
Abstract
Background
In medical research, explanatory continuous variables are frequently transformed or converted into categorical variables. If the coding is unknown, many tests can be used to identify the “optimal” transformation. This common process, involving the problems of multiple testing, requires a correction of the significance level.
Liquet and Commenges proposed an asymptotic correction of significance level in the context of generalized linear models (GLM) (Liquet and Commenges, Stat Probab Lett 71:33–38, 2005). This procedure has been developed for dichotomous and Box-Cox transformations. Furthermore, Liquet and Riou suggested the use of resampling methods to estimate the significance level for transformations into categorical variables with more than two levels (Liquet and Riou, BMC Med Res Methodol 13:75, 2013).
Results
CPMCGLM provides to users both methods of p-value adjustment. Futhermore, they are available for a large set of transformations.
This paper aims to provide insight the user an overview of the methodological context, and explain in detail the use of the CPMCGLM R package through its application to a real epidemiological dataset.
Conclusion
We present here the CPMCGLMR package providing efficient methods for the correction of type-I error rate in the context of generalized linear models. This is the first and the only available package in R providing such methods applied to this context.
This package is designed to help researchers, who work principally in the field of biostatistics and epidemiology, to analyze their data in the context of optimal cutoff point determination.
Similar content being viewed by others



Background
In applied statistics, statistical models are widely used to assess the relationship between an explanatory and a dependent variable. For instance, in epidemiology, it is common for a study to focus on one particular risk factor. Scientists may wish to determine whether the potential risk factor actually affects the risk of a disease, a biological trait, or another outcome. In this context, statisticians use regression models with an outcome Y, a risk factor X (continuous variable of interest) and q−1 adjustment variables. In clinical and psychological research, the usual approach involves dichotomizing the continuous variable, whereas, in epidemiological studies, it is more usual to create several categories or to perform continuous transformations [1]. It is important to note that the categorization of a continuous predictor can only be justified when threshold effects are suspected. Furthermore, when the assumption of linearity is found to be untenable, a fractional polynomial (FP) transformation should always be favoured.
For instance, let us consider a categorical transformation of X. When the optimal set of cutoff points is unknown, the subjectivity of the choice of this set may lead to the testing of more than one set of values, to find the “optimal” set. For each coding, the nullity of the coefficient associated with the new coded variable is tested. The coding finally selected is that associated with the smallest p-value. This practice implies multiple testing, and an adjustment of the p-value is therefore required. The CPMCGLM package [2] can be used to adjust the p-value in the context of generalized linear models (GLM).
We present here the statistical context, and the various codings available in this R package. We then briefly present the available methods for type-I error correction, before presenting an example based on the PAQUID cohort dataset.
Implementation
Statistical setting
Generalized linear model
Let us consider a generalized linear model with q explanatory variables [3], in which Y=(Y1,…,Yn) is observed and the Yi’s are all identically and independently distributed with a probability density function in the exponential family, defined as follows:
with \(\mathbb {E}[Y_{i}]=\mu _{i}=b'(\theta _{i}),\mathbb {V}ar[Y_{i}]=b''(\theta _{i})a(\phi)\) and where a(·),b(·), and c(·) are known and differentiable functions. b(·) is three times differentiable, and its first derivative b′(·) can be inverted. Parameters (θi,ϕ) belong to \(\Omega \subset \mathbb {R}^{2}\), where θi is the canonical parameter and ϕ is the dispersion parameter. The CPMCGLM package allows the use of linear, Poisson, logit and probit models. The specifications of the model are defined with formula, family and link arguments, as a glm() function.
In this context, the main goal is evaluating the association between the outcome Yi and an explanatory variable of interest Xi, adjusted on a vector of explanatory variables Zi. The form of the effect of Xi is unknown, so we may consider K transformations of this variable Xi(k)=gk(Xi) with k=1,…,K.
For instance, if we transform a continuous variable into a categorical variable with mk classes, then mk−1 dummy variables are defined from the function gk(·): \(\mathbf {X_{i}(k)}=g_{k}(X_{i})=\left (X_{i}^{1}(k),\hdots,X_{i}^{m_{k}-1}(k)\right)\). mk different levels of the categorical transformation are possible.
The model for one transformation k can be obtained by modeling the canonical parameter θi as:
where \(\mathbf {Z_{i}}=\left (1,Z_{i}^{1},\hdots,Z_{i}^{q-1}\right), \boldsymbol {\gamma }=(\gamma _{0},\hdots,\gamma _{q-1})^{T}\) is a vector of q regression coefficients, and βk is the vector of coefficients associated with the transformation k of the variable Xi.
Multiple testing problem
We consider the problem of testing
simultenaously for all k∈{1,…,K}. For each transformation k, one test score Tk(Y) is obtained for the nullity of the vector βk [4]. We ultimately obtain a vector of statistics T=(T1(Y),…,TK(Y)). Introduce the associated p-value as
where y is the realization of Y.
Significance level correction
To cope with the multiplicity problem, we aim at testing [5]:
by which we mean that X has an effect on Y if and only if at least one transformation of X has an effect on Y. A natural approach is then to consider the maximum of the individual test statistics Tk(Y), or, equivalently, the minimum of the individual p-values pk(Y), leading to the following p-values:
where P0 denote the distribution of Y under the null and TmaxT(·)=max1≤k≤K{|Tk(·)|}, or
where pminP(·)=min1≤k≤K{pk(·)}.
Moreover, if X has an effect on Y (e.g. \(\mathscr {H}_{0}\) is rejected), the best coding corresponds to the transformation k which obtains the highest individual test statistic realization Tk(y), or, equivalently, the smallest individual p-value realization pk(y).
Bonferroni method
The first method available in this package is the Bonferroni method. This is the most widely used correction method in applied statistics. It has been described by several authors in various applications [6–10]. The Bonferroni method rejects \(\mathscr {H}_{0}\) at level α∈[0,1] if
where K is related to the total number of tests performed by the user. However, this method is conservative, particularly when the correlation between test results is high and the number of transformations is high.
Exact method
The second method proposed in this package is the asymptotic exact correction developed by Liquet and Commenges for generalized linear models [11, 12]. This method is valid only for binary transformations, fractional polynomial transformations with one degree (i.e. FP1) and Box-Cox transformations. It is based on the joint asymptotic distribution of the test statistics under the null. Indeed, the p-value pmaxT can be calculated as follows:
We then calculated the probability \(\mathbb {P}_{Y\sim P_{0}} \big (T_{1}(Y)<T^{maxT}(y); \hdots ; T_{K}(Y)< T^{maxT}(y)\big)\) by numerical integration of the multivariate Gaussian density (e.g., the asymptotic joint distribution of (Tk)1≤k≤K). Several programs have been written to solve this multiple integral. In this package, we used the method developed by Genz and Bretz in 2009 [13], available in the mvtnorm R package [14].
Minimum p-value procedure
The approach based on pminP, called the minimum p-value procedure, allows to combine statistical tests for different distributions. It is therefore possible to combine dichotomous, Box-Cox, fractional polynomial and transformations into categorical variables with more than two levels. However, the distribution of pminP is unknown and we use resampling-based methods. These procedures take into account the dependence structure of the tests for evaluation of the significance level of the minimum p-value procedure. These procedures can therefore be used for all kinds of coding.
Permutation test procedure
The first resampling-based method is a permutation test procedure. This procedure is used to build the reference distribution of statistical tests based on permutations. From a theoretical point of view, the statistical test procedures are developed by considering the null hypothesis to be true, i.e. in our context, under the null hypothesis, Xi has no impact on Y. Under the null hypothesis, if the exchangeability assumption is satisfied [15–20], then resampling can be performed based on the permutation of Xi the variable of interest in our dataset. The procedure proposed by Liquet and Riou could be summarized by the following algorithm [6]:
-
1
Apply the minimum p-value procedure to the original data for the K transformations considered. We note pmin the realization of the minimum of the p-value;
-
2
Under \(\mathscr {H}_{0,k}\), Xi has no effect on the response variable Y, and a new dataset is generated by permuting the Xi variable in the initial dataset. This procedure is illustrated in the following Fig. 1;
Fig. 1 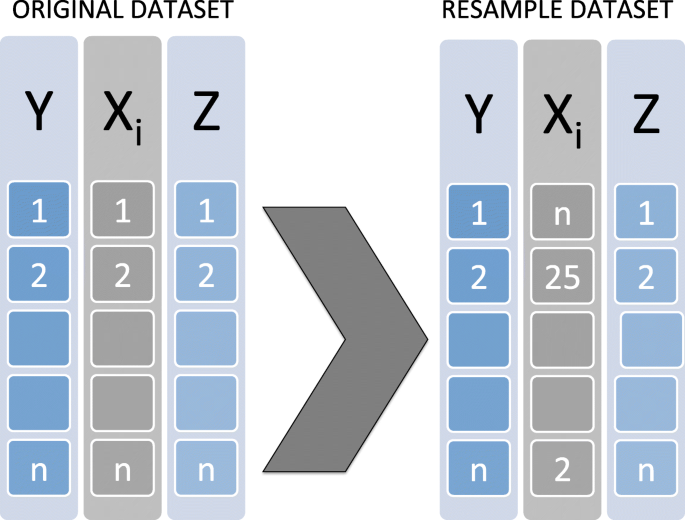
Permutation Principle under the null hypothesis \(\left (\mathscr {H}_{0,k}\right)\)
-
3
Generate B new datasets \(s^{*}_{b}\), b={1,...,B} by repeating step 2 B times;
-
4
For each new dataset, apply the minimum p-value procedure for the transformation considered. We note \(p^{*b}_{\text {min}}\) the smallest p-value for each new dataset.
-
5
The p-value is then approximated by:
$$\widehat{p^{minP}}=\frac{1}{B}\sum_{b=1}^{B}I_{\left\{p_{\text{min}}^{*b} < p_{\text{min}}\right\}},$$where I{·} is an indicator function.

This procedure can be used to control for the type-I error.
Parametric bootstrap procedure
The second resampling-based method is the parametric bootstrap procedure, which yields an asymptotic reference distribution. This procedure makes it possible to control for type-I error with fewer assumptions [21]. This procedure is summarized in the following algorithm [6]:
-
1
Apply the minimum p-value procedure to the original data for the K transformations considered. We note pmin the realization of the minimum of the p-value;
-
2
Fit the model under the null hypothesis, using the observed data, and obtain \(\boldsymbol {\hat {\gamma }}\), the maximum likelihood estimate (MLE) of γ;
-
3
Generate a new outcome \(Y_{i}^{*}\) for each subject from the probability measure defined under \(\mathscr {H}_{0,k}\).
-
4
Repeat this for all the subjects to obtain a sample denoted \(s^{*}=\{Y^{*}_{i},\mathbf {Z_{i}},X_{i}\}\)
-
5
Generate B new datasets \(s_{b}^{*}, b=1,\hdots,B\) by repeating step 3 B times ;
-
6
For each new dataset, apply the minimum p-value procedure for the transformation considered. We note \(p^{*b}_{\text {min}}\) the smallest p-value for each new dataset.
-
7
The p-value is then approximated by:
$$\widehat{p^{minP}}=\frac{1}{B}\sum_{b=1}^{B}I_{\left\{p_{\text{min}}^{*b} < p_{\text{min}}\right\}}.$$
Codings
We now provide some examples of available transformations in the CPMCGLM package.
Dichotomous coding
Dichotomous coding is often used in clinical and psychological research, either to facilitate interpretation, or because a threshold effect is suspected. In regression models with multiple explanatory variables, it may be seen as easier to interpret the regression coefficient for a binary variable than to understand a one-unit change in the continuous variable. In this context, dichotomous transformations of the variable of interest X are defined as:
where ck denotes the cutoff value for the transformation k (1≤k≤K).
In this R package, the dicho argument of the CPMCGLM() function allows the definition of desired cutoff points based on quantiles in a vector. An example of the dicho argument is provided below:

In this example, the user wants to try three dichotomous transformations of the variable of interest. For the first transformation, the cutoff point is the second decile; for the second, it is the median, and for the third, the seventh decile. The user can also opt to use our quantile-based method. The choice of this method leads to use of the nb.dicho argument. This argument makes it possible to use a quantile-based method, by entering the desired number of transformations. If the user asks for three transformations, the program uses the quartiles as cutoff points. If two transformations are requested, the program uses the terciles, and so on. This argument is also defined as follows.

It is important to note that only one of these arguments (dicho and nb.dicho) can be used in a given CPMCGLM()function.
Coding with more than two classes
In epidemiology, it is usual to create several categories, often four or five. These transformations into categorical variables are defined as follows:
where \(c_{k^{j}}\phantom {\dot {i}\!}\) denotes the jth cutoff point (0≤j≤m−2), for the transformation k (1≤k≤K).
The categ argument of the CPMCGLM() function allows the user to define the desired set of cutoff points using quantiles. This argument must take the form of a matrix, with a number of columns matching the maximum number of cutoff points used in almost all transformations, and a number of rows corresponding to the number of transformations tried. An example of this argument definition is presented below:

In this example, the user will realize four transformations. Two involve transformation into three classes, and two into four classes. It is important to note that binary transformations could not be defined here. The maximum number of cutoff points used in almost all transformations is three. The matrix therefore has the following dimensions: (4×3). For the first transformation, we will define a transformation into a three-class categorical variable with the third and seventh deciles as cut-points, and so on for the other transformations.
The user could also use a quantile-based method to define the transformations. In this case, the user would need to define the number of categorical transformations in the nb.categ argument. If two transformations are requested, then this method will create a two-class categorical variable using the terciles as cutoff points, and a three-class categorical variable using the quartiles as cutoff points. If the user asks for three transformations, the first and second transformations remain the same, and the program creates another categorical variable with four classes based on the quintiles, and so on. For four transformations, the argument is defined in R as follows:

However, users may also wish to define their own set of thresholds. For this reason, the function also includes the argument cutpoint, which can be defined on the basis of true values for the transformations desired. This argument is a matrix, defined as the argument categ. The difference between this argument and that described above is that it is possible to define dichotomous transformations for this argument and quantiles are not used.

Box-Cox transformation
Other transformations are also used, including Box-Cox transformations in particular, defined as follows [22]:
This family of transformations incorporates many traditional transformations:
-
λk = 1.00: no transformation needed; produces results identical to original data
-
λk = 0.50: square root transformation
-
λk = 0.33: cube root transformation
-
λk = 0.25: fourth root transformation
-
λk = 0.00: natural log transformation
-
λk = -0.50: reciprocal square root transformation
-
λk = -1.00: reciprocal (inverse) transformation
The boxcox argument is used to define Box-Cox transformations. This argument is a vector, and the values of its elements denote the desired λk. An example of the boxcox argument for a reciprocal transformation, a natural log transformation, and a square root transformation is provided below:

Fractional polynomial transformation
Royston et al. showed that traditional methods for analyzing continuous or ordinal risk factors based on categorization or linear models could be improved [23, 24]. They proposed an approach based on fractional polynomial transformation. Let us consider generalized linear models with canonical parameters defined as follows:
where \(\mathbf {Z_{i}}=\left (1,Z_{i}^{1},\hdots,Z_{i}^{q-1}\right), \boldsymbol {\gamma }=(\gamma _{0},\hdots,\gamma _{q-1})^{T}\) is a vector of q regression coefficients, and β is the coefficient associated with the Xi variable.
Consider the arbitrary powers a1≤…≤aj≤…≤ am, with 1≤j≤m, and a0=0.
If the random variable X is positive, i.e. ∀i∈{1,…,n},Xi>0, then the fractional polynomial transformation is defined as:
where for 0≤j≤m ξj is the coefficient associated with the fractional polynomial transformation:
where H0(Xi)=1.
However, if non-positive values of X can occur, a preliminary transformation of X to ensure positivity is required. The solution proposed by Royston and Altman is to choose a non-zero origin ζ<Xi and to rewrite the canonical parameter of the model for fractional polynomial transformation as follows:
ζ is set to the lower limit of the rounding interval of samples values for the variable of interest.
Royston and Altman suggested using m powers from a predefined set \(\mathscr {P}\) [25]:
The FP argument is used to define these transformations. This argument is a matrix. The number of rows correspond to the number of transformations tested, and the number of columns is the maximum number of degrees tested for a single transformation. An example of the FP argument:

In this example, the user performs three transformations of the variable of interest. The first is a fractional polynomial transformation with one degree and a power of − 2. The second transformation is a fractional polynomial transformation with four degrees and powers of 0.5,1,−0.5, and 2. The third transformation is a fractional polynomial transformation with two degrees and powers of − 0.5, and 1.
Motivating example
We revisited the example presented in the article of Liquet and Commenges in 2001 based on the PAQUID database [11], to illustrate the use of the CPMCGLM package, in the context of logistic regression.
PAQUID database
PAQUID is a longitudinal, prospective study of individuals aged at least 65 years on December 31, 1987 living in the community in France. These residents live in two administrative areas in southwestern France. This elderly population-based cohort of 3111 community residents aimed to identify the risk factors for cognitive decline, dementia, and Alzheimer’s disease. The data were obtained in a nested case-control study of 311 subjects from this cohort (33 subject with dementia and 278 controls).
Scientific aims
The analysis focused on the influence of HDL(high-density lipoprotein)-cholesterol on the risk of dementia. We considered the variables age, sex, education level, and wine consumption as adjustment variables. Bonarek et al initially considered HDL-cholesterol as a continuous variable [26]. Subsequently, to facilitate clinical interpretation, they decided to transform this variable into a categorical variable with different thresholds, and different numbers of classes. This strategy implied the use of multiple models, and multiple testing. A correction of type-I error taking into account the various transformations performed was therefore required to identify the best association between dementia and HDL-cholesterol.
Methods
We applied the various types of correction method described in this article to correct the type-I error rate in the model defined above. These corrections are easy to apply with the CPMCGLM package. The following syntax provided the desired results for one categorical coding, three binary codings, one Box-Cox transformation with λ=0, and one fractional polynomial transformation with two degrees and powers of -0.5, and 1:

By using the "dicho", and "categ" arguments, the function could also be used as follows, for exactly the same analysis:

Results
In R software, the results obtained with the CPMCGLM package described above are summarized as follows:

We can also use the summary function for the main results, which are described as follows for this specific result:

As we can see, for this example, the best coding was obtained for the logistic regression with dichotomous coding of the HDL-cholesterol variable. The cutoff point retained for this variable was the third quartile. Exact correction was not available for this application, due to the use of transformation into categorical variables with more than two classes. Resampling methods gave similar results, and both the resampling methods tested were more powerful than Bonferroni correction. In conclusion, the correction of type-I error is required. Naive correction is not satisfactory, and resampling methods seem to give the best results for p-value correction in this example.
Conclusion
We present here CPMCGLM, an R package providing efficient methods for the correction of type-I error rate in the context of generalized linear models. This is the only available package in R providing such methods applied to this context. We are currently working on the generalization of these methods to proportional hazard models, which we will make available as soon as possible in the CPMCGLM package.
In practice, it is important to correct the multiplicity on all the codings that have been tested. Indeed, if this is not done, the type-I error is not controlled, and then it is possible to obtain some false positive results.
To conclude, this package is designed to help researchers who work principally in epidemiology to analyze with riguor their data in the context of optimal cutoff point determination.
Availability and requirements
Project name: CPMCGLM
Project home page: https://cran.r-project.org/web/packages/CPMCGLM/index.html
Operating system(s): Platform independent
Programming language: R
Other requirements: R 2.10.0 or above
License: GPL-2
Any restrictions to use by non-academics: none
Abbreviations
- FP:
-
Fractional polynomial
- GLM:
-
Generalized linear model
- HDL:
-
High-density lipoprotein
- MLE:
-
Maximum likelihood estimate
- PAQUID:
-
Personnes agées QUID
References
Royston P, Altman DG, Sauerbrei W. Dichotomizing continuous predictors in multiple regression: a bad idea. Stat Med. 2006; 25(1):127–41.
Riou J, Diakite A, Liquet B. CPMCGLM: Correction of the Pvalue After Multiple Coding. 2017. R package. http://CRAN.R-project.org/package=CPMCGLM.
McCullagh P, Nelder JA. Generalized Linear Models, Second Edition. Chapman & Hall/CRC Monographs on Statistics & Applied Probability. London: Taylor & Francis; 1989.
Rao CR. Large sample tests of statistical hypotheses concerning several parameters with applications to problems of estimation. In: Mathematical Proceedings of the Cambridge Philosophical Society, vol. 44. Cambridge University Press: 1948. p. 50–57.
Berger RL. Multiparameter hypothesis testing and acceptance sampling. Technometrics. 1982; 24(4):295–300.
Liquet B, Riou J. Correction of the significance level when attempting multiple transformations of an explanatory variable in generalized linear models. BMC Med Res Methodol. 2013; 13(1):75.
Delorme P, Micheaux PL, Liquet B, Riou J. Type-ii generalized family-wise error rate formulas with application to sample size determination. Stat Med. 2016; 35(16):2687–714.
Simes R. An improved Bonferroni procedure for multiple tests of significance. Biometrika. 1986; 73(3):751–4.
Worsley KJ. An improved bonferroni inequality and applications. Biometrika. 1982; 69:297–302.
Hochberg Y. A sharper bonferroni procedure for multiple test procedure. Biometrika. 1988; 75:800–2.
Liquet B, Commenges D. Correction of the p-value after multiple coding of an explanatory variable in logistic regression. Stat Med. 2001; 20:2815–26.
Liquet B, Commenges D. Computation of the p-value of the minimum of score tests in the generalized linear model, application to multiple coding. Stat Probab Lett. 2005; 71:33–38.
Genz A, Bretz F. Computation of Multivariate Normal and T Probabilities. Lecture Notes in Statistics. Heidelberg: Springer; 2009.
Genz A, Bretz F, Miwa T, Mi X, Leisch F, Scheipl F, Hothorn T. mvtnorm: Multivariate Normal and T Distributions. 2016. R package version 1.0-5. http://CRAN.R-project.org/package=mvtnorm.
Romano JP. On the behavior of randomization tests without a group invariance assumption. J Am Stat Assoc. 1990; 85:686.
Xu H, Hsu JC. Applying the generalized partitioning principle to control the generalized familywise error rate. Biom J. 2007; 49(1):52–67.
Kaizar EE, Li Y, Hsu JC. Permutation multiple tests of binary features do not uniformly control error rates. J Am Stat Assoc. 2011; 106(495):1067–74.
Commenges D, Liquet B. Asymptotic distribution of score statistics for spatial cluster detection with censored data. Biometrics. 2008; 64(4):1287–9.
Commenges D. Transformations which preserve exchangeability and application to permutation tests. J Nonparametric Stat. 2003; 15(2):171–85.
Westfall PH, Troendle JF. Multiple testing with minimal assumptions. Biom J. 2008; 50(5):745–55.
Good PI. Permutation Tests. New York: Springer; 2000.
Box GE, Cox DR. An analysis of transformations. J R Stat Soc Ser B Methodol. 1964:211–52.
Royston P, Altman DG. Regression using fractional polynomials of continuous covariates: parsimonious parametric modelling. Appl Stat. 1994:429–67.
Royston P, Ambler G, Sauerbrei W. The use of fractional polynomials to model continuous risk variables in epidemiology. Int J Epidemiol. 1999; 28(5):964–74.
Royston P, Altman DG. Approximating statistical functions by using fractional polynomial regression. J R Stat Soc Ser D (The Stat). 1997; 46(3):411–22.
Bonarek M, Barberger-Gateau P, Letenneur L, Deschamps V, Iron A, Dubroca B, Dartigues J. Relationships between cholesterol, apolipoprotein e polymorphism and dementia: a cross-sectional analysis from the paquid study. Neuroepidemiology. 2000; 19:141–48.
Acknowledgements
We thank Luc Letenneur for his help on the PAQUID dataset, and Marine Roux for her help during the review process.
Funding
No funding was obtained for this study.
Availability of data and materials
The data that are used to illustrate this package are available from Centre de recherche INSERM U1219, Université de Bordeaux, ISPED but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of Centre de recherche INSERM U1219 Université de Bordeaux, ISPED.
Author information
Authors and Affiliations
Contributions
BL and JR developed the methodology, the R code, performed the analysis on the dataset as well as wrote the manuscript. Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The PAQUID study was approved by the ethics committee of the University of Bordeaux Segalen (France) in 1988, and each participant provided written informed consent.
Consent for publication
Not applicable.
Competing interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Liquet, B., Riou, J. CPMCGLM: an R package for p-value adjustment when looking for an optimal transformation of a single explanatory variable in generalized linear models. BMC Med Res Methodol 19, 79 (2019). https://doi.org/10.1186/s12874-019-0711-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-019-0711-2