
Abstract
Objectives
Currently, endometrial adenocarcinoma lacks an effective prognostic indicator. This study was to develop and validate a gene biomarker and a nomogram to predict the survival of endometrial adenocarcinoma, explore potential mechanisms and select sensitive drugs.
Methods
425 endometrial adenocarcinoma cases with RNA sequencing data from TCGA were used to identify the most immune-related module by WGCNA. As an external test set, 103 cases from GSE17025 were used. Immune-related genes were downloaded from Innate DB. The three sets of data were used to identify the prognostic genes. Based on 397 cases with complete clinical data from TCGA, randomly divided into the training set (n = 199) and test set (n = 198), we identified CXCR3 as the prognostic gene biomarker. Age, grade, FIGO stage, and risk were used to develop and validate a predictive nomogram. AUC, C-index, calibration curve and K–M estimate evaluated the model's predictive performance. KEGG enrichment analysis, immune functions, TMB, the effectiveness of immunotherapy, and drug sensitivity between the high-risk and low-risk groups.
Results
CXCR3 was identified as a prognostic biomarker. We calculated the risk score and divided the cases into the high-risk and low-risk groups by the median value of the risk score. The OS of the high-risk group was better than the low-risk group. The risk was the prognostic indicator independent of age, grade, and FIGO stage. We constructed the nomogram including age, grade, FIGO stage, and risk to predict the prognosis of endometrial adenocarcinoma. The top five KEGG pathways enriched by the DEGs between the high- and low-risk groups were viral protein interaction with cytokine and cytokine receptors, cytokine-cytokine receptor interaction, chemokine signaling pathway, natural killer cell-mediated cytotoxicity, and cell adhesion molecules. We analyzed the difference in immune cells and found that CD8+ T cells, activated CD4+ T cells, T helper cells, monocytes, and M1 macrophages were infiltrated more in the low-risk group. However, M0 macrophages and activated dendritic cells were more in the high-risk group. The immune function including APC coinhibition, APC costimulation, CCR, checkpoint, cytolytic activity, HLA, inflammation-promoting, MHC-I, parainflammation, T cell coinhibition, T cell costimulation, type I-IFN-response, and type II-IFN-response were better in the low-risk group. TMB and TIDE scores were both better in the low-risk group. By ‘the pRRophetic’ package, we found 56 sensitive drugs for different risk groups.
Conclusion
We identified CXCR3 as the prognostic biomarker. We also developed and validated a predictive nomogram model combining CXCR3, age, histological grade, and FIGO stage for endometrial adenocarcinoma, which could help explore the precise treatment.
Similar content being viewed by others

Introduction
Endometrial adenocarcinoma is the most common pathological type of endometrial cancer, which is the most common gynecological cancer in the United States. Since the mid-1990s, the mortality and related mortality of uterine corpus cancer has increased [1]. The disease was frequently symptomatic at an early stage, and endometrial cancer is often diagnosed at stage I [2]. Surgery is the preferred treatment for endometrial cancer, and the staging is based on the pathological evaluation after surgery [3]. Immunotherapy has a considerable clinical response in some relapsed or refractory cases [4,5,6]. With the continuous elucidation of the pathogenesis of endometrial cancer, more and more evidence indicate that many immune cells and cytokines can be seen in endometrial cancer tissue and stimulate an endogenous anti-tumor immune response. Compared with other gynecological malignancies, endometrial cancer is most likely to benefit from immunotherapy [7,8,9].
An integrated genomic analysis by The Cancer Genome Atlas (TCGA) resulted in the molecular classification of endometrioid and serous carcinomas into four distinct subgroups, POLE (ultramutated), microsatellite instability (hypermutated), copy number low (endometrioid), and copy number high (serous-like) [10]. In March 2020, the National Comprehensive Cancer Network (NCCN) recommended the molecular typing of the Cancer Genome Map Research Network for endometrial cancer for the first time. The main cancer immunotherapy methods include Immune checkpoint inhibitors, cancer vaccines, adoptive cell transfer, and lymphocyte-promoting cytokines [11]. Compared with TCGA molecular classification, gene testing is required to determine POLE status first, which is expensive. ProMisE, another commonly used molecular typing, is a simplified version. The typing first determines DNA MMR status and then determines POLE and P53 status, divided into POLE mutant, MMRd type, P53wt normal/wild type, and P53aba abnormal/mutant type [12, 13]. The relatively low cost is the advantage of using this typing to guide treatment. Combined with PD-L1 and TMB-H, molecular typing was used to help evaluate choosing immunotherapy, but it cannot be decided. Several immune-related biomarkers exist [14,15,16,17,18], consisting of multiple genes in endometrial cancer. Therefore, it will be more appliable and convenient to develop a simple prognostic biomarker consisting of fewer genes in endometrial adenocarcinoma for helping clinical practice. TCGA [19, 20] and Gene Expression Omnibus (GEO) [21, 22] have become popular sources of gene databases. Bioinformatics tools, such as weighted gene co-expression network analysis (WGCNA) [23], least absolute shrinkage and selection operator (LASSO) [24], and TIDE (Tumor Immune Dysfunction and Exclusion) algorithm (http://tide.dfci.harvard.edu) have been used to process data. Combining bioinformatics tools and these databases in the scientific study is reliably supported [25,26,27,28,29]. RNA sequencing (RNA-seq) data has the advantage of direct sequencing, a large amount of data, species restriction, and high data flexibility over expression array and NanoString. As RNA-seq data was more suitable for biomarker identification, we analyzed RNA-seq data and clinical data from databases with bioinformatics tools to identify an immune-related prognostic biomarker including only one gene, CXCR3, and develop a predictive nomogram for only endometrial adenocarcinoma to predict the prognosis and help select the sensitive drugs.
Materials and methods
Data collection and differentially expressed genes (DEGs)
Four hundred twenty-five endometrial adenocarcinoma cases with RNA-seq data from TCGA were used to identify the most immune-related module by WGCNA. (Additional file 1: Table S1). The immune score, stromal score, and estimated score for each patient were calculated by ESTIMATE [30], and 5559 immune-related genes (IRGs) were downloaded from InnateDB [31] (Additional file 1: Table S1). One hundred three cases with RNA-seq data from GSE17025 [21, 22] were used as an external test, and their DEGs were processed by GEO2R (Additional file 1: Table S1). The above three sets were used to identify and validate the prognostic genes to predict the prognosis of endometrial adenocarcinoma.
Three hundred ninety-seven endometrial adenocarcinoma cases from TCGA had complete clinical data, including age, histological grade, FIGO stage, vital status, time to death, and time to the last follow-up. These cases were randomly divided into a training set (n = 199) and a test set (n = 198) to develop and validate the risk model and predictive nomogram.
WGCNA
WGCNA is a proper bioinformatics method for exploring immune-related modules. We first removed outlier genes and genes with extremely low expression from the data. A weighted gene network was constructed to raise co-expression similarity to calculate adjacency by choosing the soft thresholding power β. 22 was chosen as the soft threshold based on the approximate scale-free topology. We calculated adjacency and generated a hierarchical clustering tree. 11 modules with similar expression profiles were identified by dynamic tree cutting. Modules with highly co-expressed genes were merged. Finally, we associated the modules with the immune traits (i.e., immune score, stromal score, and estimate score) and chose the most relevant module.
Identification and validation of the most immune-related gene biomarker
The overlapping genes were intersected by the most relevant module of WGCNA (module dark-orange), DEGs of GSE17025, and IRGs from InnateDB. Univariate Cox regression analysis, LASSO regression analysis, and multivariate Cox regression analysis were successively used to obtain the prognostic gene biomarker on the training set and tested by the test set. The risk score was calculated by multivariate Cox regression analysis. The risk score formula was: Risk score = ∑ni = 1Coefi × Expi. In this formula, Coefi is the coefficient of the prognosis-related gene, and Exp is the expression level of each retained gene. The median value of the risk score divided the cases into high- and low-risk groups. The predictive performance of the gene biomarker was evaluated by the area under the curve (AUC), concordance index (C-index), and Kaplan–Meier (K–M) estimate. The theoretical value of the C-index is between 0 and 1. If the C-index exceeds 0.5, the prediction performance is better than a random guess. Independent prognostic analysis can determine whether our model can be used as an independent prognostic factor independent of other clinical factors.
Database for annotation, visualization, and integrated discovery (DAVID)
DAVID (version 6.8) [32, 33] is an online annotation tool used to interpret the biological function of gene sets. Here, we used the gene set of the most relevant module from WGCNA to do the Kyoto Encyclopedia of Genes and Genomes (KEGG) Pathway and Gene Ontology (GO) analysis by DAVID. GO analysis can provide biological information on gene function. KEGG pathway analysis can indicate the possible signaling pathways of the gene set. We input gene symbols onto the website and chose Homo Sapiens as the species. GO-BP-direct, Go-CC-Direct, Go-MF-Direct, and KEGG PATHWAY were selected for functional annotation. Other parameters were set to default.
Comprehensive analysis of protein–protein interaction (PPI) network
PPI was performed by STRING [34], a Search Tool for the Retrieval of Interacting Genes Database (https://www.string-db.org/). The website analyzed overlapping genes to explore the possible relationships between them.
Evaluating the difference in immune function and immune cells between the high- and low-risk group
Based on the 'limma' [35], 'GSVA' [36], 'GSEABase' [37], ‘ggpubr’ [38], and 'reshape2' [39] R packages, we calculated the different immune functions and cells between the high-risk and low-risk groups.
Evaluating tumor mutation burden between the high- and low-risk group
TMB refers to the relative number of gene mutations in specific tumor tissue. Calculation formula: TMB (mut/Mb) = total mutation number (including synonymous, non-synonymous point mutation, replacement, insertion, and deletion mutation)/coding area size of a target area.
Perl (https://www.perl.org/) was used to extract somatic mutation information and estimate the TMB value. Then we used R to combine the patient's TMB information with clinical information, including survival time and status. The ' survminer ' [40]package was used to calculate the best cutoff value of TMB. According to the optimal critical value, the patients were divided into a high-TMB group and a low-TMB group. K–M survival analysis and the log-rank tests were performed to compare the OS differences between the above two TMB groups, and the OS differences in the four TMB groups combined with the risk score were compared. In addition, we explored the difference in TMB between the high-risk group and the low-risk group.
Drug sensitivity and immunotherapy
We estimated the half-maximal inhibitory concentration (IC50) of commonly used chemotherapy drugs via the 'pRRophetic' [41] package. The potential response to immunotherapy was predicted and verified by the TIDE algorithm (http://tide.dfci.harvard.edu). The lower the TIDE score is, the more sensitive to immune checkpoint blockade (ICB).
Development and validation of a nomogram
To explore the prognostic significance of gene biomarkers and clinical traits (such as age, histological grade, and FIGO stage), we developed a predictive nomogram to evaluate the prognosis of endometrial adenocarcinoma. First, the cases were grouped by the median predicted risk score, and the survival differences between the two groups were compared by K–M plot and log-rank test. Second, calibration curves evaluated the consistency between the predicted and the actual survival probability at 3 and 5 years. A 45-degree calibration curve indicates a perfect prediction.
RNA extraction and quantitative RT-PCR
Trans Script All-in-One First-Strand cDNA Synthesis SuperMix for qPCR (One-Step gDNA Removal) by TransGen Biotech (Beijing, China) was used to extract total RNA from tissues. Reverse transcription of total RNA into cDNA was performed with EasyPure RNA Kit by TransGen Biotech (Beijing, China) for real-time PCR analysis. Specific PCR primers were designed by Comate Bioscience Co., LTD. (Jilin, China). The fold change in expression was calculated using the 2-∆∆Ct method, with GAPDH as an internal control. The primer sequences: GAPDH: Forward: AATTCCATGGCACCGTCAAG, Reverse: AGCATCGCCCCACTTGATTT; CXCR3: Forward: TACTGCTATGCCCACATCCTG, Reverse: TGATAGGGGGTCCAGCAGAG.
Statistical analyses
All statistical analysis was performed in the R Studio software (version 3.6.1). R packages such as ‘caret’ [42], ‘dplyr’ [43], ‘WGCNA’ [23, 44], ‘limma’ [35], ‘GSVA’ [36], ‘GSEABase’ [37], ‘ggpubr’ [38], and ‘reshape2’ [39], ‘pheatmap’ [45], ‘pec’ [46], ‘regplot’ [47], ‘stringr’ [48], ‘flashClust’ [44], ‘glmnet’ [49, 50], ‘ggplot2’ [51], ‘org.Hs.eg.db’ [52], ‘DOSE’ [53], ‘enrichplot’ [54], ‘survival’ [55, 56], ‘survminer’ [40], ‘timeROC’ [57], ‘rms’ [58], ‘circlize’ [59], ‘RColorBrewer’ [60], ‘ComplexHeatmap’ [61],’ maftools’ [62], ‘clusterProfiler’ [63, 64], and 'pRRophetic' [41] were used. Continuous variables between the two groups were analyzed using a t-test. The Wilcoxon test performed a non-parametric comparison between the two groups. P < 0.05 was considered statistically significant.
Result
Study protocol
The schematic diagram of the study protocol is shown in Fig. 1.

Flow chart depicting the protocol. 1Four hundred twenty-five endometrial adenocarcinoma cases with RNA-seq data from TCGA were used to analyze the most immune-related genes. One hundred three endometrial adenocarcinoma cases with RNA-seq data from GSE17025 were used as an external test set. Moreover, 5559 immune-related genes were downloaded from InnateDB. The three sets were used to identify and validate prognostic gene biomarkers. 2We used KEGG analysis and GO analysis to determine if the most relevant module correlated to immunity. 3The gene biomarker was identified and validated from 53 overlapping IRGs using univariate Cox regression analysis, LASSO regression analysis, and multivariate Cox regression analysis based on the training set (n = 199) and the test set (n = 198). Twenty-eight cases with missing clinical data were excluded from the study. 4Age, histological grade, FIGO stage, and risk group were used to develop and validate the prognostic nomogram. 5QPCR verified the relative expression between normal endometrium tissue and endometrial adenocarcinoma tissue
Identification of GSE17025 DEGs in endometrial adenocarcinoma
One hundred three cases of endometrial adenocarcinoma from GSE17025 were used as an external gene set to develop the prognostic gene biomarker using RNA-seq data. 4697 DEGs were obtained by GEO2R. Adjust P value < 0.05 and | log FC |> 1 were set as the criteria. DEGs were displayed in the volcano plot (Fig. 2A).

Identification and validation of immune-related modules A. Volcano plot of GSE17025 DEGs. B, C Determination of soft threshold power in WGCNA. B The panel showed a scale-free index for various soft-threshold powers (β). C This panel showed the mean connectivity for various soft-threshold powers. D Clustering dendrogram of genes, with dissimilarity based on the topological overlap, together with assigned module colors. E Module-trait association. Each row represents a module, and each column represents a feature. Each cell contains the corresponding correlation and P value. The dark-orange module (MEdarkorange) was most correlated with the immune score (P = 2e−54, r = 0.67). F Most of the KEGG pathways were also associated with immunity, demonstrating that the dark-orange module was immune-related. G Most of the categories in GO enrichment analysis based on genes in the dark-orange module were related to immunity, supporting that the dark-orange module was immune-related
Identification and validation of the most immune-related module
The 425 cases with RNA-seq data and the corresponding immune score of each endometrial adenocarcinoma case were analyzed by WGCNA to identify the most immune-related module. 38,589 genes with extremely low expression levels were filtered out. 16,299 WGCNA candidate genes were obtained. 22 was set to be the soft threshold (Fig. 2B–C). All genes were classified and merged into the 11 highly co-expressed modules (Fig. 2D). Among them, the dark-orange module was the strongest immune-related module (P = 2e−54, r = 0.67). The module contained 325 genes. In addition, the dark-orange module was also significantly correlated to the stromal scores and estimate scores in endometrial adenocarcinoma (Fig. 2E). DAVID analyzed 325 genes in the dark-orange module to testify whether this module was immune-related. All pathways in GO and KEGG were found to be immune-related. (Fig. 2F–G).
Identification of overlapping genes and PPI network
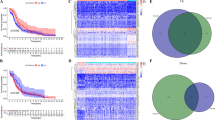
Fifty-three overlapping genes were obtained by intersecting 325 genes from Module dark-orange, 5559 IRGs from InnateDB, and 4697 DEGs from GSE17025 to select eligible immune genes to develop the immune-related gene biomarker (Additional file 1: Table S1, Fig. 3A). STRING was used to explore the interaction between overlapping genes (Fig. 3B).

Identification of the overlapping genes by intersecting the genes from the dark-orange module, IRGs from InnateDB, and DEGs from GSE17025. A Venn diagram of GSE17025, the dark-orange module, and IRGs. B PPI network of overlapping genes
Identification and validation of prognostic immune-gene biomarker
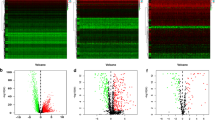
Three hundred ninety-seven endometrial adenocarcinoma cases with RNA-seq data and complete survival data from TCGA were randomly divided into a training set (n = 199) and a test set (n = 198) (Additional file 2: Table S2). Baseline characteristics were comparable between the sets (Table 1). First, 28 genes were selected from 53 overlapping genes based on the training set with univariate Cox regression analysis (P < 0.05) (Fig. 4A). Second, CXCR3, successively screened by LASSO regression and multivariate cox regression, was identified as the gene biomarker in the training set and validated in the test set (Fig. 4B–D). Third, based on the gene biomarker, we calculated the risk score of each case with multivariate Cox regression and then separated all the endometrial adenocarcinoma cases into the high-and low-risk group by the median value of the predicted risk score (the median value of risk score in the training set was 0.97) (Fig. 5A–J). The survival difference between the two groups was significant (P < 0.05; Fig. 4E–G). Fourth, the AUC of the risk, age, histological grade, and FIGO stage was 0.724, 0.616, 0.683, and 0.728, separately (Fig. 6A). The AUC for one year, three years, and five years was 0.724, 0.630, and 0.64, separately (Fig. 6B). The C-index of the risk score was larger than 0.5 (Fig. 6C). Fifth, independent prognostic analysis testified that risk score was a prognostic indicator independent of age, histological grade, and FIGO stage (Fig. 6D–E). In the subgroup analysis of patients by age, histological grade, and FIGO stage, we found the survival probability in the low-risk group was higher than the high-risk group in stratification such as histological grade of G2, G3, age more than 60 years, age less than 60 years, FIGO stage I–II and FIGO stage III–IV. For patients with a histological grade of G1, the survival probability between the two groups was no different (Fig. 6F–L).

Identification and validation of the gene biomarker. A–D Univariate Cox regression analysis was used to identify the potential prognostic gene biomarkers. LASSO regression was used to eliminate redundant genes further. A Twenty-eight genes were screened to basing on univariate Cox regression analysis. B Tuning parameter (λ) selection in the LASSO model used tenfold cross-validation via minimum criteria. C LASSO coefficient profiles of 2 variables against the log (λ) sequence. D Multivariate Cox regression analysis was used to screen for genes significantly associated with overall survival. As shown in the forest plot, CXCR3 with a P value less than 0.05 was significantly associated with overall survival. E–G The survival difference between the low-risk and high-risk groups was divided by the median risk score threshold using multivariate Cox regression analysis. In the all-set, training, and test set, the survival of the low-risk group was significantly longer than that of the high-risk group

Risk curves. A–C The vertical axis represents patients' risk score, and the horizontal axis represents the number of patients. The patients were divided into high- and low-risk groups according to the median value of the risk score. The low-risk group was shown in blue, and the high-risk group was shown in red. D–F The vertical axis represented the survival time (unit: years), and the horizontal axis represented the number of patients. The red dot represented the dead patient, and the blue dot represented the living patient. As the risk increased, the number of dead patients increased. G–I It represented the difference in CXCR3 expression between high- and low-risk groups. The low-risk group had a high expression, and the high-risk group had a low expression, indicating that CXCR3 might be an anti-tumor gene

AUC and the independent prognostic analysis. A–B AUC and C-index were calculated for the gene marker. A AUC was calculated for the risk score, age, histological grade, and FIGO stage. B AUC was calculated at one year, three years, and five years. C The C-index of the risk, age, histological grade, and FIGO stage was calculated separately. D–E Univariate Cox regression analysis and multivariate Cox regression analysis were used to doing the independent prognostic analysis, which indicated that risk score was the prognostic marker independent of age, histological grade, and FIGO stage. D Univariate Cox regression analysis. E Multivariate Cox regression analysis. F–L Subgroup analysis of age, histological grade, and FIGO stage. F In patients of histological grade G1, the survival probability of the two risk groups had no difference (P = 0.948). G–H In patients of histological grades G2 and G3, the survival probability of the low-risk group was higher than the high-risk group (P = 0.015, P = 0.008 separately). I–J In patients younger than 60 years and elder than 60 years, the survival probability of the low-risk group was higher than the high-risk group (P = 0.007, P = 0.014 separately). K–L In patients of stage I–II and stage III–IV, the survival probability of the low-risk group was higher than the high-risk group (P = 0.044, P = 0.001 separately)
Functional enrichment analysis between the high- and low-risk groups
The potential mechanism of the DEGs between the high and low-risk groups was explored by KEGG pathway analysis. KEGG analysis showed that the DEGs were mainly enriched in viral protein interaction with cytokine and cytokine receptor, cytokine-cytokine receptor interaction, chemokine signaling pathway, natural killer cell-mediated cytotoxicity, and cell adhesion molecules (Fig. 7A).

Exploration of the enrichment difference between the two risk groups. A Difference of KEGG pathway between the two risk groups. B Difference of GO analysis between the two risk groups
We performed a GO analysis to determine the biological characteristics of the DEGs between the two groups. BP analysis showed that the biological processes were significantly enriched in antigen binding, immunoglobulin receptor binding, cytokine receptor activity, cytokine receptor activity, and cytokine binding. CC analysis showed that the DEGs functioned in the external side of the plasma membrane, immunoglobulin complex, plasma membrane signaling receptor complex, T cell receptor complex, and circulating immunocomplex. MF analysis showed that the DEGs were mainly enriched in antigen binding, immunoglobulin receptor binding, immune receptor activity, cytokine receptor activity, and cytokine binding (Fig. 7B).
Immune function and TMB difference between the high- and low-risk groups and the response to immunotherapy
We found that the low-risk group had better immune functions in APC coinhibition, APC costimulation, CCR, checkpoint, cytolytic activity, HLA, inflammation-promoting, MHC class I, parainflammation, T cell coinhibition, T cell costimulation, type I interferon response, and type II interferon response (Fig. 8A).

Exploration of the immune functions, TMB difference, immunotherapy and chemotherapy sensitivity between the two risk groups. A The difference in immune functions. B The difference in immune cells fractions. C The difference in tumor mutation burden. D The survival probability of the high-TMB group was better than the low-TMB group. E The survival probability of the TMB group combined with different risks. The group with the high TMB and the low risk score had the best prognosis, and the group with the low TMB and the high risk score had the worst prognosis. F The TIDE score of the low-risk group was higher than that of the high-risk group, indicating that the immunotherapy effect in the low-risk group was worse than that in the high-risk group. G–H IC50 Values of YM155 and Thapsigargin were higher in the low-risk group
CD8 T cells, activated CD4 memory T cells, follicular helper T cells, monocytes, and M1 macrophages in the low-risk group were more than in the high-risk group. M0 macrophage and activated dendritic cells in the high-risk group were more than in the low-risk group (Fig. 8B).
TMB was significantly higher in the low-risk group than in the high-risk group (P < 0.001) (Fig. 8C). Kaplan–Meier analysis was used to evaluate the prognosis of endometrial adenocarcinoma according to TMB combined with the risk score. The results showed that TMB (Fig. 8D, P = 0.02) was significantly positively associated with prognosis. Patients in the high-TMB group had a better prognosis than the low-TMB group, no matter with a high risk or a low risk. High-TMB patients with low-risk scores had the best prognosis (Fig. 8E, P < 0.001). In addition, the TIDE score was calculated by the TIDE online tool to investigate the effectiveness of immune checkpoint inhibitors in the two groups. The TIDE score of the low-risk group was higher than that of the high-risk group, indicating that the immunotherapy effect in the low-risk group was worse than that in the high-risk group (Fig. 8F, P < 0.001).
Response of high- and low-risk patients to chemotherapy
According to the “pRRophetic" algorithm, we predicted the IC50 values of 56 chemotherapeutic drugs relevant to risk score, including 5-Fluorouracil, AC220, AP-24534, AS605240, AUY922, BAY 61-3606, Bexarotene, Bleomycin, CAL-101, CGP-60474, CGP-082996, CP466722, Crizotinib, Cyclopamine, DMOG, FMK, FR-180204, FTI-277, Genentech Cpd 10, GSK429286A, HG-6-64-1, IPA-3, JQ12, JW-7-24-1, KIN001-102, LAQ824, LFM-A13, LY317615, Midostaurin, NG-25, PAC-1, Paclitaxel, Pazopanib, PHA-665752, Phenformin, Rapamycin, Roscovitine, Ruxolitinib, Salubrinal, STF-62247, Sunitinib, TGX221, Thapsigargin, Tipifarnib, TL-1-85, TL-2-105, Tubastatin A, WH-4-023, WZ-1-84, XL-184, XMD8-85, XMD14-99, YM155, Zibotentan, Z-LLNle-CHO, and ZSTK474 (Additional files 3, 4, 5: Figs. S1–S3). By comparing the IC50 values of these associated drugs in the two-risk group, the values of YM155 and Thapsigargin were higher in the low-risk group, and the values of the other drugs were higher in the high-risk group (Wilcoxon test, P < 0.001; Fig. 8G–H, Additional files 6, 7, 8: Figs. S4–S6).
Development and validation of a prognostic nomogram
Considering the prognostic significance of the gene biomarker, we tried to combine it with clinical factors to better predict the survival of patients with endometrial adenocarcinoma. First, age, histological grade, FIGO stage, and risk group were included to develop the predictive nomogram of endometrial adenocarcinoma. Total points were calculated by summing up each item in the nomogram and predicting the survival rate of one year, three years, and five years (Fig. 9A). Second, the 1-year, 3-year, and 5-year calibration curves indicated high consistency between the predicted and actual survival ratios (Fig. 9B).

Development and validation of a new predictive nomogram and qPCR verification. A The predictive nomogram was used to predict the survival probability at one year, three years, and five years). B Calibration curves of the nomograms at one year, three years, and five years. The X-axis represents the predicted probability, and the Y-axis represents the actual probability. The error line represents a 95% confidence interval. 45° represents a perfect prediction and the excellent performance of our nomogram. C The qPCR verification of the relative expression of CXCR3 between the normal endometrium and the endometrial adenocarcinoma patients (t-test, P < 0.001)
The relative expression of CXCR3 in endometrial adenocarcinoma
The expression of CXCR3 was tested by qPCR with clinical samples from adenocarcinoma patients and normal endometrium from patients with other diseases that need to remove the uterus to identify the effect of CXCR3 (Fig. 9C), indicating that the expression of CXCR3 was lower in endometrial adenocarcinoma.
Discussion
In our study, we developed and validated a gene biomarker and prognostic nomogram model combining gene markers and clinical factors (age, histological grade, and FIGO stage) for patients with endometrial adenocarcinoma, which had not been reported before. In endometrial adenocarcinoma, CXCR3 was identified as a meaningful anti-tumor gene. The Nomogram model can effectively predict 1-year, 3-year, and 5-year survival ratios.
CXCR3 is a G protein-coupled receptor that binds to ELR-negative CXC chemokines, which could affect immune responses [65] and be required for the efficacy of anti-PD-1 therapy [66]. CXCR3 consists of CXCR3-A, CXCR3-B, and CXCR3-alt. The first two have opposite physiological functions. CXCR3-A mainly exists in hematopoietic cells, which could promote tumor progression by survival, cell proliferation, chemotaxis, invasion, and metastasis [65]. CXCR3-B mainly exists in epithelial cells, which could lead to growth inhibition, apoptosis, and anti-angiogenesis [65]. Higher CXCR3 expression has been reported to be related to a good prognosis of renal and gastric cancer [67,68,69]. However, there were also some studies indicating that higher CXCR3 expression predicted poor survival in solid tumor l [70].
CXCR3 expressed on regulatory T cells could induce peripheral CD4 T cells to differentiate into regulatory T cells and improves effector T cell function [71], which is consistent with the higher fraction of CD4+ T cells and CD8+ T cells in the low-risk group in our study. Chemokine ligands 9, 10, 11 (CXCL 9-11) interacting with CXCR3 expressed on monocytes, T cells, and NK cells may be involved in inhibiting angiogenesis [72], which is consistent with our study that high expression of CXCR3 had better survival outcome and the fraction of CD4+ T cells, CD8+ T cells and monocytes were higher in the low-risk group. CXCL11 could inhibit angiogenesis, affect the proliferation of different cell types, increase adhesion properties, inhibit M2 macrophage polarization and promote the migration of some immune cells [73], which was consistent with the higher fraction of M1 macrophage in the low-risk group. However, CXCL9/CXCR3 axis has been reported to activate Akt signaling pathway, accompany EMT and cytoskeleton rearrangement, and promote invasion and metastasis in tongue squamous cell carcinoma [74]. CXCL10 promotes CXCR3 expressing cancer cells transported to bone [75]. These different functions of CXCR3 may be attributed to its different variant types and different cell types.
Nevertheless, in our study, the qPCR result showed that the relative expression of CXCR3 in endometrial adenocarcinoma was lower than in normal endometrium. This result indicated that CXCR3 in endometria adenocarcinoma might be an anti-tumor effect. T-follicular helper cells (TFH) may contribute to the treatment of endometrial cancer, and high TFH infiltration shows clinical application potential in anti-PD-1 treatment [76]. The increase in the number of CD8+ T cells at the invasive boundary may improve the survival of patients with endometrial cancer [77]. In our study, the follicular T cells and CD8+ T cells were all significantly increased in the low-risk group, which had a higher anti-tumor effect.
In addition, we revealed the immune function, including APC coinhibition, APC costimulation, CCR, checkpoint, cytolytic activity, HLA, inflammation-promoting, MHC-I, parainflammation, T cell coinhibition, T cell costimulation, type I-IFN-response, and type II-IFN-response were better in the low-risk group. By KEGG pathway and GO analysis based on the DEGs between the two risk groups, we found that viral protein interaction with cytokine and cytokine receptor, cytokine-cytokine receptor interaction, chemokine signaling pathway, natural killer cell-mediated cytotoxicity and cell adhesion molecules were enriched obviously. The most critical immune-related pathway in the low-risk group was the cytokine-cytokine receptor pathway, which played an important role in B cell-related immune diseases, such as autoimmune diseases, and malignant diseases including, lymphoma, leukemia [78], colorectal cancer [79], renal cell carcinoma [80] hepatocellular carcinoma [81], non-squamous non-small cell lung cancer [82], lung adenocarcinoma [83], and AIDS-related Kaposi sarcoma (AIDS-KS) [84]. TMB could be a candidate biomarker to estimate the possible response to immunotherapy [85, 86]. Zhou [87] reported that the survival of the low-TMB group was worse than the high-TMB group, which was consistent with our study. High TMB might possess a good prognosis for PD-1/PD-L1 blockade in diverse tumors [86]. High-TMB tumors with microsatellite stability can better respond to pembrolizumab with longer PFS than low/intermediate TMB tumors [88]. All these findings contribute to developing new therapeutic strategies for endometrial adenocarcinoma and provide an opportunity for the further immune exploration of endometrial adenocarcinoma.
Currently, there already exist some different immune-related signatures. For example, Chen [89] found that immune and stromal scores had a relationship with the prognosis of EC patients by the “ESTIMATE” R tool. Based on the immune and stromal scores and the intersected differentially expressed genes, eight immune-related genes (AQP4, ARHGAP36, CACNA2D2, CTSW, NOL4, SIGLEC1, TMEM150B, and TRPM5) were then identified by LASSO algorithm and Random-forest algorithm. Tang [90]used the Spearman correlation analysis to identify immune-related pseudogenes and then developed a risk signature consisting of nine immune-related pseudogenes by univariate Cox regression, LASSO, and multivariate to predict the prognosis. Meng [91] used the conjoint Cox regression model to develop a signature consisting of seven immune-related genes (CBLC, PLA2G2A, TNF, NR3C1, APOD, TNFRSF18, and LTB). They all indicated that patients in the low-risk group had a significantly longer survival time than those in the high-risk group. However, analyzed by different bioinformatic tolls, the signatures were identified differently and consisted of multiple genes leading to needing to be more convenient for helping clinical practice.
However, first, our study identified CXCR3 as the solely optimized immune-related prognostic biomarker. Although it was not newly found, it was first used as a predictive gene marker in adenocarcinoma. As CXCR3 has been studied for years, its effect on cancer is more well-known and convenient for clinical applications. Moreover, it had been developed and validated in the TCGA cohort, which had many cases to guarantee its reliability and stability. Second, we revealed the potential immune pathways, immune cells, tumor mutation burden, and TIDE scores between the low-risk and the high-risk group, which might help find effective immunotherapy. Third, we establish a nomogram to predict the prognosis. The last but most crucial finding was the discovery of sensitive drugs in the high-risk and low-risk groups. The high-risk group was more sensitive to YM155 and Thapsigargin, and the low-risk group was more sensitive to the other 54 drugs by comparing the IC50 values of the 56 sensitive drugs between the two groups [92].
This study also has some limitations and deserves further investigation. First, no suitable external cohort with clinical data can be used to demonstrate the model further. Second, more in vitro and in vivo studies are needed to explore the physiological mechanisms. Critical immune cells, including M1 macrophages, memory-activated CD4+ T cells, CD8+ T cells, and follicular helper T cells, have been proven beneficial to the survival of endometrial adenocarcinoma patients, and the exact underlying mechanism needs to be further studied.
In conclusion, we successfully developed and validated a simple gene biomarker and a new nomogram prognosis model based on exploiting the data from TCGA and GEO databases with bioinformatics tools. Our study also revealed some interesting immune cells and pathways in endometrial adenocarcinoma, which can be used as potential immunotherapeutic targets.
Availability of data and materials
The datasets analyzed during this study are available in the TCGA repository (https://portal.gdc.cancer.gov/) and the GEO database (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=gse17025).
References
Siegel RL, Miller KD, Fuchs HE, et al. Cancer statistics. CA Cancer J Clin. 2022;72(1):7–33.
Morice P, Leary A, Creutzberg C, et al. Endometrial cancer. Lancet (London, England). 2016;387(10023):1094–108.
Lu KH, Broaddus RR. Endometrial cancer. N Engl J Med. 2020;383(21):2053–64.
Wolchok JD, Chiarion-Sileni V, Gonzalez R, et al. Overall survival with combined Nivolumab and Ipilimumab in advanced melanoma. N Engl J Med. 2017;377(14):1345–56.
Motzer RJ, Tannir NM, McDermott DF, et al. Nivolumab plus Ipilimumab versus Sunitinib in advanced renal-cell carcinoma. N Engl J Med. 2018;378(14):1277–90.
Maude SL, Laetsch TW, Buechner J, et al. Tisagenlecleucel in children and young adults with B-cell lymphoblastic leukemia. N Engl J Med. 2018;378(5):439–48.
Di Tucci C, Capone C, Galati G, et al. Immunotherapy in endometrial cancer: new scenarios on the horizon. J Gynecol Oncol. 2019;30(3): e46.
Nishio H, Iwata T, Aoki D. Current status of cancer immunotherapy for gynecologic malignancies. Jpn J Clin Oncol. 2021;51(2):167–72.
Di Tucci C, Schiavi MC, Faiano P, et al. Therapeutic vaccines and immune checkpoints inhibition options for gynecological cancers. Crit Rev Oncol Hematol. 2018;128:30–42.
Bell DW, Ellenson LH. Molecular genetics of endometrial carcinoma. Annu Rev Pathol. 2019;24(14):339–67.
Cao W, Ma X, Fischer JV, et al. Immunotherapy in endometrial cancer: rationale, practice and perspectives. Biomark Res. 2021;9(1):49.
Talhouk A, McConechy MK, Leung S, et al. A clinically applicable molecular-based classification for endometrial cancers. Br J Cancer. 2015;113(2):299–310.
Kommoss S, McConechy MK, Kommoss F, et al. Final validation of the ProMisE molecular classifier for endometrial carcinoma in a large population-based case series. Ann Oncol Off J Eur Soc Med Oncol. 2018;29(5):1180–8.
Chen H, Li L, Qin P, et al. A 4-gene signature predicts prognosis of uterine serous carcinoma. BMC Cancer. 2021;21(1):154.
de Andrade DAP, da Silva LS, Laus AC, et al. A 4-gene signature associated with recurrence in low- and intermediate-risk endometrial cancer. Front Oncol. 2021;11: 729219.
Ouyang D, Li R, Li Y, et al. A 7-lncRNA signature predict prognosis of Uterine corpus endometrial carcinoma. J Cell Biochem. 2019;120(10):18465–77.
Qiao Z, Jiang Y, Wang L, et al. Mutations in KIAA1109, CACNA1C, BSN, AKAP13, CELSR2, and HELZ2 are associated with the prognosis in endometrial cancer. Front Genet. 2019;10:909.
Zeng Z, Cheng J, Ye Q, et al. A 14-methylation-driven differentially expressed RNA as a signature for overall survival prediction in patients with uterine corpus endometrial carcinoma. DNA Cell Biol. 2020;39(6):975–91.
Grossman RLHA, Ferretti V, Varmus HE, Lowy DR, Kibbe WA, et al. Toward a shared vision for cancer genomic data. N Engl J Med. 2016;375:1109–12.
Weinstein JNCE, Mills GB, Shaw KR, Ozenberger BA, Ellrott K, et al. The cancer genome atlas pan-cancer analysis project. Nat Genet. 2013;45:1113–20.
Day RSMK, Chandran UR, Lisovich A, et al. Identifier mapping performance for integrating transcriptomics and proteomics experimental results. BMC Bioinf. 2011;12:213.
Day RSMK. A decision theory paradigm for evaluating identifier mapping and filtering methods using data integration. BMC Bioinf. 2013;14:223.
Langfelder PHS. WGCNA: an R package for weighted correlation network analysis. BMC Bioinf. 2008;9:559.
Sauerbrei WRP, Binder H. Selection of important variables and determination of functional form for continuous predictors in multivariable model building. Stat Med. 2007;26:5512–28.
Kimball ABGR, Wang F, Osborne R, Tiesman JP. Beyond the blot: cutting edge tools for genomics, proteomics and metabolomics analyses and previous successes. Br J Dermatol. 2012;166(Suppl 2):1–8.
Shu LLY, Li J, Wu X, Li Y, Huang H. Landscape profiling analysis of DPP4 in malignancies: therapeutic implication for tumor patients with coronavirus disease 2019. Front Oncol. 2021;11: 624899.
Man ZCY, Gao L, Xie G, Li Q, Lu Q, et al. A prognostic model based on RNA binding protein predicts clinical outcomes in hepatocellular carcinoma patients. Front Oncol. 2020;10: 613102.
Guan XXZ, Chen R, Qin JJ, Cheng XD. Identification of an immune gene-associated prognostic signature and its association with a poor prognosis in gastric cancer patients. Front Oncol. 2020;10: 629909.
Jung SYPJ, Sobel EM, Pellegrini M, Yu H, Zhang ZF. Genetically predicted C-reactive protein associated with postmenopausal breast cancer risk: interrelation with estrogen and cancer molecular subtypes using mendelian randomization. Front Oncol. 2020;10: 630994.
Yoshihara K, Shahmoradgoli M, Martínez E, et al. Inferring tumour purity and stromal and immune cell admixture from expression data. Nat Commun. 2013;4:2612.
Breuer K, Foroushani AK, Laird MR, et al. InnateDB: systems biology of innate immunity and beyond–recent updates and continuing curation. Nucleic Acids Res. 2013;41:D1228–33.
Huang DWSB, Lempicki RA. Systematic and integrative analysis of large gene lists using DAVID bioinformatics resources. Nature Protoc. 2009;4(1):44–57.
Huang DWSB, Lempicki RA. Bioinformatics enrichment tools: paths toward the comprehensive functional analysis of large gene lists. Nucleic Acids Res. 2009;37(1):1–13.
Szklarczyk D, Gable AL, Lyon D. STRING v11: protein-protein association networks with increased coverage, supporting functional discovery in genome-wide experimental datasets. Nucleic Acids Res. 2019;47(D1):D607–13.
Smyth ME. Limma powers differential expression analyses for {RNA}-sequencing and microarray studies. Nucleic Acids Res. 2015;43(7):e47.
Guinney SH. GSVA: gene set variation analysis for microarray and RNA-Seq data. BMC Bioinf. 2013;14:7.
Morgan M, Falcon S, Gentleman R. GSEABase: Gene set enrichment data structures and methods. 2020. R package version 1.52.1.
Kassambara A. ggpubr: 'ggplot2' Based Publication Ready Plots. 2020. R package version 0.4.0. https://CRAN.R-project.org/package=ggpubr.
Wickham H. Reshaping data with the reshape package. J Stat Softw. 2007;21(12):1–20.
Alboukadel Kassambara MK. Survminer: drawing survival curves using 'ggplot2'. 2021. R package version 0.4.9. https://CRAN.R-project.org/package=survminer.
Geeleher P. pRRophetic: predict clinical chemotherapeutic response from before-treatment tumor gene expression levels. 2014. R package version 0.5.
Kuhn M. Caret: classification and regression training. 2022. R package version 6.0-92. https://CRAN.R-project.org/package=caret.
Müller HW. dplyr: a grammar of data manipulation. 2021. R package version 1.0.7. https://CRAN.R-project.org/package=dplyr.
Peter Langfelder SH. Fast R functions for robust correlations and hierarchical clustering. J Stat Softw. 2012;46(11):1–17.
Kolde R. pheatmap: pretty heatmaps. 2019. R package version 1.0.12. https://CRAN.R-project.org/package=pheatmap.
Gerds UB. Evaluating random forests for survival analysis using prediction error curves. J Stat Softw. 2012;50(11):1–23.
Marshall R. regplot: enhanced regression nomogram plot. 2020. R package version 1.1. https://CRAN.R-project.org/package=regplot.
Wickham H. stringr: simple, consistent wrappers for common string operations. 2019. R package version 1.4.0. https://CRAN.R-project.org/package=stringr.
Jerome Friedman TH, Robert T. Regularization paths for generalized linear models via coordinate descent. J Stat Softw. 2010;33(1):1–22.
Noah Simon JF, Trevor H, Rob T. Regularization paths for cox’s proportional hazards model via coordinate descent. J Stat Softw. 2011;39(5):1–13.
Wickham H. ggplot2: elegant graphics for data analysis. 2016. ISBN: 978-3-319-24277-4. https://ggplot2.tidyverse.org.
Carlson M. org.Hs.eg.db: genome wide annotation for human. 2020. R package version 3.12.0.
Yu G, Wang LG, Yan GR, He QY. DOSE: an R/Bioconductor package for disease ontology semantic and enrichment analysis. Bioinformatics. 2015;31(4):608-9.
Yu G. enrichplot: Visualization of Functional Enrichment Result. 2021. R package version 1.10.2. https://yulab-smu.top/biomedical-knowledge-mining-book/.
T T. A Package for Survival Analysis in R. R package version 3.3-1. https://CRAN.R-project.org/package=survival.
Terry M. Therneau PMG. Modeling survival data: extending the cox model. 2000. Springer, New York. ISBN 0-387-98784-3.
Jacqmin-Gadda PB. Estimating and comparing time-dependent areas under receiver operating characteristic curves for censored event times with competing risks. Stat Med. 2013;32(30):5381–97.
Jr FEH. rms: regression modeling strategies. 2021. R package version 6.2-0. https://CRAN.R-project.org/package=rms.
Brors ZG. circlize implements and enhances circular visualization in R. Bioinformatics. 2014;30(19):2811–2.
Neuwirth E. RColorBrewer: ColorBrewer Palettes. 2014. R package version 1.1-2. https://CRAN.R-project.org/package=RColorBrewer.
Gu Z, Eils R, Schlesner M. Complex heatmaps reveal patterns and correlations in multidimensional genomic data. Bioinformatics. 2016;32(18):2847–9. https://doi.org/10.1093/bioinformatics/btw313.
Mayakonda A, Lin DC, Assenov Y, Plass C, Koeffler HP. Maftools: efficient and comprehensive analysis of somatic variants in cancer. Genome Res. 2018;28(11):1747–56. https://doi.org/10.1101/gr.239244.118.
Wu EH, Xu S, Chen M, Guo P, Dai Z, Feng T, Zhou L, Tang W, Zhan L, Fu X, Liu S, Bo X, Yu G. clusterProfiler 40: a universal enrichment tool for interpreting omics data. Innov. 2021;2(3):100141.
Guangchuang YLGW, Yanyan H, Qing-Yu H. clusterProfiler: an R package for comparing biological themes among gene clusters. OMICS: J Integr Biol 2012;16(5):284–287.
Ma B, Khazali A, Wells A. CXCR3 in carcinoma progression. Histol Histopathol. 2015;30(7):781–92.
Chow MT, Ozga AJ, Servis RL, et al. Intratumoral activity of the CXCR3 chemokine system is required for the efficacy of anti-PD-1 therapy. Immunity. 2019;50(6):1498-1512.e5.
Geissler K, Fornara P, Lautenschläger C, et al. Immune signature of tumor infiltrating immune cells in renal cancer. Oncoimmunology. 2015;4(1): e985082.
Koh HM, Hyun CL, Jang BG, et al. CXCR3 expression as a prognostic factor in gastric cancer: a meta-analysis. Transl Cancer Res. 2021;10(3):1449–56.
Hu M, Li K, Maskey N, et al. Overexpression of the chemokine receptor CXCR3 and its correlation with favorable prognosis in gastric cancer. Hum Pathol. 2015;46(12):1872–80.
Zhang Y, Xu L, Peng M. CXCR3 is a prognostic marker and a potential target for patients with solid tumors: a meta-analysis. Onco Targets Ther. 2018;11:1045–54.
Abron JD, Singh NP, Murphy AE, et al. Differential role of CXCR3 in inflammation and colorectal cancer. Oncotarget. 2018;9(25):17928–36.
Gudowska-Sawczuk M, Kudelski J, Mroczko B. The role of chemokine receptor cxcr3 and its ligands in renal cell carcinoma. Int J Mol Sci. 2020;21(22):8582.
Gao Q, Zhang Y. CXCL11 signaling in the tumor microenvironment. Adv Exp Med Biol. 2021;1302:41–50.
Li Z, Liu J, Li L, et al. Epithelial mesenchymal transition induced by the CXCL9/CXCR3 axis through AKT activation promotes invasion and metastasis in tongue squamous cell carcinoma. Oncol Rep. 2018;39(3):1356–68.
Lee JH, Kim HN, Kim KO, et al. CXCL10 promotes osteolytic bone metastasis by enhancing cancer outgrowth and osteoclastogenesis. Can Res. 2012;72(13):3175–86.
Chen Y, You S, Li J, et al. Follicular helper T-cell-based classification of endometrial cancer promotes precise checkpoint immunotherapy and provides prognostic stratification. Front Immunol. 2021;12: 788959.
Kondratiev S, Sabo E, Yakirevich E, et al. Intratumoral CD8+ T lymphocytes as a prognostic factor of survival in endometrial carcinoma. Clin Cancer Res Off J Am Assoc Cancer Res. 2004;10(13):4450–6.
Bao Y, Cao X. Epigenetic control of B cell development and B-cell-related immune disorders. Clin Rev Allergy Immunol. 2016;50(3):301–11.
Bajenova O, Gorbunova A, Evsyukov I, et al. The genome-wide analysis of carcinoembryonic antigen signaling by colorectal cancer Cells using RNA sequencing. PLoS ONE. 2016;11(9): e0161256.
Bai D, Chen S, Feng H, et al. Integrated analysis of immune-related gene subtype and immune index for immunotherapy in clear cell renal cell carcinoma. Pathol Res Pract. 2021;225: 153557.
Chen G, Fan X, Li Y, et al. Promoter aberrant methylation status of ADRA1A is associated with hepatocellular carcinoma. Epigenetics. 2020;15(6–7):684–701.
Baty F, Joerger M, Früh M, et al. 24h-gene variation effect of combined bevacizumab/erlotinib in advanced non-squamous non-small cell lung cancer using exon array blood profiling. J Transl Med. 2017;15(1):66.
Budczies J, Kirchner M, Kluck K, et al. Deciphering the immunosuppressive tumor microenvironment in ALK- and EGFR-positive lung adenocarcinoma. Cancer Immunol Immunother CII. 2022;71(2):251–65.
Bailer RT, Ng-Bautista CL, Ness GM, et al. Expression of interleukin-6 receptors and NF-kappa B in AIDS-related Kaposi sarcoma cell strains. Lymphology. 1997;30(2):63–76.
Yarchoan M, Hopkins A, Jaffee EM. Tumor mutational burden and response rate to PD-1 inhibition. N Engl J Med. 2017;377(25):2500–1.
Goodman AM, Kato S, Bazhenova L, et al. Tumor mutational burden as an independent predictor of response to immunotherapy in diverse cancers. Mol Cancer Ther. 2017;16(11):2598–608.
Zhou H, Chen L, Lei Y, et al. Integrated analysis of tumor mutation burden and immune infiltrates in endometrial cancer. Curr Probl Cancer. 2021;45(2): 100660.
Goodman AM, Sokol ES, Frampton GM, et al. Microsatellite-stable tumors with high mutational burden benefit from immunotherapy. Cancer Immunol Res. 2019;7(10):1570–3.
Chen P, Yang Y, Zhang Y, et al. Identification of prognostic immune-related genes in the tumor microenvironment of endometrial cancer. Aging. 2020;12(4):3371–87.
Tang S, Zhuge Y. An immune-related pseudogene signature to improve prognosis prediction of endometrial carcinoma patients. Biomed Eng Online. 2021;20(1):64.
Meng Y, Yang Y, Zhang Y, et al. The role of an immune signature for prognosis and immunotherapy response in endometrial cancer. Am J Transl Res. 2021;13(2):532–48.
Memczak S, Jens M, Elefsinioti A, et al. Circular RNAs are a large class of animal RNAs with regulatory potency. Nature. 2013;495(7441):333–8.
Acknowledgements
We thank all the colleagues from the Department of Gynecologic Oncology and the Department of Cancer Immunology of the First Hospital of Jilin University for their help in clinical sample collection and experimental guidance.
Funding
None.
Author information
Authors and Affiliations
Contributions
HD and YY designed the study and analyzed the data. HD and MS performed the statistical analyses and completed the visualization. HD and HL wrote the manuscript. YY collected the clinical samples. HD performed the experimental verification with qPCR. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study adhered to the tenets of the Declaration of Helsinki. All experiments and study protocols were approved by the Institutional Review Board (IRB) of the First Hospital of Jilin University. Written informed consent was obtained from all participants or their legal guardians. Biobanking protocols, including deposition and the collection procedures for the samples, were approved by the IRB of the First Hospital of Jilin University. All participants or legal guardians provided written, informed biorepository consent, including consent for future genomics research.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1
: Table S1. Identification of overlapping genes and estimate scores.
Additional file 2
: Table S2. Identification and validation of the prognostic immune-gene biomarker
Additional file 3
: Fig. S1. Screening the sensitive drugs relevant to the risk scores.
Additional file 4
: Fig. S2. Screening the sensitive drugs relevant to the risk scores.
Additional file 5
: Fig. S3. Screening the sensitive drugs relevant to the risk scores.
Additional file 6
: Fig. S4. Comparing the two risk groups' IC50 values of the relevantly sensitive drugs.
Additional file 7
: Fig. S5. Comparing the two risk groups' IC50 values of the relevantly sensitive drugs.
Additional file 8
: Fig. S6. Comparing the two risk groups' IC50 values of the relevantly sensitive drugs.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Dong, H., Sun, M., Li, H. et al. CXCR3 predicts the prognosis of endometrial adenocarcinoma. BMC Med Genomics 16, 20 (2023). https://doi.org/10.1186/s12920-023-01451-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12920-023-01451-9