
Abstract
While deep learning technologies have made remarkable progress in generating deepfakes, their misuse has become a well-known concern. As a result, the ubiquitous usage of deepfakes for increasing false information poses significant risks to the security and privacy of individuals. The primary objective of audio spoofing detection is to identify audio generated through numerous AI-based techniques. Several techniques for fake audio detection already exist using machine learning algorithms. However, they lack generalization and may not identify all types of AI-synthesized audios such as replay attacks, voice conversion, and text-to-speech (TTS). In this paper, a deep layered model, i.e., VGGish, along with an attention block, namely Convolutional Block Attention Module (CBAM) for spoofing detection, is introduced. Our suggested model successfully classifies input audio into two classes: Fake and Real, converting them into mel-spectrograms, and extracting their most representative features due to the attention block. Our model is a significant technique to utilize for audio spoofing detection due to a simple layered architecture. It captures complex relationships in audio signals due to both spatial and channel features present in an attention module. To evaluate the effectiveness of our model, we have conducted in-depth testing using the ASVspoof 2019 dataset. The proposed technique achieved an EER of 0.52% for Physical Access (PA) attacks and 0.07 % for Logical Access (LA) attacks.
Similar content being viewed by others


1 Introduction
With the emerging challenges of deep fake spoofing attacks, a new generation of deepfake researchers must focus on audio solemnly. Malicious users have exploited this technology for illegal and conspiratorial purposes. Several approaches have been suggested to mitigate the risk of spoofed speech attacks. Due to the development of automatic speaker verification (ASV) and countermeasures challenges, spoofed audio detection has gained significant attention. There exist two major types of spoofing detection systems. The first is an effective classifier based on neural networks [1], while the second involves acoustic features based on signal processing [2]. Although these algorithms have shown excellent results, research demonstrated that their efficiency decreases when unseen spoofed attacks occur. The ASVspoof 2019 challenge introduced PA and LA tasks for detecting replay attacks and synthesized speeches to aid in developing anti-spoofing techniques. Research bodies and individuals have suggested numerous strategies to combat audio spoofing assaults [3]. Moreover, advanced ML-based approaches are employed to differentiate audio using knowledge-based and data-driven countermeasures [4].
In contrast, conventional ML approaches take time to manually craft feature extraction, which may lead them to overlook the profound information that underlies audio spectrograms. Dinkel et al. suggested a Convolution Neural Network (CNN)-based end-to-end Model employing raw waveforms as input [5]. Chintha et al. proposed a Recurrent Convolution Neural Network (RCNN) structure to detect fake audio [6]. To recognize anti-spoofed attacks, [7] employed a lightweight CNN model (LCNN) using the SoftMax loss function. Combining multiple classifiers enhances the classification performance. Hence, utilizing various feature representations along with Resnet [8] or additional classifiers was examined in [9] for better efficiency.
Nevertheless, there exists a generalization problem regarding unseen attacks, therefore it is necessary to develop a reliable and effective system that can detect fraudulent audio from any source. Therefore, our primary goal is to develop a novel and efficient framework to address this issue. This paper aims to demonstrate an effective framework for identifying fake audio based on a VGGish network combined with a Convolutional Block Attention Module (CBAM) block. Our model is an effective technique to utilize for audio spoofing detectors due to a simple layered architecture. It captures complex relationships within the data in feature maps due to both spatial locations and specific channels present in mel-spectrograms. CBAM provides an adaptive mechanism to adjust the attention based on the content of the input data.
Our designed framework is based on three distinct stages. In the first stage, the mel-spectrograms, which are visual representations of auditory features, are generated. Next, a deep multilayer system is trained on the ASV2019 [2] dataset to distinguish between real and spoofed audio. Finally, the network classifies mel-spectrograms into two classes: real and spoofed. More precisely, our model on the ASV2019 dataset is trained and cross-validated over the ASVSpoof 2021 dataset, which is comprised of an additional deepfake speech set. According to the experiments, the classification accuracy achieved over the ASVS2019 dataset is 99.2%, with a 0.8% error. Furthermore, in the cross-validation phase, the proposed detector efficiently distinguishes fake audio.
The following are the main contributions of our proposed model:
-
To propose an effective method for audio classification, analogous to image classification technique, based on an enhanced deep learning model attached to the CBAM module.
-
CBAM is an effective and powerful attention block to select the most relevant representations from mel-spectrograms.
-
The proposed model is examined against the Physical Access (PA) and the Logical Access (LA) sets of ASV2019, and cross-validated over ASVspoof 2021 dataset. The proposed model produced remarkable results; hence, it is clearly visible that the proposed technique is highly effective for fake audio classification tasks.
-
The attention block makes our technique more robust towards variations in the input audio’s mel-spectrograms such as changes in background noise, scale, and orientation.
The subsequent sections of the paper are presented as follows: Section 2 outlines relevant work; Section 3 describes the methodology; Section 4 explains the experiments accomplished and results; and finally, Section 5 concludes the work.
2 Related work
The increase usage of fabricated or modified audio has risen with the arrival of advanced Artificial Intelligence technologies, especially deep neural networks. The ease of producing audio deepfakes raises multiple privacy and security threats. Therefore, deepfake audio detection techniques are inevitably needed. When considering the misuse of such techniques and the possible harm they may bring, numerous researchers have developed a number of deepfake detection algorithms. Monteiro et al. [1] introduced a dual-adversarial domain adaption paradigm as well as a multi-model ensemble strategy. However, these solutions required equal both authentic and fake data. Mahum et al. [3] proposed an ensemble-based learning method for the detection of text-to-speech synthesized speech and attained significant results. However, they only focused on text-based speeches and did not consider the other types of synthesized speeches.
A support vector machine-based classifier was used for speaker verification utilizing the Gaussian mixture model (GMM) [4]. They achieved an equivalent error rate of 4.92% and 7.78% in the 2006 NIST speaker recognition evaluation test. The researchers suggested the Gaussian mixture model (GMM) and a Relative Phase shift with a support vector machine (SVM) to minimize the limitations of the speaker authentication system.
Furthermore, for the identification of fake speech, a comprehensive comparison of the hidden Markov model (HMM) and deep neural network (DNN) was conducted [5]. The suggested approach in [6] used spectrograms in the form of images as input to the convolutional neural network (CNN), establishing a foundation for audio processing using visuals. Multiple feature descriptors, such as Mel frequency cepstral coefficient (MFCC), spectrogram, and others, were employed [7], and the influence of GMM-UBM on accuracy was investigated in terms of EER. The result showed that combining diverse feature descriptors produce superior outcomes. Chao et al. [8] used two key methods to verify speakers, including kernel fisher discriminant (KFD) and support vector machine (SVM). They achieved better results than their earlier work using GBM and UBM methods. Furthermore, by replacing the dot product between two utterances with two i-vectors, the computational cost of the polynomial kernel support vector machine was decreased. The authors used a features selection strategy to achieve a 64% dimensionality reduction in features with an EER of 1.7% [9].
Loughran et al. [10] used a genetic algorithm (GA) with an altered cost function to overcome the problem of imbalanced data (where one class sample is bigger than the other). Malik et al. [11] investigated audio integrity and created a method for audio fraud detection based on acoustic impressions of the surroundings. However, these proposed models were unable to address generated audio content precisely. In [12], a DNN-based classifier was proposed to detect and use human log-likelihoods (HLL) as a scoring measure, which was shown to be superior to traditional log-likelihood ratios (LLR). They also used a variety of cepstral coefficients in the training of the classifier. Moreover, a convolutional neural network (CNN) was employed for audio classification [13, 14]. In [15], an exhaustive comparison of deep learning approaches for fake audio detection was made, indicating that CNN and RNN-based models outperform all other strategies [16]. showed that spectral features, such as MFCC features, are superior to other spectral features for the model’s input for detecting synthetic speech.
Furthermore, [17] discussed the problems and weaknesses of fake detection methods. A bispectral approach for analyzing and detecting synthetic sound was developed in [18]. They looked at bispectral characteristics, which were unusual spectral aspects in fake speech synthesis by DNNs. To distinguish the fake audio, they looked for high-order polyspectral characteristics. In [19], a capsule network-based technique was proposed. They improved the suggested system’s generalization and thoroughly evaluated the artifacts to improve the model’s overall performance. They also used their network to explore replay attacks in audio. In [20], authors proposed a model for fake audio detection named DeepSonar. They analyzed the network layers and the activation patterns for various input audios to examine the difference between fake and real speeches. They employed three English and Chinese datasets and attained an average accuracy of 98.1%.
In [21]. Mahum et al. proposed a model, namely DeepDet for the detection of TTS synthesis using Yet Another Mobile Network (YAMNet). The authors attached the attention block, i.e., BottleNeck Attention Module to improve the detection performance. The proposed model attained significant performance, however it was not intended to identify several types of fake speeches. Furthermore, for specific tasks, temporal convolutional networks (TCN) [22] have excelled in classical algorithms, such as RNNs and LSTMs [23]. used original speech recordings to clone the voice utilizing the most recent deep-learning techniques for text-to-speech synthesis systems. It took a couple of minutes to capture a real voice and seconds to generate fake audio. Although the approaches have advanced since [24], the difficulty of naturalness persists. Furthermore, signal processing strategies rather than machine learning algorithms are used to generate fake utterances in the VOCo and double voice models [25, 26]. Based on the mapping, the synthesized voice copies the original speech’s tone, tempo, rhythms, genre, and plain text. The number of false speeches was determined by the magnitude of the real speech. Because real and synthetic voices sound so similar, it is quite easy to deceive the listener, and fake speech could be used as evidence in court.
Although various models based on machine learning algorithms are employed to identify fake audio, machine learning-based systems require numerous steps, such as pre-processing of audio data, custom feature extraction, feature selection, and classification, which may increase computational cost and human effort. On the other hand, few researchers have used CNN for feature extraction before using a conventional classifier for classification [27].
A small number of datasets dedicated to fake audio detection systems have recently been generated. Reimao et al. [28] produced a synthetic speech identification dataset. The collection contained fake speech generated by open-source tools that employ contemporary speech synthesis technology. Wang et al. [29] created a fake English and Mandarin dataset using an open-source audio converter and voice synthesis engine. However, the ASVspoof databases are significant since they contain a variety of ways to generate spoofed speech to conduct tests for the development of fake audio detectors. Several existing techniques for spoofing detection are reported in Table 1.
3 Methodology
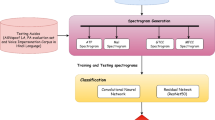
The proposed system comprises three phases: Features Extraction, Training, and Classification. First, the data is gathered and resampled to 16,000 Hz with a single channel using the ASVspoof 2019 dataset. Then, a feature extraction layer to generate mel-spectrograms is employed. Our proposed model extracts the most representative features from the mel-spectrograms generated from audio since the mel-spectrograms of fake audio differ from real audio due to presence of breathing sound in the later form [43]. CBAM module was employed to extract most representative feature maps. Further, our proposed detector is a novel and robust model for audio spoofing detection, and it performs significantly for all sorts of spoofed speeches, according to the observations. Figure 1 illustrates the system’s flow diagram. Figure 2 shows the architecture of the deep learning network, and Fig. 3 exhibits the structure of CNN.

Flow diagram of the proposed method

General architecture of deep learning model

General architecture of CNN
3.1 Convolutional Block Attention Module (CBAM)
Convolutional Block Attention Module progressively infers a 1-dimensional attention map Nc ∈ R c×1×1 and a 2-dimensional spatial attention map Ns ∈ R 1 × h × w from an input intermediary feature map E ∈ R c × h × w [44]. The general attention process is as follows:
Channel attention values are propagated along the spatial dimension during multiplication and vice versa. Element-wise multiplication is represented by ⊗, whereas G′′ represents the final polished output. The processing behind each attention map is shown in Fig. 4.

Overview of CBAM
The specifics of each attention module are listed below:
Channel attention module: A channel attention map is constructed by leveraging the inter-channel correlation of features. Channel attention concentrates on “what” is significant based on the input image since each feature map is regarded as a feature depictor [45]. The input feature map’s spatial dimensions are suppressed to determine the channel attention effectively. According to Zhou et al. [46], average pooling has been widely used to aggregate spatial data. Figure 5 gives an illustration of each attention sub-module.

Channel attention module
Hu et al. [47] adopted it in their attention module to analyze spatial statistics, while [46] recommended employing it to efficiently learn the scope of the target object. In contrast to earlier research and findings, max-pooling captures another crucial piece of information about distinguishing object features to infer better channel-wise attention. Therefore, max-pooled and average-pooled features are used simultaneously. The empirical confirmation demonstrated the effectiveness of our design by integrating both features rather than each one alone. It significantly enhances the network’s representation power. Below is a description of the intricate process. Employing both max and average pooling techniques, initially, the spatial data of a feature map is gathered to construct two distinct spatial context descriptors, \({G}_{\textrm{max}}^c\) and \({G}_{\textrm{avg}}^c\), representing max-pooled features and average-pooled features, respectively. Our channel attention map Nc ∈ ℝc ×1×1 is produced by broadcasting both descriptors to a shared network. A single hidden layer is present in the multilayer perceptron that composes the shared network. To minimize the parameter overhead, the activation size of the hidden layer is adjusted to ℝc/r ×1×1, where r represents the reduction ratio. The resulting feature maps were integrated with element-wise summation after each feature map traversed the sharing network (MLP). The following is a brief computation of the channel attention:
where the sigmoid function is denoted by the σ, W0ℝc/r × c and W1ℝc × c/r, the Multilayer Perceptron’s weights W0 and W1 are shared by both inputs, W0 solely comes just after the Nonlinear Activation Function ReLU.
Spatial attention module: By leveraging the inter-spatial connections of features, spatial attention mapping was performed. In contrast to channel attention, spatial attention emphasizes “where,” which is an informational component and works in conjunction with channel attention. Then, the max pooling and average pooling operations along the channel axes are performed and combined to produce an effective feature descriptor before computing the spatial attention. It has been demonstrated that applying pooling techniques along the channel axis effectively identifies informative representations [48]. To produce a spatial attention map Ns(G) ∈Rh × w that specifies where to concentrate, a convolution operation to feature descriptor was performed. The spatial attention module is shown in Fig. 6.

Spatial attention module
Below, a thorough explanation of the procedure is given. First, max and average pooling operations are used to integrate the channel information of a feature map, creating two 2-dimensional mappings: \({G}_{\textrm{max}}^s\) and \({G}_{\textrm{avg}}^s\in {\mathbb{R}}^{1\times h\times w}\). Each represents the channel’s max and average-pooled features. Our 2-dimensional spatial attention map is then created by concatenating and convolving those with a standard conv. layer. The computation of the spatial attention is given below, where t7×7 is a convolution operation with a seven-by-seven filter size, and σ represents the sigmoid function.
Organization of the attention modules: When given an input image, the channel and spatial attention modules calculate complementary attention, emphasizing the “what” and the “where” of the image. This allows for the placement of two modules either in a parallel or sequential fashion. It is observed that the sequential structure yields better outcomes than a parallel structure.
3.2 Our proposed VGGish
VGGish-CBAM is an enhanced convolutional neural network, and its architecture is influenced by VGG networks. It is widely used for image classification. A sequence of convolution and activation layers is followed by a max pooling layer present in the network. It transforms audio input data into a semantically significant 128-D embedding that can be used as input to a downstream classification model. VGGish-CBAM embedding is more semantically compact than raw audio features. Our proposed version contains twenty-nine layers altogether. Then, the network also included four batch normalization layers along with the max-pooling and ReLU Layer. A CBAM module is introduced before the flattening layer. The improved model is exhibited in Fig. 7. The layer-wise details for VGGish is presented in Table 2.

The modified VGGish (VGGish-CBAM) architecture
The convolutional layer uses the 128 groups with a 3 × 3 filter size having stride 1, and the same padding. Next, the ReLU layer is used with a scale of 0.1 to utilize the features coming from the convolutional layer and introduce non-linearity in the training. In the next step, the max pooling layer reduces the dimensions with stride 2. Furthermore, a convolutional layer is utilized with a 3 × 3 filter size of 128 groups using stride 1. After the convolutional procedure, the features from the convolutional layer are activated using ReLU activation function. In the next step, two convolutional layers are utilized using 256 groups with 3 × 3 convolutions, and a stride of 1 with the same padding. Then, ReLU with a 0.1 scale is used. After that, a max pooling layer with size 2 × 2 and stride 2 is employed. After that, a convolutional layer with a 3 × 3 filter with a size of 512 using stride 1 is placed. After the convolutional procedure, the features from the convolutional layer are activated using ReLU as an activation function. Lastly, a CBAM module is placed, preceded to the fully connected layer.
In Fig. 8, a difference between real and fake mel-spectrogram is presented. It is clearly visible from the image that when a pause occurs during speech, in real speech, there exists a sound of breathing, whereas in fake audio, there is a sharp blue gap, which is the main difference that our proposed model is learning. This is the reason that our model generalized well due to the similar differences among all types of synthesized audio and real speech .

The mel-spectrogram of real and fake speech [3]
4 Experimental framework
This section explains the details of experiments conducted to assess the model’s performance. Additionally, details of the dataset that was used to assess the performance are also provided. Tandem detection cost function (t-DCF), accuracy, precision, equal error rate (EER), and recall are utilized as assessment measures for the ASVspoof 2019 dataset. For implementation, the MATLAB 2021 was used and the system had the following specifications: Core i5, 7th generation, and 12 GB RAM.
4.1 Dataset
The ASVspoof contest began with the establishment of the ASVspoof 2015 dataset [41], which was created to assess TTS and voice conversion (VC) recognition systems. The ASVspoof 2017 dataset [17] was released to assess Replay Detection (RA) detection systems. For the experimentations, the ASVspoof 2019 [2] is used: a diverse and extensive public dataset comprising all types such as TTS, VC, and RA, separated into two data collections: Logical Access (LA) and Physical Access (PA). Furthermore, the Logical and Physical Access corpora are subdivided into three subsets: Training, Evaluation, and Development. Tables 3 and 4 present the statistics on the LA and PA sets of the dataset.
The LA set comprises spoof and real speech data produced by 17 different VC and TTS systems. The details of the LA set are presented in Table 4.
To improve the ASV consistency in reverberant conditions [49, 50], ASVspoof 2019 [2] comprises simulated replay recordings [51,52,53] in deep acoustic environments as opposed to the ASVspoof 2017 dataset [17], which contained the replay attacks. For the collection of PA samples, physical characteristics were considered, for example, room sizes in which the audios were synthesized, which were divided into three categories: small, medium, and large. The talker to ASV distance (Ds), was classified into three categories: short, medium, and large distance. Various factors, such as physical space, including the floor walls, ceiling, and positions within the room were also considered. The reverberation level was described in terms of T60 reverberation time and is divided into three categories: short, medium, and high. Three different zones (A, B, and C) were used for recording, each of which corresponds to a particular talking distance (Da). In comparison to zones B and C, zone A recordings were perceived to be of higher quality. Table 5 contains the data on cloning algorithms.
4.2 Experimental protocols
This section contains information on the experimental protocols utilized to assess the model. To evaluate our model on the LA set, a training set of 25,380 samples (2580 genuine and 22,800 spoofed) was used. The proposed technique is evaluated on both the evaluation set and the development set. The development set comprises 24,844 samples (2548 genuine and 22,296 spoofed samples), whereas the evaluation set contains 71,237 samples (63,882 genuine and 7355 spoofed).
To evaluate the model on the PA set, a training set of 54,000 samples is employed (5400 genuine and 48,600 spoofed). The proposed model is assessed on both sets: the evaluation set and the development set. The development set comprises 29,700 samples (5400 genuine and 24,300 spoofed), whereas the evaluation set contains 134,730 samples (18,090 genuine and 116,640 spoofed samples).
4.3 Evaluation metrics
To assess the performance of our proposed VGGish model, various metrics are employed, i.e., equal error rate (EER), tandem-detection cost function (t-DCF), precision, recall, and accuracy. They rely on true positive (TP), true negative (TN), false positive (FP), and false negative (FN). The term “TP” signifies fake audios that our classifier accurately identified, and FP denotes the number of audio samples that were mistakenly categorized as fake. Moreover, correctly identified audio samples as negative or real are denoted by true negative (TN). In contrast, incorrectly identified audio samples as negative are referred to as false negatives (FN). Additionally,
Precision is the proportion of true positive (TP) overall audio samples labeled as positive. The equation is shown below:
Accuracy implies that how much proposed system has accurately categorized audio samples. This is computed as follows:
Recall is the proportion of actual positives (TP) that a system accurately identifies. The more closely the recall value approaches to 1, the better the model is. The following gives the recall equation:
Moreover, EER and t-DCF are standard metrics that are used to analyze the performance of the proposed spoofing detector.
In equal error rate, speaker verification systems (SVS) are often assessed using two types of errors: false acceptance rate (FAR) and false rejection rate (FRR). When a genuine speaker is rejected by the system or when a fake speaker is accepted by the system, there has been a false rejection or false acceptance [54] respectively. Once the ratio of the false acceptance rate (FAR) is equal to the false rejection rate, it is known as the equal error rate (EER). Lower EER values imply a higher system’s accuracy.
5 Performance evaluation and discussion
5.1 Performance evaluation on PA attacks
The primary objective of this experiment is to evaluate how well our proposed audio spoofing detector works on PA attacks. To achieve this, the audio samples are presented as mel-spectrograms from the PA set using the proposed VGGish model for classifying genuine and replay samples. As shown in Table 6, an EER of 0.52% and 3.0% is attained on the evaluation and development sets, while min-tDCF was 0.05 and 0.07, respectively. Based on the outcomes, it is concluded that our proposed spoofing detector did great, particularly on the evaluation set.
Our proposed spoofing detection system has excellent classification performance. A 99.2% accuracy is attained for the evaluation set and 99.5% accuracy for the development set, respectively. These experimental results demonstrate that our spoofing detector is more effective at identifying physical access attacks on a large and diverse ASVspoof 2019 dataset. The results of this experiment allow us to conclude that the features of our proposed spoofing detector can efficiently capture the microphone anomalies and fingerprint data included in the replay samples. The performance plot over the PA set is shown in Fig. 9, where the y-axis presents the value across each metric.

Performance plot over PA corpus
5.2 Performance comparison of voice cloning algorithm
This experiment aims to identify the type of algorithm used to synthesize samples of the LA set in the ASVspoof 2019 dataset. The voice conversion (VC) and synthesized samples are both included in the Logical Access (LA) dataset. The LA set of ASVspoof 2019 employs 6 distinct cloning algorithms for speech synthesis. In this experiment, a model is trained on 22,800 samples of the LA training dataset and evaluated on 22,296 samples using the development set of the LA corpus of the ASVspoof 2019 dataset. The EER for the algorithms A01 to A09 is 0.7%, 2.2%, 1.09%, 1.02%, 1.01%, and 1.05%, respectively. Table 7 summarizes the results.
The result shows that our proposed technique achieved the best performance over A02 and performed the least accurately on A04 and A06 algorithms. The proposed spoofing detector better detects the WORLD waveform generator’s cloning artifacts since the vocoder A02 uses voice synthesis with the WORLD waveform generator. The Waveform-Concat generator is used for the voice synthesis model A04. In contrast, model A06 employs spectral filtering along with the OLA waveform generator. Consequently, our method is marginally less effective than earlier in capturing the cloning artifacts of waveform-concat and spectrum filtering + OLA waveform generators. Overall, remarkable results have been achieved for the cloning algorithm’s detection. A performance plot of our proposed model using cloning algorithms of ASVspoof 2019 is shown in Fig. 10.

A comparison plot of ASVspoof 2019’s cloning algorithms
5.3 Performance assessment over TTS and VC
The primary objective of this test is to evaluate the efficacy of our proposed detector on voice conversion (VC) and TTS samples. The proposed model used 96 × 64-sized mel-spectrograms and related features to train our model to differentiate between genuine and falsified TTS and VC samples separately. The spoofed samples of the training dataset of the LA corpus are generated by four text-to-speech spoofing algorithms, namely A1–A4 and 2 voice conversion spoofing algorithms, A5 and A6, respectively. There exist thirteen spoofing algorithms utilized to generate the fake samples for the evaluation dataset of LA corpus, including 3 Voice Conversions (A17, A18, and A19), 7 text-to-speech (A7, A8, A9, A10, A11, A12, and A16), and 3 VC-TTS (A13, A14, and A15) spoofing algorithms.
A multi-stage experiment is used to assess the efficacy of our proposed approach for detecting voice conversion (VC) and text-to-speech (TTS) spoofing individually. In the first step, the model is trained using genuine and fake samples (text-to-speech) from the training dataset of the LA corpus. Next, the model is evaluated using genuine and fake samples (TTS) from the evaluation set of the LA corpus. As a result, an EER achieved 0.54% and a minimum TDCF of 0.04. In the second step, the model is trained using the genuine and fake samples (VC) from the training dataset of the LA corpus. Then, the model is evaluated using the genuine and spoofed samples (VC) from the evaluation dataset of the LA corpus. The proposed model attained a minimum tDCF of 0.40 and an EER of 1.3%. Table 8 presents the comprehensive results of TTS and VC spoofing detection. The performance plot over TTS and VC sets is shown in Fig. 11.

Performance plot over TTS and VC
The above findings demonstrate that, in comparison to voice conversion (VC) detection, our proposed method is more effective at text-to-speech (TTS) spoofing detection. The suggested approach more effectively replicates the artifacts produced by Griffin Lim, Vocoder TTS, and neural waveforms. This may be because text-to-speech (TTS) samples lack the speakers’ periodic features. In contrast, the voice conversion spoofing model employs the actual voices as a source, retaining those features. The suggested system works efficiently on the LA corpus, with an EER of 0.07%, demonstrating the efficacy of our approach.
5.4 Performance assessment for detecting unseen attacks
This experiment aims to assess how well the suggested system performs against hidden Logical Access attacks such as A7–A19. The evaluation set of the Logical Access dataset contains 63,895 instances of unknown attacks, which are synthesized employing the spoofing algorithms. First, the model is trained using genuine and spoofed data from the Logical Access training set. Then, the model is evaluated using the samples from the evaluation set containing bonafide and spoofed samples from hidden assaults. The results are summarized in Table 9, and the plot is shown in Fig. 12. Our approach performed admirably for A07, A10, A11, and A13.

Performance plot on unseen LA
In addition, our method performed poorly for A17, A18, and A19. This experiment indicates that voice cloning-based artificial speech is harder to distinguish from text-to-speech-based artificial speech. A comparison of waveform-generating techniques demonstrates that attacks using waveform filtering-based approaches (voice cloning (VC) vocoder, voice cloning (VC) waveform filtering, and spectral filtering are used by A17, A18, and A19 assaults) are among the most challenging to identify. Even though our approach experienced difficulties in efficiently capturing the artifacts generated by voice-cloned assaults, it worked better against the overall Logical Access assaults.
5.5 Performance evaluation against existing DL models
In this experiment, our proposed model is compared to various traditional Deep Learning Models, including InceptionNetV4, DenseNet201 MobileNetV2, and EfficientNet. Our suggested model, an enhanced VGGish classifier for accurately detecting fake speeches, is sustainable. A comparative analysis is performed on the above-mentioned models using metrics: EER, min-tCDF, accuracy, precision, and recall, as displayed in Table 10. The flowchart describing the algorithms utilized in this experiment is shown in Fig. 13.

Flowchart for deepfake audio detection models used for comparative analysis
To detect whether an audio sample is fake or authentic, audio samples are transformed into Mel spectrograms and fed into these deep learning models. In total, 800 audio samples have been utilized from the PA corpus of the ASVspoof 2019 dataset. When comparing the outcomes of each of these methods, it is evident that our algorithm exceeds the other deep learning algorithms by a substantial margin, with 99.78% accuracy and 98.86% precision.
Our suggested method surpasses all others with an EER of 0.07% and a min-tDCF of 0.030. This comparative study allows us to conclude that our suggested model outperforms conventional DL models and can detect fake audio accurately. The plot is shown in Fig. 14.

Performance plot on evaluation set against existing models
5.6 Cross-validation
The ASVspoof 202 1[55] dataset is used to evaluate the robustness of the proposed model. ASVspoof 202 1[55] dataset is designed to be more challenging than earlier versions. While the training and development partitions remained the same as the ASVspoof 2019 LA dataset, there is a variation within the assessment set. An additional evaluation segment of Deepfake tasks is incorporated in the ASVspoof 2021 database. The Deepfake(DF) set of the ASVspoof 2021 is used, which consists of audios produced by fusing real and synthetic speech generated through Voice Conversion (VC) and Text-to-voice (TTS) synthesis techniques. The hyperparameters are identical to the first experiment. The suggested approach has shown outstanding generalization ability and delivered promising results. Table 11 presents the results obtained. These results confirm that our suggested detector is robust enough and performs significantly.
5.7 Comparison with existing fake audio detectors
In this experiment, the proposed model is compared with existing deepfake audio detectors. Several models have been proposed for the fake audio synthesis using deep learning [56]. Most of the existing models take input as raw audio, whereas some models take input in the form of extracted features. The same dataset, i.e., ASVspoof 2019, is used for this experiment. It is clearly visible from the reported results in Table 12 that our proposed VGGish-CBAM-based model achieves better results than other existing detectors. The better performance is due to the added attention module that extracts the spatial and channel feature maps in the VGGish network. Moreover, the audios are transformed into mel-spectrograms to consider the visual representations of the raw audio. This attribute makes it easy for our proposed technique to differentiate fake audio from real ones. The fake audio mel-spectrograms show flat patterns during the pauses, whereas in real audio, the pauses are shown with varying patterns.
Therefore, our proposed technique effectively identifies the fake audios. The comparison plot on EER is shown in Fig. 15.

EER Comparison plot of several fake audio detectors
6 Discussion
Our approach surpasses state-of-the-art techniques in terms of EER when compared to existing approaches. Our model systematically outperformed existing research [57,58,59,60,61,62] due to its simple and effective architecture and exhibited a remarkable ability to identify Logical Access (LA) attacks. The best-performing solution, which claimed an EER of 1.02% utilizing a TO-RawNet Orth - AASIST architecture [62] for LA assaults, which is substantially greater than our model score (0.07%). A remarkable 0.07% EER for Logical Access attacks is attained, proving the resilience of our model in recognizing complex attacks with various replay scenarios and microphone configurations. Our Physical Access (PA) attack outcomes, i.e., 0.52%, are nevertheless competitive when compared to other approaches. The advantage of our model is that it can detect both PA and LA attacks with similar effectiveness, unlike other systems such as [60], which obtained lower EERs for PA attacks, specifically. Moreover, cross-validation using the ASVSpoof 2021 dataset has demonstrated its generalizability, highlighting its applicability to more recent datasets.
In summary, our VGGish-CBAM model is an essential advancement in voice spoofing detection. In addition to its innovative performance in detecting both Physical Access (PA) and Logical Access (LA) attacks and its versatility in handling diverse attack scenarios, it contributes to the security of voice-based systems.
Along with the significant outcomes, some limitations were faced. For example, the model required high computational resources to transform the audio signal into mel-spectrograms of large size, such as 220 × 190 dimensions. We assessed the performance of the detector using varying sizes of mel-spectrograms, i.e., 220 × 190, 180 × 120, and 96 × 64. The training and computational time was reduced when the smaller size was used for mel-spectrograms. Therefore, we chose 96 × 64 dimensions to feed them to the network, attaining the maximum performance. The reason behind the better performance while using smaller sizes is that the stacked bins in mel-spectrograms are taken with respect to time, and it provides enough audio information. Thus, the proposed model reduces the computational overhead due to the attached attention block by providing better performance on small-sized mel-spectrograms.
7 Conclusion
This work aims to develop an audio spoofing detection system that can identify several types of attacks such as text-to-speech, voice conversion, and replay attacks using an enhanced deep learning model. A customized VGGish network along with a CBAM attention block is used to extract features from real and fake audio’ mel-spectrograms and categorize them. Our suggested model successfully captures sample dynamics, and environment artifacts, as well as different microphone settings of the replay attacks. Furthermore, our model is a significant technique for audio spoofing detectors due to a simple layered architecture. It captures complex relationships within the data in feature maps due to both spatial locations and specific channels present in an attention module. Moreover, the ASVspoof 2019 corpus is employed to evaluate the performance of the suggested technique, and the results show that our system is effective at identifying various spoofing attacks. More specifically, the model achieved an EER of 0.52% for PA attacks and 0.07% for LA attacks, respectively. The proposed approach also provides considerable results on cross-validation utilizing the ASVSpoof 2021 dataset.
It is analyzed that when the noisy audios are fed, the model’s performance degraded due to similar patterns of loudness in mel-spectrograms. Therefore, in the future, we aim to fine-tune our model to make it lightweight and more efficient.
Availability of data and materials
The datasets generated and analyzed during the current study are available in the [asvspoof.org], [https://www.asvspoof.org/database].
References
J. Monteiro, J. Alam, T.H, Falk, An ensemble based approach for generalized detection of spoofing attacks to automatic speaker recognizers. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (IEEE, 2020), pp. 6599–6603
M. Todisco, X. Wang, V. Ville, Md Sahidullah, H. Delgado, A. Nautsch, J, Yamagishi, N. Evans, T. Kinnunen, K. Lee, "ASVspoof 2019: Future horizons in spoofed and fake audio detection." arXiv preprint arXiv:1904.05441 (2019)
R. Mahum, A. Irtaza, A. Javed, EDL-Det: A Robust TTS Synthesis Detector Using VGG19-Based YAMNet and Ensemble Learning Block. IEEE. Access. 11, 134701–134716 (2023)
Y.-H. Chao et al., Using kernel discriminant analysis to improve the characterization of the alternative hypothesis for speaker verification. IEEE. Transact. Audio. Speech. Language. Process. 16(8), 1675–1684 (2008)
H. Zen, A. Senior, M. Schuster, Statistical parametric speech synthesis using deep neural networks. In 2013 ieee international conference on acoustics, speech and signal processing (IEEE, 2013), pp. 7962–7966
Dörfler, M., R. Bammer, and T. Grill. Inside the spectrogram: Convolutional Neural Networks in audio processing. In 2017, there was an international conference on sampling theory and applications (SampTA). 2017. IEEE.
B. Balamurali et al., Toward robust audio spoofing detection: A detailed comparison of traditional and learned features. IEEE. Access. 7, 84229–84241 (2019)
Y.-H. Chao, Using LR-based discriminant kernel methods with applications to speaker verification. Speech. Commun. 57, 76–86 (2014)
S. Yaman, J., Pelecanos Using polynomial kernel support vector machines for speaker verification. IEEE. Signal. Process. Lett. 20(9), 901–904 (2013)
R. Loughran et al., Feature selection for speaker verification using genetic programming. Evolution. Intelligence. 10(1), 1–21 (2017)
H. Zhao, H. Malik, Audio recording location identification using acoustic environment signature. IEEE. Transact. Inform. Forensics. Security. 8(11), 1746–1759 (2013)
H. Yu et al., Spoofing detection in automatic speaker verification systems using DNN classifiers and dynamic acoustic features. IEEE. Transact. Neural Netw. Learn. Syst. 29(10), 4633–4644 (2017)
A. Maccagno et al., in Progresses in Artificial Intelligence and Neural Systems. A CNN approach for audio classification in construction sites (Springer, 2021), pp. 371–381
S. Bai, J.Z. Kolter, V. Koltun, "An empirical evaluation of generic convolutional and recurrent networks for sequence modeling." arXiv preprint arXiv:1803.01271 (2018)
C. Zhang, C. Yu, J.H. Hansen, An investigation of deep-learning frameworks for speaker verification anti-spoofing. IEEE. J. Select. Topics. Signal. Process. 11(4), 684–694 (2017)
D. Paul, M. Pal, G. Saha, Spectral features for synthetic speech detection. IEEE. J Select. T. Signal. Process. 11(4), 605–617 (2017)
T. Kinnunen, Md. Sahidullah, H. Delgado, M. Todisco, N. Evans, J. Yamagishi, KA. Lee, The ASVspoof 2017 Challenge: Assessing the Limits of Replay Spoofing Attack Detection. Proceedings of the 18th Annual Conference of the International Speech Communication Association, 2-6. (2017). https://doi.org/10.21437/Interspeech.2017-1111
EA. AlBadawy, S. Lyu, H. Farid "Detecting AI-Synthesized Speech Using Bispectral Analysis." In CVPR workshops, pp. 104-109. (2019)
Luo, A., et al. A capsule network-based approach for detection of audio spoofing attacks. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2021. IEEE.
Wang, R., et al. Deepsonar: Towards effective and robust detection of ai-synthesized fake voices. In Proceedings of the 28th ACM International Conference on Multimedia. 2020.
R. Mahum, A. Irtaza, A. Javed, et al., DeepDet: YAMNet with BottleNeck Attention Module (BAM) for TTS synthesis detection. J. Audio. Speech. Music. Proc. 2024, 18 (2024). https://doi.org/10.1186/s13636-024-00335-9
Lea, C., et al. Temporal convolutional networks: A unified approach to action segmentation. in European Conference on Computer Vision. 2016. Springer.
Arık, S.Ö., et al. Deep voice: Real-time neural text-to-speech. In International Conference on Machine Learning. 2017. PMLR.
W. Ping, K. Peng, A. Gibiansky, SO. Arik, A. Kannan, S. Narang, J. Raiman, J. Miller, "Deep voice 3: Scaling text-to-speech with convolutional sequence learning." arXiv preprint arXiv:1710.07654 (2017)
Ballesteros L, DM, and J.M. Moreno A, Highly transparent steganography model of speech signals using Efficient Wavelet Masking. Expert Systems with Applications, 2012. 39(10): 9141-9149.
Ballesteros L, DM, and J.M. Moreno A, On the ability of adaptation of speech signals and data hiding. Expert. Syst. Appl., 2012. 39(16): 12574-12579.
T. Liu et al., Identification of Fake Stereo Audio Using SVM and CNN. Inform. 12(7), 263 (2021)
Reimao, R. and V. Tzerpos. For: A dataset for synthetic speech detection. In 2019, the International Conference on Speech Technology and Human-Computer Dialogue (SpeD) was 2019. IEEE.
Zhang, R., et al., Bstc: A large-scale Chinese-english speech translation dataset. arXiv preprint arXiv:2104.03575, 2021.
G. Lavrentyeva, S. Novoselov, E. Malykh, A. Kozlov, O. Kudashev, V. Shchemelinin, "Audio replay attack detection with deep learning frameworks." In Interspeech, pp. 82-86. (2017)
M. Alzantot, Z. Wang, MB. Srivastava, "Deep residual neural networks for audio spoofing detection." arXiv preprint arXiv:1907.00501 (2019)
Lai, C.-I., et al., ASSERT: Anti-spoofing with squeeze-excitation and residual networks. arXiv preprint arXiv:1904.01120, 2019.
M. Todisco, H. Delgado, NW. Evans, "A New Feature for Automatic Speaker Verification Anti-Spoofing: Constant Q Cepstral Coefficients." In Odyssey, vol. 2016, pp. 283-290. 2016
I. Saratxaga et al., Synthetic speech detection using phase information. Speech. Commun. 81, 30–41 (2016)
Alam, M.J., et al. Development of CRIM system for the automatic speaker verification spoofing and countermeasures challenge 2015. in the Sixteenth annual conference of the International Speech Communication Association. 2015.
Liu, Y., et al. Simultaneous utilization of spectral magnitude and phase information to extract supervectors for speaker verification anti-spoofing. At the Sixteenth annual conference of the International Speech Communication Association. 2015.
Wang, L., et al. Relative phase information for detecting human speech and spoofed speech. At the Sixteenth Annual Conference of the International Speech Communication Association. 2015.
Xiao, X., et al. Spoofing speech detection using high dimensional magnitude and phase features: the NTU approach for ASVspoof 2015 challenge. In Interspeech. 2015.
Chen, N., et al. Robust deep feature for spoofing detection—The SJTU system for ASVspoof 2015 challenge. In Sixteenth Annual Conference of the International Speech Communication Association. 2015.
Gomez-Alanis, A., et al. A light convolutional GRU-RNN deep feature extractor for ASV spoofing detection. In Proc. Interspeech. 2019.
Alam, M.J., et al. Spoofing Detection on the ASVspoof2015 Challenge Corpus Employing Deep Neural Networks. in Odyssey. 2016.
Y. Qian, N. Chen, K. Yu, Deep features for automatic spoofing detection. Speech. Commun. 85, 43–52 (2016)
Hershey, S., et al. CNN architectures for large-scale audio classification. In 2017, I attended an international conference on Acoustics, speech, and signal processing (Picasso). 2017. IEEE.
Woo, S., et al. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV). 2018.
Zeiler, M.D. and R. Fergus. Visualizing and understanding convolutional networks. In European conference on computer vision. 2014. Springer.
Zhou, B., et al. Learning deep features for discriminative localization. in Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Hu, J., L. Shen, and G. Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
Zagoruyko, S. and N. Komodakis Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv preprint arXiv:1612.03928, 2016.
Ko, T., et al. A study on data augmentation of reverberant speech for robust speech recognition. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2017. IEEE.
H. Dawood, S. Saleem, F. Hassan, A. Javed, "A robust voice spoofing detection system using novel CLS-LBP features and LSTM." J. King Saud Univ. Comput. Inf. Sci. 34(9), 7300–7312 (2022)
A. Janicki, F. Alegre, N. Evans, An assessment of automatic speaker verification vulnerabilities to replay spoofing attacks. Secur. Commun. Netw. 9(15), 3030–3044 (2016)
D. Campbell, K. Palomaki, G. Brown, A Matlab simulation of" shoebox" room acoustics for use in research and teaching. Comput. Inform. Syst. 9(3), 48 (2005)
A. Novak, P. Lotton, L. Simon, Synchronized swept-sine: Theory, application, and implementation. J. Audio. Eng. Soc. 63(10), 786–798 (2015)
A. Qadir, R. Mahum, S. Aladhadh, A Robust Approach for Detection and Classification of KOA Based on BILSTM Network. Comp. Syst. Sci. Eng. 47(2) (2023)
Yamagishi, J., et al., ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection. arXiv preprint arXiv:2109.00537, 2021.
R. Mahum, A. Irtaza, A. Javed, in Intelligent Multimedia Signal Processing for Smart Ecosystems. Text to speech synthesis using deep learning (Springer International Publishing, Cham, 2023), pp. 289–305
A. Nautsch et al., ASVspoof 2019: spoofing countermeasures for the detection of synthesized, converted, and replayed speech. IEEE. Transact. Biomet. Behav. Ident. Sci. 3(2), 252–265 (2021)
Tak, H., et al. End-to-end anti-spoofing with rawnet2. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2021. IEEE.
Y. Zhang, F. Jiang, Z. Duan, One-class learning towards synthetic voice spoofing detection. IEEE. Signal. Process. Lett. 28, 937–941 (2021)
X. Li, X. Wu, H. Lu, X. Liu, H. Meng, "Channel-wise gated res2net: Towards robust detection of synthetic speech attacks." arXiv preprint arXiv:2107.08803 (2021)
Jung, J.-w., et al. Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2022. IEEE.
Wang, C., et al., TO-Rawnet: Improving RawNet with TCN and Orthogonal Regularization for Fake Audio Detection. arXiv preprint arXiv:2305.13701, 2023.
Code availability
The code can be provided on demand.
Funding
The authors present their appreciation to King Saud University for funding this research through the Researchers Supporting Program number (RSPD2024R704), King Saud University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study’s conception and design.
Corresponding author
Ethics declarations
Consent to participate
All authors gave their consent to participate.
Ethics approval
Not applicable.
Consent for publication
All authors agreed to submit the manuscript for publication in the journal.
Competing interests
The authors have no conflicts of interest to declare that they are relevant to the content of this article.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kanwal, T., Mahum, R., AlSalman, A.M. et al. Fake speech detection using VGGish with attention block. J AUDIO SPEECH MUSIC PROC. 2024, 35 (2024). https://doi.org/10.1186/s13636-024-00348-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13636-024-00348-4