
Abstract
Background
Honorary authorship refers to the practice of naming an individual who has made little or no contribution to a publication as an author. Honorary authorship inflates the output estimates of honorary authors and deflates the value of the work by authors who truly merit authorship. This manuscript presents the protocol for a systematic review that will assess the prevalence of five honorary authorship issues in health sciences.
Methods
Surveys of authors of scientific publications in health sciences that assess prevalence estimates will be eligible. No selection criteria will be set for the time point for measuring outcomes, the setting, the language of the publication, and the publication status. Eligible manuscripts are searched from inception onwards in PubMed, Lens.org, and Dimensions.ai. Two calibrated authors will independently search, determine eligibility of manuscripts, and conduct data extraction. The quality of each review outcome for each eligible manuscript will be assessed with a 14-item checklist developed and piloted for this review. Data will be qualitatively synthesized and quantitative syntheses will be performed where feasible. Criteria for precluding quantitative syntheses were defined a priori. The pooled random effects double arcsine transformed summary event rates of five outcomes on honorary authorship issues with the pertinent 95% confidence intervals will be calculated if these criteria are met. Summary estimates will be displayed after back-transformation. Stata software (Stata Corporation, College Station, TX, USA) version 16 will be used for all statistical analyses. Statistical heterogeneity will be assessed using Tau2 and Chi2 tests and I2 to quantify inconsistency.
Discussion
The outcomes of the planned systematic review will give insights in the magnitude of honorary authorship in health sciences and could direct new research studies to develop and implement strategies to address this problem. However, the validity of the outcomes could be influenced by low response rates, inadequate research design, weighting issues, and recall bias in the eligible surveys.
Systematic review registration
This protocol was registered a priori in the Open Science Framework (OSF) link: https://osf.io/5nvar/.
Similar content being viewed by others

Background
Authorship has been called ‘the currency of an academic career’ [1]. As with all currencies, they can be obtained through hard work, but also through less transparent means which has resulted in widely reported honorary authorship disputes [2,3,4]. Honorary authorship (HA) violates ethical publication principles and skews the output estimates of both honorary authors and those that merit authorship. This manuscript presents a protocol for a systematic review to assess the prevalence of 5 HA issues in the health sciences.
HA refers to authorship assigned to individuals that should not have been included as authors of a publication, because they made no or insufficient contributions to qualify as authors (Table 1). Discussions on assigning authorship can be complicated especially if the power between stakeholders is imbalanced, e.g., junior versus senior scientists, mentees versus mentors, PhD students versus promotors, individuals with administrative power versus those without [8, 9]. Senior scientists assign specific tasks to junior scientists to complete their research projects, and indirectly, to extend their number of publications. This output is important for senior scientists, because the number of published papers, particularly in journals with high impact factors, is considered a key element of their CV and often a predominant measure in the decisional process for hiring, promotion, and tenure of researchers [10,11,12]. Power games between senior and junior scientists can lead to authorship disputes and to not-merited assignments of authorship, i.e., HA. In our personal experience as research integrity teachers, the irritation among junior researchers about these practices is a recurrent theme. A salient example of HA is automatically assigning authorship to a senior member, often the head of a department [13, 14]. Explicit academic bullying by scientists of junior team members on authorship issues is also a serious concern [15, 16]. Kovacs [9] reports on the phenomenon of publication cartels, i.e., groups of researchers that frequently publish articles together with the explicit agreement that the HAs will be granted reciprocally.
The prevalence of HA is commonly [17,18,19] measured as perceived HA or International Committee of Medical Journal Editors (ICMJE)-based HA [7]. These and other key terms are defined in Table 1. The ICMJE has developed their authorship criteria to reduce authorship disputes and to discourage scientists from granting credit to researchers who do not merit authorship.
However, the prevalence of ICMJE-based HA could be misleading for the following reasons: (1) not all surveyees might be aware of the ICMJE criteria or their definitions when completing the surveys (2) the ICMJE criteria have changed over the years ([20] (3) the risk of subjective interpretation by surveyees of the various terms in the criteria such as ‘substantial’, ‘critically’, ‘important’, ‘appropriately’ (Table 1). In this planned systematic review, we will assess HA issues for both perceived as well as ICMJE-based HA and how they change over time. These issues are summarized under review items 1–5 in Table 1. The latter 3 review items report on self-admitted HA issues by the surveyee. These statistics are important, because surveyees are likely to underreport their own misconduct and overestimate those of co-authors. This was found in meta-analyses of surveys on research integrity issues such as scientists admitting plagiarism [21] or having fabricated or falsified data [22].
A scoping search in PubMed was undertaken by 2 reviewers (RMR and NDG) to assess whether previous reviews on our research questions have been published. Only 2 earlier reviews were identified, but these manuscripts gave narrative reviews on authorship issues [23], publication practices and responsible authorship [24] or systematically reviewed other authorship issues [25]. On the basis of the findings in our scoping search, we concluded that HA merits a systematic review and that no prior systematic reviews seem to have covered our research questions. Understanding the magnitude of the various HA issues under review may accelerate the design of future studies and bring ideas on how to counteract HA. These strategies could reduce stress among a broad spectrum of researchers, reduce time wasted on authorship issues, boost meritocracy, reduce power games, implement the fining of those guilty of HA, improve collaboration between researchers, and possibly increase the overall happiness in research and academic settings. This is important, because a recent survey of almost 4000 scientists showed that the majority (55%) had a negative impression of the research culture they are working in [26].
Objectives
For the primary objectives of this systematic review the prevalence of the following 2 review items will be assessed (Table 1):
Review item 1
Researchers perceiving other co-author(s) as honorary author(s) on a publication.
Review item 2
Researchers having been approached by others to include honorary author(s) on a publication.
The secondary research objectives will focus on self-declared HA issues. For these objectives the prevalence of the following review items will be assessed (Table 1).
Review item 3
Researchers admitting being an honorary author on a publication.
Review item 4
Researchers admitting adding an honorary author(s) on a publication.
Review item 5
Researchers admitting having approached others to include honorary author(s) on a publication.
All five review items will be assessed for perceived-and ICMJE-based HA separately. We will also assess how outcomes change over time.
Methods
We used The Preferred Reporting Items for Systematic review and Meta-Analysis Protocols (PRISMA-P) 2015 statement [27, 28] and the Joanna Briggs Reviewers manual for systematic reviews of prevalence and incidence [29, 30] to develop and report this protocol. This manuscript is registered in the Open Science Framework (OSF) [31] and not in PROSPERO [32], because our research questions do not meet the inclusion criteria for the latter register.
Eligibility criteria
Table 2 presents eligibility criteria for domain, study designs, participants, survey instruments, outcomes, time point, setting, language, publication status, and publication dates [27, 28].
Information sources and search strategy
PRISMA-S was consulted to report the literature search [33], as well as a previous systematic review on the meaning, ethics and the practices of authorship published by Marušić et al. [25], which used “authorship” as the only word for their search strategy. We will perform a systematic search in the following electronic databases from inception onwards: PubMed, Lens.org, and Dimensions.ai, with no language or date filters, but applying health sciences filters for Lens.org and Dimensions.ai for full search strategies. Additionally, all included papers will be checked for additional refences mentioned in their introduction or discussion sections. The full search strategies are presented in Additional file 1. These strategies were developed by one of the authors (MM) with the aim to capture all surveys on authorship, as honorary authorship might have been only one question in those surveys, or a secondary outcome that was not mentioned in the abstract. Additionally, these searches captured all studies we identified in the pilot, expect 4 that did not have indexed abstracts and were short reports. These 4 however were referenced in studies we identified, so would have been captured by checking the introduction or discussions or papers, which, as mentioned above, we will do for all included studies.
Data management and selection process
Two authors (RMR and NDG) will be calibrated a priori through pilot tests. These investigators will screen titles and abstracts independently to select potentially relevant papers. Identified records will be imported in Rayyan [34] and duplicate records will be removed. Rayyan will be subsequently used for the initial screening of titles and abstracts to identify potentially relevant papers. In the initial search phase, the selection of studies will be overinclusive [35]. Full texts of potentially eligible manuscripts will be retrieved and assessed for eligibility. We will implement Cochrane’s strategies to identify multiple reports from the same study [35]. We will further assess whether relevant studies were retracted, fraudulent, or whether errata or comments were given [35]. Authors will be contacted to verify the eligibility of their surveys.
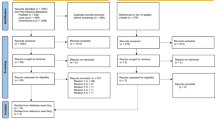
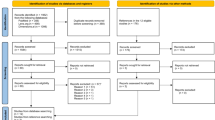
After these assessments we will make final decisions on study eligibility. Reference lists and citing articles of the selected eligible papers will also be crosschecked for additional relevant studies. A list of excluded studies with rationales for exclusion will be given. This list will focus on all studies that initially appear eligible, but after further inspection do not meet the eligibility criteria [35]. Our search strategy will not include a filter for manuscripts published in the health sciences. All non-health science manuscripts that assess authorship issues will also be presented in the list of excluded studies with the reason for exclusion. The study selection procedures will be reported in a PRISMA flow chart [36, 37].
Data collection process and data items
For the development of our data extraction forms we consulted the reporting checklists of the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement for reporting cross-sectional studies [38], the Checklist for Reporting Results of Internet E-Surveys (CHERRIES) for reporting the survey [39, 40], and the Checklist for polls by Bethlehem [41]. To ensure consistency in the data collection process, we will conduct calibration exercises for both data extractors a priori. These investigators (RMR and NDG) will independently extract the pertinent data from each eligible study. The pilot-tested data collection forms are listed in Additional file 2A. A description of each data item is given in these forms. Disagreement between investigators on study inclusion and issues regarding data extraction will be resolved through discussions. Persistent disagreements will be resolved through arbitration by a third author (GTR) or through contacting the authors of the pertinent publications [28]. We will document when and why this was deemed necessary.
Outcomes and prioritization
The prevalence of researchers perceiving other co-author(s) as honorary author(s) on a publication and the prevalence of researchers having been approached by others to include honorary author(s) on a publication will be the primary outcomes. The prevalence of researchers admitting being an honorary author on a publication, the prevalence of researchers admitting adding an honorary author(s) on a publication, and the prevalence of researchers admitting having approached others to include honorary author(s) on a publication will be the secondary outcomes. The definitions of these outcomes and the pertinent numerators and denominators are given in Table 3. The various response rates measured are also reported in these tables. These outcomes will be calculated separately for perceived HA and ICMJE-based HA (Table 1). We included ICMJE-based HA in this updated version of our protocol, because our initial screening and data extraction revealed that many surveys operationalize ICMJE-based HA. We are convinced that including ICMJE-based HA outcomes will considerably strengthen our systematic review. For each included survey we will report the exact question on which each outcome was based.
Assessment of methodological quality
The methodological quality of each survey will be assessed with a survey checklist of 14 items that was tailored to our research questions on HA issues. To develop this quality checklist, we conducted pilot tests and consulted existing appraisal tools [29, 30, 39,40,41,42,43,44,45,46]. To rate the overall confidence in the results of the survey, we adopted the rating scheme reported for the AMSTAR 2 critical appraisal tool [47], which is based on an assessment of critical-and non-critical items. As in the AMSTAR 2 tool we labeled 7 of the 14 items of our quality checklist as ‘critical’, because we believe that these items can critically affect the validity of the outcomes of a survey. In congruence with AMSTAR 2 we will assign 4 ratings: ‘high’, ‘moderate’, ‘low’, and ‘critically low’ rating of the overall confidence in the results of the survey. These ratings reflect how non-implementation of one or more of these quality safeguards possibly have impacted bias of the results of the survey. A detailed description of this survey checklist and guidance on the rating scheme are given in Additional file 2B. We will list the critical appraisal scores for each included survey and will calculate the prevalence of yes scores (all yes scores/number of surveys) for each critical appraisal question (Additional file 2C) [48]. Two reviewers (RMR and NDG) will independently implement the methods reported for the 14-item quality checklist. This tool will be used for each of the 5 outcomes of this review. A third reviewer (GTR) will be consulted in the case of persistent disagreements. We will report when and why these consultations were necessary. Four surveys will be used a priori to calibrate the operators.
Data synthesis
Criteria for a quantitative synthesis
Outcomes in this review are prevalence statistics (proportions), which can be quantitatively synthesized. We may preclude meta-analyses for the following scenarios: (1) only 1 or no included studies, (2) very different definitions of outcomes, (3) incomplete reporting of proportions, (4) biased evidence such as ‘low’, and ‘critically low’ ratings of the overall confidence in the results of the survey, (5) explained and unexplained heterogeneity [49]. We will consider a I2 larger than 50% as an approximate rule of thumb for not conducting meta-analyses. When applying this rule we will consider that the value of I2 depends on the direction and magnitude of the outcomes and the strengths of the evidence for the identified heterogeneity [50]. Prior to precluding meta-analyses we will assess if solutions are possible for dealing with one or more of these limiting criteria [49].
Summary measures for a quantitative synthesis
The prevalence proportions and their exact (method = Wilson) 95% confidence limits across studies will be visually displayed in a forest plot. If the criteria for calculating a pooled estimate are met, we will pool the proportions and report them with their 95% confidence intervals. Double arcsine transformation will be performed prior to any statistical pooling. Summary estimates will be displayed after back-transformation [51]. These calculations will be performed using the metaprop command in Stata 16 [52]. We plan to implement a random-effects model, because between-study variance is expected.
Unit of analysis issues
To address unit-of-analysis issues, we will assess in each study whether surveyees underwent more than one survey, e.g., surveys conducted at multiple time points on the same individuals.
Dealing with missing data
To address missing data, we will contact the corresponding author and the author that was acknowledged as involved in the statistical analysis of the pertinent research studies. Such authors will be contacted by email. A first reminder will be sent one week after the first one and a second after 2 weeks. We will then wait for 2 weeks and accept the data to be missing and proceed.
Assessment of heterogeneity
We will assess the presence and the extent of heterogeneity. In the forest plots we will assess the overlap of the confidence intervals for the results of the individual surveys. We will calculate Tau2 (estimate of between study variance) and Chi2 tests to measure statistical heterogeneity and I2 to quantify inconsistency [50].
Investigation of heterogeneity
We will assess survey-related and methodological diversity [50]. We will conduct subgroup analyses and meta-regression to investigate heterogeneity. The following explanatory variables for these investigations will be considered for these analyses:
Survey-related diversity
-
The type of authors that were surveyed, i.e., first authors versus corresponding or any other author in between (Table 1)
-
Career levels of the surveyee, e.g., PhD students, post doctorates, department chairpersons
-
The field of research on which the surveyee was interviewed, e.g., radiology, urology, dentistry
-
The country of the first institution listed in the manuscript
-
The journal impact factor, e.g., above or below 5.00
-
The year of conducting the survey
-
The method of survey delivery, e.g., administered by email, internet platforms, by post
-
Anonymity of the surveyee
-
Definitions of HA
-
The magnitude of the response rates, e.g., above or below 25%
Methodological diversity
-
The method of sampling, e.g. randomly selected or not
-
Sample size
-
The time point for measuring outcome (the recall period), e.g., before or after 1 year of publication of the manuscript on which authors were surveyed.
-
Study quality, e.g., low, moderate, or high quality
-
Response rate
We will visually display the individual effects for each planned prevalence outcome in stratified forest plots according to these explanatory variables. To avoid misinterpretation of the findings, we will not give the combined effect estimate in these plots if the criteria for a meta-analysis are not met [53].
We will also build generalized linear mixed models (GLMMs) to assess what factors contribute to each of the five review outcomes on HA issues. For each study that reported prevalence data on these issues, the following data will be extracted and tabulated in an electronic spreadsheet: number of respondents and the number of individuals reporting each outcome. Each individual respondent was listed as a row in the electronic spreadsheet. For the GLMMs, the presence/absence of an HA issue will be the dependent variable and all the explanatory variables reported previously as the predictors. Study ID will be included as a random effect, in order to account for clustering at a study level. The other variables will be included as fixed effect. The linearity assumption of the continuous variables will be assessed as described elsewhere [54,55,56]: (1) the variables will be binned in quartiles; (2) the multivariate model will be fitted replacing the continuous variables with the four-level binned variables; (3) log odds of the upper three quartiles (the lower quartile will be used as indicator) will be plotted versus the respective quartile midpoints; (4) the four plotted points will be connected with straight lines and the plot will be visually inspected for linearity. Specific categories of categorical predictors will depend on categories used by primary investigators in their surveys. Depending on the total number of individual response data available, different modeling approach will be employed to include/exclude independent variables and avoid overfitting of the model. We will apply the same methods for additional explanatory variables that will be identified during the review process. We will explain in the final review why these variables were added.
Qualitative synthesis
We will conduct a systematic narrative synthesis whether quantitative syntheses will be possible or not.
Tables will be developed to report the characteristics of included surveys as reported in Additional file 2A. We will consult these tables for the data synthesis and assess relationships and diversity within and between surveys.
Sensitivity analysis
We will undertake sensitivity analyses to investigate the impact of certain decisions on the outcomes of the systematic review. Such decisions could refer to the searching for surveys, the choice of certain eligibility criteria such as the characteristics of the survey design, methods to be used for the analysis (fixed-effect or random-effects methods), and the quality of the included surveys. However, which specific issues to explore in sensitivity analyses will be decided during the review process [50]. We will report the findings of these analyses in a summary table [50].
Meta-biases
We will assess the presence of non-reporting biases. Such biases occur when results are missing from surveys that should have been included in the syntheses of the review [57, 58]. Non-reporting biases can come in many forms such as publication, time-lag, language, citation, multiple publication, location, and selective (non-) reporting bias [57]. We will implement a variety of strategies to address the risk of non-reporting biases such as:
-
1)
Use a broad spectrum search strategy and searching studies in a wide body of search engines.
-
2)
Assess the availability of study protocols and registers and if available assess whether the planned outcomes in the protocols are the same as those reported in the included studies.
-
3)
Contacting authors regarding issues such as multiple publications of research data, information on the availability of protocols, unpublished, or ongoing studies.
-
4)
After the implementation of these 3 strategies we will adopt the 6-step Cochrane framework for assessing risk of bias as a result of missing results in a synthesis, e.g., a meta-analysis [58]. For the sixth step of this protocol, an overall judgment on the risk of bias as a result of missing results for each synthesis will be given.
Confidence in the cumulative evidence
We will present summary of findings tables that report the magnitude of the outcome, the certainty, or quality of evidence for each primary and secondary outcome, and other key data (Additional file 2B and C). We will adopt the GRADE approach to assess the overall certainty of the body of evidence for each outcome that was sought in this review [59]. For this approach we will assess: (1) bias in the included surveys, i.e., the overall confidence in the results of each survey based on our 14-item quality checklist (Additional file 2B), (2) heterogeneity or inconsistency of results, (3) indirectness of evidence, (4) imprecision of results, and (5) publication bias [59]. The GRADE approach assigns four levels of certainty: ‘high’, ‘moderate’, ‘low’, and ‘very low certainty’ [59]. The rationale for assigning these ratings will be given. Guidance for grading the certainty or quality of evidence is reported in Additional file 2B.
Differences between the protocol and the review
Any differences between what is described in this protocol and the methods implemented in the final systematic review will be reported with rationale. We will also explain, if possible, the potential consequences of these changes for the direction, magnitude, and the validity of the results [60].
Discussion
What will this research study investigate?
We will search the literature for surveys in the health sciences that assessed the prevalence of a variety of HA issues. In addition, we will compare the statistics for self-and non-self-reporting by the respondents of the surveys. Our scoping searches showed that no previous systematic reviews have assessed our research questions.
What are its strengths?
The strengths of this review include (1) the broad-spectrum search strategy and information sources, (2) contacting authors to verify the eligibility of surveys and to retrieve additional research data on these surveys such as obtaining questionnaires, (3) pre-registration of the protocol in Open Science Framework, (4) the use of a 14-item quality checklist developed and piloted for the review questions, (5) a research team that covers all disciplines for conducting systematic reviews including topic expertise, and (6) assessing both self-and-non-self-reported authorship issues.
What are its limitations?
However, this review could also have some limitations. We expect that the validity of its findings could be conditioned by factors such as the magnitude of the response rates, sample size, differences in characteristics of the responders and non-responders, poor reporting, non-anonymous surveys, survey-related and methodological diversity, missing data, quality of the data analysis, and the intrinsic nature of surveys, e.g., the risk of recall bias, in particular when much time has passed between the completion of a research study and the survey on the pertinent study.
Why this research study is important
HA causes inflated output estimates of honorary authors and deflates the importance of the work done by authors who truly merit authorship. These distorted numbers could subsequently have effects on (1) the careers and riches of these stakeholders, (2) the order of authors in the author list, (3) peer review (big names in the author list), (4) norms perception by others, e.g., juniors, in science.
The outcomes of this research study will provide insight in the magnitude of the prevalence of HA issues.
High prevalence statistics could direct new research studies on these issues and accelerate the development and implementation of tailored strategies to address them such as education in publication ethics [61, 62], redefining and fine-tuning criteria for authorship and adopting the Contributor Roles Taxonomy (CRediT) [63], and possibly even devalue authorship. However, high prevalence statistics could also be used as a confirmation by violators of authorship issues that HA is common, so why should I behave differently? Deans of universities, research directors, editors, peer reviewers, authors, publishers, and research sponsors are just some of the key players that can make a difference. If they are willing to address HA issues they could reduce stress among researchers, reduce time wasted on authorship issues, boost meritocracy, improve collaboration between researchers, and possibly even the overall quality of life at universities and other research institutes. Addressing HA issues could also be an important step in improving the trust between the general public and the research community [64].
Availability of data and materials
All data generated or analyzed for this research study will be reported in the systematic review.
Abbreviations
- CHERRIES:
-
Checklist for Reporting Results of Internet E-Surveys
- CRediT:
-
Contributor Roles Taxonomy
- GLMM:
-
Generalized linear mixed model
- HA:
-
Honorary Authorship
- ICMJE:
-
International Committee of Medical Journal Editors
- ORCID:
-
Open Researcher and Contributor ID
- OSF:
-
Open Science Framework
- STROBE:
-
Strengthening the Reporting of Observational Studies in Epidemiology
References
Patience GS, Galli F, Patience PA, Boffito DC. Intellectual contributions meriting authorship: Survey results from the top cited authors across all science categories. PLoS One. 2019;14(1):e0198117. https://doi.org/10.1371/journal.pone.0198117 eCollection 2019.
Dance A. Authorship: Who's on first? Nature. 2012;489(7417):591–3.
Faulkes Z. Resolving authorship disputes by mediation and arbitration. Res Integr Peer Rev. 2018;3:12. https://doi.org/10.1186/s41073-018-0057-z eCollection 2018.
Kornhaber RA, McLean LM, Baber RJ. Ongoing ethical issues concerning authorship in biomedical journals: an integrative review. Int J Nanomedicine. 2015;10:4837–46. https://doi.org/10.2147/IJN.S87585 eCollection 2015.
Wikipedia Survey. Available from: https://en.wikipedia.org/wiki/Survey_(human_research). Accessed 30 Mar 2020.
Wikipedia Health sciences. [online] Available from: https://en.wikipedia.org/wiki/Outline_of_health_sciences . Accessed 23 Apr 2021.
International Committee of Medical Journal Editors (ICMJE). Recommendations for the Conduct, Reporting, Editing, and Publication of Scholarly Work in Medical Journals Updated 2019. Available from: http://www.icmje.org/icmje-recommendations.pdf . Accessed 23 Apr 2021.
Committee On Publication Ethics (COPE) Discussion document: authorship. Available from: https://publicationethics.org/files/COPE_DD_A4_Authorship_SEPT19_SCREEN_AW.pdf. Accessed 4 Apr 2021.
Kovacs J. Honorary authorship and symbolic violence. Med Health Care Philos. 2017;20(1):51–9. https://doi.org/10.1007/s11019-016-9722-5.
McKiernan EC, Schimanski LA, Muñoz Nieves C, Matthias L, Niles MT, Alperin JP. Use of the Journal Impact Factor in academic review, promotion, and tenure evaluations. Elife. 2019;8:e47338. https://doi.org/10.7554/eLife.47338.
Moher D, Naudet F, Cristea IA, Miedema F, Ioannidis JPA, Goodman SN. Assessing scientists for hiring, promotion, and tenure. PLoS Biol. 2018;16(3):e2004089. https://doi.org/10.1371/journal.pbio.2004089 eCollection 2018 Mar.
Walker RL, Sykes L, Hemmelgarn BR, Quan H. Authors' opinions on publication in relation to annual performance assessment. BMC Med Educ. 2010;10:21. https://doi.org/10.1186/1472-6920-10-21.
Gadjradj PS, Peul WC, Jalimsing M, Arjun Sharma JRJ, Verhemel A, Harhangi BS. Who should merit co-authorship? An analysis of honorary authorships in leading spine dedicated journals. Spine J. 2020;20(1):121–3. https://doi.org/10.1016/j.spinee.2019.08.008.
Kayapa B, Jhingoer S, Nijsten T, Gadjradj PS. The prevalence of honorary authorship in the dermatological literature. Br J Dermatol. 2018;178(6):1464–5. https://doi.org/10.1111/bjd.16678.
Mahmoudi M. Academic bullies leave no trace. Bioimpacts. 2019;9(3):129–30. https://doi.org/10.15171/bi.2019.17.
Smith E, Williams-Jones B, Master Z, et al. Researchers' perceptions of ethical authorship distribution in collaborative research teams [published online ahead of print, 2019 Jun 4]. Sci Eng Ethics. 2019. https://doi.org/10.1007/s11948-019-00113-3.
Eisenberg RL, Ngo LH, Heidinger BH, Bankier AA. Honorary Authorship in Radiologic Research Articles: Assessment of Pattern and Longitudinal Evolution. Acad Radiol. 2018;25(11):1451–6. https://doi.org/10.1016/j.acra.2018.02.023.
Luiten JD, Verhemel A, Dahi Y, Luiten EJT, Gadjradj PS. Honorary authorships in surgical literature. World J Surg. 2019;43(3):696–703. https://doi.org/10.1007/s00268-018-4831-3.
Noruzi A, Takkenberg JJM, Kayapa B, Verhemel A, Gadjradj PS. Honorary authorship in cardiothoracic surgery [published online ahead of print, 2019 Nov 9]. J Thorac Cardiovasc Surg. 2019;S0022-5223(19):32489–4. https://doi.org/10.1016/j.jtcvs.2019.10.104.
International Committee of Medical Journal Editors (ICMJE) Archives. http://www.icmje.org/recommendations/archives/ . Accessed 23 Apr 2021.
Pupovac V, Fanelli D. Scientists admitting to plagiarism: a meta-analysis of surveys. Sci Eng Ethics. 2015;21(5):1331–52. https://doi.org/10.1007/s11948-014-9600-6.
Fanelli D. How many scientists fabricate and falsify research? A systematic review and meta-analysis of survey data. PLoS One. 2009;4(5):e5738. Published 2009 May 29. https://doi.org/10.1371/journal.pone.0005738.
Aliukonis V, Poškutė M, Gefenas E. Perish or publish dilemma: challenges to responsible authorship. Medicina (Kaunas). 2020;56(3):123. Published 2020 Mar 12. https://doi.org/10.3390/medicina56030123.
Tarkang EE, Kweku M, Zotor FB. Publication practices and responsible authorship: a review article. J Public Health Afr. 2017;8(1):723. Published 2017 Jun 27. https://doi.org/10.4081/jphia.2017.723.
Marušić A, Bošnjak L, Jerončić A. A systematic review of research on the meaning, ethics and practices of authorship across scholarly disciplines. PLoS One. 2011;6(9):e23477. https://doi.org/10.1371/journal.pone.0023477.
Welcome. What researchers think about the culture they work in [online] Available from: https://wellcome.ac.uk/sites/default/files/what-researchers-think-about-the-culture-they-work-in.pdf . Accessed 23 Apr 2021.
Moher D, Shamseer L, Clarke M, Ghersi D, Liberati A, Petticrew M, et al. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement. Syst Rev. 2015;4(1):1.
Shamseer L, Moher D, Clarke M, Ghersi D, Liberati A^, Petticrew M, et al. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015: elaboration and explanation. BMJ. 2015;349:g7647.
Munn Z, Moola S, Lisy K, Riitano D, Tufanaru C. (2015) Methodological guidance for systematic reviews of observational epidemiological studies reporting prevalence and incidence data. Int J Evid Based Healthc. 2015;13:147–53.
Munn Z, Moola S, Lisy K, Riitano D, Tufanaru C. Chapter 5: Systematic reviews of prevalence and incidence. In: Aromataris E, Munn Z, editors. Joanna Briggs Institute Reviewer's Manual: The Joanna Briggs Institute; 2017. Available from: https://reviewersmanual.joannabriggs.org/ . Accessed 15 Feb 2020.
Open Science Framework (OSF). Available from: https://osf.io/ . Accessed 23 Apr 2021.
PROSPERO: Centre for Reviews and Dissemination. University of York, UK. Available from: http://www.crd.york.ac.uk/PROSPERO/. Accessed 23 Apr 2021.
Rethlefsen ML, Kirtley S, Waffenschmidt S, Ayala AP, Moher D, Page MJ, et al. PRISMA-S: an extension to the PRISMA Statement for Reporting Literature Searches in Systematic Reviews. Syst Rev. 2021;10(1):39. https://doi.org/10.1186/s13643-020-01542-z PMID: 33499930; PMCID: PMC7839230.
Rayyan QRCI. Available from: https://rayyan.qcri.org/welcome . Accessed 23 Apr 2021.
Lefebvre C, Glanville J, Briscoe S, Littlewood A, Marshall C, Metzendorf M-I, et al. Chapter 4: Searching for and selecting studies. In: JPT H, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA, editors. Cochrane Handbook for Systematic Reviews of Interventions version 6.2 (updated February 2021). Cochrane; 2021. Available from www.training.cochrane.org/handbook.
Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ. 2021;372:n71. https://doi.org/10.1136/bmj.n71 PMID: 33782057; PMCID: PMC8005924.
Page MJ, Moher D, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. PRISMA 2020 explanation and elaboration: updated guidance and exemplars for reporting systematic reviews. BMJ. 2021;(372):n160. https://doi.org/10.1136/bmj.n160 PMID: 33781993; PMCID: PMC8005925.
Von Elm E, Altman DG, Egger M, Pocock SJ, Gøtzsche PC, Vandenbroucke JP, et al. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies. Ann Intern Med. 2007;147(8):573–7.
Eysenbach G. Improving the Quality of Web Surveys: The Checklist for Reporting Results of Internet E-Surveys (CHERRIES). J Med Internet Res. 2004;6(3):e34.
Eysenbach G. Correction: Improving the Quality of Web Surveys: the Checklist for Reporting Results of Internet E-Surveys (CHERRIES). J Med Internet Res. 2012;14(1):e8.
Bethlehem J. Chapter 12: A checklist for polls. In: Understanding Public Opinion Polls. Boca Raton: Chapman and Hall/CRC; 2017. ISBN: 978-1498769747.
American Association for Public Opinion Research (AAPOR). Evaluating Survey Quality in Today's Complex Environment. Available from: https://www.aapor.org/Education-Resources/Reports/Evaluating-Survey-Quality.aspx . Accessed 24 Apr 2021.
Center for Evidence-Based Management. Critical appraisal of a cross-sectional study (Survey). Available from: https://cebma.org/wp-content/uploads/Critical-Appraisal-Questions-for-a-Cross-Sectional-Study-July-2014-1.pdf . Accessed 24 Apr 2021.
Munn Z, Moola S, Riitano D, Lisy K. The development of a critical appraisal tool for use in systematic reviews addressing questions of prevalence. Int J Health Policy Manag. 2014;3(3):123–8. Published 2014 Aug 13. https://doi.org/10.15171/ijhpm.2014.71.
Roever L. Critical appraisal of a questionnaire study. Evid Med Pract. 2015;1:1.e110.
Survey Quality Assessment Framework (SQAF) 2009. Available from: https://ihsn.org/projects/survey-quality-assessment-framework-SQAF . Accessed 24 Apr 2021.
Shea BJ, Reeves BC, Wells G, Thuku M, Hamel C, Moran J, et al. AMSTAR 2: a critical appraisal tool for systematic reviews that include randomised or non randomised studies of healthcare interventions, or both. BMJ. 2017;358:j4008. https://doi.org/10.1136/bmj.j4008.
Gibson O, Lisy K, Davy C, et al. Enablers and barriers to the implementation of primary health care interventions for Indigenous people with chronic diseases: a systematic review. Implement Sci. 2015;10:71. Published 2015 May 22. https://doi.org/10.1186/s13012-015-0261-x.
McKenzie JE, Brennan SE. Chapter 12: Synthesizing and presenting findings using other methods. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA, editors. Cochrane Handbook for Systematic Reviews of Interventions version 6.2 (updated February 2021). Cochrane; 2021. Available from www.training.cochrane.org/handbook.
Deeks JJ, Higgins JPT, Altman DG. Chapter 10: Analysing data and undertaking meta-analyses. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA, editors. Cochrane Handbook for Systematic Reviews of Interventions version 6.2 (updated February 2021). Cochrane; 2021. Available from www.training.cochrane.org/handbook.
Barendregt JJ, Doi SA, Lee YY, Norman RE, Vos T. Meta-analysis of prevalence. J Epidemiol Community Health. 2013;67(11):974–8. https://doi.org/10.1136/jech-2013-203104.
StataCorp. Stata Statistical Software: Release 16. College Station: StataCorp LLC; 2019.
McKenzie JE, Brennan SE, Ryan RE, Thomson HJ, Johnston RV. Chapter 9: Summarizing study characteristics and preparing for synthesis. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA, editors. Cochrane Handbook for Systematic Reviews of Interventions version 6.2 (updated February 2021). Cochrane; 2021. Available from www.training.cochrane.org/handbook.
Hosmer DW, Lemeshow S, Sturdivant RX. Applied logistic regression. 3rd ed. Oxford: Wiley; 2013.
Royston P, Altman DG. Regression using fractional polynomials of continuous covariates: Parsimonious parametric modelling (with discussion) Journal of the Royal Statistical Society. Series C. 1994;43:429–67.
Royston P, Sauerbrei W. mfpa: Extension of mfp using the ACD covariate transformation for enhanced parametric multivariable modeling. Stata J. 2016;16(1):72–87 PMID: 29398977; PMCID: PMC5796636.
Boutron I, Page MJ, Higgins JPT, Altman DG, Lundh A, Hróbjartsson A. Chapter 7: Considering bias and conflicts of interest among the included studies. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA, editors. Cochrane Handbook for Systematic Reviews of Interventions version 6.2 (updated February 2021). Cochrane; 2021. Available from www.training.cochrane.org/handbook.
Page MJ, Higgins JPT, Sterne JAC. Chapter 13: Assessing risk of bias due to missing results in a synthesis. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA, editors. Cochrane Handbook for Systematic Reviews of Interventions version 6.2 (updated February 2021). Cochrane; 2021. Available from www.training.cochrane.org/handbook.
Schünemann HJ, Higgins JPT, Vist GE, Glasziou P, Akl EA, Skoetz N, et al. Chapter 14: Completing ‘Summary of findings’ tables and grading the certainty of the evidence. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA, editors. Cochrane Handbook for Systematic Reviews of Interventions version 6.2 (updated February 2021). Cochrane; 2021. Available from www.training.cochrane.org/handbook.
Chalmers I, Glasziou P. Avoidable waste in the production and reporting of research evidence. Lancet. 2009;374(9683):86–9.
Eisenberg RL, Ngo LH, Bankier AA. Honorary authorship in radiologic research articles: do geographic factors influence the frequency? Radiology. 2014;271(2):472–8. https://doi.org/10.1148/radiol.13131710.
Rajasekaran S, Lo A, Aly AR, Ashworth N. Honorary authorship in postgraduate medical training. Postgrad Med J. 2015;91(1079):501–7. https://doi.org/10.1136/postgradmedj-2015-133493.
McNutt MK, Bradford M, Drazen JM, et al. Transparency in authors' contributions and responsibilities to promote integrity in scientific publication. Proc Natl Acad Sci U S A. 2018;115(11):2557–60. https://doi.org/10.1073/pnas.1715374115.
Hendriks F, Kienhues D, Bromme R. Trust in Science and the Science of Trust. In: Blöbaum B, editor. Trust and Communication in a Digitized World. Progress in IS. Cham: Springer; 2016. https://doi.org/10.1007/978-3-319-28059-2_8. Accessed 6 May 2020.
Acknowledgements
Not applicable
Patient and public involvement
Patients and the public were not involved in the development of this protocol. We plan to disseminate the findings of the systematic review to deans of universities and directors of research institutes.
Funding
All expenses for preparing this protocol and for conducting the subsequent research study will be paid evenly by each author.
Author information
Authors and Affiliations
Contributions
RMR, GTR, NDG, and MM conceived and designed the study protocol and drafted the manuscript. All four authors have made a substantive intellectual contribution in the development of this protocol. All authors read and edited the manuscript and approved the final protocol. RMR is the guarantor and attests that all listed authors meet the ICMJE criteria for authorship and that no others meeting these criteria have been omitted.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable
Consent for publication
Not applicable.
Competing interests
Reint Meursinge Reynders is an Associate Editor for Systematic Reviews. All four authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
Search strategy.
Additional file 2.
Data collection forms, quality checklists, and summary of findings tables.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Meursinge Reynders, R., ter Riet, G., Di Girolamo, N. et al. Honorary authorship in health sciences: a protocol for a systematic review of survey research. Syst Rev 11, 57 (2022). https://doi.org/10.1186/s13643-022-01928-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13643-022-01928-1