
Abstract
Background
Data integration to build a biomedical knowledge graph is a challenging task. There are multiple disease ontologies used in data sources and publications, each having its hierarchy. A common task is to map between ontologies, find disease clusters and finally build a representation of the chosen disease area. There is a shortage of published resources and tools to facilitate interactive, efficient and flexible cross-referencing and analysis of multiple disease ontologies commonly found in data sources and research.
Results
Our results are represented as a knowledge graph solution that uses disease ontology cross-references and facilitates switching between ontology hierarchies for data integration and other tasks.
Conclusions
Grakn core with pre-installed “Disease ontologies for knowledge graphs” facilitates the biomedical knowledge graph build and provides an elegant solution for the multiple disease ontologies problem.
Similar content being viewed by others

Background
Disease ontologies are used for annotation, integration and analysis of biological data, and knowledge graph construction. The range and diversity of disease ontologies are high due to various specific areas they are used in, e.g. medical practice, rare disease domain, biological experiments and biobanks. To build a biomedical knowledge graph, we integrate data from different databases that may use different disease ontologies and from publications where authors also have their preferred ontologies. The following sentence can describe the data integration challenge: one disease—multiple disease terms (IDs) and hierarchies originating from different disease ontologies.
There are two parts to the challenge: firstly, we require matches between different disease ontologies; secondly, we need a system that can exploit this matching, e.g. perform data queries that can collect data from the desired disease hierarchy, in order to map one ontology to another. Ontological matching is a separate research area with a number of findings and approaches [1,2,3]. We used cross-reference information (ontological matching results) in disease ontologies to collect matchings and curation to achieve the atomicity of the mappings needed for this project. We used Grakn logical reasoning to solve the second challenge: switching between different ontologies and their hierarchies to integrate data and retrieve a particular disease domain view onto the disease of interest.
There are two conventional approaches to data integration: “data factory”, where the data is integrated before ingestion into the knowledge graph and data integration on the fly, where the data is integrated directly inside the knowledge graph. We used a combined approach in this work—disease ontology data is pre-prepared using R scripts before loading. Simultaneously, we used a database schema that supports ad-hoc data integration, leading to flexible data loading and reasoning. We are not changing the disease ontology data per se or factoring the data to use one specific ontology; rather, we combine existing information and focus on exact matching terms, leaving the data integration task to the database. The keyword here is flexibility: a user can easily change data prepared for loading, focusing on a disease area of interest and adding more ontologies, including custom ones.
Implementation
Data preparation
We created a matching file using R scripts to extract cross-referencing data from ontologies of interest.
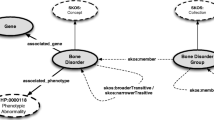
There are 21,696 records in the matching file (./data/prepared_ontologies/cross-reference.tsv). We used Bioportal [4] and Ontology Lookup Service [5] to collect up-to-date cross-reference information from the following ontologies: MeSH [6], UMLS [7], EFO [8], NCIT [9], OMIM [10, 11], DOID [12], Orphanet [13], HP [14], MONDO [15] and ICD-10 [16]. These particular disease ontologies were chosen pragmatically—EFO, Orphanet, DOID, HP, NCIT, OMIM and MONDO are broadly used in biomedical databases and archives. MeSH is used for indexing articles in PubMed [17] and as a result, is the primary source of disease referencing in document retrieval systems and Natural Language Processing (NLP) pipelines [18,19,20]. UMLS was included as a single source of cross-referencing for some of the disease ontologies. We added ICD-10 for genomic data integration from UK Biobank [21]. To build the foundation for biomedical data integration, we are interested in atomic matching between disease ontology terms. Formally, we define ontological matching as a triple \(m= <{t}_{id}, {t}_{j}, s>, s\in \{\mathrm{0,1}\}\), where \({t}_{id}\) is the preferred disease term from the ontology that defines the disease label, s is the binary similarity degree. An atomic mapping in this matching is a pair \(\mu = <{t}_{id}, {t}_{j}>\), where \({t}_{id}\) and \({t}_{j}\) are homogeneous ontology terms from the list of ontologies mentioned above. For example, the record from cross referencing file for “chronic kidney disease” (Fig. 1) shows that the disease term has \({t}_{id}\) = “MONDO_0005300” and defines 6 matching pairs: \(\mu = <{t}_{id}, {t}_{j}>\), where \({t}_{j}\in\) {MeSH:“D007676”, UMLS:”C0022661”, EFO: “EFO_0003884”, NCIT:”NCIT_C80078”, DOID: “DOID_784”, ICD-10: “N18.9”}. This induces 6 triples of the form \(<{t}_{id}, {t}_{j}, 1>\) in our ontological matching, all other \({t}_{j}\) will map to. The MONDO ontology is chosen to represent preferred terms since it covers most of the terms from other disease ontologies. However, the preferred ontology can be changed by user preference. We chose to only consider exact matching terms rather than close matches to reduce noise and prevent problems in the ontology merging. We do not lose too much information as several Ontologies have more exact matches than close matches.

The disease ontology basis for the knowledge graph. Data Preparation: ontology matching presented as cross-reference flat-file and ontological hierarchies are created using Bioportal and Ontology Lookup Service data processed by R scripts. Chronic kidney disease and its presentation from six disease ontologies perspective are shown as a diagram to give an example of a cross-reference file record. Grakn Knowledge Base: data is loaded into the database from data files with python scripts
In the last few years, ontological matching quality and amount of cross-referencing data present in disease ontologies has improved significantly. However, there are references to obsolete terms, absence of matching, one source for ontological matching (UMLS in the case of NCIT), ontological matching to parental terms instead of atomic matching (a complex type of matching) and other issues. By combining multiple ontologies and their cross-referencing information, we validated cross-references, found discrepancies and/or matchings that are not atomic and fixed them. There are two types of discrepancies: reference to non-existing term (ontology A references ontology B where the referenced term is obsolete); reference to all hierarchical levels (ontology A term a references ontology B terms b, b1, b2, …, bn where b1, …, bn are children of b). In the latter case, nothing is incorrect from an ontology A perspective. However, it is not an atomic reference, and for our purpose of atomic matching, we had to fix this type of reference (ontology A term a is referenced to ontology B term b).
Changes were done only on the level of the cross-reference file that is available on Github repository. The user of the software can change cross-references if needed. The only principle that should be held in place for the intended functionality is the atomicity of the matchings.
We believe that disease cross-references in a flat file that is easily accessible and editable will improve ontological matching in particular disease areas. Disease ontology hierarchies is another source of data for the project. We use ontologies from Bioportal and R scripts to extract relevant hierarchical information based on the matching file described above. The GitHub repository explains how to repeat the data preparation process. Table 1 describes in detail individual ontology contributions into cross-referencing and unique terms.
Grakn knowledge base
We provide a Grakn schema with logical rules to make ontological inferences and a preloaded Grakn database. Example queries and use cases are available together with loading scripts written in python to rebuild and extend the database. Figure 2 shows a schema diagram for a disease node with multiple attributes for ontological terms. The Grakn database was chosen due to its flexible schema and its logical reasoning capabilities, allowing us to switch between different disease ontologies with ease or to incorporate all available ontological hierarchies together for an overall view of a particular disease. Grakn’s logical reasoning engine supports transitivity rules essential for ontological matching [22]. From a practical perspective, transitivity rules enable access to all the children of a particular disease term in a straightforward query and the use of multiple disease ontology hierarchies together, e.g. to get all subordinate diseases for a particular disease considering all available ontologies.

available at Github repository
Grakn Knowledge Base: part of the schema diagram shows a disease node with multiple attributes for ontological terms. Grakn schema with all nodes, attributes and logical rules is
Results
Our results consist of a Grakn knowledge base, schema and loading scripts that allow the building of a biomedical knowledge graph foundation—creating a practical solution that allows easier data integration from NLP pipelines and a variety of biomedical databases. This knowledge graph solution enables comprehensive exploration and interaction with disease ontologies. It visualises disease ontologies, allowing query of all sub-classes of a particular term regardless of the ontology using one command, facilitating switching between different ontologies, and remapping one ontology terms, e.g. MeSH, to the hierarchical structure of another ontology (e.g. MONDO).
After loading over prepared data, obtaining all sub-classes of "chronic kidney disease" from the available hierarchies of disease ontologies is now trivial using Graql query:

Multiple other common ontological problems are solved, and examples are available in the Github repository.
We also provide data preparation R scripts to process disease ontology data in a format understandable for the Grakn knowledge base, together with pre-processed data files for MONDO, DOID, EFO, HP, MESH, Orphanet, UMLS, ICD-10 and NCIT disease ontologies.
Conclusions
Disease ontologies for knowledge graphs is a knowledge base solution that uses Grakn core with its logical inference and disease ontologies cross-references to allow easy switching between ontology hierarchies for data integration purpose. This software makes it straightforward to run common ontological queries. It is relatively easy to add new ontologies due to the python loading scripts, and the Grakn reasoning rules are easy to extend. We hope this software will make it easier for bioinformaticians to integrate data that uses multiple ontologies.
Availability and requirements
Project name: Disease_ontologies_for_knowledge_graphs; Project home page: https://github.com/natacourby/Disease_ontologies_for_knowledge_graphs; Operating system(s): Platform independent; Programming language: Python, R; Other requirements: The community edition of Grakn Core License: Affero GPL v3; Any restrictions to use by non-academics: no.
Availability of data and materials
The datasets generated and/or analysed during the current study are available in the Github repository, https://github.com/natacourby/Disease_ontologies_for_knowledge_graphs /tree/master/data.
Abbreviations
- MeSH:
-
Medical subject headings
- UMLS:
-
The Unified Medical Language System
- EFO:
-
Experimental Factor Ontology
- NCIT:
-
NCI Thesaurus
- OMIM:
-
Online Mendelian Inheritance in Man
- DOID:
-
Human Disease Ontology
- Orphanet:
-
Orphanet Rare Disease Ontology
- HP:
-
Human Phenotype Ontology
- MONDO:
-
Mondo Disease Ontology
- ICD-10:
-
International Statistical Classification of Diseases and Related Health Problems: tenth revision
References
Euzenat J, Shvaiko P. Ontology matching. Berlin: Springer; 2013.
Rappaport N, et al. MalaCards: an integrated compendium for diseases and their annotation. Database (Oxford). 2013;2013:bat018. https://doi.org/10.1093/database/bat018.
Hu W, Qiu H, Huang J, Dumontier M. BioSearch: a semantic search engine for Bio2RDF. Database (Oxford). 2017. https://doi.org/10.1093/database/bax059.
Musen MA, et al. The National Center for Biomedical Ontology. J Am Med Inform Assoc. 2012;19(2):190–5. https://doi.org/10.1136/amiajnl-2011-000523.
Jupp S, Burdett T, Malone J, Leroy C, Pearce M, Parkinson H. A new ontology lookup service at EMBL-EBI, in Proceedings of SWAT4LS international conference. 2015.
Rogers FB. Medical subject headings. Bull Med Libr Assoc. 1963;51(1):114–6.
Bodenreider O. The Unified Medical Language System (UMLS): integrating biomedical terminology. Nucleic Acids Res. 2004;32(Database issue):D267-270. https://doi.org/10.1093/nar/gkh061.
Malone J, et al. Modeling sample variables with an Experimental Factor Ontology. Bioinformatics. 2010;26(8):1112–8. https://doi.org/10.1093/bioinformatics/btq099.
Fragoso G, de Coronado S, Haber M, Hartel F, Wright L. Overview and utilization of the NCI thesaurus, in Comparative and Functional Genomics. 2004. https://www.hindawi.com/journals/ijg/2004/461209/. Accessed 14 Sept 2020.
Online Mendelian Inheritance in Man, OMIM®. McKusick-Nathans Institute of Genetic Medicine, Johns Hopkins University (Baltimore, MD). 2020. World Wide Web, https://omim.org/.
McKusick VA. Mendelian inheritance in man. A catalog of human genes and genetic disorders. 12th ed. Baltimore: Johns Hopkins University Press; 1998.
Schriml LM, et al. Human Disease Ontology 2018 update: classification, content and workflow expansion. Nucleic Acids Res. 2019;47(D1):D955–62. https://doi.org/10.1093/nar/gky1032.
Orphanet: an online database of rare diseases and orphan drugs. Copyright, INSERM 1997. http://www.orpha.net. Accessed (date of access).
Köhler S, et al. Expansion of the Human Phenotype Ontology (HPO) knowledge base and resources. Nucleic Acids Res. 2019;47(D1):D1018–27. https://doi.org/10.1093/nar/gky1105.
Mungall CJ, et al. The Monarch Initiative: an integrative data and analytic platform connecting phenotypes to genotypes across species. Nucleic Acids Res. 2017;45(D1):D712–22. https://doi.org/10.1093/nar/gkw1128.
World Health Organization. ICD-10: international statistical classification of diseases and related health problems: tenth revision. Geneva: World Health Organization; 2004.
Sayers EW, et al. Database resources of the National Center for Biotechnology Information. Nucleic Acids Res. 2019;47(D1):D23–8. https://doi.org/10.1093/nar/gky1069.
Lussier Y, Borlawsky T, Rappaport D, Liu Y, Friedman C. Phenogo: assigning phenotypic context to gene ontology annotations with natural language processing, in Biocomputing 2006, World Scientific; 2005. p. 64–75.
Chen X, Xie H, Wang FL, Liu Z, Xu J, Hao T. A bibliometric analysis of natural language processing in medical research. BMC Med Inform Decis Mak. 2018;18(1):14. https://doi.org/10.1186/s12911-018-0594-x.
Zhang Y, Chen Q, Yang Z, Lin H, Lu Z. BioWordVec, improving biomedical word embeddings with subword information and MeSH. Sci Data. 2019. https://doi.org/10.1038/s41597-019-0055-0.
Sudlow C, et al. UK Biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med. 2015. https://doi.org/10.1371/journal.pmed.1001779.
François L, van Eyll J, Godard P. Dictionary of disease ontologies (DODO): a graph database to facilitate access and interaction with disease and phenotype ontologies. F1000Res. 2020;9:942. https://doi.org/10.12688/f1000research.25144.1.
Acknowledgements
We thank Dr Stephen Bonner from AstraZeneca Cambridge and Tomás Sabat from GraknAI London for the help in manuscript preparation.
Funding
The work was supported by AstraZeneca internal funding. The funding body did not play any roles in the design of the study and collection, analysis, and interpretation of data and in writing the manuscript.
Author information
Authors and Affiliations
Contributions
The software and data integration were conceived and designed by NK. Software implementation, tests and examples were carried out by NK and RS. The manuscript was written by NK and RS. Both authors have read and approved the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests, apart from the fact that both authors are employed by AstraZeneca Ltd.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Kurbatova, N., Swiers, R. Disease ontologies for knowledge graphs. BMC Bioinformatics 22, 377 (2021). https://doi.org/10.1186/s12859-021-04173-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12859-021-04173-w