
Abstract
Background
Both environmental and social factors have been linked to birth weight and adiposity at birth, but few studies consider the effects of exposure mixtures. Our objective was to identify which components of a mixture of neighborhood-level environmental and social exposures were driving associations with birth weight and adiposity at birth in the Healthy Start cohort.
Methods
Exposures were assessed at the census tract level and included air pollution, built environment characteristics, and socioeconomic status. Prenatal exposures were assigned based on address at enrollment. Birth weight was measured at delivery and adiposity was measured using air displacement plethysmography within three days. We used non-parametric Bayes shrinkage (NPB) to identify exposures that were associated with our outcomes of interest. NPB models were compared to single-predictor linear regression. We also included generalized additive models (GAM) to assess nonlinear relationships. All regression models were adjusted for individual-level covariates, including maternal age, pre-pregnancy BMI, and smoking.
Results
Results from NPB models showed most exposures were negatively associated with birth weight, though credible intervals were wide and generally contained zero. However, the NPB model identified an interaction between ozone and temperature on birth weight, and the GAM suggested potential non-linear relationships. For associations between ozone or temperature with birth weight, we observed effect modification by maternal race/ethnicity, where effects were stronger for mothers who identified as a race or ethnicity other than non-Hispanic White. No associations with adiposity at birth were observed.
Conclusions
NPB identified prenatal exposures to ozone and temperature as predictors of birth weight, and mothers who identify as a race or ethnicity other than non-Hispanic White might be disproportionately impacted. However, NPB models may have limited applicability when non-linear effects are present. Future work should consider a two-stage approach where NPB is used to reduce dimensionality and alternative approaches examine non-linear effects.
Similar content being viewed by others
Background
Birth weight and adiposity at birth are important neonatal indicators of infant, childhood, and long-term health. At the population level, seemingly small shifts in mean birth weight over the past few decades have been associated with population-level increases in the proportion of neonates born low birth weight (LBW; < 2500 g) or small for gestational age (SGA; below the 10th percentile for each completed week of gestation) [1,2,3]. SGA and LBW babies are at higher risk of childhood obesity, asthma, delayed neurodevelopment, and metabolic disorders later in adulthood [4,5,6,7,8,9,10]. Similarly, adiposity at birth, which is a measure of the proportion of body mass that is fat mass, is a potentially important predictor of obesity and metabolic disease risk later in life [11, 12].
The existing literature demonstrates the ability of both individual-level and neighborhood-level exposures to influence birth weight and adiposity in the neonatal period. Individual-level factors include maternal characteristics such as age and race/ethnicity, maternal behaviors such as active smoking and physical activity, and metabolic factors such as obesity or gestational diabetes [13,14,15]. At the neighborhood level, both environmental and social factors have been linked to these neonatal outcomes. These factors include higher neighborhood deprivation index scores [16], low neighborhood affluence [17], poor quality built environments (e.g., higher rates of vacant buildings or proximity to major roadways) [18, 19], and higher ambient air pollutant exposures [20,21,22,23,24].
Although there is evidence to suggest that both social and environmental factors are associated with birth weight and adiposity, few studies have examined the combined effects of exposures to hazards in multiple domains (i.e., physical, social, and chemical exposures). There is growing interest in understanding the joint effects of both environmental hazards and social stressors to understanding how total neighborhood contexts can impact early life outcomes [25, 26]. Although the underlying mechanisms have not been fully elucidated, there are several hypothesized pathways by which prenatal exposure to environmental hazards and social stressors might impact neonatal growth and development. For example, oxidative stress and inflammation are pathways common to both environmental hazards and social stressors [27, 28]. Alternatively, social stressors experienced during the prenatal period may modify the effects of environmental hazards [29,30,31]. Evidence from previous studies suggests there may be important interactions between neighborhood factors environmental and social hazards, and that the effect of these combined stressors on birth outcomes may be synergistic [32,33,34,35]. Additionally, neighborhood environmental and social conditions reflect the legacy of structural racism in the United States perpetuated by redlining and racial segregation [36,37,38,39]. Thus, investigating the combined effects of neighborhood level factors that influence health represents an important opportunity to address longstanding health disparities.
We previously tested associations between neonatal outcomes combined prenatal factors at the neighborhood level in the Healthy Start cohort using an index-based exposure assessment method [40]. We reported lower birth weights and lower adiposity for infants born to mothers with higher combined exposure index scores after controlling for key individual-level risk factors. Our index-based approach provided information on where public health interventions might be most effective for improving neonatal outcomes. However, the use of an index did not allow us to identify which exposures or combination of exposures were driving these associations and thus identify the underlying etiologic agent. Alternative approaches that accommodate large numbers of exposure variables and potential interactions between these exposures are needed to better characterize these associations and identify targets for future public health interventions [41].
Using data from the Healthy Start cohort, we expanded upon our previous study by employing a non-parametric Bayes shrinkage (NPB) approach to examine linear associations between our neighborhood-level determinants and neonatal outcomes. For this data set, we needed to identify a statistical method that would be capable of handling variable selection among potentially highly correlated exposures within the context of interactions between exposures and between exposures and covariates. NPB is designed to facilitate selection among a large number of correlated predictors in a single model, thus having an advantage over traditional multipollutant models [42, 43]. We compared the results of our NPB model to single-exposure models (linear regression models). Because NPB is a linear modeling framework, we also utilized generalized additive models to explore potential non-linear exposure–response relationships. Based on the results of our previous study [40], we hypothesized that specific social exposures (e.g., neighborhood level socioeconomic status) within the prenatal exposure mixture measured were driving associations with lower birth weight and adiposity.
Methods
Study population and study area
We used data from the ongoing Healthy Start pre-birth cohort study for this analysis. Details on the Healthy Start cohort are available elsewhere [44]. Briefly, pregnant women aged 16 or older expecting singleton births were recruited from the University of Colorado Hospital outpatient obstetrics clinics between 2009 and 2014. Two prenatal study visits that included a physical exam and questionnaires were conducted at median 17- and 27-weeks of gestation; additional data were abstracted from medical records. Our analysis did not exclude infants based on their term birth status (i.e., we included pre-, full- and post-term births). All mother–child dyads who had an address at enrollment within the study area were eligible for this analysis. The Healthy Start study protocol was approved by the Colorado Multiple Institutional Review Board.
Although the Healthy Start study originally recruited participants from the nine county Denver metropolitan area, the study area for this analysis consisted of most census tracts within a smaller three county area (Adams, Arapahoe, and Denver counties). These counties were included due to the availability of exposure data (described next). We excluded the two eastern most census tracts within these counties because they were rural and not considered part of the metropolitan area. Census tracts were chosen to represent neighborhoods as they were the smallest spatial unit for which reliable exposure data were available.
Exposure assessment
We selected our environmental and social exposures based on the indicators used by the CalEnviroScreen tool [45, 46] with some additional area-specific variables to reflect sources relevant to Denver, CO. Because our research question focused on the neighborhood context, all exposure variables were assessed at the census tract level and assigned to participants based on their address at the time of enrollment into the Healthy Start study. We briefly describe our exposure variables below. Additional details on our exposure variables are available elsewhere [40].
Ambient air pollution and temperature
We included two measures of ambient air pollution, fine particulate matter (PM2.5) and ozone (O3) and a variable for temperature. Monitoring data collected between 2009 and 2014 were obtained from the US Environmental Protection Agency [47]. Daily measurements at each monitor were averaged to biweekly concentrations. For PM2.5 and temperature we used the mean of all 24-h measurements and for O3 we used the mean of all daily 8-h maximum concentrations recorded during the two-week period. We used ordinary kriging to estimate biweekly measurements at each census tract centroid. Biweekly air pollutant and temperature exposures were then assigned to each participant based on the address at enrollment and the timing of conception and delivery and averaged over the duration of the pregnancy.
Built environment characteristics
We included nine exposure variables related to the built environment. The temporal resolution for these data was usually one year; we assumed minimal change in these variables between the start and end of our study period (2009–2014) These included: the mean percent tree cover and mean percent impervious surface within the census tract from the 2011 National Land Cover Database [48]; the mean annual average daily traffic (AADT) of road segments within the census tract from the Highway Performance Monitoring System [49]; and the minimum distance (in km) from the census tract centroid to hazardous land use sites, including Toxic Release Inventory sites, National Priority List sites, waste management sites, major emitters of criteria pollutants, confined animal feeding operations, and oil and gas wells [50,51,52].
Social stressors
Social stressor variables were intended to capture socioeconomic status (SES), demographic trends, and susceptibility at the neighborhood level. We included five variables from the 2010–2014 American Community Survey: the percentage of the population with less than a high school diploma, that was unemployed, and that identified as a race/ethnicity other than non-Hispanic white and the percentage of household speaking limited English or in poverty [53]. Crime incidence data were available from the Inter-university Consortium for Political and Social Research and the Denver Open Data Catalog [54, 55]. We used these incidence data to calculate 5-year rates of violent crimes and property crimes for each census tract. Data to calculate census-tract level hospitalization rates for respiratory and cardiovascular diseases came from the Colorado Hospital Association.
Outcomes
Our two outcomes of interest were birth weight and adiposity at birth. Birth weight was measured at the time of delivery or was abstracted from medical records. Fat mass and fat-free (lean) body mass were measured within three days of birth using air displacement plethysmography (PEA POD, COSMED, Rome, Italy). Additional details on the PEA POD measurements for the Healthy Start cohort are available elsewhere [44]. We calculated adiposity (% fat mass) as fat mass divided by total body mass [56].
Covariates
We selected our model covariates a priori by considering those included in our previous study [40] and other studies investigating the effect of neighborhood-level exposures on neonatal outcomes [16,17,18, 57,58,59]. Final covariate selection was informed by a directed acyclic graph. We included: maternal race/ethnicity, pre-pregnancy body mass index (BMI), and active smoking and secondhand smoke exposure. We excluded alcohol consumption because previous work in this cohort found levels were generally low among cohort participants and not associated with infant body composition measures [60, 61]. Consistent with our prior work and that of others [40, 62], maternal educational attainment was included as a proxy for family-level socioeconomic status (SES) because it is a consistent and reliable predictor of health outcomes for women and children [63, 64] and tends to be a more stable proxy for SES over time compared to income [65, 66]. We also included two measures of stress and depressive symptoms, Cohen’s Perceived Stress Scale (CPSS) and the Edinburgh Postnatal Depression Scale (EPDS), which were administered to mothers during their prenatal visits. Infant covariates included year of conception and sex. To address the potential for residual spatial autocorrelation, we included the longitude, latitude, and an interaction term (longitude × latitude) for the participant residential location. To account for temporal trends, we included the season of conception. For the adiposity models, we also included the number of days between delivery and PEA POD measurements. We did not adjust for gestational age in our models because our directed acyclic graph indicated gestational age was on the causal pathway.
Because individual-level race or ethnicity may modify the relationships between exposures and neonatal outcomes [67], we conducted sensitivity analyses where we stratified our results by maternal race/ethnicity (non-Hispanic White (NHW) vs. all other race and ethnic categories).
Statistical analysis
All analyses were performed in R version 4.0.3 [68]. Prior to model fitting, exposures, outcomes, and covariates were summarized as means and standard deviations (SD) or frequencies as appropriate. To examine the potential for selection bias we assessed differences between included and excluded participants using chi square tests for categorical variables and t-tests for continuous variables. Categorical covariates were converted to indicator variables. To account for differences in units across the exposure variables and covariates, continuous variables were scaled prior to fitting the regression models.
Non-parametric Bayes shrinkage model
Our goal for this paper was to select from a complex mixture of neighborhood-level factors exposures that were associated with birth weight and adiposity. Therefore, our primary analysis used NPB, which is a Bayesian statistical method that fits a linear model with main effects of all exposures and all pairwise interactions while implementing both variable selection and regularization [42]. Specifically, NPB applies a Dirichlet zero-spiked process prior to the regression coefficients for each exposure. The Dirichlet process prior has a point mass at 0, which allows the model to select out exposures that have little influence on the outcome. Exposures with similar effects on the outcome can be clustered and assigned the same regression coefficient in the model. This reduces the variance in the presence of high correlation between the exposures. A similar approach is applied to the interaction effects. Here we included two-way interaction terms between each of the exposure variables and between each exposure and covariate. All interaction terms were selected with an additional zero-spiked Dirichlet process.
Our NPB model has the following form:
where \({x}_{i}\) is a vector of exposures, \({z}_{i}\) is a vector of pairwise multiplicative interactions between the exposures or the exposures and the covariates, \({w}_{i}\) is a vector of covariates, and \({\sigma }^{2}\) is the error variance. We implemented our NPB model using the “mmpack” package in R [69]. Posterior means and 95% credible intervals for the regression coefficients are reported for a standard deviation increase in each exposure metric. Consistent with other studies, we used 0.5 as the threshold for which posterior inclusion probabilities (PIPs) were considered to be indicative of an important effect of the exposure on the health outcome [70, 71]. Additional details on fitting the NPB model, including a description of the priors, is included in the Supplemental Materials.
Because variable selection by the NPB model may depend on the specification of hyperparameters, we conducted a sensitivity analysis in which the α and β values of the Gamma distributions for hyperparameters \({\alpha }_{1}\) and \({\alpha }_{2}\)(see Text S1 in the Supplemental Materials) were set to 0.5, 1, 2, and 4.
Single exposure linear regression models
To serve as a comparison to the NPB method, we fit separate linear regression models for each exposure-outcome pair. These linear models were adjusted for all relevant covariates listed in Covariates. Results from these linear regression models were reported for a standard deviation increase in each exposure.
Generalized additive model
In a supplemental analysis meant to assess potential non-linear effects of our NPB-selected exposures of interest on birth weight or adiposity, we fit separate generalized additive models (GAMs) for any variables selected with NPB based on a PIP > 0.5. We used a smoothed term with penalized splines for the continuous exposures identified in the NPB model. Models were adjusted for all covariates listed in Covariates. We also repeated our sensitivity analysis and stratified GAMs by maternal race and ethnicity as described in Covariates. GAMs were fit in R using the “mgcv” package [72] and visualized using the “mgcViz” package [73].
Results
Study population
Our analytic cohort consisted of 897 mother–child dyads enrolled in the Healthy Start study, representing 64% of the original study population (Table 1). Of the excluded participants, n = 51 were excluded because they were missing data on birth weight, n = 259 were excluded because they lived outside the three-county study area, n = 172 were excluded because they were missing data on smoking exposures, and n = 37 were excluded because they were missing data on infant sex. There were few differences between included and excluded study participants (Table 1). Although birth weights were similar on average, we observed slightly higher adiposity for excluded participants. Included participants were also less likely to be non-Hispanic white and had higher mean CPSS compared to excluded participants. We did not observe any other differences between included and excluded participants for any of the other covariates of interest in this study.
Exposure assessment
Exposures to environmental and social factors varied across participants (Table 2). Coefficients of variation were generally high (> 25%) for most (74%) of the exposures. Variability was lowest for the air pollutant exposures (mean PM2.5 and mean O3) and mean temperature across pregnancy. Correlations between environmental exposures and between environmental and social exposures were generally moderate (Pearson’s coefficients ranged from -0.5 to 0.7). Correlations tended to be stronger between the social determinants of health (Pearson’s coefficients ranged from -0.1 to 0.9; Figure S1).
Regression results
Nonparametric Bayes shrinkage
The NPB model, which included all exposures of interest in the same model, suggested that few of our exposures were strongly associated with birth weight (Table 3) based on our criterion of PIP = 0.5. Credible intervals for the posterior means were generally wide and contained zero. Only one variable had a PIP above 0.5 and a credible interval that did not contain zero: the interaction between mean ambient ozone concentration and temperature across pregnancy. A 3.1 ppb increase in mean O3 assessed across the pregnancy was associated with a 6.4 g decrease in birth weight (95% credible interval: -65.1 g to 6.9 g) and a 4.8 °F increase in mean temperature across pregnancy was associated with a 13.1 g increase (95% credible interval: -18.6 g to 189.3 g). For every 1 SD increase in temperature, the decrease in birth weight for a 1 SD increase in ozone was 162.0 g (95% CI: -242.3 g to -117.8 g) greater than expected if effects of the two exposures were additive. A plot showing the relationship between predicted and observed birth weight is included in the Supplemental Materials (Figure S2).
None of the exposures considered in the NPB model for adiposity had credible interval that did not contain zero nor a PIP greater than the 0.5 threshold (Table 3). In general, we did not observe relationships between our exposures of interest and adiposity at birth. A plot showing the relationship between predicted and observed adiposity is included in the Supplemental Materials (Figure S3).
Neither the birth weight nor the adiposity model was sensitive to changes in the gamma distribution parameters for the mass concentration hyperparameter (Tables S2 and S3). For the four sensitivity analyses conducted, no differences in variables selected by the NPB model were observed.
We observed evidence of effect modification by maternal race/ethnicity in our NPB models for birth weight (Table 4). When stratifying by maternal race/ethnicity, we only observed an effect of temperature and ozone for participants who identified as a race or ethnicity other than NHW. For mothers who did not identify as NHW, for every 1 SD increase in temperature, the decrease in birth weight for a 1 SD increase in ozone was 206.2 g (95% CI: -258.3 g to -156.1 g) greater than expected if effects of the two exposures were additive.
Linear models
Following traditional epidemiological approaches, we also examined linear relationships between each individual exposure variable and our outcomes of interest. Of the 21 exposure variables included in our study, most (n = 14; 67%) were associated with lower birth weight, though most confidence intervals for the coefficients were wide and contained zero (Table S1). The strongest associations were seen for the percentage of adults in the census tract who were unemployed (β = -40.9 g, 95% CI: -76.8 g to -4.9 g) and the distance (km) to the nearest waste site (β = 39.7 g, 95% CI: 4.1 g to 75.4 g).
For adiposity (% fat mass), the linear regression models showed similar lack of association with most of the exposures of interest (Table S1). The strongest effect on % fat mass was observed for the rate of property crimes at the census tract level (β = -0.31 percentage points, 95% CI: -0.59 g to -0.04 percentage points) and the distance to waste sites (β = 0.36 percentage points, 95% CI: 0.07 to 0.66 percentage points). For most exposures, the confidence intervals were wide and contained 0.
Generalized additive models
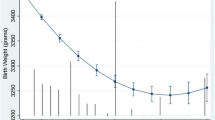
We examined potential non-linear effects for ozone and temperature using a GAM, adjusting for the same covariates included in the main NPB model (Fig. 1). To avoid overinterpreting effects at the margins, we restricted the axes to show the middle 95% of O3 and temperature observations. Plots showing the full range of data are available in the SDC (Figure S4). The exposure–response curve for the smoothed O3 and temperature term suggested a non-linear association between these exposures and birth weight (Fig. 1A). The accumulated local effect (ALE) plot for temperature showed an inverted-U shaped exposure–response relationship (Fig. 1B); the non-linear effect for ozone was less evident, with the ALE plot suggesting a more linear effect (Fig. 1C). The plots shown in Fig. 1 also suggest that the effect of temperature on birth weight is stronger than the effect of O3. We conducted a sensitivity analysis fitting the GAM with a dataset restricted to the middle 95% of O3 and temperature observations (Figure S5). These plots showed similar trends as those in Fig. 1.

Exposure response curve for the 2D smoothed term for ozone and temperature in the generalized additive model (A) and accumulated local effects (ALE) plots showing the effect of temperature (B) and ozone (C) on birth weight. Note: axes are restricted to the middle 95% of observed ozone and temperature values
Results from GAMs stratified by maternal race/ethnicity showed similar effect modification as observed for the NPB models (Fig. 2, Figure S6). For stratified models where extreme values were excluded (Fig. 2), we observed non-linear associations between temperature and ozone for mothers who identified as a race/ethnicity other than non-Hispanic White (Fig. 2D-F) but not for non-White mothers (Fig. 2A-C).

GAMs stratified by maternal race/ethnicity and restricted to the middle 95% of ozone and temperature observations. Plots show the exposure–response curve for the 2D smoothed term for ozone and temperature in the generalized additive model (A) and accumulated local effects (ALE) plots showing the effect of temperature (B) and ozone (C) on birth weight for non-Hispanic White (NHW) mothers and the exposure response curve for the 2-D smoothed term for ozone and temperature in the generalized additive model (D) and ALE plots showing the effect of temperature (E) and ozone (F) on birth weight for mothers identifying as any race or ethnicity other than non-Hispanic White
Discussion
Here we leveraged a non-parametric Bayesian shrinkage approach to identify which components of a mixture of exposures were driving previously reported associations between an exposure index and lower birth weight among infants born in the Denver metropolitan area. Using our mixtures approach (NPB), we identified the interaction between mean O3 concentrations and mean temperatures across the entire pregnancy as an important predictor of birth weight. Additional analyses using a GAM indicated that the relationship between O3, temperature, and birth weight may be non-linear. Our NPB results differed from those of the linear regression models, which identified only distance to waste sites, property crime rates, and unemployment as associated with our outcomes of interest and were likely biased by confounding from other correlated exposures.
Our results differ in some ways from other studies reported in the literature. For example, we did not identify an association between PM2.5 and birth weight in our cohort, which contradicts several other studies (as reviewed by Sun et al.) [74]. Our inability to detect this association may be in part due to the exposure metric used or due to low PM2.5 exposures in the study area. Average and maximum PM2.5 exposures across pregnancy in our cohort (7.5 and 9.1 µg/m3, respectively) were below the National Ambient Air Quality Standard for PM2.5 (annual average of 12 µg/m3). A similar Healthy Start study relying on trimester-specific averages derived from monitoring data also reported no association between PM2.5 and birth weight or adiposity [75]. In general, intraurban gradients of PM2.5 tend to be relatively flat and regulatory monitors poorly reflect variability from local sources [76]. Other pollutants such as black carbon that better reflect local sources in the region and characterize intraurban gradients in concentration may be more useful in future studies [77].
Our results indicating an interaction between temperature and O3 on birth weight are more consistent with previous studies [78]. Although this association has been reported less frequently in the literature, O3 exposures have been associated with lower birth weight (measured continuously) or increased odds of low birth weight (< 2,500 g) [78, 79]. Associations between both higher and lower temperatures and lower birth weight have also been reported [80,81,82,83]. Both ozone and ambient temperature exposures have been linked to systemic inflammation in adults [84,85,86,87,88]. Thus, we hypothesize that our results showing a relationship between temperature and O3 on birth weight may be due to maternal systemic inflammation, which is known to influence fetal growth [89].
Importantly, our study provides additional evidence of effect modification by maternal race and ethnicity on associations between environmental hazards and child health outcomes. Associations between our exposures of interest and birth weight were stronger for mothers from historically minoritized race or ethnicity groups compared to non-Hispanic White mothers. Several studies in the past two decades have reported racial disparities in low birth weight, which is more likely as population mean birthweights shift downward, over the last few decades [90,91,92]. Relationships between race or ethnicity, neighborhood quality, and neonatal outcomes are complicated, but stress is a likely mediating factor [93].
There were important differences between the results of the single-exposure linear regression analysis and the results from the NPB model. In the linear regression models, higher exposures to social stressors tended to be associated with lower birth weights and adiposity in the linear regression models, though the confidence intervals for the regression coefficients tended to be wide and contain zero. These results are consistent with our previous index-based analysis which found that associations between a combined exposure index and birth weight were likely driven by the social stressor component of the score [40]. However, the NPB model identified the interaction between ozone and temperature as being an important predictor of birth weight. Neither temperature nor ozone were associated with birth weight in the linear regression models. Differences between results derived from the NPB model and the linear regression models may be due to residual confounding by co-exposures in the single-exposure linear regression models. These models also do not include the interaction term that was important in the NPB model. The exposures included in our data set are moderately to highly correlated, and a single-exposure model is likely not sufficient to address this correlation. Using NPB as a modeling approach allowed us to consider each of these exposures at once in a framework that allows correlated exposures to be assigned similar coefficients when effects cannot be separated [43].
Additionally, differences between our NPB model and our original index-based approach also suggest that our combined exposure index may have characterized factors in the neighborhood that are not fully explained by any one variable. Notably, temperature was not included in our original index. Our exposures were originally chosen to reflect the combination of factors often included in screening tools for environmental justice concerns, e.g., CalEnviroScreen [45] or EJScreen [94]; thus, we may have captured trends in neighborhood quality rather than specific etiologic factors for lower birth weight and adiposity. Future mixtures-based approaches for birth weight should consider moving beyond the typical indicators of health and neighborhood quality and focus more on those exposures that are suspected of being causally linked to neonatal outcomes.
There are some important limitations to our approach that should be considered when interpreting these results. First, the census tract estimates of exposure generally have limited temporal resolution. Due to the limitations of publicly available data at the spatial resolution used here, we relied on annual or five-year average estimates for most of our exposures. Second, there is no universal definition for neighborhood, and census tracts may not be the most meaningful unit of analysis; boundaries that reflect policy or other jurisdictional boundaries (e.g., school districts or municipal boundaries) may be more appropriate for some exposures [95].Third, as discussed above, we chose our exposures based on existing screening tools rather than specific exposures known to be associated with birth weight and adiposity. Future work should consider how and for what purpose existing public health indices are developed and may develop separate indices for different types of health outcomes. Lastly, we focused on a single metropolitan area where the range of exposures is limited. Replication of these methods in multi-city studies should broaden the range of exposures and better elucidate the relationships between multiple environmental and social hazards and neonatal health.
Despite these limitations, our approach demonstrated the strengths of using NPB in a mixtures context. Our use of NPB allowed us to include a large number of correlated exposures, which would otherwise be a challenge in a multipollutant model due to the potential for multicollinearity and variance inflation [42]. In this context, NPB has advantages over the least absolute shrinkage and selection operator (LASSO) which is widely used for variable selection. In particular, LASSO tends to perform poorly when variables are highly correlated [96, 97]. Additionally, LASSO does not account for uncertainty in variable selection [42]. In contrast, NPB can cluster and assign equal regression coefficients to exposures, which reduces the effect of correlation among exposures and is a strength when it is difficult to separate the effects of the two exposures [43]. In future cases where more than two exposures are identified, methods like Bayesian Kernel Machine Regression (BKMR) may be useful. BKMR is a flexible approach for modeling the effects of exposure mixtures that is capable of identifying nonlinear main effects and interactions among mixture components [98], though it may not be well suited for selecting among a large number of predictors [43], Thus, a two-stage approach where NPB models reduce the number of candidate predictors and methods like BKMR explore the complex interactions between exposures of interest might be most appropriate.
Overall, our NPB model, which was designed to select among a large number of correlated exposures, identified a joint effect of O3 and temperature as important predictor of birth weight, and the GAM indicated these association may be non-linear. Our results suggest there is a potential role for neighborhood-level environmental and social stressors in the prenatal period to influence fetal growth, but that additional studies are needed to identify important drivers in this exposure mixture. Future work may consider imputing missing values for key covariates to increase the sample size available for more complex statistical approaches such as BKMR. Further, it will be crucial to examine non-linear dose response relationships when assessing the effects of joint exposures assessed at the neighborhood level. When non-linear relationships are anticipated, additional variable selection approaches could be considered [99].
Availability of data and materials
The analysis code used in this study are available on the primary author’s GitHub page (https://github.com/smartenies/ECHO_Aim1_CEI_Mixtures). The Healthy Start data set is not publicly available because it contains sensitive personal health information. Deidentified data from the Healthy Start study are available for analyses related to the aims of the study upon reasonable request.
Abbreviations
- AATD:
-
Annual average daily traffic
- ALE:
-
Accumulated local effect
- BKMR:
-
Bayesian Kernel Machine Regression
- BMI:
-
Body mass index
- CPSS:
-
Cohen’s Perceived Stress Scale
- EPDS:
-
Edinburgh Postnatal Depression Scale
- GAM:
-
Generalized additive model
- LBW:
-
Low birth weight
- NHW:
-
Non-Hispanic White
- NPB:
-
Non-parametric Bayes shrinkage
- O3 :
-
Ozone
- PIP:
-
Posterior inclusion probability
- PM2.5 :
-
Particulate matter with an aerodynamic diameter less than 2.5 microns
- SD:
-
Standard deviation
- SES:
-
Socioeconomic status
- SGA:
-
Small for gestational age
References
Donahue SMA, Kleinman KP, Gillman MW, Oken E. Trends in birth weight and gestational length among singleton term births in the United States. Obstet Gynecol. 2010;115:357–64.
Morisaki N, Esplin MS, Varner MW, Henry E, Oken E. Declines in birth weight and fetal growth independent of gestational length. Obstet Gynecol. 2013;121:51–8.
Oken E. Secular trends in birthweight. Recent advances in growth research: nutritional, molecular and endocrine perspectives. 2013;71:103–14.
Ong KK, Loos RJF. Rapid infancy weight gain and subsequent obesity: systematic reviews and hopeful suggestions. Acta Paediatr. 2006;95:904–8.
Nam H-K, Lee K-H. Small for gestational age and obesity: epidemiology and general risks. Ann Pediatr Endocrinol Metab. 2018;23:9–13.
Longo S, Bollani L, Decembrino L, Di Comite A, Angelini M, Stronati M. Short-term and long-term sequelae in intrauterine growth retardation (IUGR). J Matern Fetal Neonatal Med. 2013;26:222–5.
van Wassenaer A. Neurodevelopmental consequences of being born SGA. Pediatr Endocrinol Rev. 2005;2:372–7.
Savchev S, Sanz-Cortes M, Cruz-Martinez R, Arranz A, Botet F, Gratacos E, et al. Neurodevelopmental outcome of full-term small-for-gestational-age infants with normal placental function. Ultrasound Obstet Gynecol. 2013;42:201–6.
Xu X-F, Li Y-J, Sheng Y-J, Liu J-L, Tang L-F, Chen Z-M. Effect of low birth weight on childhood asthma: a meta-analysis. BMC Pediatr. 2014;14. Available from: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4288645/. Cited 2018 Sep 10.
Jornayvaz FR, Vollenweider P, Bochud M, Mooser V, Waeber G, Marques-Vidal P. Low birth weight leads to obesity, diabetes and increased leptin levels in adults: the CoLaus study. Cardiovasc Diabetol. 2016;15. Available from: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4855501/. Cited 2018 May 17.
Demerath EW, Fields DA. Body composition assessment in the infant. Am J Hum Biol. 2014;26:291–304.
Moore BF, Harrall KK, Sauder KA, Glueck DH, Dabelea D. Neonatal adiposity and childhood obesity. Pediatrics. 2020;146:e20200737.
Valero de Bernabé J, Soriano T, Albaladejo R, Juarranz M, Calle ME, Martı́nez D, et al. Risk factors for low birth weight: a review. Eur J Obstet Gynecol Reprod Biol. 2004;116:3–15.
Sewell MF, Huston-Presley L, Super DM, Catalano P. Increased neonatal fat mass, not lean body mass, is associated with maternal obesity. Am J Obstet Gynecol. 2006;195:1100–3.
Harvey NC, Poole JR, Javaid MK, Dennison EM, Robinson S, Inskip HM, et al. Parental determinants of neonatal body composition. J Clin Endocrinol Metab. 2007;92:523–6.
Vos AA, Posthumus AG, Bonsel GJ, Steegers EAP, Denktaş S. Deprived neighborhoods and adverse perinatal outcome: a systematic review and meta-analysis. Acta Obstet Gynecol Scand. 2014;93:727–40.
Kane JB, Miles G, Yourkavitch J, King K. Neighborhood context and birth outcomes: Going beyond neighborhood disadvantage, incorporating affluence. SSM - Population Health. 2017;3:699–712.
Nowak AL, Giurgescu C. The built environment and birth outcomes: a systematic review. MCN Am J Matern Child Nurs. 2017;42:14–20.
Woods N, Gilliland J, Seabrook JA. The influence of the built environment on adverse birth outcomes. J Neonatal Perinatal Med. 2017;10:233–48.
Chiu Y-HM, Hsu H-HL, Wilson A, Coull BA, Pendo MP, Baccarelli A, et al. Prenatal particulate air pollution exposure and body composition in urban preschool children: examining sensitive windows and sex-specific associations. Environ Res. 2017;158:798–805.
Fioravanti S, Cesaroni G, Badaloni C, Michelozzi P, Forastiere F, Porta D. Traffic-related air pollution and childhood obesity in an Italian birth cohort. Environ Res. 2018;160:479–86.
Schembari A, de Hoogh K, Pedersen M, Dadvand P, Martinez D, Hoek G, et al. Ambient air pollution and newborn size and adiposity at birth: differences by maternal ethnicity (the Born in Bradford Study Cohort). Environ Health Perspect. 2015;123:1208–15.
Westergaard N, Gehring U, Slama R, Pedersen M. Ambient air pollution and low birth weight - are some women more vulnerable than others? Environ Int. 2017;104:146–54.
Stieb DM, Chen L, Eshoul M, Judek S. Ambient air pollution, birth weight and preterm birth: a systematic review and meta-analysis. Environ Res. 2012;117:100–11.
Padula AM, Rivera-Núñez Z, Barrett ES. Combined impacts of prenatal environmental exposures and psychosocial stress on offspring health: air pollution and metals. Curr Envir Health Rpt. 2020;7:89–100.
Koman PD, Hogan KA, Sampson N, Mandell R, Coombe CM, Tetteh MM, et al. Examining joint effects of air pollution exposure and social determinants of health in defining “at-risk” populations under the clean air act: susceptibility of pregnant women to hypertensive disorders of pregnancy. World Med Health Policy. 2018;10:7–54.
Rakers F, Rupprecht S, Dreiling M, Bergmeier C, Witte OW, Schwab M. Transfer of maternal psychosocial stress to the fetus. Neurosci Biobehav Rev. 2020;117:185–97.
Erickson AC, Arbour L. The shared pathoetiological effects of particulate air pollution and the social environment on fetal-placental development. J Environ Public Health. 2014;2014:901017.
Brunst KJ, Sanchez-Guerra M, Chiu Y-HM, Wilson A, Coull BA, Kloog I, et al. Prenatal particulate matter exposure and mitochondrial dysfunction at the maternal-fetal interface: effect modification by maternal lifetime trauma and child sex. Environ Int. 2018;112:49–58.
Deguen S, Kihal-Talantikite W, Gilles M, Danzon A, Carayol M, Zmirou-Navier D. Are the effects of air pollution on birth weight modified by infant sex and neighborhood socioeconomic deprivation? A multilevel analysis in Paris (France). PLoS ONE. 2021;16:e0247699.
Erickson AC, Ostry A, Chan LHM, Arbour L. The reduction of birth weight by fine particulate matter and its modification by maternal and neighbourhood-level factors: a multilevel analysis in British Columbia. Canada Environ Health. 2016;15:51.
Généreux M, Auger N, Goneau M, Daniel M. Neighbourhood socioeconomic status, maternal education and adverse birth outcomes among mothers living near highways. J Epidemiol Community Health. 2008;62:695–700 BMJ Publishing Group Ltd.
Padula AM, Mortimer KM, Tager IB, Hammond SK, Lurmann FW, Yang W, et al. Traffic-related air pollution and risk of preterm birth in the San Joaquin Valley of California. Ann Epidemiol. 2014;24:888-895.e4.
Ponce NA, Hoggatt KJ, Wilhelm M, Ritz B. Preterm birth: the interaction of traffic-related air pollution with economic hardship in Los Angeles neighborhoods. Am J Epidemiol. 2005;162:140–8.
Yi O, Kim H, Ha E. Does area level socioeconomic status modify the effects of PM10 on preterm delivery? Environ Res. 2010;110:55–61.
Bailey ZD, Feldman JM, Bassett MT. How structural racism works — racist policies as a root cause of U.S. racial health inequities. N Engl J Med. 2021;384:768–73 Massachusetts Medical Society.
Groos M, Wallace M, Hardeman R, Theall K. Measuring inequity: a systematic review of methods used to quantify structural racism. J Health Disparities Res Pract. 2018;11. Available from: https://digitalscholarship.unlv.edu/jhdrp/vol11/iss2/13
Gutschow B, Gray B, Ragavan MI, Sheffield PE, Philipsborn RP, Jee SH. The intersection of pediatrics, climate change, and structural racism: Ensuring health equity through climate justice. Curr Probl Pediatr Adolesc Health Care. 2021;51:101028.
Payne-Sturges DC, Gee GC, Cory-Slechta DA. Confronting racism in environmental health sciences: moving the science forward for eliminating racial inequities. Environ Health Perspect. 2021;129:055002.
Martenies SE, Allshouse WB, Starling AP, Ringham BM, Glueck DH, Adgate JL, et al. Combined environmental and social exposures during pregnancy and associations with neonatal size and body composition: the Healthy Start study. Environ Epidemiol. 2019;3:e043.
Appleton AA, Holdsworth EA, Kubzansky LD. A systematic review of the interplay between social determinants and environmental exposures for early-life outcomes. Curr Environ Health Rep. 2016;3:287–301.
Herring AH. Nonparametric bayes shrinkage for assessing exposures to mixtures subject to limits of detection. Epidemiology. 2010;21(Suppl 4):S71-76.
Hoskovec L, Benka-Coker W, Severson R, Magzamen S, Wilson A. Model choice for estimating the association between exposure to chemical mixtures and health outcomes: a simulation study. PLoS ONE. 2021;16:e0249236.
Harrod CS, Chasan-Taber L, Reynolds RM, Fingerlin TE, Glueck DH, Brinton JT, et al. Physical activity in pregnancy and neonatal body composition: the Healthy Start study. Obstet Gynecol. 2014;124:257–64.
Cushing L, Faust J, August LM, Cendak R, Wieland W, Alexeeff G. Racial/ethnic disparities in cumulative environmental health impacts in California: Evidence From a Statewide Environmental Justice Screening Tool (CalEnviroScreen 1.1). Am J Public Health. 2015;105:2341–8.
Office of Environmental Health Hazard Assessment. CalEnviroScreen 3.0. OEHHA. 2016. Available from: https://oehha.ca.gov/calenviroscreen/report/calenviroscreen-30. Cited 2017 Nov 28.
US Environmental Protection Agency [US EPA]. AQS data mart. 2017. Available from: https://aqs.epa.gov/api. Cited 2016 Jul 30.
Multi-Resolution Land Characteristics Consortium. National land cover database. 2017. Available from: https://www.mrlc.gov/. Cited 2017 Nov 17.
US Department of Transportation [US DOT]. Highway performance monitoring system. 2018. Available from: https://www.fhwa.dot.gov/policyinformation/hpms.cfm. Cited 2018 Jul 23.
Colorado Department of Public Health and Environment [CDPHE]. Maps and GIS for health and environment. 2018. Available from: https://www.colorado.gov/pacific/cdphe/maps-and-spatial-data. Cited 2018 Jul 23.
Colorado Oil and Gas Conservation Commission [COGCC]. Colorado oil and gas information system. 2018. Available from: https://cogcc.state.co.us/data.html#/cogis. Cited 2018 Jul 23.
US Environmental Protection Agency. 2011 National Emissions Inventory (NEI) Data. US EPA. 2015. Available from: https://www.epa.gov/air-emissions-inventories/2011-national-emissions-inventory-nei-data. Cited 2018 Aug 27.
US Census Bureau. 2010–2014 American Community Survey (ACS) 5-year estimates. 2014. Available from: https://www.census.gov/programs-surveys/acs/. Cited 2016 Oct 6.
Inter-university Consortium for Political and Social Research [ICPSR]. Uniform Crime Reporting Program Data Series. 2018. Available from: https://www.icpsr.umich.edu/icpsrweb/ICPSR/series/57. Cited 2018 Jul 23.
City and County of Denver. Denver Open Data Catalog. 2017. Available from: https://www.denvergov.org/opendata/. Cited 2017 Nov 17.
Starling AP, Brinton JT, Glueck DH, Shapiro AL, Harrod CS, Lynch AM, et al. Associations of maternal BMI and gestational weight gain with neonatal adiposity in the Healthy Start study. Am J Clin Nutr. 2015;101:302–9.
Morello-Frosch R, Jesdale BM, Sadd JL, Pastor M. Ambient air pollution exposure and full-term birth weight in California. Environ Health. 2010;9:44.
Ncube CN, Enquobahrie DA, Albert SM, Herrick AL, Burke JG. Association of neighborhood context with offspring risk of preterm birth and low birthweight: a systematic review and meta-analysis of population-based studies. Soc Sci Med. 2016;153:156–64.
Shmool JLC, Bobb JF, Ito K, Elston B, Savitz DA, Ross Z, et al. Area-level socioeconomic deprivation, nitrogen dioxide exposure, and term birth weight in New York City. Environ Res. 2015;142:624–32.
Shapiro ALB, Kaar JL, Crume TL, Starling AP, Siega-Riz AM, Ringham BM, et al. Maternal diet quality in pregnancy and neonatal adiposity: the Healthy Start study. Int J Obes (Lond). 2016;40:1056–62.
Sauder KA, Kaar JL, Starling AP, Ringham BM, Glueck DH, Dabelea D. Predictors of infant body composition at 5 months of age: the Healthy Start study. J Pediatr. 2017;183:94-99.e1.
Dunlop AL, Essalmi AG, Alvalos L, Breton C, Camargo CA, Cowell WJ, et al. Racial and geographic variation in effects of maternal education and neighborhood-level measures of socioeconomic status on gestational age at birth: findings from the ECHO cohorts. PLoS ONE. 2021;16:e0245064 Public Library of Science.
Kramer Ms, Séguin L, Lydon J, Goulet L. Socio-economic disparities in pregnancy outcome: why do the poor fare so poorly? Paediatr Perinat Epidemiol. 2000;14:194–210.
Parker JD, Schoendorf KC, Kiely JL. Associations between measures of socioeconomic status and low birth weight, small for gestational age, and premature delivery in the United States. Ann Epidemiol. 1994;4:271–8.
Metcalf P, Scragg R, Davis P. Relationship of different measures of socioeconomic status with cardiovascular disease risk factors and lifestyle in a New Zealand workforce survey. N Z Med J. 2007;120:U2392.
Herd P, Goesling B, House JS. Socioeconomic position and health: the differential effects of education versus income on the onset versus progression of health problems. J Health Soc Behav. 2007;48:223–38 American Sociological Association, Sage Publications, Inc.
Jones CP. Invited commentary: “race”, racism, and the practice of epidemiology. Am J Epidemiol. 2001;154:299–304 discussion 305-306.
R Core Team. R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing; 2020. Available from: http://www.R-project.org/.
Hoskovec L. mmpack: Implement methods for multipollutant mixtures analyses. 2019. Available from: https://github.com/lvhoskovec/mmpack.
Coull BA, Bobb JF, Wellenius GA, Kioumourtzoglou MA, Mittleman MA, Koutrakis P, et al. Part 1. Statistical learning methods for the effects of multiple air pollution constituents. Res Rep Health Eff Inst. 2015;(183 Pt 1-2):5–50.
Barbieri MM, Berger JO. Optimal predictive model selection. Ann Stat Inst Math Stat. 2004;32:870–97.
Wood SN. Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J Royal Statistical Soc Series B. 2011;73:3–36.
Fasiolo M, Nedellec R, Goude Y, Wood SN. Scalable visualisation methods for modern generalized additive models. Archix preprint. 2018;10632.
Sun X, Luo X, Zhao C, Zhang B, Tao J, Yang Z, et al. The associations between birth weight and exposure to fine particulate matter (PM2.5) and its chemical constituents during pregnancy: a meta-analysis. Environ Pollut. 2016;211:38–47.
Starling AP, Moore BF, Thomas DSK, Peel JL, Zhang W, Adgate JL, et al. Prenatal exposure to traffic and ambient air pollution and infant weight and adiposity: the Healthy Start study. Environ Res. 2020;182:109130.
Matte TD, Ross Z, Kheirbek I, Eisl H, Johnson S, Gorczynski JE, et al. Monitoring intraurban spatial patterns of multiple combustion air pollutants in New York City: design and implementation. J Expos Sci Environ Epidemiol. 2013;23:223–31.
Martenies SE, Keller JP, WeMott S, Kuiper G, Ross Z, Allshouse WB, et al. A spatiotemporal prediction model for black carbon in the Denver Metropolitan Area, 2009–2020. Environ Sci Technol. 2021. Available from: https://doi.org/10.1021/acs.est.0c06451. American Chemical Society; cited 2021 Feb 26.
Bekkar B, Pacheco S, Basu R, DeNicola N. Association of air pollution and heat exposure with preterm birth, low birth weight, and stillbirth in the US: a systematic review. JAMA Netw Open. 2020;3:e208243–e208243.
Salam MT, Millstein J, Li Y-F, Lurmann FW, Margolis HG, Gilliland FD. Birth outcomes and prenatal exposure to ozone, carbon monoxide, and particulate matter: results from the children’s health study. Environ Health Perspect. 2005;113:1638–44.
Chersich MF, Pham MD, Areal A, Haghighi MM, Manyuchi A, Swift CP, et al. Associations between high temperatures in pregnancy and risk of preterm birth, low birth weight, and stillbirths: systematic review and meta-analysis. BMJ. 2020;371:m3811 British Medical Journal Publishing Group.
Li S, Wang J, Xu Z, Wang X, Xu G, Zhang J, et al. Exploring associations of maternal exposure to ambient temperature with duration of gestation and birth weight: a prospective study. BMC Pregnancy Childbirth. 2018;18:513.
Sun S, Spangler KR, Weinberger KR, Yanosky JD, Braun JM, Wellenius GA. Ambient temperature and markers of fetal growth: a retrospective observational study of 29 million U.S. Singleton Births. Environ Health Perspect. 2019;127. Available from: https://ehp.niehs.nih.gov/doi/10.1289/EHP4648. Cited 2021 Apr 8.
Lawlor DA, Leon DA, Smith GD. The association of ambient outdoor temperature throughout pregnancy and offspring birthweight: findings from the Aberdeen Children of the 1950s cohort. BJOG. 2005;112:647–57.
Arjomandi M, Wong H, Donde A, Frelinger J, Dalton S, Ching W, et al. Exposure to medium and high ambient levels of ozone causes adverse systemic inflammatory and cardiac autonomic effects. Am J Physiol Heart Circ Physiol. 2015;308:H1499–509 American Physiological Society.
Balmes JR, Arjomandi M, Bromberg PA, Costantini MG, Dagincourt N, Hazucha MJ, et al. Ozone effects on blood biomarkers of systemic inflammation, oxidative stress, endothelial function, and thrombosis: the Multicenter Ozone Study in oldEr Subjects (MOSES). PLoS One. 2019;14. Available from: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6760801/. Cited 2020 Nov 9.
Khafaie MA, Yajnik CS, Mojadam M, Khafaie B, Salvi SS, Ojha A, et al. Association between ambient temperature and blood biomarker of systemic inflammationin (C-reactive protien) in diabetes patients. Arch Med. 2016;8. Available from: https://www.archivesofmedicine.com/abstract/association-between-ambient-temperature-and-blood-biomarker-of-systemic-inflammationin-creactive-protien-in-diabetes-patients-9582.html. iMedPub; Cited 2021 Apr 8.
Peters A, Panagiotakos D, Picciotto S, Katsouyanni K, Löwel H, Jacquemin B, et al. Air temperature and inflammatory responses in myocardial infarction survivors. Epidemiology. 2008;19:391–400 Lippincott Williams & Wilkins.
Halonen JI, Zanobetti A, Sparrow D, Vokonas PS, Schwartz J. Associations between outdoor temperature and markers of inflammation: a cohort study. Environ Health. 2010;9:42.
Dimasuay KG, Boeuf P, Powell TL, Jansson T. Placental responses to changes in the maternal environment determine fetal growth. Front Physiol. 2016;7. Available from: https://www.frontiersin.org/articles/10.3389/fphys.2016.00012/full. Frontiers; Cited 2021 Feb 17.
Blumenshine P, Egerter S, Barclay CJ, Cubbin C, Braveman PA. Socioeconomic disparities in adverse birth outcomes: a systematic review. Am J Prev Med. 2010;39:263–72.
Grobman WA, Parker CB, Willinger M, Wing DA, Silver RM, Wapner RJ, et al. Racial disparities in adverse pregnancy outcomes and psychosocial stress. Obstet Gynecol. 2018;131:328–35.
Lu MC, Halfon N. Racial and ethnic disparities in birth outcomes: a life-course perspective. Matern Child Health J. 2003;7:13–30.
Almeida J, Bécares L, Erbetta K, Bettegowda VR, Ahluwalia IB. Racial/ethnic inequities in low birth weight and preterm birth: the role of multiple forms of stress. Matern Child Health J. 2018;22:1154–63.
US Environmental Protection Agency [US EPA]. EJSCREEN. 2015. Available from: http://ejscreen.epa.gov/mapper/. Cited 2015 Jun 11.
Riley AR. Neighborhood Disadvantage, residential segregation, and beyond—lessons for studying structural racism and health. J Racial and Ethnic Health Disparities. 2018;5:357–65.
Zou H, Hastie T. Regularization and variable selection via the elastic net. J Royal Statistical Soc Series B. 2005;67:301–20.
Barrera-Gómez J, Agier L, Portengen L, Chadeau-Hyam M, Giorgis-Allemand L, Siroux V, et al. A systematic comparison of statistical methods to detect interactions in exposome-health associations. Environ Health. 2017;16:74.
Bobb JF, Valeri L, Claus Henn B, Christiani DC, Wright RO, Mazumdar M, et al. Bayesian kernel machine regression for estimating the health effects of multi-pollutant mixtures. Biostatistics. 2015;16:493–508.
Marra G, Wood SN. Practical variable selection for generalized additive models. Comput Stat Data Anal. 2011;55:2372–87.
Acknowledgements
Not Applicable
Funding
This work was funded by grants R01DK076648 (PI: Dabelea) from the National Institute of Diabetes and Digestive and Kidney Diseases, 5UH3OD023248 (PI: Dabelea) from the National Institutes of Health, and RD-839278 (PI: Magzamen) from the US Environmental Protection Agency.
Author information
Authors and Affiliations
Contributions
SEM and SM conceived the original study question. SEM conducted the statistical analysis and wrote the initial draft of the manuscript. LH consulted on the statistical methods, wrote the R package used to facilitate the statistical analysis, and drafted sections related to statistical methods. AW contributed to the study design and the interpretation of results. BFM consulted on the birth outcome data and the interpretation of results. APS consulted on the design of the study, the use of birth outcome data, and the interpretation of results. WBA developed spatial data sets used in this work and contributed to the interpretation of results. JLA consulted on the study design and the exposure assessment methods and contributed to the interpretation of results. DD consulted on the study design and interpretation of the results. DD is the principal investigator for grants R01DK076648 and 5UH3OD023248 (National Institutes of Health) which funded this work. SM consulted on the study design and statistical methods and the interpretation of results. SM is the principal investigator for grant RD-839278 (US Environmental Protection Agency) which funded this work in part. All authors reviewed the manuscript and contributed to the final version. The authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The Healthy Start study protocol was approved by the Colorado Multiple Institutional Review Board. All participants provided informed consent.
Consent for publication
Not Applicable.
Competing interests
The authors declare they have no actual or potential competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
Supplemental Materials.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Martenies, S.E., Hoskovec, L., Wilson, A. et al. Using non-parametric Bayes shrinkage to assess relationships between multiple environmental and social stressors and neonatal size and body composition in the Healthy Start cohort. Environ Health 21, 111 (2022). https://doi.org/10.1186/s12940-022-00934-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12940-022-00934-z