benefit from these values if more than one creatinine level is available during the hospitalization course. However, this is not a limitation, since there were many patients with only one creatinine level for which the model was also optimized. With the use of electronic records, the mean and SD of all creatinine levels measured before PCI can be added to the model to enhance predictive ability.
Based on the LR model coefficients, LVEF and age had the highest negative and positive correlation with AKI occurrence post-PCI, in both pre-procedural and all features. The RF model also showed LVEF as the most important feature, followed by FPG and the last creatinine, mean creatinine, and eGFR using pre-procedural findings. Previously, several investigations showed that hypotension, intra-aortic balloon pump, congestive heart failure, chronic kidney disease, diabetes, age > 75 years, anemia, and volume of contrast (known as Mehran score) contributed to AKI incidence after PCI [18, 30], while several of them have been associated with major adverse events as well [31,32,33]. Also, the combination of age, serum creatinine, EF, and eGFR levels (calculated as ACEF-MDRD score) was found to be associated with the risk of AKI after PCI [34, 35]. Similarly, a study reported that contrast-induced AKI (CI-AKI) following PCI was observed more frequently in patients with diabetes, LVEF < 50%, older age, severe heart failure following acute MI, previous aspirin use, and higher ACEF-MDRD score [36]. Additionally, it has been suggested that reduced LVEF and heart failure could increase the risk of AKI in patients who underwent coronary artery bypass grafting [37]. So far, evidence has demonstrated that higher FPG levels can participate in impaired kidney function, leading to an increased risk of AKI while higher FPG levels are often associated with other risk factors for AKI, which can further increase the likelihood of developing AKI after PCI [38].
In a study, Lasso and SHAP methods in ML selected that ST-elevation MI, eGFR, age, preprocedural hemoglobin, non-ST-elevation MI/unstable angina, heart failure at admission, and cardiogenic shock as the pertinent predictor for AKI risk after PCI [8]. On the other hand, Ma et al. reported 11 important predictors of CI-nephropathy after PCI, including uric acid, peripheral vascular disease, cystatin C, creatine kinase-MB, hemoglobin, N-terminal pro-brain natriuretic peptide, age, diabetes, systemic immune-inflammatory index, total protein, and low-density lipoprotein, using SHAP method [28]. Also, age, serum creatinine level, and LVEF were among the top 20 ranked important variables concerning CI-AKI risk stratification after acute MI, using the Boruta ML algorithm [1].
Given the potential importance of AKI as an adverse event after PCI, models such as the ones investigated in this study can have clinical applications in the prediction of AKI post-PCI in patients with ACS, after further confirmation in larger studies. With implementing easy-to-use variables both pre-procedural and procedural, these ML-based models provided acceptable predictions. Our models showed similar prediction ability between models with and without procedural variables. It is of importance since intra-procedural features are dependent on the skill of the team performing PCI which makes it subjective and, hence, makes the inherent risk of patients less highlighted [18, 39]. Individualized risk stratification in predicting PCI can lead to better prevention of AKI after PCI. LVEF, age, and FPG were the main predictors of AKI which are easy to measure in patients with ACS admitted to PCI units. Clinicians could take advantage of these models for the prediction of AKI and therefore, provide better care for those at higher risk. These kinds of models could be used regionally or even internationally when assessed in different settings and on different populations.
Several limitations to our research need to be mentioned. Firstly, the single-center nature of our study could affect our findings. Furthermore, it is essential to consider the potential impact of not incorporating confounding variables. It is also important to note that electrocardiogram data and follow-up laboratory data were not available in this databank. Another limitation of our study was missing data that we handled by replacing with median in continuous variables and with mode in categorical ones, which might not have been the optimal way for doing so; however, the prediction of missing data was not possible due to not having a large enough dataset. Moreover, since we tuned the threshold for classifying the groups to optimize sensitivity (recall), we were not able to assess the calibration of our models, and the probabilities in models were only used to identify the optimal threshold. Also, the fact that our data were imbalanced and we tuned our models for better prediction of AKI based on AUC using five-fold cross-validation, led to relatively lower specificities, compared to AUCs and sensitivities. This is a limitation of our study; however, it should be considered that in these types of adverse events, higher sensitivity is much favored over higher specificity since the clinician’s aim is to not miss any potentially high-risk case in terms of AKI. Also, in our study, the threshold was adjusted for higher sensitivity while in other clinical settings, it could be tuned for higher specificity based on clinical settings. Finally, despite using fivefold cross-validation in our training cohort and evaluating the models on an unseen test cohort, the lack of external validation in our study might threaten the generalizability of our findings and models.
Conclusion
In conclusion, the ML models such as RF, LR, CB, MLP, and NB algorithms, showed an acceptable predictive performance for the risk of AKI following PCI, with RF and CB providing the greatest discriminations. Also, the most important features for the AKI prediction were detected, and LVEF demonstrated the largest coefficient in all predicting models. Therefore, it could be suggested that ML models, particularly the RF model, improve the accuracy of AKI prediction in patients undergoing PCI, which has significant implications for clinical decision-making and management to prevent AKI incidence. However, further studies are necessitated to validate the findings of the present study.
Availability of data and materials
The data used in this study will be made available upon reasonable request from the corresponding author.
Abbreviations
- AKI:
-
Acute kidney injury
- PCI:
-
Percutaneous coronary intervention
- ML:
-
Machine learning
- ACS:
-
Acute coronary syndrome
- NB:
-
Naïve Bayes
- LR:
-
Logistic Regression
- RF:
-
Random Forest
- CB:
-
CatBoost
- MLP:
-
Multi-layer perception
- AUC:
-
Area under the receiver operating characteristics curve
- CI-AKI:
-
Contrast induced-AKI
- STEMI:
-
ST-elevation myocardial infarction
- UA:
-
Unstable angina
- LVEF:
-
Left ventricular ejection fraction
- AF:
-
Atrial fibrillation
- FPG:
-
Fasting plasma glucose
- TG:
-
Triglycerides
- TC:
-
Total cholesterol
- LDL-C:
-
Low-density lipoprotein cholesterol
- HDL-C:
-
High-density lipoprotein cholesterol
- BMI:
-
Body mass index
- eGFR:
-
Estimated glomerular filtration rate
- Cr:
-
Creatinine
- CABG:
-
Coronary artery bypass grafting
- NSTEMI:
-
Non-ST elevation myocardial infarction
- CAG:
-
Coronary angiography
- CPR:
-
Cardiopulmonary resuscitation
- AKIN:
-
Acute kidney injury necrosis
- ESRD:
-
End-stage renal disease
- PMH:
-
Past medical history
- CI:
-
Confidence interval
- AVM:
-
Support vector machine
- KNN:
-
K-nearest
- GBM:
-
Gradient boosting model
- SHAP:
-
SHapley Additive exPlanations
References
Sun L, Zhu W, Chen X, Jiang J, Ji Y, Liu N, et al. Machine learning to predict contrast-induced acute kidney injury in patients with acute myocardial infarction. Front Med. 2020;7: 592007.
Tsai TT, Patel UD, Chang TI, Kennedy KF, Masoudi FA, Matheny ME, et al. Contemporary incidence, predictors, and outcomes of acute kidney injury in patients undergoing percutaneous coronary interventions: insights from the NCDR Cath-PCI registry. JACC Cardiovasc Interventions. 2014;7(1):1–9.
Chalikias G, Serif L, Kikas P, Thomaidis A, Stakos D, Makrygiannis D, et al. Long-term impact of acute kidney injury on prognosis in patients with acute myocardial infarction. Int J Cardiol. 2019;283:48–54.
Ng AK, Ng PY, Ip A, Lam LT, Ling IW, Wong AS, et al. Impact of contrast-induced acute kidney injury on long-term major adverse cardiovascular events and kidney function after percutaneous coronary intervention: insights from a territory-wide cohort study in Hong Kong. Clin Kidney J. 2022;15(2):338–46.
Maksimczuk J, Galas A, Krzesiński P. What promotes acute kidney injury in patients with myocardial infarction and multivessel coronary artery disease-contrast media, hydration status or something else? Nutrients. 2022;15(1):21.
Huang C, Murugiah K, Mahajan S, Li SX, Dhruva SS, Haimovich JS, et al. Enhancing the prediction of acute kidney injury risk after percutaneous coronary intervention using machine learning techniques: a retrospective cohort study. PLoS Med. 2018;15(11): e1002703.
Tsai TT, Patel UD, Chang TI, Kennedy KF, Masoudi FA, Matheny ME, et al. Validated contemporary risk model of acute kidney injury in patients undergoing percutaneous coronary interventions: insights from the National Cardiovascular Data Registry Cath-PCI Registry. J Am Heart Assoc. 2014;3(6): e001380.
Kuno T, Mikami T, Sahashi Y, Numasawa Y, Suzuki M, Noma S, et al. Machine learning prediction model of acute kidney injury after percutaneous coronary intervention. Sci Rep. 2022;12(1):749.
Negassa A, Ahmed S, Zolty R, Patel SR. Prediction model using machine learning for mortality in patients with heart failure. Am J Cardiol. 2021;153:86–93.
Khalaji A, Behnoush AH, Jameie M, Sharifi A, Sheikhy A, Fallahzadeh A, et al. Machine learning algorithms for predicting mortality after coronary artery bypass grafting. Front Cardiovasc Med. 2022;9: 977747.
de Oliveira Gomes BF, da Silva TMB, Dutra GP, Peres LS, Camisao ND, Junior WSH, et al. Late mortality after myocardial injury in critical care non-cardiac surgery patients using machine learning analysis. Am J Cardiol. 2023;204:70–6.
Mehta RL, Kellum JA, Shah SV, Molitoris BA, Ronco C, Warnock DG, et al. Acute Kidney Injury Network: report of an initiative to improve outcomes in acute kidney injury. Crit Care. 2007;11(2):R31.
Lundberg SM, Lee S-I. Consistent feature attribution for tree ensembles. arXiv preprint arXiv:170606060. 2017.
Meacham S, Isaac G, Nauck D, Virginas B, editors. Towards explainable AI: design and development for explanation of machine learning predictions for a patient readmittance medical application. Intelligent Computing. Cham: Springer International Publishing; 2019.
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, et al. Scikit-learn: machine learning in Python. J Mach Learn Res. 2011;12:2825–30.
Mandrekar JN. Receiver operating characteristic curve in diagnostic test assessment. J Thorac Oncol. 2010;5(9):1315–6.
Thakker RA, Albaeni A, Alwash H, Gilani S. Prevention and management of AKI in ACS patients undergoing invasive treatments. Curr Cardiol Rep. 2022;24(10):1299–307.
Mehran R, Aymong ED, Nikolsky E, Lasic Z, Iakovou I, Fahy M, et al. A simple risk score for prediction of contrast-induced nephropathy after percutaneous coronary intervention: development and initial validation. J Am Coll Cardiol. 2004;44(7):1393–9.
Chen YL, Fu NK, Xu J, Yang SC, Li S, Liu YY, et al. A simple preprocedural score for risk of contrast-induced acute kidney injury after percutaneous coronary intervention. Catheter Cardiovasc Interv. 2014;83(1):E8–16.
Behnoush AH, Khalaji A, Rezaee M, Momtahen S, Mansourian S, Bagheri J, et al. Machine learning-based prediction of 1-year mortality in hypertensive patients undergoing coronary revascularization surgery. Clin Cardiol. 2023;46(3):269–78.
Jiang F, Jiang Y, Zhi H, Dong Y, Li H, Ma S, et al. Artificial intelligence in healthcare: past, present and future. Stroke Vasc Neurol. 2017;2(4):230–43.
Mohamadlou H, Lynn-Palevsky A, Barton C, Chettipally U, Shieh L, Calvert J, et al. Prediction of acute kidney injury with a machine learning algorithm using electronic health record data. Can J Kidney Health Dis. 2018;5:2054358118776326.
Li K, Yu N, Li P, Song S, Wu Y, Li Y, et al. Multi-label spacecraft electrical signal classification method based on DBN and random forest. PLoS ONE. 2017;12(5): e0176614.
Amaratunga D, Cabrera J, Lee YS. Enriched random forests. Bioinformatics. 2008;24(18):2010–4.
Speiser JL, Miller ME, Tooze J, Ip E. A comparison of random forest variable selection methods for classification prediction modeling. Expert Syst Appl. 2019;134:93–101.
Chen R-C, Dewi C, Huang S-W, Caraka RE. Selecting critical features for data classification based on machine learning methods. J Big Data. 2020;7(1):52.
Niimi N, Shiraishi Y, Sawano M, Ikemura N, Inohara T, Ueda I, et al. Machine learning models for prediction of adverse events after percutaneous coronary intervention. Sci Rep. 2022;12(1):6262.
Ma X, Mo C, Li Y, Chen X, Gui C. Prediction of the development of contrast-induced nephropathy following percutaneous coronary artery intervention by machine learning. Acta Cardiol. 2023;78:1–10.
Khalilia M, Chakraborty S, Popescu M. Predicting disease risks from highly imbalanced data using random forest. BMC Med Inform Decis Mak. 2011;11(1):51.
Wi J, Ko YG, Shin DH, Kim JS, Kim BK, Choi D, et al. Prediction of contrast-induced nephropathy with persistent renal dysfunction and adverse long-term outcomes in patients with acute myocardial infarction using the Mehran Risk Score. Clin Cardiol. 2013;36(1):46–53.
Helber I, Alves CMR, Grespan SM, Veiga ECA, Moraes PIM, Souza JM, et al. The impact of advanced age on major cardiovascular events and mortality in patients with ST-elevation myocardial infarction undergoing a pharmaco-invasive strategy. Clin Interv Aging. 2020;15:715–22.
Hosseini K, Khalaji A, Behnoush AH, Soleimani H, Mehrban S, Amirsardari Z, et al. The association between metabolic syndrome and major adverse cardiac and cerebrovascular events in patients with acute coronary syndrome undergoing percutaneous coronary intervention. Sci Rep. 2024;14(1):697.
Jonas M, Kagan M, Sella G, Haberman D, Chernin G. Cardiovascular outcomes following percutaneous coronary intervention with drug-eluting balloons in chronic kidney disease: a retrospective analysis. BMC Nephrol. 2020;21(1):445.
Wykrzykowska JJ, Garg S, Onuma Y, de Vries T, Goedhart D, Morel MA, et al. Value of age, creatinine, and ejection fraction (ACEF score) in assessing risk in patients undergoing percutaneous coronary interventions in the ‘all-comers’ leaders trial. Circ Cardiovasc Interventions. 2011;4(1):47–56.
Capodanno D, Marcantoni C, Ministeri M, Dipasqua F, Zanoli L, Rastelli S, et al. Incorporating Glomerular filtration rate or creatinine clearance by the modification of diet in renal disease equation or the Cockcroft-Gault equations to improve the Global Accuracy of the Age, Creatinine, Ejection Fraction [ACEF] score in patients undergoing percutaneous coronary intervention. Int J Cardiol. 2013;168(1):396–402.
Araujo GN, Pivatto Junior F, Fuhr B, Cassol EP, Machado GP, Valle FH, et al. Simplifying contrast-induced acute kidney injury prediction after primary percutaneous coronary intervention: the age, creatinine and ejection fraction score. Cardiovasc Interv Ther. 2018;33(3):224–31.
Hertzberg D, Sartipy U, Lund LH, Rydén L, Pickering JW, Holzmann MJ. Heart failure and the risk of acute kidney injury in relation to ejection fraction in patients undergoing coronary artery bypass grafting. Int J Cardiol. 2019;274:66–70.
Schöttker B, Brenner H, Koenig W, Müller H, Rothenbacher D. Prognostic association of HbA1c and fasting plasma glucose with reduced kidney function in subjects with and without diabetes mellitus. Results from a population-based cohort study from Germany. Prev Med. 2013;57(5):596–600.
Bartholomew BA, Harjai KJ, Dukkipati S, Boura JA, Yerkey MW, Glazier S, et al. Impact of nephropathy after percutaneous coronary intervention and a method for risk stratification. Am J Cardiol. 2004;93(12):1515–9.
Acknowledgements
None.
Funding
None.
Author information
Authors and Affiliations
Contributions
AHB, MMS, AK: study conception/data analysis/drafting the manuscript/revision; MA, AY, MR, HS, AS, AA: drafting the manuscript/revision; SY, YJ, FM, MM, MI: critical revision; KH: study conception/drafting the manuscript/critical revision. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The study protocol was approved by the Ethics Committee of Tehran Heart Center and conformed to the ethical guidelines.
Competing interests
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Behnoush, A.H., Shariatnia, M.M., Khalaji, A. et al. Predictive modeling for acute kidney injury after percutaneous coronary intervention in patients with acute coronary syndrome: a machine learning approach. Eur J Med Res 29, 76 (2024). https://doi.org/10.1186/s40001-024-01675-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40001-024-01675-0