
Abstract
Introduction
Prolonged Length of Stay (LOS) in ED (Emergency Department) has been associated with poor clinical outcomes. Prediction of ED LOS may help optimize resource utilization, clinical management, and benchmarking. This study aims to systematically review models for predicting ED LOS and to assess the reporting and methodological quality about these models.
Methods
The online database PubMed, Scopus, and Web of Science (10 Sep 2023) was searched for English language articles that reported prediction models of LOS in ED. Identified titles and abstracts were independently screened by two reviewers. All original papers describing either development (with or without internal validation) or external validation of a prediction model for LOS in ED were included.
Results
Of 12,193 uniquely identified articles, 34 studies were included (29 describe the development of new models and five describe the validation of existing models). Different statistical and machine learning methods were applied to the papers. On the 39-point reporting score and 11-point methodological quality score, the highest reporting scores for development and validation studies were 39 and 8, respectively.
Conclusion
Various studies on prediction models for ED LOS were published but they are fairly heterogeneous and suffer from methodological and reporting issues. Model development studies were associated with a poor to a fair level of methodological quality in terms of the predictor selection approach, the sample size, reproducibility of the results, missing imputation technique, and avoiding dichotomizing continuous variables. Moreover, it is recommended that future investigators use the confirmed checklist to improve the quality of reporting.
Similar content being viewed by others
Introduction
Overcrowding in the Emergency Department (ED) is an important worldwide problem [1,2,3] and it has received considerable international attention in recent years [4,5,6,7,8]. Rising demand for ED services and relative shortage of hospital beds are major causes of ED crowding and longer waiting times [4]. Length of Stay (LOS) in ED is usually defined as the time from patient registration in ED to patient discharge or transfer to another facility, or ward [2, 9]. ED LOS is perceived as an important component of ED overcrowding [7, 9] and a quality indicator for ED throughput [6].
Longer LOS in ED had poor clinical outcomes such as increased mortality/morbidity [7] and complication rates, decreased quality of care [1, 2] and patient satisfaction, ambulance diversion, and higher levels of recurrent ED crowding [2, 3]. Thus, LOS is an important measure of treatment timeliness when correcting for the severity of illness, patient safety, patient satisfaction, and quality of care in ED [2, 6, 8, 9]. Predicting length of stay is important in clinical and informatics research [10] and important to improve ED care and efficiency [3, 11]. The model’s predicted ED LOS may provide useful information for physicians or patients to better anticipate an individual’s LOS and to help the administrative level plan its staffing policy [12]. Additionally, the development of a prediction tool could assist in bed management and patient flow through ED and hospitals [13].
Many studies have been conducted to develop ED LOS prediction models. However, to the best of our knowledge, no previous systematic literature review has summarized these studies. Given the lack of evidence, additional research is needed to explore the related studies in this area and to address this knowledge gap. Considering recent evidence demonstrating the limited implementation and thus limited impact of hospital policies to improve patient flow through the ED is important [10, 11].
This study aims to systematically review and appraise the reporting and methodological quality of all development (with or without internal validation) and external validation studies describing a model aimed at predicting LOS in ED. It also provides recommendations for improving their reporting a prediction model for ED LOS.
Methods
Search strategy
We searched the PubMed (Medline), Scopus, and Web of Science databases for journal articles based on keywords in all fields until 10 September 2023, using the following query: ("length of stay") AND (emergency OR urgent) AND (prognostic OR prognosis OR predict*). All references were imported into the literature management program EndNote. All results were screened for relevance against our inclusion and exclusion criteria.
Inclusion and exclusion criteria
All original papers were included if they have described either the development (with or without internal validation) or external validation of a prediction model for LOS in emergency department patients. All duplicate articles, conference abstracts, and reviews were excluded. Only English articles were included. The review follows the 2020 Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines recommended by the Cochrane Handbook for Systematic Reviews of Interventions [13].
Selection of studies
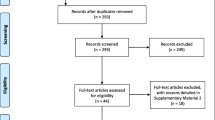
Two reviewers (H. K and R. F) independently screened the titles and abstracts using RayyanFootnote 1 research tool. Rayyan provides cooperative work on the systematics review and easy to orders articles and extracts data for blinded screening and automatic removal of duplicates. The results were compared and discussed until a consensus was reached. Discrepancies between the two reviewers were resolved by consensus involving a third reviewer (S. E). Figure 1 shows the search flowchart.

PRISMA flow diagram of the study screening process
Assessment of methodological and reporting quality
We used a checklist developed for critical appraisal and data extraction for systematic reviews of prediction modeling studies (CHARMS) [14]. This consists of eleven domains, each containing several (one to six) key items, resulting in a total of 32 key items [14]. We extended this checklist with three additional items taken from a scoring framework for assessing the quality of reporting in prediction model development studies [12] (Table 1). The total number of included key items was 39 for 12 different domains.
We extracted 11 items from the literature to evaluate the methodological quality of model development studies [12, 14, 49, 50] (Table 2).
Each key item was rated as ‘yes’, ‘partly’, or ‘not’ for the reporting as well as for the methodological quality, with a respective score of 2, 1, or 0. We summarized these results to rate the reporting and methodological quality of the model development studies. Table 2 describes the extracted data items to quantify each particular domain of the checklist.
Results
Search strategy
Online searching resulted in 12,193 articles. Initial screening of titles and abstracts rendered 124 articles for full-text review. Based on the full-text review, 90 articles were excluded because they focused on factors associated with ED LOS, or no prediction model was reported. As shown in Table 3, 34 articles were included for full-text analysis and data extraction. In total, 29 models were developed [15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37, 39, 42, 43, 45, 47, 48] and five studies [40, 41, 44, 46, 47] described the validation of the Emergency Severity Index (ESI), Canadian emergency department Triage and Acuity Scale (CTAS), or ENP-stream models.
Assessment of methodological and reporting quality
Source of data
All studies used a cohort study design. A total of 28 studies were retrospective [15,16,17,18,19,20, 22,23,24,25,26,27,28,29,30,31,32,33,34,35,36, 40,41,42,43, 45,46,47] and four were prospective [37, 39, 44, 48]. One study used the case–control design [38] and one study used cross-sectional analysis [21].
Participants
Only one paper did not report the year of study [45]. The year of emergency admission for the rest of the studies ranged from 1989 [48] to 2022 [17, 29, 32]. The minimum and maximum duration of data collection was 2 months [15] and 4 years [16, 20], respectively. All studies were conducted in 13 countries of which 12 studies were performed in the United States [16, 21, 22, 24, 38, 40, 42, 43, 45, 46, 48, 51] and other studies done in The Netherlands [41], France[37, 39, 52], Taiwan [23, 30, 34, 44], Andorra [47], Australia [15, 26, 28, 31, 32], South Africa [25]), Thailand [27], Brazil [29], Korea [18, 20], New Zealand [36], Italy [17] and China [33]. Studies were conducted in general (N = 20) [15,16,17, 20,21,22, 24, 26,27,28, 30, 32, 33, 36, 41, 43, 45,46,47,48], mental (N = 3) [35, 38, 42], adult (N = 5) [18, 23, 25, 39, 44, 53], old people (N = 4) [26, 29, 31, 37] and pediatric (N = 2) EDs [40, 52]. All studies included all patients who were admitted in EDs during the period of their study and most of them extracted patient data from electronic patient databases. Table 3 shows the characteristics of the selected studies for the systematic review.
As shown in Table 1, eight studies [15, 18, 19, 28, 35, 45, 46, 48] had no specific exclusion/inclusion criteria and selected all patients who were admitted to EDs. There were different exclusion criteria in the rest of the studies. ED deaths and trauma or mental patients were excluded from 11 studies [17, 23, 26, 27, 31, 33, 38,39,40, 42,43,44]. Other studies excluded patients who left without being seen or without physician assessment [17, 23, 30, 32, 33, 38, 41, 43, 47], left after medical advice [23, 38, 43], eloped [23, 38] or those considered as outpatients [17, 23, 42]. Other exclusion criteria were: age restrictions [16, 20, 21, 26, 27, 29, 30, 37, 39, 40, 42, 44], ethnicity restriction [36], registration errors, incomplete or missing data [20, 21, 24, 27, 38, 43, 47], no confirmation of COVID-19 [22], treated elsewhere and not in the study EDs, and visits with multiple missing time or invalid discharge time [34, 43].
Only one study included patients who left the ED against medical advice (including discharge due to critical condition), who were transferred to another hospital, or were discharged from the ED after LOS > 24 h of observation, and/or died in the ED [44]. Other studies did not mention readmissions, transfer from or to another ED/Hospital, and patients who did not survive ED stay.
Outcome(s) to be predicted
Number of (primary and secondary) outcome variables in the included studies varied from one [16, 18, 19, 22, 23, 25, 27, 28, 30, 35,36,37, 44] to five [29]. Eighteen studies clearly defined outcome variable(s) [15,16,17,18,19,20, 22,23,24,25, 27, 31,32,33, 36,37,38,39,40,41, 46]. The others did not provide a clear definition for LOS. The lack of a unique definition for the LOS in ED might have led to different results. Seven studies defined ED LOS as a number of minutes (or hours) between a patient’s arrival/identification to ED and discharge [24, 27, 38,39,40,41, 46]. The primary outcome measure in the reviewed studies was ED LOS (N = 28) [15,16,17,18,19,20, 22, 23, 25,26,27,28, 30,31,32,33, 35,36,37,38,39,40,41,42, 45,46,47,48], triage level (N = 1) [43, 44], ED resource usage (N = 1) [24], hospital admission (N = 1) [29], disposition from ED (N = 1) [21] and ED waiting room time (n = 1) [43, 44]. The twenty-three studies reported on the granularity of ED LOS in minutes [19, 32, 36, 39,40,41, 43, 44, 46, 47] or hours [18, 20, 22, 23, 25,26,27,28, 31, 33, 35, 38, 42, 48]. Some of these studies reported the mean or median of all patient ED stay. The mean of ED LOS ranged from 1 h to 9.2 days [15, 18, 33, 36, 37, 39,40,41,42, 44, 46] and the median of ED LOS ranged from 15 min to 54.6 h [20, 22, 27, 31, 33,34,35, 38, 43, 44, 46, 47]. Two studies did not provide a clear description of the statistical analysis methods [32, 45].
Candidate predictors
Not all studies reported on the predictor selection strategy. Table 2 shows the number and type of predictors in each model. Predictor variables were mostly measured at admission time or within the first 24 h of admission. Predictors selected for inclusion in modeling may have a large but spurious association with the outcome, which leads to predictor selection bias. Including such predictors increases the likelihood of over-fitting and thus over-optimistic predictions of a model’s performance for other individuals [49]. The number of continuous predictors was 0 [24, 36, 39, 41, 45, 47, 48] or 1 (age) [17, 21, 28, 35, 38, 40, 42,43,44, 46] or 2 [15, 20, 30] or 3 [26, 31] or 4 [33, 34] or 7 [29] or 8 [25] or 9 [19] or ten [27] or eleven [37] or eighteen [23]. The number of categories of all categorical predictors ranged from 0 to 19. Two studies used cut points to categorize continuous variables [20, 39]. Only one study used logarithmic transformation to transform the skewed continuous variables to approximately conform to normality [41].
As shown in Table 2, age, gender, acuity level, mode of arrival, patient disposition, and insurance type are important predictors for ED LOS that were used in most studies.
Sample size
The number of registered patients ranged from 100 [42] to over 4 million [16, 43] and the number of patients selected for model development or validation was between 42 [42] and 4,645,483 [16] patients.
Missing data
Most studies did not describe the completeness of data and/or handling of missing data. Some studies excluded all missing data for development and validation models. Ignoring the missing data can introduce bias. It is especially poor when the percentage of missing values per attribute varies considerably [23]. Differences between studies in the amount, type of missing data, and the methods used to handle this missing data may markedly influence model development and predictive performance. Only eight studies reported on the percentage of missing values [17, 21, 23, 28, 38, 42, 43, 47] and two studies described the handling of missing data [19, 22]. Specifically, these studies excluded all missing data for development and validation models.
Model development
Twenty-nine studies developed one or more new models for predicting emergency department LOS [24,25,26,27,28,29,30,31,32,33, 35, 38, 39, 42, 43, 45, 48]. Models were developed using Logistic Regression [15, 18, 20, 21, 23,24,25,26, 29, 31, 35, 38, 39, 45, 48], Artificial Neural Network (ANN) [15, 16, 22, 37, 45], convolutional neural networks (CNN) [15], generative adversarial network (GAN) [19], accelerated failure time (AFT) [34], time series [48], Gradient Boosting Machine (GBM) [32], Coxian phase-type distribution model [33], Decision tree algorithm [28], linear regression [21, 30, 36, 43], Poisson regression [27, 36], and various machine learning methods (Random Forest (RF), Support Vector Machines (SVM), Gradient Boosting (GB), AdaBoost, K-Nearest Neighbours (KNN), CatBoost, XGBoost, Decision Tree, Naïve Bayes) [15, 17, 18, 22, 23]. Note that these papers have used some of these machine learning models. It should be noted that only one study used the quantile regression analysis since the distribution of the response variable (ED service completion) was highly skewed, with long right tails [43].
Eight studies evaluated univariate associations with a prolonged LOS [24, 25, 27,28,29, 32, 35, 36]. Three studies used all candidate variables. The remaining studies did not mention how the initial set of variables was selected. Further details are shown in Table 2. Also, Table 4 shows the factors analyzed and statistics of the selected studies for this systematic review.
Model performance measures
Fourteen studies reported calibration measures (i.e. the agreement between predictions and observed outcomes) among which six studies used the Hosmer–Lemeshow goodness-of-fit test [17, 18, 31, 34, 35, 39, 48], two studies used the visual inspection of the observed vs. predicted proportions [31, 43], five studies used the mean squared error [15, 17, 19, 30, 31], one study used the life-table method [34], two studies used calibration plots [17, 29], one study used the kappa statistic [45], and one study used the linear regression method to inspect the association of forecasts with the actual outcomes [48]. A total of 13 studies used the Receiver Operating Characteristic (ROC) curve to quantify the discrimination power of the prediction model (i.e. the ability of the model to discriminate between those with and those without the event) [15,16,17,18, 22,23,24, 29, 31, 32, 35, 37, 39]. Nine studies also calculated the sensitivity, specificity, and positive and negative predictive values [15,16,17,18, 22, 23, 29, 31, 37]. Note that limited use of the popular performance measures prevents us from integrating the prediction powers of the models.
Model evaluation
Among development studies, sixteen studies performed internal validation, which useda subset of the training dataset to estimate the model performance (N = 9 split sample and N = 7 cross-validation) [15,16,17,18,19, 22,23,24, 28,29,30,31,32, 43, 45, 48], three studies used the entire dataset for both training and evaluating the model [34, 35, 39], and twelve studies performed no evaluation approach [20, 21, 25, 26, 33,34,35,36,37, 40, 44, 47]. All six external validation studies assessed the predictive validity of the previously published models by investigating the relationship between scores and ED LOS, mostly using the correlation coefficients.
Emergency severity index (ESI), Canadian Emergency Department Triage and Acuity Scale (CTAS), Charlson comorbidity index (CCI), Korean Triage and Acuity Scale (KTAS), Pronto Atendimento Geriátrico Especializado (ProAGE) and Emergency Nurse Practitioners (ENPs) were six triage instruments that were validated by nine studies to assess these instruments in predicting ED LOS, hospital admission, and number of resources utilized. The results of these studies showed that there was an excellent correlation between the ESI (version 3&4), CTAS, and ENP-streaming and patients’ injury severity. The findings of these studies showed that mean LOS was significantly shorter for the patients in the ENP stream in comparison with their counterparts [41]. The mean of LOS in ED was also significantly higher for the patients with higher acuity levels in comparison with the patients with lower acuity levels (257 vs. 143, P < 0.001) [40]. Moreover, the patients with ESI 4–5 and 2–3 had the shortest and longest LOS in ED, respectively [44, 46].
Reporting on the developed model
All studies that developed a new model (n = 29) reported the final model. However, since it was not possible to provide a comprehensible representation of the ANN model, only the relative importance of each variable was estimated by counting the number of times each variable was selected as one of the top five variables by each NN in the ensemble. An ensemble is a 'committee' of neural networks that usually outperforms single neural networks. [45]. Six studies reported the regression coefficients [22, 29, 30, 38, 39, 43] and eleven studies were reproducible, since the final model, initial predictors, and final set of variables included in the model were reported [16,17,18,19, 22, 23, 28, 29, 34, 39, 45, 48].
Interpretation and discussion of the eligible studies
All studies presented the intended use and interpretation of the validated or developed model(s). Use intentions were mostly as a patient triage or risk management [9, 24,25,26,27,28,29,30,31, 33, 34, 45, 48], ED resource utilization [24, 25, 30, 44, 46,47,48], identifying patients suitable for treatment [41], and determining valid factors that are significant predictors for hospital/ED admission and ED LOS [26, 27, 29, 31, 32, 38,39,40, 42, 43]. All reviewed models were discussed based on the validation results of the studies. However, only five development studies [26, 28, 29, 45, 48] and three validation studies [41, 44, 46] have discussed the strengths and weaknesses of the models.
Reporting and methodological quality assessment score
Table 1 shows domains and (key) items of the used CHARMS [15] checklist accompanied with the reporting and methodological scores used for quality assessment of the studies. The highest possible reporting scores for the development and validation studies were 67 and 43 respectively. The total score per reporting item ranged from 0 to 68 which is the sum of the reporting score [0, 1, 2] over models. The highest methodological score was 8 for development studies and 6 for validation studies. The total score achieved per methodological item (the sum of the methodological scores [0, 1, 2] over models) ranged from 0 to 68.
Discussion
The average length of stay is an increasingly concerning issue and an important index for bed administration, patient care, and consequently benchmarking of the emergency departments. Accurate prediction of LOS in ED will help physicians make informed decisions during risk assessment and patient stratification. This study aimed to quantify the methodological and reporting quality of prediction models which have been developed or externally evaluated to predict the LOS in ED.
The most important finding of this study is the remarkable differences in methods used for model development, different thresholds used to categorize the dependent variable, and inclusion of different patient groups which affected the comparability of the models. A total of 34 studies were published from 1994 to 2023 aiming to develop (N = 29) or externally validate (N = 5) the prediction models for LOS in ED. Different modeling approaches were used to generate the function predicting the outcome. Since the linear regression method is not applicable when the normality assumption is violated, about %44 of the development studies dichotomized the dependent variable using different thresholds and applied the Logistic Regression method. Five studies used different machine learning techniques to predict ED LOS. Of these, Gradient Boosting (GB) in two studies and CATBoost and generative adversarial network (GAN) in two other studies had the best results in predicting LOS [17, 19, 22, 23]. In one study Logistic Regression shows better results than machine learning methods [18]. In addition, Logistic Regression still had similar results compared to machine learning approaches.
Two studies used the Coxian phase-type distribution method and quantile regression because the response variable was highly skewed to the left [33, 40]. These methods seemed to be useful because, in the emergency setting, we need to make a serious investigation not only on the middle of the distribution but also on extreme events. ANN was also used in five studies [15, 16, 22, 37, 45]. Using different types of ANN, multilayer perceptron (MLP) had significant results than another type of ANN [37]. It has the advantage over Logistic Regression when the relationships between the inputs and the outputs are not straightforwardly expressed in a pre-specified parametric model. However, the lack of model specification and proneness to over-fitting makes it difficult to be used in clinical and administrative judgments. Tandberg et al. used time series analysis [35]. This approach can be useful when data are repeatedly measured over time. Gill et al. reported that they used the GBM method because it allows for modeling of interactions and nonlinearities within the data and can handle a large number of variables [33]. One study used a decision tree. This method can demonstrate important patterns intuitively, helping the clinician to make sense of potentially complex combinations of factors [28].
About 40% and 33% of the studies reported calibration and discrimination measures for categorized outcomes, respectively. The Hosmer–Lemeshow goodness-of-fit test was the most frequently used test to assess the agreement between predicted probabilities and observed outcomes for categorized outcomes. However, this widely used test has several drawbacks (e.g., poor interpretation and limited power). Moreover, the ROC curve which is the most popular method to evaluate the discrimination power of the prediction models with binary variables was only used in thirteen studies among which only nine studies calculated the classification-based performance measures (e.g., sensitivity, specificity, etc.). There are numerous traditional and novel performance measures for estimating the prediction power of the models [54] which have been rarely used in both development and evaluation studies.
Patient triage and resource optimization was the most mentioned intention of the model in the included studies. Triage is commonly used to rapidly identify the patients who require immediate care and the patients who cannot wait before being evaluated and treated. Once the LOS is precisely predicted, the physicians will perform an informed and accurate risk assessment and consequently patient stratification. This will also result in helping optimize the bed occupation rate as well as resource utilization in crowded Eds [55].
Both development and validation studies completely reported the following key items: number and type of predictors, definition of the candidate predictors, time of predictor measurement, number of participants and outcomes/events, and event/(binary) variable ratio, model interpretation, source of data, and sample size.
Limitations and strengths
A strength of our study is that we systematically assessed the studies found by a framework published by Moons et al. (CHARMS) [14] extended with additional items from other studies that developed a prediction model [12, 56, 57] to assess the studies and models on reporting and methodological quality. We included studies that developed prediction models for ED LOS and did not include studies that evaluate whether a specific characteristic influences or is a predictor for ED LOS. Another strength is that this is the first systematic review of ED LOS prediction models for emergency department patients.
Our study has some limitations over previous reviews of prediction models for LOS in emergency departments. First, there exist some prediction models developed for patients with ED LOS which do not meet our inclusion criteria because they partly addressed the prediction of ED LOS. Second, there is possible some papers are missed in our review. Third, we limited our research to English-language articles. Fourth, we researched only one database, PubMed. Our research terms may not have revealed all aspects of the topic.
Implications for clinicians/policymakers/researchers/model developers
Available prediction models for LOS in ED have poor to fair levels of methodological and reporting quality which makes them barely useful for clinical practice and administrative decision making. Many important issues are required to be addressed to provide accurate predictions of the LOS in ED.
Future research
We recommend that all development and validation studies use a clear definition of LOS in ED. This might be considered as an essential prerequisite for the comparability of the models. Moreover, models that have not been validated may not perform well in practice because of deficiencies in the development methods or because the new sample is too different from the original. Thus, it is highly recommended to evaluate available models on different datasets and update them if required. It should be noted that using the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD) checklist can help future investigators to improve the reporting quality and indirectly the methodological quality of prediction model studies.
Conclusion
Various studies on prediction models for ED LOS were published but they are fairly heterogeneous and suffer from methodological and reporting issues. Model development studies were associated with a poor to a fair level of methodological quality in terms of the predictor selection approach, the sample size, reproducibility of the results, missing imputation technique, and avoiding dichotomizing continuous variables. Moreover, it is recommended that future investigators use the confirmed checklist to improve the quality of reporting. Physicians considering using these models to predict ED LOS should interpret them with reservation until a validation study using recent local data has shown that they obtain moderate calibration and produce accurate predictions.
Availability of data and materials
The data that support the findings of this study is available by corresponding author upon request.
Abbreviations
- ED:
-
Emergency Department
- ED LOS:
-
Emergency Department Length of Stay
- ANN:
-
Artificial Neural Network
- ESI:
-
Emergency Severity Index
- CTAS:
-
Canadian Emergency Department Triage and Acuity Scale
- PRISMA:
-
Preferred Reporting Items for Systematic Reviews and Meta-Analyses
- CHARMS:
-
Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modelling Studies
- CNN:
-
Convolutional Neural Networks
- GAN:
-
Generative Adversarial Network
- GBM:
-
Gradient Boosting Machine
- DT:
-
Decision tree
- LR:
-
Logistic Regression
- KNN:
-
K-Nearest Neighbours
- AFT:
-
Accelerated Failure Time
- NYHA:
-
New York Heart Association
References
Forster AJ, Stiell I, Wells G, Lee AJ, van Walraven C. The effect of hospital occupancy on emergency department length of stay and patient disposition. Acad Emerg Med Off J Soc Acad Emerg Med. 2003;10(2):127–33.
Mahmoud I, Hou XY, Chu K, Clark M. Language affects length of stay in emergency departments in Queensland public hospitals. World J Emerg Med. 2013;4(1):5–9.
Morley C, Unwin M, Peterson GM, Stankovich J, Kinsman L. Emergency department crowding: a systematic review of causes, consequences, and solutions. PLoS One. 2018;13(8):e0203316.
Wiler JL, Handel DA, Ginde AA, Aronsky D, Genes NG, Hackman JL, et al. Predictors of patient length of stay in 9 emergency departments. Am J Emerg Med. 2012;30(9):1860–4.
Bekmezian A, Chung PJ. Boarding admitted children in the emergency department impacts inpatient outcomes. Pediatr Emerg Care. 2012;28(3):236–42.
Bekmezian A, Chung PJ, Cabana MD, Maselli JH, Hilton JF, Hersh AL. Factors associated with prolonged emergency department length of stay for admitted children. Pediatr Emerg Care. 2011;27(2):110–5.
Di Somma S, Paladino L, Vaughan L, Lalle I, Magrini L, Magnanti M. Overcrowding in emergency department: an international issue. Intern Emerg Med. 2015;10:171–5.
Savioli G, Ceresa IF, Gri N, Bavestrello Piccini G, Longhitano Y, Zanza C, et al. Emergency department overcrowding: understanding the factors to find corresponding solutions. J Pers Med. 2022;12(2):279.
Gardner RL, Sarkar U, Maselli JH, Gonzales R. Factors associated with longer ED lengths of stay. Am J Emerg Med. 2007;25(6):643–50.
Mohr NM, Wessman BT, Bassin B, Elie-Turenne M-C, Ellender T, Emlet LL, et al. Boarding of critically ill patients in the emergency department. Crit Care Med. 2020;48(8):1180–7.
Warner LSH, Pines JM, Chambers JG, Schuur JD. The most crowded US hospital emergency departments did not adopt effective interventions to improve flow, 2007–10. Health Aff. 2015;34(12):2151–9.
Medlock S, Ravelli AC, Tamminga P, Mol BW, Abu-Hanna A. Prediction of mortality in very premature infants: a systematic review of prediction models. PLoS One. 2011;6(9):e23441.
Page MJ, Moher D, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. PRISMA 2020 explanation and elaboration: updated guidance and exemplars for reporting systematic reviews. BMJ. 2021;372:n160.
Moons KG, de Groot JA, Bouwmeester W, Vergouwe Y, Mallett S, Altman DG, et al. Critical appraisal and data extraction for systematic reviews of prediction modelling studies: the CHARMS checklist. PLoS Med. 2014;11(10):e1001744.
Bacchi S, Gluck S, Tan Y, Chim I, Cheng J, Gilbert T, et al. Prediction of general medical admission length of stay with natural language processing and deep learning: a pilot study. Intern Emerg Med. 2020;15(6):989–95.
Lee S, Mudireddy AR, Pasupula DK, Adhaduk M, Barsotti EJ, Sonka M, et al. Novel machine learning approach to predict and personalize length of stay for patients admitted with syncope from the emergency department. J Pers Med. 2023;13(1):7.
Zeleke AJ, Palumbo P, Tubertini P, Miglio R, Chiari L. Machine learning-based prediction of hospital prolonged length of stay admission at emergency department: a Gradient Boosting algorithm analysis. Front Artif Intell. 2023;6:1179226.
Lee H, Lee S, Kim H. Factors affecting the length of stay in the emergency department for critically Ill patients transferred to regional emergency medical center. Nurs Open. 2023;10(5):3220–31.
Kadri F, Dairi A, Harrou F, Sun Y. Towards accurate prediction of patient length of stay at emergency department: a GAN-driven deep learning framework. J Ambient Intell Humaniz Comput. 2023;14(9):11481–95.
Lee KS, Min HS, Moon JY, Lim D, Kim Y, Ko E, et al. Patient and hospital characteristics predict prolonged emergency department length of stay and in-hospital mortality: a nationwide analysis in Korea. BMC Emerg Med. 2022;22(1):183.
Srivastava S, Vemulapalli B, Okoh AK, Kassotis J. Disparity in hospital admissions and length of stay based on income status for emergency department hypertensive crisis visits. J Hypertens. 2022;40(8):1607–13.
Etu EE, Monplaisir L, Arslanturk S, Masoud S, Aguwa C, Markevych I, et al. Prediction of length of stay in the emergency department for COVID-19 patients: a machine learning approach. IEEE Access. 2022;10:42229–37.
Chang YH, Shih HM, Wu JE, Huang FW, Chen WK, Chen DM, et al. Machine learning–based triage to identify low-severity patients with a short discharge length of stay in emergency department. BMC Emerg Med. 2022;22(1):88.
d’Etienne JP, Zhou Y, Kan C, Shaikh S, Ho AF, Suley E, et al. Two-step predictive model for early detection of emergency department patients with prolonged stay and its management implications. Am J Emerg Med. 2021;40:148–58.
Laher AE, Paruk F, Richards GA, Venter WD. Predictors of prolonged hospital stay in HIV-positive patients presenting to the emergency department. PLoS One. 2021;16(4):e0249706.
Sweeny A, Keijzers G, O’Dwyer J, Arendts G, Crilly J. Predictors of a long length of stay in the emergency department for older people. Intern Med J. 2020;50(5):572–81.
Sricharoen P, Phinyo P, Patumanond J, Piyayotai D, Sittichanbuncha Y, Yuksen C, et al. Clinical predictors influencing the length of stay in emergency department patients presenting with acute heart failure. Medicina. 2020;56(9):434.
Rahman MA, Honan B, Glanville T, Hough P, Walker K. Using data mining to predict emergency department length of stay greater than 4 hours: Derivation and single-site validation of a decision tree algorithm. Emerg Med Australas. 2020;32(3):416–21.
Curiati PK, Gil-Junior LA, Morinaga CV, Ganem F, Curiati JA, Avelino-Silva TJ. Predicting hospital admission and prolonged length of stay in older adults in the emergency department: the PRO-AGE scoring system. Ann Emerg Med. 2020;76(3):255–65.
Chen C-H, Hsieh J-G, Cheng S-L, Lin Y-L, Lin P-H, Jeng J-H. Early short-term prediction of emergency department length of stay using natural language processing for low-acuity outpatients. Am J Emerg Med. 2020;38(11):2368–73.
Street M, Mohebbi M, Berry D, Cross A, Considine J. Influences on emergency department length of stay for older people. Eur J Emerg Med. 2018;25(4):242–9.
Gill SD, Lane SE, Sheridan M, Ellis E, Smith D, Stella J. Why do ‘fast track’patients stay more than four hours in the emergency department? An investigation of factors that predict length of stay. Emerg Med Australas. 2018;30(5):641–7.
Zhu T, Luo L, Zhang X, Shen W. Modeling the length of stay of respiratory patients in emergency department using coxian phase-type distributions with covariates. IEEE J Biomed Health Inform. 2017;22(3):955–65.
Chaou CH, Chen HH, Chang SH, Tang P, Pan SL, Yen AMF, et al. Predicting length of stay among patients discharged from the emergency department—using an accelerated failure time model. PloS One. 2017;12(1).
Warren MB, Campbell RL, Nestler DM, Pasupathy KS, Lohse CM, Koch KA, et al. Prolonged length of stay in ED psychiatric patients: a multivariable predictive model. Am J Emerg Med. 2016;34(2):133–9.
Prisk D, Jonathan Godfrey AR, Lawrence A. Emergency Department length of stay for maori and european patients in New Zealand. Western J Emerg Med. 2016;17(4):438–48.
Launay CP, Rivière H, Kabeshova A, Beauchet O. Predicting prolonged length of hospital stay in older emergency department users: Use of a novel analysis method, the Artificial Neural Network. Eur J Intern Med. 2015;26(7):478–82.
Stephens RJ, White SE, Cudnik M, Patterson ES. Factors associated with longer length of stay for mental health emergency department patients. J Emerg Med. 2014;47(4):412–9.
Casalino E, Wargon M, Peroziello A, Choquet C, Leroy C, Beaune S, et al. Predictive factors for longer length of stay in an emergency department: a prospective multicentre study evaluating the impact of age, patient’s clinical acuity and complexity, and care pathways. Emerg Med J. 2014;31(5):361–8.
Green NA, Durani Y, Brecher D, DePiero A, Loiselle J, Attia M. Emergency Severity Index version 4: a valid and reliable tool in pediatric emergency department triage. Pediatr Emerg Care. 2012;28(8):753–7.
van der Linden C, Lindeboom R, van der Linden N, Lucas C. Managing patient flow with triage streaming to identify patients for Dutch emergency nurse practitioners. Int Emerg Nurs. 2012;20(2):52–7.
Nejtek VA, Hardy S, Hall JR, Winter AS. Characteristics and psychosocial predictors of psychiatric emergency center transport and length of stay in patients with dementia and Alzheimer’s disease: a preliminary report. J Psychiatr Pract. 2011;17(4):251–7.
Ding R, McCarthy ML, Desmond JS, Lee JS, Aronsky D, Zeger SL. Characterizing waiting room time, treatment time, and boarding time in the emergency department using quantile regression. Acad Emerg Med Off J Soc Acad Emerg Med. 2010;17(8):813–23.
Chi CH, Huang CM. Comparison of the Emergency Severity Index (ESI) and the Taiwan Triage System in predicting resource utilization. J Formos Med Assoc. 2006;105(8):617–25.
Walsh P, Cunningham P, Rothenberg SJ, O’Doherty S, Hoey H, Healy R. An artificial neural network ensemble to predict disposition and length of stay in children presenting with bronchiolitis. Eur J Emerg Med. 2004;11(5):259–64.
Tanabe P, Gimbel R, Yarnold PR, Adams JG. The emergency severity index (version 3) 5-level triage system scores predict ED resource consumption. J Emerg Nurs. 2004;30(1):22–9.
Jiménez JG, Murray MJ, Beveridge R, Pons JP, Cortés EA, Garrigós JB, et al. Implementation of the Canadian Emergency Department Triage and Acuity Scale (CTAS) in the Principality of Andorra: Can triage parameters serve as emergency department quality indicators? CJEM. 2003;5(5):315–22.
Tandberg D, Qualls C. Time series forecasts of emergency department patient volume, length of stay, and acuity. Ann Emerg Med. 1994;23(2):299–306.
Mallett S, Royston P, Dutton S, Waters R, Altman DG. Reporting methods in studies developing prognostic models in cancer: a review. BMC Med. 2010;8:20.
Mallett S, Royston P, Waters R, Dutton S, Altman DG. Reporting performance of prognostic models in cancer: a review. BMC Med. 2010;8:21.
Steyerberg EW. Clinical prediction models: a practical approach to development, validation, and updating (Statistics for Biology and Health). Springer; 2009.
Kadri F, Dairi A, Harrou F, Sun Y. Towards accurate prediction of patient length of stay at emergency department: a GAN-driven deep learning framework. J Ambient Intell Humaniz Comput. 2022.
AMI team buckles down to improve outcomes. Hosp Case Manag. 1998;6(3):46-9.
Lee Y-H, Bang H, Kim DJ. How to establish clinical prediction models. Endocrinol Metabol. 2016;31(1):38–44.
Ruger JP, Richter CJ, Spitznagel EL, Lewis LM. Analysis of costs, length of stay, and utilization of emergency department services by frequent users: implications for health policy. Acad Emerg Med. 2004;11(12):1311–7.
Mallett S, Royston P, Dutton S, Waters R, Altman DG. Reporting methods in studies developing prognostic models in cancer: a review. BMC Med. 2010;8(1):1–11.
Mallett S, Royston P, Waters R, Dutton S, Altman DG. Reporting performance of prognostic models in cancer: a review. BMC Med. 2010;8(1):1–11.
Acknowledgements
This study is the result of a research project approved by Mashhad University of Medical Sciences.
Funding
The present study has no funding.
Author information
Authors and Affiliations
Contributions
Writing-original draft preparation, investigation, design the study, R.M and H. K; papers review, R.M, H. K, A. Atashi, and S.E; editing, K.B, F.T, A. Abu-Hanna; supervision: S. E; All authors have read and approved the content of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The present study was approved by the ethics committee of the deputy of Research and Technology, Mashhad University of Medical Sciences.
Consent for publication
This paper didn’t include any individual person’s data. Rights and permissions. Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Farimani, R.M., Karim, H., Atashi, A. et al. Models to predict length of stay in the emergency department: a systematic literature review and appraisal. BMC Emerg Med 24, 54 (2024). https://doi.org/10.1186/s12873-024-00965-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12873-024-00965-4