
Abstract
Purpose
Metabolic syndrome (Mets) is a pathological condition that includes many abnormal metabolic components and requires a simple detection method for rapid use in a large population. The aim of the study was to develop a diagnostic model for Mets in a Chinese population with noninvasive anthropometric and demographic predictors.
Patients and methods
Least absolute shrinkage and selection operator (LASSO) regression was used to screen predictors. A large sample from the China National Diabetes and Metabolic Disorders Survey (CNDMDS) was used to develop the model with logistic regression, and internal, internal-external and external validation were conducted to evaluate the model performance. A score calculator was developed to display the final model.
Results
We evaluated the discrimination and calibration of the model by receiver operator characteristic (ROC) curves and calibration curve analysis. The area under the ROC curves (AUCs) and the Brier score of the original model were 0.88 and 0.122, respectively. The mean AUCs and the mean Brier score of 10-fold cross validation were 0.879 and 0.122, respectively. The mean AUCs and the mean Brier score of internal–external validation were 0.878 and 0.121, respectively. The AUCs and Brier score of external validation were 0.862 and 0.133, respectively.
Conclusions
The model developed in this study has good discrimination and calibration performance. Its stability was proved by internal validation, external validation and internal-external validation. Then, this model has been displayed by a calculator which can exhibit the specific predictive probability for easy use in Chinese population.
Similar content being viewed by others

Introduction
Metabolic syndrome (Mets) is a group of complex metabolic disorders, including abdominal fat accumulation, high triglyceride, high cholesterol, hypertension, and hyperglycaemia. Mets is not a specific disease but a cluster of multiple risk factors, an intermediate state between health and disease, whose primary role is to bring attention to the possibility of disease in people with an abnormal metabolism. The main components of Mets are insulin resistance and obesity, especially central obesity. Obesity plays an important role in the occurrence and development of Mets [1,2,3,4].
Obesity is increasingly recognized as a serious, worldwide public health problem. According to recent studies, obesity is responsible for population-level deaths worldwide [5, 6]. Various methods have been developed to assess the degree of body obesity. Methods for directly measuring or calculating total body fat content include laboratory underwater weighing [7], dual-energy X-ray absorptiometry (DXA) [8,9,10], magnetic resonance imaging (MRI) [11, 12], skin calliper measurement, girth measurement, bioelectrical impedance analysis (BIA) [8, 13], and some calculation formulas, such as the Clinica Universidad de Navarra-Body Adiposity Estimator (CUN-BAE) [14]. Scholars have also developed anthropometric indices to describe body fat distribution and body shape in humans. The most commonly used indices include body mass index (BMI), waist circumference (WC), hip circumference (HC), waist to hip ratio (WHR), and waist to height ratio (WHtR). Other novel indices include the Body Roundness Index (BRI) [15], A Body Shape Index (ABSI) [16], Body Adiposity Index (BAI) [17], Conicity Index (C-Index) [18], and Abdominal Volume Index (AVI) [19].
BMI is the most commonly used index to assess obesity. However, recent studies have found that people with normal BMI still have a risk of Mets [20, 21]. Our previous studies have also found that normal weight obesity (NWO) populations have a risk of long-term cardiovascular disease and diabetes [22, 23]. It is obvious that the use of BMI alone to assess the risk of metabolic syndrome is flawed. It cannot accurately reflect the degree of obesity of the human body. Therefore, an accurate diagnostic tool is needed to determine whether a person has Mets to better prevent possible cardiovascular diseases and diabetes in the future.
In previous studies on Chinese populations, WHtR, BRI and AVI have been found to have a good ability to discriminate Mets or its components from BMI [21, 24, 25]. However, their AUCs were generally approximately or under 0.8, which did not take into account calibrations, and the studies did not screen these anthropometric indices and demographic information together to fit a more accurate prediction model.
Therefore, this study aims to use a variable selection technique to screen anthropometric indices, establish a simple metabolic diagnosis model in a Chinese population, evaluate the model performance by discrimination and calibration and assess the overfit by internal, internal-external and external validation. The final model will be displayed by a scoring system in an Excel document [26, 27].
This study is reported in accordance with the TRIPOD (Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis) Statement, a guideline specifically designed for the reporting of studies developing or validating a multivariable prediction model [28].
Methods
Source of data and Participants
The development set for this study came from a large cross-sectional study: the China National Diabetes and Metabolic Disorders Survey (CNDMDS). This is a nationwide epidemiological survey from June 2007 to May 2008, which was completed by 17 clinical centres in 14 provinces and cities across the country. A multistage, stratified cluster sampling method was used to select persons aged 20 years or older. In total, 152 urban street districts and 112 rural villages were selected, 54,240 participants were invited to participate in the study, and 47,325 persons (18,976 men and 28,349 women) accepted the invitation. Finally, 46,239 adults completed the survey. The validation set came from phase 3 follow-up surveys of CNDMDS in Shaanxi Province, which were conducted from October 2016 to November 2017. A total of 1072 participants were included in phase 3 follow-up surveys. Relevant information on the dataset can be found in our previous studies [22, 23, 29, 30].
Because some centres did not conduct BIA testing in the development set, we included 27,494 participants from 9 centres. Because of the measurement error of BIA, any data points of PBF that were 3 interquartile ranges below the first quartile (Q1) or 3 interquartile ranges above the third quartile (Q3) were considered outliers and excluded from the analysis. Some participants with missing information on family history, height, weight, BP (blood pressure), TGs (triglycerides), HDL-C (high-density lipoprotein cholesterol), and BG (blood glucose) were also excluded. Then, participants who were using antihypertensive medications, lipid medications and diabetes medications were excluded.
Finally, a total of 19,685 participants from 9 centres were included in the development set. Similarly, a total of 671 participants were included in the validation set (Fig. 1).

The flowchart of details of participant inclusion and exclusion criteria of development dataset and validation dataset
Outcome
The outcome definition is according to the Asian criteria of the 2009 Joint Interim.
Statement of several international societies (2009 JIS). Specifically, participants having three or more of the following clinical measures were considered as having Mets:
-
1)
central obesity (WC ≥ 90 cm (males) or ≥ 80 cm (females));
-
2)
elevated BP: SBP (systolic blood pressure) ≥130 mmHg or DBP (diastolic blood pressure) ≥85 mmHg, or the use of antihypertensive medications;
-
3)
elevated fasting TG: ≥ 1.69 mmol/l or the use of lipid medications;
-
4)
elevated FBG (fasting blood glucose): ≥ 5.6 mmol/l or the use of diabetes medications;
-
5)
decreased HDL-C: < 1.04 mmol/l (males) or < 1.29 mmol/l (females) [4].
Predictors
According to a previous review [24, 25, 31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48] and our current study [22, 23, 30], the following variables were considered candidate predictors to judge a patient with or without metabolism: age, sex, education level, smoking history, physical activity history, family history of metabolic disorders (abbreviated as family history), SBP, DBP, WC, HC, WHR, WHtR, BRI, BMI, PBF, ABSI, CUN_BAE, BAI, C-Index, and AVI.
Participants were asked to wear a single layer of light clothing when they were measured for weight, height, PBF, WC and HC. The definition or calculation formula of each factor is as follows:
Age was measured as of the date of completing the survey.
Education level: Those who had a college degree or above were defined as having a high education level, and those who had a secondary education or below were defined as having a low education level.
Smoking history: Those who had smoked more than 100 cigarettes in their lifetime and were still smoking now were defined as category yes, those who had smoked in the past and had quit for more than 1year were defined as category quit, and the others who had never smoked were defined as category no.
Physical activity history: Those who had regular exercise more than three times a week with each session lasting at least half an hour were defined as category regular, and the others were defined as category never.
Family history of metabolic disorders: A family history of hypertension was defined as having at least one of the parents, siblings, and children diagnosed with hypertension in their lifetime. Similarly, we defined the family history of diabetes and hyperlipidaemia and calculated the cumulative number of these three metabolic disorders.
Blood pressure: A mercury column sphygmomanometer was used to measure blood pressure. The participant was required to rest quietly and relax before measurement.
Height and weight: A height and weight scale was used to measure height and weight. The measurement results were required to be accurate to 0.5 cm and 0.5 kg.
WC andHC: A measuring tape was used to measure WC andHC. The measurement results were required to be accurate to 0.5 cm.
PBF: A Tanita body composition analyser (TBF-300 WA; Tanita Corporation Limited, Tokyo, Japan) was used to measure PBF.
Calculation formula:
Where male = 0 and female = 1 for Sex.
Missing data and Sample size
All missing values were removed, and a total of 19,685 participants were included in this study. According to relevant research, the events per variable (EPV) required in multivariate analysis must be 10 or greater, namely, the positive event should be more than 10 times the number of predictors. A total of 6505 participants were diagnosed with Mets, so the sample size was large enough [27, 49].
Statistical analysis
The baseline information in the dataset was compared using the chi-square test or Fisher’s exact test for categorical variables and the two-sample t test or Mann–Whitney U test for continuous variables. Anthropometric indices, SBP, DBP and age were analysed as continuous variables, while sex, education level, smoking history, physical activity history and family history were analysed as discrete variables. To avoid overfitting of the prediction model and multicollinearity among predictors, least absolute shrinkage and selection operator (LASSO) regression was performed to screen the predicted variables. With the increase in the penalty parameter lambda, the coefficients of each predictor shrank, and the number of predictors was reduced. Then, according to the number of predictors, area under the receiver operator characteristic curves (AUCs), and misclassification error, we selected some factors as independent variables to establish the logistic regression model [26].
The overall model performance was evaluated mainly by the Brier score, which is simply defined as (y − p) ^ 2, with y the outcome and p the prediction for each subject. The average score of all subjects is the Brier score of the model. It refers to the distance between the predicted outcome and actual outcome. The Brier score is a proper scoring rule that combines calibration and discrimination, similar to Nagelkerke’s R2 [27]. Then, the discrimination and calibration of the model were evaluated. Harrell’s concordance statistic (C-index) is the most commonly used performance index to measure the discriminative ability of generalized linear regression models. It gives the probability a randomly selected subject which experienced an event had a higher risk score than a subject which had not experienced the event. For a binary outcome, the C statistic was the same as the area under the receiver operating characteristic (ROC) curve (AUC). Calibration refers to the agreement between observed outcomes and predictions, which refers to if we observe p% positive event among subjects with a predicted risk of p% in ideally situation. Calibration was usually evaluated by a calibration plot with predictions on the x-axis and the outcome on the y-axis, meaning the agreement between observed outcomes and predictions, perfect predictions should be at the 45° line. For different sample size data, different smoothing techniques were used to estimate the difference between the observed probabilities of outcomes and the prediction probabilities. As Steyerberg recommended, locally weighted least squares regression (loess) smoother was used to draw the calibration curve of development set because its sample size is greater than 5000, and restricted cubic spline (RCS) smoother was used to draw the calibration curve of validation set [26, 50].
For internal validation, we computed using a 10-fold cross validation procedure to validate the model performance: 90% of the data were used to train the model, and the remaining 10% were used to compute the model performance; this process was repeated 10 times.
For internal-external validation, as Steyerberg and Harrell advocated [51], 8 of the 9 centres’ data were selected as the development set to generate the model, the data of the 1 remaining centre was used as a validation set to evaluate the model performance, and this process was repeated to verify each centre sequentially and calculate the mean performance.
For external validation, we used a new dataset as a validation cohort to evaluate the model performance of the original model.
The final model is displayed by a scoring system made in Excel, which is convenient to use. All statistical analyses were performed using R 4.1.1 (R Foundation for Statistical Computing, Vienna, Austria) and RStudio 1.4.1106, the Integrated Development for R (250 Northern Ave, Boston, MA 02210, USA). The package “compareGroups” was used to make baseline tables, the package “glmnet” was used to perform LASSO regression, the package “rms” was used to build a prediction model, the package “pROC” was used to plot ROC curves, and the package “CalibrationCurves” was used to plot calibration curves.
Results
A total of 19,685 participants from 9 centres were included in model training, and 5138 participants were diagnosed with Mets, accounting for 26.1% of the total number. The differences in all baseline characteristics and predictors between the Mets group and the Non-Mets group are shown in Table 1. Categorical variables were compared using the chi-squared or Fisher’s exact test, and all continuous variables were verified to conform to a normal distribution, so they were compared using the t test or ANOVA (analysis of variance) test. The p values of the overall groups significance were shown in the table.
Model selection and development
To reduce the overfitting of the model and the collinearity among the dependent variables, the LASSO method was used to screen the prediction factors, which achieves the selection of predictors by shrinking some coefficients to zero by penalizing the absolute values of the regression coefficients (Fig. 2).

Plot the change trend of AUC and misclassification error with the increase of Log(λ). The AUC and misclassification error on the left side of the blue solid line do not change significantly. The number of predictors corresponding to the blue solid line is 6, and the AUC is above 0.85, the misclassification error is below 0.2
Figure 2 shows the change trend of AUCs and misclassification error (percentage of predicted values that do not match observed known values; the lower the misclassification error is, the better the model) with the increase in log (λ). The coefficients for the final model can be chosen at the lowest cross validated log (λ) value (the position of a black dotted line on the left of Fig. 2), or more conservatively, at a 1 standard error larger value of log(λ) (the position of a black dotted line on the right of Fig. 2). However, we conclude that in the first half of the increase in the contraction penalty λ, the increase in misclassification error and the decrease in AUCs are not significant. After comprehensive consideration, we chose the corresponding model at a 1 standard error larger value of log(λ) for AUCs; at this time, the misclassification error was close to 0.2, and the AUCs were still higher than 0.85.
Therefore, the model finally included SBP, DBP, WC, WHtR, PBF and CUN_BAE as predictors, and we used these 6 variables to establish the logistic regression equation as a final model. The regression coefficient of each variable and intercept is shown in our score calculator.
Model performance and validation: discrimination and calibration
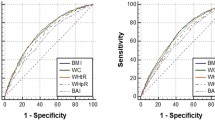
Model discrimination was evaluated by ROC curves, and model calibration was evaluated by calibration curves. We assessed discrimination and calibration in the development set through internal (via 10-fold cross validation), internal–external (across centres) and external (via another dataset) methods. The ROC curves and calibration curves are shown in Fig. 3A. In the original model performance, the C statistic/AUC was 0.88 (95% CI: 0.875-0.885), and the Brier score was 0.122. After 10-fold cross validation, the mean C statistic/AUCs was 0.879, and the mean Brier score was 0.122 (Table 2), which are extremely close to the original model performance. In the internal-external validation, the model performance of each centre is shown in Table 3. The mean C statistic/AUC of the 9 centres was 0.878, and the mean Brier score of the 9 centres was 0.121, which were also very close to the original model performance. In the validation set, the C statistic/AUC was 0.862 (95% CI: 0.833-0.891), and the Brier score was 0.133 (Fig. 3B). Consequently, these results suggested that the prediction models had good performance.

The ROC curves and calibration curves of development set (A) and validation set (B). In the ROC curve, the y-axis is the sensitivity from 0 to 100%, and the x-axis is the specificity from 100% to 0. The y-axis of the calibration curve is the proportion of positive outcomes observed in the corresponding group, and the x-axis is the average prediction probability of the model, the perfect prediction should be on the 45-degree line. The calibration curve of development set is constructed with the restricted cubic spline (RCS) smoother and the calibration curve of validation set is constructed with the “loess” smoother
Model visualization: making a risk score calculator
The formulas of these anthropometric indices were quite complicated, and it is not convenient to calculate all anthropometric indices manually; therefore, we created an Excel file that included all of the formulas and coefficients of predictors. When entering age, height, weight, WC and other simple values, it can automatically calculate anthropometric indices and the probability of Mets (Fig. 4). We randomly entered the data of a participant as a demonstration; this was a 49-year-old man with Mets, and his predicted probability of Mets calculated by the model was 79.05%.

The models were presented as logistic regression equations in this Excel document, it will calculate the predictor (lp) first. According to logit transformation, \(\mathrm{lp}=\mathrm{logit}\left(\mathrm{p}\right)=\log \left(\frac{\mathrm{p}}{1-\mathrm{p}}\right)\), so \(\mathrm{p}=\frac{\exp \left(\mathrm{lp}\right)}{1+\exp \left(\mathrm{lp}\right)}\), the p value will be displayed in the purple cell. *p=The prediction of probability of Mets.
Discussion
To our knowledge, this is the first study that developed a diagnostic model with noninvasive anthropometric indices for Mets in a large representative Chinese population and many minority groups. When screening predictive variables, we excluded indices such as the triglyceride-glucose index (TyG) [32] and the visceral adiposity index (VAI) because their calculation formulas included serum triglyceride or HDL-C, which were included in the diagnosis standard of Mets, and we also hoped to use some noninvasive measurement indices as predictors.
LASSO regression was used to improve the multicollinearity among predictors and prevent model overfitting, and 6 predictors were selected by shrinking the coefficients towards zero. Among the predictors, SBP, DBP and WC are part of the diagnostic criteria for Mets, and WHtR, PBF and CUN_BAE have been proven to have separate predictive values for Mets in previous studies [24, 41, 52], so the prediction model established by these 6 predictors has very good performance.
To evaluate the performance of the model, we calculated the AUCs, plotted the calibration curve and calculated the Brier score of the model to evaluate the calibration. The AUCs of the model are greater than 0.8, which is considered to indicate better discrimination, and the Brier score of the model is less than 0.2, which is considered to indicate better calibration. However, we also found that the model was significantly overestimated in groups with high predictive probabilities: at the right third of the calibration curve, the actual prevalence was lower than the average predictive probability, and this result is consistent with Wang’s study. The AUCs of this study is slightly lower than that of Wang’s study (AUC 0.901), but the development set of Wang’s study came from Spanish workers without external validation set. And the model of Wang’s study was shown by nomogram, the corresponding indicator such as body fat percentage (calculated as body fat percentage = 1.2 × (BMI) + 0.23 × age (years) − 10.8 × gender (male, 1; female, 0) − 5.4) need to be calculated well in advance before using the nomogram [53]. Similarly, Zhang’s study established a prediction model for 4-year risk of Mets with age, TC (serum total cholesterol), UA (serum uric acid), ALT (Alanine aminotransferase), and BMI, this was a longitudinal study (AUC 0.783, Brier score 0.156) but included invasive biochemical indicators as predictors [54]. Compared to Zhang’s study, our study lacks longitudinal validation because our study is a cross-sectional study, we cannot use this model to predict the probability of being diagnosed with Mets in the future, But we believe that this overestimation is useful to remind people of metabolic disorders. People who have been misdiagnosed have a high predictive probability, and they are likely to have metabolic problems in the future. We will conduct research to verify the ability of this model to predict the long-term outcomes of Mets.
We carried out 10-fold cross internal validation, external validation, and multicentre internal-external validation, which were rarely conducted at the same time in previous studies. The average AUCs and Brier score showed no significant changes in the internal validation and multicentre internal-external validation and were almost equal to the values in the original model. The performance of the validation set dropped slightly but was still in a good range. These results showed that the model has good performance and a stable predictive ability in population of different provinces in China, which is conducive for use in different centres.
Previous studies have mostly used nomographs to display predictive models, but nomographs are not accurate enough and convenient to use, and some predictors in this study need to be calculated indirectly, so a scoring system is used to display the model.
There are still some shortcomings in our study. 1) This study is a national study that was focused on investigating the prevalence of diabetes in China. The lifestyle, exercise history and eating habits of participants were kept simple, resulting in poor predictive ability of relevant predictors, and their coefficient in LASSO regression shrank to zero early; they were not selected as the final prediction factor. 2) The first phase of this study was conducted in approximately 2008. Due to the limited personnel and equipment, some new anthropometric indices could not be recorded. In future research, we will discuss how to add new prediction factors to improve the performance of the model. 3) In the 10-fold cross-validation, the performance of the model is not obviously decreased, but the performance of some centres has declined in internal and external validation, indicating that regional and ethnic differences may adversely affect the model’s performance. 4) The external validation datasets came from Shaanxi Province’s phase 3 follow-up data. Strictly speaking, the validation of these repeated participants belongs to the period validation of external validation, so the model needs more studies to conduct external validation to confirm its stability.
Conclusions
The model developed in this study has good discrimination and calibration performance, external validation and internal-external validation show that this model can maintain good stability in different space or time. Then, this model has been displayed by a calculator which can easily, accurately and quickly identify individuals with risk of Mets, help clinicians understand the physical condition of patients, and formulate treatment or rehabilitation plans in time.
Availability of data and materials
The datasets analysed during the current study are not publicly available because this is a national study covering the intellectual property rights of these 14 centres. However, some data can be obtained from the corresponding author upon reasonable request.
References
Alberti KG, Zimmet PZ. Definition, diagnosis and classification of diabetes mellitus and its complications. Part 1: diagnosis and classification of diabetes mellitus provisional report of a WHO consultation. Diabet Med. 1998;15:539–53.
Grundy SM, Brewer HB, Cleeman JI, Smith SC, Lenfant C. Definition of Metabolic Syndrome: Report of the National Heart, Lung, and Blood Institute/American Heart Association Conference on Scientific Issues Related to Definition. Circulation. 2004;109:433–8.
Alberti KGMM, Zimmet P, Shaw J. Metabolic syndrome-a new world-wide definition. A Consensus Statement from the International Diabetes Federation. Diabet Med. 2006;23:469–80.
Alberti KGMM, Eckel RH, Grundy SM, Zimmet PZ, Cleeman JI, Donato KA, et al. Harmonizing the Metabolic Syndrome: A Joint Interim Statement of the International Diabetes Federation Task Force on Epidemiology and Prevention; National Heart, Lung, and Blood Institute; American Heart Association; World Heart Federation; International Atherosclerosis Society; and International Association for the Study of Obesity. Circulation. 2009;120:1640–5.
Flegal KM, Kit BK, Orpana H, Graubard BI. Association of all-cause mortality with overweight and obesity using standard body mass index categories: a systematic review and meta-analysis. JAMA. 2013;309:71.
Di Angelantonio E, Bhupathiraju SN, Wormser D, Gao P, Kaptoge S, de Gonzalez AB, et al. Body-mass index and all-cause mortality: individual-participant-data meta-analysis of 239 prospective studies in four continents. Lancet. 2016;388:776–86.
Heymsfield SB, Wang ZM. Measurement of total-body fat by underwater weighing: new insights and uses for old method. Nutrition. 1993;9:472–3.
Lazzer S, Bedogni G, Agosti F, De Col A, Mornati D, Sartorio A. Comparison of dual-energy X-ray absorptiometry, air displacement plethysmography and bioelectrical impedance analysis for the assessment of body composition in severely obese Caucasian children and adolescents. Br J Nutr. 2008;100:918–24.
Mazess RB, Barden HS, Bisek JP, Hanson J. Dual-energy x-ray absorptiometry for total-body and regional bone-mineral and soft-tissue composition. Am J Clin Nutr. 1990;51:1106–12.
Clark RR, Kuta JM, Sullivan JC. Prediction of percent body fat in adult males using dual energy x-ray absorptiometry, skinfolds, and hydrostatic weighing. Med Sci Sports Exerc. 1993;25:528–35.
Mitsiopoulos N, Baumgartner RN, Heymsfield SB, Lyons W, Gallagher D, Ross R. Cadaver validation of skeletal muscle measurement by magnetic resonance imaging and computerized tomography. J Appl Physiol. 1998;85:115–22.
Sizoo D, de Heide LJM, Emous M, van Zutphen T, Navis G, van Beek AP. Measuring muscle mass and strength in obesity: a review of various methods. Obes Surg. 2021;31:384–93.
Lukaski HC. Methods for the assessment of human body composition: traditional and new. Am J Clin Nutr. 1987;46:537–56.
Gomez-Ambrosi J, Silva C, Catalan V, Rodriguez A, Galofre JC, Escalada J, et al. clinical usefulness of a new equation for estimating body fat. Diabetes Care. 2012;35:383–8.
Thomas DM, Bredlau C, Bosy-Westphal A, Mueller M, Shen W, Gallagher D, et al. Relationships between body roundness with body fat and visceral adipose tissue emerging from a new geometrical model: Body Roundness with Body Fat & Visceral Adipose Tissue. Obesity. 2013;21:2264–71.
Krakauer NY, Krakauer JC. A New Body Shape Index Predicts Mortality Hazard Independently of Body Mass Index. PLoS One. 2012;7:e39504.
Bergman RN, Stefanovski D, Buchanan TA, Sumner AE, Reynolds JC, Sebring NG, et al. A Better Index of Body Adiposity. Obesity. 2011;19:1083–9.
Valdez R. A simple model-based index of abdominal adiposity. J Clin Epidemiol. 1991;44:955–6.
Guerrero-Romero F, Rodrı́guez-Morán M. Abdominal volume index. an anthropometry-based index for estimation of obesity is strongly related to impaired glucose tolerance and type 2 diabetes mellitus. Arch Med Res. 2003;34:428–32.
Zhu Q, Shen F, Ye T, Zhou Q, Deng H, Gu X. Waist-to-height ratio is an appropriate index for identifying cardiometabolic risk in Chinese individuals with normal body mass index and waist circumference. J Diabetes. 2014;6:527–34.
Wu L, Zhu W, Qiao Q, Huang L, Li Y, Chen L. Novel and traditional anthropometric indices for identifying metabolic syndrome in non-overweight/obese adults. Nutr Metab (Lond). 2021;18:3.
Xu S, Ming J, Jia A, Yu X, Cai J, Jing C, et al. Normal weight obesity and the risk of diabetes in Chinese people: a 9-year population-based cohort study. Sci Rep. 2021;11:6090.
Jia A, Xu S, Xing Y, Zhang W, Yu X, Zhao Y, et al. Prevalence and cardiometabolic risks of normal weight obesity in Chinese population: A nationwide study. Nutr Metab Cardiovasc Dis. 2018;28:1045–53.
Wang H, Liu A, Zhao T, Gong X, Pang T, Zhou Y, et al. Comparison of anthropometric indices for predicting the risk of metabolic syndrome and its components in Chinese adults: a prospective, longitudinal study. BMJ Open. 2017;7:e016062.
Tian T, Zhang J, Zhu Q, Xie W, Wang Y, Dai Y. Predicting value of five anthropometric measures in metabolic syndrome among Jiangsu Province, China. BMC Public Health. 2020;20:1317.
Steyerberg EW. Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating. Cham: Springer International Publishing; 2019. http://link.springer.com/10.1007/978-3-030-16399-0. Accessed 14 Aug 2021
Harrell FE. Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis. Cham: Springer International Publishing; 2015. https://doi.org/10.1007/978-3-319-19425-7.
Collins GS, Reitsma JB, Altman DG, Moons KGM. Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD): The TRIPOD Statement. Eur Urol. 2015;67:1142–51.
Yang W, Lu J, Weng J, Jia W, Ji L, Xiao J, et al. Prevalence of Diabetes among Men and Women in China. N Engl J Med. 2010;362:1090–101.
Jia A, Xu S, Ming J, Xing Y, Guo J, Zhao M, et al. Body fat percentage cutoffs for risk of cardiometabolic abnormalities in the Chinese adult population: a nationwide study. Eur J Clin Nutr. 2018;72:728–35.
Chin Y-T, Lin W-T, Wu P-W, Tsai S, Lee C-Y, Seal DW, et al. Characteristic-Grouped Adiposity Indicators for Identifying Metabolic Syndrome in Adolescents: Develop and Valid Risk Screening Tools Using Dual Population. Nutrients. 2020;12:3165.
Chiu T-H, Huang Y-C, Chiu H, Wu P-Y, Chiou H-YC, Huang J-C, et al. Comparison of Various Obesity-Related Indices for Identification of Metabolic Syndrome: A Population-Based Study from Taiwan Biobank. Diagnostics. 2020;10:1081.
Głuszek S, Ciesla E, Głuszek-Osuch M, Kozieł D, Kiebzak W, Wypchło Ł, et al. Anthropometric indices and cut-off points in the diagnosis of metabolic disorders. PLoS One. 2020;15:e0235121.
He Y-H, Chen Y-C, Jiang G-X, Huang H-E, Li R, Li X-Y, et al. Evaluation of anthropometric indices for metabolic syndrome in Chinese adults aged 40 years and over. Eur J Nutr. 2012;51:81–7.
Jayawardana R, Ranasinghe P, Sheriff MHR, Matthews DR, Katulanda P. Waist to height ratio: A better anthropometric marker of diabetes and cardio-metabolic risks in South Asian adults. Diabetes Res Clin Pract. 2013;99:292–9.
Liu B, Liu B, Wu G, Yin F. Relationship between body-roundness index and metabolic syndrome in type 2 diabetes. DMSO. 2019;12:931–5.
Liu J, Tse LA, Liu Z, Rangarajan S, Hu B, Yin L, et al. Predictive Values of Anthropometric Measurements for Cardiometabolic Risk Factors and Cardiovascular Diseases Among 44 048 Chinese. JAHA. 2019;8. https://doi.org/10.1161/JAHA.118.010870.
Perona JS, Schmidt Rio-Valle J, Ramírez-Vélez R, Correa-Rodríguez M, Fernández-Aparicio Á, González-Jiménez E. Waist circumference and abdominal volume index are the strongest anthropometric discriminators of metabolic syndrome in Spanish adolescents. Eur J Clin Investig. 2018:e13060.
Perona JS, Schmidt-RioValle J, Fernández-Aparicio Á, Correa-Rodríguez M, Ramírez-Vélez R, González-Jiménez E. Waist Circumference and Abdominal Volume Index Can Predict Metabolic Syndrome in Adolescents, but only When the Criteria of the International Diabetes Federation are Employed for the Diagnosis. Nutrients. 2019;11:1370.
Rico-Martín S, Calderón-García JF, Sánchez-Rey P, Franco-Antonio C, Martínez Alvarez M, Sánchez Muñoz-Torrero JF. Effectiveness of body roundness index in predicting metabolic syndrome: A systematic review and meta-analysis. Obes Rev. 2020;21. https://doi.org/10.1111/obr.13023.
Suliga E, Ciesla E, Głuszek-Osuch M, Rogula T, Głuszek S, Kozieł D. The Usefulness of Anthropometric Indices to Identify the Risk of Metabolic Syndrome. Nutrients. 2019;11:2598.
Wang F, Wu S, Song Y, Tang X, Marshall R, Liang M, et al. Waist circumference, body mass index and waist to hip ratio for prediction of the metabolic syndrome in Chinese. Nutr Metab Cardiovasc Dis. 2009;19:542–7.
Zhang Y, Zeng Q, Li X, Zhu P, Huang F. Application of conicity index adjusted total body fat in young adults-a novel method to assess metabolic diseases risk. Sci Rep. 2018;8:10093.
Zhou C, Zhan L, Yuan J, Tong X, Peng Y, Zha Y. Comparison of visceral, general and central obesity indices in the prediction of metabolic syndrome in maintenance hemodialysis patients. Eat Weight Disord. 2020;25:727–34.
Davila-Batista V, Molina AJ, Vilorio-Marqués L, Lujan-Barroso L, de Souza-Teixeira F, Olmedo-Requena R, et al. Net contribution and predictive ability of the CUN-BAE body fatness index in relation to cardiometabolic conditions. Eur J Nutr. 2019;58:1853–61.
Romero-Saldaña M, Fuentes-Jiménez FJ, Vaquero-Abellán M, Álvarez-Fernández C, Molina-Recio G, López-Miranda J. New non-invasive method for early detection of metabolic syndrome in the working population. Eur J Cardiovasc Nurs. 2016;15:549–58.
RG de O, Guedes DP. Performance of anthropometric indicators as predictors of metabolic syndrome in Brazilian adolescents. BMC Pediatr. 2018;18:33.
Stefanescu A, Revilla L, Lopez T, Sanchez SE, Williams MA, Gelaye B. Using A Body Shape Index (ABSI) and Body Roundness Index (BRI) to predict risk of metabolic syndrome in Peruvian adults. J Int Med Res. 2020;48:030006051984885.
Peduzzi P, Concato J, Kemper E, Holford TR, Feinstein AR. A simulation study of the number of events per variable in logistic regression analysis. J Clin Epidemiol. 1996;49:1373–9.
Steyerberg EW, Vickers AJ, Cook NR, Gerds T, Gonen M, Obuchowski N, et al. Assessing the Performance of Prediction Models: A Framework for Traditional and Novel Measures. Epidemiology. 2010;21:128–38.
Steyerberg EW, Harrell FE. Prediction models need appropriate internal, internal–external, and external validation. J Clin Epidemiol. 2016;69:245–7.
Kawamoto R, Kikuchi A, Akase T, Ninomiya D, Kumagi T. Usefulness of waist-to-height ratio in screening incident metabolic syndrome among Japanese community-dwelling elderly individuals. PLoS One. 2019;14:e0216069.
Wang S, Wang S, Jiang S, Ye Q. An anthropometry-based nomogram for predicting metabolic syndrome in the working population. Eur J Cardiovasc Nurs. 2020;19:223–9.
Zhang H, Chen D, Shao J, Zou P, Cui N, Tang L, et al. Development and Internal Validation of a Prognostic Model for 4-Year Risk of Metabolic Syndrome in Adults: A Retrospective Cohort Study. DMSO. 2021;14:2229–37.
Funding
This research was funded by the National Key Research and Development Program of China, grant number 2017YFC1309803, and the National Natural Science Foundation of China, grant number 82073663. National Natural Science Foundation of China, grant number 81873639.
Author information
Authors and Affiliations
Contributions
Qiuhe Ji and Jie Zhou conceived this paper, Qian Xu completed most data analysis and article compilation, and Changsheng Chen provided guidance on the statistical methodology. The other authors participated in CNDMDS. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
This study was approved by Xijing Hospital’s Institutional Review Board and was conducted in accordance with the ethical standards set out in the 1964 Declaration of Helsinki and subsequent amendments. All participants signed a written informed consent form before obtaining the data.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Xu, Q., Wang, L., Ming, J. et al. Using noninvasive anthropometric indices to develop and validate a predictive model for metabolic syndrome in Chinese adults: a nationwide study. BMC Endocr Disord 22, 53 (2022). https://doi.org/10.1186/s12902-022-00948-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12902-022-00948-1