
Abstract
KIAA0319, a well-studied candidate gene, has been shown to be associated with reading ability and developmental dyslexia. In the present study, we investigated whether KIAA0319 affects reading ability by interacting with the parental education level and whether rapid automatized naming (RAN), phonological awareness and morphological awareness mediate the relationship between KIAA0319 and reading ability. A total of 2284 Chinese children from primary school grades 3 and 6 participated in this study. Chinese character reading accuracy and word reading fluency were used as measures of reading abilities. The cumulative genetic risk score (CGS) of 13 SNPs in KIAA0319 was calculated. Results revealed interaction effect between CGS of KIAA0319 and parental education level on reading fluency. The interaction effect suggested that individuals with a low CGS of KIAA0319 were better at reading fluency in a positive environment (higher parental educational level) than individuals with a high CGS. Moreover, the interaction effect coincided with the differential susceptibility model. The results of the multiple mediator model revealed that RAN mediates the impact of the genetic cumulative effect of KIAA0319 on reading abilities. These findings provide evidence that KIAA0319 is a risk vulnerability gene that interacts with environmental factor to impact reading abilities and demonstrate the reliability of RAN as an endophenotype between genes and reading associations.
Similar content being viewed by others


Introduction
Reading ability is a complex behavioral characteristic that mainly includes reading accuracy and reading fluency. The acquisition of reading skills are associated with series of reading-related linguistic processes, such as phonological awareness, orthographic awareness, morpheme awareness and rapid automatized naming [1]. It is known that genetic variation accounts for 20–80% of the total variation in reading skills, and the genetic variations discovered thus far only explain the “tip of the iceberg” of estimated heritability [1, 2].
Among the susceptibility genes of reading dis/ability identified to date, KIAA0319 is an important candidate gene. KIAA0319 affects neuronal migration, neurite outgrowth, cortical morphogenesis, and ciliary structure and function [3,4,5,6]. Schmitz et al. analyzed DNA methylation in the KIAA0319 promoter region to investigate whether epigenetic markers of language lateralization could be identified in nonneuronal tissue [7]. These data provide a framework to interpret the effects of the dyslexia-associated genetic variants that reside in KIAA0319 noncoding regulatory regions [8].
Franks et al. used quantitative trait loci (QTL) analysis and found that single nucleotide polymorphisms (SNPs) in KIAA0319 were associated with word reading, phonological awareness, and orthographic rules [9]. Moreover, rs2143340 in KIAA0319 was replicated in the Avon Longitudinal Study of Parents and Children (ALSPAC) and found to be associated with poor performance of reading and spelling [10]. In subsequent studies, Scerri et al. found that rs2143340 was significantly correlated with word reading accuracy in their quantitative analysis of reading phenotypes [11]. Quantitative analysis of samples from Dutch children with developmental dyslexia found that rs761100 and rs2038137 in KIAA0319 were related to digit rapid automatized naming, and that rs6935076 in KIAA0319 was related to word reading fluency [12]. However, there were also studies reporting no significant relationship between KIAA0319 and reading ability [13, 14].
These inconsistencies can be explained in part by heterogeneity between studies, possibly due to the different criteria for phenotypic assessment, age, sample size, population genetic background, and environmental factors. On the one hand, environmental factors can influence the probability of gene expression in behavior [15].
Studies have shown gene‒environment interactions on several environmental factors, e.g., the home literacy environment (HLE), socioeconomic status (SES), the prenatal education, and computer game interventions [14, 16,17,18]. For example, the presence of an interaction between maternal stress during pregnancy and the rs12193738 polymorphism in KIAA0319 was shown to affect reading ability at 16 years of age [16]. However, one polymorphism cannot represent the variation in gene function, and many variants with small effects cannot be detected. The cumulative genetic score (CGS) can be used to investigate the influence of multiple genetic polymorphisms [19,20,21,22]. The CGS was combined into a single score by assigning points (0, 1 or 2) according to the number of sensitive alleles [23]. Using the CGS can increase statistical power and model more variants on a gene. Therefore, the first aim of the present study was to use the CGS approach to explore whether the CGS of KIAA0319 impacts reading ability by interacting with the environmental factor of parental education level.
Nevertheless, three gene‒environment models (G × E) exist at present. The diathesis-stress model emphasizes that individuals with disease risk alleles or vulnerability genotypes have higher negative environmental sensitivity [24, 25]. The vantage sensitivity model aims to describe the different responses of individuals in positive environments [25]. According to the differential susceptibility model, the same genetic traits or genotypes also have the effect of making individuals better (for better) or worse (for worse) under environmental factors [26]. To explore whether KIAA0319 should be considered a vulnerable or plastic gene [27], the second aim of the present study was to conduct interaction and competing model analyses to examine which gene-environment model of the interaction between KIAA0319 and parental education follows.
On the other hand, when studying the role of candidate genes, endophenotypes (EPs) can also reduce the effect of heterogeneity [15]. Endophenotypes are more useful than macroscopic behavior indicators and serve as mediating variables for understanding complex pathways [28, 29]. EPs reflect neurophysiological, biochemical, endocrinological, cognitive or neuropsychological processes that are associated with traits or diseases and may reflect specific genes that are associated with behavioral phenotypes [30,31,32].
Reading-related linguistic skills might be important EPs between candidate genes and reading abilities. Rapid automatized naming (RAN), a well-studied reading-related skill, has been widely used in studies of reading acquisition and has been found to be reliably related to reading achievement [33, 34]. Several studies have identified RAN to be independent of reading and reading-related cognitive processes, such as orthographic processing, phonological awareness, and short-term memory [35,36,37]. Moreover, RAN has been found to be heritable. Genome-wide association studies reported the effects of SNPs on RAN, and classical twin studies found heritability estimates ranging from 0.56 to 0.70 for RAN [38,39,40,41,42]. The latest results explored RAN as an endophenotype that mediates the association between genes and reading ability [14, 43]. Therefore, RAN was investigated as a mediator between KIAA0319 and reading ability in the present study.
Phonological awareness and morphological awareness have also found to contribute to the development of reading ability and significantly predict word recognition and reading speed [44,45,46,47]. However, as reading-related linguistic skills, no studies have explored the possibility of phonological awareness and morphological awareness as endophenotypes. The heritability estimates of phonological awareness and morphological awareness were 0.19–0.83 [40, 48, 49] and 0.44–0.55 [50], respectively. Candidate gene studies have also discussed the association of KIAA0319 with phonological and morphological awareness [51, 52]. Therefore, this study also aimed to investigate the mediating effects of phonological awareness and morphological awareness as intermediate phenotypes.
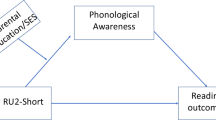
In sum, we aimed to investigate 1) the effect of the KIAA0319 interaction with the environment on reading abilities (Fig. 1A); 2) which gene‒environmental interaction model better fits the G × E effect; and 3) whether genes affect reading abilities through endophenotypes of rapid automatized naming, phonological awareness, and morphological awareness (Fig. 1B).

The plot of the moderation effect of environment in genetic influence on reading-related phenotypes (A); the multiple mediation model plot of cognitive skills in gene-phenotype association (B)
Materials and methods
Participants
A total of 2284 participants (primary school students from Shaanxi, Gansu and Inner Mongolia) were recruited. All participants were normal school-age students from grade 3 to grade 6 without any history of mental illness. In this study, saliva samples were collected (gene samples were extracted). Participants completed two reading tests, including Chinese character recognition task (N = 2270) and Chinese word reading fluency task (N = 2270), six reading-related linguistic tasks, including four rapid automatized naming tasks (digit, picture, color, and dice) and phonological awareness and morphonological awareness tasks (N = from 1968 to 2244).
Genotyping and SNP selection
An Illumina Asian Screening Array (ASA, 700 K–750 K) chip was used for genotyping the obtained DNA samples using the Beijing Compass biotechnology formula. PLINK was used to screen the following genotypes for standard quality control (Aderson et al., 2010; Chang, 2015): a single sample SNP detection rate higher than 0.9 (sample call rate > 0.90); single SNP detection rates (SNP call rate > 0.95); Hardy–Weinberg equilibrium coefficients (p < 10–5); minor allele frequencies (MAF > 0.01); and those with first degree of kinship was removed (PI_HAT > 0.50). MACH 4.0 software was used to carry out full genome data (imputation) analysis based on the Asian population data in the Genome Asia Pilot (GAsp) project, and the filled data were consistent with the previous quality control standards. Thirteen SNPs were extracted by PLINK v1.90.
Phenotypes
Reading fluency (RF). Wordlist reading task [53, 54] was used to measure each child’s reading fluency. In this task, children were asked to name a list of 180 two-character words as rapidly and accurately as possible. All these words were from primary school text books and have been learned before grade 3, such as “我们(we)” and “太阳(sun)”. Since words included in this task were all simple, this task was administrated to test children’s reading fluency. The total time for naming the whole word list was recorded as measurement of reading fluency.
Character recognition (CR): Chinese character recognition test was used to measure each child’s reading accuracy [53, 54]. The test consisted of 150 single Chinese characters selected from China’s Elementary School Textbooks (1996), with a reliability of 0.95 [53]. Each child was individually tested and required to read aloud each character at a time.
Rapid automatized naming tasks. The rapid automatized naming tasks include four tasks: rapid automatized naming of digits, pictures, colors, and dices [54]. Four series of 40 items (digits, pictures, dices, and colors) were presented to each child, with each type of items on a separate sheet of paper. The digits (2, 4, 6, 7, and 9) were used as stimuli of rapid automatized digit naming task. The pictures (dog, flower, book, shoe, and window) were used as stimuli of rapid automatized picture naming task. Pictures of dices (one, two, three, four, and five) were used as stimuli of rapid automatized dice naming task. The colors (red, yellow, black, green, and blue) were used as stimuli of rapid automatized color naming task. Each sheet includes eight rows with five items in a row. Children were required to name each type of items as rapidly as possible. Each child named twice for each sheet. The measurement of rapid automatized naming was the average naming times for the two times of each type of items. The test–retest reliabilities of rapid automatized digit, picture, dice, and color naming tasks were 0.87, 0.82, 0.74, and 0.74, respectively.
Phonological awareness task. In this task, a child is verbally presented with a one-syllable word. The child’s task is to remove a given phoneme from the syllable in the word and speak out the rest of the syllable. The task consists of 16 items: initial phoneme deletion items (e.g., /mei4/ (sister) without /m/), middle phoneme deletion items (e.g., /tuan4/ (group) without /u/), and final phoneme deletion items (e.g., /guan1/ (close) without /n/). This task has been widely used in language studies of Chinese children [46, 55, 56]. The reliability (Chronbach’s alpha) of the test was 0.90 [54].
Morphological awareness task. Children are asked to identify one of the morphemes among two-morpheme words and to create two new words with the target morpheme [55, 57]. One of the morphemes in a word has the same meaning as the target morpheme; conversely, one of the morphemes in the other word has a different meaning. Presented with the word /bei1 bao1/ (which means backpack), children are asked to produce two new words containing /bao1/. In one word, /bao 1/ has the same meaning as /bei1 bao1/, such as /shu1 bao1/ (which means bag). And in the other word, /bao 1/ is different from that of /bei1 bao1/, such as /bao1 zi1/ (which means steamed stuffed bun). The Cronbach’s alpha of this questionnaire was 0.80 [57].
Parental Education (PE) levels
A total of 1620 participants in this study had information about their parents' educational levels, with 1 representing the lowest educational level and 8 representing the highest educational level: 1 = primary school education, 2 = junior high school education, 3 = senior high school education, 4 = junior college education, 5 = undergraduate degree, 6 = master’s degree, 7 = doctoral degree, and 8 = postdoc. The average score of mother’s and father’s educational levels was used as a child’s parental educational level. Finally, 1,588 children had data on both character recognition and parental educational level, and 1,589 children had data on both reading fluency and parental educational level.
Data analysis
SNP coding and cumulative genetic scores (CGSs)
The SNPs on KIAA0319 were reported in our recent GWAS of dyslexia and were replicated in reading fluency in the Chinese sample [58, 80]. The sample of the current study and the Chinese sample in Doust et al. were from the same cohort [58]. We therefore adopted the β values for the phenotype of reading fluency and character recognition from our Chinese sample in this study [80]. The cumulative genetic score (CGS) of the KIAA0319 gene was calculated by combining risk alleles of the 13 SNPs. Coding was based on the first allele and beta value. When the value of β was positive, the homozygous with the first allele was 2 and the heterozygous was 1, 0 was the homozygous for the minor allele. When the beta value was negative, it was opposite to the encoding genotype.
Gene by Enviornment Interaction analysis
Stratified regression analysis was performed to explore the interactions of 13 SNPs and the CGS with the parental education level. The standard multiple regression equation is as follows:
where Y is the dependent variable (i.e., reading fluency); X1 is the environmental variable (PE); X2 is the genetic variable, X1 × X2 is the product term of the gene‒environment interaction; B1 and B2 are the regression slopes of the main effects of environment X1 and gene X2, respectively; B3 is the regression coefficient of their interaction term; B0 is the intercept; and E is the random error.
Reparameterized regression model tests
The reparametric equation [59] is as follows:
Equation 2 is a 5-parameter equation (i.e., B0, B1, B2, B3, B4, C). C is the intersection of the predicted values of the environmental variables of the two groups; if the crossover of C and its confidence interval (CI) is within the range of values in the environment, the interaction is disordinal, reflecting the differential susceptibility model, and if it falls outside the range, the interaction is ordinal and conforms to the diathesis-stress model [59].
In this study, B1 is the slope of PE, and B2 is the slope of the interaction term. Point C is not fixed. If Point C is within the range of the parental education level, the interaction of G × E conforms to the differential susceptibility model. If Point C is fixed, a crossover point that falls at the maximum value of the environment variable is added (C = Max (PE)). At this point, the interaction of G × E is orderly and conforms to the diathesis-stress model. ANOVA, the Akaike information criterion (AIC) and the Bayesian information criterion (BIC) were used to evaluate the two models. For the AIC and BIC, the lower the value is, the higher the efficiency of the model.
Mediation analysis
The series of structural equation modeling (SEM) analyses were conducted by using Mplus 17.0 to explore whether rapid automatized naming, phonological awareness, and morphological awareness mediate the effect of cumulative genetic scores on reading fluency and reading accuracy after controlling for age and sex. All the phenotypes and endophenotypes were transformed into Z score according to separately each grade [54]. All the predictor measures were allowed to be related to each other. Indirect effects were tested using the 5000 bootstrap technique [60], and confidence intervals (95% CIs) that did not contain zero indicated significant indirect effects [61]. We reported a variety of indices to reflect the model fit [62].
Results
Correlation analysis
The 13 SNPs conformed to Hardy–Weinberg equilibrium (Additional file 1: Table S1). Figure 2 presents the correlation among variables for the total sample. Due to correlations between behavioral phenotypic variables, we adopted FDR correction (Benjaminiand Hochberg correction) for multiple corrections to reduce the type I error (Additional file 1: Table S2). The CGS of reading fluency (RF_CGS) was marginally correlated with reading fluency (rp = 0.040, p = 0.06) and significantly correlated with digit rapid automatized naming (rp = 0.052, p = 0.02). The CGS of character recognition (CR_CGS) were marginally significantly correlated with color rapid automatized naming (rp = 0.053, p = 0.02). For the mean Z-score of the four RAN tasks, it was significantly correlated with CR_CGS (rp = 0.061, p = 0.007), and significantly correlated with RF_CGS (rp = 0.055, p = 0.02). Reading fluency and all of the rapid automatized naming tasks were significantly correlated. Moreover, there was no correlation between PE and genetic variables.

The heat map of Pearson correlation coefficient and p-value between CGS and behavioral phenotypic variables. CR_CGS: the cumulative genetic socre of KIAA0319 on character recognition, RF_CGS: the cumulative genetic socre of KIAA0319 on reading fluency, RF: reading fluency, CR: character recognition, PA: phonological awareness, MA: morphological awareness, R1: digit rapid automatized naming, R2: dice rapid automatized naming, R3: picture rapid automatized naming, R4: color rapid automatized naming, R.mean: the mean Z-score of four RANs, PE: parental education. *p < 0.05, **p < 0.01
Standard exploratory analysis
Standard regression equations were used to test the G × E effect of a single SNP, CR_CGS (Additional file 1: Table S3 and Table S4) and RF_CGS (Table 1). In reading fluency and character recognition, no single SNP reached significance in the interaction terms after Bonferroni correction (adjusted-p: 0.05/13 = 0.0038). PE level was significant in all regression main effects. In Model 1 (Table 1), before adding the G × E interaction term, the main effect of the PE level was significant (B1 = -5.27, p < 0.001), and the predicting effect of RF_CGS for reading fluency was not (B2 = 0.51, p = 0.07). In Model 2, the G × E effect was significant (B3 = 0.53, p = 0.026, R2 = 0.088). Simple slope analysis showed (Fig. 3A) that with the increase in the PE level, the time of reading fluency of the low RF_CGS group was significantly faster than that of the high RF_CGS group. However, the interaction between CR_CGS and the PE level did not predict character recognition.

Simple slope analysis of reading fluency in the Low and High CGS subgroups (A); the plot for the results of the interaction between the CGS and PE level to predict reading fluency in the differential susceptibility model (B)
Competing test selection
Reparameterized Eq. 2 was used to verify the interaction between the KIAA0319 gene and parental education level. Table 2 shows that Model 3 (i.e., the differential susceptibility model) had the best fitting effect on reading fluency (Fig. 3B). Compared with Model 4, Model 3 had an estimated parameter added, and the interpretation rate of R2 increased significantly (△R2 = 0.004, p = 0.006), so Model 4 was rejected. Furthermore, by comparing Model 3 and Model 4, the AIC and BIC of Model 4 were both larger than those of Model 3, and Model 3b was rejected. Overall, Model 3 had better fitting performance. In the G × E effect, RF_CGS and the parental education (PE) level fit the differential susceptibility model.
Test of the mediation model
A series of structural equation modeling (SEM) analyses were conducted to explore whether rapid automatized naming, phonological awareness, and morphological awareness mediated the effect of the KIAA0319 gene on reading fluency after controlling for sex and age (Fig. 4). The indices of the Model 5 in Table 3 provided a good fit to the data: the CFI (comparative fit index) = 0.997 > 0.90; the TLI (Tucker‒Lewis index) = 0.981 > 0.90; the RMSEA (root mean square error of approximation) = 0.024 < 0.80; and χ2/df = 2.35 < 3. Using 5000 bootstrap analyses and 95% CIs, we found that the significant mediation of RAN (average z score of the four RAN tasks) in reading fluency (p = 0.034), and the 95% CI [0.001, 0.017], did not include 0 (Model 5 in Table 4, Fig. 4A) and total indirect effect was significant (p = 0.021, 95% CI [0.001, 0.019]).

Significant specific indirect of the RAN effect from RF_CGS to reading fluency after controlling for sex and age (standardized estimates of the path coefficients are depicted in Model 5) (A); Significant specific indirect of the RAN effect from RF_CGS to reading fluency after controlling for sex and age (standardized estimates of the path coefficients are depicted in Model 6) (B).The model was adjusted because of the correlations between individual RAN (some path coefficients have been omitted for brevity). RAN: the mean Z-score of four RAN tasks
We further analyzed four RAN tasks as parallel mediating variables. The results showed that the mediating effect of digit RAN (p = 0.04, 95% CI [0.001, 0.041]) and total indirect effect (p = 0.03, 95% CI [0.004, 0.056]) were significant in reading fluency (Model 6 in Table 4, Fig. 4B). Model 6 has a good model fit index: the CFI (comparative fit index) = 1.000 > 0.90; the TLI (Tucker‒Lewis index) = 0.994 > 0.90; the RMSEA (root mean square error of approximation) = 0.019 < 0.80; and χ2/df = 1.90 < 3 (Table 3). According to the β values, the specific indirect effect pathways were positive. The result suggested that the higher the RF_CGS, the longer the RAN time, and correspondingly, the longer the reading fluency time.
The mediation model from CR_CGS to character recognition showed that there were also significant mediating effects of RAN. Though the total indirect effect is not significant (p = 0.12, 95% CI [-0.034, 0.003]), the mediating effect of RAN (average Z score of the four RAN tasks) was significant (Model 7 in Additional file 1: Table S5, Figure S1). In the separate RANs mediation model, the mediating effects of digit RAN (p = 0.03, 95% CI [-0.019, -0.002]) and picture RAN were significant (p = 0.01, 95% CI [0.004, 0.019]) (Model 8 in Additional file 1: Table S5, Figure S2).
Discussion
The present study examined the cumulative effect of KIAA0319 on reading skills by a moderation effect of parental educational level and a mediation effect of reading-related linguistic skills. The interaction between individual SNPs in KIAA0319 and the parental education level was not significant. However, the interaction between the CGS of KIAA0319 and the parental education level on reading fluency was significant, suggesting that KIAA0319 may affect children's reading abilities through multiple minor effects. We also found that the CGS of KIAA0319 can affect children's reading abilities through rapid automatized naming, mainly by digit rapid automatized naming. Additionally, we built four moderated mediation models according to the significant mediator variables and found that these models did not fit well (Additional file 1: Table S6 and Figure S3). These results suggested that KIAA0319 influence behavioral phenotypes either through mediation model or moderation model independently.
The present study is the first to assess the cumulative effect of candidate gene KIAA0319 on reading ability in Chinese children using the cumulative genetic risk score. As already noted, in most G × E work, one polymorphism is studied at a time. The CGS model accounts for more variance than individual SNPs, which, to a certain extent, reduced the problem of repeated analysis of individual polymorphisms [63]. In present study, the cumulative effect of KIAA0319 only accounted for 0.1% variance and G × E effect accounted for 0.3% variance in reading fluency. The pathway from gene to reading behavior is far away and might be through complex and comprehensive mediation processes, it is reasonable that the cumulative effect of KIAA0319 is very weak. This is indeed the reason that we should investigate the mediation phenotypes that could explain the relations between genes and behaviors [58].
In terms of G × E, individuals with a low CGS were better at reading fluency in a positive environment than individuals with a high CGS. These results suggested that the more risk alleles an individual carries, the worse their performance, and KIAA0319 is theoretically a vulnerability gene. The G × E effect on reading fluency was found to be consistent with the differential susceptibility model by competing model analysis. This result indicated that “vulnerability genes” can be appropriately described as “plastic genes” because they make individuals more susceptible to environmental influences and thus exhibit better or worse behavior [23, 26]. In this study, the negative effects of KIAA0319 on reading ability were verified for the first time through reparameterized regression models. In other words, the more risk alleles an individual carries, the more vulnerable they are, potentially causing irreversible harm, and the environment has little effect on the individual. Conversely, individuals carrying fewer vulnerability alleles are more susceptible to environmental influences and thus perform well.
To some extent, the finding is also consistent with the vantage sensitivity model due to the small value of the cross point. The notion is that salutary environments can moderate the influence of genetic variations on behaviors [25, 64] but not adverse environments [65]. Although there have been some findings of vantage sensitivity models in other domains, the study of cognitive ability has shown that the cumulative genetic scores of the COMT and DRD2 genes and the effect of father authoritarianism on creativity are consistent with the vantage sensitivity model [66], the evidence is lacking in the field of reading. Therefore, the results of the vantage sensitivity model need to be further validated.
Finally, our study also supports the mediating role of digit RAN between KIAA0319 and reading abilities [47, 67]. For the first time, we found that the cumulative effect of KIAA0319 can affect Chinese word reading fluency and character recognition through RAN. The correlations between the CGS and RAN were consistent with previous results that KIAA0319 can affect RAN [12, 52]. Although previous studies have also consistently reported RAN is an important predictor for Chinese reading accuracy [68] and reading fluency [34, 69] as well as for reading abilities in various orthographies [70,71,72], no study has examined whether RAN can mediate a gene-reading association. The current research provided the first hand evidence for RAN as a possible endophenotype between gene and behavioral phenotype. Our data also suggest that digit RAN might be the best RAN endophenotype among all RAN tasks. This is consistent with previous behavioral studies, in which digit RAN has been used more widely than other RAN tasks in predicting reading abilities and dyslexia [55, 57, 73]. However, it should be noted that we also found picture RAN can mediate KIAA0319 and reading accuracy, but not for reading fluency. This suggests that other than digit RAN, sometimes picture RAN might also be able to serve as a surrogate endophenotype.
Previous studies have indicated that KIAA0319 was mainly expressed in the cerebral cortex, amygdala and cerebellum [74,75,76], suggested the alternative level of KIAA0319 could be the cause of neuronal migration abnormalities that might lead to the development of dyslexia. Furthermore, Jamadar et al. found a significant association between KIAA0139 and cerebellar gray matter volume in dyslexic patients [77]. Rapid automatized naming as an ability to retrieve familiar phonological information automatically is a reliable indicator of reading skills [67]. Cerebellum theory of dyslexia [78] provides a theoretical framework which indicates that cerebellum might be a key to automatic decoding and processing of words, which affects the accuracy and fluency of word reading [79]. Recently, our GWAS study discovered that EVC expression in the cerebellum affected reading fluency, further supporting the cerebellar theory [80]. Thus, it is reasonable to speculate that the cumulative effect might affect the expression of KIAA0319 in the cerebellum, and in turn, impair the automated processing and reading speed.
Alternatively, KIAA0319 has also been found to associate with the rapid auditory processing deficit of dyslexia [3, 81]. The expression of KIAA0319 has been found to influence the temporal lobe [74, 81, 82], whose biological signals may have an impact on the neuronal temporal coding, and in turn, impact the auditory processing. Indeed, the rapid auditory processing deficit theory suggests that the individuals who are impaired in reading might be due to poor hearing for short and rapidly changing sounds [83]. Phoneme processing problems might result from imprecise acoustic input encoding [84]. Hence, phonological impairment of dyslexia is actually caused by rapid auditory processing deficit [83]. Therefore, an alternative explanation for the mediation effect between KIAA0319, RAN, and reading might be that KIAA0319 have an impact on the expression in temporal lobe and auditory processing, then further affect RAN and reading.
There were several limitations in the current study. First, contrary to our findings, previous studies did not provide sufficient evidence for RAN as an EP [43, 85], whereas in our study, RAN was found to mediate gene-phenotype associations. This might be due to different measurement methods of endophenotypes, different languages and fewer selected SNPs in these studies. Second, we used β values derived from the phenotype of reading abilities, so the individual variant and cumulative genetic scores encoded do not provide an accurate estimate of the effect on RAN. This independent cumulative effect might affect the mediation effect of RAN, which means that, coincident with models of multiple deficits, the influence of genetic variation in reading ability through RAN, especially for rapid automatized naming tasks of color and dice is limited [1, 86]. Third, we did not find significant mediating effects of phonological awareness and morphological awareness. In this study we only used phoneme deletion and morphological production to test phonological awareness and morphological awareness. Future studies might be valuable to use other tasks (e.g., spoonerism, morphological judgment) to further investigate whether phonological awareness and morphological awareness can mediate gene and reading as endophenotypes. Finally, the SNPs we selected did not show significant interaction effects. A possible reason is the insufficient statistical power, since the number of samples verifying the interaction was more than the number of samples for which the effect was found alone [87]. The significant results of cumulative gene score might be the increased power of the cumulative effect, which should be replicated in an independent cohort to verify the interaction effects.
Conclusion
KIAA0139, a candidate gene for reading ability, is a risk factor of reading disability, not a protective factor. The more risk alleles a person carries, the worse their reading fluency is. The finding that KIAA0319 impacts reading fluency by interacting with parental education level suggests that environmental variables can modulate the effects of KIAA0319 on children’s reading behaviors. Individuals with a low CGS of KIAA0319 were better at reading fluency in a positive environment (higher parental educational level) than individuals with a high CGS. In addition, the impact of the genetic cumulative effect of KIAA0319 on reading abilities can be mediated by cognitive intermediate phenotypes of rapid automatized naming. These findings provide evidence that KIAA0319 is a risk vulnerability gene that interacts with environmental factor to impact reading abilities and demonstrate the reliability of RAN as an endophenotype between gene and reading associations.
Availability of data and materials
Codes used in this study are available from the authors upon request.
References
Pennington BF. From single to multiple deficit models of developmental disorders. Cognition. 2006;101(2):385–413.
Shaywitz SE, Shaywitz BA. Dyslexia (specific reading disability). Biol Psychiatry. 2005;57(11):1301–9.
Szalkowski CE, Fiondella CF, Truong DT, Rosen GD, LoTurco JJ, Fitch RH. The effects of Kiaa0319 knockdown on cortical and subcortical anatomy in male rats. Int J Dev Neurosci. 2013;31(2):116–22.
Velayos-Baeza A, Levecque C, Kobayashi K, Holloway ZG, Monaco AP. The dyslexia-associated KIAA0319 protein undergoes proteolytic processing with γ-secretase-independent intramembrane cleavage*. J Biol Chem. 2010;285(51):40148–62.
Peschansky VJ, Burbridge TJ, Volz AJ, Fiondella C, Wissner-Gross Z, Galaburda AM, Turco JJL, Rosen GD. The Effect of variation in expression of the candidate dyslexia susceptibility gene homolog Kiaa0319 on neuronal migration and dendritic morphology in the rat. Cereb Cortex. 2009;20(4):884–97.
Poon M-W, Tsang W-H, Chan S-O, Li H-M, Ng H-K, Waye MM-Y. Dyslexia-associated Kiaa0319-like protein interacts with axon guidance receptor nogo receptor 1. Cell Mol Neurobiol. 2011;31(1):27–35.
Schmitz J, Kumsta R, Moser D, Güntürkün O, Ocklenburg S. KIAA0319 promoter DNA methylation predicts dichotic listening performance in forced-attention conditions. Behav Brain Res. 2018;337:1–7.
Gostic M, Martinelli A, Tucker C, Yang Z, Gasparoli F, Ewart J-Y, Dholakia K, Sillar KT, Tello JA, Paracchini S. The dyslexia susceptibility KIAA0319 gene shows a specific expression pattern during zebrafish development supporting a role beyond neuronal migration. J Comp Neurol. 2019;527(16):2634–43.
Francks C, Paracchini S, Smith SD, Richardson AJ, Scerri TS, Cardon LR, Marlow AJ, MacPhie IL, Walter J, Pennington BF, et al. A 77-kilobase region of chromosome 6p22.2 is associated with dyslexia in families from the United Kingdom and from the United States. Am J Hum Genetics. 2004;75(6):1046–58.
Paracchini S, Steer CD, Buckingham L-L, Morris AP, Ring S, Scerri T, Stein J, Pembrey ME, Ragoussis J, Golding J. Association of the KIAA0319 dyslexia susceptibility gene with reading skills in the general population. Am J Psychiatry. 2008;165(12):1576–84.
Scerri TS, Morris AP, Buckingham L-L, Newbury DF, Miller LL, Monaco AP, Bishop DVM, Paracchini S. DCDC2, KIAA0319 and CMIP are associated with reading-related traits. Biol Psychiatry. 2011;70(3):237–45.
Carrion-Castillo A, Maassen B, Franke B, Heister A, Naber M, van der Leij A, Francks C, Fisher SE. Association analysis of dyslexia candidate genes in a Dutch longitudinal sample. Eur J Hum Genet. 2017;25(4):452–60.
Becker J, Czamara D, Scerri TS, Ramus F, Csépe V, Talcott JB, Stein J, Morris A, Ludwig KU, Hoffmann P, et al. Genetic analysis of dyslexia candidate genes in the European cross-linguistic NeuroDys cohort. Eur J Hum Genet. 2014;22(5):675–80.
Mascheretti S, Riva V, Giorda R, Beri S, Lanzoni LFE, Cellino MR, Marino C. KIAA0319 and ROBO1: evidence on association with reading and pleiotropic effects on language and mathematics abilities in developmental dyslexia. J Hum Genet. 2014;59(4):189–97.
Manuck SB, McCaffery JM. Gene-environment interaction. Annu Rev Psychol. 2014;65(1):41–70.
D’Souza S, Backhouse-Smith A, Thompson JMD, Slykerman R, Marlow G, Wall C, Murphy R, Ferguson LR, Mitchell EA, Waldie KE. Associations between the KIAA0319 dyslexia susceptibility gene variants, antenatal maternal stress, and reading ability in a longitudinal birth cohort. Dyslexia. 2016;22(4):379–93.
Plak RD, Merkelbach I, Kegel CAT, van Ijzendoorn MH, Bus AG. Brief computer interventions enhance emergent academic skills in susceptible children: a gene-by-environment experiment. Learn Instr. 2016;45:1–8.
Su M, Wang J, Maurer U, Zhang Y, Li J, McBride C, Tardif T, Liu Y, Shu H. Gene–environment interaction on neural mechanisms of orthographic processing in Chinese children. J Neurolinguistics. 2015;33:172–86.
Enge S, Sach M, Reif A, Lesch K-P, Miller R, Fleischhauer M. Cumulative Dopamine Genetic Score predicts behavioral and electrophysiological correlates of response inhibition via interactions with task demand. Cogn Affect Behav Neurosci. 2020;20(1):59–75.
Pearson R, Palmer RHC, Brick LA, McGeary JE, Knopik VS, Beevers CG. Additive genetic contribution to symptom dimensions in major depressive disorder. J Abnorm Psychol. 2016;125:495–501.
Steiger H, Thaler L, Gauvin L, Joober R, Labbe A, Israel M, Kucer A. Epistatic interactions involving DRD2, DRD4, and COMT polymorphisms and risk of substance abuse in women with binge-purge eating disturbances. J Psychiatr Res. 2016;77:8–14.
Walton E, Turner J, Gollub RL, Manoach DS, Yendiki A, Ho B-C, Sponheim SR, Calhoun VD, Ehrlich S. Cumulative genetic risk and prefrontal activity in patients with schizophrenia. Schizophr Bull. 2012;39(3):703–11.
Belsky J, Beaver KM. Cumulative-genetic plasticity, parenting and adolescent self-regulation. J Child Psychol Psychiatry. 2011;52(5):619–26.
Hyde LW, Bogdan R, Hariri AR. Understanding risk for psychopathology through imaging gene–environment interactions. Trends Cogn Sci. 2011;15(9):417–27.
Manuck SB, McCaffery JM. Genetics of stress: gene–stress correlation and interaction. In: Steptoe A, editor. Handbook of behavioral medicine. New York: Springer; 2010. p. 455–78.
Belsky J, Pluess M. Beyond diathesis stress: differential susceptibility to environmental influences. Psychol Bull. 2009;135:885–908.
Belsky J, Jonassaint C, Pluess M, Stanton M, Brummett B, Williams R. Vulnerability genes or plasticity genes? Mol Psychiatry. 2009;14(8):746–54.
Gottesman Irving I, Gould Todd D. The endophenotype concept in psychiatry: etymology and strategic intentions. Am J Psychiatry. 2003;160(4):636–45.
Kendler KS, Neale MC. Endophenotype: a conceptual analysis. Mol Psychiatry. 2010;15(8):789–97.
Flint J, Timpson N, Munafò M. Assessing the utility of intermediate phenotypes for genetic mapping of psychiatric disease. Trends Neurosci. 2014;37(12):733–41.
Braff DL. The importance of endophenotypes in schizophrenia research. Schizophr Res. 2015;163(1):1–8.
Szatmari P, Maziade M, Zwaigenbaum L, Mérette C, Roy M-A, Joober R, Palmour R. Informative phenotypes for genetic studies of psychiatric disorders. Am J Med Genet B Neuropsychiatr Genet. 2007;144B(5):581–8.
Jones MW, Ashby J, Branigan HP. Dyslexia and fluency: parafoveal and foveal influences on rapid automatized naming. J Exp Psychol Hum Percept Perform. 2013;39:554–67.
Liao C-H, Deng C, Hamilton J, Lee CS-C, Wei W, Georgiou GK. The role of rapid naming in reading development and dyslexia in Chinese. J Exp Child Psychol. 2015;130:106–22.
Bowey JA, McGuigan M, Ruschena A. On the association between serial naming speed for letters and digits and word-reading skill: towards a developmental account. J Res Reading. 2005;28(4):400–22.
Pan J, McBride-Chang C, Shu H, Liu H, Zhang Y, Li H. What is in the naming? A 5-year longitudinal study of early rapid naming and phonological sensitivity in relation to subsequent reading skills in both native Chinese and English as a second language. J Educ Psychol. 2011;103:897–908.
Savage R, Frederickson N. Evidence of a highly specific relationship between rapid automatic naming of digits and text-reading speed. Brain Lang. 2005;93(2):152–9.
Truong DT, Adams AK, Paniagua S, Frijters JC, Boada R, Hill DE, Lovett MW, Mahone EM, Willcutt EG, Wolf M, et al. Multivariate genome-wide association study of rapid automatised naming and rapid alternating stimulus in Hispanic American and African-American youth. J Med Genet. 2019;56(8):557.
Gialluisi A, Andlauer TFM, Mirza-Schreiber N, Moll K, Becker J, Hoffmann P, Ludwig KU, Czamara D, St Pourcain B, Brandler W, et al. Genome-wide association scan identifies new variants associated with a cognitive predictor of dyslexia. Transl Psychiatry. 2019;9(1):77.
Andreola C, Mascheretti S, Belotti R, Ogliari A, Marino C, Battaglia M, Scaini S. The heritability of reading and reading-related neurocognitive components: a multi-level meta-analysis. Neurosci Biobehav Rev. 2021;121:175–200.
Olson RK, Hulslander J, Christopher M, Keenan JM, Wadsworth SJ, Willcutt EG, Pennington BF, DeFries JC. Genetic and environmental influences on writing and their relations to language and reading. Ann Dyslexia. 2013;63(1):25–43.
Byrne B, Samuelsson S, Wadsworth S, Hulslander J, Corley R, DeFries JC, Quain P, Willcutt EG, Olson RK. Longitudinal twin study of early literacy development: Preschool through Grade 1. Read Writ. 2007;20(1):77–102.
Mascheretti S, Riva V, Feng B, Trezzi V, Andreola C, Giorda R, Villa M, Dionne G, Gori S, Marino C, et al. The Mediation role of dynamic multisensory processing using molecular genetic data in dyslexia. Brain Sci. 2020;10(12):993.
Kirby JR, Deacon SH, Bowers PN, Izenberg L, Wade-Woolley L, Parrila R. Children’s morphological awareness and reading ability. Read Writ. 2012;25(2):389–410.
Ku Y-M, Anderson RC. Development of morphological awareness in Chinese and English. Read Writ. 2003;16(5):399–422.
Pan J, Song S, Su M, McBride C, Liu H, Zhang Y, Li H, Shu H. On the relationship between phonological awareness, morphological awareness and Chinese literacy skills: evidence from an 8-year longitudinal study. Dev Sci. 2016;19(6):982–91.
Tighe EL, Schatschneider C. Examining the relationships of component reading skills to reading comprehension in struggling adult readers: a meta-analysis. J Learn Disabil. 2016;49(4):395–409.
Betjemann RS, Keenan JM, Olson RK, DeFries JC. Choice of reading comprehension test influences the outcomes of genetic analyses. Sci Stud Read. 2011;15(4):363–82.
Gayán J, Olson RK. Genetic and environmental influences on individual differences in printed word recognition. J Exp Child Psychol. 2003;84(2):97–123.
Xie Q, Zheng M, Ho CS-H, McBride C, Fong FLW, Wong SWL, Chow BW-Y. Exploring the genetic and environmental etiologies of phonological awareness, morphological awareness, and vocabulary among chinese-english bilingual children: the moderating role of second language instruction. Behav Genet. 2022;52(2):108–22.
Lim CK-P, Wong AM-B, Ho CS-H, Waye MM-Y. A common haplotype of KIAA0319 contributes to the phonological awareness skill in Chinese children. Behav Brain Funct. 2014;10(1):23.
Venkatesh SK, Siddaiah A, Padakannaya P, Ramachandra NB. Analysis of genetic variants of dyslexia candidate genes KIAA0319 and DCDC2 in Indian population. J Hum Genet. 2013;58(8):531–8.
Pan J, Shu H. Rapid automatized naming and its unique contribution to reading: evidence from Chinese dyslexia. In: Chen Xi, Wang Qiuying, Luo Yang Cathy, editors. Reading development and difficulties in monolingual and bilingual Chinese children. Dordrecht: Springer; 2014.
Cheng C, Yao Y, Wang Z, Zhao J. Visual attention span and phonological skills in Chinese developmental dyslexia. Res Dev Disabil. 2021;116: 104015.
Shu H, McBride-Chang C, Wu S, Liu H. Understanding chinese developmental dyslexia: morphological awareness as a core cognitive construct. J Educ Psychol. 2006;98:122–33.
Li H, Shu H, McBride-Chang C, Liu H, Peng H. Chinese children’s character recognition: visuo-orthographic, phonological processing and morphological skills. J Res Reading. 2012;35(3):287–307.
Song S, Zhang Y, Shu H, Su M, McBride C. Universal and specific predictors of Chinese children with dyslexia-exploring the cognitive deficits and subtypes. Front Psychol. 2020;10:2904.
Doust C, Fontanillas P, Eising E, Gordon SD, Wang Z, Alagöz G, Molz B, Pourcain BS, Francks C, Marioni RE, et al. Discovery of 42 genome-wide significant loci associated with dyslexia. Nat Genet. 2022;54:1621–1629.
Widaman KF, Helm JL, Castro-Schilo L, Pluess M, Stallings MC, Belsky J. Distinguishing ordinal and disordinal interactions. Psychol Methods. 2012;17:615–22.
Fritz MS, MacKinnon DP. Required sample size to detect the mediated effect. Psychol Sci. 2007;18(3):233–9.
Tofighi D, MacKinnon DP. RMediation: an R package for mediation analysis confidence intervals. Beh Res Meth. 2011;43(3):692–700.
Preacher KJ, Hayes AF. Asymptotic and resampling strategies for assessing and comparing indirect effects in multiple mediator models. Beh Res Meth. 2008;40(3):879–91.
Docherty SJ, Kovas Y, Plomin R. Gene-environment interaction in the etiology of mathematical ability using SNP sets. Behav Genet. 2011;41(1):141–54.
Sweitzer MM, Halder I, Flory JD, Craig AE, Gianaros PJ, Ferrell RE, Manuck SB. Polymorphic variation in the dopamine D4 receptor predicts delay discounting as a function of childhood socioeconomic status: evidence for differential susceptibility. Soc Cogn Affect Neurosci. 2012;8(5):499–508.
Pluess M, Belsky J. Vantage sensitivity: Individual differences in response to positive experiences. Psychol Bull. 2013;139:901–16.
Si S, Su Y, Zhang S, Zhang J. Genetic susceptibility to parenting style: DRD2 and COMT influence creativity. Neuroimage. 2020;213: 116681.
Norton ES, Wolf M. Rapid Automatized Naming (RAN) and reading fluency: implications for understanding and treatment of reading disabilities. Annu Rev Psychol. 2012;63(1):427–52.
McBride-Chang C, Lam F, Lam C, Chan B, Fong CYC, Wong TTY, Wong SWL. Early predictors of dyslexia in Chinese children: familial history of dyslexia, language delay, and cognitive profiles. J Child Psychol Psychiatry. 2011;52(2):204–11.
Song S, Georgiou GK, Su M, Hua S. How well do phonological awareness and rapid automatized naming correlate with Chinese reading accuracy and fluency? Meta-analysis Sci Stud Read. 2016;20(2):99–123.
Georgiou GK, Papadopoulos TC, Fella A, Parrila R. Rapid naming speed components and reading development in a consistent orthography. J Exp Child Psychol. 2012;112(1):1–17.
Papadopoulos TC, Spanoudis GC, Georgiou GK. How is RAN related to reading fluency? A comprehensive examination of the prominent theoretical accounts. Front Psychol. 2016;7:1217.
Peng P, Wang C, Tao S, Sun C. The deficit profiles of Chinese children with reading difficulties: a meta-analysis. Educ Psychol Rev. 2017;29(3):513–64.
Landerl K, Ramus F, Moll K, Lyytinen H, Leppänen PH, Lohvansuu K, O’Donovan M, Williams J, Bartling J, Bruder J. Predictors of developmental dyslexia in European orthographies with varying complexity. J Child Psychol Psychiatr. 2013;54(6):686–94.
Paracchini S, Thomas A, Castro S, Lai C, Paramasivam M, Wang Y, Monaco AP. The chromosome 6p22 haplotype associated with dyslexia reduces the expression of KIAA0319, a novel gene involved in neuronal migration. Human Mol Genet. 2006;15(10):1659–66.
Velayos-Baeza A, Toma C, Paracchini S, Monaco AP. The dyslexia-associated gene KIAA0319 encodes highly N- and O-glycosylated plasma membrane and secreted isoforms. Hum Mol Genet. 2007;17(6):859–71.
Londin ER, Meng H, Gruen JR. A transcription map of the 6p22. 3 reading disability locus identifying candidate genes. BMC Genomics. 2003;4(1):1–8.
Jamadar S, Powers NR, Meda SA, Gelernter J, Gruen JR, Pearlson GD. Genetic influences of cortical gray matter in language-related regions in healthy controls and schizophrenia. Schizophr Res. 2011;129(2–3):141–8.
Nicolson R, Fawcett AJ, Dean P. Dyslexia, development and the cerebellum. Trends Neurosci. 2001;24(9):515–6.
Li H, Yuan Q, Luo YJ, Tao W. A new perspective for understanding the contributions of the cerebellum to reading: the cerebro-cerebellar mapping hypothesis. Neuropsychologia. 2022;170:108231.
Wang Z, Zhao S, Zhang L, Yang Q, Cheng C, Ding N, Zhao J. A genome-wide association study identifies a new variant associated with word reading fluency in Chinese children. Genes Brain Behav. 2023;22(1):e12833.
Centanni TM, Booker AB, Sloan AM, Chen F, Maher BJ, Carraway RS, Kilgard MP. Knockdown of the dyslexia-associated gene Kiaa0319 impairs temporal responses to speech stimuli in rat primary auditory cortex. Cereb Cortex. 2014;24(7):1753–66.
Pinel P, Fauchereau F, Moreno A, Barbot A, Lathrop M, Zelenika D, Dehaene S. Genetic variants of FOXP2 and KIAA0319/TTRAP/THEM2 locus are associated with altered brain activation in distinct language-related regions. J Neurosci. 2012;32(3):817–25.
Ramus F, Rosen S, Dakin SC, Day BL, Castellote JM, White S, Frith U. Theories of developmental dyslexia: insights from a multiple case study of dyslexic adults. Brain. 2003;126(4):841–65.
Neef NE, Müller B, Liebig J, Schaadt G, Grigutsch M, Gunter TC, Friederici AD. Dyslexia risk gene relates to representation of sound in the auditory brainstem. Dev Cognit Neurosci. 2017;24:63–71.
Mascheretti S, Gori S, Trezzi V, Ruffino M, Facoetti A, Marino C. Visual motion and rapid auditory processing are solid endophenotypes of developmental dyslexia. Genes Brain Behav. 2018;17(1):70–81.
McGrath LM, Peterson RL, Pennington BF. The multiple deficit model: progress, problems, and prospects. Sci Stud Read. 2020;24(1):7–13.
Thomas D. Gene–environment-wide association studies: emerging approaches. Nat Rev Genet. 2010;11(4):259–72.
Funding
This work was funded by National Natural Science Foundation of China (61807023), Funds for Humanities and Social Sciences Research of the Ministry of Education (17XJC190010), Natural Science Foundation of Shaanxi Province (2018JQ8015 and 2023-JC-YB-703), and Fundamental Research Funds for the Central Universities (GK201702011) to Jingjing Zhao. This study was also supported by Funds for Humanities and Social Sciences Research of the Ministry of Education (19YJC190023), the China Postdoctoral Science Foundation funding project (2019M663924XB), Natural Science Foundation of Shaanxi Province (2021JQ-309), and Planning Subject for the 14th Five Year Plan of Shaanxi Education Sciences (SGH21Y0040) to Zhengjun Wang.
Author information
Authors and Affiliations
Contributions
JZ and ZW conceived of the presented idea. ZW, QY, and CC performed the experiments and data analysis and assisted in writing the manuscript. QY, CC, and ZW performed the experiments and analyzed the data. JZ, QY, and ZW designed the study and wrote the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
All experimental procedures have been authorized by the Shaanxi Normal University and written informed consent was obtained from all participants’ parents.
Consent for publication
Not applicable.
Competing interests
The research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1
: Table S1. Characteristics of the single-nucleotide polymorphismsof KIAA0319. Table S2. Correlation matrix of cumulative genetic scores, cognitive skills, reading fluency, character recognition. Table S3. Results for standard parameterization models for 13 SNPs on reading fluency. Table S4. Results for standard parameterization models for 13 SNPs and CR_CGS on character recognition. Table S5. Specific indirect effects of RANs, phonological awareness and morphological awareness from CGS to character recognition in modified models. Table S6. Fitting index of cumulative genetic score of Reading fluency on moderated mediation model. Figure S1. Significant specific indirect of the RAN effect from CR_CGS to character recognition after controlling for sex and age. Figure S2. Significant specific indirect effects of the digit RAN and picture RAN from CR_CGS to character recognition after controlling for sex and age. The model was adjusted for the correlations between different RAN tasks. Figure S3. The moderated-mediation model of Parental Education and RAN.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Zhao, J., Yang, Q., Cheng, C. et al. Cumulative genetic score of KIAA0319 affects reading ability in Chinese children: moderation by parental education and mediation by rapid automatized naming. Behav Brain Funct 19, 10 (2023). https://doi.org/10.1186/s12993-023-00212-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12993-023-00212-z