
Abstract
Background
The automated collection of non-specific data from livestock, combined with techniques for data mining and time series analyses, facilitates the development of animal health syndromic surveillance (AHSyS). An example of AHSyS approach relates to the monitoring of bovine fallen stock. In order to enhance part of the machinery of a complete syndromic surveillance system, the present work developed a novel approach for modelling in near real time multiple mortality patterns at different hierarchical administrative levels. To illustrate its functionality, this system was applied to mortality data in dairy cattle collected across two Spanish regions with distinct demographical, husbandry, and climate conditions.
Results
The process analyzed the patterns of weekly counts of fallen dairy cattle at different hierarchical administrative levels across two regions between Jan-2006 and Dec-2013 and predicted their respective expected counts between Jan-2014 and Jun- 2015. By comparing predicted to observed data, those counts of fallen dairy cattle that exceeded the upper limits of a conventional 95% predicted interval were identified as mortality peaks. This work proposes a dynamic system that combines hierarchical time series and autoregressive integrated moving average models (ARIMA). These ARIMA models also include trend and seasonality for describing profiles of weekly mortality and detecting aberrations at the region, province, and county levels (spatial aggregations). Software that fitted the model parameters was built using the R statistical packages.
Conclusions
The work builds a novel tool to monitor fallen stock data for different geographical aggregations and can serve as a means of generating early warning signals of a health problem. This approach can be adapted to other types of animal health data that share similar hierarchical structures.
Similar content being viewed by others


Background
Animal health surveillance is essential for planning and implementing efficient prevention and control measures that are important for animal and public health [1, 2]. Current advances in data mining techniques and spatial-temporal analysis facilitate the development of novel animal health syndromic surveillance (AHSyS) approaches. These methods allow us to obtain information regarding the health status of animal populations to be extracted from diverse automated data sources of a non-specific nature in near real-time [3,4,5]. AHSyS may enhance traditional animal surveillance systems by identifying subpopulations at high risk, assessing the impact of previous prevention or control measures, supporting claims of freedom from disease, and serving as an early warning system [6]. This AHSyS approach involves the continuous analysis of mortality data registered at farm level. The potential of mortality data for this purpose has been demonstrated in previous studies conducted in a number of European countries [7,8,9,10,11,12]. In Catalonia (North-Eastern Spain), patterns of fallen bovine were modelled, for the main cattle production types between 2006 and 2013, using time series analyses [7, 8]. In those studies, bovine fallen stock data weekly aggregated at the regional level were fitted using autoregressive integrated and moving average (ARIMA) models. These models included trend and seasonal patterns as covariates. According to these ARIMA models and assuming regularity in the bovine population patterns over time, both the number of visits to carcass disposal and the total weight collected in these visits (in kg) were predicted at n-week ahead. These models provided information to assess the impacts of different events occurred over time at the regional level. However, to identify high-risk subpopulations and/or to serve as an early warning system, the number of fallen bovines must be assessed at more spatially discrete administrative aggregations. With this aim, fallen bovine data aggregated at province and county levels were plotted using hierarchical time series structures (HTS) according to the methodology proposed by Hyndman et al. [13, 14]. These plots indicated that patterns in fallen bovine data varied substantially among different subpopulations. This implied that multiple time series would have to be modelled at more refined spatial scales in order to get well-fitting models for different spatial aggregations.
This work is a methodological extension to the modelling approach introduced in the previous papers of Alba et al. [7, 8]. In [7, 8] the indicator of fallen stock was only modelled at the region level. Although the modelling of these data aggregated at higher levels allowed the quantification of the total impact (or lack thereof) on a population in the event of a potential animal threat, using only this level of analysis, the likelihood of detecting local and moderate variations was limited. The problem was that the selection of an appropriate and parsimonious ARIMA model accounting for seasonality and trend for specific time series involved the testing and checking of many combinations of values for each parameter. This process was not automatic and modelling many time series from different subpopulations was very tedious. Previously, Alba et al. plotted the time series of smaller subpopulations using HTS structures. However, these HTS did not quantify temporal patterns, forecast mortality based on previous observations, or detect aberrations over time at different administrative levels. The present study solves this problem by creating an automated process to analyze patterns of multiple fallen cattle subpopulations with lower numbers and high variability. This modelling process aimed to analyze and predict fallen stock patterns at both low and high geographical levels. Moreover, in this work, we used as an indicator of fallen dairy cattle the “counts of fallen bovines”, which is more accurate than the “counts of carcass disposal visits” or the “total of kg collected” used before by Alba et al. 2015 [7].
To illustrate the functionality of our method in different contexts, it was put in motion by using the retrospective fallen stock data of dairy cattle collected between 2006 and 2015 in two regions of Spain with different demographical structure, husbandry systems, and climate conditions.
Results
These results describe the basic traits of two Spanish regions with distinct dairy cattle populations (R1 and R2) and the monitoring of counts of fallen bovines collected by week at three administrative levels (i.e., region, province, and county) over a 10-year period.
The region R1 had registered 3469 dairy farms (with an annual median of 2958 dairy farms and 117,572 heads of cattle), while region R2 had 984 farms registered (with an annual median of 797 farms and 124,953 heads of cattle). This system covered 77 and 81% of all these dairy farms of R1 and R2, respectively. Figure 1 shows the administrative levels monitored in this study, i.e. across R1 seven of its 17 counties, and across R2 two of its four provinces, and in seven of its 26 counties.

Spanish regions, provinces, and counties within which the levels of fallen dairy cattle were monitored. The figure is own-created
Over this period of study in these two regions, the number of dairy cattle farms decreased and the sizes of the herds increased; but the total number of bovines in these populations did not change substantially. R1 had 3.4 times more dairy farms than R2 and the herd size was 2.8 times smaller. This difference was also evidenced consistently at smaller administrative levels, such as provinces and counties. The proportion of herds in extensive production also varied, being around 0% in R2 and 25% in R1. Regarding the climate, this was quite similar across counties of R1, but differed among the counties of R2. Moreover, in some counties of R2 the high proportion of herds housed all-year-round combined with a continental climate with warm summers could cause heat stress problems and an increase of mortality. Initially, each administrative level was described through the number of dairy farms, the herd size, the type of husbandry, the climate, and the number of fallen bovines collected in total and by week. This preliminary exploration indicated that most of these subpopulations differed substantially in relation to demographical and climate traits as shown in Table 1.
Plots of the HTS of weekly counts of fallen bovines at region, province and county levels are shown in S2 and S3 Figs.
The respective plots of HTS for each region indicated that the fallen stock patterns varied among subpopulations. For this reason, it was important to model these patterns at each administrative level to obtain robust information, detect and investigate abnormal mortality events and support the decision-making.
For each administrative aggregation the most appropriate ARIMA model, which could include trend and seasonal effects, was fitted based on the training dataset collected between Jan-2006 and Dec-2013.
The main traits of the two dairy cattle subpopulations and the monitored fallen stock data are summarized in Table 1.
In most of these administrative levels of both regions R1 and R2, the fallen dairy cattle presented annual and biannual seasonality, with an increasing trend over time. Interestingly, this pattern was consistent for all the counties of R2, but differed among counties of R1. Both regions (i.e., all the series in R2 and six series of R1) exhibited an increased trend and seasonal pattern that rose during January and February, coinciding with the coldest season (Figs. 2 and 3). During July and August, in the warmest period of the year, there was also an increase of mortality, but this rise was only very evident in R2 and especially in some counties (see Table 1). The weekly counts of fallen bovines collected were much lower in R1 than in R2 (i.e., a median of 221 heads in R1, versus 308 in R2). However, the number of farms involved in each peak was higher in R1 than in R2 (a median of 145 farms in R1, versus 38 in R2). Moreover, it should be noted that in R1 the trend and seasonal patterns among counties were more disparate and irregular, mainly in counties with lower counts such as C5 and C7. Finally, based on these models, the fallen bovines expected by week were forecasted for each subpopulation during Jan-2014 and Jun-2015. Those observations that exceeded the predicted upper confidence limits were signaled as mortality aberrations.

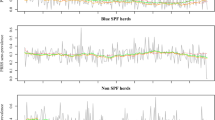
Time series plots of fallen bovines in the training data set collected weekly together with mortality peaks (A) detected in the testing dataset for R1 (P1)

Time series plots of fallen bovines in the training dataset collected by week together with mortality peaks (A) detected in the testing dataset for R2
Considering a conventional upper 95% confidence limit, six mortality aberrations would be signaled at a province level (four in R1 and two in R2) affecting a total of 553 farms (466 in R1 and 87 in R2). Two of the four peaks detected in R1 at a province level were also detected at a county level, while in R2 all peaks detected at a province level would be also detected at a county level (see Figs. 2 and 3).
In both regions there was a marked increase in counts of mortality during Jan-2015, being identified as unusual events in all administrative aggregations except for one county (C14 in R2).
Discussion
Despite the growing interest of using syndromic information for AHSyS [6], its implementation as a part of an early warning system has to be validated in the field yet. In many European countries, bovine fallen stock data have been gathered consistently over several years by carcass disposal services, covering a significant proportion of active farms. The potential use of bovine fallen stock data for AHSyS was described in previous studies [7,8,9,10,11,12]. In [9, 11], some authors also demonstrated the usefulness of these methods for assessing the impact of past events, such as the incursion of bluetongue or the heat waves in 2003 and 2006 in the French cattle population. However, many technical challenges must still be faced when putting in place the monitoring of bovine fallen stock as part of an alert system or as a support tool for decision making [7, 10].
One of the main challenges relates to the heterogeneity of the animal populations under surveillance. In the context of animal health surveillance, the target population usually comprises different subpopulations with disparate managements, structures and risks. Moreover, the official animal health services of different administrative levels coordinate which prevention and control measures should be applied in each population. The modelling approach proposed in this study allows for an assessment of bovine fallen stock baselines and the detection of mortality peaks in different populations. The results of this study indicate that the baselines of fallen bovines vary among different administrative aggregations. Consequently, an effective monitoring system based on fallen stock data should be able to provide information and detect alerts for each population in near real time.
In this work we combined the expertise from veterinary epidemiologists and statisticians to lead to a robust tool that constitutes an important step towards its implementation. Its functionality has been illustrated across two regions of Spain from populations with different husbandry systems and environmental conditions. Accordingly, this study demonstrated the capability of this approach to analyze, model and predict, in an automatic way, the number of fallen dairy cattle by week for different subpopulations.
The system used as an indicator of mortality the number of carcasses collected each week, assuming that the studied populations remained relatively constant over time. To support this assumption, the behavior of the dairy population was explored year-by-year for both regions. This exploration indicated that, although the number of dairy cattle farms decreased throughout the study, the number of dairy cattle heads slightly increased.
Initially, the weekly counts of fallen bovines were described and plotted for all administrative levels using HTS. This technique was used to explore, compare fallen dairy cattle patterns among different administrative levels, and select those series that would be immediately modelled using a time series methodology such ARIMA modelling, including trend and seasonality as covariates.
A computer programming routine was developed to fit an ARIMA model for each selected administrative aggregation, forecast the counts of fallen dairy cattle that would be expected at n-ahead period and identify those counts that exceeded the upper 95% confidence limit, as presumed mortality peaks. This system can be applied to different dairy cattle population structures (such as those seen in R1 or R2).
Classical time series models such ARIMA had the advantage that they can deal with trend and seasonal components as well as temporal correlation structures, which in the case of fallen bovine data were especially marked (see S1 and S2 Tables). The trend and seasonal components could be modelled using trigonometric functions [15], simple exponential smoothing [16, 17] or Holt-Winters [18, 19]. The temporal autocorrelation could be fitted using autoregressive integrated moving average (ARIMA) models [20, 21]. In this work ARIMA modelling, including possible trends and seasonal effects as covariates, demonstrated to best fit data related to weekly counts of fallen bovines without requiring excessive computation time and using standard software. Moreover, if the response variable would depart from the normality assumption (e.g. time series with counts less than 10 in average), these models could be replaced by Integer-valued Autoregressive (INAR) models [12, 22]. Other more sophisticated methodologies of time series have been proposed. For instance, Le Strat and Carrat [23] used Hidden Markov Models (HMM) to monitor epidemiological data by segmenting series into epidemic and non-epidemic unobserved phases. These unobserved phases could be modelled by a two-state homogeneous Markov chain of order 1 (epidemic and non-epidemic); higher orders could also be considered. As an alternative, Martinez-Beneito [24] proposed a Markov switching model in which the response variable did not depend only on the hidden states, but also on the lagged observable variable. However, according to [25], these methodologies both require extensive computation time and are therefore not suited to monitoring epidemiological data in near real time. Furthermore, in general, Bayesian methods were computationally intensive and strongly dependent on prior information, which in our case did not exist [26]. Parametric regression techniques, including a variety of models such as simple regression, could be explored. These include naive regression that estimated the response variable at time by the mean of responses at times t-1, t and t + 1 to adjust for possible seasonal effects [27] or extended regression that incorporated trigonometric functions with linear trend accounting for both trends and seasonal effects [28]. Additionally, when the response variable departed from normality (i.e. low counts with many zeros), some authors [29,30,31] have proposed Poisson regression models with logarithmic link to model possible trends and seasonal patterns. Hierarchical generalized linear mixed models [32] are another methodology for fitting non-normal correlated data. Another approach of semiparametric regression could be considered; these combine parametric models for representing series data and non-parametric models for including possible trends and seasonal effects, such as smoothing methods [33] and generalized additive models [34]. Although these regression methods take into account trends and seasonal components, the major disadvantage of using these techniques for fallen stock data is that the models did not consider the temporal correlation structure.
Similar drawbacks exist for methods related to statistical control process, which are mainly based on control charts (cumulative sum and exponentially weighted moving average) [35, 36], temporal scan statistics [37] or intervened times [38]. As in the case for regression techniques, these models seemed to be simpler in terms of interpretation and computation, but they did not adequately handle the autocorrelation structures of our data.
Other possible alternatives might be those based on models which take into account spatial information (i.e. cumulative sum charts, temporal scan statistics or spatial regression) [39,40,41,42,43] or methods of multivariate outbreak detection that dealt with several correlated series related to the same process [44, 45]. In contrast to previous techniques, spatial and multivariate models allow for the incorporation of correlation structures in the data, but there was the inconvenience that they would likely require the inclusion of new data, such as point locations of farms [39,40,41,42,43], or the application of dimension reduction methods [46].
Comparison of baselines among different populations obtained from the models
Based on the selected ARIMA models, we observed that in region R2 all counties exhibited an increasing linear trend, and an annual or biannual seasonality. This region (and its provinces and counties) presented a more homogeneous behavior in mortality data than region R1.
This method could provide relevant information to point out or discard different health problems in these populations by comparing the number of mortality peaks detected among subpopulations, the time and season of detection, and the number of farms involved in each peak. For example, some mortality peaks detected at a regional level were also detected at a province and county levels (marked with dotted lines in Figs. 2 and 3). In particular, in R1, there were two peaks in weeks 466 and 470 that were detected at a region and county (C1, C2, and C3) levels. On the other hand, in R2, there was a mortality peak in week 469 that was identified at a region, province (P3), and county (C14) level. This suggested that the cattle populations of these hierarchical series were affected by a common cause. However, it is also important to underline that there were mortality peaks that were only detected at a county level, and were thus likely linked to the occurrence of more local events.
These results provide evidence that the analysis of bovine fallen stock data throughout several hierarchical administrative levels may bring relevant information to assess the evolution and the impact of different events occurred and/or detect earlier the start of a health threat that can spread to other areas. The assessment of mortality at lower aggregation level may put in evidence the occurrence of a local health problem (e.g. a food-borne infection locally transmitted), but also may sign the start of a contagious disease outbreak. In this last case, if mortality counts are uniquely studied at higher aggregation level, some problems may be unnoticed and get worse due to the lack of implementation of prevention measures on due time. Contrarily, the analyses conducted at higher aggregation level provide information to determine more easily the domain and global impact of a specific event on the study population and support the policy decision-making to coordinate actions of prevention and/or control at this level if it is necessary. Our outcomes (see Table 1 and Figs. 2 and 3) are consistent with the rationale that the analysis of this kind of data, aggregated at different hierarchical levels, enhances the detection of unusual aberrations, both globally and locally.
Limitations of the study
Despite the benefits of our approach for AHSyS use, it is also important to discuss some constraints. First, the use of counts of fallen cattle as a proxy measure of mortality without taking into account the farm size could cause an over-expression of larger farms, masking unusual mortality events occurred in small farms. Besides, the baselines of fallen bovines might vary according to other factors, such as age, breed or sex. To enhance the accuracy of the system and identify unusual events of mortality for different populations, it would be important to include these covariates in the future. Unfortunately, these covariates could not be incorporated within our present study due to the lack of accuracy of the available records relating to these fields.
Second, it is important to recall that ARIMA models can only be used when populations and subpopulations show regular average counts. On this matter, it was first necessary to disaggregate and describe the series using HTS, to select those that could adequately be fitted using ARIMA models. Thus, the current results only covered a part of the subpopulations at province and county levels. A future innovation of the system to model the mortality in these subpopulations with very low counts would be to use integer-valued autoregressive models (INAR) [22], Hermite integer-valued autoregressive models (HINAR) [12], Bayesian approaches for seasonal count time series [20] or one of the other techniques reviewed in [25].
Third, the use of historical data without any prior exploration or filtering as a training set presented important limitations. For instance, if the population under study had suffered any unusual health problem during this period, the problem could be misclassified as a regular event and be included as a part of the basal pattern of the series, leading to a loss of sensitivity for similar alerts.
Fourth, to illustrate how our system forecasts and detects unusual aberrations, we used a conventional upper confidence limit of 95% a year and a half ahead. However, considering the unspecific nature of fallen stock data and the heterogeneity among subpopulations, it is plausible to think that the causes that underlie each mortality pattern and produced unusual aberrations could differ for each subpopulation. This implies that the optimal upper limits may have to be set according to the context of each subpopulation. Unfortunately, currently, the available information to determine these limits is scarce and unspecific, and any validation of this system in the field would require significant additional effort. Accordingly, we believe that the validation of this method as an early warning system would require more robust and updated data as well as the establishment of a more effective hierarchical communication between the field and each administrative level. All these aspects have led us to plan for a follow-on study to conduct an accurate validation using a multidisciplinary approach and more recent data.
Conclusions
This work proposes a novel methodology to enhance the monitoring of bovine fallen stock data at different administrative levels and detect unusual mortality events. The system may provide essential information to identify spatiotemporal populations at high risk and allocate more effectively resources destined to control and prevent potential health problems. Moreover, the methodology proposed in this work can be applied to other populations and adapted to other AHSyS initiatives that require the follow-up of many populations with disparate husbandry systems.
Methods
The populations under surveillance were dairy cattle in two Spanish regions: R1 (Principado de Asturias) and R2 (Catalonia). The region R1 included a large number of farms with small herd sizes, mostly in extensive husbandry systems. This region R1 had green landscapes and was characterized by coastal oceanic climate with moderate to high precipitations and moderate temperatures. In contrast, the region R2 had fewer farms but with larger herd sizes, most of which were in intensive production. Region R2 was characterized by a complex and diverse orography and a combination of a continental, coastal Mediterranean and alpine climates. These regions were monitored between 1st of Jan-2006 and 31th of Jun-2015.
During this period in both regions, and according to the European Union regulations [47], fallen animals were removed from farms using specialist disposal services. According to the Royal Decree 728/2007 (Annex III) [48], all the cattle farmers were obliged to use national fallen stock companies to collect and dispose their fallen stock and communicate the cattle casualties to the official animal health services.
Types and sources of data
Two types of data from dairy cattle populations were used: fallen stock and demographic data. Fallen bovines data were provided by two national insurance companies: Entidad de Seguros Agrarios (ENESA) and Agrupación Española de Entidades Aseguradoras de los Seguros Agrarios Combinados S.A. (AGROSEGURO). For every visit where carcass disposal occurred, the following information was recorded: the identification code of the farm, date of pick-up, number of carcasses, and number of kilograms collected. On the other hand, demographic data yearly updated, were provided by the Sub-Directorate General for Animal Health and Hygiene and Traceability of the Ministry of Agriculture, Fisheries and Food of Spain (MAPA). This data set included: the identification code of the farm, type of production, number of dairy cattle per holding, and administrative aggregations (i.e. region, province, and county). Both sets of data, fallen bovine stock and bovine population, were merged in a final dataset using the identification code of the farm as a primary key.
According to the legal basis on the protection of personal data [49], the non-public staff and scientists involved in the analyses of these data signed a confidentiality agreement to set out the terms and conditions to limit the collection, handling, and disclosure of non-public information from farmers.
Statistical analysis
We built a routine that consisted of a sequence of analytical methods designed to:
-
(1)
describe and select longitudinal fallen stock data aggregated at different levels (i.e., region, province, and county);
-
(2)
fit, for each subpopulation, appropriate time series models;
-
(3)
forecast the number of fallen bovine stock at n- ahead period; and
-
(4)
detect and register aberrations in mortality counts over time, considering the conventional upper confidence limit of 95%.
Hierarchical time series structures
Firstly, for exploring and comparing baseline patterns from different sub-populations, fallen stock data aggregated at each of the three administrative levels were described and represented using HTS [13, 14]. HTS provide a rapid means to visualize, aggregate, and disaggregate series from different subpopulations. The HTS were designed by combining the information on the fallen dairy cattle at the most disaggregated level of the time series (in our case, counties) and the hierarchical organization. This dictates how the information, at the county level, had to be aggregated into provinces and regions. An explanatory illustration has been included in the supplemental material (S1 Fig) to explain the methodology used to build the HTS structures. The ‘base’ and ‘hts’ packages in the software R were used to support their creation [14].
ARIMA modelling including trend and seasonal terms
The patterns and forecasting of weekly fallen bovines at different administrative levels were analyzed using ARIMA models that included trend and seasonal components as covariates. It is important to remark that ARIMA models are preferable for regular time series of normally distributed observations. Therefore, once the data were disaggregated into regions, provinces, and counties through HTS, each series that showed counts greater than or equal to 10 in average and normally distributed [50] were considered for ARIMA modelling. Since we were dealing with counts, most of the time series were Poisson distributed [12]. According to [51], for those series with an average higher than 10 counts, the Poisson distribution is well approximated by the Normal distribution; thus our selected series could be properly modelled through a classical parametric approach such ARIMA. These series also coincided with those administrative levels in which the dairy populations were larger within these two regions of study.
The ARIMA model, an extension of the ARMA (Autoregressive and Moving Average) model, has been widely used in the classical time series analysis and has also been applied in many contexts related to veterinary and public health [7, 50, 52, 53]. The autoregressive part of an ARIMA model (AR) indicates that the temporal response variable (i.e., weekly fallen bovine counts) is regressed by its lags. While the moving average part (MA) indicates that the model error is regressed by its lags (i.e., at time t, the lags of a random variable Zt are essentially temporal delays such as Zt − 1, Zt − 2 …). The latter means that the error does not behave like white noise. These ARIMA models can also be used even if the series are non-stationary (i.e., when they present positive, negative, or quadratic trends, and/or annual and biannual seasonality, among other). In these cases, some initial differentiation can be applied one (d = 1) or more times (d > 1) to make the series stationary. Conceptually, when series are differentiating, the count at time t-1 is subtracting from the count at time t. The general ARIMA model is defined by the parameters p (autoregressive part), d (differentiation), and q (moving average part).
Let the random variable Xt be an ARMA (p, q) model such that:
where Xt is a stationary series at time t, α is the intercept of the model, ρ1, ρ2, …, ρp are the coefficients of the autoregressive term, θ1, θ2, …, θq are the coefficients of the moving average term, and Zt, Zt − 1, …, Zt − q are the error terms of the model which are normally distributed. In case of lack of stationarity, the series Xt can be differentiated (d > 0) before estimating the parameters in Eq.1 to avoid possible trend and seasonal effects, leading to an ARIMA (p, d, q) model. Additionally, trends and seasonal influences can be included in the ARIMA (p, d, q) model as covariates. In particular, we accounted for trend and seasonality effects in the ARIMA (p, d, q) model by using the following equation:
where Yt is the observed series at time t (which can be non-stationary), Xt is the stationary ARIMA (p, d, q) model expressed in Eq. 1., γ1is the trend coefficient, γ2 and γ3 are the coefficients of the annual seasonality aggregated at a weekly level, and γ4 and γ5 the coefficients of the biannual seasonality aggregated at a weekly level. Here the trigonometric part corresponds to the first and second-order Fourier terms commonly used in the analysis of time series [54].
These models were used to monitor the number of weekly fallen bovines for each subpopulation at every selected administrative level and identify abnormal peaks of mortality by comparing the predictions to the observations.
The number of weekly fallen bovines recorded between Jan-2006 and Jun-2015 at the regional, provincial, and county levels were divided into training and testing data sets. The data collected between Jan-2006 and Dec-2013 were used for estimating the model parameters for each population, while the data collected between Jan-2014 and Jun-2015 were used for testing the models and identifying unusual increases of mortality.
To estimate the most appropriate values of parameters p, d and q for the ARIMA models (Eq. 1), and also the linear trend and seasonal coefficients (Eq. 2) we built a programming routine. This routine explored a range of values between 0 and 5 for parameters p and q. For instance, if p = 5, the observed count at week t was regressed by the counts at weeks t-1, t-2, t-3, t-4 and t-5; while if q = 5, the error at week t was regressed by the errors at weeks t-1, t-2, t-3, t-4 and t-5. Here, the parameter d was constrained to a binary indicator, taking 0 (not differentiating) or 1 (differentiating once and removing the linear trend). Note that in those series in which the trend was not linear, but quadratic, the series was differentiated, and a coefficient of the linear trend (Eq. 2) was also included in the candidate model. The inclusion of this coefficient was because the trend was not linear, and hence it was not entirely removed by differentiating only once. In some scenarios, this problem could have been addressed by considering values of d greater than 1.
In order to select the most suitable ARIMA model for each time series among all candidates, three criteria were considered. The first one was based on the Bayesian Information Criterion (BIC) proposed by Schwarz [55]. The model with the smallest BIC was preferred over the whole set of candidates. The BIC was used because it typically provides more parsimonious models (in terms of the number of parameters) than those proposed by the Akaike Information Criterion (AIC). In addition, the BIC is also more robust than the AIC when coping with heterogeneity in samples [56]. The second and third criteria consisted of assessing the statistical significance of the model parameters given a significance level (i.e., 5%), and checking the behavior of the model residuals through the Auto-Correlation Function (ACF) and the Partial Auto-Correlation Function (PACF), respectively. The best ARIMA model was the one for which the third criterion was not only completely satisfied but also demonstrated good results for both the first and the second criteria. Full details can be found in [20, 21, 54].
Subsequently, each selected model was used to predict the expected number of carcasses that would be collected weekly between Jan-2014 and Jun-2015 in each population from every selected administrative aggregation. Those observed counts of fallen dairy cattle that exceeded the 95% confidence limits predicted by the selected ARIMA models were identified as mortality peaks. Reasonably, any relevant increase in mortality could sign an unusual event in the population, and thus require further investigation at field level to determine the specific causes. In case a presumed mortality peak would be detected, this routine provided a list with the identification codes of all involved farms. Additionally, the list also provided information on the number of carcasses recorded during the peak and over the preceding two weeks in those farms.
The programming routine was built using the base package of R [28].
Availability of data and materials
The authors (AFF & AA) were required to analyze these data. Public access to these data is only possible through written permission of the Spanish Ministry of Agriculture and Fisheries and Food The access of programming routines and analyses generated during this study are possible through the contact of the corresponding author of this paper.
Abbreviations
- ACF:
-
Auto-Correlation Function
- AGROSEGURO:
-
Agrupación Española de Entidades Aseguradoras de los Seguros Agrarios Combinados S.A
- AIC:
-
Akaike Information Criterion
- AHSyS:
-
Animal Health Syndromic Surveillance
- AR:
-
Autoregressive
- ARIMA:
-
Autoregressive Integrated and Moving Average
- ARMA:
-
Autoregressive and Moving Average
- BIC:
-
Bayesian Information Criterion
- C:
-
County
- d:
-
Order of differentiation
- ENESA:
-
Entidad de Seguros Agrarios
- HINAR:
-
Hermite Integer-Valued Autoregressive
- HMM:
-
Hidden Markov Models
- HTS:
-
Hierarchical time series structures
- INAR:
-
Integer-valued Autoregressive
- MA:
-
Moving Average
- MAPA:
-
Ministry of Agriculture, Fisheries and Food
- p:
-
Order of autoregressive part
- P:
-
province
- PACF:
-
Partial Auto-Correlation Function
- q:
-
Order of moving average part
- R:
-
Region
References
Hoinville LJ, Alban L, Drewe JA, Gibbens JC, Gustafson L, Hasler B, et al. Proposed terms and concepts for describing and evaluating animal-health surveillance systems. Prev Vet Med. 2013;112(1):1–12. https://doi.org/10.1016/j.prevetmed.2013.06.006.
Kuiken T, Leighton FA, Fouchier RAM, LeDuc JW, Peiris JSM, Schudel A, et al. Public health. Pathogen surveillance in animals. Science. 2005;309(5741):1680–1. https://doi.org/10.1126/science.1113310.
Dorea FC, Sanchez J, Revie CW. Veterinary syndromic surveillance: current initiatives and potential for development. Prev Vet Med. 2011;101(1):1–7. https://doi.org/10.1016/j.prevetmed.2011.05.004.
Dorea FC, McEwen BJ, McNab WB, Revie CW, Sanchez J. Syndromic surveillance using veterinary laboratory data: data pre-processing and algorithm performance evaluation. J R Soc Interface. 2013;10(83):20130114. https://doi.org/10.1098/rsif.2013.0114.
Dupuy C, Bronne A, Watson E, Wuyckhuise-Sjouke L, Reist M, Fouillet A, et al. Inventory of veterinary syndromic surveillance initiatives in Europe (triple-S project): current situation and perspectives. Prev Vet Med. 2013;111:220–9. https://doi.org/10.1016/j.prevetmed.2013.06.005.
Dorea FC, Vial F. Animal health syndromic surveillance: a systematic literature review of the progress in the last 5 years (2011-2016). VMRR. 2013;7:157170.
Alba A, Dorea FC, Arinero L, Sanchez J, Cordon R, Puig P, et al. Exploring the surveillance potential of mortality data: nine years of bovine fallen stock data collected in Catalonia. PLoS One. 2015a;10(4):e0122547. https://doi.org/10.1371/journal.pone.0122547.
Alba A, Fernández-Fontelo A, Revie CW, Dorea F, Sanchez J, Romero L, et al. Development of new strategies to model bovine fallen stock data from large and small subpopulations for syndromic surveillance use. Epidemiol et sante anim. 2015b;67:67–76.
Morignat E, Perrin JB, Gay E, Vinard JL, Calavas D, Henaux V. Assessment of the impact of the 2003 and 2006 heat waves on cattle mortality in France. PLoS One. 2014;9(3):e93176. https://doi.org/10.1371/journal.pone.0093176.
Perrin JB, Ducrot C, Vinard JL, Morignat E, Gauffier A, Calavas D, Hendrikx P. Using the National Cattle Register to estimate the excess mortality during an epidemic: application to an outbreak of bluetongue serotype 8. Epidemics. 2010;2(4):207–14.
Perrin JB, Ducrot C, Vinard JL, Morignat E, Calavas D, Hendrikx P. Assessment of the utility of routinely collected cattle census and disposal data for syndromic surveillance. Prev Vet Med. 2012;105:244–52. https://doi.org/10.1016/j.prevetmed.2011.12.015.
Fernández-Fontelo A, Fontdecaba S, Alba A, Puig P. Integer-valued AR processes with Hermite innovations and time-varying parameters: an application to bovine fallen stock surveillance. Stat Model. 2017;17(3):1–24.
Hyndman RJ, Ahmed RA, Athanasopoulos G, Shang HL. Optimal combination forecasts for hierarchical time series. Comput Stat Data Anal. 2011;55:25792589. https://doi.org/10.1016/j.csda.2011.03.006.
Hyndman RJ, Ahmed RA, Shang HL, Wang E. hts: Hierarchical and grouped time series. R package version 4.00, URL: http://CRAN.R- project.org/package=hts; 2014.
Serfling R. Methods for current statistical analysis of excess pneumonia-influenza deaths. Publ Hlth Rep. 1963;78:494–506.
Healy MJR. A simple method for monitoring routine statistics. Statistician. 1983;32:347–9.
Ngo L, Tager IB, Hadley D. Application of exponential smoothing for nosocomial infection surveillance. Am J Epidem. 1996;143:637–47.
Holt CC. Forecasting Seasonals and trends by exponentially weighted moving averages, Memorandum ONR 52/1957. Pittsburgh: Carnegie Institute of Technology; 1957.
Winters PR. Forecasting sales by exponentially weighted moving averages. Management Sci. 1960;6:324–42.
Chatfield CH. The analysis of time series: an introduction. 6th ed. Boca Raton: Chapman and Hall/CRC; 2004.
Cowpertwait PSP, Metcalfe AV. Introductory time series with R. Heidelberg, London, New York: Springer Dordrecht; 2009.
Moriña D, Puig P, Rios J, Vilella A, Trilla A. A statistical model for hospital admissions caused by seasonal diseases. Stat Med. 2011;30(26):3125–36. https://doi.org/10.1002/sim.4336.
Le Strat Y, Carrat F. Monitoring epidemiologic surveillance data using hidden Markov models. Stat Med. 1999;18:3463–78.
Martinez-Beneito MA, Conesa D, Lopez-Quilez A, Lopez-Maside A. Bayesian Markov switching models for the early detection of influenza epidemics. Statt Med. 2008;27:4455–68.
Unkel S, Farrington CP, Garthwaite PH. Statistical methods for the prospective detection of infectious disease outbreaks: a review. J R Stat Soc. 2012;175(1):48–82.
Jornet-Sanz M, Ana Corberan-Vallet A, Santonja F, Villanueva R. A Bayesian stochastic SIRS model with a vaccination strategy for the analysis of respiratory syncytial virus. SORT. 2017;41(1):159176.
Stroup DF, Williamson GD, Herndon JL, Karon JM. Detection of aberrations in the occurrence of notifiable diseases surveillance data. Statist Med. 1989;8:323–9.
R Core Team. R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing; 2015. URL https://www.R- project.org/.
Parker RA. Analysis of surveillance data with Poisson regression: a case study. Statist Med. 1989;8:285–94.
Jackson MJ, Baer A, Painter I, Duchin J. A simulation study comparing aberration detection algorithms for syndromic surveillance. BMC Med Informat Decsn Makng. 2007;7:6.
Farrington CP, Andrews NJ, Beale AD, Catchpole MA. A statistical algorithm for the early detection of outbreaks of infectious disease. J R Statist Soc. 1996;159:547–63.
Molenberghs G, Verbeke G, Demétrio CGB. Hierarchical models with normal and conjugate random effects: a review. SORT. 2017;41(2):191–254.
Stern L, Lightfoot D. Automated outbreak detection: a quantitative retrospective analysis. Epidem Infectn. 1999;122:103–10.
Wieland SC, Brownstein JS, Berger B, Mandl KD. Automated real-time constant specificity surveillance for disease outbreaks. BMC Med. Informat. DesnMakng. 2007;7:15.
Shewart, W.A. (1931) Nostr and Reinhold. Roberts, S. W. (1959) Control chart tests based on geometric moving averages. Technometrics, 1, 239–250.
Page ES. Continuous inspection schemes. Biometrika. 1954;41:100–15.
Naus J, Wallenstein S. Temporal surveillance using scan statistics. Statist Med. 2006;25:311–24.
Sego LH, Woodall WH, Reynolds MR. A comparison of surveillance methods for small incidence rates. Statist Med. 2008;27:1225–47.
Rogerson PA. Surveillance systems for monitoring the development of spatial patterns. Statist Med. 1997;26:2081–93.
Rogerson PA. Monitoring point patterns for the development of spacetime clusters. J R Statist Soc. 2001;164:87–96.
Wallenstein S, Gould M, Kleinman M. Use of the scan statistic to detect time-space clustering. Am J Epidem. 1989;130:1057–64.
Lawson AB. Spatial and spatio-temporal disease analysis. In: Lawson AB, Kleinman K, editors. Spatial and Syndromic surveillance for public health. Chichester: Wiley; 2005. p. 55–76.
Clark AB, Lawson AB. Surveillance of individual level disease maps. Statist Meth Med Res. 2006;15:353–62.
McCabe GJ, Greenhalgh D, Gettingby G, Holmes E, Cowden J. Prediction of infectious diseases: an exception reporting system. J Med Informat Technol. 2003;5:67–74.
Kulldorff M. A spatial scan statistic. Communs Statist Theor Meth. 1997;26:1481–96.
Jolliffe IT. Principal component analysis. 2nd ed. New York: Springer; 2002.
European Union Commission, et al. Regulation (EC) no. 1774/2002 of the European Parliament and of the Council of 3 October 2002 laying down health rules concerning animal by-products not intended for human consumption. Off J Eur Communities L. 2002;273:1–95.
Royal Decree 728 / 2007, Of 13 Of June, By Which Is Sets And Regulates The Register General Of Movements Of Won And The Register General Of Identification Individual Of Animals. (Real Decreto 728/2007, de 13 de junio, por el que se establece y regula el Registro general de movimientos de ganado y el Registro general de identificación individual de animales).
Royal Decree 1720/2007, of December 21th, which approves the regulation implementing Organic Law 15/1999 of December 13th on the protection of personal data in any type of clinical research. (Real Decreto por el que se aprueba el Reglamento de desarrollo de la Ley Orgánica 15/1999, de protección de datos de carácter personal, BOE 17 of January 19th, 2008).
Lee HS, Her M, Levine M, Moore GE. Time series analysis of human and bovine brucellosis in South Korea from 2005 to 2010. Prev Vet Med. 2013;110(2):190–7. https://doi.org/10.1016/j.prevetmed.2012.12.003.
Rosner B. Fundamentals of biostatistics. 8th ed. Boston: Cengage Learning; 2016.
Neumann E, Hall W, Stevenson M, Morris R. Descriptive and temporal analysis of post-mortem lesions recorded in slaughtered pigs in New Zealand from 2000 to 2010. N Z Vet J. 2014;62(3):110–6.
Chamba Pardo FO, Alba-Casals A, Nerem J, Morrison RB, Puig P, Torremorell M. Influenza herd-level prevalence and seasonality in breed-to-wean pig farms in the Midwestern United States. Front Vet Sci. 2017;4:167.
Brockwell PJ, Davids RA. Introduction to time series and forecasting. 2nd ed. New York: Springer-Verlag New York, Inc; 2002.
Schwarz G. Estimating the dimension of a model. AnnStatist. 1978;6(2):461464.
Brewer MJ, Butler A, Cooksley SL. The relative performance of AIC, AICC and BIC in the presence of unobserved heterogeneity. MEE. 2016;7(6):679–92.
Acknowledgements
The authors of this work want to thank the technical staff of ENESA, AGROSEGURO and REGA for their valuable contribution and also for supplying the data. We also thank the technical staff of Los Servicios Oficiales del MAPA, the researchers of CReSA-IRTA and, a special thanks to Dr. Joaquim Segales (CReSA-IRTA), Dr. Jordi Casal (CReSA-IRTA) and Dr. Andres Perez (University of Minnesota) for their support during the elaboration of this work.
Funding
The Spanish Ministry of Agriculture, Food and Environment have supported this work as a minor contract, whose primary role was as data providers.
Author information
Authors and Affiliations
Contributions
A.F.F and A.A.C. designed the system, analyzed and interpreted data. A.F.F. built the programming routine. A.A.C. designed the maps. P.P. was a major contributor in the performance of statistical modeling techniques. G.C. and L. R participated in the design of the study, the data organization, collection and interpretation of result. C.R, F.C.D and J.S. contributed to the discussion and to the preparation of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This work has been written in agreement with the data providers: AGROSEGURO SA and the Spanish Ministry of Agriculture, Food, and Environment. The data have been analyzed aggregately, and guaranteeing the digital rights, their privacy and security under the signed agreement -following the Organic Law 3/2018, of December 5, on the Protection of Personal Data- and the Council Regulation (EC) 1069/2009 that sets the health rules as regards animal by-products and non-human-consumption derived products. This research did not involve any specific clinical study using animal experimentation.
Consent for publication
Not Applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1: S1 Fig
Illustration of hierarchical time series structures (hts).
Additional file 2: S2 and S3 Figs
show the hierarchical time series by region, provinces and county in both regions R1 and R2. These Figures are computed by using the hts package included in R.
Additional file 3: S1 Table
. Estimates and standard errors of the selected ARIMA (p,d,q) models for region R1, its province and counties between 2006 and 2013. S2 Table. Estimates and standard errors of the selected ARIMA(p,d,q) models for region R2, its provinces and counties between 2006 and 2013.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Fernández-Fontelo, A., Puig, P., Caceres, G. et al. Enhancing the monitoring of fallen stock at different hierarchical administrative levels: an illustration on dairy cattle from regions with distinct husbandry, demographical and climate traits. BMC Vet Res 16, 110 (2020). https://doi.org/10.1186/s12917-020-02312-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12917-020-02312-8