
Abstract
Background
Magnetic resonance imaging (MRI) plays an increasingly important role in radiotherapy, enhancing the accuracy of target and organs at risk delineation, but the absence of electron density information limits its further clinical application. Therefore, the aim of this study is to develop and evaluate a novel unsupervised network (cycleSimulationGAN) for unpaired MR-to-CT synthesis.
Methods
The proposed cycleSimulationGAN in this work integrates contour consistency loss function and channel-wise attention mechanism to synthesize high-quality CT-like images. Specially, the proposed cycleSimulationGAN constrains the structural similarity between the synthetic and input images for better structural retention characteristics. Additionally, we propose to equip a novel channel-wise attention mechanism based on the traditional generator of GAN to enhance the feature representation capability of deep network and extract more effective features. The mean absolute error (MAE) of Hounsfield Units (HU), peak signal-to-noise ratio (PSNR), root-mean-square error (RMSE) and structural similarity index (SSIM) were calculated between synthetic CT (sCT) and ground truth (GT) CT images to quantify the overall sCT performance.
Results
One hundred and sixty nasopharyngeal carcinoma (NPC) patients who underwent volumetric-modulated arc radiotherapy (VMAT) were enrolled in this study. The generated sCT of our method were more consistent with the GT compared with other methods in terms of visual inspection. The average MAE, RMSE, PSNR, and SSIM calculated over twenty patients were 61.88 ± 1.42, 116.85 ± 3.42, 36.23 ± 0.52 and 0.985 ± 0.002 for the proposed method. The four image quality assessment metrics were significantly improved by our approach compared to conventional cycleGAN, the proposed cycleSimulationGAN produces significantly better synthetic results except for SSIM in bone.
Conclusions
We developed a novel cycleSimulationGAN model that can effectively create sCT images, making them comparable to GT images, which could potentially benefit the MRI-based treatment planning.
Similar content being viewed by others

Introduction
Magnetic resonance imaging (MRI) has become an essential imaging modality in both staging and targets volume (TV) delineation for head and neck (H&N) cancer radiotherapy (RT) owing to its intrinsically superior soft-tissue contrast, functional information, high resolution and non-radiation [1,2,3]. Precise contouring is crucial when treating H&N cancer patients presenting with primary soft tissue invasion or subtle intra-cranial invasion for accurate dose delivery to TV, and consequently improve the treatment outcomes [4,5,6]. Several studies have proven that MRI was more accurate than Computer Tomography (CT) and Positron Emission Tomography (PET) and was even closer to the pathological specimen measurements considered the “gold standard”, which can also substantially decrease the inter-observer variability of TV and organs at risks (OARs) delineation [1, 2, 7]. Recently, the MRI-guided-radiotherapy has been implemented in clinical practice brought personalized medicine one step forward. The perfect combination of a Linac and the multifunctional imaging modality provides unique opportunities to adaptive RT [8,9,10]. However, due to the inherent limitations of physical imaging characteristics, conventional MRI cannot provide bone information and electron density information of the tissue like CT images, which are necessary for accurate dose calculation in treatment planning, preventing further clinical application of MR-only-radiotherapy [11, 12]. In the aggregate, CT is an indispensable imaging modality in the current RT workflow, and the acquisition of both CT and MR images increases cancer patient costs and additional irradiation [13]. Of particular importance is the introduction of MR-CT registration uncertainty could reduce the accuracy of delineation [14,15,16].
To address the aforementioned limitations, estimating Hounsfield Unit (HU) and generating synthetic-CT (sCT) from MR images using artificial intelligence (AI) algorithms may be a potential and effective solution in clinical setting, which have gained significant attention for image-to-image translation [17,18,19,20,21,22,23]. In recent years, data-driven AI has made tremendous developments in image processing, computer vision and pattern recognition. By providing new capabilities such as real-time guidance and personalized intervention, AI has upended conventional wisdom and has the power to improve the availability and efficiency of cancer treatment worldwide [24,25,26]. Deep learning (DL) with convolutional neural network (CNN) automatically abstracts the multiscale features and integrates them into an end-to-end network for prediction, which contributes to eliminating the reliance on manual features [27,28,29]. Recently, many DL-based models have shown success when applied to image segmentation, dose prediction, patient-specific quality assurance, and have been introduced to the field of sCT generation from MRI [30,31,32]. By establishing the complex and nonlinear mapping mechanism from self-learning and self-optimizing strategies between two image domains, the feature information between MR/CT can be transferred, so as to solve the deficiencies of the single-modality imaging in clinical RT implementation [33,34,35]. Once the optimal DL parameters are estimated, sCT images can be easily obtained within a few seconds by feeding the new MR images into the trained model.
A variety of mature DL networks have been improved and applied to generate sCT from MRI images [36,37,38,39,40]. The deep CNN-based approaches improved the efficiency and quality of sCT generation compared with traditional atlas-based and segmentation-based methods, while its performance is affected by the accuracy of MR-CT registration, and tiny voxel-wise misalignments may lead to blurring of synthesized images [37]. Recently, increasing interest focused on generative adversarial network (GAN) and its variants, the GAN-based architecture has been demonstrated to synthesize high-quality sCT images with less blurriness compared with the CNN approaches [38,39,40,41,42,43,44]. Unfortunately, the GAN-based models still require properly aligned paired dataset for training and some studies have also found that they cannot preserve details during transformation [38]. Since CNN and GAN training, models have high requirements for MRI-CT image registered, which is usually difficult for clinical practice. To solve this problem, CycleGAN proposed by Zhu et al. [45] is essentially a circular network composed of two mirror-symmetric GANs based on the principle of cycle-consistency, which not only does not require paired images but is also able to utilize different modality images. However, cycleGAN lacks a direct constraint between the input and synthetic images, which makes it unable to guarantee structural-consistency between these two images, and thus gets an undesirable outcome in the given application. From the perspective of clinical application, the accuracy of pixel-wise HU and structural-consistency of the generated sCT directly determines the accuracy of subsequent radiotherapy. Furthermore, another major issue should be considered when building a machine learning (ML)/DL model for sCT generation from MRI in clinical practice. In the current RT simulation process, big-aperture CT and RT dedicated MR-scanners are usually used to obtain anatomical images at complex positions, the field of view of CT/MR scans is often too large, thus results in a large proportion of the acquired MR/CT images being background. In order to make the synthetic models focus on the human body region or the most critical part of the synthetic images, DL networks require additional partial truncation of the input data to save computational resources and improve prediction accuracy.
In this study, we overcome the aforementioned issues by designing a novel channel-wise attention enhanced and structural similarity constrained cycleGAN called cycleSimulationGAN for unpaired MR-to-CT synthesis. Specifically, we introduce the contour mutual information loss function to constrain the structural similarity between the original MR and the synthetic MR, such as contour shape and area, so as to constrain the synthetic CT to have better structural retention characteristics. Additionally, we propose to equip a novel channel-wise attention mechanism based on the traditional generator of GAN to enhance the feature representation capability of deep network and extract more effective features. Extensive experiments show that our method outperforms state-of-the-art CT synthesis methods such as conventional and improved cycleGAN.
Methods
Data acquisition and processing
One hundred and sixty nasopharyngeal carcinoma (NPC) patients underwent volumetric-modulated arc radiotherapy (VMAT) between Dec 2020 and Dec 2021 in our hospital were enrolled in this study. The planning CT (pCT) images and simulated MRI were acquired from a CT (SOMATOM Definition AS, Siemens Medical Systems) and MRI (Ingenia 3.0T, Philips Medical Systems), respectively. This study was approved by the medical ethics committee of our hospital (2022ky298). The original dataset is split into training (120), validation (20), and test set (20), which contain 5734, 954 and 935 images, respectively. Both the dimension of CT and MR images were 512 × 512 on the axial plane, while the spatial resolution was 1.27 mm × 1.27 mm × 3.00 mm for CT scans, and 0.729 mm × 0.729 mm × 3 mm for MR scans. All images were preprocessed with in-house developed software in the following ways. First, all the MR and CT images are normalized to have a resolution of 1 mm ×1 mm ×1 mm, and then CT and MRI were rigidly registered to align them. After that, deformable registration from CT to MRI was performed. Afterward, the pCT images were used as a benchmark for the sCTs during training and testing.
Architecture of cycleSimulationGAN
Figure 1 illustrates the overall workflow of our method. The original MRI is output through the generator to sCT images, and the sCT images are then used to reconstruct the original MR images through the generator, thus forming a cycle. The original cycleGAN learns to discriminate between sCT and real CT (unpaired data) by using the discriminator of the generative adversarial network under the constraint of the corresponding loss function, and the generator gradually learns to synthesize CT with better quality. In addition, cycleGAN also constrains the reconstructed MR to be as similar to the original MR as possible by applying an L1 loss function between the original MR and the reconstructed MR as a cycle loss [45]. On this basis, our method makes the following two innovations, which can effectively improve the structural retention characteristics, and the degree of detail recovery of synthetic CT results. Moreover, background interference is also effectively suppressed. The cycleSimulationGAN architecture is shown in Fig. 2.

The overall process of this study

Proposed cycleSimulationGAN architecture used to map a MRI image to a CT image
Structural similarity constraint based on contour mutual information loss
The contours of the original MRI and the synthesized CT are first extracted, and then the contours of the synthesized CT are more similar to those of the original MRI constrained by the mutual information loss function. In order to extract the contours of the original MRI and synthetic CT effectively, the pixel value of the original MR and synthetic CT greater than a certain threshold value is set to 1, and the pixel value less than the threshold value is set to 0, so that the body region segmentation results of the two different modal images can be obtained, and the body contour results can be effectively preserved. Later, in order to effectively measure the similarity of the regional contours of MRI and CT images, a contour loss calculation method based on mutual information was proposed. For the regional contours extracted from the original MRI and synthetic CT images, the following mutual information method is used to calculate contour similarity.
P (x) and P (y) represent the probability distribution of the contour extracted from the original MR image \( {I}_{MR}\) and the synthesized CT image \( G\left({I}_{MR}\right)\), respectively. And \( p(x,y)\) represents the joint probability distribution of \( p\left(x\right)\) and \( p\left(y\right)\). It can be observed that when calculating the loss of contours of different modes, the above formula no longer pays attention to the difference of pixel value per pixel at the bottom level, but to the data distribution characteristics of contours of different modes, thus paying more attention to the similarity of overall contours of higher levels.
Channel-wise attention enhanced mechanism
In order to enhance the feature representation capability of deep network and effectively extract more effective features representing images, a channel-wise attention mechanism is used to selectively enhance the multi-channel features (channel dimension is 256 in our experiment) extracted from the encoder of U-NET structure generator in cycleGAN network architecture. The channel-wise attention operation flow chart is shown in Fig. 3. The attention mechanism of the feature channel dimension (selective enhancement) can be achieved through end-to-end learning of the feature channel with stronger information enhancement and the feature channel with suppression of information redundancy.

The channel-wise attention operation flow chart
The channel attention map\( \varvec{X}\in {R}^{ C\times C}\) is directly calculated from the original features \( \varvec{A}\in {R}^{ C\times H\times W}\). Specifically, \( \varvec{A}\) is reshaped to \( {R}^{ C\times C}\), and then perform a matrix multiplication between \( \varvec{A}\) and the transpose of \( \varvec{A}\). Finally, a softmax layer is applied to obtain the channel attention map \( \in {R}^{ C\times C}\):
where \( {x}_{ji}\) measures the \( {i}^{th}\) channel’s impact on the \( {j}^{th} \)channel. In addition, we perform a matrix multiplication between the transpose of \( \varvec{X}\) and \( \varvec{A}\) and reshape their result to \( {R}^{ C\times H\times W}\). Then we multiply the result by a scale parameter β and perform an element-wise sum operation with A to obtain the final output \( \varvec{E}\)∈ \( {R}^{ C\times H\times W}\):
where β gradually learns a weight from 0. Equation 3 shows that the final feature of each channel is a weighted sum of the features of all channels and original features, which models the long-range semantic dependencies between feature maps. It helps to boost feature discriminability. Note that we do not employ convolution layers to embed features before computing relationships of two channels, since it can maintain the relationship between different channel maps. In addition, we exploit spatial information at all corresponding positions to model channel correlations.
Experimental evaluation and statistical analysis
Four criteria including mean absolute error (MAE), root-mean-square error (RMSE), peak-signal-noise-ratio (PSNR), and structural similarity index (SSIM) were used to evaluate the performance of different synthetic image generators from pixel-wise HU accuracy, noise level, and structure similarity. The formula of MAE, RMSE, PSNR, and SSIM are shown in Eqs. 4, 5, 6, and 7, respectively.
where \( sCT\left(i,j\right)\) is the value of the pixel at \( \left(i,j\right)\) in the sCT, \( CT\left(i,j\right)\) is the value of the pixel at \( \left(i,j\right)\) in the pCT, \( {n}_{x}{n}_{y}\) is the total number of pixels in one slice, MAX is the maximum intensity in sCT,\( {\mu }_{sCT}\) is the mean of pixel values of sCT, \( {\mu }_{CT}\) is the mean of pixel values of pCT image, \( {\sigma }_{sCT}\) is the standard deviation of sCT, \( {\sigma }_{CT}\) is the standard deviation of pCT image. As described in the above formulas, MSE and RMSE calculate the difference between the generated image and the original image, and the larger the value, the worse the quality, and the smaller the value, indicating that the prediction model has better accuracy. The denominator of PSNR is the energy difference between the generated image and the original image, which is also equivalent to noise. The smaller the noise, the better PSNR. MAE, PSNR and RMSE are all based on gray values to calculate the differences, while SSIM mainly considers image contrast, brightness and structure information. The larger the value, the more similar the SSIM is, and the maximum value is 1 entropy: it reflects the amount of average information in the image.
To validate and evaluate the performance of the present cycleSimulationGAN, two additional approaches were carried out for comparison purpose including the original cycleGAN and the structural similarity constrained cycleGAN (SSC-cycleGAN). SSC-cycleGAN is derived from cycleGAN, which proposes a contour consistency loss function that explicitly imposes structural constraints between the reconstructed MR and the original MR, aiming to effectively preserve structural features such as contour shape during sCT, as described above in our innovation 1 of cycleSimulationGAN. The three different networks (original cycleGAN, SSC-cycleGAN, and cycleSimulationGAN) were trained with the same training and validation dataset under the same environment.
Through a large number of experiments and quantitative analysis, all the related parameters were appropriately determined in the multiple tuning. The proposed deep network architecture was implemented in Pytorch and the training/validation was run on an Nvidia Geforce RTX 3090 GPU (24G memories) with CUDA acceleration. An Adam algorithm was chosen as the optimizer to minimize the L1 loss function with a learning rate of 1 × 10− 5, the maximum number of epochs is set as 200 and the convolution block sizes was set to 3 × 3. With the trained generation model, which takes about 46 h of computation time, the sCT for a new case with MR data takes only a few tenths of a second. All statistical analyses were performed to compare the three models using a paired t-test, a p-value ≤ 0.05 was considered statistically significant.
Results
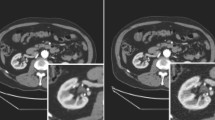
The three models were trained in 23 (cycleGAN), 25 (SSC-cycleGAN), and 26 (cycleSimulationGAN) hours, respectively. Once the models have been trained, it took a few seconds to generate sCT images from new MR volume image. Figure 4 shows the visual comparison at different anatomical locations of one test patient, which contains the axial view of the original MR, the corresponding real CT, and sCT images generated from original cycleGAN, the SSC-cycleGAN, the proposed cycleSimulationGAN. Maps in pseudo color represent the differences between the ground truth pCT and each sCT image. In the visual inspection, the generated results of our method are more consistent with the pCT compared with other two methods in terms of global and local imaging regions. As can be seen from the difference maps, the sCT generated using cycleSimulationGAN showed sharper boundaries than the sCT generated using the original cycleGAN and SSC-cycleGAN. To further display the gains of the present cycleSimulationGAN approach, we added the zoomed ROI images, the zoomed images of the ROI, as indicated by the blue dashed square in error images. From the zooming ROI images, the proposed approach was superior to the original cycleGAN and the SSC-cycleGAN approaches according to the boundary preservation and internal structural-consistency.

Comparison of PCT and sCT images generated by different models. The first and third rows show the MR images (a1, c1), pCT (a2, c2) and the sCT images generated by the cycleGAN method (a3, c3), the SSC-cycleGAN method (a4, c4), and the proposed cycleSimulationGAN method (a5, c5). The second and fourth rows show the error images for each sCT.
In order to further visualize the dose difference, two horizontal profiles of the resulting maps were drawn across the black line labeled in Fig. 5. The first and third rows show the pCT and the sCT images obtained by cycleGAN, SSC-cycleGAN, and cycleSimulationGAN. The second and fourth rows show the profiles along the black lines in pCT images. By observing the color curves, we see that cycleSimulationGAN is closer to the pCT, thus further demonstrating that the proposed models outperform the cycleGAN and SSC-cycleGAN, both in terms of definitive tissue/bone boundaries and accurate HU values.

Visualization results of the pseudo-CT images based on different models. The first row shows the pCT and the sCT images generated by other three methods. The second and fourth rows show the profiles along the black lines in pCT images
The quantitative results of MAE, RMSE, SSIM, and PSNR for all test patients’ sCT images compared with pCT images are summarized in Table 1. It is found that sCT from cycleSimulationGAN had smaller errors (MAE and RMSE) and higher similarities (PSNR, SSIM) relative to pCT than sCT from cycleGAN and SSC-cycleGAN. The mean ± standard deviation (SD) of MAE between the sCT and pCT images within the body were (71.32 ± 1.37) HU, (63.18 ± 1.80) HU, and (61.88 ± 1.42) HU for the cycleGAN, SSC-cycleGAN and cycleSimulationGAN, respectively. The details of the corresponding MAE and RMSE in different tissues are listed in Table 1. Compared with the conventional cycleGAN, the cycleGAN with an extra contour consistency loss (denoted as “SSC-cycleGAN”) produces better synthetic results (p <.001) except for PSNR (0.877) and SSIM (0.742) in bone. In terms of SSC-cycleGAN and cycleSimulationGAN, a slight improvement in all structures was observed for our model. Additionally, Table S1 lists the characteristics of median and range for the four metrics included in this study (supplementary material).
Discussion
CT synthesis from MRI can be seen as a style conversion problem from a macro point of view. With the rapid development of promising data-to-data translation in the generative frameworks in recent years, a large number of studies have focused on improving sCT image quality through GAN or its variants. Existing methods can be roughly divided into three categories: segmentation-based, atlas-based, and DL-based method [7]. The segmentation-based methods generate sCT images by predelineating the tissue types on the MR images and assigning uniform bulk densities to each segmented structure. However, these methods are limited by the requirement to predetermine tissue types and heavily rely on the accuracy of organ segmentation and further fail to account for heterogeneity within each structure [46]. Besides, atlas-based methods are limited by heavy computational burden, the accuracy of deformable image registration, and lack robustness when there are large anatomical variations [38]. In recent years, DL methods, especially for GAN-based methods have attracted significant attention in the medical image generation field. Nevertheless, the only sigmoid cross-entropy loss function often causes unstable training in the original GAN. Although the unpaired cycleGAN owns superior performance and a better visual effect, the obtained sCT images exist certain differences between the pCT images in terms of local imaging details. Furthermore, for the current sCT generation from mismatched MRI images by cycleGAN, the L1 loss function is widely used to constrain the similarity between the original MR and reconstructed images. However, the L1-based loss function only imposes pixel-level constraints and calculates the loss values of the reconstructed MR pixel by pixel, which makes it difficult to accurately measure the structural similarity in terms of global structural cues, such as contour or shape consistency, thus leads to many shortcomings in the sCT images, especially in air-bearing bone structures. For example, Peng et al. showed that for patients with NPC, the mean absolute error (MAE, the lower the value the more accurate) of sCT images was higher in the cycleGAN than that of the cGAN, with 69.67 ± 9.27 HU and 100.62 ± 7.9 HU in body, 170.62 ± 36.38 HU and 201.89 ± 34.11HU in air, 203.71 ± 28.22HU and 288.17 ± 17.22 HU in bone, respectively [20]. Kang et al. concluded that the mean SSIM and PSNR used cycleGAN was only 0.90 ± 0.03 and 26.3 ± 0.7 in pelvic, thoracic and abdominal tumor patients [22]. All these deficiencies can lead to inaccurate dose calculations.
In this study, the improved unsupervised network based on cycleGAN framework that integrates novel contour consistency loss function and channel-wise attention mechanism was proposed to synthesize high-quality CT-like images from H&N MRI. We aimed at training our cycleSimulationGAN model to effectively eliminate the redundant background information and capture the critical information of the untruncated area during the sCT generation process. The proposed method innovatively incorporated both channel-wise attention enhanced and structural similarity constrained cycleGAN to address the information redundancy and L1 loss function issues for effective sCT generation. The resulting sCT images are visually similar to pCT images, especially for high-density bony tissues, thus it will be capable of being directly used for quantitative applications, such as dose calculation and adaptive treatment planning (shown in Figs. 4 and 5). Recently, various efforts with different capabilities on modified-cycleGAN have been proposed to improve the accuracy and efficiency of sCT generation from MRI. For instance, Yang et al. developed an extra structure-consistency loss based on the modality independent neighborhood descriptor for unsupervised MR-to-CT synthesis [47]. They found that their method produces better synthetic CT images in terms of accuracy and visual quality compared to original cycleGAN. By modifying the cycle-consistency loss in the traditional cycleGAN, a novel compensation-cycleGAN was proposed to simultaneously create sCT images and compensate the missing anatomy from the truncated MR images [7]. Focusing on cervical cancer patients, Sun et al. used the multiple discriminator-based cycle generative adversarial network to synthesize sCT images from the MRI images of patients with pelvic tumors from global and local aspects [40]. Another previous study used 23 MR-CT pairs from NPC patients to train a U-net [22] and reported a MAE (131 ± 24) HU within the body. Their results indicated the feasibility of reducing the training samples for traditional GAN or U-net while achieving a reasonable sCT image estimation accuracy. The geometrical and structural precision of the sCT is especially important for radiotherapy, which help in planning accurate radiation dose. Subtle compromises in anatomical accuracy could lead to serious radiation outcomes. With the aim of effectively maintain the structural characteristics and focus on the human body region or the most critical part of the sCT, in this work, we proposed the cycleSimulationGAN to constrain the sCT images for better structural preserving property and evaluated our cycleSimulationGAN on 20 independent test patients (as shown in Table 1); the results also demonstrated that although cycleGAN and SSC-cycleGAN can generate real-looking CT images, regions with low MR signals, such as bone/air interfaces, can cause uncertainties.
Compared with the other two methods, in terms of MAE, RMSE and SSIM of bone, the sCT image generated by cycleSimulationGAN achieves better image quality possibly due to the design of this network that retains the advantages of cycleGAN and incorporates the features of channel-wise attention mechanism (as shown in Table 1). In terms of MAE, RMSE and SSIM of soft tissue, SSC-cycleGAN and cycleSimulationGAN showed similar results, while cycleSimulationGAN was superior to cycleGAN. One main disadvantage of MR-to-CT is HU tends to be less accurate compared with the pCT images, the three methods implemented in this work have a good ability to rectify the CT value of MRI, among them, cycleSimulationGAN gives the best results, SSC-cycleGAN the second, and original cycleGAN the worst. The cycleGAN requires the fake image to keep all the information in the original image, as a result, its CT correction ability was reduced in some degree. Compared with previous studies, the results of Zhao et al. [6] showed the average MAE, PSNR, and SSIM calculated over test patients were 91.3 HU, 27.4 dB, and 0.94 for the proposed Comp-cycleGAN models trained with body-contour information. However, our cycleSimulationGAN model scored better on the three quantitative metrics with MAE (60.88), PSNR (36.23), and SSIM (0.985). Wang et al. [48] found that the results based on cycle-contrastive unpaired translation network (cycleCUT) can be decreased from 78.05 HU to 69.62 HU. For comparison, our model generated comparable MAE, SSIM and even better pCTs visually. For the U-Net method, it uses paired data for training, which can obtain more information about the corresponding CT, including HU values. Furthermore, the above accurate sCT generation of our model helps oncologists to contour accurate targets, resulting in precise radiotherapy plans for cancer patients, which benefits the survival.
CycleSimulationGAN with the framework that integrates novel contour consistency loss function and channel-wise attention mechanism also has limitations. In this work, we only concentrated on the H&N Cancer. The applicability of our proposed model other disease sites would be considered and plan to collect more patients to train and test our method in the future. In addition, dosimetric evaluation of our sCT not be analyzed in the current work, using the sCT for quantitative applications such as multicenter testing, dose calculation, adaptive treatment planning is the focus of our future studies.
Conclusions
A novel unsupervised method for synthesizing sCT images from MRI scans based on cycleSimulationGAN was investigated in this study. Qualitative and quantitative experiments revealed that our approach outperformed both cycleGAN and SSC-cycleGAN in terms of both structural preserving and HU accuracy. The difference between the sCT and the pCT images obtained by our method is small and the visual effect is also better than other two cycleGAN models. In general, the cycleSimulationGAN is a promising method to facilitate adaptive radiotherapy treatments.
Data availability
The data used and analyzed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- CT:
-
Computer tomography
- MRI:
-
Magnetic resonance imaging
- MAE:
-
mean absolute error
- HU:
-
Hounsfield units
- CT:
-
Computed tomography
- ART:
-
Adaptive radiation therapy
- HU:
-
Hounsfield unit
- PSNR:
-
Peak signal-to-noise ratio
- RMSE:
-
Root-mean-square error
- SSIM:
-
structural similarity index
- sCT:
-
synthetic CT
- GT:
-
Ground truth
- NPC:
-
Nasopharyngeal carcinoma
- VMAT:
-
Volumetric-modulated arc radiotherapy
- TV:
-
Targets volume
- H&N:
-
Head and neck
- RT:
-
Radiotherapy
- PET:
-
Positron emission tomography
- OARs:
-
Organs at risks
- AI:
-
Artificial intelligence
- DL:
-
Deep learning
- CNN:
-
Convolutional neural network
- GAN:
-
Generative adversarial network
- CycleGAN:
-
Cycle generative adversarial network
- ML:
-
Machine learning
- pCT:
-
Planning CT
- SSC-cycleGAN:
-
Structural similarity constrained cycleGAN
References
Pathmanathan AU, McNair HA, Schmidt MA, et al. Comparison of prostate delineation on multimodality imaging for MR-guided radiotherapy. Br J Radiol. 2019;92(1095):20180948.
Kerkmeijer LGW, Maspero M, Meijer GJ, et al. Magnetic Resonance Imaging only Workflow for Radiotherapy Simulation and planning in prostate Cancer. Clin Oncol. 2018;30(11):692–701.
Salembier C, Villeirs G, De Bari B, et al. ESTRO ACROP consensus guideline on CT- and MRI-based target volume delineation for primary radiation therapy of localized prostate cancer. Radiother Oncol. 2018;127(1):49–61.
Chung NN, Ting LL, Hsu WC, Lui LT, Wang PM. Impact of magnetic resonance imaging versus CT on nasopharyngeal carcinoma: primary tumor target delineation for radiotherapy. Head Neck. 2004;26(3):241–6. https://doi.org/10.1002/hed.10378.
Rasch CR, Steenbakkers RJ, Fitton I, et al. Decreased 3D observer variation with matched CT-MRI, for target delineation in nasopharynx cancer. Radiat Oncol. 2010;5(1):21. https://doi.org/10.1186/1748-717X-5-21.
Zhao Y, Wang H, Yu C, et al. Compensation cycle consistent generative adversarial networks (Comp-GAN) for synthetic CT generation from MR scans with truncated anatomy [published online ahead of print, 2023 Jan 25]. Med Phys. 2023. https://doi.org/10.1002/mp.16246.
Jonsson J, Nyholm T, Söderkvist K. The rationale for MR-only treatment planning for external radiotherapy. Clin Transl Radiat Oncol. 2019;18:60–5. https://doi.org/10.1016/j.ctro.2019.03.005.
Corradini S, Alongi F, Andratschke N, Belka C, Boldrini L, Cellini F et al. MR-guidance in clinical reality: current treatment challenges and future perspectives. Radiat Oncol 2019:14. https://doi.org/10.1186/s13014-019-1308-y.
Chin S, Eccles CL, McWilliam A, Chuter R, Walker E, Whitehurst P, et al. Magnetic resonance-guided radiation therapy: a review. J Med Imaging Radiat Oncol. 2020;64:163–77. https://doi.org/10.1111/1754-9485.12968.
Hall WA, Paulson ES, van der Heide UA, Fuller CD, Raaymakers BW, Lagendijk JJW, et al. The transformation of radiation oncology using real-time magnetic resonance guidance: a review. Eur J Cancer. 2019;122:42–52. https://doi.org/10.1016/j.ejca.2019.07.021.
Karlsson M, Karlsson MG, Nyholm T, et al. Dedicated magnetic resonance imaging in the radiotherapy clinic. Int J Radiat Oncol Biol Phys. 2009;74(2):644–51.
Kraft SL, Gavin P. Physical principles and technical considerations for equine computed tomography and magnetic resonance imaging. Vet Clin North Am Equine Pract. 2001;17(1):115–vii.
Schmidt MA, Payne GS. Radiotherapy planning using MRI. Phys Med Biol. 2015;60(22):R323–61.
Devic S. MRI simulation for radiotherapy treatment planning. Med Phys. 2012;39(11):6701–11.
Nyholm T, Nyberg M, Karlsson MG, et al. Systematisation of spatial uncertainties for comparison between a MR and a CT-based radiotherapy workflow for prostate treatments. Radiat Oncol. 2009;4:54.
Witt JS, Rosenberg SA, Bassetti MF. MRI-guided adaptive radiotherapy for liver tumours: visualising the future. Lancet Oncol. 2020;21(2):e74–82.
Johnstone E, Wyatt JJ, Henry AM, et al. Systematic review of Synthetic computed Tomography Generation methodologies for Use in magnetic resonance imaging-only Radiation Therapy. Int J Radiat Oncol Biol Phys. 2018;100(1):199–217.
Xiang L, Wang Q, Nie D, et al. Deep embedding convolutional neural network for synthesizing CT image from T1-Weighted MR image. Med Image Anal. 2018;47:31–44.
Boulanger M, Nunes JC, Chourak H, et al. Deep learning methods to generate synthetic CT from MRI in radiotherapy: a literature review. Phys Med. 2021;89:265–81.
Peng Y, Chen S, Qin A, et al. Magnetic resonance-based synthetic computed tomography images generated using generative adversarial networks for nasopharyngeal carcinoma radiotherapy treatment planning. Radiother Oncol. 2020;150:217–24.
Brou Boni KND, Klein J, Vanquin L, et al. MR to CT synthesis with multicenter data in the pelvic area using a conditional generative adversarial network. Phys Med Biol. 2020;65(7):075002.
Kang SK, An HJ, Jin H, et al. Synthetic CT generation from weakly paired MR images using cycle-consistent GAN for MR-guided radiotherapy. Biomed Eng Lett. 2021;11(3):263–71.
Yoo GS, Luu HM, Kim H, et al. Feasibility of Synthetic computed tomography images generated from magnetic resonance imaging scans using various deep learning methods in the planning of Radiation Therapy for prostate Cancer. Cancers (Basel). 2021;14(1):40.
Kalet IJ et al. Aug., Knowledge-based computer systems for radiotherapy planning, Am. J. Clin. Oncol., vol. 13, no. 4, pp. 344–351, 1990.
Laramore GE et al. Jun., Applications of data bases and AI/expert systems in radiation therapy, Am J Clin Oncol., vol. 11, no. 3, pp. 387–393, 1988.
Sanders GD et al. May., The potential use of expert systems to enable physicians to order more cost- effective diagnostic imaging examinations, J. Digit.Imaging., vol. 4, no. 2, pp. 112–122, 1991.
Largent A, Barateau A, Nunes J-C, et al. Pseudo-CT generation for MRI-Only Radiation Therapy Treatment Planning: comparison among Patch-Based, Atlas-Based, and Bulk Density methods. Int J Radiat Oncol Biol Phys. 2019;103:479–90.
Choi JH, Lee D, O’Connor L et al. Bulk anatomical density based dose calculation for patient-specific Quality Assurance of MRI-Only prostate Radiotherapy. Front Oncol 2019;9.
LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521:436–44.
Largent A, Barateau A, Nunes J-C, et al. Comparison of Deep Learning-Based and Patch-based methods for Pseudo-CT generation in MRI-Based prostate dose planning. Int J Radiat Oncol Biol Phys. 2019;105:1137–50.
Nie D, Cao X, Gao Y et al. Estimating CT Image from MRI Data Using 3D Fully Convolutional Networks. Deep Learn Data Label Med Appl 2016:170–8.
Spadea MF, Pileggi G, Zaffino P, et al. Deep convolution neural network (DCNN) Multiplane Approach to Synthetic CT Generation from MR images—application in Brain Proton Therapy. Int J Radiat Oncol Biol Phys. 2019;105:495–503.
Olberg S, Zhang H, Kennedy WR, et al. Synthetic CT reconstruction using a deep spatial pyramid convolutional framework for MR-only breast radiotherapy. Med Phys. 2019;46(9):4135–47.
Wang Q, Zhou X, Wang C, Liu Z, Huang J, Zhou Y, Li C, Zhang H, Cheng JZ. WGAN-based synthetic minority over-sampling technique: improving semantic fine-grained classification for lung nodules in CT images. IEEE Access (2019) 18450–63.
Hemsley M, Chugh B, Ruschin M, Lee Y, Tseng CL, Stanisz G, Lau A. Deep generative model for synthetic-CT generation with uncertainty predictions, Med. Image Comput Comput -Assist Intervent (MICCAI) (2020) 834–44.
Klages P, Benslimane I, Riyahi S, et al. Patch-based generative adversarial neural network models for head and neck MR-only planning. Med Phys. 2020;47(2):626–42.
Lei Y, Harms J, Wang T, et al. MRI-only based synthetic CT generation using dense cycle consistent generative adversarial networks. Med Phys. 2019;46(8):3565–81.
Liu Y, Chen A, Shi H, et al. CT synthesis from MRI using multi-cycle GAN for head-and-neck radiation therapy. Comput Med Imaging Graph. 2021;91:101953. https://doi.org/10.1016/j.compmedimag.2021.101953.
Zhu JY, Park T, Isola P, Efros AA. Unpaired image-to-image translation using cycle-consistent adversarial networks, in: IEEE international conference on computer vision (ICCV, 2017, pp. 2223–2232.
Sun H, Fan R, Li C, Lu Z, Xie K, Ni X, Yang J. Imaging study of pseudo-CT synthesized from cone-beam CT based on 3D CycleGAN in radiotherapy. Front Oncol. 2021;11:603844.
Hosseinzadeh M, Gorji A, Fathi Jouzdani A, Rezaeijo SM, Rahmim A, Salmanpour MR. Prediction of Cognitive decline in Parkinson’s Disease using clinical and DAT SPECT Imaging features, and Hybrid Machine Learning systems. Diagnostics (Basel). 2023;13(10):1691.
Rezaeijo SM, Jafarpoor Nesheli S, Fatan Serj M, Tahmasebi Birgani MJ. Segmentation of the prostate, its zones, anterior fibromuscular stroma, and urethra on the MRIs and multimodality image fusion using U-Net model. Quant Imaging Med Surg. 2022;12(10):4786–804.
Rezaeijo SM, Chegeni N, Baghaei Naeini F, Makris D, Bakas S. Within-modality synthesis and Novel Radiomic evaluation of Brain MRI scans. Cancers (Basel). 2023;15(14):3565.
Salmanpour MR, Hosseinzadeh M, Rezaeijo SM, Rahmim A. Fusion-based Tensor radiomics using reproducible features: application to survival prediction in head and neck cancer. Comput Methods Programs Biomed. 2023;240:107714.
Zhu J-Y, Park T, Isola P, Efros AA. Unpaired image-to-image translation using cycle-consistent adversarial networks. Proceedings of the IEEE International Conference on Computer Vision. 2017,2223–2232.
Sun H, Xi Q, Fan R, et al. Synthesis of pseudo-CT images from pelvic MRI images based on an MD-CycleGAN model for radiotherapy. Phys Med Biol. 2022;67(3). https://doi.org/10.1088/1361/6560/ac4123.
Yang H, Sun J, Carass A, et al. Unsupervised MR-to-CT synthesis using structure-constrained CycleGAN. IEEE Trans Med Imaging. 2020;39(12):4249–61.
Wang J, Yan B, Wu X, Jiang X, Zuo Y, Yang Y. Development of an unsupervised cycle contrastive unpaired translation network for MRI-to-CT synthesis. J Appl Clin Med Phys. 2022;23(11):e13775.
Acknowledgements
Not applicable.
Funding
The National Natural Science Foundation of China (No.82360357), The Jiangxi Provincial Natural Science Foundation (No.20224BAB206070), the Jiangxi Cancer Hospital scientific research open fund project (KFJJ2023ZD07) and (KFJJ2023YB21) and the Science and Technology Project of Jiangxi Provincial Health Commission of China ( No.202310023).
Author information
Authors and Affiliations
Contributions
Changfei Gong and Yun Zhang wrote the main manuscript text, Yuling Huang prepared all figures. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The study has been approved by the Institution Review Board and Ethics Committee of Jiangxi Cancer Hospital, and the approval number is 2022ky298.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Gong, C., Huang, Y., Luo, M. et al. Channel-wise attention enhanced and structural similarity constrained cycleGAN for effective synthetic CT generation from head and neck MRI images. Radiat Oncol 19, 37 (2024). https://doi.org/10.1186/s13014-024-02429-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13014-024-02429-2