
Abstract
We present NNFF1.0, a new determination of the fragmentation functions (FFs) of charged pions, charged kaons, and protons/antiprotons from an analysis of single-inclusive hadron production data in electron–positron annihilation. This determination, performed at leading, next-to-leading, and next-to-next-to-leading order in perturbative QCD, is based on the NNPDF methodology, a fitting framework designed to provide a statistically sound representation of FF uncertainties and to minimise any procedural bias. We discuss novel aspects of the methodology used in this analysis, namely an optimised parametrisation of FFs and a more efficient \(\chi ^2\) minimisation strategy, and validate the FF fitting procedure by means of closure tests. We then present the NNFF1.0 sets, and discuss their fit quality, their perturbative convergence, and their stability upon variations of the kinematic cuts and the fitted dataset. We find that the systematic inclusion of higher-order QCD corrections significantly improves the description of the data, especially in the small-z region. We compare the NNFF1.0 sets to other recent sets of FFs, finding in general a reasonable agreement, but also important differences. Together with existing sets of unpolarised and polarised parton distribution functions (PDFs), FFs and PDFs are now available from a common fitting framework for the first time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the framework of Quantum Chromodynamics (QCD), Fragmentation Functions (FFs) [1] encode the long-distance dynamics of the interactions among quarks and gluons which lead to their hadronisation in a hard-scattering process [2, 3]. In order to obtain theoretical predictions for the observables involving identified hadrons in the final state, FFs have to be convoluted [4] with partonic cross-sections encoding instead the short-distance dynamics of the interaction. If the hard-scattering process is initiated by nucleons, additional convolutions with the Parton Distribution Functions (PDFs) [5,6,7], the space-like counterparts of FFs, are required.
The knowledge of FFs is an important ingredient in our understanding of non-perturbative QCD dynamics, as well as an essential tool in the description of a number of processes used to examine the internal structure of nucleons. For example, processes probing nucleon momentum, spin, flavour and spatial distributions [8], as well as the dynamics of cold [9] and hot [10] nuclear matter. While partonic cross-sections can be computed perturbatively in QCD, FFs cannot, although their dependence on the factorisation scale results in the perturbatively computable DGLAP evolution equations [11,12,13,14]. In this respect, FFs and PDFs are on the same footing. Therefore, as PDFs, FFs need to be determined from a global analysis of a suitable set of experimental measurements, possibly from a variety of hard-scattering processes (see e.g. Refs. [15, 16] for a review).
These processes include hadron production in electron–positron Single-Inclusive Annihilation (SIA), in lepton–nucleon Semi-Inclusive Deep-Inelastic Scattering (SIDIS), and in proton–proton (pp) collisions. Information from SIDIS multiplicities and from pp collisions is particularly useful in order to achieve a complete flavour decomposition into quark and antiquark FFs alongside a direct determination of the gluon FF. However, SIA remains the theoretically cleanest process among the three, since its interpretation does not require the simultaneous knowledge of PDFs.
Recent progress in the determination of FFs has been focussed on charged pions and kaons, for which data are more abundant as they dominate the identified hadron yields. In the last few years, at least three groups have determined sets of FFs with uncertainties for these two hadronic species: DEHSS [17, 18], HKKS [19], and JAM [20]. All these determinations were performed at next-to-leading order (NLO) accuracy in perturbative QCD. Their primary focus was put on quantifying the effects of the inclusion of new measurements, although in the HKKS and JAM fits these were limited to SIA. These FF analyses also introduced some methodological and theoretical improvements over previous determinations. Specifically, in order to achieve a more reliable estimate of the uncertainties of FFs, various techniques widely used in PDF determinations have been adopted. For example, the iterative Hessian approach developed in Refs. [21, 22] has been used in the DEHSS analyses, while the iterative Monte Carlo procedure developed in Ref. [23] has been used in the JAM analysis. Separately, theoretical investigations of the effect of next-to-next-to-leading order (NNLO) QCD corrections [24], of a general treatment of heavy-quark mass effects [25], and of all-order small-z resummation [26] were performed in the framework of the DEHSS analyses, although only for the SIA production of charged pions.
Despite this progress, available determinations of FFs are still potentially affected by some sources of procedural bias, the size and effect of which are difficult to quantify. First, the parametrisation of FFs in terms of a simple functional form, customary in current analyses, may not encapsulate all the possible functional behaviours of the FFs. Second, the Hessian method supplemented with a tolerance parameter, used to determine FF uncertainties for instance in the HKKS analysis, lacks a robust statistical interpretation. Third, if a global analysis of FFs including PDF-dependent processes is carried out, PDFs and FFs should be determined within a consistent methodology. This is not the case in current global analyses like DEHSS.
This work represents a first step in overcoming some of these limitations. Building on the preliminary results of Refs. [27, 28], here we present NNFF1.0, a new determination of the FFs of charged pions, charged kaons, and protons/antiprotons from a comprehensive set of SIA measurements. This analysis is performed at leading order (LO), NLO, and NNLO accuracy in perturbative QCD. This analysis is based on the NNDPF methodology, a fitting framework designed to provide a statistically sound representation of FF uncertainties and to reduce potential procedural biases as much as possible. This is achieved by representing FFs as a Monte Carlo sample, from which central values and uncertainties can be computed, respectively, as a mean and a standard deviation, and by parametrising FFs with a flexible function provided by a neural network.
The NNPDF methodology for the determination of PDFs was originally applied to the analysis of inclusive Deep-Inelastic Scattering (DIS) structure functions [29, 30], and then extended to a determination of the PDFs of the proton, first from DIS data only [31,32,33] and then from a wider dataset including hadron collider data [34,35,36]. Several developments have been achieved since then. These include determinations of PDFs with LHC data [37,38,39], of PDFs with effects of threshold resummation [40], of PDFs with QED corrections [41], of a fitted charm PDF [42], and of longitudinally polarised PDFs [43, 44]. Applying the NNPDF framework to a determination of FFs is therefore a natural extension of the NNPDF fits. It is also a first step towards a simultaneous determination of polarised and unpolarised PDFs and FFs, as recently attempted by the JAM Collaboration [45].
This paper is organised as follows. In Sect. 2 we present the dataset used in our analysis, along with the corresponding observables and kinematic cuts. In Sect. 3 we discuss the theoretical details of the NNFF1.0 determination, including the computation of the observables, the evolution of FFs, and our choice of physical parameters. In Sect. 4 we revisit the NNPDF fitting methodology and its application to our current determination of FFs. Specifically, we focus on the aspects of the parametrisation and minimisation strategy which are introduced here for the first time. We validate the fitting methodology by means of closure tests. In Sect. 5 we present the NNFF1.0 sets, their fit quality, their perturbative convergence, and their comparison with other available FF sets. In Sect. 6 we study their stability upon variations in the kinematic cuts and the fitted dataset. Finally, in Sect. 7 we conclude and outline possible future developments. The delivery of the NNFF1.0 sets is discussed in Appendix A.
2 Experimental data
The determination of FFs presented in this work is based on a comprehensive dataset from SIA, i.e. electron–positron annihilation into a single identified hadron h, inclusive over the rest of the final state X,
This process is the time-like counterpart of inclusive DIS, to which it is related by crossing symmetry. Similarly to the Bjorken-x variable in DIS, one usually defines the scaling variable
with \(P_h\) the four-momentum of the outgoing identified hadron, \(q=k_1+k_2\) the four-momentum of the exchanged virtual gauge boson, \(\sqrt{q^2}=Q\). The center-of-mass energy of the electron–positron collision is given by \(\sqrt{s}=Q\). In this section we provide the details of the dataset included in this analysis. We describe first the experiments considered, then the corresponding physical observables and finally the kinematic cuts that we apply to the data.
2.1 The NNFF1.0 dataset
The dataset entering the NNFF1.0 analysis is based on electron–positron SIA cross-sections for the sum of charged pion, charged kaon, and proton/antiproton production, i.e. \(h=\pi ^++\pi ^-,K^++K^-,p+\bar{p}\) in Eq. (2.1). These cross-sections are differential with respect to either the scaling variable z, Eq. (2.2), or a closely related quantity (see Sect. 2.2). We include measurements performed by experiments at CERN (ALEPH [46], DELPHI [47], and OPAL [48]), DESY (TASSO [49,50,51]), KEK (BELLE [52, 53] and TOPAZ [54]), and SLAC (BABAR [55], TPC [56], and SLD [57]).
In addition to inclusive measurements, we also include flavour-tagged measurements from TPC [58], DELPHI [47] and SLD [57] experiments. The tagged quark flavour refers to the primary quark–antiquark pair produced in the \(Z/\gamma ^*\) decay. For these measurements, differential cross-sections corresponding to either the sum of light quarks (u, d, s) or to individual charm and bottom quarks (c, b) are provided, with the former obtained by subtracting the latter from the inclusive untagged cross-sections. Unlike inclusive untagged data, heavy-flavour tagged data cannot be measured directly, but are instead unfolded from flavour enriched samples based on Monte Carlo simulations. These are therefore affected by additional model uncertainties. The OPAL experiment has also measured fully separated flavour-tagged probabilities for a quark flavour to produce a jet containing the hadron h [59]. We do not include these data because they do not allow for an unambiguous interpretation in perturbative QCD beyond LO.
We now discuss specific features of some of the datasets included in the NNFF1.0 analysis. In the case of the BABAR experiment, two sets of data are available, based on prompt and conventional yields, respectively. The former includes primary hadrons or decay products from particles with lifetime shorter than \(\tau =10^{-11}\) s. The latter includes all decay products with lifetime up to \(3\times 10^{-1}\) s. The conventional cross-sections are about 5–15% larger than the prompt ones for charged pions and about 10–30% for protons/antiprotons. They are almost the same for charged kaons. Although the conventional dataset was derived by means of an analysis closer to that adopted by other experiments, we include the prompt dataset in our baseline fit of charged pions and proton/antiproton FFs. The motivation for this choice is that the prompt measurements are more consistent with other SIA data than the conventional measurements. A similar choice based on similar considerations was adopted in previous analyses of charged pion FFs [17, 20].
In the case of the BELLE experiment, various sets of data are also available. In a first analysis [52], based on an integrated luminosity \(\mathcal {L}=68\) fb\(^{-1}\), differential cross-sections were extracted only for charged pions and charged kaons. A second analysis [53], based on an increased luminosity \(\mathcal {L}=159\) fb\(^{-1}\), was focussed instead on the determination of the proton/antiproton cross-sections. In this study charged pion and kaon measurements were updated, although they were not intended to be publicly released [60]. The second analysis differs from the first in a less dense z binning (particularly in the large-z region), a moderately improved coverage at small z (\(z\sim 0.1\) instead of \(z\sim 0.2\)), smaller systematic uncertainties, and a slightly larger center-of-mass energy (\(\sqrt{s}=10.58\) GeV instead of \(\sqrt{s}=10.52\) GeV). Here we include the data from Ref. [52] for charged pions and kaons, and the data from Ref. [53] for protons/antiprotons.
In the case of the OPAL experiment, we have excluded the proton/antiproton measurements because we experienced difficulties in providing a satisfactory description of the data. This approach was also adopted in a previous FF analysis [61], where the proton/antiproton OPAL data were shown to be in tension with other SIA data at the same center-of-mass energy, \(\sqrt{s}=M_Z\) (see also Ref. [62]).
The dataset included in the NNFF1.0 analysis is summarised in Table 1, where experiments are ordered by increasing center-of-mass energy. In Table 1, we specify the name of the experiment, the corresponding publication reference, the measured observable, the relative normalisation uncertainty (r.n.u.), and the number of data points included in the fit for each hadronic species. Available datasets that are not included (n.i.) in the NNFF1.0 analysis, for the reasons explained above, are also indicated. The kinematic coverage of the dataset is illustrated in Fig. 1.

The kinematic coverage in the \((z,\sqrt{s})\) plane of the NNFF1.0 dataset (see Table 1). Data are from DESY (black), KEK (green) and CERN (red)
As one can see from Table 1 and Fig. 1, the bulk of the NNFF1.0 dataset is composed of the LEP and SLD measurements, taken at \(\sqrt{s}=M_Z\), and of the B-factory measurements, taken at the lower scale \(\sqrt{s}\simeq 10\) GeV. They collectively account for about two thirds of the total dataset and feature relative uncertainties at the level of a few percent. The rest of the dataset corresponds to measurements taken at intermediate energy scales that are typically affected by larger uncertainties. From Fig. 1 one also observes that the coverage in z is limited roughly to the region \(0.006\lesssim z \lesssim 0.95\). As expected from kinematic considerations, experiments at higher center-of-mass energies provide data at smaller values of z, while experiments at lower center-of-mass energies provide data at larger values of z.
The quantity and the quality of the available data varies depending on the hadronic species (see also Figs. 4, 5, 6, 7). Measurements for charged pions, for which the yield is the largest, are the most abundant and precise. In comparison, measurements for charged kaons are slightly less abundant and precise, while protons/antiprotons measurements are the most sparse and the most uncertain among the three hadronic species. As a consequence, charged pion FFs are better constrained than charged kaon and proton/antiproton FFs (see Sect. 5.2).
We now briefly discuss the differences between the NNFF1.0 dataset and the dataset included in some of the most recent determinations of FFs.
In comparison to JAM [20], we do not consider the ARGUS inclusive [63], the HRS inclusive [64], and the OPAL fully flavour-tagged data. Note that these differences are restricted to the charged pion and charged kaon FFs, as proton/antiproton FFs were not determined in the JAM analysis.
In comparison to HKKS [19], we include the TPC tagged data for charged pions and remove the HRS data for charged pions and kaons. A determination of the proton/antiproton FFs was not performed in Ref. [19], but in an earlier analysis based on a similar framework [62]. In comparison to this, here we exclude the OPAL inclusive data and include the BELLE and BABAR data, which were not available when the analysis in Ref. [62] was performed.
In comparison to DEHSS [17, 18], we include the older TASSO (at \(\sqrt{s}=12,14,22,30\) GeV) and TOPAZ measurements. These datasets are affected by rather large experimental uncertainties. Their effect in the DEHSS fits was deemed negligible and hence they were removed. Note that the DEHSS determinations also include the OPAL fully flavour-tagged data, not considered here, as well as additional measurements of hadroproduction in SIDIS and pp collisions. Similar considerations also apply to their earlier analysis for proton/antiproton FFs [61], in comparison to which we also include the BELLE and BABAR data. In the case of proton/antiproton FFs, the NNFF1.0 analysis is the first to include the B-factory measurements.
We take into account all the available information on statistical and systematic uncertainties, including their correlations. The full breakdown of bin-by-bin correlated systematics is provided only by the BABAR experiment. No information on correlations among various sources of systematics is provided for all the other experiments. In these cases we sum in quadrature statistical and systematic uncertainties. Normalisation uncertainties are assumed to be fully correlated across all data bins in each experiment. The asymmetric uncertainties quoted by BELLE are symmetrised as described in Ref. [30].
Systematic uncertainties, with the exception of normalisation uncertainties, are treated as additive. Because the naive inclusion of multiplicative normalisation uncertainties in the covariance matrix would lead to a biased result [65], we treat them according to the \(t_0\) method [66, 67]. This method is based on constructing a modified version of the covariance matrix where the contribution from multiplicative uncertainties is determined from theory predictions rather than from the experimental central values for each measurement. This procedure is iterative, with the results of a fit being used for the subsequent one until convergence is reached.
The available information on statistical, systematic, and normalisation uncertainties is used to construct the covariance matrix associated to each experiment. Following the NNPDF methodology, this covariance matrix is used to generate a Monte Carlo sampling of the probability distribution determined by the data. The statistical sample used in the NNFF1.0 fits is obtained by generating \(N_\mathrm{rep}=100\) pseudo-data replicas according to a multi-Gaussian distribution around the data central values and with the covariance of the original data [32].
2.2 Physical observables
The SIA differential cross-section involving a hadron h in the final state can be expressed as
where \(\alpha \) is the Quantum Electrodynamics (QED) running coupling and \(F_2^h\) is the fragmentation (structure) function, defined in analogy with the structure function \(F_2\) in DIS. While in the literature \(F_2^h\) is often called fragmentation function, we will denote it as fragmentation structure function in order to avoid any confusion with the partonic FFs.
The SIA cross-sections used in this analysis are summarised in the third column of Table 1. For some experiments, they are presented as multiplicities, i.e. they are normalised to \(\sigma _\mathrm{tot}\), the total cross-section for the inclusive electron–positron annihilation into hadrons. In addition to the normalisation to \(\sigma _\mathrm{tot}\), the format of the experimental data can differ among the various experiments due to the choice of scaling variable and/or an additional overall rescaling factor. These differences are indicated in Table 1, where the following notation is used: \(z=E_h/E_b=2E_h/\sqrt{s}\) is the energy \(E_h\) of the observed hadron h scaled to the beam energy \(E_b\); \(x_p=|\mathbf {p}_h|/|\mathbf {p}_b|=2|\mathbf {p}_h|/\sqrt{s}\) is the hadron three-momentum \(|\mathbf {p}_h|\) scaled to the beam three-momentum \(|\mathbf {p}_b|\); \(\xi =\ln (1/x_p)\); and \(\beta =|\mathbf {p}_h|/E_h\) is the velocity of the observed hadron h.
Starting from the measured observables defined in Table 1, the corresponding data points have been rescaled by the inverse of \(s/\beta \) or \(1/\beta \) whenever needed to match Eq. (2.3), modulo the normalisation to \(\sigma _\mathrm{tot}\). Corrections depending on the hadron mass \(m_h\) are retained according to the procedure described in Ref. [68]. This implies that the distributions differential in \(x_p\), \(p_h\) or \(\xi \) are modified by a multiplicative Jacobian factor determined by the following relations between the scaling variables:
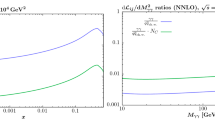
The typical size of these hadron-mass corrections is illustrated in the left plot of Fig. 2, where we show the ratio \(x_p/z\) as a function of z, at three representative values of \(\sqrt{s}\), for pions, kaons, and protons. Hadron-mass corrections become larger when z and/or \(\sqrt{s}\) decrease, as well as when \(m_h\) is increased. These corrections can become significant in the kinematic region covered by the data. For instance, at \(z=0.1\) and \(Q=M_Z\) hadron-mass corrections are less than \(10\%\) for all hadronic species, while at \(z=0.1\) and \(Q=10\) GeV they rise up to \(20\%\) (\(70\%\) or more) for pions (kaons and protons/antiprotons). For protons/antiprotons, these corrections are already larger than \(30\%\) around \(z=0.4\) at the center-of-mass energy of the B-factory data. Therefore, the inclusion of hadron-mass corrections should improve the description of the data.

Left the scaling variable ratio \(x_p/z\) as a function of z, at three representative values of \(\sqrt{s}\), for pions, kaons and protons. Right the SIA K-factor, defined as the ratio \(F_2^h(\mathrm{N}^\mathrm{m}\mathrm{LO})/F_2^h(\mathrm{N}^\mathrm{m-1}\mathrm{LO})\) for \(m=1,2\), at the same three values of \(\sqrt{s}\). The K-factors have been computed with fixed NLO charged pion FFs from the DEHSS determination [17]
In the case of the BELLE experiment we multiply all data points by a factor 1 / c, with \(c=0.65\) for charged pions and kaons [69] and with c a function of z for protons/antiprotons [53]. This correction is required in order to treat the BELLE data consistently with all the other SIA measurements included in NNFF1.0. The reason is that a kinematic cut on radiative photon events was applied to the BELLE data sample in the original analysis instead of unfolding the radiative QED effects. Specifically, the energy scales in the measured events were kept within \(0.5\%\) of the nominal fragmentation scale Q / 2; a Monte Carlo simulation was then performed to estimate the fraction of events with initial-state (ISR) or final-state radiation (FSR) photon energies below \(0.5\%\times Q/2\). For each bin, the measured yields are then reduced by these fractions in order to exclude events with large ISR or FSR contributions.
Finally, note that the B-factory measurements correspond to samples where the effect of bottom-quark production is not included because they were taken at a center-of-mass energy below the threshold to produce a B-meson pair. The corresponding theoretical predictions should therefore be computed without the bottom-quark contribution, as explained in Sect. 3.1.
2.3 Kinematic cuts
Our baseline determination of FFs is based on a subset of all the available data points described above. Specifically, we impose two kinematic cuts at small and large values of z, \(z_\mathrm{min}\) and \(z_\mathrm{max}\), and retain only the data points with z in the interval \([z_\mathrm{min}, z_\mathrm{max}]\). These cuts are needed to exclude the kinematic regions where effects beyond fixed-order perturbation theory should be taken into account for an acceptable description of the data. For instance, soft-gluon logarithmic terms proportional to \(\ln z\) and threshold logarithmic terms proportional to \(\ln (1-z)\) can significantly affect the time-like splitting functions and the SIA coefficient functions below certain values of \(z_\mathrm{min}\) and above certain values of \(z_\mathrm{max}\). As a consequence, the convergence of the fixed-order expansion can be spoiled.
While all-order resummation techniques have been developed both at small [70,71,72,73] and large z [74,75,76,77,78], their inclusion is beyond the scope of the present work. However, we note that the impact of small- and large-z unresummed logarithms is alleviated when higher-order corrections are included in the perturbative expansion of splitting and coefficient functions. To illustrate the perturbative convergence of the SIA structure function in Eq. (2.3), we show in Fig. 2 the SIA K-factors at three representative values of \(\sqrt{s}\). They are defined as the ratios \(F_2^h(\mathrm{N}^\mathrm{m}\mathrm{LO})/F_2^h(\mathrm{N}^\mathrm{m-1}\mathrm{LO})\), for \(m=1,2\), and have been computed with fixed NLO charged pion FFs taken from the DEHSS determination [17]. The NNLO/NLO K-factors are significantly smaller than the NLO/LO ones for most of the kinematic range, except at small z and \(\sqrt{s}\), where they become comparable. For most of the values of z in the kinematic range of the data, the NNLO corrections are at the level of about \(10\%\) or less, except below \(z\sim 0.02\) (\(z\sim 0.07\)) and above \(z\sim 0.9\) at \(Q=M_Z\) (\(Q=10\) GeV), where they become larger. This suggests that in these regions large logarithms can spoil the convergence of the truncated perturbative series even at NNLO, indicating the need of resumming them.
In general the values of \(z_\mathrm{min}\) and \(z_\mathrm{max}\) can vary with the center-of-mass energy \(\sqrt{s}\). Based on the considerations above, here we choose the following values of \(z_\mathrm{min}\) and \(z_\mathrm{max}\): \(z_\mathrm{min}=0.02\) for experiments at \(\sqrt{s}=M_Z\); \(z_\mathrm{min}=0.075\) for all other experiments; and \(z_\mathrm{max}=0.9\) for all experiments. The same kinematic cuts are applied to the three hadronic species. The number of data points before applying these kinematic cuts is reported in parentheses in Table 1. Further motivation for our choice of \(z_\mathrm{min}\) is provided by studying the deterioration of the fit quality upon its variation, as we will discuss in detail in Sect. 6.1. Specifically, we find that our choice of \(z_\mathrm{min}\) leads to the smallest total \(\chi ^2\). The value of \(z_\mathrm{max}\) used here also minimises possible tensions between different datasets in the large-z region.
3 From fragmentation functions to physical observables
In this section we review the collinear factorisation of the fragmentation structure function and the time-like DGLAP evolution of FFs. We also provide the details of the numerical computation of the SIA cross-sections, including our choice of the theoretical settings and the physical parameters.
3.1 Factorisation and evolution
The factorised expression of the inclusive fragmentation structure function \(F_2^h(z,Q)\) in Eq. (2.3) is given as a convolution between coefficient functions and FFs,
where both factorisation and renormalisation scales are set equal to the center-of-mass energy of the collision, \(\mu _F=\mu _R=\sqrt{s}=Q\). In Eq. (3.1) \(\otimes \) denotes the usual convolution integral with respect to z,
and
is the average of the effective quark electroweak charges \(\hat{e}_q\) (see e.g. Appendix A of Ref. [79] for their definition) over the \(n_f\) active flavours at the scale Q; \(\alpha _s\) is the QCD running coupling; and \(C_{2,q}^\mathrm{S}\), \(C_{2,q}^\mathrm{NS}\), \(C_{2,g}^\mathrm{S}\) are the coefficient functions corresponding, respectively, to the singlet and nonsinglet combinations of FFs,
and to the gluon FF, \(D_g^{h}\). The notation \(D_{q^+}^h \equiv D_q^h+D_{\bar{q}}^h\) has been used.
The total cross-section for \(e^+e^-\) annihilation into hadrons \(\sigma _\mathrm{tot}\), required to normalise the differential cross-section in Eq. (2.3) in the case of multiplicities, is
The coefficients \(K_\mathrm{QCD}^{(i)}\) indicate the QCD perturbative corrections to the LO result and are currently known up to \(\mathcal {O}(\alpha _s^3)\) [80].
The evolution of FFs with the energy scale Q is governed by the DGLAP equations [11,12,13,14]
where \(P_{ji}\) are the time-like splitting functions. The choice of FF combinations defined in Eq. (3.4) allows one to rewrite Eq. (3.6) as a decoupled evolution equation
for the nonsinglet combination of FFs, and a system of two coupled equations
for the singlet combination of quark FFs and the gluon FF. In comparison to the space-like case, the off-diagonal splitting functions are interchanged and multiplied by an extra colour factor.
Both the coefficient functions in Eq. (3.1) and the splitting functions in Eqs. (3.7)–(3.8) allow for a perturbative expansion in powers of the QCD coupling
where \(i,j=q,g\) and \(a_s \equiv \alpha _s/(4\pi )\). The SIA coefficient functions have been computed up to \(\mathcal {O}\left( a_s^2\right) \) (\(k=2\)) [81,82,83,84,85], and the time-like splitting functions up to \(\mathcal {O}\left( a_s^3\right) \) (\(k=2\)) [86,87,88], both in the \(\overline{\mathrm{MS}}\) scheme. A residual theoretical uncertainty on the exact form of \(P^{qg,(2)}\) still remains, though this is unlikely to have any phenomenological relevance [87]. Note that space- and time-like splitting functions are identical at LO, while they differ at NLO and beyond.
Expressing the SIA fragmentation structure function \(F_2^h\) in Eq. (3.1) in terms of the quark flavour singlet and non-singlet combinations of FFs defined in Eq. (3.4) allows one to identify some of the limitations that affect a determination of FFs based exclusively on SIA data. These include the following.
-
Quark and antiquark FFs always appear through the combinations \(D_{q^+}^h\) in Eqs. (3.1) and (3.4). Therefore, SIA measurements are not sensitive to the separation between quark and antiquark FFs.
-
The leading contribution to the gluon coefficient function \(C_{2,g}^\mathrm{S}\) in Eq. (3.1) is \(\mathcal {O}(a_s)\), hence the gluon FF directly enters the fragmentation structure function starting at NLO.
-
The separation between different light quark flavour FFs is probed indirectly via the dependence of the electroweak charges \(\hat{e}_q\) on the energy scale Q. For instance, at the scale of the LEP/SLC data, \(Q=M_Z\), the fragmentation structure function in Eq. (3.1) receives its leading contribution from a Z-boson exchange, which couples almost equally to up- and down-type quarks. At this scale, the term \(\hat{e}_q^2/\left\langle \hat{e}^2 \right\rangle \), which appears in Eq. (3.4) is close to one, therefore the quark nonsinglet contribution to the structure function is suppressed. Conversely, at the typical scale of the B-factory measurements, \(Q\sim 10\) GeV, SIA largely proceeds via a photon exchange, which couples differently to up- and down-type quarks. Therefore the term \(\hat{e}_q^2/\left\langle \hat{e}^2 \right\rangle \) is significantly different from one, and the relative contribution of the quark nonsinglet combination to \(F_2^h\) is sizeable.
-
A direct handle on the separation between light- and heavy-quark flavour FFs is provided by the heavy-flavour tagged data from the LEP, SLC, and TPC experiments.
3.2 Computation of SIA cross-sections
The computation of the SIA cross-sections and the DGLAP evolution of the FFs are performed in the \(\overline{\mathrm{MS}}\) factorisation scheme using the z-space public code APFEL [89]. The numerical solution of the time-like evolution equations, Eqs. (3.7)–(3.8), has been extensively benchmarked up to NNLO QCD in APFEL; see Ref. [90]. The FastKernel method, introduced in Refs. [34, 37] and revisited in Ref. [38], is used to ensure a fast evaluation of the theoretical predictions. We include QED running coupling effects in these calculations.
Concerning the treatment of heavy-quark mass effects, here we adopt the zero-mass variable-flavour-number (ZM-VFN) scheme in which they are neglected. Taking into account such effects would require the use of a general-mass variable-flavour-number (GM-VFN) scheme, as customarily done in the case of unpolarised PDF fits [91,92,93]. Their inclusion into a fit of FFs could improve the description of some of the SIA datasets, particularly the BELLE and BABAR measurements whose center-of-mass energy is not far above the bottom-quark mass [25]. We leave a possible extension of our analysis along the lines of Ref. [25] for a future work.
Whenever multiplicities should be computed, the differential cross-section in Eq. (2.3) is normalised to the total cross-section for electron–positron annihilation \(\sigma _\mathrm{tot}\) defined in Eq. (3.5). In the calculation of \(\sigma _\mathrm{tot}\), perturbative corrections are consistently included up to \(\mathcal {O}(1)\), \(\mathcal {O}(a_s)\), and \(\mathcal {O}(a_s^2)\) in the LO, NLO and NNLO fits, respectively.
As mentioned in Sect. 2.1, the BELLE and BABAR measurements correspond to an observable for which the contribution from bottom quarks is explicitly excluded. This is taken into account in the corresponding theoretical calculation by setting to zero the bottom-quark electroweak charge appearing in Eq. (3.1). Analogously, only the contributions proportional to the electroweak charges of the relevant flavours are retained in Eq. (3.1) for the computation of the light- and heavy-quark tagged cross-sections.
The values of the physical parameters used in the computation of the SIA cross-sections and in the evolution of FFs are the same as those used in the NNPDF3.1 global analysis of unpolarised PDFs [39], supplemented with the PDG averages [94] for those parameter values not specified there. Specifically, we use: \(M_Z=91.1876\) GeV for the Z-boson mass, \(\alpha _s(M_Z)=0.118\) and \(\alpha (M_Z)=1/128\) as reference values for the QCD and QED couplings, and \(m_c=1.51\) GeV and \(m_b=4.92\) GeV for the charm- and bottom-quark pole masses. For the Weinberg mixing angle and Z-boson decay width, entering the definition of the electroweak charges \(\hat{e}_q\), we use \(\sin ^2\theta _W=0.231\) and \(\Gamma _Z=2.495\) GeV. Finally, the values of the hadron masses used to correct the scaling variables in Eq. (2.4) are \(m_\pi =0.140\) GeV, \(m_K=0.494\) GeV, and \(m_p=0.938\) GeV.
4 Fitting methodology
The NNPDF fitting methodology has been described at length in previous publications [29,30,31,32,33,34,35,36]. In this section, we present its aspects specific to the NNFF1.0 analysis, some of which are introduced here for the first time. We first discuss the parametrisation of FFs in terms of neural networks, then the minimisation strategy to optimise their parameters, and finally a comprehensive validation of the whole methodology by means of closure tests.
4.1 Neural network parametrisation
As discussed in Sect. 3.1, inclusive SIA data allow for the determination of only three independent combinations of FFs, namely the singlet and nonsinglet combinations in Eq. (3.4) and the gluon FF. In addition, charm- and bottom-quark tagged data make possible to constrain two additional nonsinglet combinations involving heavy-quark FFs, adding up to a total of five independent combinations of FFs.
We adopt the parametrisation basis
where the light-flavour combinations of quark FFs in Eq. (3.4) have been separated according to the values of the corresponding electroweak charges. In Eq. (4.1) we have used the shorthand notation \(D^h_{d^++s^+}=D^h_{d^+}+D^h_{s^+}\). This parametrisation basis is used for all hadronic species. The superscript h in Eq. (4.1) denotes in turn the sum of positive and negative pions, \(h=\pi ^\pm =\pi ^++\pi ^-\), of positive and negative kaons, \(h=K^\pm =K^++K^-\), or of protons and antiprotons, \(h=p/\bar{p}=p+\bar{p}\). The choice of the parametrisation basis is of course not unique. Any linear combination of the FFs in Eq. (4.1) could be used.
Each FF in the basis defined in Eq. (4.1) is parametrised at the initial scale \(Q_0\) as
where \(\mathrm{NN}_i\) is a neural network, specifically a multi-layer feed-forward perceptron [29, 31]. It consists of a set of nodes organised into sequential layers, in which the output \(\xi _i^{(l)}\) of the ith node of the lth layer is
where the function g is a given activation function. The parameters \(\{\omega _{ij}^{(l)},\theta _i^{(l)}\}\), known as weights and thresholds, respectively, are determined during the minimisation procedure.
As in previous NNPDF analyses, here we use the same neural network architecture for all the fitted FFs, namely 2–5–3–1 (that is, four layers with 2, 5, 3 and 1 nodes each). This corresponds to 37 free parameters for each FF, and to a total of 185 free parameters for each hadronic species. This is to be compared to about 15–30 free parameters per hadronic species typically used in other determinations of FFs. The 2–5–3–1 architecture is sufficiently flexible to avoid any parametrisation bias, as we will demonstrate by means of closure tests in Sect. 4.3.
In contrast with previous NNPDF analyses, here we do not supplement the neural network parametrisation with a preprocessing function of the form \(z^\alpha (1-z)^\beta \). Such a function is used in previous NNPDF fits in order to speed up the minimisation process. By absorbing in this prefactor the bulk of the behaviour in the extrapolation regions, the neural network only has to fit deviations from it. In order to minimise potential biases in the final result, the values of the exponents \(\alpha \) and \(\beta \) are chosen for each replica at random within a suitable range determined iteratively [38, 43].
A typical fit of FFs in this analysis is by far computationally less expensive than a typical NNPDF fit of PDFs. This is because the quantity, the quality, and the variety of the data are much more limited in the former case than in the latter. Therefore, removing the preprocessing function from the FF parametrisation does not significantly affect the efficiency of the fitting procedure. Moreover, it avoids the need for the iterative determination of the preprocessing exponents. However, the absence of the preprocessing function in Eq. (4.2) affects the behaviour of the FFs in the extrapolation regions at small and large values of z, and requires further modifications of the parametrisation.
At large z, it is sufficient to explicitly enforce the constraint that \(D_i^h(z,Q_0)\) vanishes in the limit \(z\rightarrow 1\) by subtracting the term \(\mathrm{NN}_i(1)\) in Eq. (4.2). Indeed, in the case of FFs, the large-z extrapolation region is significantly reduced as compared to the PDF case. Data from the B-factory and LEP/SLD experiments ensure a kinematic coverage up to the large-z kinematic cut \(z_\mathrm{max}=0.9\) for all hadronic species (see Fig. 1).
At small z instead, the available experimental information becomes more sparse as the lower kinematic cut \(z_\mathrm{min}=0.02\) (\(z_\mathrm{min}=0.075\)) at \(\sqrt{s}=M_Z\) (\(\sqrt{s}<M_Z\)) is approached. Therefore, without the preprocessing function, the behaviour of the FFs in the small-z extrapolation region will exhibit a significant dependence on the choice of the activation function g in Eq. (4.3). For instance, if g is chosen to be the sigmoid function, \(g(x)=\left[ 1+\exp (-x)\right] ^{-1}\), as usual in NNPDF fits, all FF replicas freeze out to a constant in a region close and below \(z_\mathrm{min}\). Such a behaviour is clearly unphysical, thus it should be avoided.
In order to overcome this issue, an activation function that preserves the features of the sigmoid in the data region and avoids its limitations in the extrapolation region should be adopted. Specifically, we choose g as
Like the sigmoid, the function in Eq. (4.4) exhibits two different regimes: it is linear for values of a close to zero and becomes nonlinear for values of a far from zero. In contrast with the sigmoid, the function in Eq. (4.4) does not saturate asymptotically to zero (one) for large negative (positive) values of a. This feature prevents FFs from freezing out to a constant for values of z close and below the low-z cut \(z_\mathrm{min}\). We have explicitly verified that the choice of activation function does not affect the behaviour of the fitted FFs in the kinematic region covered by data.
An important theoretical requirement on FFs is that they must satisfy positivity, i.e. any physical cross-section computed from them must be positive. At LO, this simply implies that FFs are positive definite. Beyond LO FFs do not need to be positive definite, and positivity could be imposed for instance by requiring a set of at least as many independent observables as the parametrised FFs to be positive. However, for simplicity, here we impose positivity by requiring that FFs are positive definite at all orders, as it is customarily assumed in all other analyses of FFs. This is achieved by squaring the output of Eq. (4.2). We have explicitly checked that this choice does not bias our determination, in that the differences with a fit in which positivity is not imposed at all are negligible. This suggests that the quality of the dataset included in our analysis is good enough to ensure the positivity of FFs for most of the relevant kinematics.
Finally, we should mention that the initial parametrisation scale in Eq. (4.2) is \(Q_0=5\) GeV. This value is both above the bottom-quark threshold (\(m_b=4.92\) GeV) and below the lowest center-of-mass energy of the data included in the fits (\(\sqrt{s}=10.52\) GeV). This choice is advantageous for two reasons. First, it implies that no heavy-quark thresholds have to be crossed in the evolution between the initial scale and the scale of the data. Therefore, the number of active flavours is always \(n_f=5\) and no matching is required. This is advantageous because time-like matching conditions are currently known only up to NLO [95]. Second, in a VFN scheme, our choice implies that charm- and bottom-quark FFs are parametrised on the same footing as the light-quark and gluon FFs. This is beneficial because heavy-quark FFs receive large non-perturbative contributions. Indeed, perturbatively generated heavy-quark FFs lead to a poor description of the data, in particular of heavy-quark tagged data.
4.2 Optimisation of neural network parameters
The determination of neural network parameters in a fit of FFs to experimental data is a fairly involved optimisation problem. In our analysis, it requires the minimisation of the \(\chi ^2\) estimator
where i and j run over the number of experimental data points \(N_\mathrm{dat}\), \(D_i\) are their measured central values, \(T_i\) are the corresponding theoretical predictions computed with a given set of FFs f, and \(C_{ij}^{t_0}\) is the \(t_0\) covariance matrix discussed in Sect. 2.1.
In most situations where neural networks are applied, optimisation is performed by means of some variation of simple gradient descent. In order to optimise the model parameters in this way, it is necessary to be able to straightforwardly compute the gradient of \(\chi ^2\) with respect to model parameters,
Computing these gradients in the case of PDF or FF fits is complicated by the non-trivial relationship between PDFs/FFs and physical observables.
In previous NNPDF analyses of PDFs, minimisation was performed by means of a simple example of a genetic algorithm. At each iteration of the fit, variations (or mutants) of PDFs are generated by random adjustment of the previous best-fit neural-network parameters. The mutant PDF parameters with the lowest \(\chi ^2\) to data are then selected as the best-fit for the next iteration. Such a procedure is blind to the higher-order structure of the problem in parameter space and does not require the computation of the gradients in Eq. (4.6). The most prominent drawback of such a procedure is that it is considerably less efficient than standard gradient descent. Furthermore, while this basic procedure is adequate in the case of PDF fits to a global dataset, it can be sensitive to the noise in the \(\chi ^2\) driven by noisy experimental data.
In the present fit of FFs, the dataset is much more limited than in typical global PDF fits. It is therefore worth considering alternative minimisation strategies that may be less sensitive to such effects. There are a great deal of strategies available in the literature for the optimisation of problems where standard gradient descent methods are difficult or impossible to apply. One such strategy, the Covariance Matrix Adaption-Evolutionary Strategy (CMA-ES) family of algorithms [96, 97], finds regular application in this context.
In this analysis we apply a standard variant of the CMA-ES procedure for the minimisation of the neural network parameters. While we leave the details and the specification of algorithm parameters to Ref. [97], we will outline the procedure schematically here. We denote the set of fit parameters \(\{\omega _{ij}^{(l)},\theta _i^{(l)}\}\) as a single vector \(\mathbf {a}^{(i)}\). In all relevant quantities described here, the superscript i indicates the values at the \(i^{th}\) iteration of the algorithm. The fit parameters are initialised at the start of the fit according to a multi-Gaussian distribution \(\mathcal {N}\) with zero mean and unit covariance
where we use \(\sim \) to denote the distribution of the random vector. This vector is then used as the centre of a search distribution in parameter space. At every iteration of the algorithm, \(\lambda =80\) mutants \(\mathbf {x}_1, \ldots , \mathbf {x}_\lambda \) of the parameters are generated as
that is, mutants are generated around the search centre according to a multi-Gaussian \(\mathcal {N}\) with covariance \(\mathbf {C}^{(i)}\) and according to a step-size \(\sigma ^{(i)}\) initialised as \(\sigma ^{(0)}=0.1\). The mutants are then sorted according to their fitness such that \(\chi ^2(\mathbf {x}_k) < \chi ^2(\mathbf {x}_{k+1})\) and the new search centre is computed as a weighted average over the \(\mu =\lambda /2\) best mutants
where the weights \(\{w_k\}\) are internal parameters of the CMA-ES algorithm.
A key feature of the CMA-ES algorithms is that both the step size \(\sigma ^{(i)}\) and the search distribution covariance matrix \(\mathbf {C}^{(i)}\) are optimised by the fit procedure. To this purpose, the information present in the ensemble of mutants is used to learn preferred directions in parameter space without the need for the explicit computation of gradients. This adaptive behaviour improves the efficiency of the minimisation procedure in comparison to the genetic algorithm adopted in all previous NNPDF fits. Also, we implement a non-elitist version of the CMA-ES, whereby each iteration’s best fit is computed by means of weighted average over some number of mutants. In contrast an elitist selection would take only the best mutant from each iteration. In this way the effect of the noise induced in the \(\chi ^2\) by a relatively small dataset should be reduced.
The procedure outlined in Eqs. (4.8)–(4.9) is iterated until the optimal fit is achieved. As in previous NNPDF analyses, the stopping point is determined by means of a cross-validation method [32], based on the separation of the whole dataset into two subsets: a training set and a validation set. Equal training and validation data fractions are chosen for each experimental dataset, except for those datasets with less than 10 data points. In this case, 80% of the data are included in the training set and the remaining 20% in the validation set. The \(\chi ^2\) of the training set is then minimised while the \(\chi ^2\) of the validation set is monitored. The best-fit configuration is determined according to the look-back criterion [38], according to which the stopping point is identified as the absolute minimum of the validation \(\chi ^2\) within a maximum number of generations, \(N_\mathrm{gen}^\mathrm{max}\). Here we take \(N_\mathrm{gen}^\mathrm{max}=4\times 10^4\). This value is large enough to guarantee that the best-fit FFs do not depend on it.
Finally, as in the NNPDF3.0 [38] and NNPDF3.1 [39] PDF fits, an a posteriori selection on the resulting sample of Monte Carlo replicas is performed for each fit. Specifically, replicas whose \(\chi ^2\) is more than four-sigma away from its average value are discarded and replaced by other replicas which instead satisfy this condition. This ensures that outliers, which might be present in the Monte Carlo ensemble due to residual inefficiencies of the minimisation procedure, are removed.
4.3 Closure testing fragmentation functions
The determination of FFs through a fit to experimental data is a procedure that necessarily implies a number of assumptions, mostly concerning their parametrisation and the propagation of the experimental uncertainties into them. Therefore it is crucial to systematically validate the fitting methodology in order to avoid any procedural bias that could limit the reliability of the fitted quantities.
As discussed in Ref. [38], the robustness of the fitting procedure used in a global QCD analysis can be assessed by means of closure tests. The basic idea of a closure test is to perform a fit of FFs to a set of pseudo-data generated using theoretical predictions obtained with a pre-existing set of FFs as an input. In such a scenario, the underlying physical behaviour of the FFs is known by construction. Therefore, it is possible to assess the reliability of the fitting methodology by comparing the distributions obtained from the fit to those used as an input. We refer the reader to Ref. [38] for a thorough description of the various levels of closure tests and of the statistical estimators designed to validate different aspects of the fitting methodology. Here we focus on two types of closure tests.
-
Level 0 (L0). Pseudo-data in one-to-one correspondence with the data discussed in Sect. 2.1 are generated using the theoretical predictions obtained with a given set of FFs; no random noise is added at this level. Then \(N_\mathrm{rep}\) fits, each to exactly the same set of pseudo-data, are performed. In order to take into account correlations, the error function that is minimised (i.e. the \(\chi ^2\) evaluated for each replica) is still computed using the covariance matrix of the real data, even though the pseudo-data have zero uncertainty.
In a L0 closure test, provided a sufficiently flexible parametrisation and a sufficiently efficient minimisation algorithm, the fit quality can become arbitrarily good. The \(\chi ^2\) should decrease to arbitrarily small values, and the resulting FFs should coincide with the input ones in the kinematic region covered by the pseudo-data.
-
Level 2 (L2). Exactly as in the case of the fits to real data, \(N_\mathrm{rep}\) Monte Carlo replicas of the data are generated applying the standard NNPDF procedure. The only difference is that the central values of the single measurements are replaced by the respective theoretical predictions obtained using the input FFs. Then a set of FFs is fitted to each replica.
In a L2 closure test, the final \(\chi ^2\) should be close to unity, provided that the fitted procedure correctly propagates the fluctuations of the pseudo-data, due to experimental statistical, systematic, and normalisation uncertainties, into the FFs. In the kinematic region covered by the data, the input FFs should fall inside the one-\(\sigma \) band of their fitted counterparts with a probability of around 68%.
In summary, the goal of a L0 closure test is to assess whether the fitting methodology, including the parametrisation form and the minimisation algorithm, is such to avoid any procedural bias. The goal of a L2 closure test, instead, is to verify whether the fitting methodology allows for a faithful propagation of the data uncertainties into the FFs.

Comparison between the central value of the charged pion HKNS07 FFs [62] (red dashed line) and the corresponding FFs obtained from the L0 (blue bands) and L2 (green bands) closure tests. The five panels show the \(D_g^{\pi ^\pm }\), \(D_{u^+}^{\pi ^\pm }\), \(D_{d^++s^+}^{\pi ^\pm }\), \(D_{c^+}^{\pi ^\pm }\), and \(D_{b^+}^{\pi ^\pm }\) FFs at \(Q=5\) GeV, in the z range which roughly matches the kinematic coverage of the fitted data. Shaded bands indicate their one-\(\sigma \) uncertainties. The central (lower) inset show the ratio of the L0 (L2) FFs to the HKNS07 FFs
Here we present results for the L0 and L2 closure tests applied to the determination of the charged pion FFs at NLO. We use as input FFs the central distributions of the HKNS07 set [62]. We have also verified that closure tests are successful for all the hadronic species considered in the NNFF1.0 analysis, when either the HKNS07 or the DSS07 sets [61, 98] at LO or NLO are used as an input.
The value of the total \(\chi ^2/N_\mathrm{dat}\) resulting from the L0 and L2 closure tests is displayed in Table 2. In Fig. 3 we compare the input FFs from the HKNS07 set and the corresponding fitted FFs from the L0 and L2 closure tests. The comparison is shown for the five combinations of FFs parametrised in our analysis, see Eq. (4.1), at the input scale \(Q = 5\) GeV, and in a range of z which roughly corresponds to the kinematic coverage of the data included in the fits. The upper panel of the plots in Fig. 3 displays the absolute distributions, while the central and the lower panels show the ratio of the L0 and L2 FFs to the input HKNS07 FFs, respectively. The shaded bands for the L0 and L2 distributions indicate the one-\(\sigma \) FF uncertainty.
From Table 2, as expected, the \(\chi ^2/N_\mathrm{dat}\) is close to zero for the L0 closure test and close to one for the L2 closure test. These results indicate that our fitting methodology is adequate to reproduce the input FFs without introducing any significant procedural bias.
From Fig. 3, it is evident that the FFs of the L0 closure test are almost identical to the input HKNS07 FFs all over the range in z, hence the \(\chi ^2\) close to zero. However, we also observe a spread of the uncertainty bands in the very large-z region. This is due to the upper kinematic cut (\(z_\mathrm{max} = 0.9\)) imposed on the fitted dataset, such that distributions at large values of z remain unconstrained. This effect is more enhanced for the gluon, due to the reduced sensitivity of the data included in the fit to this distribution and to the smallness of its input FF in that region. Analogously, in the small-z region, where the data included in the fit are rather sparse, the fitted FFs display an increase of the uncertainties. This confirms that the fitting methodology used here can faithfully reproduce the input FFs in the region where the data are sufficiently constraining.
From Fig. 3, it is also apparent that the fitted FFs in the L2 closure test are in good agreement with the input FFs within their uncertainties, hence the \(\chi ^2\) close to one. This indicates that our fitting methodology correctly propagates the experimental uncertainty of the data into the uncertainties of the fitted FFs. As in the case of the L0 closure test, we note that the uncertainty bands of the FFs in the large- and small-z regions inflate.
In the light of the results of the L0 and L2 closure tests, we conclude that the fitting methodology adopted here for the determination of FFs is suitable to ensure a negligible procedural bias and a faithful representation of their uncertainties.
5 The NNFF1.0 fragmentation functions
In this section we present the main results of this work, namely the NNFF1.0 sets of FFs for charged pions, charged kaons, and protons/antiprotons at LO, NLO, and NNLO. First we discuss the quality of the fits and compare the NNFF1.0 predictions to the fitted dataset. Then we show the resulting FFs and their uncertainties, focusing on their perturbative convergence upon inclusion of higher-order QCD corrections, on a comparison of the NLO pion and kaon FFs with their counterparts in the DEHSS and JAM analyses, and on the momentum sum rule.
5.1 Fit quality and data/theory comparison
In Table 3 we report the values of the \(\chi ^2\) per data point, \(\chi ^2/N_\mathrm{dat}\), for both the individual and the total datasets included in the NNFF1.0 analysis. The values are shown at LO, NLO, and NNLO for all the hadronic species.
Concerning the fit quality of the total dataset, the most noticeable feature is the sizeable improvement upon inclusion of higher-order corrections. The improvement of the total \(\chi ^2/N_\mathrm{dat}\) is particularly pronounced when going from LO to NLO, and more moderate, but still significant, when going from NLO to NNLO. This demonstrates that the inclusion of the NNLO corrections improves the description of the data. This effect is particularly evident for the charged pion fits, which are based on the most abundant and accurate dataset.

Comparison between the dataset for charged pions, charged kaons, and protons/antiprotons from the BELLE and BABAR experiments and the corresponding NNLO theoretical predictions using our best-fit NNLO FFs. We show both the absolute distributions (left and central panel) and the data/theory ratios (right panel). Shaded areas indicate the kinematic regions excluded by our cuts, and the bands correspond to one-\(\sigma \) FF uncertainties
Concerning the fit quality of the individual experiments, the general trend of the \(\chi ^2/N_\mathrm{dat}\) is the same as that of the total \(\chi ^2/N_\mathrm{dat}\), with two main exceptions. First, the \(\chi ^2/N_\mathrm{dat}\) value for charged kaons and protons/antiprotons data in the BELLE experiment, despite remaining good, increases as higher-order QCD corrections are included. Such an increase is accompanied by a decrease of the \(\chi ^2/N_\mathrm{dat}\) value in the BABAR experiment. Since the kinematic coverage of these two experiments largely overlaps, and given the precision of the corresponding measurements, the opposite trend of the \(\chi ^2/N_\mathrm{dat}\) suggests a possible tension between the two. Such a tension was already reported in Ref. [19], although its origin is still not completely understood. Second, the \(\chi ^2/N_\mathrm{dat}\) value for inclusive and light-tagged charged pion data in the DELPHI experiment deteriorates as higher-order QCD corrections are included. This behaviour indicates a possible tension between the DELPHI measurements and the other datasets at the same scale (\(\sqrt{s}=M_Z\)), whose description instead significantly improves when going from LO to NNLO. The origin of such a tension arises mostly from the large-z region, where the DELPHI inclusive and light-tagged measurements for charged pions are undershot by the theoretical predictions.
From Table 3 we also observe that in all our fits the \(\chi ^2/N_\mathrm{dat}\) value for the BELLE experiment is anomalously small. This result was already observed in previous analyses [17,18,19,20] and is likely to be due to an overestimate of the uncorrelated systematic uncertainty.
We also notice that for some datasets the \(\chi ^2/N_\mathrm{dat}\) is poor even at NNLO: this happens specifically for the TASSO14, TASSO22, TASSO44 and OPAL experiments in the case of charged pions, for the TASSO14, TASSO22, and OPAL experiments in the case of charged kaons, and for the BABAR experiment in the case of protons/antiprotons. As we will show below, the experimental data points for the TASSO datasets fluctuate around the theoretical predictions by an amount that is typically larger than their uncertainties. This explains the poor \(\chi ^2/N_\mathrm{dat}\) values reported in Table 3 at all perturbative orders. For charged kaons and pions, the large \(\chi ^2/N_\mathrm{dat}\) associated to the OPAL data comes from the large-z region, where theoretical predictions overshoot the data. For charged protons/antiprotons, the large \(\chi ^2/N_\mathrm{dat}\) of the BABAR experiment is driven by a genuine tension between BABAR and TPC/TASSO34 data below \(z=0.2\). Indeed, if the TPC and TASSO34 data are removed from the fits, the value of the \(\chi ^2/N_\mathrm{dat}\) for the BABAR experiment improves significantly (see Sect. 6.2).
In order to give further weight to these considerations, we present a comparison of the dataset used in this analysis to the corresponding NNLO theoretical predictions obtained using the NNLO FFs from our fits. In Fig. 4 such a comparison is displayed for the BELLE and BABAR data for charged pions, charged kaons, and protons/antiprotons. The plots on the r.h.s. of Fig. 4 display the corresponding data/theory ratios. The uncertainty bands indicate the one-\(\sigma \) FF uncertainty, while the shaded areas represent the regions excluded by kinematic cuts (see Sect. 2.2). In Fig. 5 we show the same comparison as in Fig. 4 for all the inclusive measurements at \(\sqrt{s}=M_Z\). To complete the picture, we display the data/theory ratios for all the remaining datasets: in Fig. 6 for charged pions, in Fig. 7 for charged kaons, and in Fig. 8 for protons/antiprotons.

Same as Fig. 4 for the ALEPH, DELPHI, OPAL and SLD inclusive measurements

The data/theory ratio for the charged pion data included in the NNFF1.0 fit and not accounted for in Figs. 4 and 5. As before, theoretical predictions are computed at NNLO with our best-fit NNLO FFs, shaded areas indicate the regions excluded by kinematic cuts, and the bands correspond to one-\(\sigma \) FF uncertainties

Same as Fig. 6 but for charged kaons

Same as Fig. 6 but for protons/antiprotons, \(p/\bar{p}\)
In general, an overall good agreement between data and theoretical predictions is achieved for all experiments, consistently with the \(\chi ^2/N_\mathrm{dat}\) values reported in Table 3. Remarkably, theoretical predictions and data are in reasonable agreement also in the small- and large-z extrapolation regions excluded by kinematic cuts, although the uncertainties of the predictions inflate in these regions.
A few remarks concerning the individual datasets are in order. A significant deviation from the theoretical predictions is observed for the low-z proton/antiproton measurements from the BABAR experiment. This is the origin of the large \(\chi ^2\) reported in Table 3. As already mentioned and as we will further demonstrate in Sect. 6.2, this is a consequence of the tension between the BABAR and TPC/TASSO34 measurements. We have explicitly verified that the low-z BABAR data can be satisfactorily described if the TPC and TASSO34 datasets are removed from the fit. However, we have chosen to keep these two experiments in our baseline dataset because FFs turn out to be very stable irrespective of their inclusion (see Sect. 6.2).
The BABAR measurements for pions and kaons tend to be overshot by the NNLO theoretical predictions at large z. This is not the case for the BELLE data that cover a similar large-z region and are fairly described by the predictions. This points to a tension between the BELLE and BABAR measurements in that region. We also note that, as compared to pions and kaons, the BELLE and BABAR proton/antiproton measurements are affected by larger experimental uncertainties, especially at \(z\gtrsim 0.6\). This consistently propagates into larger uncertainty bands for the corresponding predictions.
In the case of the DELPHI experiment, theoretical predictions undershoot the data for charged pions at \(z\gtrsim 0.3\). This is the reason of the large \(\chi ^2/N_\mathrm{dat}\) value reported in Table 3 for this experiment. The tension between DELPHI and the other experiments at the same value of \(\sqrt{s}\) (ALEPH, OPAL, and SLD), which are instead well described by our FFs, is apparent from Fig. 5.
Some of the observations made in this section on possible tensions between different experiments in certain kinematic regions will be quantified in Sect. 6.2, where a thorough study of the stability of our fits upon variations of the dataset will be presented.
5.2 Fragmentation functions
We now turn to discuss the NNFF1.0 sets. In order to study the perturbative convergence of the FFs upon inclusion of higher-order QCD corrections, we first compare our LO, NLO, and NNLO determinations among each other. Then we compare our best-fit NLO pion and kaon FFs to their counterparts in the DEHSS and JAM analyses. Finally, we conclude with a comment on the momentum sum rule.
5.2.1 Perturbative stability
We display the five FF combinations parametrised in our fits, Eq. (4.1), and their one-\(\sigma \) uncertainties in Figs. 9, 10, and 11 for charged pions, charged kaons and protons/antiprotons, respectively. For each hadronic species, the FFs are shown at LO, NLO, and NNLO as functions of z at \(Q=10\) GeV. The upper panel of each plot displays the absolute distributions, while the central and the lower panels display the NLO/LO and NNLO/NLO ratios.

Comparison among the LO, NLO, and NNLO NNFF1.0 charged pion FFs, together with their one-\(\sigma \) uncertainties, in the parametrisation basis of Eq. (4.1) at \(Q=10\) GeV. The corresponding NLO/LO and NNLO/NLO ratios are displayed in the two insets below each FF

Same as Fig. 9 but for the sum of charged kaons, \(K^\pm \)

Same as Fig. 9 but for the sum of protons and antiprotons, \(p/\bar{p}\)
A remarkable feature of the distributions shown in Figs. 9, 10 and 11 is their perturbative convergence. While LO and NLO distributions can in some cases differ by more than one standard deviation (see for example \(D_{u^+}^h\) for the three hadronic species in the medium-/large-z region), the differences between NLO and NNLO FFs are small. This is consistent with the perturbative convergence of the global \(\chi ^2\) discussed in Sect. 5.1.

Comparison among the NLO NNFF1.0, DEHSS and JAM FF sets for the sum of charged pions, \(\pi ^\pm \). The FFs in the parametrisation basis, Eq. (4.1), are shown at \(Q=10\) GeV as a function of z, together with their corresponding one-\(\sigma \) uncertainties. The ratios of NNFF1.0 to DEHSS and JAM are displayed, respectively, in the two insets below each FF

Same as Fig. 12, but for the sum of charged kaons, \(K^\pm \)
A further noticeable aspect of the comparison in Figs. 9, 10 and 11 is related to the size of the FF uncertainties. While the NLO and NNLO uncertainties are similar in size, the LO uncertainty bands are in general visibly larger, particularly those of the gluon FFs. This was expected because LO predictions for SIA data are only indirectly sensitive to the gluon FF through DGLAP evolution. This entails a broadening of the uncertainties of all FFs due to the cross-talk induced by DGLAP evolution.
5.2.2 Comparison with other FF sets
We now compare our FFs to the most recent determinations available in the literature, namely the DEHSS [17, 18] and the JAM [20] sets. The HKKS sets [19] mentioned in Sect. 2.1 were also recently presented but were not intended to be publicly released [99]. Since these analyses were performed only for pions and kaons at NLO, we limit the comparison to these hadronic species and this perturbative order. Such a comparison is shown in Figs. 12 and 13 at \(Q=10\) GeV in the basis of Eq. (4.1). The upper panel of each plot shows the absolute distributions, while the central and the lower insets show the ratio to NNFF1.0 of DEHSS and JAM, respectively. Note that the JAM FFs are not extrapolated below the lowest kinematic cut used in their fits (\(z=0.05\)), hence the truncated curves in Figs. 12 and 13.
Concerning the shapes of the FFs, a number of interesting differences between the three sets can be seen from the comparisons in Figs. 12 and 13.
For the charged pion FFs, the NNFF1.0 and DEHSS results are in fairly good agreement, despite differences in the dataset (see Sect. 2.1). Moderate differences are observed only for \(D_{u^+}^{\pi ^\pm }\) at \(0.2\lesssim z \lesssim 0.5\), for \(D_{u^+}^{\pi ^\pm }\) and \(D_{c^+}^{\pi ^\pm }\) below \(z\sim 0.1\), and for all quark combinations of FFs above \(z\sim 0.7\). A more pronounced difference in shape is observed for the gluon FF, \(D_g^{\pi ^\pm }\), for which the NNFF1.0 distribution is more suppressed at large z. However, the two sets still agree at the one-\(\sigma \) level. The NNFF1.0 and JAM results are also in fair agreement, except for \(D_{d^++s^+}^{\pi ^\pm }\) above \(z\sim 0.1\) and for \(D_g^{\pi ^\pm }\) around \(z\sim 0.2\), where the discrepancy exceeds two standard deviations. Again, the gluon FF from NNFF1.0 is more suppressed at large z than that from JAM. Differences are also seen for all quark FF combinations at large z, although they are always compatible within uncertainties.
For charged kaons, the differences in shape among the three FF sets are more marked than in the case of charged pions. A fair agreement is observed only in the case of \(D_{b^+}^{K^\pm }\). The discrepancies are typically within a couple of standard deviations for the \(D_{d^++s^+}^{K^\pm }\) and \(D_g^{K^\pm }\) and more than three/four standard deviations for \(D_{u^+}^{K^\pm }\) and \(D_{c^+}^{K^\pm }\).
The origin of the differences among the three sets, at low z for most of the quark FFs and over the whole z range for the gluon FF, is likely to be mostly due to the hadron-mass corrections. These are included in NNFF1.0 but not in the other two sets. Using a more conservative small-z cut in the NNFF1.0 analysis, similar to that adopted in the DEHSS and JAM analyses, can exclude the region where hadron-mass corrections are sizeable (see Fig. 2). If a fit is performed with such a conservative cut, most of the differences among the three FF sets are reconciled, as we will explicitly show in Sect. 6.1. The differences at large z might arise from our choice of the kinematic cut too. Indeed, we exclude all data above \(z=0.9\), which are instead retained in the DEHSS and JAM analyses.
Concerning the FF uncertainties, we observe that for the quark distributions the three FF sets are in good agreement in the region covered by the common data, roughly \(0.1\lesssim z \lesssim 0.7\). Conversely, in the regions where a different amount of experimental information is included or where such information is more sparse, differences are more significant. Typically, the uncertainties of the NNFF1.0 FFs are larger than those of their DEHSS and JAM counterparts at small and large values of z, where data are less abundant or even absent. Exceptions to this trend are the uncertainties of the \(D_{c^+}^{K^\pm }\) and \(D_{b^+}^{K^\pm }\) DEHSS distributions below \(z\sim 0.1\). They are larger than the NNFF1.0 ones, again because of their more conservative small-z cuts.
The uncertainty of the gluon FFs, for both pions and kaons, deserves a separate comment. As already mentioned, SIA cross-sections are directly sensitive to the gluon FF only beyond LO. As a consequence, one would expect that the gluon FF is determined with larger uncertainties than the quark FFs. This is clearly shown in Figs. 12 and 13 for the NNFF1.0 sets. The gluon FFs of the DEHSS and JAM sets, instead, have uncertainties comparable to those of the quark FFs. While the smaller uncertainties of the DEHSS gluon FFs may be due to the larger dataset used in their analysis (which also includes pp measurements sensitive to the gluon FF already at LO), this is not the case for the JAM sets, whose dataset mostly coincides with that of NNFF1.0 (see Sect. 2.1). We ascribe this difference to the more restrictive functional form used in the JAM analysis to parametrise their FFs. An underestimate of the gluon FF uncertainty due to the functional form might also affect the DEHSS determinations.
5.2.3 The momentum sum rule
We conclude this section with a brief discussion of the momentum sum rule
which must be satisfied by FFs irrespective of the value of Q. Note that the sum in Eq. (5.1) runs over all possible hadrons h produced in the fragmentation of the parton i, not only over those determined in the present analysis. The physical interpretation of Eq. (5.1) is very simple: it ensures that the momentum carried by all hadrons produced in the fragmentation of a given parton i is the same as that carried by the parton itself. If Eq. (5.1) is true at some scale Q, it must remain true at all scales. This is guaranteed by DGLAP evolution as a direct consequence of the energy conservation.
In principle Eq. (5.1) could be used in a fit to constrain simultaneously the behaviour of the FFs for different hadrons, especially in the small-z region where no experimental information is available. In practice we determine the FFs of pions, kaons, and protons/antiprotons separately and we do not impose the momentum sum rule. The momentum sum rule cannot be enforced in our fits for two reasons. First, it requires the knowledge of the FFs of all hadronic species h, while we consider only a subset of them. Second, it requires one to integrate FFs down to \(z=0\), while our FFs are determined only down to \(z=10^{-2}\).
This said, Eq. (5.1) can still be used as an a posteriori check of the consistency of the fitted FFs. In particular, one expects that
with \(z_\mathrm{min}=10^{-2}\). Since the lower bound of the integral in Eq. (5.2) is not zero, the quantity \(M_i\) depends on Q. We have computed the central value and the uncertainty of \(M_i\) for the gluon FFs (\(i=g\)) using the NNLO NNFF1.0 FF sets for three different values of Q, obtaining
The uncertainties from each hadronic species have been added in quadrature. Remarkably, we find that Eq. (5.2) is fulfilled in the range of energies covered by the data included in the fits.
We cannot unambiguously check Eq. (5.2) for the individual quark and antiquark FFs, unless some ad hoc assumptions are imposed to separate them from the fitted FF combinations in Eq. (4.1). Nevertheless, we can check a modified, less restrictive, version of Eq. (5.2)
where \(N=2\) for \(i=u^+,c^+,b^+\) and \(N=4\) for \(i=d^++s^+\). We have verified that also Eq. (5.4) is satisfied by the NNFF1.0 FFs. For instance, at \(Q=5\) GeV we find
in agreement with the expectations.
6 Fit stability
In this section we study the stability of the results presented in Sects. 5.1 and 5.2 upon variations of the small-z kinematic cuts and of the dataset defined in Sect. 2.1.
6.1 Dependence on the small-z kinematic cuts
We first study the dependence of our results upon the small-z kinematic cuts applied to the data included in the NNFF1.0 fits. Our aim is to assess the interplay between higher-order QCD corrections and the description of small-z data, in order to motivate the choice of kinematic cuts made in Sect. 2.2. To this purpose, we perform some additional fits, all to the same baseline dataset described in Sect. 2.1 but with different small-z cuts. For each value of the kinematic cut, the additional fits are performed at LO, NLO, and NNLO.
The various small-z kinematic cuts considered here are summarised in Table 4, together with our baseline choice (denoted as BL henceforth). For each hadronic species we consider the two limiting cases in which the small-z kinematic cuts are either completely removed or set to conservative values. The latter are defined in such a way that only data in the kinematic region where both hadron-mass and NNLO QCD corrections are expected to be negligible are included in the fit. Conservative cuts are similar to those adopted in other analyses of FFs. Additional choices of small-z kinematic cuts between the two cases above are also investigated. As the data for charged pions extend down to smaller values of z than data for charged kaons and protons/antiprotons, a more dense scanning is adopted in the first case.

The values of \(\chi ^2/N_\mathrm{dat}\) for each fit to \(\pi ^\pm \) data with the choices of small-z kinematic cuts summarised in Table 4, at LO, NLO, and NNLO

Same as Fig. 14, but for \(K^\pm \)

Same as Fig. 14, but for \(p/\bar{p}\)
In Figs. 14, 15 and 16 we show the values of \(\chi ^2/N_\mathrm{dat}\) for the LO, NLO, and NNLO fits of charged pions, charged kaons, and protons/antiprotons FFs performed with the kinematic cuts in Table 4. Inspection of the \(\chi ^2/N_\mathrm{dat}\) values for the total dataset in Figs. 14, 15 and 16 allows us to draw three remarks.
First, there is clear evidence of perturbative convergence: irrespective of the specific choice of the small-z cuts, the \(\chi ^2/N_\mathrm{dat}\) values at NNLO are always lower than at NLO, which are in turn always lower than at LO.
Second, the spread of the \(\chi ^2/N_\mathrm{dat}\) values for different cuts at a fixed perturbative order is reduced as the perturbative order is increased. The value of the \(\chi ^2/N_\mathrm{dat}\) for the less restrictive cuts moves closer to the corresponding value for the conservative cuts. This confirms that the inclusion of higher-order QCD corrections significantly improves the description of the data at small z and that the results become accordingly less dependent on the choice of small-z cuts. These results are consistent with what was reported in Ref. [26] where, at least for charged pions, it was found that a fixed-order NNLO fit is able to describe data down to \(z_\mathrm{min}=0.02\) with the same accuracy as a small-z resummed NNLO+NNLL fit.
Third, at any perturbative order, the \(\chi ^2/N_\mathrm{dat}\) of the fit with baseline kinematic cuts is always very close to the lowest \(\chi ^2/N_\mathrm{dat}\), usually associated to the fit with conservative cuts. The only exception is the proton/antiproton case, where the fit with the baseline cuts has a \(\chi ^2/N_\mathrm{dat}\) significantly larger than the fit with conservative cuts. This behaviour is mostly driven by the high value of the \(\chi ^2/N_\mathrm{dat}\) for the BABAR data. However, as already mentioned in Sect. 5.1, this is due to a genuine tension between the BABAR and TPC/TASSO34 data below \(z=0.2\). This will be explicitly demonstrated in Sect. 6.2 by studying fits to reduced datasets.
Similar conclusions as those for the total dataset can be drawn for the individual datasets, based on Figs. 14, 15 and 16. However, the baseline cuts do not always minimise the \(\chi ^2/N_\mathrm{dat}\) of the individual experiments, especially of those with a limited number of data points. This is a feature of any global analysis, where the total \(\chi ^2\) always represents a compromise among the different pulls from individual experiments.
In order to gauge the impact of the different choices of small-z kinematic cuts on FFs, in Figs. 17, 18 and 19 we compare the NNLO results from the two extreme choices (no kinematic cuts and conservative cuts) with those from the baseline fit. By comparing the fit with no cuts to the baseline results, one can infer by how much uncertainties would decrease if the small-z data excluded by the baseline cuts were included. This is relevant in view of a possible fit with small-z resummation, which is expected to provide a better description of the small-z data below our baseline choice of \(z_\mathrm{min}\).

Comparison among the NNLO charged pion FFs at \(Q=10\) GeV for three different small-z kinematic cuts: baseline, conservative cuts, and no cuts (see Table 4). The two insets below each distribution show the ratios of the fits with conservative cuts and without cuts to the baseline fit

Same as Fig. 17, but for the sum of charged kaons, \(K^\pm \)

Same as Fig. 17, but for the sum of protons and antiprotons, \(p/\bar{p}\)
We find that varying the small-z kinematic cuts does not affect the FFs for any hadronic species in the region above \(z=0.1\). Conversely, significant differences in shape emerge at small z, where the typical effect of the data is to suppress FFs. This behaviour is observed for all FFs and all hadronic species, particularly when moving from the conservative to the baseline cuts. The effect is milder, especially for protons/antiprotons, when the cuts are completely removed because the amount of the additional data included in this case is more limited.
Importantly, the gluon FFs for charged pions and kaons are particularly affected by the choice of the small-z cuts. In the fit with conservative cuts the shape of the gluon FFs becomes similar to that of their counterparts in the JAM and DEHSS sets, and they are always compatible with them within uncertainties. This is not unexpected because our conservative cuts are similar to those adopted in these analyses.
Concerning the FF uncertainties in the small-z region, they decrease approximately by a factor two for charged pions and kaons when moving from the conservative to the baseline cuts, while they remain almost unchanged for protons/antiprotons. They decrease by a further factor of two for charged pions and kaons in comparison to the baseline when cuts are removed, while they remain mostly unchanged for protons/antiprotons. This reduction highlights the importance of including small-z data to tame the FF uncertainties in the small-z region, provided that the theoretical calculations used are accurate enough to describe the corresponding measurements.
6.2 Dependence on the fitted dataset
We now study the dependence of the NNFF1.0 NNLO FFs upon two variations of the fitted dataset. In comparison to the baseline dataset listed in Table 1, we consider first a dataset from which the BELLE and BABAR experiments are removed, and second a dataset in which only the BELLE, BABAR, ALEPH, DELPHI, OPAL, and SLD experiments are retained. The first dataset is denoted as noBB, the second dataset is denoted as BBMZ.
For each hadronic species, we perform an additional NNLO fit to each of these reduced datasets. All fit settings, including the kinematic cuts, are identical to the baseline fits. With the first fit we intend to assess the impact on the light-quark FF flavour separation and on the gluon FF of the B-factory data, the most recent and precise piece of experimental information. The motivation for the second fit is instead to assess the impact on the FFs and their uncertainties of the older and less accurate SIA measurements.
In Table 5 we show the values of \(\chi ^2/N_\mathrm{dat}\) for the fits to the noBB and BBMZ datasets. For ease of comparison, we also report the \(\chi ^2/N_\mathrm{dat}\) values for the fit to the baseline dataset (denoted as BL) from Table 3. The numbers in squared brackets refer to the experiments not included in the corresponding fits. We display the resulting FFs at \(Q=10\) GeV in Fig. 20 for charged pions, in Fig. 21 for charged kaons, and in Fig. 22 for protons/antiprotons.

Comparison among the NNFF1.0 NNLO FFs for charged pions for three variations of the fitted dataset: BL, noBB and BBMZ (see the text for details). The bands indicate their one-\(\sigma \) uncertainties. The ratios of the noBB and BBMZ fits to the BL fit are displayed in the lower insets

Same as Fig. 20, but for the sum of charged kaons, \(K^\pm \)

Same as Fig. 20, but for the sum of protons and antiprotons, \(p/\bar{p}\)
We now discuss the main features of these two fits based on reduced datasets.
The noBB fit. In comparison to the baseline, the overall quality of the noBB fit, as quantified by its total \(\chi ^2/N_\mathrm{dat}\) value, slightly deteriorates for charged pions, while it slightly improves for charged kaons and protons/antiprotons. For pions, this effect is due to a significant deterioration in the description of the TPC measurements, in particular the inclusive multiplicities, for which the \(\chi ^2/N_\mathrm{dat}\) grows from 0.85 in the baseline fit to 2.12 in the fit without the BELLE and BABAR data. For kaons, the improvement is driven by a better description of the TPC, TOPAZ, and all the TASSO datasets, except TASSO12. For protons/antiprotons, the improvement is determined by the exclusion of the BABAR dataset, whose rather high \(\chi ^2/N_\mathrm{dat}\) raises the total \(\chi ^2/N_\mathrm{dat}\) in the baseline fit.
Apart from these small differences, the overall quality of the fit to the reduced dataset is comparable to that of the baseline fit. We note, however, that the BELLE and BABAR datasets are poorly described if they are not included in the fit. In this case their \(\chi ^2/N_\mathrm{dat}\) value is indeed significantly higher, particularly for the latter experiment. This indicates that these two experiments carry a significant amount of information.
The effect of this information on FFs, is apparent from Figs. 20, 21 and 22. Flavour separation between the light-quark FF combinations \(D_{u^+}^h\) and \(D_{d^++s^+}^h\) is moderately affected. For pions, \(D_{u^+}^{\pi ^\pm }\) is slightly more suppressed below \(z=0.1\) in the BL fit than in the noBB fit, while \(D_{d^++s^+}^{\pi ^\pm }\) is slightly larger, especially in the region \(0.05\lesssim z \lesssim 0.5\). For kaons, differences in the FF shapes are more marked, especially in the small-z region, where hadron-mass and higher-order QCD corrections are more important for the BELLE and BABAR data than for the data at higher energies. For protons/antiprotons, the shape of \(D_{u^+}^{p/\bar{p}}\) and \(D_{d^++s^+}^{p/\bar{p}}\) is almost unaffected by the BELLE and BABAR data. For all hadronic species, the uncertainties of the light-quark FF combinations are slightly reduced when the measurements from BELLE and BABAR are included in the fit.
The gluon FFs is also affected. For pions and kaons, significant differences in shape are observed over the whole z range, while for protons/antiprotons only a small enhancement is seen when the BELLE and BABAR data are included. As expected, heavy-quark FFs for all hadronic species, \(D_{c^+}^h\) and \(D_{b^+}^h\), are not affected by the BELLE and BABAR data to which they are not directly sensitive.
The importance of the B-factory measurements is demonstrated also by the fact that the uncertainty of the gluon FFs for all hadronic species is reduced by up to a factor two above \(z=0.4\) upon their inclusion in the fit. These results prove that the BELLE and BABAR data represent an important ingredient for any state-of-the-art determination of FFs.
The BBMZ fit. In comparison to the baseline, the overall quality of the BBMZ fit improves for all hadronic species; see Table 5. Individual experiments included in both fits are described with similar accuracy in most cases. The only exception is the BABAR experiment, for which the \(\chi ^2/N_\mathrm{dat}\) increases from 0.78 to 0.88 for charged pions, from 0.95 to 1.21 for charged kaons, and decreases from 3.25 to 0.84 for protons/antiprotons when moving from the baseline to the BBMZ fit. In the case of pions and kaons, the BABAR measurements stabilise the fit. In the case of protons/antiprotons instead they might be in tension with the rest of the dataset.
This is confirmed by the \(\chi ^2/N_\mathrm{dat}\) values of the experiments excluded from the BBMZ fit. In most cases, they are equally good or slightly worse than in the baseline fit. In the case of protons/antiprotons, instead, the \(\chi ^2/N_\mathrm{dat}\) value of the TPC and TASSO34 experiments is significantly worse in the fit to the reduced dataset than in the baseline fit. Since this deterioration is accompanied by an improvement in the \(\chi ^2/N_\mathrm{dat}\) value of the BABAR experiment, we conclude that there is some tension between this experiment and the TPC and TASSO34 data. The origin of this tension is likely to be due to a limited number of data points at small z, as this effect disappears if more conservative kinematic cuts are applied (see Sect. 6.1).
At the level of FFs, results are remarkably stable as one can see by comparing the FFs from the BL fit to those from the BBMZ fit in Figs. 20, 21 and 22. For all hadronic species, the FFs in the BL and BBMZ fits are compatible within uncertainties and no significant differences in shape are observed. As far as flavour separation is concerned, \(D_{u^+}^h\) is slightly larger (smaller) in the fit to the reduced dataset than in the fit to the baseline dataset for charged pions and kaons (protons/antiprotons). This is accompanied by a slightly smaller (larger) \(D_{d^++s^+}^h\), so that the total singlet FF is almost equivalent in the two fits. The gluon FF is slightly larger for all hadronic species in the BBMZ fit, although this effect is mostly localised above \(z=0.2\) for charged pions and kaons and below \(z=0.2\) for protons/antiprotons. As expected, heavy quark FFs \(D_{c^+}^h\) and \(D_{b^+}^h\) for all hadronic species are unaffected. The two fits do not differ by any relevant heavy-quark tagged measurements (except for the TPC tagged data for pions, which, however, carry a very small weight). Uncertainties of FFs are slightly smaller for all hadronic species and flavours in the baseline fit as compared to the BBMZ fit.
We conclude that the BBMZ fit is competitive with the baseline fit. Nonetheless, we also find that the measurements at \(\sqrt{s}\) between the B-factory scale and \(M_Z\) still carry some amount of experimental information that should be taken into account.
7 Conclusions and outlook
In this work we have presented NNFF1.0, a new determination of the FFs of charged pions, charged kaons, and protons/antiprotons at LO, NLO, and NNLO accuracy in perturbative QCD. This analysis is based on a comprehensive set of SIA data, including the recent and precise measurements from the B-factory experiments BELLE and BABAR. The well-established NNPDF fitting methodology, widely used to determine polarised and unpolarised PDFs, was extended to FFs here for the first time. This methodology is specifically designed to provide a faithful representation of the experimental uncertainties and to minimise any bias related to the parametrisation of FFs and to the minimisation procedure.
In this analysis we have introduced some methodological improvements aimed at reducing even further any possible procedural bias.
As a first improvement, we have removed from the usual NNPDF parametrisation the preprocessing function governing the FF behaviour in the small- and large-z extrapolation regions. As a consequence, we do not need to iterate the fits anymore in order to determine the optimal ranges of the preprocessing exponents. This came at the price of modifying the activation function in the neural network in order to avoid an unphysical behaviour of the FFs in the small- and large-z extrapolation regions.
As a second improvement, we have used a minimisation procedure based on the CMA-ES family of algorithms. This procedure allows for a more efficient exploration of the parameter space in comparison to the genetic algorithm used in previous NNPDF fits of PDFs. The fitting framework has finally been validated by means of closure tests.
We have presented the NNFF1.0 sets of FFs. We have discussed the quality of our fits and showed that the inclusion of QCD corrections up to NNLO improves the description of the data for all the hadronic species considered, especially in the small-z region. We have then examined the FFs resulting from our fits. We highlighted their perturbative stability and observed a reduction of the FF uncertainties at NLO and NNLO with respect to LO. We have then compared the NNFF1.0 FFs to the recent DEHSS and JAM FFs for charged pions and kaons at NLO. We found a general fair agreement among the three sets with some noticeable differences mostly for the gluon FFs and their uncertainties.
We concluded our discussion by studying the stability of our fits upon variations of the small-z kinematic cuts and of the fitted dataset. The primary aim was that of justifying our particular choices for the default kinematic cuts and dataset. However, these studies have also clarified the role of the higher-order QCD corrections on the description of the low-z data and shed light on the tension among some of the datasets included in our analysis.
The analysis presented in this paper represents the first step of a broader program. A number of updates and improvements are foreseen.
The most important limitation of the NNFF1.0 analysis is the fact that it is based only on SIA measurements. Despite SIA is the cleanest process for the determination of FFs, it carries little information on flavour separation, is scarcely sensitive to the gluon FF, and is completely blind to the separation between quark and antiquark FFs. To improve on this, future updates of the NNFF fits will include measurements from other processes that provide a handle on these aspects. This will be achieved by including in our future analyses SIDIS data (e.g. from the COMPASS and HERMES experiments) and pp collision data (e.g. from the LHC and RHIC experiments). This will require an efficient numerical implementation of the corresponding observables which are more involved than SIA observables.
A further improvement for future NNFF analyses is the inclusion of heavy-quark mass corrections. Such corrections are expected to improve the description of the data at the lowest center-of-mass energy.
Finally, as a long-term project, we aim at carrying out a simultaneous determination of FFs and (un)polarised PDFs. We will take advantage of the fact that unpolarised and polarised PDFs, and now FFs, are already separately available from the common, mutually consistent NNPDF fitting framework.
The NNFF1.0 FF sets presented in this work are available via the LHAPDF6 interface [100]
The list of the available FF sets is the following.
-
The FF sets for \(\pi ^{\pm }=\pi ^++\pi ^-\) (PIsum), \(\pi ^+\) (PIp), and \(\pi ^-\) (PIm) at LO, NLO, and NNLO:
-
NNFF10_PIsum_lo, NNFF10_PIp_lo, NNFF10_PIm_lo,
-
NNFF10_PIsum_nlo, NNFF10_PIp_nlo, NNFF10_PIm_nlo,
-
NNFF10_PIsum_nnlo, NNFF10_PIp_nnlo, NNFF10_PIm_nnlo.
-
-
The FF sets for \(K^{\pm }=K^++K^-\) (KAsum), \(K^+\) (KAp), and \(K^-\) (KAm) at LO, NLO, and NNLO:
-
NNFF10_KAsum_lo, NNFF10_KAp_lo, NNFF10_KAm_lo,
-
NNFF10_KAsum_nlo, NNFF10_KAp_nlo, NNFF10_KAm_nlo,
-
NNFF10_KAsum_nnlo, NNFF10_KAp_nnlo, NNFF10_KAm_nnlo.
-
-
The FF sets for \(p/\bar{p}=p+\bar{p}\) (PRsum), p (PRp), and \(\bar{p}\) (PRm) at LO, NLO, and NNLO:
-
NNFF10_PRsum_lo, NNFF10_PRp_lo, NNFF10_PRm_lo,
-
NNFF10_PRsum_nlo, NNFF10_PRp_nlo, NNFF10_PRm_nlo,
-
NNFF10_PRsum_nnlo, NNFF10_PRp_nnlo, NNFF10_PRm_nnlo.
-
We refer the reader to Appendix A for the details on the assumptions used to construct these sets of FFs and on the features of the (x, Q) tabulation.
References
R.D. Field, R.P. Feynman, A parametrization of the properties of quark jets. Nucl. Phys. B 136, 1 (1978)
J.C. Collins, D.E. Soper, Back-to-back jets in QCD. Nucl. Phys. B 193, 381 (1981) [Erratum: Nucl. Phys. B 213, 545 (1983)]
J.C. Collins, D.E. Soper, Parton distribution and decay functions. Nucl. Phys. B 194, 445 (1982)
J.C. Collins, D.E. Soper, G.F. Sterman, Factorization of hard processes in QCD. Adv. Ser. Direct. High Energy Phys. 5, 1–91 (1988). arXiv:hep-ph/0409313
S. Forte, Parton distributions at the dawn of the LHC. Acta Phys. Polon. B 41, 2859–2920 (2010). arXiv:1011.5247
S. Forte, G. Watt, Progress in the determination of the partonic structure of the proton. Ann. Rev. Nucl. Part. Sci. 63, 291–328 (2013). arXiv:1301.6754
J. Rojo et al., The PDF4LHC report on PDFs and LHC data: results from Run I and preparation for Run II. J. Phys. G42, 103103 (2015). arXiv:1507.00556
S. Albino et al., Parton fragmentation in the vacuum and in the medium. arXiv:0804.2021
R. Sassot, M. Stratmann, P. Zurita, Fragmentations functions in nuclear media. Phys. Rev. D 81, 054001 (2010). arXiv:0912.1311
ALICE Collaboration, K. Aamodt et al., Suppression of charged particle production at large transverse momentum in central Pb–Pb collisions at \(\sqrt{s_{NN}} =\) 2.76 TeV. Phys. Lett. B 696, 30–39 (2011). arXiv:1012.1004
V. Gribov, L. Lipatov, Deep inelastic \(ep\) scattering in perturbation theory. Sov. J. Nucl. Phys. 15, 438–450 (1972)
L. Lipatov, The parton model and perturbation theory. Sov. J. Nucl. Phys. 20, 94–102 (1975)
G. Altarelli, G. Parisi, Asymptotic freedom in parton language. Nucl. Phys. B 126, 298 (1977)
Y.L. Dokshitzer, Calculation of the structure functions for deep inelastic scattering and \(e^+e^-\) annihilation by perturbation theory in quantum chromodynamics. Sov. Phys. JETP 46, 641–653 (1977)
S. Albino, The hadronization of partons. Rev. Mod. Phys. 82, 2489–2556 (2010). arXiv:0810.4255
A. Metz, A. Vossen, Parton fragmentation functions. Prog. Part. Nucl. Phys. 91, 136–202 (2016). arXiv:1607.02521
D. de Florian, R. Sassot, M. Epele, R.J. Hernndez-Pinto, M. Stratmann, Parton-to-pion fragmentation reloaded. Phys. Rev. D 91(1), 014035 (2015). arXiv:1410.6027
D. de Florian, M. Epele, R.J. Hernandez-Pinto, R. Sassot, M. Stratmann, Parton-to-kaon fragmentation revisited. Phys. Rev. D 95(9), 094019 (2017). arXiv:1702.06353
M. Hirai, H. Kawamura, S. Kumano, K. Saito, Impacts of B-factory measurements on determination of fragmentation functions from electron-positron annihilation data. PTEP 2016(1), 113B04 (2016). arXiv:1608.04067
N. Sato, J.J. Ethier, W. Melnitchouk, M. Hirai, S. Kumano, A. Accardi, First Monte Carlo analysis of fragmentation functions from single-inclusive \(e^+ e^-\) annihilation. Phys. Rev. D 94(11), 114004 (2016). arXiv:1609.00899
J. Pumplin, D.R. Stump, W.K. Tung, Multivariate fitting and the error matrix in global analysis of data. Phys. Rev. D 65, 014011 (2001). arXiv:hep-ph/0008191
J. Pumplin, D. Stump, R. Brock, D. Casey, J. Huston, J. Kalk, H.L. Lai, W.K. Tung, Uncertainties of predictions from parton distribution functions. 2. The Hessian method. Phys. Rev. D 65, 014013 (2001). arXiv:hep-ph/0101032
Jefferson Lab Angular Momentum Collaboration, N. Sato, W. Melnitchouk, S.E. Kuhn, J.J. Ethier, A. Accardi, Iterative Monte Carlo analysis of spin-dependent parton distributions. Phys. Rev. D 93(7), 074005 (2016). arXiv:1601.07782
D.P. Anderle, F. Ringer, M. Stratmann, Fragmentation functions at next-to-next-to-leading order accuracy. Phys. Rev. D 92(11), 114017 (2015). arXiv:1510.05845
M. Epele, C.A. Garcia Canal, R. Sassot, Role of heavy quarks in light hadron fragmentation. Phys. Rev. D 94(3), 034037 (2016). arXiv:1604.08427
D.P. Anderle, T. Kaufmann, M. Stratmann, F. Ringer, Fragmentation functions beyond fixed order accuracy. Phys. Rev. D 95(5), 054003 (2017). arXiv:1611.03371
E.R. Nocera, Towards a neural network determination of charged pion fragmentation functions, in 22nd International symposium on spin physics (SPIN 2016), Urbana (2017). arXiv:1701.09186
V. Bertone, S. Carrazza, E.R. Nocera, N.P. Hartland, J. Rojo, Towards a neural network determination of pion fragmentation functions, in Parton radiation and fragmentation from LHC to FCC-ee (2017), pp. 19–25
S. Forte, L. Garrido, J.I. Latorre, A. Piccione, Neural network parametrization of deep inelastic structure functions. JHEP 05, 062 (2002). arXiv:hep-ph/0204232
NNPDF Collaboration, L. Del Debbio, S. Forte, J.I. Latorre, A. Piccione, J. Rojo, Unbiased determination of the proton structure function F(2)**p with faithful uncertainty estimation. JHEP 03, 080 (2005). arXiv:hep-ph/0501067
NNPDF Collaboration, L. Del Debbio, S. Forte, J.I. Latorre, A. Piccione, J. Rojo, Neural network determination of parton distributions: the Nonsinglet case. JHEP 03, 039 (2007). arXiv:hep-ph/0701127
NNPDF Collaboration, R.D. Ball, L. Del Debbio, S. Forte, A. Guffanti, J.I. Latorre, A. Piccione, J. Rojo, M. Ubiali, A determination of parton distributions with faithful uncertainty estimation. Nucl. Phys. B 809, 1–63 (2009). arXiv:0808.1231 [Erratum: Nucl. Phys. B 816, 293 (2009)]
NNPDF Collaboration, R.D. Ball, L. Del Debbio, S. Forte, A. Guffanti, J.I. Latorre, A. Piccione, J. Rojo, M. Ubiali, Precision determination of electroweak parameters and the strange content of the proton from neutrino deep-inelastic scattering. Nucl. Phys. B 823, 195–233 (2009). arXiv:0906.1958
R.D. Ball, L. Del Debbio, S. Forte, A. Guffanti, J.I. Latorre et al., A first unbiased global NLO determination of parton distributions and their uncertainties. Nucl. Phys. B 838, 136–206 (2010). arXiv:1002.4407
R.D. Ball, V. Bertone, F. Cerutti, L. Del Debbio, S. Forte, A. Guffanti, J.I. Latorre, J. Rojo, M. Ubiali, Impact of heavy quark masses on parton distributions and LHC phenomenology. Nucl. Phys. B 849, 296–363 (2011). arXiv:1101.1300
NNPDF Collaboration, R.D. Ball, V. Bertone, F. Cerutti, L. Del Debbio, S. Forte, A. Guffanti, J.I. Latorre, J. Rojo, M. Ubiali, Unbiased global determination of parton distributions and their uncertainties at NNLO and at LO. Nucl. Phys. B 855, 153–221 (2012). arXiv:1107.2652
R.D. Ball et al., Parton distributions with LHC data. Nucl. Phys. B 867, 244–289 (2013). arXiv:1207.1303
NNPDF Collaboration, R.D. Ball et al., Parton distributions for the LHC Run II. JHEP 04, 040 (2015). arXiv:1410.8849
NNPDF Collaboration, R.D. Ball et al., Parton distributions from high-precision collider data. arXiv:1706.00428
M. Bonvini, S. Marzani, J. Rojo, L. Rottoli, M. Ubiali, R.D. Ball, V. Bertone, S. Carrazza, N.P. Hartland, Parton distributions with threshold resummation. JHEP 09, 191 (2015). arXiv:1507.01006
NNPDF Collaboration, R.D. Ball, V. Bertone, S. Carrazza, L. Del Debbio, S. Forte, A. Guffanti, N.P. Hartland, J. Rojo, Parton distributions with QED corrections. Nucl. Phys. B 877, 290–320 (2013). arXiv:1308.0598
NNPDF Collaboration, R.D. Ball, V. Bertone, M. Bonvini, S. Carrazza, S. Forte, A. Guffanti, N.P. Hartland, J. Rojo, L. Rottoli, A determination of the charm content of the proton. Eur. Phys. J. C 76(11), 647 (2016). arXiv:1605.06515
NNPDF Collaboration, R.D. Ball et al., Unbiased determination of polarized parton distributions and their uncertainties. Nucl. Phys. B 874, 36–84 (2013). arXiv:1303.7236
NNPDF Collaboration, E.R. Nocera, R.D. Ball, S. Forte, G. Ridolfi, J. Rojo, A first unbiased global determination of polarized PDFs and their uncertainties. Nucl. Phys. B 887, 276–308 (2014). arXiv:1406.5539
J.J. Ethier, N. Sato, W. Melnitchouk, First simultaneous extraction of spin-dependent parton distributions and fragmentation functions from a global QCD analysis. arXiv:1705.05889
ALEPH Collaboration, D. Buskulic et al., Inclusive pi+-, K+- and (p, anti-p) differential cross-sections at the Z resonance, Z. Phys. C 66, 355–366 (1995)
DELPHI Collaboration, P. Abreu et al., Eur. Phys. J. C 5, 585–620 (1998)
OPAL Collaboration, R. Akers et al., Measurement of the production rates of charged hadrons in e+ e\(-\) annihilation at the Z0. Z. Phys. C 63, 181–196 (1994)
TASSO Collaboration, R. Brandelik et al., Charged pion, kaon, proton and anti-proton production in high-energy e+ e\(-\) annihilation. Phys. Lett. B 94, 444 (1980)
TASSO Collaboration, M. Althoff et al., Charged hadron composition of the final state in e+ e\(-\) annihilation at high-energies. Z. Phys. C 17, 5–15 (1983)
TASSO Collaboration, W. Braunschweig et al., Pion, kaon and proton cross-sections in \(e^+ e^-\) annihilation at 34-GeV and 44-GeV center-of-mass energy. Z. Phys. C 42, 189 (1989)
M. Belle Collaboration, Leitgab et al., Precision measurement of charged pion and kaon multiplicities in electron-positron annihilation at Q = 10.52 GeV. Phys. Rev. Lett. 111, 062002 (2013). arXiv:1301.6183
Belle Collaboration, R. Seidl et al., Inclusive cross sections for pairs of identified light charged hadrons and for single protons in \(e^+e^-\) at \(\sqrt{s}=\) 10.58 GeV. Phys. Rev. D 92(9), 092007 (2015). arXiv:1509.00563
TOPAZ Collaboration, R. Itoh et al., Measurement of inclusive particle spectra and test of MLLA prediction in e+ e- annihilation at s**(1/2) = 58-GeV. Phys. Lett. B 345, 335–342 (1995). arXiv:hep-ex/9412015
J. BaBar Collaboration, Lees et al., Production of charged pions, kaons and protons in e+e- annihilations into hadrons at sqrts = 10.54 GeV. Phys. Rev. D 88, 032011 (2013). arXiv:1306.2895
TPC/Two Gamma Collaboration, H. Aihara et al., Charged hadron inclusive cross-sections and fractions in \(e^+e^-\) annihilation \(\sqrt{s}=29\) GeV. Phys. Rev. Lett. 61, 1263 (1988)
S.L.D. Collaboration, K. Abe et al., Production of pi+, pi\(-\), K+, K\(-\), p and anti-p in light (uds), c and b jets from Z0 decays. Phys. Rev. D 69, 072003 (2004). arXiv:hep-ex/0310017
X.-Q. Lu, Heavy quark jets from e+ e\(-\) annihilation at 29-GeV, Ph.D. thesis. Johns Hopkins University (1986)
OPAL Collaboration, G. Abbiendi et al., Leading particle production in light flavor jets. Eur. Phys. J. C 16, 407–421 (2000). arXiv:hep-ex/0001054
R. Seidl. Private communication
D. de Florian, R. Sassot, M. Stratmann, Global analysis of fragmentation functions for protons and charged hadrons. Phys. Rev. D 76, 074033 (2007). arXiv:0707.1506
M. Hirai, S. Kumano, T.-H. Nagai, K. Sudoh, Determination of fragmentation functions and their uncertainties. Phys. Rev. D 75, 094009 (2007). arXiv:hep-ph/0702250
ARGUS Collaboration, H. Albrecht et al., Inclusive production of charged pions, charged and neutral kaons and anti-protons in \(e^+ e^-\) annihilation at 10-GeV and in direct \(\Upsilon \) it decays. Z. Phys. C 44, 547 (1989)
M. Derrick, E. Fernandez, R. Fries, L. Hyman, P. Kooijman et al., Hadron Production in \(e^+ e^-\) Annihilation at \(\sqrt{s}=29\)-GeV. Phys. Rev. D 35, 2639 (1987)
G. D’Agostini, On the use of the covariance matrix to fit correlated data. Nucl. Instrum. Methods A 346, 306–311 (1994)
NNPDF Collaboration, R.D. Ball, L. Del Debbio, S. Forte, A. Guffanti, J.I. Latorre, J. Rojo, M. Ubiali, Fitting parton distribution data with multiplicative normalization uncertainties. JHEP 05, 075 (2010). arXiv:0912.2276
R.D. Ball et al., Parton distribution benchmarking with LHC data. JHEP 04, 125 (2013). arXiv:1211.5142
S. Albino, B.A. Kniehl, G. Kramer, A.K.K. Update, Improvements from new theoretical input and experimental data. Nucl. Phys. B 803, 42–104 (2008). arXiv:0803.2768
M. Leitgab, Precision measurement of charged pion and kaon multiplicities in \(e^{+}e^{-}\) annihilation at Q \(=\) 10.52 GeV, Ph.D. Thesis, University of Illinois at Urbana Champaign, 2013
A. Vogt, Resummation of small-x double logarithms in QCD: semi-inclusive electron-positron annihilation. JHEP 10, 025 (2011). arXiv:1108.2993
S. Albino, P. Bolzoni, B.A. Kniehl, A. Kotikov, Fully double-logarithm-resummed cross sections. Nucl. Phys. B 851, 86–103 (2011). arXiv:1104.3018
S. Albino, P. Bolzoni, B.A. Kniehl, A.V. Kotikov, Timelike Single-logarithm-resummed Splitting Functions. Nucl. Phys. B 855, 801–814 (2012). arXiv:1108.3948
C.H. Kom, A. Vogt, K. Yeats, Resummed small-x and first-moment evolution of fragmentation functions in perturbative QCD. JHEP 10, 033 (2012). arXiv:1207.5631
M. Cacciari, S. Catani, Soft gluon resummation for the fragmentation of light and heavy quarks at large x. Nucl. Phys. B 617, 253–290 (2001). arXiv:hep-ph/0107138
J. Blumlein, V. Ravindran, QCD threshold corrections to Higgs decay and to hadroproduction in l+ l\(-\) annihilation. Phys. Lett. B 640, 40–47 (2006). arXiv:hep-ph/0605011
S. Moch, A. Vogt, Higher-order threshold resummation for semi-inclusive e+ e\(-\) annihilation. Phys. Lett. B 680, 239–246 (2009). arXiv:0908.2746
D.P. Anderle, F. Ringer, W. Vogelsang, QCD resummation for semi-inclusive hadron production processes. Phys. Rev. D 87(3), 034014 (2013). arXiv:1212.2099
A. Accardi, D.P. Anderle, F. Ringer, Interplay of threshold resummation and hadron mass corrections in deep inelastic processes. Phys. Rev. D 91(3), 034008 (2015). arXiv:1411.3649
D. de Florian, M. Stratmann, W. Vogelsang, QCD analysis of unpolarized and polarized Lambda baryon production in leading and next-to-leading order. Phys. Rev. D 57, 5811–5824 (1998). arXiv:hep-ph/9711387
S. Gorishnii, A. Kataev, S. Larin, The O (alpha-s**3) corrections to sigma-tot into hadrons) in QCD. Phys. Lett. B 259, 144–150 (1991)
P. Rijken, W. van Neerven, \(\cal{O}(\alpha _s^2)\) contributions to the longitudinal fragmentation function in \(e^+e^-\) annihilation. Phys. Lett. B 386, 422–428 (1996). arXiv:hep-ph/9604436
P. Rijken, W. van Neerven, Higher order QCD corrections to the transverse and longitudinal fragmentation functions in electron - positron annihilation. Nucl. Phys. B 487, 233–282 (1997). arXiv:hep-ph/9609377
P. Rijken, W. van Neerven, \(\cal{O}(\alpha _s^2)\) contributions to the asymmetric fragmentation function in \(e^+e^-\) annihilation. Phys. Lett. B 392, 207–215 (1997). arXiv:hep-ph/9609379
A. Mitov, S.-O. Moch, QCD corrections to semi-inclusive hadron production in electron-positron annihilation at two loops. Nucl. Phys. B 751, 18–52 (2006). arXiv:hep-ph/0604160
J. Blumlein, V. Ravindran, \(\cal{O}(\alpha ^2_s\)) timelike Wilson coefficients for parton-fragmentation functions in Mellin space. Nucl. Phys. B 749, 1–24 (2006). arXiv:hep-ph/0604019
A. Mitov, S. Moch, A. Vogt, Next-to-next-to-leading order evolution of non-singlet fragmentation functions. Phys. Lett. B 638, 61–67 (2006). arXiv:hep-ph/0604053
S. Moch, A. Vogt, On third-order timelike splitting functions and top-mediated Higgs decay into hadrons. Phys. Lett. B 659, 290–296 (2008). arXiv:0709.3899
A. Almasy, S. Moch, A. Vogt, On the next-to-next-to-leading order evolution of flavour-singlet fragmentation functions. Nucl. Phys. B 854, 133–152 (2012). arXiv:1107.2263
V. Bertone, S. Carrazza, J. Rojo, APFEL: a PDF evolution library with QED corrections. Comput. Phys. Commun. 185, 1647–1668 (2014). arXiv:1310.1394
V. Bertone, S. Carrazza, E.R. Nocera, Reference results for time-like evolution up to \( \cal{O}\left({\alpha }_s^3\right) \). JHEP 1503, 046 (2015). arXiv:1501.00494
S. Forte, E. Laenen, P. Nason, J. Rojo, Heavy quarks in deep-inelastic scattering. Nucl. Phys. B 834, 116–162 (2010). arXiv:1001.2312
M. Guzzi, P.M. Nadolsky, H.-L. Lai, C.P. Yuan, General-mass treatment for deep inelastic scattering at two-loop accuracy. Phys. Rev. D 86, 053005 (2012). arXiv:1108.5112
R.S. Thorne, R.G. Roberts, A variable number flavor scheme for charged current heavy flavor structure functions. Eur. Phys. J. C 19, 339–349 (2001). arXiv:hep-ph/0010344
Particle Data Group Collaboration, C. Patrignani et al., Review of particle physics. Chin. Phys. C 40(10), 100001 (2016)
M. Cacciari, P. Nason, C. Oleari, Crossing heavy-flavor thresholds in fragmentation functions. JHEP 10, 034 (2005). arXiv:hep-ph/0504192
N. Hansen, The CMA Evolution Strategy: A Comparing Review (Springer, Berlin, 2006), pp. 75–102
N. Hansen, The CMA evolution strategy: a tutorial, CoRR. arXiv:1604.00772 (2016)
D. de Florian, R. Sassot, M. Stratmann, Global analysis of fragmentation functions for pions and kaons and their uncertainties. Phys. Rev. D 75, 114010 (2007). arXiv:hep-ph/0703242
S. Kumano. Private communication
A. Buckley, J. Ferrando, S. Lloyd, K. Nordstrm, B. Page et al., LHAPDF6: parton density access in the LHC precision era. Eur. Phys. J. C 75, 132 (2015). arXiv:1412.7420
Acknowledgements
We thank A. Accardi, D. P. Anderle, R. Sassot and N. Sato for useful discussions. We thank I. Garzia for assistance with the BABAR measurements, and R. Seidl for his help with the BELLE measurements, in particular for providing us with the proton/antiproton cross-section measurements of Ref. [53]. We thank N. Sato for providing us with the TPC tagged data of Ref. [58]. We thank D. P. Anderle for a benchmark of the NNLO computation of SIA observables. We thank M. Stratmann for providing us with the charged pion FF sets determined in Ref. [17]. We thank R. Sassot for providing us with the charged kaon FF sets determined in Ref. [18], and for his help with the corresponding interpolating routines. We are finally grateful to our colleagues of the NNPDF Collaboration for their support. In particular, we thank S. Forte and M. Ubiali for a critical reading of the manuscript. V. B., N. P. H. and J. R. are supported by an European Research Council Starting Grant “PDF4BSM”; S. C. is supported by the HICCUP ERC Consolidator Grant (614577); E. R. N. is supported by the UK STFC Grant ST/M003787/1.
Author information
Authors and Affiliations
Corresponding author
Delivery of the NNFF1.0 sets
Delivery of the NNFF1.0 sets
The determination of FFs presented in this work is based on SIA data whose measurements are provided for the sum of the charged hadrons of a given species (see Sect. 2.1). Specifically, cross-sections are measured for \(\pi ^\pm =\pi ^++\pi ^-\), \(K^\pm =K^++K^-\), and \(p/\bar{p} =p+\bar{p}\) production. As a consequence, for each partonic species, what we actually extract is the sum of the distributions belonging to the positive and negative hadrons. However, many phenomenological applications require sets of FFs for positive and negative hadrons separately. In this appendix, we discuss the assumptions adopted to perform this separation.
Considering that opposite-charge hadrons are related by charge conjugation
and that the relevant SIA observables are sensitive only to the sum of quark and antiquark distributions (i.e. \(D_{q^+}^h=D_{q}^h+D_{\bar{q}}^h\) with \(h=\pi ^\pm ,K^\pm ,p/\bar{p} \) and \(q=u,d,s,c,b\)), it is possible to separate quark and antiquark contributions as follows:
where we have omitted the dependence of FFs on the momentum fraction z and the factorisation scale Q. In fact, charge conjugation is an exact symmetry that connects particles and antiparticles. Therefore, the rightmost relation in Eq. (A.2) has to be true for any value of z and Q.
In order to disentangle the up- and down-quark contributions to the pion FFs and the up- and strange-quark contributions to the kaon FFs, we assume SU(2) and SU(3) isospin symmetry respectively. This assumption leads to the equalities
which we take to be valid for all values of z and Q. However, SU(2) and SU(3) isospin symmetries are only approximate, in that they are broken by terms proportional to the difference of quark masses \(m_u-m_d\) and \(m_u-m_s\), respectively. Given the spread between the light-quark masses, this implies that SU(2) is expected to be more accurate than SU(3). Indeed, the amount of SU(2) violation in a fit of pion FFs was found to be negligible in Ref. [17].
For the protons fragmentation functions it is not possible to write similar equalities based on isospin symmetry because the SU(2) isospin transformation turns protons into neutrons rather than connecting protons with antiprotons. However, in what follows we will derive a relation of the same kind of Eq. (A.3) that will allow us to separate up and down contributions also for protons. As we will see, this will require the introduction of further assumptions.
A further step is that of separating the distributions of positive and negative hadrons. This step is necessarily artificial because the experimental information included in our fits is not sensitive to such a separation. Consequently, we need to make some assumptions that will allow us to isolate the positive contributions from the negative ones. However, it should be kept in mind that the resulting distributions might be affected by a bias that only the inclusion of processes sensitive to this separation, such as SIDIS and hadron-collider measurements, might possibly resolve.
The assumption that we make in order to separate the opposite-charge contributions is based on the concept of favoured, unfavoured, and sea components. The (anti)flavours that preferably fragment into a particular hadron are said favourite. For the species considered in this work, such contributions are the following:
where for each quark we have also indicated the “preference” factors, which is the relative probability with which it fragments into the child hadron. We assume that the favoured distributions of a given hadron are equal to one another up to a factor equal to the inverse of the preference factor. This requirement, together with charge conjugation symmetry, leads to the following relations:
Next, we assume that all unfavoured distributions, defined as the antiparticle counterparts of the favoured ones, and the light sea distributions, defined as the remaining distributions associated to light flavours, are equal. Again using charge conjugation symmetry, this translates into the following equalities:
We emphasise again that the assumptions that lead to Eqs. (A.5) and (A.6) are not based on any exact or approximated physical symmetry. Rather, they are instrumental in separating distributions that otherwise could not be disentangled neither on the base of the experimental data nor considering a physical symmetry. Therefore, we limit ourselves to impose these equalities only at the initial scale \(Q_0=5\) GeV and let the perturbative evolution generate any possible breaking at higher scales.
We can now come back to the question of separating up and down contributions of the proton/antiproton FFs. Using Eqs. (A.5) and (A.6), we can establish the following relation:
that, on the same footing as Eq. (A.3), provides a further constrain to separate the sum \(D_{d^++u^+}^{p/\bar{p}}=D_{d^+}^{p/\bar{p}}+D_{s^+}^{p/\bar{p}}\) which is the quantity determined in our fits.
The remaining step to separate quark FFs of the opposite-charge hadrons is to relate the favoured and unfavoured combinations to the fitted FFs. This is achieved by using Eqs. (A.2), (A.3), (A.7), (A.5), and (A.6) to relate the unfavoured distributions \(D_\mathrm{fav}^\pi \), \(D_\mathrm{fav}^K\), and \(D_\mathrm{fav}^p\) and the unfavoured distributions \(D_\mathrm{unf}^\pi \), \(D_\mathrm{unf}^K\), and \(D_\mathrm{unf}^p\) to the distributions \(D_{u^+}^h\) and \(D_{d^++s^+}^h\), which are extracted from the fits, finding the following relations:
Finally, in order to determine the gluon and the heavy-quark distributions of the single hadrons, we simply assume that
Eqs. (A.5)–(A.9) are used to tabulate the FFs determined in our fits in the LHAPDF format [100]. For each hadronic species and each perturbative order considered in this work, we deliver an LHAPDF grid for the sum of the charged hadrons and two additional grids for the positive and the negative hadrons. It should be stressed that, for kaons and pions, the grids associated to the sum of the opposite-charge hadrons reflect very closely the information extracted from the fit because they only rely on the exact charge conjugation symmetry, Eq. (A.2), and the SU(2) and SU(3) isospin symmetries, Eq. (A.3). Conversely, all the grids for proton/antiproton FFs and the grids for the separate charged pions and kaons have been produced by making empirical assumptions on the relation between favoured, unfavoured, and sea distributions, Eqs. (A.5) and (A.6), which are not based on any fundamental physical symmetry.
Another important remark concerns the tabulation range in z and Q of the LHAPDF grids produced in this work. We have chosen to deliver our FF set in the range \([10^{-2}:1]\) in z and [1 : 10, 000] GeV in Q. The choice of the range in z is motivated by the fact that our lowest default kinematic cut is \(z_\mathrm{min} = 0.02\). Therefore, in order to avoid unreliable extrapolations far below \(z_\mathrm{min}\), our grids extend only slightly below this value. As far as the range in Q is concerned, despite our FFs are parametrised at \(Q_0=5\) GeV, our grids extend down to 1 GeV in order to make them usable also for low-energy predictions. As discussed in Sect. 3.2, in this analysis \(Q_0\) has been chosen to be larger of the bottom threshold in such a way to avoid any crossing of heavy-quark thresholds during the fit. However, 1 GeV is below the charm threshold \(m_c\) and thus we need to evolve our FFs backward from \(Q_0\) to 1 GeV crossing both the bottom and the charm thresholds. Such crossings are delicate for two reasons. The first is related to the fact that we fit charm and bottom FFs that thus contain a non-perturbative contribution that is not accounted by the perturbative matching conditions at the thresholds. To overcome this problem, we set to zero the bottom and charm FFs below the respective thresholds. The second reason has to do with the fact that time-like matching conditions are currently known to \(\mathcal {O}(\alpha _s)\), i.e. NLO. Therefore, when evolving backward our NNLO determinations, we still assume NLO matching conditions at the heavy-quark thresholds.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3.
About this article

Cite this article
Bertone, V., Carrazza, S., Hartland, N.P. et al. A determination of the fragmentation functions of pions, kaons, and protons with faithful uncertainties. Eur. Phys. J. C 77, 516 (2017). https://doi.org/10.1140/epjc/s10052-017-5088-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-017-5088-y