
Abstract
Precision electroweak tests are a powerful probe of physics beyond the Standard Model, but the sensitivity is limited by the precision with which the W boson mass (\(M_W\)) has been measured. The Parton Distribution Function (PDF) uncertainties are a potential limitation for measurements of \(M_W\) with LHC data. It has recently been pointed out that, thanks to LHCb’s unique forward rapidity acceptance, a new measurement of \(M_W\) by LHCb can improve this situation. Here we report on a detailed study on the mechanism driving the PDF uncertainty in the LHCb measurement of \(M_W\), and propose an approach which should reduce this uncertainty by roughly a factor of two using LHCb Run 2 data.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Global fits to precision electroweak data are sensitive to physics beyond the standard model (SM). Of notable interest is the mass of the W boson (\(M_W\)) because, currently, it is predicted with higher precision than it is measured. The 2018 update of the electroweak fit by the gFitter collaboration indirectly predicts \(M_W = 80354 \pm 7\) MeV/c\(^2\) [1]. This prediction is more precise than the average of direct measurements reported by the Particle Data Group, \(M_W = 80379 \pm 12\) MeV/c\(^2\) [2], which is dominated by measurements using \(W\rightarrow \ell \nu _\ell \) decays at hadron collider experiments, where \(\ell \) can be either an electron or a muon.
Measurements of \(M_W\) at hadron colliders are performed by comparing data to templates of the charged lepton transverse momentum, missing transverse energy, and transverse mass in samples of \(W\rightarrow \ell \nu _\ell \) decays. The combination of measurements by the CDF [3] and D0 [4] experiments at the Fermilab Tevatron \(p\bar{p}\) collider is \(M_W = 80387 \pm 16\,\hbox {MeV/c}^2\) [4]. In \(p\bar{p}\) collisions W bosons are primarily produced by the annihilation of valence quarks and antiquarks. By contrast, gluons and sea quarks play a critical role in the pp collisions at the LHC. Measurements of \(M_W\) at the LHC are therefore expected to be more susceptible to theoretical uncertainties in the modeling of W production, in particular those related to the Parton Distribution Functions (PDFs), than at the Tevatron [5,6,7,8,9]. The ATLAS Collaboration reported a measurement of \(M_W = 80370 \pm 13 \pm 14\) MeV/c\(^2\) where the first and second uncertainties are experimental and theoretical, respectively [10]. The dominant contribution to the theoretical uncertainty can be attributed to the PDFs. A key challenge of future measurements by ATLAS and CMS will be to reduce the PDF uncertainty.
The current ATLAS and CMS detectors are capable of reconstructing charged leptons in the approximate pseudorapidity range \(|\eta |<2.5\), where \(\eta = -\ln (\tan (\theta /2))\) with \(\theta \) being the angle between the particle direction and the beam axis. LHCb [11] is a single-arm spectrometer with full charged particle tracking and identification capabilities over the range \(2< \eta < 5\), which is mostly orthogonal to the acceptance of ATLAS and CMS. While LHCb is primarily designed for the study of beauty and charm hadrons, it has a strong track record in measurements of W and Z production in muonic final states [12, 13]. As for precision electroweak tests, LHCb has already measured the effective weak mixing angle \(\sin ^2\theta _{\mathrm{eff}}^{\mathrm{lept}}\) [14], but the potential for a measurement of \(M_W\) was not realised until recently.

The simulated muon \(p_T^\mu \) distributions in \(W\rightarrow \mu \nu \) decays (left \(W^+\), right \(W^-\)) with five different \(M_W\) hypotheses. The ratios are with respect to the prediction with \(M_W = 80.3\) GeV/c\(^2\)
Reference [15] proposed a new measurement of \(M_W\) by LHCb based on the muon transverse momentum (\(p_T^\mu \)) distribution with \(W \rightarrow \mu \nu \) decays. Figure 1 shows how the shape of the \(p_T^\mu \) distribution varies with the \(M_W\) hypothesis in simulated events. The maximum variation in the normalised distribution, which occurs at \(p_T^\mu \sim \) 42 GeV/c, is around \(10^{-4}\) per MeV/c\(^2\) of shift in \(M_W\). Large W samples are therefore required to resolve this subtle change in the shape of the \(p_T^\mu \) distribution. After the successful completion of LHCb Run 2 roughly 6 fb\(^{-1}\) of pp collisions at \(\sqrt{s} =\) 13 TeV have been recorded, complementing the 3 fb\(^{-1}\) recorded at lower \(\sqrt{s}\) values in Run 1. Using the methods described in this paper we estimate that the Run 2 data could yield a \(M_W\) measurement with a statistical uncertainty of roughly 10 MeV/c\(^2\). The obvious next question is how well the theoretical uncertainties, in particular those related to the PDFs, can be controlled. Reference [15] estimated that the PDF uncertainties in a standalone LHCb measurement would be larger than those in ATLAS and CMS. However, the uncertainty on the LHCb measurement would be partially anticorrelated with those of ATLAS and CMS. It is therefore claimed that the introduction of a LHCb measurement into a LHC \(M_W\) average could reduce the overall PDF uncertainty. Similar improvements may be possible with the extended angular coverage of the upgraded ATLAS and CMS detectors in the HL-LHC era, as explored in a recent study by ATLAS [16]. Given the large size of the LHCb Run 2 dataset, and anticipated future data with LHCb Upgrade I [17] and the proposed Upgrade II [18], it seems worthwhile to study in greater detail the cause of the PDF uncertainty in a measurement of \(M_W\) by LHCb, and possible strategies to reduce it.
2 Simulation of W production
A sample of \(10^{8}\) Monte Carlo events of the type \(pp\rightarrow W \rightarrow \mu \nu + X\), at a centre-of-mass energy \(\sqrt{s}=\) 13 TeV, is generated using POWHEG [19] with the CT10 [20] PDFs. These events are subsequently processed with PYTHIA [21] to simulate the parton showering. No LHCb detector response is simulated. Unless otherwise specified, events are analysed if they satisfy \(30<p_T^\mu <50\) GeV/c and \(2<|\eta |<4.5\).Footnote 1 Roughly 10% of the initial event sample falls into this kinematic region. The invariant mass of the W decay products (m) is assumed to follow a relativistic Breit-Wigner distribution:
where \(M_W\) and \(\varGamma _W\) are the mass and the width of the W boson, respectively. The events are generated with a nominal value of \(M_W\) [2] but can be reweighted according to Eq. 1 to emulate a different \(M_W\) hypothesis.

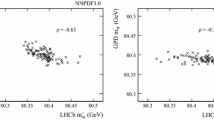
Upper: the distribution of the \(\chi ^2\) versus \(M_W\) for a fit to a single toy dataset, which assumes the LHCb Run 2 statistics, with each of the 1000 NNPDF3.1 replicas. Lower: the distribution of the \(M_W\) values with a Gaussian fit function overlaid
A similar set of weights can be assigned to map the sample to different PDFs. As in Ref. [15] the full PDF uncertainty should consider an envelope of PDF sets from several groups, including for example the MMHT14 [22] and CT14 [23] sets, but for the current study we focus on the NNPDF3.1 [24] set with 1000 equiprobable replicas.
3 Fitting method
Scaling the generated event samples to the 6 fb\(^{-1}\) of LHCb Run 2 data yields an expectation of 7.2 (4.8) million \(W^+\) (\(W^-\)) events in the 30 \(<p_T^\mu<\) 50 GeV/c and 2 \(<\eta<\) 4.5 region. Toy data histograms are generated by randomly fluctuating the bins around the nominal distribution, assuming these yields and Poisson statistics. These histograms can be generated with different PDF sets using the reweighting procedure already described. The current study neglects experimental systematic uncertainties, such as those due to the knowledge of the momentum scale and the dependence of the muon identification efficiency on \(p_T^\mu \) and \(\eta \), and does not address the treatment of higher order QCD corrections in the \(p_T^W\) modelling [25, 26].
The data histograms are compared to templates with different PDF and \(M_W\) hypotheses. The normalisation of each template is scaled to match the data such that the fit only considers the shape information. For a given PDF hypothesis a single-parameter (1D) fit determines the value of \(M_W\) that minimises the \(\chi ^2\) between a toy and the templates. The 68% C.L. statistical uncertainty corresponds to a variation of \(\varDelta \chi ^2 = 1\) with respect to the parabola minimum.
Figure 2 shows, separately for the two W charges, how the results of a fit to a single toy dataset vary with the PDF replica used in the templates. Forty bins in \(p_T^\mu \) (with bin width of 0.5 GeV/c) are used in the template fit. The fitted \(M_W\) values follow approximately Gaussian distributions with widths of 15 (20) MeV/c\(^2\) for the \(W^+\) (\(W^-\)). The broadly parabolic distributions of the best-fit \(\chi ^2\) (\(\chi ^2_{\text {min}}\)) versus \(M_W\) indicate that the PDF replicas that most severely bias \(M_W\) tend to give a measurably poorer fit quality. Before evaluating how this information could be used to constrain the PDF uncertainty let us first try to understand in more detail the underlying mechanism behind the PDF uncertainty.

The (left) \(W^+\) and (right) \(W^-\) rapidity distributions decomposed into the main partonic subprocesses

The ratios of a subset of NNPDF3.1 replicas with respect to the central replica, for the x dependence of the (clockwise from upper left) u, d, \(\bar{u}\) and \(\bar{d}\) PDFs. Each line is marked with a colour indicating the shift of the \(M_W\) value determined from a fit to the \(p_T^\mu \) distribution of a single toy dataset. For clarity, the replicas for which the shift in \(M_W\) is close to zero are not drawn
4 Understanding the PDF uncertainties
Figure 3 shows how the different partonic subprocesses contribute to the cross-section for W production as a function of rapidity (y). The dominant \(W^+\)(\(W^-\)) production subprocesses involve valence u(d) quarks. Annihilation of gluons with sea quarks (\(gq_s\)) contributes for around a 20% factor. Contributions from only second generation quarks annihilation are below 10% or so.

The variations in the shapes of the \(p_T^W\), y and \(\cos \theta ^*\) distributions predicted with a subset of NNPDF3.1 replicas. Each line is marked with a colour indicating the shift of the \(M_W\) value determined from a fit to the \(p_T^\mu \) distribution of a single toy dataset. For clarity, the replicas for which the shift in \(M_W\) is close to zero are not drawn
Since the u, \(\bar{d}\), d and \(\bar{u}\) species seem to be the most important it is interesting to see if there are any obvious patterns in their respective PDFs for the replicas corresponding to biased \(M_W\) determinations. The final results are derived using the full set of 1000 NNPDF3.1 equiprobable replicas but, for visual purposes, the studies in this section make use of a subset of them. Figure 4 shows how the x dependencies of the u, \(\bar{d}\), d and \(\bar{u}\) PDFs vary between the subset of replicas. Each line is a ratio with respect to the central replica, and is assigned a colour according to the bias in \(M_W\) as evaluated using the method described in Sect. 3. For clarity, the replicas for which the shift in \(M_W\) is close to zero (\(|\varDelta M|< 10\) MeV/c\(^2\)) are not drawn. In the study of the single partonic species, only the relevant W charges templates are included in the fit. No obvious patterns can be seen in the u and \(\bar{d}\) PDFs, which dominate \(W^+\) production. However, a clear pattern can be seen for the high-x (above \(x \sim 0.1\)) d PDF, whereby the replicas that tend to bias \(M_W\) upwards (downwards) tend to have a smaller (larger) parton density. A qualitatively similar pattern, though with the opposite sign, is seen in the \(\bar{u}\) PDF.

The distributions of \(\langle p_T^W\rangle \) and \(\langle y\rangle \) for a subset of replicas of the NNPDF3.1 set. Each marker is assigned a colour according to the shift of the \(M_W\) value determined from a fit to the \(p_T^\mu \) distribution of a single toy dataset. The markers drawn with an up (down) pointing triangle correspond to \(\varDelta M\) values greater (less) than zero
The PDF uncertainty on the \(M_W\) measurement arises because the \(p_T^\mu \) distribution depends on the W production kinematics, which are characterised by the transverse momentum (\(p_T^W\)), rapidity and polarisation. As a proxy for the polarisation, the distribution of the angle \(\theta ^*\) in the Collins-Soper frame [27] can be considered. Figure 5 shows how the \(p_T^W\), y and \(\cos \theta ^{*}\) distributions vary between a subset of NNPDF3.1 replicas. Each line is assigned a colour according to the bias in \(M_W\) for that replica. The underlying shapes of the distributions are also indicated by the filled histograms. A particularly striking pattern can be seen in the variation of the y distributions. The replicas that bias \(M_W\) upwards (downwards) tend to enhance (suppress) the \(W^+\) cross-section at large rapidities. The opposite is seen for the \(W^-\). Other clear patterns, though with smaller absolute variations, can be seen in the \(p_T^W\) and \(\cos \theta ^{*}\) projections. It is instructive to consider the two-dimensional projections of these patterns. Figure 6 shows the mean of the y distribution versus the mean of the \(p_T^W\) distribution. Each point represents a single NNPDF3.1 replica using the already described \(M_W\) dependent colour scale. There is a clear anticorrelation between the changes in the shapes of the y and \(p_T^W\) distributions which is expected from the kinematics and is enhanced by the forward acceptance cuts applied to the lepton, but further patterns can be seen in the colour distribution. In the \(W^+\) case, the replicas that bias \(M_W\) upwards (downwards) tend to predict larger (smaller) \(\langle y \rangle \) values and smaller (larger) \(\langle p_T^W \rangle \) values. The opposite pattern is seen for the \(W^-\) case. These striking patterns are helpful in understanding how biases in \(M_W\) are correlated to the underlying W production kinematics.
Our attention is now switched to the muon kinematic distributions. Reference [28] showed that correlated changes in the shapes of the \(\eta \) and \(p_T^\mu \) distributions in the phase-space acceptance of ATLAS and CMS can be used to further constrain the PDFs. It is therefore interesting to consider a similar approach in the LHCb phase-space acceptance. Figure 7 shows how the muon \(p_T^\mu \) and \(\eta \) distributions vary with the PDF replicas. As expected the replicas that bias \(M_W\) upwards (downwards) correspond to a decrease (increase) in the predicted cross-section at high \(p_T^\mu \) with respect to low \(p_T^\mu \). An intriguing observation, however, is that the replicas that provide the largest bias on \(M_W\) change not only the shape of the \(p_T^\mu \) distribution but also that of the \(\eta \) distribution. This is a measurable change of up to several percent, which could be exploited to constrain the PDF uncertainty. Figure 8 shows the mean \(p_T^\mu \) versus the mean \(\eta \) for each replica, with the \(M_W\) dependent colour scale as before. The replicas that bias \(M_W\) tend to be clearly separated in this two-dimensional plane, which encourages us to consider exploiting this information to constrain the PDF uncertainty.

The variations in the shapes of the \(p_T^\mu \) and \(\eta \) distributions predicted with a subset of NNPDF3.1 replicas. Each line is marked with a colour indicating the shift of the \(M_W\) value determined from a fit to the \(p_T^\mu \) distribution of a single toy dataset. For clarity, the replicas for which the shift in \(M_W\) is close to zero are not drawn

The distribution of \(\langle p_T^\mu \rangle \) and \(\langle \eta \rangle \) produced using a subset of replicas of the NNPDF3.1 set and divided by the central replica. Each marker is assigned a colour according to the shift of the \(M_W\) value determined from a fit to the \(p_T^\mu \) distribution of a single toy dataset. The markers drawn with an up (down) pointing triangle correspond to \(\varDelta M\) values greater (less) than zero
5 PDF uncertainty reduction
In Sect. 3 it was noted that the traditional one-dimensional fit to the \(p_T^\mu \) distribution already suggests a potential for in situ constraints of the PDF uncertainty [29]. The fit is now compared with and without the inclusion of replica weights. Using the NNPDF prescription [30, 31], each replica is assigned a weight according to the best-fit \(\chi ^2\) (\(\chi ^2_{\text {min}}\)) for a fit with n degrees of freedom (n):

Upper: the distribution of the \(\chi ^2\) versus \(M_W\) for a two-dimensional fit to a single toy dataset, which assumes the LHCb Run 2 statistics, with each of the 1000 NNPDF3.1 replicas. Lower: the distribution of the extracted \(M_W\) values, with a Gaussian fit function overlaid, without (black) and with (red) weighting
This has the effect of disregarding replicas that are incompatible with the data. An alternative approach is to use the PDFs represented by Hessian eigenvectors and profile them in the analysis [32]. Section 4 encourages the consideration of a fit to the two-dimensional (\(p_T^\mu \) versus \(\eta \)) distribution to further constrain the PDF uncertainty. The two-dimensional fit uses three bins in \(\eta \) within the (\(2< \eta < 4.5\)) range and forty bins in \(p_T^\mu \) within the (\(30< p_T^\mu <50\) GeV/c) range already described. Figure 9 shows, separately for the \(W^+\) and \(W^-\) cases, the distribution of \(M_W\) and \(\chi ^2\) values for the two-dimensional fit to a single toy dataset. The distributions of \(M_W\) values are shown with and without the replica weights. In the \(W^+\) case the width of weighted distribution is roughly a factor of three smaller than the unweighted distribution. For the \(W^-\) the width is reduced by roughly 50%. The effective number of replicas after reweighting
where N is the total number of replicas, gives an indication of the statistical reliability of the method. It is estimated that \(N_{\text {eff}} =\) 113 (105) for the \(W^+\) (\(W^-\)) sample. The high constraining power of the proposed method is manifest in the large reduction of the effective number of replicas.
The weights are clearly dependent on the toy data, so it is now important to consider the results with multiple toy datasets. For a single toy dataset the PDF uncertainty is defined by the RMS of the \(M_W\) values for the 1000 replicas. Figure 10 shows the distribution of the PDF uncertainty for 1000 toy datasets, comparing the one-dimensional fit with and without weights, and the two-dimensional fit with weights. In the one-dimensional case the weighting reduces the uncertainty by an average factor of 10 (20)% for the \(W^+\) (\(W^-\)), with a larger spread of the distributions under data fluctuations. In the one-dimensional weighted case this is estimated to be about 0.8 (1.2) MeV/c\(^2\) for the \(W^+\) (\(W^-\)), in contrast to the 0.04 (0.07) MeV/c\(^2\) of the unweighted case. The two-dimensional weighted case corresponds to a most probable improvement by a factor of roughly two (1.5) for the \(W^+\) (\(W^-\)), with a spread under data fluctuations of 0.9 (1.2) MeV/c\(^2\). Since the outcome of the PDF replica weighting depends on the data, the computation of the PDF uncertainty becomes much more sensitive to the statistical fluctuations of the data themselves. This explains the broadening of the PDF uncertainty distributions once the weighting is applied. This effect becomes even larger for the two-dimensional fit because of its higher constraining power. However, even considering the broadening effect, there is a clear separation between the two-dimensional weighted PDF uncertainty distribution and that of the one-dimensional unweighted (reference) fit approach. These encouraging results strongly motivate the adoption of the two-dimensional fit method by LHCb.

The distribution of the PDF uncertainty evaluated for 1000 toy datasets using three different methods: \(p_T^\mu \) fit without weighting, \(p_T^\mu \) fit with weighting, (\(p_T^\mu \), \(\eta \)) fit with weighting. The one-dimensional unweighted distribution is arbitrarily scaled down by a factor of ten

The distribution of the \(W^-\) versus \(W^+\) mass determined from a single toy dataset with each of the NNPDF3.1 replicas. Ten percent of the replicas with the highest \(P(\chi ^2)\) (product over the two W charges) are assigned red markers

Upper: the distribution of \(\chi ^2\) versus \(M_W\) for a one-dimensional (left) and two-dimensional (right) simultaneous fit to a single toy dataset, which assumes the LHCb Run 2 statistics, with each of the 1000 NNPDF3.1 replicas. Lower: the extracted \(M_W\) values, with a Gaussian fit function overlaid, without (black) and with (red) weighting. In the simultaneous fit the \(W^+\) and \(W^-\) templates share the same normalisation
5.1 Simultaneous fit of \(W^+\) and \(W^-\) samples
Following the promising results shown for separate fits to the \(W^+\) and \(W^-\) data it is now interesting to consider the combination of the two charges. Figure 11 shows, separately for the one-dimensional and two-dimensional approaches, the \(W^+\) versus \(W^-\) fit results for a single toy dataset. Each point represents a different PDF replica. Interestingly, for both fit approaches, there is a clear negative correlation, which implies a partial cancellation of the PDF uncertainty when the \(W^+\) and \(W^-\) data are combined. It is now interesting to see how this partial anti-correlation is affected by (i) the weights and (ii) moving to a two-dimensional fit. Therefore, in Fig. 11 ten percent of the points corresponding to the largest product (over the two W charges) of \(P(\chi ^2_{\text {min}})\) values are highlighted. Unfortunately, in both the one- and two-dimensional fit cases, the subset of favoured replicas exhibits a correlation coefficient with a reduced magnitude. Figure 12 shows the \(\chi ^2_{\text {min}}\) versus \(M_W\) values for combined (\(W^+\) and \(W^-\)) fits to a single toy dataset. The normalisation for both the datasets is scaled by the same parameter to take into account the integrated charge asymmetry constraint on the PDFs. Each point corresponds to a different NNPDF3.1 replica, and the results are shown separately for the one-dimensional and two-dimensional fits. The weighted and unweighted \(M_W\) distributions are shown with corresponding Gaussian fits overlaid. With these data the weights have very little effect on the width of the distribution in the one-dimensional case. The effective number of replicas (\(N_{\text {eff}}\)) after reweighting, computed using Eq. 3, is indeed 928. In the two-dimensional case, however, there is roughly a factor of two of improvement. The effective number of replicas estimated for this case (\(N_{\text {eff}}\) = 35) is showing a very large constraining power of the data and suggests that, for the final measurement, a more robust approach like the Hessian method or an increase of the number of replicas in the reweigting procedure, is necessary to guarantee the statistical reliability of the results obtained with the two-dimensional fit.
Figure 13 (left) shows the distribution of the PDF uncertainty in 1000 toy datasets, in combined fits of the \(W^+\) and \(W^-\) data. Compared to the traditional one-dimensional fit, the addition of the weighting typically improves the PDF uncertainty by around 10%. The two-dimensional fit with weighting is, however, typically around a factor of two better. If the normalisation is no longer shared between the \(W^+\) and \(W^-\) the uncertainty is typically slightly larger, but this change is usually less than 1 MeV/c\(^2\). Figure 13 (right) considers an alternative approach whereby the \(W^+\) and \(W^-\) data are analysed separately, and the corresponding \(M_W\) values are combined in a weighted average. This results in larger uncertainties, and therefore encourages the simultaneous fit of \(W^+\) and \(W^-\) data with a single shared \(M_W\) fit parameter.

The distribution of the PDF uncertainty evaluated for 1000 toy datasets from (left) a simultaneous fit where the \(W^+\) and \(W^-\) templates share the same normalisation or (right) a weighted average of single W charges measurements. Three different fit methods are compared: \(p_T^\mu \) fit without weighting, \(p_T^\mu \) fit with weighting, (\(p_T^\mu \), \(\eta \)) fit with weighting. The one-dimensional unweighted distribution is arbitrarily scaled down by a factor of ten
5.2 Dependence on the detector acceptance
The study has thus far restricted to events in the range \(30< p_T^\mu < 50\) GeV/c and \(2< \eta < 4.5\). It is interesting to now consider how the results depend on this choice, since the LHCb acceptance extends slightly outside this eta range, and LHCb is able to trigger on muons with far smaller \(p_T^\mu \) values without any prescales. Figure 14 shows how the PDF uncertainties depend on the width of the \(p_T^\mu \) interval, which is symmetric around \(M_W/2\). Each band is centered on the mean of the distribution of the PDF uncertainty evaluated for 1000 toy datasets and its width is defined as the RMS of the same distribution. With the simple one-dimensional unweighted fit the PDF uncertainty grows approximately linearly with the width of the \(p_T^\mu \) interval. This is also the case for the one- and two-dimensional weighted fits, though the slope is less severe. Despite this study suggests that choosing a smaller fit range yields to smaller PDF uncertainties, the reduction of this range has an impact on the statistical precision of the measurement as well. Figure 15 considers separately the dependence on the minimum and maximum \(\eta \) value. The uncertainty is found to reduce when the \(\eta \) range is extended in either direction. The uncertainty is not significantly changed if the number of \(\eta \) bins is increased from the nominal value of three. Using only three bins in \(\eta \) should make the experimental control of the \(\eta \) dependence of the muon efficiency more straightforward to control than if more bins are required.

PDF uncertainty as a function of the \(p_T^\mu \) range (the full width, centered around \(M_W/2\)) used in the simultaneous fit. The bands report the mean and the RMS of the distribution of the PDF uncertainty evaluated for 1000 toy datasets. The \(\eta \) range is set to 2 \(<\eta<\) 4.5. In the two dimensional fits three \(\eta \) bins are used

PDF uncertainty as a function of the lower (left) and upper (right) \(\eta \) cut used in the simultaneous fit. The bands report the mean and the RMS of the distribution of the PDF uncertainty evaluated for 1000 toy datasets. The \(p_T^\mu \) is in the range 30 \(<p_T^\mu<\) 50 GeV/c. Left (Right): the upper (lower) \(\eta \) cut set to 4.5 (2). In the two dimensional fits three \(\eta \) bins are used
6 Conclusions
It has recently been suggested that LHCb should perform a measurement of \(M_W\) based on a one-dimensional fit to the muon \(p_T^\mu \) distribution in samples of \(W \rightarrow \mu \nu \) decays. Thanks to LHCb’s unique angular coverage this measurement would complement those performed by ATLAS and CMS, particularly when considering PDF uncertainties. Here we report on a detailed study of the PDF uncertainty, restricting to the NNPDF3.1 set, on the proposed LHCb measurement. It is found that the variations in the PDFs that tend to bias the determination of \(M_W\) lead to clear patterns of variation in the shapes of the W kinematic distributions, in particular the rapidity distribution. A particularly interesting observation is that those variations also lead to a measurable change in the shape of the muon \(\eta \) distribution. An analysis performed on a two-dimensional (\(p_T^\mu \) versus \(\eta \)) plane would reduce the capability of the PDFs to give rise to changes in the \(p_T^\mu \) distribution that can be misidentified as variations of \(M_W\). Therefore, with large enough data samples, a two-dimensional fit to the \(p_T^\mu \) versus \(\eta \) distribution, with PDF replica weighting, would allow the PDF uncertainty to be further constrained. A study with 1000 experiments, assuming the LHCb Run 2 statistics, indicates a typical improvement of around a factor of two, compared to the one-dimensional fit to the \(p_T^\mu \) spectrum alone, when fitting the \(W^+\) and \(W^-\) data simultaneously. Alternative approaches to the PDF replica reweighting, such as the Hessian method, should be considered in future studies towards the real measurement. The full PDF uncertainty should also include the variation between results from different PDF fitting groups, but this is a very encouraging result. In order to facilitate the study of the possible impact of other data a table of \(M_W\) biases for the first 100 NNPDF3.1 replicas is provided as supplementary material. The main study considers events in which the muon satisfies \(2< \eta < 4.5\) and \(30< p_T^\mu < 50\) GeV/c, but the dependence on these choices is also studied since there are likely to be many considerations on the optimal fit range for the real measurement.
Data Availability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: A subset of the derived data is included in the supplementary information files with this published article. The full raw datasets generated and analysed during the current study are available from the corresponding author on reasonable request.]
Notes
The \(2<|\eta |<4.5\) selection is chosen to make better use of the available samples: the events falling in the negative \(\eta \) region are equivalently treated as those with positive \(\eta \).
References
J. Haller, A. Hoecker, R. Kogler, K. Mönig, T. Peiffer, J. Stelzer, Eur. Phys. J. C 78(8), 675 (2018). https://doi.org/10.1140/epjc/s10052-018-6131-3
C. Patrignani et al., Chin. Phys. C 40(10), 100001 (2016). https://doi.org/10.1088/1674-1137/40/10/100001
T. Aaltonen et al., Phys. Rev. Lett. 108, 151803 (2012). https://doi.org/10.1103/PhysRevLett.108.151803
V.M. Abazov et al., Phys. Rev. Lett. 108, 151804 (2012). https://doi.org/10.1103/PhysRevLett.108.151804
M.W. Krasny, F. Dydak, F. Fayette, W. Placzek, A. Siodmok, Eur. Phys. J. C 69, 379 (2010). https://doi.org/10.1140/epjc/s10052-010-1417-0
G. Bozzi, J. Rojo, A. Vicini, Phys. Rev. D 83, 113008 (2011). https://doi.org/10.1103/PhysRevD.83.113008
J. Rojo, A. Vicini, in Proceedings, 2013 Community Summer Study on the Future of U.S. Particle Physics: Snowmass on the Mississippi (CSS2013): Minneapolis, MN, USA, July 29–August 6, 2013 (2013). http://www.slac.stanford.edu/econf/C1307292/docs/submittedArxivFiles/1309.1311.pdf
G. Bozzi, L. Citelli, A. Vicini, Phys. Rev. D 91(11), 113005 (2015). https://doi.org/10.1103/PhysRevD.91.113005
S. Quackenbush, Z. Sullivan, Phys. Rev. D 92(3), 033008 (2015). https://doi.org/10.1103/PhysRevD.92.033008
M. Aaboud et al., Eur. Phys. J. C 78(2), 110 (2018). https://doi.org/10.1140/epjc/s10052-018-6354-3. https://doi.org/10.1140/epjc/s10052-017-5475-4 (Erratum: Eur. Phys. J. C78, no. 11,898 (2018))
R. Aaij et al., Int. J. Mod. Phys. A 30(07), 1530022 (2015). https://doi.org/10.1142/S0217751X15300227
R. Aaij et al., JHEP 01, 155 (2016). https://doi.org/10.1007/JHEP01(2016)155
R. Aaij et al., JHEP 09, 136 (2016). https://doi.org/10.1007/JHEP09(2016)136
R. Aaij et al., JHEP 11, 190 (2015). https://doi.org/10.1007/JHEP11(2015)190
G. Bozzi, L. Citelli, M. Vesterinen, A. Vicini, Eur. Phys. J. C 75(12), 601 (2015). https://doi.org/10.1140/epjc/s10052-015-3810-1
Prospects for the measurement of the W-boson mass at the HL- and HE-LHC. Tech. Rep. ATL-PHYS-PUB-2018-026, CERN. https://cds.cern.ch/record/2645431
Impact of the LHCb upgrade detector design choices on physics and trigger performance. Tech. Rep. LHCb-PUB-2014-040, CERN. https://cds.cern.ch/record/1748643
R. Aaij, others. LHCB-PUB-2018-009. (2018). arXiv:1808.08865
S. Alioli, P. Nason, C. Oleari, E. Re, JHEP 07, 060 (2008). https://doi.org/10.1088/1126-6708/2008/07/060
J. Gao, M. Guzzi, J. Huston, H.L. Lai, Z. Li, P. Nadolsky, J. Pumplin, D. Stump, C.P. Yuan, Phys. Rev. D 89(3), 033009 (2014). https://doi.org/10.1103/PhysRevD.89.033009
T. Sjostrand, S. Mrenna, P.Z. Skands, JHEP 05, 026 (2006). https://doi.org/10.1088/1126-6708/2006/05/026
L.A. Harland-Lang, A.D. Martin, P. Motylinski, R.S. Thorne, Eur. Phys. J. C 75(5), 204 (2015). https://doi.org/10.1140/epjc/s10052-015-3397-6
T.J. Hou et al., JHEP 03, 099 (2017). https://doi.org/10.1007/JHEP03(2017)099
R.D. Ball et al., Eur. Phys. J. C 77(10), 663 (2017). https://doi.org/10.1140/epjc/s10052-017-5199-5
S. Alioli et al., Eur. Phys. J. C 77(5), 280 (2017). https://doi.org/10.1140/epjc/s10052-017-4832-7
M.L. Mangano, Adv. Ser. Direct. High Energy Phys. 26, 231 (2016). https://doi.org/10.1142/9789814733519_0013
J.C. Collins, D.E. Soper, Phys. Rev. D 16, 2219 (1977). https://doi.org/10.1103/PhysRevD.16.2219
E. Manca, O. Cerri, N. Foppiani, G. Rolandi, JHEP 12, 130 (2017). https://doi.org/10.1007/JHEP12(2017)130
W.T. Giele, S. Keller, Phys. Rev. D 58, 094023 (1998). https://doi.org/10.1103/PhysRevD.58.094023
R.D. Ball, V. Bertone, F. Cerutti, L. Del Debbio, S. Forte, A. Guffanti, J.I. Latorre, J. Rojo, M. Ubiali, Nucl. Phys. B 849, 112 (2011). https://doi.org/10.1016/j.nuclphysb.2011.03.017. https://doi.org/10.1016/j.nuclphysb.2011.10.024. https://doi.org/10.1016/j.nuclphysb.2011.09.011. [Erratum: Nucl. Phys. B855,927 (2012)]
R.D. Ball, V. Bertone, F. Cerutti, L. Del Debbio, S. Forte, A. Guffanti, N.P. Hartland, J.I. Latorre, J. Rojo, M. Ubiali, Nucl. Phys. B 855, 608 (2012). https://doi.org/10.1016/j.nuclphysb.2011.10.018
J. Pumplin, D. Stump, R. Brock, D. Casey, J. Huston, J. Kalk, H.L. Lai, W.K. Tung, Physical Review D 65, (2001). https://doi.org/10.1103/PhysRevD.65.014013
Acknowledgements
We thank W. Barter, M. Charles, G. Bozzi, A. Vicini, A. Cooper-Sakar, L. Harland-Lang and J. Rojo for their helpful comments and suggestions during the preparation of this manuscript. OL thanks the CERN LBD group for their support during the period when most of this work was carried out, and MV thanks the Science and Technologies Facilities Council for their support through an Ernest Rutherford Fellowship.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3
About this article

Cite this article
Farry, S., Lupton, O., Pili, M. et al. Understanding and constraining the PDF uncertainties in a W boson mass measurement with forward muons at the LHC. Eur. Phys. J. C 79, 497 (2019). https://doi.org/10.1140/epjc/s10052-019-6997-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-019-6997-8