
Abstract
Background
Machine learning (ML) can identify and integrate connections among data and has the potential to predict events. Heart failure is primarily caused by cardiomyopathy, and different etiologies require different treatments. The present study examined the diagnostic value of a ML algorithm that combines echocardiographic data to automatically differentiate ischemic cardiomyopathy (ICM) from dilated cardiomyopathy (DCM).
Methods
We retrospectively collected the echocardiographic data of 200 DCM patients and 199 ICM patients treated in the First Affiliated Hospital of Guangxi Medical University between July 2016 and March 2022. All patients underwent invasive coronary angiography for diagnosis of ICM or DCM. The data were randomly divided into a training set and a test set via 10-fold cross-validation. Four ML algorithms (random forest, logistic regression, neural network, and XGBoost [ML algorithm under gradient boosting framework]) were used to generate a training model for the optimal subset, and the parameters were optimized. Finally, model performance was independently evaluated on the test set, and external validation was performed on 79 patients from another center.
Results
Compared with the logistic regression model (area under the curve [AUC] = 0.925), neural network model (AUC = 0.893), and random forest model (AUC = 0.900), the XGBoost model had the best identification rate, with an average sensitivity of 72% and average specificity of 78%. The average accuracy was 75%, and the AUC of the optimal subset was 0.934. External validation produced an AUC of 0.804, accuracy of 78%, sensitivity of 64% and specificity of 93%.
Conclusions
We demonstrate that utilizing advanced ML algorithms can help to differentiate ICM from DCM and provide appreciable precision for etiological diagnosis and individualized treatment of heart failure patients.
Similar content being viewed by others
Background
Cardiomyopathy is the leading cause of heart failure (HF), which carries high risks of mortality and morbidity [1]. The two major types of cardiomyopathy are ischemic cardiomyopathy (ICM), which is mainly characterized by myocardial ischemia, degeneration, necrosis, fibrosis and scar formation, and dilated cardiomyopathy (DCM), which is mainly characterized by obvious enlargement of the left ventricle (LV), thinning of the ventricular wall and decreased LV systolic function [2, 3]. These two CM types have different pathophysiological characteristics but may have a similar clinical presentation, i.e., impaired LV function with disease progression to HF. Determining whether the decreased LV function in HF patients is caused by ICM due to coronary heart disease or by DCM is of great importance to early treatment planning and improving prognosis [4, 5].
At present, in studies in China and elsewhere, coronary angiography is an important technique for the differentiation of ICM and DCM [6]. However, because it is invasive examination, acceptance in the clinic is problematic, and more importantly, this technique cannot be carried out in many primary hospitals due to limited conditions. A considerable number of patients with HF and left ventricular dysfunction show clinical improvement in left ventricular function after appropriate use of coronary revascularization [7, 8]. Therefore, finding a clinically more acceptable and feasible method for the diagnosis of HF-related etiology, such as ICM and DCM, is an important objective in this field. Traditionally, noninvasive tests to distinguish the two have included electrocardiograms, echocardiograms or exercise echocardiography, chest radiographs, cardiac computed tomography (CT), cardiac positron emission tomography (PET), cardiac magnetic resonance imaging (CMRI), radionuclide studies, and genetic studies [9,10,11], where simple electrocardiograms are sometimes not diagnostic. In previous studies, when used to predict cardiovascular outcomes, ECG parameters have generally shown poor predictive accuracy and to possibly even reduce the incremental validity of the model [12,13,14]. Echocardiography is the first diagnostic step following collection of the patient’s family history, physical examination, and electrocardiography, and is crucial for the morphological diagnosis of most cardiomyopathy cases [15, 16]. Cardiac MRI is the gold standard for high-quality diagnostic imaging, if echocardiography does not clearly identify phenotypes, but the use of more advanced imaging methods is limited due to technical difficulties, high costs, and other reasons. Therefore, to avoid the influence of relevant confounding factors, this study attempted to further improve the diagnostic effectiveness of echocardiography by utilizing the power of big data.
Machine learning (ML) is a statistical learning and modeling technique that can make predictions about invisible or new data through learning from available data [17, 18]. This study aimed to use a ML algorithm based on clinical data derived from echocardiography to develop and verify a predictive model to distinguish ICM from DCM. Our novel model further improves the accuracy of diagnosis and reduces the risk of misdiagnosis, and thus, can provide practical assistance in the differential diagnosis of ICM and DCM, especially for hospitals that cannot carry out coronary angiography.
Methods
Study population
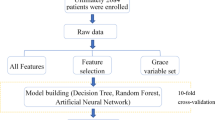
This study collected data for a total of 437 consecutive patients (199 with ICM and 238 with DCM) from the First Affiliated Hospital of Guangxi Medical University. The included patients were diagnosed with HF according to recently published guidelines [1]. All patients underwent invasive coronary angiography for diagnosis of ICM or DCM. DCM was defined as LV or biventricular contractile dysfunction and dilatation, rather than the presence of severe coronary artery disease and abnormal loading conditions. The diagnosis of dilated cardiomyopathy was confirmed after a systematic diagnostic procedure based on the definition of dilated cardiomyopathy published by the World Health Organization/International Society and Cardiology Federation and the latest Guidelines of China [19,20,21]. The diagnostic requirements were: (1) left ventricular ejection fraction (LVEF) decreased by < 45%, and left ventricular short axis shortening rate (LVFS) decreased by < 25%; (2) the left ventricular end diastolic volume or diameter of the standard map adjusted by body surface area and age was > 2 standard deviations (SDs) compared with the normal value; and (3) coronary angiography was used to evaluate coronary artery disease (CAD). However, even in the presence of CAD, the diagnosis of DCM can still be considered when the severity of HF is not proportional to the degree of CAD [22]. The inclusion criteria for ischemic cardiomyopathy were as follows: (1) history of symptomatic HF (New York Heart Association Functional grade II or higher) and a decrease in the LVEF by < 40% and (2) one or more of the following: a history of myocardial infarction or revascularization (coronary artery bypass graft or percutaneous coronary intervention), or with stenosis of 75% or more in the left main stem or left anterior descending artery, or with greater than 75% stenosis in two or more epicardial vessels [3, 20, 23]. To avoid influencing the results of the study, 38 patients with LVEF of 40–45% were excluded, and patients with missing echocardiographic and coronary angiographic data or with congenital heart disease, acute or sub-acute myocarditis, hypertrophic cardiomyopathy, primary valvular disease [24], infiltrative disease, restrictive cardiomyopathy, incomplete myocardial densification, infiltrative disease, and/or evidence of immune-mediated disease were excluded from this study. Ultimately, the study group consisted of 399 patients (199 with ICM and 200 with DCM). Figure 1 shows the patient selection and modeling process. This study was approved by the Ethics Committee of First Affiliated Hospital of Guangxi Medical University and was conducted according to the principles defined in the Declaration of Helsinki. Written informed consent was obtained from all individual participants included in this study.

Machine learning workflow for differentiation of ICM and DCM. A machine learning model was developed to differentiate between ICM and DCM. The machine method included feature selection using a statistical method and 10-fold cross-validation, and 4 different algorithms were compared. ICM: ischemic cardiomyopathy; DCM: dilated cardiomyopathy
Variables
Continuous variables are presented as mean ± SD and were compared with the t-test. Categorical variables are presented as percentages and were compared with the chi-square test. Non-normal distributed data were compared with the nonparametric test. Statistical analysis was performed using the R software package (R version 3.6.2). The feature selection method and ML algorithm were realized with R software package, and a P value < 0.05 was considered statistically significant. In the final analysis, a total of 16 variables (10 continuous variables and 6 categorical variables) were included, consisting of baseline demographics (3 variables) and echocardiographic outcome parameters (13 variables), including LV end-diastolic diameter (LVEDD), left atrial diameter (LAD), LV end-systolic diameter (LVESD), LVEF, LV posterior wall thickness (LVPWT), abnormal wall motion (2 variables DWMA (diffuse ventricular wall motion abnormalities) and SWMA (segmental ventricular wall motion abnormalities)), the ratio of peak E to peak A (E/A), cardiac output (CO), LV fractional shortening (FS), stroke volume (SV), moderate to severe mitral regurgitation (MR(m-s)), and moderate to severe multiple valve regurgitation (MVR(m-s)).
ML methodology
Data processing
For categorical variables, we implemented 1-hot-encoding, the process of dividing categorical values into zero and nonzero value pairs in order to convert variables into a format that can be used in the classification algorithm. In this method, the presence of missing values in variables presents a particular challenge. To handle this issue, the data with missing values for variables greater than 20% were removed, and the mean filling method was used for continuous variables with fewer missing values. Because of the fewer missing values, the filling had little impact on the overall distribution of variables. Categorical variables were predicted by combining the decision tree algorithm with other variables to obtain the predicted value to replace the missing value, which explained the statistical uncertainty related to interpolation.
Prior to the model construction, value correlation of variables was performed using the R software package (R version 3.6.2) to remove variables that may cause numerical instability, which leads to over-fitting of the model and/or affect model interpretability (Fig. 2). When the linear relationship between two variables is enhanced, the correlation coefficient tends to be 1 or -1. If when one variable increases, the other variable also increases, this indicates a positive correlation between them, and the correlation coefficient will be greater than 0. In contrast, if one variable increases and another variable decreases, a negative correlation is found between them and the correlation coefficient will be less than 0. If the correlation coefficient is equal to 0, this indicates there is no linear correlation between two variables. In this case, no variables were excluded based on the correlation coefficients and clinical significance.

Analysis of correlations between variables in the dataset. The inclusion of highly correlated variables can lead to numerical instability, obscure the interactions between different features, affect the interpretability of machine learning models, and also lead to overfitting. Therefore, it is best to exclude one of the two relevant variables. The correlation graph shows that the dataset did not contain many relevant variables, indicating that the model is simple and stable
Supervised ML approach
Predictive classifiers were developed for the data of the training set using four supervised ML methods: (1) logistic regression (LR), (2) extreme gradient boosting (XGBoost), (3) random forest (RAN), and (4) artificial neural network (NNET). The above-mentioned ML-based algorithms were used in the present study, because they represented a full-spectrum analysis method from the traditional LR used with statistical analysis to traditional ML algorithms (RAN), human neuron mimetic algorithms (NNET), and integrated enhancement (XGBoost) [25]. Boosting is used with increasing frequency in ML, because it involves sequential model creation, with each iteration aiming to correct a bug in the previous model. XGBoost, which is based on a gradient enhanced decision tree. We used a grid search merging cross-validation method to adjust the hyperparameters of the XGBoost model. We used the traditional grid search for simultaneous optimization of multiple parameters and specify the range of candidate values for each parameter of the model. As for tree booster, eta can improve the robustness of the model by reducing the weight of each step. Values of 0.1 and 0.3 were selected. Min_child_weight determines the minimum leaf node sample weight and adopts the combination of 1, 6, 10, and 12. Max_depth of the tree was set to 5, 6, 10, and 16, respectively. Gamma specifies the minimum loss function drop value required for node splitting. Subsample controls the proportion of random samples for each tree. This parameter was set to be 0.5, 0.7, and 1, respectively. Colsample_bytree controls the proportion of random samples for each tree. The default value was 1. Finally, we selected 13 times, 50 times, 100 times and 200 times of iterations and carried out model cross validation through grid arrangement and combination of all parameters. Generally, 10 times of cross validation was selected and multiple parameters were selected through observation accuracy and Kappa value. Finally, relevant parameters of the model were determined as follows: nround = 13, eta = 0.1, gamma = 0, subsample = 1, max depth = 5, colsample_bytree = 1, min_child_weight = 6 to produce good performance.
In addition, to evaluate the validity of each model, we also used the K-fold cross-validation technique on a random under-sampled subset of the entire dataset. We performed 10 cross-validations by randomly dividing the entire dataset into 10 parts for 10 iterations. In each iteration, we selected 9 parts as training data and 1 part as test set. The average result was 10% of test data unused for each model. The overall performance of the predictive model on the test set was evaluated by calculating the area under the curve (AUC) from the receiver operating characteristic curve. Finally, the calibration results for each model were reported. Calibration further reflected the stability of the model.
Results
Patient characteristics
The demographic and echocardiographic data of all patients in the ICM (n = 199) and DCM (n = 200) groups are summarized in Table 1. The ICM patients were older (mean age 64 years, P < 0.001) and included a higher proportion of men (88.4% vs. 75.5%, P = 0.001) compared with DCM patients. ICM patients also more often had significant segmental ventricular wall motion abnormalities (57.8% vs. 13.5%, P < 0.001), with an E/A ratio less than 1, while more DCM patients had diffuse ventricular wall motion abnormalities (98% vs. 67.8%, P < 0.001). Analysis of correlation parameters such as LAD, LVEDD, and LVESD suggested that heart chamber enlargement was more significant (P < 0.001). There were also significant differences in FS and LVEF between the two groups (P < 0.001).
ML analysis
Variable selection
Variable importance graphs were obtained after training with tuning parameters on the training data set (90% of total cohort). Figure 3 C shows the ranking of the most significant variables in the study cohort that differentiated ICM from DCM. In the best-performing XGBoost model, segmental wall motion anomalies were the most important predictor, followed by age, LVESD and LAD. Other significant variables worth noting were sex, BMI, and FS.

Ranking of feature importance. The importance graph for the variables was obtained after training with tuning parameters on the training data set. The most important variables in the study cohort for the differentiation of ICM and DCM are ranked. (A) random forest, (B) logistic regression, (C) extreme gradient boosting, and (D) artificial neural network
ML model
For the classification of ICM versus DCM, the performances of 4 ML models using all 16 features are presented in Tables 2 and 3; Figs. 4 and 5. For the XGBoost model, the average F-score was 0.73, with a sensitivity of 72%, specificity of 78%, the average accuracy of 75%, and AUC of the optimal subset of 0.934 (Table 2; Fig. 4). This model also showed good differentiation of ischemic/dilated cardiomyopathy in the externally validated cohort (AUC = 0.804, Fig. 5), with a sensitivity of 64% and a specificity of 93% (Table 3). Among the other models, the logistic regression model (AUC: internal verification 0.925, external verification 0.750), artificial neural network model (AUC: internal verification 0.893, external verification 0.780), and random forest model also had good discriminant performance (AUC: internal verification: 0.900, external validation: 0.761) (Fig. 5).

Receiver operating characteristic curves for prediction of ICM and DCM in the test sample. XGboost model presented a higher AUC for distinguishing ICM and DCM than all other models (LR, RAN and NNET). AUC: area under the curve; LR: logistic regression; NNET: neural network algorithm; RAN: random forest; XGboost: extreme gradient boosting

Receiver operating characteristic curves for prediction of ICM and DCM in the external validation. XGboost model presented a higher AUC for distinguishing ICM and DCM than all other models (LR, RAN and NNET). AUC: area under the curve; LR: logistic regression; NNET: neural network algorithm; RAN: random forest; XGboost: extreme gradient boosting
Calibration of the prediction models
Calibration was performed on this two-class classification task (identification of ICM versus DCM) for evaluating class assignment probability distribution. The XGBoost model’s Brier score, which measures the accuracy of the probabilistic predictions, for predicting cardiomyopathy in the optimal training set was 0.177, and that for the test set was 0.164, indicating that the ML-based model was well fitted and had good stability. Table 4 summarizes the Brier scores for the additional models.
Discussion
Here we present, to the best of our knowledge, the first accurate and robust diagnostic classification method for the differential diagnosis between DCM and ICM, which we developed using four different supervised ML algorithms. Compared with the traditional diagnostic methods, the use of ICM and DCM clinical models provides a powerful ML framework for distinguishing similar clinical manifestations between these two types of cardiomyopathy.
Previous literature
The high prevalence of HF and its association with diminished quality of life support the need for targeted treatment. The existing methods require certain techniques and equipment, which limits their clinical application for rapid diagnosis and effective treatment. In addition, it has been shown that in patients with new onset HF, the detection deficiencies identified in the study analysis were not limited to ischemic detection, indicating a larger problem that patients hospitalized with new HF may not have received appropriate HF testing [26]. In an increasingly cost-conscious era, there are concerns about overtesting in low-risk patients, and there is clearly underutilization of appropriate tests in high-risk patients. The use of ML algorithms for big data analysis in clinical research contributes to the development of widely applicable predictive models. As a non-invasive, low-cost and highly accurate tool, ML models may also help to better balance the relationship between risk assessment, cost-effectiveness and related testing, further helping community hospitals transfer patients most at risk or with a high probability of ICM to second-tier facilities, improving the detection rate of HF etiology, and strengthening timely referral management [27]. Previous studies have generated various models, including those to predict the readmission rate or death due to HF as well as prognosis of HF, and a diagnostic model for early recognition of HF. However, there are still some gaps in establishing a diagnostic model for predicting the etiology of HF [28,29,30,31]. ICM and DCM are both common causes of HF [4]. In a previous study for the classification and prediction of cardiomyopathy, Alimadadi et al. developed a ML prediction algorithm based on cardiac transcriptomic data [32]. The enrolled patients include 41 DCM patients, 47 ICM patients and 49 non-HF controls. The selected variables included related genes with strong contributions to cardiomyopathy. The model accuracy for differentiating ICM from DCM was as high as 85%. However, it may be difficult to apply in the clinic because of the difficulty in obtaining variables. In another study including 25 ICM patients, 13 DCM patients, and 30 elderly controls, Rodriguez et al. developed a ML model based on the analysis of electrocardiography (ECG) and blood pressure signal data [33]. The selected variables included the time series of beat-to-beat intervals (from the ECG signal) and end-systolic and diastolic pressure amplitude (from the BP signal). The best accuracy of the model for differentiating ICM from DCM was 84.2% [33]. However, the small sample size included in this study reduces the significance of the findings.
Discussion of main results
Studies have shown the potential for the improved diagnostic performance of ML algorithms for cardiomyopathy; however, their application has been flawed due to the difficulty in obtaining clinical results and the characteristics of patients from various examination methods. In the present study, we developed a recognition ML algorithm by using only easy-to-obtain, highly sensitive and specific echocardiographic features and compared the diagnostic performances of four ML models on an unknown dataset. We found that four ML algorithms, including NNET, RAN, the integrated enhancement algorithm XGboost, and LR, all performed well in predicting and classifying ICM and DCM, which may be attributed to the high diagnostic value of the original data itself. Among these four models, the XGboost algorithm had the highest discriminant performance. The results from both internal verification and external verification in our study support the notion that ML can integrate a number of variables to build advanced algorithms that distinguish ICM from DCM. In addition, we also found clinically important factors related to the two kinds of cardiomyopathy in a ML model, including wall motion abnormalities. From physiological and pathological studies, in DCM patients with myocardial extensive diffuse damage, with tension reducing myocardial relaxation the four cardiac chambers were expanded, showing diffuse ventricular wall motion abnormalities. Coronary vessel distribution in ICM patients is associated with myocardial ischemia, and heart damage is limited to one side of the left ventricle, generating segmental disturbance of ventricular wall movement. The clinical consensus is that the difference in ventricular wall motion between the two groups has differential diagnostic significance, which is basically consistent with the structure of our model and also proves the reliability of ML. Although the data integration process is complex, clinicians can still readily understand the final outcomes of the analysis obtained from using the prediction model.
The four different ML algorithms used different structures to predict the end point. Each model also ended up correctly predicting different patients, and thus, the important variables in the XGBoost model were different from those in the RAN, LR and NNET models, as seen in Fig. 3. Hence, different algorithms can show efficient mutual complementation. As a result, many researchers have attempted to combine prediction algorithms to achieve a high degree of predictive accuracy [34, 35]. This approach, which is referred to as ensemble algorithms, is the next frontier in our studies.
Clinical implications
Compared with traditional diagnostic methods, ML models serve as platforms for integrating multiple types of information [35], which may be more useful than one standardized interpretation of the data [36]. ML approaches do not underestimate the contribution of traditional echocardiography in the identification of cardiovascular diseases; rather, it provides a modern solution to integrate increasing numbers of parameters into the clinical database, thus simplifying the diagnostic process [37]. Considering the complexity of cardiovascular phenotypes and associated comorbidities, the potential of ML algorithms in personalized diagnosis and treatment cannot be overlooked [18]. Previously, we established a data-driven diagnostic system to accurately classify individual cases [38]. Despite the complexity of the data process, this process can be automated and easily performed in primary hospitals with limited conditions.
Limitations
Despite the outstanding strengths of the novel prediction model generated in this study, there are some limitations in our study. First, although we fit the ML algorithm by determining the weight of each variable, we were not able to explain the algorithm in terms of clinical end point decision making. For instance, if a patient was predicted to have ICM by the ML algorithm in this study, the reason for the prediction could not be determined. Hence, explaining ML remains to be explored. In addition, this study did not include a comparative analysis of expert inspection results and machine results, which is a very important limitation. However, the model developed in our study can provide a valuable reference for primary-level hospitals with limited resources and conditions, as well as for inexperienced novice doctors and outpatient physicians who are not cardiac specialists. Current practice relies on the clinician’s interpretation of echocardiograms of heart failure patients, which is a subjective judgment based on the clinician’s knowledge and experience. Therefore, the findings cannot be quantified and integrated into any quantitative estimate for risk stratification. In contrast, machine learning models facilitate automated interpretation and risk quantification of echocardiograms, reduce variability and cost between human observers, and minimize variation in access to medical service. We see the primary role of the developed model as complementing rather than replacing the existing work of clinical teams. However, a prospective randomized study is indeed needed in the future to evaluate and compare the clinical outcomes achieved with the use of ML- and human-guided diagnostic strategies to adapt clinical practice applications. Second, because the analysis included patients of single race and was conducted in only two hospitals in China, this study may be subject to selection bias. It is necessary to validate this model in patients with ischemic/dilated cardiomyopathy in other countries. In addition, although the developed model was validated in test sets and external validation queues, the possibility of overfitting cannot be completely ruled out. Third, patients were assigned to the ischemic CM group based on the burden of coronary artery disease as assessed by invasive coronary angiography and prior medical history. However, a recent cardiac MRI study found that 11.8% of patients were traditionally classified as having ischemic CM (via angiography) and 1.5% of patients with non-ischemic CM showed a mixed CM pattern on MRI [39]. Therefore, there may also be a subset of patients in our cohort with mixed CM, which is inconsistent with the binary results of our model. A mixed CM pattern may lead to false positives or false negatives in our model, thus reducing its prediction accuracy. Fourth, the sample size of this study was small and included patients with WMAs. WMAs account for a large proportion in both clinical consensus and model structure, making a significant contribution to the classification of both. However, this group of patients is more difficult to classify. Future studies may require a larger sample size and exclusion of this group of patients to provide more reliable results for clinical practice. Fifth, differences between the two may have an impact on judgment, including clinical diagnosis and machine diagnosis, such as different ranges for LVEF, ventricular volume, and inner diameter. We excluded patients with 40–45% LVEF to reduce such effects, but still could not completely avoid them. Sixth, we can try to explore other features, including more advanced and accurate non-invasive imaging data, which can further improve the prediction accuracy of the model, such as exercise echocardiography, PET, CT, and CMRI features [40]. Exercise echocardiography can differentiate VDIC from DM with a reasonable degree of diagnostic precision, measuring changes in overall and regional systolic function with exercise, but the relevant research is largely dependent on the technique used, which in turn requires an observer with extensive experience [41]. Although CT can be used to evaluate perfusion [42], left ventricular function [43], and scarring [44], it is mainly used for coronary artery imaging in the clinic. Especially in patients with chronic CAD, CT may be restricted by a high calcium load. Dedicated cardiac PET-CT systems can simultaneously assess the presence and extent of coronary artery anatomy, ischemia, and hibernation myocardium. Similarly, this approach may be hampered by high cumulative effective doses of ionizing radiation [45]. Studies have shown that CMR is useful for ventricular volume and function evaluation as well as scar visualization, with a high degree of accuracy in assessing systolic reserve and ischemia in a single examination in the case of no exposure to ionizing radiation [46]. The ML framework discussed herein relies on data-driven echocardiographic diagnosis, which opens up a promising frontier for a cardiomyopathy classification system. In the near future, we will attempt to include more comprehensive information, and multi-dimensional and high space data are expected to produce better results and increase the generalization of groups. Seventh, instead of using the original echocardiographic image signals, we used the features. Our goal was to make the ML model easier to use in general clinics and to achieve high-precision predictions under limited conditions. However, this approach may potentially limit the performance of the recognition algorithm. In our future studies, we plan to use raw echocardiographic image signals to predict cardiomyopathy.
Conclusion
We generated ML prediction models based on the parameters derived from echocardiography to differentiate ICM- and DCM-induced HF. Our study provides evidence that ML algorithms using demographic and echocardiographic features can distinguish ICM and DCM and have the potential for application in precision medicine in the clinic, providing a new possibility and reference for the etiological diagnosis of HF.
Data Availability
The datasets generated and analyzed during the current study are not publicly available due to none of the data types requiring uploading to a public repository but are available from the corresponding author on reasonable request.
Abbreviations
- ICM:
-
ischemic cardiomyopathy
- DCM:
-
dilated cardiomyopathy
- ML:
-
machine learning
- CM:
-
cardiomyopathy
- HF:
-
heart failure
- CAD:
-
coronary artery disease
- BMI:
-
body Mass Index
- LAD:
-
left atrial diameter
- LVEDD:
-
left ventricle end-diastolic diameter
- LVESD:
-
left ventricle end-systolic diameter
- LVPWT:
-
left ventricle posterior wall thickness
- DWMA:
-
diffuse ventricular wall motion abnormalities
- SWMA:
-
segmental ventricular wall motion abnormalities
- LVEF:
-
left ventricle ejection fraction
- E/A:
-
the ratio of peak E to peak A
- FS:
-
left ventricle fractional shortening
- SV:
-
stroke volume
- MR(m-s):
-
moderate to severe mitral regurgitation
- MVR(m-s):
-
moderate to severe multiple valve regurgitation
- CO:
-
cardiac output
- LR:
-
logistic regression
- NNET:
-
neural network algorithm
- RAN:
-
random forest
- XGboost:
-
extreme gradient boosting
- AUC:
-
area under the curve
- ECG:
-
electrocardiography
References
Ponikowski P, Voors AA, Anker SD, Bueno H, Cleland JG, Coats AJ, et al. 2016 ESC Guidelines for the diagnosis and treatment of acute and chronic heart failure: the Task Force for the diagnosis and treatment of acute and chronic heart failure of the European Society of Cardiology (ESC). Developed with the special contribution of the heart failure Association (HFA) of the ESC. Eur J Heart Fail. 2016;18:891–975.
Weintraub RG, Semsarian C, Macdonald P. Dilated cardiomyopathy. The Lancet. 2017;390:400–14.
Briceno N, Schuster A, Lumley M, Perera D. Ischaemic cardiomyopathy: pathophysiology, assessment and the role of revascularisation. Heart. 2016;102:397–406.
Ziaeian B, Fonarow GC. Epidemiology and aetiology of heart failure. Nat Rev Cardiol. 2016;13:368–78.
Sisakian H, Cardiomyopathies. Evolution of pathogenesis concepts and potential for new therapies. World J Cardiol. 2014;6:478–94.
Hare JM, Walford GD, Hruban RH, Hutchins GM, Deckers JW, Baughman KL. Ischemic cardiomyopathy: endomyocardial biopsy and ventriculographic evaluation of patients with congestive failure, dilated cardiomyopathy and coronary artery disease. J Am Coll Cardiol. 1992;20:1318–25.
Allman KC, Shaw LJ, Hachamovitch R, Udelson JE. Myocardial viability testing and impact of revascularization on prognosis in patients with coronary artery disease and left ventricular dysfunction: a meta-analysis. J Am Coll Cardiol. 2002;39:1151–8.
Bonow RO. The hibernating myocardium: implications for management of congestive heart failure. Am J Cardiol. 1995;75:17A–25A.
Westphal JG, Rigopoulos AG, Bakogiannis C, Ludwig SE, Mavrogeni S, Bigalke B, et al. The MOGE(S) classification for cardiomyopathies: current status and future outlook. Heart Fail Rev. 2017;22:743–52.
Ommen SR, Mital S, Burke MA, Day SM, Deswal A, Elliott P, et al. 2020 AHA/ACC Guideline for the diagnosis and treatment of patients with hypertrophic cardiomyopathy: executive summary: a report of the American College of Cardiology/American Heart Association Joint Committee on Clinical Practice Guidelines. Circulation. 2020;142:e533–e57.
Chrysohoou C, Greenberg M, Stefanadis C. Non-invasive methods in differentiating ischaemic from non-ischaemic cardiomyopathy. A review paper. Acta Cardiol. 2006;61:454–62.
Carey MG, Al-Zaiti SS, Canty JM Jr., Fallavollita JA. High-risk electrocardiographic parameters are ubiquitous in patients with ischemic cardiomyopathy. Ann Noninvasive Electrocardiol. 2012;17:241–51.
Walsh JL, AlJaroudi WA, Lamaa N, Abou Hassan OK, Jalkh K, Elhajj IH, et al. A speckle-tracking strain-based artificial neural network model to differentiate cardiomyopathy type. Scand Cardiovasc J. 2020;54:92–9.
Laszlo R, Kunz K, Dallmeier D, Klenk J, Denkinger M, Koenig W, et al. Accuracy of ECG indices for diagnosis of left ventricular hypertrophy in people > 65 years: results from the ActiFE study. Aging Clin Exp Res. 2016;29:875–84.
Cheitlin MD, Armstrong WF, Aurigemma GP, Beller GA, Bierman FZ, Davis JL, et al. ACC/AHA/ASE 2003 Guideline Update for the clinical application of Echocardiography: Summary Article. J Am Soc Echocardiogr. 2003;16:1091–110.
Nihoyannopoulos P, Vanoverschelde JL. Myocardial ischaemia and viability: the pivotal role of echocardiography. Eur Heart J. 2011;32:810–9.
Miyazawa AA. Artificial intelligence: the future for cardiology. Heart. 2019;105:1214.
Krittanawong C, Zhang H, Wang Z, Aydar M, Kitai T. Artificial Intelligence in Precision Cardiovascular Medicine. J Am Coll Cardiol. 2017;69:2657–64.
Pinto YM, Elliott PM, Arbustini E, Adler Y, Anastasakis A, Bohm M, et al. Proposal for a revised definition of dilated cardiomyopathy, hypokinetic non-dilated cardiomyopathy, and its implications for clinical practice: a position statement of the ESC working group on myocardial and pericardial diseases. Eur Heart J. 2016;37:421–34.
Zhao J, Yang S, Jing R, Jin H, Hu Y, Wang J, et al. Plasma metabolomic profiles differentiate patients with dilated cardiomyopathy and ischemic cardiomyopathy. Front Cardiovasc Med. 2020;7:597546.
Chinese Society of Cardiology CMCCG. Chinese guidelines for diagnosis and treatment of dilated. J J Clin Cardiol. 2018;34:421–34.
Japp AG, Gulati A, Cook SA, Cowie MR, Prasad SK. The diagnosis and evaluation of dilated cardiomyopathy. J Am Coll Cardiol. 2016;67:2996–3010.
elker GM, Shaw LK. CM. OC. A standardized definition of ischemic cardiomyopathy for use in clinical research. J Am Coll Cardiol. 2002;39:210–8.
Nishimura RA, Otto CM, Bonow RO, Carabello BA, Erwin JP 3rd, Guyton RA, et al. 2014 AHA/ACC guideline for the management of patients with valvular heart disease: a report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines. J Am Coll Cardiol. 2014;63:e57–185.
Deo RC. Machine learning in Medicine. Circulation. 2015;132:1920–30.
Doshi D, Ben-Yehuda O, Bonafede M, Josephy N, Karmpaliotis D, Parikh MA, et al. Underutilization of coronary artery Disease Testing among Patients hospitalized with New-Onset Heart failure. J Am Coll Cardiol. 2016;68:450–8.
Goecks J, Jalili V, Heiser LM, Gray JW. How machine learning will transform Biomedicine. Cell. 2020;181:92–101.
Awan SE, Bennamoun M, Sohel F, Sanfilippo FM, Dwivedi G. Machine learning-based prediction of heart failure readmission or death: implications of choosing the right model and the right metrics. ESC Heart Fail. 2019;6:428–35.
Kwon JM, Kim KH, Jeon KH, Kim HM, Kim MJ, Lim SM, et al. Development and Validation of Deep-Learning Algorithm for Electrocardiography-Based Heart failure identification. Korean Circ J. 2019;49:629–39.
Frizzell JD, Liang L, Schulte PJ, Yancy CW, Heidenreich PA, Hernandez AF, et al. Prediction of 30-Day all-cause readmissions in patients hospitalized for heart failure: comparison of machine learning and other statistical approaches. JAMA Cardiol. 2017;2:204–9.
Przewlocka-Kosmala M, Marwick TH, Dabrowski A, Kosmala W. Contribution of Cardiovascular Reserve to Prognostic categories of heart failure with preserved ejection fraction: a classification based on machine learning. J Am Soc Echocardiogr. 2019;32:604 – 15 e6.
Alimadadi A, Manandhar I, Aryal S, Munroe PB, Joe B, Cheng X. Machine learning-based classification and diagnosis of clinical cardiomyopathies. Physiol Genomics. 2020;52:391–400.
Rodriguez J, Schulz S, Voss A, Giraldo BF. Cardiovascular Coupling-Based classification of ischemic and dilated cardiomyopathy patients. Annu Int Conf IEEE Eng Med Biol Soc. 2019;2019:2007–10.
Dinh A, Miertschin S, Young A, Mohanty SD. A data-driven approach to predicting diabetes and cardiovascular disease with machine learning. BMC Med Inform Decis Mak. 2019;19:211.
Narula S, Shameer K, Salem Omar AM, Dudley JT, Sengupta PP. Machine-learning algorithms to automate morphological and functional assessments in 2D Echocardiography. J Am Coll Cardiol. 2016;68:2287–95.
Adler ED, Voors AA, Klein L, Macheret F, Braun OO, Urey MA, et al. Improving risk prediction in heart failure using machine learning. Eur J Heart Fail. 2020;22:139–47.
Kwon JM, Kim KH, Jeon KH, Park J. Deep learning for predicting in-hospital mortality among heart disease patients based on echocardiography. Echocardiography. 2019;36:213–8.
Al’Aref SJ, Anchouche K, Singh G, Slomka PJ, Kolli KK, Kumar A, et al. Clinical applications of machine learning in cardiovascular disease and its relevance to cardiac imaging. Eur Heart J. 2019;40:1975–86.
Kim EK, Chang SA, Choi JO, Glockner J, Shapiro B, Choe YH, et al. Concordant and discordant Cardiac magnetic resonance imaging delayed hyperenhancement patterns in patients with ischemic and non-ischemic cardiomyopathy. Korean Circ J. 2016;46:41–7.
Ananthasubramaniam K, Dhar R, Cavalcante JL. Role of multimodality imaging in ischemic and non-ischemic cardiomyopathy. Heart Fail Rev. 2011;16:351–67.
Peteiro Vázquez J, Monserrat Iglesias L, Vázquez Rey E, Calviño Santos R, Vázquez Rodríguez JM, Fabregas Casal R, et al. [Exercise echocardiography to differentiate dilated cardiomyopathy from ischemic left ventricular dysfunction]. Rev Esp Cardiol. 2003;56:57–64.
Blankstein R, Shturman LD, Rogers IS, Rocha-Filho JA, Okada DR, Sarwar A, et al. Adenosine-induced stress myocardial perfusion imaging using dual-source cardiac computed tomography. J Am Coll Cardiol. 2009;54:1072–84.
Raman SV, Shah M, McCarthy B, Garcia A, Ferketich AK. Multi–detector row cardiac computed tomography accurately quantifies right and left ventricular size and function compared with cardiac magnetic resonance. Am Heart J. 2006;151:736–44.
Gerber BL, Belge B, Legros GJ, Lim P, Poncelet A, Pasquet A, et al. Characterization of acute and chronic myocardial infarcts by multidetector computed tomography: comparison with contrast-enhanced magnetic resonance. Circulation. 2006;113:823–33.
Fazel R, Krumholz HM, Wang Y, Ross JS, Chen J, Ting HH, et al. Exposure to low-dose ionizing radiation from medical imaging procedures. N Engl J Med. 2009;361:849–57.
Schuster A, Morton G, Chiribiri A, Perera D, Vanoverschelde JL, Nagel E. Imaging in the management of ischemic cardiomyopathy: special focus on magnetic resonance. J Am Coll Cardiol. 2012;59:359–70.
Acknowledgements
None.
Funding
The grants for this study were supported stage-wise by the National Natural Science Foundation of China (grant no. 82260069 and 81860071), the China Postdoctoral Science Foundation (Grant No. 2021MD703817), and The Project for Innovative Research Team in Guangxi Natural Science Foundation (2018GXNSFGA281006).
Author information
Authors and Affiliations
Contributions
M Z and XC Z contributed to the conception and design of the study. M Z and Y L analyzed the data. M Z wrote the first draft of the manuscript. M Z, X L S, and YJ D contributed to data collection. All authors contributed to manuscript revision and read and approved the submitted version.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study was approved by the Ethics Committee of First Affiliated Hospital of Guangxi Medical University and was conducted according to the principles defined in the Declaration of Helsinki. Written informed consent was obtained from all individual participants included in this study.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Zhou, M., Deng, Y., Liu, Y. et al. Echocardiography-based machine learning algorithm for distinguishing ischemic cardiomyopathy from dilated cardiomyopathy. BMC Cardiovasc Disord 23, 476 (2023). https://doi.org/10.1186/s12872-023-03520-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12872-023-03520-4