
Abstract
Background
Early diagnosis of Pancreatic Ductal Adenocarcinoma (PDAC) is the main key to surviving cancer patients. Urine proteomic biomarkers which are creatinine, LYVE1, REG1B, and TFF1 present a promising non-invasive and inexpensive diagnostic method of the PDAC. Recent utilization of both microfluidics technology and artificial intelligence techniques enables accurate detection and analysis of these biomarkers. This paper proposes a new deep-learning model to identify urine biomarkers for the automated diagnosis of pancreatic cancers. The proposed model is composed of one-dimensional convolutional neural networks (1D-CNNs) and long short-term memory (LSTM). It can categorize patients into healthy pancreas, benign hepatobiliary disease, and PDAC cases automatically.
Results
Experiments and evaluations have been successfully done on a public dataset of 590 urine samples of three classes, which are 183 healthy pancreas samples, 208 benign hepatobiliary disease samples, and 199 PDAC samples. The results demonstrated that our proposed 1-D CNN + LSTM model achieved the best accuracy score of 97% and the area under curve (AUC) of 98% versus the state-of-the-art models to diagnose pancreatic cancers using urine biomarkers.
Conclusion
A new efficient 1D CNN-LSTM model has been successfully developed for early PDAC diagnosis using four proteomic urine biomarkers of creatinine, LYVE1, REG1B, and TFF1. This developed model showed superior performance on other machine learning classifiers in previous studies. The main prospect of this study is the laboratory realization of our proposed deep classifier on urinary biomarker panels for assisting diagnostic procedures of pancreatic cancer patients.
Similar content being viewed by others


Introduction
Pancreatic cancer (PC) is the third leading cause of death in the world as reported by cancer statistics in 2022 [1]. Pancreatic ductal adenocarcinoma (PDAC) is the most common type of exocrine tumor affecting the pancreas [2]. Although PDAC is the 12th most common cancer worldwide, its aggressive nature and the lack of obvious symptoms make it a major public health burden. The PDAC has the lowest 5-year overall survival rate of any malignancy due to late diagnosis (11%) [1]. The procedure of early PDAC diagnosis is the main key to surviving cancer patients. That requires a concerted effort among clinicians, radiologists, biologists, and computer scientists.
Clinical data is the initial stage in the diagnosing process of any disease. Electronic health records (EHR) represent tremendous heterogeneous data. EHRs contain clinical information such as diagnoses, procedures, information within clinical notes, and medications. Recent studies succeeded in identifying high-risk PDAC patients from national EHRs [3]. Such population-based studies improve awareness of PDAC risk and recommend patients for more diagnostic procedures like biomarker testing and medical image scanning [4]. Medical imaging-guided procedures are fundamental techniques for diagnosing PDAC, including magnetic resonance imaging (MRI), computed tomography (CT), endoscopic ultrasound (EUS), and Immuno-Positron Emission Tomography (Immuno-PET) [5]. Despite the difficulty of imaging early pancreatic cancer, numerous promising recent studies are reported in [6]. The high cost of radiological imaging makes it an unlikely choice for general PDAC screening. As a result, the researchers’ attention turns to utilizing biomarkers as a preliminary step toward PDAC early detection. There are rapid developments in genomic sequencing and their different strategies such as proteomics, epigenomics, and transcriptomics create large-scale multi-omics data. The Cancer Genome Atlas (TCGA) project [7] was established by the National Cancer Institute in 2006. It provides multi-omics data for more than 20,000 tumors spanning 33 cancer types. Many recent efforts have been made to integrate omics science with cancer research for different cancer types including PDAC [8, 9]. According to these studies, informative biomarkers with genomics can assist pathologists to get more advanced PDAC indicators.
Body fluids are rich with informative biomarkers that are crucial for the early identification of PDAC [10, 11]. For example, cyst fluid, pancreatic juice, and bile need invasive procedures like surgery or endoscopy to be collected. Blood is also a minimally invasive, inexpensive, and reproducible source of tumor biomarkers [12]. It is enriched with proteomic biomarkers such as carbohydrate antigen 19–9 (CA19-9) and transcriptomic biomarkers based on RNA sequencing which is called Circulating micro RNAs (miRNAs) [13, 14]. In addition, blood exosomes which are nano-sized, extracellular vesicles that carry various pathogenic RNAs, DNAs, and proteins were used to diagnose cancerous cells in the pancreas [15].
Urine represents a promising alternative body fluid for biomarker discovery. It is an ideal fluid for public diagnostic screening tests because patients may easily provide a significant volume of it in an entirely non-invasive inexpensive way [16]. Like blood, urine contains proteomic biomarkers in addition to transcriptomic biomarkers miRNAs. In 2015, Radon et al. [17] proposed a three-protein biomarker panel that is able to detect patients with early-stage PDAC in urine samples. They considered TFF1, LYVE-1, and REG1A as candidate proteomic biomarkers. On the micro-scale, a study reported the use of miRNA in urine for early detection of PDAC [18]. In 2020, Debernardi et al. [19] improved the existing panel by substituting REG1A with REG1B. In addition, they can differentiate between benign hepatobiliary disease and PDAC cases which represent a challenge in early-stage of PDAC because of the overlapping symptoms. They validate their panel using the PancRISK score [19]. The accurate detection and quantification of biomarkers in liquid biopsy are the millstone for the success of body fluid-based diagnostics methods which can be achieved using micro-and nano-based technologies [20].
Rapid technical innovation in microfluidics and nanofluidic technologies allows the detection of high-quality biomarkers from liquid biopsies with high specificity, and sensitivity [21, 22]. Different microfluidic chips have been designed for different body fluids such as blood [23], and urine [24]. Microfluidics technologies can improve cancer diagnosis by analyzing various tumor biomarkers such as circulating tumor DNA (ctDNA), circulating tumor cells (CTC), cell-free DNA (cfDNA), cell-free RNAs (cfRNAs), tumor-secreted exosomes, and proteins [25, 26]. However, the clinical interpretation of these biomarkers and their inter-relationships remain a challenge. Therefore, artificial intelligence (AI) plays an important role in assisting clinicians to automatically analyze the extracted biomarkers and detect PDAC at early stages.
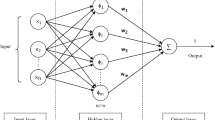
Machine learning (ML) and deep learning (DL) techniques have recently become the core of computer-aided diagnosis (CAD) that can deal with different forms of clinical data, medical images, genomics, and biomarkers. Figure 1 shows a generic schematic diagram of AI-based applications to categorize pancreatic patients into three main groups, namely healthy and two diseased cases of benign and PDAC, based on various forms of input medical data. ML models can learn from patient data in a supervised or unsupervised manner to predict the health status of the pancreas, as proposed in previous studies [22, 27,28,29]. Advanced DL methods can learn from complex, interrelated, and non-linear features in medical datasets to gain higher diagnostic ability. Hence, some studies employed DL models to detect PDAC tumors using medical imaging modalities, such as multi-parametric MRI [30, 31] and CT [32]. Convolutional neural network (CNN) is one of the main DL architectures for accomplishing medical diagnosis tasks of cancer tumors [33, 34]. Recurrent neural networks (RNNs) are also widely used as a deep learning model for processing sequential data [35]. One of the most common types of RNNs is Long short-term memory (LSTM) networks, which can be integrated with CNNs to improve classification performance in many medical applications [36,37,38] and PC detection in EUS images [39].

Schematic diagram of applying artificial intelligence techniques to assist diagnosis of pancreatic cancer patients using different forms of medical data
In this article, we propose a new DL model to enhance diagnostic procedures of pancreatic patients using urine biomarkers. This study contributed the following advancements:
-
Integrated one-dimensional (1D) CNN with LSTM has been proposed to aid the accurate detection of PDAC based on inexpensive urine biomarkers.
-
A comparative evaluation of different ML and DL models has been done to verify the promising results of our developed 1D CNN + LSTM for identifying diseased pancreas cases of benign and PDAC.
-
The developed model achieved outperformance in the accurate multi-class classification of pancreatic patients into three groups, namely healthy pancreas, benign, and PDAC cases versus other AI-based models in the current existing state-of-the-art studies.
The rest of this article is structured as follows. Section "Related Works" gives a review of the related works including different clinical modalities with previous ML and DL models to identify PC cases. Section "Dataset and methods" describes both the tested dataset of urine biomarkers and our developed 1D CNN + LSTM classifier in detail. Experiments including results evaluation and discussion of this study are presented in Sects. "Medical data" and "1D Convolutional Neural Network", respectively. At the end of the paper, the conclusion and future directions of this research work are given in Section "Long short‑term memory layer".
Related Works
This section explores how AI can support early diagnosis of PDAC using different diagnostic methods. We focus on early diagnosis systems based on urine proteomic biomarkers because it is the ultimate goal of this study. A population-based study made by Lee et al. [28] represented a predictive model for the early screening of high-risk patients. They accredited that their diagnostic model will support medical care community to know the risk of pancreatic cancer. Their study was built on Taiwan Health Insurance Database (NHIRD). They used four models including logistic regression (LR), deep neural networks DNN, ensemble learning, and voting ensemble to develop their predictive model. The model achieved accuracy ranging from 73 to 75%, and the area under curve (AUC) from 0.71 to 0.76.
Many studies have utilized AI techniques to assist radiologists with interpreting medical images. Liang et al. [30] developed a CNN model for auto-segmentation of pancreatic gross tumor volume (GTV) in multiparametric MRI. They employed a square window-based CNN architecture with three convolutional layer blocks for automatic segmentation of the pancreatic GTV. They achieved mean values and standard deviations of the performance metrics on the test set as, dice similarity coefficient (DSC) = 0.73 ± 0.09 and mean surface distance (MSD) = 1.82 ± 0.84 mm. Chen et al. [32] validated a new deep learning (DL)–based tool to detect pancreatic cancer on CT scans with reasonable sensitivity for tumors smaller than 2 cm. Their DL tool distinguished between CT malignant and control studies with 89.7% sensitivity, 92.8% specificity, and 0.95 AUC. In addition, the EUS imaging modality needs real-time decision support to differentiate between pancreatic cancer (PC) and non-pancreatic cancer (NPC) lesions. Tian et al. [37] suggested that the YOLOv5m would generate attractive results and allow for real-time detection using EUS images. The suggested model resulted in 95% sensitivity, 75% specificity, and 0.85 AUC.
On the genomic scale, Long et al. [27] integrated data mining and multi-omics data for the identification and validation of oncogenic biomarkers of pancreatic cancer. They constructed their prediction model based on a random forest (RF) algorithm because it is an easy-to-comprehend approach. They successfully explored hidden biological insights from multi-omics data and suggested robust biomarkers for early diagnosis, prognosis, and management of PC. The proposed RF model reported an accuracy of 96%.
Using blood samples, Lee et al. [13] identified (miRNA) biomarkers derived from blood serum and used them to build the prediction model for PC. They selected 39 miRNA markers using a smoothly clipped absolute deviation-based penalized support vector machine (SVM) and built a PC diagnosis model. Their model obtained an accuracy of 93% and an AUC of 0.98. Hsu et al. [14] suggested a new machine-learning model that combines plasma-based biomarker CA19-9 and methylation signals to build a joint multi-omics prediction model for PDAC. This approach achieved a sensitivity of 93% and a specificity of 96%. Ko et al. [15] combined machine learning and nanofluidic technology to diagnose PC using exosomes. They developed a multichannel nanofluidic system to analyze crude clinical samples. Then, the linear discriminant analysis (LDA) algorithm is applied to these exosomes to assist in the final diagnosis of cancer patients. This prediction model resulted in an AUC of 0.81 for classifying pancreatic tumors versus healthy samples.
For urine specimens, Debernardi et al. [18] identified diagnostic (miRNAs) for early-stage PDAC. They applied LR algorithms to determine the discriminatory candidate miRNA biomarkers. The best results of these models were a sensitivity of 83.3%, a specificity of 96.2%, and an AUC of 0.92. Blyuss et al. [40] developed a urine biomarker-based risk (PancRISK) score for stratified screening of pancreatic cancer patients. This model was built based on the three-protein biomarker panel in addition to urine creatinine and age. They compared the results of several ML algorithms including neural network (NN), random forest (RF), support vector machine (SVM), neuro-fuzzy (NF) system, and LR model. Then, they used LR to incorporate it into a PancRISK score. The PancRisk score can stratify between two cases (PDAC) and controls (healthy patients), resulting in a specificity of 90% and AUC of 0.94. ALPU et al. [41] studied different regularization methods based on the LR model. This comparative study was conducted on the developed biomarker panel in [19]. It is found that the LR model with adaptive group lasso estimator outperformed other regularization techniques in terms of performance measures. The best classification model resulted in an accuracy score of 76% and an AUC of 0.77. A deep-learning-based PDAC diagnostic system was proposed in [42]. The proposed system used an enhanced CNN model to classify pancreatic diseases based on a multi-categorical urine biomarker panel, achieving 95% accuracy and 0.97 AUC.
Dataset and methods
Medical data
The public dataset of this study was collected by Debernardi et al. [19]. It includes four featured urinary biomarkers, which are creatinine, LYVE1, REG1B, and TFF1. Creatinine is a protein that indicates the functionality of the kidney. YVLE1 is an acronym for lymphatic vessel endothelial hyaluronan receptor 1. It is a protein that potentially has a role in malignant tumors. The third biomarker REG1B is also a protein and may be associated with regenerating cells of the pancreas. Finally, trefoil factor 1 (TFF1) is a protein, which is potentially a prognostic biomarker associated with the development of PDAC disease. This dataset contains a total of 590 urine samples. It is divided into three patient groups, namely healthy patients (183 samples), benign and PDAC cases of 208 and 199 samples, respectively, as illustrated in Table 1.
1D Convolutional Neural Network
CNN represents an effective tool to extract features and accomplish classification tasks in medicine [33]. In this study, it has been developed to identify pancreas diseases by analyzing 1D data of urine biomarkers. The general architecture of 1D CNN includes convolutional operations, subsampling, dropout regularization, and SoftMax layers [43], as shown in Fig. 2. Each layer of the general 1D CNN architecture can be described as follows. Convolutional and subsampling layers provide feature detection of input 1D samples by performing different filtering operations via convolutions, kernels, and rectifier linear unit (ReLU). The max pooling layer performs a pooling process to select the most prominent features from the overall feature map covered by the predefined filter. The function of Flatten layer is to reshape the multi-dimensional feature map array into a single 1D array, as depicted in Fig. 2. To prevent neural network overfitting, the dropout is applied as a regularization technique for self-modifying the architecture of CNN. Then, the outputs of fully connected network layer are processed by a SoftMax function to give the final output of predicted classes.

Main layers of 1D convolution neural network for predicting n classes
Long short-term memory layer
The LSTM is one of the most popular architectures of recurrent neural networks (RNNs) to manipulate data sequentially [44]. The main problem of RNN’s vanishing gradients or long-term dependencies has been solved in the LSTM network, because it can ignore useless information in the neural network for long sequence datasets, such as urine biomarkers in this study. An LSTM layer has mainly three successive gates, i.e., forget gate, input and output gates [44], as shown in Fig. 3. The forget gate is responsible for passing or ignoring data/information flow, as defined by
where Ft is the output of forget gate, WF and bF present the weight matrix and bias coefficient associated with forget gate. Xt is the current timestamp input and ht-1 is the previous timestamp hidden state. σ is the sigmoid activation function. In Fig. 3, Ct and Ct-1 present the updating and current timestamp cell states, respectively, such that Ct-1 is multiplied by Ft as given in (2).

Basic structure of LSTM block
The input gate selects the information to be updated using the sigmoid function, It, then compresses the input sequence in the range of -1 and 1 using the hyperbolic tangent (tanh) function, \({\widetilde{\mathrm{C}}}_{t}\), to add the immediate state to the long-term impact. The mathematical expressions of the input gate are presented as
where WI and bI present the weight matrix and bias coefficient associated with the input gate, while WC and bC are the weight matrix and bias coefficient associated with the candidate state \({\widetilde{\mathrm{C}}}_{t}\).
The third gate of the LSTM block is the output gate, Ot, which determines the consideration of the long-term effect and updates the outputs of both the current cell state, Ct, and the hidden state, ht, using the sigmoid and tanh functions, as depicted in Fig. 3. The related mathematical expressions of the output gate are given as follows.
where WO and bO are the weight matrix and bias coefficient associated with the output gate outcome Ot.
Automated pancreatic cancer classification
Figure 4 depicts our proposed smart urine biomarkers classification framework for diagnosing pancreatic patients using 1D CNN-LSTM model. First, urine samples are taken from the patient. Second, urine microfluidics device is used to extract four featured biomarkers, i.e., creatinine, LYVE1, REG1B and TFF1, as described above. Then, these four urine biomarkers are fed into our developed 1D CNN-LSTM classifier to predict one of three classes, which are healthy pancreas, benign and PDAC diseases, as shown in Fig. 4. Detailed structural layers of the 1D CNN-LSTM model are depicted in Fig. 5. It includes an input data layer, two 1D convolutional layers, one maximum pooling layer, one LSTM, one fully connected dense layer, and final SoftMax output layer. The 1D CNN-LSTM is considered a lightweight deep neural network with fully trainable parameters of 83,8111.

Proposed smart urine biomarkers classification to diagnose pancreatic cancers using 1D CNN-LSTM

Developed 1D CNN-LSTM model for pancreatic cancer classification
Experiments
Experimental setting
Experiments have been retrospectively conducted to analyze the PDAC classification performance of our developed 1D CNN-LSTM and other machine-learning models, based on the public pancreas dataset of urine biomarkers [19]. The implementation of all tested deep classifiers has been done via Anaconda Navigator V2.3 of Python programming language with Tensorflow-Keras packages and web-based interactive computing notebook (Jupyter V6.4) [45]. These experiments were conducted on a high-performance computing (HPC) laptop equipped with 8 GB NVIDIA GeForce GPU, 16 GB RAM, 256 GB SSD and Intel Core i7-12700H (12th Gen) processor.
Using cross-validation estimation [46], a confusion matrix is generated to evaluate the PDAC classification performance of developed 1D CNN-LSTM and other tested models in this study. As shown in Fig. 6, the confusion matrix has four expected outcomes by comparing ground-truth pancreas conditions with the predicted results of any tested classifier. These outcomes are true positive (TP), true negative (TN), false positive (FP), and false negative (FN). In addition, five evaluation metrics, i.e., accuracy, recall or sensitivity, precision, F1-score and AUC have been used to verify the performance of all tested classifiers. Here, other models, i.e., RF, multi-layer perceptron (MLP) neural network, and 1D CNN without LSTM have been implemented to be compared with the performance of our developed 1D CNN-LSTM model.

Confusion matrix with evaluation metrics for analyzing the performance of tested classifiers in this study
For starting the training phase of all tested models, the urine samples dataset, as illustrated in Table 1, was randomly split 80 –20 percent, such that the testing phase used 20% of these urine samples, i.e., 118 of 590 samples for accomplishing multi-class classification procedure of healthy pancreas, benign and PDAC cases.
4.2 Results and evaluation
Figure 7 shows the confusion matrices for multi-class classification of urine biomarkers into healthy pancreas, benign, and PDAC cases. These results are achieved by our 1D CNN-LSTM and three AI-based models, which are MLP neural network, RF, and 1D CNN. The developed 1D CNN-LSTM model achieved the highest accuracy with no misclassified samples of the PDAC case, but only two urine samples are misclassified for both healthy pancreas and benign cases. In the absence of an LSTM layer, the classification performance of 1D CNN model is decreased, such that the number of misclassified samples is increased for the healthy pancreas (3 samples) and the benign case (5 samples), but no misclassified sample is detected for the PDAC. The MLP neural network and RF could not handle the classification task of urine biomarkers precisely, achieving the worst accuracy scores in these experiments.

Confusion matrices of the classified healthy pancreas, benign, and PDAC cases using all tested classifiers
Six quantitative metrics, named recall (sensitivity), precision, specificity, F1-score, AUC and accuracy, have been applied to evaluate all tested classifiers, as illustrated in Table 2. The developed 1D CNN-LSTM and 1D CNN still achieved the best accuracy scores of 97% and 93%, respectively. They can be used to diagnose PDAC cases accurately. In contrast, MLP network and RF classifiers achieved the worst accuracy scores of approximately 75%. But the RF model showed better performance than the MLP network model to identify pancreas conditions.
Using the same urine biomarkers analysis, Table 3 illustrates a comparative performance evaluation of our developed 1D CNN-LSTM with other AI-based models in previous studies of automated pancreatic cancer diagnosis. Machine learning models such as logistic regression (LR) [41] could not achieve a high accuracy score (76%) similar to the performance of the RF classifier in Table 2. Additionally, other models like support vector machine (SVM) and neural network (NN) showed an improvement in identifying PDAC cases with AUC = 0.94 [40]. In [42], the application of the employed CNN model achieved 95% accuracy to identify pancreatic cancer conditions. However, our developed 1D CNN-LSTM showed superior classification performance over these previous classifiers by achieving the best values of classification evaluation metrics and the highest accuracy score of 97%.
Discussion
Intelligent CAD systems have recently become popular in the clinical routine of patients, particularly in the diagnostic procedure of cancer diseases such as the PDAC. Featured urine biomarkers, named creatinine, LYVE1, REG1B, and TFF1 can be extracted from urine microfluidics devices. Here, these four urine biomarkers have been successfully analyzed using our developed 1D CNN-LSTM classifier to identify healthy pancreas, benign and PDAC patients, as depicted in Fig. 4. As illustrated in Tables 2 and 3, the above evaluation results demonstrated that the developed 1D CNN-LSTM outperforms other AI-based models in previous studies with the highest accuracy score of 97%.
Traditional machine learning models, e.g., LR, RF, and SVM showed insufficient performance to identify pancreatic cancer conditions accurately, as introduced previously in [40]. Therefore, supervised 1D CNN-LSTM classifier has been developed to perform automated multi-class classification of 1D urine biomarkers, identifying the health status of pancreatic patients correctly. As described above, the advantageous architecture of the LSTM block showed its capability to ignore useless information in the neural network for long sequence datasets, such as urine biomarkers. Hence, the LSTM layer in our developed model (see Fig. 5) has a main role in significantly improving the classification performance of 1D CNN from an accuracy score of 93% to 97%, as given in Table 2. Moreover, it showed better classification performance than the previous CNN model (95% accuracy) [42], as illustrated in Table 3. Furthermore, the structure of the developed 1D CNN-LSTM model is simple and efficient to achieve targeted diagnostic procedures for pancreatic cancers without high-cost computing resources, e.g., GPUs.
The lack of public medical datasets is a common problem for training supervised learning models, because the number of training samples affects mainly their classification performance. Therefore, accuracy scores of CNN and machine learning classifiers of pancreas cancers are relatively limited to 97%. Consequently, developing deep learning models such as a generative adversarial network (GAN) presents a good solution to handle small medical datasets in semi-supervised or unsupervised learning frameworks [47, 48]. Also, meta-heuristic optimization techniques such as Teaching–Learning-Based Optimization (TLBO) [49, 50] can be applied to automatically update the design of the 1D CNN-LSTM model. Nevertheless, our developed classifier is still capable of achieving a successful and automated diagnosis of pancreas cancer diseases based on urine biomarkers.
Conclusion and future work
In this article, a new efficient 1D CNN-LSTM model is successfully developed for multi-class classification of pancreas cancer patients using featured urine biomarkers. The classification results categorize the pancreas condition into healthy pancreas, benign and PDAC cases. The developed model achieved the highest values of evaluation metrics including an accuracy of 97% compared to other machine-learning and CNN-based models in the literature, as illustrated in Table 3. Developed CNN models with and/or without the LSTM layer achieved accurate identification of tested PDAC samples, as depicted in Fig. 7.
The main prospect of this research work is to integrate our developed 1D CNN-LSTM with an actual urine microfluidics device for conducting online clinical trials on urine samples of pancreatic cancer patients. Additionally, the Internet of medical things (IoMT) technology can be utilized in this field of study to provide a mobile-based automatic diagnosis of patient samples via medical cloud services.
Availability of data and materials
The data that supports the findings of this research is publicly available as indicated in the references.
Abbreviations
- PDAC:
-
Pancreatic Ductal Adenocarcinoma
- 1D CNN:
-
One-Dimensional Convolutional Neural Network
- LSTM:
-
Long Short-Term Memory
- PC:
-
Pancreatic Cancer
- HER:
-
Electronic Health Record
- MRI:
-
Magnetic Resonance Imaging
- CT:
-
Computed Tomography
- EU:
-
Endoscopic Ultrasound
- Immuno-PET:
-
Immuno-Positron Emission Tomography
- TCGA:
-
The Cancer Genome Atlas
- CA19-9:
-
Carbohydrate Antigen 19–9
- miRNAs:
-
Circulating micro RNAs
- ctDNA:
-
Circulating tumor DNA
- CTC:
-
Circulating Tumor Cells
- cfDNA:
-
Cell-free DNA (cfDNA),
- cfRNAs:
-
Cell-free RNAs
- AI:
-
Artificial Intelligence
- ML:
-
Machine learning
- DL:
-
Deep Learning
- CAD:
-
Computer-Aided Diagnosis
- RNNs:
-
Recurrent neural networks
- LR:
-
Logistic Regression
- DNN:
-
Deep Neural Networks
- GTV:
-
Gross Tumor Volume
- MSD:
-
Mean Surface Distance
- NPC:
-
Non-Pancreatic Cancer
- RF:
-
Random Forest
- SVM:
-
Support Vector Machine
- LDA:
-
Linear Discriminant Analysis
- NN:
-
Neural Network
- NF:
-
Neuro-Fuzzy
- YVLE1:
-
Lymphatic Vessel Endothelial hyaluronan receptor 1
- TFF1:
-
Trefoil Factor 1
- ReLU:
-
Rectifier Linear Unit (ReLU)
- HPC:
-
High-Performance Computing (HPC)
- TP:
-
True Positive
- TN:
-
True Negative
- FP:
-
False Positive
- FN:
-
False Negative
- MLP:
-
Multi-Layer Perceptron (MLP)
- GAN:
-
Generative Adversarial Network (GAN)
- TLBO:
-
Teaching–Learning-Based Optimization
- IoMT:
-
Internet of medical things
References
Siegel RL, Miller KD, Fuchs HE, Jemal A. Cancer statistics, 2022. CA Cancer J Clin. 2022;72(1):7–33.
Taherian M, Wang H, Wang H: Pancreatic Ductal Adenocarcinoma: Molecular Pathology and Predictive Biomarkers. Cells. 2022; 11:3068.
Chen Q, Cherry DR, Nalawade V, Qiao EM, Kumar A, Lowy AM, Simpson DR, Murphy JD. Clinical Data Prediction Model to Identify Patients With Early-Stage Pancreatic Cancer. JCO Clin Cancer Inform. 2021;5:279–87.
Malhotra A, Rachet B, Bonaventure A, Pereira SP, Woods LM. Can we screen for pancreatic cancer? Identifying a sub-population of patients at high risk of subsequent diagnosis using machine learning techniques applied to primary care data. PLoS One. 2021;16(6):e0251876.
González-Gómez R, Pazo-Cid RA, Sarría L, Morcillo MÁ, Schuhmacher AJ: Diagnosis of Pancreatic Ductal Adenocarcinoma by Immuno-Positron Emission Tomography. J Clin Med. 2021; 10:1151.
Hameed BS, Krishnan UM: Artificial Intelligence-Driven Diagnosis of Pancreatic Cancer. Cancers. 2022; 14:5382.
Chang K, Creighton CJ, Davis C, Donehower L, Drummond J, Wheeler D, Ally A, Balasundaram M, Birol I, Butterfield YSN, et al. The Cancer Genome Atlas Pan-Cancer analysis project. Nat Genet. 2013;45(10):1113–20.
Arjmand B, Hamidpour SK, Tayanloo-Beik A, Goodarzi P, Aghayan HR, Adibi H, Larijani B: Machine learning: a new prospect in multi-omics data analysis of cancer. Front Genet. 2022; 13:824451.
Cai Z, Poulos RC, Liu J, Zhong Q: Machine learning for multi-omics data integration in cancer. iScience 2022, 25(2):103798.
Wu H, Ou S, Zhang H, Huang R, Yu S, Zhao M, Tai S. Advances in biomarkers and techniques for pancreatic cancer diagnosis. Cancer Cell Int. 2022;22(1):220.
Zhang W-H, Wang W-Q, Han X, Gao H-L, Li T-J, Xu S-S, Li S, Xu H-X, Li H, Ye L-Y, et al. Advances on diagnostic biomarkers of pancreatic ductal adenocarcinoma: A systems biology perspective. Comput Struct Biotechnol J. 2020;18:3606–14.
Karar ME, Alotaibi B, Alotaibi M. Intelligent medical IoT-enabled automated microscopic image diagnosis of acute blood cancers. 2022;22(6):2348.
Lee J, Lee HS, Park SB, Kim C, Kim K, Jung DE, Song SY: Identification of circulating serum miRNAs as novel biomarkers in pancreatic cancer using a penalized algorithm. Int J Mol Sci. 2021; 22:1007.
Hsu T-K, Liu T-Y, Gould B, Decapite C, Zureikat A, Paniccia A, Ariazi E, Bertin M, Bourgon R, Coil K et al: Abstract PO-007: Plasma-based detection of pancreatic cancer: A multiomics approach. Cancer Res 2021, 81(22_Supplement):PO-007-PO-007.
Ko J, Bhagwat N, Yee SS, Ortiz N, Sahmoud A, Black T, Aiello NM, McKenzie L, O’Hara M, Redlinger C, et al. Combining machine learning and nanofluidic technology to diagnose pancreatic cancer using exosomes. ACS Nano. 2017;11(11):11182–93.
Lepowsky E, Ghaderinezhad F, Knowlton S, Tasoglu S. Paper-based assays for urine analysis Biomicrofluidics. 2017;11(5): 051501.
Radon TP, Massat NJ, Jones R, Alrawashdeh W, Dumartin L, Ennis D, Duffy SW, Kocher HM, Pereira SP, Guarner L, et al. Identification of a three-biomarker panel in urine for early detection of pancreatic adenocarcinoma. Clin Cancer Res. 2015;21(15):3512–21.
Debernardi S, Massat NJ, Radon TP, Sangaralingam A, Banissi A, Ennis DP, Dowe T, Chelala C, Pereira SP, Kocher HM, et al. Noninvasive urinary miRNA biomarkers for early detection of pancreatic adenocarcinoma. Am J Cancer Res. 2015;5(11):3455–66.
Debernardi S, O’Brien H, Algahmdi AS, Malats N, Stewart GD, Plješa-Ercegovac M, Costello E, Greenhalf W, Saad A, Roberts R, et al. A combination of urinary biomarker panel and PancRISK score for earlier detection of pancreatic cancer: A case–control study. PLoS Med. 2020;17(12): e1003489.
Ko J, Carpenter E, Issadore D. Detection and isolation of circulating exosomes and microvesicles for cancer monitoring and diagnostics using micro-/nano-based devices. Analyst. 2016;141(2):450–60.
Hyenne V, Goetz JG, Osmani N. Liquid Biopsies: Flowing Biomarkers. In: Caballero D, Kundu SC, Reis RL, editors. Microfluidics and Biosensors in Cancer Research: Applications in Cancer Modeling and Theranostics. Cham: Springer International Publishing; 2022. p. 341–68.
Liu Y, Li S, Liu Y: Machine learning-driven multiobjective optimization: an opportunity of microfluidic platforms applied in cancer research. Cells. 2022; 11:905.
Chavez-Pineda OG, Rodriguez-Moncayo R, Cedillo-Alcantar DF, Guevara-Pantoja PE, Amador-Hernandez JU, Garcia-Cordero JL. Microfluidic systems for the analysis of blood-derived molecular biomarkers. Electrophoresis. 2022;43(16–17):1667–700.
Mukhin N, Konoplev G, Oseev A, Schmidt M-P, Stepanova O, Kozyrev A, Dmitriev A, Hirsch S: Label-free protein detection by micro-acoustic biosensor coupled with electrical field sorting. Theoretical study in urine models. Sensors. 2021; 21:2555 .
Garcia-Cordero JL, Maerkl SJ. Microfluidic systems for cancer diagnostics. Curr Opin Biotechnol. 2020;65:37–44.
Žvirblytė J, Mažutis L. Microfluidics for cancer biomarker discovery, research, and clinical application. In: Caballero D, Kundu SC, Reis RL, editors. Microfluidics and biosensors in cancer research: applications in cancer modeling and theranostics. Cham: Springer International Publishing; 2022. p. 499–524.
Long NP, Jung KH, Anh NH, Yan HH, Nghi TD, Park S, Yoon SJ, Min JE, Kim HM, Lim JH et al: An integrative data mining and omics-based translational model for the identification and validation of oncogenic biomarkers of pancreatic cancer. Cancers. 2019; 11:155.
Lee H-A, Chen K-W, Hsu C-Y: Prediction model for pancreatic cancer-A population-based study from NHIRD. Cancers. 2022; 14:882.
Yokoyama S, Hamada T, Higashi M, Matsuo K, Maemura K, Kurahara H, Horinouchi M, Hiraki T, Sugimoto T, Akahane T, et al. Predicted prognosis of patients with pancreatic cancer by Machine learning. Clin Cancer Res. 2020;26(10):2411–21.
Liang Y, Schott D, Zhang Y, Wang Z, Nasief H, Paulson E, Hall W, Knechtges P, Erickson B, Li XA. Auto-segmentation of pancreatic tumor in multi-parametric MRI using deep convolutional neural networks. Radiother Oncol. 2020;145:193–200.
Aurna NF, Yousuf MA, Taher KA, Azad AKM, Moni MA. A classification of MRI brain tumor based on two stage feature level ensemble of deep CNN models. Comput Biol Med. 2022;146: 105539.
Chen PT, Wu T, Wang P, Chang D, Liu KL, Wu MS, Roth HR, Lee PC, Liao WC, Wang W: Pancreatic cancer detection on CT Scans with deep learning: a nationwide population-based study. Radiology 2022: 10.1148/radiol.220152.
Zeineldin RA, Karar ME, Elshaer Z, Coburger J, Wirtz CR, Burgert O, Mathis-Ullrich F. Explainability of deep neural networks for MRI analysis of brain tumors. Int J Comput Assist Radiol Surg. 2022;17(9):1673–83.
Faruqui N, Yousuf MA, Whaiduzzaman M, Azad AKM, Barros A, Moni MA. LungNet: A hybrid deep-CNN model for lung cancer diagnosis using CT and wearable sensor-based medical IoT data. Comput Biol Med. 2021;139: 104961.
Dhruv P, Naskar S: Image Classification Using Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN): A Review. In: Machine Learning and Information Processing: 2020// 2020; Singapore. Springer Singapore: 367–381.
Shouman MA, El-Fiky A, Hamada S, El-Sayed A, Karar ME. Computer-assisted lung diseases detection from pediatric chest radiography using long short-term memory networks. Comput Electr Eng. 2022;103: 108402.
Demir F. DeepCoroNet: A deep LSTM approach for automated detection of COVID-19 cases from chest X-ray images. Appl Soft Comput. 2021;103: 107160.
Tonozuka R, Itoi T, Nagata N, Kojima H, Sofuni A, Tsuchiya T, Ishii K, Tanaka R, Nagakawa Y, Mukai S. Deep learning analysis for the detection of pancreatic cancer on endosonographic images: a pilot study. 2021;28(1):95–104.
Udriștoiu AL, Cazacu IM, Gruionu LG, Gruionu G, Iacob AV, Burtea DE, Ungureanu BS, Costache MI, Constantin A, Popescu CF, et al. Real-time computer-aided diagnosis of focal pancreatic masses from endoscopic ultrasound imaging based on a hybrid convolutional and long short-term memory neural network model. PLoS One. 2021;16(6)e0251701.
Blyuss O, Zaikin A, Cherepanova V, Munblit D, Kiseleva EM, Prytomanova OM, Duffy SW, Crnogorac-Jurcevic T. Development of PancRISK, a urine biomarker-based risk score for stratified screening of pancreatic cancer patients. Br J Cancer. 2020;122(5):692–6.
Alpu Ö. PEKDEMİR G: The classification capability of urine biomarkers in the diagnosis of pancreatic cancer with logistic regression based on regularized approaches: a methodological research. Turkiye Klinikleri J Biostat. 2022;14(2):118–28.
Laxminarayanamma K, Krishnaiah RV, Sammulal P. Enhanced CNN model for pancreatic ductal adenocarcinoma classification based on proteomic data. Ingénierie des Systèmes d’Information. 2022;27(1):127–33.
Malek S, Melgani F, Bazi Y. One-dimensional convolutional neural networks for spectroscopic signal regression. J Chemom. 2018;32(5): e2977.
Van Houdt G, Mosquera C, Nápoles G. A review on the long short-term memory model. Artif Intell Rev. 2020;53(8):5929–55.
Gulli A, Kapoor A, Pal S: Deep Learning with TensorFlow 2 and Keras: Regression, ConvNets, GANs, RNNs, NLP, and more with TensorFlow 2 and the Keras API, 2nd Edition: Packt Publishing; 2019.
Sokolova M, Lapalme G. A systematic analysis of performance measures for classification tasks. Inf Process Manage. 2009;45(4):427–37.
Yi X, Walia E, Babyn P. Generative adversarial network in medical imaging: A review. Med Image Anal. 2019;58: 101552.
Karar ME, Shouman MA, Chalopin C. Adversarial neural network classifiers for COVID-19 diagnosis in ultrasound images. Comput Mat Continua. 2022;70(1):1683–97.
Rao RV. Teaching Learning Based Optimization Algorithm: And Its Engineering Applications, 1st Edition, Cham: Springer International Publishing; 2015.
Ang KM, El-kenawy E-SM, Abdelhamid AA, Ibrahim A, Alharbi AH, Khafaga DS, Tiang SS, Lim WH: Optimal design of convolutional neural network architectures using teaching-learning-based optimization for image classification. Symmetry. 2022; 14:2323.
Acknowledgements
Not Applicable.
Funding
All authors report that this research had no funding from any individual or organization.
Author information
Authors and Affiliations
Contributions
The authors confirm contribution to the paper as follows: Study conception and design: All authors. Analysis, implementation and interpretation of results: Mohamed Esmail Karar. Draft manuscript preparation: Mohamed Esmail Karar and Marwa Radad. All authors reviewed the results and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interest
The authors declare that they have no conflicts of interest to report regarding the present study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Karar, M.E., El-Fishawy, N. & Radad, M. Automated classification of urine biomarkers to diagnose pancreatic cancer using 1-D convolutional neural networks. J Biol Eng 17, 28 (2023). https://doi.org/10.1186/s13036-023-00340-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13036-023-00340-0