
Abstract
We report on an analysis of the impact of available experimental data on hard processes in proton–lead collisions during Run I at the large hadron collider on nuclear modifications of parton distribution functions. Our analysis is restricted to the EPS09 and DSSZ global fits. The measurements that we consider comprise production of massive gauge bosons, jets, charged hadrons and pions. This is the first time a study of nuclear PDFs includes this number of different observables. The goal of the paper is twofold: (i) checking the description of the data by nPDFs, as well as the relevance of these nuclear effects, in a quantitative manner; (ii) testing the constraining power of these data in eventual global fits, for which we use the Bayesian reweighting technique. We find an overall good, even too good, description of the data, indicating that more constraining power would require a better control over the systematic uncertainties and/or the proper proton–proton reference from LHC Run II. Some of the observables, however, show sizeable tension with specific choices of proton and nuclear PDFs. We also comment on the corresponding improvements as regards the theoretical treatment.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
The main physics motivations [1] for the proton–lead (p–Pb) collisions at the large hadron collider (LHC) were to obtain a reliable baseline for the heavy-ion measurements and to shed light on the partonic behaviour of the nucleus, particularly at small values of momentum fraction x. As such, this program constitutes a logical continuation of the deuteron–gold (d–Au) experiments at the relativistic heavy-ion collider (RHIC) but at significantly higher energy. The p–Pb data have, however, proved richer than initially pictured and also entailed genuine surprises (see the review [2]).
One of the key factors in interpreting the p–Pb data are the nuclear parton distribution functions (nPDFs) [3, 4]. It is now more than three decades ago that, unexpectedly, large nuclear effects in deeply inelastic scattering were first found (for a review, see Ref. [5]), which were later on shown to be factorisable into the PDFs [6]. However, the amount and variety of experimental data that go into the global determinations of nPDFs has been very limited and the universality of the nPDFs has still remained largely as a conjecture—with no clear violation found to date, however. The new experimental data from the LHC p–Pb run give a novel opportunity to further check these ideas and also provide new constraints. The aim of this paper is, on the one hand, to chart the importance of nPDFs in describing the data (both globally and separately for individual data sets) and, on the other hand, to estimate the quantitative constraints that these data render. The latter question would have traditionally required a complete reanalysis adding the new data on top of the old ones. Luckily, faster methods, collectively known as reweighting techniques, have been developed [7–13].
In a preceding work [14], a specific version [10] of the Bayesian reweighting technique was employed to survey the potential impact of the p–Pb program on nPDFs by using pseudodata. However, at that point the reweighting method used was not yet completely understood and certain caution regarding the results has to be practiced. Along with the developments of Ref. [13], we can now more reliably apply the Bayesian reweighting. Also, instead of pseudodata we can now use the available p–Pb measurements. We will perform the analysis with two different sets of nPDFs (EPS09 [15] and DSSZ [16]) and, in order to control the bias coming from choosing a specific free-proton reference set, we will consider two sets of proton PDFs (MSTW2008 [17] and CT10 [18]). The procedure is completely general and can be applied to any process with at least one hadron or nucleus in the initial configuration. In particular it is feasible in the application to nucleus–nucleus collisions, at least for those observables that are expected to be free from effects other than the nuclear modification of PDFs. In the present situation, data on EW bosons could be used. However, in contrast to p–Pb collisions, the precision of these data is inferior, the constraining power smaller by construction in the symmetric Pb–Pb case [19], and also a higher computational load would be involved. For these reasons we do not include Pb–Pb data in the present analysis.
The paper is organised as follows: in Sect. 2 we briefly explain the Bayesian reweighting, devoting Sect. 3 to the observables included in the present analysis. In Sect. 4 we show the impact of the data on the nPDFs, and we discuss similarities and differences between the four possible PDF-nPDF combinations. Finally, in Sect. 5 we summarise our findings.
2 The reweighting procedure
2.1 The Bayesian reweighting method
The Bayesian reweighting technique [7–13] is a tool to quantitatively determine the implications of new data within a set of PDFs. In this approach, the probability distribution \(\mathcal {P}_\mathrm{old}(f)\) of an existing PDF set is represented by an ensemble of PDF replicas \(f_k\), \(k=1, \ldots , N_\mathrm{rep}\), and the expectation value \(\langle \mathcal {O} \rangle \) and variance \(\delta \langle \mathcal {O} \rangle \) for an observable \(\mathcal {O}\) can be computed as
Additional information from a new set of data \(\mathbf {y}\equiv \lbrace y_{i}, i=1, ..., N_\mathrm{data} \rbrace \) can now be incorporated, by the Bayes theorem, as
where \(\mathcal {P}(\mathbf {y} \vert f)\) stands for the conditional probability for the new data, for a given set of PDFs. It follows that the average value for any observable depending on the PDFs becomes a weighted average:
where the weights \(\omega _{k}\) are proportional to the likelihood function \(\mathcal {P}(\mathbf {y} \vert f)\). For PDF sets with uncertainties based on the Hessian method (with \(N_\mathrm{eig}\) eigenvalues resulting in \(2 N_\mathrm{eig}+1\) members) and fixed tolerance \(\Delta \chi ^2\) (which is the case in the present study), the functional form of the likelihood function that corresponds to a refit [13] is
where
with C the covariance matrix of the new data \(\mathbf {y}\) and the theoretical values \(y_i \left[ f \right] \) estimated by
The ensemble of PDFs required by this approach is defined by
where \(f_{S_0}\) is the central fit, and \(f_{S^\pm _i}\) are the ith error sets. The coefficients \(R_{ik}\) are random numbers selected from a Gaussian distribution centred at zero and with variance one. After the reweighting, the values of \(\chi ^2\) are evaluated as
where \(\langle y_i \rangle \) are computed as in Eq. (4). An additional quantity in the Bayesian method is the effective number of replicas \(N_\mathrm{eff}\), a useful indicator defined as
Having \(N_\mathrm{eff} \ll N_\mathrm{rep}\) indicates that some of the replicas are doing a significantly better job in describing the data than others, and that the method becomes inefficient. In this case a very large number of replicas may be needed to obtain a converging result. In this work we have taken \(N_\mathrm{rep}=10^4\).
2.2 Bayesian reweighting in the linear case
The reweighting procedure begins by first generating the replicas \(f_k\) by Eq. (9), which are then used to compute the observables required to evaluate the values of \(\chi ^{2}_{k}\) that determine the weights. In general, this involves looping the computational codes over the \(N_\mathrm{rep}\) replicas, which can render the work quite CPU-time consuming. There is, however, a way to reduce the required time if the PDFs that we are interested in enter the computation linearly. Let us exemplify this with the process \(\mathrm{p} + \mathrm{Pb} \rightarrow \mathcal {O}\). The cross section corresponding to the kth replica can be schematically written as
where \(\otimes \) denotes in aggregate the kinematic integrations and summations over the partonic species. If now we replace \(f^\mathrm{Pb}_{k}\) by Eq. (9), we have
which can be written as
where \(d\sigma _{S_0}\) is the cross section obtained with the central set, and \(d\sigma _{S_i^\pm }\) are the cross sections evaluated with the error sets.
In this way, only \(2N_\mathrm{eig}+1\) (31 for EPS09, 51 for DSSZ) cross-section evaluations are required (instead of \(N_\mathrm{rep}\)).
3 Comparison with the experimental data
All the data used in this work (165 points in total) were obtained at the LHC during Run I, in p–Pb collisions at a centre-of-mass energy \(\sqrt{s}=5.02 \, \mathrm{TeV}\) per nucleon: W from ALICE and CMS, Z from ATLAS and CMS, jets from ATLAS, dijets from CMS, charged hadrons from ALICE and CMS, and pions from ALICE. Some of them are published as absolute distributions and some as ratios. We refrain from directly using the absolute distributions as they are typically more sensitive to the free-proton PDFs and not so much to the nuclear modifications. In ratios of cross sections, the dependence of the free-proton PDFs usually becomes suppressed. The ideal observable would be the nuclear modification \(\sigma (\mathrm{p}\)–\(\mathrm{Pb})/\sigma (\mathrm{p}\)–\(\mathrm{p})\). However, no direct p–p measurement exists yet at the same centre-of-mass energy and such a reference is sometimes constructed by the experimental collaborations from their results at \(\sqrt{s}=2.76 \, \mathrm{TeV}\) and \(\sqrt{s}=7 \, \mathrm{TeV}\). This brings forth a non-trivial normalisation issue and, with the intention of avoiding it, we decided to use (whenever possible) ratios between different rapidity windows instead—this situation is expected to be largely improved in the near future thanks to the reference p–p run at \(\sqrt{s}=5.02 \, \mathrm{TeV}\) from LHC Run II. We note that, apart from the luminosity, no information on the correlated systematic uncertainties is given by the experimental collaborations. Thus, when constructing ratios of cross sections, we had no other option than adding all the uncertainties in quadrature. In the (frequent) cases where the systematic uncertainties dominate, this amounts to overestimating the uncertainties which sometimes reflects in absurdly small logarithmic likelihood, \(\chi ^2/N_\mathrm{data} \ll 1\). The fact that the information of the correlations is not available undermines the usefulness of the data to constrain the theory calculations. This is a clear deficiency of the measurements and we call for publishing the information on the correlations as is usually done in the case of p–p and p–\(\overline{\mathrm{p}}\) collisions. It is also worth noting that we (almost) only use minimum-bias p–Pb data. While centrality dependent data are also available, it is known that any attempt to classify event centrality results in imposing a non-trivial bias on the hard-process observable in question; see e.g. Ref. [20].

Forward-to-backward asymmetries based on \(W^{\pm }\) measurements by the ALICE collaboration. The upper (lower) graphs correspond to the theoretical calculation with EPS09 (DSSZ) nuclear PDFs. The comparisons with no nuclear effects are included as dashed lines

Forward-to-backward asymmetries for \(W^{+}\) (upper panels) and \(W^{-}\) (lower panels) measured by the CMS collaboration [22], as a function of the charged-lepton pseudorapidity in the laboratory frame. The left-hand (right-hand) graphs correspond to the theoretical calculations with EPS09 (DSSZ) nPDFs. Results with no nuclear effects are included as dashed lines
Note that not all PDF+nPDF combinations will be shown in the figures to limit the number of plots. Moreover, the post-reweighting results are not shown when they become visually indistinguishable from the original ones.
3.1 Charged electroweak bosons
Charged electroweak bosons (\(W^{+}\) and \(W^{-}\)) decaying into leptons have been measured by the ALICE [21] and CMS [22] collaborations.Footnote 1 The theoretical values were computed at next-to-leading order (NLO) accuracy using the Monte Carlo generator MCFM [24] fixing all the QCD scales to the mass of the boson.
The preliminary ALICE data include events with charged leptons having \(p_\mathrm{T}>10 \, \mathrm{GeV}\) at forward (\(2.03 < y_\mathrm{c.m.}< 3.53\)) and backward (\(-4.46 < y_\mathrm{c.m.} < -2.96\)) rapidities in the nucleon–nucleon centre-of-mass (c.m.) frame. From these, we constructed “forward-to-backward” ratios as
A data-versus-theory comparison is presented in Fig. 1. While the theoretical predictions do agree with the experimental values, the experimental error bars are quite large. Table 1 (the left-hand columns) lists the corresponding values of \(\chi ^{2}\) before the reweighting together with those obtained assuming no nuclear modifications in PDFs. It is clear that these data have no resolution with respect to the nuclear effects in PDFs.
The CMS collaboration has measured laboratory-frame pseudorapidity (\(\eta _\mathrm{lab}\)) dependent differential cross sections in the range \(|\eta _\mathrm{lab}| < 2.4\) with the transverse momentum of the measured leptons \(p_\mathrm{T} > 25 \, \mathrm{GeV}\). The measured forward-to-backward ratios are compared to the theory computations in Fig. 2 and the \(\chi ^2\) values are given in Table 1 (the right-hand columns). While the \(W^+\) data are roughly compatible with all the PDF combinations, the \(W^-\) data show a clear preference for nuclear corrections as implemented in EPS09 and DSSZ. These measurements probe the nuclear PDFs approximately in the range \(0.002 \lesssim x \lesssim 0.3\) (from most forward-to-most backward bin), and the nuclear effects in the forward-to-backward ratio result from the sea-quark shadowing (small x) becoming divided by the antishadowing in valence quarks. While the impact of these data looks somewhat limited here, they may be helpful for constraining the flavour separation of nuclear modifications. However, as both EPS09 and DSSZ assume flavour-independent sea and valence quark modifications at the parametrisation scale (i.e. the initial scale for DGLAP evolution), the present analysis cannot address to which extent this may happen.Footnote 2
3.2 Z boson production
The Z boson production in its dilepton decay channel has been measured by three collaborations: CMS [26], ATLAS [27] and LHCb [28].Footnote 3 As in the case of \(W^{\pm }\), the theoretical values were computed using MCFM, with all scales fixed to the invariant mass of the lepton pair.
In the case of CMS, the kinematic cuts are similar to the ones applied for W bosons: the leptons are measured within \(|\eta _\mathrm{lab}| < 2.4\) with a slightly lower minimum \(p_\mathrm{T}\) for both leptons (\(p_\mathrm{T} > 20\) GeV), and \(60 \, \mathrm{GeV} < M_{l^{+}l^{-}} < 120 \, \mathrm{GeV}\). The \(A_\mathrm{F/B}\) data are binned as a function of \(y^{l^{+}l^{-}}_\mathrm{c.m.}\) (rapidity of the lepton pair). Figure 3 presents a comparison between the data and theory values before the reweighting (NNE stands for no nuclear modification of parton densities but includes isospin effects) and Table 2 (the right-hand column) lists the \(\chi ^2\) values. The data appear to slightly prefer the calculations which include nuclear modifications. Similarly to the case of W production, the use of nuclear PDFs leads to a suppression in \(A_\mathrm{F/B}\). The rapid fall-off of \(A_\mathrm{F/B}\) towards large \(y^{l^{+}l^{-}}_\mathrm{c.m.}\) comes from the fact that the lepton pseudorapidity acceptance is not symmetric in the nucleon–nucleon c.m. frame. Indeed the range \(|\eta _\mathrm{lab}| < 2.4\) translates to \(-2.865 < \eta _\mathrm{c.m.} < 1.935\) and since there is less open phase space in the forward direction, the cross sections at a given \(y^{l^{+}l^{-}}_\mathrm{c.m.}\) tend to be lower than those at \(-y^{l^{+}l^{-}}_\mathrm{c.m.}\). This is clearly an unwanted feature, since it gives rise to higher theoretical uncertainties (which we ignore in the present study) than if a symmetric acceptance (e.g. \(-1.935 < \eta _\mathrm{c.m.} < 1.935\)) had been used.

Forward-to-backward asymmetry of Z bosons measured by CMS [26] as a function of the lepton pair rapidity. The left-hand panel (right-hand panel) shows the predictions obtained with EPS09 (DSSZ). Results with no nuclear effects (NNE) are shown as dashed lines

As in Fig. 3 but for the ATLAS measurement
The ATLAS data correspond to the full phase space of the daughter leptons within \(66 \, \mathrm{GeV} < M_{l^{+}l^{-}} < 116 \, \mathrm{GeV}\) and \(|y^{Z}_\mathrm{c.m.}|<3.5\). The data are only available as absolute cross sections from which we have constructed the forward-to-backward ratio \(A_\mathrm{F/B}\). A comparison between the theoretical predictions (with and without nuclear modifications) and the experimental values before the reweighting can be seen in Fig. 4 and the \(\chi ^2\) values are given in Table 2 (the left-hand column). The calculations including the nuclear modifications are now clearly preferred. For the larger phase space, \(A_\mathrm{F/B}\) is now significantly closer to unity than in Fig. 3.

Forward-to-backward ratios based on the ATLAS jet cross-section measurements as a function of jet \(p_\mathrm{T}\). The theoretical predictions and uncertainty bands were computed using the eigenvectors of EPS09 (left) and DSSZ (right). Upper panels \(0.3 < |y*| < 0.8\). Middle panels \(0.8 < |y*| < 1.2\). Lower panels \(1.2 < |y*| < 2.1\)
3.3 Jets and dijets
Jet and dijet distributions were computed at NLO [29–31] and compared with the results from the ATLAS [32] and CMS [33] collaborations, respectively. The factorisation and renormalisation scales were fixed to half the sum of the transverse energy of all two or three jets in the event. For ATLAS jets we used the anti-\(k_T\) algorithm [34] with \(R=0.4\). For the CMS dijets we used the anti-\(k_T\) algorithm with \(R=0.3\) and only jets within the acceptance \(|\eta _\mathrm{jet}|<3\) were accepted, and the hardest (1) and next-to-hardest (2) jet within the acceptance had to fulfill the conditions \(p_{T\mathrm{jet},1}>120\) GeV/c, \(p_{T\mathrm{jet},2}>30\) GeV/c and their azimuthal distance \(\Delta \phi _{12}>2\pi /3\).

The CMS dijet data presented as differences between the data and the theory calculations. The dashed lines correspond to the nPDF uncertainty
The ATLAS collaboration measured jets with transverse momentum up to \(1 \, \mathrm{TeV}\) in eight rapidity bins. Strictly speaking, these data are not minimum bias as they comprise the events within the 0–\(90~\%\) centrality class. It is therefore somewhat hazardous to include them into the present analysis but, for curiosity, we do so anyway. The ATLAS data are available as absolute yields from which we have constructed the forward-to-backward asymmetries adding all the uncertainties in quadrature. Let us remark that, by proceeding this way, we lose the most forward \(2.1 < y^* < 2.8\) and central \(-0.3 < y^* < 0.3\) bins. The results before the reweighting are presented in Fig. 5 and Table 3 (left-hand column). For EPS09 the forward-to-backward ratio tends to stay below unity since at positive rapidities the spectrum gets suppressed (gluon shadowing) and enhanced at negative rapidities (gluon antishadowing). For DSSZ, the effects are milder. The data do not appear to show any systematic tendency from one rapidity bin to another which could be due to the centrality trigger imposed. Indeed, the best \(\chi ^2\) is achieved with no nuclear effects at all, but all values of \(\chi ^2/N_\mathrm{data}\) are very low. This is probably due to overestimating the systematic uncertainties by adding all errors in quadrature. It is worth mentioning here that, contrary to the ATLAS data, the preliminary CMS inclusive jet data [35] (involving no centrality selection) do show a consistent behaviour with EPS09.
Di-jet production by the CMS collaboration [33] was the subject of study in [36], where sizeable mutual deviations between different nuclear PDFs were found. The experimental observable in this case is normalised to the total number of dijets and the proton reference uncertainties tend to cancel to some extent, especially around midrapidity. A better cancellation would presumably be attained by considering the forward-to-backward ratios, but this would again involve the issue of correlated systematic uncertainties mentioned earlier. Comparisons between the data and theoretical predictions are shown in Fig. 6 and the \(\chi ^2\) values are tabulated in Table 3 (right-hand column). The data clearly favour the use of EPS09 nPDFs, and in all other cases \(\chi ^2/N_\mathrm{data}= 3.8\ldots 7.8\), which is a clear signal of incompatibility. The better agreement follows from the gluon antishadowing and EMC effect at large x present in EPS09 but not in DSSZ. However, the significant dependence of the employed free-proton PDFs is a bit alarming: indeed, one observes around 50 % difference when switching from CT10 to MSTW2008. This indicates that the cancellation of proton PDF uncertainties is not complete at all and that they must be accounted for (unlike we do here) if this observable is to be used as an nPDF constraint. The proton–proton reference data taken in Run II may improve the situation.

Backward-to-forward ratios for charged-hadron production measured by the CMS collaboration. The theoretical curves were computed with EPS09 (left-hand plots) and DSSZ (right-hand plots)

Backward-to-central ratios of charged-hadron production measured by the ALICE collaboration compared to calculations with EPS09 (left-hand panel) and DSSZ (right-hand panel)

Ratio of minimum-bias \(\pi ^{+}+\pi ^{-}\) production in p–Pb and the same observable in p–p collisions measured by the ALICE collaboration. Theoretical values and uncertainties were calculated with EPS09 (left-hand panel) and DSSZ (right-hand panel)
3.4 Charged-particle production
Now let us move to the analysis of charged-particle production. Here we consider both charged-hadron (ALICE [37] and CMS [38]) and pion (ALICE [39]) production. Apart from the PDFs, the particle production depends on the fragmentation functions (FFs), which are not well constrained. Indeed, it has been shown that any of the current FFs cannot give a proper description of the experimental results [40] on charged-hadron production. In the same reference, a kinematic cut \(p_\mathrm{T} > 10 \, \mathrm{GeV}\) was advocated to avoid contaminations from other than independent parton-to-hadron fragmentation mechanism described by FFs. The same cut is applied here. Regarding the final state pions, we relaxed the requirement to \(p_\mathrm{T} > 2 \, \mathrm{GeV}\), since cuts like this have been used in the EPS09 and DSSZ analyses. The theoretical values were determined with the same code as in [41], using the fragmentation functions from DSS [42] for the charged hadrons. In the case of the DSSZ nPDFs medium-modified fragmentation functions were used [43], in accordance with the way in which the RHIC pion data [44] were treated in the original DSSZ extraction. This is, however, not possible in the case of unidentified charged hadrons, as medium-modified fragmentation functions are available for pions and kaons only.
The use of CMS data [38] poses another problem since it is known that, at high-\(p_\mathrm{T}\), the data show a 40 % enhancement that cannot currently be described by any theoretical model. However, it has been noticed that the forward-to-backward ratios are nevertheless more or less consistent with the expectations. While it is somewhat hazardous to use data in this way, we do so anyway hoping that whatever causes the high-\(p_\mathrm{T}\) anomaly cancels in ratios. A comparison between these data and EPS09/DSSZ calculations is shown in Fig. 7 and the values of \(\chi ^2\) are listed in Table 4 (left-hand column). These data have a tendency to favour the calculations with DSSZ but with \(\chi ^2/N_\mathrm{data}\) being absurdly low.
The ALICE collaboration [37] took data relatively close to the central region and the data are available as backward-to-central ratios \(A_\mathrm{B/C}\)
with backward comprising the intervals \(-1.3 < \eta _\mathrm{c.m.} < -0.8\) and \(-0.8 < \eta _\mathrm{c.m.} < -0.3\). A theory-to-data comparison is shown in Fig. 8 and the corresponding \(\chi ^2\)s are in Table 4 (middle column). The data appear to slightly favour the use of EPS09/DSSZ but the \(\chi ^2/N_\mathrm{data}\) remain, again, always very low.

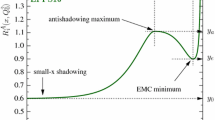
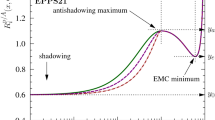
Impact of the LHC Run I data on the nPDFs of EPS09 (left) and DSSZ (right) before (black/grey) and after the reweighting (red/light red), for valence (upper panels), sea (middle panels) and gluon (lower panels) distributions at \(Q^{2}=1.69 \, \mathrm{GeV}^{2}\), except the DSSZ gluons that are plotted at \(Q^{2}=2 \, \mathrm{GeV}^{2}\)
Finally, we consider the preliminary pion data (\(\pi ^{+}+\pi ^{-}\)) shown by ALICE [39]. In this case the measurement was performed only in the \(|y|<0.5\) region so no \(A_\mathrm{F/B}\) or any similar quantity could be constructed. For this reason we had to resort to the use of \(R_\mathrm{pPb}\) ratio which involves a \(6~\%\) normalisation uncertainty.Footnote 4 A comparison between data and theory before the reweighting can be seen in Fig. 9 and the values of \(\chi ^2\) are in Table 4 (right-hand column).
The very low values of \(\chi ^2/N_\mathrm{data}\) attained in these three measurements indicate that the uncertainties have been overestimated and these data are doomed to have a negligible constraining power—notice that the uncertainties are dominated by the systematic errors which we add in quadrature with the statistical ones, in absence of a better experimental information.
4 Implications for nPDFs
The comparisons presented in the previous section demonstrate that many of the considered data (CMS W, CMS Z, ATLAS Z, CMS dijet) show sensitivity to the nuclear PDFs while others (ALICE W, ATLAS jets, CMS hadrons, ALICE hadrons, ALICE pions) remain inconclusive. Some of the considered observables (ATLAS jets, CMS hadrons) are also known to pose issues that are not fully understood, so the comparisons presented here should be taken as indicative. The most stringent constraints are provided by the CMS dijet measurements, which alone would rule out all but EPS09. However, upon summing all the \(\chi ^2\)’s from the different measurements, this easily gets buried under the other data. This is evident from the total values of \(\chi ^2/N_\mathrm{data}\) shown in Table 5 (upper part), as considering all the data it would look like all the PDF combinations were in agreement with the data (\(\chi ^2/N_\mathrm{data} \sim 1 \)). However, excluding one of the dubious data sets (ATLAS jets) for which the number of data is large but \(\chi ^2/N_\mathrm{data}\) very small, the differences between different PDFs grow; see the lower part of Table 5. The effective number of replicas remains always quite high. The reason for the high \(N_\mathrm{eff}\) is that the variation of the total \(\chi ^2\) within a given set of nPDFs (that is, the variation among the error sets) is small even if some of the data sets are not properly described at all (in particular, CMS dijets with DSSZ). We must notice also that even though the initial \(\chi ^{2}\) values for EPS09 are lower than for DSSZ regardless of the proton PDF used, the final number of replicas is lower for the former. This is due to the fact the DSSZ parameterisation does not allow for an ample variation of the partonic densities and therefore not many replicas fall far from the central prediction. Thus, \(N_\mathrm{eff}\) alone should not be blindly used to judge whether a reanalysis is required.
Given the tiny improvements in reweighted \(\chi ^2\) values one expects no strong modifications to be induced in the nPDFs either. Indeed, the only noticeable effect, as can be seen in Fig. 10, is in the EPS09 gluons for which the CMS dijet data place new constraints [45].Footnote 5 It should be recalled that, for technical reasons, in the EPS09 analysis the RHIC pion data were given a rather large additional weight and they still overweight the \(\chi ^2\) contribution coming from the dijets. In a fit with no extra weights the dijet data would, on the contrary, give a larger contribution than the RHIC data. Therefore these data will have a different effect from what Fig. 10 would indicate. In the case of DSSZ the assumed functional form is not flexible enough to accommodate the dijet data and in practice nothing happens upon performing the reweighting. However, it is evident that these data will have a large impact on the DSSZ gluons if an agreement is required (see Fig. 6), so a refit appears mandatory.
The impact of the LHC p–Pb data is potentially higher than what is found here also since, in the context of our study, it is impossible to say anything concerning the constraints that these data may provide for the flavour separation of the nuclear PDFs, which again calls for a refit. Another issue is the form of the fit functions whose rigidity especially at small x significantly underestimates the true uncertainty. In this sense, our study should be seen merely as a preparatory work towards nPDFs analyses including LHC data. More data for p–Pb will also still appear (at least CMS inclusive jets, W production from ATLAS) and many of the data sets used here are only preliminary.
5 Summary
In the present work we have examined the importance of PDF nuclear modifications in describing some p–Pb results from Run I at the LHC, and the impact that the considered data have on the EPS09 and DSSZ global fits of nPDFs. We have found that while some data clearly favour the considered sets of nuclear PDFs, some sets are also statistically consistent with just proton PDFs. In this last case abnormally small values of \(\chi ^2/N_\mathrm{data}\) are obtained, however. The global picture therefore depends on what data sets are being considered. We have chosen to use, in our analysis, most of the available data from the p–Pb run, it should, however, be stressed that some of the considered data sets are suspicious in the sense that unrealistically small values of \(\chi ^2/N_\mathrm{data}\) are obtained and these sets, as we have shown, can easily twist the overall picture. Incidentally, these sets are the ones that have smallest \(\chi ^2\) when no nuclear effects in PDFs are included. The small values of \(\chi ^2/N_\mathrm{data}\) are partly related to unknown correlations between the systematic uncertainties of the data but also, particularly in the case of ALICE pions, presumably to the additional uncertainty added to the interpolated p–p baseline. The p–p reference data at \(\sqrt{s}=5.02 \, \mathrm{TeV}\), recently recorded at the LHC, may eventually improve this situation.
The considered data are found to have only a mild impact on the EPS09 and DSSZ nPDFs. This does not, however, necessarily mean that these data would be useless. Indeed, they may facilitate to relax some rather restrictive assumptions made in the fits. An obvious example is the functional form for DSSZ gluon modification which does not allow for a similar gluon antishadowing as the EPS09 fit functions. This leads to a poor description of the CMS dijet data by DSSZ that the reweighting (being restricted to all assumptions made in the original analysis) cannot cure. Thus, in reality, these data are likely to have a large impact. In general, these new LHC data may allow one to implement more flexibility into the fit functions and also to release restrictions related to the flavour dependence of the quark nuclear effects. Also, the EPS09 analysis used an additional weight to emphasise the importance of the data set (neutral pions at RHIC) sensitive to gluon nPDF. Now, with the use of the new LHC data, such artificial means are likely to be unnecessary. Therefore, for understanding the true significance of these data, new global fits including these and upcoming data are thus required.
Hence, both theoretical and experimental efforts, as explained above, are required to fully exploit the potentiality of both already done and future p–Pb runs at the LHC for constraining the nuclear modifications of parton densities.
Notes
Also preliminary ATLAS data have been shown [23] and they appear consistent with the CMS results.
During our analysis, an extraction of nPDFs with flavour separation was released [25], but the fit shows no improvement with respect to those not including flavour decomposition.
The statistical uncertainties of the two LHCb data points are huge so we do not consider them here as they provide no constraining power.
Here we have deliberately ignored the normalisation uncertainty—even by doing so the obtained values of \(\chi ^2/N_\mathrm{data}\) are unrealistically small.
These are results using all the data, including those whose consistency is in doubt.
References
C.A. Salgado et al., J. Phys. G 39, 015010 (2012). doi:10.1088/0954-3899/39/1/015010. arXiv:1105.3919 [hep-ph]
N. Armesto, E. Scomparin (2016). arXiv:1511.02151 [nucl-ex]
K.J. Eskola, Nucl. Phys. A 910–911, 163 (2013). doi:10.1016/j.nuclphysa.2012.12.029. arXiv:1209.1546 [hep-ph]
H. Paukkunen, Nucl. Phys. A 926, 24 (2014). doi:10.1016/j.nuclphysa.2014.04.001. arXiv:1401.2345 [hep-ph]
M. Arneodo, Phys. Rep. 240, 301 (1994). doi:10.1016/0370-1573(94)90048-5
K.J. Eskola, V.J. Kolhinen, P.V. Ruuskanen, Nucl. Phys. B 535, 351 (1998). doi:10.1016/S0550-3213(98)00589-6. arXiv:hep-ph/9802350
W.T. Giele, S. Keller, Phys. Rev. D 58, 094023 (1998). arXiv:hep-ph/9803393
R.D. Ball et al. [NNPDF Collaboration], Nucl. Phys. B 849, 112 (2011) [Erratum-ibid. B 854 (2012) 926] [Erratum-ibid. B 855 (2012) 927]. arXiv:1012.0836 [hep-ph]
R.D. Ball, V. Bertone, F. Cerutti, L. Del Debbio, S. Forte, A. Guffanti, N.P. Hartland, J.I. Latorre et al., Nucl. Phys. B 855, 608 (2012). arXiv:1108.1758 [hep-ph]
G. Watt, R.S. Thorne, JHEP 1208, 052 (2012). arXiv:1205.4024 [hep-ph]
B.J.A. Watt, P. Motylinski, R.S. Thorne, (2014). arXiv:1311.5703 [hep-ph]
N. Sato, J.F. Owens, H. Prosper. arXiv:1310.1089 [hep-ph]
H. Paukkunen, P. Zurita, JHEP 1412, 100 (2014). arXiv:1402.6623 [hep-ph]
N. Armesto, J. Rojo, C.A. Salgado, P. Zurita, JHEP 1311, 015 (2013). arXiv:1309.5371 [hep-ph]
K.J. Eskola, H. Paukkunen, C.A. Salgado, JHEP 0904, 065 (2009). arXiv:0902.4154 [hep-ph]
D. de Florian, R. Sassot, P. Zurita, M. Stratmann, Phys. Rev. D 85, 074028 (2012). arXiv:1112.6324 [hep-ph]
A.D. Martin, W.J. Stirling, R.S. Thorne, G. Watt, Eur. Phys. J. C 63, 189 (2009). arXiv:0901.0002 [hep-ph]
H.-L. Lai, M. Guzzi, J. Huston, Z. Li, P.M. Nadolsky, J. Pumplin, C.-P. Yuan, Phys. Rev. D 82, 074024 (2010). arXiv:1007.2241 [hep-ph]
H. Paukkunen, C.A. Salgado, JHEP 1103, 071 (2011). doi:10.1007/JHEP03(2011)071. arXiv:1010.5392 [hep-ph]
N. Armesto, D.C. Gulhan, J.G. Milhano, Phys. Lett. B 747, 441 (2015). arXiv:1502.02986 [hep-ph]
J. Zhu [ALICE Collaboration], J. Phys. Conf. Ser. 612(1), 012009 (2015)
V. Khachatryan et al. [CMS Collaboration], Phys. Lett. B 750, 565 (2015). doi:10.1016/j.physletb.2015.09.057. arXiv:1503.05825 [nucl-ex]
ATLAS Collaboration, ATLAS-CONF-2015-056
J.M. Campbell, R.K. Ellis, C. Williams, JHEP 1107, 018 (2011). arXiv:1105.0020 [hep-ph]
K. Kovarik et al., (2014). arXiv:1509.00792 [hep-ph]
V. Khachatryan et al. [CMS Collaboration], (2014). arXiv:1512.06461 [hep-ex]
G. Aad et al. [ATLAS Collaboration], (2014). arXiv:1507.06232 [hep-ex]
R. Aaij et al. [LHCb Collaboration], JHEP 1409, 030 (2014). arXiv:1406.2885 [hep-ex]
S. Frixione, Z. Kunszt, A. Signer, Nucl. Phys. B 467, 399 (1996). arXiv:hep-ph/9512328
S. Frixione, Nucl. Phys. B 507, 295 (1997). arXiv:hep-ph/9706545
S. Frixione, G. Ridolfi, Nucl. Phys. B 507, 315 (1997). arXiv:hep-ph/9707345
G. Aad et al. [ATLAS Collaboration], Phys. Lett. B 748, 392 (2015). arXiv:1412.4092 [hep-ex]
S. Chatrchyan et al. [CMS Collaboration], Eur. Phys. J. C 74(7), 2951 (2014). arXiv:1401.4433 [nucl-ex]
M. Cacciari, G.P. Salam, G. Soyez, JHEP 0804, 063 (2008). arXiv:0802.1189 [hep-ph]
V. Khachatryan et al. [CMS Collaboration]. arXiv:1601.02001 [nucl-ex]
K.J. Eskola, H. Paukkunen, C.A. Salgado, JHEP 1310, 213 (2013). arXiv:1308.6733 [hep-ph]
B.B. Abelev et al. [ALICE Collaboration], Eur. Phys. J. C 74(9), 3054 (2014). arXiv:1405.2737 [nucl-ex]
V. Khachatryan et al. [CMS Collaboration], Eur. Phys. J. C 75(5), 237 (2015). doi:10.1140/epjc/s10052-015-3435-4. arXiv:1502.05387 [nucl-ex]
J. Adam et al. [ALICE Collaboration], (2016). arXiv:1601.03658 [nucl-ex]
D. d’Enterria, K.J. Eskola, I. Helenius, H. Paukkunen, Nucl. Phys. B 883, 615 (2014). arXiv:1311.1415 [hep-ph]
R. Sassot, P. Zurita, M. Stratmann, Phys. Rev. D 82, 074011 (2010). arXiv:1008.0540 [hep-ph]
D. de Florian, R. Sassot, M. Stratmann, Phys. Rev. D 76, 074033 (2007). arXiv:0707.1506 [hep-ph]
R. Sassot, M. Stratmann, P. Zurita, Phys. Rev. D 81, 054001 (2010). arXiv:0912.1311 [hep-ph]
S.S. Adler et al. [PHENIX Collaboration], Phys. Rev. Lett. 98, 172302 (2007). arXiv:nucl-ex/0610036
H. Paukkunen, K.J. Eskola, C. Salgado, Nucl. Phys. A 931, 331 (2014). doi:10.1016/j.nuclphysa.2014.07.012. arXiv:1408.4563 [hep-ph]
Acknowledgments
We thank E. Chapon and A. Zsigmond, Z. Citron, and M. Ploskon, for their help with the understanding of the CMS, ATLAS and ALICE data, respectively. This research was supported by the European Research Council Grant HotLHC ERC-2011-StG-279579; the People Programme (Marie Curie Actions) of the European Union’s Seventh Framework Programme FP7/2007–2013/ under REA Grant agreement #318921 (NA); Ministerio de Ciencia e Innovación of Spain under project FPA2014-58293-C2-1-P; Xunta de Galicia (Consellería de Educación)—the group is part of the Strategic Unit AGRUP2015/11.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3
About this article

Cite this article
Armesto, N., Paukkunen, H., Penín, J.M. et al. An analysis of the impact of LHC Run I proton–lead data on nuclear parton densities. Eur. Phys. J. C 76, 218 (2016). https://doi.org/10.1140/epjc/s10052-016-4078-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-016-4078-9