
Abstract
Background
The Household Health Survey (HHS) was developed to understand the socioeconomic determinants of mental and physical health, and health inequalities in health and social care. This paper aims to provide a detailed rationale of the development and implementation of the survey and explore socio-economic variations in physical and mental health and health care.
Methods
This comprehensive longitudinal public health survey was designed and piloted in a disadvantaged area of England, comprising questions on housing, physical health, mental health, lifestyle, social issues, environment, work, and finances. After piloting, the HHS was implemented across 28 neighbourhoods – 10 disadvantaged neighbourhoods for learning (NfLs), 10 disadvantaged comparator sites, and eight relatively advantaged areas, in 2015 and 2018. Participants were recruited via random sampling of households in pre-selected neighbourhoods based on their areas of deprivation.
Results
7731 residents participated in Wave 1 (N = 4319) and 2 (n = 3412) of the survey, with 871 residents having participated in both. Mental health, physical health, employment, and housing quality were poorer in disadvantaged neighbourhoods than in relatively advantaged areas.
Conclusions
This survey provides important insights into socio-economic variations in physical and mental health, with findings having implications for improved care provision to enable residents from any geographical or socio-economic background to access suitable care.
Similar content being viewed by others

Background
Areas with different levels of wealth and opportunity are typically subject to large inequalities in health outcomes [1]. A combination of social and economic circumstances, such as high unemployment rates and high levels of chronic illness and disability in poor neighbourhoods, can contribute to poor access to healthcare services, which can negatively impact health outcomes [2]. Indeed, residents of the poorest neighbourhoods in England have a shortened average life expectancy of eight years less compared to those living in the wealthiest parts of the country [3]. This life expectancy inequality between neighbourhoods is predicted to rise [4]. The costs of those health inequalities in Europe alone equate to approximately 20% of health services in middle- and high-income countries [5]. Given the human and financial costs of this inequality, there is a need to conduct robust research to inform interventions and public health policy. Here, we describe details of a large public health survey (Household Health Survey; HHS) designed to explore and explain health inequalities, noting the key outcomes of the research.
Socio-economic status (SES) is one of the primary predictors of health inequalities [2, 6,7,8], and is closely linked to poorer mental and physical health [9, 10]. A recent survey offered insights into health and lifestyle factors associated with deprivation [11]. However, in order to understand the social and economic determinants relating to physical and mental health issues, there is a clear need to conduct a comprehensive survey with input from varied stakeholders and disciplines. As stated in the Marmot review [5], an active reduction in health inequalities requires addressing all social determinants of health, including education, occupation, income, the home environment and the community. With the development of measures such as The Health Inequalities Assessment Tool (HIAT) [12] and the research infrastructure we’ve developed for co-production and community involvement; comes the opportunity to assess the health inequality implications of proposed research by undertaking relevant comprehensive data collections from households in areas participating in the programme and matched areas. Considering the high levels of socio-economic disadvantage in the North West Coast (NWC) region of England [13], this geographical area was highly suitable for such a survey.
Trends in life expectancy in both men and women have increased steadily in the UK as a whole for over 150 years. However, these improvements are stalling at best in most areas in the last decade, and falling in some of the most deprived areas. Differences in average life expectancy is almost 10 years among men and nearly 8 years among women between the most and least deprived neighbourhoods (Marshall et al., 2019). Statistics demonstrate a long-term North South divide in life expectancy and inequity trends (Barr et al., 2017; ONS, 2019). The North West of England historically and recently vies with the North East for the lowest average absolute and healthy life expectancies and gaps between the highest and lowest areas within the regions. Within the area covered by this survey healthy life expectancy can vary by up to 20 years between the least and most deprived neighbourhoods, with Blackpool having the lowest healthy life expectancy of any local authority area in England. These gaps are increasing and are considered to result from systemic socio-economic differences between populations (Marmot et al., 2020).
The HHS combines data on physical and mental health, social factors, environmental factors, self-reported medications, as well as geographical information, thereby exploring the variety of determinants of health inequalities [1, 14]. The overall HHS aimed to investigate a range of objectives all pertinent to reducing health inequalities, including:
-
To understand the geographic and socioeconomic determinants of mental and physical health in mostly disadvantaged neighbourhoods.
-
To understand health inequalities in the utilisation of health and social care.
-
To inform the integration and design of better health and social care services.
-
To provide a baseline for policy and person-level implementation projects within neighbourhoods.
-
To provide a vehicle for capacity building and knowledge exchange.
The aim of the present study was to explore the overarching mental and physical health, social support, housing, and other public health factors of participants from disadvantaged and less disadvantaged neighbourhoods captured in the longitudinal HHS.
Methods
Survey development
The NWC HHS is coordinated by researchers at the University of Liverpool and funded by the NIHR Collaboration for Leadership in Applied Health Research and Care (CLAHRC) North West Coast (NWC). The survey development was an iterative and collaborative process involving the core Applied Research Collaboration (ARC) NWC HHS team, local authorities, NHS clinicians, members of the public, acting in the capacity of public advisers and a private research company (BMG Research). Public advisers were involved in the development of the survey (TW, KH). Figure 1 shows a flowchart, which illustrates the steps involved from the design stage through to the pilot and data collection, analysis, and dissemination.

Flowchart of different stages of Household Health Survey. HES=Hospital Episode Statistics; PLDR = Place-based Longitudinal Data Resource
Survey process
BMG Research conducted all data collection. Ethical approval was obtained from the University of Liverpool (Ref: RETH000836). Sampled households were mailed a letter and information leaflet at least two weeks before being approached for an interview. Interviewers then approached residents and potential participants by knocking on the resident’s door up to five times on different days and at different times of the day until it was considered as a non-response. All interviewers were trained in conducting the interview via a one-day training course. Survey interviews for the first wave were conducted on a face-to-face basis at the respondent’s homes between mid-August 2015 and early January 2016, and for the second wave between August 2018 and December 2018. All addresses were loaded electronically on to Computer Aided Personal Interviewing (CAPI) units, so that all contact information could be effectively monitored, whilst also reducing the scope for interviewer error with ID numbers, names and addresses already pre-loaded. Interviews lasted on average around 45 min.
Prior to the full survey, a pilot survey was conducted to establish any necessary changes to the methodology. For the pilot, 36 residents from NfLs and two residents from relatively advantaged areas participated. Findings from the pilot led to minor amendments of survey documents.
Participants and recruitment
Participants were recruited from 28 neighbourhoods across the North West Coast of England in Wave 1 (2015) via random sampling of individual households. This is a region with some of the most disadvantaged neighbourhoods in the country as well as some of the most advantaged neighbourhoods, and is therefore subject to some of the greatest health and care inequalities [13]. Twenty disadvantaged neighbourhoods were identified by local authority (LA) partners. Ten of these (across eight LA areas) were subsequently identified as CLAHRC NWC’s Neighbourhoods for Learning (NfLs) where programmes of action research focused on improving the resilience of the wider health determinants governance system (known as the System Resilience Programme) were to be developed and implemented. This involved a partnership between academics, LAs and residents. The aim was to utilise research evidence alongside the experiential knowledge of those who live and work in these neighbourhoods to enhance resilience and thus address social, economic, and environmental determinants of health inequalities. Data from the HHS has been utilised in the early phases of the System Resilience Programme to support local stakeholders in identifying local issues for action, and it is being evaluated using a mixed-method approach including longitudinal data from Waves 1 and 2 of the HHS. Figure 2 shows the criteria necessary to be considered as a disadvantaged area for the purpose of the survey.

Deprivation criteria applied in the sample selection. To be considered a disadvantaged area, the neighbourhood had to meet the above five criteria. These referred to the Index of Multiple Deprivation (IMD) from the English Indices of Deprivation (ONS, 2015)
For Wave 2 (2018), only the 20 disadvantaged neighbourhoods were surveyed. Firstly, participants from Wave 1 who had expressed an interest in taking part in Wave 2 were contacted to participate. Where participants were no longer interested in a follow-up survey, or had moved away, researchers contacted other participants from the same household or residence for participation. Alternatively, new residents in the neighbourhoods were approached for participation.
Survey data
Table 1 shows the list of questions and scales within the HHS, which included sections on demographics, housing, physical health, mental health, lifestyle, social issues, neighbourhood environment, health and social care use, and work and finances. Specific health and mental health measures include the Personalised Health Questionnaire 9 (PHQ9) [15], the Generalised Anxiety Disorder Assessment 7 (GAD7) [16], the Warwick-Edinburgh Mental Wellbeing Scale (WEMWBS) [17], and the EQ-5D [18]. The survey was newly designed and is attached in Supplementary 1.
Data analysis
Data were prepared using weighting adjustment in applying survey weights to account for the differential sample sizes in each area, and to account for over- and under-response rates in certain areas which are not representative of that area’s population. Weights were applied by ward/ Lower Level Super Output Area (LSOA) using the following auxiliary variables in the following order: gender, ethnicity, economic status, and age; followed by a rim weight by population within each ward/LSOA.
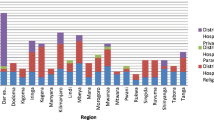
To test the quality of the sampling we conducted a series of parametric (ANOVA) and non-parametric (Chi-square test of independence) tests to determine whether there were differences between the NfLs, disadvantaged comparator neighbourhoods and relatively advantaged neighbourhooods, as well as between waves, on key demographic, socioeconomic, and health-related variables. Neighbourhood differences on key health and service use measures are shown in Fig. 3. ANOVAs were employed for continuous variables to detect mean differences between neighbourhood types. Follow-up comparisons employed Bonferroni adjustment to control for familywise error associated with conducting multiple tests. Chi square tests for independence were used to compare frequency statistics. This analysis tests whether the observed frequencies differ from expected frequencies if there was no relationship between neighbourhood type and the variable of interest. In other words, it tests whether there are more or less people in a particular type of neighbourhood (NfL, disadvantaged comparator, less disadvantaged) with a particular characteristic (e.g., a mental health condition) than would be expected due to chance alone. The significance of chi-square follow-up tests was assessed using chi-square tables, hence exact p-values are not reported. We also compared results to national statistics where appropriate and if data were available. Data were analysed in STATA version 14.

Percentage of people with Long-term conditions, mental health conditions, and who have attended A&E in the past 12 months across neighbourhood types
Results
In total, 7731 visits were conducted in Wave 1 and 2 of the survey. Specifically, 4319 residents participated in Wave 1 of the survey (NfLs = 2009; disadvantaged comparator neighbourhoods =1501; relatively advantaged neighbourhoods = 809), which is an overall adjusted response rate of 61% of the households approached by the survey team. Of those residents that answered the door, 63.6% responded to the survey, and 32% refused in the NfLs; 57.9% responded and 36.4% refused to participate in the comparator sites; and 58.1% responded and 35.7% refused to participate in the relatively advantaged areas. Of the 10 initially identified NfLs, two failed to implement System Resilience Programme interventions and one has since dropped out from the survey. However, these neighbourhoods were maintained as NFLs in the analysis. 3412 residents participated in Wave 2, of which 871 (20.2%) residents had been followed up from Wave 1. This included 2026 (59.4%) participants from the NfLs and 1386 (40.6%) from the disadvantaged comparator neighbourhoods. With unequal variances assumed, participants who completed both waves of the survey (M = 51.73, SD = 17.40) were significantly older than participants who only completed the wave 1 survey (M = 48.42, SD = 19.51; t (1405.93) = 4.70, p < .001. Chi-square tests indicated participants completing both waves were also more likely to identify as female χ2 (1, N = 4319) = 15.43, p < .001, were less likely to be in paid employment (χ2 (1, N = 4319) = 26.34, p < .001) and were more likely to have a long-term health condition, χ2 (1, N = 4319) = 48.56, p < .001.
No participants were missing more than 50% of data and the level of missing data for each participant ranged from 3 to 18%. The average amount of missing data per participant was 10.75%. Of the 376 total variables, 300 variables had complete data and 9.88% of all data points were missing. Data were not missing completely at random (Little’s MCAR χ2 = 7773.03, p < .001). Listwise deletion was used to account for missing values.
Demographics
Demographic characteristics for each neighbourhood type are reported in Table 2. In Wave 1, the majority of the total sample were female (57.1%), between 25 and 34 years old (17.9%), and from a white ethnic background (89.4%). Gender [χ2(2, N = 4319) = 4.44, p = 0.109] and ethnicity [χ2(2, N = 4319) = .684, p = 0.710] did not differ by neighbourhood type. However, age was not consistent across neighbourhood type, F (2,3857) = 25.47, p < .001. Follow-up comparisons with Bonferroni adjustment indicated that participants in relatively advantaged neighbourhoods (M = 53.48, SD = 18.30) were significantly older than participants in the NfLs (M = 47.51, SD = 19.43; t = 5.97, p < 0.001) and disadvantaged comparator (M = 49.00, SD = 18.79; t = 4.48, p < .001) neighbourhoods.
In Wave 1 there was also a significant association between education and neighbourhood type [χ2 (4, N = 4319) =232.13, p < .001]. The number of participants who held a degree was higher in relatively advantaged neighbourhoods [χ2(4, N = 4319) = 169.4, p < .01] and lower in the NfLs [χ2 (4, N = 4319) = 16.8, p < .01] and disadvantaged comparator neighbourhoods [χ2 (4, N = 4319) =15.1, p < .05]. Proportions of people in employment also varied across neighbourhood types, [χ2 (2, N = 4319) = 30.13, p < .001]. Examining employment as a dichotomous variable (employed, not employed), participants in relatively advantaged neighbourhoods had higher levels of employment [χ2 (2, N = 4319) =10.4, p < .01], while participants in NfLs had lower levels of employment [χ2 (2, N = 4319) =7.0, p < .05]. Observed frequencies in the disadvantaged comparator neighbourhoods did not differ from expected values [χ2(2, N = 4319) = .05, p > .05].
Consistent with Wave 1, the majority of the sample in Wave 2 were female (56.3%), between 25 and 34 years of age (18.7%), and from white ethnic backgrounds (89.6%). Age (t (3123) = .10, p = .923), gender [χ2(1, N = 3412) = 3.15, p = .076], and ethnicity [χ2(1, N = 3381) = .01, p = .931] proportions did not differ between NfLs and deprived comparator neighbourhoods. Education level did not vary according to neighbourhood type [χ2(2, N = 3408) = 2.37, p = 0.306]. Employment was related to neighbourhood type in the overall chi-square test [χ2(1, N = 3396) = 10.09, p = .001, but no individual proportions varied significantly from expected values (all χ2’s < 3.7, all p’s > .05).
Neighbourhood deprivation
Differences in deprivation at the neighbourhood level as measured by the Index of Multiple Deprivation (IMD) were examined via a one-way ANOVA (Wave 1) and an independent-samples t-test for unequal variances (Wave 2). In Wave 1, deprivation varied according to neighbourhood type, F (2, 4316) = 1842.92, p < .001. Post-hoc Least Significant Difference tests indicated that the relatively advantaged neighbourhoods (M = 11.32, SD = 7.58) had significantly lower levels of deprivation compared to the NfLs (M = 50.51, SD = 17.76, p < .001) and disadvantaged comparator neighbourhoods, M = 42.76, SD = 14.56, p < .001. The NfLs were also significantly more deprived than the disadvantaged comparator neighbourhoods. In Wave 2, the NfLs (M = 54.22, SD = 16.56) were significantly more deprived than the deprived comparator neighbourhoods (M = 42.27, SD = 14.54), t (3206.87) = 22.27, p < .001.
Caring responsibilities
In Wave 1, the number of people who reported caring responsibilities for a family member, friend, neighbour or other because of long-term physical or mental ill-health or disability or problems related to old age was consistent across neighbourhood types, [χ2(2, N = 4319) = .64, p > .05], with the majority of respondents reporting no caring responsibilities (~ 85%). In Wave 2, the proportions of people reporting caring responsibilities did not significantly differ between NfL and deprived comparator neighbourhoods, χ2(1, N = 3412) = 3.86, p = .145.
Physical health
There was a significant association between the number of people reporting long-term health conditions and neighbourhood type [χ2 (2, N = 4319) =14.08, p < .001]. Fewer people in relatively advantaged neighbourhoods reported having a long-term condition [χ2 (2, N = 4319) =6.3, p < .05]. Multimorbidity, however, did not differ between the three neighbourhood types [χ2 (4, N = 4319) =2.98, p = .562].
There was an association between long-term physical health conditions and neighbourhood type in wave 2 of the survey, χ2(1, N = 3389) = 14.41, p < 0.001. The deprived comparator neighbourhoods had significantly fewer people with long-term conditions than expected, χ2 (1, N = 3389) = 4.7, p < .05. A Chi-square test indicated that multimorbidity in the wave 2 sample varied by neighbourhood type, χ2(1, N = 3412) =4.94, p = .026. However, the follow-up analyses indicted no significant effect of neighbourhood type.
Self-reported medicine intake by class
The percentage of people reporting use of prescription medication ranged between 1.4 and 16.8% in the whole Wave 1 sample. Analgesics (16.8%) and anti-hypertension medication (16.7%) were the most frequently prescribed classes of drugs. Anti-depressants (11.1%), lipid-lowering medication (10.5%), and asthma medication (9.7%) were each prescribed to approximately one tenth of the total sample. Proton-pump inhibitors (7.4%), anti-diabetics (5.2%), anti-platelets (5.1%), anti-bacterial (3.5%), and anti-psychotics (1.4%) were prescribed less often. Chi square tests revealed significant associations with neighbourhood type for analgesics [χ2 (2, N = 4319) = 26.20, p < .001] and antidepressants [χ2 (2, N = 4319) =29.28, p < .001]. Reports of analgesic use were lower than expected in less disadvantaged neighbourhoods, χ2 (2, N = 4319) = 16.8, p < 0.05. Antidepressant use was also lower than expected in the less deprived neighbourhoods, χ2 (2, N = 4319) =17.6, p < .05. All other medication class usage was consistent across neighbourhood types.
In Wave 2, prescription rates ranged from 1.1% (anti-psychotics) to 14.4% (anti-depressants). Anti-depressants and analgesics (13.7%) were the most frequently prescribed medication. In order of frequency, people also reported taking hypertensive (11.4%), lipid lowering (9.3%), asthma (9.3%), cardiovascular (8.9%), anti-diabetic (5.4%) proton-pump inhibitor (5.0%), anti-bacterial (2.5%), and anti-platelet medications. The rates of prescription of all medication classes did not significantly differ between NfL and deprived comparator neighbourhoods with alpha set at .05.
Self-reported symptoms of mental ill-health
The numbers and proportions of people who reported symptoms of anxiety and depression to a level consistent with diagnosis of anxiety or depression are described in Table 2. In Wave 1, there was a significant relationship between the number of people reporting anxiety or depression and neighbourhood type [χ2 (2, N = 4317) =93.84, p < 0.001]. Specifically, there were significantly more than expected reports of mental health problems in the NfLs [χ2 (2, N = 4317) = 25.4, p < 0.01], and significantly fewer than expected reports of mental health problems in the relatively advantaged neighbourhoods [χ2 (2, N = 4317) = 46.9, p < 0.01]. The number of people reporting anxiety or depression in the disadvantaged comparator neighbourhoods did not differ from expected values [χ2 (2, N = 4317) =0.6, ns].
The proportion of people reporting anxiety or depression in Wave 2 varied according to neighbourhood type, χ2(1, N = 3404) = 12.30, p < 0.001. Specifically, the number of people in the deprived comparator neighbourhoods reporting anxiety or depression was higher than expected, χ2 (1, N = 3404) =5.4, p < .05.
Housing and environment
There was an uneven distribution of people in social housing across neighbourhood type [χ2 (2, N = 4319) = 337.21, p < 0.001]. Significantly more people than expected in the NfLs resided in social housing [χ2 (2, N = 4319) = 56.2, p < 0.01], while significantly fewer people than expected from the relatively advantaged neighbourhoods reported living in social housing [χ2 (2, N = 4319) =183.3, p < 0.01]. The number of people living in social housing for the disadvantaged comparator neighbourhoods did not differ from expected values [χ2 (2, N = 4319) =1.6, ns].
There was an overall association between “having problems with condensation” and neighbourhood type [χ2(2, N = 4205) =6.25, p < .05]. However, follow-up tests revealed no individual proportions were significant at the 0.05 level for any neighbourhood type. Reports of mould showed an association with neighbourhood type [χ2 (2, N = 4224) =20.77, p < 0.001]. The number of people reporting mould in the relative advantaged neighbourhoods was lower than expected [χ2 (2, N = 4205) =11.3, p < 0.01]. A similar pattern was observed when assessing the frequencies of people reporting problems with keeping warm in winter across neighbourhood types. The overall association was significant [χ2 (2, N = 4233) = 53.88, p < 0.001] and follow-up tests revealed that in the NfLs there were more reports of heating problems than expected [χ2 (2, N = 4205) =17, p < 0.01], whilst there were fewer reports than expected in the relatively advantaged neighbourhoods, χ2 (2, N = 4205) = 32.7, p < 0.01. The number of people who reported problems keeping warm in the disadvantaged comparator neighbourhoods did not differ from expected values [χ2 (2, N = 4205) = .3, ns].
Consistent with the Wave 1 data, there was an uneven distribution of people in social housing across the two neighbourhood types in Wave 2, χ2(1, N = 3412) =65.81, p < .001. There were significantly more people than expected living in social housing in the NfLs [χ2 (1, N = 3412) = 16.6, p < 0.05] and significantly fewer people than expected living in social housing in the deprived comparator neighbourhoods, χ2 (1, N = 3412) = 65.81, p < .05.
Work and finances
An overall chi-square test revealed that financial struggle was associated with neighbourhood type [χ2 (2, N = 4279) =19.44, p = .001]. However, follow-up tests revealed that no individual proportions were significant at the 0.05 level. In Wave 2, the proportion of people experiencing various levels of financial struggles was consistent across the neighbourhood types, χ2(2, N = 3386) =3.29, p = .345.
Healthcare service usage
In Wave 1, the overall percentage of people in our survey, who reported attending A&E or visiting a GP in the past 12 months was 25.75, and 69.23% respectively. 21.4% of participants visited both A&E and their GP, 51.9% visited one of these two services, and 26.3% visited neither A&E nor their GP in the previous 12 months. There was a significant association between neighbourhood type and A&E attendance [χ2 (2, N = 4307) =15.64, p < .001]. Follow-up tests indicated that there were lower than expected numbers of people attending A&E in relatively advantaged neighbourhoods [χ2(2, N = 4307) =9.3, p < .01], but proportions of A&E attendance in the NfLs and disadvantaged comparator neighbourhoods were not different from expected values. GP attendance rates were not significantly related to neighbourhood type [χ2 (2, N = 4307) =1.62, p = .444].
In Wave 2, 24.33% of respondents reported attending A&E in the previous 12 months and 62.43% of respondents visited their GP. A&E attendances varied according to neighbourhood type, χ2(1, N = 3402) = 4.88, p = 0.027, as did GP attendances, χ2(1, N = 3401) =5.80, p = .016. However, no individual frequency was significantly different to the expected value for either type of service use, χ2 ‘s < 2.3, p’s > .05. Previous analysis of the data showed that poor housing and unemployment were linked to increased A&E attendance rates [19], whereas those from an ethnic minority background had a 39% lower risk of attending A&E [20].
Discussion
This study reports the first overarching findings of the longitudinal NWC HHS, which explores health inequalities in accessing health and social care services in some of the most disadvantaged neighbourhoods in the country.
This longitudinal survey captures a broad range of variables ranging from mental and physical health to socioeconomic factors in some of the most socio-economically disadvantaged areas of England [13]. The design process of this survey was unique in that a range of stakeholders contributed to the survey development, including researchers, local authority partners, NHS partners and to a more limited extent, members of the public. The in-depth and collaborative design process and the subsequent conduct of the survey were strongly supported by the collaborative structure of the lead research organisation, the CLAHRC NWC. The very foundation of the CLAHRC is collaboration between researchers, health professionals, and other partner organisations, thereby facilitating co-produced research and building capacity in non-research partners. Co-production has been shown in other health research to be beneficial because it allows the experiences of people with a condition and trained staff to shape services and research [21, 22]. Similarly, here, we found that different perspectives improved the quality of the research and its dissemination, whilst being mindful of limited co-production in the design and implementation stages with some local authorities and the potential impact on lower survey response rates in those areas. This could be addressed by more active co-production in future in the very early stages.
Comparing the survey data to national data, the present sample was biased towards female respondents (our sample: 57.1%, census: 50.9%) [23] and Black and Minority ethnic participants (our sample: 11%, census: 8%) compared to census data for North West England [24]. However, ethnicity and gender did not vary as a function of disadvantage. People in more disadvantaged neighbourhoods were younger than people in relatively advantaged neighbourhoods. Taken together, the neighbourhood types were well matched demographically and were slightly biased on gender and ethnicity compared to census statistics.
Looking at the variations between more and relatively advantaged neighbourhoods, socioeconomic factors differed between neighbourhoods in the expected directions, with less employment, lower education, and higher proportions of social housing in disadvantaged areas. Social housing, however, was only found to be higher in the NfLs, but not in the comparator sites. General health status was better in the relatively advantaged areas, but health seemed to be worse in the NfLs compared to the disadvantaged comparator neighbourhoods. Nevertheless, of the healthcare utilization variables examined, only A&E attendance was found to be higher in disadvantaged neighbourhoods compared to the relatively advantaged areas, whilst GP attendance rates did not differ between neighbourhoods. Comparing this to national data, A&E attendance in our survey (20–27%) was lower than the 36% reported at the national level in 2017. GP attendance in our survey (69–70%) was also lower than figures reported in the GP patient survey, which reported 83.4% of respondents having attended a GP in the previous 12 months [25]. Divergent findings on A&E attendance may be due to the nature of our sampling which involved recall over the previous 12 months as opposed to hospital data at time of attendance. The two GP surveys were both self-report, so the reason for this discrepancy is less clear. One possibility is that people who attend GPs more frequently are more likely to complete a GP patient survey. Our survey, on the other hand, may not be subject to this specific bias.
Whilst the survey collected data from a wide geographical area from both disadvantaged and relatively advantaged areas, there were some limitations that should be considered. For example, interviewers ensured to knock on residents’ houses during different times of the day, but evening sampling was limited due to practical constraints. Because of this, people in full-time employment who were at work all day are likely to be underrepresented in our sample. Considering the focus on people living in disadvantaged neighbourhoods, data are limited to those with a fixed address. Thus, the survey was not able to capture some of the most disadvantaged groups in the population, such as homeless people and unregistered migrants. In addition, because specific neighbourhoods were selected for recruitment, this survey does not comprise a random sample of the general population. However, neighbourhoods were purposefully selected based on their level of deprivation, therefore providing a suitable sample for the focus of this survey. In addition, there were health and demographic differences between people who participated in both waves of the survey and those who did not, insofar as people who dropped out were more likely to be male, in paid employment, and not have a long-term health condition. This has implications for future recruitment strategies, which may benefit from extra measures to reduce drop-out among specific groups, such as instigating higher number call-backs before terminating follow-up or adjusting call-back times to increase retention of people in paid employment.
One of the lessons learned from designing, setting up, conducting, and analysing this survey is the benefit of having co-produced the survey with partners. Involving partners at every step of the process has helped to guide the research and outputs, but also to interpret findings and contribute to outputs from a non-researcher point of view. However, partner involvement was only very small at the beginning, and needs to be amplified further in future steps. Members of the public have been particularly involved in the current dissemination of the findings [26], including in this write up (TW, KH), and have helped shape the planning for Wave 2.
Conclusions
The NWC HHS has already highlighted several inequalities in accessing health care services, and is one of the first longitudinal public health surveys across England to specifically focus on people living in some of the most disadvantaged neighbourhoods in the country. Findings can help identify key areas of needs to tackle to reduce health inequalities, thereby addressing the World Health Organisation’s recent Health Equity Status Report [23] and providing guidance for how to address one of the five essential conditions for healthy lives for everyone: “good quality and accessible health services” [5].
Availability of data and materials
Users can obtain access to the ARC NWC HHS data files after submitting a brief proposal (including agreement to HHS’ conditions of use) at [info@pldr.org]. Users will also be required to outline which version of the survey dataset they wish to access, data security arrangements in place and how they meet the criteria for access. Access to the data will be authorized following approval from the PLDR governance board.
Abbreviations
- HHS:
-
Household Health Survey
- HIAT:
-
Health Inequalities Assessment Toolkit
- NWC:
-
North West Coast
- SES:
-
Socio-economic status
References
WHO Commission on Social Determinants of Health, and World Health Organization. Closing the Gap in a Generation: Health Equity through Action on the Social Determinants of Health : Commission on Social Determinants of Health Final Report. Geneva: World Health Organization, Commission on Social Determinants of Health; 2008..
Grintsova O, Maier W, Mielck A. Inequalities in health care among patients with type 2 diabetes by individual socio-economic status (SES) and regional deprivation: a systematic literature review. Int J Equity Health. 2014;13:43.
Institute of Health Equity. Marmot Indicators Briefing 2017. http://www.instituteofhealthequity.org/resources-reports/marmot-indicators-2017-institute-of-health-equity-briefing/marmot-indicators-briefing-2017-updated.pdf (last Accessed 19.04.2018), 2017.
Bennett JE, Li G, Foreman K, et al. The future of life expectancy and life expectancy inequalities in England and Wales: Bayesian spatiotemporal forecasting. Lancet. 2015;386(9989):163–70.
World Health Organization. Healthy, prosperous lives for all: the European Health Equity Status Report (2019). Copenhagen: WHO; 2019.
Cookson R, Propper C, Asaria M, Raine R. Socio-economic inequalities in health Care in England. Fiscal Studies: The Journal of Applied Public Economics. 2016;37:371–403.
Eibich P, Ziebarth NR. Analyzing regional variation in health care utilization using (rich) household microdata. Health Policy. 2014;114(1):41–53.
Morris S, Sutton M, Gravelle H. Inequity and inequality in the use of health care in England: an empirical investigation. Soc Sci Med. 2005;60(6):1251–66.
Allen J, Balfour R, Bell R, Marmot M. Social determinants of mental health. Int Review Psychiatr. 2014;26:392–407.
Meyer OL, Castro-Schilo L, Aguilar-Gaxiola S. Determinants of mental health and self-rated health: a model of socioeconomic status, Neighbourhood safety, and physical activity. Am J Public Health. 2014;104(9):1734–41.
Williamson S, McGregor-Shenton M, Brumble B, et al. Deprivation and healthy food access, cost and availability: a cross-sectional study. J Human Nutrition Dietetics. 2017. https://doi.org/10.1111/jhn.12489.
Popay JM, Porroche-Escudero A, Sadler G, Simpson S. The CLAHRC NWC health inequalities assessment toolkit V.3. Lancaster: NIHR CLAHRC NWC; 2017.
Office for National Statistics. The English Indices of Deprivation 2015. London: Deprivation for communities and local government; 2017.
Braveman P, Gottlieb L. The social determinants of health: It’s time to consider the causes of the causes. Public Health Rep. 2014;129:19–31.
Kroenke K, Spitzer RL, Williams JB. The PHQ-9: validity of a brief depression severity measure. J Gen Intern Med. 2001;16(9):606–13.
Spitzer RL, Kroenke K, Williams JB, Lowe B. A brief measure for assessing generalized anxiety disorder: the GAD-7. Arch Intern Med. 2006;16(10):1092–7.
Tennant R, Hiller L, Fishwick R, et al. The Warwick-Edinburgh mental well-being scale (WEMWBS): development and UK validation. Health Qual Life Outcomes. 2007;5:63.
EuroQoL Group. EuroQol – a new facility for the measurement of health-related quality of life. Health Policy. 1990;16(3):199–208.
Giebel C, McIntyre JC, Daras K, Pirmohamed M, Gabbay M, Downing J, et al. What are the predictors of a&E attendance in deprived neighbourhoods? Results from a cross-sectional household health survey in the north west of England. BMJ Open. 2019. https://doi.org/10.1136/bmjopen-2018-022820.
Saini P, McIntyre J, Corcoran R, Daras K, Giebel C, Fuller L, et al. Social and Mental Health Predictors of Emergency Department and General Practitioner Usage. Br J Gen Practice. 2020;70(690):e1–8. https://doi.org/10.3399/bjgp19X707093.
Hales S, Fossey J. Caring for me and you: the co-production of a computerized cognitive behavioural therapy (cCBT) package for carers of people with dementia. Aging Ment Health. 2017. https://doi.org/10.1080/13607863.2017.1348475.
Vaeggemose U, Ankersen PV, Aagaard J, et al. Co-production of community mental health services: Organising the interplay between public services and civil society in Denmark. Health Soc Care Comm. 2018;26(1):122–30.
Office for National Statistics. 2011 Census: key statistics for England and Wales, March 2011. London: Office for National Statistics; 2011.
Young R, Sly F. Regional trends: portrait of the north west. London: Office for National Statistics; 2011.
GP Patient Survey. https://gp-patient.co.uk/SurveysAndReports (last Accessed 10.01.2020).
Giebel C, Hassan S, McIntyre J, Corcoran R, Comerford T, Barr B, Gabbay M, Downing J, Alfirevic A. Public involvement in the dissemination of the north west coast household health survey: experiences and lessons of co-producing research together. Health Expect. 2019;22(4):643–9.
Acknowledgements
We wish to thank BMG Research for their support in conducting this survey, and all residents who have participated in the survey.
Funding
This report is independent research funded by the National Institute for Health Research Applied Research Collaboration North West Coast (ARC NWC). The views expressed in this publication are those of the author(s) and not necessarily those of the National Institute for Health Research or the Department of Health and Social Care. The funding body had no role in any aspect of this study, including the design, data collection, analysis, interpretation, and write up.
Author information
Authors and Affiliations
Contributions
BB, AA, RC, MG, JP, RB designed the survey. CG drafted the manuscript. JCM performed statistical analysis. JCM, AA, RC, KD, JD, MG, MP, JP, PW, KH, TW, RB, and BB through drafts of the manuscript and approved the final version. All authors have read and approved the final version.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Ethical approval was obtained from the University of Liverpool (Ref: RETH000836). Participants provided written informed consent prior to taking part in the study.
Consent for publication
Not applicable.
Competing interests
The authors have no conflicts of interest to report.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1.
The CLAHRC NWC Household Health Survey. Public health survey.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Giebel, C., McIntyre, J.C., Alfirevic, A. et al. The longitudinal NIHR ARC North West Coast Household Health Survey: exploring health inequalities in disadvantaged communities. BMC Public Health 20, 1257 (2020). https://doi.org/10.1186/s12889-020-09346-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12889-020-09346-5