
Abstract
A search for the associated production of a heavy resonance with a top-quark or a top-antitop-quark pair, and decaying into a \(t{\bar{t}}\) pair is presented. The search uses the data recorded by the ATLAS detector in pp collisions at \(\sqrt{s}= 13\) \(\text {TeV}\) at the Large Hadron Collider during the years 2015–2018, corresponding to an integrated luminosity of 139 \(\text {fb}^{-1}\). Events containing exactly one electron or muon are selected. The two hadronically decaying top quarks from the resonance decay are reconstructed using jets clustered with a large radius parameter of \(R=1\). The invariant mass spectrum of the two top quark candidates is used to search for a resonance signal in the range of 1.0 \(\text {TeV}\) to 3.2 \(\text {TeV}\). The presence of a signal is examined using an approach with minimal model dependence followed by a model-dependent interpretation. No significant excess is observed over the background expectation. Upper limits on the production cross section times branching ratio at 95% confidence level are provided for a heavy \(Z^\prime \) boson based on a simplified model, for \(Z^\prime \) mass between 1.0 \(\text {TeV}\) and 3.0 \(\text {TeV}\). The observed (expected) limits range from 21 (14) fb to 119 (86) fb depending on the choice of model parameters.
Similar content being viewed by others

1 Introduction
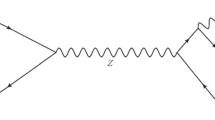
The discovery of a new particle consistent with the Standard Model (SM) Higgs boson by the ATLAS [1] and CMS [2] collaborations was a major milestone in high-energy physics. However, the underlying nature of electroweak symmetry breaking remains unknown. Naturalness arguments suggest that the large quantum corrections to the Higgs boson mass are cancelled by some new mechanism to prevent an excessive level of fine-tuning. Such a mechanism has been proposed in several theories of Beyond the SM (BSM) physics. The large Yukawa coupling of the top quark to the Higgs boson motivates various top-quark-based resonance searches. In many BSM theories, such as composite Higgs scenarios [3,4,5,6], new ‘top-philic’ vector resonances are predicted. These resonances couple more strongly to the top quark than to the light quarks, such that all the other couplings except for the one with top quarks can be neglected. Typical \(t{\bar{t}}\) resonance searches target new resonances produced through \(q{\bar{q}}\) annihilation, assuming sizeable couplings to light quarks [7,8,9,10]. Top-philic resonances, on the other hand, require different production modes, such as the production of the heavy resonance in association with a top-quark or a \(t{\bar{t}}\) pair, resulting in three or four top quarks in the final state. Figure 1 shows tree-level diagrams for the production of a top-philic resonance \(Z'\).

Examples of tree-level Feynman diagrams for \(Z^\prime \) production in association with (a) \(t{\bar{t}} \), (b) tj (where j refers to any light quark), and (c) tW. The \(Z^\prime \) generation modes are derived from top quark final states produced via (a) strong, (b) electroweak, and (c) mixed QCD and electroweak interactions
This analysis searches for a new top-philic heavy resonance above a mass of 1.0 \(\text {TeV}\). The ATLAS and CMS collaborations have previously published measurements of SM four-top-quark (\(t\bar{t}t\bar{t}\)) production [11,12,13,14,15]. with the first observation of this process reported by both experiments recently [16, 17]. Three-top-quark production, with a much smaller cross section of \({\mathcal {O}}\)(1 fb) predicted by the SM [18,19,20], has not been measured. In resonant BSM models, the two top quarks from the resonance decay, referred to as the ‘resonance top quarks’, are expected to be highly boosted. The other top quarks are referred to as the ‘spectator top quarks’ and are expected to have lower momenta. While previous BSM searches explored the \(t\bar{t}t\bar{t}\) final state for several target models [21, 22], this analysis uniquely attempts to reconstruct the resonance explicitly, enabling a search of a new physics contribution with minimal model dependence.
In addition, a simplified model [23] considering a colour-singlet vector particle \(Z^\prime \) is used to generate simulated samples for further model-dependent interpretations, however without relying on how the resonance couples to other particles in a specific model. The interaction Lagrangian reads:
where \(\gamma _{\mu }\) are the Dirac matrices and \(P_{L/R} = (1 \mp \gamma _{5}) / 2\) are the chirality projection operators with \(\gamma _5=i\gamma ^0\gamma ^1\gamma ^2\gamma ^3\). The coupling of the vector singlet to the top quarks is defined as \(c_t = \sqrt{c_L^2 + c_R^2}\), with components that couple only to left-handed and right-handed top-quarks \(c_L\) and \(c_R\), respectively. The tangent of the chirality angle is defined as \(\tan {\theta } = c_R / c_L\). For the mass range which is explored in this search with a \(Z'\) mass (\(m_{Z^\prime } \)) much larger compared to the top-quark mass (\(m_t\)), the \(Z'\) decay width can be approximated by \(\Gamma /m_{Z^\prime } \approx c_t^2/(8\pi )\). To minimise model dependence, only the tree-level production of a heavy top-philic resonance is considered. At the LHC a large contribution comes from \(t\bar{t}Z^\prime \) (Fig. 1a) which is independent of \(\theta \). Further contributions arise from \(tjZ'\) (Fig. 1b) and \(tWZ'\) (Fig. 1c) production modes, which are negligible for \(\theta =\pi /2\), and are largest for \(\theta = 0\) with similar magnitude as \(t\bar{t}Z^\prime \).
This search uses the data recorded by the ATLAS detector in ppcollisions at \(\sqrt{s}=13\) \(\text {TeV}\) between 2015 and 2018, corresponding to 139 \(\text {fb}^{-1}\). In the SM, the top quark is expected to decay into a W boson and a b-quark with a branching ratio of approximately 100% with subsequent hadronic or leptonic decay of the W boson. This analysis targets final states for which both resonance top quarks decay hadronically and one of the spectator top quarks decays leptonically. The single-lepton channel is preferred over the fully hadronic channel due to the significantly lower background arising from multijet processes, and the ability to trigger on events with at least one lepton. The top quarks from the resonance decay are expected to be highly boosted, and therefore their hadronic decays are reconstructed using jets with a large radius parameter and identified by requiring the jets to have a large mass and momentum. This final state with one leptonFootnote 1 suffers from a large background that is mostly composed of \(t{\bar{t}}\) production in association with additional jets (\(t\bar{t}\)+jets), especially when the associated jets contain b-hadrons. A data-driven technique assisted by simulations is used to overcome the challenge of modelling the \(t\bar{t}\)+jets background. The presence of a signal is tested in signal-enriched regions using an approach with minimal model dependence followed by a model-dependent interpretation.
2 The ATLAS detector
The ATLAS detector [24] at the LHC is a multipurpose particle detector with a forward–backward symmetric cylindrical geometry with a nearly \(4\pi \) coverage in solid angle.Footnote 2 It consists of an inner tracking detector (ID) surrounded by a superconducting solenoid, electromagnetic (EM) and hadron calorimeters, and a muon spectrometer (MS).
The ID covers the pseudorapidity range \(|\eta | < 2.5\). The high-granularity silicon pixel detector covers the vertex region and typically provides four measurements per track, the first hit normally being in the insertable B-layer (IBL) installed before Run 2 [25, 26]. It is surrounded by a silicon microstrip detector and a straw tube transition-radiation tracking detector. The calorimeter system covers the pseudorapidity range \(|\eta | < 4.9\). It consists of lead/liquid-argon (LAr) sampling calorimeters which provide EM energy measurements with high granularity. A steel/scintillator-tile hadron calorimeter covers the central pseudorapidity range (\(|\eta | < 1.7\)). The endcap and forward regions are instrumented with LAr calorimeters for EM and hadronic energy measurements up to \(|\eta | = 4.9\). The MS surrounds the calorimeters and is based on three large air-core toroidal superconducting magnets with eight coils each. The field integral of the toroids ranges between 2.0 and \({6.0}\,{\textrm{T}}\,\textrm{m}\) across most of the detector. The MS includes a system of precision tracking chambers and fast detectors for triggering. The ATLAS trigger and data acquisition system [27] consists of a two-level trigger system in order to select events. The first-level trigger is implemented in hardware and uses a subset of the detector information to accept events at a maximum rate of nearly \({100}\,\textrm{kHz}\). The second-level is a software-based trigger that reduces the accepted event rate to \({1}\,\textrm{kHz}\), on average, depending on the data-taking conditions [27]. An extensive software suite [28] is used for real and simulated data reconstruction and analysis, for operation and in the trigger and data acquisition systems of the experiment.
3 Object reconstruction and event selection
This analysis uses a set of data events collected by the ATLAS detector between 2015 and 2018 at \(\sqrt{s}=13\) \(\text {TeV}\). Only events for which all detector subsystems were operational are considered. The data set corresponds to an integrated luminosity of 139 \(\text {fb}^{-1}\) [29, 30].
This analysis is based on events where the detector read-out is triggered by the presence of at least one electron or one muon, referred to as single-lepton triggers. Events are selected if the leptons satisfy either low transverse momentum \(p_{\text {T}}\) thresholds, with identification and isolation requirements, or a looser identification criterion with no isolation requirement and higher \(p_{\text {T}}\) thresholds. The lowest \(p_{\text {T}}\) requirement used in the single-lepton triggers varies from 20 to 26 \(\text {GeV}\) depending on the data-taking period and the lepton flavour [31, 32].
Events are required to have at least one primary vertex reconstructed from at least two ID tracks with \(p_{\text {T}} > 500~\text {MeV}\). For events with several primary vertices, the one with the largest sum of the squared transverse momenta of the associated tracks is taken [33].
Electron candidates are reconstructed from an isolated electromagnetic calorimeter energy deposit which is matched to a track in the ID [34]. The pseudorapidity of the calorimeter energy cluster, \(\eta _{\text {cluster}}\), must satisfy \(|\eta _{\text {cluster}}|<2.47\), excluding the transition region between the barrel and the end-cap EM calorimeter (\({|\eta _{\text {cluster}}|\not \in [1.37,1.52]}\)). Muon candidates are reconstructed by combining tracks in the ID with tracks in the MS [35] and are required to have \(|\eta |<2.5\). Both electron and muon candidates are required to have a \(p_{\text {T}}\) above 28 \(\text {GeV}\). Further selections on the longitudinal and transverse impact parameters are imposed. The transverse impact parameter divided by its estimated uncertainty, \({|d_{0} |/\sigma (d_{0})}\), has to be less than five (three) for electron (muon) candidates. The longitudinal impact parameter \(z_0\) is required to be \({|z_{0} \sin (\theta ) |<0.5}\) mm for both electron and muon candidates. Electron candidates must pass a ‘Tight’ likelihood-based identification working point [34] employing calorimeter and tracking information that provides separation between electrons and jets. They are also required to be isolated according to the ‘Tight’ selection, a criteria based on the properties of the topological clusters in the calorimeter and of the ID tracks around the reconstructed electron [34]. Muon candidates must satisfy the ‘Medium’ cut-based identification working point [36]. They are also required to be isolated using the ‘TightTrackOnly’ selection, a criteria based on the properties of the ID tracks around the reconstructed muon [36].
Jets are reconstructed from topological clusters of calorimeter cells and tracking information using the anti-\(k_{t}\) algorithm [37, 38] with a radius parameter of \(R=0.4\), processed using a particle-flow algorithm [39]. They are referred to as ‘small-R jets’. Jets are required to have \(p_{\text {T}} > {25}\,\textrm{GeV}\) and \(|\eta | < 2.5\) and are calibrated as described in Ref. [40]. The Jet Vertex Tagger (JVT) discriminant [41] is used to identify jets originating from the hard-scatter interaction through the use of tracking and vertexing information. Jets with \(p_{\text {T}} < {60}\,\textrm{GeV}\) and \(|\eta | < 2.4\) are required to satisfy the requirement \(\text {JVT} > 0.50\), corresponding to a selection efficiency for hard-scatter jets of about 96% [42]. The DL1r classification algorithm based on recurrent neural networks [43, 44] is used to identify jets containing b-hadrons (\(b\)-jets). This algorithm identifies \(b\)-jets against backgrounds of light-flavour and charm-quark-initiated jets using information about the impact parameters of tracks associated with the jet and the topological properties of the displaced vertices reconstructed within the jet. This analysis uses a \(b\)-jet efficiency working point of 77% as measured for jets with \(p_{\text {T}} > 20~\text {GeV}\) and \(|\eta | < 2.5\) in simulated \(t{\bar{t}}\) events [45]. The tagging algorithm gives an expected rejection factor (defined as the inverse of the efficiency) of about 192 against light-flavour jets, and about 5.6 against jets originating from charm quarks [44, 46].
To resolve the potential ambiguities of a single detector response being assigned to two objects by the reconstruction algorithm, a sequential overlap removal procedure is applied. First, any electron found to share a track with another electron with higher \(p_{\text {T}}\) is removed. Second, electrons sharing their track with a muon candidate are removed. Third, the closest jet in rapidity y and in \(\phi \) using \(\Delta R_y = \sqrt{(\Delta y)^2+(\Delta \phi )^2} = 0.2\) of an electron is removed.Footnote 3 Fourth, the electrons within \(\Delta R_y = 0.4\) of a remaining jet are removed. Fifth, the jets with less than three associated tracks that are within \(\Delta R_y = 0.2\) of a muon are removed. Finally, remaining muons are removed if their track is within \(\Delta R_y = \min (0.4,0.04+ {10}\,\textrm{GeV}/{p_{\text {T}}}_{\mu })\) of a remaining jet.
After the overlap removal, the selected and calibrated small-R jets are used as inputs for jet reclustering [47] using the anti-\(k_{t}\) algorithm with a radius parameter of \(R=1\). These reclustered jets are referred to as ‘large-R jets’, and are used as proxies of the hadronically decaying top quarks in this analysis. The calibration corrections and uncertainties for the reclustered large-R jets are inherited from the small-R jets [47]. A trimming procedure [48] is applied to reclustered large-R jets which removes all the associated small-R jets that have a \(p_{\text {T}}\) below 5% of the \(p_{\text {T}}\) of the reclustered jet to suppress gluon radiation and mitigate pile-up effects. The large-R jets are required to have \(p_{\text {T}} > {300}\, \textrm{Gev}\), \(|\eta | < 2\), mass \(m > {100}\,\textrm{Gev}\), and at least two constituent jets.
At preselection level, the events are required to have exactly one lepton with \(p_{\text {T}} >{28}\,\textrm{Gev}\) that matches the lepton that fired the trigger, and at least two large-R jets to capture the two resonance top quarks that decay hadronically. Additional jets are expected from the decay of the spectator top quarks for \(t\bar{t}Z^\prime \) signal events, as well as from the associated production in the \(tjZ'\) and \(tWZ'\) production modes. The number of additional jets is counted using small-R jets with \(\Delta R > 1\) to any of the selected large-R jets in an event. Events are further required to have at least two additional small-R jets and at least two \(b\)-tagged small-R jets. The b-tagged jets can be either inside or outside of the large-R jets and therefore can also count towards additional jets.
4 Event simulation
Monte Carlo (MC) samples of simulated events were produced to model the signal and background processes. The samples are normalised using the best theory predictions available. The generated event samples are processed through the full ATLAS detector [49] based on Geant4 [50]. Only the MC samples describing SM \(t\bar{t}t\bar{t}\) production and systematic variations of the \(t{\bar{t}}\) simulation are processed through a faster simulation making use of parameterised showers in the calorimeters [51]. Additional simulated ppcollisions generated using Pythia 8.186 [52] using the A3 set of tuned parameters (tune) [53] and the MSTW2008LO parton distribution function (PDF) set [54] were overlaid to model the effects of multiple interactions in the same and nearby bunch crossings (pile-up). The distribution of the number of additional ppinteractions in the MC samples is re-weighted to match the one observed in data. All simulated samples were processed through the same reconstruction algorithms and analysis chain as the data. For all samples of simulated events, except those generated using Sherpa [55], the EvtGen 1.2.0 program [56] was used to describe the decays of bottom and charm hadrons. The NNPDF3.0NLO [57] PDF set was used in all matrix element (ME) calculations if not stated otherwise.
The signal samples are simulated using the MadGraph5_aMC@NLO 2.8.1 [58] generator at leading-order (LO) in the five-flavour scheme with the NNPDF3.1LO [57] PDF set. The model implementation is based on the simplified top-philic resonance of Ref. [59] where a colour singlet vector particle is considered to exclusively couple to top and anti-top quarks. Six mass points are generated, spaced according to the experimental resolution. The \(Z^\prime \) masses are: \({1.0}\,\textrm{TeV}\), \({1.25}\,\textrm{TeV}\), \({1.5}\,\textrm{TeV}\), \({2.0}\,\textrm{TeV}\), \({2.5}\,\textrm{TeV}\), and \({3.0}\,\textrm{TeV}\). Interference effects between \(s\)- and \(t\)-channel processes for \(t\bar{t}Z^\prime \) production are simulated. The interference with SM four-top-quark production was found to be negligible. Only the resonant \(Z'\) production mode is included in the simulation of the \(tW Z'\) and \(tj Z'\) channels. The signal samples are generated with baseline choices of the chirality parameter \(\theta = \pi / 4\) and the coupling between \(Z^\prime \) and top quarks of \(c_{t} = 3\). Other choices of these parameters are realised using MadGraph matrix element reweighting [60]. The width of the resonance is computed automatically using MadGraph5_aMC@NLO and corresponds to a relative width of about 4% for \(c_t = 1\) and increases to 64% for \(c_t = 4\).
The production of \(t{\bar{t}}\) events is modelled using the HVQ program [61, 62] in the Powheg Box 2 [61, 63,64,65] generator at next-to-leading order (NLO) in QCD. The \(h_{\text {damp}}\) parameter, which controls the transverse momentum \(p_{\text {T}}\) of the first additional emission beyond the Born configuration, was set to 1.5 \(m_{\text {t}}\) [66].
The \(t\bar{t}\)+jets MC events are classified according to the flavour of the particle jets. The particle jets are reconstructed from the simulated stable particles using the anti-\(k_{t}\) algorithm with a radius parameter \(R=0.4\), and are required to have \(p_{\text {T}} >15\) \(\text {GeV}\) and \(|\eta | <2.5\). Events are labeled as \(t\bar{t}{+}{\ge }1b\) if at least one particle jet is matched within \(\Delta R < 0.3\) to any b-hadron with \(p_{\text {T}} >5\) \(\text {GeV}\). In the remaining events, if at least one particle jet is matched within \(\Delta R<0.3\) to any c-hadron with \(p_{\text {T}} >5\) \(\text {GeV}\), the events are labeled as \(t\bar{t}{+}{\ge }1c\). Only hadrons not associated with b- and c-quarks from top-quark and W-boson decays are considered. All other events are labeled as \(t\bar{t}+\)light. Events categorised as \(t\bar{t}{+}{\ge }1b\) and \(t\bar{t}{+}{\ge }1c\) are collectively referred to as \(t{\bar{t}} +\text {heavy flavour}\) (HF) events.
Samples of single-top quark production backgrounds corresponding to the \(Wt\) associated production, \(s\)-channel and \(t\)-channel production, were modelled using the Powheg Box 2 generator at NLO in QCD. Overlaps between the \(t{\bar{t}}\) and \(Wt\) final states are removed using the ‘diagram removal’ scheme [67].
A sample of \(t{\bar{t}} +H\) events is modeled using the Powheg Box generator at NLO. The production of \(t{\bar{t}} + V\) (with \(V = W, Z\), including non-resonant \(Z/\gamma ^{*}\) contributions and \(t{\bar{t}} +WW\)) events are modeled using the MadGraph5_aMC@NLO 2.3.3 generator at NLO. Samples of \(V+\)jets (\(V=W, Z\)) events are generated with the Sherpa 2.2.1 [68] generator using NLO-accurate MEs for up to two partons and LO-accurate MEs for up to four partons. Samples of diboson final states (VV) were also simulated using the Sherpa 2.2.1 generator. The production of SM \(t\bar{t}t\bar{t}\) events is modeled using the MadGraph5_aMC@NLO 2.6.2 generator at NLO with the NNPDF3.1NLO [57] PDF. The rare process of single-top-quark associated \(Z\) boson production, \(tZ\), is modeled using the MadGraph5_aMC@NLO generator at LO.
All events generated using Powheg Box or MadGraph5_aMC@NLO are interfaced with Pythia 8.230 [69] using the A14 tune [70] and the NNPDF2.3LO [57] PDF set. Events generated using Sherpa employ the set of tuned parameters developed by the Sherpa authors.
To assess the uncertainty due to the choice of generator, the \(t{\bar{t}}\) and single-top-quark samples produced with the nominal generator set-ups are compared with alternative samples generated with MadGraph5_aMC@NLO (interfaced with Pythia 8) for the calculation of the hard-scattering processes. These alternative samples were generated using the same PDF in the ME as in the nominal samples. Additional \(t{\bar{t}}\) and single-top-quark samples were produced by replacing Pythia 8 with Herwig 7.04 [71, 72] for parton showering and hadronisation, using the H7UE tune [72] and the MMHT2014LO [73] PDF set. These samples are used to evaluate uncertainties due to the choice of parton shower and hadronisation model.
5 Analysis strategy
This analysis targets events where both resonance top quarks decay hadronically. For a heavy resonance signal with \(m_{Z^\prime } \ge 1.0~\text {TeV}\), the two resonance top quarks are expected to be highly boosted. Large-R jets are used as proxies for the two highly boosted top quarks. The invariant mass distribution of the two large-R jets with the highest \(p_{\text {T}}\), labelled as \(m_\text {JJ}\), is scanned for an excess over the background prediction.

The \(m_\text {JJ}\) distributions from the top-philic \(Z'\) signals compared to the total background after the event preselection. The signal distributions are shown for two values of the chirality angle, (a) \(\theta =0\) and (b) \(\theta =\pi /2\). In each case, four signal samples with different mass resolutions are presented for the possible combinations of \(m_{Z^\prime } = 1.5\) \(\text {TeV}\), 3 \(\text {TeV}\) and \(c_t=1\), 4. All predictions are given by MC simulations. The contributions from the SM \(t\bar{t}t\bar{t}\), diboson, and VH processes are combined in the category ‘Other’. The total background and all signal distributions are normalised to unit area
The \(m_\text {JJ}\) distributions for the top-philic \(Z'\) signal with different \(m_{Z^\prime }\) and \(c_t\) values are shown in Fig. 2. A peak near the generated value of \(m_{Z^\prime }\) is typically observed for masses \(m_{Z^\prime }\) \(\le 2\) TeV and coupling strengths \(c_t\le 1\). The peak at the resonance mass in general is wider for higher \(Z'\) masses and for higher \(c_t\) values due to the increase of the \(Z'\) natural width. All distributions are skewed towards the lower mass end for multiple reasons. One factor is the contamination from large-R jets that do not capture or only capture part of the decay products from a hadronically-decaying resonance top quark. Moreover, the parton luminosity effect and QCD radiation from the highly boosted top quarks also contribute to the lower mass side. The difference between the two chirality hypotheses, \(\theta =0\) and \(\theta =\pi /2\), is small, with a slightly better mass resolution in case of \(\theta =0\). This is due to the maximal contribution from \(tjZ'\) and \(tWZ'\) production modes, which have smaller ambiguity in reconstructing the \(Z'\) resonance using the two large-R jets given the lower expected jet and b-jet multiplicities.

The (a) \(N_{\text {add.-jets}}\) and (b) \(N_{b\text {-jets}}\) distributions from the top-philic \(Z'\) signals compared to the total background after the event preselection. The predictions are given by MC simulations. The contributions from the SM \(t\bar{t}t\bar{t}\), diboson, and VH processes are combined in the category ‘Other’. Four signal samples are presented with \(m_{Z^\prime } = 1.5\) and 3.0 \(\text {TeV}\) and \(\theta = 0\) and \(\pi /2\). All distributions are normalised to unit area
Despite the above effects that degrade the resolution for reconstructing the \(Z'\) mass, the \(m_\text {JJ}\) distributions for the signal with small \(m_{Z^\prime }\) and \(c_t\) are still distinct from those for background, as shown in Fig. 2. For the signal hypotheses with larger \(m_{Z^\prime }\) and \(c_t\), the distributions become more background-like given the increasing resonance width and the low-mass shoulder. According to MC simulations, about 90% of background after the preselection consists of \(t\bar{t}\)+jets events. Other background events mainly come from the production of \(t\bar{t}Z\), \(t\bar{t}W\), \(t\bar{t}H\), single top-quark and W/Z bosons in association with jets. The SM \(t\bar{t}t\bar{t}\), diboson and other rare processes contribute less than 1% of all background events. For background events, a smoothly falling \(m_\text {JJ}\) distribution is expected once \(m_\text {JJ}\) passes the turn-on threshold due to the minimum requirements on the large-R jet mass and \(p_{\text {T}}\).
The search is performed in the range of the \(m_\text {JJ}\) distribution between 1.0 \(\text {TeV}\) and 3.2 \(\text {TeV}\). The lower bound was chosen to minimise the impact due to the turn-on threshold on the background modelling, whereas the upper bound was motivated by the vanishing amount of expected SM background events at the high end of the \(m_\text {JJ}\) spectrum. The product of the efficiency and acceptance of the signal in the \(t\bar{t}Z^\prime \) production mode after the preselection varies from 3.1% to 7.2% for the different signal hypotheses, estimated using the simulated samples described in Sect. 4.

An illustration of the analysis regions defined using \(N_{\text {add.-jets}}\) and \(N_{b\text {-jets}}\). The source, validation and signal regions are highlighted in blue, gray and red, respectively. The names of the regions used in the rest of the document are also shown
In the single-lepton final state, \(Z'\) signal events are expected to have a high multiplicity of jets in addition to the two large-R jets (\(N_{\text {add.-jets}}\)) and the b-tagged jets (\(N_{b\text {-jets}}\)). The distributions of \(N_{\text {add.-jets}}\) and \(N_{b\text {-jets}}\) are shown for the signals and the background in Fig. 3, demonstrating clear discriminating power to separate these contributions. These two variables are used to categorise events into regions with different signal-to-background ratios. As illustrated in Fig. 4, nine regions are defined, denoted by ‘Na’, ‘Mb’, where Na and Mb represent \(N_{\text {add.-jets}}\) and \(N_{b\text {-jets}}\), respectively, and both range from 2 to \({\ge }4\). The region with the lowest signal contamination, \((2a,2b)\), is referred to as the ‘source region’ and used to derive the data-driven background estimate detailed in Sect. 6. The highest \(N_{\text {add.-jets}}\) and \(N_{b\text {-jets}}\) regions are chosen according to the expected signature of the \(t\bar{t}Z^\prime \) events and help to maintain a statistically significant background estimation. All regions with at least three b-tagged jets have relatively higher expected signal contributions compared to other regions. They are used for signal extraction and are referred to as the ‘signal regions’. In the \((3a,2b)\) and \(({\ge }4a,2b)\) regions, the small signal contribution provides little gain in sensitivity, and the expected signal contamination is not negligible for the data-driven background estimate. Therefore they are not used as either signal nor source region. However, they are used as validation regions to verify the modelling of the background. Scaling the top-philic simplified signal model to the expected exclusions achieved by this search, the largest signal contamination is below 2% in the source region and below 5% in the validation regions, depending on the model parameter choices. Figure 3 illustrates the background composition in bins of \(N_{\text {add.-jets}}\) and \(N_{b\text {-jets}}\) expected from the MC predictions. The fractions of non-\(t{\bar{t}}\) background are similar in most bins. The most dramatic change is in the fraction of \(t\bar{t}{+}{\ge }1b\) events. From MC simulations, the fraction of \(t\bar{t}{+}{\ge }1b\) events with respect to the total sum of background events is expected to increase from 8% in regions with two b-tagged jets to 68% in the most signal-like regions with at least four b-tagged jets.
6 Background estimation
The search for the resonance in the \(m_\text {JJ}\) distribution heavily relies on the modelling of the continuum background. However, the MC prediction is expected to be unreliable and susceptible to large modelling systematic uncertainties due to various factors discussed in the following. The top-philic \(Z'\) signal in the one-lepton channel features a large jet multiplicity. For the main background, \(t\bar{t}\)+jets, events with a similar final state contain multiple partons beyond Born level. This means that in the nominal \(t\bar{t}\)+jets sample generated using NLO ME, most of the jets in the final state are from the parton shower with limited precision [74]. These jets form the large-R jets used to construct \(m_\text {JJ}\). Additional mismodelling and uncertainties come from the prediction of the boosted large-R jets, which are subject to the often badly modelled collinear radiation. Finally, the \(t\bar{t}+\textrm{HF}\) background that populates the signal regions is underestimated by the current MC predictions [75, 76].
A data-driven technique is used to provide a reliable background prediction. It is based on the similarity of the background \(m_\text {JJ}\) shape in all analysis regions observed in MC simulations. Therefore, the shape of the background is obtained from data in the source region where there is negligible signal contamination. The background shape is then extrapolated to the signal regions. The extrapolation factors are derived from the MC simulations, accounting for the reduced event rate in higher \(N_{\text {add.-jets}}\) and \(N_{b\text {-jets}}\) bins and the minor differences in the shape of \(m_\text {JJ}\) between the regions. The final background model is obtained using a profile likelihood fit via further adjustments according to all systematic variations considered in this analysis.
Firstly, the shape of the background is obtained by fitting the data in the source region, \((2a,2b)\), using the following parameterization [77, 78]:
where \(x = m_\text {JJ}/\sqrt{s}\), with \(\sqrt{s}\) being the pp collision center-of-mass energy, and \(p_1\) to \(p_3\) are the fit parameters controlling the shape of the function. The fit result is presented in Fig. 5, showing that the fitted function describes the data well within the uncertainties due to the limited number of data events. Alternative parameterizations considering additional parameters or alternative functional forms have been tested, but were found to provide no improvement in the performance of the background estimate.

The distribution of data in the source region, along with the fitted function to data. The bands show the three independent variations obtained by diagonalising the covariance matrix of the fit. The third eigen variation is not visible due to its smallness
The fitted function from the previous step is scaled by extrapolation factors for each signal region, in order to obtain the background prediction in that region. The extrapolation factors are derived from MC simulation in bins of \(m_\text {JJ}\), as the ratio of the expected number of events in the region of interest to that in the source region. To minimize the impact due to the limited number of MC events, the function in Eq. 1 is used, fitting the \(m_\text {JJ}\) distribution predicted by MC simulation in both the region of interest and the source region. The extrapolation factors are then obtained by taking the ratio of these fitted functions. The shape of the background in the various analysis regions differs by up to \(\pm 15\%\) with respect to that in the source region, according to the prediction of the extrapolation factors. The extrapolation is performed with all backgrounds combined. The shape of the \(m_\text {JJ}\) distribution from the different background processes are compared using MC simulations. For the \(t\bar{t}\)+jets, single top-quark and \(t{\bar{t}}Z/W/H\) processes, constituting about 95% of the total background, the shapes are consistent within the uncertainties due to the limited number of MC events. Furthermore, the composition and the shape of the small backgrounds, i.e. those other than the \(t\bar{t}\)+jets backgrounds, are found to be similar across all analysis regions. As an additional check, alternative extrapolation factors were derived with \(t\bar{t}\)+jets MC simulation only, to account for the effect due to variation in the non-\(t{\bar{t}}\) backgrounds. The resulting difference was found to be smaller than the uncertainty due to the limited number of MC events, and is therefore neglected.
The extrapolation factors are based on the MC predictions in each of the analysis regions. Systematic uncertainties affecting the predicted distributions (\(m_\text {JJ}\), \(N_{\text {add.-jets}}\) and \(N_{b\text {-jets}}\)) are therefore propagated to the background estimate via the extrapolation factors. These include modelling uncertainties in all background MC samples and experimental uncertainties. For each systematic variation, the extrapolation factors are rederived using the same procedure as for the nominal background prediction. To account for the deficit of \(t\bar{t}+\textrm{HF}\) events in MC simulation, additional normalisation uncertainties are assigned to \(t\bar{t}{+}{\ge }1c\) and \(t\bar{t}{+}{\ge }1b\) events. Furthermore, dedicated uncertainties in the data-driven background estimate and the extrapolation are considered. The details on the systematic uncertainties included in this analysis are described in Sect. 7. All systematic uncertainties are incorporated in a profile likelihood fit to data in the signal regions, as discussed in Sect. 8.
7 Systematic uncertainties
Different sources of systematic uncertainty affect the search presented here, including those related to the luminosity, the identification and reconstruction of the physics objects, the MC simulation of the signal and background processes, and the method used to estimate the background. In the following, a brief description of the sources of systematic uncertainty is provided. A particular emphasis is put on the ones related to the \(t{\bar{t}}\) background prediction, which will be shown to have the largest impact on the sensitivity of the search. The systematic variations can affect the normalisation of the signal and background templates estimated in the different regions as well as the shape of the \(m_\text {JJ}\) distributions. All systematic uncertainties on the background prediction enter the analysis exclusively via extrapolation factors, except for the uncertainties related to the functional fits to data and MC described in Sect. 7.2, and the signal bias uncertainty described in Sect. 7.5. The luminosity uncertainty only applies to the signal.
7.1 Experimental uncertainties
The uncertainty in the combined 2015–2018 integrated luminosity is 1.7 % [29], obtained using the LUCID-2 detector [30] for the primary luminosity measurements. This uncertainty affects the signal prediction in the model-dependent interpretation.
Other experimental uncertainties arise from corrections and calibrations applied to MC simulations. These uncertainties affect the background estimate via the extrapolation factors, as well as the MC prediction of the \(Z'\) signals. An uncertainty is considered for the reweighting factors that correct the pile-up profile in MC simulations to match those in data. Uncertainties on the modelling of leptons arise from their momentum and energy scale calibration and resolution, as well as the trigger, reconstruction, identification, isolation efficiencies [34, 35]. Uncertainties on the modelling of jets mainly come from their energy scale (JES) and resolution (JER), containing effects from jet flavour composition, single-particle response, and pile-up [79, 80]. An uncertainty is assigned for the efficiencies of the JVT requirement on jets [42]. Uncertainties are considered for the calibration of the b-tagging efficiencies, including the efficiencies of tagging b-jets as well as the rates of mis-tagging c-jets and light-flavour jets [45, 46, 81].
7.2 Uncertainties on functional fit and extrapolation
Dedicated uncertainties are assigned for the data-driven background estimate and the MC extrapolation from the source region to other regions. The uncertainties from each functional fit are obtained from the covariance error matrix of the fit. Three statistically independent variations are extracted from an eigen-decomposition of the covariance matrix. This leads to three uncertainties associated to the functional fit in the source regions to data and MC, respectively. In addition, three uncertainties are also associated to the fit of the MC in each of the six signal regions which leads to 24 components of uncertainty in total. The resulting uncertainties due to the functional fit to data and MC in the source region are both correlated across the signal regions.
7.3 Theoretical uncertainties for the \(t{\bar{t}}\) background
An uncertainty of \(50\%\) in the normalisation of the \(t\bar{t}{+}{\ge }1b\) events as well as the \(t\bar{t}{+}{\ge }1c\) events is applied [75, 76], and an uncertainty of \(10\%\) is considered for the \(t\bar{t}+\)light events. The uncertainties due to the choice of generator and parton shower model used to simulate the inclusive \(t{\bar{t}}\) sample are evaluated by comparing the nominal \(t{\bar{t}}\) sample with alternative \(t{\bar{t}}\) samples, detailed in Sect. 4. The uncertainties associated with the choice of NLO generator are estimated by comparing the predictions of Powheg Box and MadGraph5_aMC@NLO. The effect of the choice of parton shower and hadronisation model is estimated from comparing the prediction of Powheg + Pythia 8 to Powheg + Herwig 7.04. These two uncertainties are split into four components, each affecting either only the shape of the \(m_\text {JJ}\) distributions or the acceptance and migration for the 3b regions and the \({\ge }4b\) regions separately. This treatment is motivated by the different compositions of \(t\bar{t}+\)light, \(t\bar{t}{+}{\ge }1c\) and \(t\bar{t}{+}{\ge }1b\) events in the two b-jet multiplicity bins and the large effect on the overall acceptance and migration of the events across the regions due to different parton shower and hadronisation models. Uncertainties due to missing higher-order QCD corrections are estimated by separately varying the renormalisation and the factorisation scales by factors of 2.0 and 0.5 in the nominal \(t{\bar{t}}\) sample and taking the envelope. Additionally, uncertainties in the amounts of initial- and final-state radiation (ISR and FSR) from the parton shower (PS) are assessed by respectively varying the corresponding parameter of the A14 PS tuneFootnote 4 and by varying the FSR renormalisation scale by factors of 2.0 and 0.625. The uncertainty related to the parton distribution function (PDF) is evaluated by using the PDF4LHC systematic variations [82].
7.4 Modelling uncertainties for non-\(t{\bar{t}}\) backgrounds
Non-\(t{\bar{t}}\) background processes represent a minor fraction of the total background. Therefore, the relevant uncertainties have a small impact on the result of the analysis. Similar to the \(t{\bar{t}}\) background, uncertainties due to missing higher-order QCD corrections, the amounts of initial- and final-state radiation, and the parton distribution function are also considered for most of the non-\(t{\bar{t}}\) backgrounds.
An uncertainty of 30% in the total cross section of the three single-top-quark production modes is included. This conservative number is motivated by the uncertainties due to the modelling of several associated jets and heavy flavour jets in the production. Uncertainties associated with the parton shower and hadronisation model and the generator choice are evaluated by comparing the nominal Powheg + Pythia 8 sample for each process with alternative samples produced with Powheg + Herwig 7 and aMC@NLO + Pythia 8. An additional uncertainty on the interference between \(tW\) and \(t{\bar{t}}\) production at NLO is evaluated by comparing the nominal tW sample produced using the diagram removal scheme with an alternative sample produced with the same generator but using the ‘diagram subtraction’ scheme [67].
Modelling uncertainties in the \(t\bar{t}W\), \(t\bar{t}Z\), and \(t\bar{t}H\) processes are evaluated in a similar way. Uncertainties of \(60\%, 15\%,\) and \(20\%\) are applied to the \(t\bar{t}W\), \(t\bar{t}Z\), and \(t\bar{t}H\) cross sections, respectively [83,84,85].
An uncertainty of 60% is assumed for the \(V+\)jets production cross section. It is estimated by adding a 24% uncertainty in quadrature for each additional jet based on a comparison among different algorithms for merging LO matrix elements and parton showers [86]. An uncertainty of 20% is assumed for the SM \(t\bar{t}t\bar{t}\) production cross section [87]. A conservative cross section uncertainty of 50% is applied to all other small background processes.
7.5 Signal bias uncertainty
A dedicated uncertainty is considered in the model-dependent interpretation of the results, accounting for the bias on the extraction of the signal yields caused by the background model. The details on the signal extraction and the model-dependent interpretation are described in Sect. 8. To evaluate the size of the bias, a large number of pseudo-datasets are sampled using the expected background directly from MC simulations. The model-dependent signal extraction (as described in Sect. 8.3) is performed for each of these pseudo-datasets, taking into account all systematic uncertainties described previously. The resulting distribution of the signal strengths is fitted with a Gaussian function. The deviation of the fitted central value from zero is taken as the size of the bias. This procedure is repeated for all signal mass points. The three points with the largest bias are used to compute a second order polynomial function. The eventual size of the bias for each mass point is evaluated from the fitted polynomial function. To obtain dedicated uncertainties for all choices of model parameters, this procedure is repeated for all distinct \(c_t\) and chirality parameter \(\theta \) values explored in this search. The uncertainty is determined using the MC signal template scaled by the corresponding value of bias, and is implemented as an uncertainty on the background expectation. Depending on the analysis region and signal point, this translates to uncertainties up to 14% in the individual signal regions, with the majority of values being a few percent in size.
8 Statistical analysis
The search for a resonance signal is conducted using the binned \(m_\text {JJ}\) distributions in all signal regions. An approach with minimal model dependence is adopted, followed by a model-dependent interpretation. A profile likelihood fit is used to obtain the final background model and make further statistical inference regarding the presence of a signal. The search with minimal model dependence is performed using BumpHunter [88], a hypothesis-testing tool that searches for local data excesses compared to the expected background. To obtain the expected background, the profile likelihood fit is performed with a background-only hypothesis. In the model-dependent interpretation, the \(Z'\) signal samples described in Sect. 4 are used to interpret the data. Profile likelihood fits are performed with the signal-plus-background hypothesis, testing the compatibility between data and the models with different \(m_{Z^\prime }\), \(c_t\) and chirality parameter \(\theta \).
8.1 Profile likelihood fit
The statistical analysis is based on a binned profile likelihood function. The bin width is chosen to be 100 \(\text {GeV}\), with two large bins of 500 \(\text {GeV}\) and 700 \(\text {GeV}\) at the high mass end of the \(m_\text {JJ}\) spectrum to avoid empty bins. Each bin in the signal regions is represented by a Poisson probability term for the observed data, with the total expected yield given by the background model described in Sect. 6 and the \(Z'\) signal samples. The likelihood function \({\mathcal {L}}(\mu , \pmb {\theta })\) is constructed as the product of the Poisson probability terms over all bins. This function depends on the signal-strength parameter \(\mu \), a multiplicative factor to the assumed pre-fit signal cross section, and \(\pmb {\theta }\), a set of nuisance parameters encoding the effect of systematic uncertainties. The nuisance parameters are implemented in the likelihood function as Gaussian or log-normal constraints. The total number of expected events in a given bin therefore depends on \(\mu \) and \(\pmb {\theta }\). The fit is performed by finding the values of \(\mu \) and \(\pmb {\theta }\) that maximise the likelihood function. In the case of a fit with the background-only hypothesis \(\mu \) is fixed to 0. The nuisance parameters \(\pmb {\theta }\) allow variations of the expectations for signal and background according to the corresponding systematic uncertainties, whilst penalising the likelihood function for any deviation according to the specified constraints. The fit also reduces the impact of systematic uncertainties on the search sensitivity by exploiting the highly populated and background-dominated regions. The result of the profile likelihood fit is further used for the signal extraction.
8.2 Search with minimal model dependence
In the search using BumpHunter, the data and the expected background in each of the six fitted regions are compared in sliding windows of variable sizes. The smallest window is required to contain two bins with the binning shown in Figs. 7 and 8 in Sect. 9, corresponding to a width that is slightly smaller than the expected resolution extracted from the \(Z'\) MC samples. The Poisson probability is evaluated for all windows. For each region, the window with the smallest Poisson probability is chosen to be the most prominent window. The corresponding probability \(p_{\text {min}}\) is used to construct the BumpHunter test statistic t defined as
where d and b represent the number of observed data and the expected background events in the window, respectively. A deviation of data from background is only considered as evidence against the background-only hypothesis if data exceed the expectation. To obtain the local p-value and the significance of the most interesting bump, \(10^5\) pseudo-experiments are sampled from the expected background, and the t value from data is compared to the distribution of the t values from the pseudo-experiments. The global p-value and significance are then computed for the most prominent window of each region, taking into account the trial factors that incorporate the look-elsewhere effect [89].
8.3 Model-dependent interpretation
The model-dependent interpretation is based on the signal samples described in Sect. 4. The signal strength is extracted by performing the profile likelihood fit with the signal-plus-background hypothesis. The fit and the subsequent statistical analysis are performed for each mass point. The test statistics are defined based on the likelihood ratio \(\lambda (\mu ) = {{\mathcal {L}}}(\mu ,\pmb {\hat{{\hat{\theta }}}}_\mu )/{{\mathcal {L}}}({\hat{\mu }},\pmb {{\hat{\theta }}})\), where \({\hat{\mu }}\) and \(\pmb {{\hat{\theta }}}\) are the values of the parameters that maximise the likelihood function, and \(\pmb {\hat{{\hat{\theta }}}}_\mu \) are the values of the nuisance parameters that maximise the likelihood function for a given value of \(\mu \). To evaluate the compatibility of the observed data with the background-only hypothesis, the test statistic \(q_0\), defined as
is used. The resulting p-value represents the compatibility \(p_0\). A small \(p_0\) indicates that the background-only model does not describe the data well, and the significance of the corresponding signal is further examined. In the absence of any significant excess above the background expectation, upper limits on the signal production cross section at 95% confidence level are derived. The test statistic \(q_\mu \), defined as
is used with the \(\text {CL}_{\text {S}}\) method [90, 91]. Both \(p_0\) and the upper limits are computed using the asymptotic approximation [92]. All statistical analyses are performed using the RooStats framework [93,94,95].
9 Results
The results of the statistical analysis are presented in this section. Prior to the analysis using real data, the profile likelihood fit model and the statistical methods were tested against pseudo-datasets constructed using simulated events. Both the background modelling and the signal extraction were validated, using background-only and signal-plus-background pseudo-datasets. In particular, alternative \(t{\bar{t}}\) background predictions were considered when building the pseudo-datasets. They were used to stress-test the fit, especially the incorporated systematic uncertainties related to \(t{\bar{t}}\) background modelling. These alternative predictions include an enhanced composition of the \(t\bar{t}+\textrm{HF}\) backgrounds, as well as a \(t{\bar{t}}\) sample generated with Sherpa 2.2.10,Footnote 5 which is not used in the definition of any uncertainty. These stress-tests demonstrated the capability of the fit to constrain the relevant systematic uncertainties, and to model the data correctly in case of mismodelling in the extrapolation factors from MC predictions.

Comparison of the \(m_\text {JJ}\) distribution between data and the post-fit prediction under the background-only hypothesis in the validation regions. Note that the validation regions do not enter the fit. The post-fit prediction is obtained by propagating the post-fit nuisance parameters from the fit to the validation regions. The shaded area surrounding the background expectation represents the total uncertainty from the post-fit computation. The ratio of the data to the background prediction is shown in the bottom panel

Comparison of the \(m_\text {JJ}\) distribution between data and the post-fit prediction under the background-only hypothesis in the two most sensitive signal regions (with four additional jets), as well as the BumpHunter results. The shaded area surrounding the background expectation represents the total uncertainty from the post-fit computation. The window with the largest deviation between the data and the background expectation is highlighted in each region. The local significance of each bin is illustrated in the middle panel. The ratio of the data to the background prediction is shown in the bottom panel. The top-philic \(Z'\) signal with \(m_{Z^\prime } =1.5\) \(\text {TeV}\) from MC simulation is illustrated in the top panel with dashed lines. The signal sample is stacked on top of the total background prediction, and is scaled to have an arbitrary large cross section of 51 fb for visualisation purposes

Comparison of the \(m_\text {JJ}\) distribution between data and the post-fit prediction under the background-only hypothesis in the signal regions with two or three additional jets. The shaded area surrounding the background expectation represents the total uncertainty from the post-fit computation. The window with the largest deviation between the data and the background expectation is highlighted in each signal region. The local significance of each bin is illustrated in the middle panel for the signal regions. The ratio of the data to the background prediction is shown in the bottom panel. The top-philic \(Z'\) signal with \(m_{Z^\prime } =1.5\) \(\text {TeV}\) from MC simulation is illustrated in the top panel with dashed lines. The signal sample is stacked on top of the total background prediction, and is scaled to have an arbitrary large cross section of 51 fb for visualisation purposes
The search result with minimal model-dependence is derived based on a simultaneous fit to all signal regions with a background-only hypothesis. The background estimate is examined in validation regions. This is done by propagating to the validation regions the post-fit nuisance parameters obtained from the fit to the signal regions. The resulting agreement between data and the estimated background in the validation regions is shown in Fig. 6. The largest discrepancies are evaluated and found to be insignificant after taking into account the look elsewhere effect. Figure 7 shows the post-fit \(m_\text {JJ}\) distribution with the background-only hypothesis compared to the observed data in the two most sensitive signal regions, along with the results from BumpHunter. The rest of the signal regions are shown in Fig. 8. All fitted distributions show reasonable agreement with data within uncertainties. The goodness of fit was evaluated using a likelihood-ratio test in which the likelihood of the nominal fit is compared to that of a saturated model [102]. The result indicates a good description of the data by the background model. The post-fit nuisance parameter values are all within 1\(\sigma \) of the prior uncertainty. No significant excess was found in the BumpHunter search. The most significant deviation between data and the background expectation was observed in the \((2a,{\ge }4b)\) region at 1.2 \(\text {TeV}\). The window with the largest deviation has a local significance of 1.04\(\sigma \); the corresponding global p-value is 0.15. The expected distribution with the presence of a top-philic \(Z'\) signal from MC simulation is illustrated in the top panels of Figs. 7 and 8. The top-philic \(Z'\) signal considered has \(m_{Z^\prime } =1.5\) \(\text {TeV}\) with \(c_{t} = 1\) and \(\theta = \pi /2\), and is normalised to have an arbitrary large cross section of 51 fb, obtained using the cross section predicted by the simplified model [59] with these parameters scaled by a factor of 100.
The model-dependent signal extraction also reveals no significant excess in data. For all model parameter choices, the fitted signal strength \(\mu \) is compatible with zero. The smallest local \(p_0\) value is 3.8%, obtained with the 1.25 \(\text {TeV}\) mass point for \(c_t=1\) and \(\theta = 0\). In addition, the fitted values of the nuisance parameter are compared to those obtained in the fit with the background-only hypothesis and found to be consistent. The observed and expected upper limits on the signal production cross section at 95% confidence level are shown for specific signal scenarios in Fig. 9. The observed (expected) limits range from 21 (14) fb to 119 (86) fb depending on the choice of model parameters. The strongest observed exclusion is observed at \(m_{Z^\prime }\) = 2.5 TeV with \(c_t = 1\) and \(\theta = \pi /2\). At the higher mass range cross section limits are stronger for the smaller couplings \(c_t\) due to the narrower signal width. While for the cross section limits there is no strong dependence on the chirality parameter \(\theta \), one can observe a stronger model constraint for \(\theta = 0\) because of the additional contributions from \(tjZ'\) and \(tWZ'\) production to the expected signal cross section. For \(c_t=4\) top-philic \(Z'\) mass of 1.0 TeV is excluded for both chirality parameter choices (\(\theta = 0\) and \(\pi /2\)).

Expected and observed 95% confidence level upper limits on the production cross section of the top-philic \(Z'\) signal with different \(m_{Z^\prime }\) and for two chirality parameter choices (a) \(\theta = 0\) and (b) \(\theta =\pi /2\). In each plot two coupling-strength scenarios are shown, for \(c_t = 1\) (in gray) and \(c_t = 4\) (in black). The light (dark) blue curves illustrate the signal cross sections based on the model described in Ref. [59] for \(c_t = 1\) \((c_t = 4).\) The green bands surrounding the expected limits for \(c_t = 1\) and \(c_t = 4\) correspond to the 68% confidence intervals. All limit lines are obtained by interpolating linearly between the different mass hypotheses
Table 1 lists the impacts of various groups of uncertainties relative to the total uncertainty on the fitted signal strength for two examples of the top-philic \(Z'\) signal: (\(m_{Z^\prime } =1.5~\text {TeV}\), \(c_t = 1\), \(\theta =0\)) and (\(m_{Z^\prime } =3.0~\text {TeV}\), \(c_t=4\), \(\theta =0\)). The results are dominated by systematic uncertainties. The most important source of systematic uncertainty is the modelling of the \(t\bar{t}\)+jets background. The uncertainties due to the migration and acceptance effect of the ME and PS generator choices in the \({\ge }4b\) regions play a dominant role. They contribute 26% and 31% (36% and 48%) of the total uncertainty, respectively, for the signal with \(m_{Z^\prime } =1.5~\text {TeV}\) and \(c_t = 1\) (\(m_{Z^\prime } =3.0~\text {TeV}\) and \(c_t=4\)). This reflects the large difference between the predictions of the different generators in the phase space explored by this search. The uncertainties in the normalisation of \(t\bar{t}{+}{\ge }1b\) also contribute 18% of the total uncertainty for both signal hypotheses shown in Table 1. The uncertainties from the jet energy scale and resolution are also an important source, given the large jet multiplicity in the signal regions. This is followed by the uncertainties from the data-driven background estimate.
10 Conclusion
A search for a top-philic heavy resonance produced in association with a top quark or a top-quark pair and decaying to \(t{\bar{t}}\) is presented. The search is performed using 139 \(\text {fb}^{-1}\) of pp collision data at \(\sqrt{s} = 13~\text {TeV}\) collected by the ATLAS detector at the LHC. Large-R jets are used as proxies of the top quarks from the heavy resonance decay. The invariant mass spectra of the two large-R jets with the largest \(p_{\text {T}}\) are used to test for the presence of a resonance signal in the range of 1.0 \(\text {TeV}\) to 3.2 \(\text {TeV}\). Events in the single-lepton final state are selected and categorised according to the number of additional jets and b-tagged jets. The search is conducted in regions with at least three b-tagged jets, with and without assuming a specific \(Z'\) signal model. No significant excess was observed above the expected background. The upper limits on the \(Z'\) production cross section at 95% confidence level are computed for signals with six values of \(m_{Z^\prime }\) between 1.0 \(\text {TeV}\) and 3.0 \(\text {TeV}\) based on a simplified model. The observed (expected) limits range from 21 (14) fb to 119 (86) fb depending on the choice of model parameters.
Data Availability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: All ATLAS scientific output is published in journals, and preliminary results are made available in Conference Notes. All are openly available, without restriction on use by external parties beyond copyright law and the standard conditions agreed by CERN. Data associated with journal publications are also made available: tables and data from plots (e.g. cross section values, likelihood profiles, selection efficiencies, cross section limits, ...) are stored in appropriate repositories such as HEPDATA (http://hepdata.cedar.ac.uk/). ATLAS also strives to make additional material related to the paper available that allows a reinterpretation of the data in the context of new theoretical models. For example, an extended encapsulation of the analysis is often provided for measurements in the framework of RIVET (http://rivet.hepforge.org/).” This information is taken from the ATLAS Data Access Policy, which is a public document that can be downloaded from http://opendata.cern.ch/record/413 [opendata.cern.ch].]
Notes
In the rest of this article, ‘lepton’ refers exclusively to an electron or a muon. Tau leptons are not explicitly considered although their decay products can be accepted by the electron, muon and jet selection criteria.
ATLAS uses a right-handed coordinate system with its origin at the nominal interaction point (IP) in the centre of the detector and the \(z\)-axis along the beam pipe. The \(x\)-axis points from the IP to the centre of the LHC ring, and the \(y\)-axis points upwards. Cylindrical coordinates \((r,\phi )\) are used in the transverse plane, \(\phi \) being the azimuthal angle around the \(z\)-axis. The pseudorapidity is defined in terms of the polar angle \(\theta \) as \(\eta = -\ln \tan (\theta /2)\). Angular distance is measured in units of \(\Delta R \equiv \sqrt{(\Delta \eta )^{2} + (\Delta \phi )^{2}}\).
The rapidity is defined as \(y=\frac{1}{2} \ln {\frac{E+p_z}{E-p_z}}\), where E is the energy and \(p_z\) is the longitudinal component of the momentum along the beam pipe.
The A14 tune’s variations of \(\alpha _\textrm{S}^\textrm{ISR}(m_Z)\) are usually referred to as Var3c, and correspond to \(\alpha _\textrm{S}^\textrm{ISR}(m_Z)=0.127^{+0.013}_{-0.012}\) [70].
This \(t{\bar{t}}\) MC sample was generated with Sherpa 2.2.10 using NLO-accurate matrix elements for up to one additional parton, and LO-accurate matrix elements for up to four additional partons. The additional parton emissions are matched and merged with the Sherpa parton shower based on Catani–Seymour dipole factorisation [96, 97] using the MEPS@NLO prescription [98,99,100,101].
References
ATLAS Collaboration, Observation of a new particle in the search for the Standard Model Higgs boson with the ATLAS detector at the LHC. Phys. Lett. B 716, 1 (2012). https://doi.org/10.1016/j.physletb.2012.08.020. arXiv:1207.7214 [hep-ex]
CMS Collaboration, Observation of a new boson at a mass of 125 GeV with the CMS experiment at the LHC. Phys. Lett. B 716, 30 (2012). https://doi.org/10.1016/j.physletb.2012.08.021. arXiv:1207.7235 [hep-ex]
G. Ferretti, D. Karateev, Fermionic UV completions of composite Higgs models. JHEP 03, 077 (2014). https://doi.org/10.1007/JHEP03(2014)077. arXiv:1312.5330 [hep-ph]
L. Vecchi, A dangerous irrelevant UV-completion of the composite Higgs. JHEP 02, 094 (2017). https://doi.org/10.1007/JHEP02(2017)094. arXiv:1506.00623 [hep-ph]
K. Agashe, A. Delgado, M.J. May, R. Sundrum, RS1, custodial isospin and precision tests. JHEP 08, 050 (2003). https://doi.org/10.1088/1126-6708/2003/08/050. arXiv:hep-ph/0308036
K. Agashe, R. Contino, A. Pomarol, The minimal composite Higgs model. Nucl. Phys. B 719, 165 (2005). https://doi.org/10.1016/j.nuclphysb.2005.04.035. arXiv:hep-ph/0412089
ATLAS Collaboration, Search for heavy particles decaying into a top-quark pair in the fully hadronic final state in \(pp\) collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. Phys. Rev. D 99, 092004 (2019). https://doi.org/10.1103/PhysRevD.99.092004. arXiv:1902.10077 [hep-ex]
ATLAS Collaboration, Search for heavy particles decaying into top-quark pairs using lepton-plus-jets events in proton-proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. Eur. Phys. J. C 78, 565 (2018). https://doi.org/10.1140/epjc/s10052-018-5995-6. arXiv:1804.10823 [hep-ex]
CMS Collaboration, Search for \(t\bar{t}\) resonances in highly-boosted lepton+jets and fully hadronic final states in proton–proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\). JHEP 07, 001 (2017). https://doi.org/10.1007/JHEP07(2017)001. arXiv:1704.03366 [hep-ex]
CMS Collaboration, Search for resonant \(t\bar{t}\) production in proton–proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\). JHEP 04, 031 (2019). https://doi.org/10.1007/JHEP04(2019)031. arXiv:1810.05905 [hep-ex]
ATLAS Collaboration, Evidence for \(t\bar{t}t\bar{t}\) production in the multilepton final state in proton–proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. Eur. Phys. J. C 80, 1085 (2020). https://doi.org/10.1140/epjc/s10052-020-08509-3. arXiv:2007.14858 [hep-ex]
ATLAS Collaboration, Measurement of the \(t\bar{t}t\bar{t}\) production cross section in \(pp\) collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. JHEP 11, 118 (2021). https://doi.org/10.1007/JHEP11(2021)118. arXiv:2106.11683 [hep-ex]
CMS Collaboration, Search for production of four top quarks in final states with same-sign or multiple leptons in proton–proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\). Eur. Phys. J. C 80, 75 (2020). https://doi.org/10.1140/epjc/s10052-019-7593-7. arXiv:1908.06463 [hep-ex]
CMS Collaboration, Search for the production of four top quarks in the single-lepton and opposite-sign dilepton final states in proton–proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\). JHEP 11, 082 (2019). https://doi.org/10.1007/JHEP11(2019)082. arXiv:1906.02805 [hep-ex]
CMS Collaboration, Evidence for four-top quark production in proton–proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\). Phys. Lett. B 844, 138076 (2023). https://doi.org/10.1016/j.physletb.2023.138076. arXiv:2303.03864 [hep-ex]
ATLAS Collaboration, Observation of four-top-quark production in the multilepton final state with the ATLAS detector. Eur. Phys. J. C 83, 496 (2023). https://doi.org/10.1140/epjc/s10052-023-11573-0arXiv:2303.15061 [hep-ex]
CMS Collaboration, Observation of four top quark production in proton–proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\). Phys. Lett. B 847, 138290 (2023). https://doi.org/10.1016/j.physletb.2023.138290. arXiv:2305.13439 [hep-ex]
V. Barger, W.-Y. Keung, B. Yencho, Triple-top signal of new physics at the LHC. Phys. Lett. B 687, 70 (2010). https://doi.org/10.1016/j.physletb.2010.03.001. arXiv:1001.0221 [hep-ph]
C.-R. Chen, Searching for new physics with triple-top signal at the LHC. Phys. Lett. B 736, 321 (2014). https://doi.org/10.1016/j.physletb.2014.07.041
E. Boos, L. Dudko, Triple top quark production in standard model. Int. J. Mod. Phys. A 37, 2250023 (2022). https://doi.org/10.1142/S0217751X22500233. arXiv:2107.07629 [hep-ph]
ATLAS Collaboration, Search for pair production of up-type vector-like quarks and for four-top-quark events in final states with multiple \(b\)-jets with the ATLAS detector. JHEP 07, 089 (2018). https://doi.org/10.1007/JHEP07(2018)089. arXiv:1803.09678 [hep-ex]
ATLAS Collaboration, Search for new phenomena in events with same-charge leptons and \(b\)-jets in \(pp\) collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. JHEP 12, 039 (2018). https://doi.org/10.1007/JHEP12(2018)039. arXiv:1807.11883 [hep-ex]
N. Greiner, K. Kong, J.-C. Park, S.C. Park, J.-C. Winter, Model-independent production of a top-philic resonance at the LHC. JHEP 04, 029 (2015). https://doi.org/10.1007/JHEP04(2015)029. arXiv:1410.6099 [hep-ph]
ATLAS Collaboration, The ATLAS experiment at the CERN large hadron collider. JINST 3, S08003 (2008). https://doi.org/10.1088/1748-0221/3/08/S08003
ATLAS Collaboration, ATLAS insertable B-layer: technical design report. ATLAS-TDR-19; CERN-LHCC-2010-013 (2010). https://cds.cern.ch/record/1291633. [Addendum: ATLAS-TDR-19-ADD-1; CERN-LHCC-2012-009 (2012). https://cds.cern.ch/record/1451888]
B. Abbott et al., Production and integration of the ATLAS Insertable B-Layer. JINST 13, T05008 (2018). https://doi.org/10.1088/1748-0221/13/05/T05008. arXiv:1803.00844 [physics.ins-det]
ATLAS Collaboration, Performance of the ATLAS trigger system in 2015. Eur. Phys. J. C 77, 317 (2017). https://doi.org/10.1140/epjc/s10052-017-4852-3. arXiv:1611.09661 [hep-ex]
ATLAS Collaboration, The ATLAS collaboration software and firmware. ATL-SOFT-PUB-2021-001 (2021). https://cds.cern.ch/record/2767187
ATLAS Collaboration, Luminosity determination in \(pp\) collisions at \(\sqrt{s} = 13\, \text{ TeV }\) using the ATLAS detector at the LHC. ATLAS-CONF-2019-021 (2019). https://cds.cern.ch/record/2677054
G. Avoni et al., The new LUCID-2 detector for luminosity measurement and monitoring in ATLAS. JINST 13, P07017 (2018). https://doi.org/10.1088/1748-0221/13/07/P07017
ATLAS Collaboration, Performance of electron and photon triggers in ATLAS during LHC Run 2. Eur. Phys. J. C 80, 47 (2020). https://doi.org/10.1140/epjc/s10052-019-7500-2. arXiv:1909.00761 [hep-ex]
ATLAS Collaboration, Performance of the ATLAS muon triggers in Run 2. JINST 15, P09015 (2020). https://doi.org/10.1088/1748-0221/15/09/p09015. arXiv:2004.13447 [hep-ex]
ATLAS Collaboration, Vertex reconstruction performance of the ATLAS detector at \(\sqrt{s} = 13\, \text{ TeV }\). ATL-PHYS-PUB-2015-026 (2015). https://cds.cern.ch/record/2037717
ATLAS Collaboration, Electron and photon performance measurements with the ATLAS detector using the 2015–2017 LHC proton–proton collision data. JINST 14, P12006 (2019). https://doi.org/10.1088/1748-0221/14/12/P12006. arXiv:1908.00005 [hep-ex]
ATLAS Collaboration, Muon reconstruction performance of the ATLAS detector in proton–proton collision data at \(\sqrt{s} = 13\, \text{ TeV }\). Eur. Phys. J. C 76, 292 (2016). https://doi.org/10.1140/epjc/s10052-016-4120-y. arXiv:1603.05598 [hep-ex]
A. Collaboration, Muon reconstruction and identification efficiency in ATLAS using the full Run 2 \(pp\) collision data set at \(\sqrt{s} = 13\, \text{ TeV }\). Eur. Phys. J. C 81, 578 (2021). https://doi.org/10.1140/epjc/s10052-021-09233-2. arXiv:2012.00578 [hep-ex]
M. Cacciari, G.P. Salam, G. Soyez, The anti-\(k_t\) jet clustering algorithm. JHEP 04, 063 (2008). https://doi.org/10.1088/1126-6708/2008/04/063. arXiv:0802.1189 [hep-ph]
M. Cacciari, G.P. Salam, G. Soyez, FastJet user manual. Eur. Phys. J. C 72, 1896 (2012). https://doi.org/10.1140/epjc/s10052-012-1896-2. arXiv:1111.6097 [hep-ph]
ATLAS Collaboration, Jet reconstruction and performance using particle flow with the ATLAS detector. Eur. Phys. J. C 77, 466 (2017). https://doi.org/10.1140/epjc/s10052-017-5031-2. arXiv:1703.10485 [hep-ex]
A. Collaboration, Jet energy scale and resolution measured in proton–proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. Eur. Phys. J. C 81, 689 (2021). https://doi.org/10.1140/epjc/s10052-021-09402-3. arXiv:2007.02645 [hep-ex]
ATLAS Collaboration, Tagging and suppression of pileup jets with the ATLAS detector. ATLAS-CONF-2014-018 (2014). https://cds.cern.ch/record/1700870
ATLAS Collaboration, Performance of pile-up mitigation techniques for jets in \(pp\) collisions at \(\sqrt{s} = 8\, \text{ TeV }\) using the ATLAS detector. Eur. Phys. J. C 76, 581 (2016). https://doi.org/10.1140/epjc/s10052-016-4395-z. arXiv:1510.03823 [hep-ex]
ATLAS Collaboration, ATLAS flavour-tagging algorithms for the LHC Run 2 \(pp\) collision dataset. Eur. Phys. J. C 83, 681 (2022). https://doi.org/10.1140/epjc/s10052-023-11699-1. arXiv:2211.16345 [physics.data-an]
ATLAS Collaboration, Measurement of \(b\)-tagging efficiency of \(c\)-jets in \(t\bar{t}\) events using a likelihood approach with the ATLAS detector. ATLAS-CONF-2018-001 (2018). https://cds.cern.ch/record/2306649
ATLAS Collaboration, ATLAS \(b\)-jet identification performance and efficiency measurement with \(t\bar{t}\) events in \(pp\) collisions at \(\sqrt{s} = 13\, \text{ TeV }\). Eur. Phys. J. C 79, 970 (2019). https://doi.org/10.1140/epjc/s10052-019-7450-8. arXiv:1907.05120 [hep-ex]
ATLAS Collaboration, Calibration of the light-flavour jet mistagging efficiency of the \(b\)-tagging algorithms with \(Z\)+jets events using \(139\, \text{ fb}^{-1}\) of ATLAS proton–proton collision data at \(\sqrt{s} = 13\, \text{ TeV }\). Eur. Phys. J. C 83, 728 (2023). https://doi.org/10.1140/epjc/s10052-023-11736-zarXiv:2301.06319 [hep-ex]
ATLAS Collaboration, Jet reclustering and close-by effects in ATLAS Run 2. ATLAS-CONF-2017-062 (2017). https://cds.cern.ch/record/2275649
D. Krohn, J. Thaler, L.-T. Wang, Jet trimming. JHEP 02, 084 (2010). https://doi.org/10.1007/JHEP02(2010)084. arXiv:0912.1342 [hep-ph]
ATLAS Collaboration, The ATLAS simulation infrastructure. Eur. Phys. J. C 70, 823 (2010). https://doi.org/10.1140/epjc/s10052-010-1429-9. arXiv:1005.4568 [physics.ins-det]
GEANT4 Collaboration, S. Agostinelli et al., Geant4—a simulation toolkit. Nucl. Instrum. Methods A 506, 250 (2003). https://doi.org/10.1016/S0168-9002(03)01368-8
ATLAS Collaboration, The simulation principle and performance of the ATLAS fast calorimeter simulation FastCaloSim. ATL-PHYS-PUB-2010-013 (2010). https://cds.cern.ch/record/1300517
T. Sjöstrand, S. Mrenna, P. Skands, A brief introduction to PYTHIA 8.1. Comput. Phys. Commun. 178, 852 (2008). https://doi.org/10.1016/j.cpc.2008.01.036. arXiv:0710.3820 [hep-ph]
ATLAS Collaboration, Summary of ATLAS Pythia 8 tunes. ATL-PHYS-PUB-2012-003 (2012). https://cds.cern.ch/record/1474107
A.D. Martin, W.J. Stirling, R.S. Thorne, G. Watt, Parton distributions for the LHC. Eur. Phys. J. C 63, 189 (2009). https://doi.org/10.1140/epjc/s10052-009-1072-5
T. Gleisberg et al., Event generation with SHERPA 1.1. JHEP 02, 007 (2009). https://doi.org/10.1088/1126-6708/2009/02/007. arXiv:0811.4622 [hep-ph]
D.J. Lange, The EvtGen particle decay simulation package. Nucl. Instrum. Methods A 462, 152 (2001). https://doi.org/10.1016/S0168-9002(01)00089-4
R.D. Ball et al., Parton distributions for the LHC run II. JHEP 04, 040 (2015). https://doi.org/10.1007/JHEP04(2015)040. arXiv:1410.8849 [hep-ph]
J. Alwall et al., The automated computation of tree-level and next-to-leading order differential cross sections, and their matching to parton shower simulations. JHEP 07, 079 (2014). https://doi.org/10.1007/JHEP07(2014)079. arXiv:1405.0301 [hep-ph]
J.H. Kim, K. Kong, S.J. Lee, G. Mohlabeng, Probing TeV scale top-philic resonances with boosted top-tagging at the high luminosity LHC. Phys. Rev. D 94, 035023 (2016). https://doi.org/10.1103/PhysRevD.94.035023. arXiv:1604.07421 [hep-ph]
O. Mattelaer, On the maximal use of Monte Carlo samples: re-weighting events at NLO accuracy. Eur. Phys. J. C 76, 674 (2016). https://doi.org/10.1140/epjc/s10052-016-4533-7. arXiv:1607.00763 [hep-ph]
S. Frixione, G. Ridolfi, P. Nason, A positive-weight next-to-leading-order Monte Carlo for heavy flavour hadroproduction. JHEP 09, 126 (2007). https://doi.org/10.1088/1126-6708/2007/09/126. arXiv:0707.3088 [hep-ph]
S. Frixione, P. Nason, G. Ridolfi, The POWHEG-hvq manual version 1.0 (2007). arXiv:0707.3081 [hep-ph]
P. Nason, A new method for combining NLO QCD with shower Monte Carlo algorithms. JHEP 11, 040 (2004). https://doi.org/10.1088/1126-6708/2004/11/040. arXiv:hep-ph/0409146
S. Frixione, P. Nason, C. Oleari, Matching NLO QCD computations with parton shower simulations: the POWHEG method. JHEP 11, 070 (2007). https://doi.org/10.1088/1126-6708/2007/11/070. arXiv:0709.2092 [hep-ph]
S. Alioli, P. Nason, C. Oleari, E. Re, A general framework for implementing NLO calculations in shower Monte Carlo programs: the POWHEG BOX. JHEP 06, 043 (2010). https://doi.org/10.1007/JHEP06(2010)043. arXiv:1002.2581 [hep-ph]
ATLAS Collaboration, Studies on top-quark Monte Carlo modelling for Top2016. ATL-PHYS-PUB-2016-020 (2016). https://cds.cern.ch/record/2216168
S. Frixione, E. Laenen, P. Motylinski, C. White, B.R. Webber, Single-top hadroproduction in association with a \(W\) boson. JHEP 07, 029 (2008). https://doi.org/10.1088/1126-6708/2008/07/029. arXiv:0805.3067 [hep-ph]
E. Bothmann et al., Event generation with Sherpa 2.2. SciPost Phys. 7 (2019). https://doi.org/10.21468/scipostphys.7.3.034
T. Sjöstrand et al., An introduction to PYTHIA 8.2. Comput. Phys. Commun. 191, 159 (2015). https://doi.org/10.1016/j.cpc.2015.01.024. arXiv:1410.3012 [hep-ph]
ATLAS Collaboration, ATLAS Pythia 8 tunes to 7 TeV data. ATL-PHYS-PUB-2014-021 (2014). https://cds.cern.ch/record/1966419
M. Bähr et al., Herwig++ physics and manual. Eur. Phys. J. C 58, 639 (2008). https://doi.org/10.1140/epjc/s10052-008-0798-9. arXiv:0803.0883 [hep-ph]
J. Bellm et al., Herwig 7.0/Herwig++ 3.0 release note. Eur. Phys. J. C 76, 196 (2016). https://doi.org/10.1140/epjc/s10052-016-4018-8. arXiv:1512.01178 [hep-ph]
L.A. Harland-Lang, A.D. Martin, P. Motylinski, R.S. Thorne, Parton distributions in the LHC era: MMHT 2014 PDFs. Eur. Phys. J. C 75, 204 (2015). https://doi.org/10.1140/epjc/s10052-015-3397-6. arXiv:1412.3989 [hep-ph]
ATLAS Collaboration, Measurements of top-quark pair differential and double-differential cross-sections in the \(\ell +jets\) channel with \(pp\) collisions at \(\sqrt{s} = 13\, \text{ TeV }\) using the ATLAS detector. Eur. Phys. J. C 79, 1028 (2019). https://doi.org/10.1140/epjc/s10052-019-7525-6. arXiv:1908.07305 [hep-ex]. [Erratum: Eur. Phys. J. C 80, 1092 (2020). https://doi.org/10.1140/epjc/s10052-020-08541-3]
ATLAS Collaboration, Measurements of inclusive and differential fiducial cross-sections of \(t\bar{t}\) production with additional heavy-flavour jets in proton–proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. JHEP 04, 046 (2019). https://doi.org/10.1007/JHEP04(2019)046. arXiv:1811.12113 [hep-ex]
CMS Collaboration, Measurement of the \(t\bar{t}b\bar{b}\) production cross section in the all-jet final state in \(pp\) collisions at \(\sqrt{s} = 13\, \text{ TeV }\). Phys. Lett. B 803, 135285 (2020). https://doi.org/10.1016/j.physletb.2020.135285. arXiv:1909.05306 [hep-ex]
ATLAS Collaboration, Search for new resonances in mass distributions of jet pairs using \(139\, \text{ fb}^{-1}\) of \(pp\) collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. JHEP 03, 145 (2020). https://doi.org/10.1007/JHEP03(2020)145. arXiv:1910.08447 [hep-ex]
ATLAS Collaboration, Search for \(t\bar{t}\) resonances in fully hadronic final states in \(pp\) collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. JHEP 10, 061 (2020). https://doi.org/10.1007/JHEP10(2020)061. arXiv:2005.05138 [hep-ex]
ATLAS Collaboration, Jet calibration and systematic uncertainties for jets reconstructed in the ATLAS detector at \(\sqrt{s} = 13\, \text{ TeV }\). ATL-PHYS-PUB-2015-015 (2015). https://cds.cern.ch/record/2037613
ATLAS Collaboration, Jet energy measurement with the ATLAS detector in proton–proton collisions at \(\sqrt{s} = 7\, \text{ TeV }\). Eur. Phys. J. C 73, 2304 (2013). https://doi.org/10.1140/epjc/s10052-013-2304-2. arXiv:1112.6426 [hep-ex]
ATLAS Collaboration, Measurement of the \(b\)-jet mistagging efficiency in \(t\bar{t}\) events using \(pp\) collision data at \(\sqrt{s} = 13\, \text{ TeV }\) collected with the ATLAS detector. Eur. Phys. J. C 82, 95 (2021). https://doi.org/10.1140/epjc/s10052-021-09843-w. arXiv:2109.10627 [hep-ex]
J. Butterworth et al., PDF4LHC recommendations for LHC Run II. J. Phys. G 43, 023001 (2016). https://doi.org/10.1088/0954-3899/43/2/023001. arXiv:1510.03865 [hep-ph]
D. de Florian et al., Handbook of LHC Higgs cross sections: 4. Deciphering the nature of the Higgs sector (2016). https://doi.org/10.23731/CYRM-2017-002. arXiv:1610.07922 [hep-ph]
ATLAS Collaboration, Combined measurements of Higgs boson production and decay using up to \(80\, \text{ fb}^{-1}\) of proton–proton collision data at \(\sqrt{s} = 13\, \text{ TeV }\) collected with the ATLAS experiment. Phys. Rev. D 101, 012002 (2020). https://doi.org/10.1103/PhysRevD.101.012002. arXiv:1909.02845 [hep-ex]
ATLAS Collaboration, Evidence for \(t\bar{t}t\bar{t}\) production in the multilepton final state in proton-proton collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. Eur. Phys. J. C 80, 1085 (2020). https://doi.org/10.1140/epjc/s10052-020-08509-3. arXiv:2007.14858 [hep-ex]
J. Alwall et al., Comparative study of various algorithms for the merging of parton showers and matrix elements in hadronic collisions. Eur. Phys. J. C 53, 473 (2008). https://doi.org/10.1140/epjc/s10052-007-0490-5. arXiv:0706.2569 [hep-ph]
A. Collaboration, Measurement of the \(t\bar{t}t\bar{t}\) production cross section in \(pp\) collisions at \(\sqrt{s} = 13\, \text{ TeV }\) with the ATLAS detector. JHEP 11, 118 (2021). https://doi.org/10.1007/JHEP11(2021)118. arXiv:2106.11683 [hep-ex]
G. Choudalakis, On hypothesis testing, trials factor, hypertests and the BumpHunter, in Proceedings, PHYSTAT 2011 Workshop on Statistical Issues Related to Discovery Claims in Search Experiments and Unfolding, CERN,Geneva, Switzerland 17–20 January 2011 (2011). arXiv:1101.0390 [physics.data-an]
E. Gross, O. Vitells, Trial factors for the look elsewhere effect in high energy physics. Eur. Phys. J. C 70, 525 (2010). https://doi.org/10.1140/epjc/s10052-010-1470-8. arXiv:1005.1891 [physics.data-an]
T. Junk, Confidence level computation for combining searches with small statistics. Nucl. Instrum. Methods A 434, 435 (1999). https://doi.org/10.1016/S0168-9002(99)00498-2. arXiv:hep-ex/9902006
A.L. Read, Presentation of search results: the \(CL_{S}\) technique. J. Phys. G 28, 2693 (2002). https://doi.org/10.1088/0954-3899/28/10/313
G. Cowan, K. Cranmer, E. Gross, O. Vitells, Asymptotic formulae for likelihood-based tests of new physics. Eur. Phys. J. C 71, 1554 (2011). https://doi.org/10.1140/epjc/s10052-011-1554-0. arXiv:1007.1727 [physics.data-an]. [Erratum: Eur. Phys. J. C 73, 2501 (2013). https://doi.org/10.1140/epjc/s10052-013-2501-z]
K. Cranmer, G. Lewis, L. Moneta, A. Shibata, W. Verkerke, HistFactory: a tool for creating statistical models for use with RooFit and RooStats. Technical report, New York U. (2012). https://cds.cern.ch/record/1456844
W. Verkerke, D. Kirkby, The RooFit toolkit for data modeling (2003). arXiv:physics.data-an/0306116
L. Moneta et al., The RooStats project (2011). arXiv:1009.1003 [physics.data-an]
T. Gleisberg, S. Höche, Comix, a new matrix element generator. JHEP 12, 039 (2008). https://doi.org/10.1088/1126-6708/2008/12/039. arXiv:0808.3674 [hep-ph]
S. Schumann, F. Krauss, A parton shower algorithm based on Catani–Seymour dipole factorisation. JHEP 03, 038 (2008). https://doi.org/10.1088/1126-6708/2008/03/038. arXiv:0709.1027 [hep-ph]
S. Höche, F. Krauss, M. Schönherr, F. Siegert, A critical appraisal of NLO+PS matching methods. JHEP 09, 049 (2012). https://doi.org/10.1007/JHEP09(2012)049. arXiv:1111.1220 [hep-ph]
S. Höche, F. Krauss, M. Schönherr, F. Siegert, QCD matrix elements + parton showers. The NLO case. JHEP 04, 027 (2013). https://doi.org/10.1007/JHEP04(2013)027. arXiv:1207.5030 [hep-ph]
S. Catani, F. Krauss, B.R. Webber, R. Kuhn, QCD matrix elements + parton showers. JHEP 11, 063 (2001). https://doi.org/10.1088/1126-6708/2001/11/063. arXiv:hep-ph/0109231
S. Höche, F. Krauss, S. Schumann, F. Siegert, QCD matrix elements and truncated showers. JHEP 05, 053 (2009). https://doi.org/10.1088/1126-6708/2009/05/053. arXiv:0903.1219 [hep-ph]
R.D. Cousins, Generalization of Chisquare goodness-of-fit test for binned data using saturated models, with application to histograms (2013). http://www.physics.ucla.edu/~cousins/stats/cousins_saturated.pdf. Accessed Nov 2022
ATLAS Collaboration, ATLAS computing acknowledgements. ATL-SOFT-PUB-2021-003 (2021). https://cds.cern.ch/record/2776662
Acknowledgements
We thank CERN for the very successful operation of the LHC, as well as the support staff from our institutions without whom ATLAS could not be operated efficiently. We acknowledge the support of ANPCyT, Argentina; YerPhI, Armenia; ARC, Australia; BMWFW and FWF, Austria; ANAS, Azerbaijan; CNPq and FAPESP, Brazil; NSERC, NRC and CFI, Canada; CERN; ANID, Chile; CAS, MOST and NSFC, China; Minciencias, Colombia; MEYS CR, Czech Republic; DNRF and DNSRC, Denmark; IN2P3-CNRS and CEA-DRF/IRFU, France; SRNSFG, Georgia; BMBF, HGF and MPG, Germany; GSRI, Greece; RGC and Hong Kong SAR, China; ISF and Benoziyo Center, Israel; INFN, Italy; MEXT and JSPS, Japan; CNRST, Morocco; NWO, The Netherlands; RCN, Norway; MEiN, Poland; FCT, Portugal; MNE/IFA, Romania; MESTD, Serbia; MSSR, Slovakia; ARRS and MIZŠ, Slovenia; DSI/NRF, South Africa; MICINN, Spain; SRC and Wallenberg Foundation, Sweden; SERI, SNSF and Cantons of Bern and Geneva, Switzerland; MOST, Taiwan; TENMAK, Türkiye; STFC, United Kingdom; DOE and NSF, United States of America. In addition, individual groups and members have received support from BCKDF, CANARIE, Compute Canada and CRC, Canada; PRIMUS 21/SCI/017 and UNCE SCI/013, Czech Republic; COST, ERC, ERDF, Horizon 2020 and Marie Skłodowska-Curie Actions, European Union; Investissements d’Avenir Labex, Investissements d’Avenir Idex and ANR, France; DFG and AvH Foundation, Germany; Herakleitos, Thales and Aristeia programmes co-financed by EU-ESF and the Greek NSRF, Greece; BSF-NSF and MINERVA, Israel; Norwegian Financial Mechanism 2014-2021, Norway; NCN and NAWA, Poland; La Caixa Banking Foundation, CERCA Programme Generalitat de Catalunya and PROMETEO and GenT Programmes Generalitat Valenciana, Spain; Göran Gustafssons Stiftelse, Sweden; The Royal Society and Leverhulme Trust, United Kingdom. The crucial computing support from all WLCG partners is acknowledged gratefully, in particular from CERN, the ATLAS Tier-1 facilities at TRIUMF (Canada), NDGF (Denmark, Norway, Sweden), CC-IN2P3 (France), KIT/GridKA (Germany), INFN-CNAF (Italy), NL-T1 (The Netherlands), PIC (Spain), ASGC (Taiwan), RAL (UK) and BNL (USA), the Tier-2 facilities worldwide and large non-WLCG resource providers. Major contributors of computing resources are listed in Ref. [103].
Author information
Authors and Affiliations
Consortia
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Funded by SCOAP3.
About this article

Cite this article
ATLAS Collaboration. Search for top-philic heavy resonances in pp collisions at \(\sqrt{s}=13\) \(\text {TeV}\) with the ATLAS detector. Eur. Phys. J. C 84, 157 (2024). https://doi.org/10.1140/epjc/s10052-023-12318-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-023-12318-9