
Abstract
In this paper, we develop the optimal source precoding matrix and relay amplifying matrices for non-regenerative multiple-input multiple-output (MIMO) relay communication systems with parallel relay nodes using the projected gradient (PG) approach. We show that the optimal relay amplifying matrices have a beamforming structure. Exploiting the structure of relay matrices, an iterative joint source and relay matrices optimization algorithm is developed to minimize the mean-squared error (MSE) of the signal waveform estimation at the destination using the PG approach. The performance of the proposed algorithm is demonstrated through numerical simulations.
Similar content being viewed by others
1 Introduction
Recently, multiple-input multiple-output (MIMO) relay communication systems have attracted much research interest and provided significant improvement in terms of both spectral efficiency and link reliability [1–17]. Many works have studied the optimal relay amplifying matrix for the source-relay-destination channel. In [2, 3], the optimal relay amplifying matrix maximizing the mutual information (MI) between the source and destination nodes was derived, assuming that the source covariance matrix is an identity matrix. In [4–6], the optimal relay amplifying matrix was designed to minimize the mean-squared error (MSE) of the signal waveform estimation at the destination.
A few research has studied the joint optimization of the source precoding matrix and the relay amplifying matrix for the source-relay-destination channel. In [7], both the source and relay matrices were jointly designed to maximize the source-destination MI. In [8, 9], source and relay matrices were developed to jointly optimize a broad class of objective functions. The author of [10] investigated the joint source and relay optimization for two-way MIMO relay systems using the projected gradient (PG) approach. The source and relay optimization for multi-user MIMO relay systems with single relay node has been investigated in [11–14].
All the works in [1–14] considered a single relay node at each hop. In general, joint source and relay precoding matrices design for MIMO relay systems with multiple relay nodes is more challenging than that for single-relay systems. The authors of [15] developed the optimal relay amplifying matrices with multiple relay nodes. A matrix-form conjugate gradient algorithm has been proposed in [16] to optimize the source and relay matrices. In [17], the authors proposed a suboptimal source and relay matrices design for parallel MIMO relay systems by first relaxing the power constraint at each relay node to the sum relay power constraints at the output of the second-hop channel and then scaling the relay matrices to satisfy the individual relay power constraints.
In this paper, we propose a jointly optimal source precoding matrix and relay amplifying matrices design for a two-hop non-regenerative MIMO relay network with multiple relay nodes using the PG approach. We show that the optimal relay amplifying matrices have a beamforming structure. This new result is not available in [16]. It generalizes the optimal source and relay matrices design from a single relay node case [8] to multiple parallel relay nodes scenarios. Exploiting the structure of relay matrices, an iterative joint source and relay matrices optimization algorithm is developed to minimize the MSE of the signal waveform estimation. Different to [17], in this paper, we develop the optimal source and relay matrices by directly considering the transmission power constraint at each relay node. Simulation results demonstrate the effectiveness of the proposed iterative joint source and relay matrices design algorithm with multiple parallel relay nodes using the PG approach.
The rest of this paper is organized as follows. In Section 2, we introduce the model of a non-regenerative MIMO relay communication system with parallel relay nodes. The joint source and relay matrices design algorithm is developed in Section 3. In Section 4, we show some numerical simulations. Conclusions are drawn in Section 5.
2 System model
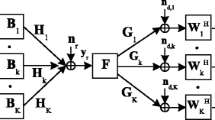
In this section, we introduce the model of a two-hop MIMO relay communication system consisting of one source node, K parallel relay nodes, and one destination node as shown in Figure 1. We assume that the source and destination nodes have Ns and Nd antennas, respectively, and each relay node has Nr antennas. The generalization to systems with different number of antennas at each relay node is straightforward. Due to its merit of simplicity, a linear non-regenerative strategy is applied at each relay node. The communication process between the source and destination nodes is completed in two time slots. In the first time slot, the Nb×1(Nb≤Ns) modulated source symbol vector s is linearly precoded as

Block diagram of a parallel MIMO relay communication system.
where B is an Ns×Nb source precoding matrix. We assume that the source signal vector satisfies , where I n stands for an n×n identity matrix, (·)H is the matrix (vector) Hermitian transpose, and E [·] denotes statistical expectation. The precoded vector x is transmitted to K parallel relay nodes. The Nr×1 received signal vector at the i th relay node can be written as
where Hsr,i is the Nr×Ns MIMO channel matrix between the source and the i th relay nodes and vr,i is the additive Gaussian noise vector at the i th relay node.
In the second time slot, the source node is silent, while each relay node transmits the linearly amplified signal vector to the destination node as
where F i is the Nr×Nr amplifying matrix at the i th relay node. The received signal vector at the destination node can be written as
where Hrd,i is the Nd×Nr MIMO channel matrix between the i th relay and the destination nodes, and vd is the additive Gaussian noise vector at the destination node.
Substituting (1) to (3) into (4), we have
where is a K Nr×Ns channel matrix between the source node and all relay nodes, is an Nd×K Nr channel matrix between all relay nodes and the destination node, is the K Nr×K Nr block diagonal equivalent relay matrix, is obtained by stacking the noise vectors at all the relays, is the effective MIMO channel matrix of the source-relay-destination link, and is the equivalent noise vector. Here, (·)T denotes the matrix (vector) transpose, bd [ ·] constructs a block-diagonal matrix. We assume that all noises are independent and identically distributed (i.i.d.) Gaussian noise with zero mean and unit variance. The transmission power consumed by each relay node (3) can be expressed as
where tr(·) stands for the matrix trace.
Using a linear receiver, the estimated signal waveform vector at the destination node is given by , where W is an Nd×Nb weight matrix. The MSE of the signal waveform estimation is given by
where is the equivalent noise covariance matrix given by . The weight matrix W which minimizes (7) is the Wiener filter and can be written as
where (·)-1 denotes the matrix inversion. Substituting (8) back into (7), it can be seen that the MSE is a function of F and B and can be written as
3 Joint source and relay matrix optimization
In this section, we address the joint source and relay matrix optimization problem for MIMO multi-relay systems with a linear minimum mean-squared error (MMSE) receiver at the destination node. In particular, we show that optimal relay matrices have a general beamforming structure. Based on (6) and (9), the joint source and relay matrices optimization problem can be formulated as
where , (11) is the transmit power constraint at the source node, while (12) is the power constraint at each relay node. Here, Ps>0 and Pr,i>0, i=1,⋯,K, are the corresponding power budget. Obviously, to avoid any loss of transmission power in the relay system when a linear receiver is used, there should be Nb≤min(K Nr,Nd). The problem (10)-(12) is non-convex, and a globally optimal solution of B and {F i } is difficult to obtain with a reasonable computational complexity. In this paper, we develop an iterative algorithm to optimize B and {F i }. First, we show the optimal structure of {F i }.
3.1 Optimal structure of relay amplifying matrices
For given source matrix B satisfying (11), the relay matrices {F i } are optimized by solving the following problem:
Let us introduce the following singular value decompositions (SVDs):
where Λs,i and Λr,i are Rs,i×Rs,i and Rr,i×Rr,i diagonal matrices, respectively. Here, , , i=1,⋯,K, and rank(·) denotes the rank of a matrix. Based on the definition of matrix rank, Rs,i≤ min(Nr,Nb) and Rr,i≤ min(Nr,Nd). The following theorem states the structure of the optimal {F i }.
Theorem 1.
Using the SVDs of (15), the optimal structure of Fi as the solution to the problem (13)-(14) is given by
where A i is an Rr,i×Rs,i matrix, i=1,⋯,K.
Proof
See Appendix 1.
The remaining task is to find the optimal Ai, i=1,⋯,K. From (31) and (32) in Appendix 1, we can equivalently rewrite the optimization problem (13)-(14) as
Both the problem (13)-(14) and the problem (17)-(18) have matrix optimization variables. However, in the former problem, the optimization variable F i is an Nr×Nr matrix, while the dimension of A i is Rr,i×Rs,i, which may be smaller than that of F i . Thus, solving the problem (17)-(18) has a smaller computational complexity than solving the problem (13)-(14). In general, the problem (17)-(18) is non-convex, and a globally optimal solution is difficult to obtain with a reasonable computational complexity. Fortunately, we can resort to numerical methods, such as the projected gradient algorithm [18] to find (at least) a locally optimal solution of (17)-(18).
Theorem 2.
Let us define the objective function in (17) as f(A i ). Its gradient ∇f(Ai) with respect to A i can be calculated by using results on derivatives of matrices in [19] as
where M i , R i , S i , D i , E i , and G i are defined in Appendix 2.
Proof
See Appendix 2.
In each iteration of the PG algorithm, we first obtain by moving A i one step towards the negative gradient direction of f(A i ), where s n >0 is the step size. Since might not satisfy the constraint (18), we need to project it onto the set given by (18). The projected matrix is obtained by minimizing the Frobenius norm of (according to [18]) subjecting to (18), which can be formulated as the following optimization problem:
Obviously, if , then . Otherwise, the solution to the problem (20)-(21) can be obtained by using the Lagrange multiplier method, and the solution is given by
where λ>0 is the solution to the non-linear equation of
Equation (22) can be efficiently solved by the bisection method [18].
The procedure of the PG algorithm is listed in Algorithm 1, where (·)(n) denotes the variable at the n th iteration, δ n and s n are the step size parameters at the n th iteration, ∥·∥ denotes the maximum among the absolute value of all elements in the matrix, and ε is a positive constant close to 0. The step size parameters δ n and s n are determined by the Armijo rule [18], i.e., s n =s is a constant through all iterations, while at the n th iteration, δ n is set to be . Here, m n is the minimal non-negative integer that satisfies the following inequality , where α and γ are constants. According to [18], usually α is chosen close to 0, for example, α∈[10-5,10-1], while a proper choice of γ is normally from 0.1 to 0.5.
3.2 Optimal source precoding matrix
With fixed {F i }, the source precoding matrix B is optimized by solving the following problem:

where , and , i=1,⋯,K. Let us introduce , and a positive semi-definite (PSD) matrix X with , where A≽B means that A-B is a PSD matrix. By using the Schur complement [20], the problem (23)-(25) can be equivalently converted to the following problem:
The problem (26)-(29) is a convex semi-definite programming (SDP) problem which can be efficiently solved by the interior point method [20]. Let us introduce the eigenvalue decomposition (EVD) of , where Λ Ω is a R Ω ×R Ω eigenvalue matrix with R Ω =rank(Ω). If R Ω =Nb, then from Ω=B BH, we have . If R Ω >Nb, the randomization technique [21] can be applied to obtain a possibly suboptimal solution of B with rank Nb. If R Ω <Nb, it indicates that the system (channel) cannot support Nb independent data streams, and thus, in this case, a smaller Nb should be chosen in the system design.
Now, the original joint source and relay optimization problem (10)-(12) can be solved by an iterative algorithm as shown in Algorithm 2, where (·)(m) denotes the variable at the m th iteration. This algorithm is first initialized at a random feasible B satisfying (11). At each iteration, we first update {F i } with fixed B and then update B with fixed {F i }. Note that the conditional updates of each matrix may either decrease or maintain but cannot increase the objective function (10). Monotonic convergence of {F i } and B towards (at least) a locally optimal solution follows directly from this observation. Note that in each iteration of this algorithm, we need to update the relay amplifying matrices according to the procedure listed in Algorithm 1 at a complexity order of and update the source precoding matrix through solving the SDP problem (26)-(29) at a complexity cost that is at most using interior point methods [22]. Therefore, the per-iteration computational complexity order of the proposed algorithm is . The overall complexity of this algorithm depends on the number of iterations until convergence, which will be studied in the next section.

4 Simulations
In this section, we study the performance of the proposed jointly optimal source and relay matrix design for MIMO multi-relay systems with linear MMSE receiver. All simulations are conducted in a flat Rayleigh fading environment where the channel matrices have zero-mean entries with variances and for Hsr and Hrd, respectively. For the sake of simplicity, we assume Pr,i=Pr, i=1,⋯,K. The BPSK constellations are used to modulate the source symbols, and all noises are i.i.d. Gaussian with zero mean and unit variance. We define and as the signal-to-noise ratio (SNR) for the source-relay link and the relay-destination link, respectively. We transmit 1000Ns randomly generated bits in each channel realization, and all simulation results are averaged over 200 channel realizations. In all simulations, we set Nb=Ns=Nr=Nd=3, and the MMSE linear receiver in (8) is employed at the destination for symbol detection.
In the first example, a MIMO relay system with K=3 relay nodes is simulated. We compare the normalized MSE performance of the proposed joint source and relay optimization algorithm using the projected gradient (JSR-PG) algorithm in Algorithm 2, the optimal relay-only algorithm using the projected gradient (ORO-PG) algorithm in Algorithm 1 with , and the naive amplify-and-forward (NAF) algorithm. Figure 2 shows the normalized MSE of all algorithms versus SNRs for SNRr= 20 dB. While Figure 3 demonstrates the normalized MSE of all algorithms versus SNRr for SNRs fixed at 20 dB. It can be seen from Figures 2 and 3 that the JSR-PG and ORO-PG algorithms have a better performance than the NAF algorithm over the whole SNRs and SNRr range. Moreover, the proposed JSR-PG algorithm yields the lowest MSE among all three algorithms.

Example 1. Normalized MSE versus SNRs with K=3, SNRr=20 dB.

Example 1. Normalized MSE versus SNRr with K=3, SNRs=20 dB.
The number of iterations required for the JSR-PG algorithm to converge to ε=10-3 in a typical channel realization are listed in Table 1, where we set K=3 and SNRr=20 dB. It can be seen that the JSR-PG algorithm converges within several iterations, and thus, it is realizable with the advancement of modern chip design.
In the second example, we compare the bit error rate (BER) performance of the proposed JSR-PG algorithm in Algorithm 2, the ORO-PG algorithm in Algorithm 1, the suboptimal source and relay matrix design in [17], the one-way relay version of the conjugate gradient-based source and relay algorithm in [16], and the NAF algorithm. Figure 4 displays the system BER versus SNRs for a MIMO relay system with K=3 relay nodes and fixed SNRr at 20 dB. It can be seen from Figure 4 that the proposed JSR-PG algorithm has a better BER performance than the existing algorithms over the whole SNRs range.

Example 2. BER versus SNRs with K=3, SNRr=20 dB.
In the third example, we study the effect of the number of relay nodes to the system BER performance using the JSR-PG and ORO-PG algorithms. Figure 5 displays the system BER versus SNRs with K=2, 3, and 5 for fixed SNRr at 20 dB. It can be seen that at BER = 10-2, for both the ORO-PG algorithm and JSR-PG algorithm, we can achieve approximately 3-dB gain by increasing from K=2 to K=5. It can also be seen that the performance gain of the JSR-PG algorithm over the ORO-PG algorithm increases with the increasing number of relay nodes.

Example 3. BER versus SNRs for different K, SNRr=20 dB.
5 Conclusions
In this paper, we have derived the general structure of the optimal relay amplifying matrices for linear non-regenerative MIMO relay communication systems with multiple relay nodes using the projected gradient approach. The proposed source and relay matrices minimize the MSE of the signal waveform estimation. The simulation results demonstrate that the proposed algorithm has improved the MSE and BER performance compared with existing techniques.
Appendices
Appendix 1
Proof of Theorem 1
Without loss of generality, F i can be written as
where , , such that and are Nr×Nr unitary matrices. Matrices A i ,X i ,Y i ,Z i are arbitrary matrices with dimensions of Rr,i×Rs,i, Rr,i×(Nr-Rs,i), (Nr-Rr,i)×Rs,i, (Nr-Rr,i)×(Nr-Rs,i), respectively. Substituting (15) and (30) back into (13), we obtain that and . Thus, we can rewrite (13) as
It can be seen that (31) is minimized by , i=1,⋯,K.
Substituting (15) and (30) back into the left-hand side of the transmission power constraint (14), we have
From (32), we find that , , and minimize the power consumption at each relay node. Thus, we have .
Appendix 2
Proof of Theorem 2
Let us define and . Then, f(A i ) can be written as
Applying , (33) can be written as
Let us now define , , and . We can rewrite (34) as
The derivative of f(A i ) with respect to A i is given by
Defining , , , and , we can rewrite (36) as
Finally, the gradient of f(A i ) is given by
where (·)∗ stands for complex conjugate.
References
Wang B, Zhang J, Høst-Madsen A: On the capacity of MIMO relay channels. IEEE Trans. Inf. Theory 2005, 51: 29-43.
Tang X, Hua Y: Optimal design of non-regenerative MIMO wireless relays. IEEE Trans. Wireless Commun 2007, 6: 1398-1407.
Muñoz-Medina O, Vidal J, Agustín A: Linear transceiver design in nonregenerative relays with channel state information. IEEE Trans. Signal Process 2007, 55: 2593-2604.
Guan W, Luo H: Joint MMSE transceiver design in non-regenerative MIMO relay systems. IEEE Commun. Lett 2008, 12: 517-519.
Li G, Wang Y, Wu T, Huang J: Joint linear filter design in multi-user cooperative non-regenerative MIMO relay systems. EURASIP J. Wireless Commun. Netw 2009, 2009: 670265. 10.1155/2009/670265
Rong Y: Linear non-regenerative multicarrier MIMO relay communications based on MMSE criterion. IEEE Trans. Commun 2010, 58: 1918-1923.
Fang Z, Hua Y, Koshy JC: Joint source and relay optimization for a non-regenerative MIMO relay. In Proc. IEEE Workshop Sensor Array Multi-Channel Signal Process. Waltham, WA, USA, 12–14 July 2006; 239-243.
Rong Y, Tang X, Hua Y: A unified framework for optimizing linear non-regenerative multicarrier MIMO relay communication systems. IEEE Trans. Signal Process 2009, 57: 4837-4851.
Rong Y, Hua Y: Optimality of diagonalization of multi-hop MIMO relays. IEEE Trans. Wireless Commun 2009, 8: 6068-6077.
Rong Y: Joint source and relay optimization for two-way linear non-regenerative MIMO relay communications. IEEE Trans. Signal Process 2012, 60: 6533-6546.
Khandaker MRA, Rong Y: Joint transceiver optimization for multiuser MIMO relay communication systems. IEEE Trans. Signal Process 2012, 60: 5997-5986.
Khandaker MRA, Rong Y: Joint source and relay optimization for multiuser MIMO relay communication systems. In Proceedings of the 4th International Conference on Signal Processing and Communication Systems. Gold Coast, Australia, 13–15 Dec 2010;
Wan H, Chen W: Joint source and relay design for multiuser MIMO nonregenerative relay networks with direct links. IEEE Trans. Veh. Technol 2012, 61: 2871-2876.
Zeng J, Chen Z, Li L: Iterative joint source and relay optimization for multiuser MIMO relay systems. In Proceedings of the IEEE Vehicular Technology Conference. Quebec City, QC, Canada, 3–6 Sept 2012;
Behbahani AS, Merched R, Eltawil AM: Optimizations of a MIMO relay network. IEEE Trans. Signal Process 2008, 56: 5062-5073.
Hu C-C, Chou Y-F: Precoding design of MIMO AF two-way multiple-relay systems. IEEE Signal Process. Lett 2013, 20: 623-626.
Toding A, Khandaker MRA, Rong Y: Joint source and relay optimization for parallel MIMO relay networks. EURASIP J. Adv. Signal Process 2012, 2012: 174. 10.1186/1687-6180-2012-174
Bertsekas DP: Nonlinear Programming. Athena Scientific, Belmont,; 1999.
Petersen KB, Petersen MS: The Matrix Cookbook. . Accessed 9 Sept 2014 http://www2.imm.dtu.dk/pubdb/p.php?3274
Boyd S, Vandenberghe L: Convex Optimization. Cambridge University Press, Cambridge; 2004.
Tseng P: Further results on approximating nonconvex quadratic optimization by semidefinite programming relaxation. SIAM J. Optim 2003, 14(1):268-283. 10.1137/S1052623401395899
Nesterov Y, Nemirovski A: Interior Point Polynomial Algorithms in Convex Programming. SIAM, Philadelphia; 1994.
Acknowledgements
The work of Yue Rong was supported in part by the Australian Research Council’s Discovery Projects funding scheme (project number DP140102131).
The first author (Apriana Toding) would like to thank the Higher Education Ministry of Indonesia (DIKTI) and the Paulus Christian University of Indonesia (UKI-Paulus) of Makassar, Indonesia, for providing her with a PhD scholarship at Curtin University, Perth, Australia.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit https://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Toding, A., Khandaker, M.R. & Rong, Y. Joint source and relay design for MIMO multi-relay systems using projected gradient approach. J Wireless Com Network 2014, 151 (2014). https://doi.org/10.1186/1687-1499-2014-151
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-1499-2014-151