
Abstract
Background
A fundamental problem in RNA-seq data analysis is to identify genes or exons that are differentially expressed with varying experimental conditions based on the read counts. The relativeness of RNA-seq measurements makes the between-sample normalization of read counts an essential step in differential expression (DE) analysis. In most existing methods, the normalization step is performed prior to the DE analysis. Recently, Jiang and Zhan proposed a statistical method which introduces sample-specific normalization parameters into a joint model, which allows for simultaneous normalization and differential expression analysis from log-transformed RNA-seq data. Furthermore, an ℓ0 penalty is used to yield a sparse solution which selects a subset of DE genes. The experimental conditions are restricted to be categorical in their work.
Results
In this paper, we generalize Jiang and Zhan’s method to handle experimental conditions that are measured in continuous variables. As a result, genes with expression levels associated with a single or multiple covariates can be detected. As the problem being high-dimensional, non-differentiable and non-convex, we develop an efficient algorithm for model fitting.
Conclusions
Experiments on synthetic data demonstrate that the proposed method outperforms existing methods in terms of detection accuracy when a large fraction of genes are differentially expressed in an asymmetric manner, and the performance gain becomes more substantial for larger sample sizes. We also apply our method to a real prostate cancer RNA-seq dataset to identify genes associated with pre-operative prostate-specific antigen (PSA) levels in patients.
Similar content being viewed by others


Introduction
A fundamental problem in RNA-seq data analysis is to identify genes or exons that are differentially expressed with varying experimental conditions based on the read counts. Some widely used methods for differential expression analysis in RNA-seq data are edgeR [1, 2], DESeq2 [3] and limma-voom [4, 5]. In edgeR and DESeq2, the read counts are assumed to follow negative binomial (NB) distributions; while in limma-voom, the logarithmic transformation is taken on the data which compresses the dynamic range of the read counts so that the outliers become more “normal”. Consequently, existing statistical methods that are designed for analyzing normally distributed data can be employed to analyze RNA-seq data.
Due to the relative nature of RNA-seq measurements for transcript abundances as well as differences in library sizes and sequencing depths across samples [6], between-sample normalization of read counts is essential in differential expression (DE) analysis with RNA-seq data. A widely used approach for data normalization in RNA-seq is to employ a sample-specific scaling factor, e.g., CPM/RPM (counts/reads per million) [7], upper-quartile normalization [8], trimmed mean of M values [7] and DESeq normalization [9]. A review of normalization methods in RNA-data data analysis is given in [6]. In most existing methods for DE analysis in RNA-seq, the normalization step is performed prior to the DE detection step, which is sub-optimal because ideally normalization should be based on non-DE genes for which the complete list is unknown until after the DE analysis.
In [10], a statistical method for robust DE analysis using log-transformed RNA-seq data is proposed, where sample-specific normalization factors are introduced as unknown parameters. This allows for more accurate and reliable detection of DE genes by simultaneously performing between-sample normalization and DE detection. An ℓ0 penalty is introduced to enforce that a subset of genes are selected as being differentially expressed. The experimental conditions are restricted to be categorical (e.g., 0 and 1 for control and treatment groups, respectively), and a one-way analysis of variance (ANOVA) type model is employed to detect differentially expressed genes across two or more experimental conditions.
In [11], the model of [10] is generalized to continuous experimental conditions, and the sparsity-inducing ℓ0 penalty is relaxed as the ℓ1 penalty. An alternating direction method of multipliers (ADMM) algorithm is developed to solve the resultant convex problem. Due to the relaxation of the ℓ0 regularization, the method in [11] may not be as robust against noise and efficient in inducing sparse solutions as that in [10]. In this paper, we again generalize the model in [10] from categorical to continuous experimental conditions. But different from [11], we retain the ℓ0 penalty in our model to efficiently induce sparsity. We formulated two hypothesis tests suited to different applications: the first hypothesis test is that considered in [10] and answers the question of whether the expression of a gene is significantly affected by any covariate; and in addition, a second hypothesis is formulated to test whether the expression of a gene is significantly affected by a particular covariate, when all other covariates in the regression model are adjusted for.
Due to the use of the ℓ0 penalty, the resulting problem is high-dimensional, non-differentiable and non-convex. To fit the proposed model, we study the optimality conditions of the problem and develop an efficient algorithm for its solution. We also propose a simple rule for the selection of tuning parameters. Experiments on synthetic data demonstrate that the proposed method outperforms existing ones in terms of detection accuracy when a large fraction of genes are differentially expressed in an asymmetric manner, and the performance gain becomes more substantial for larger sample sizes. We also apply our method to a real prostate cancer RNA-seq dataset to identify genes associated with pre-operative prostate-specific antigen (PSA) levels in patients.
Methods
Given m genes and n samples, let yij,i=1,…,m,j=1,…,n, be the log-transformed gene expression values of the i-th gene in the j-th sample. A small positive constant can be added prior to taking the logarithm to avoid taking logarithm of zeros. We formulate the following model:
where αi is the intercept,
is the regression coefficient vector of the linear model for gene i, and
is a vector of p predictor variables for sample j representing its experimental conditions (drug dosage, blood pressure, age, BMI, etc.), dj represents the normalization factor for sample j, and \(\varepsilon _{ij} \sim \mathcal {N}\left (0,\sigma _{i}^{2}\right)\) is i.i.d. Gaussian noise. Our goal is for each gene to determine whether its expression level is significantly associated with the experimental conditions or not.
Remark 1
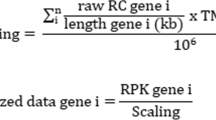
The αi and dj in (1) model gene-specific factors (e.g., gene length) and sample-specific factors (i.e., sequencing depth), respectively. Thus, model (1) can accommodate any gene expression levels summarized in the form of cij/(li·qj), where cij is the read count, li is the gene-specific scaling factor (e.g., gene length) associated with gene i and qj is the sample-specific scaling factor (e.g., sequencing depth) associated with sample j. Special cases are read count (i.e., li=qj=1), CPM/RPM (i.e., li=1) [7], RPKM/FPKM [12,13] and TPM [14].
Since the random noise in gene expression measurements are independent across genes and samples, the likelihood is given by
The negative log-likelihood is
where C depends on \(\left \{\sigma _{i}^{2}\right \}\) but not on {αi},{βi} and {dj}. In “Maximum likelihood estimation of noise variance” section, we will describe how to estimate \(\sigma _{i}^{2}, i=1,\dots,m\). Hereafter, we assume that \(\sigma _{i}^{2}\)’s are known and simply denote the negative log-likelihood as \(l\left (\boldsymbol {\alpha }, \{\boldsymbol {\beta }_{i}\}_{i=1}^{m}, \boldsymbol {d}; \boldsymbol {Y} \right)\).
In practice, typically only a subset of genes are differentially expressed. We introduce a sparse penalty to the negative log likelihood function:
where λi’s are tuning parameters that control the sparsity level of the solution, and p(βi) is a penalty function
In this paper, we use the following two types of penalty functions.
- i)
Type I penalty:
$$ p\left(\boldsymbol{\beta}_{i}\right) = 1_{\boldsymbol{\beta}_{i} \neq \boldsymbol{0}}. $$(7)This penalty function applies to applications where all covariates are of interest and we want to identify genes for which at least one covariate is associated with its expression.
- ii)
Type II penalty:
$$ p\left(\boldsymbol{\beta}_{i}\right) = 1_{\beta_{ip} \neq 0}. $$(8)This penalty applies to applications where only one (the p-th) covariate is of main interest (e.g., treatment) while we want to adjust for all other covariates (e.g., age, sex, etc).
Algorithm development
Note that without dj, model (1) would be decoupled as m independent linear regression models, one for each gene. The first step of our algorithm is to solve for dj and express it as a function of βi’s.
Note that the optimization problem (6) is convex in (α,d). Therefore, the minimizer of (α,d) is one of its stationary points.
Taking partial derivatives of \(f\left (\boldsymbol {\alpha }, \{\boldsymbol {\beta }_{i}\}_{i=1}^{m}, \boldsymbol {d}\right)\) with respect to dj,j=1,…,n, and setting them to zeros, we have
The solution to model (1) is not unique because an arbitrary constant can be added to dj’s and subtracted from αi’s, while having the same model fit. To address this issue, we fix d1=0. Therefore
where
Here the superscript (w) denotes “weighted mean".
Calculating the partial derivatives of \(f\left (\boldsymbol {\alpha }, \{\boldsymbol {\beta }_{i}\}_{i=1}^{m}, \boldsymbol {d}\right)\) with respect to αi,i=1,…,m, and setting them to zeros, we have
where
From (10) it follows
where
Substituting (16) into (13) yields
The sum of (10) and (18) yields
Substituting (19) into (6), the problem becomes an ℓ0-regularized linear regression problem with \(\{\boldsymbol {\beta }_{i}\}_{i=1}^{m}\) being the only variables to be optimized:
where
It is easy to see that
In the next two sections, we will describe algorithms to solve Problem (20) with type I and type II penalties, respectively.
Fitting the model with type I penalty
Denote \(\boldsymbol {\delta }=\boldsymbol {\bar {\beta }}^{(w)}\), and let
where βi’s are considered as functions of δ. The objective in Problem (20) can be written as \(f\left (\boldsymbol {\beta }\right) = {\sum _{i=1}^{m}} g_{i}\left (\boldsymbol {\beta }_{i}\right)\). Assume that δ is fixed, f can be minimized by minimizing each gi(βi) separately.
Next we express the minimizing solution of gi(βi) as a function of δ.
When βi=0,
When βi≠0,
Taking partial derivatives of (26) with respect to βi,i=1,…,m, and setting them to zeros yields
where the superscript (ols) indicates an ordinary least squares estimate for the model,
and \(\boldsymbol {\tilde {y}}_{i}\) is a column vector containing the centered expression of gene i in all samples, i.e., the i-th row of \(\boldsymbol {\tilde {Y}}\):
The objective function value at \(\boldsymbol {\beta }_{i}=\boldsymbol {\beta }_{i}^{\text {(ols)}}\) is
The change in the objective value gi(βi) from \(\boldsymbol {\beta }_{i}=\boldsymbol {\beta }_{i}^{\text {(ols)}} \neq 0\) in Eq. (30) to βi=0 in Eq. (25) is
Therefore, the solution is
Now we only need to solve for δ. We have
where the second equality is due to the fact that \(g_{i}\left (\boldsymbol {\beta }_{i}^{\text {(ols)}}\right)\) is a constant independent of δ, and the third equality follows from (31). Problem (33) can be solved exactly using an exhausted grid search for p=1 or 2, and approximately using a general global optimization algorithm (e.g., the optim function in R) for larger p. A more efficient algorithm proposed in [15] can also be used.
After we obtain the estimate of δ, we substitute it into (32) to get the estimate of βi. Algorithm 1 describes the complete model fitting procedure.

Fitting the model with type II penalty
Denote \(\boldsymbol {\delta }=\boldsymbol {\bar {\beta }}^{(w)}\), and let
where βi’s are considered as functions of δ. The objective function in Eq. (20) is \(f\left (\boldsymbol {\beta }\right) \,=\, {\sum \limits _{i=1}^{m}} h_{i}\left (\boldsymbol {\beta }_{i}\right)\). Assume that δ is fixed, f can be optimized by minimizing each hi(βi) separately.
Next we find the solution for βi’s as a function of δ by minimizing hi(βi).
Denote
When βip=0,
Taking derivatives of (35) with respect to \(\boldsymbol {\beta }_{i}^{-}, i=1,\ldots,m,\) and setting them to zeros yields
where
Denote \(\boldsymbol {\beta }_{i}^{\text {(r)}} = \left [\begin {array}{c} \boldsymbol {\beta }_{i}^{-} \\ 0 \\ \end {array}\right ]\), where the superscript (r) denotes the reduced model. Substituting \(\boldsymbol {\beta }_{i} = \boldsymbol {\beta }_{i}^{\text {(r)}}\) into (35) and after some matrix algebraic manipulation, we have
When βip≠0,
The minimizing solution of hi(βi) is \(\boldsymbol {\beta }_{i}^{\text {(ols)}}\) shown in (27), and its p-th coordinate is
where the second equality follows from \(\boldsymbol {\tilde {X}}= \begin {bmatrix} \boldsymbol {\tilde {X}}^{-} & \boldsymbol {x}^{p} \\ \end {bmatrix}\) and the inverse formula for the partitioned matrix of \(\boldsymbol {\tilde {X}}^{\mathrm {T}} \boldsymbol {\tilde {X}}\). The value of hi(βi) at \(\boldsymbol {\beta }_{i}=\boldsymbol {\beta }_{i}^{\text {(ols)}}\) is
The decrease in the objective value from βip=0 in Eq. (38) to βip≠0 in Eq. (41) is
where the second equality employs the following equality:
which is obtained by partitioning \(\boldsymbol {\tilde {X}}^{\mathrm {T}} \boldsymbol {\tilde {X}}\) into a 2×2 block matrix and then substituting the formula for its inverse, and \(\beta _{ip}^{\text {(ols)}}\) is defined in Eq. (40).
Therefore, the solution is
Now we only need to solve for δp. We have
where the second equality is due to the fact that \(h_{i}\left (\boldsymbol {\beta }_{i}^{\text {(ols)}}\right)\) is a constant independent of δ.
Substituting (42) into (44) yields
where the \(\beta _{ip}^{\text {(ols)}} \left (\delta _{p}\right)\) as a function of δp is defined in Eq. (40).
After \(\hat {\delta }_{p}\) is estimated, the estimate of βip is obtained by substituting \(\delta _{p}=\hat {\delta }_{p}\) into (43). Algorithm 2 describes the complete model fitting procedure.

Next, we introduce a simple method for the selection of the tuning parameters in our model, which is based on the property of the solution (32) or (43).
Tuning parameter selection: regression with type I penalty
Substituting (19) into (1) and assuming that \(\boldsymbol {\delta }=\boldsymbol {\bar {\beta }}^{(w)}\) is fixed, we have
where \(\tilde {y}_{ij} + \boldsymbol {\delta }^{\mathrm {T}} \boldsymbol {\tilde {x}}_{j} \) are the normalized data, which we use here as the response variables, and \(\varepsilon _{ij} \sim \mathcal {N}\left (0,\sigma _{i}^{2}\right)\).
The condition for βi=0 in (32) can be rewritten as
Under the null hypothesis, βi=0; the left-hand side of (47) follows a chi-squared distribution with p degrees of freedom, i.e., \(\chi _{p}^{2}\). This suggests us choose λi=1/2·F−1(1−q; p)=1/2·{x:F(x; p)=1−q}, where F(x; p) is the cumulative distribution function of \(\chi _{p}^{2}\), and q is a pre-specified significance level.
Tuning parameter selection: regression with type II penalty
Let \(\tilde {y}_{ij} + \boldsymbol {\delta }^{\mathrm {T}} \boldsymbol {\tilde {x}}_{j} \) denote the normalized data:
where \(\varepsilon _{ij} \sim \mathcal {N}\left (0,\sigma _{i}^{2}\right)\).
The condition for βip=0 in (43) can be rewritten as
where \(\beta _{ip}^{\text {(ols)}}\) is defined in (40) and
is the standard error of the estimate \(\beta _{ip}^{\text {(ols)}}\).
Under the null hypothesis, βip=0; the left-hand side of (49) follows the standard Gaussian distribution. This suggests us choose λi=1/2·[Φ−1(1−q/2)]2, where Φ(·) is the cumulative distribution function of the standard Gaussian distribution, and q is a pre-specified significance level.
Maximum likelihood estimation of noise variance
To estimate \(\sigma _{i}^{2}, i=1,\dots,m\), consider the negative log-likelihood function with \(\sigma _{i}^{2}\)’s being unknown as well:
Setting partial derivatives of l(·) with respect to αi,βi,i=1,…,m, and dj,j=1,…,n to zeros, and after some mathematical manipulation, we obtain
where \(\boldsymbol {\tilde {X}}, \boldsymbol {\tilde {x}}_{j}\) and \(\bar {y}_{\cdot j}^{(w)}\) are defined in (28), (22) and (11), respectively.
Taking partial derivatives of l(·) with respect to \(\sigma _{i}^{2}, i=1,\ldots,m,\) and setting them to zeros gives
Substituting (19) into (52), we have
where \(\bar {y}_{i\cdot }\) and \(\bar {y}^{(w)}\) are as defined in (14) and (17), respectively.
Given initial estimates of \(\sigma _{i}^{2}\)’s and \(\boldsymbol {\bar {\beta }}^{(w)}, \{\boldsymbol {\beta }_{i}\}, \{\sigma _{i}^{2}\}\) and \(\boldsymbol {\bar {\beta }}^{(w)}\) can be updated alternately using Eqs. (51), (53), and (12) until convergence.
After \(\{\sigma _{i}^{2}\}_{i=1}^{m}\) are estimated, they can be robustified using a “shrinkage toward the mean” scheme [16]:
where
The noise variance estimates \(\hat {\hat {\sigma }}_{i}^{2}, i=1,\dots,m\), can then be used in Algorithm 1 or 2 to solve for \(\{\boldsymbol {\beta }_{i}\}_{i=1}^{m}\).
Remark 2
Note that when \( \sigma _{1}^{2} = \sigma _{2}^{2} = \dotsb = \sigma _{m}^{2} = \sigma ^{2} \), it is no longer needed to estimate σ2 since σ2 in (6) can be incorporated into the tuning parameters λi’s.
Results and discussion
We demonstrate the performance of our proposed method (named rSeqRobust) by comparing it with other existing methods for DE gene detection from RNA-seq data: edgeR-robust [1,2], DESeq2 [3], limma-voom [4,5], and ELMSeq (which fits a similar model but with ℓ1 rather than ℓ0 penalty) [11]. We consider the simple regression model (p=1), in which case Algorithms 1 and 2 coincide. For ELMSeq, the tuning parameter is set as the 5th percentile of m values: \(\left |\frac {1}{\hat {\sigma }_{1}^{2}} \boldsymbol {\tilde {x}}^{\mathrm {T}} \boldsymbol {\tilde {y}}_{1}\right |, \left |\frac {1}{\hat {\sigma }_{2}^{2}} \boldsymbol {\tilde {x}}^{\mathrm {T}} \boldsymbol {\tilde {y}}_{2}\right |, \dots, \left |\frac {1}{\hat {\sigma }_{m}^{2}} \boldsymbol {\tilde {x}}^{\mathrm {T}} \boldsymbol {\tilde {y}}_{m}\right |\) [11]. The tuning parameters λ is set based on the significant level of q=0.01.
Simulations on synthetic data
We simulate both log-normally distributed and negative-binomially distributed read counts, with m=20,000 genes and n=7, 20 or 200 samples. The RNA-seq read counts are generated as \(c_{ij} \sim \lceil \mathrm {e}^{\mathcal {N}(\log \mu _{ij},\sigma _{i}^{2})}\rceil \) under the log-normal (LN) distribution assumption, and as \(c_{ij} \sim \mathcal {NB}(\mu _{ij},\phi _{i})\) [2] under the NB distribution assumption, where μij is the mean read counts of gene i in sample j. The generation of μij is described in Table 1. The variance of the normal distribution is set as \(\sigma _{i}^{2}=0.01\), and the dispersion parameter of the NB distribution is set as ϕi=0.25.
After estimating the sample-specific normalization factors dj’s using Algorithm 1, we substitute \(\hat {d}_{j}\)’s into model (1) to obtain m decoupled gene-wise linear regression models. For each gene i, we test the null hypothesis that βi=0, and calculate the p-value. We decide there is a significant linear association between the experimental variable xj and the gene expression yij if the p-value is less than a predefined threshold (e.g., 0.05). With the p-value for each gene, we rank the genes and vary the p-value threshold from 0 to 1 to determine significant DE genes and calculate the area under the ROC curve (AUC).
Table 2 shows the AUCs of the five methods on log-normally distributed data with sample size n=20. We observe the followings: i) In relatively easy scenarios where a small percent of genes are differentially expressed (i.e., DE% =1% or 10%) or the up- and down-regulated genes are equal in portions (i.e., Up% =50%), all five methods perform equally well (within one standard error of AUC difference); ii) In challenging scenarios where a large percent of genes are differentially expressed (i.e., DE% ≥30%) and the up- and down-regulated genes are different in portions (i.e., Up% =75% or 100%), rSeqRobust outperforms ELMSeq, which in turn outperforms the rest; iii) In the most challenging scenarios with 70% or 90% DE genes that are all overexpressed (i.e., Up% =100%), only rSeqRobust achieves good results (AUC=0.9638 or 0.8276).
Table 3 shows the AUCs of different methods for negative-binomially distributed data. The same observations are obtained as in Table 2: In relatively easy settings with small percent of DE genes or symmetric over- and under-expression pattern, rSeqRobust performs as well as other methods; In challenging settings with large percent of DE genes (DE% ≥10%) and asymmetric over- and under-expression pattern (Up% =75% or 100%), rSeqRobust consistently performs the best, and ELMSeq ranks second in all except extreme cases: (Up%, DE%) =(70%, 100%), (90%, 75%) or (90%, 100%) where most methods suffer from severe performance degradation or complete failure.
In Tables 4 and 5, the sample size is reduced to n=7. Again, we observe similar patterns: when a small subset of genes are differentially expressed (i.e., DE% =1% or 10%), or the up- and down-regulated DE genes are imbalanced in numbers, rSeqRobust and other methods perform equally well; when most genes are differentially expressed (i.e., DE% = 50% or 70%) in an asymmetric manner (i.e., Up% =75% or 100%), rSeqRobust outperforms all other methods. Note that in the presence of 70% DE genes that are all up-regulated, only rSeqRobust achieves good results (AUC =0.9059 for LN data and AUC =0.8623 for NB data).
In Tables 6 and 7, the sample size is increased to n=200. As the sample size increases from n=20 to n=200, the AUCs of edgeR-robust, DESeq2 and limma-voom increase for easy cases (small percent of DE genes or symmetric over- and under-expression patterns). However, for challenging cases (i.e., DE% =50%, 70% or 90%, Up% =75% or 100%), the AUCs decrease. On the contrary, the AUC of rSeqRobust increases consistently in all cases. The performance gain of rSeqRobust over other methods is more significant for more challenging cases. Note that rSeqRobust performs nearly as well in the most challenging cases (Up%, DE%) =(50%, 100%), (70%, 100%), (90%, 75%) or (90%, 100%) as in easy cases. In contrast, ELMSeq only works for (Up%, DE%) =(50%, 100%) and edgeR-robust, DESeq2, limma-voom completely fail in all these cases. This indicates that rSeqRobust is more robust than ELMSeq, which in turn is more robust than edgeR-robust, DESeq2 and limma-voom.
Table 8 shows the average running times (in seconds) of the five methods on an Intel Core i3 processor with 8GB of memory and a clock frequency of 3.9GHz. We can see that rSeqRobust is slower than limma-voom; however, it scales well for large sample sizes and is much faster than ELMSeq.
Application to a real RNA-seq dataset
We further assess the proposed method on a real RNA-seq dataset from The Cancer Genome Atlas (TCGA) project [17], which contains 20,531 genes from 187 prostate adenocarcinoma patient samples. The dataset was downloaded from the TCGA data portal (https://portal.gdc.cancer.gov). In this experiment, we aim at identifying genes associated with pre-operative prostate-specific antigen (PSA), which is an important biomarker for prostate cancer. The data are pre-processed using the procedures described in [11]. We use the Bonferroni correction and determined DE genes using a p-value threshold of 0.05/m. Figure 1 shows the Venn diagram based on the sets of differentially expressed genes discovered by five methods.

Venn diagram based on the set of differentially expressed genes identified by edgeR, DESeq2, limma-voom, ELMSeq and rSeqRobust
There are twelve genes that are detected by rSeqRobust and ELMSeq, but not by edgeR, DESeq2 and limma-voom: EPHA5, RNF126P1, BCL11A, RIC3, AJAP1, CDH3, WIT1, PRSS16, CEACAM1, DCHS2, CRHR1 and SRD5A2. For the majority of these twelve genes, there are existing publications reporting their associations with prostate cancer. For instance, EPHA5 is known to be underexpressed in prostate cancer [18]. CEACAM1 is known to suppress prostate cancer cell proliferation when overexpressed [19]. Two of the twelve genes, CRHR1 and SRD5A2, are identified only by rSeqRobust, where SRD5A2 is associated with racial/ethnic disparity in prostate cancer risk [20].
There are twelve genes that are detected by all five methods: KANK4, RHOU, TPT1, SH2D3A, EEF1A1P9, ZCWPW1, ZNF454, RACGAP1, PTPLA, POC1A, AURKA and TIMM17A. Similarly, there are existing publications reporting their associations with prostate cancer. For instance, RHOU is associated with the invasion, proliferation and motility of prostate cancer cells [21].
Conclusion & discussion
In this paper, we present a unified statistical model for joint normalization and differential expression detection in RNA-seq. Different from existing methods, we explicitly model sample-specific normalization factors as unknown parameters, so that they can be estimated simultaneously together with detection of differentially expressed genes. Using an ℓ0-regularized regression approach, our method is robust against large proportion of DE genes and asymmetric DE pattern, and is shown in empirical studies to be more accurate in detecting differential gene expression patterns.
This model generalizes [10] from categorical experimental conditions using an ANOVA-type model to continuous covariates using a regression model. In addition, two hypothesis tests are formulated: i) Is the expression level of a gene associated with any covariates of the regression model? This is the test considered in [10]; ii) Is the expression level of a gene associated with a specific covariate of our interest, when all other variables in the regression model are adjusted for? Although the model is high-dimensional, non-differentiable and non-convex due to the ℓ0 penalty, we manage to develop an efficient algorithms to find their its solution by making use of the optimality conditions of the ℓ0-regularized regression. It can be shown that for categorical experimental data, the developed algorithm for the first hypothesis test for the slopes in a regression model with p binary covariates reduces to that in [10] for the (p+1)-group model.
Availability of data and materials
The computer programs for the algorithms described in this paper are available at http://www-personal.umich.edu/~jianghui/rseqrobust.
Abbreviations
- ANOVA:
-
Analysis of variance
- AUC:
-
Area under the ROC curve
- CPM/RPM:
-
Counts/reads per million
- DE:
-
Differential expression
- LN:
-
Log-normal
- NB:
-
Negative binomial
- PSA:
-
prostate-specific antigen
- RNA-seq:
-
RNA sequencing
- ROC:
-
Receiver operating characteristic
- RPKM/FPKM:
-
Reads/fragments per kilobase of exon per million mapped reads
- TCGA:
-
The Cancer Genome Atlas
- TPM:
-
Transcripts per million
References
Robinson MD, McCarthy DJ, Smyth GK. edgeR: a bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics. 2010; 26:139–40.
Zhou X, Lindsay H, Robinson MD. Robustly detecting differential expression in RNA sequencing data using observation weights. Nucleic Acids Res. 2014; 42(11):91.
Love MI, Huber W, Anders S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 2014; 15(12):550.
Ritchie ME, Phipson B, Wu D, Hu Y, Law CW, Shi W, Smyth GK. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015; 43(7):47.
Law CW, Chen Y, Shi W, Smyth GK. Voom: precision weights unlock linear model analysis tools for RNA-seq read counts. Genome Biol. 2014; 15(2):29.
Dillies M-A, Rau A, Aubert J, Hennequet-Antier C, Jeanmougin M, Servant N, Keime C, Marot G, Castel D, Estelle J, Guernec G, Jagla B, Jouneau L, Laloe D, Le Gall C, Schaeffer BLffer, Le Crom S, Guedj M, Jaffrezic F, FSC. A comprehensive evaluation of normalization methods for illumina high-throughput RNA sequencing data analysis. Brief Bioinform. 2013; 14(6):671–83.
Robinson MD, Oshlack A. A scaling normalization method for differential expression analysis of RNA-seq data. Genome Biol. 2010; 11(3):25.
Bullard JH, Purdom E, Hansen KD, Dudoit S. Evaluation of statistical methods for normalization and differential expression in mRNA-Seq experiments. BMC Bioinf. 2010; 11:94.
Anders S, Huber W. Differential expression analysis for sequence count data. Genome Biol. 2010; 11(10):106.
Jiang H, Zhan T. Unit-free and robust detection of differential expression from rna-seq data. Stat Biosci. 2017; 9(1):178–99.
Liu K, Ye J, Yang Y, Shen L, Jiang H. A Unified Model for Joint Normalization and Differential Gene Expression Detection in RNA-Seq data. IEEE/ACM Trans Comput Biol Bioinforma. 2019; 16(2):442–54. https://doi.org/10.1109/tcbb.2018.2790918.
Mortazavi A, Williams BA, McCue K, Schaeffer L, Wold B. Mapping and quantifying mammalian transcriptomes by RNA-Seq,. Nat Methods. 2008; 5(7):621–8.
Trapnell C, Williams BA, Pertea G, Mortazavi A, Kwan G, van Baren MJ, Salzberg SL, Wold BJ, Pachter L. Transcript assembly and quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation. Nat Biotechnol. 2010; 28(5):511–5.
Li B, Ruotti V, Stewart RM, Thomson JA, Dewey CN. RNA-Seq gene expression estimation with read mapping uncertainty. Bioinformatics. 2010; 26(4):493–500.
Liu T-Y, Jiang H. Minimizing sum of truncated convex functions and its applications. J Comput Graph Stat. 2019; 28(1):1–10. (just-accepted). https://doi.org/10.1080/10618600.2017.1390471.
Ji H, Wong WH. TileMap: create chromosomal map of tiling array hybridizations. Bioinformatics. 2005; 21(18):3629–36.
Network CGAR. The molecular taxonomy of primary prostate cancer. Cell. 2015; 163:1011–25. https://doi.org/10.1016/j.cell.2015.10.025.
Li S, Zhu Y, Ma C, Qiu Z, Zhang X, Kang Z, Wu Z, Wang H, Xu X, Zhang H, et al.Downregulation of EphA5 by promoter methylation in human prostate cancer. BMC Cancer. 2015; 15(1):18.
Busch C, Hanssen TA, Wagener C, Öbrink B. Down-regulation of CEACAM1 in human prostate cancer: correlation with loss of cell polarity, increased proliferation rate, and gleason grade 3 to 4 transition. Hum Pathol. 2002; 33(3):290–8.
Ross RK, Pike MC, Coetzee GA, Reichardt JK, Yu MC, Feigelson H, Stanczyk FZ, Kolonel LN, Henderson BE. Androgen metabolism and prostate cancer: establishing a model of genetic susceptibility. Cancer Res. 1998; 58:4497–504.
Alinezhad S, Väänänen R-M, Mattsson J, Li Y, Tallgrén T, Ochoa NT, Bjartell A, Åkerfelt M, Taimen P, Boström PJ, et al.Validation of novel biomarkers for prostate cancer progression by the combination of bioinformatics, clinical and functional studies. PLoS ONE. 2016; 11(5):0155901.
Acknowledgements
Not applicable.
About this supplement
This article has been published as part of BMC Bioinformatics Volume 20 Supplement 16, 2019: Selected articles from the IEEE BIBM International Conference on Bioinformatics & Biomedicine (BIBM) 2018: bioinformatics and systems biology. The full contents of the supplement are available online at https://bmcbioinformatics.biomedcentral.com/articles/supplements/volume-20-supplement-16.
Funding
HJ’s research was supported in part by a startup grant from the University of Michigan and the National Cancer Institute grants P30CA046592 and P50CA186786. The publication costs are funded by the University of Michigan (HJ’s start-up fund). The funding body(s) played no role in the design or conclusions of the study.
Author information
Authors and Affiliations
Contributions
HJ conceived the study and designed the experiments. KL developed the algorithms and performed the experiments. KL, HJ and LS wrote the paper. All authors read and approved this version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Liu, K., Shen, L. & Jiang, H. Joint between-sample normalization and differential expression detection through ℓ0-regularized regression. BMC Bioinformatics 20 (Suppl 16), 593 (2019). https://doi.org/10.1186/s12859-019-3070-4
Published:
DOI: https://doi.org/10.1186/s12859-019-3070-4