
Abstract
Background
Epidemiological studies of incidence play an essential role in quantifying disease burden, resource planning, and informing public health policies. A variety of measures for estimating cancer incidence have been used. Appropriate reporting of incidence calculations is essential to enable clear interpretation. This review uses colorectal cancer (CRC) as an exemplar to summarize and describe variation in commonly employed incidence measures and evaluate the quality of reporting incidence methods.
Methods
We searched four databases for CRC incidence studies published between January 2010 and May 2020. Two independent reviewers screened all titles and abstracts. Eligible studies were population-based cancer registry studies evaluating CRC incidence. We extracted data on study characteristics and author-defined criteria for assessing the quality of reporting incidence. We used descriptive statistics to summarize the information.
Results
This review retrieved 165 relevant articles. The age-standardized incidence rate (ASR) (80%) was the most commonly reported incidence measure, and the 2000 U.S. standard population the most commonly used reference population (39%). Slightly more than half (54%) of the studies reported CRC incidence stratified by anatomical site. The quality of reporting incidence methods was suboptimal. Of all included studies: 45 (27%) failed to report the classification system used to define CRC; 63 (38%) did not report CRC codes; and only 20 (12%) documented excluding certain CRC cases from the numerator. Concerning the denominator estimation: 61% of studies failed to state the source of population data; 24 (15%) indicated census years; 10 (6%) reported the method used to estimate yearly population counts; and only 5 (3%) explicitly explained the population size estimation procedure to calculate the overall average incidence rate. Thirty-three (20%) studies reported the confidence interval for incidence, and only 7 (4%) documented methods for dealing with missing data.
Conclusion
This review identified variations in incidence calculation and inadequate reporting of methods. We outlined recommendations to optimize incidence estimation and reporting practices. There is a need to establish clear guidelines for incidence reporting to facilitate assessment of the validity and interpretation of reported incidence.
Similar content being viewed by others


Introduction
Epidemiological studies of incidence play an essential role in quantifying disease burden, healthcare resource planning, and informing public health policies. Incidence is a crucial measure of epidemiology representing the number of new disease cases in a specific population divided by the population’s size at risk during a particular period [1]. A variety of measures for estimating cancer incidence in population-based studies have been reported in the literature. The magnitude and interpretation of incidence estimates depend on methodological choices such as the definition of numerator and denominator and the standard population used to calculate the age-standardized rate (ASR) [1,2,3,4].
Variations in incidence calculation influence comparisons of regional and global rates and trends and their interpretation. Thus, crucial requirements for generating comparable and reproducible incidence statistics include: i) a precise definition of the disease of interest with a specification of the classification used and coding, ideally validated within data source; ii) a clear description of the numerator data and the population at risk; and iii) an explicit explanation of the methods used to estimate denominator size [1, 5, 6]. Additionally, quantifying and reporting uncertainty around health estimates in population-based studies is imperative to inform readers who draw conclusions from these estimates [7, 8].
Population-based studies often utilize data from cancer registries to derive incidence statistics. The primary purpose of these registries is to provide a reliable source of information for assessing cancer risk. The International Agency for Research on Cancer (IARC) advises registries to continually evaluate data quality by several quantitative and qualitative methods [5, 9]. Yet, the extent of detail provided by researchers about these quality indicators remains unclear, and results of evaluations are rarely publicly available.
Furthermore, cancer registries rely on trained registrars to abstract data from patients’ medical records. Some abstracted data may be incomplete due to human error or poor quality documentation within the medical record, leading to inaccurate and missing values within cancer registries [10]. Thus, quantification of missingness, explicit and detailed reporting of assumptions and handling of missing data help readers make informed interpretations of the findings.
There is a growing body of evidence to suggest that the level of reproducibility in scientific research is inadequate. Poor reporting of incidence methods might negatively affect research findings’ credibility, comparability, and reproducibility [11]. The Enhancing the Quality and Transparency of Health Research (EQUATOR) network provides reporting guidelines for observational studies; yet none of the current guidelines adequately address the reporting of methods used in measuring incidence.
Because it was not practical to consider all cancers in this study, we chose colorectal cancer (CRC) as an exemplar. CRC is of particular interest due to its increasing global burden among women and men and to the role of screening in prevention and early detection. CRC is a type of cancer that starts in the rectum or colon. CRC can be categorized into three sub-types based on its anatomical site: proximal colon, distal colon, and rectum [12]. According to the GLOBOCAN 2020 estimates of cancer incidence, CRC is the third most common cancer and the second leading cause of cancer-related deaths worldwide [13]. The rate of CRC has been steadily increasing in some regions [14]. Survival outcomes for CRC are closely related to the cancer stage at diagnosis [15], and thereby it is one of the few cancers where screening is considered a key preventive measure [16]. A growing number of population-based studies globally have been closely monitoring CRC incidence. Yet, fair comparisons of CRC incidence estimates between different data sources or countries depend on the methods used, which must be explicitly reported.
This article aims to systematically review population-based studies using cancer registries to measure CRC incidence, summarize and describe variation in the commonly employed incidence measures, and evaluate the quality of reporting incidence methods. Our review was set up to answer the following questions: 1- What are the most reported incidence measures for estimating CRC incidence?; 2- What standard populations are commonly used to estimate the age-standardized rate in population-based studies?; 3- Are CRC incidence rates commonly stratified by anatomical site?; 4- What is the quality of reporting the methods used to estimate CRC incidence?
Methods
The reporting of this systematic review followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) [17].
Study identification
We developed a search strategy in consultation with an information specialist. The search included keywords and a combination of subject headings incorporating “colorectal cancer,” “incidence,” “trends,” and “registry” (the complete search strategy is provided in Additional file 5). We limited the search to articles written in English and to studies published from 1 January 2010 to 31 May 2020. Adding a time frame to the search strategy helped select the most up-to-date studies. The electronic literature search included Embase, Medline, Web of Science, and the Cochrane Library. We also checked reference lists of identified articles for identification of additional potentially relevant articles missed.
Study selection
Studies were eligible for inclusion in this review based on the inclusion and exclusion criteria presented in Table 1.
Selection process
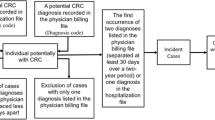
We imported all potential abstracts into the web app “Rayyan” (a screening software) [18], and two independent reviewers screened all titles and abstracts using the inclusion–exclusion criteria. Any disagreements between reviewers were resolved through discussion. If a consensus decision was not reached by screening the title and abstract, the reviewers examined the full text. We calculated the inter-reviewer agreement rate for title/abstract screening using Cohen’s κ statistic (results are presented in Additional file 3: Table 3.1). After the screening process, we further assessed articles selected for full-text review. In cases where eligibility was unclear, we consulted a third reviewer for a final decision. Details of the selection process are displayed in Fig. 1.

PRISMA flowchart of the study selection process
Data extraction and synthesis
We developed and piloted two standardized extraction forms. Form A was used to extract general details about the study, including author and publication year, country, cancer type, main study outcomes, observation period, measures of incidence rate, and the anatomical site used in incidence calculation. Form B was for extracting data necessary to assess the quality of reporting the methods used to calculate incidence. We defined a list of potential indicators to evaluate the reporting quality based on relevant literature on incidence calculation [1,2,3] and the Guidelines for Accurate and Transparent Health Estimates Reporting (GATHER) statement for reporting global health estimates [6]. This criteria list included: the quality of cancer registry data, the definition of CRC, definition of the numerator, estimation of the denominator, the time interval over which incidence was calculated, presentation of incidence rates, standardization process of rates, age bands for measuring incidence, assessment of uncertainty, evaluation of missing data, and software information. A detailed description of each of these criteria is provided in Table 2. One reviewer extracted the data for all included studies, and a second reviewer cross-checked a random sample of 25% (n = 41). Discrepancies were resolved by consensus agreement.
Quality assessment
We appraised the quality of all included studies using a prespecified checklist adapted for this review and based on the Joanna Briggs Institute Critical Appraisal tool for prevalence studies [19] and the Appraisal tool for Cross-Sectional Studies (AXIS) [20]. Both of these tools were previously employed in a systematic review assessing CRC incidence rates [21]. We chose relevant criteria from each tool to create a 10-item checklist for this study. Items were assigned a score of 1 if “demonstrated in the study” or 0 if “not demonstrated or unclear”. We calculated and presented an overall quality score for each study. Quality appraisal checklist and results of quality assessment are presented in Additional file 4.
Data analysis
The characteristics of included studies, incidence methods, and the quality of reporting incidence were all described in tables. We used descriptive summary statistics to analyse the extracted data and reported the results as frequencies and percentages.
Results
The combined search initially yielded 5,348 papers, and after the deletion of duplicates, we identified and screened 2906 titles. The inter-reviewer agreement for the title/abstract screening had a Cohen’s κ value of 94% (Additional file 3: Table 3.1). After applying the inclusion–exclusion criteria,165 titles were deemed eligible for the systematic review. Details on excluded reports are depicted in the PRISMA flow diagram (Fig. 1).
Characteristics of included studies
The eligible articles comprised studies from North America, including the United States of America (USA) (n = 66, 40%) and Canada (n = 5, 3%), Oceania (n = 7, 4%), Europe (n = 38, 23%), Asia (n = 36, 22%), Africa (n = 5, 3%), Central and South America (n = 2, 1%), and six (4%) multi-country study. In addition to incidence, the two other study outcomes most commonly reported were mortality (n = 41, 25%) and survival (n = 36, 22%). Most studies evaluated the incidence of colorectal cancer (n = 160, 97%), while the remaining evaluated the incidence of either rectal or colon cancer (n = 5, 3%). All studies reported the observation period over which incidence was calculated. The periods covered ranged from a single year (n = 5, 3%) to 55 years of observation, and 79% covered a study period of ten years or more. The characteristics and details of included studies [22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187] are provided in Additional files 1, 2, 3.
Measures of incidence rate
The most commonly reported measure of incidence was the age-standardized incidence rate (ASR) (n = 132, 80%), followed by the age-specific incidence rate (ASIR) (n = 50, 30%), and the crude rate (CR) (n = 31, 19%). Five studies reported the calculation of the ASIR but did not present the results of this analysis in the manuscript [22, 30, 34, 36, 62]. The cumulative incidence rate and cumulative risk were reported in three and seven studies, respectively. Some studies also reported the truncated ASR (n = 3, 2%), the delay-adjusted rate (n = 4, 2%), and the risk-adjusted rate (n = 1, 1%) (Table 3).
Eighteen studies (11%) reported the incidence rate with no further specification. Two of these studies described the incidence as mainly the frequency of new cases [77, 150], four obtained incidence rates via linear modelling [32, 41, 48, 159], and two defined incidence as the percentage of CRC cases among different age groups [119, 120]. Additional details are provided in Additional files 1, 3: Table 3.2.
The standard population for calculating the age-standardized rate
The 2000 U.S. standard population was the most commonly reported reference population (n = 52, 39%), mainly by studies from the USA. The World standard population developed by the World Health Organization (WHO) was the second most reported reference population (n = 27, 20%), followed by the European population (n = 23, 17%), and the Segi standard population (n = 16, 12%)-an older version of the World standard population. Table 3.3 in Additional file 3 provides further details on the reported standard populations used in calculating the ASR.
Of the 127 studies that reported a standard population for ASR estimation, 64 (50%) reported a local reference, 71 (56%) employed an external standard, and four (3%) used both a local and an external standard population [65, 82, 143, 181].
All studies that aimed to conduct international comparisons of ASRs used an external reference population (n = 13); three however compared their ASRs with studies that used a different standard population for measuring ASR [44, 97, 175]. Among studies that used standardized rates to assess local incidence rates (n = 114), 62 (54%) employed a local reference, while 52 (46%) used an external standard population.
Stratification of incidence rate by anatomical site
This review noted that 54% of the 160 identified studies that reported CRC incidence stratified rates by anatomical site. There were variations in terms of the anatomical sites chosen. Of the 86 studies that reported incidence stratified by anatomical location, 77 (90%) stratified rates according to the site (colon/rectum), 33 (38%) by colon site (proximal/distal), and 11 (13%) by the categorization of CRC into “right-sided” or “left-sided” tumour. Seven studies (8%) reported the incidence rate for multiple anatomical sites within the colon, and only four (5%) reported the anus incidence. Details on the anatomical sites used for CRC incidence stratification are provided in Additional files 1, 3: Table3.2.
The quality of reporting incidence
Table 2 describes the 11 criteria employed to assess quality of incidence reporting. Detailed results for all indicators are provided in Additional files 2–3: Table 3.2.
The quality of cancer registry data
Eight studies (5%) reported indicators of data validity, such as the proportion of morphologically verified cases (MV%), percentage of death certificate only cases (DCO%), and mortality to incidence ratio (M/I). Of these studies, five reported estimates for at least one of these indicators [62, 82, 109, 148, 181], and three reported estimates based on external references [139, 173, 184].
Ten studies (6%) cited a reference for previously conducted research as evidence of cancer registry data quality (8 referenced studies or reports including validation or completeness assessments; 2 referenced similar epidemiological studies conducted in the same data source). Six studies (4%) reported that data quality was checked by a cancer registration program such as CanReg4 and CANREGT, but none of these studies provided further details on their inspection results. Singh et al. [154] indicated complete case ascertainment of cancer data used to estimate incidence, but without referencing a specific study. Nine studies (6%) indicated that registration quality was being audited by a certification body. Seven reports (4%) stated that the cancer registry was meeting or utilizing standards for data quality set by national or international agencies. None of these studies provided details on specific quality indicators.
The definition of colorectal cancer
There were variations in how studies defined CRC. Only 31 studies (19%) reported whether primary or secondary cancers were considered in the incidence calculation. Forty-five articles (27%) failed to report the classification system used to determine CRC, and 63 (38%) did not provide information about the CRC codes considered. Some studies (n = 32, 19%) failed to report both the classification system and CRC codes. In terms of CRC coding, six studies reported only morphological codes, 11 topography and morphology codes, and 85 only topography codes. Furthermore, only 28 articles (17%) explicitly stated whether malignant or in situ cancers were included in the incidence analysis.
Among the studies reporting the classification system used (n = 120, 73%), the third revision of the International Classification of Disease for Oncology (ICD-O) was the most commonly reported (n = 63, 53%) to define CRC, followed by the 10th revision of the International Statistical Classification of Diseases and Related Health Problems (ICD) (n = 40, 33%).
Of the 40 studies using the ICD-10 classification system, thirteen (33%) included data from years that preceded its development in 1992. Most of these 13 studies (n = 12) failed to document whether they used a different classification system for earlier years or if they mapped codes. Only Wu et al. [174] reported converting earlier ICD codes into those used in the 10th revision. Similarly, of the 63 articles that used the ICD-O-3rd edition, 23 (37%) included data from years that preceded the development of the 3rd or even the 2nd edition of ICD-O with no information provided about conversion of earlier codes.
Definition of the numerator
Concerning the reporting of the numerator data, only 20 studies (12%) explicitly explained excluding certain CRC cases from the numerator. The exclusion of non-microscopically confirmed cases [25, 35, 50, 64, 68, 108, 110, 166], and in-situ cancers [54, 65, 68, 110, 145] were the most reported. Details on other restrictions for included CRC cases are provided in Additional file 3: Table 3.2.
Definition of the denominator
Concerning reporting of denominator size estimation, over half of the studies failed to state the source of population data used to analyse incidence (n = 100, 61%). Only one study explained the calculation used to estimate the annual mid-year population [174]. Twenty-four (15%) of the 165 identified studies indicated the census years employed to derive population counts. Ten studies (6%) reported the method used to estimate yearly population counts (i.e., interpolation or extrapolation).
Only five studies (3%) explicitly explained the population size estimation procedure in calculating the overall average incidence rate (for a given study period). Of these, one study calculated actual person-time at risk by creating closed cohorts of the population on various census nights and following them over time [126]. Three estimated the average population size by multiplying the population count in a particular census year by the number of years included in the study [54, 156, 157]. Sammour et al. [118] estimated the denominator size by averaging population counts of two censuses conducted at the beginning and near the end of the study period.
Estimation of the age-standardized rate
Of the studies that calculated the ASR (n = 132, 80%), 36 (27%) described the method used for standardization (direct or indirect), with the direct method being the only one reported. Five studies did not report the standard population used to derive ASR.
Of the 127 studies that reported the reference population used for standardization, only five (4%) justified their chosen standard population. Four studies explained that choosing an external (international) reference population will enable future comparisons of incidence rates with other published studies [25, 45, 49, 177]. Jayarajah et al. [83] reported using the WHO World standard population due to its similarity to the age structure of Asian populations.
Time interval and presentation of the incidence
Concerning the time interval over which incidence was calculated, over half the studies (n = 103, 62%) did not explicitly report whether they calculated a single year or an overall average rate. Assessing how incidence rates were expressed among all included studies, we noted that most articles (n = 119, 72%) expressed rates without a time unit (i.e., whole years or person-time).
Age bands for measuring the incidence
Among the 165 identified studies, the majority (n = 131, 79%) reported the age bands used to calculate incidence. The age bands used for calculating incidence ranged from one (n = 12) to 33 (n = 1). Detailed information on all reported age bands is provided in Additional file 3: Table 3.2.
Assessment of uncertainty and evaluation of missing data
Concerning uncertainty analysis, only 20% (n = 33) reported the confidence interval (CI) associated with the incidence estimate. In examining the reporting of missing data (MD), seven studies (4%) reported details on how MD were handled in the analysis but failed to report assumptions on the reasons for the MD. Of these studies, five reported excluding incident cases with specific MD [53, 92, 99, 111, 114], another study estimated MD by multiple imputation [96], and Zorzi et al. [184] estimated missing variables via join point regression. Missing data in these studies included demographics (such as age, sex, race, country of residence), anatomic subsites, disease stage, and the number of incident cases for some of the years evaluated. One author assumed MD was missed at random, with no justification for this assumption or treatment method reported [115]. Rejali et al. [151] vaguely indicated that incidence rates were corrected for the missing age-related data. Only two studies reported the exact amount of MD [96, 151].
Software information
More than half of the studies (n = 110, 67%) reported the software used for incidence rate analysis. The most common was The Surveillance Epidemiology and End Results (SEER) statistical software (36%) [188], mainly by studies from the USA. Other reported software included SAS (17%) [189], STATA (16%) [190], and SPSS (16%) [191] (Additional file 3: Table 3.2).
Discussion
To our knowledge, this is the first study to examine variations in the methods employed in calculating incidence rates and the quality of reporting these methods. The 165 articles retrieved provided valuable findings and insights that will aid future investigators in making informed decisions about which methods and reporting practices will enhance the quality and comparability of their research.
Measures of incidence rate
Incidence is an essential measure in epidemiology that examines the burden of a disease in a population and highlights variations among different population subgroups. Therefore, incidence measures are imperative for underscoring health care needs and developing policies and interventions accordingly. This review noted that the age-standardized rate (ASR) was the most commonly reported measure of incidence. Only one-third of the studies examined the age-specific incidence rate (ASIR).
ASR is an artificial rate that facilitates comparative analysis as it controls for differences in the population age structure. Relying only on ASRs to describe incidence might conceal valuable information. Thus, the ASIR should always be the starting point when researchers want to derive an accurate measurement of cancer risk in a population [2, 192]. Because ASIRs do not always have a consistent pattern over time, researchers should evaluate patterns of age-specific rates before applying standardization. This analysis would help determine how rates change over time in certain age groups and highlight any irregular patterns requiring further investigation. Furthermore, when possible, researchers should also assess potential effects of birth cohorts (exposures/experiences that vary from one generation to the next) and period (external factors that affect all age groups similarly at a specific calendar time) on age-specific trends [193]. Thus, after initially calculating and graphically presenting the ASIR for different periods or cohorts, regression analysis could be employed to disentangle the effects of age, cohort, and period. This type of analysis however can only be performed when appropriate data is available for long time periods.
In addition to the ASIR, the cumulative rate (calculated using the ASIR), which is a form of standardization not requiring an arbitrary standard population, could be calculated to understand the life-time risk of developing cancer.
In calculating the ASR, only 12 studies, in addition to studies from the USA, employed a local reference, and no study used an internal standard population (the average age distribution of all groups studied). The selection of a standard population is somewhat arbitrary and depends on the study's goals [194]. When the aim is to assess temporal patterns of incidence in a specific population, it is vital to carefully choose a standard that better reflects the study population’s age distribution. On the other hand, when the goal is to compare rates between different populations, an international standard might better serve this purpose [192]. This review noted that most studies failed to justify the selected standard population used to assess CRC incidence. External standards were the most commonly reported, even when a study’s goal was not to compare rates internationally.
The selected standard population can influence the interpretation of incidence. Thus, studies with no international focus but an intention to assess temporal trends could use an internal standard population or employ the base-year population at the start of the study period as the standard [192]. Conversely, if a study aims to compare incidence rates between different countries, conventional external standard populations, such as the WHO World standard [194] and the European standard [195], could be used. To facilitate international comparisons, the WHO emphasized implementing the new revised World standard population, proposed in 2001, reflecting the average age structure of all populations [194]. Using the most updated and appropriate standard population is essential for a more accurate and updated representation of rates. This review noted that 16 studies employed an older version of the World standard- proposed by Segi in 1960- although the new WHO standard was a better fit given the observation study period. Likewise, the European standard (presented in 1976) was employed in six studies where a newer version was available.
Among studies from the USA, a common practice was to standardize rates using the 2000 US standard population. Although this usage is understandably justified, international comparisons with USA rates would be compromised. Meaningful comparisons between populations are only possible when the same reference population is employed. Therefore, investigators could report different ASRs computed by distinct standard populations (an external and the study’s local population) for comprehensive incidence analysis.
In cancer epidemiology, providing incidence estimates according to cancer subsite may highlight critical differences in disease risk. This review noted a lack of consensus concerning the categorization of anatomical subsite for measuring CRC incidence. While almost half of the studies reported only an overall incidence measure for CRC, the other half provided rates according to different categorizations of anatomical sites (e.g., colon/rectal, proximal/distal colon, and right/left colon). Furthermore, descriptions of these anatomical categories varied across studies. Ideally, there should be a consensus among the scientific community on which CRC subsites to consider and on the anatomical categories. Using a standard definition will guide future researchers in reporting comparable incidence rates.
Additionally, when the main study aim is to quantify CRC burden, reporting overall CRC incidence in addition to site-specific rates would facilitate comparison with other studies and evaluation of time trends. Yet, due to data limitations, it might not be feasible for some researchers to include specific subsites in the analysis or to measure site-specific rates. Clarifying these limitations would help the reader better understand the chosen analytical approach.
The quality of reporting incidence
This review uncovered several limitations in the quality of reporting incidence methods. There was a substantial deficit in reporting registry-data quality control procedures and findings. Population-based cancer registries (PBCR) play a unique role in monitoring and evaluating cancer control efforts. In measuring incidence, PBCR captures all cancer cases in a specified geographical area (numerator) and retrieves population statistics (denominator) from census data. To provide reliable information on cancer burden, it is of utmost importance to ensure that the data are valid and of good quality.
In 1994 The IARC published a report describing standards and methodologies for evaluating data quality in cancer registries [196]. In 2009, two articles updated and summarised these methods in terms of four primary standard indicators: comparability, timeliness, completeness, and validity [5, 9]. This review noted that no study reported details about timeliness issues although many publications didn’t cover recent years in their observation, which may be related to data collection and reporting delays in the registry.
Despite WHO advocacy for strengthening cancer registries, according to the last volume of Cancer Incidence in Five Continents [197], only 65 of 194 WHO Member States provided high-quality cancer incidence data. The proportion of high-quality cancer registries included in the report was 100% in Oceania, 97% in North America, 88% in Europe, 69%, 53%, and 23% in Central and South America, Asia, and Africa, respectively. Additionally, there were considerable discrepancies in total population coverage between continents. Transparent reporting and presentation of quality indicator measures and any registry limitations are essential for accurate interpretation of cancer incidence.
This review noted insufficient reporting of CRC definitions in terms of classification system, codes, and cancer type (primary or secondary tumours). More authors relied solely on topography codes and ignored the importance of reporting the morphology of CRC cases included.
There were also discrepancies across studies concerning the anatomical sites included in CRC incidence calculation; thus, it is essential to comprehensively describe the codes used to define CRC. We also noted limitations in reporting codes conversion between different classification versions. The SEER program and the IARC provide tools to facilitate ICD code mapping between different versions [198, 199]. Authors should clearly document any code conversion implemented. Concerning cancer type, the IARC has set international rules for defining cancer cases as primary or secondary [200]. Cancer registries should use these rules to describe cancer or explicitly acknowledge situations where obtaining this information is not feasible.
Furthermore, this review revealed limitations in reporting the numerator and denominator data used for incidence calculation (e.g., excluding certain CRC cases from the numerator). Being explicit about such information is valuable for interpreting and comparing rates. However, it is important to note that cancer registries differ in the type of data collected. For example, some registries collect data regarding hereditary syndromes or risk factors for CRC, while others do not. Limitations in terms of data availability should be acknowledged.
More than half of the studies included in this review presented an overall average incidence measure although only five articles described the calculation of the total population estimate (over several years of observation). Furthermore, there was an evident lack in reporting the source of population data, how yearly mid-year population statistics were estimated, and the census years used for obtaining population statistics. In analysing incidence rates, describing the estimation of the denominator is usually overlooked, especially when calculating the ASR. Although the standardization process controls for the effect of population age structure, some might understand this process as eliminating the impact of population structure on incidence rates [2]. Population size estimations used as denominators have their limitations that authors should explicitly recognize. Explaining how these estimates were derived is essential for understanding cancer risk and ensuring that readers have sufficient details to reproduce the findings.
The results of this review also highlighted other deficiencies in reporting incidence rates, such as the indication of the time interval over which incidence is calculated, the expression of rates, and the reporting of uncertainty estimates. In terms of quantifying and reporting uncertainty around incidence estimates, we noted that only 33 studies reported CI. Population-based studies tend to underestimate the importance of reporting CIs for estimates drawn from population-level data [201]. For some researchers, the observed rates represent accurate measurements for the population rather than estimates, and thus, accounting for random error might not be needed. However, Redelings et al. [201] argue that as rates and trends tend to fluctuate randomly over time, due to a myriad of factors, reporting the CI is imperative for assessing the reliability of these estimates and will consequently aid the formation of public health interventions and policies [201].
This review also highlighted inadequate reporting of MD analysis, including assumptions on the reasons for the missingness and their justification, the amount of MD, and the methods used to handle them in the analysis. Reporting guidelines for observational studies emphasized the need for a complete and transparent reporting of missing data and its analysis [6, 202]. Thus, researchers should explicitly acknowledge and document all details pertaining to MD analysis.
Strengths and limitations
To our knowledge, this study is the first to comprehensively review the methods employed to estimate incidence rate and the degree of quality and transparency in their reporting. The identified studies were conducted in different populations and settings. We used multiple indicators for quality assessment, based on relevant literature on incidence calculation and guidelines for reporting methods, which enriches the evidence provided in this review. Although detailed reporting of methods might sometimes be limited by journal policies (i.e., word count restrictions), information could be made available as supplemental or web-based data.
This review is limited to studies assessing incidence in CRC using registry data. Despite this, our results inform about the most commonly used measures of estimating disease incidence and provide general considerations for improving the quality of reporting for other cancer types or diseases.
Another limitation was limiting the search to articles published within the past decade to limit the scope of the review. Given that there have been no substantial changes to the measures used for estimating incidence rates, we believe that the time-frame restriction did not affect the findings. Although we searched multiple databases and included studies from different countries, we included only English articles in this review. Thus, we might have missed relevant papers in other languages.
Future research
This review highlighted variations in reporting standards despite continuous efforts by scientific organizations, such as the EQUATOR Network, to provide guidance to help achieve an acceptable standardized level of reporting.
The GATHER statement promotes good quality reporting of global health estimates by providing a list of items that should be described when reporting health estimates [6]. Our review emphasized reporting some of the GATHER items relating to the study’s methodology, including data source, the uncertainty of estimates, handling missing data, and software package. This study, however, recommends other areas for consideration when reporting incidence measures. Future research on disease incidence should comprehensively describe their methodology based on these recommendations. We hope this study will be the starting point toward developing a specific guideline for reporting disease incidence in large-population studies.
Conclusion
This review summarized the most commonly reported incidence measures and examined variations in estimating CRC incidence over the past decade. We also highlighted many deficiencies in incidence reporting and provided recommendations for future studies on how to optimize their communication of the methods used for estimating incidence. Ideally, reporting should provide sufficient detail on the methodology to enable replicating the analysis. Better reporting will facilitate interpreting and comparing results with other studies and help identify and address limitations of the analysis.
Availability of data and materials
All data generated and analysed during this study are included in this article and its supplementary information files.
Abbreviations
- ASIR:
-
Age-specific incidence rate
- ASR:
-
Age-standardized rate
- AXIS:
-
Appraisal Tool for Cross-Sectional Studies
- CI:
-
Confidence interval
- CR:
-
Crude rate
- CRC:
-
Colorectal cancer
- DCO:
-
Death certificate only
- EQUATOR:
-
Enhancing the Quality and Transparency of Health Research
- GATHER:
-
Guidelines for Accurate and Transparent Health Estimates Reporting
- IARC:
-
International Agency for Research on Cancer
- ICD:
-
International Statistical Classification of Diseases and Related Health Problems
- ICD-O:
-
International Classification of Disease for Oncology
- MD:
-
Missing data
- M/I:
-
Mortality to incidence ratio
- MV:
-
Morphologically verified
- PRISMA:
-
Preferred Reporting Items for Systematic Reviews and Meta-Analyses
- PBCR:
-
Population-based cancer registries
- SAS:
-
Statistical Analysis System
- SEER:
-
Surveillance Epidemiology and End Results
- SPSS:
-
Statistical Package for The Social Sciences
- USA:
-
United States of America
- WHO:
-
World Health Organization
References
Boyle P, Parkin DM. Cancer registration: principles and methods. Statistical methods for registries. IARC Sci Publ. 1991;95:126–58.
Boniol M, Heanue M. Age-standardisation and denominators. Cancer Incidence in five continents. 2007;9:99–101.
Brooke HL, Talbäck M, Feychting M, Ljung R. Methodological choices affect cancer incidence rates: a cohort study. Popul Health Metr. 2017;15(1):2.
Spronk I, Korevaar JC, Poos R, Davids R, Hilderink H, Schellevis FG, et al. Calculating incidence rates and prevalence proportions: not as simple as it seems. BMC Public Health. 2019;19(1):512.
Bray F, Parkin DM. Evaluation of data quality in the cancer registry: principles and methods. Part I: comparability, validity and timeliness. Eur J Cancer. 2009;45(5):747–55.
Stevens GA, Alkema L, Black RE, Boerma JT, Collins GS, Ezzati M, et al. Guidelines for accurate and transparent health estimates reporting: the GATHER statement. PLoS Med. 2016;13(6):e1002056.
Murray CJL, Frenk J. Health metrics and evaluation: strengthening the science. Lancet. 2008;371(9619):1191–9.
Attia A. Why should researchers report the confidence interval in modern research. Middle East Fertil Soc J. 2005;10(1):78–81.
Parkin DM, Bray F. Evaluation of data quality in the cancer registry: principles and methods Part II. Completeness. Eur J Cancer. 2009;45(5):756–64.
Yang DX, Khera R, Miccio JA, Jairam V, Chang E, Yu JB, et al. Prevalence of missing data in the National Cancer Database and association with overall survival. medRxiv. 2021:2020.10.30.20220855.
Munafò MR, Nosek BA, Bishop DVM, Button KS, Chambers CD, du PercieSert N, et al. A manifesto for reproducible science. Nature Human Behaviour. 2017;1(1):0021.
Shelton BK. Introduction to colorectal cancer. Semin Oncol Nurs. 2002;18(2 Suppl 2):2–12.
Sung H, Ferlay J, Siegel RL, Laversanne M, Soerjomataram I, Jemal A, et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2021;71(3):209–49.
Keum N, Giovannucci E. Global burden of colorectal cancer: emerging trends, risk factors and prevention strategies. Nat Rev Gastroenterol Hepatol. 2019;16(12):713–32.
Gorin SS. Multilevel approaches to reducing diagnostic and treatment delay in colorectal cancer. Ann Fam Med. 2019;17(5):386–9.
Schreuders EH, Ruco A, Rabeneck L, Schoen RE, Sung JJ, Young GP, et al. Colorectal cancer screening: a global overview of existing programmes. Gut. 2015;64(10):1637–49.
Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ. 2021;372:n71.
Ouzzani M, Hammady H, Fedorowicz Z, Elmagarmid A. Rayyan—a web and mobile app for systematic reviews. Syst Rev. 2016;5(1):210.
Munn Z, Moola S, Riitano D, Lisy K. The development of a critical appraisal tool for use in systematic reviews addressing questions of prevalence. Int J Health Policy Manag. 2014;3(3):123–8.
Downes MJ, Brennan ML, Williams HC, Dean RS. Development of a critical appraisal tool to assess the quality of cross-sectional studies (AXIS). BMJ Open. 2016;6(12):e011458.
Saad El Din K, Loree JM, Sayre EC, Gill S, Brown CJ, Dau H, et al. Trends in the epidemiology of young-onset colorectal cancer: a worldwide systematic review. BMC Cancer. 2020;20(1):288.
Abdifard E, Amini S, Bab S, Masroor N, Khachian A, Heidari M. Incidence trends of colorectal cancer in Iran during 2000–2009: a population-based study. Med J Islam Repub Iran. 2016;30:382.
Abdifard E, Ghaderi S, Hosseini S, Heidari M. Incidence trends of colorectal cancer in the West of Iran during 2000–2005. Asian Pac J Cancer Prev. 2013;14(3):1807–11.
Abreu MH, Matos E, Castro Pocas F, Rocha R, Pinto J, Lopes C. Staging and survival of rectal cancer in Vila Nova de Gaia. Portugal Eur J Gastroenterol Hepatol. 2010;22(2):151–6.
Abu Hassan MR, Ismail I, Mohd Suan MA, Ahmad F, Wan Khazim WK, Othman Z, et al. Incidence and mortality rates of colorectal cancer in Malaysia. Epidemiol Health. 2016;38:e2016007.
Abualkhair WH, Zhou M, Ahnen D, Yu Q, Wu XC, Karlitz JJ. Trends in incidence of early-onset colorectal cancer in the United States Among those approaching screening age. JAMA Netw Open. 2020;3(1):e1920407.
Al Dahhan SA, Al Lami FH. Epidemiology of colorectal cancer in Iraq, 2002–2014. Gulf J Oncolog. 2018;1(26):23–6.
Araghi M, Fidler MM, Arnold M, Jemal A, Bray F, Soerjomataram I. The future burden of colorectal cancer among US blacks and whites. J Natl Cancer Inst. 2018;110(7):791–3.
Araghi M, Soerjomataram I, Bardot A, Ferlay J, Cabasag CJ, Morrison DS, et al. Changes in colorectal cancer incidence in seven high-income countries: a population-based study. Lancet Gastroenterol Hepatol. 2019;4(7):511–8.
Ashktorab H, Vilmenay K, Brim H, Laiyemo AO, Kibreab A, Nouraie M. Colorectal cancer in young African Americans: is it time to revisit guidelines and prevention? Dig Dis Sci. 2016;61(10):3026–30.
Austin H, Henley SJ, King J, Richardson LC, Eheman C. Changes in colorectal cancer incidence rates in young and older adults in the United States: what does it tell us about screening. Cancer Causes Control. 2014;25(2):191–201.
Aziz H, Pandit V, DiGiovanni RM, Ohlson E, Gruessner AC, Jandova J, et al. Increased incidence of early onset colorectal cancer in Arizona: a comprehensive 15-year analysis of the Arizona cancer registry. J Gastrointest Dig Syst. 2015;5(5):345.
Bailey CE, Hu CY, You YN, Bednarski BK, Rodriguez-Bigas MA, Skibber JM, et al. Increasing disparities in the age-related incidences of colon and rectal cancers in the United States, 1975–2010. JAMA Surg. 2015;150(1):17–22.
Baniasadi N, Moghtader E, Khajehkazemi R, Mohebbi E. Increasing trend in colorectal cancer incidence in the Southeast of Iran 2003–2013: a population based cancer registry study. Asian Pac J Cancer Prev. 2015;16(13):5257–60.
Bhurgri Y, Khan T, Kayani N, Ahmad R, Usman A, Bhurgri A, et al. Incidence and current trends of colorectal malignancies in an unscreened, low risk Pakistan population. Asian Pac J Cancer Prev. 2011;12(3):703–8.
Boyce S, Nassar N, Lee CY, Suen MK, Al Zahrani S, Gladman MA. Young-onset colorectal cancer in New South Wales: a population-based study. Med J Aust. 2016;205(10):465–70.
BraendegaardWinther S, Baatrup G, Pfeiffer P, Qvortrup C. Academy of Geriatric Cancer R. Trends in colorectal cancer in the elderly in Denmark, 1980–2012. Acta Oncol. 2016;55(Suppl 1):29–39.
Brenner H, Schrotz-King P, Holleczek B, Katalinic A, Hoffmeister M. Declining bowel cancer incidence and mortality in Germany. Dtsch Arztebl Int. 2016;113(7):101–6.
Brouwer NPM, Bos A, Lemmens V, Tanis PJ, Hugen N, Nagtegaal ID, et al. An overview of 25 years of incidence, treatment and outcome of colorectal cancer patients. Int J Cancer. 2018;143(11):2758–66.
Caldarella A, Crocetti E, Messerini L, Paci E. Trends in colorectal incidence by anatomic subsite from 1985 to 2005: a population-based study. Int J Colorectal Dis. 2013;28(5):637–41.
Carroll R, Zhao S. Trends in colorectal cancer incidence and survival in Iowa SEER data: the timing of it all. Clin Colorectal Cancer. 2019;18(2):e261–74.
Chambers AC, Dixon SW, White P, Williams AC, Thomas MG, Messenger DE. Demographic trends in the incidence of young-onset colorectal cancer: a population-based study. Br J Surg. 2020;107(5):595–605.
Chatterjee S, Chattopadhyay A, Levine PH. Between-ward disparities in colorectal cancer incidence and screening in Washington DC. J Epidemiol Glob Health. 2015;5(4 Suppl 1):S1-9.
Alsanea N, Abduljabbar AS, Alhomoud S, Ashari LH, Hibbert D, Bazarbashi S. Colorectal cancer in Saudi Arabia: incidence, survival, demographics and implications for national policies. Ann Saudi Med. 2015;35(3):196–202.
Chauvenet M, Cottet V, Lepage C, Jooste V, Faivre J, Bouvier AM. Trends in colorectal cancer incidence: a period and birth-cohort analysis in a well-defined French population. BMC Cancer. 2011;11:282.
Chen TA, Kang HY, Chang HC, Lin WC, Chao TM, Horng JT. Gender differences in colorectal cancer during the past 20 years in Taiwan. Int J Colorectal Dis. 2012;27(3):345–53.
Cheng L, Eng C, Nieman LZ, Kapadia AS, Du XL. Trends in colorectal cancer incidence by anatomic site and disease stage in the United States from 1976 to 2005. Am J Clin Oncol. 2011;34(6):573–80.
Chernyavskiy P, Kennerley VM, Jemal A, Little MP, Rosenberg PS. Heterogeneity of colon and rectum cancer incidence across 612 SEER counties, 2000–2014. Int J Cancer. 2019;144(8):1786–95.
Chittleborough TJ, Gutlic I, Pearson JF, Watson A, Bhatti LA, Buchwald P, et al. Increasing incidence of young-onset colorectal carcinoma a 3-country population analysis. Dis Colon Rectum. 2020;63(7):903–10.
Chong VH, Telisinghe PU, Bickle I, Abdullah MS, Lim E, Chong CF. Increasing incidence of colorectal cancer, starting at a younger age for rectal compared to colon cancer in Brunei Darussalam. Asian Pac J Cancer Prev. 2015;16(12):5063–7.
Clarke N, McDevitt J, Kearney PM, Sharp L. Increasing late stage colorectal cancer and rectal cancer mortality demonstrates the need for screening: a population based study in Ireland, 1994–2010. BMC Gastroenterol. 2014;14:92.
Crocetti E, Buzzoni C, Zappa M. Colorectal cancer incidence rates have decreased in central Italy. Eur J Cancer Prev. 2010;19(6):424–5.
Crosbie AB, Roche LM, Johnson LM, Pawlish KS, Paddock LE, Stroup AM. Trends in colorectal cancer incidence among younger adults-disparities by age, sex, race, ethnicity, and subsite. Cancer Med. 2018;7(8):4077–86.
Danos DM, Ferguson TF, Simonsen NR, Leonardi C, Yu Q, Wu XC, et al. Neighborhood disadvantage and racial disparities in colorectal cancer incidence: a population-based study in Louisiana. Ann Epidemiol. 2018;28(5):316–21.
Dehghani SL, Rezaianzadeh A, Safe M, Tabatabaee H. Trends of incidence of colorectal cancer in Iran, 2003–2010: Revista Latinoamericana de Hiperten. 2019;14(4):456–61.
Edwards BK, Ward E, Kohler BA, Eheman C, Zauber AG, Anderson RN, et al. Annual report to the nation on the status of cancer, 1975–2006, featuring colorectal cancer trends and impact of interventions (risk factors, screening, and treatment) to reduce future rates. Cancer. 2010;116(3):544–73.
Ellis L, Abrahao R, McKinley M, Yang J, Somsouk M, Marchand LL, et al. Colorectal cancer incidence trends by age, stage, and racial/ethnic group in California, 1990–2014. Cancer Epidemiol Biomarkers Prev. 2018;27(9):1011–8.
Enayatrad M, Yavari P, Etemad K, Khodakarim S, Mahdavi S. Association of urbanization levels and colorectal cancer incidence in Iran. Int J Cancer Manag. 2018;11(8):7
Eser S, Chang J, Charalambous H, Silverman B, Demetriou A, Yakut C, et al. Incidence patterns of colorectal cancers in four countries of the Middle East Cancer Consortium (Cyprus, Jordan, Israel, and Izmir, Turkey) compared with those in the United States Surveillance, Epidemiology, and End Results Program. Turk J Gastroenterol. 2018;29(1):36–44.
Exarchakou A, Donaldson LJ, Girardi F, Coleman MP. Colorectal cancer incidence among young adults in England: trends by anatomical sub-site and deprivation. PLoS One. 2019;14(12):e0225547.
Feletto E, Yu XQ, Lew JB, St John DJB, Jenkins MA, Macrae FA, et al. Trends in colon and rectal cancer incidence in Australia from 1982 to 2014: analysis of data on over 375,000 cases. Cancer Epidemiol Biomarkers Prev. 2019;28(1):83–90.
Hasanpour-Heidari S, Fazel A, Semnani S, Khandoozi SR, Amiriani T, Sedaghat S, et al. Temporal and geographical variations in colorectal cancer incidence in Northern Iran 2004–2013. Cancer Epidemiol. 2019;59:143–7.
Lemmens V, van Steenbergen L, Janssen-Heijnen M, Martijn H, Rutten H, Coebergh JW. Trends in colorectal cancer in the south of the Netherlands 1975–2007: rectal cancer survival levels with colon cancer survival. Acta Oncol. 2010;49(6):784–96.
May FP, Glenn BA, Crespi CM, Ponce N, Spiegel BMR, Bastani R. Decreasing black-white disparities in colorectal cancer incidence and stage at presentation in the United States. Cancer Epidemiol Biomarkers Prev. 2017;26(5):762–8.
Fusco M, Pezzi A, Benatti P, Roncucci L, Chiodini P, Di Maio G, et al. Clinical features and colorectal cancer survival: an attempt to explain differences between two different Italian regions. Eur J Cancer. 2010;46(1):142–9.
Klugarova J, Klugar M, Muzik J, Jarkovsky J, Licenik R, Burilova P, et al. Use of epidemiological analyses in development of colorectal cancer clinical practice guidelines in the Czech Republic. Int J Evid Based Healthc. 2019;17(Suppl 1):S57–61.
Koblinski J, Jandova J, Nfonsam V. Disparities in incidence of early- and late-onset colorectal cancer between hispanics and whites: a 10-year SEER database study. Am J Surg. 2018;215(4):581–5.
Martinsen RP, Morris CR, Pinheiro PS, Parikh-Patel A, Kizer KW. Colorectal cancer trends in California and the need for greater screening of hispanic men. Am J Prev Med. 2016;51(6):e155–63.
Giddings BH, Kwong SL, Parikh-Patel A, Bates JH, Snipes KP. Going against the tide: increasing incidence of colorectal cancer among Koreans, Filipinos, and South Asians in California, 1988–2007. Cancer Causes Control. 2012;23(5):691–702.
Missaoui N, Jaidaine L, Abdelkader AB, Trabelsi A, Mokni M, Hmissa S. Colorectal cancer in Central Tunisia: increasing incidence trends over a 15-year period. Asian Pac J Cancer Prev. 2011;12(4):1073–6.
Kelly JJ, Alberts SR, Sacco F, Lanier AP. Colorectal cancer in alaska native people, 2005–2009. Gastrointest Cancer Res. 2012;5(5):149–54.
Loomans-Kropp HA, Umar A. Increasing Incidence of colorectal cancer in young adults. J Cancer Epidemiol. 2019. https://doi.org/10.1155/2019/9841295.
Gandhi J, Davidson C, Hall C, Pearson J, Eglinton T, Wakeman C, et al. Population-based study demonstrating an increase in colorectal cancer in young patients. Br J Surg. 2017;104(8):1063–8.
Lopez A, Bouvier AM, Jooste V, Cottet V, Romain G, Faivre J, et al. Outcomes following polypectomy for malignant colorectal polyps are similar to those following surgery in the general population. Gut. 2019;68(1):111–7.
Lopez-Abente G, Ardanaz E, Torrella-Ramos A, Mateos A, Delgado-Sanz C, Chirlaque MD, et al. Changes in colorectal cancer incidence and mortality trends in Spain. Ann Oncol. 2010;21(Suppl 3):iii76-82.
McClements PL, Madurasinghe V, Thomson CS, Fraser CG, Carey FA, Steele RJ, et al. Impact of the UK colorectal cancer screening pilot studies on incidence, stage distribution and mortality trends. Cancer Epidemiol. 2012;36(4):e232–42.
Gan T, Sinner HF, Walling SC, Chen Q, Huang B, Tucker TC, et al. Impact of the affordable care act on colorectal cancer screening, incidence, and survival in Kentucky. J Am Coll Surg. 2019;228(4):342–53.
Ladabaum U, Clarke CA, Press DJ, Mannalithara A, Myer PA, Cheng I, et al. Colorectal cancer incidence in Asian populations in California: effect of nativity and neighborhood-level factors. Am J Gastroenterol. 2014;109(4):579–88.
Fowler B, Samadder NJ, Kepka D, Ding Q, Pappas L, Kirchhoff AC. Improvements in colorectal cancer incidence not experienced by nonmetropolitan women: a population-based study from Utah. J Rural Health. 2018;34(2):155–61.
Meester RGS, Mannalithara A, Lansdorp-Vogelaar I, Ladabaum U. Trends in incidence and stage at diagnosis of colorectal cancer in adults aged 40 through 49 years, 1975–2015. JAMA. 2019;321(19):1933–4.
Li Z, Yang L, Du C, Fang X, Wang N, Gu J. Characteristics and comparison of colorectal cancer incidence in Beijing with other regions in the world. Oncotarget. 2017;8(15):24593–603.
Liu S, Zheng R, Zhang M, Zhang S, Sun X, Chen W. Incidence and mortality of colorectal cancer in China, 2011. Chin J Cancer Res. 2015;27(1):22–8.
Jayarajah U, Udayanga V, Fernando A, Samarasekera DN, Seneviratne S. The incidence and patterns of colorectal cancers in Sri Lanka from 2001 to 2010: Analysis of national cancer registry data. Eur J Cancer Care (Engl). 2020;29(4):e13247.
Katsidzira L, Chokunonga E, Gangaidzo IT, Rusakaniko S, Borok M, Matsena-Zingoni Z, et al. The incidence and histo-pathological characteristics of colorectal cancer in a population based cancer registry in Zimbabwe. Cancer Epidemiol. 2016;44:96–100.
Fournel I, Bourredjem A, Sauleau EA, Cottet V, Dejardin O, Bouvier AM, et al. Small-area geographic and socioeconomic inequalities in colorectal tumour detection in France. Eur J Cancer Prev. 2016;25(4):269–74.
Lee Y-C, Hsu C-Y, Chen SL-S, Yen AM-F, Chiu SY-H, Fann JC-Y, et al. Effects of screening and universal healthcare on long-term colorectal cancer mortality. Int J Epidemiol. 2019;48(2):538–48.
Khiari H, Hsairi M. Colorectal cancer incidence and clinicopathological features in northern Tunisia 2007–2009. Colorectal Cancer. 2017;6(4):131–41.
Khosravi Shadmani F, Ayubi E, Khazaei S, Sani M, Mansouri Hanis S, Khazaei S, et al. Geographic distribution of the incidence of colorectal cancer in Iran: a population-based study. Epidemiol Health. 2017;39:e2017020.
Merrill RM, Anderson AE. Risk-adjusted colon and rectal cancer incidence rates in the United States. Dis Colon Rectum. 2011;54(10):1301–6.
Klimczak A, Kempinska-Miroslawska B, Mik M, Dziki L, Dziki A. Incidence of colorectal cancer in Poland in 1999–2008. Arch Med Sci. 2011;7(4):673–8.
Khiari H, Ben Ayoub HW, Ben Khadhra H, Hsairi M. Colorectal cancer incidence trend and projections in Tunisia (1994–2024). Asian Pac J Cancer Prev. 2017;18(10):2733–9.
Jandova J, Ohlson E, Torres BSM, DiGiovanni R, Pandit V, Elquza E, et al. Racial disparities and socioeconomic status in the incidence of colorectal cancer in Arizona. Am J Surg. 2016;212(3):485–92.
Li K, Lin GZ, Li Y, Dong H, Xu H, Song SF, et al. Spatio-temporal analysis of the incidence of colorectal cancer in Guangzhou, 2010–2014. Chin J Cancer. 2017;36(1):60.
Meza R, Jeon J, Renehan AG, Luebeck EG. Colorectal cancer incidence trends in the United States and United kingdom: evidence of right- to left-sided biological gradients with implications for screening. Cancer Res. 2010;70(13):5419–29.
Jafri NS, Gould M, El-Serag HB, Duan Z, Davila JA. Incidence and survival of colorectal cancer among Hispanics in the United States: a population-based study. Dig Dis Sci. 2013;58(7):2052–60.
McDevitt J, Comber H, Walsh PM. Colorectal cancer incidence and survival by sub-site and stage of diagnosis: a population-based study at the advent of national screening. Ir J Med Sci. 2017;186(1):113–21.
Khachfe HH, Salhab HA, Fares MY, Khachfe HM. Probing the colorectal cancer incidence in Lebanon: an 11-year epidemiological study. J Gastrointest Cancer. 2020;51(3):805–12.
Meyer JE, Narang T, Schnoll-Sussman FH, Pochapin MB, Christos PJ, Sherr DL. Increasing incidence of rectal cancer in patients aged younger than 40 years: an analysis of the surveillance, epidemiology, and end results database. Cancer. 2010;116(18):4354–9.
Garcia S, Pruitt SL, Singal AG, Murphy CC. Colorectal cancer incidence among Hispanics and non-Hispanic Whites in the United States. Cancer Causes Control. 2018;29(11):1039–46.
Fournel I, Cottet V, Binquet C, Jooste V, Faivre J, Bouvier AM, et al. Rural-urban inequalities in detection rates of colorectal tumours in the population. Dig Liver Dis. 2012;44(2):172–7.
Brenner DR, Ruan Y, Shaw E, De P, Heitman SJ, Hilsden RJ. Increasing colorectal cancer incidence trends among younger adults in Canada. Prev Med. 2017;105:345–9.
Brenner DR, Heer E, Sutherland RL, Ruan Y, Tinmouth J, Heitman SJ, et al. National trends in colorectal cancer incidence among older and younger adults in Canada. JAMA Netw Open. 2019;2(7):e198090.
Fedewa SA, Siegel RL, Jemal A. Are temporal trends in colonoscopy among young adults concordant with colorectal cancer incidence? J Med Screen. 2019;26(4):179–85.
Augustus GJ, Roe DJ, Jacobs ET, Lance P, Ellis NA. Is increased colorectal screening effective in preventing distant disease? PloS One. 2018;13(7):e0200462.
Davis DM, Marcet JE, Frattini JC, Prather AD, Mateka JJ, Nfonsam VN. Is it time to lower the recommended screening age for colorectal cancer? J Am Coll Surg. 2011;213(3):352–61.
Domati F, Maffei S, Kaleci S, Di Gregorio C, Pedroni M, Roncucci L, et al. Incidence, clinical features and possible etiology of early onset (</=40 years) colorectal neoplasms. Intern Emerg Med. 2014;9(6):623–31.
Koblinski J, Jandova J, Pandit V, Omesiete P, Nfonsam V. Disparities in colon and rectal cancer queried individually between Hispanics and Whites. J Gastrointest Oncol. 2019;10(4):632–40.
Purim O, Gordon N, Brenner B. Cancer of the colon and rectum: potential effects of sex-age interactions on incidence and outcome. Med Sci Monit. 2013;19:203–9.
Vuik FE, Nieuwenburg SA, Bardou M, Lansdorp-Vogelaar I, Dinis-Ribeiro M, Bento MJ, et al. Increasing incidence of colorectal cancer in young adults in Europe over the last 25 years. Gut. 2019;68(10):1820–6.
Shafqat H, Ali S, Salhab M, Olszewski AJ. Survival of patients with neuroendocrine carcinoma of the colon and rectum: a population-based analysis. Dis Colon Rectum. 2015;58(3):294–303.
Safaee A, Fatemi SR, Ashtari S, Vahedi M, Moghimi-Dehkordi B, Zali MR. Four years incidence rate of colorectal cancer in Iran: a survey of national cancer registry data - implications for screening. Asian Pac J Cancer Prev. 2012;13(6):2695–8.
Siegel RL, Miller KD, Fedewa SA, Ahnen DJ, Meester RGS, Barzi A, et al. Colorectal cancer statistics, 2017. CA Cancer J Clin. 2017;67(3):177–93.
Singh H, Nugent Z, Decker K, Deniers A, Samaddar J, Torabi M. Geographic variation and factors associated with colorectal cancer incidence in Manitoba. Can J Public Health. 2017;108(5–6):e558–64.
Savijarvi S, Seppa K, Malila N, Pitkaniemi J, Heikkinen S. Trends of colorectal cancer incidence by education and socioeconomic status in Finland. Acta Oncol. 2019;58(11):1557–63.
Rahman R, Schmaltz C, Jackson CS, Simoes EJ, Jackson-Thompson J, Ibdah JA. Increased risk for colorectal cancer under age 50 in racial and ethnic minorities living in the United States. Cancer Med. 2015;4(12):1863–70.
Nfonsam VN, Vijayasekaran A, Pandit V, E V, Aziz H, Nzuonkwelle S, et al. Patients diagnosed with colorectal cancer in rural areas in Arizona typically present with higher stage disease. J Gastrointest Dig Syst. 2015;5(5):346.
Van Beck KC, Jasek J, Roods K, Brown JJ, Farley SM, List JM. Colorectal cancer incidence and mortality rates among New York City adults ages 20–54 years during 1976–2015. JNCI Cancer Spectr. 2018;2(4):pky048.
Sammour T, Kahokehr A, Vather R, Connolly AB, Hill AG. Ethnic disparity in colonic cancer outcomes in New Zealand–biology or an access issue? Colorectal Dis. 2010;12(7 Online):e50–6.
Mosli MH, Al-Ahwal MS. Colorectal cancer in the Kingdom of Saudi Arabia: need for screening. Asian Pac J Cancer Prev. 2012;13(8):3809–13.
Mosli MH, Al-Ahwal MS. Does the increasing trend of colorectal cancer incidence in jeddah reflect a rise in the Kingdom of Saudi Arabia? Asian Pac J Cancer Prev. 2012;13(12):6285–8.
Russo AG, Andreano A, Sartore-Bianchi A, Mauri G, Decarli A, Siena S. Increased incidence of colon cancer among individuals younger than 50 years: a 17 years analysis from the cancer registry of the municipality of Milan. Italy Cancer Epidemiol. 2019;60:134–40.
Sheneman DW, Finch JL, Messersmith WA, Leong S, Goodman KA, Davis SL, et al. The impact of young adult colorectal cancer: incidence and trends in Colorado. Colorectal Cancer. 2017;6(2):49–56.
Oliphant R, Brewster DH, Morrison DS. The changing association between socioeconomic circumstances and the incidence of colorectal cancer: a population-based study. Br J Cancer. 2011;104(11):1791–6.
Perdue DG, Haverkamp D, Perkins C, Daley CM, Provost E. Geographic variation in colorectal cancer incidence and mortality, age of onset, and stage at diagnosis among American Indian and Alaska Native people, 1990–2009. Am J Public Health. 2014;104(Suppl 3):S404–14.
Murphy CC, Sandler RS, Sanoff HK, Yang YC, Lund JL, Baron JA. Decrease in incidence of colorectal cancer among individuals 50 years or older after recommendations for population-based screening. Clin Gastroenterol Hepatol. 2017;15(6):903–9.
Shah AB, Sarfati D, Blakely T, Atkinson J, Dennett ER. Trends in colorectal cancer incidence rates in New Zealand, 1981–2004. ANZ J Surg. 2012;82(4):258–64.
Siegel RL, Miller KD, Goding Sauer A, Fedewa SA, Butterly LF, Anderson JC, et al. Colorectal cancer statistics, 2020. CA Cancer J Clin. 2020;70(3):145–64.
Murphy G, Devesa SS, Cross AJ, Inskip PD, McGlynn KA, Cook MB. Sex disparities in colorectal cancer incidence by anatomic subsite, race and age. Int J Cancer. 2011;128(7):1668–75.
Shin A, Kim KZ, Jung KW, Park S, Won YJ, Kim J, et al. Increasing trend of colorectal cancer incidence in Korea, 1999–2009. Cancer Res Treat. 2012;44(4):219–26.
Patel P, De P. Trends in colorectal cancer incidence and related lifestyle risk factors in 15–49-year-olds in Canada, 1969–2010. Cancer Epidemiol. 2016;42:90–100.
Pakzad R, Moudi A, Pournamdar Z, Pakzad I, Mohammadian-Hashejani A, Momenimovahed Z, et al. Spatial analysis of colorectal cancer in Iran. Asian Pac J Cancer Prev. 2016;17(S3):53–8.
Siegel RL, Fedewa SA, Anderson WF, Miller KD, Ma J, Rosenberg PS, et al. Colorectal cancer incidence patterns in the United States, 1974–2013. J Natl Cancer Inst. 2017;109(8):djw322.
Pescatore P, Scheiden R, Abeywickrama KH, Braun M, Capesius C. Evolution of colorectal cancer epidemiology in a setting of opportunistic screening. A 20 year national survey in Luxembourg. Acta Gastroenterol Belg. 2013;76(1):25–33.
Murphy CC, Singal AG, Baron JA, Sandler RS. Decrease in Incidence of young-onset colorectal cancer before recent increase. Gastroenterology. 2018;155(6):1716–9.
Siegel RL, Ward EM, Jemal A. Trends in colorectal cancer incidence rates in the United States by tumor location and stage, 1992–2008. Cancer Epidemiol Biomarkers Prev. 2012;21(3):411–6.
Siegel RL, Medhanie GA, Fedewa SA, Jemal A. State variation in early-onset colorectal cancer in the United States, 1995–2015. J Natl Cancer Inst. 2019;111(10):1104–6.
Sung JJY, Chiu HM, Jung KW, Jun JK, Sekiguchi M, Matsuda T, et al. Increasing trend in young-onset colorectal cancer in Asia: more cancers in men and more rectal cancers. Am J Gastroenterol. 2019;114(2):322–9.
Rafiemanesh H, Pakzad R, Abedi M, Kor Y, Moludi J, Towhidi F, et al. Colorectal cancer in Iran: epidemiology and morphology trends. EXCLI J. 2016;15:738–44.
Sierra MS, Forman D. Burden of colorectal cancer in Central and South America. Cancer Epidemiol. 2016;44(Suppl 1):S74–81.
Oliveira AG, Curado MP, Koechlin A, Oliveira JC, Silva DR. Incidence and mortality from colon and rectal cancer in Midwestern Brazil. Rev Bras Epidemiol. 2016;19(4):779–90.
Palmieri G, Paliogiannis P, Scognamillo F, Budroni M, Cesaraccio R, Pulighe F, et al. Colorectal cancer epidemiology in an area with a spontaneous screening program. Acta Medica Mediterranea. 2013;29:231.
Paquette IM, Ying J, Shah SA, Abbott DE, Ho SM. African Americans should be screened at an earlier age for colorectal cancer. Gastrointest Endosc. 2015;82(5):878–83.
Reggiani-Bonetti L, Di Gregorio C, Pedroni M, Domati F, Barresi V, Marcheselli L, et al. Incidence trend of malignant polyps through the data of a specialized colorectal cancer registry: clinical features and effect of screening. Scand J Gastroenterol. 2013;48(11):1294–301.
Nowicki A, Dahms S. Incidence, morbidity and 5-year survival of colorectal cancer patients in the Kujawsko-Pomorskie voivodship in 2005–2011, based on data from the National Health Fund. Pol Przegl Chir. 2018;90(4):1–8.
Phipps AI, Scoggins J, Rossing MA, Li CI, Newcomb PA. Temporal trends in incidence and mortality rates for colorectal cancer by tumor location: 1975–2007. Am J Public Health. 2012;102(9):1791–7.
Oppelt KA, Luttmann S, Kraywinkel K, Haug U. Incidence of advanced colorectal cancer in Germany: comparing claims data and cancer registry data. BMC Med Res Methodol. 2019;19(1):142.
Murphy CC, Wallace K, Sandler RS, Baron JA. Racial disparities in incidence of young-onset colorectal cancer and patient survival. Gastroenterology. 2019;156(4):958–65.
Innos K, Reima H, Baburin A, Paapsi K, Aareleid T, Soplepmann J. Subsite- and stage-specific colorectal cancer trends in Estonia prior to implementation of screening. Cancer Epidemiol. 2018;52:112–9.
Siegel R, Desantis C, Jemal A. Colorectal cancer statistics, 2014. CA Cancer J Clin. 2014;64(2):104–17.
Sia CS, Paul E, Wale RJ, Lynch AC, Heriot AG, Warrier SK. No increase in colorectal cancer in patients under 50 years of age: a Victorian experience from the last decade. Colorectal Dis. 2014;16(9):690–5.
Rejali M, Daneshi S, Hadipour M, Tavazohi H, Vardanjani HM. Temporal trends of incidence of colorectal cancer in Isfahan, Iran, 2000–2011. Int J Prev Med. 2018;9:22.
Sarakarn P, Suwanrungruang K, Vatanasapt P, Wiangnon S, Promthet S, Jenwitheesuk K, et al. Joinpoint analysis trends in the incidence of colorectal cancer in Khon Kaen, Thailand (1989–2012). Asian Pac J Cancer Prev. 2017;18(4):1039–43.
Keum N, Giovannucci EL. Folic acid fortification and colorectal cancer risk. Am J Prev Med. 2014;46(3):S65–72.
Singh KE, Taylor TH, Pan CG, Stamos MJ, Zell JA. Colorectal cancer incidence among young adults in California. J Adolesc Young Adult Oncol. 2014;3(4):176–84.
Sjostrom O, Silander G, Syk I, Henriksson R, Melin B, Hellquist BN. Disparities in colorectal cancer between Northern and SouthernSweden - a report from the new RISK North database. Acta Oncol. 2018;57(12):1622–30.
Steinbrecher A, Fish K, Clarke CA, West DW, Gomez SL, Cheng I. Examining the association between socioeconomic status and invasive colorectal cancer incidence and mortality in California. Cancer Epidemiol Biomarkers Prev. 2012;21(10):1814–22.
Stern MC, Zhang J, Lee E, Deapen D, Liu L. Disparities in colorectal cancer incidence among Latino subpopulations in California defined by country of origin. Cancer Causes Control. 2016;27(2):147–55.
Stock C, Pulte D, Haug U, Brenner H. Subsite-specific colorectal cancer risk in the colorectal endoscopy era. Gastrointest Endosc. 2012;75(3):621–30.
Stromberg U, Peterson S, Holmen A, Holmberg E, Hultcrantz R, Martling A, et al. Rational targeting of population groups and residential areas for colorectal cancer screening. Cancer Epidemiol. 2019;60:23–30.
Sun M, Wang Y, Sundquist J, Sundquist K, Ji J. Temporal trends of sex disparity in incidence and survival of colorectal cancer: variations by anatomical site and age at diagnosis. Clin Epidemiol. 2020;12:73–81.
Tawadros PS, Paquette IM, Hanly AM, Mellgren AF, Rothenberger DA, Madoff RD. Adenocarcinoma of the rectum in patients under age 40 is increasing: impact of signet-ring cell histology. Dis Colon Rectum. 2015;58(5):474–8.
Thirunavukarasu P, Sathaiah M, Singla S, Sukumar S, Karunamurthy A, Pragatheeshwar KD, et al. Medullary carcinoma of the large intestine: a population based analysis. Int J Oncol. 2010;37(4):901–7.
Thuraisingam R, Jandova J, Pandit V, Michailidou M, Nfonsam VN. Assessing the national trends in colon cancer among Native Americans: a 12 year SEER database study. Am J Surg. 2017;214(2):228–31.
Troeung L, Sodhi-Berry N, Martini A, Malacova E, Ee H, O’Leary P, et al. Increasing incidence of colorectal cancer in adolescents and young adults aged 15–39 years in Western Australia 1982–2007: examination of colonoscopy history. Front Public Health. 2017;5:179.
Ugarte MD, Etxeberria J, Goicoa T, Ardanaz E. Gender-specific spatio-temporal patterns of colorectal cancer incidence in Navarre, Spain (1990–2005). Cancer Epidemiol. 2012;36(3):254–62.
Ullah MF, Fleming CA, Mealy K. Changing trends in age and stage of colorectal cancer presentation in Ireland - from the nineties to noughties and beyond. Surgeon. 2018;16(6):350–4.
Veruttipong D, Soliman AS, Gilbert SF, Blachley TS, Hablas A, Ramadan M, et al. Age distribution, polyps and rectal cancer in the Egyptian population-based cancer registry. World J Gastroenterol. 2012;18(30):3997–4003.
Wan Ibrahim NR, Chan HK, Soelar SA, Azmi AN, Mohd Said R, Abu Hassan MR. Incidence, clinico-demographic profiles and survival rates of colorectal cancer in Northern Malaysia: comparing patients above and below 50 years of age. Asian Pac J Cancer Prev. 2020;21(4):1057–61.
Wang DY, Thrift AP, Zarrin-Khameh N, Wichmann A, Armstrong GN, Thompson PA, et al. Rising incidence of colorectal cancer among young hispanics in Texas. J Clin Gastroenterol. 2017;51(1):34–42.
Wang H, de MejiaGrubb MC, Gonzalez SJ, Sidani M, Ma J, Zoorob RJ. Temporal trends in colorectal cancer incidence among Asian American populations in the United States, 1994‐2013. Fam Med Commun Health. 2017;5(1):56–64.
Wang W, Chen W, Lin J, Shen Q, Zhou X, Lin C. Incidence and characteristics of young-onset colorectal cancer in the United States: an analysis of SEER data collected from 1988 to 2013. Clin Res Hepatol Gastroenterol. 2019;43(2):208–15.
Wen D, Zou W, Wen X, Yang Y, Chen Y, He Y, et al. Urban-rural disparity in colorectal cancer incidence and increasing trend in relation to socioeconomic development and urbanization in China. J Int Med Res. 2018;46(10):4181–96.
Wessler JD, Pashayan N, Greenberg DC, Duffy SW. Age-period-cohort analysis of colorectal cancer in East Anglia, 1971–2005. Cancer Epidemiol. 2010;34(3):232–7.
Wu H, Zhou P, Zhang W, Jiang Y, Liu XL, Zhang L, et al. Time trends of incidence and mortality in colorectal cancer in Changning District, Shanghai, 1975–2013. J Dig Dis. 2018;19(9):540–9.
Yee YK, Gu Q, Hung I, Tan VP, Chan P, Hsu A, et al. Trend of colorectal cancer in Hong Kong: 1983–2006. J Gastroenterol Hepatol. 2010;25(5):923–7.
Yeo H, Betel D, Abelson JS, Zheng XE, Yantiss R, Shah MA. Early-onset colorectal cancer is distinct from traditional colorectal cancer. Clin Colorectal Cancer. 2017;16(4):293–9.
Yoon M, Kim N, Nam B, Joo J, Ki M. Changing trends in colorectal cancer in the Republic of Korea: contrast with Japan. Epidemiol Health. 2015;37:e2015038.
Young SW, Nishri ED, Candido E, Marrett LD. Colorectal cancer incidence in the Aboriginal population of Ontario, 1998 to 2009. Health Rep. 2015;26(4):3–9.
Zhabagin K, Igissinov N, Manambayeva Z, Adylkhanov T, Sandybayev M, Nurgazin M, et al. Temporal epidemiological assessment of colorectal cancer incidence and mortality in East Kazakhstan, 2004–2013. Asian Pac J Cancer Prev. 2015;16(15):6413–6.
Zhang B, Xie SH, Yu IT. Differential incidence trends of colon and rectal cancers in Hong Kong: an age-period-cohort analysis. Cancer Commun (Lond). 2018;38(1):42.
Zheng ZX, Zheng RS, Zhang SW, Chen WQ. Colorectal cancer incidence and mortality in China, 2010. Asian Pac J Cancer Prev. 2014;15(19):8455–60.
Zhou Q, Li K, Lin GZ, Shen JC, Dong H, Gu YT, et al. Incidence trends and age distribution of colorectal cancer by subsite in Guangzhou, 2000–2011. Chin J Cancer. 2015;34(8):358–64.
Zhu C, Bassig BA, Zaridze D, Boyle P, Dai M, Li Q, et al. A birth cohort analysis of the incidence of ascending and descending colon cancer in the United States, 1973–2008. Cancer Causes Control. 2013;24(6):1147–56.
Zorzi M, Dal Maso L, Francisci S, Buzzoni C, Rugge M, Guzzinati S, et al. Trends of colorectal cancer incidence and mortality rates from 2003 to 2014 in Italy. Tumori. 2019;105(5):417–26.
Zorzi M, Mangone L, Sassatelli R, Baracco S, Budroni M, Castaing M, et al. Incidence trends of colorectal cancer in the early 2000s in Italy. Figures from the IMPATTO study on colorectal cancer screening. Epidemiologia e prevenzione. 2015;39:115–25.
Ohri A, Robinson A, Liu B, Bhuket T, Wong R. Updated assessment of colorectal cancer incidence in the U.S. by Age, Sex, and race/ethnicity. Dig Dis Sci. 2020;65(6):1838–49.
Enayatrad M, Yavari P, Etemad K, Khodakarim S, Mahdavi S. Association of urbanization levels and colorectal cancer incidence in Iran. Int J Cancer Manag. 2018;11(8):e68476.
Surveillance Research Program, National Cancer Institute SEER*Stat software. https://seer.cancer.gov/seerstat.
SAS software® Release 9.4 SAS Institute Inc. Cary, NC, USA, 2013.
StataCorp. Stata statistical software: release 16. College Station, TX: StataCorp LLC; 2019.
Corp IBM, Released,. IBM SPSS statistics for windows, version 27.0. Armonk, NY: IBM Corp; 2020.
Choi BCK, de Guia NA, Walsh P. Look before you leap: stratify before you standardize. Am J Epidemiol. 1999;149(12):1087–96.
Murphy CC, Yang YC. Use of age-period-cohort analysis in cancer epidemiology research. Curr Epidemiol Rep. 2018;5(4):418–31.
Ahmad O, Boschi-Pinto C, Lopez AD, Murray C, Lozano R, Inoue M. Age standardization of rates: a new WHO standard. Geneva, Switzerland: World Health Organization; 2001.
Pace M, Lanzieri G, Glickman M, Grande E, Zupanic T, Wojtyniak B, et al. Revision of the European Standard Population. Eurostat Methodologies and Working Papers. 2013.
Parkin D. Comparability and quality control in cancer registration. IARC Technical Report. 1994;19:18–9.
Bray FCM, Mery L, Piñeros M, Znaor A, Zanetti R, Ferlay J. Cancer incidence in five continents, Vol.XI. Lyon: International Agency for Research on Cancer; 2021.
ICD Conversion Programs. Surveillance epidemiology and end results (SEER). 2021. http://seer.cancer.gov/tools/conversion/.
IARCcrgTools Conversion Programs. IARC; 2021. http://www.iacr.com.fr/index.php?option=com_content&view=article&id=72:iarccrgtools&catid=68&Itemid=445.
International Association of Cancer Registries. International rules for multiple primary cancers. Asian Pac J Cancer Prev. 2005;6(1):104–6.
D Redelings M, Sorvillo F, V Smith L, Greenland S. Why confidence intervals should be used in reporting studies of complete populations. Open Public Health J. 2012;5(1):52–4.
von Elm E, Altman DG, Egger M, Pocock SJ, Gøtzsche PC, Vandenbroucke JP. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies. PLoS Med. 2007;4(10):e296.
Acknowledgements
The authors wish to acknowledge Natalie King (Information Specialist, University of Leeds) for her help with the development of the search strategy for this systematic review.
Funding
This study is part of Norah Alsadhan’s PhD study, funded by King Saud University, Riyadh, Kingdom of Saudi Arabia.
Author information
Authors and Affiliations
Contributions
NA and MPR conceived the idea for this review and the research questions. NA developed and conducted the search, screened the studies, performed data extraction and analysis, and wrote the first draft. AA participated in the screening process. SA participated in data extraction. RW, CB, and FS provided overall supervision and critically appraised the results. All authors have read, commented on and edited the manuscript draft and approved the final manuscript for publication.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests. MPR is currently employed by UCB Biopharma.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
Data extraction sheet (form A).
Additional file 2.
Data extraction sheet (form B).
Additional file 3.
Results tables.
Additional file 4.
Quality assessment.
Additional file 5.
Search strategy.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Alsadhan, N., Almaiman, A., Pujades-Rodriguez, M. et al. A systematic review of methods to estimate colorectal cancer incidence using population-based cancer registries. BMC Med Res Methodol 22, 144 (2022). https://doi.org/10.1186/s12874-022-01632-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-022-01632-7