
Abstract
The global asymptotical synchronization problem is discussed for a general class of uncertain stochastic discrete-time neural networks with time delay in this paper. Time delays include time-varying delay and distributed delay. Based on the drive-response concept and the Lyapunov stability theorem, a linear matrix inequality (LMI) approach is given to establish sufficient conditions under which the considered neural networks are globally asymptotically synchronized in the mean square. Therefore, the global asymptotical synchronization of the stochastic discrete-time neural networks can easily be checked by utilizing the numerically efficient Matlab LMI toolbox. Moreover, the obtained results are dependent not only on the lower bound but also on the upper bound of the time-varying delays, that is, they are delay-dependent. And finally, a simulation example is given to illustrate the effectiveness of the proposed synchronization scheme.
Similar content being viewed by others

1 Introduction
Since Chua and Yang in [1, 2] proposed the theory and applications of cellular neural networks, the dynamical behaviors of neural networks have attracted a great deal of research interest in the past two decades. Those attentions have mainly concentrated on the stability and the synchronization problems of neural networks (see [3–28]). Especially after synchronization problems of chaotic systems had been studied by Pecora and Carroll in [29, 30], in which they proposed the drive-response concept, the control and synchronization problems of chaotic systems have been thoroughly investigated [5–8, 14–18, 31–35]. And many applications of such systems have been found in different areas, particularly in engineering fields such as creating secure communication systems (see [33–35]). As long as we can reasonably design the receiver so that the state evolution of the response system synchronize to that of the driven system, the message obtained by the receiver can be hidden in a chaotic signal, hence, secure communication can be implemented.
It is well known that neural networks, including Hopfield neural networks (HNNs) and cellular neural networks (CNNs), are large-scale and complex nonlinear high-dimensional systems composed of a large number of interconnected neurons. And they have also been found effective applications in many areas such as image processing, optimization problems, pattern recognition, and so on. Therefore, it is not easy to achieve the control and synchronization of these systems. In [8, 16, 19, 22], by drive-response method, some results are given for different type neural networks to guarantee the synchronization of drive system and response system in the models discussed. It is easy to apply those results to real neural networks. And in [5–7, 18], synchronization in an array of linearly or nonlinearly coupled networks has been analyzed in details. The authors studied the global asymptotic or exponential synchronization of a complex dynamical neural networks through constructing a synchronous manifold and showed that it is globally asymptotically or exponentially stable. To the best of our knowledge, up till now, most of the synchronization methods of chaotic systems (especially neural networks) are of drive-response type (which is also called a master-slave system).
At the same time, most of the papers mentioned above are concerned with continuous-time neural networks. When implementing these networks for practical use, discrete-time types of models should be formulated. The readers may refer to [3, 23] for more details as regards the significance of investigating discrete-time neural networks. Therefore, it is important to study the dynamical behaviors of discrete-time neural networks. On the other hand, because the synaptic transmission is probably a noisy process brought about by random fluctuations from the release of neurotransmitters, and a stochastic disturbance must be considered when formulating real artificial neural networks. Recently, the stability and synchronization analysis problems for stochastic or discrete-time neural networks have been investigated; see e.g. [3, 10–13, 19–21, 23], and references therein. So, in this paper, based on drive-response concept and Lyapunov functional method, some different decentralized control laws will be given for global asymptotical synchronization of a general class of discrete-time delayed chaotic neural networks with stochastic disturbance. In the neural network model, the parameter uncertainties are norm-bounded, the neural networks are subjected to stochastic disturbances described in terms of a Brownian motion, and the delay includes time-varying delay and distributed delay. Up to now, to the best of our knowledge, there are few works about the synchronization problem of discrete-time neural networks with distributed delay. And the master-slave system’s synchronization problem for the uncertain stochastic discrete-time neural networks with distributed delay is little investigated.
This paper is organized as follows. In Section 2, model formulation and some preliminaries are presented for our main results. In Section 3, based on the drive-response concept and the Lyapunov functional method, we discuss global asymptotical synchronization in mean square for uncertain stochastic discrete-time delayed neural networks with mixed delays. A numerical example is given to illustrate the effectiveness and feasibility of our results in Section 4. And finally, in Section 5, we give the conclusions.
Notations Throughout this paper, ℝ, , and are used to denote, respectively, the real number field, the real vector space of dimension n, and the set of all real matrices. And denotes a n-dimensional identity matrix. The set of all integers on the closed interval is denoted as , where a, b are integers and . We use ℕ to denote the set of all positive integers. Also, we assume that represents the set of all functions . The superscript ‘T’ represents the transpose of a matrix or a vector, and the notation (respectively, ) means that is a positive semi-definite matrix (respectively, a positive definite matrix) where X and Y are symmetric matrices. The notation denotes the Euclidian norm of a vector and refers to an m-dimensional identity matrix. Let be a complete probability space with a natural filtration satisfying the usual conditions (i.e., the filtration contains all  -null sets and is right continuous) and generated by Brownian motion . stands for the mathematical expectation operator with respect to the given probability measure . The asterisk ∗ in a matrix is used to denote the term that is induced by symmetry. Usually, if not explicitly specified, matrices are always assumed to have compatible dimensions.
-null sets and is right continuous) and generated by Brownian motion . stands for the mathematical expectation operator with respect to the given probability measure . The asterisk ∗ in a matrix is used to denote the term that is induced by symmetry. Usually, if not explicitly specified, matrices are always assumed to have compatible dimensions.
2 Model formulation and preliminaries
It is well known that most of the synchronization methods of chaotic systems are of the master-slave (drive-response) type. The system, which is called a slave system or a response system, can be driven by another system, which is called a master system or drive system, so that the behavior of the slave system can be influenced by the master system, i.e., the master system is independent to the slave system but the slave system is driven by the master system. In this paper, our aim is to design the controller reasonably such that the behavior of the slave system synchronizes to that of the master system.
Now, let us consider a general class of n-neuron discrete-time neural networks with time-varying and distributed delays which is described by the following difference equations:
that is,
where is the state vector associated with the n neurons. The positive integer corresponds to the time-varying delay satisfying
where and are known positive integers. and are real diagonal constant matrices (corresponding to the state feedback and the delayed state-feedback coefficient matrices, respectively) with , , , , , and are the connection weight matrix, the discretely delayed connection weight matrix and the distributively delayed connection weight matrix, respectively. The functions , and in denote the neuron activation functions. The real vector is the exogenous input.
Remark 1 The term of the distributed time delays, , in the discrete-time form, is included in the model (1). It can be interpreted as the discrete analog of the following well-discussed continuous-time complex network with time-varying and distributed delays:
Obviously, such a distributed delay term will bring about an additional difficulty in our analysis.
For the activation functions in the model (1), we have the following assumptions:
Assumption 1 The activation functions , , and () in model (1) are all continuous and bounded.
The activation functions , , and () in model (1) satisfy
where , , , , , are some constants.
Remark 2 The constants , , , , , in Assumption 2 are allowed to be positive, negative or zero. So, the activation functions in this paper are less conservative than the usual sigmoid functions.
The time-varying matrices , , , , and in model (1) represent the parameter uncertainties, which are generated by the modeling errors and are assumed satisfying the following admissible condition:
in which M and () are known real constant matrices, and is the unknown time-varying matrix-valued function subject to the following condition:
Also, the initial conditions of model (1) are given by
In this paper, we consider model (1) as the master system. And the response system is
namely,
where the related parameters and the activation functions are all same as model (1), is the controller which is to be designed later, this is also our main aim. is the error state, is a n-dimensional Brownian motion defined on a complete probability space with
and is a continuous function with and
where and are known constant scalars.
The initial conditions of the slave system model (9) are given by
here denotes the family of all -measurable -valued random variables satisfying .
Now let us define the error state as , subtracting (9) from (1), it yields the error dynamical systems as follows:
where , , . Denoted the error state vector as . Correspondingly, from (8) and (12), the initial condition of error system (12) is . Here it is necessary to assume that .
Now, we firstly give the definition of the globally robust asymptotical synchronization in mean square of the master system (1) and the slave system (9) as follows.
Definition 1 System (1) and system (9) are said to be globally asymptotically synchronized in the mean square if all parameter uncertainties satisfying the admissible condition (6) and (7), and the trajectories of system (1) and system (9) satisfy
That is, if the error system (13) is globally robustly asymptotically stable in the mean square, then system (1) and system (9) are robustly globally asymptotically synchronized in the mean square.
Remark 3 Assumption 1 and Assumption 2 can derive that the error system (13) has at least an equilibrium point. Our main aim is to design the controller reasonably such that the equilibrium point of the error system (13) is robustly globally asymptotically stable in the mean square.
In many real applications, we are interested in designing a memoryless state-feedback controller as
where is a constant gain matrix.
However, as a special case where the information on the size of time-varying delay is available, we can also consider a discretely delayed-feedback controller of the following form:
Moreover, we can design a more general form of a delayed-feedback controller as
Although a memoryless controller (14) has the advantage of easy implementation, its performance cannot be better than a discretely delayed-feedback controller which utilizes the available information of the size of time-varying delay. Therefore, in this respect, the controller (16) could be considered as a compromise between the performance improvement and the implementation simplicity.
Now, let , and substituting it into (13), and denoting
it follows that
To complete this particular issue, we still need several lemmas to be used later.
Lemma 1 Let ,  , and H be real matrices of appropriate dimensions with H satisfying . Then the following inequality:
, and H be real matrices of appropriate dimensions with H satisfying . Then the following inequality:
holds for any scalar .
Lemma 2 (Schur complement)
Given constant matrices  ,
,  , ℛ, where , , then
, ℛ, where , , then
is equivalent to the following conditions:
Let be a positive semi-definite matrix. If the series concerned are convergent, we have the following inequality:
holds for any and ().
3 Main results and proofs
In this section, some sufficient criteria are presented for the globally asymptotically synchronization in the mean square of the neural networks (1) and (9).
Before our main work, for presentation convenience, in the following, we denote
Then, along the same line as with [21, 23], from Assumption 2, we can easily get, for ,
which are equivalent to
where and represents the unit column vector having ‘1’ as the element on its i th row and zeros elsewhere.
Multiplying both sides of (22), (23), and (24) by , , and , respectively, and summing up from 1 to n with respect to i, it will follow that
The main results are as follows.
Theorem 1 Under Assumptions 1 and 2, the discrete-time neural networks (1) and (9) are globally robustly asymptotically synchronized in the mean square if there exist three positive definite matrices P, Q, and R, three diagonal matrices , , and , and two scalars and such that the following LMIs hold:
and
where
Proof To verify that the neural networks (1) and (9) are globally asymptotically synchronized in the mean square, a Lyapunov-Krasovskii function V is defined as follows:
where
Calculating the difference of along the trajectory of the model (18) and taking the mathematical expectation, one obtains
where
and
The above inequality (41) results by Lemma 3.
On the other hand, from (11) and (28), we have
Substituting (38)-(43) into (37) yields
where
with , , .
From (25), (26), and (27), it follows that
where
with , , and .
Denote
where
Let
It follows easily from (6) and Lemma 1 that
Substituting (47) and (48) into (46), one obtains
where
and , , , , , , , are defined in (30).
By Lemma 2, we have
Therefore, it is not difficult from (29), (45), (46), (49), and (50) to get
with .
Let N be a positive integer. Summing up both sides of (51) from 1 to N with respect to k, it easily follows that
which implies that
By letting , it can be seen that the series is convergent, and therefore we have
According to Definition 1, it can be deduced that the master system (1) and the slave system (9) are globally robustly asymptotically synchronized in the mean square, and the proof is then completed. □
In the following, we will consider four special cases. Firstly, we can consider a state-feedback controller , and the slave system model (9) can then be rewritten to
Corollary 1 Under Assumptions 1 and 2, the discrete-time neural networks (1) and (52) are globally robustly asymptotically synchronized in the mean square if there exist three positive definite matrices P, Q, and R, three diagonal matrices , , and , and two scalars and such that the following LMIs hold:
and
where , , , , , , , are defined in (30).
This corollary is very easily accessible from Theorem 1.
Secondly, if the considered model is without stochastic disturbance, the response system (9) will be specialized to
Corollary 2 Under Assumptions 1 and 2, the discrete-time neural networks (1) and (55) are globally robustly asymptotically synchronized if there exist three positive definite matrices P, Q, and R, three diagonal matrices , , and , and two scalars and such that the following LMIs hold:
and
where , , and , , , , , are defined in (30).
Thirdly, let us consider the uncertainty-free case, that is, there are no parameter uncertainties in the models. Then the master system (1) and the response system (9) can be reduced, respectively, to the following models:
and
Corollary 3 Under Assumptions 1 and 2, the discrete-time neural network (58) and (59) are globally robustly asymptotically synchronized in the mean square if there exist three positive definite matrices P, Q, and R, three diagonal matrices , , and , and a scalar such that the following LMIs hold:
and
with , , and is defined as (30).
Moreover, in this case, if the stochastic disturbance in the response system (59) is (), then we need only rewrite and as and , and the corollary will still be true.
The proofs of Corollary 2 and Corollary 3 are similar to that of Theorem 1 and are therefore omitted.
Finally, we consider the systems without the distributed delay influence. The master system (1) and the response system (9) will become, respectively, the following difference equations:
and
Then the error system is
In this case, we will show that the neural networks (62) and (63) are not only globally, robustly, and asymptotically synchronized in the mean square, but also globally, robustly, and exponentially synchronized in the mean square. The definition of the globally robustly exponentially synchronization in the mean square is given firstly in the following.
Definition 2 Systems (62) and (63) are said to be globally exponentially synchronized in the mean square if all parameter uncertainties satisfy the admissible condition (6) and (7), and if there exist two constants and , and a big enough positive integer N, such that the following inequality:
holds for and all .
Then we have the following theorem.
Theorem 2 Under Assumptions 1 and 2, the discrete-time neural networks (62) and (63) are globally robustly exponentially synchronized in the mean square if there exist two positive definite matrices P and Q, two diagonal matrices and , and two scalars and such that the following LMIs hold:
and
where and , , , , , , are defined in (30).
Proof A Lyapunov-Krasovskii function is needed to guarantee that the neural networks (62) and (63) are globally exponentially synchronized in the mean square:
where , , and are similar to (32), (33), and (34).
Then, along a similar line to the proof of Theorem 1, one can obtain
where , and
Now, we are in a position to establish the robust global exponential stability in the mean square of the error system (64).
First, from the definition of function , it is easy to see that
where
For any , inequalities (68) and (69) imply that
where
Let N be a sufficient big positive integer satisfying . Summing up both sides of the inequality (71) from 0 to with respect to k, one can obtain
while for ,
Then, it follows from (72) and (73) that
Considering , , and for , it can be verified that there exists a scalar such that . So, it is not difficult to derive
On the other hand, it also follows easily from (69) that
where . Therefore, from (70), (75), and (76), one has
According to Definition 2, this completes the proof. □
Remark 4 Based on the drive-response concept, synchronization problems of discrete-time neural networks are little investigated. To the best of our knowledge, for master-slave systems, the synchronization analysis problem for stochastic neural networks with parameter uncertainties, especially distributed delay, is for the first time discussed.
4 Numerical example
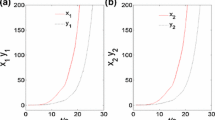
In this section, an example will be illustrated to show the feasibility of our results.
Example 1 Consider the drive system (1) and the response system (9) with the following parameters:
Therefore, it can be derived that , , , and the activation functions satisfy Assumption 2 with
We design a delayed-feedback controller as , that is, the distributed delayed controller is omitted. By using the Matlab LMI Toolbox, LMI (28) and (29) can be solved and the feasible solutions are obtained as follows:
and
Then Corollary 1 proves that the response system (9) and the drive system (1) with the given parameters can achieve globally robustly asymptotically synchronization in the mean square.
5 Conclusions
In this paper, based on Lyapunov stability theorem and drive-response concept, the globally asymptotically synchronization has been discussed for a general class of uncertain stochastic discrete-time neural networks with mixed time delays which consist of time-varying discrete and infinite distributed time delays. The proposed controller is robust to a stochastic disturbance and to the parameter uncertainties. In comparison with previous literature, the distributed delay is taken into account in our models, which are few investigated in the discrete-time complex networks. By using the linear matrix inequality (LMI) approach, several easy-to-verify sufficient criteria have been established to ensure the uncertain stochastic discrete-time neural networks to be globally robustly asymptotically synchronized in the mean square. The LMI-based criteria obtained are dependent not only on the lower bound, but also on the upper bound of the time-varying delay, and they can be solved efficiently via the Matlab LMI Toolbox. Also, the proposed synchronization scheme is easy to implement in practice.
Authors’ information
Zhong Chen (1971-), male, native of Xingning, Guangdong, M.S.D., engages in the groups theory and differential equation.
References
Chua LO, Yang L: Cellular neural networks: theory. IEEE Trans. Circuits Syst. 1988, 35(10):1257-1272. 10.1109/31.7600
Chua LO, Yang L: Cellular neural networks: applications. IEEE Trans. Circuits Syst. 1988, 35(10):1273-1290. 10.1109/31.7601
Mohamad S, Gopalsamy K: Exponential stability of continuous-time and discrete-time cellular neural networks with delays. Appl. Math. Comput. 2003, 135(1):17-38. 10.1016/S0096-3003(01)00299-5
Lu W, Chen T: Synchronization analysis of linearly coupled networks of discrete time systems. Physica D 2004, 198: 148-168. 10.1016/j.physd.2004.08.024
Chen G, Zhou J, Liu Z: Global synchronization of coupled delayed neural networks and applications to chaotic CNN models. Int. J. Bifurc. Chaos 2004, 14(7):2229-2240. 10.1142/S0218127404010655
Lu W, Chen T: Synchronization of coupled connected neural networks with delays. IEEE Trans. Circuits Syst. 2004, 51(12):2491-2503. 10.1109/TCSI.2004.838308
Wu CW: Synchronization in arrays of coupled nonlinear systems with delay and nonreciprocal time-varying coupling. IEEE Trans. Circuits Syst. 2005, 52(5):282-286.
Chen C, Liao T, Hwang C: Exponential synchronization of a class of chaotic neural networks. Chaos Solitons Fractals 2005, 24(2):197-206.
Wang Z, Liu Y, Liu X: On global asymptotic stability of neural networks with discrete and distributed delays. Phys. Lett. A 2005, 345: 299-308. 10.1016/j.physleta.2005.07.025
Liu Y, Wang Z, Liu X: On global exponential stability of generalized stochastic neural networks with mixed time-delays. Neurocomputing 2006, 70: 314-326. 10.1016/j.neucom.2006.01.031
Wang Z, Liu Y, Yu L, Liu X: Exponential stability of delayed recurrent neural networks with Markovian jumping parameters. Phys. Lett. A 2006, 356: 346-352. 10.1016/j.physleta.2006.03.078
Wang Z, Shu H, Fang J, Liu X: Robust stability for stochastic Hopfield neural networks with time delays. Nonlinear Anal., Real World Appl. 2006, 7: 1119-1128. 10.1016/j.nonrwa.2005.10.004
Wang Z, Liu Y, Fraser K, Liu X: Stochastic stability of uncertain Hopfield neural networks with discrete and distributed delays. Phys. Lett. A 2006, 354: 288-297. 10.1016/j.physleta.2006.01.061
Cao J, Li P, Wang W: Global synchronization in arrays of delayed neural networks with constant and delayed coupling. Phys. Lett. A 2006, 353: 318-325. 10.1016/j.physleta.2005.12.092
Zhou J, Chen TP: Synchronization in general complex delayed dynamical networks. IEEE Trans. Circuits Syst. 2006, 53(3):733-744.
Lou X, Cui B: Asymptotic synchronization of a class of neural networks with reaction-diffusion terms and time-varying delays. Comput. Math. Appl. 2006, 52: 897-904. 10.1016/j.camwa.2006.05.013
Cao J, Li P, Wang W: Global synchronization in arrays of delayed neural networks with constant and delayed coupling. Phys. Lett. A 2006, 353: 318-325. 10.1016/j.physleta.2005.12.092
Wang W, Cao J: Synchronization in an array of linearly coupled networks with time-varying delay. Physica A 2006, 366: 197-211.
Yu W, Cao J: Synchronization control of stochastic delayed neural networks. Physica A 2007, 373: 252-260.
Wang Z, Lauria S, Fang J, Liu X: Exponential stability of uncertain stochastic neural networks with mixed time-delays. Chaos Solitons Fractals 2007, 32: 62-72. 10.1016/j.chaos.2005.10.061
Liu Y, Wang Z, Serrano A, Liu X: Discrete-time recurrent neural networks with time-varying delays: exponential stability analysis. Phys. Lett. A 2007, 362: 480-488. 10.1016/j.physleta.2006.10.073
Yan J, Lin J, Hung M, Liao T: On the synchronization of neural networks containing time-varying delays and sector nonlinearity. Phys. Lett. A 2007, 361: 70-77. 10.1016/j.physleta.2006.08.083
Liu Y, Wang Z, Liu X: Robust stability of discrete-time stochastic neural networks with time-varying delays. Neurocomputing 2008, 71(4-6):823-833. 10.1016/j.neucom.2007.03.008
Chen T, Wu W, Zhou W: Global μ -synchronization of linearly coupled unbounded time-varying delayed neural networks with unbounded delayed coupling. IEEE Trans. Neural Netw. 2008, 19(10):1809-1816.
Liu X, Chen T: Robust μ -stability for uncertain stochastic neural networks with unbounded time-varying delays. Physica A 2008, 387: 2952-2962. 10.1016/j.physa.2008.01.068
Liu Y, Wang Z, Liu X: On synchronization of coupled neural networks with discrete and unbounded distributed delays. Int. J. Comput. Math. 2008, 85(8):1299-1313. 10.1080/00207160701636436
Liu Y, Wang Z, Liang J, Liu X: Synchronization and state estimation for discrete-time complex networks with distributed delays. IEEE Trans. Syst. Man Cybern., Part B, Cybern. 2008, 38(5):1314-1325.
Liu Y, Wang Z, Liu X: On synchronization of discrete-time Markovian jumping stochastic complex networks with mode-dependent mixed time-delays. Int. J. Mod. Phys. B 2009, 23(3):411-434. 10.1142/S0217979209049826
Pecora LM, Carroll TL: Synchronization chaotic systems. Phys. Rev. Lett. 1990, 64(8):821-824. 10.1103/PhysRevLett.64.821
Carroll TL, Pecora LM: Synchronization chaotic circuits. IEEE Trans. Circuits Syst. 1991, 38(4):453-456. 10.1109/31.75404
Wu CW, Chua LO: A unified framework for synchronization and control of dynamical systems. Int. J. Bifurc. Chaos 1994, 4(4):979-998. 10.1142/S0218127494000691
Wu CW, Chua LO: Synchronization in an array of linearly coupled dynamical systems. IEEE Trans. Circuits Syst. 1995, 42(8):430-447. 10.1109/81.404047
Liao T, Tsai S: Adaptive synchronization of chaotic systems and its application to secure communications. Chaos Solitons Fractals 2000, 11(9):1387-1396. 10.1016/S0960-0779(99)00051-X
Lu J, Wu X, Lv J: Synchronization of a unified chaotic system and the application in secure communications. Phys. Lett. A 2002, 305(6):365-370. 10.1016/S0375-9601(02)01497-4
Feki M: An adaptive chaos synchronization scheme applied to secure communications. Chaos Solitons Fractals 2003, 18: 141-148. 10.1016/S0960-0779(02)00585-4
Acknowledgements
This work was supported by the NSF of Guangdong Province of China under Grant S2013010015944 and by the National Science Foundation of China (10576013; 10871075). The authors wish specially to thank the managing editor and referees for their very helpful comments and useful suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
ZC and JL carried out the design of the study and performed the analysis. BX participated in its design and coordination. All authors read and approved the final manuscript.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit https://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, Z., Xiao, B. & Lin, J. Synchronization of a class of uncertain stochastic discrete-time delayed neural networks. Adv Differ Equ 2014, 212 (2014). https://doi.org/10.1186/1687-1847-2014-212
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-1847-2014-212