
Abstract
Based on a specific decomposition of discrete singular systems, in this paper, we study the problem of state tracking control by using PD-type algorithm of iterative learning control. The convergence conditions and theoretical analysis of the PD-type algorithm are presented in detail. An illustrative example supporting the theoretical results and the effectiveness of the PD-type iterative learning control algorithm for discrete singular systems is shown at the end of the paper.
Similar content being viewed by others

1 Introduction
Iterative learning control (ILC) is an effective control scheme in handling a system that repetitively perform the same task with a view to sequentially improving the accuracy on a finite interval. The research of ILC is of great significance for dynamic systems with complex modeling, strong nonlinear coupling effects, and uncertainty [1–5]. The aim of ILC is to look for a proper learning control algorithm of the controlled systems so that the output state can track the given desired trajectory over a finite interval time and in the meantime the constructed learning control sequences can uniformly converge to the desired control. Since Arimito proposed the concept of iterative learning control in 1984, the research of ILC has become a topic of focus in the field of control and fruitful research progress has been made in theory and application [6–12].
Singular systems have been a subject of interest over the last two decades due to their many practical applications. For instance, we have engineering systems, social systems, economic systems, biological systems, network analysis, time-series analysis, etc. [13, 14]. Such systems describe a wider class of systems, including physical models and non-dynamic constraints. Currently, ILC of singular system has also attracted the attentions of many scholars. The existing ILC methods of singular discrete systems use either a P-type algorithm or a D-type algorithm to track the desired output trajectory. Compared with these existing ILC methods, we use a PD-type algorithm related to the current error and the following error to improve the accuracy. Considering the equivalence of two norms, we use the λ norm in the paper to prove the convergence of the PD-type algorithm. Reference [15] studied the state tracking problem of the singular system with time-delay and proved that the iterative learning algorithm is convergent under certain conditions. In [16], the convergence of the P-type iterative learning control algorithm for a fast subsystem of a linear singular system is proved under a certain sufficient condition. Reference [17] proposes the convergence results for a continue linear time-invariant singular system by the close-loop PD-type iterative learning control algorithm. In [18], a new iterative learning control algorithm to study the state tracking for a class of singular systems is proposed and the convergence of the algorithm is completely analyzed.
As a result, the PD-type iterative learning control algorithm is applied to study the state tracking for a class of discrete singular systems. And then the convergence conditions are proposed and analyzed from the theoretical perspective. Finally, the numerical simulation results, showing that the given ILC algorithm for the state tracking of singular system is effective, are presented.
2 Description of singular discrete system
A repeatable discrete singular system is descried as follows:
where \(E,A\in R^{n\times n}\), \(B\in R^{n\times m}\) are constant matrices. E is singular matrix and \(\operatorname{rank}(E)= q< n\). i denotes the time index and \(i\in[0,1,\ldots,T]\), k is the repetitive time and \(k=1,2,\ldots \) .
According to the theorem in [13, 14], the system (1) could be expressed as
where \(x_{k}^{(1)}(i)\in R^{q}\), \(x_{k}^{(2)}(i)\in R^{(n-q)}\), \(x_{k}(i)=[x_{k}^{(1)}(i)\ x_{k}^{(2)}(i)]^{T}\).
Based on decomposed form of the singular discrete system in (2), we propose the following PD-type iterative learning control algorithm:
where \(e_{1k}(i)=x_{d}^{(1)}(i)-x_{k}^{(1)}(i)\), \(e_{2k}(i)=x_{d}^{(2)}(i)-x_{k}^{(2)}(i)\). \(\varGamma _{1}\in R^{m\times q}\), \(\varGamma _{2}\in R^{m\times(n-q)}\) are the iterative learning gain matrices.
Since the target of this paper is to discuss the state tracking problem of the discrete system, in the following context, we can consider the singular discrete system (2). Assume that the singular discrete system (2) satisfies the following conditions:
-
(1)
The singular discrete system is regular, controllable, and observable, \(A_{22}\) is invertible.
-
(2)
The system (2) satisfies the initial conditions: \(x_{k}(0)=x_{d}(0)\), \(k=0,1,\ldots\) .
-
(3)
For a given desired target \(x_{d}(i)\), there always exists a corresponding control input \(u_{d}(i)\) over the finite interval \([0, T]\), such that
$$ \left \{ \textstyle\begin{array}{l} x_{d}^{(1)}(i+1) = A_{11}x_{d}^{(1)}(i)+A_{12}x_{d}^{(2)}(i)+B_{1}u_{d}(i), \\ 0 = A_{21}x_{d}^{(1)}(i)+A_{22}x_{d}^{(2)}(i)+B_{2}u_{d}(i). \end{array}\displaystyle \right . $$(4)
3 Convergence analysis of PD-type iterative learning control algorithm
Throughout this paper, we will use the following notation.
The λ norm of the discrete-time vector \(h:\{0,1,\ldots,T\} \rightarrow R^{n}\) is defined as
where \(\|\cdot\|\) is a kind of vector norm in \(R^{n}\). For \(\lambda ^{T}\leqslant\lambda^{i}\leqslant\lambda^{0}\) (\(0\leqslant i\leqslant T\)), it is straightforward to get
Theorem 1
Assuming that the discrete singular system (2) satisfies the given conditions (1)-(3), if the condition \(\|G\|<1\) holds, where
then the PD-type iterative learning control algorithm (3) is uniformly convergent on \([0,T]\). Furthermore, the state \(x_{k}(i)\) of the system (2) uniformly converges to the desired trajectory \(x_{d}(i)\) on \([0,T]\), when the iteration \(k\rightarrow\infty\), that is,
Proof
Since \(0=A_{21}x_{k}^{(1)}(i)+A_{22}x_{k}^{(2)}(i)+B_{2}u_{k}(i)\) and \(A_{22}\) is an invertible matrix,
Denoting \(\hat{A}_{21}=A_{22}^{-1}A_{21}\), \(\hat{B}_{2}=A_{22}^{-1}B_{2}\), then (5) can be written as
Substituting (6) into the system (2), we get
letting \(\hat{A}_{11}=A_{11}-A_{12}\hat{A}_{21}\), \(\hat {B}_{1}=B_{1}-A_{12}\hat{B}_{2}\), then (7) becomes
Denote \(\varDelta u_{k}(i)=u_{d}(i)-u_{k}(i)\). From (3), we obtain
From (6) and (8), one derives that
and
Substituting (10), (11) into (9), we have
labeling \(G=I-\varGamma _{1}\hat{B}_{1}+\varGamma _{2}\hat{B}_{2}\), \(H=\varGamma _{2}\hat {A}_{21}-\varGamma _{1}\hat{A}_{11}\), then
Considering the initial condition \(x_{k}(0)=x_{d}(0)\), \(k=0,1,\ldots\) , and (10), we have
Thus, (13) can be rewritten as
Taking norms on both sides of (15) and multiplying by \(\lambda^{i}\), we obtain
Denote \(h=\|H\|\), \(b=\sup_{\substack{1\leqslant i\leqslant T\\ 0\leqslant j\leqslant{i-1}}}\|\hat{A}_{11}^{i-j-1}\hat{B}_{1}\|\). According to the definition of the λ norm, it yields
Because the right side of (17) is irrespective of time, we obtain
For \(\|G\|<1\), there exists a λ small enough such that
Then it follows from (18) and (19) that as long as λ is small enough, one derives that
According to the properties of λ-norm we have \(\sup_{1\leqslant i\leqslant T}\|\varDelta u_{k}(i)\| \leqslant\lambda^{-T}\|\varDelta u_{k}\|_{\lambda}\), which yields
That means algorithm (3) is uniformly convergent.
For λ to meet (19), taking norms on both sides of (5) and multiplying by λ, we get
Similar to the derivation of (18), we have
Combining (20) and (21), we obtain
Similarly,we have
We have
Therefore \(\lim_{k\rightarrow\infty}{x_{k}(i)}=x_{d}(i)\) is true on the interval \([0,T]\). □
4 Simulation of the new algorithm
In the paper, we discussed a two-dimensional singular discrete-time system. A system model is mentioned as follows:
As shown above, we can see that
From the restricted equivalence transformation of singular systems, we have the following form:
According to the PD-type algorithm (3), let the gain matrix be
and E, A, B satisfy the conditions in Theorem 1. We denote
with the initial conditions of \(x_{k}(0)= [0 \ 0] ^{T}\), \(u_{0}(t)= [0 \ 0]^{T}\), and it satisfies the condition \(\max \|G\|=0.7<1\), where
and we take
then the simulation results are shown in Figures 1-4.

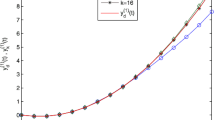
The system state tracking of \(\pmb{x_{d}^{(1)}(i)}\) .
Figure 1 shows the tracking process of the desired trajectory \(x_{d}^{(1)}(i)\) of the discrete singular system by using iterative learning control algorithm (3) at 18th and 25th iterations. According to the definition of complete tracking and the simulation data we can derive that the algorithm can track the desired trajectory completely at the 30th iteration.
Figure 2 shows the tracking process of the desired trajectory \(x_{d}^{(2)}(i)\) of the discrete singular system by using iterative learning control algorithm (3) at the 18th and 25th iterations. According to the definition of complete tracking and the simulation data we can derive that the algorithm can track the desired trajectory completely at the 30th iterations.

The system state tracking of \(\pmb{x_{d}^{(2)}(i)}\) .
Figures 3 and 4 show the variation curves of the maximum tracking error. With the increase number of iterations, the state tracking error can converge to zero.

The variation curves of the maximum tracking error of \(\pmb{x_{d}^{(1)}(i)}\) .

The variation curves of the maximum tracking error of \(\pmb{x_{d}^{(2)}(i)}\) .
The simulation examples illustrate the effectiveness of PD-type iterative learning control algorithm for discrete singular systems. It shows that the research on discrete iterative learning control problem of a class of singular systems has obtained good results in this paper.
5 Conclusions
In this paper, an iterative learning control problem for a class of discrete singular systems is studied by using the dynamic decomposition standard of singular systems. The PD-type iterative learning control algorithm and the sufficient condition are designed, and we have proved in theory the algorithm can guarantee that the output can track the desired trajectory completely on a finite time interval. The simulation example shows the effectiveness of PD-type iterative learning control algorithm for the discrete singular system.
References
Bien, Z, Xu, JX: Iterative Learning Control: Analysis, Design, Integration and Applications. Kluwer Academic, Dordrecht (1998)
Xu, JX, Tan, Y: Linear and Nonlinear Iterative Learning Control. Lecture Notes in Control and Information Science. Springer, Berlin (2003)
Tayebi, A, Chien, CJ: A unified adaptive iterative learning control framework for uncertain nonlinear systems. IEEE Trans. Autom. Control 52, 1907-1913 (2007)
Wijdeven, J, Donkers, T, Bosgra, O: Iterative learning control for uncertain systems: robust monotonic convergence analysis. Automatica 45(10), 2383-2391 (2009)
Chen, Y, Gong, Z, Wen, C: Analysis of a high-order iterative learning control algorithm for uncertain nonlinear systems with state delays. Automatica 34, 345-353 (1998)
Arimoto, S, Kawamuraand, S, Miyazaki, F: Bettering operation of robots by learning. J. Robot. Syst. 1(2), 123-140 (1984)
Wang, YQ, Gao, F, Doyle, FJ III: Survey on iterative learning control, repetitive control,and run-to-run control. J. Process Control 19(10), 1589-1600 (2009)
Hou, Z, Xu, JX, Zhong, H: Freeway traffic control using iterative learning control-based ramp metering and speed signaling. IEEE Trans. Veh. Technol. 56(2), 466-477 (2007)
Cichy, B, Gakowski, K, Rogers, E: Iterative learning control for spatio-temporal dynamics using Crank-Nicholson discretization. Multidimens. Syst. Signal Process. 23(1-2), 185-208 (2012)
Chi, RH, Hou, ZS, Xu, JX: A discretetime adaptive ILC for systems with iterationvarying trajectory and random initial condition. Automatica 44(8), 2207-2213 (2008)
Qu, ZH: An iterative learning algorithm for boundary control of a stretched moving string. Automatica 38(1), 821-827 (2002)
Sun, MX, Wang, DW: Initial shift issues on discrete-time iterative learning control with system relative degree. IEEE Trans. Autom. Control 48(1), 144-148 (2003)
Dai, LY: Singular Control Systems. Lecture Notes in Control and Information Sciences. Springer, New York (1989)
Campbell, SL: Singular Systems of Differential Equations (I). Pitman, San Francisco (1980)
Xie, SL, Xie, ZD, Liu, YQ: Learning control algorithm for state tracking of singular systems with delay. J. Syst. Eng. Electron. 21(5), 10-16 (1999)
Piao, FX, Zhang, QL, Wang, ZF: Iterative learning control for a class of singular systems. Acta Autom. Sin. 33(6), 658-659 (2007)
Piao, FX, Zhang, QL: Iterative learning control for linear singular systems. Control Decis. 22(3), 349-351 (2007)
Tian, SP, Zhou, XJ: State tracking algorithm for a class of singular ILC systems. J. Syst. Sci. Math. Sci. 32(6), 731-738 (2012)
Acknowledgements
First and foremost, we would like to show our deepest gratitude to the editors and the reviewers for giving the chance for our paper to be published. The comments we received were all valuable and very helpful for revising and improving our paper, as well as being of significance and important as a guide to our researches. This work was supported by the National Natural Science Foundation of China (Nos. 61374104, 61364006) and the Natural Science Foundation of Guangdong Province, China (No. 2016A030313505).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
ST and QL conceived and designed the study. XD and JZ performed the simulation. QL and JZ wrote the paper. QL and ST reviewed and edited the manuscript. All authors read and approved the manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Tian, S., Liu, Q., Dai, X. et al. A PD-type iterative learning control algorithm for singular discrete systems. Adv Differ Equ 2016, 321 (2016). https://doi.org/10.1186/s13662-016-1047-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13662-016-1047-4