
Abstract
Background
To assess the efficacy of artificial intelligence (AI) models in diagnosing and prognosticating acute appendicitis (AA) in adult patients compared to traditional methods. AA is a common cause of emergency department visits and abdominal surgeries. It is typically diagnosed through clinical assessments, laboratory tests, and imaging studies. However, traditional diagnostic methods can be time-consuming and inaccurate. Machine learning models have shown promise in improving diagnostic accuracy and predicting outcomes.
Main body
A systematic review following the PRISMA guidelines was conducted, searching PubMed, Embase, Scopus, and Web of Science databases. Studies were evaluated for risk of bias using the Prediction Model Risk of Bias Assessment Tool. Data points extracted included model type, input features, validation strategies, and key performance metrics.
Results
In total, 29 studies were analyzed, out of which 21 focused on diagnosis, seven on prognosis, and one on both. Artificial neural networks (ANNs) were the most commonly employed algorithm for diagnosis. Both ANN and logistic regression were also widely used for categorizing types of AA. ANNs showed high performance in most cases, with accuracy rates often exceeding 80% and AUC values peaking at 0.985. The models also demonstrated promising results in predicting postoperative outcomes such as sepsis risk and ICU admission. Risk of bias was identified in a majority of studies, with selection bias and lack of internal validation being the most common issues.
Conclusion
AI algorithms demonstrate significant promise in diagnosing and prognosticating AA, often surpassing traditional methods and clinical scores such as the Alvarado scoring system in terms of speed and accuracy.
Similar content being viewed by others
Introduction
Acute abdominal pain constitutes 7–10% of all emergency department visits. Acute appendicitis (AA) is a prevalent etiology of lower abdominal pain, prompting individuals to seek emergency care, and is the predominant diagnosis in young patients hospitalized for acute abdominal conditions [1]. Although the majority of cases manifest acutely within a 24-h frame, some can evolve into chronic conditions [2]. AA can be further stratified into distinct categories, namely simple, perforated, and gangrenous forms [3]. Primarily affecting individuals between the ages of 5 and 45, appendicitis has an incidence rate of about 233 per 100,000 people. It is slightly more prevalent in males, with a lifetime risk of 8.6% compared to 6.7% in females [4].
Traditionally, appendicitis diagnosis has relied on a combination of clinical evaluation, laboratory tests, and imaging studies, including ultrasound and computed tomography (CT) scans [5]. However, these methods are fraught with limitations, such as diagnostic inaccuracies and time-consuming procedures, which could result in severe complications like appendix perforation and sepsis [6].
To overcome these challenges, advancements in artificial intelligence (AI) have begun to augment conventional diagnostic frameworks. AI refers to machine capabilities that simulate human cognitive processes to perform tasks autonomously [7].
The terms AI, machine learning (ML), and deep learning (DL) represent a nested hierarchy of intelligent systems, where DL is a specialized subtype of ML, which itself falls under the broader category of AI [8]. In some studies, ML techniques like support vector machines (SVM) and random forests (RF) have been utilized for classification tasks. These techniques enhance diagnostic precision by learning from data and experience [9, 10]. DL involves using multilayer (“deep”) neural networks for data-driven computation and processing [11]. DL architectures like convolutional neural networks (CNNs) have demonstrated superior performance in analyzing intricate patterns in imaging data, occasionally surpassing human-level expertise [12]. Natural language processing (NLP) algorithms are another AI avenue that is applied to extract relevant clinical information from electronic health records, aiding in diagnostic and prognostic evaluations [13]. Reinforcement learning models have also been explored for their potential to optimize treatment strategies, such as deciding between surgical intervention and conservative management, by simulating various clinical scenarios [14]. Furthermore, ensemble techniques that amalgamate various AI models have emerged to offer more reliable and robust diagnostic solutions [15].
In light of these innovations, there has been an increasing number of studies focusing on the potential of AI in the diagnosis and management of appendicitis, exploring a multitude of input variables and ML approaches [12]. Despite these promising advances, the acute and potentially life-threatening nature of appendicitis underscores the necessity for highly reliable and efficacious AI algorithms [6, 16].
In this systematic review, we investigate how AI contributes to diagnosing AA and predicting its outcomes. We aim to assess the effectiveness of different AI models and compare them to traditional methods in diagnosing AA, classifying its types, and forecasting the outcomes after surgery.
Methods
Study Design
This study is a systematic review aimed at evaluating the applications of AI in the diagnosis and prognosis of appendicitis in adult patients. The review follows the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines [17] (Additional file 1). Furthermore, the study protocol has been formally registered in the International Prospective Register of Systematic Reviews, with the identification number CRD42023444627.
Search Strategy
We conducted a thorough systematic search in PubMed, Embase, Scopus, and Web of Science databases using a set of keywords pertinent to “artificial intelligence” and “appendicitis.” The search was designed to include articles published up to August 2023. A comprehensive description of the search strategy for each database can be found in Additional file 2.
Study Selection and Eligibility Criteria
Two independent reviewers (M.I. and D.Z.) initially screened the search results based on titles and abstracts. After this initial screening, full-text articles were carefully examined for their relevance. Inclusion criteria encompassed original research articles that were peer-reviewed and focused on the application of any AI-based model in diagnosing or prognosticating appendicitis. Exclusion criteria included studies specifically dealing with pediatric appendicitis, those relying on pre-existing external databases, those with insufficient data, or those that trained their models only using radiology reports or clinicians’ notes. Articles such as case reports, reviews, conference proceedings, and editorials were also excluded.
Data Extraction
Data extraction was carried out independently by two reviewers (M.I. and D.Z.). In cases where discrepancies arose, a third reviewer was consulted to reach a consensus (A.S.). The data points extracted included study design, primary objectives, sample size, data sources, reference standards, input features used for model training, techniques to address data imbalance, types of algorithms employed, preprocessing measures, model training and validation strategies, comparator models, key performance metrics like AUC, sensitivity, specificity, and accuracy, key findings, and limitations.
Risk of Bias Assessment
The studies included in the research were evaluated using the Prediction Model Risk of Bias Assessment Tool (PROBAST), a tool designed to assess the risk of bias across four distinct domains while also evaluating the applicability of diagnostic and prognostic models within the research context [18]. The quality assessment was conducted independently by two authors (M.I. and D.Z.), and any discrepancies were resolved by a third author (A.S.). Based on the established criteria of the PROBAST tool, the studies were then classified into one of three risk categories: low, unclear, or high. In this context, a study was considered to have a high risk of bias if it received a high-risk classification in any one of the four domains assessed by PROBAST.
Data Synthesis and Analysis
Studies were categorized based on their primary focus: diagnosis or prognosis. Whenever possible, a meta-analysis will be conducted; however, if heterogeneity or diverse input variables preclude this, findings will be presented descriptively and categorically.
Results
Study Selection
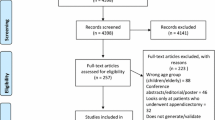
Our initial search across multiple databases led to the identification of 628 articles. An additional four articles were included from auxiliary sources. Following the removal of duplicates, 382 articles remained for screening. After a comprehensive review of titles and abstracts, 84 articles were deemed eligible based on our predetermined criteria. Following an in-depth examination of the full texts, 29 articles ultimately met the inclusion standards. The flowchart in Additional file 3: Figure S1 delineates each step of the article selection process.
Characteristics of the Studies
Among the 29 articles that met the inclusion criteria, 21 articles (72%) focused on the diagnosis of AA, seven (24%) on its prognosis, and one article addressed both diagnosis and prognosis [19]. Over half of the studies (51%) adopted a cross-sectional research design. Furthermore, a substantial portion of the included studies, 16 of them (55%), were conducted within the past 5 years (2019 and later). Remarkably, all prognosis-related studies were carried out within the last 3 years (2021 and later). A comprehensive overview can be found in Additional file 4: Figure S2.
Risk of Bias Assessment
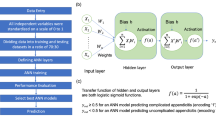
Utilizing the PROBAST, our assessment revealed that among the reviewed studies, 11 exhibited low risk of bias [3, 12, 19,20,21,22,23,24,25,26,27], while 18 exhibited high risks of bias [28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45]. The primary factor contributing to a high risk of bias was selection bias [30, 32, 33, 36, 39, 42, 44, 45], identified in eight studies. Furthermore, seven studies lacked internal validation and thus were excluded from further quality assessment [34, 35, 37, 38, 40, 41, 43]. Additionally, six studies had issues related to their analyses [29,30,31,32, 42, 44]. In two studies, a high risk of bias was associated with the outcome or its determination [28, 32]. One study had a high risk of bias introduced by their predictors or assessment [32]. The comprehensive evaluation of each domain’s quality across the studies is illustrated in Fig. 1. For a detailed breakdown of the quality assessment and PROBAST domains, please refer to Additional file 5: Table S1.

Quality assessment of included studies
Artificial Intelligence Algorithms
A total of 24 distinct artificial intelligence algorithms were applied across the selected articles. These algorithms fell into six main categories: (1) Statistical classifiers, encompassing Logistic Regression (LR) and Naïve Bayes (NB); (2) ML classifiers such as SVM, Decision Trees (DT), and K-Nearest Neighbors (KNN); (3) Ensemble ML techniques, which include RFs, Pre-clustering Ensemble Learning (PEL), and variants of Boosted DT like Gradient Boosting (GB), Extreme Gradient Boosting (XGB), and CatBoost; (4) ML Neural Networks, including Artificial Neural Networks (ANN) and other specialized forms like Multilayer Perceptron (MLP), Backpropagation Neural Network (BPNN), Radial Basis Function Network (RBFN), Adaptive Resonance Theory (ART), Self-Organizing Maps (SOMs), Learning Vector Quantization (LVQ), Multilayer Neural Network (MLNN), Probabilistic Neural Network (PNN), Extreme Learning Machines (ELM), and Kernel ELM (KELM); (5) DL techniques, particularly CNNs; and (6) other miscellaneous algorithms including fuzzy rule-based and neuro-fuzzy approaches.
Over half of the studies (51%) utilized a singular algorithmic model, while the remainder employed multiple models, varying from two [26, 40, 43, 44] to six [25] in number. Comprehensive data on the types of models employed are outlined in Tables 1 and 3.
The ANN model and its variants were the most commonly employed, being featured in 13 studies [21, 24,25,26,27, 32,33,34, 37, 38, 40, 42, 45]. LR followed in frequency, appearing in nine studies [3, 24,25,26, 28, 30, 32, 42, 43]. DT [25, 30, 35, 36, 40, 41, 43] and SVM [23, 24, 28, 30, 37, 45] were each utilized in seven studies, while RF [23, 24, 29, 31, 45] was implemented in six studies.
The distribution of algorithms and their subtypes is outlined in Fig. 2, and temporal trends are depicted in Fig. 3.

Algorithms utilized in studies

Trends of different algorithms
Diagnosis of Appendicitis
A total of 22 studies applied algorithms for the diagnosis of AA. The detailed information on the included studies is summarized in Tables 1 and 2.
Input Features
Each study employed a unique spectrum of input variables to train their models. A majority of the studies predominantly utilized the incorporation of demographic factors, clinical indicators, and laboratory measurements as the primary features for model training [21, 24, 26, 34, 35, 37, 39, 42, 44]. Radiological assessments, particularly CT images, were the chosen input modality in three studies [12, 20, 22]. Laboratory data served as the exclusive input for four studies [19, 23, 32, 36]. Additionally, three studies deployed a combination of clinical observations and laboratory data as their input features [38, 40, 41]. In one particular study, the input comprised a fusion of demographic and laboratory data [33]. Infrared thermographic evaluations of the abdomen were employed in a single study [31], while another study showcased a multivariable approach, incorporating demographic, clinical, laboratory, and ultra-sonographic data [30].
Performance Metrics
In each study, different measures were used to evaluate how well the models performed. The most frequently used metrics were sensitivity and specificity, appearing in 82% of the studies. Next in line was area under the curve (AUC) and accuracy, featured in 68% and 64% of studies, respectively. Positive predictive value (PPV) was used in 45% of the studies, and negative predictive value (NPV) in 41%. Less commonly, metrics like F1-score, usefulness index (UI), and mean squared error (MSE) were each used in just one study, making up 5% of all studies.
Performance
The comprehensive performance data for each model can be found in Table 2. The models’ performance underwent no types of validation in seven studies [34, 35, 37, 38, 40, 41, 43], underwent solely internal validation in 21 studies [3, 19,20,21,22,23,24,25,26,27,28,29,30,31,32,33, 39, 42, 44, 45], and was subject to both internal and external validation in only one study [12].
Numerous AI algorithms were employed in the diagnosis of AA, with ANN being the most commonly utilized in ten studies. Owing to the diversity in these algorithms, a direct performance comparison is not feasible. Regarding ANN and its variants, all studies that disclosed their accuracy rates reported figures exceeding 80%, peaking at 97.8% [38]. The AUCs ranged from 0.55 [32] to 0.985 [38].
In studies employing DT, the accuracy metrics span from 78.87 [36] to 84.4% [30] with AUC values ranging from 0.803 [36] to 0.93 [40]. As for studies that employed LR, the accuracy metrics were observed to vary from 82% [24] to 87.5% [30], and AUC values spanning from 0.677 [32] to 0.87 [24]. Regarding DL techniques, specifically CNN, accuracy rates were found to lie between 72.5 [20] and 97.5% [12]. The AUC values for these studies ranged from 0.724 [20] to 0.951 [22]. Supplementary parameters for these algorithms, as well as other less frequently utilized algorithms, are detailed in Table 2.
Prognosis of Appendicitis
Eight articles in the review focused on the prognosis of AA. Six articles aimed to differentiate between complicated and uncomplicated cases [3, 19, 25, 27, 43, 45] and two studies focused on postoperative outcomes. One such study specifically analyzed the post-surgical outcomes of perforated appendicitis [29], while the other scrutinized the likelihood of sepsis following surgery, and its impact as a 30-day mortality risk factor [28]. Comprehensive information on the studies included in this domain is summarized in Tables 3 and 4.
Predicting the Type of Appendicitis
Six studies examined the classification of appendicitis into complicated (CA) or uncomplicated (UCA) categories, all using laboratory results as a key input. Two of these investigations employed a blend of demographic, clinical, and laboratory data as their input data [3, 45]. Another study utilized a mixture of ultrasound observations alongside demographic, clinical, and laboratory data [43]. Additionally, one study focused on the integration of ultrasonography with demographic and laboratory findings [25], and yet another utilized CT data in conjunction with laboratory outcomes as their input variables [27].
Various algorithms were employed across the research for the categorization of appendicitis types. ANN [25, 27, 45] and LR [3, 25, 43] were the predominant methods, each featured in three studies. Following these, SVM [25, 45], DT [25], and ensemble techniques (GB [25, 43] and CatBoost [19]) were each implemented in two studies. Methods such as KNN [25], RF [45], ELM [45], and KELM [45] were each utilized in a single study.
In a majority of the studies, sensitivity [3, 19, 27, 43, 45], specificity [3, 19, 27, 43, 45], and AUC [3, 19, 25, 27, 43] emerged as the most commonly employed performance measures. Accuracy [3, 19, 25, 43] was highlighted in four research works. Singular studies made use of additional metrics such as F1-score [19], PPV [43], NPV [43], positive and negative likelihood ratios [27], as well as the Matthew Correlation Coefficient (MCC) [45].
Among the scrutinized studies, the study by Lin et al. [27] stood out for achieving an AUC of 0.950 by integrating both laboratory results and CT findings to forecast the type of AA. On a similar note, Akbulut et al. [19] employed CatBoost algorithms to forecast the types of appendicitis and achieved an AUC of 0.947 along with an 88.2% accuracy rate, solely based on laboratory findings as input variables. In a comparative analysis, Li et al. [43] demonstrated that LR outperformed DT in terms of AUC. A study by Phan-Mai et al. [25] highlighted that the GB algorithm yielded the most robust performance, attaining an accuracy rate of 82%. Similarly, Xia et al. [45] verified that the Opposition-Based Learning Grasshopper Optimization Algorithm (OBLGOA), a specialized form of SVM, achieved an accuracy of 83.5%. Kang et al. [3] employed LR to distinguish among different forms of appendicitis such as simple appendicitis (SA), perforated appendicitis (PA), and gangrenous perforated appendicitis (GPA), either relying exclusively on T cell data or coupling it with clinical information. In the context of differentiating SA from PA, the model that integrated both T cell metrics and clinical findings yielded a superior accuracy of 90.6%, compared to 87.5% when relying solely on T cell data. Conversely, when the objective was to differentiate PA from GPA, the model that exclusively utilized T cell data outstripped the composite-input model, with respective accuracy rates of 80.6% and 77.4%.
Predicting Postoperative Outcomes
Two studies focused on outcomes following surgery [28, 29]. In the investigation led by Eickhoff et al. [29], the RF algorithm was used to assess post-surgical outcomes. Various types of data were employed for predictive analysis, including patient demographics, clinical history, and perioperative data such as the interval between hospital admission and appendectomy, surgery duration, laboratory test results, type of surgery such as open or laparoscopic methods, conversions, additional procedures conducted during the appendectomy, and the use of surgical drains. The model’s performance varied across distinct clinical outcomes. It achieved an accuracy of 77.2% for the requirement of ICU admission, 87.5% for an extended ICU stay exceeding 24 h, and 68.2% for complications identified by the Clavien-Dindo score greater than 3 in newly diagnosed cases. Additionally, the likelihood of reoperation following the initial appendectomy was forecasted with a 74.2% accuracy rate, while surgical site infection rates were anticipated at 66.4% accuracy. The model also predicted the necessity for oral antibiotic treatment post-discharge with 78.8% accuracy, and hospital stays lasting more than 7 and 15 days were forecasted with accuracies of 76.2% and 83.6%, respectively. For model evaluation, accuracy, sensitivity, and specificity were used as the key performance indicators. Notably, the model demonstrated strong predictive capabilities for extended ICU stays greater than 24 h and for hospitalizations exceeding 15 days, achieving accuracies above 80% for these particular outcomes.
In research carried out by Corinne Bunn et al. [28], they assessed the likelihood of developing sepsis following an appendectomy and its contribution to mortality within 30 days. Various AI techniques were employed, with performance metrics compared across models. The feature set incorporated demographic data, pre-existing medical conditions, pre-surgical laboratory results, days, and details about the surgical procedure itself. Models utilized in their analysis included SVM, LR, XGB, and Random Forest Decision Trees (RFDT). Additionally, they created an ensemble model by amalgamating RFDT, LR, and XGB. The ensemble model and XGB demonstrated superior efficacy in forecasting post-appendectomy sepsis risk. While both models matched in terms of accuracy and sensitivity, the ensemble model lagged in specificity. RFDT and LR performed similarly but were surpassed by the aforementioned models, with SVM trailing in last place.
When evaluating sepsis as a contributing factor to 30-day mortality, RFDT took the lead in model performance. Following RFDT, the models ranked in descending order of effectiveness were: the ensemble model, XGB, LR, and finally SVM.
Discussion
Appendicitis represents a surgical emergency demanding swift and precise diagnosis to avert potentially life-threatening complications such as peritonitis and sepsis [46]. AI algorithms have emerged as a transformative tool, significantly enhancing diagnostic accuracy and prognostic capabilities, thus potentially revolutionizing AA management [47]. In this systematic review, focused on AA in adult patients, we observe that the majority of research endeavors (72%) have been dedicated to diagnostic applications. This emphasis underscores the immediate clinical need for accurate AA diagnosis.
While diagnostic applications have dominated the landscape, a discernible surge in prognostic studies has emerged over the last 3 years. This trend reflects an evolving recognition of AI’s potential to diagnose and forecast patient outcomes, providing valuable insights for treatment strategies.
A diverse array of AI algorithms has been applied in both the diagnosis and prognosis of AA. These include ANN, SVM, DT, LR, RF, DL (CNN), and various other algorithms. Notably, traditional diagnostic approaches, such as the Alvarado scoring system, ultrasound findings, Eskelinen score, laboratory assessments, and clinical evaluation, have been included in some studies for comparative purposes. Encouragingly, AI consistently outperformed these traditional scoring systems, highlighting the superiority of ML algorithms in medical diagnosis and prognosis.
However, it is important to acknowledge the challenges in directly comparing these AI models. The considerable heterogeneity among studies, encompassing factors like single-center designs, small sample sizes, retrospective methodologies, variations in input features, diverse algorithms, and differing performance metrics, precluded a meta-analysis. This complexity underscores the need for caution when drawing quantitative comparisons between the various models.
Within the realm of studies employing multiple AI algorithms, ANN and its subtypes emerge as the top performers for diagnosing AA, demonstrating their robustness and versatility in this clinical context.
Moreover, individual studies have contributed unique insights. For instance, Rajpurkar et al. [20] demonstrated that CNN achieved superior performance when pretrained on video sequences, showcasing the potential benefits of data augmentation techniques. Sun et al. [36] highlighted that DT yielded more favorable results when combined with univariate analysis rather than multivariate analysis, underlining the importance of optimizing algorithm combinations.
In the prognostic domain, CatBoost demonstrated a stronger performance in prognosis compared to diagnosis, as evident in one study [19].
Timely and accurate diagnosis of appendicitis during pregnancy is crucial to minimize perinatal and maternal morbidity and mortality, yet is often delayed due to prevalent gastrointestinal symptoms and challenges in interpreting clinical and laboratory findings. Anatomical and physiological alterations, such as the displacement of the appendix by the enlarging uterus and pregnancy-induced leukocytosis, exacerbate these diagnostic difficulties, resulting in accurate preoperative diagnosis in merely 1/2 to 3/4 of cases [48]. In light of these diagnostic challenges, the selection of appropriate predictive algorithms becomes paramount. For instance, when predicting the type of appendicitis during pregnancy, LR outperforms DT, underscoring the importance of algorithm selection in enhancing diagnostic accuracy in specific clinical contexts [43].
A specific focus by Gudelis et al. [40] on ANN and DT revealed that both algorithms performed similarly for differential diagnoses of right iliac fossa pain, but ANN was significantly more effective for the diagnosis of AA.
Examining postoperative consequences in the context of perforated appendicitis [29], the RF algorithm consistently achieved an accuracy exceeding 70% across various clinical endpoints. These included admission to the ICU, ICU stays exceeding 24 h, the need for post-appendectomy reoperation, prescription of oral antibiotics following discharge, and extended hospital stays. These findings underscore the potential of AI to contribute to postoperative decision-making and patient care.
In the prediction of post-appendectomy sepsis risk [28], both the ensemble model (XGB + RFDT + LR) and XGB demonstrated high effectiveness, with similar accuracy and sensitivity. However, the ensemble model exhibited lower specificity. When assessing sepsis as a contributing factor to 30-day mortality, RFDT emerged as the top-performing model, offering valuable insights into postoperative patient management.
Our systematic review offers distinct advantages. We have incorporated both diagnostic and prognostic studies, providing a holistic view of AI’s role in adult AA management. This comprehensive approach enhances our understanding of AI’s clinical potential. By employing the PROBAST tool, we have critically evaluated the risk of bias, offering readers a transparent assessment of study reliability. Furthermore, our review furnishes detailed insights into the performance of various AI algorithms, aiding healthcare professionals and researchers in selecting suitable models for specific clinical applications. Additionally, by identifying limitations and research gaps, our review serves as a guiding compass for future investigations, emphasizing the importance of robust study designs and enhanced methodological rigor.
The findings of this systematic review hold significant practical implications for the field of appendicitis management. With AI algorithms consistently outperforming traditional diagnostic methods, clinicians may consider integrating these advanced tools into their decision-making processes. This could lead to more accurate and timely diagnoses, potentially reducing the risk of misdiagnoses and unnecessary surgeries. Moreover, the insights gained from prognostic studies could aid in tailoring treatment plans to individual patient needs, optimizing postoperative care, and improving outcomes. As for future research, these practical implications emphasize the importance of further investigating the implementation of AI in clinical settings, considering factors such as user-friendliness, accessibility, and cost-effectiveness to ensure real-world utility.
Despite its strengths, our systematic review does have limitations. The inherent heterogeneity among the included studies, characterized by factors such as single-center designs, limited sample sizes, retrospective methodologies, variations in input features, diverse AI algorithms, varying performance metrics, and outcome measures, hindered our ability to conduct a meta-analysis and draw direct quantitative comparisons between models. Furthermore, a majority of the reviewed studies exhibited a high risk of bias, particularly in terms of selection bias and the absence of internal validation, potentially impacting the generalizability of the evaluated AI models. Additionally, the dynamic nature of AI in healthcare suggests that new research may emerge, potentially influencing or altering our current findings over time.
While this systematic review provides a comprehensive overview of the current landscape, it also highlights several areas where future research can make valuable contributions. Firstly, studies that directly compare different AI algorithms in controlled clinical settings could provide insights into which algorithms perform best under specific conditions, facilitating algorithm selection for clinicians. Additionally, investigating the integration of AI systems into electronic health records and clinical workflows is crucial to ensure seamless adoption in healthcare settings. Furthermore, exploring the long-term impact of AI-driven decision support systems on patient outcomes and healthcare costs is an avenue for research. Finally, as AI technologies continue to evolve, ongoing research should focus on adapting these tools to emerging diagnostic and prognostic challenges in appendicitis management, ultimately enhancing patient care and safety.
Conclusion
In conclusion, the application of AI in the context of appendicitis holds immense promise. It has already demonstrated its potential to significantly enhance diagnostic accuracy and prognostic capabilities, marking a transformative shift in how we approach this critical medical condition. The robust performance of various AI algorithms, outperforming traditional diagnostic methods, underscores their relevance in clinical practice.
Availability of Data and Materials
All data are included in the main manuscript and supplemental files.
References
Di Saverio S, Podda M, De Simone B, Ceresoli M, Augustin G, Gori A, et al. Diagnosis and treatment of acute appendicitis: 2020 update of the WSES Jerusalem guidelines. World J Emerg Surg. 2020;15(1):27.
Jones M, Godana I, Hoilat G, Deppen J (2021) StatPearls [Internet]. StatPearls Publishing
Kang CB, Li XW, Hou SY, Chi XQ, Shan HF, Zhang QJ, et al. Preoperatively predicting the pathological types of acute appendicitis using machine learning based on peripheral blood biomarkers and clinical features: a retrospective study. Ann Transl Med. 2021;9(10):835.
Addiss DG, Shaffer N, Fowler BS, Tauxe RV. The epidemiology of appendicitis and appendectomy in the United States. Am J Epidemiol. 1990;132(5):910–25.
Terasawa T, Blackmore C, Bent S, Kohlwes RJ. Systematic review: computed tomography and ultrasonography to detect acute appendicitis in adults and adolescents. Ann Intern Med. 2004;141:537–46.
Flum DR, Koepsell T. The clinical and economic correlates of misdiagnosed appendicitis: nationwide analysis. Arch Surg. 2002;137(7):799–804.
Deo RC. Machine learning in medicine. Circulation. 2015;132(20):1920–30.
Sarker IH. AI-based modeling: techniques, applications and research issues towards automation, intelligent and smart systems. SN Comput Sci. 2022;3(2):158.
Sarker IH. Machine learning: algorithms, real-world applications and research directions. SN Comput Sci. 2021;2(3):160.
Cortes C, Vapnik VN. Support-vector networks. Mach Learn. 1995;20:273–97.
Sarker IH. Deep learning: a comprehensive overview on techniques, taxonomy, applications and research directions. SN Comput Sci. 2021;2(6):420.
Park JJ, Kim KA, Nam Y, Choi MH, Choi SY, Rhie J. Convolutional-neural-network-based diagnosis of appendicitis via CT scans in patients with acute abdominal pain presenting in the emergency department. Sci Rep. 2020;10(1):9556.
Jagannatha AN, Yu H. Structured prediction models for RNN based sequence labeling in clinical text. Proc Conf Empir Methods Nat Lang Process. 2016;2016:856–65.
Sutton RS, Barto AG. Reinforcement learning: an introduction. 2nd ed. Cambridge: The MIT Press; 2018.
Zhou Z-H. Ensemble methods: foundations and algorithms. Boca Raton: Chapman & Hall/CRC; 2013.
Salminen P, Paajanen H, Rautio T, Nordström P, Aarnio M, Rantanen T, et al. Antibiotic therapy vs appendectomy for treatment of uncomplicated acute appendicitis: the APPAC randomized clinical trial. JAMA. 2015;313(23):2340–8.
Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ. 2021;372: n71.
Wolff RF, Moons KGM, Riley RD, Whiting PF, Westwood M, Collins GS, et al. PROBAST: a tool to assess the risk of bias and applicability of prediction model studies. Ann Intern Med. 2019;170(1):51–8.
Akbulut S, Yagin FH, Cicek IB, Koc C, Colak C, Yilmaz S. Prediction of perforated and nonperforated acute appendicitis using machine learning-based explainable artificial intelligence. Diagnostics (Basel). 2023;13(6):1173.
Rajpurkar P, Park A, Irvin J, Chute C, Bereket M, Mastrodicasa D, et al. AppendiXNet: deep learning for diagnosis of appendicitis from a small dataset of CT exams using video pretraining. Sci Rep. 2020;10(1):3958.
Prabhudesai SG, Gould S, Rekhraj S, Tekkis PP, Glazer G, Ziprin P. Artificial neural networks: useful aid in diagnosing acute appendicitis. World J Surg. 2008;32(2):305–9 (discussion 10-1).
Park SH, Kim YJ, Kim KG, Chung JW, Kim HC, Choi IY, et al. Comparison between single and serial computed tomography images in classification of acute appendicitis, acute right-sided diverticulitis, and normal appendix using EfficientNet. PLoS ONE. 2023;18(5 May):e0281498.
Zhao Y, Yang L, Sun C, Li Y, He Y, Zhang L, et al. Discovery of urinary proteomic signature for differential diagnosis of acute appendicitis. Biomed Res Int. 2020;2020:3896263.
Hsieh CH, Lu RH, Lee NH, Chiu WT, Hsu MH, Li YC. Novel solutions for an old disease: diagnosis of acute appendicitis with random forest, support vector machines, and artificial neural networks. Surgery. 2011;149(1):87–93.
Phan-Mai TA, Thai TT, Mai TQ, Vu KA, Mai CC, Nguyen DA. Validity of machine learning in detecting complicated appendicitis in a resource-limited setting: findings from Vietnam. Biomed Res Int. 2023;2023:5013812.
Sakai S, Kobayashi K, Toyabe S, Mandai N, Kanda T, Akazawa K. Comparison of the levels of accuracy of an artificial neural network model and a logistic regression model for the diagnosis of acute appendicitis. J Med Syst. 2007;31(5):357–64.
Lin HA, Lin LT, Lin SF. Application of artificial neural network models to differentiate between complicated and uncomplicated acute appendicitis. J Med Syst. 2023;47(1):38.
Bunn C, Kulshrestha S, Boyda J, Balasubramanian N, Birch S, Karabayir I, et al. Application of machine learning to the prediction of postoperative sepsis after appendectomy. Surgery. 2021;169(3):671–7.
Eickhoff RM, Bulla A, Eickhoff SB, Heise D, Helmedag M, Kroh A, et al. Machine learning prediction model for postoperative outcome after perforated appendicitis. Langenbecks Arch Surg. 2022;407(2):789–95.
Ghareeb WM, Emile SH, Elshobaky A. Artificial intelligence compared to alvarado scoring system alone or combined with ultrasound criteria in the diagnosis of acute appendicitis. J Gastrointest Surg. 2022;26(3):655–8.
Ramirez-GarciaLuna JL, Vera-Bañuelos LR, Guevara-Torres L, Martínez-Jiménez MA, Ortiz-Dosal A, Gonzalez FJ, Kolosovas-Machuca ES. Infrared thermography of abdominal wall in acute appendicitis: proof of concept study. Infrared Phys Technol. 2020;105: 103165.
Forsström JJ, Irjala K, Selén G, Nyström M, Eklund P. Using data preprocessing and single layer perceptron to analyze laboratory data. Scand J Clin Lab Investig Suppl. 1995;222:75–81.
Afshari Safavi A, Zand Karimi E, Rezaei M, Mohebi H, Mehrvarz S, Khorrami MR. Comparing the accuracy of neural network models and conventional tests in diagnosis of suspected acute appendicitis. J Mazandaran Univ Med Sci. 2015;25(128):58–65.
Pesonen E, Eskelinen M, Juhola M. Comparison of different neural network algorithms in the diagnosis of acute appendicitis. Int J Biomed Comput. 1996;40(3):227–33.
Ting HW, Wu JT, Chan CL, Lin SL, Chen MH. Decision model for acute appendicitis treatment with decision tree technology–a modification of the Alvarado scoring system. J Chin Med Assoc. 2010;73(8):401–6.
Son CS, Jang BK, Seo ST, Kim MS, Kim YN. A hybrid decision support model to discover informative knowledge in diagnosing acute appendicitis. BMC Med Inform Decis Mak. 2012;12(1):17.
Yoldaş Ö, Tez M, Karaca T. Artificial neural networks in the diagnosis of acute appendicitis. Am J Emerg Med. 2012;30(7):1245–7.
Park SY, Kim SM. Acute appendicitis diagnosis using artificial neural networks. Technol Health Care. 2015;23(Suppl 2):S559–65.
Jamshidnezhad A, Azizi A, Zadeh SR, Shirali S, Shoushtari MH, Sabaghan Y, et al. A computer based model in comparison with sonography imaging to diagnosis of acute appendicitis in Iran. J Acute Med. 2017;7(1):10–8.
Gudelis M, Lacasta Garcia JD, Trujillano Cabello JJ. Diagnosis of pain in the right iliac fossa. A new diagnostic score based on decision-tree and artificial neural network methods. Cir Esp (Engl Ed). 2019;97(6):329–35.
Kang HJ, Kang H, Kim B, Chae MS, Ha YR, Oh SB, Ahn JH. Evaluation of the diagnostic performance of a decision tree model in suspected acute appendicitis with equivocal preoperative computed tomography findings compared with Alvarado, Eskelinen, and adult appendicitis scores: A STARD compliant article. Medicine (Baltimore). 2019;98(40): e17368.
Shahmoradi L, Safdari R, Mir Hosseini M, Arji G, Jannt B, Abdar M. Predicting risk of acute appendicitis: a comparison of artificial neural network and logistic regression models. Acta Med Iran. 2019;56(12):785.
Li P, Zhang Z, Weng S, Nie H. Establishment of predictive models for acute complicated appendicitis during pregnancy-a retrospective case-control study. Int J Gynaecol Obstet. 2023;162(2):744–51.
Lee YH, Hu PJ, Cheng TH, Huang TC, Chuang WY. A preclustering-based ensemble learning technique for acute appendicitis diagnoses. Artif Intell Med. 2013;58(2):115–24.
Xia J, Wang Z, Yang D, Li R, Liang G, Chen H, et al. Performance optimization of support vector machine with oppositional grasshopper optimization for acute appendicitis diagnosis. Comput Biol Med. 2022;143: 105206.
Stahlfeld K, Hower J, Homitsky S, Madden J. Is acute appendicitis a surgical emergency? Am Surg. 2007;73(6):626–9 (discussion 9-30).
Busnatu Ș, Niculescu AG, Bolocan A, Petrescu GED, Păduraru DN, Năstasă I, et al. Clinical applications of artificial intelligence-an updated overview. J Clin Med. 2022;11(8):2265.
Basaran A, Basaran M. Diagnosis of acute appendicitis during pregnancy: a systematic review. Obstet Gynecol Surv. 2009;64(7):481–8 (quiz 99).
Funding
None.
Author information
Authors and Affiliations
Contributions
MI and DZ conceptualized the study, did the literature search and data curation, and prepared the original draft. AS provided research methodology consultation, appraised the manuscript, and supervised the project. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1
. PRISMA 2020 Checklist.
Additional file 2
. Search Strategy for Four Databases.
Additional file 3
. Figure S1. Study Selection.
Additional file 4
. Figure S2. Frequency of AI research in appendicitis across various years.
Additional file 5
. Assessment of the Included Studies Using PROBAST.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Issaiy, M., Zarei, D. & Saghazadeh, A. Artificial Intelligence and Acute Appendicitis: A Systematic Review of Diagnostic and Prognostic Models. World J Emerg Surg 18, 59 (2023). https://doi.org/10.1186/s13017-023-00527-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13017-023-00527-2