
Abstract
Background
A growing number of studies suggest that social isolation and loneliness are associated with premature mortality and are more prevalent among people with mental illness than in the general population, outlining many potential paths to disease still to be elucidated. The purpose of this meta-analysis is to examine the relationship between loneliness, social isolation, and established cardiovascular/metabolic risk factors and disorders, especially in severe mental illness, and to account for potential heterogeneity in the literature.
Methods/design
Studies that report measures of loneliness and/or social isolation along with cardiovascular/metabolic risk factors will be identified. PubMed, EMBASE (through Ovid SP), Scopus, and PsycINFO (through Ovid SP) will be searched, along with citation lists of retrieved articles and the Cochrane Database of Systematic Reviews. Grey literature will be searched using Google Scholar. Data will be extracted from eligible studies for a random effects meta-analysis. For each study, a summary effect size, heterogeneity, risk of bias, publication bias, and the effect of categorical and continuous moderator variables will be determined.
Discussion
This proposed systematic review and meta-analysis will identify and synthesise evidence to determine if there is an association between loneliness, social isolation, and cardiovascular/metabolic risk factors, with a special focus on severe mental illnesses. The results will help determine links and promising avenues of further research.
Systematic review registration
PROSPERO CRD42018111911
Similar content being viewed by others


Background
A growing number of studies suggest that social isolation and loneliness are associated with general morbidity and premature mortality [1, 2] and are more prevalent among people with severe mental illness than in the general population [3], outlining many potential paths to disease [4,5,6,7]. Loneliness has been described as the distressing subjective experience of lacking relationships or missing a certain level of quality in them [8]. Social isolation, on the other hand, concerns the objective characteristics of one’s relationships and refers to shortcomings in the size of their social network [9]. Although the relationship between loneliness and social isolation is complex [9], both have been associated with mental health and cardiometabolic disease and mortality [10], particularly among the elderly. Furthermore, although people with severe mental illness (SMI) experience high levels of both loneliness [11, 12] and cardiometabolic disease [13], little is known about the relationship between loneliness and social isolation and cardiometabolic health in patients with SMI, and to which degree such associations may be related to the reduced life expectancy in patients with SMI [13, 14]. Thus, a better understanding of the relationships between loneliness and social isolation and cardiometabolic health is needed, both in the general population and in patients with SMI. To this end, we will conduct a meta-analysis of studies on loneliness, social isolation, and their associations with cardiovascular and metabolic risk, building on the methodology of a previous systematic review and meta-analysis of the role of social isolation and loneliness as risk factors for coronary heart disease and stroke [15]. Compared to the previous publication [15], the present meta-analysis has a broader scope by looking at more general cardiometabolic conditions, including risk factors and some diseases of the cardiovascular system, as well as a special attention to SMI.
Methods/design
Aims
The aim of the present meta-analysis is to examine the relationship between loneliness, social isolation, and established cardiovascular/metabolic risk factors and disorders, and to elucidate the possible mechanisms in which these two measures of quality and quantity of interpersonal relationships can affect metabolic and cardiovascular health, with special regard to these relations in SMI. We focus on these associations in the general population and in patients with SMI. This protocol has been registered in PROSPERO (registration number CRD42018111911) and is outlined in agreement with the PRISMA-P guidelines [16] (Additional file 1).
Search strategy
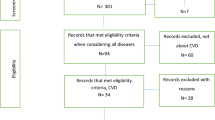
We will conduct a systematic literature search to identify studies that evaluate the relationship between measures of loneliness and social isolation and established cardiovascular and metabolic risk factors. After consultation with an academic librarian, the first searches will be performed in PubMed, EMBASE (through Ovid SP), Scopus, PsycINFO (through Ovid SP), the Cochrane Database of Systematic Reviews, and Google Scholar with a search based on the following terms: loneliness/or social isolation/or social deprivation/or social alienation/or psychosocial deprivation/. This search strategy was independently proofread by a second academic librarian at the University of Oslo. It should be noted that this is a partial snippet of the entire, more comprehensive, search strategy (Additional file 2). Bibliographies of review articles found from this search will be consulted for relevant citations and subsequently reference lists within studies and citing articles of selected studies will be examined for remaining studies that could be relevant. There will be no limitations based on publication period or language (Fig. 1).

Number of hits per year of a focused search strategy in PubMed. Scripts to generate the illustration are available at this link: https://osf.io/p2sb3/ [17]
Inclusion and exclusion criteria
Prospective cohorts, retrospective cohorts, and case-control studies will be included in the study if they include measurements of loneliness and/or social isolation and some measure of cardiovascular and metabolic risk and disease, as described below.
Loneliness
Measures used in included studies should be consistent with the definition of loneliness as a subjective negative feeling associated with someone’s subjective perception that their relationships with others are quantitatively and/or qualitatively deficient (e.g. the de Jong Gierveld Loneliness Scale, the UCLA Loneliness Scale [8]). We anticipate that many studies will not use tools that exclusively measure loneliness, so other tools will also be considered: (a) tools where loneliness is not identified as the concept being measured alone, but where questions or subscores might fit the definition of loneliness above (e.g. the Multidimensional Scale of Perceived Social Support [18], the Duke-UNC Functional Social Support Questionnaire [19]); (b) single-item measurement tools, though these may present unique challenges, as participants’ understanding of the concept may be different. Some researchers have also suggested that, given the stigma associated with loneliness, a direct, single question, such as: “do you feel lonely”, is not appropriate for capturing people’s feelings of loneliness [15]. To avoid discarding potentially useful information, studies with this type of measurement will not be excluded from this review, their findings will be analysed separately to explore how they might differ from those associated with other approaches to measurement, and the type of test will be included as a factor when estimating bias and included as a moderator.
Social isolation
Measures used in included studies should be consistent with social isolation as an objective measure of the lack of relationships, ties, or contacts with other people (e.g. The Lubben Social Network Scale and its shortened version [20, 21]). Few tools and studies explicitly measure social isolation; therefore, the search strategy includes numerous terms relating to interpersonal interaction (see supplement). Studies that only include questions focusing on the presence or absence of a specific relationship (e.g. marital status) will not be included, as the definition of social isolation used in this review is broader.
Loneliness and social isolation
Some tools combine items relating to loneliness and some items relating to social isolation (e.g. the Older Americans Resources and Services Social Resource Scale [22]). Studies that used such tools will be included in the review, and a subgroup analysis will be performed to look at how findings reported using these tools compare with tools focusing on either of the two elements.
Reliability and validity of the measures
Studies will not be excluded based on the reliability and validity of the tools used to measure loneliness or social isolation. Subgroup analyses will be carried out to explore the relationship between the choice of measurement tools and the effects reported, and bias will be estimated for each.
Type of measure
The types of measures used are expected to vary and are likely to include dichotomous (e.g. lonely vs. not lonely) and continuous (e.g. score on loneliness scale) measures. The type of measure used will be taken into account when extracting and synthesising the data but will not constitute a criterion for exclusion.
Cardiovascular and metabolic risk and disease
Studies will be included if they report cardiovascular or metabolic risk factors and diseases/outcomes. We define a risk factor as a measurable element or characteristic that is causally associated with an increased rate of a disease and that is an independent and significant predictor of the risk of presenting a disease [23]. In the case of cardiovascular and metabolic disorders, these have been the focus of innumerable studies in the past decades, given that they are the greatest cause of death globally [24] and their incidence has steeply increased worldwide [25], with the decrease in high-income countries counterbalanced by the increase in low- and middle-income ones. We plan on including both outcomes (stroke, diabetes, MetS, CHD) and known risk factors (hypertension, BMI and other indices of obesity, dyslipidaemia, inflammation markers [where applicable], smoking, and physical activity).
Titles and abstracts of studies retrieved using the search strategy and those from additional sources will be screened independently by two independent reviewers (AW and LR) to identify studies that potentially meet the inclusion criteria. The full text of these studies will be retrieved and independently assessed for eligibility by two review team members. Any disagreement between them over the eligibility of studies will be resolved through discussion with a third reviewer (DQ).
Moderators
Some study and population factors will be considered in the analysis—age, gender ratio, type of obesity index used, mental health status, somatic health status, medications, socio-economic status, ethnicity and/or region, specific diagnostic criteria used for metabolic syndrome, loneliness, and social isolation models—as independent factors or linked factors. The mental health status will be used for subgroup analyses to give a more accurate picture in SMI. As mentioned above, the specific tool used to measure social isolation and/or loneliness will also be used as a moderator, as well as risk of bias and year of publication.
Quality assessment (risk of bias)
Two review authors will independently assess bias risk for each of the included studies using the RTI item bank [26], which evaluates selection bias, confounding, performance bias, detection bias, attrition bias, and selective outcome reporting. Any discrepancies in assessment will be assessed and resolved by a third author.
Small study bias will be evaluated through the use of funnel plots and Egger’s test; publication bias will be assessed with the p-uniform* method using the “puniform” tool by van Aert [27] (https://rdrr.io/github/RobbievanAert/puniform/man/puniform.html).
Data extraction and management
Two independent reviewers (AW and LR) will extract data from all eligible studies using the data extraction form (Additional file 3). This form includes general information on studies including authors, title, number of effect sizes, sample size, and effect sizes with regard to stroke, coronary heart disease, diabetes, hypertension, BMI, metabolic syndrome, smoking, and physical activity; information about the participants including gender, age, physical and mental health status, and ethnicity or location of the study; information on other moderator variables, including study type, type of scale used (for loneliness, social isolation, or both), diagnostic criteria used (for diabetes, metabolic syndrome, etc.), the model used for loneliness and social isolation and their potential interaction, and adjustment for potential confounders; and information concerning study quality including publication year and the risk of bias measures as defined by the RTI item bank.
Statistical analysis
All statistical analyses will be performed using the metafor [28] and puniform [27] packages in R. Summary effect sizes will be obtained from effect sizes and sample size of each study, with correlations transformed to Fisher’s z. The modality of extraction will depend on the individual study. If effect sizes are reported in the publication, these will be transformed to Fisher’s z; if the effect sizes are not reported, but individual results are, then r will be obtained and converted to z. For studies published within the last 15 years that do not report the effect sizes numerically, authors will be contacted and asked to provide, if possible, that information. For studies published earlier than 15 years ago, or whose authors do not respond, and that report results in scatterplot graphs, a conversion to numerical values will be performed using a plot digitiser (https://automeris.io/WebPlotDigitizer/). The numerical values will then be used to calculate r and transformed into z. Studies for which it is not possible to perform any of the above will not be included into the meta-analysis. The Grading of Recommendations, Assessment, Development and Evaluations (GRADE) framework will be used to assess the strength of the body of evidence.
Power analysis
We performed a power analysis following the equations of Valentine et al. [29], using a custom script (https://osf.io/k8jth/ [30]) to estimate the ranges of effect sizes that this meta-analysis would be suitable to detect, using average number per group (n = 764) and average number of effects (n = 6) calculated from a previous meta-analysis [31]. Given the expected effect size (0.2) at medium levels of heterogeneity, we would achieve at least 99% power. Even if these values were adjusted conservatively (effect size of 0.1 and high heterogeneity), statistical power remains above 99%.
Summary effect size
Summary effect sizes will be computed assuming a random effects model, as the effect sizes of individual studies are expected to vary substantially due to differences in populations. In case this is not true, the random effects model collapses to a fixed effect model, so there is no loss of information. In addition, in the presence of heterogeneity, relative weights are more balanced than those assigned under fixed effects, as standard random effects methods add a common component of variance to each study weight to account for between-study variability in treatment effects. Consequently, this double source of variability (within and between study) will lead to wider variance, standard error, and CI for the summary effect.
Sample heterogeneity
The Q-statistic is the weighted sum of the products of squared differences between study effect sizes and summary effect sizes. As such, it is a measure of the total observed dispersion of the estimated effect sizes. A significant Q-statistic is indicative of significantly different effect sizes between the studies included in the meta-analysis. In this meta-analysis, we follow the convention of an alpha level of .05 for the Q-statistic.
Calculated on Q, the I2 statistic expresses the proportion of the total dispersion that accounts for true dispersion, being the ratio between the excess of dispersion and total dispersion. It is not the estimate of an underlying amount of heterogeneity but only a descriptive statistic, rather it is a measure of inconsistency among the findings of the studies, and it is not affected by the number of studies included in the meta-analysis. The I2 statistic is useful for determining whether the amount of real effect size variance between studies is relatively higher than chance variability. The Q-statistic, the significance of the Q-statistic, and I2 will be computed and reported.
Cluster-robust analysis
When studies provide more than one effect size, these are statistically dependent from each other, forming groups of internally correlated effect size estimates. Conventional meta-analytical techniques rely on the assumption that the effect size estimates from different studies are independent when this is not true, adjustments need to be performed. If the covariance of the effect size is known, it can be included in models to adjust for this [32].
Without access to original datasets, however, the covariance between effect size estimates of included studies is rarely available, as covariances are seldom reported; moreover, assuming a fixed covariance value can lead to errors in effect size estimation. Cluster-robust meta-analyses can account for statistically dependent clusters without assuming a fixed covariance value when covariances are not reported [32]. As such, cluster-robust meta-analysis will be applied to assess outcomes. A random mixed-effects meta-analysis assuming a diagonal v matrix will be used to construct cluster-robust models for each outcome.
Moderator analysis
For each categorical moderators, a random effects model will be applied, calculating summary mean effects for each subgroup. The inter-study variation metric T2 will be obtained for each subgroup, and means will then be compared using a two-tailed z-test in order to determine the probability for the difference of observed means given equality of true means, assuming normal distribution. A p value below .05 will be seen as indicative of moderating properties of the variable in question. A comparison of the effect sizes calculable for these subgroups will be performed in such cases.
For the continuous moderator variables (age, risk of bias, and year of publication), meta-regression will be performed to estimate an unstandardized regression coefficient along with the coefficient’s significance level.
Discussion
Research on the association between loneliness and social isolation and health has increased over the last decade, with growing evidence regarding associations to overall mortality [6, 15]. The goal of this meta-analysis is to give a clearer picture of the mechanisms that connect loneliness/social isolation and cardiometabolic health, with a particular focus on this connection in SMI.
The mechanisms by which loneliness and social isolation impact health outcomes are unclear for a number of reasons, including that [4] social isolation is associated with general morbidity and mortality rather than with the aetiology of any specific disease, [5] the term “social isolation” can be applied to numerous kinds of social relations (e.g. spousal relationship, membership in clubs, contacts with friends), and the effects of social relationships on long-term morbidity and mortality take years to unfold and many measurements of loneliness do not take this into account, specifically in cross-sectional studies [4]. It is also unclear whether the association between social relationships and cardiometabolic health varies according to age, sex, socioeconomic status, mental health, and somatic health. This meta-analysis aims to fill these gaps with a more nuanced look at the specifics of these associations.
Loneliness and social isolation are also of great interest with regard to the cardiovascular mortality tied to mental illness [4]. Loneliness appears to be heavily determined by genetics, personality, and cognition of the individual [33, 34]. It has been shown to be deleterious for mental health as well as physical health, and a bidirectional causal relation between loneliness and social cognition has also been proposed [35, 36]. Impaired social cognition, a common trait of many types of mental illness, is thought to play a causal role in the experience of loneliness [34, 37].
Conclusion
A more nuanced overview of the specific cardiovascular mortality and morbidity risks tied to loneliness and social isolation are needed to understand and clarify the underlying biological mechanisms. Several possible pathways to disease have been proposed [4, 38, 39], involving sleep quality, effect on lifestyle habits, and homeostatic changes. Importantly, given the high prevalence of loneliness among people with mental health problems and the evidence for its harmful effects in other populations [40], it is important to analyse these associations in SMI. A promising connection between loneliness, social isolation, and homeostatic regulation is oxytocin, due to its involvement in metabolic regulation, social functioning, and feeding behaviours [38, 39, 41,42,43,44,45], though some of the findings are from animal models. This meta-analysis hopes to shed light on this and become a solid foundation for further studies on these underlying pathways.
Availability of data and materials
Not applicable
References
Stickley A, Koyanagi A. Physical multimorbidity and loneliness: a population-based study. Bayer A, editor. PLoS One. 2018;13(1):e0191651 Available from: http://www.ncbi.nlm.nih.gov/pubmed/29364978.
Hawkley LC, Cacioppo JT. Loneliness matters: a theoretical and empirical review of consequences and mechanisms. Ann Behav Med. 2010;40(2):218–27 Available from: https://www.ncbi.nlm.nih.gov/pubmed/20652462.
Rico-Uribe LA, Caballero FF, Martín-María N, Cabello M, Ayuso-Mateos JL, Miret M. Association of loneliness with all-cause mortality: a meta-analysis. PLoS One. 2018;13(1):e0190033 Available from: http://www.ncbi.nlm.nih.gov/pubmed/29300743.
Hawkley LC, Cacioppo JT. Loneliness and pathways to disease. Brain Behav Immun. 2003;17(1 SUPPL):98–105.
Hawkley LC, Cacioppo JT. Aging and loneliness: downhill quickly? Curr Dir Psychol Sci. 2007;16(4):187–91 Available from: http://journals.sagepub.com/doi/10.1111/j.1467-8721.2007.00501.x.
Holt-Lunstad J, Smith TB, Baker M, Harris T, Stephenson D. Loneliness and social isolation as risk factors for mortality. Perspect Psychol Sci. 2015;10(2):227–37 Available from: http://journals.sagepub.com/doi/10.1177/1745691614568352.
Patterson AC, Veenstra G. Loneliness and risk of mortality: a longitudinal investigation in Alameda County. California. Soc Sci Med. 2010;71(1):181–6 Available from: https://doi.org/10.1016/j.socscimed.2010.03.024.
De Jong GJ, Van Tilburg T. The De Jong Gierveld short scales for emotional and social loneliness: tested on data from 7 countries in the UN generations and gender surveys. Eur J Ageing, 121. 2010;7(2):–30 Available from: http://www.ncbi.nlm.nih.gov/pubmed/20730083.
de Jong GJ, Havens B. Cross-national comparisons of social isolation and loneliness: introduction and overview. Can J Aging / La Rev Can du Vieil. 2004;23(02):109–13 Available from: http://www.ncbi.nlm.nih.gov/pubmed/15334811.
Xia N, Li H. Loneliness, social isolation, and cardiovascular health. Antioxid Redox Signal. 2017;28(9):ars.2017.7312. Available from: http://www.ncbi.nlm.nih.gov/pubmed/28903579.
Badcock JC, Shah S, Mackinnon A, Stain HJ, Galletly C, Jablensky A, et al. Loneliness in psychotic disorders and its association with cognitive function and symptom profile. Schizophr Res. 2015;169(1–3):268–73 Available from: https://www.sciencedirect.com/science/article/pii/S0920996415300281?via%3Dihub.
Stain HJ, Galletly CA, Clark S, Wilson J, Killen EA, Anthes L, et al. Understanding the social costs of psychosis: the experience of adults affected by psychosis identified within the second Australian national survey of psychosis. Aust New Zeal J Psychiatry. 2012;46(9):879–89 Available from: http://journals.sagepub.com/doi/10.1177/0004867412449060.
Correll CU, Solmi M, Veronese N, Bortolato B, Rosson S, Santonastaso P, et al. Prevalence, incidence and mortality from cardiovascular disease in patients with pooled and specific severe mental illness: a large-scale meta-analysis of 3,211,768 patients and 113,383,368 controls. World Psychiatry. 2017;16(2):163–80 Available from: http://www.ncbi.nlm.nih.gov/pubmed/28498599.
Westman J, Eriksson SV, Gissler M, Hällgren J, Prieto ML, Bobo WV, et al. Increased cardiovascular mortality in people with schizophrenia: a 24-year national register study. Epidemiol Psychiatr Sci. 2018;27(05):519–27 Available from: http://www.ncbi.nlm.nih.gov/pubmed/28580898.
Valtorta NK, Kanaan M, Gilbody S, Ronzi S, Hanratty B. Loneliness and social isolation as risk factors for coronary heart disease and stroke: systematic review and meta-analysis of longitudinal observational studies. Vol. 102, Heart. BMJ Publishing Group Ltd and British Cardiovascular Society; 2016. p. 1009–16. Available from: http://www.ncbi.nlm.nih.gov/pubmed/27091846.
Moher D, Shamseer L, Clarke M, Ghersi D, Liberati A, Petticrew M, et al. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement. Syst Rev. 2015;4(1):1. Available from: http://www.ncbi.nlm.nih.gov/pubmed/25554246.
Winterton A, Quintana DS. Associations of loneliness and social isolation with cardiovascular and metabolic health: a systematic review and meta-analysis - literature graph - osf.io. OSF; 2019. Available from: https://osf.io/6nwm9/.
Zimet GD, Dahlem NW, Zimet SG, Farley GK. The multidimensional scale of perceived social support. J Pers Assess. 1988;52(1):30–41 Available from: https://doi.org/10.1207/s15327752jpa5201_2.
Broadhead WE, Gehlbach SH, de Gruy FV, Kaplan BH. The Duke-UNC functional social support questionnaire: measurement of social support in family medicine patients. Med Care. 1988;26(7):709–23 Available from: http://www.jstor.org/stable/3765493.
Lubben JE. Assessing social networks among elderly populations. Fam Community Health. 1988;11(3) Available from: https://journals.lww.com/familyandcommunityhealth/Fulltext/1988/11000/Assessing_social_networks_among_elderly.8.aspx.
Lubben J, Blozik E, Gillmann G, Iliffe S, Von Kruse WR, Beck JC, et al. Performance of an abbreviated version of the lubben social network scale among three European community-dwelling older adult populations. Gerontologist. 2006;46(4):503–13.
Burholt V, Windle G, Ferring D, Balducci C, Fagerstrom C, Thissen F, et al. Reliability and validity of the Older Americans Resources and Services (OARS) social resources scale in six European countries. Journals Gerontol Ser B Psychol Sci Soc Sci. 2007;62(6):S371–9 Available from: https://academic.oup.com/psychsocgerontology/article-lookup/doi/10.1093/geronb/62.6.S371.
O’Donnell CJ, Elosua R. Cardiovascular risk factors. Insights from Framingham Heart Study. Rev Española Cardiol (English Ed). 2008;61(3):299–310 Available from: http://linkinghub.elsevier.com/retrieve/pii/S1885585708601188.
World Health Organization. Noncommunicable Diseases Progress Monitor. 2017. Geneva: WHO; 2017.
NCD Risk Factor Collaboration (NCD-RisC) B, Bentham J, Di CM, Bixby H, Danaei G, Cowan MJ, et al. Worldwide trends in blood pressure from 1975 to 2015: a pooled analysis of 1479 population-based measurement studies with 19·1 million participants. Lancet (London, England). 2017;389(10064):37–55 Available from: http://www.ncbi.nlm.nih.gov/pubmed/27863813.
Viswanathan M, Berkman ND. Item bank for assessment of risk of bias and precision for observational studies of interventions or exposures. 2011; Available from: https://www.ncbi.nlm.nih.gov/books/NBK82267/.
Van Aert RCM. Dissertation R.C.M. Van Aert. BITSS. 2018; Available from: https://osf.io/preprints/bitss/eqhjd/.
Viechtbauer W. Conducting meta-analyses in R with the metafor package. J Stat Softw. 2010;36(3):1–48 Available from: http://www.jstatsoft.org/v36/i03/.
Valentine JC, Pigott TD, Rothstein HR. How many studies do you need?: A primer on statistical power for meta-analysis. J Educ Behav Stat. 2010;35(2):215–47 Available from: http://jeb.sagepub.com/cgi/doi/10.3102/1076998609346961.
Winterton A, Quintana DS. Associations of loneliness and social isolation with cardiovascular and metabolic health: a systematic review and meta-analysis - power analysis - osf.io. OSF; 2019. Available from: https://osf.io/uczmd/.
Holt-Lunstad J, Smith TB, Layton JB. Social relationships and mortality risk: a meta-analytic review. Brayne C, editor. PLoS Med. 2010;7(7):e1000316 Available from: https://dx.plos.org/10.1371/journal.pmed.1000316.
Hedges LV, Tipton E, Johnson MC. Robust variance estimation in meta-regression with dependent effect size estimates. Res Synth Methods. 2010;1(1):39–65.
McGuire S, Clifford J. Genetic and environmental contributions to loneliness in children. Psychol Sci. 2000;11(6):487–91 Available from: https://doi.org/10.1111/1467-9280.00293.
Trémeau F, Antonius D, Malaspina D, Goff DC, Javitt DC. Loneliness in schizophrenia and its possible correlates. An exploratory study. Psychiatry Res. 2016;246(September):211–7.
Sorkin D, Rook KS, Lu JL. Loneliness, lack of emotional support, lack of companionship, and the likelihood of having a heart condition in an elderly sample. Ann Behav Med. 2002;24(4):290–8 Available from: https://academic.oup.com/abm/article/24/4/290-298/4630310.
Ong AD, Uchino BN, Wethington E. Loneliness and health in older adults: a mini-review and synthesis. Gerontology. 2016;62(4):443–9 Available from: https://www.ncbi.nlm.nih.gov/pubmed/26539997.
Eglit GML, Palmer BW, Martin AS, Tu X, Jeste DV. Loneliness in schizophrenia: construct clarification, measurement, and clinical relevance. PLoS One. 2018;13(3):1–20.
Insel TR. Oxytocin - A neuropeptide for affiliation: evidence from behavioral, receptor autoradiographic, and comparative studies. Vol. 17, Psychoneuroendocrinology. Pergamon; 1992. p. 3–35. Available from: http://www.sciencedirect.com/science/article/pii/030645309290073G.
Davis MC, Horan WP, Nurmi EL, Rizzo S, Li W, Sugar CA, et al. Associations between oxytocin receptor genotypes and social cognitive performance in individuals with schizophrenia. Schizophr Res. 2014;159(2–3):353–7.
Wang J, Mann F, Lloyd-Evans B, Ma R, Johnson S. Associations between loneliness and perceived social support and outcomes of mental health problems: a systematic review. BMC Psychiatry. 2018;18(1):156 Available from: http://www.ncbi.nlm.nih.gov/pubmed/29843662.
Quintana DS, Dieset I, Elvsåshagen T, Westlye LT, Andreassen OA. Oxytocin system dysfunction as a common mechanism underlying metabolic syndrome and psychiatric symptoms in schizophrenia and bipolar disorders. Front Neuroendocrinol. 2017;45:1–10 Available from: https://www.sciencedirect.com/science/article/pii/S0091302216300644?np=y.
Andari E. The need for a theoretical framework of social functioning to optimize targeted therapies in psychiatric disorders. Vol. 79, Biological Psychiatry. Elsevier; 2016. p. e5–e7. Available from: http://www.sciencedirect.com/science/article/pii/S0006322315009919.
Masunari K, Khan MSI, Cline MA, Tachibana T. Central administration of mesotocin inhibits feeding behavior in chicks. Regul Pept. 2013;187:1–5 Available from: http://www.ncbi.nlm.nih.gov/pubmed/24183984.
Morton GJ, Thatcher BS, Reidelberger RD, Ogimoto K, Wolden-Hanson T, Baskin DG, et al. Peripheral oxytocin suppresses food intake and causes weight loss in diet-induced obese rats. AJP Endocrinol Metab. 2012;302(1):E134–44 Available from: http://www.ncbi.nlm.nih.gov/pubmed/22008455.
Carter CS, Williams JR, Witt DM, Insel TR. Oxytocin and social bonding. Ann N Y Acad Sci. 1992;652(1):204–11 Available from: http://doi.wiley.com/10.1111/j.1749-6632.1992.tb34356.x.
Acknowledgements
We thank Marie Susanna Isachsen (University of Oslo Library) for providing guidance on our systematic search strategy.
Funding
AW and DSQ are supported by an Excellence Grant from the Novo Nordisk Foundation (NNF16OC0019856). LR, NES, and OA are supported by the Research Council of Norway (223273, 262656, 248828), K.B. Jebsen Stiftelsen (SKGJ-MED- 008), South-East Norway Health Authority (2017-112), and the Novo Nordisk Foundation (NNF16OC0019856). OA has received speaker’s honorarium from Lundbeck.
Author information
Authors and Affiliations
Contributions
DSQ, AW, and OAA conceived the study idea. AW, LR, and DSQ contributed to the design of the systematic review. AW and DSQ contributed to the data analysis plan. All authors contributed to the write up and editing of the manuscript and approved the final manuscript. DSQ takes responsibility, and acts as guarantor, for the contents of the protocol and review.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable
Consent for publication
Not applicable
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1:.
PRISMA-P (Preferred Reporting Items for Systematic Review and Meta-Analysis Protocols) 2015 checklist. Recommended items to address in a systematic review protocol.
Additional file 2:.
Complete search strategy.
Additional file 3:.
Data extraction form. Record of pertinent study characteristics for each included study.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Winterton, A., Rødevand, L., Westlye, L.T. et al. Associations of loneliness and social isolation with cardiovascular and metabolic health: a systematic review and meta-analysis protocol. Syst Rev 9, 102 (2020). https://doi.org/10.1186/s13643-020-01369-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13643-020-01369-8