
Abstract
Objective
Our study aimed to identify predictors as well as develop machine learning (ML) models to predict the risk of 30-day mortality in patients with sepsis-associated encephalopathy (SAE).
Materials and methods
ML models were developed and validated based on a public database named Medical Information Mart for Intensive Care (MIMIC)-IV. Models were compared by the area under the curve (AUC), accuracy, sensitivity, specificity, positive and negative predictive values, and Hosmer–Lemeshow good of fit test.
Results
Of 6994 patients in MIMIC-IV included in the final cohort, a total of 1232 (17.62%) patients died following SAE. Recursive feature elimination (RFE) selected 15 variables, including acute physiology score III (APSIII), Glasgow coma score (GCS), sepsis related organ failure assessment (SOFA), Charlson comorbidity index (CCI), red blood cell volume distribution width (RDW), blood urea nitrogen (BUN), age, respiratory rate, PaO2, temperature, lactate, creatinine (CRE), malignant cancer, metastatic solid tumor, and platelet (PLT). The validation cohort demonstrated all ML approaches had higher discriminative ability compared with the bagged trees (BT) model, although the difference was not statistically significant. Furthermore, in terms of the calibration performance, the artificial neural network (NNET), logistic regression (LR), and adapting boosting (Ada) models had a good calibration—namely, a high accuracy of prediction, with P-values of 0.831, 0.119, and 0.129, respectively.
Conclusions
The ML models, as demonstrated by our study, can be used to evaluate the prognosis of SAE patients in the intensive care unit (ICU). Online calculator could facilitate the sharing of predictive models.
Similar content being viewed by others


Introduction
Sepsis-associated encephalopathy (SAE) is characterized by diffuse cerebral dysfunction resulted from a dysregulated host response without central nervous system (CNS) infection [1]. It develops in 8–70% of septic patients, based on the sepsis severity, patients’ profile, and SAE diagnostic criteria [2,3,4,5]. Symptoms in the acute stage contain sickness behavior, delirium, coma and so on. Further, survivors of the acute stage have a tendency to develop persistent neurocognitive impairment, including cognitive alterations, and even overt dementia [6,7,8]. It is reported that SAE was associated with longer duration of mechanical ventilation (MV) and prolonged lengths of stay (LOS) in the intensive care unit (ICU) as well as poor overall prognosis [9, 10].
Also, it was related to higher severity of scoring systems, including the Glasgow coma score (GCS), sequential organ failure assessment score (SOFA), and the Acute Physiology and Chronic Health Evaluation (APACHE II) [7, 10]. Moreover, with a mortality rate of up to 63% [3], SAE can be detrimental to patients’ health as well as add a heavy burden to the financial system. Accordingly, early identification, especially individual and measurable prediction models, and prompt management are of vital importance for the survival and prognosis of SAE patients [11]. Recently, the advent of machine learning (ML) algorithms has enabled us to predict disease events dynamically based on complicated clinical information. ML, an artificial intelligence method, can develop models “learning” from existing data [12]. Moreover, without particular model assumptions, ML, may be adept at handling intricate interactions between variables of one sort or another [13]. The present study aimed to investigate independent factors and then develop predictive models to quantitatively predict the likelihood of 30-day mortality in patients with SAE.
Methods
Data source
This retrospective study was conducted on the Medical Information Mart for Intensive Care (MIMIC)-IV version 1.0 [14]. Specifically, the MIMIC-IV database contained comprehensive, de-identified data of patients who have been admitted to the ICUs at the Beth Israel Deaconess Medical Center in Boston, Massachusetts, between 2008 and 2019, containing data from 383,220 admissions (single center). One author (CP) has obtained access to both databases and was responsible for data extraction (Certification number: 41657645). This study was approved by the Institutional Review Boards of Beth Israel Deaconess Medical Center (Boston, MA). Requirement for individual patient consent was waived due to the fact that all protected health information was deidentified.
Participant selection
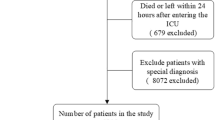
Inclusion criteria were patients with a diagnosis of sepsis in accordance with the Third International Consensus Definitions for Sepsis (Sepsis-3) [15]. People with an age of younger than 16 years old, ICU stays less than 48 h, primary brain injury (traumatic brain injury, ischemic stroke, hemorrhagic stroke, epilepsy, or intracranial infection), pre-existing liver or kidney failure affecting consciousness, chronic alcohol or drug abuse, and severe electrolyte imbalances were excluded from the study. In addition, for patients with multiple ICU admissions, only data of the first ICU admission of the first hospitalization were included in the analysis.
Predictors of 30-day mortality in SAE patients
In this study, the data extracted from MIMIC-IV included age, gender, race, and coexisting disorders. Hereafter, the Charlson comorbidity index (CCI) was calculated from its component variables [myocardial infarction, congestive heart failure, peripheral vascular disease, cerebrovascular disease, dementia, chronic pulmonary disease, rheumatic disease, peptic ulcer disease, diabetes, paraplegia, renal disease, malignant cancer, severe liver disease, metastatic solid tumor and acquired immunodeficiency syndrome (AIDS)]. Additionally, we retrospectively extracted the following data: vital signs, laboratory findings, injury types, different therapy strategies and scoring systems on the first day of ICU admission. Since values were missing at random, we used multiple imputation to deal with missing data. Details of missing data are shown in Supplementary Table 1 (Table S1).
Statistical analysis
Values were presented as means with standard deviations (if normal) or medians with interquartile ranges (IQR) (if non-normal) for continuous variables, and total numbers (%) for categorical variables. Continuous variables were compared by the t test or Wilcoxon rank sum test while proportions were compared using χ2 test or Fisher exact tests, if appropriate.
Recursive feature elimination (RFE), a resource selection method, was utilized to select the most relevant variables. In a word, RFE recursively fits into a model based on smaller resource sets until a specified termination criterion is reached. In each loop, characteristics are classified in accordance with their importance in the trained model. Ultimately, highly correlated and collinear variables were eliminated. The characteristics were then considered in groups of 15/25/35/45/ALL (ALL = 56 variables, as represented in Fig. 1) organized by the ranks obtained after the method of selection of the characteristics. In order to find the optimal hyperparameters, fivefold cross-validation was used as the resampling method. In each iteration, every four folds were used as a training subset, and the remaining one-fold was processed to adjust the hyperparameters. This training-test process was repeated thirty times. Thus, each sample would be involved in both the training model and the testing model, so that all data were used as much as possible.

Overview of the methods used for data extraction, training, and testing. ICU, intensive care unit; MIMIC, Medical Information Mart for Intensive Care; ML, machine learning; NNET, artificial neural network; NB, naïve bayes; LR, logistic regression; GBM, gradient boosting machine; Ada, adapting boosting; RF, random forest; BT, bagged trees; XGB, eXtreme Gradient Boosting
In this study, we employed nine different ML algorithms to develop models, including artificial neural network (NNET), bayes naive (NB), logistic regression (LR), gradient boosting machine (GBM), adaptating boosting (Ada), random forest (RF), bagged trees (BT), eXtreme Gradient Boosting (XGB) and CatBoost. Firstly, the population was divided into development set and validation set. As for internal validation, bootstrap resampling technique with 100 iterations was employed. Median and 95% confidence intervals of area under the curve (AUC) were calculated. Other evaluation indicators, such as, accuracy, sensitivity, specificity, negative predictive value and positive predictive value were also calculated. Moreover, the calibration curve was employed by the Hosmer–Lemeshow test of good adaptation. More precisely, the chi-square value was calculated based on the actual observed and predicted value of the model for each group and, subsequently, the corresponding p value was obtained. Ultimately, the “Shiny” package in R was used to build a visual data analysis platform. All analyses were performed by the statistical software packages R version 4.0.2 (http://www.R-project.org, The R Foundation). In our study, we also used the “Caret” R packages and “Shiny” R packages to achieve the process. P values less than 0.05 (two-sided test) were considered as statistically significant.
Results
Baseline characteristic
In accordance with the inclusion and exclusion criteria, 6994 patients were finally included in the dataset. The process of data extraction, training preparation, data testing by diverse ML algorithms is demonstrated in Fig. 1. The characteristics of the participants are depicted in Table 1. People who died were more likely to be older, with more comorbidities (myocardial infarction, congestive heart failure, chronic pulmonary disease, rheumatic disease, mild liver disease, renal disease, malignant cancer, severe liver disease, metastatic solid tumor), higher heart rate, higher respiratory rate, higher white blood cell (WBC), higher mean corpuscular volume (MCV), higher red blood cell volume distribution width (RDW), longer activated partial thromboplastin time (APTT), longer prothrombin time (PT), higher international normalized ratio (INR), higher lactate, higher buffer excess (BE), higher anion gap, higher potassium, higher creatinine (CRE), higher blood urea nitrogen (BUN), higher vasopressor, higher sepsis related organ failure assessment (SOFA), higher acute physiology score III (APSIII), and higher systemic inflammatory response syndrome (SIRS). Furthermore, they were more likely to have lower temperature, lower mean artery pressure (MAP), lower red blood cell (RBC), lower mean corpuscular hemoglobin concentration (MCHC), lower platelet (PLT), lower hematocrit (HCT), lower pH, lower bicarbonate, lower PaO2, lower chloride, lower sodium, and lower Glasgow coma score (GCS).
Variable importance
Based on the threshold measure of importance, a total of 15 important predictors were selected by the RFE algorithm. (Fig. 2) These variables included APSIII, GCS, SOFA, CCI, RDW, BUN, age, respiratory rate, PaO2, temperature, lactate, CRE, malignant cancer, metastatic solid tumor, and PLT. Then, these 15 variables were used in all the subsequent analysis for all models in both training and testing sets.

Association between the number of variables allowed to be considered at each split and the prediction accuracy in the REF algorithm. REF, recursive feature elimination
Comparisons among different ML models
The discriminatory abilities of all models for the prediction of 30-day mortality in SAE patients are shown in Fig. 3 and Table 2. Within the training set, the NNET, NB, LR, GBM, Ada, RF, BT, XGB, and CatBoost models were established, and the testing set obtained AUCs of 0.833, 0.816, 0.833, 0.824, 0.834, 0.825, 0.804, 0.830, and 0.830, respectively. Comparatively, the BT had the lowest discriminative ability (AUC 0.804, 95% CI 0.786 to 0.820) while the other eight models had a relatively higher discriminative ability (Table S2). In terms of the calibration performance, the NNET, LR, Ada models had a good calibration—namely, a high accuracy of prediction, with P-values of 0.831, 0.119, and 0.129, respectively (Fig. 4).

AUC of ROC curve by ML models in the validation cohort. AUC, area under the curve; ROC, receiver operate characteristics; ML, machine learning; NNET, artificial neural network; NB, naïve bayes; LR, logistic regression; GBM, gradient boosting machine; Ada, adapting boosting; RF, random forest; BT, bagged trees; XGB, eXtreme Gradient Boosting

Calibration curve in the validation cohort. NNET, artificial neural network; NB, naive bayes; LR, logistic regression; GBM, gradient boosting machine; Ada, adapting boosting; RF, random forest; BT, bagged trees; XGB, eXtreme Gradient Boosting
In the Fig. 5, fifth predictor variables in the ML are demonstrated. Each variable incorporated in the study had varying importance over SAE depending on the ML approach. In general, APSIII was the variable with greatest importance across all ML algorithms, followed by GCS, RDW, and so forth.

Variable importance in nine different ML models. ML, machine learning; NNET, artificial neural network; NB, naïve bayes; LR, logistic regression; GBM, gradient boosting machine; Ada, adapting boosting; RF, random forest; BT, bagged trees; XGB, eXtreme Gradient Boosting;
Application of model
The Shiny package analyzed the entire training set, demonstrating the impact of each variable on predicting SAE (Fig. 6). For example, the information of one patient was input into the model: no metastatic solid tumor, no malignant cancer, APSIII (121), GCS (3), CCI (6), SOFA (16), age (92), temperature (32 ℃), respiratory rate (19 per/min), RDW (17.5%), PLT (158 × 109/L), lactate (4.6 mmol/L), BUN (20 mg/dL), CRE (1.1 mg/dL), PaO2 (85 mmHg). The model analyzed that the risk of in-hospital mortality in this patient was 84.20%, indicating that the 30-day mortality for this SAE patient was relatively high, and precaution measures were recommended. In order to better apply this model, we also made a web-based calculator (https://pengchi2009.shinyapps.io/Mortality_of_sepsis_associated_encephalopathy/).

Examples of website usage. Entering the input value determined the mortality and displayed how each value contributed to the prediction. CCI, Charlson Comorbidity Index
Discussion
Herein, nine ML models were developed and further validated to predict 30-day mortality of SAE patients. In terms of the discrimination and calibration performance, the NNET, LR and Ada model outperformed the remaining models. To make it easier for surgeons to use the model, a web-based calculator was then developed. Only by inputting the variable values can the 30-day death rate be shown. Both physicians and patients could perform an individualized prediction of the 30-day mortality of SAE, which is consistent with the personalized medicine trend. Undoubtedly, this calculator is conducive to correct clinical decisions, and more importantly, timely treatment strategy.
A study of 69 cases of sepsis patients demonstrated that in patients with no encephalopathy (n = 20), mild encephalopathy (n = 17), severe encephalopathy (n = 32), the mortality rate was 0, 35%, and 53%, respectively, showing that mortality was correlated to the severity of SAE [16]. In this study, fifteen variables were identified as risk factors, involving APSIII, GCS, SOFA, CCI, RDW, BUN, age, respiratory rate, PaO2, temperature, lactate, CRE, malignant cancer, metastatic solid tumor, and PLT.
Published study conducted by Chen J et al. [17] indicated that APACHE II and SOFA were independent risk factors for 28-day mortality in SAE patients, which was similar to our findings. A range of previous studies also have found that the mortality rate of sepsis patients is related to higher values of the GCS, SOFA, and the APACHE II score [10, 18, 19]. As an established method of summarizing patient severity of illness on admission to the ICU, APSIII is a part of the APACHE system of equations for the prediction of outcomes for ICU patients [20, 21]. In our study, APSIII and SOFA were variables with the relatively higher weight in the importance plot, demonstrating that they had strong power to predict 30-day mortality of SAE patients. It is manifest that SAE patients with multiple organ dysfunction syndrome (MODS) are associated with an increased risk of mortality. Cascade immune response, circulatory abnormalities, mitochondrial dysfunction as well as hypoxia endothelial permeability increases may be responsible for such a complicated pathophysiological process [22,23,24,25]. Consequently, the treatment of SAE is based both on the management of sepsis and on the correction of potential neurotoxic factors.
Similar to previous study conducted by Yang Y et al. [26], RDW was an important predictor for 30-day death of SAE patients. Although the mechanism remains, to a wide extent, unclear, it is estimated that inflammation reaction and oxidative stress might invite an increase in RDW values, and simultaneously, these mechanisms may play a pivotal role in the poor prognosis of SAE [27,28,29]. Furthermore, in keeping with previous study, we also unearthed that age was independently associated with 30-day mortality [17]. It was probably attributable to the fact that elderly patients exhibit a higher risk and mortality from sepsis [30]. Further, our research offered insight into the fact that renal function (BUN, CRE), respiratory rate, PaO2, and PLT were identified as predictors for 30-day death in SAE patients. Previous study also found that sepsis patients with renal or multi-organ failure were more frequently affected than those without organ complications [3].
Additionally, renal function alteration is not only associated with biological alterations including severe acidosis and uremia but also associated with neurotoxic substances accumulation, such as, antibiotics and hypnotics [10]. Notably, caused by the enhanced activation of cytokine expression and vascular endothelial cells, platelet abnormalities may proceed to disseminated intravascular coagulation (DIC) [31, 32]. Accordingly, it is advisable that we properly improve respiratory and circulation status, and correct coagulation function to reduce the mortality of SAE patients.
Result from previous study indicated that temperature and lactate were significantly correlated with mortality in SAE patients [33], these findings have also been confirmed in our research. As is well known, lactate was an important indictor which reflected the prognosis of sepsis patients [34, 35]. In other words, serum lactate was used to evaluate disease severity and guide treatment plan [34], thereby indicating that SAE patients experienced microcirculation obstacles, which may induce tissue ischemia and hypoxia. Accordingly, for patients with lactate acidosis and hyperlactic acidosis, timely rehydration and other treatments are needed.
The strengths of this study lied in the fact that it applied modern ML approaches to predict 30-day mortality, ensured that surgeons can conduct triage of patients at risk timely. Another important point to note was that the use of cross-validation is instrumental in decreasing potential overfitting. Further, based on a real-world data with relatively large samples (n = 6994), this study underwent a rigorous statistical test.
There were limitations in this study. First, although cohorts were divided into training set and validation set (70%: 30%), external verification is still a necessity. And compared to traditional models, the evaluation indicators including AUCs and accuracy of Ada have a slight edge. Second, as an administrative database, there exist inherent limitations. For example, the neuroimaging data were not available. Third, as with all potential retrospective studies, there was a potential for unmeasured confounders. Fourth, since it was based on ICU patients, this study could not be generalizable to other population. Lastly, although the shiny package was utilized to help visualize the results, a more applicable model is still needed in clinical practice.
Conclusions
On a whole, ML models, are able to individually predict 30-day mortality in SAE patients. and thereby assisting in the early screening for SAE patients who are at risk. This is particularly crucial as early treatment may facilitate the neurocognitive outcome. Future studies should be concentrated on investigating the long-term prognosis of SAE patients and the underlying mechanism of SAE.
Availability of data and materials
Publicly available datasets were analyzed in this study. These data can be found in the physionet (https://physionet.org/content/mimiciv/1.0/).
References
Gofton TE, Young GB. Sepsis-associated encephalopathy. Nat Rev Neurol. 2012;8(10):557–66.
Fraser GL, Riker RR, Coursin DC. Long-term cognitive impairment after critical illness. N Engl J Med. 2014;370(2):184.
Eidelman LA, Putterman D, Putterman C, Sprung CL. The spectrum of septic encephalopathy. Definitions, etiologies, and mortalities. JAMA. 1996;275(6):470–3.
Young GB, Bolton CF, Austin TW, Archibald YM, Gonder J, Wells GA. The encephalopathy associated with septic illness. Clin Invest Med. 1990;13(6):297–304.
Ely EW, Shintani A, Truman B, Speroff T, Gordon SM, Harrell FE Jr, Inouye SK, Bernard GR, Dittus RS. Delirium as a predictor of mortality in mechanically ventilated patients in the intensive care unit. JAMA. 2004;291(14):1753–62.
Chung HY, Wickel J, Brunkhorst FM, Geis C. Sepsis-associated encephalopathy: from delirium to dementia? J Clin Med. 2020;9(3):703.
Iwashyna TJ, Ely EW, Smith DM, Langa KM. Long-term cognitive impairment and functional disability among survivors of severe sepsis. JAMA. 2010;304(16):1787–94.
Widmann CN, Heneka MT. Long-term cerebral consequences of sepsis. Lancet Neurol. 2014;13(6):630–6.
Salluh JI, Wang H, Schneider EB, Nagaraja N, Yenokyan G, Damluji A, Serafim RB, Stevens RD. Outcome of delirium in critically ill patients: systematic review and meta-analysis. BMJ. 2015;350:h2538.
Sonneville R, de Montmollin E, Poujade J, Garrouste-Orgeas M, Souweine B, Darmon M, Mariotte E, Argaud L, Barbier F, Goldgran-Toledano D, et al. Potentially modifiable factors contributing to sepsis-associated encephalopathy. Intensive Care Med. 2017;43(8):1075–84.
Barr J, Fraser GL, Puntillo K, Ely EW, Gélinas C, Dasta JF, Davidson JE, Devlin JW, Kress JP, Joffe AM, et al. Clinical practice guidelines for the management of pain, agitation, and delirium in adult patients in the intensive care unit. Crit Care Med. 2013;41(1):263–306.
Kuhle S, Maguire B, Zhang H, Hamilton D, Allen AC, Joseph KS, Allen VM. Comparison of logistic regression with machine learning methods for the prediction of fetal growth abnormalities: a retrospective cohort study. BMC Pregnancy Childbirth. 2018;18(1):333.
Goecks J, Jalili V, Heiser LM, Gray JW. How Machine Learning Will Transform Biomedicine. Cell. 2020;181(1):92–101.
Goldberger AL, Amaral LA, Glass L, Hausdorff JM, Ivanov PC, Mark RG, Mietus JE, Moody GB, Peng CK, Stanley HE. PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals. Circulation. 2000;101(23):E215-220.
Singer M, Deutschman CS, Seymour CW, Shankar-Hari M, Annane D, Bauer M, Bellomo R, Bernard GR, Chiche JD, Coopersmith CM, et al. The Third International Consensus Definitions for Sepsis and Septic Shock (Sepsis-3). JAMA. 2016;315(8):801–10.
Young GB, Bolton CF, Archibald YM, Austin TW, Wells GA. The electroencephalogram in sepsis-associated encephalopathy. J Clin Neurophysiol. 1992;9(1):145–52.
Chen J, Shi X, Diao M, Jin G, Zhu Y, Hu W, Xi S. A retrospective study of sepsis-associated encephalopathy: epidemiology, clinical features and adverse outcomes. BMC Emerg Med. 2020;20(1):77.
Sprung CL, Peduzzi PN, Shatney CH, Schein RM, Wilson MF, Sheagren JN, Hinshaw LB. Impact of encephalopathy on mortality in the sepsis syndrome. The Veterans Administration Systemic Sepsis Cooperative Study Group. Crit Care Med. 1990;18(8):801–6.
Zhang LN, Wang XT, Ai YH, Guo QL, Huang L, Liu ZY, Yao B. Epidemiological features and risk factors of sepsis-associated encephalopathy in intensive care unit patients: 2008–2011. Chin Med J. 2012;125(5):828–31.
LeGall JR, Loirat P, Alpérovitch A. APACHE II–a severity of disease classification system. Crit Care Med. 1986;14(8):754–5.
Le Gall JR, Lemeshow S, Saulnier F. A new Simplified Acute Physiology Score (SAPS II) based on a European/North American multicenter study. JAMA. 1993;270(24):2957–63.
Nolt B, Tu F, Wang X, Ha T, Winter R, Williams DL, Li C. Lactate and immunosuppression in sepsis. Shock. 2018;49(2):120–5.
Vincent JL, De Backer D. Circulatory shock. N Engl J Med. 2013;369(18):1726–34.
Sun J, Zhang J, Tian J, Virzì GM, Digvijay K, Cueto L, Yin Y, Rosner MH, Ronco C. Mitochondria in sepsis-induced AKI. J Am Soc Nephrol. 2019;30(7):1151–61.
Opal SM, van der Poll T. Endothelial barrier dysfunction in septic shock. J Intern Med. 2015;277(3):277–93.
Yang Y, Liang S, Geng J, Wang Q, Wang P, Cao Y, Li R, Gao G, Li L. Development of a nomogram to predict 30-day mortality of patients with sepsis-associated encephalopathy: a retrospective cohort study. J Intensive Care. 2020;8:45.
Lippi G, Targher G, Montagnana M, Salvagno GL, Zoppini G, Guidi GC. Relation between red blood cell distribution width and inflammatory biomarkers in a large cohort of unselected outpatients. Arch Pathol Lab Med. 2009;133(4):628–32.
Vayá A, Sarnago A, Fuster O, Alis R, Romagnoli M. Influence of inflammatory and lipidic parameters on red blood cell distribution width in a healthy population. Clin Hemorheol Microcirc. 2015;59(4):379–85.
Perlstein TS, Weuve J, Pfeffer MA, Beckman JA. Red blood cell distribution width and mortality risk in a community-based prospective cohort. Arch Intern Med. 2009;169(6):588–94.
Martin GS, Mannino DM, Moss M. The effect of age on the development and outcome of adult sepsis. Crit Care Med. 2006;34(1):15–21.
Claushuis TA, van Vught LA, Scicluna BP, Wiewel MA, Klein Klouwenberg PM, Hoogendijk AJ, Ong DS, Cremer OL, Horn J, Franitza M, et al. Thrombocytopenia is associated with a dysregulated host response in critically ill sepsis patients. Blood. 2016;127(24):3062–72.
Levi M, Toh CH, Thachil J, Watson HG. Guidelines for the diagnosis and management of disseminated intravascular coagulation. British Committee for Standards in haematology. Br J Haematol. 2009;145(1):24–33.
Zhao L, Li Y, Wang Y, Gao Q, Ge Z, Sun X, Li Y. Development and validation of a nomogram for the prediction of hospital mortality of patients with encephalopathy caused by microbial infection: a retrospective cohort study. Front Microbiol. 2021;12:737066.
Suetrong B, Walley KR. Lactic acidosis in sepsis: it’s not all anaerobic: implications for diagnosis and management. Chest. 2016;149(1):252–61.
Liu Z, Meng Z, Li Y, Zhao J, Wu S, Gou S, Wu H. Prognostic accuracy of the serum lactate level, the SOFA score and the qSOFA score for mortality among adults with Sepsis. Scand J Trauma Resusc Emerg Med. 2019;27(1):51.
Collins GS, Reitsma JB, Altman DG, Moons KG. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. BMJ. 2015;350:g7594.
Acknowledgements
We would like to thank the Massachusetts Institute of Technology and the Beth Israel Deaconess Medical Center for the MIMIC project.
Funding
The authors received no financial support for the research, author-ship, and/or publication of this article.
Author information
Authors and Affiliations
Contributions
(I) Concept and design: L Peng, C Peng; (II) Acquisition of data: F Yang, C Peng; (III) Data analysis and interpretation: C Peng, J Wang, W Zuo, C Cheng, Z Mao; (IV) Manuscript writing: L Peng; (V) Revising it critically for important intellectual content: All authors; (VI) Final approval of manuscript: All authors.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
The authors are accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved. Owing to the fact that this de-identified database is publicly available, the institutional review board approval and the written informed consents are waived by the Institutional Review Boards of Beth Israel Deaconess Medical Center (Boston, MA). The study was reported in accordance with the Transparent Reporting of a multivariable Prediction model for Individual Prognosis or Diagnosis (TRIPOD) statement [36]. All methods were performed in accordance with the relevant guidelines and regulations.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1:
Table S1. Missing number (%) for included variables in the dataset. Table S2. The comparison of different ROC curve by De Long’s method.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Peng, L., Peng, C., Yang, F. et al. Machine learning approach for the prediction of 30-day mortality in patients with sepsis-associated encephalopathy. BMC Med Res Methodol 22, 183 (2022). https://doi.org/10.1186/s12874-022-01664-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-022-01664-z