
Abstract
Background
Among the most widely anticipated climate-related impacts to biodiversity are geographic range shifts, whereby species shift their spatial distribution in response to changing climate conditions. In particular, a series of commonly articulated hypotheses have emerged: species are expected to shift their distributions to higher latitudes, greater elevations, and deeper depths in response to climate change, reflecting an underlying hypothesis that species will move to cooler locations to track spatial changes in the temperature of their current range. Yet, many species are not demonstrating range shifts consistent with these hypotheses. Resolving this discrepancy and providing effective explanations for the observed variability in species’ range shifts is urgently needed to help support a range of natural resource management decisions. Here, we propose a protocol to review the body of evidence for commonly-held climate change range shift hypotheses at the species level focusing on observed latitudinal, longitudinal, elevational, and depth shifts in response to temperature and precipitation changes. We aim to answer the question: what is the impact of anthropogenic climate change (specifically changes in temperature and precipitation) on species ranges?
Methods
In this review protocol, we propose to conduct a systematic search of literature from internet databases and search engines in English. Articles will be screened in a two-stage process (title/abstract and full text) to evaluate whether they meet a list of eligibility criteria (e.g., presents species-level data, compares > 1 time period). Initial data coding and extraction will be completed by four reviewers and checked by a secondary reviewer from among our co-authors. We will perform a formal meta-analysis to document estimated effect size using the subset of available range-shift data expressed in distance per time (e.g., km/decade). We will also use multinomial logistic regression models to assess the probability that species are shifting in a direction that supports our hypotheses (i.e. towards higher latitudes, greater elevations, and deeper depths). We will account for study methodology as a potential source of variation.
Similar content being viewed by others

Background
Climate change represents one of the foremost drivers of ecological change, yet its current and future impacts on biodiversity remain uncertain. Such uncertainty impedes effective planning and decision making for conservation and natural resource management. This uncertainty is driven in part by high variability in biological responses to climate change [1]: despite a range of commonly-held hypotheses supported by ecological theory and a solid empirical evidence base, many species are failing to conform to general expectations or are even responding in counter-intuitive ways. Among the most significant and widely discussed of these changes are shifts in species’ spatial distribution (i.e., range shifts). Range shifts have the potential to reshape ecological communities, alter ecosystem function and the provision of ecosystem services, and impact human health and well-being. Species shifts can also have feedback effects on the climate system [2]. Understanding how species are expected to shift as a function of climate change is important for effectively managing species and habitats.
Climate-driven range shifts are well documented [3,4,5,6] and relatively well studied [7,8,9]. Over the past two decades, as the research community has conducted an increasing number of studies devoted to documenting geographic range shifts driven by climate change [10], a series of broad, commonly-held hypotheses have emerged that have structured investigations into this field. Species are generally expected to shift their distributions in response to rising temperatures and altered precipitation patterns so that they maintain their preferred climatic niche [5, 11,12,13]. Niche tracking is easier to predict for temperature than precipitation, as temperatures generally decrease with increasing latitude and elevation on land and with increasing depth in the oceans and lakes [5, 14]. In particular, there are two prominent range shift hypotheses [15]:(i) in response to rising temperatures, species will shift their ranges poleward to higher latitudes, upslope to higher elevations (for terrestrial species), and to greater depths (for aquatic species) [3, 4]; and (ii) in response to changing precipitation patterns, species will shift their ranges to stay within preferred precipitation envelopes [11, 16, 17]. These hypotheses have become so widespread that they are rarely tested explicitly or linked to observed climate trends, limiting the ability to infer mechanisms for non-conforming responses. Other related hypotheses have also been proposed in the literature, including that species ranges may respond more strongly at the leading edge of the range due to higher exposure and/or greater sensitivity to temperature changes at the poleward edge of their range [5, 18, 19], and that some taxa and subpopulations are likely to experience greater range shifts due to differences in sensitivity and adaptive capacity [20, 21], but these have not been tested to the same extent.
A number of previous reviews have demonstrated that there is strong general support for these commonly-held hypotheses across taxonomic groups and regions [4,5,6]; yet, substantial variation across species has also been documented [1, 6, 22]. Numerous studies have found that many species, populations, and taxonomic groups have not demonstrated the expected shifts, or have even displayed contradictory shifts (e.g., equatorial or downslope movement) [1, 23, 24]. Moreover, previous reviews have been hampered by a number of limitations, including conflation of range shift parameters (e.g., leading edge, trailing edge, and measures of centroid distribution) [5, 25]; a failure to consider studies measuring changes in abundance [26]; exclusion of single-species studies [6]; and failure to account for potentially confounding sources of variation (e.g., land-use change) [1, 27, 28] that may be driving non-conforming responses or concealing significant shifts. In addition, climate isotherms in some areas may be shifting in the opposite direction than expected [29], complicating the interpretations of observed range shifts.
Given the pervasive nature of climate impacts, and the strong role of climate in determining species’ ranges, the substantial body of non-conforming observations deserves greater investigation. An updated assessment and repository of climate-driven range shifts is needed to clarify sources of variation in the empirical data and to provide a more coherent explanatory and predictive framework for understanding climate-driven range shifts. A clearer understanding of climate-driven range shifts is highly relevant to natural resource managers [10, 30, 31]. Indeed, a recent survey by the Association of Fish and Wildlife Agencies (AFWA) identified research on climate-driven range shifts as a top knowledge need for coastal and marine natural resource managers, indicating the priority for this kind of research and additional synthesis directed towards wildlife and habitat managers [32].
Objective of the review
The objective of this review protocol is to provide guidelines and a road map to assess how anthropogenic climate change is affecting the ranges of animals and plants. We intend to assess overall confidence in a series of widely accepted range shift hypotheses. We will improve upon previous studies by analyzing range shift parameters separately, as well as by incorporating single-species (which were excluded from many previous meta-analyses because of the belief that single species studies might be more prone to publication bias) and abundance shift studies. We will also document non-climate drivers identified in the original studies as potential factors influencing species range shifts. Our primary objective is to review evidence for temperature- and precipitation-driven hypotheses: namely, that species will demonstrate expected patterns in range shifts as they adapt to changing environments.
Our secondary objective is to evaluate a series of related, secondary hypotheses that have been promoted in the literature. These include hypotheses that: leading edges (i.e., the edge of the range that is expected to expand as climatic conditions become more suitable) are more sensitive to climate change than trailing edges (i.e., the edge of the range that is expected to contract as climatic conditions become less suitable), and range shifts should therefore be more readily observed on leading edges [5, 18, 19]; and that certain taxa or subpopulations with higher adaptive capacity (e.g., juveniles, migratory populations) will demonstrate greater range shifts [20, 21].
Research question
What is the impact of anthropogenic climate change (specifically changes in temperature and precipitation) on species ranges?
We will assess the degree to which documented observations (i.e. articles that document or attempt to document distributional shifts based on empirical observations), rather than projections, support temperature- and precipitation-driven hypotheses. We will collect documented examples of climate-driven range shifts globally, including studies that attempted to document, but did not find, significant range shifts, and assess the body of evidence using both quantitative (i.e., average km/decade shifts) and categorical assessments of species range shifts. Following the PECO (Population, Exposure, Comparator, Outcome) question framework [33, 34], we identified the four key elements of our study that will structure and guide our literature search, and include: population of interest: species of animals and plants, exposure: climate change variables (temperature and precipitation), comparator: baseline temperature and/or precipitation conditions during the historical period., and outcome: shift in spatial/geographic distribution.
Methods
This systematic review protocol follows the guidelines of Collaboration for Environmental Evidence and complies with the ROSES reporting standards. The ROSES form is included as an Additional file 1.
Searching for articles
Online databases
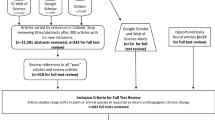
We will conduct the review with two online databases: Web of Science and Scopus (Fig. 1). For Web of Science, we will use the Science Citation Index Expanded Science collection (the citation collection option available for the U.S. Geological Survey) within their Core Collection Database. We will select the ‘all years (1985 to 2019)’ timespan. For both Web of Science and Scopus, we will enter our search terms using the advanced search tool. We will upload our search results to Colandr, a machine learning tool that iteratively sorts articles based on relevance as defined by the user (i.e. it continually learns to rank articles based on which articles are included and excluded) [35]. This process will allow us to review the most relevant articles based on our inclusion criteria. Given the particularly broad scope of this review (i.e., global range shifts across all animals and plants), the number of retrieved articles is likely to exceed our capacity to complete an exhaustive review of every article. To determine when to stop reviewing article abstracts, we will construct an accumulation curve following the method outlined in [36]. Using the Colandr relevance ranking function, highly relevant articles will appear earlier in the search. We will review abstracts 100 at a time, recording the number of included vs. excluded articles. Once 300 articles have been reviewed with no new relevant titles, we will stop searching the database results. To validate our stopping criteria, we will select a random subset of unreviewed articles for title and abstract review. If any additional relevant articles are found, we will evaluate whether inclusion of the articles significantly changes the results of the meta-analysis (similar to the displacement method described in [37]). If no significant change is found, we will consider our search sufficiently comprehensive. Our approach attempts to balance specificity with comprehensiveness by adopting a technique used successfully elsewhere (i.e., calculating an accumulation curve to describe marginal benefit of additional searches) and applying it to the question of when to stop reviewing articles. Using an accumulation curve to define the end of our search, rather than a more constrained set of key words, will allow us to be more comprehensive than previous reviews in a way that is still feasible and reproducible. Moreover, a recent review found that using a “found vs. effort” stopping criteria when articles were prioritized by relevance was an effective strategy for large meta-analyses [37].

Search methodology and article review process overview
Search engine
We will then conduct a follow-up search in the search engine Google Scholar, and will review all 1000 articles retrieved [38]; only articles not previously identified will be included. We will use the advanced search options and enter our search terms in the “with all of the words” field.
The results of all three searches will not be constrained by date, year, or author. All searches will be conducted in English, and only English-language articles will be accepted into the review since this is the primary language of the reviewers. This may introduce geographical bias in our search results, but it will circumvent the difficulties associated with translation of materials, and potentially different interpretations. In the future, our methodology could be conducted by others fluent in other languages.
Search terms
To identify articles relevant to species’ geographic/spatial response to climate change, the review team comprised of a subset of authors, established a preliminary set of search terms based on our knowledge of climate change and ecological literature. We began with a broad set of search terms and conducted preliminary searches with different combinations of those terms. For each combination, we compared the total number of articles retrieved and the number of articles whose title and abstract were judged to be relevant based on our eligibility criteria in the first 500 returns. We selected our final search terms, TS = ((“climate” OR “global warming” OR “temperature” OR “precipitation”) AND (“range” OR “distribution” OR “habitat extent” OR “occupancy”) AND (“species”)),Footnote 1 based on the combination of terms that returned the most relevant articles in the first 500 reviewed. To test the sensitivity of the search terms, we compiled a list of all articles included in a recent meta-analysis [4], as well as a few relevant articles chosen based on the author team’s previous knowledge of the literature (35 articles total; see Additional file 2 for complete list) that were all successfully returned in the Web of Science, Scopus, and/or Google Scholar search results.
Additional search methods
We will also use the snowball method [39], whereby the citations of all articles that passed title/abstract review will be screened to determine if there are any additional articles that should be included. We will also screen opportunistically retrieved articles. These are articles that we come across outside of the formal search process, such as those sent to us by colleagues or found by chance in an unrelated capacity. For example, a colleague working on a similar analysis [1] shared the preprint of his article, which included articles that were not already in our database. We will record the citation information of any opportunistically retrieved articles and will review this list for any potentially relevant articles not already identified through the Web of Science, Google Scholar, or snowball search methodologies.
After we have completed our Web of Science and Google Scholar review, we will set up alerts for new articles that match our search terms in Google Scholar and Web of Science: this will allow us to capture any newly published articles that may have come out after our search but before publication of the systematic review [5, 6]. Alerts will be checked on a regular basis by a trained reviewer, and the articles listed in the alert will be subject to title/abstract review. Citation information of “passed” articles will be collected and after all the original articles have had their data extracted and coded, we will do full text review on these new articles and the opportunistically retrieved articles.
Other considerations
We will not accept review articles or previous meta-analyses (e.g., 3, 4, 6) directly into our review; instead, we will use review articles to identify original articles that may contain relevant data. We will flag review articles to be inspected after the preliminary title and abstract review. Each review article and its citations will be read to identify the relevant primary source; we will then evaluate the primary source and include it as appropriate based on a title/abstract review.
Our methodology has a number of challenges with regards to reproducibility, one of which is that our literature search in Web of Science, Google Scholar, and Scopus will not be completely reproducible. Search results from both sources vary as a function of date and location. In order to address this, we will maintain an offline spreadsheet of all search results used in our assessment, whether they pass or fail title/abstract review and/or full-text review, as well as the reasons for the decisions. This will allow us to share the complete database of potential studies with any researchers interested in repeating or comparing our analysis.
Article screening and study eligibility criteria
Screening process
We will use a two-stage screening process to determine eligibility: (1) title/abstract review, and (2) full text review. Four internal reviewers (among our co-authors) will independently review the first 500 articles; results (e.g., pass/fail) will be compared and discrepancies discussed to ensure that screening criteria (Table 1) are being consistently applied. After the first 500 articles, one of the four trained reviewers will review individual articles independently. Any questions about whether an article meets screening criteria will be reviewed with other co-authors.
During the first stage of the screening process, the reviewer will read titles to determine relevance. For example, a relevant title might be one that contains one or more of our keywords, but not those that are clearly from another subject or field. If the title is determined to be relevant, the reviewer will read the abstract and check that the article contains the necessary components for our study (Table 1). If the abstract indicates that the study may meet the required components or eligibility is unclear, the article will be passed on to full text review. During the second stage, at least two reviewers will read articles in their entirety and verify that the article meets all eligibility criteria before moving on to data coding and extraction. Any uncertainties about a paper will be discussed with at least one additional co-author to resolve how to move forward. Reviewers that have authored an article under consideration will be recused from decisions regarding the eligibility of the article. A full list of articles excluded from title/abstract review and those excluded at full-text review will be available in an additional file with the reasons for exclusion in our final review paper.
Eligibility criteria
To determine eligibility for inclusion in the review, we established a number of review criteria (Table 1). These criteria were based on a priori familiarity with climate change research and the scope of our research objectives (e.g., [3,4,5,6]), and were refined after preliminary scoping of the available literature. Because the objective of our study is to assess empirical evidence for climate-driven range shifts, we will only accept articles that document or attempt to document distributional shifts based on empirical observations, and not those that describe projected future changes based on models or simulations. Our review is focused on species-level range shifts, so that we can examine the variability of responses at this scale. Consequently, we will only accept articles that present species-specific results. For articles that fail to report results at a species or subspecies level, but which appear to have used underlying species-specific data, we will contact the corresponding author for data [6]. Additionally, we will only include articles related to observed shifts in animals and plants, since these are both the most well-represented taxonomic groups in the literature and are likely to be of greater interest to natural resource managers. Since we are interested in understanding spatial changes in response to recent anthropogenic climate change, we will not include articles that are related to paleoclimatic conditions or temporary or seasonal climate variations, such as the El Niño-Southern Oscillation (ENSO). Our hypotheses are specific to trends in temperature and precipitation, so only studies that consider both or either of these climatic variables will be eligible.
Study validity assessment
All eligible studies will be critically appraised for risk of bias and coded based on their methodology and data quality [5, 6]. We will categorize studies according to a few basic metrics of methodology that may influence or bias study outcomes [5, 6]:
Number of taxa included in the study;
Frequency of sampling (comparison of two or multiple periods);
Regularity of sampling [regular (i.e. authors sampled ranges continuously throughout study period at specified time intervals) or irregular (i.e. authors sampled ranges periodically throughout study period at irregular time intervals)].
Type of shift observation (abundance or occurrence);
Spatial resolution (fine—spatial resolution < 10 km, medium—spatial resolution 10–100 km, coarse—spatial resolution > 100 km);
Quality of methods used to estimate range shift, i.e. how the authors measured and compared ranges in both time periods [low (no data cleaning, e.g. authors resurveyed species range in same general area but may use different and/or different numbers of survey points), balanced (data cleaned to balance datasets, e.g., the authors reduced the number of sampling points so that they match in both time periods), modeled (model output used to estimate shifts, e.g. occupancy models using data collected in both time periods), resurveyed (shifts calculated from paired design, e.g. authors resurveyed the same points in both time periods)];
Rather than excluding studies using certain methodologies, we will include these metrics as covariates in our analysis. This will enable us to standardize for differences in methodology and estimate the size and direction of bias associated with different study methods [40]. Studies that do not have enough details to assess these metrics will be excluded from the review. All study validity assessments will be reviewed by a second co-author to ensure consistency. These factors will allow us to account for methodological differences in studies by including them as covariates in our models (see data synthesis & presentation section below), similar to [5] and [6].
Other information extracted from studies such as sub-population differences or geographical differences (see potential effect modifiers/reasons for heterogeneity section below) will be considered for possible introductions of selection bias. Additional observations on the study design and findings, such as missing data or unreported outcomes will be noted, and authors will either be contacted to provide the information, or studies will be excluded if the absence of the data is likely to affect the outcome.
Data coding and extraction strategy
Data will be extracted from each article that passes title/abstract and full text review. A table in Google Sheets will hold all relevant data extracted. This spreadsheet will be converted to an excel file and stored on Data Basin [41] and ScienceBase [42], as well as made available as additional files. We will extract data on observed range shifts for each species described in a paper; therefore, if a study contains results for more than one species, that study will have more than one row in the table. In addition, we will report data on distinct regions, sub-groups or sub-populations (i.e., juveniles vs. adults, males vs. females), time periods and range shift parameters on separate rows, if the authors report these data separately. Each entry will include an attribute to identify its source (i.e., an article identifier) so that we can account for non-independence in our analysis.
Broadly, we will extract data from studies into our table in five general categories: (i) basic information about the study (i.e., study duration, study location, species names and taxonomic grouping/information) (see also [5, 6]); (ii) information about the climate drivers considered in the study (i.e., the specific temperature and/or precipitation variable considered, the direction of the observed change or trend, and whether or not statistical significance with the climate driver was assessed); (iii) information about the type of range-shift observation described in the study (e.g., latitude/longitude/elevation/depth, shift in occupancy or abundance, leading/trailing edge) [5]; (iv) description of the shift (categorical and quantitative assessment); and (v) any observations or details on species’ vulnerability (i.e. authors’ considerations of exposure to climatic and non-climatic drivers, as well as species’ sensitivity to and adaptive capacity). For category iv (description of the range shift), we will include a quantitative description of the observed shift, if provided by the authors in a “unit distance per unit time” format. We will report the quantitative shift as reported by the authors but will also translate to kilometers per decade. This will allow us to calculate a global effect size across all quantitative data. For studies where quantitative range shift data are not provided, but range shifts are described qualitatively, we will describe the range shift categorically (e.g., latitudinal increase/decrease, elevational increase/decrease). For all studies, we will indicate whether the observation supports or fails to support the dominant hypotheses. For example, in temperature-driven studies where a poleward shift is expected, an observation of latitudinal decrease would be categorized as “fails to support.” Most data fields will have a drop-down list to ensure consistency in data entry by the trained reviewers. To obtain missing information such as species-specific data, we will create an additional spreadsheet with authors’ contact information. For each of those studies, we will email the corresponding author to request the missing data. If authors do not respond or deny our request for any reason, the study will be excluded from the analysis.
We will ensure reproducibility and consistency in data coding and extraction by writing a detailed manual of instructions on the process of entering data into our spreadsheet. This will be detailed enough for any of our co-authors to follow, and will include instructions clarifying our eligibility criteria and answer common questions encountered during the review process. We will make this manual publicly available with our data in the final publication. In addition, we will train reviewers to ensure consistency in how data is entered. We will implement a dual-review system so that all articles and associated data entry will be reviewed by a second co-author. To resolve any questions or problems, the authors will convene and review questionable entries.
Potential effect modifiers/reasons for heterogeneity
In order to better understand the variation in species responses, we will extract and consider several potential effect modifiers from each study [5, 6, 40]. Basic information on study location and subject will likely contribute to some variation in observed results, since regional and taxonomic variation in climate-driven range shifts is well established [4, 17, 43]. Therefore, we will include basic information on study location (e.g., region, habitat type), ecosystem type (i.e., terrestrial, freshwater, marine), taxonomic group (i.e., fish, bird, reptile, amphibian, insect, plant, other), and any relevant subpopulation information (e.g., sex, age class) when applicable. Information on study methodology and data quality (see study validity assessment section above) will also be included as a potential effect modifier; the importance of methodology in explaining some portion of range-shift variability has recently been established by several studies [5, 6, 40].
Finally, we will take note of any component of the article that addresses species sensitivity, adaptive capacity, and/or exposure to other non-climate drivers. This may include information from articles about thermal tolerances and thresholds, or other measures of species sensitivity to climatic changes; information about dispersal capacity or other measures of species capacity to shift range in response to climate change; and/or information about other drivers of change (e.g., land-use change) that may explain observed results. These covariates are likely to explain some portion of variability in observed results [6, 24, 44, 45], and will therefore be a valuable component of our overall conclusions. We will not systematically assess the role of these covariates in explaining observed variability (e.g., through formal meta-analysis), as they are not systematically reported in most studies, but will instead use information on these covariates to provide context for interpreting non-conforming observations. Our findings will help to inform a future research effort aimed at systematically explaining variability in range shift observations.
Data synthesis and presentation
We will provide a table with basic summary statistics on the database (e.g., number of species, geographic regions). We will also fit mixed-effects multinomial logistic regression models to all data collected through the review process to model the probability that species are shifting in a direction that supports our hypotheses, shifting in a direction that fails to support our hypotheses, or are not shifting at all (similar to [44, 45]). We will fit separate models for each range shift parameter (e.g., leading edge, trailing edge) and hypothesis being evaluated (i.e. temperature or precipitation). Models will use fixed effects for taxonomic group or ecosystem type (depending on whether we have compiled sufficient data for each category) and study methodology (see study validity section above) [5, 40], and a random effect for article identifier to avoid pseudoreplication. Several previous meta-analyses have excluded single-species studies to reduce the influence of publication bias (e.g., [3, 4]). We will include number of species studied in the paper as a model covariate to control for this potential effect (i.e. we will be able to account for whether single species studies are more likely report a range shift).
We will also use multiple linear regression models to conduct a quantitative meta-analysis for the subset of data in our table which allows for this kind of analysis; this will include only data expressed as shift in distance per unit time. As described above, we will convert all quantitative observations into kilometers per decade to allow for comparison across studies (and with previous meta-analyses). We will calculate average km/decade for the global dataset, as well as for particular subsets of observations (e.g., by parameter (leading edge vs trailing edge), taxonomic group, region). As with the categorical analysis, we will control for the effects of study methodology by including the variables described in the study validity section as covariates [5, 6, 40]. In this way, we will be able to compare effect size across these groupings and identify which, if any, of these covariates plays an important role in driving heterogeneity in observed responses. We will conduct a sensitivity analysis to assess how significant a source of bias these methodological differences may be, by calculating overall effect size with and without different categories of studies. These results will clarify the robustness of our overall approach, and will provide insight to future research efforts as to the impact of methodological choices on quantitative outcomes.
Notes
“TS” is a field tag that represents topic. It was used in the Web of Science Search, but not Google Scholar. In Scopus the field code “ALL” was used which indicates search terms may appear in all fields.
References
Lenoir J, Gegout JC, Guisan A, Vittoz P, Wohlgemuth T, Zimmermann NE, et al. Going against the flow: potential mechanisms for unexpected downslope range shifts in a warming climate. Ecography (Cop). 2010;33(2):295–303.
Pecl GT, Araújo MB, Bell JD, Blanchard J, Bonebrake TC, Chen IC, et al. Biodiversity redistribution under climate change: impacts on ecosystems and human well-being. Science. 2017;355:6332.
Parmesan C, Yohe G. A globally coherent fingerprint of climate change impacts across natural systems. Nature. 2003;421(6918):37–42. https://doi.org/10.1038/nature01286.
Chen IC, Hill JK, Ohlemüller R, Roy DB, Thomas CD. Rapid range shifts of species associated with high levels of climate warming. Science. 2011;333(6045):1024–6.
Lenoir J, Svenning JC. Climate-related range shifts—a global multidimensional synthesis and new research directions. Ecography (Cop). 2015;38(1):15–28.
Lenoir J, Bertrand R, Comte L, Bourgeaud L, Hattab T, Murienne J, et al. Species better track the shifting isotherms in the oceans than on lands. bioRxiv. 2019.
Hughes L. Biological consequences of global warming: is the signal already apparent? Trends Ecol Evol. 2000;15(2):56–61.
Walther G-R, Post E, Convey P, Menzel A, Parmesan C, Beebee TJC, et al. Ecological responses to recent climate change. Nature. 2002;416(6879):389–95.
Thomas CD. Climate, climate change and range boundaries. Divers Distrib. 2010;16(3):488–95.
Bonebrake TC, Brown CJ, Bell JD, Blanchard JL, Chauvenet A, Champion C, et al. Managing consequences of climate-driven species redistribution requires integration of ecology, conservation and social science. Biol Rev. 2018;93(1):284–305.
Tingley MW, Monahan WB, Beissinger SR, Moritz C. Birds track their Grinnellian niche through a century of climate change. Proc Natl Acad Sci USA. 2009;106(SUPPL. 2):19637–43.
Bellard C, Bertelsmeier C, Leadley P, Thuiller W, Courchamp F. Impacts of climate change on the future of biodiversity. Ecol Lett. 2012;15(4):365–77.
Monahan WB, Tingley MW. Niche tracking and rapid establishment of distributional equilibrium in the house sparrow show potential responsiveness of species to climate change. PLoS ONE. 2012;7(7):e42097.
Lathrop RC, Lillie RA. Thermal stratification of Wisconsin lakes. Trans Wisconsin Acad Sci Arts Lett. 1980;68:90–6.
Lenoir J, Svenning J-C. Latitudinal and elevational range shifts under contemporary climate change. In: Encycl Biodivers. 2013. p. 599–611.
Crimmins SM, Dobrowski SZ, Greenberg JA, Abatzoglou JT, Mynsberge AR. Changes in climatic water balance drive downhill shifts in plant species’ optimum elevations. Science. 2011;331:324–7.
Tingley MW, Koo MS, Moritz C, Rush AC, Beissinger SR. The push and pull of climate change causes heterogeneous shifts in avian elevational ranges. Glob Chang Biol. 2012;18(11):3279–90.
Sunday JM, Bates AE, Dulvy NK. Thermal tolerance and the global redistribution of animals. Nat Clim Chang. 2012;2(9):686–90. https://doi.org/10.1038/nclimate1539.
Brusca RC, Wiens JF, Meyer WM, Eble J, Franklin K, Overpeck JT, et al. Dramatic response to climate change in the Southwest: Robert Whittaker’s 1963 Arizona Mountain plant transect revisited. Ecol Evol. 2013;3(10):3307–19.
Boisvert-Marsh L, Périé C, De Blois S. Shifting with climate? Evidence for recent changes in tree species distribution at high latitudes. Ecosphere. 2014;5(7):1–33.
Hovick TJ, Allred BW, McGranahan DA, Palmer MW, Dwayne Elmore R, Fuhlendorf SD. Informing conservation by identifying range shift patterns across breeding habitats and migration strategies. Biodivers Conserv. 2016;25(2):345–56.
La Sorte FA, Jetz W. Tracking of climatic niche boundaries under recent climate change. J Anim Ecol. 2012;81(4):914–25.
Archaux F. Breeding upwards when climate is becoming warmer: no bird response in the French Alps. Ibis (Lond). 2004;146(1):138–44.
Fei S, Desprez JM, Potter KM, Jo I, Knott JA, Oswalt CM. Divergence of species responses to climate change. Sci Adv. 2017;3(5):1603055. https://doi.org/10.1126/sciadv.1603055.
Maggini R, Lehmann A, Kéry M, Schmid H, Beniston M, Jenni L, et al. Are Swiss birds tracking climate change? Detecting elevational shifts using response curve shapes. Ecol Modell. 2011;222(1):21–32.
Bates AE, Pecl GT, Frusher S, Hobday AJ, Wernberg T, Smale DA, et al. Defining and observing stages of climate-mediated range shifts in marine systems. Glob Environ Chang. 2014;26(1):27–38. https://doi.org/10.1016/j.gloenvcha.2014.03.009.
Warren MS, Hill JK, Thomas JA, Asher J, Fox R, Huntley B, et al. Rapid responses of British butterflies to opposing forces of climate and habitat change. Nature. 2001;414(6859):65–9.
Guo F, Lenoir J, Bonebrake TC. Land-use change interacts with climate to determine elevational species redistribution. Nat Commun. 2018;9(1):1–7. https://doi.org/10.1038/s41467-018-03786-9.
Pinsky ML, Worm B, Fogarty MJ, Sarmiento JL, Levin SA. Marine Taxa Track Local Climate Velocities. Science. 2013;341:1239–42.
Lawler JJ. Climate change adaptation strategies for resource management and conservation planning. Ann N Y Acad Sci. 2009;1162:79–98.
Lawler JJ, Tear TH, Pyke C, Shaw RM, Gonzalez P, Kareiva P, et al. Resource management in a changing and uncertain climate. Front Ecol Environ. 2010;8(1):35–43.
Ernest Johnson M (Association of F and WA. 2018 AFWA Climate Adaptation Surveys : A Review of Activities at State Fish and Wildlife Agencies. 2018.
Schardt C, Adams MB, Owens T, Keitz S, Fontelo P. Utilization of the PICO framework to improve searching PubMed for clinical questions. BMC Med Inform Decis Mak. 2007;7:1–6.
Morgan RL, Whaley P, Thayer KA, Schünemann HJ. Identifying the PECO: a framework for formulating good questions to explore the association of environmental and other exposures with health outcomes. Environ Int. 2018;121(September):1027–31.
Cheng SH, Augustin C, Bethel A, Gill D, Anzaroot S, Brun J, et al. Using machine learning to advance synthesis and use of conservation and environmental evidence. Conserv Biol. 2018;32(4):762–4.
Romulo CL, Basher Z, Lynch AJ, Kao YC, Taylor WW. Assessing the global distribution of river fisheries harvest: a systematic map protocol. Environ Evid. 2017;6(1):1–10.
Norman CR, Leeflang MMG, Porcher R, Névéol A. Measuring the impact of screening automation on meta-analyses of diagnostic test accuracy. Syst Rev. 2019;8(1):1–18.
Search Tips: Citation Export. Google Scholar.
Greenhalgh T, Peacock R. Effectiveness and efficiency of search methods in systematic reviews of complex evidence: audit of primary sources. BMJ. 2005;331(7524):1064–5.
Brown CJ, O’Connor MI, Poloczanska ES, Schoeman DS, Buckley LB, Burrows MT, et al. Ecological and methodological drivers of species’ distribution and phenology responses to climate change. Glob Chang Biol. 2016;22(4):1548–60.
Data Basin. Conservation Biology Institute, Corvallis. 2019.
ScienceBase. U.S. Geological Survey, Reston. 2019.
Bonebrake TC, Mastrandrea MD. Tolerance adaptation and precipitation changes complicate latitudinal patterns of climate change impacts. Proc Natl Acad Sci USA. 2010;107(28):12581–6.
Jump AS, Peñuelas J. Running to stand still: adaptation and the response of plants to rapid climate change. Ecol Lett. 2005;8(9):1010–20.
Foden WB, Butchart SHM, Stuart SN, Vié JC, Akçakaya HR, Angulo A, et al. Identifying the World’s most climate change vulnerable species: a systematic trait-based assessment of all birds, amphibians and corals. PLoS ONE. 2013;8(6):e65427.
Acknowledgements
We thank J. Lenoir for feedback on this manuscript and A.N. Shiklomanov for feedback on data analysis. Any use of trade, firm, or product names is for descriptive purposes only and does not imply endorsement by the U.S. Government.
Funding
Funding to support this project comes from the National Climate Adaptation Science Center, U.S. Geological Survey.
Author information
Authors and Affiliations
Contributions
MAR, SRW, and SLC conceived of the research question and designed the research question. MAR and SRW led the research team and coordinated data acquisition and analysis. MJE, AJL, BWM, TLM, AT, and LMT contributed to design of research methodology/protocol, contributed to data analysis, and served as reviewers. MAR, SRW, and MR led the revision of the manuscript. MR and CJ conducted data acquisition and analysis. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1.
ROSES for Systematic Review Protocols.
Additional file 2.
Articles used to test the sensitivity of our literature search terms.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Rubenstein, M.A., Weiskopf, S.R., Carter, S.L. et al. Do empirical observations support commonly-held climate change range shift hypotheses? A systematic review protocol. Environ Evid 9, 10 (2020). https://doi.org/10.1186/s13750-020-00194-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13750-020-00194-9