
Abstract
Background
The prevalence of type 2 diabetes has dramatically increased in the past years. Increasing evidence supports that blood DNA methylation, the best studied epigenetic mark, is related to diabetes risk. Few prospective studies, however, are available. We studied the association of blood DNA methylation with diabetes in the Strong Heart Study. We used limma, Iterative Sure Independence Screening and Cox regression to study the association of blood DNA methylation with fasting glucose, HOMA-IR and incident type 2 diabetes among 1312 American Indians from the Strong Heart Study. DNA methylation was measured using Illumina’s MethylationEPIC beadchip. We also assessed the biological relevance of our findings using bioinformatics analyses.
Results
Among the 358 differentially methylated positions (DMPs) that were cross-sectionally associated either with fasting glucose or HOMA-IR, 49 were prospectively associated with incident type 2 diabetes, although no DMPs remained significant after multiple comparisons correction. Multiple of the top DMPs were annotated to genes with relevant functions for diabetes including SREBF1, associated with obesity, type 2 diabetes and insulin sensitivity; ABCG1, involved in cholesterol and phospholipids transport; and HDAC1, of the HDAC family. (HDAC inhibitors have been proposed as an emerging treatment for diabetes and its complications.)
Conclusions
Our results suggest that differences in peripheral blood DNA methylation are related to cross-sectional markers of glucose metabolism and insulin activity. While some of these DMPs were modestly associated with prospective incident type 2 diabetes, they did not survive multiple testing. Common DMPs with diabetes epigenome-wide association studies from other populations suggest a partially common epigenomic signature of glucose and insulin activity.
Similar content being viewed by others
Introduction
The burden of diabetes has dramatically increased worldwide over the past decades, leading to excessive health, social and economic costs [1, 2]. Diabetes is one of the main risk factors for cardiovascular disease [3] and other complications such as kidney disease, blindness, cancer and liver disease [1]. Most of the Genome-Wide Association Studies (GWAS) of diabetes have been conducted in European populations [4]. The loci identified as associated with T2D were validated in other ethnicities such as Mexican Americans [5]. However, the identified loci only explain about 20% of the heritability of T2D in Europeans [6]. Environmental factors, including diet, physical activity, obesogenic chemicals and their impact in excess adiposity, are major determinants of diabetes [7]. These environmental factors, together with genetics, are in turn major regulators of epigenetic marks [8], supporting that epigenetics provides a framework to advance our understanding of relevant pathways for diabetes and diabetes-related outcomes.
DNA methylation refers to the covalent attachment of a methyl group to the DNA molecule [9]. Several studies have highlighted the association between blood DNA methylation and diabetes [10,11,12,13]; however, the temporality between DNA methylation dysregulations and diabetes is unclear and those dysregulations might also be a consequence of metabolic processes induced by subclinical diabetes. In addition, DNA methylation dysregulations associated with diabetes have also been found in other relevant tissues such as liver, adipose tissue and pancreatic islets [14]. As the prediabetes period is long and the diabetes diagnostic criteria are established in advanced phases, DNA methylation dysregulations might be a powerful biomarker for early detection [15], which might help with early treatment and to reduce healthcare costs. In addition, DNA methylation has been suggested to have a higher predictive ability than genetics for type 2 diabetes in high-risk subjects [16].
Native Americans suffer a disproportionate burden of diabetes compared to other race/ethnic groups in the USA [17]. American Indian and Alaska Native adults are almost three times more likely than non-Hispanic white adults to be diagnosed with diabetes [18]. The Strong Heart Study [19] is the largest prospective cohort study of cardiovascular disease and its risk factors in American Indian communities and provides an opportunity to evaluate the association of DNA methylation with diabetes in a population with a high burden of metabolic disease.
Most of the previous epigenome-wide association studies (EWAS) of diabetes have been cross-sectional, have evaluated associations of DNA methylation with prevalence rather than incidence, have been conducted among individuals with clinically diagnosed diabetes or lack a time-to-event framework [10,11,12,13, 20]. Comparing epigenetic signatures associated cross-sectionally with subclinical markers of diabetes and those associated prospectively with diabetes incidence can contribute to better understand the natural history of diabetes development. We first examined the cross-sectional association between markers of glucose and insulin sensitivity (fasting glucose and HOMA-IR) and blood DNA methylation measured at almost 800,000 genomic loci. Second, we determined whether those epigenetic variations were also associated with incident diabetes in participants of the Strong Heart Study that were free of diabetes at baseline.
Methods
Study population
The SHS is the largest and longest prospective cohort study of American Indians. It was funded to study cardiovascular diseases and risk factors in American Indian adults [19]. In 1989–1991 (visit 1), 4549 men and women between 45 and 75 years old belonging to 13 tribes from Arizona, Oklahoma and North Dakota and South Dakota agreed to participate. In 2016, a Tribal Nation from Arizona declined further participation, leaving 3517 potential participants for this study. Eligibility for blood DNA methylation analysis has been described in a previous publication [21], leaving 2325 participants for epigenetic research. For this study, 967 participants with prevalent diabetes (assessed by whether participants took diabetes medication, by measurements of fasting glucose and by the HbA1c test) and 46 participants with missing diabetes information at exam 2 (1993–1995) and exam 3 (1998–1999) or missing values in fasting glucose or HOMA-IR at baseline were excluded, leaving a total of 1312 participants (Additional file 1: Figure S1). The Strong Heart Study protocol was approved by institutional review boards, participating tribal communities and the respective area Indian Health Service IRBs in each tribal community, and all participants provided informed consent.
Participant characteristics
Data on sociodemographic factors, medical history, smoking status and alcohol consumption were collected in a personal interview. Participants who reported smoking < 100 cigarettes in their lifetime were considered never smokers. Participants who reported smoking ≥ 100 cigarettes in their lifetime and smoking at the time of the interview were considered current smokers. Participants who reported smoking ≥ 100 cigarettes in their lifetime but currently not smoking were classified as former smokers. Current alcohol consumption was defined as self-report of any alcohol consumption within the past year. Former alcohol consumption was defined as no consumption of any alcohol during the last year but previous consumption of > 12 drinks of alcohol in a single year. The physical examination included anthropometric measures (height and weight) and collected fasting blood and spot urine samples.
Fasting glucose, insulin resistance and incident diabetes
Participants fasted for 12 h or more before the physical examination. An oral glucose tolerance test was conducted, which included 75-g oral glucose and blood collection at 2 h [22]. The MedStar Health Research Institute laboratory [22, 23] analyzed plasma glucose and insulin using a hexokinase method and radioimmunoassay (Linco, St. Louis, Missouri), respectively. The analysis of hemoglobin A1c (HbA1c) in blood was conducted at the National Institute of Diabetes and Digestive and Kidney Diseases Epidemiology and Clinical Research Branch, Phoenix, Arizona using high-performance liquid chromatography [24].
We defined diabetes as having one of the following: fasting glucose greater or equal than 126 mg/dL, 2-h post-load plasma glucose greater or equal than 200 mg/dL, HbA1c greater or equal than 6.5%, using insulin or an oral hypoglycemic agent [25]. We used the equation [fasting plasma insulin (mU/L) × fasting plasma glucose (mmol/L)]/22.5 to calculate HOMA-IR [26]. Individuals having prevalent diabetes were excluded, and incident diabetes was assessed in two follow-up visits (1993–1995 and 1998–1999) (Additional file 1: Figure S1).
Blood DNA methylation determinations
Details of the DNA methylation analysis from white blood cells using Illumina’s MethylationEPIC BeadChip (850 K) have been published [27]. Buffy coats from fasting blood samples were collected in 1989–1991. Biological specimens were stored at − 70 °C. DNA from white blood cells was extracted and stored at the Penn Medical Laboratory, MedStar Health Research Institute under a strict quality-control system. In 2015, blood DNA was shipped to the analytical laboratory at the Texas Biomedical Research Institute for DNAm analysis. DNA was bisulfite-converted with the EZ DNAm kit (Zymo Research) according to the manufacturer’s instructions. Bisulfite-converted DNA was measured using the Illumina MethylationEPIC BeadChip (850 K). CpGs with a p-detection value greater than 0.01 in more than 5% of the individuals (6159 CpGs) were removed. Single sample normalization for background correction [28] and Regression on Correlated Probes normalization for probe type bias [29] were applied. We excluded cross-hybridizing DNA methylation sites, sex chromosomes DNA methylation sites and single nucleotide polymorphisms with minor allele frequency > 0.05 [30]. We calculated blood cell proportions (CD8T, CD4T, NK cells, B cells, monocytes and neutrophils) using the Houseman method as implemented by the R package FlowSorted.Blood.EPIC. We used those data to adjust all models for blood cell type proportions. The final sample size after these corrections was of 1312 participants. The total number of CpG sites available was 788,368 CpG sites.
Statistical analysis
Cross-sectional association: one marker at a time
We conducted an epigenome-wide association study to evaluate the association of each CpG site separately with both fasting glucose and HOMA-IR (in separate models). We used linear regression models as implemented by the limma R package, together with an empirical Bayes method that shrinks standard errors to a common value in order to borrow information from all the genes. We used methylation M values (logit2 transformation of methylation proportions) as the outcome. Models were adjusted for age, sex, study center, smoking status (never, former, current), alcohol consumption (never, former, current), education level (no high school, some high school, completed high school), BMI, estimated cell proportions (CD8T, CD4T, NK, B cells and monocytes) and five genetic principal components (PCs). P-values were corrected for multiple comparisons using the FDR method.
Cross-sectional association: all markers at a time
We used Iterative Sure Independence Screening coupled with Adaptive Elastic-Net (ISIS-AENET) to analyze the association of the 788,368 CpGs simultaneously with fasting glucose or HOMA-IR. ISIS-AENET uses data-driven weights to improve effect estimation while allowing to analyze highly correlated predictors, similar to elastic-net models [31, 32]. The combination of ISIS and regularization methods has shown to be a highly effective variable selection method relative to other approaches in ultra-high-dimensional settings [31, 33, 34]. A combination of the R packages SIS [35] and gcdnet [36] was used to perform this analysis. To remove the variability in methylation due to differences in cell type proportions, methylation data were regressed on cell type proportions (CD8 T cells, CD4 T cells, NK cells, B cells and monocytes) and five genetic principal components (PCs) and the residuals of those models were used as predictors in ISIS-AENET models. In addition, the two outcomes (fasting glucose and HOMA-IR) were separately regressed on relevant baseline covariates (age, sex, study center, smoking status (never, former, current), alcohol consumption (never, former, current), education level (no high school, some high school or completed high school) and BMI, and the residuals of those models were used as outcomes in the ISIS-AENET model.
Prospective association with incident diabetes
The beta values (DNA methylation proportions) of the differentially methylated CpG positions (DMPs) selected by the ISIS-AENET model as associated with either fasting glucose or HOMA-IR were evaluated for prospective association with incident diabetes using Cox proportional hazards models of one CpG at a time. We used diabetes status at visits 2 and 3 to determine the time to event, with age as time scale and individual entry times (age at baseline) treated as staggered entries. Models were adjusted for sex, smoking status, study center, alcohol consumption, education level, cell counts and five genetic PCs. We conducted two sensitivity analyses additionally adjusting the models for fasting glucose and for HOMA-IR. As a secondary analysis, we assessed the association between DNA methylation and incident impaired glucose tolerance (IFG) on the CpG sites associated with incident type 2 diabetes. IFG was defined as two-hour glucose levels of 140 to 199 mg/dL on the 75-g oral glucose tolerance test. We used IFG status at visits 2 and 3 to determine the time to event, with age as time scale and individual entry times treated as staggered entries. Models were adjusted for the same covariates as diabetes models.
Protein–protein interaction network
We displayed a protein–protein interaction network for the CpGs selected by ISIS-AENET for either fasting glucose or HOMA-IR based on their annotation to the nearest protein coding gene. We used the STRING database v11.0 to identify the interactions between nodes that had a confidence score of at least 0.4 [37]. We used Cytoscape v3.8.2 to display the network [38].
Enrichment analysis
We performed functional enrichment analysis on the genes that were annotated to all CpGs selected via the ISIS-AENET models for either fasting glucose or HOMA-IR. We used the clusterProfiler R package [39] to test for over-representation of GO terms [40] in the biological pathways (BP), molecular functions (MF) and cellular component (CC) databases, for biological pathways in the Kyoto Encyclopedia of Genes and Genomes (KEGG) [41] and Reactome [42] databases, and for hallmark gene sets from the Molecular Signatures Database (MSigDB) [43]. We present the top 20 enriched pathways and gene sets, ranked by p-values from the hypergeometric test, and use false discovery rate (FDR) < 0.05 to distinguish significant enrichment.
Results
At baseline, SHS participants who developed incident diabetes were younger than those who remained diabetes-free through the follow-up and had higher BMI. They were less likely to be current smokers and drink alcohol and had higher HOMA-IR (Table 1).
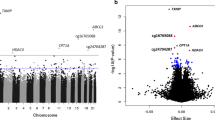
The one-marker-at-a-time approach identified one DMP (annotated to the DNAH10 gene) associated with fasting glucose after multiple comparisons. In models not adjusted by BMI, we found three more DMPs (annotated to ABCG1, SREBF1 and DNAH10). For HOMA-IR, no DMPs were significant at 0.05 FDR threshold. In models not adjusted for BMI, six DMPs (annotated to genes ABCG1, SREBF1, HSF4 and CPT1A) were significant.
The ISIS-AENET model identified 182 DMPs as associated with fasting glucose (Additional file 2: Table S1) and 182 DMPs as associated with HOMA-IR (Additional file 2: Table S2), with an overlap of six DMPs annotated to the genes MRPS31 (associated with type 1 diabetes in previous studies), SH2B1 (associated with severe obesity and insulin resistance), ABCG1 (associated with type 2 diabetes), ABHD11 (involved in weight gain regulation), PSMF1 (control of proteasome function) and HMGN1 (associated with the process of transcriptionally active chromatin).
Among the 358 DMPs that were associated either with fasting glucose or with HOMA-IR, 49 were associated with incident diabetes at a nominal p value of 0.05. None of them passed the FDR cutoff of 0.05. The 16 DMPs associated with incident diabetes at a nominal p value < 0.01 are shown in Table 2. Adjustment for baseline fasting glucose or HOMA-IR in these models attenuated the effect estimates. The CpG cg06500161, annotated to the gene ABCG1, which was one of the overlapping DMPs between fasting glucose and HOMA-IR, was in the top five DMPs for incident diabetes, showing a strong positive association (Table 2). The other overlapping DMPs for fasting glucose and HOMA-IR did not reach statistical significance for incident diabetes. The two top signals for incident diabetes, annotated to genes SREBF and ABCG1, were also associated with IFG, with hazard ratios (95% CI-s) 2.4 (1.2, 5.1) and 1.9 (1.1, 3.6), respectively.
In the protein–protein interaction network using the 358 CpGs that were selected by the ISIS-AENET model, a network with 203 nodes and 360 connections was obtained. The hub node was HDAC1 (differentially methylated for fasting glucose), with 23 interactions, followed by ELOB and UBE2N nodes (both of them differentially methylated for HOMA-IR), with 14 interactions each (Fig. 1).

Protein–protein interaction network for fasting glucose and HOMA-IR
The 358 CpGs that were selected by the ISIS-AENET models for fasting glucose or HOMA-IR were annotated to 303 genes with Entrez Gene identifiers. We highlight the top 15 GO terms (Fig. 2A–C), KEGG and Reactome pathways (Fig. 2D, E) and hallmark gene sets (Fig. 2F) that were over-represented among these 303 genes. The pathways and gene sets that were significantly enriched with FDR < 0.05 (Table 3) tended to represent DNA and RNA biosynthesis and maintenance, telomerase activity, autophagy, transcriptional regulation and upregulated genes in response to transforming growth factor beta 1 (TGFB1).

Top 15 GO Terms (A–C), pathways (D–E) and gene sets (F). The x-axis represents the ratio genes from our fasting glucose and HOMA-IR set that were also within the gene set listed on the y-axis; the count represents the number of genes in our fasting glucose and HOMA-IR set that were within each gene set listed on the y-axis, and the color coding represents the p values from the hypergeometric tests, with red indicating smaller and blue indicating larger p-values
Discussion
In this EWAS of blood DNA methylation, we identified several DMPs prospectively associated with type 2 diabetes in an American Indian population across the Southwest and the Northern Plains of the USA. Using statistical methods that allow the joint evaluation of high-dimensional and highly correlated epigenetic markers, we found 182 DMPs associated with fasting glucose and 182 DMPs associated with HOMA-IR. Of those, 49 were associated with incident diabetes at a nominal p-value of 0.05. No DMPs remained significant after correction for multiple comparisons. The bioinformatics analyses pointed to several important regulatory biological pathways for type 2 diabetes, such as autophagy.
Many of the genes annotated to the top DMPs in our EWAS in both the one marker at a time and the multiple markers at a time approaches have biological functions related to type 2 diabetes. The SREBF1 gene is associated with obesity, type 2 diabetes and insulin sensitivity, and the gene ABCG1 is involved in cholesterol and phospholipids transport. Importantly, these two genes have been identified in other diabetes EWAS conducted in Indian Asian [44], Mexican American [10] and European [45] populations and have been proposed as potential valuable markers for personalized type 2 diabetes risk prediction [46]. The fact that these two genes were among the top DMPs identified in our study provides evidence in favor of a common epigenomic signature of type 2 diabetes across populations.
However, to our knowledge, this is the first study that investigates the association between blood DNA methylation with type 2 diabetes prospectively. According to the meta-analysis conducted by Raciti et al. [16], which was published by the end of 2021, all the previous studies in blood DNA methylation were either cross-sectional [10, 44, 47,48,49,50], focused on targeted genes rather than epigenome-wide [46, 51, 52], or focused on global DNA methylation, rather than site-specific methylation [53]. Although an EWAS conducted in a European population [45] evaluated incident diabetes, they did not account for time to event in the EWAS models, which were conducted using a logistic regression (with a dichotomous outcome) rather than survival analysis.
Several genes annotated to top DMPs in our study also with known diabetes-related functions have not been identified in previous blood EWAS, which suggests that some of the epigenetic markers that are related to diabetes might be population-specific or the high burden of diabetes in our study population enabled the identification of those signals. For example, the gene PLAGL1 is associated with neonatal diabetes mellitus [54]; FAM3C is a therapeutical target for type 2 diabetes and non-alcoholic fatty liver disease [55]; OAZ2 is differentially methylated in children exposed to maternal diabetes in utero versus unexposed [56]; HEG1 is a regulator of heart and vessel formation [57]; and DECR2 is involved in lipid metabolism [58], which might also be related to diabetes [59]. Overall, many of the genes annotated to the top DMPs identified in our study have biological functions related to diabetes, which suggests that DNA methylation might be involved in or be informative about the pathogenesis of diabetes.
The enrichment analysis also revealed biological pathways relevant for diabetes, such as autophagy [60], which was significantly enriched in both KEGG pathways and Reactome pathways analyses. Autophagy is a relevant regulatory signaling pathway for type 2 diabetes and is closely related to glucose and lipid metabolism, in addition to secretion of insulin. Autophagic dysfunction has been implicated in the pathogenesis of diabetes, and some diabetes therapies appear to improve autophagy in parallel with β-cell function, although more research is needed to clarify the specific mechanisms [61]. Additionally, TGF-β signaling has pleiotropic roles, including the development and function of pancreatic islet β cells [62], and TGF-β1 is known to play a role in the pathogenesis of diabetes nephropathy, a common cause of renal failure among persons with diabetes mellitus [63]. Our findings suggest that some of these processes that are known to be involved in the development and/or consequences of diabetes may be reflected in differential DNA methylation of peripheral blood immune cells.
Environmental factors such as diet and lifestyle are known to be major regulators of epigenetic marks [64]. Several studies have highlighted the association between dietary patterns and DNA methylation changes. In particular, a Mendelian Randomization study including five population-based cohorts of European, African and Hispanic participants revealed potential causal associations of diet-related CpGs with type 2 diabetes [65]. In addition, the Make Better Choices 2 study found differential patterns of DNA methylation following a healthy diet and physical activity intervention [66]. While the clinical implications of these findings are still unclear, future studies can investigate whether interventions addressing lifestyles (e.g., healthy diet, increase physical activity) modify DNA methylation changes on type 2 diabetes in populations. Beyond understanding the role of DNAm in the development of diabetes, additional work is still needed (such as longitudinal epigenetic assessments) to improve prediction of diabetes risk.
This work has some limitations. First, diabetes incidence could not be assessed with exact diagnosis dates, which is typical of prospective cohort studies that identify diabetes through examination visits. Although we know that all participants were free of diabetes diagnosis at the time of DNA methylation data collection, subclinical metabolic disorders that are related to diabetes risk were likely present in many participants, as reflected in the common signals related to baseline glucose and HOMA-IR and incident diabetes. Our study evaluated participants 45–74 years of age in a population with a high burden of diabetes, likely resulting in an evaluation late in the natural history of the disease, as reflected by the fact that increasing age was not associated with diabetes risk, which has already been described in the SHS [67]. Long prospective studies in younger populations with diabetes incidence follow-up are needed to confirm if our findings are relevant only for older populations with a high burden of diabetes or also for younger populations and populations with lower diabetes risk. In addition, future studies should assess diabetes-related DNA methylation changes over time. Of note, no DMPs were significant after multiple comparisons. However, the fact that some of the top identified genes were shared among the one marker at a time and the multiple markers at a time approaches supports the biological meaningfulness of those signals.
Strengths of this study include the high-quality DNA methylation data, measured with one of the largest microarrays available with nowadays technology, the detailed data on potential confounders and the innovative statistical methods. This is, to our knowledge, the first study that uses the ISIS-AENET tool with both continuous and dichotomous health outcomes applied to real data.
In conclusion, DNA methylation dysregulations were associated with fasting blood glucose levels and HOMA-IR, some of which were also associated with incident diabetes in the Strong Heart Study population, although no DMPs reached the significance threshold after correction for multiple comparisons. The biological functions of the genes found in the differential methylation analysis and in the bioinformatic analyses support a biological link between DNA methylation profiles, metabolic processes and diabetes risk. Further prospective and experimental studies are needed to assess the potential role of DNA methylation in diabetes.
Availability of data and materials
The data underlying this article cannot be shared publicly in an unrestricted manner due to limitations in the consent forms and in the agreements between the Strong Heart Study tribal communities and the Strong Heart Study investigators. The data can be shared to external investigators following the procedures established by the Strong Heart Study, available at https://strongheartstudy.org/. All analyses were conducted in R version 3.6.2, and all packages used are freely available in the CRAN repository.
References
Cho NH, Shaw JE, Karuranga S, Huang Y, da Rocha Fernandes JD, Ohlrogge AW, et al. IDF diabetes atlas: global estimates of diabetes prevalence for 2017 and projections for 2045. Diabetes Res Clin Pract. 2018;138:271–81.
Rojo-Martínez G, Valdés S, Soriguer F, Vendrell J, Urrutia I, Pérez V, et al. Incidence of diabetes mellitus in Spain as results of the nation-wide cohort di@bet.es study. Sci Rep. 2020;10:19. https://doi.org/10.1038/s41598-020-59643-7.
Leon BM. Diabetes and cardiovascular disease: epidemiology, biological mechanisms, treatment recommendations and future research. World J Diabetes. 2015;6:1246.
Mahajan A, Taliun D, Thurner M, Robertson NR, Torres JM, Rayner NW, et al. Fine-mapping type 2 diabetes loci to single-variant resolution using high-density imputation and islet-specific epigenome maps. Nat Genet. 2018;50:1505–13.
Goodarzi MO, Palmer ND, Cui J, Guo X, Chen YDI, Taylor KD, et al. Classification of type 2 diabetes genetic variants and a novel genetic risk score association With insulin clearance. J Clin Endocrinol Metab. 2020;105:1251–60.
Goodarzi MO, Rotter JI. Genetics insights in the relationship between type 2 diabetes and coronary heart disease. Circ Res. 2020;126(11):1526–48. https://doi.org/10.1161/CIRCRESAHA.119.316065.
Kim M. DNA methylation: a cause and consequence of type 2 diabetes. Genomics Inform. 2019;17:e38.
Martin EM, Fry RC. Environmental influences on the epigenome: exposure-associated DNA methylation in human populations. Annu Rev Public Health. 2018;39:309–33. https://doi.org/10.1146/annurev-publhealth-040617-014629.
Jin B, Li Y, Robertson KD. DNA methylation: superior or subordinate in the epigenetic hierarchy? Genes Cancer. 2011;2:607–17.
Kulkarni H, Kos MZ, Neary J, Dyer TD, Kent JW, Göring HHH, et al. Novel epigenetic determinants of type 2 diabetes in Mexican-American families. Hum Mol Genet. 2015;24:5330–44.
Walaszczyk E, Luijten M, Spijkerman AMW, Bonder MJ, Lutgers HL, Snieder H, et al. DNA methylation markers associated with type 2 diabetes, fasting glucose and HbA1c levels: a systematic review and replication in a case–control sample of the lifelines study. Diabetologia. 2018;61(2):354–368. https://doi.org/10.1007/s00125-017-4497-7.
Johnson RK, Vanderlinden LA, Dong F, Carry PM, Seifert J, Waugh K, et al. Longitudinal DNA methylation differences precede type 1 diabetes. Sci Rep. 2020;10:1–13. https://doi.org/10.1038/s41598-020-60758-0.
Florath I, Butterbach K, Heiss J, Bewerunge-Hudler M, Zhang Y, Schöttker B, et al. Type 2 diabetes and leucocyte DNA methylation: an epigenome-wide association study in over 1,500 older adults. Diabetologia. 2016;59:130–8.
Ahmed SAH, Ansari SA, Mensah-Brown EPK, Emerald BS. The role of DNA methylation in the pathogenesis of type 2 diabetes mellitus. Clin Epigene. 2020;12:1–23.
Willmer T, Johnson R, Louw J, Pheiffer C. Blood-based DNA methylation biomarkers for type 2 diabetes: potential for clinical applications front. Endocrinol. 2018;9:744.
Raciti GA, Desiderio A, Longo M, Leone A, Zatterale F, Prevenzano I, et al. DNA methylation and type 2 diabetes: Novel biomarkers for risk assessment? Int J Mol Sci. 2021;22:11652.
Population NRC (US) C on, Sandefur GD, Rindfuss RR, Cohen B. Diabetes mellitus in native Americans: the problem and its implications. National Academies Press; 1996.
Diabetes and American Indians/Alaska Natives - The Office of Minority Health [Internet]. Available from: https://minorityhealth.hhs.gov/omh/browse.aspx?lvl=4&lvlid=33
Lee ET, Welty TK, Fabsitz R, Cowan LD, Le NA, Oopik AJ, et al. The strong heart study. A study of cardiovascular disease in American Indians: design and methods. Am J Epidemiol. 1990;132:1141–55.
Fraszczyk E, Spijkerman AMW, Zhang Y, Brandmaier S, Day FR, Zhou L, et al. Epigenome-wide association study of incident type 2 diabetes: a meta-analysis of five prospective European cohorts. Diabetologia. 2022;65:763–76.
Domingo-Relloso A, Huan T, Haack K, Riffo-Campos AL, Levy D, Fallin MD, et al. DNA methylation and cancer incidence: lymphatic–hematopoietic versus solid cancers in the Strong Heart Study. Clin Epigene. 2021;13:43–43. https://doi.org/10.1186/s13148-021-01030-8.
Lee ET, Howard BV, Savage PJ, Cowan LD, Fabsitz RR, Oopik AJ, et al. Diabetes and impaired glucose tolerance in three American Indian populations aged 45–74 years: the strong heart study. Diabetes Care. 1995;18:599–610.
Gribble MO, Howard BV, Umans JG, Shara NM, Francesconi KA, Goessler W, et al. Arsenic exposure, diabetes prevalence, and diabetes control in the strong heart study. Am J Epidemiol. 2012;176:865–74.
Wang W, Lee ET, Howard BV, Fabsitz RR, Devereux RB, Welty TK. Fasting plasma glucose and hemoglobin A 1cin identifying and predicting diabetes: the strong heart study. Diabetes Care. 2011;34:363–8.
Diagnosis and classification of diabetes mellitus [Internet]. Diabetes Care. Diabetes Care; 2011. Available from: https://pubmed.ncbi.nlm.nih.gov/21193628/
Matthews DR, Hosker JP, Rudenski AS, Naylor BA, Treacher DF, Turner RC. Homeostasis model assessment: insulin resistance and β-cell function from fasting plasma glucose and insulin concentrations in man. Diabetologia. 1985;28:412–9.
Domingo-Relloso A, Riffo-Campos AL, Haack K, Rentero-Garrido P, Ladd-Acosta C, Fallin DM, et al. Cadmium, smoking, and human blood DNA methylation profiles in adults from the strong heart study. Environ Health Perspect. 2020;128:067005.
Fortin JP, Triche Jr TJ, Hansen KD. Preprocessing, normalization and integration of the Illumina HumanMethylationEPIC array with minfi. Bioinformatics. 2017;33(4):558–60. https://doi.org/10.1093/bioinformatics/btw691.
Niu L, Xu Z, Taylor JA. RCP: a novel probe design bias correction method for Illumina Methylation BeadChip. Bioinformatics. 2016;32:2659–63.
McCartney DL, Walker RM, Morris SW, McIntosh AM, Porteous DJ, Evans KL. Identification of polymorphic and off-target probe binding sites on the Illumina Infinium MethylationEPIC BeadChip. Genom data. 2016;9:22–4.
Zou H, Hao A, Zhang H. On the adaptive elastic-net with a diverging number of parameters. Ann Stat. 2009;37:1733–51.
Fan J, Lv J. Sure independence screening for ultrahigh dimensional feature space. J R Stat Soc Ser B. 2008;70:849–911.
Hasinur M, Khan R, Ewart J, Shaw H. Variable selection for survival data with a class of adaptive elastic net techniques. Stat Comput. 2016;26:725–41. https://doi.org/10.1007/s11222-015-9555-8
Wang T, Zhu L. Consistent tuning parameter selection in high dimensional sparse linear regression. J Multivar Anal Academic Press. 2011;102:1141–51.
Saldana DF, Feng Y. SIS: an R package for sure independence screening in ultrahigh-dimensional statistical models. J Stat Softw. 2018;83:1–25.
CRAN - Package gcdnet. 2021. Available from: https://cran.r-project.org/web/packages/gcdnet/index.html
Szklarczyk D, Gable AL, Lyon D, Junge A, Wyder S, Huerta-Cepas J, et al. STRING v11: protein–protein association networks with increased coverage, supporting functional discovery in genome-wide experimental datasets. Nucleic Acids Res. 2019;47:D607–13.
Shannon P, Markiel A, Ozier O, Baliga NS, Wang JT, Ramage D, et al. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Res. 2003;13:2498–504.
Wu T, Hu E, Xu S, Chen M, Guo P, Dai Z, et al. clusterProfiler 4.0: a universal enrichment tool for interpreting omics data. Innov. 2021;2:100141.
Carbon S, Douglass E, Good BM, Unni DR, Harris NL, Mungall CJ, et al. The gene ontology resource: enriching a GOld mine. Nucleic Acids Res. 2021;49:D325–34.
Kanehisa M, Goto S. KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000;28:27–30.
Yu G, He QY. ReactomePA: an R/Bioconductor package for reactome pathway analysis and visualization. Mol Biosyst. 2016;12:477–9.
Liberzon A, Birger C, Thorvaldsdóttir H, Ghandi M, Mesirov JP, Tamayo P. The molecular signatures database (MSigDB) hallmark gene set collection. Cell Syst. 2015;1:417–25.
Chambers JC, Loh M, Lehne B, Drong A, Kriebel J, Motta V, et al. Epigenome-wide association of DNA methylation markers in peripheral blood from Indian Asians and Europeans with incident type 2 diabetes: a nested case-control study. Lancet Diabetes Endocrinol. 2015;3:526.
Cardona A, Day FR, Perry JRB, Loh M, Chu AY, Lehne B, et al. Epigenome-wide association study of incident type 2 diabetes in a British population: EPIC-Norfolk study. Diabetes. 2019;68:2315–26.
Krause C, Sievert H, Geißler C, Grohs M, El Gammal AT, Wolter S, et al. Critical evaluation of the DNA-methylation markers ABCG1 and SREBF1 for Type 2 diabetes stratification. Epigenomics. 2019;11:885–97.
Toperoff G, Aran D, Kark JD, Rosenberg M, Dubnikov T, Nissan B, et al. Genome-wide survey reveals predisposing diabetes type 2-related DNA methylation variations in human peripheral blood. Hum Mol Genet. 2012;21:371.
Walaszczyk E, Luijten M, Spijkerman AMW, Bonder MJ, Lutgers HL, Snieder H, et al. DNA methylation markers associated with type 2 diabetes, fasting glucose and HbA1c levels: a systematic review and replication in a case–control sample of the Lifelines study. Diabetologia. 2018;61:354.
Juvinao-Quintero DL, Marioni RE, Ochoa-Rosales C, Russ TC, Deary IJ, van Meurs JBJ, et al. DNA methylation of blood cells is associated with prevalent type 2 diabetes in a meta-analysis of four European cohorts. Clin Epigenet. 2021;13:40.
Yuan W, Xia Y, Bell CG, Yet I, Ferreira T, Ward KJ, et al. An integrated epigenomic analysis for type 2 diabetes susceptibility loci in monozygotic twins. Nat. 2014;5:1–7.
Canivell S, Ruano EG, Sisó-Almirall A, Kostov B, González-De Paz L, Fernandez-Rebollo E, et al. Differential methylation of TCF7L2 promoter in peripheral blood DNA in newly diagnosed, drug-naïve patients with Type 2 diabetes. PLoS ONE. 2014;9:99310.
Dayeh T, Tuomi T, Almgren P, Perfilyev A, Jansson PA, de Mello VD, et al. DNA methylation of loci within ABCG1 and PHOSPHO1 in blood DNA is associated with future type 2 diabetes risk. Epigenetics. 2016;11:482.
Bacos K, Gillberg L, Volkov P, Olsson AH, Hansen T, Pedersen O, et al. Blood-based biomarkers of age-associated epigenetic changes in human islets associate with insulin secretion and diabetes. Nat Commun. 2016;7:1–7.
Azzi S, Sas TCJ, Koudou Y, Le Bouc Y, Souberbielle JC, Dargent-Molina P, et al. Degree of methylation of ZAC1 (PLAGL1) is associated with prenatal and post-natal growth in healthy infants of the EDEN mother child cohort. Epigenetics. 2014;9:338–45.
Zhang X, Yang W, Wang J, Meng Y, Guan Y, Yang J. FAM3 gene family: A promising therapeutical target for NAFLD and type 2 diabetes. Metabolism. 2018;81:71–82.
West NA, Kechris K, Dabelea D. Exposure to maternal diabetes in utero and DNA methylation patterns in the offspring. Immunometabolism. 2013;1:1.
Kleaveland B, Zheng X, Liu JJ, Blum Y, Tung JJ, Zou Z, et al. Regulation of cardiovascular development and integrity by the heart of glass-cerebral cavernous malformation protein pathway. Nat Med. 2009;15:169–76.
DECR2 Gene - GeneCards | DECR2 Protein | DECR2 Antibody. Available from: https://www.genecards.org/cgi-bin/carddisp.pl?gene=DECR2
Erion DM, Park HJ, Lee HY. The role of lipids in the pathogenesis and treatment of type 2 diabetes and associated co-morbidities. BMB Rep. 2016;49:139.
Bhattacharya D, Mukhopadhyay M, Bhattacharyya M, Karmakar P. Is autophagy associated with diabetes mellitus and its complications?. A review. EXCLI J. 2018;17:709.
Yao D, GangYi Y, QiNan W. Autophagic dysfunction of β cell dysfunction in type 2 diabetes, a double-edged sword. Genes Dis. 2020;8:438–47.
Lee JH, Lee JH, Rane SG. TGF-β signaling in pancreatic islet β cell development and function. Endocrinology. 2021;162:bqaa233.
Chang AS, Hathaway CK, Smithies O, Kakoki M. Transforming growth factor-β1 and diabetic nephropathy. Am J Physiol Ren Physiol. 2016;310:F689.
Alegría-Torres JA, Baccarelli A, Bollati V. Epigenetics and lifestyle. Epigenomics. 2011;3:267.
Ma J, Rebholz CM, Braun KVE, Reynolds LM, Aslibekyan S, Xia R, et al. Whole blood DNA methylation signatures of diet are associated with cardiovascular disease risk factors and all-cause mortality. Circ Genomic Precis Med. 2020;13:e002766.
Hibler E, Huang L, Andrade J, Spring B. Impact of a diet and activity health promotion intervention on regional patterns of DNA methylation. Clin Epigenet. 2019;11:133. https://doi.org/10.1186/s13148-019-0707-0.
Howard BV, Cowan LD, Go O, Welty TK, Robbins DC, Lee ET. Adverse effects of diabetes on multiple cardiovascular disease risk factors in women: the strong heart study. Diabetes Care. 1998;21(8):1258–65. https://doi.org/10.2337/diacare.21.8.1258.
Acknowledgements
We thank the dedication of the Strong Heart Study participants, investigators and staff, without whom this work would not have been possible.
Funding
The Strong Heart Study was supported by Grants from the National Heart, Lung, and Blood Institute (NHLBI) (contract numbers 75N92019D00027, 75N92019D00028, 75N92019D00029 and 75N92019D00030) and previous Grants (R01HL090863, R01HL109315, R01HL109301, R01HL109284, R01HL109282 and R01HL109319 and cooperative agreements: U01HL41642, U01HL41652, U01HL41654, U01HL65520 and U01HL65521) and by the National Institute of Environmental Health Sciences (Grant numbers R01ES021367, R01ES025216, P42ES033719, P30ES009089). ADR was supported by a fellowship from “la Caixa” Foundation (ID 100010434) (fellowship code “LCF/BQ/DR19/11740016”). MTP was supported by the Strategic Action for Research in Health sciences (PI15/00071) and CIBERCV, which are initiatives from Instituto de Salud Carlos III and the Spanish Ministry of Science and Innovation and co-funded with European Funds for Regional Development (FEDER), by the Third AstraZeneca Award for Spanish Young Researchers and by the State Agency for Research (PID2019-108973RB-C21). The content of this manuscript is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health (USA) or the National Health Institute Carlos III (Spain). The funders had no role in the planning, conducting, analysis, interpretation or writing of this study.
Author information
Authors and Affiliations
Contributions
ADR conducted data analysis and writing. MOG, ANA and TME conducted conception, design, interpretation and review. ARC conducted data analysis. KH and SAC and MDF received funding. MTP, JGU and AF conducted review. KH and YZ were responsible for the management of the Strong Heart Study data. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study was approved by Institution Review Boards of the academic organizations, tribal communities and the Indian Health Service for the Strong Heart Study.
Consent for publication
Informed consent from participants was obtained for the Strong Heart Study.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1: Fig. S1
. Flowchart of included participants in each study visit of the Strong Heart Study.
Additional file 2: Table S1
. DMPs identified by ISIS-AENET as associated with fasting glucose. Table S2. DMPs identified by ISIS-AENET as associated with HOMA-IR.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Domingo-Relloso, A., Gribble, M.O., Riffo-Campos, A.L. et al. Epigenetics of type 2 diabetes and diabetes-related outcomes in the Strong Heart Study. Clin Epigenet 14, 177 (2022). https://doi.org/10.1186/s13148-022-01392-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13148-022-01392-7