
Abstract
Background
Colon cancer occurrence is increasing worldwide, making it the third most frequent cancer. Although many therapeutic options are available and quite efficient at the early stages, survival is strongly decreased when the disease has spread to other organs. The identification of molecular markers of colon cancer is likely to help understanding its course and, eventually, to uncover novel genes to be targeted by drugs. In this study, we compared gene expression in a set of 95 human colon cancer samples to that in 19 normal colon mucosae, focusing on 401 genes from 5 selected pathways (Apoptosis, Cancer, Cholesterol metabolism and lipoprotein signaling, Drug metabolism, Wnt/beta-catenin). Deregulation of mRNA levels largely matched that of proteins, leading us to build in silico protein networks, starting from mRNA levels, to identify key proteins central to network activity.
Results
Among the analyzed genes, 10.5% (42) had no reported link with colon cancer, including the SFRP1, IGF1 and ADH1B (down), and MYC and IL8 (up), whose encoded proteins were most interacting with other proteins from the same or even distinct networks. Analyzing all pathways globally led us to uncover novel functional links between a priori unrelated or rather remotely connected pathways, such as the Drug metabolism and the Cancer pathways or, even more strikingly, between the Cholesterol metabolism and lipoprotein signaling and the Cancer pathways. In addition, we analyzed the responsiveness of some of the deregulated genes essential to network activities, to chemotherapeutic agents used alone or in presence of Lovastatin, a lipid-lowering drug. Some of these treatments could oppose the deregulations occurring in cancer samples, including those of the CHECK2, CYP51A1, HMGCS1, ITGA2, NME1 or VEGFA genes.
Conclusions
Our network-based approach allowed discovering genes not previously known to play regulatory roles in colon cancer. Our results also showed that selected drug treatments might revert the cancer-specific deregulation of genes playing prominent roles within the networks operating to maintain colon homeostasis. Among those genes, some could constitute novel testable targets to eliminate colon cancer cells, either directly or, potentially, through the use of lipid-lowering drugs such as statins, in association with selected anticancer drugs.
Similar content being viewed by others


Background
Colorectal cancer (CRC) is the third most common cancer type, and affords several hundred thousand deaths each year [1]. The implementation of screening methods has contributed significantly to reduce mortality, thanks to the early detection of precursor lesions [2]. Many curative options are available, essentially at the early stages, but survival drops down to a few percent in case of metastases. The amount of knowledge that has accumulated for this cancer is rather large, yet the means to prevent its development are dramatically insufficient. The temporality of genetic and epigenetic changes that occur in the course of CRC onset have been largely documented, including data contributed recently by the TCGA consortium, and CRC-enriched signaling pathways have been identified [3]. Many gene expression studies have been performed with whole transcriptome coverage by DNA chips and, more recently, by RNA sequencing methods [4, 5]. A recent study analyzed a reported data set distinguishing colon cancer from healthy samples with the Gene Ontology (GO) and the Kyoto Encyclopedia of Genes and Genomes (KEGG), and built a protein-protein interaction network using the Cytoscape environment [6]. Such a network analysis allowed identifying central proteins, or hubs, belonging to over- or under-represented pathways. In silico protein network construction can indeed provide sensible information on homeostasis disruption linked to disease [7, 8]. Several parameters can be characterized, which help establishing hierarchies between proteins from a network or even belonging to a priori distantly related networks [9]. Functional interactions existing between the products of deregulated genes can add to the sole knowledge of fold-change deregulation, by highlighting relationships between genes and the presence of hub genes that concentrate information transmission. Such a strategy can bring to light potential novel targets towards which corrective approaches may be developed. In this study, we used a dedicated PCR approach to identify putative novel gene expression markers relevant for colon cancer. We selected specific PCR arrays from Qiagen™, representing 5 specific signaling pathways, to compare 95 individual CRC samples to a set of 19 normal mucosae. These assays analyzed the Apoptosis, Cancer, Cholesterol metabolism and lipoprotein signaling, Drug metabolism and Wnt/beta-catenin pathways. Such a PCR-based approach, although of relatively low throughput, has the advantage to allow investigating directly, in a robust and straightforward analysis, the expression of genes involved in a given functional pathway, in this case most linked to cancer. These data led us to build up protein networks into the Cytoscape environment. A number of hierarchical links involving most of the proteins, some with key positions, both within a given pathway and across pathways, were identified. We next treated human CRC cell lines by anticancer drugs alone or in combination with Lovastatin, a cholesterol-lowering drug that can efficiently trigger apoptosis, and analyzed marker gene expression in response to the drugs. This led us to sort out genes that responded to treatments in a way that would lead to restoring gene expression as it stands in non-cancerous cells. On the whole, we believe that this work based on an integrative approach, in addition to identifying new deregulated gene expression networks in colon cancer, highlighted some interactions between the protein products of these genes, and identified genes whose cancer-specific expression could be reverted by pharmacological agents already used in the treatment of patients, or that may be so by other drugs like Lovastatin.
Methods
Tissue samples processing
Colon and rectum tissue samples were obtained after surgical removal and informed patient consent. The samples were processed anonymously: 95 colorectal carcinomas (CRC) and 19 normal tissues (NT) were collected between 2005 and 2011. Detailed patient information is presented in Table 1. Additional patient characteristics, such as potential comorbidity conditions at time of diagnosis (obesity, drug absorption, tobacco exposure or alcohol consumption, etc.) were not available. H/E staining was performed for all samples, and the tumor content within cancer samples was above 80%. Repartition of low grade (stages 0, I and II) and high-grade carcinoma samples (stages III and IV) was homogeneous. The tissue fragments were stored in RNAlater® stabilization solution (Ambion, France), a reagent that prevents mRNA from degradation. Total RNA was extracted with the AllPrep DNA/RNA Mini kit (Qiagen, Courtaboeuf, France) from homogenized tissue samples (20 mg). RNA purity and integrity were evaluated by measuring the optical density ratio (A260/A280) and the RNA Integrity Number (RIN) using the RNA 6000 Nano LabChip and the 2100 BioAnalyzer (Agilent, Massy, France), respectively. Only RNA samples with a 28S/18S ratio > 1.0 and RIN > 5.0 were used.
Cultured cell lines and viability assay
HT-29 cells were cultured in Dulbecco’s modified Eagle’s medium (DMEM; 4.5 g/L glucose) (Lonza, Belgium) supplemented with 10% fetal bovine serum (FBS) (Gibco Invitrogen, U.S.A.), and HCT-116 cells were maintained in Dulbecco’s modified Eagle’s medium: Nutrient Mixture F-12 (DMEM/F-12) (Lonza, Belgium), supplemented with 5% FBS. All cultures were incubated at 37 °C in a humidified atmosphere containing 5% CO2. The medium was changed every 2 days, and cells were passaged using 0.05%/1 mM Trypsin/EDTA.
Cell viability was measured by the colorimetric MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) test (EMD Millipore, U.S.A.). Cells (103) were seeded in 100 μL medium into each well of 96-well plates and incubated for 24 h at 37 °C. The medium was then changed with fresh medium and exposed for 72 h to the drugs at the following concentrations: 1 and 10 μM Oxaliplatin (Teva Sante, France), 1 and 10 μM 5-Fluorouracil (Pfizer, U.S.A.) or 0.01 and 0.1 μM Camptothecin (Sigma, U.S.A.), in combination or not with 5 μM Lovastatin (TCI, Belgium). After the incubation periods, 10 μL of MTT reagent (5 mg/mL in PBS) were added into each well and cells were incubated at 37 °C for 3 h to allow MTT cleavage to occur. The reaction was then stopped with 100 μL isopropanol with 10% Triton X100 and 0.1 N hydrochloric acid. The absorbance was measured within 1 h, on a multiplate reader (Thermo Labsystems Multiskan spectrum, UV/Visible Microplate Reader, U.S.A.) with a test wavelength of 570 nm and a background wavelength of 690 nm.
The effects of drug treatment on transcripts levels were evaluated after 24 h of exposure to the drugs used, as mentioned above.
Gene expression profiling by PCR array
Reverse transcription of 4 μg of total RNA was performed using the High Capacity cDNA RT kit, according to the manufacturer’s instructions (Applied Biosystems). Differential expression between CRC and NT was evaluated by real-time PCR (ABI 7000 and ABI 7300, Applied Biosystems) with the RT2 Profiler PCR array (Qiagen) in 96-wells plates according to the manufacturer’s instructions (Qiagen). Five types of plates (to assay expression of 84 specific genes each) were used: Apoptosis (PAHS-012A), Cancer pathways (PAHS-033A), Lipoprotein signaling and cholesterol metabolism (PAHS-080Z), Drug metabolism (PAHS-002A) and Wnt signaling pathway (PAHS-043A). Gene composition and Qiagen’s functional gene groups are indicated in Additional file 1. Nineteen genes were both present in two different PCR arrays: 14 genes in the “Apoptosis” and “Cancer pathways” arrays (AKT1, APAF1, BAD, BAX, BCL2, BCL2L1, CASP8, CFLAR, FAS, TNF, TNFRSF10B, TNFRSF11A, TNFRSF25 and TP53), 2 genes in the “Cancer pathways” and “Wnt signaling pathway” arrays (JUN and MYC), 2 genes in the “Lipoprotein signaling and cholesterol metabolism” and “Drug Metabolism” arrays (APOE and CYB5R3) and 1 gene (LRP6) in the “Lipoprotein signaling and cholesterol metabolism” and “Wnt signaling pathway” arrays. Data analysis was performed using the ΔΔCt method [10] with normalization of the raw data to housekeeping genes. NormFinder [11] and geNorm [12] algorithms were used to determine the optimal normalization genes. A set of 4 invariant genes was used for each specific PCR array: BIRC2, CASP8, FADD and TP53BP2 for the Apoptosis array; MTA1, MTA2, PNN and RAF1 for the Cancer pathway array; LDLRAP1, OSBPL5, PMVK and SNX17 for the Lipoprotein signaling and cholesterol metabolism array; ADH5, ALDH, CES2 and SMARCAL1 for the Drug metabolism array and BTRC, CTBP1, EP300 and PPP2CA for the Wnt pathway array. Homogeneity of gene expression in the group of normal tissues was validated through splitting randomly the samples into two groups. Gene expression showed no significant difference in fold-changes between the two groups. Subsequently we used the mean of the pooled sample of NT for the calculation of fold-changes. Statistical analyses were performed using the R software. For each gene and each pathway, the difference in means of log2-transformed fold-change between NT and CRC was tested using a Student t-test. To control for multiple testing of the genes and pathways, the raw p-values obtained from this analysis were further adjusted with the q-value method. The false discovery rate (FDR)-adjusted q-values (FDR 5%) were calculated using the p.adjust command in R. Significance was set at q < 0.05 and fold-change limit was set at 1.7-fold. The Principal Component Analyses have been performed with R and the FactoMineR package (FactoMineR: An R Package for Multivariate Analysis, Journal of Statistical Software, March 2008, Volume 25, Issue 1).
Protein extraction and Western blot analysis
Acetone precipitation of proteins was performed from the flow-through of the RNeasy spin column, according to the manufacturer’s instructions (Qiagen). Precipitated cytosolic proteins were suspended in 500 μL of boiling buffer (1% SDS, 1 mM Na3VO4, 10 mM Tris-HCl pH 7.4) for Western blot application. Protein quantification was carried out using the Bio-Rad DC Protein Assay system and the absorbance was measured within 1 h on a multiplate reader (Thermo Labsystems Multiskan spectrum, UV/Visible Microplate Reader, U.S.A.) at 750 nm. Forty micrograms of protein extracts were boiled in Laemmli buffer for 5 min before separation by SDS-PAGE using 8 to 12% polyacrylamide gels and transfer onto a polyvinylidene fluoride membrane (GE Healthcare, France) by electroblotting. Membranes were saturated using Sea Block Blocking Buffer (Thermo Scientific, France) for 1 h at room temperature. Primary antibodies (Bcl-2, Casp7 (Cell Signaling Technology, U.S.A.); Adh1c, Bcl2l1, Gstp1, Igf1, Nme1 (Abnova, Taïwan); Fdps (Epitomics, France); Cyp39a1, Gpi, Hmgcs1, Pcsk9, Pkm2, Hsc70 (Santa Cruz Biotechnology, U.S.A.)) were diluted in blocking buffer (Odyssey LI-COR Biosciences, U.S.A.), containing 0.1% Tween®20. Membranes were incubated with the suitable primary antibody, at 4 °C overnight, then washed four times with PBS / 0.1% Tween®20 at room temperature and incubated with the infrared absorbing secondary antibody (Odyssey®) for 1 h at room temperature. Membranes were washed again and protein bands revealed using the Odyssey®-LI-COR imaging system. Twenty paired CRC/NT samples were analyzed for each antibody. Protein expression fold-changes between 20 CRC and paired NT were evaluated by densitometry analysis, using Hsc-70 as normalization control.
Immunohistochemistry
Formalin-fixed and paraffin-embedded samples of colorectal adenocarcinomas (n = 27, same patients used for Western blot analyses, Table 1) were used for the immuno-histochemical (IHC) analyses. For each case, a block containing adenocarcinoma areas and adjacent normal mucosa was selected. Immuno-histochemical techniques were performed for each case on 4 μm formalin-fixed and paraffin-embedded tissue sections mounted on Superfrost® Plus slides (Thermo Scientific, Saint-Herblain, France) dried overnight at 37 °C before processing. IHC processing was performed on a Ventana Benchmark XT® automated slide preparation system (Roche Diagnostics, Meylan, France) using the UltraView Universal DAB Detection Kit (Roche Diagnostics). The following antibodies were used: NME1 (mouse monoclonal antibody, clone 1D7, Abnova, 1:200 diluted), FDPS (rabbit monoclonal antibody, clone EPR4628, Epitomics, 1:400) and CCND1 (rabbit monoclonal antibody, clone SP4, Thermo Scientific). The slides were pre-treated with cell conditioner 1 (pH 8) for 30 min., followed by incubation with each antibody at 37 °C for 1 h. After washing, the slides were counterstained with one drop of hematoxylin for 12 min and one drop of bluing reagent for 4 min. Slides were next washed in water with dishwashing detergent and mounted. For each case, the staining intensities were compared between the adenocarcinoma glands and the adjacent normal glands. Staining of the stroma was also noted.
Real-time polymerase chain reaction
To evaluate the impact of drug treatment on the transcript content of HCT-116 and HT-29 cells, the differential expression of selected genes was analyzed by real time PCR (StepOne plus, Applied Biosystems). Briefly, total RNA was extracted using TRIzol® reagent according to the manufacturer’s instructions (Invitrogen, France). Two micrograms of total RNA were reverse-transcribed using random hexamers and M-MLV (Moloney-murine-leukaemia virus) reverse transcriptase (New England Biolabs, France). Retro-transcribed RNA (~5 ng cDNA) was used as template for all PCR experiments (except for the 18S ribosomal RNA which was amplified from ~5 pg cDNA). PCR was performed with the Power SYBR GREEN PCR Master Mix, according to the manufacturer’s instructions (Applied Biosystems). All conditions were normalized relative to the 18S control rRNA. Primer sequences (and amplicons lengths) were: TCACTTGTGGCCCAGATAGGC and GGATGCCTTTGTGGAACTGT for BCL2 (136pb), AGGTTTAGCGCCACTCTGC and GAGCCTCAACATCCGACTCC for CHECK2 (98pb), TGCAGTGTCTCGGGACTTCG and CGCTGGTGTGGAACATCTGG for CYP11A1 (218pb), TGGAGGAATGGTATACCCTG and TCCTTTGACTGATGATGAAGTAGC for CYP51A1 (310pb), ATTTGGAGCACAGGTGTCTA and TGTCATTGGTGACGCCATCT for DHCR7(163pb), CCTGCACACCTTCCAAAACG and GTAGCAGTCGGCATACAGC for DHCR24 (236pb), TGTGGCACCAGATGTCTTCG and GCTGTGGCAGGGAGTCTTG for HMGCS1(271pb),TTCTGCAGCTCTGTGTGAAGG and TTTGGGGTGGAAAGGTTTGG for IL8 (97pb), GGAGTGGCTTTCCTGAGAAC and GGTGAGAAGCTGGCTGAGAG for ITGA2 (285pb), AAAGGATTCCGCCTTGTTGGT and GCCCTGAGTGCATGTATTTCAC for NME1 (124pb), TCCTGTATGGCTCCGAGACC and ACACCACGTCATACTCATCC for NOS3 (114pb), CTCAGAGCGGAGAAAGCATTTG and TCACCGCCTCGGCTTGTCAC for VEGFA (259pb), TAGAGGGACAAGTGGCGTTC and CGCTGAGCCAGTCAGTGTAG for 18S (104pb). The results were analyzed using the ΔΔCt method [10]. Reactions were run in three independent experiments. Statistical analyses were performed using the Student t-test (p<0.05).
Data integration into biological networks
To obtain biological information about this set of deregulated genes in CRC as compared to NT, we searched for direct (physical) and indirect (functionally associated with no direct interaction) associations between 111 genes identified by transcriptome analysis in the STRING (Search Tool for the Retrieval of Interacting Genes/Proteins) database (version 10.5) [13]. Briefly, interactions in STRING are derived from multiple sources (experimental/biochemical experiments, curated databases, genomic context prediction, co-expression and automated text mining). Confidence level of edge, i.e. interaction between 2 nodes or protein/gene, is computed in a combined score (ranging from 0 to 1). Interactions and transcriptome data were imported and used for network generation in the Cytoscape environment (version 3.4) [14] focusing only on deregulated genes retrieved for each specific PCR array or on all deregulated genes. Topological analysis was performed with Network Analyzer to identify nodes parameters, including degree, clustering coefficient and betweenness centrality [15].
Results
RT-qPCR analysis of selected genes in colorectal tissue samples
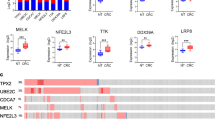
We selected five biological pathways to compare gene expression in 95 colorectal cancers (CRC) to a set of 19 normal colon tissues (NT) by RT-qPCR. These genes were classified in functional groups for each pathway (Additional file 1). We set the statistical variation threshold at a fold-change (FC) of 1.7, and a q-value of less than 0.05. From a comparison of 17 CRC to paired NT, 111 mRNAs (28% of the genes surveyed) were either up- or down-regulated in CRC samples (Fig. 1a). For each gene, we also show the % of samples with a FC of 1.7 or more (from 39% (SREBF1) to 100% (ADH1B and SFRP1)) and, secondly, with a FC of 2.0 or more (from 23% (FZD6) to 99% (ADH1B and SFRP1)). As shown in the “All” column, the data from the 17 paired samples matched well with the majority of data obtained from all samples, paired and unpaired (n = 95 CRC and 19 NT). There were 3 up- / 11 down-regulated genes in the Apoptosis array, 24 up- / 9 down-regulated genes in the Cancer pathway array, 21 up- / 8 down-regulated genes in the Lipoprotein signaling and cholesterol metabolism array, 14 up- / 9 down-regulated genes in the Drug metabolism array and 11 up- / 7 down-regulated genes in the Wnt pathway. The strongest increase in gene expression in CRC vs. NT was for the IL8 gene in paired samples (25.8-fold, 16-fold for unpaired), whereas the largest decrease was −10.5-fold for ADH1B in paired samples (−14.7-fold for unpaired).

Colorectal carcinoma classification based on gene expression profiling. a Heat map analysis of genes deregulated in colorectal carcinoma (CRC) as compared to normal tissue (NT). Representation of the log2-transformed fold-change values from 111 cellular genes identified as significantly deregulated in colorectal carcinoma (CRC), compared to normal tissue (NT), with an absolute fold-change >1.7 and a q-value <0.05 (Student-t-test adjusted by FDR) using Heat Map analysis (median centered data performed in Cluster and TreeView) [63]. Deregulated genes were shown according to the type of specific PCR array and ranging from decreasing fold-change (red color for up-regulated genes and green color for down-regulated genes): Apoptosis: 14 genes, Cancer pathway: 33 genes, Lipoprotein signaling and cholesterol metabolism: 29 genes, Drug metabolism: 23 genes, Wnt pathway: 18 genes. The mean fold-change expression obtained from paired samples analysis (n = 17 paired CRC and NT) and all samples (n = 95 CRC versus n = 19 NT) analysis is indicated on the right of each graphic. Percentage of CRC showing an absolute fold-change superior to 1.7 and superior to 2 is also indicated on the right of each graphic. A blue color for gene names indicates a deregulation (> 1.7-fold) observed in more than 75% of tumor samples. A (−) sign and a green font refer to down-regulation; a red font refers to up-regulation. b Hierarchical clustering of colorectal carcinoma and normal colon tissue based on the expression profile of 47 genes. Log2-transformed fold-change values from 47 genes fulfilling the criteria of deregulation in more than 75% of CRC samples (fold-change >1.7 and q < 0.05) were subjected to treatment by Cluster and Treeview using uncentered correlation and average linkage [63]. Red and green colors indicate transcript levels above and below the median values, respectively. NT, normal colon tissue (n = 19) and CRC, colorectal carcinoma (n = 95). Tumor samples are identified by a number followed by the Tumor Bank running number (S0, S1, S2, S3, S4) corresponding to a grading stage according to the pathological classification. Samples names above the dendrogram were colored according to stages: orange: 0 and I, red: II, purple: III and blue: IV. Genes identified by their gene symbol appear on the right side of each panel. Each column gives the gene expression profile of a sample, and each line indicates the variations in the level of expression of a given gene among tissue samples. The length of the branches on the trees forming the dendrograms on the top of each panel reflects the degree of similarity between samples; the longer the branch, the larger the difference in gene expression
Hierarchical clustering analysis from each PCR array based on differentially expressed genes showed an overall clear CRC vs. NT sample separation for all but the Apoptosis pathway (Additional file 2). About 1/4 CRC did not separate out from NT samples. The majority of samples from this set behaved similarly among the five clustering analyses. They could not be discriminated according to specific stages or other clinical data (data not shown). However, hierarchical marker clustering, taking 22 up- and 25 down-regulated genes that all displayed altered (>1.7-fold) expression in at least 75% of CRC samples, we could separate most CRC out of NT samples. Only 11 out of 95 (11%) CRC samples still clustered among the NT samples (Fig. 1b). In addition, no separation was observed among cancer samples according to stage (S1 to S4). Of note, the 47 genes-based clustering was highly contributed by genes from the Lipoprotein signaling and cholesterol metabolism and (n = 10) and Drug metabolism (n = 15) pathways. These data highlight the importance of these two pathways not previously associated to CRC pathogenesis (Table 2) but showing a deregulation in the majority of CRC.
Quite expectedly, several of our observed gene expression changes agreed with former reports, including a previous microarray study that we recently reported [16]. For all those mRNAs that were detected by both PCR arrays and microarrays, there was a 100% concordance in the up- or down-regulations observed (28 / 28 genes in CRC and 41 / 41 genes in colorectal adenomas). However, there were a few discrepancies between our studies and some other reported data (Additional file 3). For instance, BCL2 mRNA and protein levels were decreased in our samples (−2.18-fold in the PCR array, −2.71-fold in microarray in CRA, −5.62-fold in microarray in CRC and −4.76 in TCGA study [17]), but increased in the study of Sun et al. [18]. NOS3 mRNA was increased in our study and in that of Yagihashi et al. [19], but decreased in the study of Yu et al. [20] and showed no change in TCGA study [17]. GPX1 mRNA was increased in our study and in that of Yagublu et al. [21] and a small increase in TCGA study [17], but decreased in that of Nalkiran et al. [22].
To confront our data to other available data sets, we used these same genes to test for the correct separation of NT and CRC using the colorectal carcinoma cohort (COADREAD) from The Cancer Genome Atlas (TCGA) dataset (gdac.broadinstitute.org). We performed a Principal Component Analysis (PCA) using expression data for 47 genes selected in our study (fold-change >1.7, retrieved in more than 75% of CRC samples). Similarly to our hierarchical clustering (Fig. 1b), the PCA clearly distinguished two groups: NT and CRC, thereby validating the expression data from our sample (Fig. 2). Furthermore, based on expression of the same 47 genes, colon and rectum carcinoma were undistinguishable on PCA plots. A similar observation was made from PCA performed with other datasets (sets of deregulated genes related to functional Qiagen classification and all of the 111 deregulated genes identified with our samples) (Additional file 4). Finally, the colorectal tumors could not be separated according to the grading stage or the APC and KRAS mutational status of (Fig. 2, Additional file 4), indicating that the deregulated gene expression of genes identified with our samples was independent of tumor grades and of APC and KRAS mutations.

Principal Component Analysis of two independent datasets of colorectal carcinoma based on the expression of 47 genes. Principal component analysis (PCA) were performed based on the expression in normal tissue and colorectal carcinoma of 47 genes selected by the criteria of deregulation in more than 75% of CRC samples (fold-change >1.7 and q-value <0.05). PCA was performed on our samples dataset (19 NT and 95 CRC) (panels a and b) and on expression data retrieved from the colorectal cancer cohort from TCGA (gdac.broadinstitute.org) composed the TCGA tumor dataset. Repartition of grading stage of TCGA colorectal carcinoma was: I: 47, II: 86, III: 54 and IV: 34. Fifty-eight tumors were APC wild-type and 153 were mutated. One hundred and twenty-six were KRAS wild-type and 85 mutated.
Individuals were colored according to a category variable in each PCA plot: i) according to histological type (panels a and c); ii) according to grading stage (panels b and d); iii) and, only for the TCGA PCA plot, according to the mutational status of APC (panel e) and KRAS (panel f). Samples corresponding to NT and tumors that presented no available information about categorical variables were colored in black for panels b, d, e, f
A high proportion of the deregulated genes found here have not been reported in CRC, although the very large majority had been described in other cancers, mostly solid cancers, at the mRNA and/or protein levels (Table 2). Not surprisingly, the most deregulated genes had been identified in CRC in previous studies, whereas less deregulated genes were new. For instance, PCSK9 (6.3-fold increase), CEL (15.1-fold increase), or GSTM5 (3.9-fold decrease), despite their relatively important deregulation, had only been reported in lung cancer for PCSK9 [23], pancreatic and nasopharyngeal carcinoma for CEL [24, 25], Barret esophagus and glioblastoma for GSTM5 [26, 27]. Some of the deregulated genes had no known deregulation linked with cancer, including several genes that belonged to the Lipoprotein signaling and cholesterol metabolism pathway (DHCR7, CYP51A1, NSDHL, HMGCS1, IDI1, CNBP, APOL1, SREBF1), and a few from other pathways, like RHOU (Wnt signaling pathway) and EPDR1 (Cancer pathway).
To analyze the repercussion of these gene expression changes at the protein level, we selected a set of genes deregulated in more than of 75% of CRC (Fig. 1d). Western Blot analysis was conducted for 9 up-regulated (BCL2L1, CYP39A1, FDPS, GPI, GSTP1, HMGCS1, NME1, PCSK9 and PKM2) and 4 down-regulated genes (ADH1C, BCL2, CASP7 and IGF1). The majority of changes in mRNA (19 or 20 out of 20 analyzed CRC samples) levels were associated with comparable changes in protein levels, with the exception of PCSK9, which showed a large mRNA increase but a small and not significant drop at the protein level, and for GPI, which remained essentially unchanged in the majority of CRC (17 out 20) (Additional file 5: Figure S3). As expected, with respect to transcript levels, these changes occurred regardless of cancer stage, for both up- and down-regulated genes. In addition, BCL2L1 mRNA up-regulation, which occurred in 63% of CRC, was associated with a parallel increase in protein level. Immunohistochemistry analysis of NME1 and FDPS proteins conducted for 27 paired NT/CRC samples confirmed the deregulation observed in Western blot analyses (Additional file 6). CCND1, a Wnt signaling target gene that showed mRNA up-regulation in 82% of CRC, was also increased in CRC vs. NT in IHC analyses.
In silico protein pathways analyses
In view of the overall good correlation between mRNA and protein expression changes, we went on to build up presumptive protein-protein interaction maps. We used the STRING database and the Cytoscape environment to integrate interactions data into biological networks (Fig. 3) [13, 14]. STRING allows recognition of both demonstrated protein-protein interactions (PPI) or members of canonical pathways, predicted associations based on genomic context or co-expression and literature text mining. Symbols with large lines around proteins (nodes) reflect the genes showing mRNA deregulation in more than 75% of CRC, as compared to NT, and the colors indicate the level of up- and down-regulation by a color gradient (pink to dark red for up-regulated genes and light to dark green for down-regulated genes). Thick lines between proteins indicate interactions (edges) associated with a stronger probability (confidence score ranging between 0.4 and 1) and blue lines represent an experimentally validated physical PPI from the source of evidence for the considered edges.

Network building from deregulated genes in different types of PCR arrays. Interactions between sets of deregulated genes identified by transcriptome comparison of CRC and NT were retrieved from the STRING database (version 10.5) for 5 different PCR arrays: a) Apoptosis, b) Cancer pathway, c) Lipoprotein signaling and cholesterol metabolism, d) Drug metabolism and e) Wnt pathway. The interactions include direct (physical) and indirect (functional) associations. All interaction sources questioned by STRING were used and the minimum required interaction score was 0.4 (medium confidence). The blue color of edges indicated a physical interaction between 2 nodes. The thickness of edges was correlated with score confidence (large for high score). Color intensity of nodes was related to transcriptome deregulation (red for up-regulation and green for down-regulation in CRC as compared to NT). Genes showing a deregulation in more than 75% of CRC were characterized by a bold line of shape node. Star symbols indicated the node showing the highest number of interactions in the network
Taken individually, each network derived from the corresponding PCR array showed many functional associations (Fig. 3). Some proteins showed a prominent position in each pathway, characterized by a high number of degrees, i.e. interactions (also named “molecular hubs”), like BCL2, BCL2L1 and FAS (Apoptosis pathway), TP53 (Cancer pathway), FDFT1 (Lipoprotein signaling and cholesterol metabolism pathway), GSR (Drug metabolism pathway) and CTNNB1 (Wnt pathway). The Cancer and the Wnt pathways showed the highest density of interactions (33 nodes and 174 edges, and 18 nodes and 75 edges, respectively), while the apoptosis pathway showed the least interactions (14 nodes and 45 edges) (Fig. 3). Fusion of these 5 individual networks associated to each functional category (from each PCR array) led to a global network (111 nodes and 590 edges) (Additional file 7: Figure S5A). Thirty-nine percent of interactions included a physical PPI and 33.5% included components of canonical pathways. All 5 pathways showed many links with one another, with only very few proteins (8 out of 111, 7.2%) not apparently involved in any interaction with the other proteins. The original affiliations to each functional group were maintained with the Wnt pathway group at the top right, the Lipoprotein signaling and cholesterol metabolism to the bottom left, the Drug metabolism to the top left and mixed Apoptosis and Cancer groups to the center of the network. However, we also observed an association between these groups through connecting nodes (NME1, CTNNB1, CYP51A1, ABCC1, CYP2B6, NOS3, INSIG2, PCSK9, SREBF1, LDLR, NQO1 …).
To gain some insight into biological processes and identify key nodes in the global network, we performed a topological analysis with NetworkAnalyzer, a Cytoscape plugin [15]. The top-5 proteins with higher interactions, which are considered as molecular hubs, were TP53, MYC, CTTNB1, BCL2 and VEGFA (Additional file 7: Figure S5B) Fifty-two percent of the proteins had more than 10 interaction partners and 9% had more than 20 partners. These hub proteins were more important than poorly connected proteins (less than 11 partners, i.e. the median degree of nodes) and were relevant for colorectal cancer pathogenesis. To better identify important nodes, we looked at the clustering coefficient that refers to the tendency of node’s neighbors to connect to each other (Additional file 8: Figure S6A). Since many cellular processes are governed by subsets of components that form an interaction module, it is expected that nodes with high clustering coefficients should be biologically relevant. Interestingly, we could identify a group of 32 proteins, corresponding in majority to members of the Cancer pathway but also the Wnt pathway, which combined a higher degree and a higher clustering coefficient (Additional file 8: Figure S6B). To a lesser extent, we could note the presence of IL8, TIMP1 and MMP1 (Cancer group) that shared these characteristics.
A second set of proteins (n = 25), characterized by a high degree and a low clustering coefficient (inferior to the threshold, i.e. the median), retained our attention since this group concentrated: i) the hubs of the network (nodes with degree superior to 20) and ii) the top-10 proteins with highest betweenness centrality (TP53, CTNNB1, MYC, IGF1, CYP2B6, VEGFA, IL8, BCL2, LDLR and GSTP1), which measures the number of shortest paths going through a certain node. Therefore, nodes with the highest betweenness control most of the information flow in the network, representing the critical points of the network, or “bottlenecks”. Hub-bottleneck nodes are presumably most important for network organization, because their elimination leads to network disruption and, from a biological viewpoint, can abrogate the flow of information. In addition, many hubs qualified as hub-bottleneck nodes, like TP53, CTNNB1, MYC, IGF1, VEGFA, IL8, BCL2, but others, like CYP2B6, LDLR, GSTP1, should be viewed as hub-non-bottleneck nodes.
Finally, we selected 57 proteins, out of the 111 proteins from the global network (Additional file 7: Figure S5A), with a median degree above 11 (appearing to the right of the vertical dotted line, Additional file 8: Figure S6B), to build a new network (Fig. 4a). This network combined the proteins implicated in formation of topological modules i.e. with a locally dense neighborhood in the initial network (Fig. 4b). It also included other important proteins, molecular hubs, behaving or not as “bottlenecks”. Reduction of the initial network to these particular nodes highlighted the Wnt signaling, Lipoprotein signaling and cholesterol metabolism and Drug metabolism modules, characterized by a high level of interaction between these members and indirect relations with other components of the network through hub-bottleneck nodes. They could offer two angles of attack by therapeutic drugs. In the same way, targeting central nodes (as IL8, CHECK2, NME1, SFRP1, FGFR2, NOS3, CYPB6, SREBF1 etc.) could influence all partners belonging to Wnt signaling, Lipoprotein signaling and cholesterol metabolism or Drug metabolism modules. Hence, components of reduced networks (Fig. 4b) could be proposed as future targets by new chemotherapeutic strategies.

Network based on a restricted number of genes after selection of topological parameters. a Network based on 57 genes showing a node degree superior to 11 (median of node degree of 111 genes-based network). b Network based on 32 genes showing a node degree superior to 11 and a clustering coefficient superior to 0.55 (median of clustering coefficient of 111 genes-based network). Blue color of edges indicated a physical interaction between 2 nodes. The thickness of edges was correlated with the score confidence (large for a high score). The node shape illustrated the specific PCR array: Apoptosis: square, Cancer Pathway: hexagon, Lipoprotein signaling and cholesterol metabolism: circles, Drug metabolism: diamond and Wnt pathway: octagon. The color intensity of nodes was related to transcriptome deregulation (red for up-regulation and green for down-regulation in CRC as compared to NT). Genes showing a deregulation in more than 75% of CRC were characterized by bold line of shape node
Effect of drugs on selected gene expression
We have previously demonstrated the potential beneficial effects of Lovastatin, a competitive inhibitor of the 3-Hydroxy-Methyl-Glutaryl-CoA reductase (HMG-CoA reductase), the first enzyme from the cholesterol synthesis pathway, in gastric cancer. Indeed, although Lovastatin is not an anticancer agent, it triggered a high degree of apoptosis of the gastric carcinoma HGT-1 cell line, an effect linked to the shortage of intermediary metabolites from the cholesterol synthesis pathway [28]. In addition, we showed that a combination of Lovastatin and Docetaxel had a synergistic effect on induction of HGT-1 cells’ apoptosis. Here, Lovastatin (5 μM, 72 h) strongly reduced HCT116 cells’ viability. A stronger effect was observed for the combination of Lovastatin and 5-Fluorouracile or Camptothecin, even for lower concentrations of the drugs (Additional file 9: Figure S7A). However, the impact of Lovastatin on HT-29 viability was small (Additional file 9: Figure S7B) but it became quite clear when a higher concentration was used (12.5 μM; data not shown).
In order to see if any of the gene deregulations could be counteracted by these drugs, we looked at their effects on expression of a subset of genes in HCT116 and/or HT29 human colon cancer cells, according to their network behavior: hub-bottleneck genes such as BCL2, ITGA2, NOS3 and HMGCS1, hubs as VEGFA, high clustering coefficient genes like CHECK2 and IL8 and connector’s nodes i.e. genes showing edges between functional groups, like NME1, CYP51A1, CYP11A1 and DHCR7. Gene expression levels were analyzed after 24 h of treatment, i.e. before appearance of apoptotic features, by Oxaliplatin, 5-Fluorouracile or Camptothecin, either alone or combined with Lovastatin (Table 3). We observed that Oxaliplatin amplified the effects seen in CRC for most genes in both cell lines. 5-FU amplified the variation seen in CRC (for CHECK2 in HT-29, for NOS3 in HT-29 and HT-116), but opposed it (CHECK2 and CYP51A1 in HCT-116, VEGFA in HT-29, HMGCS1 in both cell lines). Camptothecin amplified the effects seen in cancer (CHECK2, BCL-2 and IL8), but opposed them for CYP51A1, ITGA2, DHCR7 or HMGCS1. Lovastatin had either no effect (in HCT116 cells), or opposed the deregulation of the CHECK2, NME1, ITGA2, IL8, NOS3 or VEGFA (in HT-29 cells). Lovastatin mixed with Oxaliplatin opposed the effect seen upon treatment by Oxaliplatin alone for the NME1 and ITGA2 genes in HCT-116 cells. The combination of Lovastatin and 5-Fluorouracile had a quite distinct effect from 5-Fluoruracile alone, especially for the NME1, ITGA2 or HMGCS1 genes that showed opposite regulations. The association of Lovastatin and Camptothecin essentially did not modify the response to Camptothecin, except for the NME1 gene that showed decreased expression in response to the combination of treatments.
Finally, we searched for potential associations between the four drugs and deregulated gene products in CRC by interrogating the STITCH database [29]. Interestingly, many links were identified with genes having a high degree or clustering coefficient, predicting a high impact on the network in the case of combination of Lovastatin and anticancer drugs (Additional file 10).
Discussion
In the present study, we analyzed expression of a subset of protein-encoding genes in human colon cancers, relative to that of healthy colon tissue. All tissue fragments were retrieved from surgical pieces from patients not taking anticancer drugs. Surprisingly, although we found already described alterations, about 10% of the changes had occurred in genes with no reported link with colon cancer. We identified 111 genes (28%), among a total set of 401 tested genes, which were deregulated in cancer samples (FC > 1.7, q-value < 0.05). Although, as expected, several of these gene deregulations occurring in CRC had already been reported, 48 (12%) had no known links with this cancer. All pathways showed clear clustering distinctions between CRC and NT, with the exception of the Apoptosis pathway, for which the FC and the number of deregulated genes were lower than for the other pathways. Although all changes were statistically significant, the proportion of genes with modified expression in at least 75% of the CRC samples ranged from 1/5 (Wnt pathway) up to 1/2 (Lipoprotein signaling and cholesterol metabolism, Drug metabolism pathways). Our clustering and PCA could not separate CRC samples according to stage (from I to IV), neither at the mRNA, nor at the protein levels, possibly due to the limited numbers of samples from each pathological category, or from the target genes surveyed (Figs. 1b and 2b). However, the same analyses conducted on an independent cohort (retrieved to TCGA) containing more samples for each grading stage (> 30 per category), have failed to discriminate CRC according to stage (Fig. 2d). Furthermore, our PCA performed with the TCGA cohort, based on expression data from different gene sets (all deregulated genes or subsets of genes from the Qiagen PCR Arrays) did not allow discriminating colon vs. rectal tumors or CRC samples according to APC or KRAS mutational status (Fig. 2, Additional file 4). Importantly, based on a set of 13 genes analyzed in 20 CRC/NT sample pairs, the same regulation occurred at both the mRNA and protein levels in at least 17 samples (roughly 90% concordance with mRNA levels), except for the PCSK9 protein, which showed no consistent protein expression pattern, or the GPI protein that remained essentially unchanged (Additional file 5: Figure S3C).
In view of the overall good correlation between mRNA and protein expression changes, we went on to build up putative protein-protein interaction maps, using the STRING interaction database. Looking at the individual PCR-based pathways, it appeared that almost all cancer proteins were densely connected. The MYC and the IL8 proteins were the most up-regulated proteins and the IGF1 and FGFR2 proteins the most down-regulated, in at least 75% of the CRC samples. These observations agreed with previous reports [30,31,32,33,34,35,36] and further emphasized the major roles played by these proteins in the control of CRC development. The SNCG protein was not interacting with any of the other proteins from the pathway, yet its down-regulation occurred in more than 75% of the CRC samples. Increased expression of the SNGG gene was suggested to be a predictor of poor prognosis in esophageal or endometrial cancer patients [37, 38], which is distinct from the negative regulation observed here. SFRP1, from the Wnt pathway, was strongly down-regulated in all CRC samples of this study, like most of the genes from the pathway, as opposed to the WNT2 and the CCND1 genes, which were increased in more than 75% of the CRC samples, agreeing with previous results [39, 40]. The number of PPI was also the highest for this network. The ADH1B and the GPX2 genes, from the Drug metabolism pathway, were the most down- and up-regulated, respectively, in more than 75% of the samples. Although the up-regulation of GPX2 by the Wnt pathway had been reported [41], this is the first instance of a deregulation in cancer for ADH1B mRNA. Similarly, no report was available for the regulation of ADH1C mRNA in cancer, and it showed no integration into our network except a physical interaction with ADH1B [42]. A recent publication identified ADH1B and XYLT1 (an enzyme implicated in the biosynthesis of glycosaminoglycan chains) as interaction partners of ADH1C using high-throughput affinity purification [42]. Furthermore, XYLT1 is an interaction partner of MYC [43], the second most up-regulated gene in CRC and the second top molecular hub identified in our network. MYC down-regulated ADH1B and ADH1C, pointing to a contribution of these detoxification enzymes in CRC pathogenesis. The Lipoprotein signaling and cholesterol metabolism pathway showed the highest number of proteins not interacting with any other protein. Notably, two of the most important changes occurred for PCSK9 (up-regulation) and NR1H4 (FXR) (down-regulation) mRNAs, both linked to the LDLR protein. Again, this is the first report of a clear link of PCSK9 up-regulation in colon cancer, while NR1H4 down-regulation has been reported to result from promoter methylation with this cancer [44]. Several of the unlinked proteins, including COLEC12 and STAB1, showed changes in at least 75% of the CRC samples. No report was available for the COLEC12 transcript, whereas PRKAA2 was shown to promote colon cancer [45]. STAB1 was increased in tumor infiltrating macrophages [46, 47]. Finally, a small number of affected proteins belonged in the Apoptosis pathway, with the down-regulation occurring in more than 75% of the CRC samples, including the CASP7, CASP5, the BCL2 and the CD27 proteins. Although CASP7 was decreased in colon cancer as a consequence of gene deletion, no data was available for the CASP5 or CD27 genes, while BCL2 was over-expressed in cancer tissue [18].
An expression change in any protein connected to another one, from either the same network or from a separate network, is expected to alter the functional links both with the immediate partner and, by association, with other activities of the network or of associated networks. Hence, one way to compensate for alterations occurring in one of these networks altered in CRC, could be to restore network function by mimicking the effect of the interactions, by drugs for instance. Despite the fact that the individual networks were quite identifiable by their position within the global network, strong links between the sub-networks - often with a high degree of confidence - could be readily distinguished. Importantly, among the main hub genes identified through the whole transcriptome-based approach [6], the IL8 gene was also sorted out here, suggesting that this gene is indeed a master gene strongly deregulated in CRC. None of the other top 10 hub genes from the global approach was surveyed in our PCR approach. However, the major hub genes identified here, such as TP53, MYC or BCL2, were not picked up by the global approach. However, the authors pointed to an enrichment of drug metabolism pathway from their down-regulated genes [6], confirming our results and further stressing the importance of components of this pathway in CRC pathogenesis.
Unexpected links were identified using different sources in the STRING database. For example, a physical interaction, indexed in the BioGRID database [48], was identified between NME1, which possesses geranyl and farnesyl pyrophosphate kinase activities, and FDPS, a key enzyme in isoprenoid biosynthesis, which catalyzes the formation of farnesyl diphosphate [49]. The up-regulation of transcript and protein levels in CRC highlights the importance of this complex for synthesizing secondary metabolites (geranyl and farnesyl pyrophosphates) in pathogenesis. Acting on the mevalonate pathway to reduce secondary metabolites and ultimately counteract the activities of FDPS and NME1 looks attracting as a novel cancer therapy, in agreement with several data [50]. Because NME1 transcript levels were decreased in colon cancer cells upon Lovastatin treatment (Table 3), it is tempting to speculate that acting on this complex might permit counteracting other members of the cholesterol metabolism pathway that act downstream of NME1, together with key cancer nodes identified by topology network analysis (MYC, CCND1, BCL2…) linked to NME1. Expectedly, blunting the mevalonate pathway in cancer cells would lead to apoptosis [28].
Another example of connection between 2 functional groups is the association, retrieved by text mining, between MYC and SREBF1 (Cancer and Lipid signaling and cholesterol metabolism, respectively). The authors showed that the SREBP-1 protein interacted with c-myc and facilitated its binding to downstream targets. This promoted mouse somatic cell reprogramming by expression of pluripotent genes [51]. In addition, we also identified the CASP7 (Apoptosis) gene as a positive target of the SREBP-1 protein [52].
NQO1, an NADPH dehydrogenase implicated in the detoxification system, has been shown to directly interact with NME1 and TP53 (Cancer Pathway) in studies retrieved from the BioGrid database [48]. Furthermore, NQO1 stabilized TP53 and partially inhibited its degradation under conditions of oxidative stress, making it a possible contributor to tumor development [53].
Putative homologs of CHECK2 and INSIG1 from Saccharomyces cerevisiae, of DHCR7 and CYP51A1 and of CYP2B6 and NSDHL were found to have physical interactions in Intact and BioGRID databases, which may explain the relations observed in our network [48, 54]. Putative homologs of CYP2B6 and NR1H4 in Caenorhabditis elegans were also found in these databases. Further studies will be required to understand this relation.
Visualization of our 113 genes-network, on the basis of two topological parameters, the degree and the clustering coefficient, highlighted 4 modules related to functional gene groups characterized by different levels of clustering coefficient and node degree (Additional file 8: Figure S6A). Because chemotherapy is commonly used to treat colon cancer patients, we looked at the activity of prototypic anticancer drugs and/or Lovastatin on expression of deregulated genes occupying central places within the networks. At first sight, a drug or drug combination that would oppose the observed deregulation of such “major genes” would be useful, provided these genes are central to normal tissue homeostasis. Conversely, drugs that would enhance the deregulation effects might be inappropriate, if the given genes are important for cancer initiation or progression, according to their expression level at baseline. The IL8 gene, which was clearly over-expressed in CRC, was further up-regulated in HT29 cells in response to all drugs or drug combinations, except in response to Lovastatin that decreased its expression. In the case of this important inflammatory mediator, it would appear that none of the common anticancer drugs used would contribute to inflammation reduction, at least at the colon cell level. Similarly, CHECK2 was always induced (HT29 cells), except in response to Lovastatin that decreased it. In this case, however, it might be beneficial to treat CRC patients bearing tumors addicted to CHECK2 for growth with common CRC anticancer drugs and CHECK2 inhibitors [55].
Several actions could be taken to reestablish normal transcript levels through using selected drugs: i) targeting proteins with high numbers of interactions (hubs proteins: large size on Additional file 8: Figure S6) or ii) targeting one protein in an interacting module (with a high clustering coefficient (yellow/orange color on Additional file 8: Figure S6) (for example the Wnt or the Lipoprotein signaling and cholesterol metabolism module). Interrogation of the STITCH database (Search Tools for Interactions of Chemicals) [29] for associations between deregulated genes in CRC and the 3 chemotherapeutic drugs tested in our study showed that these two types of genes could be targeted (Additional file 10). On the other hand, none of the drugs targeted members from the Wnt signaling pathway, except CCND1 that could be affected by Oxaliplatin and 5-Fluorouracile [56,57,58]. Anticancer agents targeting Wnt/β-catenin signaling have been developed in recent years and their use could be proposed in combination with classical colon cancer therapies. As expected, in light of our network analysis, the use of Lovastatin seems to be very interesting to target members of the Lipoprotein signaling and cholesterol metabolism pathway. Nevertheless, in absence of a comprehensive analysis of the effects of the drugs on several additional endpoints (apoptosis, gene/protein expression profiling, etc.), it is not possible to conclude on a direct role of the genes analyzed in the control of cell death and, specifically, to ascertain that the observed cytotoxicity after 72 h is directly linked to the deregulation of gene expression after 24 h of treatment. It should also be kept in mind that our data were obtained in a single cell model, and cannot be taken as fully conclusive, as this study did not address the point in the target population, i.e. human subjects. One possibility to approach this goal could be to conduct similar analyses in several other CRC cell lines and/or animals bearing human CRC (Additional file 11).
In addition, although our cohort of CRC subjects fitted well with the French population in terms of age at CRC diagnosis and sex ratio, several potentially confounding factors were not taken into account, as the data were not available to us. We should mention that we could not figure out if the RNAseq reported data on CRC patients from TCGA have taken any of these concerns into account. These included obesity (BMI above 30), which affects roughly 18.7% of the population over 65 in France, or concomitant drug absorption that occurs in virtually all subjects of 65 and above. Obesity and drugs (antidiuretics, cholesterol-lowering drugs, anti-diabetic drugs, or any combination of these) are known to modulate gene expression, at least in experimental models [59,60,61,62], but probably less so than the chemotherapeutic drugs used in our study, which act genome-wide. Although it would certainly be a major challenge to constitute homogenous groups of CRC patients on a given drug, at a given dose, for a given time, smoking or not, having alcohol drinking habits, etc., with or without a BMI above 30, this would in principle be attainable. One way to approach such composite situations could possibly be to use model systems, as CRC cells in culture or laboratory animals bearing human tumors. Further prospective recruitment of CRC patients could readily compare lean vs. obese patients using the methodology used in this manuscript.
Conclusion
In conclusion to this work, we have obtained selected transcriptome data through a dedicated PCR array approach comparing colon cancer samples with normal colon mucosae. Although the majority of deregulations were already reported in CRC, about 10% of those events were not known to occur in colon cancer or in cancer in general. The genes most important to the structures of the networks indeed were known to play important regulatory roles in the tumors, but some were new, most significantly from the Lipoprotein signaling and cholesterol metabolism pathway. Use of this array also revealed that eight genes from this pathway were not engaged in any interaction within the corresponding sub-network or with other networks. This observation, which likely reflects the smaller number of investigations on those genes, also opens the path to uncover novel targets to treat colon cancer, potentially through the use of lipid-lowering drugs such as statins whose potential in combination with anticancer drugs is under scrutiny through clinical trials, as recorded at the National Cancer Institute.
Abbreviations
- CRC:
-
Colorectal carcinoma
- FC:
-
Fold-change
- NT:
-
Normal Tissue
- STITCH:
-
Search Tools for Interactions of Chemicals
- STRING:
-
Search Tool for the Retrieval of Interacting Genes/Proteins
References
Mortality GBD, Causes of Death C. Global, regional, and national age-sex specific all-cause and cause-specific mortality for 240 causes of death, 1990-2013: a systematic analysis for the global burden of disease study 2013. Lancet. 2015;385(9963):117–71.
Kuipers EJ, Grady WM, Lieberman D, Seufferlein T, Sung JJ, Boelens PG, van de Velde CJ, Watanabe T. Colorectal cancer. Nat Rev Dis Primers. 2015;1:15065.
Cancer Genome Atlas N. Comprehensive molecular characterization of human colon and rectal cancer. Nature. 2012;487(7407):330–7.
Bianchini M, Levy E, Zucchini C, Pinski V, Macagno C, De Sanctis P, Valvassori L, Carinci P, Mordoh J. Comparative study of gene expression by cDNA microarray in human colorectal cancer tissues and normal mucosa. Int J Oncol. 2006;29(1):83–94.
Peng L, Bian XW, Li DK, Xu C, Wang GM, Xia QY, Xiong Q. Large-scale RNA-Seq Transcriptome analysis of 4043 cancers and 548 normal tissue controls across 12 TCGA cancer types. Sci Rep. 2015;5:13413.
Liang B, Li C, Zhao J. Identification of key pathways and genes in colorectal cancer using bioinformatics analysis. Med Oncol. 2016;33(10):111.
Chen G, Li H, Niu X, Li G, Han N, Li X, Li G, Liu Y, Sun G, Wang Y, et al. Identification of key genes associated with colorectal cancer based on the transcriptional network. Pathol Oncol Res. 2015;21(3):719–25.
Barabasi AL, Gulbahce N, Loscalzo J. Network medicine: a network-based approach to human disease. Nat Rev Genet. 2011;12(1):56–68.
Yu H, Kim PM, Sprecher E, Trifonov V, Gerstein M. The importance of bottlenecks in protein networks: correlation with gene essentiality and expression dynamics. PLoS Comput Biol. 2007;3(4):e59.
Schmittgen TD, Livak KJ. Analyzing real-time PCR data by the comparative C(T) method. Nat Protoc. 2008;3(6):1101–8.
Andersen CL, Jensen JL, Orntoft TF. Normalization of real-time quantitative reverse transcription-PCR data: a model-based variance estimation approach to identify genes suited for normalization, applied to bladder and colon cancer data sets. Cancer Res. 2004;64(15):5245–50.
Vandesompele J, De Preter K, Pattyn F, Poppe B, Van Roy N, De Paepe A, Speleman F. Accurate normalization of real-time quantitative RT-PCR data by geometric averaging of multiple internal control genes. Genome Biol. 2002;3(7):RESEARCH0034.
Szklarczyk D, Franceschini A, Wyder S, Forslund K, Heller D, Huerta-Cepas J, Simonovic M, Roth A, Santos A, Tsafou KP, et al. STRING v10: protein-protein interaction networks, integrated over the tree of life. Nucleic Acids Res. 2015;43(Database issue):D447–52.
Shannon P, Markiel A, Ozier O, Baliga NS, Wang JT, Ramage D, Amin N, Schwikowski B, Ideker T. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Res. 2003;13(11):2498–504.
Assenov Y, Ramirez F, Schelhorn SE, Lengauer T, Albrecht M. Computing topological parameters of biological networks. Bioinformatics. 2008;24(2):282–4.
Pesson M, Volant A, Uguen A, Trillet K, De La Grange P, Aubry M, Daoulas M, Robaszkiewicz M, Le Gac G, Morel A, et al. A gene expression and pre-mRNA splicing signature that marks the adenoma-adenocarcinoma progression in colorectal cancer. PLoS One. 2014;9(2):e87761.
Muzny DM, Bainbridge MN, Chang K, Dinh HH, Drummond JA, Fowler G, Kovar CL, Lewis LR, Morgan MB, Newsham IF, et al. Comprehensive molecular characterization of human colon and rectal cancer. Nature. 2012;487(7407):330–7.
Sun N, Meng Q, Tian A. Expressions of the anti-apoptotic genes Bag-1 and Bcl-2 in colon cancer and their relationship. Am J Surg. 2010;200(3):341–5.
Yagihashi N, Kasajima H, Sugai S, Matsumoto K, Ebina Y, Morita T, Murakami T, Yagihashi S. Increased in situ expression of nitric oxide synthase in human colorectal cancer. Virchows Arch. 2000;436(2):109–14.
Yu JX, Cui L, Zhang QY, Chen H, Ji P, Wei HJ, Ma HY. Expression of NOS and HIF-1alpha in human colorectal carcinoma and implication in tumor angiogenesis. World J Gastroenterol. 2006;12(29):4660–4.
Yagublu V, Arthur JR, Babayeva SN, Nicol F, Post S, Keese M. Expression of selenium-containing proteins in human colon carcinoma tissue. Anticancer Res. 2011;31(9):2693–8.
Nalkiran I, Turan S, Arikan S, Kahraman OT, Acar L, Yaylim I, Ergen A. Determination of gene expression and serum levels of MnSOD and GPX1 in colorectal cancer. Anticancer Res. 2015;35(1):255–9.
Demidyuk IV, Shubin AV, Gasanov EV, Kurinov AM, Demkin VV, Vinogradova TV, Zinovyeva MV, Sass AV, Zborovskaya IB, Kostrov SV. Alterations in gene expression of proprotein convertases in human lung cancer have a limited number of scenarios. PLoS One. 2013;8(2):e55752.
Li H, Ren CP, Tan XJ, Yang XY, Zhang HB, Zhou W, Yao KT. Identification of genes related to nasopharyngeal carcinoma with the help of pathway-based networks. Acta Biochim Biophys Sin Shanghai. 2006;38(12):900–10.
Reuss R, Aberle S, Klingel K, Sauter M, Greschniok A, Franke FE, Padberg W, Blin N. The expression of the carboxyl ester lipase gene in pancreas and pancreatic adenocarcinomas. Int J Oncol. 2006;29(3):649–54.
Etcheverry A, Aubry M, de Tayrac M, Vauleon E, Boniface R, Guenot F, Saikali S, Hamlat A, Riffaud L, Menei P, et al. DNA methylation in glioblastoma: impact on gene expression and clinical outcome. BMC Genomics. 2010;11:701.
Peng DF, Razvi M, Chen H, Washington K, Roessner A, Schneider-Stock R, El-Rifai W. DNA hypermethylation regulates the expression of members of the mu-class glutathione S-transferases and glutathione peroxidases in Barrett's adenocarcinoma. Gut. 2009;58(1):5–15.
Follet J, Corcos L, Baffet G, Ezan F, Morel F, Simon B, Le Jossic-Corcos C. The association of statins and taxanes: an efficient combination trigger of cancer cell apoptosis. Br J Cancer. 2012;106(4):685–92.
Szklarczyk D, Santos A, von Mering C, Jensen LJ, Bork P, Kuhn M. STITCH 5: augmenting protein-chemical interaction networks with tissue and affinity data. Nucleic Acids Res. 2016;44(D1):D380–4.
Sikora K, Chan S, Evan G, Gabra H, Markham N, Stewart J, Watson J. C-myc oncogene expression in colorectal cancer. Cancer. 1987;59(7):1289–95.
Garte SJ. The c-myc oncogene in tumor progression. Crit Rev Oncog. 1993;4(4):435–49.
Nastase A, Paslaru L, Herlea V, Ionescu M, Tomescu D, Bacalbasa N, Dima S, Popescu I. Expression of interleukine-8 as an independent prognostic factor for sporadic colon cancer dissemination. J Med Life. 2014;7(2):215–9.
Jiang W, Li X, Rao S, Wang L, Du L, Li C, Wu C, Wang H, Wang Y, Yang B. Constructing disease-specific gene networks using pair-wise relevance metric: application to colon cancer identifies interleukin 8, desmin and enolase 1 as the central elements. BMC Syst Biol. 2008;2:72.
Zhang R, Xu GL, Li Y, He LJ, Chen LM, Wang GB, Lin SY, Luo GY, Gao XY, Shan HB. The role of insulin-like growth factor 1 and its receptor in the formation and development of colorectal carcinoma. J Int Med Res. 2013;41(4):1228–35.
Tsimafeyeu I, Khasanova A, Stepanova E, Gordiev M, Khochenkov D, Naumova A, Varlamov I, Snegovoy A, Demidov L. FGFR2 overexpression predicts survival outcome in patients with metastatic papillary renal cell carcinoma. Clin Transl Oncol. 2016;
Timsah Z, Berrout J, Suraokar M, Behrens C, Song J, Lee JJ, Ivan C, Gagea M, Shires M, Hu X, et al. Expression pattern of FGFR2, Grb2 and Plcgamma1 acts as a novel prognostic marker of recurrence recurrence-free survival in lung adenocarcinoma. Am J Cancer Res. 2015;5(10):3135–48.
Tastekin D, Kargin S, Karabulut M, Yaldiz N, Tambas M, Gurdal N, Tatli AM, Arslan D, Gok AF, Aykan F. Synuclein-gamma predicts poor clinical outcome in esophageal cancer patients. Tumour Biol. 2014;35(12):11871–7.
Mhawech-Fauceglia P, Wang D, Syriac S, Godoy H, Dupont N, Liu S, Odunsi K. Synuclein-gamma (SNCG) protein expression is associated with poor outcome in endometrial adenocarcinoma. Gynecol Oncol. 2012;124(1):148–52.
Park JK, Song JH, He TC, Nam SW, Lee JY, Park WS. Overexpression of Wnt-2 in colorectal cancers. Neoplasma. 2009;56(2):119–23.
Chen Y, Jiang J, Zhao M, Luo X, Liang Z, Zhen Y, Fu Q, Deng X, Lin X, Li L, et al. microRNA-374a suppresses colon cancer progression by directly reducing CCND1 to inactivate the PI3K/AKT pathway. Oncotarget. 2016;7(27):41306–19.
Kipp AP, Muller MF, Goken EM, Deubel S, Brigelius-Flohe R. The selenoproteins GPx2, TrxR2 and TrxR3 are regulated by Wnt signalling in the intestinal epithelium. Biochim Biophys Acta. 2012;1820(10):1588–96.
Huttlin EL, Ting L, Bruckner RJ, Gebreab F, Gygi MP, Szpyt J, Tam S, Zarraga G, Colby G, Baltier K, et al. The BioPlex network: a systematic exploration of the human Interactome. Cell. 2015;162(2):425–40.
Agrawal P, Yu K, Salomon AR, Sedivy JM. Proteomic profiling of Myc-associated proteins. Cell Cycle. 2010;9(24):4908–21.
Bailey AM, Zhan L, Maru D, Shureiqi I, Pickering CR, Kiriakova G, Izzo J, He N, Wei C, Baladandayuthapani V, et al. FXR silencing in human colon cancer by DNA methylation and KRAS signaling. Am J Physiol Gastrointest Liver Physiol. 2014;306(1):G48–58.
Fisher KW, Das B, Kim HS, Clymer BK, Gehring D, Smith DR, Costanzo-Garvey DL, Fernandez MR, Brattain MG, Kelly DL, et al. AMPK promotes aberrant PGC1beta expression to support human colon tumor cell survival. Mol Cell Biol. 2015;35(22):3866–79.
Karikoski M, Marttila-Ichihara F, Elima K, Rantakari P, Hollmen M, Kelkka T, Gerke H, Huovinen V, Irjala H, Holmdahl R, et al. Clever-1/stabilin-1 controls cancer growth and metastasis. Clin Cancer Res. 2014;20(24):6452–64.
David C, Nance JP, Hubbard J, Hsu M, Binder D, Wilson EH. Stabilin-1 expression in tumor associated macrophages. Brain Res. 2012;1481:71–8.
Chatr-Aryamontri A, Breitkreutz BJ, Heinicke S, Boucher L, Winter A, Stark C, Nixon J, Ramage L, Kolas N, O'Donnell L, et al. The BioGRID interaction database: 2013 update. Nucleic Acids Res. 2013;41(Database issue):D816–23.
Kristensen AR, Gsponer J, Foster LJ. A high-throughput approach for measuring temporal changes in the interactome. Nat Methods. 2012;9(9):907–9.
Mullen PJ, Yu R, Longo J, Archer MC, Penn LZ. The interplay between cell signalling and the mevalonate pathway in cancer. Nat Rev Cancer. 2016;16(11):718–31.
Wu Y, Chen K, Liu X, Huang L, Zhao D, Li L, Gao M, Pei D, Wang C, Liu X. Srebp-1 interacts with c-Myc to enhance somatic cell reprogramming. Stem Cells. 2016;34(1):83–92.
Gibot L, Follet J, Metges JP, Auvray P, Simon B, Corcos L, Le Jossic-Corcos C. Human caspase 7 is positively controlled by SREBP-1 and SREBP-2. Biochem J. 2009;420(3):473–83.
Asher G, Lotem J, Kama R, Sachs L, Shaul Y. NQO1 stabilizes p53 through a distinct pathway. Proc Natl Acad Sci U S A. 2002;99(5):3099–104.
Orchard S, Ammari M, Aranda B, Breuza L, Briganti L, Broackes-Carter F, Campbell NH, Chavali G, Chen C, Del-Toro N, et al. The MIntAct project--IntAct as a common curation platform for 11 molecular interaction databases. Nucleic Acids Res. 2014;42(Database issue):D358–63.
Pommier Y, Sordet O, Rao VA, Zhang H, Kohn KW. Targeting chk2 kinase: molecular interaction maps and therapeutic rationale. Curr Pharm Des. 2005;11(22):2855–72.
Yang C, Liu HZ, Fu ZX. Effects of PEG-liposomal oxaliplatin on apoptosis, and expression of Cyclin a and Cyclin D1 in colorectal cancer cells. Oncol Rep. 2012;28(3):1006–12.
Adamsen BL, Kravik KL, Clausen OP, De Angelis PM. Apoptosis, cell cycle progression and gene expression in TP53-depleted HCT116 colon cancer cells in response to short-term 5-fluorouracil treatment. Int J Oncol. 2007;31(6):1491–500.
De Angelis PM, Svendsrud DH, Kravik KL, Stokke T. Cellular response to 5-fluorouracil (5-FU) in 5-FU-resistant colon cancer cell lines during treatment and recovery. Mol Cancer. 2006;5:20.
Batsaikhan BE, Yoshikawa K, Kurita N, Iwata T, Takasu C, Kashihara H, Shimada M. Cyclopamine decreased the expression of sonic hedgehog and its downstream genes in colon cancer stem cells. Anticancer Res. 2014;34(11):6339–44.
Chin CC, Li JM, Lee KF, Huang YC, Wang KC, Lai HC, Cheng CC, Kuo YH, Shi CS. Selective beta2-AR blockage suppresses colorectal cancer growth through regulation of EGFR-Akt/ERK1/2 signaling, G1-phase arrest, and apoptosis. J Cell Physiol. 2016;231(2):459–72.
Delage B, Rullier A, Capdepont M, Rullier E, Cassand P. The effect of body weight on altered expression of nuclear receptors and cyclooxygenase-2 in human colorectal cancers. Nutr J. 2007;6:20.
Liu YZ, Wang KQ, Ji DH, Zhang LC, Bi M, Shi BY. Correlations of MC4R and MSH2 expression with obesity in colon cancer patients. Eur Rev Med Pharmacol Sci. 2017;21(9):2108–13.
Eisen MB, Spellman PT, Brown PO, Botstein D. Cluster analysis and display of genome-wide expression patterns. Proc Natl Acad Sci U S A. 1998;95(25):14863–8.
Sun X, Essalmani R, Day R, Khatib AM, Seidah NG, Prat A. Proprotein convertase subtilisin/kexin type 9 deficiency reduces melanoma metastasis in liver. Neoplasia. 2012;14(12):1122–31.
Hilvo M, Denkert C, Lehtinen L, Muller B, Brockmoller S, Seppanen-Laakso T, Budczies J, Bucher E, Yetukuri L, Castillo S, et al. Novel theranostic opportunities offered by characterization of altered membrane lipid metabolism in breast cancer progression. Cancer Res. 2011;71(9):3236–45.
Khenjanta C, Thanan R, Jusakul A, Techasen A, Jamnongkan W, Namwat N, Loilome W, Pairojkul C, Yongvanit P. Association of CYP39A1, RUNX2 and oxidized alpha-1 antitrypsin expression in relation to cholangiocarcinoma progression. Asian Pac J Cancer Prev. 2014;15(23):10187–92.
Meerzaman DM, Yan C, Chen QR, Edmonson MN, Schaefer CF, Clifford RJ, Dunn BK, Dong L, Finney RP, Cultraro CM et al: Genome-wide transcriptional sequencing identifies novel mutations in metabolic genes in human hepatocellular carcinoma. Cancer Genomics Proteomics 2014, 11(1):1-12.
Hlavac V, Brynychova V, Vaclavikova R, Ehrlichova M, Vrana D, Pecha V, Trnkova M, Kodet R, Mrhalova M, Kubackova K, et al. The role of cytochromes p450 and aldo-keto reductases in prognosis of breast carcinoma patients. Medicine (Baltimore). 2014;93(28):e255.
Zhang MH, Shen QH, Qin ZM, Wang QL, Chen X. Systematic tracking of disrupted modules identifies significant genes and pathways in hepatocellular carcinoma. Oncol Lett. 2016;12(5):3285–95.
Simi L, Malentacchi F, Luciani P, Gelmini S, Deledda C, Arvia R, Mannelli M, Peri A, Orlando C. Seladin-1 expression is regulated by promoter methylation in adrenal cancer. BMC Cancer. 2010;10:201.
Battista MC, Guimond MO, Roberge C, Doueik AA, Fazli L, Gleave M, Sabbagh R, Gallo-Payet N. Inhibition of DHCR24/seladin-1 impairs cellular homeostasis in prostate cancer. Prostate. 2010;70(9):921–33.
Todenhofer T, Hennenlotter J, Kuhs U, Gerber V, Gakis G, Vogel U, Aufderklamm S, Merseburger A, Knapp J, Stenzl A, et al. Altered expression of farnesyl pyrophosphate synthase in prostate cancer: evidence for a role of the mevalonate pathway in disease progression? World J Urol. 2013;31(2):345–50.
Long Q, Xu J, Osunkoya AO, Sannigrahi S, Johnson BA, Zhou W, Gillespie T, Park JY, Nam RK, Sugar L, et al. Global transcriptome analysis of formalin-fixed prostate cancer specimens identifies biomarkers of disease recurrence. Cancer Res. 2014;74(12):3228–37.
Kapp FG, Sommer A, Kiefer T, Dolken G, Haendler B. 5-alpha-reductase type I (SRD5A1) is up-regulated in non-small cell lung cancer but does not impact proliferation, cell cycle distribution or apoptosis. Cancer Cell Int. 2012;12(1):1.
Stanbrough M, Bubley GJ, Ross K, Golub TR, Rubin MA, Penning TM, Febbo PG, Balk SP. Increased expression of genes converting adrenal androgens to testosterone in androgen-independent prostate cancer. Cancer Res. 2006;66(5):2815–25.
Wako K, Kawasaki T, Yamana K, Suzuki K, Jiang S, Umezu H, Nishiyama T, Takahashi K, Hamakubo T, Kodama T, et al. Expression of androgen receptor through androgen-converting enzymes is associated with biological aggressiveness in prostate cancer. J Clin Pathol. 2008;61(4):448–54.
Lewis MJ, Wiebe JP, Heathcote JG. Expression of progesterone metabolizing enzyme genes (AKR1C1, AKR1C2, AKR1C3, SRD5A1, SRD5A2) is altered in human breast carcinoma. BMC Cancer. 2004;4:27.
Bani MR, Nicoletti MI, Alkharouf NW, Ghilardi C, Petersen D, Erba E, Sausville EA, Liu ET, Giavazzi R. Gene expression correlating with response to paclitaxel in ovarian carcinoma xenografts. Mol Cancer Ther. 2004;3(2):111–21.
Tsukamoto Y, Uchida T, Karnan S, Noguchi T, Nguyen LT, Tanigawa M, Takeuchi I, Matsuura K, Hijiya N, Nakada C, et al. Genome-wide analysis of DNA copy number alterations and gene expression in gastric cancer. J Pathol. 2008;216(4):471–82.
Fukuma Y, Matsui H, Koike H, Sekine Y, Shechter I, Ohtake N, Nakata S, Ito K, Suzuki K. Role of squalene synthase in prostate cancer risk and the biological aggressiveness of human prostate cancer. Prostate Cancer Prostatic Dis. 2012;15(4):339–45.
Fernandez-Ranvier GG, Weng J, Yeh RF, Shibru D, Khafnashar E, Chung KW, Hwang J, Duh QY, Clark OH, Kebebew E. Candidate diagnostic markers and tumor suppressor genes for adrenocortical carcinoma by expression profile of genes on chromosome 11q13. World J Surg. 2008;32(5):873–81.
Williams MD, Zhang L, Elliott DD, Perrier ND, Lozano G, Clayman GL, El-Naggar AK. Differential gene expression profiling of aggressive and nonaggressive follicular carcinomas. Hum Pathol. 2011;42(9):1213–20.
Singel SM, Batten K, Cornelius C, Jia G, Fasciani G, Barron SL, Wright WE, Shay JW. Receptor-interacting protein kinase 2 promotes triple-negative breast cancer cell migration and invasion via activation of nuclear factor-kappaB and c-Jun N-terminal kinase pathways. Breast Cancer Res. 2014;16(2):R28.
Zhang H, Chin AI. Role of Rip2 in development of tumor-infiltrating MDSCs and bladder cancer metastasis. PLoS One. 2014;9(4):e94793.
Wang X, Jiang W, Duan N, Qian Y, Zhou Q, Ye P, Jiang H, Bai Y, Zhang W, Wang W. NOD1, RIP2 and Caspase12 are potentially novel biomarkers for oral squamous cell carcinoma development and progression. Int J Clin Exp Pathol. 2014;7(4):1677–86.
Yamashita T, Honda M, Takatori H, Nishino R, Minato H, Takamura H, Ohta T, Kaneko S. Activation of lipogenic pathway correlates with cell proliferation and poor prognosis in hepatocellular carcinoma. J Hepatol. 2009;50(1):100–10.
MacDonald TJ, Pollack IF, Okada H, Bhattacharya S, Lyons-Weiler J. Progression-associated genes in astrocytoma identified by novel microarray gene expression data reanalysis. Methods Mol Biol. 2007;377:203–22.
Bell A, Bell D, Weber RS, El-Naggar AK. CpG island methylation profiling in human salivary gland adenoid cystic carcinoma. Cancer. 2011;117(13):2898–909.
Lee S, Kwon HC, Kim SH, Oh SY, Lee JH, Lee YS, Seo D, Han JY, Kim HJ. Identification of genes underlying different methylation profiles in refractory anemia with excess blast and refractory cytopenia with multilineage dysplasia in myelodysplastic syndrome. Korean J Hematol. 2012;47(3):186–93.
Espinal-Enriquez J, Munoz-Montero S, Imaz-Rosshandler I, Huerta-Verde A, Mejia C, Hernandez-Lemus E. Genome-wide expression analysis suggests a crucial role of dysregulation of matrix metalloproteinases pathway in undifferentiated thyroid carcinoma. BMC Genomics. 2015;16:207.
Li YF, Hsiao YH, Lai YH, Chen YC, Chen YJ, Chou JL, Chan MW, Lin YH, Tsou YA, Tsai MH, et al. DNA methylation profiles and biomarkers of oral squamous cell carcinoma. Epigenetics. 2015;10(3):229–36.
Spivack SD, Hurteau GJ, Fasco MJ, Kaminsky LS. Phase I and II carcinogen metabolism gene expression in human lung tissue and tumors. Clin Cancer Res. 2003;9(16 Pt 1):6002–11.
Osman I, Bajorin DF, Sun TT, Zhong H, Douglas D, Scattergood J, Zheng R, Han M, Marshall KW, Liew CC. Novel blood biomarkers of human urinary bladder cancer. Clin Cancer Res. 2006;12(11 Pt 1):3374–80.
Dong HY, Shahsafaei A, Dorfman DM. CD148 and CD27 are expressed in B cell lymphomas derived from both memory and naive B cells. Leuk Lymphoma. 2002;43(9):1855–8.
Hui D, Satkunam N, Al Kaptan M, Reiman T, Lai R. Pathway-specific apoptotic gene expression profiling in chronic lymphocytic leukemia and follicular lymphoma. Mod Pathol. 2006;19(9):1192–202.
Metodieva SN, Nikolova DN, Cherneva RV, Dimova II, Petrov DB, Toncheva DI. Expression analysis of angiogenesis-related genes in Bulgarian patients with early-stage non-small cell lung cancer. Tumori. 2011;97(1):86–94.
Antonescu CR, Yoshida A, Guo T, Chang NE, Zhang L, Agaram NP, Qin LX, Brennan MF, Singer S, Maki RG. KDR activating mutations in human angiosarcomas are sensitive to specific kinase inhibitors. Cancer Res. 2009;69(18):7175–9.
Muller A, Lange K, Gaiser T, Hofmann M, Bartels H, Feller AC, Merz H. Expression of angiopoietin-1 and its receptor TEK in hematopoietic cells from patients with myeloid leukemia. Leuk Res. 2002;26(2):163–8.
Bunone G, Vigneri P, Mariani L, Buto S, Collini P, Pilotti S, Pierotti MA, Bongarzone I. Expression of angiogenesis stimulators and inhibitors in human thyroid tumors and correlation with clinical pathological features. Am J Pathol. 1999;155(6):1967–76.
Dales JP, Garcia S, Bonnier P, Duffaud F, Meunier-Carpentier S, Andrac-Meyer L, Lavaut MN, Allasia C, Charpin C. Tie2/Tek expression in breast carcinoma: correlations of immunohistochemical assays and long-term follow-up in a series of 909 patients. Int J Oncol. 2003;22(2):391–7.
Alinezhad S, Vaananen RM, Mattsson J, Li Y, Tallgren T, Tong Ochoa N, Bjartell A, Akerfelt M, Taimen P, Bostrom PJ, et al. Validation of novel biomarkers for prostate cancer progression by the combination of bioinformatics, Clinical and Functional Studies. PLoS One. 2016;11(5):e0155901.
Jiang H, Li F, He C, Wang X, Li Q, Gao H. Expression of Gli1 and Wnt2B correlates with progression and clinical outcome of pancreatic cancer. Int J Clin Exp Pathol. 2014;7(7):4531–8.
Katoh M, Kirikoshi H, Terasaki H, Shiokawa K. WNT2B2 mRNA, up-regulated in primary gastric cancer, is a positive regulator of the WNT- beta-catenin-TCF signaling pathway. Biochem Biophys Res Commun. 2001;289(5):1093–8.
Bonifas JM, Pennypacker S, Chuang PT, McMahon AP, Williams M, Rosenthal A, De Sauvage FJ, Epstein EH Jr. Activation of expression of hedgehog target genes in basal cell carcinomas. J Invest Dermatol. 2001;116(5):739–42.
Nuckel H, Switala M, Collins CH, Sellmann L, Grosse-Wilde H, Duhrsen U, Rebmann V. High CD49d protein and mRNA expression predicts poor outcome in chronic lymphocytic leukemia. Clin Immunol. 2009;131(3):472–80.
Wu Y, Zuo J, Ji G, Saiyin H, Liu X, Yin F, Cao N, Wen Y, Li JJ, Yu L. Proapoptotic function of integrin beta(3) in human hepatocellular carcinoma cells. Clin Cancer Res. 2009;15(1):60–9.
Partheen K, Levan K, Osterberg L, Claesson I, Fallenius G, Sundfeldt K, Horvath G. Four potential biomarkers as prognostic factors in stage III serous ovarian adenocarcinomas. Int J Cancer. 2008;123(9):2130–7.
Lerebours F, Vacher S, Andrieu C, Espie M, Marty M, Lidereau R, Bieche I. NF-kappa B genes have a major role in inflammatory breast cancer. BMC Cancer. 2008;8:41.
Park J, Yun HS, Lee KH, Lee KT, Lee JK, Lee SY. Discovery and validation of biomarkers that distinguish Mucinous and Nonmucinous pancreatic cysts. Cancer Res. 2015;75(16):3227–35.
Moiani A, Paleari Y, Sartori D, Mezzadra R, Miccio A, Cattoglio C, Cocchiarella F, Lidonnici MR, Ferrari G, Mavilio F. Lentiviral vector integration in the human genome induces alternative splicing and generates aberrant transcripts. J Clin Invest. 2012;122(5):1653–66.
Wu M, Chen S, Wu X. Differences in cytochrome P450 2C19 (CYP2C19) expression in adjacent normal and tumor tissues in Chinese cancer patients. Med Sci Monit. 2006;12(5):BR174–8.
Horning AM, Awe JA, Wang CM, Liu J, Lai Z, Wang VY, Jadhav RR, Louie AD, Lin CL, Kroczak T, et al. DNA methylation screening of primary prostate tumors identifies SRD5A2 and CYP11A1 as candidate markers for assessing risk of biochemical recurrence. Prostate. 2015;75(15):1790–801.
Sinreih M, Hevir N, Rizner TL. Altered expression of genes involved in progesterone biosynthesis, metabolism and action in endometrial cancer. Chem Biol Interact. 2013;202(1–3):210–7.
Lu D, Zhao Y, Tawatao R, Cottam HB, Sen M, Leoni LM, Kipps TJ, Corr M, Carson DA. Activation of the Wnt signaling pathway in chronic lymphocytic leukemia. Proc Natl Acad Sci U S A. 2004;101(9):3118–23.
Memarian A, Hojjat-Farsangi M, Asgarian-Omran H, Younesi V, Jeddi-Tehrani M, Sharifian RA, Khoshnoodi J, Razavi SM, Rabbani H, Shokri F. Variation in WNT genes expression in different subtypes of chronic lymphocytic leukemia. Leuk Lymphoma. 2009;50(12):2061–70.
Mangioni S, Vigano P, Lattuada D, Abbiati A, Vignali M, Di Blasio AM. Overexpression of the Wnt5b gene in leiomyoma cells: implications for a role of the Wnt signaling pathway in the uterine benign tumor. J Clin Endocrinol Metab. 2005;90(9):5349–55.
Lin YW, Shih YL, Lien GS, Suk FM, Hsieh CB, Yan MD. Promoter methylation of SFRP3 is frequent in hepatocellular carcinoma. Dis Markers. 2014;2014:351863.
Kongkham PN, Northcott PA, Croul SE, Smith CA, Taylor MD, Rutka JT. The SFRP family of WNT inhibitors function as novel tumor suppressor genes epigenetically silenced in medulloblastoma. Oncogene. 2010;29(20):3017–24.
Marsit CJ, Houseman EA, Christensen BC, Gagne L, Wrensch MR, Nelson HH, Wiemels J, Zheng S, Wiencke JK, Andrew AS, et al. Identification of methylated genes associated with aggressive bladder cancer. PLoS One. 2010;5(8):e12334.
Ekstrom EJ, Sherwood V, Andersson T. Methylation and loss of secreted frizzled-related protein 3 enhances melanoma cell migration and invasion. PLoS One. 2011;6(4):e18674.
Byun T, Karimi M, Marsh JL, Milovanovic T, Lin F, Holcombe RF. Expression of secreted Wnt antagonists in gastrointestinal tissues: potential role in stem cell homeostasis. J Clin Pathol. 2005;58(5):515–9.
Ugolini F, Adelaide J, Charafe-Jauffret E, Nguyen C, Jacquemier J, Jordan B, Birnbaum D, Pebusque MJ. Differential expression assay of chromosome arm 8p genes identifies frizzled-related (FRP1/FRZB) and fibroblast growth factor receptor 1 (FGFR1) as candidate breast cancer genes. Oncogene. 1999;18(10):1903–10.
Geraud C, Mogler C, Runge A, Evdokimov K, Lu S, Schledzewski K, Arnold B, Hammerling G, Koch PS, Breuhahn K, et al. Endothelial transdifferentiation in hepatocellular carcinoma: loss of Stabilin-2 expression in peri-tumourous liver correlates with increased survival. Liver Int. 2013;33(9):1428–40.
Acknowledgements
Not applicable.
Funding
This work was supported by the INSERM (French National Institute of Health and Medical Research, BioIntelligence program), the University of Western Brittany in Brest (UBO) and the Ligue Régionale Contre le Cancer (Comité du Finistère). The funding bodies were not involved in the design of the study and collection, analysis, and interpretation of data and in writing the manuscript.
Availability of data and materials
The datasets produced and analyzed during the current study are presented in RAW format as Supplementary material on the journal web site.
Author information
Authors and Affiliations
Contributions
Conceived and designed the experiments: SD, CLJC, LC. Performed the experiments: SD, KT, AU. Analyzed the data: SD, KT, ASP, AU, CLJC, LC. Wrote the manuscript: SD, CLJC, LC. Performed PCR array assays and Western blotting experiments: KT. Performed Immunohistochemistry: AU. Advised on the statistical analyses: ASP. Performed Network analysis: SD. Performed experiments on cell lines: SD. All authors discussed and agreed with the contents of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Collection and use of human material was approved by the Ethics Committee of Brest University Hospital. All samples used were associated with written patient consent to participate.
Consent for publication
not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional files
Additional file 1: Table S1.
List of genes from the five different RT² Profiler™ PCR Array Human Systems used in this study, classified in functional groups. See manufacturer’s information website (http://www.sabiosciences.com/PCRArrayPlate.php): A, Apoptosis (PAHS-012A); B, Cancer Pathway Finder (PAHS-033A); C, Lipoprotein Signaling & Cholesterol Metabolism (PAHS-080Z); D, Drug Metabolism (PAHS-002A); E, Wnt Signaling Pathway (PAHS-043A). Gene expression level deregulations uncovered in this study were indicated by red or green color for an up-regulation or a down-regulation, respectively, in CRC as compared to NT. (DOCX 25 kb)
Additional file 2: Figure S1.
Hierarchical clustering of colorectal carcinoma (CRC) and normal colon tissue (NT) based on gene expression profiling obtained from each type of PCR array. Log2-transformed fold-change values from genes fulfilling the criteria of PCR Data Analysis (Qiagen) obtained for each specific PCR array (fold-change > 1.7 and q < 0.05) were analyzed with Cluster and Treeview, using centered correlation and average linkage [63]. Red and green colors indicate transcript levels above and below the median values, respectively. NT, normal colon tissue (n=19) and CRC, colorectal carcinoma (n=95). Tumor samples were identified by a number followed by the Tumor Bank running number (S0, S1, S2, S3, S4) corresponding to the grading stage according to the pathological classification. Genes identified by their gene symbol appear on the right side of each panel. Each column gives the gene expression profile of a sample, and each line indicates the variations in the level of expression of a given gene among tissue samples. The length of the branches of the trees forming the dendrograms on the top of each panel reflects the degree of similarity between samples; the longer the branch, the larger the difference in gene expression. A, Hierarchical clustering based on 14 deregulated genes from the “Apoptosis” PCR array; B, Hierarchical clustering based on 33 deregulated genes from the “Cancer Pathway” PCR array; C, Hierarchical clustering based on 29 deregulated genes from the “Lipoprotein signaling and cholesterol metabolism” PCR array; D, Hierarchical clustering based on 23 deregulated genes from the “Drug metabolism” PCR array; E, Hierarchical clustering based on 18 deregulated genes from the “Wnt pathway” PCR array. (ZIP 2488 kb)
Additional file 3: Table S2.
Comparative differential expression data focused on genes identified on RT² Profiler™ PCR Array analysis and previously published data. Comparative expression data of selected genes deregulated in CRC as compared to NT in RT² Profiler™ PCR Array analysis, related to Apoptosis (2A, n=14), Cancer Pathway (2B, n= 33), Lipoprotein signaling and Cholesterol metabolism (2C, n=29), Drug metabolism (2D, n=23) and Wnt signaling pathway (2E, n=218). Differential expression data information was listed for each gene: i) from our study performed by PCR array technology in CRC (n=95) as compared to NT (n=19); ii) from our previous study performed with whole-genome microarray technology in CRC (n=25), CRA (n=55) and NT paired to CRA or CRC (n=27) [16]; iii) from microarray expression data of COADREAD cohort of TCGA consortium (153 colon and 69 rectal carcinomas as compared to 22 NT) ([17], gdac.broadinstitute.org) iv) from literature data by focusing on expression analysis obtained in CRC (RNA or protein level) and v) from other literature data obtained from genetic association, epigenetic and functional studies. Underlined gene names indicated that the genes were largely referenced in PubMed in association with colorectal cancer. (DOCX 299 kb)
Additional file 4: Figure S2.
Principal component analysis of colorectal dataset of TCGA based on the expression of genes identified in our study. Principal component analysis (PCA) was performed on expression data retrieved from colorectal cohort from TCGA ([17], gdac.broadinstitute.org) composed of 22 NT, 153 colon carcinoma and 69 rectal carcinoma. PCA were performed on different sets of deregulated genes according to functional group: Panel A) Apoptosis (14 genes); Panel B) Cancer pathway (33 genes); Panel C) Lipoprotein signaling and cholesterol metabolism (29 genes); Panel D) Drug metabolism (23 genes); Panel E) Wnt signaling pathway (18 genes); Panel F) all genes identified in our study (111 genes). Individuals are colored according to a categorical variable in each PCA plot: i) according to histological type (NT: green, colon carcinoma: red, rectal carcinoma: blue); ii) according to grading stage (I: red, II: green, III: blue, IV: light blue); iii) according to mutational status of APC and KRAS (wild type: red, mutated: green). Samples corresponding to NT and tumors that present no available information about stage and mutational status are colored in black. (PDF 494 kb)
Additional file 5: Figure S3.
Western blot analysis of protein level in paired colorectal carcinoma (CRC) and normal colon mucosae (NT). Forty µg of protein extracts from 20 CRC and paired NT samples were subjected to Western blot analysis using selected antibodies and a monoclonal HSC70 antibody (for normalization). Tumor and normal tissue were analyzed simultaneously. Quantification of protein levels was performed by measuring the fluorescence intensity (Odyssey Li-Cor). A. Western blot analysis of 9 protein-coding genes previously identified as up-regulated in CRC as compared to NT by PCR array: BCL2L1, NME1, PKM2, GSTP1, GPI, FDPS, HMGCS1, CYP39A1 and PCSK9. B. Western blot analysis of 4 protein-coding genes previously identified as down-regulated in CRC as compared to NT by PCR array: BCL2, CASP7, IGF1 and ADH1C. The numbers on the left identified the samples; the numbers at the bottom indicate the number of samples that showed a similar regulation at both the mRNA and the protein levels. C. Comparison of average fold-changes between CRC and paired NT (n=20) obtained from transcriptome (PCR array) and proteomic (Western blot) analyses. Error bars represent the Standard Error of the Mean (SEM). The upper panel represents data from 8 up-regulated genes and the lower panel represents data from 4 down-regulated genes in CRC as compared to NT. (PDF 223 kb)
Additional file 6: Figure S4.
Representative immunostaining pattern obtained for NT and CRC paired tissues. A. Strong cytoplasmic NME1-staining of the adenocarcinomatous glands (right) compared to the normal adjacent colonic glands (left) (x50, NME1 immunohistochemistry, hematoxylin counter coloration). B. Strong cytoplasmic FDPS-staining of the adenocarcinomatous glands (right) compared with the normal adjacent colonic glands (left) (x50, FDPS immunohistochemistry, hematoxylin counter coloration). C. Strong cytoplasmic and nuclear CCND1-staining (known to be over-expressed in CRC) of the adenocarcinomatous glands (left) compared with the normal adjacent colonic glands (right) (x50, CCND1 immunohistochemistry, hematoxylin counter coloration). (PDF 252 kb)
Additional file 7: Figure S5.
Network building from all deregulated genes.A. Interactions between 111 deregulated genes identified by transcriptome comparison of CRC and NT were retrieved from the STRING database (version 10.5). The interactions include direct (physical) and indirect (functional) associations. All interaction sources questioned by STRING were used and the minimum required interaction score was 0.4 (medium confidence). The blue color of edges indicated a physical interaction in the source of evidence between 2 nodes. The thickness of edges was correlated with the score confidence (large for high score). The node shape illustrates the specific PCR array: Apoptosis: square, Cancer Pathway: hexagon, Lipoprotein signaling and cholesterol metabolism: circle, Drug metabolism: diamond and Wnt pathway: octagon. The color intensity of nodes was related to transcriptome deregulation (red for up-regulation and green for down-regulation in CRC as compared to NT). Genes showing a deregulation in more than 75% of CRC were characterized by a bold line of shape node.B. Node degree distribution of 111 genes-based network. The X axis shows the degree of a node, while the Y axis shows the number of nodes for each degree in the network. This scatter plot highlights the molecular hubs of the network. Molecular hubs showing a deregulation in more than 75% of CRC were indicated by a black symbol. (PDF 234 kb)
Additional file 8: Figure S6.
Topological parameters analysis on global network building from the functional association between 111 genes deregulated in CRC vs. NT. A. Network visualization of node degree and clustering coefficient parameters. The node degree, i.e. the number of edges linked to a node, was visually mapped by the node size: nodes with a low degree were smaller, in contrast to nodes with a high degree. The clustering coefficient, another computed topological parameter reflecting the tendency of neighbors of each node to interact together, was mapped by node gradient color: nodes with lowest clustering coefficient are blue and nodes with highest clustering coefficient are orange (medium clustering coefficient are yellow). As mentioned in Additional file 7: Figure S5, the thickness of edges was correlated with score confidence (large for high score), the blue line indicated physical interaction experimentally demonstrated in the source of evidence and the node shape illustrated the specific PCR array: Apoptosis: square, Cancer Pathway: hexagon, Lipoprotein signaling and cholesterol metabolism: circle, Drug metabolism: diamond and Wnt pathway: octagon. B. Scatter plot displaying the correlation between node degrees and clustering coefficients in the global network composed of 111 nodes showing transcriptome deregulation in CRC as compared to NT. Dotted lines indicated the median of node degree (value of 11) and the median of clustering coefficient (value of 0.54). Genes showing a deregulation in more than 75% of CRC were indicated by a black symbol. (PDF 300 kb)
Additional file 9: Figure S7.
Viability assay of colorectal cell lines treated by chemotherapeutic drugs combined or not with Lovastatin. The viability of two colorectal cell lines (A: HCT-116, B: HT-29) was evaluated by MTT assays after 72h of treatment by different chemotherapeutic drugs combined (black bars) or not (white bars) with Lovastatin (5 µM). Control cells were treated by DMSO (less than 0.1% final concentration). Two different concentrations were used for the chemotherapeutic drugs: 1 µM and 10 µM for Oxaliplatin and 5-Fluorouracile, 0.01 µM and 0.1 µM for Camptothecin. The results are from three independent experiments. Error bars represent the SEM. (PDF 576 kb)
Additional file 10: Figure S8.
Gene-Drug interaction network. Interactions were retrieved in STITCH v5 (Search Tools for Interactions of Chemicals) between deregulated genes in CRC and 4 drugs: 3 chemotherapeutic drugs used in CRC treatment (5-Fluorouracile (5-FU), Oxaliplatin (OXA) and Camptothecin (CPT), and Lovastatin (LOVA). To facilitate network visualization, we have hidden edges between genes. Node size and node color reflect the interaction degree and the clustering coefficient characterizing nodes in 111 genes based-network presented in Additional file 8. The thickness of edges was correlated with score confidence (large for high score) retrieved in STITCH database (version 5) and the blue color of edges indicated a physical interaction in the source database. The bold line of shape node characterizes genes deregulated in more than 75% of CRC. (PDF 93 kb)
Additional file 11: Table S3.
Raw quantitative-PCR data for each PCR array used in this study. Clinical data associated to CRC samples were indicated in the excel file. (XLSX 412 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Durand, S., Trillet, K., Uguen, A. et al. A transcriptome-based protein network that identifies new therapeutic targets in colorectal cancer. BMC Genomics 18, 758 (2017). https://doi.org/10.1186/s12864-017-4139-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12864-017-4139-y