
Abstract
Background
Wearable sensors can be used to derive numerous gait pattern features for elderly fall risk and faller classification; however, an appropriate feature set is required to avoid high computational costs and the inclusion of irrelevant features. The objectives of this study were to identify and evaluate smaller feature sets for faller classification from large feature sets derived from wearable accelerometer and pressure-sensing insole gait data.
Methods
A convenience sample of 100 older adults (75.5 ± 6.7 years; 76 non-fallers, 24 fallers based on 6 month retrospective fall occurrence) walked 7.62 m while wearing pressure-sensing insoles and tri-axial accelerometers at the head, pelvis, left and right shanks. Feature selection was performed using correlation-based feature selection (CFS), fast correlation based filter (FCBF), and Relief-F algorithms. Faller classification was performed using multi-layer perceptron neural network, naïve Bayesian, and support vector machine classifiers, with 75:25 single stratified holdout and repeated random sampling.
Results
The best performing model was a support vector machine with 78% accuracy, 26% sensitivity, 95% specificity, 0.36 F1 score, and 0.31 MCC and one posterior pelvis accelerometer input feature (left acceleration standard deviation). The second best model achieved better sensitivity (44%) and used a support vector machine with 74% accuracy, 83% specificity, 0.44 F1 score, and 0.29 MCC. This model had ten input features: maximum, mean and standard deviation posterior acceleration; maximum, mean and standard deviation anterior acceleration; mean superior acceleration; and three impulse features. The best multi-sensor model sensitivity (56%) was achieved using posterior pelvis and both shank accelerometers and a naïve Bayesian classifier. The best single-sensor model sensitivity (41%) was achieved using the posterior pelvis accelerometer and a naïve Bayesian classifier.
Conclusions
Feature selection provided models with smaller feature sets and improved faller classification compared to faller classification without feature selection. CFS and FCBF provided the best feature subset (one posterior pelvis accelerometer feature) for faller classification. However, better sensitivity was achieved by the second best model based on a Relief-F feature subset with three pressure-sensing insole features and seven head accelerometer features. Feature selection should be considered as an important step in faller classification using wearable sensors.
Similar content being viewed by others
Background
Wearable sensors can be used to assess gait and predict elderly fall risk, with varying degrees of success [1]. Numerous gait pattern features can be derived from a wearable sensor; however, an appropriate feature set is required to avoid high computational costs, “curse of dimensionality”, and irrelevant features [2, 3]. Reducing feature-space size reduces the risk of prediction-model overfitting and may improve classification performance [3, 4]. Even with these benefits, few fall - risk models in the literature employ feature-space size reduction techniques to improve classification performance.
Various techniques have been used to reduce the feature-space size before faller classification for wearable-sensor-based elderly fall risk applications. Factor analysis uses a statistical technique to examine variability between correlated features, and represents that variability as fewer factor variables; for example, Riva et al. [5] used this method to represent 24 features as seven factors. Principal component analysis (PCA) is similar to factor analysis but uses orthogonal transformation to represent features as linearly uncorrelated variables called principal components. PCA was used to represent 24 dynamic stability features with three principal components representing global gait pattern kinetics, global gait regularity, and stride time [6]. Sequential forward floating search algorithms start with an empty set (i.e., no features) and add features, starting with the best feature, until classification accuracy is maximized. Liu et al. [7] used this method to reduce feature-space size from 123 features to as few as three features. Forward wrapper feature selection techniques can take many forms. The technique used by Caby et al. [8] was similar to a sequential forward floating search algorithm, starting with an empty set and adding features to maximize classification performance. This method reduced feature-space size from 67 features to as few as one feature [8]. Only these few studies, which used wearable sensor-derived features for faller classification, reduced feature-space size before faller classification [5,6,7,8].
To reduce feature-space size, feature selection techniques are preferable to projection techniques (e.g. PCA) and compression techniques (e.g. information theory) because the original features are not altered [4]. Three main feature selection methods can be considered: filter, wrapper, and embedded. Filter methods focus on intrinsic data properties, with features scored on relevance [3, 4]. Wrapper methods are developed for a specific classification method and different feature subsets are tested with the chosen classifier to optimize performance [3, 4]. Wrapper methods can achieve better performance than filter methods but are computationally expensive and can result in overfitting [4]. Embedded methods are similar to wrapper methods but feature selection is built into the classifier construction, which reduces computational complexity compared to wrapper methods [4]. Caby et al. [8] used a wrapper feature selection method to reduce a wearable-sensor-based feature space before using an intelligent classifier for fall risk prediction. While the wrapper approach is valid, this method ties feature selection to a specific classifier, precluding feature subset evaluation across different classifiers. A classifier-independent, filter approach is preferred because it permits direct comparisons between different classifiers and different feature sets, including a full feature set.
The objectives of this study were to identify smaller feature sets for faller classification from large feature sets derived from wearable accelerometer and pressure-sensing insole gait data, and to evaluate faller classification performance of these feature sets with different classifiers. This study also evaluated whether feature selection would improve faller classification performance compared to classification without feature selection. Successful application of feature selection techniques to faller classification would improve the clinical applicability of fall risk prediction models by reducing assessment and analysis complexity.
Methods
Participants
A convenience sample of 100 people, 65 years or older, were recruited from the community (Table 1). Participants were identified as fallers if they reported at least one fall during the six months prior to study participation. Potential participants were excluded if they had a cognitive disorder (self-reported) or were unable to walk for six minutes without an assistive device. The University of Waterloo Research Ethics Committee approved the study and all participants gave informed written consent.
Protocol
Participants reported six month retrospective fall occurrence, age, and sex. Body weight and height were measured.
Pressure-sensing insoles (F-Scan 3000E, Tekscan, Boston, MA) were equilibrated using multi-point calibration (137.9, 275.8, 413.7 kPa), fit to the shoes, and calibrated. Accelerometers (X16-1C, Gulf Coast Data Concepts, Waveland, MS) were attached to the posterior head with a band, posterior pelvis with a belt, and lateral shank, just above the ankle, with a band. Plantar pressure data were collected at 120 Hz and accelerometer data at 50 Hz. Completion time and wearable sensor gait data were collected while participants completed a 7.62 m (25 ft) walk.
Wearable sensor features
Plantar-pressure derived features were:
-
Center of Pressure (CoP) path: Number, length, and duration of posterior deviations per stance. Number, lateral length, medial length, and duration of medial-lateral (ML) deviations. Anterior-posterior (AP) and ML coefficients of variation (CoV) for the stance phase CoP path.
-
Temporal: Cadence, stride time, stance time, swing time, percent stance time, percent double support time, stride time symmetry index [9] between the left and right limbs, and CoV for stride time, stance time, and swing time.
-
Impulse: Impulse variables were determined from the total force-time curve and normalized by body mass (Ns/kg) for: I1 (foot-strike to first peak), I2 (first peak to minimum), I3 (minimum to second peak), I4 (second peak to foot-off), I5 (foot-strike to minimum), I6 (minimum to foot-off), and I7 (foot-strike to foot-off).
All variables were calculated for each stride for the left and right limbs before calculating means and standard deviations across both limbs (i.e. left and right limb combined).
For each accelerometer location, the accelerometer derived features were:
-
Descriptive statistics: Maximum, mean, and standard deviation of acceleration for the superior, inferior, anterior, posterior, right, and left axes.
-
Temporal: Cadence and stride time.
-
Fast Fourier Transform (FFT): Percentage of acceleration frequencies in the first quartile of an FFT frequency plot for vertical, AP, and ML axes.
-
Ratio of even to odd harmonics (REOH): Proportion of the acceleration signal in phase with stride frequency. The harmonic ratio was calculated for vertical, AP, and ML axes as in [10].
-
Maximum Lyapunov exponent (MLE): Average rate of expansion or contraction of the original trajectory in response to perturbations [11, 12], calculated for vertical, AP, and ML accelerations, as in [13].
For descriptive statistics and MLE parameters, acceleration data were filtered using a fifth order, low pass Butterworth filter with a 12.5 Hz cut-off frequency. Unfiltered acceleration data were used to calculate the FFT quartile and REOH.
Feature selection
Filter feature selection methods were selected because feature subsets from each filter method could be evaluated using three different classifiers, which would not be possible with wrapper or embedded methods. Furthermore, filter methods reduce the computational cost and reduce the risk of overfitting [4]. Three filter feature selection methods were used: correlation-based feature selection (CFS), fast correlation based filter (FCBF), and Relief-F. CFS and FCBF both provide a minimum subset of features whereas Relief-F provides a ranking of features.
CFS is a supervised method that identifies a subset of features that are correlated with the class label (i.e. faller or non-faller) and uncorrelated with other parameters, and eliminates irrelevant and redundant features [3]. To identify the feature subset, CFS computes the subset’s heuristic measure of ‘merit’ based on pairwise correlations [14, 15].
FCBF is a supervised method that identifies predominant features for classification and eliminates redundant features. This method avoids pairwise correlation analysis between all relevant features, reducing computational complexity compared to CFS [16]. The feature subset is selected based on the symmetrical uncertainty [14].
Relief-F is a supervised method that weights the parameter’s relative strength, and eliminates less relevant features without eliminating redundant features [2, 14]. Relief-F is useful when evaluating parameters with interdependencies and noisy data sets [15]. The number of features to include in the Relief-F feature subset was determined using the runExperiment algorithm within the Arizona State University Feature Selection Repository (ASUFSR) [14], which evaluates increasingly larger feature subsets, by five-feature increments, until the entire feature set is included in the subset. For the runExperiment algorithm, naïve Bayes (NB) and Support Vector Machine (SVM) were used as classifiers and a 75:25 stratified holdout was used for training and testing data division, which was also used for model development. The smallest feature subset that did not decrease overall accuracy, or at worst resulted in no more than a 5% decrease in accuracy from the full-feature set, was selected.
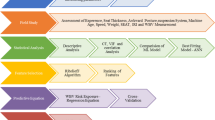
Feature selection was performed (Fig. 1) on the entire dataset for all features for each of the 31 sensor combinations (Table 2) in Matlab R2010a using ASUFSR algorithms [14]. Because the entire dataset was used for feature selection, feature selection was not performed for each iteration of the prediction stability analysis. Identical feature subsets were used as inputs for both the single stratified holdout (model development) and all 10,000 randomized holdouts (prediction stability). Pelvis accelerometer data were missing for two non-fallers and left shank accelerometer data were missing for one non-faller due to sensor power failure.

Flowchart of feature selection and model development process
Model development
Following feature selection, three classifier models were used to assess each feature set: multi-layer perceptron neural network (NN) with 5 to 25 nodes in a single hidden layer, linear and quadratic discriminant NB, and SVM with one to seven degree polynomial kernels [17]. The classification criterion was retrospective fall occurrence. For all models, 75% of participant data (18 fallers, 57 non-fallers) were used for training and 25% were used for testing (6 fallers, 19 non-fallers). Faller classification using NN, NB, and SVM without feature selection was performed previously [17] using identical train:test groupings and input data, and the top ten models from that previous analysis were used in the current study to evaluate the effect of feature selection on classification performance.
Model evaluation parameters included accuracy, specificity, sensitivity, positive predictive value (PPV), negative predictive value (NPV) [18], F1 score (harmonic mean of precision and sensitivity) [19], and Matthew’s Correlation Coefficient (MCC) [20]. A ranking method similar to the approach used in Kendell et al., 2012 [21] was employed to determine the best models. Each model evaluation parameter was ranked from best (1) to worst (n), and ranks for all model evaluation parameters were summed to identify the overall best model (lowest summed rank) (Fig. 2). Confidence intervals (CI) for model accuracy were computed using the Wilson interval (Equation 1), which is an appropriate binomial proportion interval estimation method for small sample sizes [22].

Flowchart of feature selection-based model development and ranking analysis. AV: All variable, FS: Feature selection, NB: Naïve Bayesian, NN: Neural network, SVM: Support vector machine.
where p is the model accuracy, N is the number of participants in the test dataset, and z is 1.96 for a 95% confidence interval.
Prediction stability
The prediction accuracy of the top twenty feature selection-based models and top ten all variable-based models were further examined by training 10,000 models with randomized 75:25 train:test stratified holdouts (repeated random sampling, RRS). Model evaluation parameters were calculated and averaged across all 10,000 models and then ranking was performed, as described previously.
Results
Nine feature subsets (eight Relief-F, one CFS, one FCBF: Table 3) were inputs for the twenty best models (Table 4). CFS and FCBF analyses outputted the same feature set (Feature Subset 9). For the single 75:25 train:test stratified holdout, the top fifteen models used Relief-F feature selection, with the top two models (Feature Subset 1, SVM-6 and SVM-7) including three insole measures and seven head accelerometer measures (Table 3). The top model (Feature Subset 1, SVM-7) achieved the highest accuracy (96%), sensitivity (100%), NPV (100%), F1 score (0.92) and MCC (0.90) and a specificity of 95%, and PPV of 86%. Two single-sensor-based models ranked 11th (Feature Subset 5 with head accelerometer sensor, SVM-4; and Feature Subset 6 with pelvis accelerometer sensor, SVM-4), achieving an accuracy of 88%, sensitivity 67%, specificity 95%, PPV 80%, NPV 90%, F1 score 0.73, and MCC 0.66. The twenty best models using feature selection were compared to the ten best models generated using all combinations of variables (AV) but no feature selection [17] (Table 4). The top fifteen models that used feature selection outperformed the best models that did not use feature selection.
The RRS model performance (Table 5) was lower than results from the single 75:25 train:test stratified holdout (Table 4) for all of the thirty evaluated models. The single 75:25 train:test stratified holdout used in the initial analysis resulted in model performance at the upper end of model performances observed over 10,000 randomizations. A histogram of RRS model accuracies is shown in Fig. 3, for Feature Subset 1, SVM-7, where the single holdout accuracy of 96% was one of the best accuracies. Similar to the single holdout results (Table 4), the top sixteen RRS models that used feature selection outperformed the best models that did not use feature selection (AV models). The top model (Feature Subset 1, SVM-7) from the single 75:25 train:test stratified holdout ranked second best after RRS, with 74% accuracy, 44% sensitivity, 83% specificity, 47% PPV, 83% NPV, 0.44 F1 score, and 0.29 MCC. The top RRS model (Feature Subset 9, SVM-2) achieved 78% accuracy, 26% sensitivity, 95% specificity, 65% PPV, 80% NPV, 0.36 F1 score, and 0.31 MCC.

Histogram of RRS model accuracy for 10,000 randomizations of 75:25 train:test stratified holdouts for Feature Subset 1, SVM-7
Discussion
The three feature selection techniques, CFS, FCBF, and Relief-F, successfully reduced the feature set from up to 146 features, derived from pressure-sensing insoles and four wearable accelerometers, to a viable set containing as few as one feature. Models derived using the reduced feature sets outperformed models derived using the full feature set when classifying fall risk, demonstrating the benefits of feature selection methods when creating faller classification models.
Relief-F feature selection performed well for the single 75:25 stratified holdout and RRS. A feature subset outputted by both CFS and FCBF feature selection techniques was used in the top RRS model. In other classification studies, CFS and FCBF provided the best feature subsets [16, 23]. However, these studies were not classifying elderly fall risk and instead classified human activities such as sitting, standing, and stair walking [23] or benchmark data sets that include healthcare diagnoses and census data [16]. Elderly fall risk is a complex classification problem where differences between fallers and non-fallers are often subtle and varied [24]. Relief-F feature selection has recognized strengths when dealing with noisy data sets and parameters with interdependencies [15], which may make this method suitable for elderly faller classification, in addition to CFS and FCBF feature selection techniques.
The best model (Feature Subset 1, SVM-7) for the single 75:25 stratified holdout and second best RRS model contained ten features: 3 pressure-sensing insole features and seven head accelerometer features. For the single 75:25 stratified holdout, this model achieved 96% accuracy, 0.92 F1 score, and 0.90 MCC. With 100% sensitivity, this model would be an excellent screening tool because all fallers would be identified. “Feature Subset 1, SVM-7” results were comparable to the best faller classification results in the literature: Caby et al. [8] with 100% accuracy and Giansanti et al. [25] with 97% accuracy. However, RRS model performance was lower, with an accuracy of 74%, F1 score of 0.44, and MCC of 0.29. This lower model performance is likely more indicative of future model performance given the large number of models trained with different data splits. With RRS analysis, this wearable sensor approach did not achieve 80% accuracy, which is often considered a threshold for good classification.
The pressure-sensing insole features in Feature Subset 1 were impulse measures I3, I6, and I7. I3 and I6 measure impulse during the second half of stance phase and I7 measures impulse during the entire stance phase. This indicates the importance of force magnitude and timing of force application during stance phase for faller identification, with fallers having lower I3, I6, and I7 impulse compared to non-fallers [24]. The lower impulse could indicate reduced force application due to muscle weakness, which is a fall risk factor [26, 27]. The head features were maximum, mean, and standard deviation for posterior and anterior acceleration, and mean superior acceleration. Head accelerations in the direction of progression was important for faller classification, with fallers having greater posterior and lower anterior acceleration compared to non-fallers [24].
Based on RRS model performances, the best model (Feature Subset 9, SVM-2) contained one feature from the posterior pelvis accelerometer: left acceleration standard deviation. This model achieved 78% accuracy, 26% sensitivity, 95% specificity, 65% PPV, 80% NPV, 0.36 F1 score, and 0.31 MCC. The posterior pelvis location allows unobtrusive and easy monitoring with a belt attached sensor or accelerometer-equipped smartphone, and high user acceptance was found in a 20-day case-study with a lower back sensor [28]. While this single-sensor RRS model ranked higher than the best multi-sensor RRS model, the single-sensor model had a much lower sensitivity 26% compared to 44% with the best multi-sensor model (Feature Subset 1, SVM-7). Given that the goal of the model is to identify fallers, the multi-sensor model with higher sensitivity (true positive rate), may be preferable even though the accuracy is lower (multi-sensor: 74%, single-sensor: 78%). The best RRS model sensitivity was 56% (Feature Subset 8, NB-Q) with accuracy 68%, F1 score 0.46, and MCC 0.26. The best single-sensor RRS model sensitivity was 41% (Feature Subset 9, posterior pelvis accelerometer only, NB-Q) with accuracy 71%, F1 score 0.40, and MCC 0.22.
Models with a feature subset performed better than models with a complete feature set, demonstrating the importance of including feature reduction when defining models for faller classification. Feature selection techniques removed irrelevant features and improved classification accuracy. Improved classification accuracy is one of the expected advantages of feature selection [3, 4, 23].
A stratified holdout was performed and confidence intervals calculated using the Wilson interval, as recommended by Shany et al. [29] in their recent review paper. Shany and colleagues recommended external validation as the optimal method for validating model performance, followed by holdout validation with confidence intervals computed, and finally cross validation, although it is currently not theoretically known whether cross-validation gives a better estimate of future model performance than simple holdout validation [29]. From our study, the results indicated that simple holdout validation may not accurately estimate future model performance, particularly when many models are investigated. Some accuracy confidence intervals did not include the average RRS model performance achieved across 10,000 stratified holdouts. For example, the accuracy for Feature Subset 1, SVM-7 was 96% with a 95% confidence interval of 80% to 99% for a single stratified holdout; however, the average RRS accuracy was 74%, which was 6% less than the lower confidence limit. With this older-adult gait dataset, a wide variance in model performance occurred with different train:test data divisions (Fig. 3). Therefore, cross-validation may be preferred over simple holdout validation for model development because cross-validation reduces the influence of the data partition on model performance. Furthermore, randomization of a large number of holdouts, such as the 10,000 randomizations performed in this study, may be preferred when evaluating model performance.
This study used retrospective fall occurrence as the criterion for classifying faller and non-faller status. While this is superior to using a clinical assessment based criterion [1], future studies should use prospective fall occurrence as the criterion for evaluating model classification performance. Retrospective fall occurrence is limited by inaccurate recall of falls and changes to gait patterns that occur between the fall and assessment, either in an attempt to increase stability or from fear of falling.
The use of the entire data set for feature selection allowed an analysis of consistent feature subsets across the different RRS data partitions and the comparison and recommendation of specific feature subsets. Feature selection on the entire data set may have overfit the feature subsets to the data set; therefore, the results should be confirmed with a new population sample to verify that the results are consistent for an older adult population that was not used for the feature selection process. While this study explored a large number of features (up to 146 features), other possible features could be included in future research. Additional accelerometer-based features from the literature, that were relevant to older adult fall risk, could be generated from phase-dependent local dynamic stability [30, 31], discrete wavelet transform [32, 33], sample entropy [5, 34], and power spectral density [35, 36]. Furthermore, this study examined features derived from a 7.62 m (25 ft) walking trial. This distance translates to clinical settings where the “25 ft Walk Test” [37, 38] could be performed; however, a longer walking trial may be more reflective of everyday walking for older adults. A study by Rispens et al. [34] found differences between treadmill-walking-based gait features and daily-life-walking-based gait features, with daily-life-based gait being more variable, less symmetric, and less stable compared to treadmill-based gait. Similar differences could be found when comparing lab-based, relatively short walking trials to daily-life walking. The 7.62 m walking distance may have affected MLE reliability, since stable MLE measures occurred after 35 strides in [39].
Conclusion
Feature selection provided models with smaller feature sets and improved faller classification compared to faller classification without feature selection. CFS and FCBF provided the best feature subset for faller classification with a model based on one posterior pelvis accelerometer feature. However, better sensitivity was achieved by the second best model based on a Relief-F feature subset with three pressure-sensing insole features and seven head accelerometer features. Feature selection should be considered as an important step in faller classification using wearable sensors.
Abbreviations
- AP:
-
Anterior-posterior
- ASUFSR:
-
Arizona State University Feature Selection Repository
- AV:
-
All variables
- CFS:
-
Correlation-based feature selection
- CoP:
-
Center of pressure
- CoV:
-
Coefficient of variation
- FCBF:
-
Fast correlation based filter
- FFT:
-
Fast Fourier transform
- H:
-
Head accelerometer measures
- I:
-
Pressure-sensing insole measures
- LS:
-
Left shank accelerometer measures
- MCC:
-
Matthew’s correlation coefficient
- ML:
-
Medial-lateral
- MLE:
-
Maximum Lyapunov exponent
- NB:
-
Naïve Bayes
- NB-Q:
-
Quadratic naïve Bayes
- NN:
-
Neural network
- NPV:
-
Negative predictive value
- P:
-
Pelvis accelerometer measures
- PCA:
-
Principal component analysis
- PPV:
-
Positive predictive value
- REOH:
-
Ratio of even to odd harmonics
- RS:
-
Right shank accelerometer measures
- SR:
-
Summed rank
- SVM:
-
Support vector machine
References
Howcroft J, Kofman J, Lemaire ED. Review of fall risk assessment in geriatric populations using inertial sensors. J Neuroeng Rehabil. 2013;10:91.
Zhang M, Sawchuk AA. A Feature selection-based framework for human activity recognition using wearable multimodal sensors. In: Proceedings of the 6th International Conference on Body Area Networks: November 7-10, 2011. Beijing, China. 2011. p. 92–8.
Hall MA, Smith LA. Feature selection for machine learning: Comparing a correlation-based filter approach to the wrapper. In: Proceedings of the Twelfth International Florida Artificial Intelligence Research Society Conference: May 1-5, 1999. Orlando, Florida, USA. 1999. p. 235–9.
Saeys Y, Inza I, Larranaga P. A review of feature selection techniques in bioinformatics. Bioinformatics. 2007;23:2507–17.
Riva F, Toebes MJP, Pijnappels M, Stagni R, van Dieen JH. Estimating fall risk with inertial sensors using gait stability measures that do not require step detection. Gait Posture. 2013;38:170–4.
Mignardot J-B, Deschamps T, Barrey E, Auvinet B, Berrut G, Cornu C, Constans T, de Decker L. Gait disturbances as specific predictive makers of the first fall onset in elderly people: a two-year prospective observational study. Front Aging Neurosci. 2014;6:22.
Liu Y, Redmond SJ, Narayanan MR, Lovell NH. Classification between non-multiple fallers and multiple fallers using a triaxial accelerometry-based system. In: Proceedings of the 33rd Annual Conference of IEEE EMBS: August 30-September 3, 2011. Boston, Massachusetts. 2011. p. 1499–502.
Caby B, Kieffer S, de Saint HM, Cremer G, Macq B. Feature extraction and selection for objective gait analysis and fall risk assessment by accelerometry. Biomed Eng Online. 2011;10:1.
Sadeghi H, Allard P, Prince F, Labelle H. Symmetry and limb dominance in able-bodied gait: A review. Gait Posture. 2000;12:34–45.
Smidt GL, Arora JS, Johnston RC. Accelerographic analysis of several types of walking. Am J Phys Med. 1971;50:285–300.
Liu J, Lockhart TE, Jones M, Martin T. Local dynamic stability assessment of motion impaired elderly using electronic textile pants. IEEE Trans Autom Sci Eng. 2008;5:696–702.
Toebes MJP, Hoozemans MJM, Furrer R, Dekker J, van Dieen JH. Local dynamic stability and variability of gait are associated with fall history in elderly subjects. Gait Posture. 2012;36:527–31.
van Schooten KS, Rispens SM, Pijnappels M, Daffertshofer A, van Dieen JH. Assessing gait stability: The influence of state space reconstruction on inter- and intra-day reliability of local dynamic stability during over-ground walking. J Biomech. 2013;46:137–41.
Zhao Z, Morstatter F, Sharma S, Alelyani S, Anand A, Liu H. Advancing feature selection research-ASU feature selection repository. Arizona State University. 2016. http://featureselection.asu.edu/old/featureselection_techreport.pdf. Accessed 4 Apr 2016
Liu H, Motoda H. Computational methods of feature selection. Boca Ranton: Chapman & Hall/CRC; 2008.
Yu L, Liu H. Feature selection for high dimensional data: A fast correlation-based filter solution. In: Proceedings of the 20th International Conference on Machine Learning: August 21-24, 2003. Washington, DC, USA. 2003. p. 856–63.
Howcroft J, Lemaire ED, Kofman J. Wearable-sensor-based classification models of faller status in older adults. PLoS One. 2016;11:e0153240.
Lalkhen AG, McCluskey A. Clinical tests: Sensitivity and specificity. CEACCP. 2008;8(6):221–3.
van Rijsbergen CJ. Information Retrieval. London: Butterworths; 1979.
Matthews BW. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim Biophys Acta. 1975;405:442–51.
Kendell C, Lemaire ED, Losier Y, Wilson A, Chan A, Hudgins B. A novel approach to surface electromyography: An exploratory study of electrode-pair selection based on signal characteristics. J Neuroeng Rehabil. 2012;9:24.
Brown LD, Cai TT, DasGupta A. Interval estimation for a binomial proportion. Stat Sci. 2001;16(2):101–33.
Capela NA, Lemaire ED, Baddour N. Feature selection for wearable smartphone-based human activity recognition with able bodied, elderly, and stroke patients. PLoS One. 2015;10(4):e0124414.
Howcroft J, Kofman J, Lemaire ED, McIlroy WE. Analysis of dual-task elderly gait in fallers and non-fallers using wearable sensors. J Biomech. 2016;49(7):992-1001.
Giansanti D, Macellari V, Maccioni G. New neural network classifier of fall-risk based on the Mahalanobis distance and kinematic parameters assessed by a wearable device. Physiol Meas. 2008;29:N11–9.
Martin FC. Falls risk factors: Assessment and management to prevent falls and fractures. Can J Aging. 2011;30:33–44.
Pijnappels M, van der Burg PJCE, Reeves ND, van Dieen JH. Identification of elderly fallers by muscle strength measures. Eur J Appl Physiol. 2008;102:585–92.
Giansanti D, Morelli S, Maccioni G, Constantini G. Toward the design of a wearable system for fall-risk detection in telerehabilitation. Telemed e-Health. 2009;15:296–9.
Shany T, Wang K, Liu Y, Lovell NH, Redmond SJ. Review: Are we stumbling in our quest to find the best predictor? Over-optimism in sensor-based models for predicting falls in older adults. Healthc Technol Lett. 2015;2:79–88.
Ihlen EAF, Weiss A, Helbostad JL, Hausdorff JM. The discriminant value of phase-dependent local dynamic stability of daily life walking in older adult community-dwelling fallers and nonfallers. Biomed Res Int. 2015;2015:402596.
Ihlen EA, Weiss A, Beck Y, Helbostad JL, Hausdorff JM. A comparison study of local dynamic stability measures of daily life walking in older adult community-dwelling fallers and non-fallers. J Biomech. 2016;49:1498–503.
Ganea R, Paraschiv-Ionescu A, Bula C, Rochat S, Aminian K. Multi-parametric evaluation of sit-to-stand and stand-to-sit transitions in elderly people. Med Eng Phys. 2011;33:1086–93.
Martinez-Ramirez A, Lecumberri P, Gomez M, Rodriguez-Manas L, Garcia FJ, Izquierdo M. Frailty assessment based on wavelet analysis during quiet standing balance test. J Biomech. 2011;44:2213–20.
Rispens SM, van Dieen JH, van Schooten KS, Lizama LEC, Daffertshofer A, Beek PJ, Pijnappels M. Fall-related gait characteristics on the treadmill and in daily life. J Neuroeng Rehabil. 2016;13:12.
Wang K, Lovell NH, Del Rosario MB, Liu Y, Wang J, Narayanan MR, Brodie MAD, Delbaere K, Menant J, Lord SR, Redmond SJ. Inertial measurements of free-living activities: Assessing mobility to predict falls. In: Proceedings of the 36th Annual Conference of IEEE EMBS: 26-30 August, 2014. Chicago, Illinois. 2014. p. 6892–5.
Weiss A, Brozgol M, Dorfman M, Herman T, Shema S, Giladi N, Hausdorff JM. Does the evaluation of gait quality during daily life provide insight into fall risk? A novel approach using 3-day accelerometer recordings. Neurorehabil Neural Repair. 2013;27:742–52.
Hauser SL, Dawson DM, Lehrich JR, Beal MF, Kevy SV, Propper RD, Mills JA, Weiner HL. Intensive immunosuppression in progressive multiple sclerosis. A randomized, three-arm study of high-dose intravenous cyclophosphamide, plasma exchange, and ACTH. N Engl J Med. 1983;308:173–80.
Bohannon RW. Comfortable and maximum walking speed of adults aged 20–79 years: Reference values and determinants. Age Ageing. 1997;26:15–9.
Stergiou N, Buzzi UH, Kurz MJ, Heidel J. Nonlinear tools in human movement. In: Stergiou N, editor. Innovative Analyses of Human Movement: Analytical Tools for Human Movement Research. Champaign: Human Kinetics; 2004. p. 63–90.
Acknowledgements
The authors thank Deep Shah for assistance with data collection, United Church of Canada and the University of Waterloo Retirees Association for assistance with recruitment, and Chartwell Bankside Terrace Retirement Residence for assistance with recruitment and providing space for data collection at their facility.
Funding
This project was funded by Natural Sciences and Engineering Research Council of Canada (NSERC). NSERC had no role in the design of the study and collection, analysis, interpretation of data, or writing the manuscript.
Availability of data and materials
The datasets supporting the conclusions of the article are available in the dataverse repository [http://hdl.handle.net/10864/11530].
Authors’ contributions
JH, JK, and EL all contributed substantially to all study aspects including conception and design, data acquisition, data analysis and interpretation, revising and editing the manuscript, and approving the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Consent for publication
Not applicable.
Ethics approval and consent to participate
The Office of Research Ethics at the University of Waterloo approved the study (ORE#: 19106) and all participants gave informed written consent.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Howcroft, J., Kofman, J. & Lemaire, E.D. Feature selection for elderly faller classification based on wearable sensors. J NeuroEngineering Rehabil 14, 47 (2017). https://doi.org/10.1186/s12984-017-0255-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12984-017-0255-9