
Abstract
Auscultation with stethoscope has been an essential tool for diagnosing the patients with respiratory disease. Although auscultation is non-invasive, rapid, and inexpensive, it has intrinsic limitations such as inter-listener variability and subjectivity, and the examination must be performed face-to-face. Conventional stethoscope could not record the respiratory sounds, so it was impossible to share the sounds. Recent innovative digital stethoscopes have overcome the limitations and enabled clinicians to store and share the sounds for education and discussion. In particular, the recordable stethoscope made it possible to analyze breathing sounds using artificial intelligence, especially based on neural network. Deep learning-based analysis with an automatic feature extractor and convoluted neural network classifier has been applied for the accurate analysis of respiratory sounds. In addition, the current advances in battery technology, embedded processors with low power consumption, and integrated sensors make possible the development of wearable and wireless stethoscopes, which can help to examine patients living in areas of a shortage of doctors or those who need isolation. There are still challenges to overcome, such as the analysis of complex and mixed respiratory sounds and noise filtering, but continuous research and technological development will facilitate the transition to a new era of a wearable and smart stethoscope.
Similar content being viewed by others

Background
In the long-standing history of mankind, auscultation has long been widely used for the examination of patients [1]. A stethoscope is considered one of the most valuable medical devices because it is non-invasive, available in real-time, and much informative [2]. It is particularly useful in respiratory diseases, and abnormal respiratory sounds provide information on various pathological conditions of lungs and bronchi. In 1817, French doctor Rene Laennec invented an auscultation tool and it enabled him to listen to internal noises of patients [3, 4]. Since then, the stethoscope has gradually changed to a device with a binaural form, flexible tubing, and a rigid diaphragm [5, 6].
So far, the stethoscope has been widely used and adopted as the physician’s primary medical tool. However, as chest images are developed, the degree of dependence on auscultation is relatively decreasing [7]. This phenomenon may be caused by the inherent subjectivity. The ability to recognize and differentiate the abnormal sounds depends on the listener's experience and knowledge. This discrepancy can potentially lead to inaccurate diagnosis and mistreatment. To improve this problem, there have been efforts to implement a standardized system to record and share lung sounds to analyze them accurately. Recent technical advances have allowed the recording of lung sounds with a digital stethoscope by electronical intensification of the sounds, and the sharing of recorded sound via blue-tooth transmission [6]. Besides, there have been published studies on artificial intelligence (AI)-assisted auscultation which recognizes the pattern of sounds and identifies their abnormalities, and some digital stethoscopes already adopted machine learning (ML) algorithms [8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25].
Another drawback of auscultation is the impossibility of remote care. When doctors examine patients with a stethoscope, auscultation must be implemented by contacting the stethoscope on the body of patients. Many patients with chronic diseases or limited mobility stay in nursing facilities or at home often without a medical practitioner [24, 25]. Moreover, the demand of patients in hard-to-reach area for telemedicine is increasing nowadays. However, it is difficult for doctors to examine these patients and auscultation is hardly done. Advances in battery technology developed embedded processors with low power consumption and integrated sensors to make stethoscopes wearable and wireless [26,27,28,29], so that doctors can examine patients from a distance. Auscultation became possible even while wearing personal protective equipment when treating patients with infectious diseases such as Coronavirus disease-19 (COVID-19) [30,31,32].
In this review, we will check the limitations of the existing auscultation method by checking the types of abnormal breathing sounds and the accuracy of analysis through the existing stethoscope. Next, we will introduce the new auscultation methods developed so far (AI-assisted analysis and wireless or attached stethoscopes) and the current status of breath sound analysis using them. Furthermore, we will suggest further research directions in the future.
Classification of abnormal respiratory sounds
Respiratory sounds are produced by the airflow in the respiratory tract and are divided into two categories: Normal or abnormal sound. Normal respiratory sound is made when there is no pulmonary disorder and consist of tracheal, bronchial, bronchovesicular, and vesicular sounds [33]. Abnormal respiratory sounds are caused by diseases at the lung or bronchus [34]. They can be described by the mechanism of production, location they are detected in, characteristics (such as continuity, range of pitch, timing mostly heard), and acoustic features (Table 1) [35].
Crackles are short, discontinuous, explosive sounds heard during inspiration and sometimes on expiration [36, 37]. Fine crackles are generated by inspiratory opening of small airways and associated with interstitial pneumonia or idiopathic pulmonary fibrosis (IPF), and congestive heart failure (CHF) [38]. Coarse crackles are produced by gas passing through intermittent airway opening and are related to secretory diseases such as chronic bronchitis and pneumonia [39].
Wheezes are generated in the narrowed or obstructed airway [36]. They have high frequency (> 100–5000 Hz) and sinusoidal oscillation in sound analysis [40]. They usually occur in obstructive airway diseases like asthma and chronic obstructive pulmonary disease (COPD) [39]. Rhonchi are induced by the narrowing of airways, caused by the production of secretions, so rhonchi can disappear after coughing (Table 1) [36].
Stridor is a high-pitched, continuous sound produced by turbulent airflow through a narrowed airway of upper respiratory tract [36]. It is usually a sign of airway obstruction that requires prompt intervention. In patients with pleural inflammation such as pleurisy or pleural tumor, a visceral pleura becomes rough, and its friction with the parietal pleura generates crackling sounds, a friction rub (Table 1) [41].
Although respiratory sounds are not difficult for a trained clinician to discern in usual cases, some sounds are ambiguous even for an expert to distinguish accurately. In addition, there are some cases where a mixture of several abnormal breathing sounds can be heard. Novel AI-assisted stethoscope can be useful for these challenging situations.
Limitation of conventional stethoscope and auscultation
As mentioned earlier, inherent subjectivity is considered as the largest drawback of auscultation. Many studies have been performed to assess the human’s ability to auscultate and identify respiratory sounds (Table 2).
Hafke-Dys et al. conducted a study comparing the skills of doctors and medical students in the auscultation of respiratory sounds. The pulmonologists performed remarkably better than the other groups and there was no significant difference in the rest of the groups [42]. Melbye et al. proceeded a study assessing the inter-observer variation in pediatricians and doctors for adults when classifying respiratory sounds into detailed or broader categories. The results indicated that descriptions of auscultation sounds in broader terms were more steadily shared between participants compared to more detailed descriptions [43]. Mangione et al. conducted a research assessing auscultatory skills of respiratory sounds among doctors and medical students. On average, trainees of internal medicine and family practice did not show significantly better performance than medical students. On the other hand, pulmonary fellows recorded the highest scores in all categories [44]. Mehmood et al. assessed the auscultatory accuracy of health care professionals working in medical intensive care unit (ICU). The sounds presented were wheezes, stridors, crackles, holosystolic murmur, and hyperdynamic bowel sounds. As expected, attending physicians performed best, followed by residents and subsequently nurses [45]. Andres measured the accuracy of medical students’ auscultation and investigated the efficacy of adding visual representation of sounds to support diagnosis and education. The results showed the potential of sound representation for increasing the accuracy of auscultation [46].
Overall, the studies have shown discrepancies in auscultation ability among doctors (especially in detailed classifications of respiratory sounds), suggesting that they may cause inaccurate diagnosis or incorrect treatment [47]. To reduce the subjective interpretation of sounds and complement the gap of auscultation capabilities between doctors, it would be helpful to establish a system which can record and share auscultated sounds.
Another drawback of auscultation is the impossibility of remote care. When doctors examine patients with a stethoscope, auscultation must be implemented by contacting the stethoscope on the body of patients. Many patients with chronic diseases or limited mobility stay in nursing facilities or at home often without a medical practitioner. Also, the demand of patients in hard-to-reach area for telemedicine is increasing nowadays. However, it is difficult for doctors to examine these patients and auscultation is hardly done. If a stethoscope that is easy to use even for non-specialists is developed using data transmission technology, doctors will be able to check the patient's condition from a distance.
Deep-learning based analysis of respiratory sounds
Development of a standardized system to analyze respiratory sounds accurately is required to overcome the subjectivity of human auscultation and the discrepancy in auscultation ability between doctors [8]. Recently, machine learning-based AI techniques are applied mainly by deep learning networks in many areas including chest radiograph or electroencephalography (EEG) [48,49,50]. These AI techniques enable us to obtain a new approach or more accurate analysis of respiratory sounds [9]. In order to satisfy the requirement, there have been many attempts to develop a new method of classifying and interpreting respiratory sounds automatically using deep learning-based analysis [10, 11]. However, because of the black box type algorithmic property of the deep learning algorithm, there is a certain lack of interpretability of detailed information of the analysis [51]. Though interpretability is an important factor for analysis, it is highly related to technical issues and data dependency. Moreover, it is not clearly defined nor stable yet [51]. For this reason, interpretability will be not covered in this review.
From the machine learning perspective, there are two main parts for respiratory sound analysis. The first is to develop predictive algorithms or models based on well-known machine learning methods (support vector machine [SVM], K-nearest neighbors [KNN], artificial neural network [ANN]) and deep learning architectures (convolutional neural networks [CNN], residual networks [ResNet], long short-term memory [LSTM], gated recurrent unit [GRU]) with multi-layers and the second is to define appropriate features explaining respiratory sound characteristics and extract them (short-time Fourier-transformed [STFT], wavelet transform [WT], Mel-frequency cepstrum coefficient [MFCC], singular spectrum analysis [SSA]) from given data and their ensembles. In this point of view, methods and algorithms for respiratory sound classification and prediction are summarized in more detail below (Table 3).
Fraiwan et al. conducted a study to explore the ability of deep learning algorithms in recognizing pulmonary diseases from recorded lung sounds. After several preprocessing steps (wavelet smoothing, displacement artifact removal, and z-sore normalization), two deep learning network architectures including CNN and bidirectional long short-term memory (biLSTM) units were applied. The resulting algorithm (CNN + biLSTM) achieved the highest accuracy [12]. Chen et al. proceeded with research to overcome the limitations of existing classification methods of lung sounds; artifacts and constrained feature extraction methods. The proposed method using optimized S-transform (OST) and deep ResNets outperformed the ensemble of CNN and the empirical mode decomposition (EMD)-based ANN [13]. Meng et al. combined the wavelet signal similarity with the relative wavelet energy and entropy as the feature vector to extract features of lung sounds. Applying the ANN to this system showed higher accuracy than the methods using SVM and KNN [14]. Hsu et al. applied eight kinds of AI-technique models and conducted a performance comparison between them. GRU-based models outperformed the LSTM-based models, and bidirectional models outperformed unidirectional counterparts. Moreover, adding CNN improved the accuracy of lung sounds analysis [15]. Jung et al. proposed a feature extracting process through the depthwise separable-convolution neural network (DS-CNN) to classify lung sounds accurately. Also, they found that the fusion of the STFT and the MFCC features and DS-CNN achieved a higher accuracy than other methods [16]. Grzywalski et al. compared the efficiency of auscultation of doctors and machine learning-based analysis based on neural networks and proposed that the efficiency could be improved by the implementation of automatic analysis [17]. Kevat et al. showed that a neural network-based AI algorithm detected respiratory sounds with a high accuracy [18]. Aykanat et al. found that CNN and SVM machine learning algorithms can be used to classify lung sounds, but the accuracy decreased as the number of sounds to be compared increased, as with humans [19]. Mondal et al. proposed a feature extraction technique based on EMD improving the performance of lung sound classification and the method was compared with WT, MFCC, and SSA method-based classification systems including ANN, SVM, and Gaussian mixture model (GMM) classifier. The proposed method gives a higher accuracy of 94.16 for an ANN classifier [20]. Altan applied deep belief networks (DBN) algorithm to diagnose early COPD and classify the severity of COPD, and the results showed significantly high accuracy. Since COPD is irreversible when it progresses, early diagnosis is important. In this regard, the results of their studies are groundbreaking and useful [21, 22]. Chamberlain et al. applied SVM with a semi-supervised deep learning algorithm and their algorithm achieved receiver operating characteristic (ROC) curves with a relatively high area under the ROC curve (AUC) [52].
Many studies have been conducted in collaboration with doctors and machine learning experts, and it has become possible to discriminate lung sounds with a considerable level of accuracy. However, there is still a limitation that the analysis becomes less accurate when noises caused by the stethoscope itself, surrounding environment, other organ activities, and so on are mixed among the recorded sounds or when two or more breathing sounds are present at the same time. This should be resolved through additional research in the future [53].
Development of digital stethoscopes
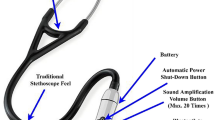
There are several available electronic stethoscopes: Littmann 3100, Stethee pro, Thinklabs one digital amplified medical stethoscope, Littman core digital stethoscope 8490, and StethoMe (Table 4). These digital stethoscopes overcome the low sound levels by electronically intensifying the respiratory sounds. Most importantly, recording of respiratory sounds with a digital stethoscope has allowed and facilitated the study of automatic respiratory sound analysis. Littmann 3100 is one of the most popular electronic stethoscopes, and many studies using respiratory sounds have been conducted with this stethoscope [54, 55]. It can save multiple sounds and transmit the data via Bluetooth transmission. Interestingly, Stethee Pro uses machine learning algorithms to capture and monitor both heart and lung sounds. This stethoscope can amplify the sound up to 96 times and visualize the sound data on the screen. Thinklabs One is the smallest digital stethoscope, and it can be used for personal protective equipment (PPE) auscultation in patients with infectious diseases such as COVID-19. StethoMe was developed for homecare service and installed AI can analyze the abnormality of respiratory sound. It is particularly specialized for monitoring airway diseases including asthma. These digital stethoscopes are continuously developing and becoming more useful for monitoring and diagnosing pulmonary disease.
In addition, recent innovative advances in battery technology, embedded processors with low power consumption, and integrated sensors have made many medical devices wearable and wireless (Table 4). Some studies have applied these techniques to stethoscopes, and the researchers developed the stethoscopes that monitor cardiorespiratory signals through wireless bio-signal acquisition [26, 27]. Certain airway diseases, such as asthma, often get worse at night or early in the morning, so doctors often cannot detect them during the daytime. Just as in the diagnosis of arrhythmia disease, Holter monitoring is used to monitor a patient's heart rate for 24 h, continuous monitoring of respiratory sound through a wearable device in airway disease will be of great help in diagnosis and emergency treatment. Some groups developed water permeable, adhesive, biocompatible acoustic devices for electrophysiological recording [28, 29]. Technologies of recording of sounds clearly and filtering out noises need further improvement, but wearable stethoscopes are expected to be used to diagnose and monitor chronic pulmonary diseases soon.
Clinical application of digital stethoscopes and AI-assisted analysis
There are several clinical studies using distal stethoscopes and AI for respiratory analysis. One study showed that CNN can classify chronic disease, non-chronic disease, and healthy groups by automatically analyzing respiratory sounds. In addition, the CNN is able to subcategorize disease group to different types of diseases including COPD, bronchiectasis, pneumonia, and bronchiolitis (Table 5) [56]. Another study adopted the acoustic characteristics of fine crackles to predict honeycombing on chest computed tomography (CT). They concluded that the presence of honeycombing was independently associated with onset time, number of crackles in the inspiratory phase, and F99 value of fine crackles [57].
Many studies related to digital stethoscope and AI analysis of auscultation sound are still currently in progress. As the need to collect and analyze the auscultation sounds of patients in quarantine facilities increases due to the recent COVID-19 crisis, related research is being conducted more actively. Several studies are trying to find a typical pattern of auditory sounds in COVID-19 patients (Table 5). One study plans to evaluate the AI-aided auscultation with automatic classification of respiratory sounds by using StethoMe stethoscope. If these studies are conducted well and AI-equipped stethoscopes can detect wheezing, rhonchi, and crackle accurately, these stethoscopes will be useful in emergency room treatment, medical screening, and telemedicine fields [58]. These smart stethoscopes will be of great help in monitoring patients with chronic pulmonary diseases, and many studies are underway for patients with idiopathic pulmonary fibrosis (IPF) and COPD (Table 5).
Conclusion
Thanks to the development of digital stethoscope and sound transmission technology, we have already been able to record and share respiratory sounds. With deep learning-based breathing sound analysis algorithm, we can distinguish respiratory sounds to some extent without a pulmonologist. This makes it possible to overcome the subjectivity in interpretation of sounds, the biggest drawback of the stethoscope, and this smart stethoscope will help the rapid diagnosis and the choice of appropriate treatment methods of respiratory diseases.
In addition, current research on battery technology, embedded processors with low power consumption, and integrated sensors are expected to make stethoscopes and other medical devices wearable in addition to wireless. Through these advances, we will be able to get over another major limitation of the existing stethoscope, the impossibility of remote care. The latest medical demands such as non-face-to-face care due to COVID-19, the monitoring of chronic respiratory diseases, and telemedicine in the hard-to-reach area will be satisfied (Fig. 1).

Summary of new medical era using smart stethoscope
However, despite the innovative developments so far, there are still some problems for the smart stethoscope to overcome. Since noises exist in the actual medical field where auscultation is performed, careful attention is required in recording and interpreting respiratory sounds. Noise filtering is one of the most crucial and challenging points in the aspect of both mechanical devices and analyzing algorithms. Although respiratory sounds are sometimes heard alone, in many cases, two or more sounds are mixed. These problems suggest the need for processing sound data acquired under noisy conditions to improve the sound quality. This would help rationally classify a wider variety of automatically auscultated sounds. Now, with the development of chest imaging, the degree of dependence on auscultation is relatively decreasing. However, as the remaining challenges are solved through further researches and clinical feedbacks, the smart stethoscope will become a definitely useful and essential tool in the diagnosis and treatment of respiratory diseases.
Availability of data and materials
Not applicable.
Abbreviations
- AI:
-
Artificial intelligence
- ML:
-
Machine learning
- COVID-19:
-
Coronavirus disease-19
- IPF:
-
Idiopathic pulmonary fibrosis
- CHF:
-
Congestive heart failure
- COPD:
-
Chronic obstructive pulmonary disease
- ICU:
-
Intensive care unit
- EEG:
-
Electroencephalography
- SVM:
-
Support vector machine
- KNN:
-
K-nearest neighbors
- ANN:
-
Artificial neural network
- CNN:
-
Convolutional neural networks
- ResNet:
-
Residual networks
- LSTM:
-
Long short-term memory
- GRU:
-
Gated recurrent unit
- STFT:
-
Short-time Fourier-transformed
- WT:
-
Wavelet transform
- MFCC:
-
Mel-frequency cepstrum coefficient
- SSA:
-
Singular spectrum analysis
- biLSTM:
-
Bidirectional long short-term memory
- OST:
-
Optimized S-transform
- EMD:
-
Empirical mode decomposition
- DS-CNN:
-
Depthwise separable-convolution neural network
- GMM:
-
Gaussian mixture model
- DBN:
-
Deep belief networks
- ROC:
-
Receiver operating characteristic
- AUC:
-
Area under the ROC curve
- PPE:
-
Personal protective equipment
- CT:
-
Computed tomography
References
Coucke PA. Laennec versus Forbes: tied for the score ! How technology helps us interpret auscultation. Rev Med Liege. 2019;74(10):543–51.
Sarkar M, et al. Auscultation of the respiratory system. Ann Thorac Med. 2015;10(3):158–68.
Bloch H. The inventor of the stethoscope: René Laennec. J Fam Pract. 1993;37(2):191.
Roguin A. Rene Theophile Hyacinthe Laënnec (1781–1826): the man behind the stethoscope. Clin Med Res. 2006;4(3):230–5.
Andrès E, et al. Respiratory sound analysis in the era of evidence-based medicine and the world of medicine 2.0. J Med Life. 2018;11(2):89–106.
Swarup S, Makaryus AN. Digital stethoscope: technology update. Med Devices (Auckl). 2018;11:29–36.
Arts L, et al. The diagnostic accuracy of lung auscultation in adult patients with acute pulmonary pathologies: a meta-analysis. Sci Rep. 2020;10(1):7347.
Gurung A, et al. Computerized lung sound analysis as diagnostic aid for the detection of abnormal lung sounds: a systematic review and meta-analysis. Respir Med. 2011;105(9):1396–403.
Palaniappan R, Sundaraj K, Sundaraj S. Artificial intelligence techniques used in respiratory sound analysis—a systematic review. Biomed Tech (Berl). 2014;59(1):7–18.
Aras S, et al. Automatic detection of the respiratory cycle from recorded, single-channel sounds from lungs. Turk J Electr Eng Comput Sci. 2018;26(1):11–22.
Altan G, et al. Chronic obstructive pulmonary disease severity analysis using deep learning on multi-channel lung sounds. Turk J Electr Eng Comput Sci. 2020;28(5):2979–96.
Fraiwan M, Fraiwan L, Alkhodari M, Hassanin O. Recognition of pulmonary diseases from lung sounds using convolutional neural networks and long short-term memory. J Ambient Intell Humaniz Comput. 2021:1–13. https://doi.org/10.1007/s12652-021-03184-y.
Chen H, et al. Triple-classification of respiratory sounds using optimized s-transform and deep residual networks. IEEE Access. 2019;7:32845–52.
Meng F, et al. Detection of respiratory sounds based on wavelet coefficients and machine learning. IEEE Access. 2020;8:155710–20.
Hsu FS, et al. Benchmarking of eight recurrent neural network variants for breath phase and adventitious sound detection on a self-developed open-access lung sound database-HF_Lung_V1. PLoS ONE. 2021;16(7):e0254134.
Jung SY, et al. Efficiently classifying lung sounds through depthwise separable CNN models with fused STFT and MFCC features. Diagnostics (Basel). 2021;11(4):732.
Grzywalski T, et al. Practical implementation of artificial intelligence algorithms in pulmonary auscultation examination. Eur J Pediatr. 2019;178(6):883–90.
Kevat A, Kalirajah A, Roseby R. Artificial intelligence accuracy in detecting pathological breath sounds in children using digital stethoscopes. Respir Res. 2020;21(1):253.
Aykanat M, et al. Classification of lung sounds using convolutional neural networks. EURASIP J Image Video Process. 2017;2017(1):1–9.
Mondal A, Banerjee P, Tang H. A novel feature extraction technique for pulmonary sound analysis based on EMD. Comput Methods Prog Biomed. 2018;159:199–209.
Altan G, et al. Deep learning with 3D-second order difference plot on respiratory sounds. Biomed Signal Process Control. 2018;45:58–69.
Altan G, Kutlu Y, Allahverdi N. Deep learning on computerized analysis of chronic obstructive pulmonary disease. IEEE J Biomed Health Inform. 2019;24:1344–50.
Chamberlain D, et al. Application of semi-supervised deep learning to lung sound analysis. In: 2016 38th Annual international conference of the IEEE engineering in medicine and biology society (EMBC); 2016. IEEE.
Fernandez-Granero MA, Sanchez-Morillo D, Leon-Jimenez A. Computerised analysis of telemonitored respiratory sounds for predicting acute exacerbations of COPD. Sensors (Basel). 2015;15(10):26978–96.
Murphy RL, et al. Automated lung sound analysis in patients with pneumonia. Respir Care. 2004;49(12):1490–7.
Yilmaz G, et al. A wearable stethoscope for long-term ambulatory respiratory health monitoring. Sensors (Basel). 2020;20(18):5124.
Klum M, et al. Wearable multimodal stethoscope patch for wireless biosignal acquisition and long-term auscultation. In: Annual international conference of IEEE engineering in medicine and biology society, vol 2019; 2019. p. 5781–5.
Klum M, et al. Wearable cardiorespiratory monitoring employing a multimodal digital patch stethoscope: estimation of ECG, PEP, LVET and respiration using a 55 mm single-lead ECG and phonocardiogram. Sensors (Basel). 2020;20(7):2033.
Liu Y, et al. Epidermal mechano-acoustic sensing electronics for cardiovascular diagnostics and human–machine interfaces. Sci Adv. 2016;2(11):e1601185.
Vasudevan RS, et al. Persistent value of the stethoscope in the age of COVID-19. Am J Med. 2020;133(10):1143–50.
White SJ. Auscultation without contamination: a solution for stethoscope use with personal protective equipment. Ann Emerg Med. 2015;65(2):235–6.
Arun Babu T, Sharmila V. Auscultating with personal protective equipment (PPE) during COVID-19 pandemic—challenges and solutions. Eur J Obstet Gynecol Reprod Biol. 2021;256:509–10.
Bardou D, Zhang K, Ahmad SM. Lung sounds classification using convolutional neural networks. Artif Intell Med. 2018;88:58–69.
Reichert S, et al. Analysis of respiratory sounds: state of the art. Clin Med Circ Respir Pulm Med. 2008;2:45–58.
Sengupta N, Sahidullah M, Saha G. Lung sound classification using cepstral-based statistical features. Comput Biol Med. 2016;75:118–29.
Bohadana A, Izbicki G, Kraman SS. Fundamentals of lung auscultation. N Engl J Med. 2014;370(8):744–51.
Serbes G, et al. Feature extraction using time-frequency/scale analysis and ensemble of feature sets for crackle detection. In: Annual international conference of IEEE engineering in medicine and biology society, vol 2011; 2011. p. 3314–7.
Vyshedskiy A, et al. Mechanism of inspiratory and expiratory crackles. Chest. 2009;135(1):156–64.
Faustino P, Oliveira J, Coimbra M. Crackle and wheeze detection in lung sound signals using convolutional neural networks. In: Annual international conference of IEEE engineering in medicine and biology society, vol 2021; 2021. p. 345–8.
Gavriely N, et al. Flutter in flow-limited collapsible tubes: a mechanism for generation of wheezes. J Appl Physiol (1985). 1989;66(5):2251–61.
Pasterkamp H, et al. Towards the standardisation of lung sound nomenclature. Eur Respir J. 2016;47(3):724–32.
Hafke-Dys H, et al. The accuracy of lung auscultation in the practice of physicians and medical students. PLoS ONE. 2019;14(8):e0220606.
Melbye H, et al. Wheezes, crackles and rhonchi: simplifying description of lung sounds increases the agreement on their classification: a study of 12 physicians’ classification of lung sounds from video recordings. BMJ Open Respir Res. 2016;3(1):e000136.
Mangione S, Nieman LZ. Pulmonary auscultatory skills during training in internal medicine and family practice. Am J Respir Crit Care Med. 1999;159(4 Pt 1):1119–24.
Mehmood M, et al. Comparing the auscultatory accuracy of health care professionals using three different brands of stethoscopes on a simulator. Med Devices (Auckl). 2014;7:273–81.
Andrès E. Advances and perspectives in the field of auscultation, with a special focus on the contribution of new intelligent communicating stethoscope systems in clinical practice, in teaching and telemedicine. In: El Hassani AH, editor. eHealth and remote monitoring. London: IntechOpen; 2012.
Pasterkamp H, Kraman SS, Wodicka GR. Respiratory sounds. Advances beyond the stethoscope. Am J Respir Crit Care Med. 1997;156(3 Pt 1):974–87.
Altan G, Yayık A, Kutlu YJNPL. Deep learning with ConvNet predicts imagery tasks through EEG. 2021. p. 1–16.
Tang YX, et al. Automated abnormality classification of chest radiographs using deep convolutional neural networks. NPJ Digit Med. 2020;3:70.
Thompson WR, et al. Artificial intelligence-assisted auscultation of heart murmurs: validation by virtual clinical trial. Pediatr Cardiol. 2019;40(3):623–9.
Goodfellow I, Bengio Y, Courville AJCM. Deep learning (adaptive computation and machine learning series). Cambridge: MIT Press; 2017. p. 321–59.
Chamberlain D, et al. Application of semi-supervised deep learning to lung sound analysis. In: Annual international conference of IEEE engineering in medicine and biology society, vol 2016; 2016. p. 804–7.
Emmanouilidou D, et al. Computerized lung sound screening for pediatric auscultation in noisy field environments. IEEE Trans Biomed Eng. 2018;65(7):1564–74.
Fontaine E, et al. In-flight auscultation during medical air evacuation: comparison between traditional and amplified stethoscopes. Air Med J. 2014;33(6):283–5.
Mamorita N, et al. Development of a Smartphone App for visualizing heart sounds and murmurs. Cardiology. 2017;137(3):193–200.
García-Ordás MT, et al. Detecting respiratory pathologies using convolutional neural networks and variational autoencoders for unbalancing data. Sensors (Basel). 2020;20(4):1214.
Fukumitsu T, et al. The acoustic characteristics of fine crackles predict honeycombing on high-resolution computed tomography. BMC Pulm Med. 2019;19(1):153.
Jaber MM, et al. A telemedicine tool framework for lung sounds classification using ensemble classifier algorithms. Measurement. 2020;162:107883.
Ono H, et al. Evaluation of the usefulness of spectral analysis of inspiratory lung sounds recorded with phonopneumography in patients with interstitial pneumonia. J Nippon Med Sch. 2009;76(2):67–75.
Acknowledgements
Not applicable.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korean Government (MSIT) (No. 2017R1A5A2015385), National Institute for Mathematical Sciences (NIMS) grant funded by the Korean government (No. B22910000) and Chungnam National University Hospital Research Fund, 2021 (No. 2021-CF-053). The funding bodies played no role in the design of the study and collection, analysis, and interpretation of data and in writing the manuscript.
Author information
Authors and Affiliations
Contributions
CC and TH suggested the idea for this article, YK, SL and SW performed the literature search and arrangement on this topic, and YH critically revised the work. All authors contributed to the elaboration and redaction of the final manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Kim, Y., Hyon, Y., Lee, S. et al. The coming era of a new auscultation system for analyzing respiratory sounds. BMC Pulm Med 22, 119 (2022). https://doi.org/10.1186/s12890-022-01896-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12890-022-01896-1