
Abstract
Introduction
Studying the relationship between unemployment and health raises many methodological challenges. In the current study, the aim was to evaluate the sensitivity of estimates based on different ways of measuring unemployment and the choice of statistical model.
Methods
The Northern Swedish cohort was used, and two follow-up surveys thereof from 1995 and 2007, as well as register data about unemployment. Self-reported current unemployment, self-reported accumulated unemployment and register-based accumulated unemployment were used to measure unemployment and its effect on self-reported health was evaluated. Analyses were conducted with G-computation, logistic regression and three estimators for the inverse probability weighting propensity scores, and 11 potentially confounding variables were part of the analyses. Results were presented with absolute differences in the proportion with poor self-reported health between unemployed and employed individuals, except when logistic regression was used alone.
Results
Of the initial 1083 pupils in the cohort, our analyses vary between 488–693 individuals defined as employed and 61–214 individuals defined as unemployed. In the analyses, the deviation was large between the unemployment measures, with a difference of at least 2.5% in effect size when unemployed was compared with employed for the self-reported and register-based unemployment modes. The choice of statistical method only had a small influence on effect estimates and the deviation was in most cases lower than 1%. When models were compared based on the choice of potential confounders in the analytical model, the deviations were rarely above 0.6% when comparing models with 4 and 11 potential confounders. Our variable for health selection was the only one that strongly affected estimates when it was not part of the statistical model.
Conclusions
How unemployment is measured is highly important when the relationship between unemployment and health is estimated. However, misspecifications of the statistical model or choice of analytical method might not matter much for estimates except for the inclusion of a variable measuring health status before becoming unemployed. Our results can guide researchers when analysing similar research questions. Model diagnostics is commonly lacking in publications, but they remain very important for validation of analyses.
Similar content being viewed by others


Introduction
Several studies have shown that unemployment is linked to deteriorated health [1, 2]. For studies on the health effect of unemployment, several methodological issues need to be handled and there are no previous study that have made a deeper investigation of this. In a review of the field, with the focus on self-assessed health, it was shown that many different statistical analysis methods, with a variety of explanatory variables, and study designs have been used for such studies [1].
In this study, we aim to investigate the key components of the analyses, including how unemployment is measured, by responding to slightly different research questions, the statistical analysis method and the variables that are included in analyses to improve estimates. In this study, we use current self-reported unemployment, and recent unemployment, both with self-reported and register-based information, as modes of unemployment. Current unemployment differs from the other modes in that it does not take accumulated exposure into account, while self-reported and register-based information can differ in many ways. Register-based unemployment is often seen as more objectively measured, while self-reported unemployment can be seen as more validly measured. Furthermore, self-reported data might not include shorter periods of unemployment between jobs, which is reported in register data. On the other hand, register data only include the number of days that people are registered as unemployed, and therefore lack information about unemployment when people are not entitled to unemployment benefits.
In a previous methodological review article of publications relating to unemployment and health, it was concluded that there were major weaknesses in many reporting aspects [3]. It was also reported that some of the reviewed manuscripts had probably used statistical analysis methods poorly fitted to the research question. A poor specification of the statistical analysis model could lead to biased results and consequently wrong conclusions [4]. A challenge in the specification is to identify a model that well describes the relationship between independent variables and outcome. Furthermore, it is essential to verify that independent variables are improving estimates of the effect of the main exposure on the outcome variable. It is therefore extremely important to understand whether data are having a relationship between them that can be well described based on the chosen method. Hence the motivation to use a thorough evaluation in this study.
To achieve an estimate of the causal effect with a small bias in observational studies, the choice of study design, and the statistical analysis to use needs to be well thought through so that it fits to the research question. Furthermore, the measurement of main exposure(s) and outcome(s) are essential; however, other variables that can play an essential role in the analysis are also crucial. For additional variables to contribute to the model, they need to confound the relation between exposure and outcome, and they should be chosen ahead of the analyses. In this study, the choice of the statistical analysis model is evaluated, as well as how sensitive results are for the selection of additional variables in the analysis. The key confounding factor to handle when unemployment and health are studied is previous health, as the risk of becoming unemployed also depends on health, and the unemployed tend to already have a poorer health [5]. This is usually referred to as health selection to unemployment, a phenomenon that has for instance been discussed and explained by Naimi et al. [6].
Within the field of unemployment and health, logistic regression is the most common statistical method, but other regression techniques are also common [1]. Despite the popularity of logistic regression, it seems that awareness of its limitations is generally poor, which have been verified by many published reviews showing a poor use and reporting of the method [3, 7]. These mistakes are likely to produce highly biased estimates. Methods based on so-called propensity scores, introduced in 1983 by Rosenbaum and Rubin [8], and G-computation have scarcely been used within public health [9], including our field of interest [1, 10]. Propensity score methods and traditional regression modelling, such as G-computation, tend to yield similar results [11], but this has yet to be investigated within our field of interest. Simulation studies have revealed that the variable selection has a bearing on the result when using propensity scores [12,13,14,15], but for unemployment and health this have not previously been investigated.
Our main aim is to evaluate the sensitivity of estimates based on the mode of unemployment and the choice of statistical model when the relationship between unemployment and health is studied.
Methods
Study design and participants
In our study, the Northern Swedish cohort was used [16], and our analyses are carried out on the same data set as was used in a previous publication, which showed that unemployment has a long-term negative health effect for those unemployed during young adulthood [10].
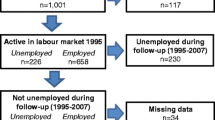
The Northern Swedish cohort was initiated in 1981, with all 1083 pupils in the last year of compulsory school during this year in a middle-sized town in Northern Sweden invited to participate in a study. Repeated questionnaires have been completed, including a matrix with detailed questions about labour market history since the last follow-up [17], for the cohort in four follow-ups (in 1983, 1986, 1995, and 2007) with a very high attrition rate (at least 94.3% of those still alive) on all occasions [16]. In this study, the follow-up questionnaires of the cohort in 1995 and 2007, which were answered by 1001 (92%) of the original participants, were combined with unemployment information from the longitudinal integration database for health insurance and labour market studies (acronym LISA) at Statistics Sweden. In LISA [18], information about labour market activity are obtained from the Swedish Public Employment Service. The Regional Ethical Board in Umeå, Sweden has approved the Northern Swedish cohort study. Further information about the cohort is available elsewhere [16].
Definition of health
In our study, self-rated health from the 2007 questionnaire was used as the outcome variable, using the question (translated to English): “How do you assess your general state of health?”. Responses “fairly good” and “poor” were defined as poor and “good” was defined as good. The same question in the 1995 questionnaire was used identically to define previous health.
Definitions of exposures
A labour market status variable was created in three different ways, referred to in this study as modes of unemployment, i) self-reported long-term unemployment, ii) register-based long-term unemployment, and iii) self-reported current unemployment. For the first, at least half a year of self-reported unemployment during last three years (1993–1995) was required. For the second, at least 6 months’ unemployment during 1992–1994 as reported in the LISA register database was required. In LISA, the information is limited to accumulated number of days of unemployment per year, which explains the choice of years as reported unemployment days in 1995 might have appeared after the participants’ response. The first two modes respond to the research question “What is the association between high exposure to unemployment in 1995 and self-rated health in 2007?”, while the last corresponds to the research question “What is the association between current unemployment 1995 and self-rated health in 2007?”.
Current unemployment required a tick at unemployed for the question “What is your current employment situation?”. Employed was defined as being active in the labour market, without unemployment, which we defined as either having “Full-time employment”, “Part-time (20–39 h a week) employment” or “Labour market measure”, for at least 1½ years, during the last three years. For current unemployment mode, a tick at any of the alternatives to the previously mentioned question defined employment. Response alternatives not considered as being in the labour market were “University/high-school”, “Other education”, “Casual job (< 20 h a week)”, “Sick leave”, “On parental leave”, and “Other”.
For all unemployment measures, analyses were conducted with unemployment episodes being allowed or not during the follow-up period. In the latter analyses, which we refer to as “censor” in current study, we required at least 1½ years in the labour market and no unemployment during follow-up for participants to be part of analyses. Being in labour market was defined similarly for the follow-up period as for the baseline definition from the 1995 survey. Details about questions and response alternatives in the two surveys for labour market status between surveys are presented in additional file 1.
If the aim is to get an unbiased estimate of the health effect of current unemployment exposure in 1995, both approaches have their weaknesses, censoring might exclude participants with recurrent unemployment caused by unemployment exposure in 1995, and with no censoring results might be affected by new episodes of unemployment or by participants moving out of the labour market. We consider both our alternatives to be proxies for our research questions, i.e. they will have limitations in measuring future health consequences of unemployment at young adulthood due to events during the follow-up.
Confounding variables
For all potentially confounding variables, the responses to the 1995 questionnaire, when respondents were around 30 years of age, were used. As potential confounders, we chose the variables that had been most frequently used in similar studies according to a review in 2014 of manuscripts studying self-assessed health and unemployment [1]. Our approach can help to understand what variables can be urged to be used in similar research questions without risking non-negligible biases.
Body mass index (BMI) was derived from self-reported weight and height, and calculated as weight/length2; those with a BMI ≥ 30 kg/cm2 were defined as obese and those with a BMI between 25 and 30 kg/cm2 as overweight, and used as exposed groups. Education was divided into three groups: at most secondary education, upper secondary school and university degree, with university studies used as reference group. Based on the nomenclature used by Statistics Sweden [19], occupation was defined with low-medium white-collar work as reference group, and high white-collar and blue-collar workers as exposure groups. For marital status, married (including “living with cohabitant/partner”) was used as reference group and single as exposed group. For cash margin, availability of 13,000 SEK (corresponding to 1276 euro on 24th November 2021) within a week was used as reference group and compared with no availability. For smoking, “not a current smoker” was used as reference group, and compared with “smoking at most 10 cigarettes a day”, and “smoking more than 10 cigarettes a day”. For social support, the instruments availability of social integration (AVSI) and availability of attachment (AVAT) were used [20]. The cut-offs for their reference groups were 13 or lower for AVSI and 10 or higher for AVAT. An index was calculated for alcohol intake based on six questions, a cut-off below 140, corresponding to low alcohol intake, was used as reference value. More details about the variables are available in a previous publication [10].
Statistics
We restricted ourselves to participants in the 1995 labour market, defined as being employed or unemployed, with complete data for all study variables. This meant that we were able to include 55% to 74% of the originally invited pupils in our analyses. For the analyses, estimates based on propensity scores, G-computation and logistic regression were used. Among the 1001 participants, there were 113 participants who lacked information about any of the variables besides labour market status.
A risk difference was estimated based on propensity scores, using counterfactual arguments [21], with the weighting estimators suggested by Lunceford and Davidian [22]. The propensity score is the conditional probability of being assigned to the exposure group based on baseline covariates, i.e. for our study how likely it is to be unemployed based on values for covariates. We estimated the propensity scores with logistic regression. The counterfactual outcome for the difference estimators estimate E[Y(1)]-E[Y(0)], where E[Y(1)] corresponds to the expected effect if all individuals are unemployed, and E[Y(0)] corresponds to the expected effect if all individuals are employed. Thus, the risk difference corresponds to the marginal effect of becoming unemployed, i.e. the increase in absolute terms of poor health that unemployment would lead to.
Of the estimators, the first is the straightforward inverse probability weighting (IPW) estimator, the second is usually referred to as the augmented estimator (AUG), and the third is a doubly-robust estimator (DR). The doubly-robust estimator does not only include a weighting on the propensity score, but also makes use of the regression model from which the propensity scores are derived.
The estimators were:
and
where Y refers to the outcome (self-rated health), X to the exposure (employed/unemployed), PS to the estimates of the propensity score. m0 and m1 refer to the estimated predictive value for the logistic regression used to derive propensity scores when only those defined as employed (m0) respectively unemployed (m1) are used to estimate beta coefficients.
For G-computation, logistic regression was first performed with all variables in the statistical model, including labour market status. The counterfactual outcome for the risk difference was calculated as the difference in effect if all individuals were unemployed with all individuals being employed. The Bootstrap technique with replacement was used to derive 10,000 replicates for the IPW and G-computing estimators and to calculate the mean square error (MSE) [23, 24]. The 2.5% and 97.5% percentiles were used to calculate 95% confidence intervals. For the doubly-robust estimator, some Bootstrap replicates had too few unemployed, which caused singularity problems and that logistic regression was not possible to conduct. Fewer replicates were then used.
The procedure for our analyses was to use all potentially confounding variables with logistic regression first in a “full” model, and thereafter a “reduced” model was applied with the significant variables in the full model for the self-reported long-term unemployment labour market mode. For the self-reported long-term unemployment mode, for both censored and non-censored analyses, we added or removed each potentially confounding variable individually. We choose this approach to show how collinear variables influence the effect estimates for the main exposure and for the logistic regression analyses for all variables.
R Studio was used for all statistical analyses, and its GLM procedure, with confidence intervals estimated using the profile likelihood estimator, was used for logistic regression estimates [25]. Statistical significance was defined at the 5% level.
Results
General characteristics
As only 22 participants who were unemployed in 1995 had experienced no unemployment during follow-up, the current unemployment mode with censoring could not provide reliable estimates and results are therefore not presented. For the unemployment modes that we used, the unemployment rate ranged from 8 to 27% (Table 1), which are explained by the definition of unemployed in the modes. For other variables, only minor differences (at most 7% between extremes) in the distribution within the variables were observed between the unemployment modes.
Estimates of the long-term effect of unemployment
For the unemployment modes, most estimates showed a statistically significant negative long-term effect of unemployment when it was compared with being employed (Table 2). The statistical models with all potential confounders had a higher point estimate than the models with only significant confounders, the only exceptions being the logistic regression and the G-computation estimator for the register-based unemployment mode with censoring. Thus, adding more variables mainly increased the estimated effect of unemployment. Applying censoring for unemployment episodes lowered the negative effect of unemployment for all analyses compared to not censoring for unemployment during follow-up, ranging from an absolute risk difference of 0.001 to 0.039 between these estimates.
For most unemployment modes, there was a rather small difference in effect estimates for the IPW estimators. The G-estimator gave a much smaller effect estimate for current unemployment mode than the IPW estimators while the difference was smaller for the other analyses, although in general greater than the one between the IPW estimators.
There were notable differences between estimates for the different unemployment definitions. The smallest effects were observed for the register-based long-term unemployment definition where the risk difference estimators ranged between 0.06–0.07 with censoring, while two IPW estimates of the current unemployment definition showed an effect as large as 0.25 poorer health for unemployed. For logistic regression, the estimates varied considerably with the odds ratio ranging from 1.4 to 1.9, with six of ten estimates giving statistical significance.
In additional file 2, we have presented characteristics for employed and unemployed. There were a different pattern for many of the background variables distribution for unemployment, which is to be expected considering the deviation in results presented.
The influence of confounders on effect estimates
In Tables 3 and 4, results are shown based on variables included in the analysis. In them, model 1 presents the result when all potentially confounding variables are included in the analysis and model 13 presents a reduced model where only variables significant in the logistic regression analyses are included. Consequently, model 16 for instance will present the result when the statistical analysis method consists of all significant variables except previous health.
For the self-reported long-term unemployment definition with no censoring, there were statistically significant odds ratios for all 24 models, with some variation dependent on the included variables, with odds ratios ranging between 1.77 and 2.00 for unemployment compared with employment (Table 3). The highest odds ratios occurred when previous health was removed in model 16, but still not higher than the crude odds ratio (2.06). For the definition with censoring, the odds ratios ranged between 1.66 and 1.88 for the different models. The crude odds ratio (1.78) was within this range. Of odds ratios other than the one for labour market status, mainly occupation and education affected each other when one of them was removed. The odds ratios then increased, in some cases even shifting to non-significance. The exclusion of previous health affected the odds ratios of some variables, including 0.03–0.15 lower odds ratio for labour market status.
For the risk difference estimators, there was an absolute increase in poor health due to unemployment that ranged from 9 to 16%, most of which was statistically significant, depending on the model and estimator (Table 4). Removal or addition of variables had some effect on estimates, where the largest effects resulted mainly from the removal of previous health from the confounders. When models were alternated with non-significant terms in the full model, the largest deviation was 0.014 for the risk difference (model 6 for censoring during follow-up) in comparison with model 1 or model 13. The deviation between models was at most 0.005 under this situation for the G-computation estimator.
Discussion
In our study, we have shown that the unemployment mode has a considerable effect on estimates of the health effect of unemployment. It was interesting to notice that the absolute difference between self-reported and register-based unemployment was so substantial, ranging from as much as 2.5% to 3.1% for the risk difference estimators when there was no censoring for unemployment episodes during the follow-up period, and even greater when censoring for unemployment episodes. The results were similar for the logistic regression estimator too.
On the other hand, our evaluation of the model specification, i.e. the variables included in the statistical analysis model, yielded only rather marginal deviations in most cases. The exceptions were mainly related to the doubly-robust estimator, which is known to be sensitive to small samples, where we were able to identify some notable differences between the full model with all its variables and the model with only significant potential confounders, and estimates based on the current unemployment mode. For other comparisons between the full and the reduced model, the difference was no greater than 1.1%, and in most cases it was at most 0.6%.
Also, in the models where we evaluated the contribution of each potential confounder to the estimates, by either adding or removing a variable to or from the full or the reduced model, the effect estimates were at most marginally affected, with the exception of the presence of previous health in the analyses. Thus, our study shows that even if a correctly specified model is advantageous, the risk of bias is likely to be rather limited for similar research questions such as those we have investigated. To avoid biases due to the model set-up, it is paramount to take health selection in unemployment into consideration.
It is interesting that the more popular logistic regression estimator seems to be more sensitive to poor model assumptions than the propensity scores and G-computation methods. The comparison of our risk difference estimators, which showed that they yield mainly similar results, is very much in line with previous comparisons between propensity score methods and conventional multivariable methods [26]. Thus, it seems that the choice of the statistical method is not the main challenge in achieving estimates with a low bias.
Even if our study indicates that the statistical model might only cause small biases, the importance of the choice of variables is undoubtedly very important. Interestingly, in a review from 2014, only 6 of the 41 reviewed articles discussed the choice of statistical method, and if any of these publications discussed how to measure unemployment it was at least very rare [3]. Thus, most researchers need to be more informative about their analysis and describe the potential limitations from their choice of statistical model.
Our interest was in the estimate for labour market status. Interestingly, when studying how other estimates were affected by the model set-up, we observed that education and occupation were in some cases not significant on their own, while they were significant in combination, while the estimate of labour market was not as sensitive to the presence of these variables in the analysis. This behaviour of the estimates for education and occupation is contrary to the expectations when a variable is added, as collinearity is expected to rather lead to neither of two estimates being statistically significant than to an estimate going from not being statistically significant to being statistically significant when one of the variables is added. This finding further highlights the importance of a well thought through variable selection in the main analyses. Nevertheless, the rationale for including variables in the statistical analysis needs to be improved as has been highlighted in previous research [3, 27].
The importance of defining a research question that is accurately measured to well respond to it was one of the key issues in our study. Whether unemployment is self-reported or taken from a register should respond to the same research question and yield similar results. In our study, the deviation between results for register-based and self-reported labour market was rather large. To some extent, this might be explained by the register data not being available until the day of the survey. We do however think that the main explanation for the deviation is that differences in how data are collected lead to slightly different research questions being answered.
In our study, we did not focus on how other variables were measured, but it is equally important that they have a high validity for their measurement. We only used self-rated health to measure health. Results for unemployment and health have varied based on the health measure [1]. Thus, it is a limitation that we have not tried our analyses on other health outcomes to evaluate whether our conclusions would be valid. Additionally, it would have been valuable to assess how a measurement error for the potential confounders affects estimates. Its potential to bias results has been highlighted in the literature [28].
The estimates for current unemployment differed between our estimators. Even with no censoring, there are few unemployed, which is likely to explain large deviations. Also notable was that with all potential confounders in the model, the IPW estimates both deviated much and showed a notably larger effect between them. We do not recommend to use the current unemployment mode, both because too few are likely to currently be unemployed, and because the group of unemployed risks to be too heterogeneous. For all our estimators it is a limitation that we had few unemployed. However, we still had sufficiently many unemployed to fulfil the criteria of at least 10 cases for the least occurring outcome divided with the number of exploratory variables when we used only significant confounders to determine the propensities. As results also showed small variations with all confounders we expect also these results to be stable despite this limitation. This criterion as well as others have been recommended for logistic regression by for instance Bagley et al. [7].
Neither the accumulated unemployment spell during recent years nor current unemployment might cover how recent or current unemployment affects health in the long term. They may both be too limited in that the accumulated unemployment relates too much to historical unemployment and current to a very short and negligible unemployment spell for the person in question. Thus, it is likely to be more complicated to know how unemployment affects health, and, hence, also the importance of including health status at the time of unemployment into the analysis. The big discrepancy between the estimates from the measures used to collect unemployment in our study highlights the importance of a well thought-through measure. Thus, the main message in our work is to gain a deep understanding of how unemployment data are collected. Based on our experience from previous research, we recommend accumulated self-reported unemployment measured with a detailed retrospective matrix.
We have made a thorough analysis of different aspects of the analysis of unemployment. A possible limitation of our study is that only one population has been analysed and we have not tried to verify that it is the most suitable population for this kind of analysis. Another possible limitation is that despite different research questions used, we have still had a somewhat limited focus of the consequences of long-term unemployment on health. Even so, we believe that our results can have a major contribution for the future understanding of the priorities needed not only for this research topic but also for other research topics.
We cannot confirm that our conclusions are valid also for other countries. The labour market varies much between countries in regard to for instance unemployment benefits, but we think that such issues should have little consequence on the relationship between explanatory variables. We think that the similarity between estimates for our statistical methods will hold also for other populations as this pattern has commonly been shown in comparative studies between for instance logistic regression and propensity score based methods [26]. Collinearity between labour market measure and other explanatory variables is a potential problem for our analyses. However, it was only for previous health that estimates were affected and this variable is not correlated with labour market status, so even if labour market status might be correlated with other variables it is not likely to affect estimates for other populations.
Conclusions
The choice of how to measure unemployment has had a rather large impact on effect estimates and if unemployment is incorrectly measured, and thus responding to a different research question, our study shows that results can vary substantially. There was even a notable deviation between results for register-based and self-reported unemployment, which probably did not depend only on the register not being able to capture unemployment until the day of the survey. In most cases, the choice of statistical method and variables in the model only had a very small effect on effect estimates, and only previous health needed to be handled well in the statistical analysis model. It should be noted that how variables interplay might differ between contexts and, thus, variables that did not affect our effect estimates might play a key role for other settings. It is therefore still of high importance that researchers put emphasis on model diagnostics and carefully evaluate whether the assumptions made in their analyses hold true and, more importantly, that any assumptions made are carefully taken care of, and better discussed and motivated in publications.
Availability of data and material
The questionnaires that were used for this study are available at https://ki.se/en/imm/the-northern-swedish-cohort. The datasets generated and/or analyzed during the current study are not publicly available because the Swedish Data Protection Act (1998:204) does not permit sensitive data on humans (like in our interviews) to be freely shared. The datasets are available based on ethical permission from the Regional Ethical board in Umeå, Sweden, from one of the co-authors (Anne Hammarström).
Abbreviations
- AVAT:
-
Availability of attachment instrument
- AVSI:
-
Availability of social integration instrument
- BMI:
-
Body mass index
- IPW:
-
Inverse probability weighting
- LISA:
-
the longitudinal integration database for health insurance and labour market studies
- MSE:
-
Mean square error
References
Norström F, Virtanen P, Hammarström A, Gustafsson P, Janlert U. How does unemployment affect self-assessed health? a systematic review focusing on subgroup effects. BMC Public Health. 2014;14(1):1310.
Paul KI, Moser K. Unemployment impairs mental health: meta-analyses. J Vocat Behav. 2009;74(3):264–82.
Norström F. Poor quality in the reporting and use of statistical methods in public health - the case of unemployment and health. Archives of Public Health. 2015;73:56.
Lucena C, Lopez JM, Pulgar R, Abalos C, Valderrama MJ. Potential errors and misuse of statistics in studies on leakage in endodontics. Int Endod J. 2013;46(4):323–31.
Stauder J. Unemployment, unemployment duration, and health: selection or causation? Eur J Health Econ. 2019;20(1):59–73.
Naimi AI, Richardson DB, Cole SR. Causal inference in occupational epidemiology: accounting for the healthy worker effect by using structural nested models. Am J Epidemiol. 2013;178(12):1681–6.
Bagley SC, White H, Golomb BA. Logistic regression in the medical literature: standards for use and reporting, with particular attention to one medical domain. J Clin Epidemiol. 2001;54(10):979–85.
Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects. Biometrika. 1983;70(1):41–55.
Snowden JM, Rose S, Mortimer KM. Implementation of g-computation on a simulated data set: demonstration of a causal inference technique. Am J Epidemiol. 2011;173(7):731–8.
Norström F, Janlert U, Hammarström A. Is unemployment in young adulthood related to self-rated health later in life? results from the Northern Swedish cohort. BMC Public Health. 2017;17(1):529.
Shah BR, Laupacis A, Hux JE, Austin PC. Propensity score methods gave similar results to traditional regression modeling in observational studies: a systematic review. J Clin Epidemiol. 2005;58(6):550–9.
Austin PC, Grootendorst P, Anderson GM. A comparison of the ability of different propensity score models to balance measured variables between treated and untreated subjects: a Monte Carlo study. Stat Med. 2007;26(4):734–53.
Brookhart MA, Schneeweiss S, Rothman KJ, Glynn RJ, Avorn J, Sturmer T. Variable selection for propensity score models. Am J Epidemiol. 2006;163(12):1149–56.
Kara Y, Kamata A, Gallegos E, Patarapi̇chayatham C, Potgi̇eter CJ. Covariate balance as a quality indicator for propensity score analysis. Eğitimde ve Psikolojide Ölçme ve Değerlendirme Dergisi. 2021.
Marsden AM, Dixon WG, Dunn G, Emsley R. The impact of moderator by confounder interactions in the assessment of treatment effect modification: a simulation study. BMC Med Res Methodol. 2022;22(1):88.
Hammarström A, Janlert U. Cohort profile: the northern Swedish cohort. Int J Epidemiol. 2012;41(6):1545–52.
Virtanen P, Lipiainen L, Hammarström A, Janlert U, Saloniemi A, Nummi T. Tracks of labour market attachment in early middle age: a trajectory analysis over 12 years. Adv Life Course Res. 2011;16(2):55–64.
Statistics Sweden. Det statistiska registrets framställning och kvalitetet: longitudinell integrationsdatabas för sjukförsäkrings- och arbetsmarknadsstudier (LISA). Statistics Sweden. 2022.
Socioekonomisk indelning (SEI) [http://www.scb.se/statistik/_publikationer/OV9999_1982A01_BR_X11%C3%96P8204.pdf]
Henderson S, Duncan Jones P, Byrne DG, Scott R. Measuring social relationships. the interview schedule for social interaction. Psychol Med. 1980;10(4):723–34.
Brookhart MA, Wyss R, Layton JB, Sturmer T. Propensity score methods for confounding control in nonexperimental research. Circ-Cardiovasc Qual Outcomes. 2013;6(5):604–11.
Lunceford JK, Davidian M. Stratification and weighting via the propensity score in estimation of causal treatment effects: a comparative study. Stat Med. 2004;23(19):2937–60.
Austin PC. Variance estimation when using inverse probability of treatment weighting (IPTW) with survival analysis. Stat Med. 2016;35(30):5642–55.
Davison AC, Hinckley DV. Bootstrap methods and their application. Cambridge, United Kingdom: cambridge university press; 1997.
R Core Team. A language and environment for statistical computing. R foundation for statistical computing. 2015.
Sturmer T, Joshi M, Glynn RJ, Avorn J, Rothman KJ, Schneeweiss S. A review of the application of propensity score methods yielded increasing use, advantages in specific settings, but not substantially different estimates compared with conventional multivariable methods. J Clin Epidemiol. 2006;59(5):437–47.
Pouwels KB, Widyakusuma NN, Groenwold RH, Hak E. Quality of reporting of confounding remained suboptimal after the STROBE guideline. J Clin Epidemiol. 2016;69:217–24.
Keogh RH, White IR. A toolkit for measurement error correction, with a focus on nutritional epidemiology. Stat Med. 2014;33(12):2137–55.
Acknowledgements
The authors would like to thank all of the participants of the study. The authors would like to thank Umeå University for collaboration around the Northern Sweden cohort.
Funding
Open access funding provided by Umea University. The study was funded by the Swedish Research Council for Health, Working Life and Welfare (dnr 2011–0839). The funder had no role in the design of the study and collection, analysis, and interpretation of data and in writing the manuscript.
Author information
Authors and Affiliations
Contributions
The study was designed by FN in collaboration with AH. FN performed the analyses and the interpretations in collaboration with AH. FN drafted the paper, and AH contributed actively. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The Regional Ethical Board in Umeå, Sweden, approved the study.
Informed consent to the study was given by the participants by returning their questionnaire. The study, and the methods used, were carried out in accordance with relevant guidelines and regulations. In the supplementary file, we have document this, following the STROBE guideline.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
Questions about labour market status between follow-ups of the Northern Swedish Cohort in the surveys in 1995 and 2007.
Additional file 2.
Characteristics for the study populations divided into employment groups for the unemployment modes.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Norström, F., Hammarström, A. Methodological perspectives on the study of the health effects of unemployment – reviewing the mode of unemployment, the statistical analysis method and the role of confounding factors. BMC Med Res Methodol 22, 199 (2022). https://doi.org/10.1186/s12874-022-01670-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-022-01670-1