
Abstract
Background
The quality of nursing clinical placements has been found to vary. Placement evaluation tools for nursing students are available but lack contemporary reviews of clinical settings. Therefore, the aim of this study was to develop a feasible, valid and reliable clinical placement evaluation tool applicable to nursing student placements in Australia.
Methods
An exploratory mixed methods co-design project. Phase 1 included a literature review; expert rating of potential question items and Nominal Group Technique meetings with a range of stakeholders for item development. Phase 2 included on-line pilot testing of the Placement Evaluation Tool (PET) with 1263 nursing students, across all year levels at six Australian Universities and one further education college in 2019–20, to confirm validity, reliability and feasibility.
Results
The PET included 19-items (rated on a 5-point agreement scale) and one global satisfaction rating (a 10-point scale). Placements were generally positively rated. The total scale score (19 items) revealed a median student rating of 81 points from a maximum of 95 and a median global satisfaction rating of 9/10. Criterion validity was confirmed by item correlation: Intra-class Correlation Co-efficient ICC = .709; scale total to global score r = .722; and items to total score ranging from .609 to .832. Strong concurrent validity was demonstrated with the Clinical Learning Environment and Supervision Scale (r = .834). Internal reliability was identified and confirmed in two subscale factors: Clinical Environment (Cronbach’s alpha = .94) and Learning Support (alpha = .96). Based on the short time taken to complete the survey (median 3.5 min) and students’ comments, the tool was deemed applicable and feasible.
Conclusions
The PET was found to be valid, reliable and feasible. Use of the tool as a quality assurance measure is likely to improve education and practice in clinical environments. Further international evaluation of the instrument is required to fully determine its psychometric properties.
Similar content being viewed by others


Background
Nursing education programs across the world incorporate clinical placement experiences to assist learners to assimilate theory and practice. Approaches to placement quality assessment vary from ‘in-house’ reviews by education and clinical providers to the use of published student, educator and organisational survey instruments [1]. Internationally, the quality of clinical placements is known to vary with reported positive [2], ambivalent [3] and negative experiences [4]. Clinical learning environments are varied and complex with multidimensional social networks which makes evaluation complex.
In Australia, the Deans of Nursing and Midwifery (Australia and New Zealand) commissioned work to improve the quality of placements, which in the first instance required the development of a contemporary instrument to measure students’ placement experiences. As such the aim of this study was to develop a feasible, valid and reliable clinical placement evaluation tool applicable to nursing student placements in Australia.
(NB: the use of the word ‘supervisor’ in this paper refers to the role of Registered Nurse mentor/ facilitator/ educator which, depending on the clinical placement model, may be a tertiary or organisational based position).
Undergraduate nursing students are required to complete clinical placement hours as part of their educational preparation. Internationally these hours vary from 800 h in Australia, 1100–1500 in New Zealand, 2300 in the UK, and 2800 in South Africa [5]. It is accepted that exposure to quality ‘real world’ clinical placement is essential to ensure competence and appropriate development of professional identity; whilst the literature identifies that organisational, relational and individual factors influence the quality of placements [6].
Within organisations there is a need for a consistent approach between educational and industry sectors to ensure appropriate management of clinical placements [7]. Enabling a sense of belonging during placement ensures that students feel welcome [8] whilst the support of a clinical supervisor generates a positive learning environment.
Relations that are encouraging and supportive promote mutual respect, trust and open and honest communication [6]. Consistent and positive approaches from supervisors can overcome challenging clinical situations [9] whilst an awareness of students’ level of competence and learning requirements improve outcomes. Effective supervisors are well versed in the curriculum, clinical expectations and teaching practice whilst being motivated and approachable [7].
Individual students also harbour wide ranging interpretations of the clinical setting depending on their experience, resilience, and ‘life skills’, with the need to reduce vulnerability and create a positive learning culture [10]. Thus, preparation of nursing students for graduate practice requires engagement in the learning process and accountability for their learning. Frameworks that support active learning across educational and clinical settings and learning partnerships between supervisors and students are known to improve the quality of clinical placements [11].
With these considerations in mind it is imperative that rigorous evaluation instruments are available that measure the quality of placement experience, enabling improvements at placements sites and enhancing educational opportunities. There is therefore a climate of readiness for change and an essential need to develop a valid, reliable and feasible contemporary evaluation instrument that promotes national standards in clinical placement [12]. The following sections describe the development of the Placement Evaluation Tool (PET).
Methods
An exploratory mixed methods project incorporating participatory co-design principals was planned to actively involve those who will become ‘users’ of the tool throughout the development process [13]. Such user-centric methods included individuals with lived experience of clinical placements (i.e. students, lecturers, supervisors, etc.) engaged as active design partners to generate ideas, prototype, gather feedback and make changes [14]. Incorporating these principals, the aim was to develop a deep understanding of clinical placements and relevant high utility assessment approaches. The project was undertaken and supported by a project team of 10 nursing academics in seven Australian tertiary educational institutions across three states. The project included a Phase 1 tool development stage, incorporating six key steps, and Phase 2 pilot testing.
Ethical approval
Ethical approval for Phase 2 of the project (pilot testing) was obtained from the lead institution (Federation University Australia B19–070) with reciprocal approval from a further six institutions/pilot sites. Informed consent was required based on the participant information sheet provided at the start of the survey. No incentives, such as gifts, payments, or course credits were offered for participation.
Phase 1: tool development
Stage 1: literature review
A literature review was conducted to identify existing placement evaluation instruments. Ten original tools published between 1995 and 2015 were identified, incorporating a total of 303 rated items (e.g. [1, 9, 15,16,17]).
Overall there was a lack of contemporaneous language, international and cultural differences, grammatical and translation errors and outdated contexts. Further, from a feasibility perspective, most tools were considered too lengthy with the majority including over 30 items.
At this stage the project team decided not to include negatively worded items based on their tendency to cause confusion. Acquiescence was thought to be unlikely as participants would be rating personal clinical experiences [18]. Further, for feasibility, transferability and dissemination the tool was developed as a one page document, with generic questions that are applicable for clinical placements in Australia and with potential for future testing in other health professions and countries.
Stage 2: review of published items
Two researchers reviewed the identified items, removing duplications and non-applicable statements, leaving 190 items for consideration. An expert panel of six clinical academics (mean years of nurse registration - 32) rated the ‘Relevance’ and ‘Clarity’ of these items to produce an Item Content Validity Index (I-CVI) [19]. This enabled the exclusion, after discussion, of items that did not reach an acceptable level, i.e. an I-CVI of < 0.78. Approximately half the items were relevant and clear and were retained for further deliberation. Finally, several items from other broad generic training evaluation tools were selected e.g. Q4T [16] and H-PEPSS [15] with the intent of triangulating items with data generated in the Nominal Group meetings in the selection and adaption stage (described below in Stage 4).
Stage 3: nominal group meetings
The Nominal Group Technique (NGT) is designed to generate ideas, explore opinions and determine priorities [20], with previous use in, for example, diabetes education [21] and emergency care [22]. The Delphi Technique is an alternative consensus generating approach, however questionnaires are circulated anonymously, as opposed to face-to-face meetings in the Nominal Group Technique, enabling a greater exploration of the field of focus [20].
Two Nominal Group University based meetings were held, one in the State of Victorian and the second in the State of Queensland, Australia. The aim was to generate ‘fresh’ or ‘novel’ additional question items related to clinical placement quality from participants with first-hand experience. In order to comply with the co-design principals of the PET project we recruited a convenience sample from a range of stakeholders in each University region to attend one of the two three-hour meetings. Participants were recruited by a researcher at each site aiming to ensure adequate representation. In the Victorian group two 2nd year students, three 3rd year students, two graduate year nurses, one clinical placement coordinator and one clinical educator attended. In the Queensland group two 2nd year students, five 3rd year students, two clinical placement coordinators and two nursing academics attended. Total attendees for the two groups was therefore 20.
The Nominal Group Technique is described in detail elsewhere [23] but in summary the process included:
-
1.
An introduction to the project aim and the NGT process.
-
2.
Silent/individual generation of potential survey items on cue cards.
-
3.
Round robin listing of items with discussion.
-
4.
Group discussion and clarification of items.
-
5.
Ranking of items.
-
6.
Review and discussion regarding final listings.
By the end of each meeting a set of high priority evaluation statements was identified based on individual participants’ ranking. Ranking was achieved by accepting only high priority items prioritized by at least three participants. Fifty-six items in total were carried over to the next stage.
Stage 4 - selection and adaption of items
The principal researcher (SC) performed an independent primary analyses of items, followed by a five-hour meeting with three additional clinical researchers. Their clinical experience ranged from 27 to 37 years (mean 32). Potential items from the above stages were selected, adapted and thematisised using a paper based tabletop approach. The principal researcher’s initial development was then used as a reference point/check aiming for consensus. Individual items were listed under key themes e.g. supervision, the culture of the clinical environment, learning outcomes. A priori specification of items to Kirkpatrick’s evaluation model [24] - Level 1 (Reaction to the experience/clinical environment), Level 2 (Learning outcomes) and Level 3 (Behavioural change/practice impact) was also performed at this point. Items were then selected and wording was adjusted if necessary, generating a 20 item questionnaire.
A five point Likert scale was selected with a scale ranging from [1] ‘strongly disagree’ to [5] ‘strongly agree’. An even numbered scale (forced choice) was not selected as participants were likely to require a mid-point response i.e. ‘neither agree or disagree’. Further, a five point scale enabled a direct concurrent validity comparison with another validated tool - the Clinical Learning Environment and Supervision Scale [17] (described below). A 20th item was included, as an overall satisfaction rating, with a response scale of 1 (very dissatisfied) to 10 (extremely satisfied).
Stage 5 – tool review (educators and students)
The draft tool was then circulated to 10 clinical educators from the Australian states of Queensland, New South Wales, and Victoria and to 12 nursing students from Queensland and Victoria, in order to calculate the I-CVI prior to final selection. The expected I-CVI of >.78 was exceeded for relevance and clarity in all but three educator rated items, which were resolved with minor changes to wording. For example item 6 was originally worded “Patient safety was integral to the work of the unit(s)” and was reworded to “Patient safety was fundamental to the work of the unit(s)”, to ensure greater clarity.
Stage 6 - deans of nursing review
A final review was provided by 37 Deans of Nursing and Midwifery (Australia and New Zealand) at a meeting in Queensland (July 2019) where minor wording changes to the demographic section were adopted.
Phase 2: pilot testing and validation
Stage 1 - pilot testing
The tool was pilot tested through an on-line survey at six Australian universities and one Technical and Further Education (TAFE) institution where Bachelor of Nursing degree students were enrolled (i.e. excluding Enrolled Nurse trainees). These sites were selected as they were led by a project team member who was also the Dean of School or their representative. One site ran a two year graduate entry Masters program whose students were excluded and a double degree nursing/midwifery four year program, where students were surveyed only after a nursing placement.
Purposive population sampling aimed to include all 1st, 2nd, 3rd and 4th year nursing students who had completed a clinical placement in 2nd Semester (July 2019 to-February 2020). Invitations to complete the PET were distributed by a clinical administrator at each site, who provided the survey access link and distributed e-mail reminders. In this pilot testing phase, participants and their review sites were not identifiable. Participants were asked to rate their ‘most recent’ clinical placement only.
The survey was uploaded to Qualtrics survey software (Qualtrics, Provo, UT, USA) enabling anonymized student responses. Three academics tested the survey for accuracy, flow, and correct response options. Access to the Participant Information Statement was enabled and consent requested via a response tick-box. Seven questions regarding demographics were included e.g. age group, year of study course, placement category. This was followed by the 20-item PET and two open ended questions relating to students’ placement experience and suggestions for improving the PET. Access to the survey was enabled via smart phones and computers. The survey remained open between July 2019 and February 2020 whilst students were completing their placements. Finally, 62 students were approached at one university in order to measure the concurrent validity of the PET against the Clinical Learning Environment and Supervision Scale. The test-retest reliability of the PET, with the same test seven days later, was reported by 22 students from two universities.
Stage 2
In this final stage the aim was to confirm the validity, reliability and feasibility of the PET using applicable statistical and descriptive analyses. Outcomes are described in the results section below.
Data analysis
Survey data downloaded from the Internet were analysed using IBM SPSS vs 26 [25]. Descriptive and summary statistics (means, standard deviations) were used to describe categorical data whilst between group associations were explored using inferential statistics (t tests, ANOVA). Pearson’s product moment correlational analysis of item-to-total ratings and item-to global-scores was conducted. The Intra-class Correlation Co-efficient (2-way random-effects model) [26] was used to examine inter-item correlation. P = < 0.05 was regarded as significant. The internal consistency reliability was computed using Cronbach’s alpha.
A Principle Component Analysis was conducted to identify scale items that grouped together in a linear pattern of correlations to form component factors, using the method of Pallant [27]. The sample exceeded the recommendation of at least 10 participants for each variable. The factorability of data was confirmed by Bartletts’s test of sphericity (<.0.5) of p = <.001 and the Kaiser-Meyer-Olkin (KMO) measure of sampling adequacy (range 0–1, .6 minimum) of .97. The high KMO of .97 indicates a compact range of correlations with data appropriate for factor analysis ([28] p.877). An eigenvalue > 1 was applied to extract the number of factors and a Scree plot showed two components. The correlation matrix was based on correlations above .3. Assisted by the large sample, the variables loaded strongly, as described below.
Prior to analyses the normality of the total scale score was confirmed by the Kolmogorov-Smirnov statistic (0.148, df 1263, p = < 0.001) and Shapiro-Wilk Test (0.875, df 1263, p = < 0.001). Although positive skewness was noted with scores clustered towards higher values (Skewness: 1.327, Kurtosis: 1.934), these data were within the acceptable normal distribution range [27].
Results
The validity and reliability of the PET was based on responses from 1263 pre-registration nursing students who completed the survey (see Table 1). The response rate was estimated at 20.2% (1263/6265). The sample comprised students enrolled in the first to fourth years of a nursing degree. Participants represented three Australian States but the majority were in Queensland (45.9%) or Victoria (44.3%). Nearly all were female (89.9%); most were in the second year of their course (42.9%) and the most common age group was 20–25 years (31.9%). The majority were responding about their experiences of clinical placement in an acute health services setting (54.5%) followed by Mental Health (19.4%) or Aged Care (17.7%).
Summary of participant ratings
Placements were generally positively rated. The total scale score (19 items) revealed a median student rating of 81 points from a maximum of 95 and a mean of 78.3% [95% CI: 77.4–79.2; SD 16.0]. Table 2 lists the means responses for each item.
Although every scale item had a response range of between 1 and 5, there was positive skewness towards higher ratings; 17 of 19 items were rated above a mean of 4.0 of five points. The highest rated item was [6]. ‘Patient safety was fundamental to the work of the unit(s)’, with a mean of 4.33, followed by item [19]. ‘I anticipate being able to apply my learning from this placement’ (M = 4.26). The lowest rated items were [7] ‘I felt valued during this placement’ (M = 3.88) and ‘I received regular and constructive feedback’ (M = 3.94). Such responses indicate areas for future exploration.
Item 20 overall satisfaction with the placement experience was rated as high (median 9 of 10) with 377 (29.8%) participants being ‘extremely satisfied’ (10 out of 10) and an additional 686 (54.3%) rating between 6 and 9. A total of 38 students (3.0%) were ‘very dissatisfied’ and a further 101 (8.0%) were dissatisfied and rated the experience between 2 and 4 points. The open-ended comments provided by participants may help to deconstruct these issues in future.
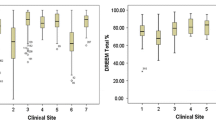
The new instrument was able to differentiate perceptions of placement quality when total scores were classified across the three States. Mean total scale scores were significantly higher for Victorian students (M = 80.68) than for New South Wales (M = 78.55) and Queensland (M = 76.01) students (F = 12.395, df2, p = < 0.001). This difference was also reflected in the Global Satisfaction rating (F = 9.360, df2, p = < 0.001) with Victorian students reporting significantly higher mean global satisfaction (M = 8.98), Queensland (M = 8.56) and New South Wales (M = 8.50).
Validity and reliability outcomes
The first objective in developing a measurement instrument is to demonstrate its validity - the degree to which it measures what it is intended to measure. This can be established using several statistical approaches including assessment of face/content validity, and construct validity [14]. The second main requirement is to test the scale reliability; the extent to which measurements are free from error and can be replicated, generally measured with correlational tests. Below, we describe the findings and present a summary in Table 3.
Adequate construct validity was demonstrated by content validity measures, concurrent and criterion related validity all of which reached or exceeded expected values. In development stages the expertise of educators and students was used as a filtering mechanism to assure face validity and usability with acceptable outcomes from the I-CVI.
Concurrent validity with a volunteer sample of second year nursing students (n = 62) in Victoria was measured using both the PET and the Clinical Learning Environment and Supervision Scale [17, 29]. Correlation was high r = .834 supporting the notion that the PET had high concurrent validity.
Criterion validity was measured via inter-item correlations, item-to-total score and correlation of the scale total score with the independent ‘global’ score. The 19 items were moderately to strongly correlated. The Intraclass Correlation Coefficient (random effects model) of .709 for single measures showed non-significant differences across the 19 scale items (p = < 0.001) - classified as a ‘good’ correlation [26]. The corrected item-to-total correlation for the scale ranged from .606 to .832 and Friedman’s Chi-square confirmed consistency (p = < 0.001). There was no redundant outlier item with a low correlation. The total scale score was also strongly correlated with the independent global score (r = .722, p = 0.01) (two-tailed).
Test-retest with a sample of 22 nursing students from two states confirmed the stability of scores over time, indicated by non-significant difference at retest after one week (Z = − 1.705, p = 0.088).
Factor analysis
PCA was conducted to ascertain how the pattern of correlated items was able to describe experience. Analysis using Varimax rotation yielded a two-factor solution that explained 73.3% of the variance. The first factor had an eigenvalue of 12.66 and explained 66.63% of the variance; the second, an eigenvalue of 1.27, explaining 6.66% of the variance (see Table 4).
The two factors that emerged were clinically meaningful: items number 1–8 formed one component that was labelled Factor 1 ‘Clinical Environment’. Items 9–19 formed a second component which was labelled Factor 2 ‘Learning Support’. Both subscales were found reliable: (1) ICC = .937 (CI .931–.942), p = < 0.001; (2) ICC = .964 (CI .961–.967), p = < 0.001.
In addition to test-retest reliability the Cronbach alpha statistic is a measure of the internal reliability/consistency with a range of 0–1 and an expected standard ≥ .7. The alpha reliability of the PET scales was: (1) Clinical Environment .94 (8 items); (2) Learning Support .96 (11 items). While these data appear high, inspection of the item-total correlation matrix for each scale revealed tightly clustered correlations with no downward influence on the overall alpha if a single item was removed [30].
Translational impact: Kirkpatrick’s four level model of evaluation
Good practice in educational evaluation has been described as incorporating four levels of evaluation [24]. Table 5 illustrates how items in the PET scale address the first three levels: Reaction, Learning and Behaviour. Level 4 Results - patient impact was not applicable in this instance.
Students’ open text comments
Respondents were asked how the PET could be improved. The few responses received indicate that the overall tool was ‘good’, relevant and clear. Students’ comments about their personal placement experiences were numerous and diverse and will be described in a later report.
Feasibility
The tool was planned as a short online survey in order to increase participant acceptability, however there was a degree of attrition with 83% of 1524 who accessed the survey completing all items. Most who exited withdrew at or before the first mandatory scale item (14%).
In relation to completion time, noting that some participants may have left the survey open to return at a later date, 16 outliers (duration > 1 h) were removed identifying a median completion time of 3.5 min (SD 4.5) (range 1.1 mins to 44.6 mins).
Discussion
There is international evidence that clinical placement experiences vary considerably (e.g. 4). Organisational management, supervisory relations and student expectations need to be considered in order to adequately prepare nursing students for safe graduate practice [6]. With these concerns in mind we aimed to produce a feasible, valid and reliable clinical placement evaluation tool that would enable students to rate the clinical and educational environment and their learning experience, generating a national profile of placement experiences and quality.
The final PET includes 20 plain English items measuring two key factors – ‘Clinical Environment’ and ‘Learning support’ and three Kirkpatrick evaluation domains - participant reactions to the experience/clinical environment, self-reported learning outcomes and behavioural change/practice impact. Whilst reactions to an experience and self-reported outcomes are frequently measured in surveys, measures of practice impact are less frequently covered [31]. However, hard measures of observed practice performance, as opposed to self-reports, would further enhance reviews of placement activity. As shown in Table 3, the tool exhibited statistically valid and reliable properties in all respects tested, for example reliability was established with a Cronbach alpha of .94 for the Clinical Environment scale and an alpha of .96 for the Learning Support scale.
The two key factors identified reflect the importance of a welcoming atmosphere and educational support, as expressed in many other published instruments (e.g. 29). In the current study, despite the high global satisfaction rate (median 9/10), 11% of respondents were dissatisfied, with comments relating to negative staff attitudes and the working environment. This finding is of concern and confirms the need for a quality assessment tool and regular placement reviews.
The final participant open access PET is listed in Additional file 1. Nineteen items are rated on a scale of 1 to 5 and the final global rating from 1 to 10, with potential scores ranging from 20 to 105. A summed score of the first 19 items and the overall global rating are likely to be useful in feedback processes. No quality assessment ‘cut score’ i.e. acceptable or unacceptable placements have been set, as institutions should consider individual placement evaluations from multiple students with a combination of evaluation approaches. In this pilot trial of the PET institutions/students were not identified, but for quality improvement future sites must be identified to enable feedback and action.
Future research will aim to produce a placement evaluation tool that is applicable across health disciplines in the developed world. As such this primary development of the PET is limited as it focusses on one discipline –nursing, three States in one country – Australia and in the English language only. Future iterations will therefore be required including a national Australian nursing trial, testing and development for other health disciplines and rigorous translations (forward- backward) into additional languages. Additionally, larger sample sizes are necessary to be sure of the test-retest reliability. Broader limitations of such tools must also be considered as the PET is an individual self-rating of experience with the need to take into account additional stakeholders reviews e.g. educators and hard outcome measures such as practice observation, student retention, employment offers etc.
In summary, widespread use of a tool such as the PET, perhaps as a suite of assessment tools within a national registry of clinical placements, is likely to have an impact on both educational and clinical outcomes through applicable quality improvement programs that ensure the right education, in the right place and at the right time.
Conclusion
In a survey of 1263 nursing students in Australia the PET was found to be valid, reliable and feasible across a range of measures. Use of the tool as a quality improvement measure is likely to improve educational and clinical environments in Australia. Further evaluation of the instrument is required to fully determine its psychometric properties. Future work with the PET will include a national nursing survey across all Australian States and Territories, international nursing surveys and additional health discipline trials.
Availability of data and materials
The datasets generated and/or analysed during the current study are not publicly available due to confidentiality but anonymised sets may be available from the corresponding author on reasonable request.
Abbreviations
- NGT:
-
Nominal Group Technique
- PET:
-
Placement Evaluation Tool
- PCA:
-
Principal component analysis
References
Mansutti I, Saiani L, Grassetti L, Palese A. Instruments evaluating the quality of the clinical learning environment in nursing education: a systematic review of psychometric properties. Int J Nurs Stud. 2017;68:60–72..
Papastavrou E, Dimitriadou M, Tsangari H, Andreou C. Nursing students’ satisfaction of the clinical learning environment: a research study. BMC Nurs. 2016;15:44.
Budden LM, Birks M, Cant R, Bagley T, Park T. Australian nursing students’ experience of bullying and/or harassment during clinical placement. Collegian. 2017;24:125–33.
Jarvelainen M, Cooper S, Jones J. Nursing students’ educational experience in regional Australia: reflections on acute events. A qualitative review of clinical incidents. Nurse Educ Pract. 2018;31:188–93.
Miller E, Cooper S. A Registered Nurse in 20 weeks. Aust Nurs Midwifery J. 2016;24(1):34.
Dale B, Leland A, Dale JG. What factors facilitate good learning experiences in clinical studies in nursing: bachelor students’ perceptions. ISRN Nursing. 2013.
Jokelainen M, Jamookeeah D, Tossavainen K, Turunen H. Finnish and British mentors' conceptions of facilitating nursing students' placement learning and professional development. Nurse Educ Pract. 2013;13:61–7.
Levett-Jones T, Lathlean J, McMillan M, Higgins I. Belongingness, a montage of nursing students' stories of their clinical placement experiences. Contemp Nurse. 2007;24:162–74.
Courtney-Pratt H, Fitzgerald M, Ford K, Marsden K, Marlow A. Quality clinical placements for undergraduate nursing students: a cross-sectional survey of undergraduates and supervising nurses. J Adv Nurs. 2012;68:1380–90.
Ford K, Courtney-Pratt H, Marlow A, Cooper J, Williams D, Mason R. Quality clinical placements: the perspectives of undergraduate nursing students and their supervising nurses. Nurse Educ Today. 2016;37:97–102.
Perry C, Henderson A, Grealish L. The behaviours of nurses that increase student accountability for learning in clinical practice: an integrative review. Nurse Educ Today. 2018;65:177–86.
Schwartz S. Educating the nurse of the future. Report of the independent review of nursing education. Commonwealth of Australia. 2019. Available at: https://www.health.gov.au/resources/publications/educating-the-nurse-of-the-future. Accessed 19 Oct 2020.
Sanders L. An evolving map of design practice and design research. Interactions. 2008;15(6):13–7.
Streiner D, Norman GR, Cairney J. Health measurement scales: a practical guide to their development and use. (5th Edn). Oxford: Oxford University Press; 2015.
Ginsburg L, Castel E, Tregunno D, Norton PG. The H-PEPSS: an instrument to measure health professionals' perceptions of patient safety competence at entry into practice. BMJ Qual Saf. 2012;21:676–84.
Grohmann A, Kauffeld S. Evaluating training programs: development and correlates of the questionnaire for professional T raining E valuation. Int J Train Dev. 2013;17:135–55.
Saarikoski M, Leino-Kilpi H, Warne T. Clinical learning environment and supervision: testing a research instrument in an international comparative study. Nurse Educ Today. 2002;22:340–9.
Dillman DA. Mail and Internet surveys: The tailored design method--2007 Update with new Internet, visual, and mixed-mode guide. London: John Wiley & Sons; 2011.
Polit DF, Beck CT. The content validity index: are you sure you know what's being reported? Critique and recommendations. Res Nurs Health. 2006;29:489–97.
McMillan SS, King M, Tully MP. How to use the nominal group and Delphi techniques. Int J Clin Pharm. 2016;38(3):655–62.
Miller D, Shewchuk R, Elliot TR, Richards S. Nominal group technique: a process for identifying diabetes self-care issues among patients and caregivers. Diabetes Educ. 2000;26(2):305–14.
Harvey N, Holmes CA. Nominal group technique: an effective method for obtaining group consensus. Int J Nurs Pract. 2012;18(2):188–94.
Cooper S, Cant R, Luders E, Waters D, Henderson A, Hood K, Reid-Searl K, Ryan C, Tower M, Willetts G. The Nominal Group Technique: Generating consensus in nursing research. J Nurs Educ. 2020;59(2):65–7.
Kirkpatrick DL, Kirkpatrick JD. Implementing the four levels : a practical guide for effective evaluation of training programs. San Francisco: Berrett-Koehler Publishers; 2007.
IBN. Statistics Paclage for Social Scientists vs 26. Armonk, NY: IBM Corp; 2016.
Koo TK, Li MY. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J Chiropractic Med. 2016;15(2):155–63. https://doi.org/10.1016/j.jcm.2016.02.012.
Pallant J. SPSS Survival Manual. London: McGraw-Hill Education (UK); 2013.
Field A. Discovering statistics using IBM SPSS statistics (4th Edn). London: Sage; 2013.
Saarikoski M, Strandell-Laine C. The CLES-scale : an evaluation tool for healthcare education. Cham: Springer; 2018.
Tavakol M, Dennick R. Making sense of Cronbach's alpha. Int J Med Educ. 2011;2:53.
Reio TG, Rocco TS, Smith DH, Chang E. A critique of Kirkpatrick's evaluation model. New Horizons in Adult Education and Human Resource Development. 2017;29(2):35–53.
Acknowledgments
Not applicable.
Funding
This work was funded by the Council of Deans of Nursing and Midwifery (Australia and New Zealand) – 2019. The funding body had no role in the design of the study and collection, analysis, and interpretation of data, or in writing the manuscript.
Author information
Authors and Affiliations
Contributions
SC, RC, DW, EL, AH, GW, MT, KR-S, CR, KH contributed to the conception and design of the project. SC, RC, DW, EL, AH, contributed to data collection and analyses. SC, RC, DW, EL, AH, GW, MT, KR-S, CR, KH contributed to the drafting of the report. SC, RC, DW, EL, AH, GW, MT, KR-S, CR, KH read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The full project received ethical approval from Federation University Human Research Ethics Committee B19–070 with reciprocal approval from the remaining six study sites. Participants were provided with a participants information sheet and consent was implied through survey access.
Consent for publication
Not applicable.
Competing interests
The authors declare they have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1.
Finalised Placement Evaluation Tool (PET).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Cooper, S., Cant, R., Waters, D. et al. Measuring the quality of nursing clinical placements and the development of the Placement Evaluation Tool (PET) in a mixed methods co-design project. BMC Nurs 19, 101 (2020). https://doi.org/10.1186/s12912-020-00491-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12912-020-00491-1