
Abstract
Background
Site performance is key to the success of large multicentre randomised trials. A standardised set of clear and accessible summaries of site performance could facilitate the timely identification and resolution of potential problems, minimising their impact.
The aim of this study was to identify and agree a core set of key performance metrics for managing multicentre randomised trials.
Methods
We used a mixed methods approach to identify potential metrics and to achieve consensus about the final set, adapting methods that are recommended by the COMET Initiative for developing core outcome sets in health care.
We used performance metrics identified from our systematic search and focus groups to create an online Delphi survey. We invited respondents to score each metric for inclusion in the final core set, over three survey rounds. Metrics scored as critical by ≥70% and unimportant by <15% of respondents were taken forward to a consensus meeting of representatives from key UK-based stakeholders. Participants in the consensus meeting discussed and voted on each metric, using anonymous electronic voting. Metrics with >50% of participants voting for inclusion were retained.
Results
Round 1 of the Delphi survey presented 28 performance metrics, and a further six were added in round 2. Of 294 UK-based stakeholders who registered for the Delphi survey, 211 completed all three rounds.
At the consensus meeting, 17 metrics were discussed and voted on: 15 metrics were retained following survey round 3, plus two others that were preferred by consensus meeting participants. Consensus was reached on a final core set of eight performance metrics in three domains: (1) recruitment and retention, (2) data quality and (3) protocol compliance. A simple tool for visual reporting of the metrics is available from the Nottingham Clinical Trials Unit website.
Conclusions
We have established a core set of metrics for measuring the performance of sites in multicentre randomised trials. These metrics could improve trial conduct by enabling researchers to identify and address problems before trials are adversely affected. Future work could evaluate the effectiveness of using the metrics and reporting tool.
Similar content being viewed by others

Background
Large multicentre randomised trials are complex projects. A key risk to their successful delivery is the performance of trial sites in recruiting and retaining participants, and in collecting complete high-quality data in a timely manner. Standardising the collection, reporting and monitoring of data relevant to site performance has the potential to improve the effective and efficient oversight of trial conduct [1,2,3,4].
Numerous variables or performance metrics can be measured to assess site performance. Measures of site performance should deliver meaningful, actionable information that can be compared within and between sites to initiate remedial action if necessary. A standardised set of clear and easily accessible summaries of site performance could facilitate the timely identification and resolution of problems, minimising their impact. Although researchers monitor data such as participant accrual, case report form returns, data quality, missing outcome data and serious protocol violations or breaches of good clinical practice, to our knowledge, no work has been conducted to establish a consensus on a core set of metrics for monitoring performance of sites in non-commercial clinical trials. Without a consensus, researchers may focus on too many or uninformative indicators. To be manageable and retain focus on items that really matter, a standardised set of site performance metrics would ideally number around eight to 12 items [1], and would be presented within a tool that could be easily monitored by a trial manager.
The aim of this study was to develop a standardised set of metrics for monitoring the performance of sites following their initiation and opening to patient recruitment in multicentre randomised trials. A further objective was to develop a visual display tool for reporting metric data.
Methods
We used three focus groups of stakeholders (paper in preparation) and a systematic literature review to identify site performance metrics [5]. To achieve consensus on the final standardised set of metrics, we used a two-stage Delphi process comprising a survey followed by a consensus meeting of UK-based stakeholders.
Delphi Survey
We identified 117 performance metrics from 21 eligible studies in the systematic literature review. Following initial analysis, we excluded 30 metrics judged as lacking clarity, unrelated to individual site performance, too specific to an individual trial methodology or pertaining to clinical outcomes rather than trial performance (Additional file 1). This left 87 for further consideration. The 32 participants in the three focus groups identified a further 19 metrics. Following deduplication and further removal of metrics considered unrelated to site performance, the remaining list of 28 metrics (Additional file 2) were organised into four thematic domains: (1) recruitment and retention, (2) data quality, (3) protocol compliance and (4) staff. These were used to create an online Delphi survey using the software COMET Delphi Manager [6].
Panel size and membership
As there is no standard method for calculating the sample size for Delphi processes, we used a pragmatic approach based on practicality and time available [2, 4]. The aim was to recruit the largest panel possible, encouraging individuals from each stakeholder group to participate via email invitations to the online survey. The stakeholder groups were:
-
chief investigators
-
members of the UK Clinical Research Network
-
clinical trials unit (CTU) directors
-
representatives of the main UK clinical trial funding bodies
-
operations managers and directors
-
clinical trial quality assurance managers
-
research associates, fellows and academics
-
research delivery managers
-
trial managers and coordinators
-
sponsors
-
statisticians
-
trial steering committee members
Recruitment of the panel
Clinical trials researchers were contacted through the UK Clinical Research Collaboration CTU Network and the UK Trial Managers’ Network. Representatives of the National Institute of Health Research (NIHR, a major funder of UK clinical trials), sponsors, chief investigators and UK Clinical Research Network representatives were identified through members of the project team, key contacts within the NIHR and the Trial Conduct Working Group of the Medical Research Council. The survey was also publicised on the Trial Forge website [7] and in a poster presentation at the 4th International Clinical Trials Methodology Conference [8]. Respondents were asked to complete the survey individually and to share the invitation with interested colleagues. Criteria for eligibility to complete the survey were being based in the UK and having at least three years’ experience of working in clinical trials.
Distributing the Delphi survey
An email invitation to the three-round Delphi survey contained a brief explanation of the study, emphasising the importance of completing all three rounds [3], an estimate of the time needed to complete each round (15 min) and a hyperlink to register with the survey. We aimed to complete each survey round within four weeks. Non-responders were sent automated reminders after one and two weeks, and a personalised email at the end of week 3. Rounds were extended by a few days if requested by participants to enable completion. Respondents were informed they would be entered into a prize draw if they completed all three rounds.
Upon registration, participants were asked to confirm that they were based in the UK and had at least three years’ experience working in clinical trials. They were asked to give their geographical region in the UK and their primary professional role. Participants’ names and contact details were recorded so that personalised reminders to complete the survey could be sent. However, the survey software prevented any individual survey responses being linked to individual names or contact details.
Conducting the Delphi survey
One thematic domain was presented per question page. Participants were asked to score each metric according to the importance of including it in a core set of essential metrics for monitoring the performance of sites during a trial. The Grading of Recommendations Assessment Development and Evaluation (GRADE) scale was used, which suggests a 9-point Likert scale (1 to 9) to rank importance [4]. Scores of 7 to 9 denote metrics of critical importance, scores of 4 to 6 are important but not critical, and scores of 1 to 3 are deemed not important. An option for unable to score (10) and a space to provide optional feedback on reasons for allocating particular scores were included. Participants could nominate additional metrics in round 1 to be included in round 2. New metrics were added to the list for round 2 if two or more participants suggested its inclusion, and it was not deemed to duplicate or overlap significantly with any other metric already in the survey [9].
Respondents were considered as a single panel. All round 1 metrics were carried forward to subsequent rounds. In rounds 2 and 3, each participant was presented with the distribution of scores from all participants in the previous round alongside their own score for each metric. Participants were asked to consider the responses from the other participants and review their score, either confirming or changing it. A space was provided for participants to explain their reasons for changing an individual score. Invitation to participate in rounds 2 and 3 was contingent upon completing the preceding round, as participants were always presented with their own scores from the previous round.
To investigate potential attrition bias [4, 10], we compared round 1 item mean scores and the percentage of respondents scoring each metric as critical for participants who completed only round 1 with those of participants who went on to complete round 2. We similarly compared round 2 data for participants who completed only rounds 1 and 2 with those participants who went on to complete round 3.
Consensus criteria
We used the definitions of consensus described in Table 1 [4, 11]. Inclusion of an item in the subset to be discussed at the consensus meeting required agreement by the majority of survey participants regarding the critical importance of the metric, with only a minority considering it unimportant.
Consensus meeting
Representatives of UK-based stakeholder groups and members of the study team were invited to attend a consensus meeting (September 2017). Prior to the meeting, we sent participants summary statistics for all 34 metrics from the Delphi survey. Ahead of the consensus meeting, participants were asked to review all the metrics that had reached the consensus in status following the survey, as only these metrics would be discussed and voted on during the meeting. Anyone wishing to make a case for discussion of any of the remaining metrics were given the opportunity to do so before the start of the meeting. At the consensus meeting, each metric was discussed in turn, and participants voted for its inclusion in the final core set using an anonymous electronic voting system. Metrics with >50% of participants voting for its inclusion were retained.
Results
Delphi Survey
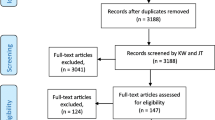
Figure 1 summarises the Delphi study. Data were collected for the three rounds of the Delphi survey between June and September 2017. Of 294 people who registered for the survey, 277/294 (94%) completed round 1, 251/277 (91%) completed round 2 and 211/277 (76%) completed round 3. The within-round completion rate for round 3 was 211/251 (84%). Of the original 294, 280 (95%) had at least three years’ experience of working in clinical trials.

Summary results of Delphi survey and consensus meeting
Table 2 shows the participation in each round of the Delphi survey by stakeholder group. Some participants represented more than one group, but are described here in their main role. Over half of all participants were involved in trial management (senior trial manager, project lead, manager, trial coordinator, or trial or research manager). The next largest group was chief investigators (13% in round 3). Although 66 participants who completed round 1 did not complete round 3, attrition appeared to be reasonably proportionate across all the stakeholder groups. Of 277 participants who completed round 1, 263 (95%) reported having at least three years’ experience working in clinical trials, compared with 200/211 (95%) who completed all three rounds. There was no evidence of attrition bias between rounds in terms of differences in metric scores between participants who did or did not complete subsequent survey rounds (Additional files 3 and 4).
The geographical region providing the largest group of participants who completed all three rounds was the East Midlands (22%), followed by London (15%) and the North-West England (12%). Other responses in round 3 were from: South-East England (10%), Scotland (8%), South-West England (8%), Yorkshire and Humber (6%), West Midlands (6%), North-East England (5%), Wales (4%) and Northern Ireland (1%).
Table 3 summarises the scores for each metric by Delphi survey round for the 211 participants who completed all three rounds and the outcome of the consensus meeting.
Round 1
Six metrics (numbered 1, 13, 21, 23, 28 and 31 in Table 3) reached the criterion for consensus in in round 1. No metrics were assigned a consensus out score. All 28 original metrics were carried forward to round 2 and six new metrics were added after round 1, following participants’ nominations. These were in the domains recruitment and retention (metrics 5–8 and 14) and staff (metric 34).
Round 2
Ten metrics (numbers 1, 10, 13, 15, 16, 18, 21, 23, 28 and 31, Table 3) reached the criterion for consensus in in round 2. All 34 metrics were carried forward to round 3.
Round 3
Altogether, 15 metrics (numbers 1, 8, 9, 10, 13, 14, 15, 16, 18, 21, 23, 27, 28, 29 and 31, Table 3) in three domains achieved the criterion for consensus in by the end of round 3 and were taken forward to the consensus meeting. No metrics from the staff domain were taken forward to the meeting. The reasons that participants reported for changing their scores between rounds related to further reflection and being influenced by the scores of others. None of the metrics reached the criterion for consensus out in any of the three survey rounds.
Consensus meeting
In total, 35 UK-based stakeholders were invited to the consensus meeting, of whom 20 accepted and 16 attended. Participants represented trial managers, data managers, statisticians, quality assurance managers, CTU directors, chief investigators, research fellows, research networks and research funders. In addition, nine members of the study team attended, of whom seven voted, giving a total of 23 voting participants.
In addition to the 15 metrics reaching the criterion for inclusion after round 3 of the Delphi survey, a further two metrics (numbers 7 and 26) were discussed and voted on at the meeting. This was because several participants expressed a preference for these when metrics 8 and 23 were considered. There was a high level of agreement among participants. Of the 17 metrics that were discussed, 13 received over 75% of votes for either inclusion or exclusion from the final set (Table 3).
Eight metrics were included in the final core set: three each in the domains recruitment and retention and data quality, and two in protocol compliance (Table 4). The final wording for some of the metrics or the expanded definitions were altered to improve clarity following discussion at the consensus meeting. Table 4 shows the final versions and a comparison with the original versions.
Reporting tool
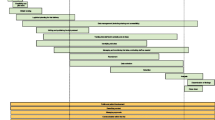
To support use of the core set of metrics, we have created a simple tool in Microsoft Excel, using a traffic light warning system to indicate potential problems (Fig. 2). The traffic light colours for each metric are linked to a set of thresholds. For example, when the percentage of participants with at least one protocol violation at a site is higher than 10%, this triggers a red traffic light. These thresholds are set by each trial team and may be quite different for different studies. The tool contains some default thresholds, but these are arbitrary and for illustration only. There are no accepted levels for any of them, although use of the tool may lead to some accepted values emerging. There may also be situations where a threshold changes during a trial. For example, an individual site’s current recruitment target could be reduced as the trial as a whole approaches its recruitment target and the certainty of meeting the overall sample size becomes clearer. The tool is freely available from the Nottingham Clinical Trials Unit website [12].

Worked example of site performance metrics reporting tool in Microsoft Excel. a Summary worksheet, b thresholds worksheet and c trial data worksheet
Discussion
Using a mixed-methods approach, we achieved consensus on a core set of eight metrics for monitoring the performance of sites in multicentre randomised trials. The core set includes three metrics on recruitment and retention, three on data quality and two on protocol compliance. No metrics from the staff domain were included in the final set. To our knowledge, this is the first study that has attempted to identify a core set of key performance metrics for monitoring the conduct of clinical trials.
It is unsurprising that the number of participants recruited at sites was deemed critical for inclusion throughout the Delphi survey and supported unanimously at the consensus meeting. However, it is also notable that none of the 34 metrics achieved the criterion for consensus out in the survey, suggesting recognition by respondents that the ‘health’ of a multicentre randomised trial is multifaceted. Underlying problems with staff training, capacity, equipoise, integration of the trial into the clinical pathway or trial processes being inconvenient or time-consuming for participants could be reflected in several of the metrics included in the final set. If not addressed, these problems may affect patient safety, increase the risk of bias, or reduce the generalisability or statistical power.
Our study has several strengths. For the survey, we recruited a large sample of stakeholders with a wide range of roles in clinical trials from throughout the UK. This is important if the core set of metrics is to have credibility and relevance among potential users. Attrition in successive survey rounds diminishes group size. This can result in a false impression of how much consensus really exists [4], and may be due to participants losing interest, having insufficient time or holding minority views [13]. Over 75% of participants who completed round 1 went on to complete rounds 2 and 3, and there was no evidence of attrition bias, either in terms of different stakeholder groups or in mean scores of previous rounds. To facilitate use of the core set of performance metrics, we have developed a simple, user-friendly reporting tool in Microsoft Excel, which uses red, amber and green indicators based on thresholds for each metric, as determined by the trial team. This provides an at a glance performance check within and between trial sites, and could be used to complement existing trial management systems and data that are presented and discussed at regular trial management group meetings. Moreover, by using Excel, trials teams can modify the tool as they see fit to meet their own requirements.
Limitations
There are also some limitations with our study. Although Delphi methods have been used successfully to develop core outcome sets and quality indicators in health-related research [2,3,4, 10, 14], there is no gold standard method for achieving consensus, and a different methodology may have produced a different final set of metrics [4, 15, 16].
Survey recruitment included a snowball sampling technique and participation was voluntary. Trial managers or those in similar roles made up the largest survey participant group, comprising half of the respondents who completed all three rounds. One could argue that this group have the greatest day-to-day role in monitoring site performance in multicentre randomised trials and therefore, should be strongly represented in the survey. However, even with half of survey participants in other roles, including senior positions, it is possible that the metrics selected for the consensus meeting reflect those considered most important by the dominant participant group.
Our focus was mainly on publicly funded trials led by academic researchers and our stakeholder representation reflects this focus. We believe that we obtained a broad and representative sample of UK-based stakeholders involved in these types of clinical trials. However, it is possible that another sample, for example with respondents from commercially led research, may have prioritised alternative metrics for inclusion.
Although we sought survey respondents who had been working in multicentre randomised trials for at least three years, a few participants who completed all three rounds indicated during survey registration that they did not have this level of experience. This was due to an error when we created the survey that allowed participants to proceed even if they reported not having at least three years’ experience in clinical trials. However, even if the length of experience is associated with which metrics are viewed as important, the small number of inexperienced participants is unlikely to have influenced the set taken forward to the consensus meeting.
As the Delphi survey is anonymous, there is no pressure for participants to conform. This may prevent those with strong views from dominating [3], but also means that conflicting views cannot be discussed or points explained [17, 18]. However, participants were able to provide feedback between rounds, and we made minor clarifications to the metric definitions in response. It is possible that participation in the consensus meeting by members of the research team may have been unintentionally influential in discussions, which may in turn have affected voting, although the meeting chairperson took care to invite and encourage wide discussion and did not permit individuals to dominate. Finally, we acknowledge the UK focus of this study and that other aspects of site performance may have greater importance in other settings.
Conclusions
By using robust methods to achieve consensus, we have established a core set of eight metrics for measuring performance of sites in multicentre randomised trials. These metrics could improve trial conduct by helping researchers to identify and address problems at sites before trials are adversely affected. Future research should evaluate the effectiveness of using these core metrics in monitoring trial performance.
Abbreviations
- CTU:
-
Clinical trials unit
- NIHR:
-
National Institute for Health Research
- SAE:
-
Serious adverse event
References
Dorricott K. Using Metrics to Direct Performance Improvement Efforts in Clinical Trial Management. Monitor. 2012;24(4):9–13 http://pages.nxtbook.com/nxtbooks/acrp/monitor_201208/offline/acrp_monitor_201208.pdf. Accessed 10 Mar 2018.
Blackwood B, Ringrow S, Clarke M, Marshall J, Rose L, Williamson P, et al. Core Outcomes in Ventilation Trials (COVenT): protocol for a core outcome set using a Delphi survey with a nested randomised trial and observational cohort study. Trials. 2015;16:368.
Sinha IP, Smyth RL, Williamson PR. Using the Delphi technique to determine which outcomes to measure in clinical trials: recommendations for the future based on a systematic review of existing studies. PLoS Med. 2011;8(1):e1000393.
Williamson PR, Altman DG, Bagley H, Barnes KL, Blazeby JM, Brookes ST, et al. The COMET Handbook: version 1.0. Trials. 2017;18(Suppl 3):280.
Walker KF, Turzanski J, Whitham D, Montgomery AA, Duley L. Monitoring performance of sites within multicentre randomised trials: A systematic review of performance metrics. Trials. 2018; Accepted for publication.
The Comet Initiative. Delphi Manager. http://www.comet-initiative.org/delphimanager/. Accessed 20 Sept 2017.
Trial Forge. Available from: https://www.trialforge.org/. Accessed 9 Feb 2018.
Meeting abstracts from the 4th International Clinical Trials Methodology Conference (ICTMC) and the 38th Annual Meeting of the Society for Clinical Trials. Trials. 2017;18(1):200.
Devane D, Begley CM, Clarke M, Horey D, OBoyle C. Evaluating maternity care: a core set of outcome measures. Birth. 2007;34(2):164–72.
Harman NL, Bruce IA, Kirkham JJ, Tierney S, Callery P, O'Brien K, et al. The Importance of Integration of Stakeholder Views in Core Outcome Set Development: Otitis Media with Effusion in Children with Cleft Palate. PLoS One. 2015;10(6):e0129514.
Harman NL, Bruce IA, Callery P, Tierney S, Sharif MO, O’Brien K, et al. MOMENT – Management of Otitis Media with Effusion in Cleft Palate: protocol for a systematic review of the literature and identification of a core outcome set using a Delphi survey. Trials. 2013;14(1):70.
The University of Nottingham: Nottingham Clinical Trials Unit. Performance Metrics 2018. http://www.nottingham.ac.uk/nctu/other-research/performance-metrics/about.aspx. Accessed 9 Feb 2018.
Hsu C-C, Sandford BA. The Delphi Technique: Making Sense Of Consensus. Pract Assess Res Eval. 2007;12(10):8–12.
Kirkham JJ, Gorst S, Altman DG, Blazeby JM, Clarke M, Devane D, et al. Core Outcome Set-STAndards for Reporting: The COS-STAR Statement. PLoS Med. 2016;13(10):e1002148.
Jones J, Hunter D. Consensus methods for medical and health services research. BMJ. 1995;311(7001):376–80.
Murphy MK, Black NA, Lamping DL, McKee CM, Sanderson CF, Askham J, et al. Consensus development methods, and their use in clinical guideline development. Health Technol Assess. 1998;2(3):i–iv 1–88.
Eubank BH, Mohtadi NG, Lafave MR, Wiley JP, Bois AJ, Boorman RS, et al. Using the modified Delphi method to establish clinical consensus for the diagnosis and treatment of patients with rotator cuff pathology. BMC Med Res Methodol. 2016;16(1):56.
Walker AM, Selfe J. The Delphi method: A useful tool for the allied health researcher. Br J Ther Rehabil. 1996;3(12):677–81.
Acknowledgements
We would like to thank:
-
Stella Tarr and Chris Rumsey (both Nottingham Clinical Trials Unit) for designing and developing the reporting tool
-
The UK Trial Managers’ Network for dissemination of the Delphi survey to their membership
-
The NIHR Clinical Research Network (Louise Lambert and Kathryn Fairbrother) for sharing their experience and insight on national portfolio management and performance indicators
-
Professor Julia Brown (director of the Leeds Institute of Clinical Trials Research and the director of the UK Clinical Research Collaboration’s CTU Network) and Saeeda Bashir for distributing the Delphi survey on behalf of the UK CTU Network
-
Professor Chris Rogers (Medical Research Council Hubs for Trials Methodology Research) for assistance with identifying consensus meeting participants
-
The focus group and Delphi survey participants
Site Performance Metrics for Multicentre Trials Collaboration
Simon Bevan
Lucy Bradshaw
Mike Clarke
Lucy Culliford
Adam Devall
Lelia Duley
Kathryn Fairbrother
Kirsteen Goodman
Catherine Hewitt
Rachel Hobson
Sarah Lawton
Stephen Lock
Alison McDonald
Alan Montgomery
John Norrie
Alastair O’Brien
Sarah Pearson
Shelley Rhodes
Lisa Shaw
Zoe Skea
Claire Snowdon
Kim Thomas
Shaun Treweek
Julie Turzanski
Kate Walker
Diane Whitham
Paula Williamson
Jill Wood
Funding
This study was supported by an NIHR Clinical Trials Unit Support Funding grant for supporting efficient and innovative delivery of NIHR research. The views expressed are those of the authors and not necessarily those of the National Health Service, the NIHR or the Department of Health and Social Care. The Health Services Research Unit, University of Aberdeen, receives core funding from the Chief Scientist Office of the Scottish Government Health Directorates. The study was not registered.
Availability of data and materials
The data generated or analysed during the current study are included in this published article (and its supplementary information files). Additional information is available from the corresponding author on reasonable request.
Author information
Authors and Affiliations
Consortia
Contributions
DW and LD conceived the idea for the study and led the study team. DW, LD, SPT, MC, PRW and AAM designed the study and obtained the funding. DW, JT, LD, KW, SPT, ZS, PRW and AAM designed the Delphi survey. JT, AAM and LB analysed the Delphi survey data. Members of the Site Performance Metrics for Multicentre Randomised Trials Collaboration organised, delivered or participated in the consensus meeting. JT, LD, KW and AAM wrote the first draft of the manuscript, with critical revisions for important intellectual content made by all authors. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The study was reviewed and approved by the Faculty of Medicine & Health Sciences Research Ethics Committee at the University of Nottingham. Individual participants were approached or self-volunteered to participate in the Delphi survey and consensus meeting. They received a short introductory email with information about the study, including explicit details about what would be involved. Participants were free to withdraw from the study at any time. Study conduct was consistent with standard practice in survey research. Consent was assumed by agreement to participate in meetings and complete online questionnaires.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional files
Additional file 1:
Examples of site performance metrics excluded from the Delphi survey. (DOCX 21 kb)
Additional file 2:
Site performance metrics (n = 34) and definitions included in the Delphi survey. (DOCX 19 kb)
Additional file 3:
Examination of possible attrition bias in round 2 of the Delphi survey. (XLSX 18 kb)
Additional file 4:
Examination of possible attrition bias in round 3 of the Delphi survey. (XLSX 18 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Whitham, D., Turzanski, J., Bradshaw, L. et al. Development of a standardised set of metrics for monitoring site performance in multicentre randomised trials: a Delphi study. Trials 19, 557 (2018). https://doi.org/10.1186/s13063-018-2940-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13063-018-2940-9