
Abstract
Background
Mexican Americans, particularly those born in the United States, are at greater risk for alcohol associated morbidity and mortality. The present study sought to investigate whether specific genetic variants may be associated with alcohol use disorder phenotypes in a select population of Mexican American young adults.
Methods
The study evaluated a cohort of 427 (age 18 – 30 years) Mexican American men (n = 171) and women (n = 256). Information on alcohol dependence was obtained through interview using the Semi-Structured Assessment for the Genetics of Alcoholism (SSAGA). For all subjects, DNA was extracted from blood samples, followed by genotyping using an Affymetrix Axiom Exome1A chip.
Results
A protective variant (rs991316) located downstream from the ADH7 (alcohol dehydrogenase 7) gene showed suggestive significance in association with alcohol dependence symptom counts derived from DSM-III-R and DSM-IV criteria, as well as to clustered alcohol dependence symptoms. Additional linkage analysis suggested that nearby variants in linkage disequilibrium with rs991316 were not responsible for the observed association with the alcohol dependence phenotypes in this study.
Conclusions
ADH7 has been shown to have a protective role against alcohol dependence in previous studies involving other ethnicities, but has not been reported for Mexican Americans. These results suggest that variants near ADH7 may play a role in protection from alcohol dependence in this Mexican American cohort.
Similar content being viewed by others
Background
Hispanic American subgroups have diversity with respect to racial heritage and their cultures also vary in economic, religious, and psychosocial bases. The importance of specifying subgroups of Hispanics in order to avoid inaccurate generalizations has been emphasized [1],[2]. Mexican Americans are the largest subgroup of Hispanic Americans, representing nearly two-thirds of the total US Hispanic population, and as such are an important target population in need of further study. The prevalence rate of past heavy drinking in Mexican Americans was estimated in one report to be 3 times higher than that reported for a non-Hispanic male population [3]. The Los Angeles site of the Epidemiologic Catchment Area Study found that Mexican American men have higher alcohol dependence rates across all age categories compared to White men [4]. However, in a study by Vega et al. [5], higher overall alcohol dependence rates were found only in US-born Mexican Americans. More recent studies, comparing Hispanic national groups in the United States, show that Mexican Americans, together with Puerto Ricans, have the highest rates of binge drinking, driving under the influence of alcohol, alcohol abuse, and dependence [6]-[8].
The emerging picture of the genetic component to alcohol dependence suggests that the frequencies of risk and protective alleles associated with alcohol dependence may vary between ethnicities. For example, the genes involved in alcohol metabolism represent candidate genes for alcohol use disorders, and thus, have been the focus of research in a number of different ethnic populations [9],[10]. The seven alcohol dehydrogenase (ADH) genes, ADH7, ADH1C, ADH1B, ADH1A, ADH6, ADH4, and ADH5, are located in a single cluster on chromosome 4q21–24 with each gene coding for a unique isozyme. Some examples of variability in response to alcohol based on differences in ADH genotype include variants in ADH1B (e.g., ADH1B*2) that confer protection against alcohol dependence in East Asians, as well as Europeans, though at a much lower frequency [11]. A proportion of individuals of African origin also have a variant in ADH1B (ADH1B*3) that has been demonstrated to be protective against alcohol dependence in African Americans [12] and Afro-Caribbeans [13].
Only a few studies have evaluated polymorphisms in alcohol metabolism genes and the risk for alcohol dependence in Mexican American populations. Of the studies conducted, one study found that the ADH1B*1 and ADH1C*2 alleles were both associated with alcohol dependence in Mexican Americans. The authors concluded that Mexican Americans might have a unique pattern of genetic risk that may be in part responsible for the elevated rates of alcohol dependence and alcohol-associated health problems in this population [14]-[17]. In a second population of Mexican Americans, presence of at least one ADH1B*2 allele was found in 13% of the population, and was associated with protection against alcohol dependence. No significant associations between alcohol dependence and polymorphisms in ADH1C were found in this study [18]. Notably, each of these studies was based on a candidate gene approach and did not use a genome-wide corrected alpha level (i.e., p < 1e-8) to correct for type 1 error.
The aims of the present study were to further explore associations between risk and protective variants and alcohol dependence in a select population of Mexican American young adults. DNA and clinical information on 3 alcohol use disorder phenotypes were collected. In order to further expand the search for potential genes associated with alcohol use disorders, the genome was interrogated using an Affymetrix Exome1A array.
Methods
Sample ascertainment
To investigate risk and protective factors for alcohol dependence in a select population of Mexican American young adults, we investigated a cohort of 427 (age 18–30) Mexican American men (n = 171) and women (n = 256). Participants were recruited using a commercial mailing list that provided the addresses of individuals with Hispanic surnames in 11 zip codes in San Diego County. The mailed invitation stated that potential participants must be of Mexican American heritage, between the ages of 18 and 30 years, residing in the United States legally, and able to read and write in English. Based on a phone interview, participants were excluded if they were pregnant, were nursing, or currently had a major medical or neurological disorder or head injury. All participants identified as having over 20% Hispanic heritage, with 92% reporting over 50% Hispanic heritage. Information on alcohol dependence was obtained through interview using the Semi-Structured Assessment for the Genetics of Alcoholism (SSAGA) [19], which was used to make lifetime substance use and other psychiatric disorder diagnoses according to DSM-III-R and DSM-IV criteria. Under DSM-III-R guidelines, there are 9 symptom groups in the criteria for alcohol dependence, while there are 7 symptom groups in the DSM-IV guidelines. In both cases, subjects with the presence of symptoms from 3 or more symptom groups are assigned a diagnosis of alcohol dependence. There have been several studies that have evaluated the concurrent diagnostic validity of the SSAGA across alcohol and drug dependencies, major depression, anxiety disorders, and antisocial personality disorder [19],[20]. These findings indicate that the SSAGA is a highly reliable and valid instrument for use in studies of psychiatric disorders, including substance dependence. The protocol for the study was approved by the Institutional Review Board (IRB) at The Scripps Research Institute, and written consent was obtained for all participants. Participants were asked to refrain from alcohol and drug usage for 24 hours prior to the testing.
Sample preparation and genotyping
For all subjects, DNA was extracted from blood samples, followed by genotyping using an Affymetrix Exome1A chip. The DNA samples were prepared and the exome chip genotyping was performed on the Affymetrix Axiom Exome 1A Array according to the Affymetrix Axiom 2.0 Assay Manual Workflow documentation. The Affymetrix Exome 1A chip contains 247,222 markers. Variant quality from the exome chip genotyping was initially assessed according to Affymetrix best practices [21]. Plink version 1.07 [22] was used to calculate Hardy-Weinberg (HWE) p-values on the set of unrelated samples, followed by the removal of 653 variants with an HWE p < 10−10.
Association analysis
PLINK was used to test for genome-wide association for three phenotypic categories: 1) counts of alcohol dependence symptom groups as defined by DSM-III-R guidelines (phenotype value of 0 through 9), 2) counts of alcohol dependence symptom groups as defined by DSM-IV guidelines (phenotype value of 0 through 7), and 3) a dichotomous variable for DSM-IV alcohol dependence where the symptoms were required to cluster within a one year period. PLINK was run with linear regression model parameters and with one million permutations. Gender and age were included as covariates. In order to test if the markers were in high linkage disequilibrium with each other, PLINK was used to LD prune based on variance inflation factor (VIF = 2), and by pairwise correlation (R2 = 0.5). To reduce the effect of extreme outliers in the phenotypic values, we used a winsorization transformation, whereby the extreme values are replaced by certain percentiles rather than discarding the outliers. In particular, the lowest 5% of the numerically sorted phenotype values were replaced by the 5th percentile value, and the highest 5% of the values were set to the 95th percentile value. Custom R code was written to generate winsorized phenotype values at the 5% and 95% cutoffs, which were then used as the phenotype values in PLINK. Manhattan plots were generated using Manhattan R library (Stephen Turner, http://gettinggeneticsdone.blogspot.com/2011/04/annotated-manhattan-plots-and-qq-plots.html), and the Integrative Genomics Viewer (IGV) [23],[24]. Annotations of the variants were obtained from the Affymetrix Exome 1A chip description file. Multiple test correction p-value thresholds were calculated for the Affymetrix Exome1A chip using the Genetic Type 1 Error Calculator (GEC) software [25].
LD analysis
In order to check for linkage disequilibrium across the ADH gene cluster, PLINK was utilized to extract a subset of variants for analysis based on the physical position of the ADH gene cluster on chromosome 4. In particular, a region of chromosome 4 from genomic location 99,500,000 to 100,450,000 was extracted from the data set. Haploview [26] was used to calculate the LD statistics and visualize the haplotype block structure of the ADH gene cluster region.
Collapsing/Gene-based analysis
Custom python code implemented by Vikas Bansal for previous studies [27],[28] was used to perform three rare variant collapsing methods based on techniques of Madsen and Browning [29], Li and Leal [30], and RareCover [31]. A detailed description of these methods can be found in the original articles above, but briefly, these methods involve combining rare variants into a single set which can be tested for differences between the case and control subjects. The implementation of the Li and Leal method [30] collapses multiple rare variants into a single variable for each subject. This variable is tested for association with the phenotype using the Fisher exact test. The implementation of the Madsen and Browning method [29] tests for the differences in the cases and controls, using the number of rare variants and a weight calculated from minor allele frequency of the rare variants. The implementation of the RareCover method [31] is similar to the Li and Leal method, but instead of collapsing all of the rare variants, it creates and examines a subset of rare variants that are most different in frequency between the cases and the controls. The set of 62 rare variant (MAF <= 0.05) markers in the Affymetrix Exome 1A chip that resided in the ADH gene region were supplied as the region of variants to collapse.
Results
Demographics of the Mexican American population
The demographics for the full sample of individuals (N = 427) that were included in the association analysis are shown in Table 1. The subjects were a mean age of 23.6 (range 18 – 30) years at the time of interview, with 40% of the sample being male and 60% of the sample being female. Participants had a mean of 13.3 years of education (SD = 1.8), and a mean income of $30,000-$49,000. Ethnic background was self-reported by the subjects, by choosing the dominant heritage of each of their great grandparents from a list of possible ethnicities. For each subject, the numbers of great grandparents reported as Mexican, Mexican-American, Chicano, Mexican Indian, Caribbean, Cuban, Puerto Rican, South American, or other Spanish, were tallied, resulting in a percentage between 0 and 100%. From these tallies, 92% of the participants reported at least 50% Hispanic heritage. The mean BMI was 27 (SD = 7, range 17–64). Approximately 29% of the participants (N = 125) were diagnosed with alcohol dependence according to DSM-III-R guidelines, indicating that these subjects had symptoms from 3 or more symptom groups, out of 9 possible symptom groups. Approximately, 20% of the participants (N = 86) were diagnosed with alcohol dependence according to DSM-IV guidelines, indicating that these subjects had symptoms from 3 or more symptom groups, out of 7 possible symptom groups. Approximately 17% of the participants (N = 74) were diagnosed with alcohol dependence when the DSM-IV symptoms were required to cluster within a one-year period.
Association analysis
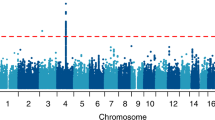
Figure 1 contains the Manhattan plots for the three phenotypic traits tested in our association analysis across the entire genome (DSM-III-R symptom group counts, DSM-IV symptom group counts, DSM-IV diagnosis with clustering). Significance of the variants was further validated using LD pruning, winsorization of the phenotype values, application of one million permutations, and the inclusion of the covariates age and gender. Although there were 48 total variants which exhibited p-values <= 1E-05, only one variant (rs991316) showed suggestive significance across all three phenotypic categories. This protective variant (rs991316) is located downstream from the alcohol dehydrogenase 7 gene (chr4:100322445 in hg19) and is common in our sample, with an allele frequency of 0.40. The variant retained its significance through permutation and winsorization. Additionally, the variant was not removed during LD pruning with PLINK, indicating that this variant was independent of other markers in the region. The association values are shown in Table 2, and the allele and genotype frequencies can be found in Table 3. The minor allele frequency of rs991316 from the 1000 Genomes project was obtained from the dbSNP website (http://www.ncbi.nlm.nih.gov/SNP/). The minor allele frequencies for the HapMap ethnicities were obtained from the International HapMap Project website (http://www.hapmap.org). Figure 2 contains the Manhattan plot of the association results across the ADH gene region only, in order to demonstrate that the SNP near ADH7 is the most highly significant variant in this region. Power analyses using GWAPower [32] showed that the samples contained 80% power to detect an effect explaining 0.053% of the variance.

Manhattan plots for alcohol dependence phenotypes. Manhattan plots for alcohol dependence phenotypes: A) ALCDep3 = alcohol dependence as defined by DSM-III-R guidelines; B) ALCDep4 = alcohol dependence as defined by DSM-IV guidelines; C) ALCDep_Cluster = DSM-IV alcohol dependence within 1 year clustering. Minor allele frequency cutoff of 0.05 applied to the plot. Suggestive significance line calculated from GEC software. Green rectangle in plots highlights SNP rs991316.

Manhattan plot of the association results across the ADH gene region. The ADH gene locations are shown in the bottom track of this plot generated by loading the PLINK results into IGV. The black rectangle highlights SNP rs991316, which exhibits a much higher significance than the other SNPs in the ADH gene region. No minor allele frequency cutoff was applied. Abbreviations: ALCDep3 = alcohol dependence as defined by DSM-III-R guidelines; ALCDep4 = alcohol dependence as defined by DSM-IV guidelines; ALCDep_Cluster = DSM-IV alcohol dependence within 1 year clustering.
Multiple test correction
Multiple test correction p-value thresholds were calculated for the Affymetrix Exome1A chip using the Genetic Type 1 Error Calculator (GEC) software [25], and the thresholds generated were thereby used to determine that this variant (rs991316) could be characterized to possess suggestive significance.
LD analysis
The evidence of LD across the ADH gene region can be observed in Figure 3. The average D’ value across the SNP pairs in the ADH region was 0.76 in this data set. The two SNPs found to be in complete LD with ADH7 (rs991316) with high confidence were: rs283413 (D’ = 1, r2 = 0.025, LOD = 3.48, CI = 0.56-1.00), and rs35719513 (D’ = 1, r2 = 0.03, LOD = 2.3, CI = 0.41-1.00). Both of these SNPs were located in ADH1C (rs283413, chr4:100268190; and rs35719513, chr4:100260783) and possessed a negative beta value, suggesting a protective role. However, these SNPs were not significantly associated with the alcohol dependence phenotypes in our sample when using PLINK for the analysis as can be seen in Figure 2.

Linkage disequilibrium (LD) plot across ADH gene cluster. This plot illustrates the linkage disequilibrium between SNPs genotyped across chromosome 4 encompassing the ADH gene cluster. LD was measured using D’. Blue bars above the plot indicate the gene locations. Increasing levels of LD are indicated by pink and red squares, with red squares demonstrating the highest confidence linkage estimates. The green rectangle highlights SNP rs991316. The yellow rectangles highlight the two SNPs in ADH1C that were in LD with SNP rs991316.
Collapsing/Gene-based analysis
The three collapsing techniques tested did not produce any significant p-values for the ADH gene region (p-value = 1.0 in all cases). Based on these results, we did not further pursue any other collapsing techniques for this data set.
Discussion
Demographics
The prevalence of alcohol dependence in this cohort ranged from 17% to 29%, depending upon the criteria used for the diagnosis, as shown in Table 1. DSM-IV alcohol dependence where the symptoms clustered within a 1-year period had the lowest prevalence rate at 17% overall, with a rate of 25% in males and 12% in females. The alcohol dependence diagnosis based on DSM-III-R had the highest overall prevalence of 29%, with 36% in males and 24% in females. The alcohol dependence diagnosis based on DSM-IV without requiring clustering was between these two ranges, at an overall rate of 20%, with a rate of 28% in males and 15% in females. Our values agree with the previous reports that males have a higher rate of alcohol dependence than females [33]. However, these values are higher than the reported rate of 9.5% for lifetime alcohol dependence in Hispanics across all age groups [34]. Since overall alcohol dependence prevalence in the U.S. is highest in the 18–30 year old age group [7],[34],[35], this may have contributed to the larger values in our study.
Recent studies have also examined the role of acculturation stress on Mexican Americans [35]-[37]. In one study, alcohol dependence in the past 12-month period was compared in Mexican Americans that lived in counties on the U.S.-Mexico border versus counties that are not near the border [35]. In that study, the alcohol dependence rate based on DSM-IV for 18–29 year old males was 24.0% for those living in bordering counties and 18.8% for those not in bordering counties. Since our subjects live in a border county, they may be exhibiting this higher rate based upon their location. In the same study, the prevalence for females also followed this same trend of higher rates in border counties, but at a lower rate than males. In particular, the rates for 18–29 year old females was 6.4% in border counties, and 1.7% in non-border counties. These reported lower values than those found in our sample, and may be due to the difference between past 12-month rates as examined in that study and lifetime rates of alcohol dependence as examined in the present study.
Association analysis
The results of the present study suggest that a variant (rs991316) located downstream of the alcohol dehydrogenase 7 gene (ADH7) may play a role in protection from alcohol dependence in this Mexican American cohort. Variants in the alcohol dehydrogenase (ADH) and aldehyde dehydrogenase (ALDH) genes have been found to influence alcohol metabolism, and thereby contribute to the effect that alcohol exerts on an individual. ADH7, in particular, is expressed in the stomach mucosa to metabolize alcohol, and therefore, provides the first line of defense against the effects of alcohol before it enters the blood [38]. The ADH7 gene has been shown to have a protective role against alcohol dependence in previous studies involving other ethnicities, but to our knowledge, has not been reported for Mexican Americans [39]-[41]. Additionally, this ADH7 SNP (rs991316) has not been identified to be significantly associated with alcohol dependence. Instead, this SNP was deposited into the dbSNP database (http://www.ncbi.nlm.nih.gov/SNP/) based on a study of hypertension in African Americans [42].
Recently, our group has reported a significant association of rs991316 with alcohol dependence in a Native American (NA) cohort [43]. In particular, in a whole genome sequencing study of Native Americans, rs991319 had a MAF of 0.347, a significant FDR p-value (0.0458), and a negative beta, suggesting a protective role. The NA sample (n = 320) had a higher rate of alcohol dependence of 46%, while the MA cohort had an alcohol dependence of approximately 20%. In addition to the whole genome sequencing data, Affymetrix Exome1A array data was available for the NA cohort. The MAF was 0.376 for the rs991316 marker for the NA cohort with the Affymetrix data, which validated the MAF obtained by the whole genome sequencing. Because variants located in the ADH gene region have been found to be associated with alcohol dependence in a Native American population [18],[40],[44], we also examined the self-reported ancestry for this Mexican American cohort. Of the 427 participants in the cohort, only 44 reported any amount of Native American heritage, which did not provide power for admixture analysis.
LD analysis
Because this particular variant near ADH7 (rs991316) had not been previously reported to be associated with alcohol dependence, we wanted to rule out the possibility that this effect was simply the result of LD with a variant in one of the other ADH genes. The LD analysis produced a high average LD across the entire ADH gene region (D’ = 0.76), demonstrating that this region is important in alcohol dependence. However, as can be seen in Figure 3, there are very few individual SNPs that are in complete LD with rs991316. This result was expected based on previous reports that there is not strong LD between ADH7 and the other ADH gene classes [39]. Even within the ADH7 gene itself, there exists substantial diversity in the haplotypes in a 23 kb region around ADH7, within and among 38 global populations [45].
Two variants in ADH1C, rs238413 and rs35719513, were found to be in complete LD with rs991316 in this study. These two SNPs had a negative beta, suggesting a protective role, but were not significantly associated with the alcohol dependence phenotypes used in this study. These two variants have been studied previously to determine their role in the rate of alcohol metabolism in white Spanish individuals [46]. In that study, rs283413 was significantly associated with the rate of alcohol metabolism, but rs35719513 was not.
The ADH1C gene has been associated with alcohol dependence in many previous studies involving various ethnic groups, including Mexican Americans [15],[17], European Americans [47],[48], African Americans [47],[48], Native Americans [44], Asians [49], Israelis [50], North Africans from Morocco and Southern Europeans from Basque Country [51] and Afro-Caribbeans [52]. These studies, along with a meta-analysis comprised of 53 previous reports [49], also demonstrate the differences in allele frequencies of variants in ADH1C across the global populations.
Several genotyping studies have targeted alcohol dependence in Mexican Americans, focusing on the genes involved in alcohol metabolism (ADH, ALDH, and CYP2E1), and a subset of neurotransmitter-related genes (DRD2, 5-HTTLPR, and GABRβ3) [14]-[18]. These studies found a significant association to variants in ADH1B, ADH1C, CYP2E1 RasI c2 allele, DRD2 -141C insertion/deletion, and 5-HTTLPR S allele. These previous studies did not find a significant association with ALDH or GABRβ3. The Affymetrix Axiom Exome 1A array does not contain markers for CYP2E1*5B, DRD2-141C, or the 5-HTTLPRS S allele, so we were not able to detect associations for these variants. It may also be the case that these previous studies were candidate gene approaches and did not use exome-wide correction as we have performed in this study. Additionally, we may have missed some associations due to low sample size and loss of power. However, the rs991316 finding is supported given that this SNP showed an association with alcohol dependence in this cohort and in an independent sample of Native Americans.
Conclusions
A number of factors have been found to contribute to alcohol dependence in Mexican Americans. Recent studies have found Mexican Americans living in counties bordering the U.S. to be particularly prone to high rates of alcohol dependence [35]. The current study is the first exome-wide association to be reported for a cohort of Mexican Americans living in a border region of the United States. By performing an exome-wide association with the Affymetrix Exome1A array using both dichotomous and quantitative phenotypes for alcohol dependence in Mexican Americans, this study was able to examine genes in the ADH region, as well as other genes previously implicated in alcohol dependence with other ethnicities. The ADH7 gene region contained the most significant variant in the three phenotypes that we evaluated. This result is in agreement with previous studies that ADH7 has a role in the protection with alcohol dependence [39], although it was not tested previously in Mexican Americans. Therefore, this study contributes to the emerging picture of genetic variation in alcohol dependence in Mexican Americans.
References
Caetano R, Clark CL: Trends in alcohol consumption patterns among whites, blacks and Hispanics: 1984 and 1995. J Stud Alcohol. 1998, 59 (6): 659-668.
Caetano R, Clark CL: Trends in alcohol-related problems among whites, blacks, and Hispanics: 1984–1995. Alcohol Clin Exp Res. 1998, 22 (2): 534-538.
Lee DJ, Markides KS, Ray LA: Epidemiology of self-reported past heavy drinking in Hispanic adults. Ethn Health. 1997, 2 (1–2): 77-88. 10.1080/13557858.1997.9961817.
Burnam MA: Prevalence of alcohol abuse and dependence among Mexican Americans and non-Hispanic Whites in the community. NIAAA Research Monograph No 18, DHHS Publication No (ADM) 89–1435; Alcohol Use Among US Ethic Minorities: Proceedings on a Conference on the Epidemiology of Alcohol Use and Abuse among Ethnic Minority Groups. Edited by: Speiger D, Tate D, Aitken S, Christian CM. 1989, U.S. Government Printing Office: USDHHS, SAMSHA, NIAAA, Rockville, MD, USA, 163-177.
Vega WA, Kolody B, Aguilar-Gaxiola S, Alderete E, Catalano R, Caraveo-Anduaga J: Lifetime prevalence of DSM-III-R psychiatric disorders among urban and rural Mexican Americans in California. Arch Gen Psychiatry. 1998, 55 (9): 771-778. 10.1001/archpsyc.55.9.771.
Caetano R, Ramisetty-Mikler S, Rodriguez LA: The Hispanic Americans Baseline Alcohol Survey (HABLAS): rates and predictors of DUI across Hispanic national groups. Accid Anal Prev. 2008, 40 (2): 733-741. 10.1016/j.aap.2007.09.010.
Caetano R, Ramisetty-Mikler S, Rodriguez LA: The Hispanic Americans Baseline Alcohol Survey (HABLAS): rates and predictors of alcohol abuse and dependence across Hispanic national groups. J Stud Alcohol Drugs. 2008, 69 (3): 441-448.
Caetano R, Vaeth PA, Ramisetty-Mikler S, Rodriguez LA: The Hispanic Americans baseline alcohol survey: alcoholic beverage preference across Hispanic national groups. Alcohol Clin Exp Res. 2009, 33 (1): 150-159. 10.1111/j.1530-0277.2008.00824.x.
Wall TL, Schoedel K, Ring HZ, Luczak SE, Katsuyoshi DM, Tyndale RF: Differences in pharmacogenetics of nicotine and alcohol metabolism: review and recommendations for future research. Nicotine Tob Res. 2007, 9 (Suppl 3): S459-S474. 10.1080/14622200701587045.
Edenberg HJ, Foroud T: Genetics and alcoholism. Nat Rev Gastroenterol Hepatol. 2013, 10 (8): 487-494. 10.1038/nrgastro.2013.86.
Han Y, Gu S, Oota H, Osier MV, Pakstis AJ, Speed WC, Kidd JR, Kidd KK: Evidence of positive selection on a class I ADH locus. Am J Hum Genet. 2007, 80 (3): 441-456. 10.1086/512485.
Edenberg HJ, Xuei X, Chen HJ, Tian H, Wetherill LF, Dick DM, Almasy L, Bierut L, Bucholz KK, Goate A, Hesselbrock V, Kuperman S, Nurnberger J, Porjesz B, Rice J, Schuckit M, Tischfield J, Begleiter H, Foroud T: Association of alcohol dehydrogenase genes with alcohol dependence: a comprehensive analysis. Hum Mol Genet. 2006, 15 (9): 1539-1549. 10.1093/hmg/ddl073.
Ehlers CL, Montane-Jaime K, Moore S, Shafe S, Joseph R, Carr LG: Association of the ADHIB*3 allele with alcohol-related phenotypes in Trinidad. Alcohol Clin Exp Res. 2007, 31 (2): 216-220. 10.1111/j.1530-0277.2006.00298.x.
Wan YJ, Poland RE, Lin KM: Genetic polymorphism of CYP2E1, ADH2, and ALDH2 in Mexican-Americans. Genet Test. 1998, 2 (1): 79-83. 10.1089/gte.1998.2.79.
Konishi T, Calvillo M, Leng AS, Feng J, Lee T, Lee H, Smith JL, Sial SH, Berman N, French S, Eysselein V, Lin KM, Wan YJ: The ADH3*2 and CYP2E1 c2 alleles increase the risk of alcoholism in Mexican American men. Exp Mol Pathol. 2003, 74 (2): 183-189. 10.1016/S0014-4800(03)00006-6.
Konishi T, Calvillo M, Leng AS, Lin KM, Wan YJ: Polymorphisms of the dopamine D2 receptor, serotonin transporter, and GABA(A) receptor beta(3) subunit genes and alcoholism in Mexican-Americans. Alcohol. 2004, 32 (1): 45-52. 10.1016/j.alcohol.2003.11.002.
Konishi T, Luo HR, Calvillo M, Mayo MS, Lin KM, Wan YJ: ADH1B*1, ADH1C*2, DRD2 (−141C Ins), and 5-HTTLPR are associated with alcoholism in Mexican American men living in Los Angeles. Alcohol Clin Exp Res. 2004, 28 (8): 1145-1152. 10.1097/01.ALC.0000134231.48395.42.
Ehlers CL, Liang T, Gizer IR: ADH and ALDH polymorphisms and alcohol dependence in Mexican and Native Americans. Am J Drug Alcohol Abuse. 2012, 38 (5): 389-394. 10.3109/00952990.2012.694526.
Bucholz KK, Cadoret R, Cloninger CR, Dinwiddie SH, Hesselbrock VM, Nurnberger JI, Reich T, Schmidt I, Schuckit MA: A new, semi-structured psychiatric interview for use in genetic linkage studies: a report on the reliability of the SSAGA. J Stud Alcohol. 1994, 55 (2): 149-158.
Hesselbrock M, Easton C, Bucholz KK, Schuckit M, Hesselbrock V: A validity study of the SSAGA–a comparison with the SCAN. Addiction. 1999, 94 (9): 1361-1370. 10.1046/j.1360-0443.1999.94913618.x.
Affymetrix: Affymetrix: Best Practice Supplement to Axiom Genotyping Solution Data Analysis User Guide Rev. 1. 2011, Affymetrix, Inc, Santa Clara, CA, USA
Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MA, Bender D, Maller J, Sklar P, de Bakker PI, Daly MJ, Sham PC: PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet. 2007, 81 (3): 559-575. 10.1086/519795.
Robinson JT, Thorvaldsdottir H, Winckler W, Guttman M, Lander ES, Getz G, Mesirov JP: Integrative genomics viewer. Nat Biotechnol. 2011, 29 (1): 24-26. 10.1038/nbt.1754.
Thorvaldsdottir H, Robinson JT, Mesirov JP: Integrative Genomics Viewer (IGV): high-performance genomics data visualization and exploration. Brief Bioinform. 2013, 14 (2): 178-192. 10.1093/bib/bbs017.
Li MX, Yeung JM, Cherny SS, Sham PC: Evaluating the effective numbers of independent tests and significant p-value thresholds in commercial genotyping arrays and public imputation reference datasets. Hum Genet. 2012, 131 (5): 747-756. 10.1007/s00439-011-1118-2.
Barrett JC, Fry B, Maller J, Daly MJ: Haploview: analysis and visualization of LD and haplotype maps. Bioinformatics. 2005, 21 (2): 263-265. 10.1093/bioinformatics/bth457.
Bansal V, Libiger O, Torkamani A, Schork NJ: Statistical analysis strategies for association studies involving rare variants. Nat Rev Genet. 2010, 11 (11): 773-785. 10.1038/nrg2867.
Bansal V, Libiger O, Torkamani A, Schork NJ: An application and empirical comparison of statistical analysis methods for associating rare variants to a complex phenotype. Pac Symp Biocomput 2011:76–87. doi:10.1142/9789814335058_0009. PMID: 21121035
Madsen BE, Browning SR: A groupwise association test for rare mutations using a weighted sum statistic. PLoS Genet. 2009, 5 (2): e1000384-10.1371/journal.pgen.1000384.
Li B, Leal SM: Methods for detecting associations with rare variants for common diseases: application to analysis of sequence data. Am J Hum Genet. 2008, 83 (3): 311-321. 10.1016/j.ajhg.2008.06.024.
Bhatia G, Bansal V, Harismendy O, Schork NJ, Topol EJ, Frazer K, Bafna V: A covering method for detecting genetic associations between rare variants and common phenotypes. PLoS Comput Biol. 2010, 6 (10): e1000954-10.1371/journal.pcbi.1000954.
Feng S, Wang S, Chen CC, Lan L: GWAPower: a statistical power calculation software for genome-wide association studies with quantitative traits. BMC Genet. 2011, 12: 12-10.1186/1471-2156-12-12.
Caetano R, Baruah J, Chartier KG: Ten-year trends (1992 to 2002) in sociodemographic predictors and indicators of alcohol abuse and dependence among whites, blacks, and Hispanics in the United States. Alcohol Clin Exp Res. 2011, 35 (8): 1458-1466.
Hasin DS, Stinson FS, Ogburn E, Grant BF: Prevalence, correlates, disability, and comorbidity of DSM-IV alcohol abuse and dependence in the United States: results from the National Epidemiologic Survey on Alcohol and Related Conditions. Arch Gen Psychiatry. 2007, 64 (7): 830-842. 10.1001/archpsyc.64.7.830.
Caetano R, Vaeth PA, Mills BA, Rodriguez LA: Alcohol abuse and dependence among U.S.-Mexico border and non-border Mexican Americans. Alcohol Clin Exp Res. 2013, 37 (5): 847-853. 10.1111/acer.12061.
Caetano R, Ramisetty-Mikler S, Rodriguez LA: The Hispanic Americans Baseline Alcohol Survey (HABLAS): the association between birthplace, acculturation and alcohol abuse and dependence across Hispanic national groups. Drug Alcohol Depend. 2009, 99 (1–3): 215-221. 10.1016/j.drugalcdep.2008.08.011.
Ehlers CL, Gilder DA, Criado JR, Caetano R: Acculturation stress, anxiety disorders, and alcohol dependence in a select population of young adult Mexican Americans. J Addict Med. 2009, 3 (4): 227-233. 10.1097/ADM.0b013e3181ab6db7.
Birley AJ, James MR, Dickson PA, Montgomery GW, Heath AC, Whitfield JB, Martin NG: Association of the gastric alcohol dehydrogenase gene ADH7 with variation in alcohol metabolism. Hum Mol Genet. 2008, 17 (2): 179-189. 10.1093/hmg/ddm295.
Osier MV, Lu RB, Pakstis AJ, Kidd JR, Huang SY, Kidd KK: Possible epistatic role of ADH7 in the protection against alcoholism. Am J Med Genet B Neuropsychiatr Genet. 2004, 126B (1): 19-22. 10.1002/ajmg.b.20136.
Gizer IR, Edenberg HJ, Gilder DA, Wilhelmsen KC, Ehlers CL: Association of alcohol dehydrogenase genes with alcohol-related phenotypes in a Native American community sample. Alcohol Clin Exp Res. 2011, 35 (11): 2008-2018. 10.1111/j.1530-0277.2011.01552.x.
Kuo PH, Kalsi G, Prescott CA, Hodgkinson CA, Goldman D, van den Oord EJ, Alexander J, Jiang C, Sullivan PF, Patterson DG, Walsh D, Kendler KS, Riley BP: Association of ADH and ALDH genes with alcohol dependence in the Irish Affected Sib Pair Study of alcohol dependence (IASPSAD) sample. Alcohol Clin Exp Res. 2008, 32 (5): 785-795. 10.1111/j.1530-0277.2008.00642.x.
Adeyemo A, Gerry N, Chen G, Herbert A, Doumatey A, Huang H, Zhou J, Lashley K, Chen Y, Christman M, Rotimi C: A genome-wide association study of hypertension and blood pressure in African Americans. PLoS Genet. 2009, 5 (7): e1000564-10.1371/journal.pgen.1000564.
Peng Q, Gizer IR, Libiger O, Bizon C, Wilhelmsen KC, Schork NJ, Ehlers CL: Association and ancestry analysis of sequence variants in ADH and ALDH using alcohol-related phenotypes in a Native American community sample. Am J Med Genet B Neuropsychiatr Genet. 2014, 165 (8): 673-683. 10.1002/ajmg.b.32272.
Mulligan CJ, Robin RW, Osier MV, Sambuughin N, Goldfarb LG, Kittles RA, Hesselbrock D, Goldman D, Long JC: Allelic variation at alcohol metabolism genes (ADH1B, ADH1C, ALDH2) and alcohol dependence in an American Indian population. Hum Genet. 2003, 113 (4): 325-336. 10.1007/s00439-003-0971-z.
Han Y, Oota H, Osier MV, Pakstis AJ, Speed WC, Odunsi A, Okonofua F, Kajuna SL, Karoma NJ, Kungulilo S, Grigorenko E, Zhukova OV, Bonne-Tamir B, Lu RB, Parnas J, Schulz LO, Kidd JR, Kidd KK: Considerable haplotype diversity within the 23 kb encompassing the ADH7 gene. Alcohol Clin Exp Res. 2005, 29 (12): 2091-2100. 10.1097/01.alc.0000191769.92667.04.
Martinez C, Galvan S, Garcia-Martin E, Ramos MI, Gutierrez-Martin Y, Agundez JA: Variability in ethanol biodisposition in whites is modulated by polymorphisms in the ADH1B and ADH1C genes. Hepatology. 2010, 51 (2): 491-500. 10.1002/hep.23341.
Zuo L, Zhang H, Malison RT, Li CS, Zhang XY, Wang F, Lu L, Lu L, Wang X, Krystal JH, Zhang F, Deng HW, Luo X: Rare ADH variant constellations are specific for alcohol dependence. Alcohol Alcohol. 2013, 48 (1): 9-14. 10.1093/alcalc/ags104.
Gelernter J, Kranzler HR, Sherva R, Almasy L, Koesterer R, Smith AH, Anton R, Preuss UW, Ridinger M, Rujescu D, Wodarz N, Zill P, Zhao H, Farrer LA: Genome-wide association study of alcohol dependence:significant findings in African- and European-Americans including novel risk loci. Mol Psychiatry. 2014, 19 (1): 41-49. 10.1038/mp.2013.145.
Li D, Zhao H, Gelernter J: Further clarification of the contribution of the ADH1C gene to vulnerability of alcoholism and selected liver diseases. Hum Genet. 2012, 131 (8): 1361-1374. 10.1007/s00439-012-1163-5.
Meyers JL, Shmulewitz D, Aharonovich E, Waxman R, Frisch A, Weizman A, Spivak B, Edenberg HJ, Gelernter J, Hasin DS: Alcohol-metabolizing genes and alcohol phenotypes in an Israeli household sample. Alcohol Clin Exp Res. 2013, 37 (11): 1872-1881. 10.1111/acer.12176.
Celorrio D, Bujanda L, Chbel F, Sanchez D, Martinez-Jarreta B, de Pancorbo MM: Alcohol-metabolizing enzyme gene polymorphisms in the Basque Country, Morocco, and Ecuador. Alcohol Clin Exp Res. 2011, 35 (5): 879-884. 10.1111/j.1530-0277.2010.01418.x.
Montane-Jaime K, Moore S, Shafe S, Joseph R, Crooks H, Carr L, Ehlers CL: ADH1C*2 allele is associated with alcohol dependence and elevated liver enzymes in Trinidad and Tobago. Alcohol. 2006, 39 (2): 81-86. 10.1016/j.alcohol.2006.08.002.
Acknowledgments
Funding for this study was provided by grants from the National Institutes of Health (NIH); from the National Institute on Alcoholism and Alcohol Abuse (NIAAA) and the National Center on Minority Health and Health Disparities (NCMHD) 5R37 AA010201 and AA006420 (CLE) and the National Institute of Drug Abuse (NIDA) DA030976 (CLE, NJS). NIAAA, NCMHD and NIDA had no further role in study design; in the collection, analysis and interpretation of data; in the writing of the report; or in the decision to submit the paper for publication. NJS and his lab are supported in part by NIH grants 5 UL1 RR025774, R21 AI085374, 5 U01 DA024417, 5 R01 HL089655, 5 R01 DA030976, 5 R01 AG035020, 1 R01 MH093500, 2 U19 AI063603, 2 U19 AG023122, 5 P01 AG027734, 1 R21 DA033813. The authors have no conflicts of interest to declare. We would also like to thank and acknowledge the following people for their role in 1) the genotyping effort: Chris Bizon, Scott Chasse, Piotr Mieczkowski, Ewa Patrycja Malc, Joshua Sailsbery, and Phil Owens; and 2) for recruiting participants and collecting the clinical data: David Gilder, Evie Phillips, Susan Lopez, and Linda Corey.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
TMNK conducted the data analysis, data interpretation, and drafted the manuscript. IRG contributed to the data interpretation and manuscript preparation. KCW contributed to the genotyping. NJS contributed to the data interpretation. CLE contributed to the recruitment, collection, analysis of the clinical and genetic data on the subjects, and manuscript preparation. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

{kind=link}
{kind=link}
{kind=link}
Cite this article
Norden-Krichmar, T.M., Gizer, I.R., Wilhelmsen, K.C. et al. Protective variant associated with alcohol dependence in a Mexican American cohort. BMC Med Genet 15, 136 (2014). https://doi.org/10.1186/s12881-014-0136-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12881-014-0136-z