
Abstract
Mass spectrometry-based proteomics empowers deep profiling of proteome and protein posttranslational modifications (PTMs) in Alzheimer’s disease (AD). Here we review the advances and limitations in historic and recent AD proteomic research. Complementary to genetic mapping, proteomic studies not only validate canonical amyloid and tau pathways, but also uncover novel components in broad protein networks, such as RNA splicing, development, immunity, membrane transport, lipid metabolism, synaptic function, and mitochondrial activity. Meta-analysis of seven deep datasets reveals 2,698 differentially expressed (DE) proteins in the landscape of AD brain proteome (n = 12,017 proteins/genes), covering 35 reported AD genes and risk loci. The DE proteins contain cellular markers enriched in neurons, microglia, astrocytes, oligodendrocytes, and epithelial cells, supporting the involvement of diverse cell types in AD pathology. We discuss the hypothesized protective or detrimental roles of selected DE proteins, emphasizing top proteins in “amyloidome” (all biomolecules in amyloid plaques) and disease progression. Comprehensive PTM analysis represents another layer of molecular events in AD. In particular, tau PTMs are correlated with disease stages and indicate the heterogeneity of individual AD patients. Moreover, the unprecedented proteomic coverage of biofluids, such as cerebrospinal fluid and serum, procures novel putative AD biomarkers through meta-analysis. Thus, proteomics-driven systems biology presents a new frontier to link genotype, proteotype, and phenotype, accelerating the development of improved AD models and treatment strategies.
Similar content being viewed by others


Background
Alzheimer’s disease (AD) is an aging-associated neurodegenerative disorder, and as the most common form of dementia, afflicts approximately 5.8 million people in the United States [1]. It is estimated that 50 million people worldwide live with Alzheimer’s and other types of dementias [2]. As human populations age progressively, the economic burden AD poses to the healthcare system currently stands at $305 billion in the U.S., and in the near future, will grow immensely [1]. Typical onset of AD occurs after the age of 65 (late onset AD, LOAD), though less than 5 % of AD cases occur early (early onset AD, EOAD), while 1–2 % are inherited within families (familial AD) [3]. The primary clinical manifestations of the disease include profound cognitive decline, progressive memory loss, retrograde and anterograde amnesia, accompanied by severe histopathological changes, such as degeneration of the hippocampus and subsequent loss of cortical matter [4]. AD often manifests with additional comorbidities, such as movement and psychological disorders, as well as various sleep disturbances [1]. These heterogeneous symptoms confound diagnosis of AD in some cases [5]. Extensive molecular studies have revealed the pathological hallmarks of this malady: amyloid plaques comprised of amyloid-β (Aβ) peptides, and neurofibrillary tangles (NFT) containing hyperphosphorylated tau, which are used to categorize the disease stage (e.g. Braak stages) [6, 7]. Despite active investigation and drug development over decades [3, 8], and recent controversial approval of aducanumab (also known as Aduhelm) for AD treatment [9], precise causes of this brain degeneration are not fully understood, and a cure for this devastating disease still remains elusive.
The fundamental insights into AD pathogenesis come from complementary genetic/genomic and biochemical/proteomic studies. In 1984, Glenner and Wong isolated Aβ peptide from plaques in AD patients [10], which was later partially sequenced [11, 12], leading to subsequent gene cloning of β-amyloid precursor protein (APP) [13, 14]. This biochemical finding was later corroborated by mapping genetic mutations in causative AD genes, including APP in 1991 [15], and presenilins (PSEN1/PSEN2) in 1995 [16, 17]. The integration of biochemical and genetic evidence substantiates an intuitive molecular mechanism to AD, whereby the sequential proteolytic cleavage of APP by β-secretase (BACE1) and γ-secretase (containing PSEN1/PSEN2) produces amyloidogenic Aβ peptides [18,19,20]. Together, these results have ushered in the amyloid hypothesis, contending that Aβ species from APP cleavage play a central role in driving AD pathogenesis [21,22,23]. In parallel, hyperphosphorylated tau was purified as the dominant component of neurofibrillary tangles in AD brain tissues around 1986 [24,25,26,27]. Mutations to the tau gene (MAPT) were linked to several other neurodegenerative diseases, such as frontotemporal dementia (FTD) [28,29,30]. Again, biochemical and genetic evidence has established the tau hypothesis to propose its critical role in AD progression [31]. Experiments from the 2000s suggest that Aβ aggregates prior to cognitive defects, and later, downstream tau accumulation drives neurotoxicity [32,33,34]. The current paradigm has shifted from Aβ deposition towards understanding the toxicity of different Aβ forms, especially soluble Aβ oligomers [35]. Misfolded Aβ and tau may also transmit as “pathological seeds” during neurodegeneration [36].
Alternatively, a myriad of other models have been postulated: cholinergic [37, 38], calcium [39, 40], mitochondrial [41, 42], membrane trafficking [43, 44], inflammatory [45,46,47], lymphatic [48, 49], microorganism infection [50,51,52], neurovascular [53, 54], and cellular phase [55] hypotheses, although these alternative concepts are still entangled with the framework of amyloid and tau theories. The fact remains that Aβ may be essential, but not sufficient, to cause AD [56]. Nevertheless, the consensus molecular pathways, cellular circuits, and pathophysiological mechanisms mediating Aβ and tau toxicity are not fully understood yet.
Discoveries in the AD field have been accelerated by the innovations of large-scale sequencing technologies in genomics [57] and proteomics [58]. In addition to APP, PSEN1, and PSEN2, early genetic studies discovered the major AD risk gene of APOE4 in 1993 [59, 60]. Current high-throughput genetic/genomic analysis revealed new risk genes, such as TREM2 [61, 62] and UNC5C [63], and more than 160 possible risk loci linked to amyloid, tau, endocytosis, and immunity (collected in Supplementary Table S1) [64,65,66,67,68]. In 2014, the National Institutes on Aging initiated the Accelerating Medicines Partnership (AMP)-AD program to leverage multidisciplinary strategies across academia and industry, aiming towards the discovery of novel therapeutic targets and biomarkers [69]. The multi-omics approach offers an indispensable, systematic tool for understanding AD’s complexity. While the AD genetics field has been reviewed extensively over the years [70,71,72,73], here we intend to review the field of AD proteomics. Searching PubMed’s literature repository with terms “Alzheimer’s or Alzheimer” and “Proteomics or Proteome” returned more than 2,000 publications, and over 300 papers in 2020, although the AD proteomics field emerged at the turn of the millennia and has steadily increased in prominence. Much of the recent work endeavors to profile deep brain proteomes [74,75,76,77], analyze large sample sizes [78], dissect sub-proteomes [79,80,81], investigate complex PTM patterns [74, 82], and identify new biomarker candidates in biofluids [74, 75, 83,84,85]. We discuss the historical, current, and future status of protein analytical technologies and application, and provide a holistic view of the AD proteomic landscape by meta-analysis, unraveling new insights into AD pathogenesis and potential biomarkers.
The Evolving Technologies of Protein Analysis and Mass Spectrometry
The major events contributing to mass spectrometry (MS)-based protein analysis during the last century are outlined (Fig. 1). Preceding MS-based proteomic analysis, Pehr Edman reported a technique (Edman degradation) for sequencing the amino acids of proteins in 1967 [86], but only up to 30 amino acids could be sequenced and each residue took approximately one hour [87]. It was this technique with which Wong et al. sequenced the first 28 residues in the Aβ peptides [11]. Several groups provided proof-of-principle evidence for sequencing amino acids of oligopeptides with commercial mass spectrometers that became available in the 1960s [88,89,90,91]. However, the MS application in protein sequencing was limited until the complete development of two Nobel Prize-winning methods for soft ionization in late 1980s [92]: matrix-assisted laser desorption/ionization (MALDI) [93] and electrospray ionization (ESI) [94]. MALDI was a popular ionization technique early on, and ESI is now the dominant method for proteomic analysis within complex mixtures [95]. The development of these technologies has made possible the high throughput analysis of proteins by mass spectrometry.

Major historical events in mass spectrometry and AD research. Edman degradation is also included. The AD proteomics studies are highlighted. The information is compiled from several online resources (https://www.nature.com/collections/aajfehieag, https://www.hupo.org/Proteomics-Timeline, https://masspec.scripps.edu/learn/ms, https://www.alzforum.org/timeline, and https://www.alzheimers.net/history-of-alzheimers) and references [74, 75, 79, 80, 82, 96,97,98,99,100,101,102]. MS detection instruments include sector MS, time-of-flight (TOF), quadrupole, Fourier-transform ion cyclotron resonance (FTICR), triple quadrupole, and orbitrap. Common ionization methods include atmospheric pressure chemical ionization (APCI), electrospray ionization (ESI), matrix-assisted laser desorption/ionization (MALDI), desorption electrospray ionization (DESI), and direct analysis in real time (DART). Biomolecules may be fractionated by nanoscale liquid chromatography (LC) with sub-2 μm resin to improve resolution, or by multi-dimensional protein identification technology (MudPIT). MS precursor ions can be fragmented by collision-induced dissociation (CID), electron-capture dissociation (ECD), electron-transfer dissociation (ETD), or higher-energy collisional dissociation (HCD). Quantitative strategies include two dimensional polyacryl amide gel electrophoresis (2D PAGE), isotope-coded affinity tag (ICAT), stable isotope labeling by/with amino acids in cell culture (SILAC), tandem mass tag (TMT), isobaric tags for relative and absolute quantitation (iTRAQ), and the data-independent acquisition (DIA) methods. Selected/multiple reaction monitoring (SRM/MRM) is a MS technique for analyzing pre-defined molecules. Database search tools contain SEQUEST, MASCOT, and the target-decoy strategy. CAA: cerebral amyloid angiopathy; LCM: laser capture microdissection; GWAS: genome-wide association study; CSF: cerebrospinal fluid; and FDA: the United States Food and Drug Administration
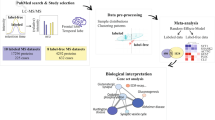
MS-based proteomic analysis often consists of three major steps (Fig. 2): (i) pre-MS sample processing, (ii) MS data acquisition, and (iii) post-MS bioinformatics; each step offers a wide variety of strategies to achieve final analytical goals of protein identification and quantification. For instance, one may choose top-down or bottom-up strategies, which analyze full-length proteins [103] or peptides (e.g., trypsin digested proteins) [104], respectively. Due to the highly diverse biochemical properties within the proteome, the top-down approach of analyzing all full-length proteins under one uniform condition is challenging. One of the most comprehensive top-down studies identified more than 3,000 protein isoforms from about 1,000 human genes [105]. In contrast, bottom-up proteomics relies on the analysis of peptides digested from full-length proteins, making the samples biochemically homogenous and thus improving proteome coverage to more than 10,000 proteins, although there is a gap to map identified peptides to proteins [106,107,108]. In bottom-up proteomics, digested peptides are usually separated by liquid chromatography (LC), ionized by ESI, and analyzed by tandem mass spectrometry (MS/MS or MS2) [109,110,111]. Isoelectric focusing is also used for high-resolution peptide separation [112]. It should be noted that MS2 itself is a powerful separation tool, enabling the selection of a single peptide from other co-eluted peptides based on the mass-to-charge ratio (m/z). Because of the sensitivity, throughput, robustness, and proteome coverage, the bottom-up method is commonly applied to untargeted proteome analysis.

Protein samples are analyzed by pre-MS sample processing, MS data acquisition and post-MS bioinformatic data processing. Protein quantification can be achieved by label-free methods, such as spectral counting (SC), extracted ion current (XIC), and data-independent acquisition (DIA), or by isotope-labeling methods, such as SILAC and TMT. In addition, MS may also be operated to analyze targeted proteins/peptides by multiple reaction monitoring (MRM) or parallel reaction monitoring (PRM)
Numerous bottom-up proteomics strategies are available, categorized into label-free and stable isotope labeling methods. The label-free methods have evolved from semi-quantitative spectral counting, which estimates the level of a protein by the total number of assigned MS2 spectra [113], to more accurate extracted ion currents in MS1 [114] or MS2 scans [115, 116]. The stable isotope labeling methods have begun with chemical protein labeling, such as Cys-reactive ICAT [117], amine-reactive dimethyl labeling [118], and then metabolic protein labeling like SILAC [119, 120], in which peptide/protein quantification is attained by MS1 peaks from the pooled samples with differential labels. However, the pooling increases the complexity of MS1 spectra, reducing the efficiency of peptide identification. To overcome this limitation, isobaric peptide labeling methods, such as iTRAQ [121], TMT [122] and DiLeu [123], have been developed to generate isobaric MS1 peaks and enable multiplexed tagging (e.g. 11-plex, 16-plex, 18-plex, and 27-plex TMT) [76, 124, 125]. After fragmentation of the isobaric peaks, different reporter ions are released for relative quantification in MS2/3 scans [126].
During MS data acquisition, the instrument is operated in the mode of data-dependent acquisition (DDA) [104], or an alternative mode of data-independent acquisition (DIA) [116]. In DDA, the spectrometer utilizes MS1 survey scans to select the most abundant peptide ions (e.g. top 10) in a small isolation window (e.g. 0.5-2 m/z), and then sequentially fragment them to generate MS2 scans. Though effective, some weak peptide ions are skipped in DDA, resulting in missing values. To alleviate this issue of undersampling, DIA sets up continuous isolation windows (e.g. 10–50 m/z) across the entire mass range and fragments all ions indiscriminately. The scanning of all DIA windows, however, increases time dependency. Therefore DIA was inefficient until rapidly scanning instruments became available [116]. Regarding MS instruments, early analyses utilized time-of-flight (TOF) mass spectrometers that were readily coupled with MALDI [92]. Later, triple quadrupoles (QqQ) and linear ion traps were popularized as low-resolution MS due to their cost effectiveness, while expensive Fourier-transform instruments (FTICR) were used for high-resolution detection [92]. Nowadays, with ion separation capacity provided by ion mobility spectrometry (IMS), TOF instruments have been significantly improved [127]. Moreover, the invention of compact Orbitrap instruments has revolutionized MS-based proteomics by offering a robust and high-resolution approach to proteome profiling [128].
Post-MS bioinformatics tools extract accurate information from raw MS data to protein identification and quantification. Large protein databases or MS spectral libraries may be searched with computational programs to assign MS2 spectra to peptides. A large number of search algorithms have been developed and reviewed elsewhere [129, 130]. One caveat to large-scale protein database search is the risk of false discovery, which has been addressed by the introduction of the target-decoy strategy to reduce the false discovery rate (FDR) of identified proteins (e.g. <1 %) [110, 131]. Following protein identification, quantification is often performed to assess protein abundances within samples, followed by differential expression (DE) and network analysis to derive testable hypotheses.
Overall, robust bottom-up proteomic methods require the seamless combination of pre-MS, MS and post-MS settings. The number of identified proteins is an indispensable metric for assessing proteomic techniques because crucial regulatory proteins are often present at low abundance in cells, which cannot be detected by a shallow proteomic analysis. To achieve ultra-deep proteome coverage [119], a common proteomics platform (e.g. TMT-LC/LC-MS/MS) utilizes multiplexed TMT labeling, two-dimensional HPLC (e.g. basic pH and acidic pH reverse phase liquid chromatography), and DDA in high resolution MS (Fig. 3) [117, 118]. This platform recently generated numerous deep AD proteomic datasets. Alternatively, LC-IMS-DIA-MS is a promising label-free platform, which combines ion mobility spectrometry, one-dimensional LC, and data-independent acquisition in MS to analyze about 10,000 proteins from brain tissue [132]. In addition to MS, proteins can be analyzed using specific affinity reagents such as antibodies (e.g. protein chips, ELISA, and proximity extension assay) [133,134,135] and aptamers (e.g. SOMAscan) [136]. These non-MS techniques are advantageous in processing a large number of samples, but current drawbacks of reagent availability and specificity prevent whole proteome coverage.

A deep proteomic workflow of TMT-LC/LC-MS/MS. The 16-plex TMT reagents are represented by different colors, which react with amine groups at peptide N-termini and lysine residues. In addition to the amine-reactive group, the isobaric TMT reagents also contain a reporter ion group and a balance group. The mass difference in the reporter group is offset by the balance group, enabling isobaric labeling and pooling. The pooled peptides are fractionated by LC/LC, and identified as mixed, isobaric precursor ions. After fragmentation, the TMT tags are cleaved between the reporter and balance groups, generating reporter ions for quantification
Towards Unbiased Analysis of the AD Proteome
Evolving proteomic technologies have explored clinical AD specimens to elucidate the underlying biomolecular mechanisms of the disease in different time periods (Fig. 1). In the pre-genomic era, incomplete protein databases limited MS analysis to known AD proteins (e.g. Aβ and tau). LC-ESI-MS and MALDI-TOF-MS investigated the composition of amyloid plaques, identifying different Aβ peptides in soluble and insoluble forms [96, 137]. MS also identified abnormally modified tau species, including phosphorylation, acetylation, and deamidation [97]. With the completion of the Human Genome Project in 2003, the first comprehensive human protein database became available, providing the foundation for large-scale and unbiased proteomic analyses; however, it took another decade for proteomics technology to develop for matching the depth of the human proteome.
Given the early challenges to analyzing the whole proteome, sub-proteome analysis appeared to be an effective strategy. In 2004, Liao et al. characterized the amyloid plaque proteome from postmortem AD brain tissues through laser capture microdissection (LCM), a technique for dissecting and isolating a tissue region of interest [98]. Amyloid plaques labeled with thioflavin-S were captured, followed by protein extraction and MS analysis [138], identifying a total of 488 proteins. Comparison between the plaques and non-plaque tissues suggested 26 DE proteins enriched in the plaque area. This pilot study demonstrated that a large number of proteins may accumulate in amyloid plaques [139]. For simplicity, we use the term “amyloidome” to represent all biomolecules in amyloid plaques. Using a similar approach, Drummond et al. quantified over 900 proteins in the amyloidome from AD subtypes, reporting protein difference of rapidly progressive AD and sporadic AD [140]. In 2019, Xiong et al. re-analyzed the AD amyloidome in greater depth with LCM and the current TMT-LC/LC-MS/MS method, increasing the proteome coverage to more than 4,000 proteins, including 40 DE proteins highly enriched in the plaque region, including APOE and complement proteins [80].
Biochemical differential extraction of AD specimens offers an alternative means of enriching the aggregate proteome due to its low solubility [141, 142]. In 2009, Gozal et al. set out to analyze the detergent-insoluble proteome in AD; sequential fractionation in conjunction with gel electrophoresis and LC-MS/MS profiled 512 proteins, of which 11 proteins were increased in the AD samples [143]. Significant progress was made in 2013 wherein Bai et al., reported the most comprehensive analysis of the brain insoluble proteome, covering 4,216 proteins with 36 DE proteins in AD [79]. As expected, the most enriched proteins were Aβ, tau, APOE and complement components, together with proteins involved with RNA splicing, phosphorylation regulation, synaptic plasticity, and mitochondrial function. Surprisingly, the entire U1 snRNP splicing complex (e.g. U1-70 K, U1A, U1C, U1 snRNA and a U1-70 K cleaved fragment) is present in the insoluble proteome and form a new type of cytoplasmic tangle-like fibril in sporadic and familial AD cases [79, 144,145,146,147]. Together with concomitant RNA splicing defects revealed by transcriptomics [79, 148, 149], these results suggest the U1 snRNP pathology and its associated RNA splicing dysfunction in AD. Further studies in cell culture, fly and mouse models link splicing defects with the pathogenesis of Alzheimer’s disease [150,151,152].
In AD, synaptic loss occurs early and is highly correlated with cognitive impairment [153]; therefore, the synapse subproteome has been frequently visited [154,155,156]. The postsynaptic density (PSD) is an integral structure for synaptic function, organized by supramolecular complexes consisting of neurotransmitter receptors, scaffold proteins, and other regulatory constitutes [157]. Zhou et al. used ultracentrifugation and differential extraction to isolate PSD from AD brain, and analyzed 494 PSD components by the label free method [154]. More recently, two groups utilized the advanced TMT method to quantitate ~ 5,000 proteins in synaptic subproteome [155, 156]. In particular, Carlyle et al. examined 100 brains in different disease stages of AD patients, revealing that cognitive impairment is associated with significant metabolic changes and the increased inflammatory response [156].
Beyond subproteome studies, numerous studies attempted to characterize the whole proteomic changes in AD brain, using both 2D gels [158] or bottom-up MS to procure < 1,000 and 1,408-6,533 proteins [78, 159,160,161,162], respectively. For example, Johnson et al. profiled the proteome in more than 2,000 brains, and network analysis revealed a large number of AD-associated protein modules involved with synapse/neuron, mitochondrial function, sugar metabolism, extracellular matrix, cytoskeleton, and RNA binding/splicing [78]. These studies also identified protein modules enriched in neurons, microglia, and astrocytes [78, 160, 161]. In 2015, an advanced LC/LC-MS/MS approach enabled the identification of > 10,000 proteins in the AD brain [163]. Coupling this approach to a TMT labeling approach, deep proteome profiling became feasible [164, 165]. In 2020, Bai et al., presented such a study to compare 14,513 proteins in five groups of postmortem brain tissues: (i) controls with low plaques and tangles, (ii) controls with high pathology but no cognitive impairment, (iii) mild cognitive impairment (MCI), (iv) AD with high pathology, and (v) progressive supranuclear palsy (PSP) with only tau pathology [74]. This study identified 173 DE proteins, in which the vast majority were specific to AD when compared to the PSP cases. The DE proteins were clustered into three major co-expression patterns as derived from the weighted gene correlation network analysis (WGCNA) algorithm [166]: (i) an Aβ-correlated pattern (continuous accumulation from the control, MCI to AD), (ii) a tau-correlated pattern (steady from the control to MCI, but increased in AD), and (iii) a reversely correlated pattern with tau (stable from the control to MCI, but decreased in AD). Combining interactome and pathway analysis of the DE proteins revealed 17 altered pathways, including Aβ, WNT, TGF-β/BMP, G protein, integrin signaling, innate immunity, adaptive immunity, complement, cytoskeleton and extracellular matrix, iron homeostasis, membrane transport, lipid metabolism, protein folding and degradation, synaptic, neurotrophic and mitochondrial functions. The deep AD proteomics result indicates a broad, dynamic proteomic perturbation during AD progression [74].
To date, three independent groups used the TMT-LC/LC-MS/MS platform to generate seven deep proteomic datasets (each identifying > 8,000 proteins) from a total of 192 AD and control cortical specimens (Fig. 4) [74,75,76,77]. These datasets offer an excellent opportunity for a meta-analysis to enhance the statistical power, compiled into a list of 12,017 unique gene products (one protein per gene, Supplementary Table S2). The log2(AD/control) ratio and associated one-tailed p-value were derived, followed by p-value combination using Fisher’s method and Benjamini-Hochberg FDR correction, resulting in 2,698 DE proteins (FDR < 1 %). Based on cell type specific gene profiles [167], the DE list contains 638 cell type specific genes/proteins, including 140 in astrocytes, 337 in neurons, 10 in oligodendrocytes, 118 in microglia, and 33 in endothelia (Supplementary Table S3), supporting the contribution of diverse cell types to AD pathogenesis.

A meta-analysis integrating 7 deep AD datasets and identifying 12,017 proteins. In each dataset, the p value for control-AD comparison is derived by one-tailed t-test. The p values are combined by the Fisher’s method, followed by multiple-hypothesis correction using the Benjamini-Hochberg FDR procedure. A total of 2,698 DE proteins are accepted with the FDR cutoff of 1 %. Compared to 167 reported AD genes and risk loci, 35 are overlapped with the protein DE list. Based on cell type specific genes, the DE list contains 638 genes/proteins specific to all five major cell types in the brain
Functional Insights from the AD Proteomic Landscape
In addition to recapitulating the known accumulation of Aβ, tau and APOE in AD brain, the proteomic landscape reveals 1,484 upregulated proteins and 1,214 downregulated proteins (Fig. 4, Supplementary Table S2) [74,75,76,77]. Interestingly, the DE list contains 35 reported AD genes and risk loci, including APP, MAPT, CLU, APOE, ICA1, PTK2B, CD2AP, SNX32, ADAM17, FERMT2, CARHSP1, ANK3, ABI3, PLEKHA1, BCKDK, GRN, COX7C, TMEM163, CNTNAP2, ADAMTS1, NDUFAF7, SEL1L, RTFDC1, AGRN, ICA1L, SPRED2, HLA-DRB1, INPP5D, TPBG, PLCG2, IDUA, CTSH, PRKCH, PFDN1, and SHARPIN (Supplementary Table S1, ranked by protein false discovery rate). Along this line, a proteome-wide association study (PWAS) was reported to integrated GWAS data with brain proteomics results to determine 11 causal AD genes [168].
Proteome-transcriptome comparison suggests both RNA-dependent and RNA-independent expression changes in AD [74, 75]. Strikingly, these RNA-independent DE proteins are often highly correlated with the Aβ level, and are enriched in amyloidome, such as MDK, PTN, NTN1, SMOC1, SFRP1, SLIT2, HTRA1, and FLT1 [74, 80, 169]. Their RNA independence was validated through complementary proteomic and transcriptomic analysis of 5xFAD mice, an AD mouse model of amyloidosis. MDK, NTN1, and SFRP1 were also shown to bind directly to Aβ peptide [74] [169]. Given that amyloid plaques grow up to 100 μm in size, the enormous three-dimensional complexity, diverse cellular structures, and vasculature [170] of these plaques may create a quasi-cellular “black hole”, trapping within itself a broad cohort of associated proteins which profoundly impacts protein turnover. Among these proteins in amyloidome, SFRP1 (a regulator of WNT signaling) was reported to affect the formation of Aβ oligomers, as SFRP1 inhibition reduces plaque formation and partially rescues cognitive deficits in an AD mouse model (APP/PS1 mice), supporting its role in AD pathogenesis [169].
AD development spans a long prodromal stage before progressive neurodegeneration, implicating a resilient mechanism to Aβ toxicity in human brain, followed by exacerbated insults to outweigh the resilience and drive irreversible degeneration [55], illustrated in an equilibrium model (Fig. 5). Prior to the onset of AD, some of the identified DE proteins might play protective roles, such as netrin-1 (NTN1), netrin-3 (NTN3), midkine (MDK), pleiotrophin (PTN), hepatocyte growth factor (HGF), and WNT5B, particularly in the human resilient cases that display high Aβ pathology but without clinical symptoms [74]. Literary evidence corroborates this evaluation, such as in the case of intracerebroventricular administration of netrin-1 which improved working memory in AD mice [171]. The netrin receptor UNC5C was identified as an AD risk gene [63], and NTN5 (another netrin family member) was located in an AD risk loci in a GWAS [68]. Midkine and pleiotrophin, in the same family of neurite growth-promoting factor, were shown to directly interact with Aβ with high affinity, possibly interfering with Aβ oligomerization and diminishing its toxicity [172, 173]. Upregulation of HGF signaling may enhance synaptogenesis, thus recompensing synaptic loss in AD [174]. Furthermore, the WNT pathway was proposed to promote the viability of microglia, which was induced by the AD risk gene TREM2 [175].

The equilibrium model of deleterious and protective factors during AD disease progression. Among the biological processes and cellular pathways activated at the asymptomatic stage of AD, some may exert protective roles. However, with exacerbation of the harmful insults during disease progression, the protective effect is exhausted. The resulting imbalance leads to neuronal degeneration and the onset of clinical symptoms. The pathway information is extracted from current AD proteomic studies [74, 75, 78, 161]
The transition from MCI to AD may be induced by the upregulation of detrimental events and the diminishing of protective events, consubstantial with marked increase of tau pathology. The DE list (Supplementary Table S2) contains a large number of complement proteins (C1QA, C1QB, C1QC, C1QL1, C1QTNF5, C1R, C1S, C3, C4A, and C4B) [74, 75]. Complement components are immensely elevated in the aggregated subproteome of the AD brain [73]. The complement system activates microglia to trim synapses in AD [176].The complement genes CR1 and C7 were identified as AD risk genes in large-scale GWAS analyses [64, 177]. Deleting C3 in the AD (APP/PS1) mice was shown to rescue synapse loss and memory decline [178]. Knocking out of C3aR (C3a receptor) in a tauopathy model (PS19 mice) also reduced inflammation, synaptic deficits and tau pathology [179]. Therefore, the complement system influences multiple molecular and cellular events during the progression of Alzheimer’s disease [180].
In contrast, many neurotrophic factors are decreased during the transition from MCI to AD, such as VGF, BDNF, NRN1, and CRH [74, 75]. Notably, the former four neurotrophic factors are connected together surrounding the BDNF hub in protein-protein interaction network. BDNF has been long viewed as a component related to cognitive deficit, aging and AD [181]. Multiscale causal network analysis of AD multi-omics datasets using the RIMBANET software ranks VGF as a master regulator [182]. The overexpression of VGF in the 5xFAD mice attenuates the pathology and improves memory performance. NRN1 can enhance neurite outgrowth and synapse maturation, and administration of recombinant NRN1 protein in a mouse model (Tg2576) improves synaptic plasticity [183]. In addition, NPTX2 (a binding protein of AMPA type glutamate receptors) is markedly decreased in AD. Its gene knockout in the AD (APP/PS1) mice leads to reduced GluA4 expression and increased neuron excitability [184]. Collectively, the decrease of these key proteins may be a pathophysiological mechanism contributing to synaptic failure and cognitive impairment in AD.
Although we use a simple equilibrium model to discuss the roles of identified DE proteins during AD progression (Fig. 5), it is highly possible that the function of these AD-associated proteins is multifactorial during the long-lasting course of disease development, and whether they play a protective or detrimental role might be dependent on the temporal, regional and cellular contexts.
Post-translationally Modified Proteomes in AD
Protein functionality in vivo is tightly regulated by a myriad of posttranslational modifications and dynamic protein-protein interactions. In neurodegenerative diseases exhibiting tauopathy, structurally distinct conformers of tau fibrils are characterized to classify disease subtypes [185]. Tau aggregation is associated with extensive PTMs, including phosphorylation, ubiquitination, acetylation, methylation, glycosylation, sumoylation, oxidation and cleavage [186,187,188]. A plausible explanation to these disease specific tau conformers could be hidden in the realms of PTMs. Arakhamia et al. utilized MS and cryo-electron microscopy (cryo-EM) to map PTMs on the structures of tau filaments, and found that ubiquitination of tau may contribute to fibril diversity [189]. Recently, tau was extracted from 32 AD patients and characterized by MS and seeding activity for protein aggregation. The seeding capacity was found to significantly correlate with phosphorylation at T231, S235 and S262 sites [190].
Tau acetylation is known to elevate during early and moderate Braak stages of tauopathy and may slow down tau degradation [191]. Acetylation of K280/K281 sites was suggested to promote the aggregation of tau [192]. The status of tau acetylation is regulated by the p300 acetyltransferase and the SIRT1 deacetylase. Chemical inhibition of the p300 activity reduced the acetylation level of tau, and thus eliminated tau-related pathology, suggesting a possible treatment strategy to alleviate the tauopathy [191].
More recently, Wesseling et al. reported the most comprehensive tau PTM analysis in AD brains by an array of MS strategies. A total of 95 modification events (55 in phosphorylation, 17 in ubiquitination, 19 of acetylation and 4 in methylation) were identified on multiple tau isoforms from 42 control and 49 AD cases. Using tau internal standards, the stoichiometry of some PTM sites was also measured. The PTM events may occur in order, and contribute to tau aggregation and seeding activity by altering surface charge. These profiles of tau PTMs in AD patients reveal molecular heterogeneity and disease stages.
Globally, Bai et al. identified 46,612 phosphopeptides (34,173 phosphosites in 7,083 proteins) in brain tissues at different stages of AD subjects by the combination of phosphopeptide enrichment and TMT-LC/LC-MS/MS approach, revealing 873 DE phosphopeptides in 398 proteins [74]. The study also identified in AD hyperphosphorylated tau (56 phosphosites) and osteopontin (SPP1), a glycoprotein in the immune response. Interestingly, the IKAP algorithm [193] was used to derive the activities of 186 kinases from the phosphoproteome, suggesting 28 differential kinase activities, covering all known 11 tau kinases [188]. Integration of kinase activities and levels collectively indicate the activation of MAP kinase signaling in AD [74]. Using the similar method, Ping et al. reported another independent quantitative dataset of AD phosphoproteome (33,652 phosphosites in 8,415 proteins) [194]. The phosphoproteome profiling provides another layer of proteomic information during AD development.
In addition, the global analysis of protein ubiquitination in AD was reported, covering 4,291 ubiquitinated sites in 1,682 proteins, in which more than 800 sites were altered in AD [195]. Specific polyubiquitination chains (Lys11, Lys48 and Lys63) were also found to accumulate in AD brain tissues [196]. These data implicate the deregulation of the ubiquitin system in AD. Protein N-glycosylation is one of the most prevalent PTMs in cells [197]. Zhang et al. profiled 2,294 N-glycosylation sites in 1,132 proteins in human brains to show AD-associated changes of 178 N-glycosylation sites, suggesting the aberration of protein N-glycosylation in the disease [198].
In summary, current MS platforms and enrichment strategies enable either focused or proteome-wide analysis of PTMs in AD specimens. Large datasets have been emerging, especially in phosphoproteome. A plethora of PTM information is also available online (www.phosphosite.org), although the data are not AD-specific. Together, these comprehensive PTM datasets will be valuable for investigation of biochemical signaling pathways during AD pathogenesis.
Proteomics-Based Biomarker Discovery in AD
Exciting progress has been made toward MS-based proteomic profiling of cerebrospinal fluid (CSF) for biomarker discovery [74, 75, 83,84,85, 199]. In many proteomic experiments, highly abundant proteins tend to mask proteins present in low amounts, so immunodepletion of these abundant proteins is a frequently used procedure for improving the detection of proteins of low abundance. Sathe et al. reported a pilot deep CSF study from 5 control and 5 AD cases, in which CSF samples were first immunodepleted to remove 14 most abundant proteins, and then analyzed by the TMT-LC/LC-MS/MS approach. The study quantified 2,327 proteins with 139 DE proteins, including MAPT, NPTX2, VGF, GFAP, NCAM1, PKM and YWHAG [83]. Higginbotham et al. also used immunodepletion to enhance the depth of CSF proteome, profiled 2,875 proteins from 20 control and 20 AD cases, revealing 528 DE proteins, including MAPT, NEFL, GAP43, FABP3, CHI3L1, NRGN; VGF, GDI1 and SMOC1 [75].
Wang et al. however performed extensive LC fractionation to bypass immunodepletion, and profiled 5,941 CSF proteins from 5 control and 8 AD cases, significantly increasing the coverage of CSF proteome [74, 85]. The study yielded 355 DE proteins, revealing increases to SMOC1 and TGFB2, and decreases to a large group of mitochondrial proteins. Alternatively, Bader et al. developed an advanced label-free platform to profile undepleted CSF samples from three independent cohorts of similar size (totaling 109 control and 88 AD cases). The study analyzed 1,445, 1,478 and 1,483 proteins in the three cohorts, highlighting the three DE proteins of tau, SOD1, and PARK7, which are also linked to neurodegeneration by genetic data [84]. In all above studies, the conclusions were also supported, at least partially, by validation experiments using antibody-based detection, targeted MS approaches, or replicated proteomic analysis.
The meta-analysis of these six deep CSF datasets above (each > 1,000 proteins, summed 260 AD and control subjects) [74, 75, 83,84,85] yielded a list of 5,939 proteins, which includes 311 upregulated and 165 downregulated proteins in AD (Fig. 6, Supplementary Table S4, FDR < 1 %). To enhance the selection of specific CSF biomarkers, integrating CSF and brain proteomes is a common strategy [74, 75, 78, 85]. We then overlapped these DE proteins in CSF with the brain proteome (Supplementary Table S2), yielding a core table of 65 upregulated proteins (e.g. MAPT, SMOC1, HTRA1, PDLIM5, PRDX6, RUVBL2, CALB2, ARFGAP3, SPP1 and DPCD) and 44 downregulated proteins in AD (e.g. NPTX2, VGF, PDHA1, NDUFV1, NDUFA2, NDUFA12, NDUFA13, NDUFS3, ATP5B and ATP5J, Supplementary Table S5). The meta-analysis (Supplementary Table S4 and S5) provides a resource of AD CSF proteome for future validation.

A meta-analysis integrating 6 deep CSF datasets and identifying 5,939 proteins. Using the same method in Fig. 4, individual and combined p values for control-AD comparison are computed, followed by the FDR analysis. With the FDR cutoff of 1 %, 476 DE proteins are accepted, 109 are overlapped with the list of DE proteins in AD brain tissues
Moreover, Wang et al. compared human CSF and 5xFAD mouse CSF datasets, pointing to 11 shared DE proteins (e.g. SOD2, PRDX3, ALDH6A1, ETFB, HADHA, and CYB5R3) that may be induced by amyloidosis [85]. Higginbotham et al. summarized the CSF DE proteins into synaptic, vascular, myelin, immunological, and metabolic panels, and applied the five biomarker panels to the classification of asymptomatic AD subjects into two subgroups [75]. In agreement with the heterogeneity of AD-related cases, three molecular subtypes are implicated by transcriptomics [200] and CSF proteomics [134].
In contrast to CSF analysis, deep MS-based profiling of AD plasma/serum samples is sparse, because molecular changes in the brain may not be readily detected in the blood due to the blood–brain barrier. The unique blood composition also imposes an analytical challenge with an extremely large dynamic range, from albumin (~ 50 mg/ml) to interleukin-6 (~ 4.2 pg/ml). Dey et al. reported an ultra-deep analysis of undepleted human sera from 5 control and 6 AD cases by TMT and exhaustive LC/LC-MS/MS, analyzing 4,826 proteins but still missing the layer of proteins at the lowest abundance (e.g. Aβ peptide and tau) [99]. Nevertheless, overlapping of serum, CSF and cortex proteomes identified 37 DE proteins including 22 mitochondrial proteins, suggesting a consistent mitochondrial signature in AD [85].
Extracellular vesicles (EV) enable the transport of brain proteins to the blood, which emerge as an alternative class of specimens by MS analysis. EVs are highly heterogeneous, nano-sized lipid vesicles released to the extracellular environment for cell communication [201], secreted by almost any cell types including neurons, astrocytes, and microglia [202]. EVs carry and spread AD-related proteins including APP, Aβ peptides, and tau [203, 204]. Increased levels of Aβ42/Aβ40 ratio, APP, Aβ monomer and oligomer forms, tau and tau phosphorylation were reported in EVs isolated from the plasma, CSF, and brain cells of AD patients and mouse models [202, 205, 206]. With accumulating evidence suggesting the correlation of EV protein components with AD, we envision more comprehensive analysis of EV proteomics for AD biomarker discovery.
In addition to untargeted search of biomarker candidates by MS, the targeted trials of known pathological markers (e.g. Aβ and tau) in CSF and blood have been ongoing and successful. For example, the CSF tests of Aβ and phosphorylated tau have been accepted by the National Institute on Aging and the International Working Group for New Research Criteria for the diagnosis of AD and MCI [207, 208]. Recent CSF tests of pTau at T181, T217 or T231 residues showed high accuracy [209]. These analyses have been further extended to blood tests. The MS-based blood test of Aβ peptides (i.e. PrecivityAD™) is commercially available. Targeted MS methods were also developed to evaluate pTau levels at T217 and T181 residues in CSF and blood [210, 211]. The pTau data were consistent with PET imaging analysis of amyloid and tau, as well as clinical stage of AD. Although the pTau analysis is promising, its concentration in blood is extremely low (< 1 pg/ml) [211], requiring antibody-affinity enrichment, or highly sensitive antibody-based SIMOA kits [209]. Further independent and large-scale trials are required to evaluate the sensitivity and specificity of pTau biomarkers.
Conclusions and Perspectives of AD Proteomics-based Systems Biology
In systems biology, biological and disease phenotypes are viewed as emergent properties regulated by components in both spatial and temporal dimensions, and their interactions confer functional consequences in a hierarchical, multi-scale system at structural, molecular, organellar, cellular, tissue, organ, and organismal levels. In this framework of systems biology, based on the introduction of recent major AD proteomics studies, we discuss the technical challenges and scientific questions in the field remaining to be resolved.
The sample quality in AD proteomics is unavoidably affected by many confounding factors, such as age, gender, postmortem interval (PMI), ischemia, etc. [212, 213]. The confounding effect on modified proteomes (e.g. phosphorylation and ubiquitination) is larger than that on the whole proteome, because protein modifications are highly transient and dynamic. While age- and gender-matched cases are selected for proteomic comparison, the effect of other confounding factors (e.g. PMI and ischemia) may be addressed by control experiments in animals [74, 214], and normalized by regression analyses [75]. Sample size is another critical parameter in AD proteomics, affected by biological and experimental variations [215]. Proteomic studies with a limited sample size often lead to biased conclusions that cannot be repeated in other studies. Reliable proteomic results should be consistent in multiple patient cohorts analyzed by different research groups.
In human brain, it is estimated that ~ 16,000 genes are expressed [163] to produce millions of proteoforms, largely attributed to RNA alternative splicing and PTMs [216]. For example, a large number of Aβ and tau proteoforms are present in AD brains due to the combination of protein modifications and proteolytic events. Although the bottom-up proteomics detects a large portion (more than 12,000 gene products, Supplementary Table S2) of brain proteome, mapping all intact proteoforms is not straightforward, as protease digestion in the bottom-up approach causes the loss of proteoform data. One may utilize the top-down MS to characterize proteins of interest, such as proteoforms of Aβ species [217] and tau proteins [218]. Innovative structural MS technologies have been developed to analyze protein structures of purified proteins, protein complexes, and even thousands of proteins [219,220,221,222], and will be applied to dissect structural changes in AD at a global scale. Eventually, the integration of bottom-up, top-down, and structural MS approaches will provide a more comprehensive view of the proteotype (defined as the state of a proteome linked to a specific phenotype) in AD patients [58]. In addition, continuously enhancing throughput, sensitivity, and affordability in proteomics is necessary. This will improve the depth and breadth of detected proteomes, and make it possible to handle large sample sizes to overcome limitations associated with protein dynamic range and clinical sample variations.
Cellular components in the brain are highly heterogeneous including different cell types in diverse cellular states of homeostasis or transition states. However, such cellular heterogeneity is masked by conventional population-based (or bulk) analyses. Recent development of single cell (SC) omics technologies (especially scRNA-seq) has allowed researchers to sample gene expression from the whole transcriptome at the single cell resolution extensively in AD animals and human brain tissues [223,224,225,226,227,228]. The resulting unbiased and holistic view of both molecular (e.g., gene expression) and cellular (i.e., single cell) dimensions enables identification of new cell (sub) populations, and those that associate with pathogenesis will be highlighted and further explored. With rapid development of single cell proteomics [229,230,231], single cell type proteomics [232, 233], and single-molecule protein sequencing technologies [234], the application to the AD field is expected in the near future.
It is critical to emphasize that there is a gap between generating proteomics data and discovering disease drivers, because proteome profiling only reveals disease-correlated components, but correlation does not imply causation. Significant investments are required to establish a cause-effect relationship in disease models and human patients. With recent identification of a large number of DE proteins in AD, the next step is to identify and validate the underlying mechanisms contributing to the molecular changes. Master regulators (e.g., transcription factors, kinases or other signaling proteins) that drive such changes are yet to be identified, partially because their expression is spatially and temporally restricted with their low abundances [235], and their functions are likely to be regulated by PTMs and/or protein-protein interactions which are largely missing. Hence it may be difficult to define some of these master regulators directly by gene/protein expression profiles. Alternatively, the driver activity can be inferred by summarizing the expression alteration of downstream target genes via systems biology approaches [236]. This network-activity based approach [237, 238], and other multi-omics network analyses [182, 239] will unveil disease drivers for AD pathogenesis. The novel disease drivers will be studied by interactome profiling and genetic approaches in cellular (e.g. induced pluripotent stem cells) [240] and animal models [241].
In summary, current deep proteomics studies have already profiled the brain and biofluids at an unprecedented scale, raising many novel hypotheses for subsequent validation. It is notable that AD is an irreversible neurodegeneration and a nearly end-stage disease, in which many cellular pathways and biological processes are perturbed. With further development in the MS-based or non-MS proteomics approaches, it is not surprising to see even more molecular alterations and characteristic proteins discovered. In parallel, it is anticipated that novel AD models are to be developed following the hypotheses from these molecular insights here we have discussed, providing potential therapeutic strategies and biomarkers for AD and subtypes of AD.
Availability of data and materials
Not applicable.
Change history
20 October 2021
A Correction to this paper has been published: https://doi.org/10.1186/s13024-021-00493-w
Abbreviations
- AD:
-
Alzheimer’s disease
- CSF:
-
Cerebrospinal fluid
- EV:
-
Extracellular vesicle
- MS:
-
Mass spectrometry
- LC/LC-MS/MS:
-
Two-dimensional liquid chromatography coupled with tandem mass spectrometry
- TMT:
-
Tandem mass tag
References
Alzheimer’s Association. Alzheimer’s disease facts and figures. Alzheimers Dement. 2020;2020(16):391–460.
Alzheimer’s Disease Interenational. World Alzheimer Report 2018 The state of the art of dementia research: New frontiers. 2018.
Long JM, et al. Alzheimer Disease: An Update on Pathobiology and Treatment Strategies. Cell. 2019;179:312–39.
Scheltens P, et al. Alzheimer’s disease. Lancet. 2016;388:505–17.
Brenowitz WD, et al. Mixed neuropathologies and estimated rates of clinical progression in a large autopsy sample. Alzheimers Dement. 2017;13:654–62.
Hyman BT, et al. National Institute on Aging-Alzheimer’s Association guidelines for the neuropathologic assessment of Alzheimer’s disease. Alzheimers Dement. 2012;8:1–13.
DeTure MA, et al. The neuropathological diagnosis of Alzheimer’s disease. Mol Neurodegener. 2019;14:32.
Cummings J, et al. Alzheimer’s disease drug development pipeline: 2020. Alzheimers Dement. 2020;6:e12050.
Mullard A. Landmark Alzheimer’s drug approval confounds research community. Nature. 2021;594:309–10.
Glenner GG, et al. Alzheimer’s disease: initial report of the purification and characterization of a novel cerebrovascular amyloid protein. Biochem Biophys Res Commun. 1984;120:885–90.
Wong CW, et al. Neuritic plaques and cerebrovascular amyloid in Alzheimer disease are antigenically related. Proc Natl Acad Sci U S A. 1985;82:8729–32.
Masters CL, et al. Amyloid plaque core protein in Alzheimer disease and Down syndrome. Proc. Natl. Acad. Sci. U. S. A 1985;82:4245–9.
Goldgaber D, et al. Characterization and chromosomal localization of a cDNA encoding brain amyloid of Alzheimer’s disease. Science. 1987;235:877–80.
Tanzi RE, et al. Amyloid beta protein gene: cDNA, mRNA distribution, and genetic linkage near the Alzheimer locus. Science. 1987;235:880–4.
Goate A, et al. Segregation of a missense mutation in the amyloid precursor protein gene with familial Alzheimer’s disease. Nature. 1991;349:704–6.
Sherrington R, et al. Cloning of a gene bearing missense mutations in early-onset familial Alzheimer’s disease. Nature. 1995;375:754–60.
Levy-Lahad E, et al. Candidate gene for the chromosome 1 familial Alzheimer’s disease locus. Science. 1995;269:973–7.
Wolfe MS, et al. Two transmembrane aspartates in presenilin-1 required for presenilin endoproteolysis and gamma-secretase activity. Nature. 1999;398:513–7.
Vassar R, et al. Beta-secretase cleavage of Alzheimer’s amyloid precursor protein by the transmembrane aspartic protease BACE. Science. 1999;286:735–41.
Yan R, et al. Membrane-anchored aspartyl protease with Alzheimer’s disease beta-secretase activity. Nature. 1999;402:533–7.
Selkoe DJ. Molecular pathology of amyloidogenic proteins and the role of vascular amyloidosis in Alzheimer’s disease. Neurobiol Aging. 1989;10:387–95.
Hardy JA, et al. Alzheimer’s disease: the amyloid cascade hypothesis. Science. 1992;256:184–5.
Selkoe DJ, et al. The amyloid hypothesis of Alzheimer’s disease at 25 years. EMBO Mol Med. 2016;8:595–608.
Braak H, et al. Evolution of the neuropathology of Alzheimer’s disease. Acta Neurol Scand Suppl. 1996;165:3–12.
Grundke-Iqbal I, et al. Microtubule-associated protein tau. A component of Alzheimer paired helical filaments. J Biol Chem. 1986;261:6084–9.
Grundke-Iqbal I, et al. Abnormal phosphorylation of the microtubule-associated protein tau (tau) in Alzheimer cytoskeletal pathology. Proc Natl Acad Sci U S A. 1986;83:4913–7.
Nukina N, et al. One of the antigenic determinants of paired helical filaments is related to tau protein. J Biochem. 1986;99:1541–4.
Spillantini MG, et al. Mutation in the tau gene in familial multiple system tauopathy with presenile dementia. Proc Natl Acad Sci U S A. 1998;95:7737–41.
Hutton M, et al. Association of missense and 5’-splice-site mutations in tau with the inherited dementia FTDP-17. Nature. 1998;393:702–5.
Clark LN, et al. Pathogenic implications of mutations in the tau gene in pallido-ponto-nigral degeneration and related neurodegenerative disorders linked to chromosome 17. Proc Natl Acad Sci U S A. 1998;95:13103–7.
Ballatore C, et al. Tau-mediated neurodegeneration in Alzheimer’s disease and related disorders. Nat Rev Neurosci. 2007;8:663–72.
Gotz J, et al. Formation of neurofibrillary tangles in P301l tau transgenic mice induced by Abeta 42 fibrils. Science. 2001;293:1491–5.
Lewis J, et al. Enhanced neurofibrillary degeneration in transgenic mice expressing mutant tau and APP. Science. 2001;293:1487–91.
Roberson ED, et al. Reducing endogenous tau ameliorates amyloid beta-induced deficits in an Alzheimer’s disease mouse model. Science. 2007;316:750–4.
Cline EN, et al. The Amyloid-beta Oligomer Hypothesis: Beginning of the Third Decade. J Alzheimers Dis. 2018;64:567–610.
Peng C, et al. Protein transmission in neurodegenerative disease. Nat Rev Neurol. 2020;16:199–212.
Davies P, et al. Selective loss of central cholinergic neurons in Alzheimer’s disease. Lancet. 1976;2:1403.
Francis PT, et al. The cholinergic hypothesis of Alzheimer’s disease: a review of progress. J Neurol Neurosurg Psychiatry. 1999;66:137–47.
Mattson MP, et al. beta-Amyloid peptides destabilize calcium homeostasis and render human cortical neurons vulnerable to excitotoxicity. J Neurosci. 1992;12:376–89.
Mattson MP, et al. Neuronal and glial calcium signaling in Alzheimer’s disease. Cell Calcium. 2003;34:385–97.
Swerdlow RH, et al. A “mitochondrial cascade hypothesis” for sporadic Alzheimer’s disease. Med Hypotheses. 2004;63:8–20.
Wang W, et al. Mitochondria dysfunction in the pathogenesis of Alzheimer’s disease: recent advances. Mol Neurodegener. 2020;15:30.
Pimplikar SW, et al. Amyloid-independent mechanisms in Alzheimer’s disease pathogenesis. J Neurosci. 2010;30:14946–54.
Jiang S, et al. Trafficking regulation of proteins in Alzheimer’s disease. Mol Neurodegener. 2014;9:6.
McGeer PL, et al. Anti-inflammatory drugs and Alzheimer disease. Lancet. 1990;335:1037.
Wyss-Coray T, et al. Inflammation in Alzheimer disease-a brief review of the basic science and clinical literature. Cold Spring Harb Perspect Med. 2012;2:a006346.
Kinney JW, et al. Inflammation as a central mechanism in Alzheimer’s disease. Alzheimers Dement. 2018;4:575–90.
Deane R, et al. LRP/amyloid beta-peptide interaction mediates differential brain efflux of Abeta isoforms. Neuron. 2004;43:333–44.
Da Mesquita S, et al. Functional aspects of meningeal lymphatics in ageing and Alzheimer’s disease. Nature. 2018;560:185–91.
Kumar DK, et al. Amyloid-beta peptide protects against microbial infection in mouse and worm models of Alzheimer’s disease. Sci Transl Med. 2016;8:340ra72.
Readhead B, et al. Multiscale Analysis of Independent Alzheimer’s Cohorts Finds Disruption of Molecular, Genetic, and Clinical Networks by Human Herpesvirus. Neuron. 2018;99:64–82.
Eimer WA, et al. Alzheimer’s Disease-Associated beta-Amyloid Is Rapidly Seeded by Herpesviridae to Protect against Brain Infection. Neuron. 2018;100:1527–32.
Iadecola C. Neurovascular regulation in the normal brain and in Alzheimer’s disease. Nat Rev Neurosci. 2004;5:347–60.
Zlokovic BV. Neurovascular pathways to neurodegeneration in Alzheimer’s disease and other disorders. Nat Rev Neurosci. 2011;12:723–38.
De Strooper B, et al. The Cellular Phase of Alzheimer’s Disease. Cell. 2016;164:603–15.
Musiek ES, et al. Three dimensions of the amyloid hypothesis: time, space and ‘wingmen’. Nat Neurosci. 2015;18:800–6.
Metzker ML. Sequencing technologies - the next generation. Nat Rev Genet. 2010;11:31–46.
Aebersold R, et al. Mass-spectrometric exploration of proteome structure and function. Nature. 2016;537:347–55.
Strittmatter WJ, et al. Apolipoprotein E: high-avidity binding to beta-amyloid and increased frequency of type 4 allele in late-onset familial Alzheimer disease. Proc Natl Acad Sci U S A. 1993;90:1977–81.
Corder EH, et al. Gene dose of apolipoprotein E type 4 allele and the risk of Alzheimer’s disease in late onset families. Science. 1993;261:921–3.
Guerreiro R, et al. TREM2 variants in Alzheimer’s disease. N Engl J Med. 2013;368:117–27.
Jonsson T, et al. Variant of TREM2 associated with the risk of Alzheimer’s disease. N Engl J Med. 2013;368:107–16.
Wetzel-Smith MK, et al. A rare mutation in UNC5C predisposes to late-onset Alzheimer’s disease and increases neuronal cell death. Nat Med. 2014;20:1452–7.
Lambert JC, et al. Meta-analysis of 74,046 individuals identifies 11 new susceptibility loci for Alzheimer’s disease. Nat Genet. 2013;45:1452–8.
Kunkle BW, et al. Genetic meta-analysis of diagnosed Alzheimer’s disease identifies new risk loci and implicates Abeta, tau, immunity and lipid processing. Nat Genet. 2019;51:414–30.
Jansen IE, et al. Genome-wide meta-analysis identifies new loci and functional pathways influencing Alzheimer’s disease risk. Nat Genet. 2019;51:404–13.
Bellenguez C, et al. New insights on the genetic etiology of Alzheimer’s and related dementia. medRxiv. 2020;Manuscript submitted online.
Wrghtman DP, et al. Largest GWAS (N = 1,126,563) of Alzheimer’s Disease Implicates Microglia and Immune Cells. medRxiv. 2020;Manuscript submitted online.
Hodes RJ, et al. Accelerating Medicines Partnership: Alzheimer’s Disease (AMP-AD) Knowledge Portal Aids Alzheimer’s Drug Discovery through Open Data Sharing. Expert Opin Ther Targets. 2016;20:389–91.
Bertram L, et al. Thirty years of Alzheimer’s disease genetics: the implications of systematic meta-analyses. Nat Rev Neurosci. 2008;9:768–78.
Karch CM, et al. Alzheimer’s disease genetics: from the bench to the clinic. Neuron. 2014;83:11–26.
Van Cauwenberghe C, et al. The genetic landscape of Alzheimer disease: clinical implications and perspectives. Genet Med. 2016;18:421–30.
Bellenguez C, et al. Genetics of Alzheimer’s disease: where we are, and where we are going. Curr Opin Neurobiol. 2020;61:40–8.
Bai B, et al. Deep Multilayer Brain Proteomics Identifies Molecular Networks in Alzheimer’s Disease Progression. Neuron. 2020;105:975–91.
Higginbotham L, et al. Integrated proteomics reveals brain-based cerebrospinal fluid biomarkers in asymptomatic and symptomatic Alzheimer’s disease. Sci Adv. 2020;6:eaaz9360.
Wang Z, et al. 27-plex Tandem Mass Tag Mass Spectrometry for Profiling Brain Proteome in Alzheimer’s Disease. Anal Chem. 2020:92:7162–70.
Sathe G, et al. Quantitative proteomic analysis of the frontal cortex in Alzheimer’s disease. J Neurochem. 2020;156:988–1002.
Johnson ECB, et al. Large-scale proteomic analysis of Alzheimer’s disease brain and cerebrospinal fluid reveals early changes in energy metabolism associated with microglia and astrocyte activation. Nat Med. 2000;26:769–80.
Bai B, et al. U1 small nuclear ribonucleoprotein complex and RNA splicing alterations in Alzheimer’s disease. Proc Natl Acad Sci U S A. 2013;110:16562–7.
Xiong F, et al. Quantitative proteomics reveals distinct composition of amyloid plaques in Alzheimer’s disease. Alzheimers Dement. 2019;15:429–40.
Drummond E, et al. Phosphorylated tau interactome in the human Alzheimer’s disease brain. Brain. 2020;143:2803–17.
Wesseling H, et al. Tau PTM Profiles Identify Patient Heterogeneity and Stages of Alzheimer’s Disease. Cell. 2020;183:1699–713.
Sathe G, et al. Quantitative Proteomic Profiling of Cerebrospinal Fluid to Identify Candidate Biomarkers for Alzheimer’s Disease. Proteomics Clin Appl. 2019;13:e1800105.
Bader JM, et al. Proteome profiling in cerebrospinal fluid reveals novel biomarkers of Alzheimer’s disease. Mol Syst Biol. 2020;16:e9356.
Wang H, et al. Integrated analysis of ultra-deep proteomes in cortex, cerebrospinal fluid and serum reveals a mitochondrial signature in Alzheimer’s disease. Mol Neurodegener. 2020;15:43.
Edman PB, Protein Sequenator GA. Eur J Biochem. 1967;1:80–9.
Peng J, et al. Proteomics: the move to mixtures. J Mass Spectrom. 2001;36:1083–91.
Barber M, et al. Determination of amino acid sequences in oligopeptides by mass spectrometry. II. The structure of peptidolipin NA. Tetrahedron Lett. 1965;6:1331–6.
Senn M, et al. Automatic amino-acid-sequence determination in peptides. Biochem Biophys Res Commun. 1966;23:381–5.
Shemyakin MM, et al. Mass spectrometric determination of the amino-acid sequence of peptides. Nature. 1966;211:361–6.
Biemann K, et al. Determination of the amino acid sequence in oligopeptides by computer interpretation of their high-resolution mass spectra. J Am Chem Soc. 1966;88:5598–606.
Griffiths J. A brief history of mass spectrometry. Anal Chem. 2008;80:5678–83.
Koichi Tanaka HW, Yutaka Ido S, Akita Y, Yoshida T, Yoshida T, Matsuo. Protein and polymer analyses up to m/z 100 000 by laser ionization time-of‐flight mass spectrometry. Rapid Commun Mass Spectrom. 1988;2:151–3.
Fenn JB, et al. Electrospray ionization for mass spectrometry of large biomolecules. Science. 1989;246:64–71.
Mann M. The ever expanding scope of electrospray mass spectrometry-a 30 year journey. Nat Commun. 2019;10:3744.
Mori H, Ogawara KT,M, Selkoe DJ. Mass spectrometry of purified amyloid beta protein in Alzheimer’s disease. J Biol Chem. 1992;267:17082–6.
Hasegawa M, et al. Protein sequence and mass spectrometric analyses of tau in the Alzheimer’s disease brain. J Biol Chem. 1992;267:17047–54.
Liao L, et al. Proteomic characterization of postmortem amyloid plaques isolated by laser capture microdissection. J Biol Chem. 2004;279:37061–8.
Dey KK, et al. Deep undepleted human serum proteome profiling toward biomarker discovery for Alzheimer’s disease. Clin Proteomics. 2019;16:16.
Yates JR. 3rd. A century of mass spectrometry: from atoms to proteomes. Nat Methods. 2011;8:633–7.
Litvinov Y, et al. 100 years of Mass Spectrometry. Int J Mass Spectrom. 2013;349–350:1–276.
Jellinger KA. Alzheimer 100 - highlights in the history of Alzheimer research. J Neural Transm. 2006;113:1603–23.
Toby TK, et al. Progress in Top-Down Proteomics and the Analysis of Proteoforms. Annu Rev Anal Chem. 2016;9:499–519.
Zhang Y, et al. Protein analysis by shotgun/bottom-up proteomics. Chem Rev. 2013;113:2343–94.
Tran JC, et al. Mapping intact protein isoforms in discovery mode using top-down proteomics. Nature. 2011;480:254–8.
Nagaraj N, et al. Deep proteome and transcriptome mapping of a human cancer cell line. Mol Syst Biol. 2011;7:548.
Beck M, et al. The quantitative proteome of a human cell line. Mol Syst Biol. 2011;7:549.
Bai B, et al. Deep Profiling of Proteome and Phosphoproteome by Isobaric Labeling, Extensive Liquid Chromatography, and Mass Spectrometry. Methods Enzymol. 2017;585:377–95.
Washburn MP, et al. Large-scale analysis of the yeast proteome by multidimensional protein identification technology. Nat Biotechnol. 2001;19:242–7.
Peng J, et al. Evaluation of multidimensional chromatography coupled with tandem mass spectrometry (LC/LC-MS/MS) for large-scale protein analysis: the yeast proteome. J Proteome Res. 2003;2:43–50.
Xu P, et al. Systematical Optimization of Reverse-Phase Chromatography for Shotgun Proteomics. J Proteome Res. 2009;8:3944–50.
Branca RM, et al. HiRIEF LC-MS enables deep proteome coverage and unbiased proteogenomics. Nat Methods. 2014;11:59–62.
Liu H, et al. A model for random sampling and estimation of relative protein abundance in shotgun proteomics. Anal Chem. 2004;76:4193–201.
Cox J, et al. Accurate proteome-wide label-free quantification by delayed normalization and maximal peptide ratio extraction, termed MaxLFQ. Mol Cell Proteomics. 2014;13:2513–26.
Gerber SA, et al. Absolute quantification of proteins and phosphoproteins from cell lysates by tandem MS. Proc Natl Acad Sci U S A. 2003;100:6940–5.
Ludwig C, et al. Data-independent acquisition-based SWATH-MS for quantitative proteomics: a tutorial. Mol Syst Biol. 2018;14:e8126.
Gygi SP, et al. Quantitative analysis of complex protein mixtures using isotope-coded affinity tags. Nat Biotechnol. 1999;17:994–9.
Hsu J-L, et al. Stable-Isotope Dimethyl Labeling for Quantitative Proteomics. Anal Chem. 2003;75:6843–52.
Zhu H, et al. Amino acid residue specific stable isotope labeling for quantitative proteomics. Rapid Commun Mass Spectrom. 2002;16:2115–23.
Mann M. Functional and quantitative proteomics using SILAC. Nat Rev Mol Cell Biol. 2006;7:952–8.
Wiese S, et al. Protein labeling by iTRAQ: a new tool for quantitative mass spectrometry in proteome research. Proteomics. 2007;7:340–50.
Thompson A, et al. Tandem mass tags: a novel quantification strategy for comparative analysis of complex protein mixtures by MS/MS. Anal Chem. 2003;75:1895–904.
Frost DC, et al. High-resolution enabled 12-plex DiLeu isobaric tags for quantitative proteomics. Anal Chem. 2015;87:1646–54.
Li J, et al. TMTpro reagents: a set of isobaric labeling mass tags enables simultaneous proteome-wide measurements across 16 samples. Nat Methods. 2020;17:399–404.
Li J, et al. TMTpro-18plex: The Expanded and Complete Set of TMTpro Reagents for Sample Multiplexing. J Proteome Res. 2021;20:2964–72.
Ting L, et al. MS3 eliminates ratio distortion in isobaric multiplexed quantitative proteomics. Nat Methods. 2011;8:937–40.
Meier F, et al. Online Parallel Accumulation-Serial Fragmentation (PASEF) with a Novel Trapped Ion Mobility Mass Spectrometer. Mol Cell Proteomics. 2018;17:2534–45.
Makarov A, et al. Performance evaluation of a hybrid linear ion trap/orbitrap mass spectrometer. Anal Chem. 2006;78:2113–20.
Nesvizhskii AI. A survey of computational methods and error rate estimation procedures for peptide and protein identification in shotgun proteomics. J Proteomics. 2010;73:2092–123.
Verheggen K, et al. Anatomy and evolution of database search engines-a central component of mass spectrometry based proteomic workflows. Mass Spectrom Rev. 2020;39:292–306.
Elias JE, et al. Target-decoy search strategy for increased confidence in large-scale protein identifications by mass spectrometry. Nat Methods. 2007;4:207–14.
Bekker-Jensen DB, et al. A Compact Quadrupole-Orbitrap Mass Spectrometer with FAIMS Interface Improves Proteome Coverage in Short LC Gradients. Mol Cell Proteomics. 2020;19:716–29.
Akbani R, et al. Realizing the promise of reverse phase protein arrays for clinical, translational, and basic research: a workshop report: the RPPA (Reverse Phase Protein Array) society. Mol Cell Proteomics. 2014;13:1625–43.
Tijms BM, et al. Pathophysiological subtypes of Alzheimer’s disease based on cerebrospinal fluid proteomics. Brain. 2020;143:3776–92.
Jiang Y, et al. Large-scale plasma proteomic profiling identifies a high-performance biomarker panel for Alzheimer’s disease screening and staging. Alzheimers Dement. 2021. [Epub ahead of print].
Sattlecker M, et al. Alzheimer’s disease biomarker discovery using SOMAscan multiplexed protein technology. Alzheimers Dement. 2014;10:724–34.
Wang R, et al. The profile of soluble amyloid beta protein in cultured cell media. Detection and quantification of amyloid beta protein and variants by immunoprecipitation-mass spectrometry. J Biol Chem. 1996;271:31894–902.
Gozal YM, et al. Merger of laser capture microdissection and mass spectrometry: a window into the amyloid plaque proteome. Methods Enzymol. 2006;412:77–93.
Zhou JY, et al. Clinical proteomics in neurodegenerative diseases. Proteomics Clin Appl. 2007;1:1342–50.
Drummond E, et al. Proteomic differences in amyloid plaques in rapidly progressive and sporadic Alzheimer’s disease. Acta Neuropathol. 2017;133:933–54.
Ross CA, et al. Protein aggregation and neurodegenerative disease. Nat Med. 2004;10:S10-17.
Lutz BM, et al. Deep Profiling of the Aggregated Proteome in Alzheimer’s Disease: From Pathology to Disease Mechanisms. Proteomes. 2018;6:46.
Gozal YM, et al. Proteomics analysis reveals novel components in the detergent-insoluble subproteome in Alzheimer’s disease. J Proteome Res. 2009;8:5069–79.
Bai B, et al. Integrated Approaches for Analyzing U1-70K Cleavage in Alzheimer’s Disease. J Proteome Res. 2014;13:4526–34.
Hales CM, et al. Aggregates of small nuclear ribonucleic acids (snRNAs) in Alzheimer’s disease. Brain Pathol. 2014;24:344–51.
Hales CM, et al. U1 small nuclear ribonucleoproteins (snRNPs) aggregate in Alzheimer’s disease due to autosomal dominant genetic mutations and trisomy 21. Mol Neurodegener. 2014;9:15.
Hales CM, et al. Changes in the detergent-insoluble brain proteome linked to amyloid and tau in Alzheimer’s Disease progression. Proteomics. 2016;16:3042–53.
Raj T, et al. Integrative transcriptome analyses of the aging brain implicate altered splicing in Alzheimer’s disease susceptibility. Nat Genet. 2018;50:1584–92.
Li HD, et al. Integrative functional genomic analysis of intron retention in human and mouse brain with Alzheimer’s disease. Alzheimers Dement. 2021;17:984–1004.
Cheng Z, et al. Presenilin 1 mutation likely contributes to U1 small nuclear RNA dysregulation and Alzheimer’s disease-like symptoms. Neurobiol Aging. 2021;100:1–10.
Hsieh YC, et al. Tau-Mediated Disruption of the Spliceosome Triggers Cryptic RNA Splicing and Neurodegeneration in Alzheimer’s Disease. Cell Rep. 2019;29:301–16.
Apicco DJ, et al. Dysregulation of RNA Splicing in Tauopathies. Cell Rep. 2019;29:4377–88.
Selkoe DJ. Alzheimer’s disease is a synaptic failure. Science. 2002;298:789–91.
Zhou JY, et al. Proteomic Analysis of Postsynaptic Density in Alzheimer Disease. Clin Chim Acta. 2013;420:62–8.
Hesse R, et al. Comparative profiling of the synaptic proteome from Alzheimer’s disease patients with focus on the APOE genotype. Acta Neuropathol Commun. 2019;7:214.
Carlyle BC, et al. Multiplexed fractionated proteomics reveals synaptic factors associated with cognitive resilience in Alzheimer’s Disease. BioRxiv. 2020;Manuscript submitted online.
Cheng D, et al. Relative and absolute quantification of postsynaptic density proteome isolated from rat forebrain and cerebellum. Mol Cell Proteomics. 2006;5:1158–70.
Butterfield DA, et al. Proteomics in Alzheimer’s disease: insights into potential mechanisms of neurodegeneration. J Neurochem. 2003;86:1313–27.
Andreev VP, et al. Label-free quantitative LC-MS proteomics of Alzheimer’s disease and normally aged human brains. J Proteome Res. 2012;11:3053–67.
Seyfried NT, et al. A Multi-network Approach Identifies Protein-Specific Co-expression in Asymptomatic and Symptomatic Alzheimer’s Disease. Cell Syst. 2017;4:60–72.
Johnson ECB, et al. Deep proteomic network analysis of Alzheimer’s disease brain reveals alterations in RNA binding proteins and RNA splicing associated with disease. Mol Neurodegener. 2018;13:52.
McKetney J, et al. Proteomic Atlas of the Human Brain in Alzheimer’s Disease. J Proteome Res. 2019;18:1380–91.
Wang H, et al. Systematic optimization of long gradient chromatography mass spectrometry for deep analysis of brain proteome. J Proteome Res. 2015;14:829–38.
Mertins P, et al. Proteogenomics connects somatic mutations to signalling in breast cancer. Nature. 2016;534:55–62.
Niu M, et al. Extensive Peptide Fractionation and y1 Ion-Based Interference Detection Method for Enabling Accurate Quantification by Isobaric Labeling and Mass Spectrometry. Anal Chem. 2017;89:2956–63.
Langfelder P, et al. WGCNA: an R package for weighted correlation network analysis. BMC Bioinformatics. 2008;9:559.
Zhang Y, et al. Purification and Characterization of Progenitor and Mature Human Astrocytes Reveals Transcriptional and Functional Differences with Mouse. Neuron. 2016;89:37–53.
Wingo AP, et al. Integrating human brain proteomes with genome-wide association data implicates new proteins in Alzheimer’s disease pathogenesis. Nat Genet. 2021;53:143–6.
Esteve P, et al. Elevated levels of Secreted-Frizzled-Related-Protein 1 contribute to Alzheimer’s disease pathogenesis. Nat Neurosci. 2019;22:1258–68.
Liebmann T, et al. Three-Dimensional Study of Alzheimer’s Disease Hallmarks Using the iDISCO Clearing Method. Cell Rep. 2016;16:1138–52.
Spilman PR, et al. Netrin-1 Interrupts Amyloid-beta Amplification, Increases sAbetaPPalpha in vitro and in vivo, and Improves Cognition in a Mouse Model of Alzheimer’s Disease. J Alzheimers Dis. 2016;52:223–42.
Yasuhara O, et al. Midkine, a novel neurotrophic factor, is present in senile plaques of Alzheimer disease. Biochem Biophys Res Commun. 1993;192:246–51.
Herradon G, et al. Targeting midkine and pleiotrophin signalling pathways in addiction and neurodegenerative disorders: recent progress and perspectives. Br J Pharmacol. 2014;171:837–48.
Wright JW, et al. The Brain Hepatocyte Growth Factor/c-Met Receptor System: A New Target for the Treatment of Alzheimer’s Disease. J Alzheimers Dis. 2015;45:985–1000.
Zheng H, et al. TREM2 Promotes Microglial Survival by Activating Wnt/beta-Catenin Pathway. J Neurosci. 2017;37:1772–84.
Hong S, et al. Complement and microglia mediate early synapse loss in Alzheimer mouse models. Science. 2016;352:712–6.
Zhang DF, et al. Complement C7 is a novel risk gene for Alzheimer’s disease in Han Chinese. Natl Sci Rev. 2019;6:257–74.
Shi QQ, et al. Complement C3 deficiency protects against neurodegeneration in aged plaque-rich APP/PS1 mice. Sci Transl Med. 2017;9:eaaf6295.
Litvinchuk A, et al. Complement C3aR Inactivation Attenuates Tau Pathology and Reverses an Immune Network Deregulated in Tauopathy Models and Alzheimer’s Disease. Neuron. 2018;100:1337–53.
Morgan BP. Complement in the pathogenesis of Alzheimer’s disease. Semin Immunopathol. 2018;40:113–24.
Budni J, et al. The involvement of BDNF, NGF and GDNF in aging and Alzheimer’s disease. Aging Dis. 2015;6:331–41.
Beckmann ND, et al. Multiscale causal networks identify VGF as a key regulator of Alzheimer’s disease. Nat Commun. 2020;11:3942.
An K, et al. Neuritin can normalize neural deficits of Alzheimer’s disease. Cell Death Dis. 2014;5:e1523.
Xiao MF, et al. NPTX2 and cognitive dysfunction in Alzheimer’s Disease. Elife. 2017;6:e23798.
Goedert M, et al. Propagation of Tau Aggregates and Neurodegeneration. Annu Rev Neurosci. 2017;40:189–210.
Gong CX, et al. Post-translational modifications of tau protein in Alzheimer’s disease. J Neural Transm. 2005;112:813–38.
Martin L, et al. Post-translational modifications of tau protein: implications for Alzheimer’s disease. Neurochem Int. 2011;58:458–71.
Wang Y, et al. Tau in physiology and pathology. Nat Rev Neurosci. 2016;17:5–21.
Arakhamia T, et al. Posttranslational modifications mediate the structural diversity of tauopathy strains. Cell. 2020;180:633–44.
Dujardin S, et al. Tau molecular diversity contributes to clinical heterogeneity in Alzheimer’s disease. Nat Med. 2020;26:1256–63.
Min SW, et al. Acetylation of tau inhibits its degradation and contributes to tauopathy. Neuron. 2010;67:953–66.
Cohen TJ, et al. The acetylation of tau inhibits its function and promotes pathological tau aggregation. Nature communications. 2011;2:1–9.
Mischnik M, et al. IKAP: A heuristic framework for inference of kinase activities from Phosphoproteomics data. Bioinformatics. 2016;32:424–31.
Ping L, et al. Global quantitative analysis of the human brain proteome and phosphoproteome in Alzheimer’s disease. Sci Data. 2020;7:315.
Abreha MH, et al. Quantitative Analysis of the Brain Ubiquitylome in Alzheimer’s Disease. Proteomics. 2018;18:e1800108.
Dammer EB, et al. Polyubiquitin linkage profiles in three models of proteolytic stress suggest the etiology of Alzheimer disease. J Biol Chem. 2011;286:10457–65.
Moremen KW, et al. Vertebrate protein glycosylation: diversity, synthesis and function. Nat Rev Mol Cell Biol. 2012;13:448–62.
Zhang Q, et al. Integrative glycoproteomics reveals protein N-glycosylation aberrations and glycoproteomic network alterations in Alzheimer’s disease. Sci Adv. 2020;6:eabc5802.
Carlyle BC, et al. Proteomic Approaches for the Discovery of Biofluid Biomarkers of Neurodegenerative Dementias. Proteomes. 2018;6:32.
Neff RA, et al. Molecular subtyping of Alzheimer’s disease using RNA sequencing data reveals novel mechanisms and targets. Sci Adv. 2021;7:eabb5398.
Cocozza F, et al. SnapShot: Extracellular Vesicles. Cell. 2020;182:262–2.
Soares Martins T, et al. Diagnostic and therapeutic potential of exosomes in Alzheimer’s disease. J Neurochem. 2021;156:162–81.
Perez-Gonzalez R, et al. The exosome secretory pathway transports amyloid precursor protein carboxyl-terminal fragments from the cell into the brain extracellular space. J Biol Chem. 2012;287:43108–15.
Muraoka S, et al. Enrichment of Neurodegenerative Microglia Signature in Brain-Derived Extracellular Vesicles Isolated from Alzheimer’s Disease Mouse Models. J Proteome Res. 2021;20:1733–43.
Rosas-Hernandez H, et al. Characterization of Serum Exosomes from a Transgenic Mouse Model of Alzheimer’s Disease. Curr Alzheimer Res. 2019;16:388–95.
Saman S, et al. Exosome-associated tau is secreted in tauopathy models and is selectively phosphorylated in cerebrospinal fluid in early Alzheimer disease. J Biol Chem. 2012;287:3842–9.
Herukka SK, et al. Recommendations for cerebrospinal fluid Alzheimer’s disease biomarkers in the diagnostic evaluation of mild cognitive impairment. Alzheimers Dement. 2017;13:285–95.
Simonsen AH, et al. Recommendations for CSF AD biomarkers in the diagnostic evaluation of dementia. Alzheimers Dement. 2017;13:274–84.
Suarez-Calvet M, et al. Novel tau biomarkers phosphorylated at T181, T217 or T231 rise in the initial stages of the preclinical Alzheimer’s continuum when only subtle changes in Abeta pathology are detected. EMBO Mol Med. 2020;12:e12921.
Barthelemy NR, et al. Cerebrospinal fluid phospho-tau T217 outperforms T181 as a biomarker for the differential diagnosis of Alzheimer’s disease and PET amyloid-positive patient identification. Alzheimers Res Ther. 2020;12:26.
Barthelemy NR, et al. Blood plasma phosphorylated-tau isoforms track CNS change in Alzheimer’s disease. J Exp Med. 2020;217:e20200861.
Skelly AC, et al. Assessing bias: the importance of considering confounding. Evid Based Spine Care J. 2012;3:9–12.
Comes AL, et al. Proteomics for blood biomarker exploration of severe mental illness: pitfalls of the past and potential for the future. Transl Psychiatry. 2018;8:160.
Mertins P, et al. Ischemia in tumors induces early and sustained phosphorylation changes in stress kinase pathways but does not affect global protein levels. Mol Cell Proteomics. 2014;13:1690–704.
Zhou C, et al. Statistical considerations of optimal study design for human plasma proteomics and biomarker discovery. J Proteome Res. 2012;11:2103–13.
Aebersold R, et al. How many human proteoforms are there? Nature chemical biology. 2018;14:206–14.
Wildburger NC, et al. Diversity of Amyloid-beta Proteoforms in the Alzheimer’s Disease Brain. Sci Rep. 2017;7:9520.
Drepper F, et al. A combinatorial native MS and LC-MS/MS approach reveals high intrinsic phosphorylation of human Tau but minimal levels of other key modifications. J Biol Chem. 2020;295:18213–25.
Mehmood S, et al. Mass spectrometry of protein complexes: from origins to applications. Annu Rev Phys Chem. 2015;66:453–74.
Lossl P, et al. The diverse and expanding role of mass spectrometry in structural and molecular biology. EMBO J. 2016;35:2634–57.
Kaur U, et al. Proteome-Wide Structural Biology: An Emerging Field for the Structural Analysis of Proteins on the Proteomic Scale. J Proteome Res. 2018;17:3614–27.
Yu K, et al. Global Profiling of Lysine Accessibility to Evaluate Protein Structure Changes in Alzheimer’s Disease. J Am Soc Mass Spectrom. 2021;32:936–45.
Keren-Shaul H, et al. A Unique Microglia Type Associated with Restricting Development of Alzheimer’s Disease. Cell. 2017;169:1276–90 e1217.
Mathys H, et al. Single-cell transcriptomic analysis of Alzheimer’s disease. Nature. 2019;570:332–7.
Grubman A, et al. A single-cell atlas of entorhinal cortex from individuals with Alzheimer’s disease reveals cell-type-specific gene expression regulation. Nat Neurosci. 2019;22:2087–97.
Zhou Y, et al. Human and mouse single-nucleus transcriptomics reveal TREM2-dependent and TREM2-independent cellular responses in Alzheimer’s disease. Nat Med. 2020;26:131–42.
Chen WT, et al. Spatial Transcriptomics and In Situ Sequencing to Study Alzheimer’s Disease. Cell. 2020;182:976–91 e919.
Habib N, et al. Disease-associated astrocytes in Alzheimer’s disease and aging. Nat Neurosci. 2020;23:701–6.
Marx V. A dream of single-cell proteomics. Nat Methods. 2019;16:809–12.
Kelly RT. Single-cell Proteomics: Progress and Prospects. Mol Cell Proteomics. 2020;19:1739–48.
Specht H, et al. Single-cell proteomic and transcriptomic analysis of macrophage heterogeneity using SCoPE2. Genome Biol. 2021;22:50.
Alvarez-Castelao B, et al. Cell-type-specific metabolic labeling of nascent proteomes in vivo. Nat Biotechnol. 2017;35:1196–201.
Wilson RS, et al. Cell-Type-Specific Proteomics: A Neuroscience Perspective. Proteomes. 2018;6:51.
Alfaro JA, et al. The emerging landscape of single-molecule protein sequencing technologies. Nat Methods. 2021;18:604–17.
Deshmukh AS, et al. Deep proteomics of mouse skeletal muscle enables quantitation of protein isoforms, metabolic pathways, and transcription factors. Mol Cell Proteomics. 2015;14:841–53.
Yu J, et al. Systems immunology: Integrating multi-omics data to infer regulatory networks and hidden drivers of immunity. Curr Opin Sys Biol. 2019;15:19–29.
Margolin AA, et al. ARACNE: an algorithm for the reconstruction of gene regulatory networks in a mammalian cellular context. BMC Bioinformatics. 2006;7(Suppl 1):7.
Alvarez MJ, et al. Functional characterization of somatic mutations in cancer using network-based inference of protein activity. Nat Genet. 2016;48:838–47.
Rayaprolu S, et al. Systems-based proteomics to resolve the biology of Alzheimer’s disease beyond amyloid and tau. Neuropsychopharmacology. 2021;46:98–115.
Penney J, et al. Modeling Alzheimer’s disease with iPSC-derived brain cells. Molecular psychiatry. 2020;25:148–67.
Sasaguri H, et al. APP mouse models for Alzheimer’s disease preclinical studies. EMBO J. 2017;36:2473–87.
Acknowledgements
The authors thank all other members in the Peng lab and the Center for Proteomics and Metabolomics for helpful discussion.
Funding
This work was partially supported by National Institutes of Health grants R01AG047928, R01AG053987, R01AG068581, R01GM114260, RF1AG064909, U54NS110435 and American Lebanese Syrian Associated Charities (ALSAC).
Author information
Authors and Affiliations
Contributions
All authors wrote the article.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
All authors read and approved the final manuscript.
Competing interests
Not applicable.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Bai, B., Vanderwall, D., Li, Y. et al. Proteomic landscape of Alzheimer’s Disease: novel insights into pathogenesis and biomarker discovery. Mol Neurodegeneration 16, 55 (2021). https://doi.org/10.1186/s13024-021-00474-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13024-021-00474-z