
Abstract
Aim
To predict survival time of Korean hepatocellular carcinoma (HCC) patients using multi-center data as a foundation for the development of a predictive artificial intelligence model according to treatment methods based on machine learning.
Methods
Data of patients who underwent treatment for HCC from 2008 to 2015 was provided by Korean Liver Cancer Study Group and Korea Central Cancer Registry. A total of 10,742 patients with HCC were divided into two groups, with Group I (2920 patients) confirmed on biopsy and Group II (5562 patients) diagnosed as HCC according to HCC diagnostic criteria as outlined in Korean Liver Cancer Association guidelines. The data were modeled according to features of patient clinical characteristics. Features effective in predicting survival rate were analyzed retrospectively. Various machine learning methods were used.
Results
Target was overall survival time, which divided into approximately 60 months (= /< 60 m, > 60 m). Target distribution in Group I (total 514 samples) was 28.8%: (148 samples) less than 60 months, 71.2% (366 samples) greater than 60 months, and in Group II (total 757 samples) was 66.6% (504 samples) less than 60 months, 33.4% (253 samples) greater than 60 months. Using NG Boost method, its accuracy was 83%, precision 84%, sensitivity 95%, and F1 score 89% for more than 60 months survival time in Group I with surgical resection. Moreover, its accuracy was 79%, precision 82%, sensitivity 87%, and F1 score 84% for less than 60 months survival time in Group II with TACE. The feature importance with gain criterion indicated that pathology, portal vein invasion, surgery, metastasis, and needle biopsy features could be explained as important factors for prediction in case of biopsy (Group I).
Conclusion
By developing a predictive model using machine learning algorithms to predict prognosis of HCC patients, it is possible to project optimized treatment by case according to liver function and tumor status.
Similar content being viewed by others


Introduction
Hepatocellular carcinoma (HCC) is characterized as a disease that spreads throughout the liver due to repeated intrahepatic recurrence of localized lesions, resulting in death due to liver failure. HCC typically originates from underlying liver disease and the major cause is hepatitis B or C virus infection with or without cirrhosis [1].
Alcohol abuse and cigarette smoking are also common factors of etiology, while metabolic diseases including obesity and diabetes as well as nonalcoholic fatty liver disease become amplifiers of risk of HCC [2]. There are various treatment methods for HCC. and it is necessary to predict the survival period and survival rate following treatment methods. Hepatic resection is the best treatment option for potential curative outcomes, but less than one-third of HCC cases are eligible for resection of HCC at the time of diagnosis [3]. In addition, the high rate of recurrence despite curative resection presents a major challenge in HCC management [4]. Most postoperative recurrence cases occur in the remnant liver as intrahepatic recurrence [5], and discerning reliable predictors is essential for patient risk evaluation, treatment decision-support and long-term survival improvement. HCC can be diagnosed with biopsy or with noninvasive imaging in high risk groups with chronic hepatitis or cirrhosis. If the imaging diagnosis is indecisive or has atypical features, biopsy is suggested. However, in case of patients with ascites, high risk of bleeding, and HCC in challenging location, biopsy is difficult, and therefore imaging diagnosis is preferred in these cases [6]. For the reason, it is necessary to predict the survival period and survival rate following treatment methods. HCC can be diagnosed on biopsy or by noninvasive imaging in high risk groups with chronic hepatitis or cirrhosis. If the imaging diagnosis is indecisive or has atypical features, biopsy is recommended. However, biopsy is difficult in patients with ascites, high risk of bleeding, or HCC in a challenging location, and in such cases, imaging diagnosis is preferred [6]. For the reason, it is necessary to predict the survival period and survival rate following treatment methods.
In order to develop a predictive model for the survival period and survival rate, we might need to obtain multi-center data, which is a sufficient number to represent the population, and including well curated features for analyzing HCC and survival period. To do this with overcoming internal data limitations in hospital, we utilized the HCC multi-center data of Korea Central Cancer Registry, National Cancer Center, and Ministry of Health and Welfare data sets, and appropriate machine learning algorithms. This artificial intelligent type predictive model could lead us to develop personalized treatment methods that consider liver function and HCC status, and data-based treatment imposing clinician's insights.
Various machine learning algorithms were used for survival rate prediction, which are voting ensembles, Logistic Regression, K-nearest neighbors, Decision Tree Classifier, Support Vector Machine, Random Forest, Extreme gradient boosting trees (XG Boost), Light GBM, and Natural Gradient Boosting (NG Boost).
The aim of this study was machine learning-based survival rate prediction of Korean hepatocellular carcinoma patients using the multi-center data as a foundation for development of a new predictive artificial intelligence model according to treatment methods.
Methods
Patients
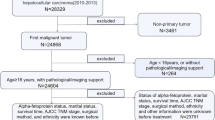
A total of 10,742 patients diagnosed with liver cancer, as registered by Korean Liver Cancer Study Group and Ministry of Health & Welfare, Korea Central Cancer Registry from 2008 to 2015, were evaluated; 101 patients had diagnoses of liver cancer other than HCC and were excluded (Fig. 1). Cases were divided into Group I diagnosed as HCC before treatment, and Group II diagnosed according to HCC diagnostic criteria as outlined in Korean Liver Cancer Association guidelines [6]. HCC is diagnosed if the histological and immunological findings after biopsy are positive or if the image findings are consistent with HCC, at a size larger than or equal to 1 cm, hyper enhancement in arterial phase and washout at portal venous or delayed phase on multi-phase CT and MRI using specific contrast, in high-risk patients. The authors divided the patients according to diagnostic modality, 2,920 patients were analyzed with HCC histologically either by needle or surgical biopsy (Group I) and 5,562 patients were included with HCC radiologically (Group II) (Fig. 1), with baseline demographic data previously published [7].

Flow diagram of the patients population
The study design was approved by the Institutional Review Board of Pusan National University Hospital (No. 2009-025-095) and was conducted in accordance with the Declaration of Helsinki.
Feature selection
Using predictive algorithms based on machine learning, the data on HCC patients collected at Korea Central Cancer Registry were used to determine the appropriate treatment (Table 1) and survival period for HCC patients with a range in liver functionality. The authors attempted to determine features that are effective in predicting survival rate and to interpret said features in keeping with the purpose of this study.
First, the process of pre-processing the data was conducted as previously explained. The analysis index of the collected data was a total of 117 features including image features and BCLC stage (Table 2). Also, Height and weight, liver function test, liver cirrhosis status, radiologic TNM findings, and histopathological TNM findings (Table 3) were included. Therefore, we used the 51 features in the biopsy (Group I) and 62 features when biopsy is not performed (Group II). In prediction of survival time rate according to treatment methods, 57 features, 48 features were used in TACE and surgical resection, respectively. After the exception is also feature more than the absolute value of the Correlation of 0.9 it was finally classified according to the treatment method the feature used.
Data splits for machine learning processing
Because of slightly imbalanced given data, we used stratified sampling with the ratio 8:2 for train and test two disjoint sets, respectively. We performed 5 different predictions (Fig. 2), which is same as fivefold but for test.

Schematic picture of 5 different prediction procedure same as 5 folds
And then the average of accuracy, precision, sensitivity and F1 score were obtained from the 5 predictions.
Machine learning method
In this study, various machine learning algorithms were used for survival rate prediction according to mortality, survival time, and treatment method. The algorithms are voting ensembles [8,9,10,11], Logistic Regression (LR) [12], K-nearest neighbors (KNN) [13, 14], Decision Tree (DT) Classifier [15,16,17], Support Vector Machine (SVM) [18,19,20,21], Random Forest (RF) [22, 23], Extreme gradient boosting trees (XG Boost) [24], Light GBM [25, 26], and Natural Gradient Boosting (NG Boost) [27, 28]. Its prediction results are compared in Tables 6, 8, and 10.
Results
The target was overall survival time, which is divided into about by 60 months (= < 60 m, > 60 m) (Table 4). After preprocessing of the given data, the target distributions for each group, were 148 samples (28.8%), whose the overall survival time is less than 60 months, 366 samples (71.2%), greater than 60 months in Group I, which has total 514 samples, and 504 samples (66.6%), less than 60 months, 253 samples (33.4%), 33.4% (253 samples) greater than 60 months in Group II, total 757 samples.
-
1.
Prediction of mortality rate according to the presence or absence of biopsy
-
2.
In case of biopsy (Group I)
When biopsy was performed (Group I), it can be seen that the surviving and deceased samples were relatively evenly distributed (Table 5). Therefore, in this case, down sampling or up sampling was not performed. Even in this case, the XG Boost method that obtained the best result among the methods used in the prediction was not significantly lower than the accuracy in precision, recall, and ROC value, but all indicators including accuracy were 70% (Table 6). Among the methods used in prediction, the XG Boost method obtained the best result. Pathology Portal invasion, method surgery, image M, Pathology T, needle biopsy, etc. can be seen as the most important factors for prediction (Fig. 3).
-
(2)
When biopsy is not performed (Group II)

Feature Importance F1 by SHAP values of Group I with surgical resection according to 5 folds shown in Fig. 2, respectively
If the biopsy was not performed, the surviving and deceased samples were unevenly distributed (Tables 7, 8), and the down sample was used to obtain the predicted results (Tables 9, 10).
It can be seen that the classification by the XG Boost method has obtained relatively the best results, and it can be seen that the precision, recall, and ROC values are not significantly lower than the accuracy.
Among the methods used in prediction, the XG Boost method obtained the best result, and when looking at the method using GAIN in the importance analysis, image portal invasion, image T, image tumor size, BCLC stage, etc. can be seen as the most important factors for prediction.
Using NG Boost method, its accuracy was 83%, precision 84%, sensitivity 95%, and F1 score 89% for more than 60 months survival time in Group I with surgical resection. Moreover, its accuracy was 79%, precision 82%, sensitivity 87%, and F1 score 84% for less than 60 months survival time in Group II with TACE. The feature importance with gain criterion indicated that Pathology Portal invasion, method surgery, image M, Pathology T, needle biopsy features could be explained as important factors for prediction in case of biopsy (Group I).
-
2.
Prediction of survival time rate according to treatment methods was analyzed.
To analyze the survival rate according to the treatment method, the analysis target was overall survival (Table 4). It was analyzed by dividing the survival period into less and more than 60 months. Five classifications were made among the various treatment methods of the collected data (Class 1: Surgical resection, Class 2: Liver transplantation, Class 3: Local ablation therapy, Class 4: Trans arterial Chemoembolization (TACE), Class 5: Others). Among the treatment methods, the prediction between liver transplantation and local ablation therapy was inaccurate. The problem often lies with too little data, and treatment method being determined by clinical experience. However, in the case of predicting only surgical resection and TACE, a model with good results of high accuracy and precision was developed (Table 4).
Significant treatment methods were TACE and surgical resection. According to these two treatment methods, survival rate analysis (Tables 11, 12) was performed with features (Figs. 3, 4).

Feature Importance F1 by SHAP values of Group II with TACE according to 5 folds shown in Fig. 2, respectively
Discussion
The value of multi-center data will depend on the degree of standardization of the collected data. In addition, it must include a sufficient number to represent the population. Using a machine learning-based prediction algorithm, the authors analyzed the appropriate treatment for HCC and the properties that influence the survival period accordingly. Through this work, the authors intended to develop an algorithm that can propose the optimal personalized treatment for each individual according to liver function and HCC condition. Recently, computer-based diagnosis and prognostic prediction by machine-learning algorithms and deep-learning systems have been widely used and more individualized prediction based on a combination of variables is provided by nomogram models [29].
By developing machine-learning algorithms and deep-learning systems to predict prognosis of HCC patients, it is possible to offer individualized recurrence surveillance and adjuvant therapy. Data collection in a standardized form is the priority of national big data management. In order to solve the limitations of national multi-center data, collection in a nationally standardized format and uniformity of the processing method of the missing data is essential.
In the results of this study, among the various treatment methods, the prediction of survival rate with liver transplantation and local ablation therapy was inaccurate. The problem often lies with too little data, and treatment method being determined by clinical experience, thus different in each case.
In addition to tumor extent, hepatic reservoir plays a major role when selecting the treatment method. Before the treatment selection, laboratory tests and imaging were performed to evaluate liver function and tumor extent, and great effort was made to combine these factors in order to choose the most suitable treatment modality and predict the prognosis [30].
Generally, late recurrence (more than 2 years) after liver resection for HCC is regarded as a multi-centric tumor or a de novo cancer. Therefore, surveillance for recurrence 2 years after surgery should be targeted to the liver [31]. In this study, machine learning (ML) model was used to evaluate the relationship between preoperative and treatment modalities with treatment results expressed by overall survival.
ML consists of input and output and is unlike past previously programmed models, in that an ML program learns from the examples and processes massive data. More accuracy can be achieved by training and therefore, more data provides better predictions [32].
Korean Primary Liver Cancer Registry data provided by Korean Liver Cancer Association will be used as input for training an ML model and predicting prognosis of HCC according to preoperative findings and treatment performed. Therefore, for the establishment of a national cohort, the standardization of data and the accuracy of collection must be followed.
By adapting ML to the medical field, increasing amounts of data exceeding that of the capacity of the human brain can be processed in an efficient, time-saving manner. By supplementing records and increasing training sources, the ML model will become an important tool for the selection of appropriate treatment modality for HCC patients in consideration of patient factor, tumor extent and prediction of prognosis. In the future, it will be possible to calculate accurate predictions using a new data set development and differentiated training source for data accumulation. Information on the patient's living environment, economic ability, and social status is also required, and regional and geopolitical locations are recommended to be included as variables.
At the present time, the limitations of developing AI using big data are reliability and missing data. The method of collecting data from various institutions retrospectively has the disadvantage of data not being uniform and the interval between observations inconsistent. It is necessary to simplify and unify the clinical research form of the Korean Society for Liver Cancer. Basic sociological factors should also be included as variables, after which national cohort results can be obtained. It is essential to collect data regularly based on a given template. By using big data collected from multi-centers nationwide, it will be possible to develop a predictive program that provides the basis for treatment response, with factors leading to recurrence after initial treatment. The establishment of a large data cohort of HCC in Korea, which plays a leading role in the epidemiology, diagnosis and treatment of HCC, will greatly advance the development of HCC treatment worldwide. HCC data owned by Pusan National University Hospital will be used to avoid the limitation of data suitability from the multi-center data, which aims to implement a predictive model for the HCC survival rate, survival period, or optimal treatment method based on machine learning..
Conclusion
With the statistical tools obtained through previous study, an ML program with a deep neural network by deep learning at each layer equipped with the Cox proportional hazard model was analyzed. By developing machine-learning algorithms and deep-learning systems to predict prognosis of HCC patients, it is possible to propose the optimal personalized treatment for each individual according to liver function and HCC status. In order to solve the limitations of multi-center data collected in a standardized form is the priority of national multi-center data management.
References
El-Serag HB. Hepatocellular carcinoma. N Engl J Med. 2011;365(12):1118–27.
Lau WY, Lai EC. Hepatocellular carcinoma: current management and recent advances. Hepatobiliary Pancreat Dis Int. 2008;7(3):237–57.
Villanueva A. Hepatocellular carcinoma. N Engl J Med. 2019;380(15):1450–62.
Poon RT, Fan ST, Ng IO, Lo CM, Liu CL, Wong J. Different risk factors and prognosis for early and late intrahepatic recurrence after resection of hepatocellular carcinoma. Cancer. 2000;89(3):500–7.
Poon RT, Fan ST, Lo CM, Liu CL, Wong J. Long-term survival and pattern of recurrence after resection of small hepatocellular carcinoma in patients with preserved liver function: implications for a strategy of salvage transplantation. Ann Surg. 2002;235(3):373–82.
Korean Liver Cancer Association, National Cancer Center. 2018 Korean Liver Cancer Association-National Cancer Center Korea practice guidelines for the management of hepatocellular carcinoma. Gut Liver. 2019;13(3):227–99.
Kwon Y, Kim JR, Park YM, Kime HY, Yoon M, et al. Predicting survival time of Korean hepatocellular carcinoma patients using the Cox proportional hazards model: a retrospective study based on big data analysis. Eur J Gastroenterol Hepatol. 2021;33:1001–8.
Dietterich TG. Machine learning research: four current directions. AI Mag. 1997;18(4):97–136.
Erp MV, Vuurpijl LG, Schomaker L. An overview and comparison of voting methods for pattern recognition. In: Proceedings of the 8th international workshop on frontiers in handwriting recognition. 2002.
Kuncheva LI. A theoretical study on six classifier fusion strategies. IEEE Trans Pattern Anal Mach Intell. 2002;24(2):281–6.
Witten IH, Frank E, Hall MA, Pal CJ. Data mining: practical machine learning tools and techniques. Burlington: Morgan Kaufmann; 2016.
Boyd CR, Tolson MA, Copes WS. Evaluating trauma care: the TRISS method trauma score and the injury severity score. J Trauma. 1987;27(4):370–8.
Zhang Z. Introduction to machine learning: k-nearest neighbors. Ann Transl Med. 2016;4(11):218.
Abu Alfeilat HA, Hassanat ABA, Lasassmeh O, Tarawneh AS, Alhasanat MB, Eyal Salman HS, Prasath VBS. Effects of distance measure choice on K-nearest neighbor classifier performance: a review. Big Data. 2019;7(4):221–48.
Rokach L, Maimon O. Data mining with decision trees: theory and applications. Singapore: World Scientific; 2008.
Breiman L, Friedman JH, Olshen RA, Stone CJ. Classification and regression trees. Wadsworth;1984.
James G, Witten D, Hastie T, Tibshirani R. An introduction to statistical learning. Berlin: Springer; 2015.
Noble WS. What is a support vector machine? Nat Biotechnol. 2006;24:1565–7.
Boser BE, Guyon IM, Vapnik VN. A training algorithm for optimal margin classifiers. In: Proceedings of the 5th annual workshop on computational learning theory. 1992.
Guyon I, Weston J, Barnhill S, Vapnik V. Gene selection for cancer classification using support vector machines. Mach Learn. 2002;46:389–422.
Vapnik V, Lerner A. Pattern recognition using generalized portrait method. Autom Remote Control. 1963;24:774–80.
Ho TK. Random decision forests. In: Proceedings of 3rd international conference on document analysis and recognition, 1995.
Breiman L. Random forests. Mach Learn. 2001;45:5–32.
Chen T, Guestrin C. XGBoost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 2016. https://doi.org/10.1145/2939672.2939785.
Ke G, Meng Q, Finley T, Wang T, Chen W, Ma W, Ye Q, Liu TY. Light GBM: a highly efficient gradient boosting decision tree. In: Proceedings of the 31st international conference on neural information processing systems. 2017.
Ju Y, Sun G, Chen Q, Zhang M, Zhu H, Rehman MU. A model combining convolutional neural network and Light GBM algorithm for ultra-short-term wind power forecasting. IEEE Access. 2019;7:28309–18.
Duan T, Avati A, Ding DY, Basu S, Ng AY, Schuler A. NGBoost: natural gradient boosting for probabilistic prediction. In: Proceedings of the 37th international conference on machine learning, PMLR. 2020.
Peng T, Zhi X, Ji Y, Ji L, Tian Y. Prediction skill of extended range 2-m maximum air temperature probabilistic forecasts using machine learning post-processing methods. Atmosphere. 2020;11:823.
Gan W, Huang JL, Zhang MX, Fu YP, Yi Y, Jing CY, et al. New nomogram predicts the recurrence of hepatocellular carcinoma in patients with negative preoperative serum AFP subjected to curative resection. J Surg Oncol. 2018;117(7):1540–7.
Marrero JA, Kudo M, Bronowicki JP. The challenge of prognosis and staging for hepatocellular carcinoma. Oncologist. 2010;15(Suppl. 4):23–33.
Xu XF, Xing H, Han J, Li ZL, Lau WY, Zhou YH, et al. Risk factors, patterns, and outcomes of late recurrence after liver resection for hepatocellular carcinoma: a multicenter study from China. JAMA Surg. 2019;154(3):209–17.
Nam KH, Seo I, Kim DH, Lee JI, Choi BK, Han IH. Machine learning model to predict osteoporotic spine with hounsfield units on lumbar computed tomography. J Korean Neurosurg Soc. 2019;62(4):442–9.
Acknowledgements
The data were provided by Korean liver Cancer Study Group and the Ministry of Health & Welfare, Korea Central Cancer Registry. This study was supported by National Institute for Mathematical Sciences (NIMS) grant funded by the Korea government, 2021 (No. NIMSB21910000). This work was supported by a 2-year Research Grant of Pusan National University.
Funding
All authors have no funding.
Author information
Authors and Affiliations
Contributions
BN, YMP, YK, CIC, BKC, KiS, YHP, KY collected data and analyzed clinical research form. BKC, SL, TH, YH contributed machine learning methodology and wrote the manuscript for machine learning accordingly. MY (corresponding author) collected data, analyzed clinical research form, and contributed to machine learning methodology. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The study design was approved by the Institutional Review Board of the Pusan National University Hospital (No. 2009-025-095) and was conducted in accordance with the Declaration of Helsinki.
Informed consent
Informed consent of subjects was obtained from the Korean Liver Cancer Study Group and the Ministry of Health & Welfare’s Korea Central Cancer Registry, which has legal authority for this data. Informed consent of the parent or legal authorized representatives for the deceased included in this data was obtained by these same authorities. The data was approved by the Institutional Review Board of Pusan National University Hospital (No. 2009-025-095).
Consent for publication
There are no details on individuals reported within the manuscript; therefore, consent for publication of images is not necessary.
Competing interests
The authors declare no competing interests.
Availability of data and materials
The data were provided by Korean liver Cancer Study Group and the Ministry of Health & Welfare, Korea Central Cancer Registry. The datasets generated and analyzed during the current study are not publicly available due to the authority of this data belonging to Korean Liver Cancer Study Group and Ministry of Health & Welfare’s Korea Central Cancer Registry; data access was granted by the two authorities to the corresponding authors, and can be made available from the corresponding author on reasonable request.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Noh, B., Park, Y.M., Kwon, Y. et al. Machine learning-based survival rate prediction of Korean hepatocellular carcinoma patients using multi-center data. BMC Gastroenterol 22, 85 (2022). https://doi.org/10.1186/s12876-022-02182-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12876-022-02182-4