
Abstract
Background
Estimating the population sizes of key populations(people who inject drugs, men who have sex with men, transgender persons, and commercial sex workers) is critical for understanding the overall Human Immunodeficiency Virus burden. This scoping review aims to synthesize existing methods for population size estimation among key populations, and provide recommendations for future application of the existing methods.
Methods
Relevant studies published from 1st January 2000 to 4th August 2020 and related to key population size estimation were retrieved and 120 of 688 studies were assessed. After reading the full texts, 81 studies were further excluded. Therefore, 39 studies were included in this scoping review. Estimation methods included five digital methods, one in-person method, and four hybrid methods.
Finding
We summarized and organized the methods for population size estimateion into the following five categories: methods based on independent samples (including capture-recapture method and multiplier method), methods based on population counting (including Delphi method and mapping method), methods based on the official report (including workbook method), methods based on social network (including respondent-driven sampling method and network scale-up method) and methods based on data-driven technologies (Bayesian estimation method, Stochastic simulation method, and Laska, Meisner, and Siegel estimation method). Thirty-six (92%) articles were published after 2010 and 23 (59%) used multiple methods. Among the articles published after 2010, 11 in high-income countries and 28 in low-income countries. A total of 10 estimated the size of commercial sex workers, 14 focused on men who have sex with men, and 10 focused on people who inject drugs.
Conclusions
There was no gold standard for population size estimation. Among 120 studies that were related to population size estimation of key populations, the most commonly used population estimation method is the multiplier method (26/120 studies). Every method has its strengths and biases. In recent years, novel methods based on data-driven technologies such as Bayesian estimation have been developed and applied in many surveys.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Background
The global Human Immunodeficiency Virus epidemic disproportionately affects key populations, including people who inject drugs (PWID), men who have sex with men (MSM), transgender persons and commercial sex workers(CSW) [1]. Key populations are vulnerable groups of HIV infection due to specific higher-risk behaviors: PWID were chosen because of the sharing of needles and syringes; MSM were chosen because of anal sex without condoms; CSW were chosen because of the total frequency of sexual behaviors (the larger total numbers, the larger risky numbers). Understanding the HIV burden among the key populations is essential for estimating the overall burden of HIV both globally and regionally. Population size estimation is an important step towards understanding the HIV burden, and accurate size estimation of key populations can inform resource allocation and distribution of HIV prevention services. However, due to the hidden nature of some of these populations, estimating the population size of key populations is challenging. First, the methods for population size estimation have intrinsic biases. For example, data inputs used by some methods may not reflect actual conditions if the quality of data can not be promised [2, 3]. Second, key populations may be hard to reach because of various reasons, such as social stigma and discrimination [4, 5].
Existing literature related to the size estimation of the key population demonstrated the strengths and shortages of the currently existing methods [6]. However, very few studies have systematically summarized the categories of previously used methods or pointed out their problems, which did not provide further guidance in using these methods in the future study. The traditionally used methods have various intrinsic biases. Besides, the availability of reliable and authentic data has been a big challenge [7]. For example, acknowledging the existence of key populations by public health facilities or the government is challenging [8]. Estimating the size of the key populations is particularly challenging in Eastern Mediterranean, Middle East, and North Africa Region because conservative social and religious values may cause harsh judgment and may even bring life-threatening punishment [9].
There are several papers comparing different population size estimation methods, though usually restricted in specific area or limited method categories [10,11,12]. However, how to find the best strategy based on the local context is the current knowledge gap. To fill the knowledge gap, this scoping review examined population size estimation methods in different settings among key populations. This study aimed to summarize the application of the existing population estimation methods and discuss their respective strengths and weaknesses.
Methods
Search strategy
Relevant studies published from January 2000 to 4th August 2020 and related to population size estimation were retrieved from PubMed [13]. Search terms were chosen based on the relevance to the topic of this study. Search terms included "people who inject drugs"; "men who have sex with men"; "transgender persons"; "sex workers" in combination with: "size estimate" and "size estimation". We used the PRISMA checklist for scoping reviews. This review was completed on 20th August 2021.
Selection criteria
After de-duplication, the nonduplicate publications were retrieved from PubMed, and further reviewed independently by two researchers to determine to identify the final studies to be included. Only publications related to the sampling methods of population size estimation among the key populations and have referential meaning for the application of these various methods were included in the final review. We excluded studies that were not related to the topic of this review or had no suggestive meaning for the future design of population size estimation methods. The titles, abstracts, and full texts of all publications were screened by two independent reviewers (FJ and CX). If it was not clear whether a study should be included in the final review, the three authors (FJ, CX, and WT) reviewed the full texts together to discuss whether the article met the inclusion criteria.
Data extraction
A standardized extraction form was performed using Microsoft Excel to extract the first author, date of publication, and size estimation sampling method of key populations. The publications were categorized into five categories. These include methods based on independent samples, methods based on population counting, methods based on the official report, methods based on social networks, and methods based on data-driven technologies.
Text mining
Text mining, also named text data mining, refers to the process that adopts computer science and artificial intelligence technologies in natural language processing tasks for extracting structured information from unstructured text. Through text mining, we can identify meaningful patterns and new insights. In order to illustrate research trends of HIV key population size estimation papers, we employed a semantic analysis tool, CiteSpace, which is particularly commonly used in the discipline of scientometrics. Text mining results based on full text of all selected studies, this tool can help us to develop relation graphs of important research words in structured items. Notice that Citespace can only run on the platform of Web of Science, then thus our full text mining results are based on studies whose full text could be retrieved on Web of Science (i.e., all eligible full-text studies). Furthermore, this tool can also display relations among key words of existing research. In summary, to develop relation graphs among keywords as well as research trends about the topic of HIV key population size estimation, we utilized text mining of all eligible full-text studies to better capture the relationships among several keywords.
Results
Overall, 688 citations were retrieved from the initial search. After reviewing the titles and abstracts, 568 manuscripts that were not relevant to the topic of this paper were excluded, leaving 120 full-text manuscripts. After reading the full texts, 81 studies were further excluded. Therefore, 39 studies were included in this scoping review (Fig. 1).

Flowchart of the review
Findings
Among the included studies, seven used capture-recapture method, six used multiplier method, two used Delphi method, three used mapping methods, three used workbook method, six used network scale-up method, six used RDS method, three used Bayesian estimation method, two used Laska, Meisner, and Siegel (LMS) estimation method [14] and one used stochastic simulation method (Appendix 2). Among the articles reviewed, 36 (92%) articles were published after 2010 and 3 (8%) were published before 2010. Sixteen (41%) studies examined one method and 23 (59%) studies used multiple methods. 11 studies set the research context in high-income countries and 28 in low- and middle-income countries. A total of 10 estimated the size of commercial sex workers, 14 focused on MSM, and 10 focused on people who injected drugs (PWIDs). These population estimation methods included five digital methods, one in-person method, and four hybrid methods. Appendix 1 summarizes the publications included in this review.
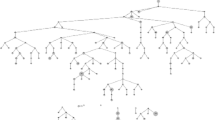
We used full-text mining of 120 full-text articles that could be retrieved on the Web of Science. Figure 2 shows relationships among several research key points including reference citing and semantic understanding. The capture-recapture method appeared three times in this graph with several edges. Social network-based methods such as RDS and network scale-up (i.e., calling 'personal network' from full-text semantic extraction) were also in relatively big word size in this knowledge graph which represents the frequency of mentions. It should be noted that the key item named 'log-linear model' is relevant to Bayesian estimation and LMS estimation. Other methods like Delphi and the workbook method are more likely to be independent as they are even not shown up in this knowledge graph. Figure 3 represents the research trend of this topic in the preceding 20 years. We observe that the methods used gradually changed from traditional methods (e.g., capture-recapture) to social network-based ways (e.g., RDS).

Relation graph of important words from full-text mining

Research trends of important words from 2001 to 2020 from full-text mining
Legend: This graph shows the relations among different keywords from full-text mining. The red font ones are important items relevant to size estimation methods, which are the research objective in our paper (because we do not study on items such as "Africa" and "risk behavior" in our study, hence they are labeled in black font). The appearing times and word size of each item can show its importance and relation centrality in this topic of research (i.e. size estimation for HIV key populations).
We summarize the methods for population size estimation and categorized them into the following five categories (Fig. 4): methods based on independent samples, methods based on population counting, methods based on the official report, methods based on the social network, and methods based on data-driven technologies. Table 1 represents the summary of 10 commonly used population size estimation methods.

Type of methods for population size estimation
Methods based on independent samples
Capture-recapture
Although some novel methods for population size estimation have emerged in recent years, a large number of surveys have been conducted using the capture-recapture method. This method can provide accurate estimates at a low cost [12, 25]. In general, the premise of this analysis is based on the overlap between several samples of the key population [26]. The process of the capture-recapture method includes two separate captures [27]. Key populations are marked and counted in the two captures independently. Some participants captured in the second capture may have already been marked in the first capture. In order to prevent the collection of personal identification information, unique objects such as coupons are commonly used to identify recaptures. However, calculating the number of recaptures is challenging because the databases used may not record the same unique objects from individuals [15]. In some cases, there is no way to determine if the person with the unique object in the second capture is the same person who received it in the first capture [28]. Bias may exist because on some occasions key populations would surround the researcher who is distributing the objects because they hope to get the object. The choice of an appropriate unique object and distributors are of vital importance to guarantee a successful capture-recapture sampling [29, 30]. This approach is highly adaptable for key populations such as drug users and commercial sex workers. It is recommended for use when a census or good-quality data are not available.
Multiplier
The multiplier method is always integrated with other methods, such as the respondent-driven sampling method to estimate the size of the key populations. There were three different types of multipliers among the publications reviewed, including service multiplier, unique object multiplier, and web/mobile Apps multiplier [10]. The service multiplier method uses the programmatic data collected from key populations by health centers [31]. The unique object multiplier method refers to randomly distributing the unique object to the key populations [12]. The web/mobile Apps multiplier method assessed the use of a certain website or mobile phone application among the key populations [32]. The accuracy of the multiplier is highly dependent on the quality of the data source [11]. In addition, different data sources can produce different estimations [33]. To improve the reliability and validity of the multiplier, the representativeness of the data source and the completeness of the benchmark should be considered in advance when conducting the survey.
Methods based on population counting
Delphi
The Delphi method refers to convening a group of experts to synthesize and interpret the information in order to estimate population size [17]. Typically, this method acts as a way to reach an agreement about the estimates from other methods. The team of experts usually consists of those who are familiar with the local geography and culture from local government, research institutions, and social community sectors. Generally, the median, upper and lower limit for the estimate are identified based on local and international data and the expert opinion of the Delphi panel [31]. Experts' opinions will be gathered with discussion to reach a consensus that represents the "best" estimates. This method is vulnerable to subjectivity. Bias may arise when the expert team has a limited understanding of the demographic or geographic features of the populations whose size is being estimated.
Mapping
Mapping is similar to the cross-sectional study in epidemiological research. This method identifies the sites where key populations gather, such as public spaces, mobile apps, and websites. Using map sites to estimate the number of populations at each site begins with identifying locations frequented by key populations [18]. Only the sites mostly frequented by key populations are identified and reported. Mapping relies on the numeric estimates of key informants instead of the count of key populations at each identified site, thus there may be differences between different respondents interviewed at various sites [34]. The variability of the estimates of different respondents could influence the accuracy of the overall estimation [35]. Overestimating or underestimating the number of key populations may happen. The participation of the key populations depends on the extent of their visibility so some individuals may have been omitted, which will lead to underestimation. This method could also overestimate the number of key populations if they frequent multiple locations.
Methods based on the official report
Workbook method
The workbook method uses data retrieved from health officials at the national or regional level [19]. It relies on the existing official records [36]. This method emphasizes a range of estimates instead of a single point estimate. The workbook method uses regional spreadsheets to make estimations of various areas. The data are from the surveillance system and large-scale screening to gain an understanding of the distribution of the key populations [37]. Inevitably, some regions may not have available data to make an estimation. Missing data are estimated by the data from the area with the most similar socioeconomic and geographic features. In addition, the estimation of missing data is usually adjusted by health officials and experts who are familiar with the area.
Methods based on social network
Network scale-up
A network scale-up method is a promising approach to population size estimation. This method starts with estimating the size of a personal network in a small sample. The size of the network of each individual is estimated by predicting the number of key populations they know instead of asking questions about their behaviors directly [38]. This follows estimating the number of people of key populations among the total population. The major assumption of this method is that the social network of individuals involved in the survey can represent the total population [20]. The average personal network size in a certain area can be calculated by averaging the individual value of reported key populations over a large number of respondents [39]. Each individual’s report of their network contributes to the estimation. The main challenge of this method is to determine the sample size required since no individual has complete knowledge about all their acquaintances [40]. The strength of the network scale-up method is that it does not require access to key populations except for people from the initial random sample. The main bias of this method is that estimating the size of a personal network can be cognitively demanding [41]. Different people may have different definitions of key populations and acquaintances [42].
Respondent-driven sampling
Respondent-driven sampling method is increasingly prevalent for population size estimation of key populations in recent years [43]. Many publications have demonstrated the success of peer-driven recruitment in collecting data for key populations. It is a network-based sampling method that starts from recruiting a selected sample from the key populations and respondents recruit their peers from their networks [44]. The purposively selected sample is named "seeds", who recruit other members [21]. There is always a limit for recruitment, usually 3–5 people [45]. Coupons, quotas, and incentives are used to assist the recruitment. The coupons are given from the "seeds" and then passed to other members of the key population [46]. The financial compensation for the participation of the key population could facilitate the development of the recruitment chain. Each recruitee could potentially become a recruiter, which makes the recruitment continue in waves [47]. The connection between recruiters and recruiters can then be traced using the unique identification of coupons. The longer the chains of recruitment, the more representative the surveyed sample [48]. Even though longer recruitment chains could reduce potential selection bias, there are still chances for bias. For example, some populations whose activity is stigmatized may decline participation. In addition, the quality of RDS highly depends on the number of seeds used at the beginning of the study [49].
Methods based on data-driven technologies
Bayesian estimation
The Bayesian estimation method is based on a prior probability distribution using Bayes' theorem to estimate the new probability. The Bayesian estimation assumes that prior probabilities can be used to enhance estimation [22]. If the countries or cities are areas with no direct data on such population size, and there exists a prior probability, the Bayesian estimation method is well suitable [50]. However, different investigators may have a different understanding of prior knowledge according to everyone's subjective realization. As a result, they might give different prior distributions and then obtain different posterior distributions, resulting in the subjectivity of this method.
Stochastic simulation
The stochastic simulation model is to estimate a population-based on epidemiologic data. Stochastic simulation (Monte Carlo) firstly generates a simulated system and then analyze it through probability models based on limited observed data [23]. When we have information from observational cohort studies and clinical trials, such data can help to set simulation parameters, and then simulation models may work. When we have rich epidemiologic data, we can use stochastic simulation models to estimate population size. The strength of this method lies in the ability to produce plausibility ranges for estimates, which describe the uncertainty surrounding the estimates, based on the data to which the model was calibrated [51]. As for shortcomings, first, some large-scale complex simulation processes can be time-consuming. Second, the validity of model estimates is highly dependent on the quality of available data used to calibrate the model.
LMS estimation
Laska, Meisner, and Siegel developed an unbiased estimator for the size of a population in a single venue based on a single sample [14]. Laska, Meisner, and Siegel estimation for MSM size population is based on one single sampling [24]. In other words, this method assumes that we only have a one-time sampling. Compared with other population size estimation methods, first, compared with the capture-recapture method, this method only needs one single-time "capture", hence it is time-saving and resource-saving. Second, when comparing with the multiplier method, it is more scientific according to some statistical principles. However, in the field of statistics, this method is quite traditional and a little hard to make some huge contributions or incorporate some novel revisions [52]. However, as this method only requires one single sample, thus its estimation accuracy might be lower than other population size estimation methods.
Issues of existing population size estimation
Data accuracy, the skills of investigators, duration of size estimation studies, the involvement of the community, geographical areas, and costs and resources required for population size estimation are all essential factors to influence the accuracy of the size estimation result [7].
The current size estimation methods have several limitations. First, further evaluation of the impact of the potential bias and how the biases may impact the size estimation of the key population is needed. Second, it is still hard to take the hardest to reach individuals into consideration. Traditional methods such as capture-recapture and the multiplier method extract independent samples from the population. It is challenging to achieve when the populations are hidden. Social stigma also makes accurate estimation of the size of key populations challenging. In addition, the engagement of people with illegal behaviors to disclose their behaviors or social network to interviewers may cause serious bias. Considering selling sex is legal in some countries but not in many other countries, this is closely related to local contexts.
We summarize things that the researchers need to think about when choosing methods for population size estimation into the following six categories (Fig. 5). Results may vary for the same population by using different methods. For example, when estimating the population size of MSM, using the capture-recapture method may overestimate the actual number of the population because the mobility of the population being estimated makes the number of recapture population decrease. Using the Multiplier method may not get the actual number of the population because it highly depends on the quality of the data source. In addition, the result may be underestimated because the population being estimated is hard to reach. Delphi method is vulnerable to the subjectivity of the expert team, especially when experts have limited understanding of the demographic or geographic features of the populations whose size is being estimated. Using the network scale-up method may underestimate the size of the population being estimated because the respondents may not have complete knowledge about all their acquaintances, which means the estimation can be cognitively demanding.

The researchers need to think about when choosing methods for population size estimation
Discussions
This scoping review has several implications. Developing improved methods to measure the size of populations of the key population is demanding. We need a novel, comprehensive method for population size estimation that avoids the aforementioned challenges. Use different methods to fill the limitation of the estimation methods and to balance the strengths and weaknesses of the used method would be critical to deriving the final estimate.
First, when choosing the method for population estimation, we should consider the potential bias associated with each approach. For example, traditional social network-based methods are collecting data from the MSM population all the time, which might cause some potential bias called convenient sample bias.
Second, for the selection of the methods, we need to tailor this based on the features of the key population, local context, and costs. Evidence from a meta-analysis of multiple sources and Delphi panels could be applied where several findings have been performed on the population whose size is being estimated [53]. Behavioral surveys among the key populations should be conducted before the survey. Planning and preparation will improve the validity of the estimates. If possible, working with members from the key population whose size is being estimated in the community may help better select the most appropriate methods. A pilot study among the subsample of the population whose size is being estimated is a valid approach.
Third, using advances in technology and data science to assist the estimation might be the future trend. As mentioned before, from Fig. 3, we can know that the research trend of utilized methods of this topic in recent 20 years is gradually changing from traditional ways like capture-recapture to social network-based ways like respondent-driven sampling. Perhaps that means the social network data could have great potential in developing accurate estimation models. With the rapid development of data-driven technologies, novel machine learning methods like graph convolutional networks [54] and generative adversarial networks [55] have become popular in Artificial Intelligence (AI) field. Using these new data-driven methods in size estimation tasks for public health research might be a valuable try in the future. Furthermore, using data-driven technologies correctly could be friendly to key populations, because such data-driven approaches depend on existing accessible non-sensitive data, as other model-driven estimation methods may require some hard-reachable data which are private.
Conclusions
The population size estimation methods continue to have limitations. Different methods are likely to give very different results. The estimates depend on subjective judgments, the quality of authentic data and assumptions are always hard to meet.
Availability of data and materials
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- MSM:
-
Men who have sex with men
- PWID:
-
People who inject drugs
- CSW:
-
Commercial sex workers
- HIV:
-
Human Immunodeficiency Virus
- RDS:
-
Respondent driven sampling
- LMS:
-
Laska, Meisner, and Siegel
- UK:
-
The United Kingdom
References
UNAIDS,. UNAIDS data 2020 2020 https://www.unaids.org/en/resources/documents/2020/unaids-data.
Fearon E, Chabata ST, Thompson JA, Cowan FM, Hargreaves JR. Sample size calculations for population size estimation studies using multiplier methods with respondent-driven sampling surveys. JMIR Public Health Surveil. 2017;3(3):e59.
Reed C, Chaves SS, Kirley PD, Emerson R, Aragon D, Hancock EB, et al. Estimating influenza disease burden from population-based surveillance data in the United States. PLoS ONE. 2015;10(3):e0118369.
Kidd R, Clay S, Carr D, Eckhaus T, Brady L, Nyblade L, et al. Understanding and challenging HIV stigma: toolkit for action. 2003.
Cao X, Sullivan SG, Xu J, Wu Z, Team CCP. Understanding HIV–related stigma and discrimination in a “blameless” population. AIDS Educ Prev. 2006;18(6):518–28.
Abdul-Quader AS, Baughman AL, Hladik W. Estimating the size of key populations: current status and future possibilities. Curr Opin HIV AIDS. 2014;9(2):107.
Safarnejad A, Groot W, Pavlova M. Study design and the estimation of the size of key populations at risk of HIV: lessons from Viet Nam. BMC Int Health Hum Rights. 2018;18(1):7.
Pico TAC, Kohler JC, Hoffmann J, Mungala L. No more broken promises: challenges and opportunities for key populations in demanding more transparency, accountability, and participation in the global response against the HIV and AIDS epidemic. Health Hum Rights. 2017;19(2):197.
Organization WH. Estimating sizes of key populations: guide for HIV programming in countries of the Middle East and North Africa. 2016.
Sulaberidze L, Mirzazadeh A, Chikovani I, Shengelia N, Tsereteli N, Gotsadze G. Population size estimation of men who have sex with men in Tbilisi, Georgia; multiple methods and triangulation of findings. PLoS ONE. 2016;11(2):e0147413.
Rich AJ, Lachowsky NJ, Sereda P, Cui Z, Wong J, Wong S, et al. Estimating the size of the MSM population in Metro Vancouver, Canada, using multiple methods and diverse data sources. J Urban Health. 2018;95(2):188–95.
Paz-Bailey G, Jacobson J, Guardado M, Hernandez F, Nieto A, Estrada M, et al. How many men who have sex with men and female sex workers live in El Salvador? Using respondent-driven sampling and capture–recapture to estimate population sizes. Sex Trans Infect. 2011;87(4):279–82.
Arksey H, O’Malley L. Scoping studies: towards a methodological framework. Int J Soc Res Methodol. 2005;8(1):19–32.
Laska EM, Meisner M, Siegel C. Estimating the size of a population from a single sample. Biometrics. 1988;1:461–72.
Apodaca K, Doshi RH, Ogwal M, Kiyingi H, Aluzimbi G, Musinguzi G, et al. Capture-recapture among men who have sex with men and among female sex workers in 11 towns in Uganda. JMIR Public Health Surveil. 2019;5(2):e12316.
Son VH, Safarnejad A, Nga NT, Linh VM, Manh PD, Long NH, et al. Estimation of the population size of men who have sex with men in Vietnam: social app multiplier method. JMIR Public Health Surveil. 2019;5(2):e12451.
Khalid FJ, Hamad FM, Othman AA, Khatib AM, Mohamed S, Ali AK, et al. Estimating the number of people who inject drugs, female sex workers, and men who have sex with men, Unguja Island, Zanzibar: results and synthesis of multiple methods. AIDS Behav. 2014;18(1):25–31.
Bunjaku DG, Deva E, Gashi L, Kaçaniku-Gunga P, Comins CA, Emmanuel F. Programmatic mapping to estimate size, distribution, and dynamics of key populations in Kosovo. JMIR Public Health Surveil. 2019;5(1):e11194.
Lu F, Wang N, Wu Z, Sun X, Rehnstrom J, Poundstone K, et al. Estimating the number of people at risk for and living with HIV in China in 2005: methods and results. Sex Transm Infect. 2006;82(suppl 3):87–91.
Baral S, Turner RM, Lyons CE, Howell S, Honermann B, Garner A, et al. Population size estimation of gay and bisexual men and other men who have sex with men using social media-based platforms. JMIR Public Health Surveil. 2018;4(1):e15.
Johnston LG, Soe P-M, Aung MY, Ammassari S. Estimating the population size of males who inject drugs in Myanmar: methods for obtaining township and national estimates. AIDS Behav. 2019;23(1):295–301.
Overstall AM, King R, Bird SM, Hutchinson SJ, Hay G. Incomplete contingency tables with censored cells with application to estimating the number of people who inject drugs in Scotland. Stat Med. 2014;33(9):1564–79.
Mooney CZ. Monte carlo simulation. New York: Sage Publications; 1997.
Chen H, Zhang Y, Tan H, Bao Y, Chen M, Lin D, et al. Characteristics and the estimated size of men who have sex with men in different venues of one city. Zhonghua liu xing bing xue za zhi Zhonghua liuxingbingxue zazhi. 2011;32(7):664.
Hook EB, Regal RR. Capture-recapture methods in epidemiology: methods and limitations. Epidemiol Rev. 1995;17(2):243–64.
Buster M, Van Den Brink W. Roaming through methodology. XXXI. Estimating partially hidden populations: heroin addicts in Amsterdan. Nederlands tijdschrift voor geneeskunde. 2001;145(4):164.
Ruiz MS, O’Rourke A, Allen ST. Using capture-recapture methods to estimate the population of people who inject drugs in Washington. DC AIDS Behav. 2016;20(2):363–8.
Karami M, Khazaei S, Poorolajal J, Soltanian A, Sajadipoor M. Estimating the population size of female sex worker population in Tehran, Iran: Application of direct capture–recapture method. AIDS Behav. 2017;21(8):2394–400.
Doshi RH, Apodaca K, Ogwal M, Bain R, Amene E, Kiyingi H, et al. Estimating the size of key populations in Kampala, Uganda: 3-source capture-recapture study. JMIR Public Health Surveil. 2019;5(3):e12118.
Li G, Lu H, Sun Y, He S, Ma X, He X. The impact of different markers regarding the estimation of population size under capture-recapture method on men who have sex with men. Zhonghua liu xing bing xue za zhi Zhonghua liuxingbingxue zazhi. 2014;35(9):1046–8.
Okal J, Geibel S, Muraguri N, Musyoki H, Tun W, Broz D, et al. Estimates of the size of key populations at risk for HIV infection: men who have sex with men, female sex workers and injecting drug users in Nairobi Kenya. Sex Transm Infect. 2013;89(5):366–71.
Burrell ER, Pines HA, Robbie E, Coleman L, Murphy RD, Hess KL, et al. Use of the location-based social networking application GRINDR as a recruitment tool in rectal microbicide development research. AIDS Behav. 2012;16(7):1816–20.
Hiebert L, Azzeri A, Dahlui M, Hecht R, Mohamed R, Hana Shabaruddin F, et al. Estimating the Population Size of People Who Inject Drugs in Malaysia for 2014 and 2017 Using the Benchmark-Multiplier Method. Subst Use Misuse. 2020;55(6):871–7.
Odek WO, Githuka GN, Avery L, Njoroge PK, Kasonde L, Gorgens M, et al. Estimating the size of the female sex worker population in Kenya to inform HIV prevention programming. PLoS ONE. 2014;9(3):e89180.
Wambura M, Nyato DJ, Makyao N, Drake M, Kuringe E, Casalini C, et al. Programmatic mapping and size estimation of key populations to inform HIV programming in Tanzania. PLoS ONE. 2020;15(1):e0228618.
Ha NTT, Nguyen QD, Le GT, Thanh DC, Morgan M, Abdul-Quader AS. Number of People who Inject Drugs in Son La, Vietnam: population size estimation based on official records. J Epidemiol Global Health. 2020;10(2):131–4.
Lansky A, Johnson C, Oraka E, Sionean C, Joyce MP, DiNenno E, et al. Estimating the number of heterosexual persons in the United States to calculate national rates of HIV infection. PLoS ONE. 2015;10(7):e0133543.
Scholz SM, Damm O, Elkenkamp S, Marcus U, Greiner W, Schmidt AJ. Population size and self-reported characteristics and sexual preferences of men-who-have-sex-with-men (MSM) in Germany based on social network data. PLoS ONE. 2019;14(2):e0212175.
Guo J, Huang X, Wang X, Weng H, Guo W. Estimation on the size of men who have sex with men among college students in Beijing through the Network Scale-Up Method (NSUM). Zhonghua liu xing bing xue za zhi Zhonghua liuxingbingxue zazhi. 2013;34(11):1080–2.
Ezoe S, Morooka T, Noda T, Sabin ML, Koike S. Population size estimation of men who have sex with men through the network scale-up method in Japan. PLoS ONE. 2012;7(1):e31184.
Maghsoudi A, Baneshi MR, Neydavoodi M, Haghdoost A. Network scale-up correction factors for population size estimation of people who inject drugs and female sex workers in Iran. PLoS ONE. 2014;9(11):e110917.
Wang J, Yang Y, Zhao W, Su H, Zhao Y, Chen Y, et al. Application of network scale up method in the estimation of population size for men who have sex with men in Shanghai, China. PLoS ONE. 2015;10(11):e0143118.
Bengtsson L, Lu X, Nguyen QC, Camitz M, Le Hoang N, Nguyen TA, et al. Implementation of web-based respondent-driven sampling among men who have sex with men in Vietnam. PLoS ONE. 2012;7(11):e49417.
Holland CE, Kouanda S, Lougué M, Pitche VP, Schwartz S, Anato S, et al. Using population-size estimation and cross-sectional survey methods to evaluate HIV service coverage among key populations in Burkina Faso and Togo. Public Health Rep. 2016;131(6):773–82.
Abramovitz D, Volz EM, Strathdee SA, Patterson TL, Vera A, Frost SD. Using respondent driven sampling in a hidden population at risk of HIV infection: Who do HIV-positive recruiters recruit? Sex Transm Dis. 2009;36(12):750.
Carballo-Diéguez A, Balan I, Marone R, Pando MA, Dolezal C, Barreda V, et al. Use of respondent driven sampling (RDS) generates a very diverse sample of men who have sex with men (MSM) in Buenos Aires, Argentina. PLoS ONE. 2011;6(11):e27447.
Buchanan R, Khakoo SI, Coad J, Grellier L, Parkes J. Hepatitis C bio-behavioural surveys in people who inject drugs—a systematic review of sensitivity to the theoretical assumptions of respondent driven sampling. Harm Reduct J. 2017;14(1):44.
Johnston LG, Sabin K. Sampling hard-to-reach populations with respondent driven sampling. Methodol Innov Online. 2010;5(2):38–48.
Lachowsky NJ, Sorge JT, Raymond HF, Cui Z, Sereda P, Rich A, et al. Does size really matter? A sensitivity analysis of number of seeds in a respondent-driven sampling study of gay, bisexual and other men who have sex with men in Vancouver, Canada. BMC Med Res Methodol. 2016;16(1):157.
Datta A, Lin W, Rao A, Diouf D, Kouame A, Edwards JK, et al. Bayesian estimation of MSM population size in Côte d’Ivoire. Statistics and Public Policy. 2019;6(1):1–13.
Nakagawa F, Van Sighem A, Thiebaut R, Smith C, Ratmann O, Cambiano V, et al. A method to estimate the size and characteristics of HIV-positive populations using an individual-based stochastic simulation model. Epidemiology. 2016;27(2):247.
Chen H, Zhang Y, Tan H, Lin D, Chen M, Chen N, et al. Estimating the population size of men who have sex with men: a modified Laska, Meisner and Siegel procedure taking into account internet populations. Sex Transm Infect. 2013;89(2):142–7.
Wesson P, Reingold A, McFarland W. Theoretical and empirical comparisons of methods to estimate the size of hard-to-reach populations: a systematic review. AIDS Behav. 2017;21(7):2188–206.
Kipf TN, Welling M. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:160902907. 2016.
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. Adv Neural Inform Process Syst. 2014.
Acknowledgements
The authors thanks SESH Global and Zhuhai CDC for their kind support.
Funding
This work was supported by the National Nature Science Foundation of China (81903371), the National Key Research and Development Program of China (2017YFE0103800), the National Institutes of Health (NIAID K24AI143471, R34MH109359, and R34MH119963), National Science and Technology Major Project (2018ZX10101-001–001-003), Guangdong Medical Science and Technology Research Fund (A2020509), Zhuhai Medical and Health Science and Technology Plan Project (20181117A010064), and the Shenzhen Healthcare Research Project [SZGW2018001]. The funders had no role in any process of this study.
Author information
Authors and Affiliations
Contributions
All authors have read and approved the final manuscript. WT, CX, and FJ designed the research study. YL, YN, WT, JT, DW, YZ, JO, and QZ contributed essential research contributions to this study. CX and FJ wrote the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
This study is a scoping review, and do not directly involve in any study participants and ethics approval is not needed.
Consent for publication
Not applicable.
Competing interests
All authors of this study declare they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Xu, C., Jing, F., Lu, Y. et al. Summarizing methods for estimating population size for key populations: a global scoping review for human immunodeficiency virus research. AIDS Res Ther 19, 9 (2022). https://doi.org/10.1186/s12981-022-00434-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12981-022-00434-7