
Abstract
Objective
To build and validate an early risk prediction model for gestational diabetes mellitus (GDM) based on first-trimester electronic medical records including maternal demographic and clinical risk factors.
Methods
To develop and validate a GDM prediction model, two datasets were used in this retrospective study. One included data of 14,015 pregnant women from Máxima Medical Center (MMC) in the Netherlands. The other was from an open-source database nuMoM2b including data of 10,038 nulliparous pregnant women, collected in the USA. Widely used maternal demographic and clinical risk factors were considered for modeling. A GDM prediction model based on elastic net logistic regression was trained from a subset of the MMC data. Internal validation was performed on the remaining MMC data to evaluate the model performance. For external validation, the prediction model was tested on an external test set from the nuMoM2b dataset.
Results
An area under the receiver-operating-characteristic curve (AUC) of 0.81 was achieved for early prediction of GDM on the MMC test data, comparable to the performance reported in previous studies. While the performance markedly decreased to an AUC of 0.69 when testing the MMC-based model on the external nuMoM2b test data, close to the performance trained and tested on the nuMoM2b dataset only (AUC = 0.70).
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Introduction
It is estimated that approximately 1 in 7 pregnant women develops gestational diabetes mellitus (GDM) during pregnancy [1]. Pregnant women with diagnosed GDM might require medication to control their blood sugar level. An uncontrolled level of blood glucose during pregnancy might contribute to large birth weight, preterm birth, pre-eclampsia, respiratory distress syndrome, jaundice, hypoglycemia, and stillbirth. In addition, GDM patients have an up to 87% risk of developing type 2 diabetes in 5–10 years after their delivery [2, 3]. The consequences of GDM for babies include, for example, an abnormally high birth weight and hypoglycemia after birth [4]. Various studies have demonstrated that early lifestyle modifications during pregnancy can have an effect in reducing the risk of developing GDM [5]. By making lifestyle adjustments (such as improving diet and physical activity) as early as possible in pregnancy, typically before week 15, and maintaining them throughout the pregnancy, this effect is enhanced [6]. Hence, to facilitate effective treatment and lifestyle adjustments, it is pivotal to accurately predict the risk of developing GDM early in pregnancy.
In the past decade, dozens of studies have been reported in the field of early risk stratification or prediction of GDM using electronic medical records (EMRs) before its diagnosis [7, 8]. We summarized 22 EMR-based GDM prediction studies published since 2010 in the Supplementary Materials. The prediction performance, measured by the area under the receiver-operating-characteristic curve (AUC), ranged from 0.57 to 0.95 [7,8,9,10]. Those studies included data from different cohorts with, for example, different sample size and GDM prevalence. Moreover, the risk factors used for GDM prediction were different between studies. The most frequently used risk factors were body mass index (BMI), age, race (or ethnicity), parity, gravidity, family history of diabetes, and history of GDM. Although some studies considered biomarkers and demonstrated their good predictability in early prediction of GDM [11, 12], many of those biomarkers are either not routinely measured or unavailable in the datasets used in our work.
In this work, we aimed at developing an early GDM prediction model based on the widely used maternal demographic and clinical risk factors available in the first trimester. We first performed internal validation on an in-house dataset and then validated the model on an external open-source dataset.
Materials and methods
Datasets
Two datasets were included in this retrospective study for model development and (internal and external) validation for GDM prediction.
The first dataset was an in-house dataset, called “MMC dataset”, containing data from pregnant women who visited the Máxima Medical Center (MMC), Veldhoven, the Netherlands, and gave birth between January 2012 and December 2017. The study received a waiver for ethical approval from the medical ethical committee of MMC. The inclusion criteria for the MMC dataset were pregnant women who delivered at MMC and had related obstetrical records, aged between 18 and 45 years, and without diagnosed type I or type II diabetes before pregnancy, i.e. pre-existing diabetes. In addition, for modelling, samples with missing data, either risk factors or GDM diagnosis, were excluded or imputed. A total of 15,709 samples from 14,015 pregnant women were analyzed in our study.
The second dataset was obtained from an open-source database called “Nulliparous Pregnancy Outcomes Study: Monitoring Mothers-to-Be” (nuMoM2b) [13]. In the nuMoM2b study, 10,038 nulliparous women with singleton pregnancies were recruited from hospitals affiliated with eight clinical centers in the USA. They were recruited if they had a viable singleton gestation and were between 6 and 14 weeks of gestation. The detailed GDM diagnosis criteria in the nuMoM2b study were described by Haas et al. [13]. The exclusion criteria for the nuMoM2b dataset were pregnant women with an age < 13 years, a history of three or more pregnancy losses, donor oocyte pregnancy, planned pregnancy termination, pre-existing diabetes, malformations likely to be lethal and aneuploidies known at or before enrolment, and inability to provide informed consent [13]. This led to a total of 8,720 pregnant women who were included in our study.
Risk factors
As stated, the most frequently used risk factors from the first trimester were considered for modelling. They were maternal demographics including age, BMI, and ethnicity, as well as clinical risk factors including parity, gravidity, family history of diabetes, and history of GDM. These risk factors are often readily available from the hospital EMR system, as they can more easily be collected during the first trimester of pregnancies compared to other variables such as biomarkers requiring a blood test or ultrasound-related records needing an ultrasound scan.
Prediction modelling
The seven risk factors were considered machine learning features for early prediction of GDM. Given the simplicity and good interpretability of logistic regression (LR), it has been the most widely used algorithm in EMR-based GDM prediction [14], which motivated us to employ LR in our study. Elastic net regularization was applied in LR modelling to cope with potential collinearity and overfitting issues, where several parameters were required to be optimized such as regularization strength C, penalty L1/L2, and class weight.
In general, for machine learning, a dataset should be divided into three subsets: training, validation, and test sets [15]. The training set is used for model training, and the validation set is used for parameter optimization of the trained model. The test set is considered a hold-out set, used only for model evaluation to avoid bias. Considering both the MMC and the nuMoM2b datasets are highly imbalanced, simple random splitting could lead to significant deviations in the fractions of positive samples between subsets, which may in turn leads to model distortion. Stratified split is a widely used method for imbalanced dataset to reduce sample bias. Because in the MMC dataset, some pregnant women had multiple birth records, it was crucial to ensure that all the records from same pregnant woman were always kept in the same set. Therefore, we used an “individual-level” stratified split on the MMC dataset. First, all individuals (pregnant women) were divided into two groups based on whether they had any delivery record diagnosed as GDM. Then a stratified method was performed on both groups of individuals to split the dataset into MMC-training (60%), MMC-validation (20%) and MMC-test (20%) sets. The prediction performance (AUC) was computed for both nulliparous and multiparous pregnancies of the MMC-test set. In the nuMoM2b dataset, all participants only had one delivery record. The stratified split method was performed in terms of GDM diagnosis to divide the entire dataset into nuMoM2b-training (60%), nuMoM2b-validation (20%) and nuMoM2b-test (20%) sets. This ensured that same or similar percentages of samples for both GDM and non-GDM were assigned into the three subsets. For external validation, the LR model was trained and optimized on the MMC-training and MMC-validation sets, while tested on the nuMoM2b-test set. Because the nuMoM2b cohort included only nulliparous pregnancies, parity, and history of GDM were set to zero. To examine the generalizability of the MMC-based model to the nuMoM2b dataset, we performed a comparison validation that trained and optimized an LR predictor on the nuMoM2b-training and nuMoM2b-validation sets, and tested on the nuMoM2b-test set.
To understand the feature contribution to the GDM prediction, feature coefficients of the LR models trained based on the MMC-training and the nuMoM2b-traning data were provided, where a higher absolute coefficient means a stronger contribution to the model. In addition, the odds ratio for each risk factor was also calculated to evaluate its correlation with GDM.
Results
The demographic and clinical risk factors in the MMC dataset and the nuMoM2b dataset are presented in Table 1.
The detailed statistics of the demographic and clinical risk factors for the subsets after data split (including MMC-training, MMC-validation, MMC-test, nuMoM2b-training, nuMoM2b-validation, and nuMoM2b-test) were described in the Supplementary Materials.
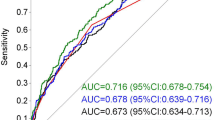
The performance of early GDM prediction using different datasets for training and testing is presented in Table 2. The internal validation showed an AUC of 0.81, indicating an 81% probability that a randomly selected patient with GDM would receive a higher risk score than whom without GDM in the MMC dataset. The model for external validation had a decreased AUC of 0.69, comparable to that obtained using the comparison model that was trained, validated, and tested on the nuMoM2b dataset (AUC = 0.70). The AUC and calibration curves for internal, external and comparison validation are plotted in Fig. 1.

a: Feature coefficient in the internal validation model. b: Feature coefficient in the comparison validation model. c: Calibration curve for internal, comparison, and external validation models. d: AUC curve for internal, comparison and external validation models. Bar colour in plot a and b represents the sign of the coefficient, where red indicates positive correlation with GDM and blue means negative correlation. Odds ratio between each feature and GDM was described in the rectangular brackets after the feature’s name. The odds ratio of Age, BMI, Parity, and Gravidity was calculated between Age > = 25 and GDM, between BMI > = 25 and GDM, between parity number > 0 and GDM, and between gravity number > 1 and GDM, respectively. Colour of the dash-dot curves in plot c and d represents different models, including internal validation model (red), comparison validation models (blue), and external validation model (green)
In Fig. 1a and b, the absolute value of each bar represents the contribution of the feature in the model. For the internal validation model, ‘history of GDM’ had the highest contribution to the model and the highest odds ratio associated with GDM. The odds ratio for ‘history of GDM’ is 38.8, indicating that pregnant women who had GDM before are 38.8 times more likely to have GDM in a following pregnancy than those who never had GDM before. For the comparison validation model, the feature ‘Age’ had the largest contribution to the model, while ‘history of GDM’ and ‘parity’ had no contribution since they were not available in the nuMoM2b dataset. To evaluate the stability of the models, mean and standard deviation as well as 95% confidence interval (CI) of AUC results for the internal, external and comparison validations were obtained after running 100 times with different stratified (random) splits of training, validation, and test sets, as reported in the Supplementary Materials. The results showed a relatively small standard deviation and range of 95% CI for almost all models.
From the calibration plot, unlike the external model, the curves for the internal and the comparison model seemed to follow the perfect calibration curve relatively well. However, for the internal validation, the highest fraction of positives in the MMC-test dataset (including both nulliparous and multiparous pregnancies) was about 0.36. The highest fraction of positives for the nulliparous pregnancies in the MMC-test set was less than 0.2, close to that in the nuMoM2b-test set with only nulliparous pregnancies.
Discussion
In this study, we developed and validated models for GDM prediction using routinely collected risk factors that are available during or before the first trimester, and the prediction results could help provide timely medical intervention and promote early lifestyle changes to reduce the risk of developing GDM. In the internal validation, a major finding is that the GDM risk prediction for the nulliparous pregnancies was much more difficult than that for multiparous pregnancies, evidenced by the model performance measured by AUC (0.75 versus 0.83). This could be partially explained by the inexistence of pregnancy history in nulliparas. Actually, the overall contribution of pregnancy history in the GDM risk prediction model can be as high as 40% as reported by Artzi et al. [8], which corroborates our finding. In addition, we found that the external validation result for GDM prediction was clearly lower than the internal validation result (AUC of 0.69 versus 0.75 for nulliparous pregnancies). This indicates that the model trained from the MMC cohort might not generalize well to another cohort (nuMoM2b) having a different distribution in some important risk factors. For example, there existed clear discrepancies in age, BMI, and family history of diabetes between the two datasets, and these factors were highly ranked with respect to their contribution to the prediction models as shown in Table 1.
The calibration plot shows that the internal model and the comparison model seemed well calibrated. However, the external validation model that trained on the MMC-training set tended to overestimate the risk of GDM in the nuMoM2b-test set, particularly for women with a higher GDM risk where the predicted risk was higher than the observed risk. This could be due to the differences in the association of the risk factors with GDM for different cohorts. For example, in the MMC dataset, the probability of pregnant women having family history of diabetes who eventually developed GDM was 49%, which was higher than that in the nuMoM2b dataset (35%). As shown in Fig. 1, the risk factor ‘family history of diabetes’ was top ranked in the LR models for both internal and comparison validations. In addition, in the MMC dataset, the probability of GDM in the Mediterranean/Hispanic population was higher than the average. However, this was the opposite in the nuMoM2b dataset, which would likely cause the probability provided by the model in external validation to be higher than the actual probability. Donovan et al. [16] also reported that the model trained on nulliparous pregnant women in a California dataset overestimated the risk of pregnant women in a dataset from Iowa.
To maximize the model’s interpretability and reproducibility, this study selected LR as the algorithm for GDM prediction. As shown in the Supplementary Materials, LR showed similar results in predicting GDM compared with the other algorithms for internal, external, and comparison validations. Nonetheless, more advanced algorithms should be evaluated when including larger datasets with more risk factors in future work.
It is important to note that, both datasets are highly imbalanced with a minority class accounting for less than 5% of the total samples per dataset, leading to difficulty in predicting GDM as the minority class, in particular when the GDM samples are insufficient to represent the entire population of GDM patients. It is worth mentioning that the ethnicity categories defined in both datasets used in this study were different. To diminish the effect caused by such difference, we harmonized the categories for both datasets in order to make them comparable, as shown in Table 1. Even though, we observed that, the ethnicity of nearly half of the pregnancies in the nuMoM2b dataset was American Black, while the dominant ethnicity in the MMC dataset was European White. In addition, unlike the MMC dataset collected in the Netherlands including both nulliparous and multiparous pregnant women, the nuMoM2b dataset includes only nulliparous pregnancies in the United States.
Limitations
The current study had several limitations. First, many often used risk factors that have demonstrated good predictive value such as glucose tolerant test, blood pressure, smoking history, polycystic ovary syndrome, daily exercise, and biomarkers, were not considered during modelling since these variables were not available in at least one of the datasets used in this study. Including more independent risk factors is therefore expected to further improve GDM prediction [17,18,19,20]. Second, the MMC and nuMoM2b datasets had different GDM diagnosis criteria as well as inclusion criteria, which would lead to bad model generalizability from one to the other dataset, regardless of the differences seen in some risk factors. Third, in both datasets, self-reported weight before pregnancy was used, where the specific time of the weight was unknown. For the MMC dataset, actual measurement of BMI before pregnancy or during the first trimester of pregnancy was not always available and for many pregnant women, their first BMI measurement was done after 20 weeks of gestation. These would lead to inaccuracy in training a GDM prediction model.
Data availability
Data from the nuMoM2b database are currently publicly available through the Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD), National Institutes of Health Data and Specimen Hub (DASH; https://dash.nichd.nih.gov/). Data from the MMC database were collected in the Máxima Medical Center, Veldhoven, The Netherlands. Due to privacy regulations, the MMC data are not publicly available. Please contact Xi Long (x.long@tue.nl) for further information.
Abbreviations
- AUC:
-
Area Under the Curve
- EMR:
-
Electrical Medical Record
- GDM:
-
Gestational Diabetes Mellitus
- MMC:
-
Máxima Medical Center
- nuMoM2b:
-
Nulliparous Pregnancy Outcomes Study: Monitoring Mothers-to-Be
- BMI:
-
Body Mass Index
- CI:
-
Confidence Interval
- LR:
-
Logistic Regression
References
Wang H, Li N, Chivese T, et al. IDF Diabetes Atlas: estimation of Global and Regional Gestational Diabetes Mellitus Prevalence for 2021 by International Association of Diabetes in Pregnancy Study Group’s Criteria. Diabetes Res Clin Pract. 2022;183:109050.
O’Sullivan JB. Diabetes mellitus after GDM. Diabetes. 1991;40(Suppl 2):131–5.
Ratner RE, Christophi CA, Metzger BE, et al. Prevention of diabetes in women with a history of gestational diabetes: effects of metformin and lifestyle interventions. J Clin Endocrinol Metab. 2008;93(12):4774–9.
Cremona A, Saunders J, Cotter A, Hamilton J, Donnelly AE, O’Gorman CS. Maternal obesity and degree of glucose intolerance on neonatal hypoglycaemia and birth weight: a retrospective observational cohort study in women with gestational diabetes mellitus. Eur J Pediatr. 2020;179(4):653–60.
Song C, Li J, Leng J, Ma RC, Yang X. Lifestyle intervention can reduce the risk of gestational diabetes: a meta-analysis of randomized controlled trials. Obes Rev. 2016;17(10):960–9.
McIntyre HD, Catalano P, Zhang C, Desoye G, Mathiesen ER, Damm P. Gestational diabetes mellitus. Nat Rev Dis Primers. 2019;5(1):47.
Lamain-de Ruiter M, Kwee A, Naaktgeboren CA, Franx A, Moons KGM, Koster MPH. Prediction models for the risk of gestational diabetes: a systematic review. Diagn Progn Res. 2017;1:3.
Artzi NS, Shilo S, Hadar E, et al. Prediction of gestational diabetes based on nationwide electronic health records. Nat Med. 2020;26(1):71–6.
Falcone V, Kotzaeridi G, Breil MH, et al. Early Assessment of the risk for gestational diabetes Mellitus: can Fasting parameters of glucose metabolism contribute to risk prediction? Diabetes Metab J. 2019;43(6):785–93.
Benhalima K, Van Crombrugge P, Moyson C, et al. Estimating the risk of gestational diabetes mellitus based on the 2013 WHO criteria: a prediction model based on clinical and biochemical variables in early pregnancy. Acta Diabetol. 2020;57(6):661–71.
Tenenbaum-Gavish K, Sharabi-Nov A, Binyamin D, et al. First trimester biomarkers for prediction of gestational diabetes mellitus. Placenta. 2020;101:80–9.
Savona-Ventura C, Vassallo J, Marre M, Karamanos BG, MGSD-GDM study group. A composite risk assessment model to screen for gestational diabetes mellitus among Mediterranean women [published correction appears in Int J Gynaecol Obstet. 2013;122(1):88. Louda, F [added]; Addi, H [added]; Joubij, M [added]; Chraibi, A [added]]. Int J Gynaecol Obstet. 2013;120(3):240–244.
Haas DM, Parker CB, Wing DA et al. A description of the methods of the Nulliparous Pregnancy Outcomes Study: monitoring mothers-to-be (nuMoM2b). Am J Obstet Gynecol. 2015;212(4):539.e1-539.e24.
Bertini A, Salas R, Chabert S, Sobrevia L, Pardo F. Using machine learning to predict complications in pregnancy: a systematic review. Front Bioeng Biotechnol. 2022;9:780389.
Chicco D. Ten quick tips for machine learning in computational biology. BioData Min. 2017;10:35.
Donovan BM, Breheny PJ, Robinson JG, et al. Development and validation of a clinical model for preconception and early pregnancy risk prediction of gestational diabetes mellitus in nulliparous women. PLoS ONE. 2019;14(4):e0215173.
Sweeting AN, Wong J, Appelblom H, et al. A novel early pregnancy risk prediction model for gestational diabetes Mellitus. Fetal Diagn Ther. 2019;45(2):76–84.
Wu YT, Zhang CJ, Mol BW, et al. Early Prediction of Gestational Diabetes Mellitus in the Chinese Population via Advanced Machine Learning. J Clin Endocrinol Metab. 2021;106(3):e1191–205.
Qiu J, Chen L, Wang X, Zhu W. Early-pregnancy maternal heart rate is related to gestational diabetes mellitus (GDM). Eur J Obstet Gynecol Reprod Biol. 2022;268:31–6.
Sirico A, Lanzone A, Mappa I, et al. The role of first trimester fetal heart rate in the prediction of gestational diabetes: a multicenter study. Eur J Obstet Gynecol Reprod Biol. 2019;243:158–61.
Acknowledgements
We would like to thank Tineke Laurs from the Máxima Medical Center for providing administrative support regarding data acquisition and analysis.
Funding
This work was performed within the framework of the Eindhoven MedTech Innovation Center (e/MTIC) and was supported by the China Scholarship Council (Grant No: 201906340168).
Author information
Authors and Affiliations
Contributions
YW, XL, SA, and MvdV conceived and designed the study; YW, PH and MBvdH provided study materials and collected clinical information; YW and PH analyzed the data; MBvdH and SGO provided clinical interpretation; YW and XL wrote the manuscript and prepared figures; SA, MvdV, SGO, MM and JB reviewed the manuscript and made substantial revisions; JB and XL acquired the funding; MM, JB, and XL supervised the study; All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The Ethics Review Board of the Eindhoven University of Technology and the Eunice Kennedy Shriver National Institute of Child Health and Human Development both approved the secondary analysis of the nuMoM2b data. All participants and/or their legal guardian(s) in the nuMoM2b dataset provided written informed consent prior to participation. The Medical Ethics Review Committee of the Máxima Medical Center approved the retrospective analysis of the MMC data. All methods were carried out in accordance with relevant guidelines and regulations.
Consent for publication
Not applicable.
Competing interests
At the time of writing, YW, PH, and SA were employed by or affiliated with Royal Philips, a health-tech company and manufacturer of consumer and medical electronic devices, commercializing products and solutions in the area of mother and child care. Philips had no role in the study design, decision to publish, or preparation of the manuscript. The other authors have no conflicts of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Wu, Y., Hamelmann, P., van der Ven, M. et al. Early prediction of gestational diabetes mellitus using maternal demographic and clinical risk factors. BMC Res Notes 17, 105 (2024). https://doi.org/10.1186/s13104-024-06758-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13104-024-06758-z