
Abstract
In this paper, we introduce two subgradient extragradient-type algorithms for solving variational inequality problems in the real Hilbert space. The first one can be applied when the mapping f is strongly pseudomonotone (not monotone) and Lipschitz continuous. The first algorithm only needs two projections, where the first projection onto closed convex set C and the second projection onto a half-space \(C_{k}\). The strong convergence theorem is also established. The second algorithm is relaxed and self-adaptive; that is, at each iteration, calculating two projections onto some half-spaces and the step size can be selected in some adaptive ways. Under the assumption that f is monotone and Lipschitz continuous, a weak convergence theorem is provided. Finally, we provide numerical experiments to show the efficiency and advantage of the proposed algorithms.
Similar content being viewed by others
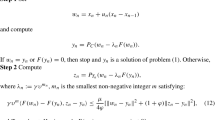
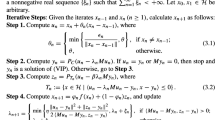
1 Introduction
Let H be a real Hilbert space with the inner product \(\langle \cdot , \cdot \rangle \). The classic variational inequality problems for f on C are to find a point \(x^{*} \in C\) such that
where C is a nonempty closed convex subset of H, and f is a mapping from H to H. The problem and its solution set will be denoted by \(VI(C,f)\) and \(\operatorname{SOL}(C,f)\). This class of variational inequality problems arises in many fields such as optimal control, optimization, partial differential equations, and some other nonlinear problems; see [1] and the references therein. Nowadays, variational inequality problems with uncertain data are a very interesting topic, and the robust optimization has recently emerged as a powerful approach to deal with mathematical programming problems with data uncertainty. For more details, we refer the readers to [18, 29, 30].
In order to solve variational inequality problems, many solution methods have been introduced [7, 12, 14, 16, 17, 31]. Among these methods, subgradient extragrdeint method has attracted much attention. This method has the following form:
where \(T_{k}:=\{w\in H| \langle x^{k}-\tau f(x^{k})-y^{k}, w-y^{k}\rangle \leq 0 \}\) is a half-space and \(\tau >0\) is a constant. Under the assumption that f is monotone and L-Lipschitz continuous, the method (1.2)-(1.3) weakly converges to a solution to \(VI(C,f)\).
The subgradient extragradient method has received a great deal of attention and many authors modified and improved it in various ways, see [9, 10, 25, 35]. To the best of our knowledge, almost subgradient extragradient-type algorithms about variational inequality problems need to assume f is monotone Lipschitz continuous and need one projection on C. These observations lead us to the following concerns:
Question 1
Can we propose a new subgradient extragradient-type algorithm for solving strongly pseudomonotone (not monotone) variational inequality problems?
Question 2
Can we propose a new subgradient extragradient-type projection algorithm such that the projection on C can be replaced by half-space?
In this paper, the main purpose is to solve the two questions. We first introduce a subgradient extragradient-type algorithm for solving Question 1. Under the assumptions that f is strongly pseudomonotone(not monotone) and Lipschitz continuous, we establish the strong convergence theorem. The first algorithm has the following form:
where \(C_{k}\) is a half-space (a precise definition will be given in Sect. 3 (3.2)). The main feature of the new algorithm is that: it only requires the strong pseudomonotonicity (not monotone) and Lipschitz continuity (there is no need to know or estimate the Lipschitz constant of f) of the involving mapping instead of the monotonicity and L-Lipschitz continuity conditions as in [4]. Moreover, in the new algorithm, the step sizes \(\lambda _{k}\) do not necessarily converge to zero, and we get the strong convergence theorem.
Note that, in the algorithms (1.2)-(1.3) and (1.4)-(1.5), one still needs to execute one projection onto the closed convex set C at each iteration. If C has a simple structure (e.g., half-space, a ball, or a subspace), the projection \(P_{C}\) can be computed easily. But, if C is a general closed convex set, one has to solve the minimal distance problem to compute the projection onto C, which is complicated in general.
To overcome this flaw, we present the second algorithm, named two-subgradient extragradient algorithm, for solving monotone and Lipschitz continuous variational inequality problems defined on a level set of a convex function. The two-subgradient extragradient algorithm has the following form:
where \(C_{k}\) is a half-space (a precise definition will be given in Sect. 4). It is well known that the projection onto half-space can be calculated directly. Clearly, the two-subgradient extragradient algorithm is easy to implement. We prove that the sequence generated by the algorithm (1.6)-(1.7) weakly converges to a solution to \(VI(C,f)\) for the case where the closed convex set C can be represented as a lower level set of a continuously differentiable convex function. Moreover, the step size \(\lambda _{k}\) in this algorithm can be selected in some adaptive way; that is, we have no need to know or to estimate any information as regards the Lipschitz constant of f.
Our paper is organized as follows: In Sect. 2, we collect some basic definitions and preliminary results. In Sect. 3, we propose an extragradient-type algorithm and analyze its convergence and convergence rate. In Sect. 4, we consider the two-subgradient extragradient algorithm and analyze its convergence and convergence rate. Numerical results are reported in Sect. 5.
2 Preliminaries
In this section, we recall some definitions and results for further use. For the given nonempty closed convex set C in H, the orthogonal projection from H to C is defined by
We write \(x^{k}\rightarrow x\) and \(x^{k} \rightharpoonup x\) to indicate that the sequence \(\{x^{k}\}\) converges strongly and weakly to x, respectively.
Definition 2.1
Let \(f: H\rightarrow H\) be a mapping. f is called Lipschitz continuous with constant \(L>0\), if
Definition 2.2
Let \(f: C\rightarrow H\) be a mapping. f is called
-
(a)
monotone on C, if
$$ \bigl\langle f(y)-f(x), y-x\bigr\rangle \geq 0, \quad \forall x,y\in C;$$ -
(b)
σ-strongly pseudomonotone on C, if there exists \(\sigma >0\) such that
$$ \bigl\langle f(x),y-x\bigr\rangle \geq 0 \quad \Rightarrow\quad \bigl\langle f(y),y-x\bigr\rangle \geq \sigma \Vert x-y \Vert ^{2}, \quad \forall x,y\in C.$$
Remark 2.1
We claim that property (b) guarantees that \(VI(C,f)\) have one solution at most. Indeed, if \(u,v\in \operatorname{SOL}(C,f)\) and if (b) is satisfied, then \(\langle f(v),u-v\rangle \geq 0\) and \(\langle f(v),v-u\rangle \geq \sigma \|v-u\|^{2}\). Adding these two inequalities yields \(\sigma \|v-u\|^{2} \leq 0\), which implies \(u=v\). Note also that property (b) and the continuity of f guarantee that \(VI(C,f)\) has a unique solution [19].
In the following, we introduce an example to illustrate that f is strongly pseudomonotone but is not monotone in general.
Example 2.1
Let \(H=l_{2}\) be a real Hilbert space whose elements are square-summable sequences of real scalars, i.e.,
The inner product and the induced norm on H are given by
for any \(u=(u_{1},u_{2},\ldots , u_{n},\ldots )\), \(v=(v_{1},v_{2},\ldots , v_{n},\ldots )\in H\).
Let α and β be two positive real numbers such that \(\beta <\alpha \) and \(1-\alpha \beta <0\). Let us set
We now show that f is strongly pseudomonotone. Indeed, let \(u,v\in C\) be such that \(\langle f(u),v-u\rangle \geq 0\). This implies that \(\langle u,v-u\rangle \geq 0\). Consequently,
where \(\gamma :=\frac{1}{1+\alpha ^{2}}>0\). Taking \(u=(\alpha ,0,\ldots ,0,\ldots )\), \(v=(\beta ,0,\ldots ,0,\ldots )\in C\), we find
This means f is not monotone on C.
Definition 2.3
Let \(f: H\rightarrow (-\infty , +\infty ]\), and \(x\in H\). Then f is weakly sequential lower semicontinuous at x if for every sequence \(\{x^{k}\}\) in H,
Definition 2.4
A mapping \(c: H \rightarrow R\), is said to be Gâteaux differentiable at a point \(x\in H\), if there exists an element, denoted by \(c^{\prime }(x) \in H\), such that
where \(c^{\prime }(x)\) is called the Gâteaux differential of c at x.
Definition 2.5
For a convex function \(c: H\rightarrow R\), c is said to be subdifferentiable at a point \(x\in H\) if the set
is not empty. Each element in \(\partial c(x)\) is called a subgradient of c at x. c is said to be subdifferentiable on H if c is subdifferentiable at each \(x\in H\).
Note that if \(c(x)\) is Gâteaux differentiable at x, then \(\partial c(x)=\{c'(x)\}\).
Definition 2.6
Suppose that a sequence \(\{x^{k}\} \) in H converges in norm to \(x^{*} \in H\). We say that
-
(a)
\(\{x^{k}\} \) converges to \(x^{*}\) with R-linear convergence rate if
$$ \lim_{k \rightarrow {\infty}} \sup \bigl\Vert x^{k}-x^{*} \bigr\Vert ^{1/k}< 1. $$ -
(b)
\(\{x^{k}\} \) converges to \(x^{*}\) with Q-linear convergence rate if there exists \(\mu \in (0,1)\) such that
$$ \bigl\Vert x^{k+1}-x^{*} \bigr\Vert \leq \mu \bigl\Vert x^{k}-x^{*} \bigr\Vert . $$for all sufficiently large k.
Note that Q-linear convergence rate implies R-linear convergence rate; see [[23], Sect. 9.3]. We remark here that R-linear convergence does not imply Q-linear convergence in general. We consider one simple example, which is derived from [15].
Example 2.2
Let \(\{x^{k}\}\in \mathbb{R}\) be the sequence of real numbers defined by
Since
\(\{x^{k}\}\) converges to 0 with an R-linear convergence rate. Note that
this implies \(\{x^{k}\}\) does not converge to 0 with the Q-linear convergence rate.
The following well-known properties of the projection operator will be used in this paper.
Lemma 2.1
Let \(P_{C}(\cdot )\) be the projection onto C. Then
-
(a)
\(\langle x-P_{C}(x), y- P_{C}(x)\rangle \leq 0\), \(\forall x\in H\), \(y\in C\);
-
(b)
\(\|x-y\|^{2}\geq \|x-P_{C}(x)\|^{2}+\|y-P_{C}(x)\|^{2}\), \(\forall x\in H\), \(y\in C\);
-
(c)
\(\|P_{C}(y)-P_{C}(x)\| \leq \langle P_{C}(y)-P_{C}(x),y-x \rangle \), \(\forall x,y\in H\);
-
(d)
\(\|P_{C}(y)-P_{C}(x)\| \leq \|y-x\|\), \(\forall x,y\in H\).
Lemma 2.2
([2])
Let \(f:H\rightarrow (-\infty , +\infty ] \) be convex. Then the following are equivalent:
-
(a)
f is weakly sequential lower semicontinuous;
-
(b)
f is lower semicontinuous.
Lemma 2.3
([22](Opial))
Assume that C is a nonempty subset of H, and \(\{x^{k}\}\) is a sequence in H such that the following two conditions hold:
-
(i)
\(\forall x\in C\), \(\lim_{k \rightarrow {\infty}}\|x^{k}-x\| \) exists;
-
(ii)
every sequential weak cluster point of \(\{x^{k}\}\) belongs to C.
Then \(\{x^{k}\}\) converges weakly to a point in C.
Lemma 2.4
([13])
Assume that the solution set \(\operatorname{SOL}(C,f)\) of \(VI(C,f)\) is nonempty. Given \(x^{*}\in C\) and C is defined in (3.1), where C is a Gâteaux differentiable convex function. Then \(x^{*}\in \operatorname{SOL}(C,f)\) if and only if we have either
-
(i)
\(f(x^{*})=0\), or
-
(ii)
\(x^{*}\in \partial C\) and there exists a positive constant η such that \(f(x^{*})=-\eta c'(x^{*})\).
Remark 2.2
According to Sect. 5: Application in [13], we remark here that determining η is an easy and/or feasible task.
Lemma 2.5
([5])
Consider the problem \(VI(C,f)\) with C being a nonempty, closed, convex subset of a real Hilbert space H and \(f:C\rightarrow H\) being pseudo-monotone and continuous. Then, \(x^{*}\) is a solution to \(VI(C,f)\) if and only if
3 Convergence of subgradient extragradient-type algorithm
In this section, we introduce a self-adaptive subgradient extragradient-type method for solving variational inequality problems. The nonempty closed convex set C will be given as follows:
where \(c:H \rightarrow R\) is a convex function.
We define the half-space as
with \(\zeta ^{k} \in \partial c(x^{k})\), where \(\partial c(x^{k})\) is the subdifferential of c at \(x^{k}\). It is clear that \(C \subset C_{k}\) for any \(k\geq 0\).
In order to prove our theorem, we assume that the following conditions are satisfied:
- C1::
-
The mapping \(f: H \rightarrow H\) is σ-strongly pseudomonotone and Lipschitz continuous (but we have no need to know or estimate the Lipschitz constant of f).
Note that strong pseudomonotonicity and the continuity of f guarantee that \(VI(C,f)\) has a unique solution denoted by \(x^{*}\).
Now we propose our Algorithm 1.

Subgradient extragradient-type algorithm
The following lemma gives an explicit formula of \(P_{C_{k}}\).
Lemma 3.1
([24])
For any \(y\in H\),
where \(u \in \partial c(x^{k})\).
Lemma 3.2
The sequence \(\{\lambda _{k}\}\) is nonincreasing and is bounded away from zero. Moreover, there exists a number \(m>0\) such that
-
(1)
\(\lambda _{k+1}=\lambda _{k}\) and \(\lambda _{k}\|f(x^{k})-f(y^{k})\|\leq \rho \|x^{k}-y^{k}\|\) for all \(k\geq m\).
-
(2)
\(\lambda _{k} \geq \lambda _{-1}\delta ^{m+1}\) for any \(k\geq 0\).
Proof
Since \(\delta \in (0,1)\), it is easy to see the sequence \(\{\lambda _{k}\}\) is nonincreasing. We claim this sequence is bounded away from zero. Suppose, on the contrary, that \(\lambda _{k}\rightarrow 0\). Then, there exists a subsequence \(\{\lambda _{k_{i}}\}\subset \{\lambda _{k} \}\) such that
Let L be the Lipschitz constant of f, we have
Obviously, this inequality contradicts the fact \(\lambda _{k}\rightarrow 0\). Therefore, there exists a number \(m>0\) such that
for all \(k\geq m\). Since the sequence \(\{\lambda _{k}\}\) is nonincreasing, the preceding relation (3.3) implies \(\lambda _{k} \geq \lambda _{m} \geq \lambda _{-1} \delta ^{m+1}\) for all k. □
The following lemma plays a key role in our convergence analysis.
Lemma 3.3
For \(x^{*} \in SOL(C,f) \), let the sequences \(\{x^{k}\}\) and \(\{y^{k}\}\) be generated by Algorithm 1. There exists a number \(m>0\) such that
for all \(k\geq m\).
Proof
For \(x^{*} \in \operatorname{SOL}(C,f)\), \(x^{*} \in C_{k}\) due to \(\operatorname{SOL}(C,f)\subset C\subset C_{k}\) for all \(k \geq 0\). Using Lemma 2.1, we have
Noting that \(y^{k}=P_{C} (x^{k}-\lambda _{k} f(x^{k},v^{k}))\), this implies that
or equivalently
By (3.4), (3.6), and Lemma 3.2, \(\forall k \geq m\), we get
where the third term in the right-hand side of (3.7) is estimated by the strong pseudomonotonicity of f. □
Theorem 3.1
Suppose that condition C1 is satisfied. Then the sequences \(\{x^{k}\}\) and \(\{y^{k}\}\) generated by Algorithm 1 strongly converge to a unique solution to \(VI(C,f)\).
Proof
Let \(x^{*} \in \operatorname{SOL}(C,f)\). Using Lemma 3.3, there exists a number \(m>0\) such that for all \(k\geq m\),
or equivalently
Continuing, we get for all integers \(n \geq 0\),
Since the sequence \(\{\sum_{k=0}^{n}(1-\rho ^{2})\|x^{k}-y^{k}\|^{2}+ \sum_{k=0}^{n} 2 \sigma \lambda _{k} \|y^{k}-x^{*}\|^{2}\} \) is monotonically increasing and bounded, we obtain
By Lemma 3.2, \(\{\lambda _{k}\}\) is bounded away from zero. Hence, we have
That is, \(x^{k} \rightarrow x^{*}\) and \(y^{k} \rightarrow x^{*}\). This completes the proof. □
We note that Algorithm 1 can give convergence when f is strongly pseudomonotone and Lipschitz continuous without \(P_{C_{k}}\) in Step 3. We now give a convergence result via the following new method.
Theorem 3.2
Assume that condition C1 is satisfied. Let \(\rho , \delta \in [a,b] \subset (0,1)\); \(\lambda _{-1}\in (0,\infty )\). Choose \(x^{-1}, x^{0}, y^{-1} \in H\). Let \(p_{k-1}=x^{k-1}-y^{k-1}\).
Suppose \(\{x^{k}\}\) is generated by
Then the sequences \(\{x^{k}\}\) and \(\{y^{k}\}\) generated by (3.14) strongly converge to a unique solution to \(VI(C,f)\).
Proof
Similar to the proof of Theorem 3.1, it is not difficult to get a conclusion. We omit the proof here. □
Remark 3.1
-
(a)
Suppose f is monotone and L-Lipschitz continuous. Let \(\lambda _{k}=\lambda \in (0,1/L)\). Then the new method (3.13)-(3.14) reduces to the algorithm proposed by Tseng in [34].
-
(b)
Tseng’s algorithm [34] has been studied extensively by many authors; see [3, 26, 27, 32, 33, 36] and the references therein. We notice that many modified Tseng’s algorithms require that the operator f is monotone and Lipschitz continuous operator. Recently, weak convergence has been obtained in several papers [3, 26, 27], even when the cost operator is pseudomonotone.
-
(c)
We obtain strong convergence under the assumptions that f is strongly pseudomonotone and Lipschitz continuous. That is to say, the new method (3.13)-(3.14) is different from the methods suggested in [3, 26, 27, 32–34, 36].
Before ending this section, we provide a result on the linear convergence rate of the iterative sequence generated by Algorithm 1.
Theorem 3.3
Let \(f:C\rightarrow H\) be strongly pseudomonotone and L-Lipschitz continuous mapping. Then the sequence generated by Algorithm 1 converges in norm to the unique solution \(x^{*}\) of \(VI(C,f)\) with a Q-linear convergence rate.
Proof
It follows from Lemma 3.3 that
Put
By Lemma 3.2\((2)\), we have
Note that
Thus, we get
Hence,
where \(\mu :=\sqrt{1-\beta}\in (0,1)\). The inequality (3.15) shows that \(\{x^{k}\}\) converges in norm to \(x^{*}\) with a Q-linear convergence rate. □
4 Convergence of two-subgradient extragradient algorithm
In this section, we introduce an algorithm named two-subgradient extragradient algorithm, which replaces the first projection in Algorithm 1 onto closed convex set C with a projection onto a specific constructible half-space \(C_{k}\). We assume that C is the same form given in (3.1). In order to prove our theorem, we assume the following conditions are satisfied:
- A1::
-
\(\operatorname{SOL}(C,f)\neq 0\).
- A2::
-
The mapping \(f: H \rightarrow H\) is monotone and Lipschitz continuous (but we do not need to know or estimate the Lipschitz constant of f).
- A3::
-
-
(a)
The feasible set \(C=\{x\in H\mid c(x) \leq 0\}\) is continuously Gâteaux differentiable convex function.
-
(b)
Gâteaux differential of c at x, denoted by \(c'(x)\), is K-Lipschitz continuous.
-
(a)
The following lemma plays an important role in our convergence analysis.
Lemma 4.1
For any \(x^{*} \in \operatorname{SOL}(X,F) \) and let the sequences \(\{x^{k}\}\) and \(\{y^{k}\}\) be generated by Algorithm 2. Then we have
for all \(k\geq m\).

Two-subgradient extragradient algorithm
Proof
By an argument very similar to the proof of Lemma 3.3, it is not difficult to get the following inequality:
where the second inequality follows by the monotonicity of f.
The subsequent proof is divided into the following two cases:
- Case 1::
-
\(f(x^{*})=0\), then Lemma 4.1 holds immediately in view of (4.1).
- Case 2::
-
\(f(x^{*})\neq 0\).
By Lemma 2.4, we have \(x^{*}\in \partial C \) and there exists \(\eta >0\) such that \(f(x^{*}) =-\eta c'(x^{*})\). Because \(c(\cdot )\) is differentiable convex function, it follows
Note that \(c(x^{*})=0\) due to \(x^{*} \in \partial C\), we have
Since \(y^{k}\in C_{k}\) and by the definition of \(C_{k}\) in step 3, we have
By the convexity of \(c(\cdot )\), we have
Adding the two above inequalities, we get
where the second inequality follows from the Lipschitz continuity of \(c'(\cdot )\). Thus, combining (4.1), (4.2), and (4.3), we get
□
Theorem 4.1
Suppose that conditions A1-A3 are satisfied. Let \(0<\lambda _{-1} \leq \frac{1-\rho ^{2}}{2\eta K}\). Then the sequence \(\{x^{k}\}\) generated by Algorithm 2 weakly converges to a solution to \(VI(C,f)\).
Proof
Let \(x^{*} \in \operatorname{SOL}(C,f)\). Using Lemma 4.1, there exists a number \(m>0\) such that
for all \(k\geq m\). By Remark 2.2, determining η is an easy and/or feasible task. So, find a number \(\lambda _{-1} \leq \frac{1-\rho ^{2}}{2\eta K}\) is a feasible task. Since \(\{ \lambda _{k} \}\) is nonincreasing, we get \(\lambda _{k} \leq \frac{1-\rho ^{2}}{2\eta K}\) for all \(k \geq 0\). Thus, we have \(1-\rho ^{2}-2\lambda _{k} \eta K \geq 0\), which implies that \(\lim_{k \rightarrow {\infty}} \|x^{k}-x^{*}\|\) exists and \(\lim_{k \rightarrow {\infty}} \|x^{k}-y^{k}\|=0\). Thus, the sequence \(\{x^{k}\}\) is bounded. Consequently, \(\{y^{k}\}\) is also bounded. Let \(\hat{x}\in H\) be a sequential weak cluster of \(\{x^{k}\}\), then there exists a subsequence \(\{x^{k_{i}}\}\) of \(\{x^{k}\}\) such that \(\lim_{i \rightarrow {\infty}} x^{k_{i}}=\hat{x}\). Since \(\|x^{k}-y^{k}\| \rightarrow 0\), we also have \(\lim_{i \rightarrow {\infty}} y^{k_{i}}=\hat{x}\). Due to \(y^{k_{i}} \in C_{k_{i}}\) and the definition of \(C_{k_{i}}\),
we can get
Since \(c'(\cdot )\) is Lipschitz continuous and \(\{x^{k_{i}}\}\) is bounded, we deduce that \(c'(x^{k_{i}})\) is bounded on any bounded sets of H. This fact means that there exists a constant \(M>0\) such that
Because \(c(\cdot )\) is convex and lower semicontinuous, using Lemma 2.2, we get \(c(\cdot )\) is weak sequential lower semicontinuous. Thus, by combining (4.5) and Definition 2.3, we obtain
which means \(\hat{x}\in C\).
Now we turn to show \(\hat{x} \in \operatorname{SOL}(C,f)\).
Note that \(C\subset C_{k}\) for all \(k \geq 0\). From \(y^{k_{i}}=P_{C_{k_{i}}}(x^{k_{i}}-\lambda _{k_{i}}f(x^{k_{i}}))\) and f is monotone, \(\forall x\in C \subset C_{k_{i}}\), we get
By Lemma 3.2, we get \(\lambda _{k}>0\) is bounded away from zero. Passing to the limit in (4.7), we have
By Lemma 2.5, we have \(\hat{x} \in \operatorname{SOL}(C,f)\). Therefore, we proved that
-
(1)
\(\lim_{k \rightarrow {\infty}} \|x^{k}-x^{*}\|\) exists;
-
(2)
If \(x^{k_{i}}\rightharpoonup \hat{x}\) then \(\hat{x}\in \operatorname{SOL}(C,f)\).
It follows from Lemma 2.3 that the sequence \(\{x^{k}\}\) converges weakly to a solution to \(VI(C,f)\). □
Before ending this section, we prove the convergence rate of the iterative sequence generated by Algorithm 2 in the ergodic sense. The base of the complexity proof ([8]) is
In order to prove the convergence rate, the following key inequality is needed. Indeed, by an argument very similar to the proof of Lemma 4.1, it is not difficult to get the following result.
Lemma 4.2
Let \(\{x^{k}\}\) and \(\{y^{k}\}\) be two sequences generated by Algorithm 2, and let \(\lambda _{k}\) be selected as Step 1 in Algorithm 2. Suppose conditions A1-A3 are satisfied. Then for any \(u \in C\), we get
Theorem 4.2
For any integer \(n>0\), there exists a sequence \(\{z^{n}\}\) satisfying \(z^{n}\rightharpoonup x^{*}\in \operatorname{SOL}(C,f)\) and
where
Proof
By Lemma 4.2, we have
Summing (4.9) over \(k=0,1,\ldots ,n\), we have
Combining (4.8) and (4.10), we derive
Note that from the fact that \(y^{k}\rightharpoonup x^{*}\in \operatorname{SOL}(C,f)\) and \(z^{n}\) is a convex combination of \(y^{0}, y^{1},\ldots ,y^{k}\), we get \(z^{n}\rightharpoonup x^{*} \in \operatorname{SOL}(C,f)\). This completes the proof. □
Denote \(\alpha :=\lambda _{-1}\delta ^{m+1}\). From Lemma 3.2(2), \(\lambda _{k} \geq \alpha \) holds for all \(k\geq 0\). This fact together with the relation (4.8) yields
The preceding inequality implies Algorithm 2 has \(O(\frac{1}{n})\) convergence rate. For a given accuracy \(\epsilon >0\) and any bounded subset \(X\subset C\), Algorithm 2 achieves
in at most \(\lceil \frac{r}{2\alpha \epsilon} \rceil \) iterations, where \(r=\sup\{\|x^{0}-u\|^{2} |u\in X\}\).
5 Numerical experiments
In order to evaluate the performance of the proposed algorithms, we present numerical examples relative to the variational inequalities. In this section, we provide some numerical experiments to demonstrate the convergence of our algorithms and compare the algorithms we proposed with the existing algorithms in [11, 21, 28]. The MATLAB codes are run on a PC (with Intel(R) Core(TM) i7-6700HQ CPU@2.60 GHz, 2.59 GHZ, RAM 16.0 GB) under MATLAB Version 9.2.0.538062 (R2017a) Service Pack 1, which contains Global optimization Toolbox version 3.4.2.
Example 5.1
We consider \(VI(C,f)\) with the constraint set \(C =\{x\in \mathbb{R}^{20}: \|x\|-5\leq 0\}\). Define \(f: \mathbb{R}^{20}\rightarrow \mathbb{R}^{20}\) by
In this case, we can verify that \(x^{*}=0\) is the solution to \(VI(C,f)\). We note that f is 1-strongly pseudomonotone and 4-Lipschitz continuous on \(\mathbb{R}^{n}\) (See Example 3.3 [20]) and is not (strongly) monotone. It means that when the methods in [11, 28] are applied to solve Example 5.1, its iteration point sequence may not converge to the solution point.
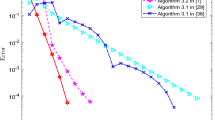
In the implementation of Algorithm 1, we take \(\rho =0.5\), \(\delta =0.1\), \(\lambda _{-1}=0.5\). In the implementation of Algorithm 3.1 in [21], we set \(\lambda =0.05\), \(\delta =0.025\) and \(\gamma =0.49\). Moreover, we choose \(x^{0}=\frac{x^{T}}{\|x^{T}\|} \), \(x^{-1}=\frac{x^{T}}{\|x^{T}\|} \) and \(y^{-1}=0\) as the staring point for Algorithm 1, where \(x^{T}=(1,1,\ldots ,1)^{T}\). We choose \(x^{0}=\frac{x^{T}}{\|x^{T}\|} \), \(x^{1}=\frac{x^{T}}{\|x^{T}\|} \) as the staring point for Algorithm 3.1 in [21]. The numerical results of Example 5.1 are shown in Fig. 1, which illustrate the sequence generated by Algorithm 1 is more efficient in comparison with Algorithm 3.1 in [21].

Example 5.2
Consider variational inequality problems \(VI(C,f)\). The constraint set \(C=\{(x_{1},x_{2})\in \mathbb{R}^{2} : x_{1}^{2}+x_{2}^{2} \leq 100 \}\). Let \(f: C\rightarrow \mathbb{R}^{2}\) be defined by \(f(x)=(2x_{1}+2x_{2}+\sin(x_{1}),-2x_{1}+2x_{2}+\sin(x_{2}))^{T}\), \(\forall x=(x_{1},x_{2})^{T}\in C\).
For Example 5.2, the following conclusions can be obtained from [6]:
-
(1)
F is 1-strongly monotone and \(\sqrt{26}\)-Lipschitz continuous mapping.
-
(2)
\(x^{*}=(0,0)^{T}\in C\) is the unique solution to \(VI(C,f)\).
In this example, we take \(\rho =0.5\), \(\delta =0.1\), \(\lambda _{-1}=0.5\) for Algorithm 1,2; \(\gamma =0.4\), \(\delta =0.2\), \(\lambda =0.05\) for Algorithm 3.1 in [21]; set \(\lambda =\frac{1}{20}\), \(\gamma =1\) and \(\alpha _{k}=\frac{1}{k+1}\) for Algorithm 4.1 in [11]; set \(\theta =0.25\), \(\sigma =0.7\), \(\gamma =0.6\) and \(\alpha _{k}=\frac{1}{k+1}\) for Algorithm 3.3 in [28]. For Example 5.2, we choose \(x^{0}=(-10,-12)^{T}\), \(x^{-1}=(0,0)^{T}\), \(y^{-1}=(-1,5)^{T}\) as the initial points for Algorithm 1 and Algorithm 2; \(x^{1}=(-10,-12)^{T}\), \(x^{0}=(0,0)^{T}\) as the initial points for [21, 28]; \(x^{0}=(-10,-12)^{T}\) as the initial point for [11]. The numerical results of Example 5.2 are shown in Fig. 2 and have suggested that our algorithms are more efficient in comparison with existing algorithms such as the methods in [11, 21, 28].

Example 5.3
Consider \(VI(C,f)\) with constraint set \(C=\{x\in R^{m}: \|x\|^{2} -100\leq 0\}\). Define \(f(x):\mathbb{R}^{m}\rightarrow \mathbb{R}^{m}\) by \(f(x)=x+q\), where \(q\in \mathbb{R}^{m}\).
It is easy to verify that f is 1-Lipschitz continuous and 1-strongly monotone mapping. Therefore, the variational inequality (1.1) has a unique solution. For \(q = 0\), the solution set \(\operatorname{SOL}(C, f) = \{0\}\). In our experiment, we take \(m=100\).
In this example, we select the parameters \(\rho =0.5\), \(\delta =0.1\), \(\lambda _{-1}=0.5\) for Algorithm 1 and Algorithm 2; \(\gamma =0.49\), \(\delta =0.2\), \(\lambda =0.05\) for Algorithm 3.1 in [21]; \(\lambda =1\), \(\gamma =1\) and \(\alpha _{k}=\frac{1}{k+1}\) for Algorithm 4.1 [11]; \(\theta =0.25\), \(\sigma =0.7\), \(\gamma =0.6\) and \(\alpha _{k}=\frac{1}{k+1}\) for Algorithm 3.3 [28]. We choose \(x^{0}=x^{T}\), \(x^{-1}=\frac{x^{T}}{\|x^{T}\|}\), \(y^{-1}=(0,0,\ldots ,0)^{T}\) as the initial points for Algorithm 1 and Algorithm 2; \(x^{1}=x^{T}\), \(x^{0}=\frac{x^{T}}{\|x^{T}\|}\) as the initial points for [21, 28]; \(x^{0}=x^{T}\) as the initial point for [11], where \(x^{T}=(1,1,\ldots ,1)^{T}\). The numerical results of Example 5.3 are shown in Fig. 3, where it can be seen that the behavior of Algorithm 1 and Algorithm 2 is better than the algorithms in [11, 21, 28].

Availability of data and materials
Not applicable.
References
Ansari, Q.H., Lalitha, C.S., Mehta, M.: Generalized Convexity, Nonsmooth Variational Inequalities and Nonsmooth Optimization. CRC Press, Boca Raton (2014)
Bauschke, H.H., Combettes, P.L.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces, 2nd edn. Springer, New York (2017)
Cai, G., Shehu, Y., Iyiola, O.S.: Inertial Tseng’s extragradient method for solving variational inequality problems of pseudo-monotone and non-Lipschitz operators. J. Ind. Manag. Optim. https://doi.org/10.3934/jimo.2021095(2021)
Censor, Y., Gibali, A., Reich, S.: The subgradient extragradient method for solving variational inequalities in Hilbert space. J. Optim. Theory Appl. 148, 318–335 (2011)
Cottle, R.W., Yao, J.C.: Pseudo-monotone complementarity problems in Hilbert space. J. Optim. Theory Appl. 75, 281–295 (1992)
Dong, Q.L., Cho, Y.J., Zhong, L.L., Rassias, T.M.: Inertial projection and contraction algorithms for variational inequalities. J. Glob. Optim. 70, 687–704 (2018)
Dong, Q.L., Jiang, D., Gibali, A.: A modified subgradient method for solving the variational in equality problem. Numer. Algorithms 5, 225–236 (2018)
Facchinei, F., Pang, J.S.: Finite-Dimensional Variational Inequalities and Complementarity Problems, Vols. I and II. Springer Series in Operations Research. Springer, New York (2003)
Fang, C., Chen, S.: A subgradient extragradient algorithm for solving multi-valued variational inequality. Appl. Math. Comput. 229, 123–130 (2014)
Fang, C.J., Chen, S.L.: A subgradient extragradient algorithm for solving multi-valued variational inequality. Appl. Math. Comput. 229, 123–130 (2014)
Gibali, A., Shehu, Y.: An efficient iterative method for finding common fixed point and variational inequalities in Hilbert spaces. Optimization 68(1), 13–32 (2019)
He, S.N., Wu, T.: A modified subgradient extragradient method foe solving monotone var iational inequalities. J. Inequal. Appl. 89, 62–75 (2017)
He, S.N., Xu, H.K.: Uniqueness of supporting hyperplanes and an alternative to solutions of variational inequalities. J. Glob. Optim. 57, 1357–1384 (2013)
Hieu, D.V., Thong, D.V.: New extragradient methods for solving variational inequality problems and fixed point problems. J. Fixed Point Theory Appl. 20, 129–148 (2018)
Khanh, P.D.: Convergence rate of a modified extragradient method for pseudomotone variational inequalities. Vietnam J. Math. 45, 397–408 (2017)
Korpelevich, G.M.: The extragradient method for finding saddle points and other problems. Èkon. Mat. Metody 12, 747–756 (1976)
Kranzow, C., Shehu, Y.: Strong convergence of a double projection-type method for monotone variational inequalities in Hilbert spaces. J. Fixed Point Theory Appl. 20, 51 (2018)
Minh, N.B., Phuong, T.T.T.: Robust equilibrium in transportation networks. Acta Math. Vietnam. 45, 635–650 (2020)
Muu, L.D., Quy, N.V.: On existence and solution methods for strongly pseudomonotone equilibrium problems. Vietnam J. Math. 43, 229–238 (2015)
Nguyen, L.V., Qin, X.L.: Some results on strongly pseudomonotone quasi-variational inequalities. Set-Valued Var. Anal. 28, 239–257 (2020)
Nwokoye, R.N., Okeke, C.C., Shehu, Y.: A new linear convergence method for a Lipschitz pseudomonotone variational inequality. Appl. Set-Valued Anal. Optim. 3, 215–220 (2021)
Opial, Z.: Weak convergence of the sequence of successive approximations for nonexpansive mappings. Bull. Am. Math. Soc. 73, 591–597 (1967)
Ortega, J.M., Rheinboldt, W.C.: Iterative Solution of Nonlinear Equations in Several Variable. Academic Press, New York (1970)
Polyak, B.T.: Minimization of unsmooth functionals. USSR Comput. Math. Math. Phys. 9, 14–29 (1969)
Shehu, Y., Dong, Q.L., Jiang, D.: Single projection method for pseudo-monotone variational inequality in Hilbert spaces. Optimization 68(1), 385–409 (2019)
Shehu, Y., Iyiola, O.S.: Projection methods with alternating inertial steps for variational inequalities: weak and linear convergence. Appl. Numer. Math. 157, 315–337 (2020)
Shehu, Y., Iyiola, O.S., Yao, J.C.: New projection methods with inertial steps for variational inequalities. Optimization. https://doi.org/10.1080/02331934.2021.1964079(2021)
Shehu, Y., Li, X.H., Dong, Q.L.: An efficient projection-type method for monotone variational inequalities in Hilbert spaces. Numer. Algorithms 84, 365–388 (2020)
Sun, X.K., Teo, K.L., Long, X.J.: Some characterizations of approximate solutions for robust semi-infinite optimization problems. J. Optim. Theory Appl. 191, 281–310 (2021)
Sun, X.K., Teo, K.L., Tang, L.P.: Dual approaches to characterize robust optimal solution sets for a class of uncertain optimization problems. J. Optim. Theory Appl. 182, 984–1000 (2019)
Thong, D.V., Hieu, D.V.: Weak and strong convergence theorems for variational inequality problems. Numer. Algorithms 78, 1045–1060 (2018)
Thong, D.V., Hieu, D.V.: New extragradient methods for solving variational inequality problems and fixed point problems. J. Fixed Point Theory Appl. 20, 129 (2018)
Thong, D.V., Triet, N.A., Li, X.H., Dong, Q.L.: Strong convergence of extragradient methods for solving bilevel pseudo-monotone variational inequality problems. Numer. Algorithms 83, 1123–1143 (2020)
Tseng, P.: A modified forward-backward splitting method for maximal monotone mapping. SIAM J. Control Optim. 38, 431–446 (2000)
Vinh, N.T., Hoai, P.T.: Some subgradient extragradient type algorithms for solving split feasibility and fixed point problems. Math. Methods Appl. Sci. 39, 3808–3823 (2016)
Wang, F., Xu, H.K.: Weak and strong convergence theorems for variational inequality and fixed point problems with Tseng’s extragradient method. Taiwan. J. Math. 16, 1125–1136 (2012)
Acknowledgements
The authors would like to thank editor in chief and the three anonymous referees for their patient and valuable comments, which improved the quality of this paper greatly.
Funding
This work is supported by the National Natural Science Foundation of China (No. 12101436). The first author was partially supported by Research Project of Chengdu Normal University (No. CS20ZB05). The second author was partially supported by Educational Reform Project of Chengdu Normal University(No. 2021JG53).
Author information
Authors and Affiliations
Contributions
BM proposed two self-adaptive subgradient extragradient type algorithms for solving variational inequalities and analyzed the convergence of the two algorithms. WW performed the numerical experiments and was a major contributor in writing the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ma, B., Wang, W. Self-adaptive subgradient extragradient-type methods for solving variational inequalities. J Inequal Appl 2022, 54 (2022). https://doi.org/10.1186/s13660-022-02793-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13660-022-02793-1